Kay, Michael. “A Streaming XSLT Processor.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Kay01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Michael Kay is the editor of the W3C XSLT specification, and is a member of the XQuery
and XML Schema Working Groups. He is the developer of the Saxon XSLT, XQuery, and
XML Schema processor.
He is the author of XSLT Programmer's Reference (now in its fourth edition) and a contributor
to many other books.
He is a member of the Advisory Board for Balisage 2010. In 2009, he chaired the associated
Symposium
on Processing XML Efficiently.
Existing XSLT implementations build a tree representation of the source document in
memory, and
are therefore limited to processing of documents that fit in memory. With many transformations,
however,
there is a direct correspondence between the order of information in the output, and
the order of the
corresponding information in the input. In such cases it ought to be possible to perform
the transformation
without allocating memory to the entire source tree.
The XSL Working Group within W3C has been working on a new version of the language
designed
to make streamed implementations feasible, and the author, who is editor of that specification,
has
at the same time been working on the implementation of streaming in the Saxon XSLT
processor. This paper
describes how far this work has progressed, and the way in which the implementation
is structured.
It adopts a chronological approach to the exposition, explaining how the streaming
features have gradually
developed from small beginnings.
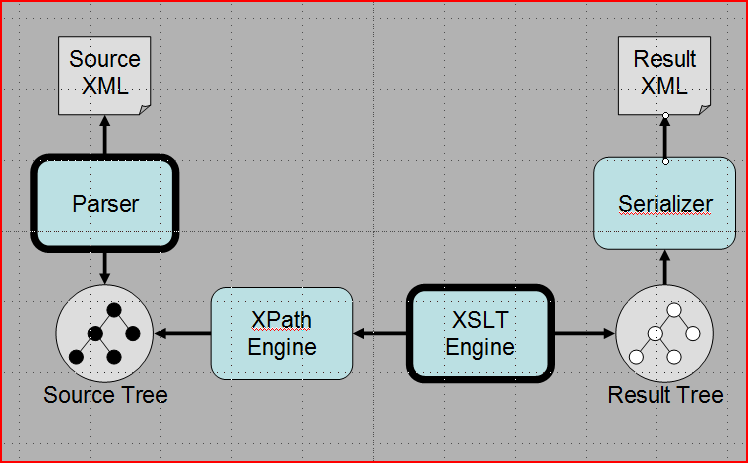
The architecture of most XSLT processors is as shown in Figure 1. The XML parser is
used
to build a tree representation of the source document in memory. XSLT instructions
are then
executed, which cause the evaluation of XPath expressions, which select nodes from
the source
tree by navigating around this tree. Because the XPath axes (child, descendant, parent,
ancestor, preceding-sibling, and so on) allow navigation around this tree in arbitrary
directions, it is necessary for the entire tree to be held in memory for the duration
of the
transformation. For some XML documents, this is simply not feasible: even sample datasets
representing virtual 3D city models run to 44Gbytes in size (CityGML).
Figure 1: Fig 1: Architecture of an XSLT Processor
In this schematic, arrows represent flow of control (not data flow). Thus the two
controlling components (outlined bold) are the Parser and the XSLT engine; the parser
writes the source tree and the XSLT engine reads it (via the XPath engine). The serializer
is invoked by the XSLT engine to process one result tree event at a time, which means
that
the result tree does not actually need to be materialized in memory.
By contrast, there is no need to hold the result tree in memory. Although the semantics
of
the language speak of a result tree, a naive execution of XSLT instructions causes
nodes to be
written to the result tree in document order, which means that data can be serialized
(to
lexical XML or HTML) as soon as it is generated. So the result tree is a fiction of
the
specification, and does not occupy real memory in a typical implementation.
It has long been recognized that the need to hold the source tree in memory is a serious
restriction for many applications. Researchers have made a number of attempts to tackle
the problem:
Some have concentrated on streaming XPath processors (Barton2003,
BarYossef2004, Joshi). The focus here is on
rewriting the reverse axes (such as preceding-sibling) in terms of forwards axes.
There
has been significant progress demonstrated in these projects, though they all leave
out
some of the most awkward features of the language, such as the last()
function. However, streamed evaluation of a single XPath expression during a single
pass
of a source document does not help much with streamed evaluation of XSLT, since a
stylesheet contains many XPath expressions, and the starting point for one is typically
dependent on the nodes found by another.
Other projects have concentrated on streamed evaluation of XQuery (Florescu2003, Li2005). Again these projects rely heavily
on rewriting the execution plan. These results are difficult to translate to XSLT,
because
XQuery has the luxury of a flow-of-control that is fully statically analyzable (there
is
no polymorphism or dynamic despatch). In XQuery, the compiler can look at a function
call
and know which function it is calling; it can therefore determine what navigation
is
performed by the called function. Template rules in XSLT, by contrast, are fired
dynamically based on input data.
Guo et al (Guo2004) describe an approach to streamed XSLT processing that restricts the supported
XSLT constructs to a small core. This core language is DTD-aware, and restricts match
patterns to those
that can be uniquely ascribed to an element declaration in the DTD grammar. XPath
expressions appear only
in the xsl:apply-templates instruction, and always select downwards by element name. As a result,
the call hierarchy becomes statically tractable, as in the XQuery case.
Zergaoui (Zergaoui2009) observes that many transformations
are intrinsically non-streamable, because the events representing the result tree
appear in a different
order from the events from the source tree on which they depend. He therefore suggests
that pure
(zero-memory) streaming is an impractical goal, and that practical engineering solutions
should
strive rather to minimize the amount of buffering needed, without restricting the
expressive
capabilities of the transformation language.
Echoing this, Dvorakova (Dvirakova2008, Dvorakova2009a,
Dvorakova2009b) and her colleagues describe an approach that supports
a rather larger subset of the XSLT language, though it still contains some serious
limitations:
match patterns in template rules are simple element names, path expressions can select
downwards only, recursive structures in the schema are not allowed. Their approach,
implemented in the Xord framework, is based on static analysis of the XSLT code in
the
context of a schema to determine the extent to which streaming can be employed, and
the
scope of input buffering needed to handle constructs (for example, non-order-preserving
constructs) where pure streaming is not possible. (An implicit assumption of their
approach, which sadly is not true in real life, is that an element name appearing
in the
match pattern of a template rule can be used to identify unambiguously a schema definition
of the structure of the elements that match this rule.)
Others have adopted the approach that if XSLT cannot be streamed, then a different
language
is needed. STX STX is one example of an alternative transformation language, designed explicitly for
streaming.
Another is the INRIA XStream project (Frisch2007) (not to be confused with other projects of the same name).
STX abandons the attempt to be purely declarative, instead giving the programmer access
to mutable
variables which can be used to remember data from the input document that might be
needed later in the transformation;
this means that the responsibility for controlling memory usage rests entirely on
the programmer.
XStream, by contrast, is a purely functional language that relies heavily on partial
evaluation of functions
as soon as relevant inputs are available; the buffering of input is thus represented
by the pool of partially-evaluated
function calls, and the efficiency of the process depends strongly on the programmer
having a good
understanding of this execution model.
What all this activity makes clear is that streaming of the XSLT language as currently
defined is seriously
difficult; it is unreasonable to treat streaming as a mere optimization that implementors
can provide if they
choose to apply themselves to the task.
Since 2007 the W3C XSL Working Group has been working on enhancements to the XSLT
language designed
to make streaming a feasible proposition. A first working draft of XSLT 2.1 has been
published (Kay2010b),
and an overview
of the design approach is available in Kay2010a.
This paper describes how streaming is implemented in the Saxon XSLT processor (Saxonica). This is influenced
by the work of the W3C specification, but it is by no means an exact match to the
specification in its current form:
many features that should be streamable according to the specification are not yet
streamable in Saxon, while Saxon
succeeds in streaming some constructs that are non-streamable according to XSLT 2.1.
Streaming facilities in Saxon have been developed over a number of years, and have
become
gradually more sophisticated in successive releases. In order to aid understanding,
the
facilities are therefore presented as a narrative, describing enhancements as they
were
introduced in successive releases. This includes features that have been implemented
but not
yet released at the time of writing, in what is destined to be Saxon 9.3.
Streamed XPath in the Schema Validator
Since version 8.0, released in June 2004, Saxon has incorporated an XML Schema 1.0
processor. This was introduced to underpin the schema-aware capabilities of the (then
draft)
XSLT 2.0 and XQuery 1.0 specifications, but can also be used as a freestanding validator
in
its own right.
XML Schema 1.0 (XSD 1.0) allows uniqueness and referential constraints to be expressed
by
means of XPath expressions. For example, in a schema describing XSLT stylesheet documents,
the
constraint that every with-param element within an call-template
element must have a distinct value for its name attribute might be expressed as
follows:
In this example the two XPath expressions are very simple. XSD 1.0 allows them to
be rather
more complicated than these examples, but they are still restricted to a very small
subset of
XPath: downward selection only; no predicates; union operator allowed at the top level
only.
The specification explicitly states the reason why the subset is so small:
In order to reduce the burden on implementers, in particular implementers of streaming
processors,
only restricted subsets of XPath expressions are allowed in {selector} and {fields}.
It was important to the designers of XML Schema 1.0 that a validator should be able
to process its input document
in a pure streaming manner with no buffering, and a subset of XPath was chosen to
make this viable.
Accordingly, Saxon 8.0 included in its schema processor a streamed implementation
of this XPath subset.
For various reasons, the schema validator in Saxon was implemented as a push pipeline
(Kay2009); the component for evaluating uniqueness and referential constraints
forms one of the steps in this pipeline. A SAX XML parser generates a sequence of
parsing
events (startElement, endElement, etc) which are piped into the validator, which in
turn
passes them on to the next stage in the process, whatever that might be. Streamed
XPath
evaluation therefore operates in push mode, and this design choice continues to affect
the way
the design evolves today. One of the great advantages of a push pipeline is that it
is easy to
direct parsing events to many different consumers: this is particularly useful with
uniqueness
constraints because many such constraints can be under evaluation at any one time,
scoped to
the same or different parent elements.
The despatching of events to the listeners involved in evaluating a uniqueness constraint
is handled by a component
called the WatchManager; each of the listening components is called a Watch. For the example
constraint given, the process is as follows:
When the startElement event for the xsl:call-template element is notified by the
parser, the validator for the xsl:call-template element is fired up. This
creates a SelectorWatch for the uniqueness constraint. The
SelectorWatch maintains a table of key values that have been encountered
(initially empty) so that it can check these for uniqueness.
All parsing events are now notified to this SelectorWatch. For each event, it
checks whether the ancestor path in the document matches the path given in the
xs:selector element. In this case this is simply a test whether the event
is a startElement event for an xsl:with-param element. More generally, it is
essentially a match of one list of element names against another list of element names,
taking account of the fact that the // operator can appear at the start of
the path to indicate that it is not anchored to the root xsl:call-template
element. When the matching startElement event is encountered, the
SelectorWatch instantiates a FieldWatch to process any nodes
that match the expression in the xs:field element.
The FieldWatch is now notified of all parsing events, and when the
@name attribute is encountered, it informs the owning
SelectorWatch, which checks that its value does not conflict with any value
previously notified. This process is more complex than might appear, because there
can be
multiple xs:field elements to define a composite key, and furthermore, the
field value can be an element rather than an attribute, in which case it may be necessary
to assemble the value from multiple text nodes separated by comments or processing
instructions. It is also necessary to check that the FieldWatch fires exactly
once. (A simplifying factor, however, is that XSD requires the element to have simple
content.)
After detecting a startElement event that matches its path expression, the
SelectorWatch must remain alert for further matching events. Before the
corresponding endElement event is encountered, another matching
startElement might be notified. This cannot happen in the above example.
But consider the constraint that within each section of a chapter, the figure numbers
must
be unique:
It is entirely possible here for chapters to be nested within chapters, and for
sections to be nested within sections. (It is not possible for figures to be nested
within
figures, however: the node selected by the xs:field element must have simple
content.) The WatchManager may therefore be distributing events
simultaneously to a large number of Watch instances, even for a single
uniqueness constraint; at the same time, of course, other uniqueness constraints may
be
active on the same elements or on different elements at a different level of the source
tree.
Streaming Copy
The next step in Saxon's journey towards becoming a streaming XSLT processor was to
exploit the mechanisms described in the previous section in contexts other than schema
validation. This was introduced in Saxon 8.5, released in August 2005, and subsequently
extended. The facility used standard XSLT 2.0 syntax, but required the user to write
code in a
highly stereotyped way for streaming to be possible.
Without the processing hint expressed by the saxon:read-once attribute, this
code would parse the source document customers.xml and build a tree
representation of the document in memory. It would then search the tree for the elements
matching the path /*/customer, and for each of these in turn it would create a
copy of the subtree rooted at this element, returning it from the function and then
applying
templates to it.
It is easy to see that in this operation, building the tree representation of the
large
customers.xml document is unnecessary; it can be bypassed if the elements
matching /*/customer can be recognized in the event stream issuing from the XML
parser. Instead of one large tree, the processor can build a series of smaller trees,
each
representing a single customer record. So long as the size of the customer record
is kept
within bounds, there is then no limit on the number of customer records present in
the input
document. This is sometimes referred to as windowing or
burst-mode streaming: the source document is processed as a sequence
of small trees, rather than as one large tree.
The use of the xsl:copy-of instruction here is significant. In the implementation, there is no physical
copying taking place, because the original whole-document tree is never built. But
the result is equivalent to the result
of building the whole-document tree and then copying the sequence of subtrees. In
particular, the nodes in one subtree
are not linked in any way to the nodes in other subtrees; there is no way the application
can navigate outside the boundaries
of a subtree. Attempting to retrieve the ancestors or siblings of the customer element returns nothing,
just as it would with a true subtree copy.
Saxon implements this construct by reusing the WatchManager machinery
described in the previous section. Having analyzed the select attribute of the
xsl:copy-of instruction to confirm that it satisfies the constraints on
streamable XPath expressions, the document customers.xml is then processed
using a SAX parser which sends parsing events to a WatchManager which in this
case notifies a new kind of Watch, a CopyWatch, of the start and
end of elements matching the path expression; between these start and end events,
the
CopyWatch is notified of all intermediate events and uses these to build a
tree representing the customer element.
Note again that two elements matching the path can be active at the same time. This
cannot happen with the example above, because
the path /*/customer has a fixed depth. But change the example to //section, and it is clear that
the set of section elements selected by the path can include one section that is a subtree of another.
This situation
requires some internal buffering: the language semantics require that the sections
are delivered in document order, which means that
the outermost section must be delivered before its nested sections. The trees representing
the nested sections must therefore
be held in memory, to be released for processing only when the endElement event for the outermost section is
notified. The code is written so that it is always prepared to do this buffering;
in practice, it is very rarely needed, and
no extra costs are incurred in the case where it is not needed. In some cases it would
be possible to determine statically
that no buffering will be needed, but this knowledge confers little benefit.
The reader may be puzzled by the choice of name for the attribute
saxon:read-once="yes". Although the implementation of the
xsl:copy-of instruction in streaming mode is very different from the
conventional execution plan, the functional behaviour is identical except in one minor
detail: there is no longer a guarantee that if the customers.xml file is read
more than once within the same transformation, its contents will be the same each
time. At
the time this feature was first implemented, the XSLT 2.0 conformance rules required
implementations to deliver stable results in this situation. The streaming implementation
necessarily departed from this rule (the only practical way to enforce the rule is
to make
an in-memory copy of the tree), so the saxon:read-once attribute was provided
as a way for the user to assert that the file would not be read more than once, thus
licensing the non-conformance in the case where the assertion was not honoured. In
the final
version of the XSLT 2.0 specification, there was explicit provision that implementations
were allowed to provide a user option to waive the stability requirement for the
doc() function, thus making this extension conformant.
A further complication in the implementation is caused by the fact that the
CopyWatch component delivers its results (the sequence of small
customer trees) using a push interface (it calls the next component in the
pipeline to deliver each one in turn), whereas the xsl:apply-templates
instruction that calls the user-defined function expects to use a pull interface (it
calls
the XPath engine to deliver each one in turn). There is thus a push-pull conflict,
which is
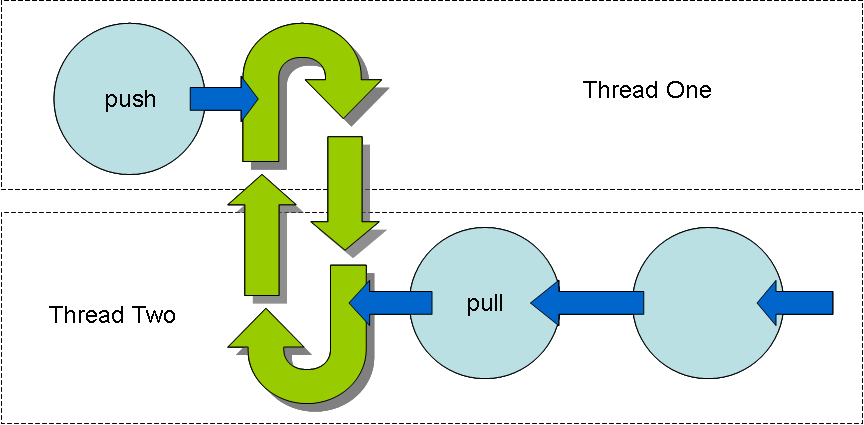
resolved using the design described in Kay2009 and shown in Figure 2. The push
code operates in one thread, writing the sequence of customer trees to a cyclic
buffer, which is then read by a parallel thread delivering the trees in response to
requests
from the xsl:apply-templates instruction.
Figure 2: Figure 2: Two-thread processing model
Thread One contains the parser and the push-mode evaluation of the streaming path
expression (the WatchManager and CopyWatch). This emits a sequence of small trees
(each
representing one customer record) to the cyclic butter, from where they are read by
the
pull-mode XPath engine running in Thread Two. Arrow represent flow of control.
Refinements of the Streaming Copy feature
In releases subsequent to Saxon 8.5, the streaming copy mechanism described in the
previous section was enhanced in a number of ways,
without changing its fundamentals.
In Saxon 8.8 (September 2006) two changes were made. Firstly, the set of XPath expressions
that could be handled in streaming mode was extended, to include union expressions
and
simple predicates. Secondly, the need for the two-thread model was eliminated in cases
where
no further processing of the copied subtrees was required: for example, in a transformation
whose output contained these subtrees without modification.
In Saxon 9.1 (July 2008) the mechanism was extended to XQuery, via a new extension
function saxon:stream(), which was also made available in XSLT. This might be
regarded as a pseudo-function: the call
saxon:stream(doc('customers.xml')/*/customer) delivers a copy of the value of
its argument (that is, a sequence of customer subtrees), but it requires its
argument to conform to the syntax of streamable path expressions. [1]
In Saxon 9.2 (August 2009) a further refinement was introduced to allow the processing
of
the input stream to terminate prematurely. For example, the query
saxon:stream(doc('customers.xml')/*/@version) will return the value of the
version attribute from the outermost element of the document, and will read
no further once this has been seen. This makes it possible to obtain information from
near
the start of an XML document in constant time, regardless of the document size, which
is
especially useful in a pipeline when making decisions on how to route a document for
processing based on information in its header. (It's a moot point whether this is
consistent
with the requirement in the XML 1.0 specification that all well-formedness errors
in a
document must be reported to the application. But the facility is so useful that we
can
ignore the standards-lawyers on this one.)
Streaming with Retained State
A limitation of the streaming copy approach as outlined above is that there is no
way of
using the information in a subtree once the processing of that subtree has finished;
so
there is no way that the processing of one subtree can influence the processing of
subsequent subtrees. (Saxon always had a workaround to this problem, the deprecated
saxon:assign instruction which introduces mutable variables to the language;
but this plays havoc with optimisation).
An answer to this problem was found in the form of the xsl:iterate
instruction defined in the XSLT 2.1 working draft. This was implemented in Saxon 9.2
in the
Saxon namespace (as saxon:iterate), but I will present it using the W3C syntax,
which becomes available in Saxon 9.3.
Consider the problem of processing a sequence of transaction elements, and outputting the
same sequence of elements but with an additional attribute holding the running balance
on the account, obtained
by accumulating the values of all the preceding transactions.
The classic solution to this would use sibling recursion:
There are a number of difficulties with this approach. Firstly, everyone who has taught
XSLT appears to agree that students have considerable difficulty producing the code
above as
the solution to this exercise, despite its brevity and apparent simplicity. Secondly,
it
relies rather heavily on the XSLT processor implementing tail call optimization; if
you run
this on a variety of popular XSLT processors, many of them will run out of stack space
after
processing 500 or so transactions, showing that they do not implement this optimization.
Finally, the analysis needed to demonstrate that a streaming implementation of this
code is
feasible is far from easy, and one suspects that minor departures from this particular
way
of writing the code will invalidate any such analysis.
For all these reasons, XSLT 2.1 introduces a new instruction xsl:iterate, which allows the solution to
be expressed as follows:
This has the appearance of a simple loop rather than functional recursion; it behaves
like
the familiar xsl:for-each instruction with the added ability to set a parameter
after the processing of one value which is then available for use when processing
the next.
A key difference compared with the recursive solution is that the set of transactions
to be
processed is identified in one place, the select attribute of the
xsl:iterate instruction, rather than being the product of a sequence of
independent calls on following-sibling. A useful consequence of this difference
is that termination is guaranteed.
Another way of looking at xsl:iterate is as syntactic sugar for the
foldl higher-order function found in many functional programming languages:
this applies a user-supplied function (the body of xsl:iterate) to each item of
an input sequence (the value of the select expression), with each iteration
delivering an accumulated value of some kind, which is made available as a parameter
to the
user-supplied function when called to process the next item.
Saxon 9.2 implements this new instruction (albeit in its own namespace) and allows
the
select expression to select the stream of subtrees arising from a streaming
copy operation: for example <xsl:iterate
select="saxon:stream(doc('transactions'xml')/*/transaction">. By this means,
information computed while processing one input transaction can be made available
while
processing the next. The implementation of xsl:iterate in fact knows nothing
about streaming; it is processing the sequence of subtrees just as it would process
any
other sequence of items.
Limitations of Streaming Copy
The streaming copy feature has enabled many applications to be written using Saxon
that
would otherwise have been impossible because of the size of the input document. Many
of the
streaming use cases published by the W3C Working Group (Cimprich2010) can be implemented using
this feature. But despite the various refinements that have been described, there
are some
serious limitations:
There is no way of getting access to part of the streamed source document other than
what is contained in the copied subtrees. This problem can be mitigated by using a
union expression to select
all the data that is needed. However, the programming then becomes rather complex.
The design pattern works well with "hedge-like" source documents: those where the
hierarchy
fans out quickly to a large number of small subtrees. But there are many large source
documents that do not fit into this pattern - this arises particularly with
"document-oriented" XML, but also for example with GML (Geography Markup Language)
[gml]
where individual geographical features represented in the data stream can each be
of
considerable size.
These limitations arise because streaming copy treats the input document as a flat
sequence of elements, not really as a hierarchy. To address these limitations, it
is
necessary to restore the ability to process the input tree using recursive descent
using
template rules. The way in which template rules can be made to work in a streaming
manner is
the subject of the next section.
Streaming Templates
Consider a stylesheet containing the following two rules:
This follows a familiar coding pattern: first a generic template which acts as the
default processing for all
elements in the source document (this example copies the element to the output, sans
attributes, and uses the
xsl:apply-templates instruction to invoke recursive processing of its children); then one or more templates
for specific named elements to process them in a way that differs from the general
rule. The effect of this stylesheet
is to copy the source document to the result document unchanged except for the loss
of all attributes, and of elements
named note together with their descendants.
It is easy to see how this stylesheet could be implemented in a single pass over the
source document, without building an in-memory tree. A simple filter can be applied
to events
emanating from the parser before passing them on to the serializer: all events are
passed on
unchanged, except for (a) events representing attribute nodes and (b) events that
occur
between the startElement event and corresponding endElement event
for a note element.
In XSLT 2.1 streamability is a property of a mode (Kay2010a).
If a mode is declared to be streamable, then all the template rules in that mode must
obey the restrictions placed on streamable templates. The analysis defined in the
XSLT 2.1
specification to determine streamability is rather complex; the rules currently implemented
in
Saxon are much simpler (and in most cases, more restrictive), while still allowing
a wide
class of transformations to be expressed. I will present first the Saxon 9.2 implementation,
which is relatively easy to understand, and then the Saxon 9.3 extensions, which add
considerable complexity and power.
Streaming Templates in Saxon 9.2
Saxon 9.2 follows the principle that streamability is a property of a mode, though
its
restrictions on streamable templates are far more severe than those in the XSLT 2.1
draft.
The rules for streamable templates can be summarised (in simplified form) as follows:
The match pattern must contain no predicates.
The template body may contain at most one drill-down construct. This may
be an xsl:apply-templates instruction with defaulted select
expression, or one of the following expressions or instructions applied to the context
node: xsl:copy-of, xsl:value-of, string(),
data() (or implicit atomization), or one of a small number of other
constructs.
The drill-down construct may have only the following as its containing (ancestor)
instructions: xsl:element, literal result elements,
xsl:value-of, xsl:attribute, xsl:comment,
xsl:processing-instruction, xsl:result-document,
xsl:variable, xsl:sequence.
Apart from the drill-down construct and its ancestors, any expression within the template
that
has a dependency on the context item must fall into one of the following categories:
(a)
a function (for example, local-name() or exists()) that
returns a local property of the node, or of one of its attributes or ancestors, or
of an
attribute of an ancestor; (b) an expression that returns the string value or typed
value
of an attribute of the node or an attribute of one of its ancestors.
The effect of these rules is that the stylesheet given above, with the addition of
the declaration
<xsl:mode streamable="yes"/>[2],
is fully streamable.
These rules allow a wide variety of transformations to be expressed. However, they
impose
many arbitrary restrictions. For example, a template cannot contain the instruction
<xsl:value-of select=". + 3"/>, because an addition expression
(+) is not an acceptable ancestor of the implicit drill-down construct
data(.). To get around this restriction, it is possible to bind a variable to
the value of data(.) and then perform the addition using the value of the
variable.
To understand the reason for such arbitrary restrictions, it is necessary to understand
something of the architecture of the implementation: whose explanation, indeed, is
the main
purpose of this paper.
Traditionally, Saxon constructed the source tree using a push pipeline. XSLT instructions
were then interpreted, and by-and-large, they evaluated their XPath subexpressions
using a
pull pipeline of iterator objects navigating the source tree, and generated output
(including temporary trees) by pushing SAX-like events to a serializer or tree builder
pipeline. To implement streaming templates, this model has been turned upside-down,
almost
literally. During streamed evaluation, everything operates in push mode, driven by
events
coming from the XML parser. In effect, the code implementing a template rule operating
in
push mode is a Jackson inversion (Kay2009) of the code used to implement
the same template rule in the traditional architecture. This inversion is analogous
to
rewriting a top-down parser as a bottom-up parser: instead of the application being
in
control and making getNextInput() calls to the parser, the application becomes
event-driven and is called when new input is available. In consequence, the application
has
to maintain its own stack to represent the current state; it can no longer rely on
the call
stack maintained by the compiler of the implementation language.
The inverted code for a template is generated by the XSLT compiler, and consists (in
Saxon
9.2) of a sequence of pre-descent actions, a drill-down action, and a sequence of
post-descent actions. The pre-descent actions generally involve writing
startElement events or evaluating complete instructions; the post-descent
actions similarly involve either complete instructions or endElement actions.
These correspond to the instructions that are permitted as ancestors of the drill-drown
construct: mainly instructions such as xsl:element, which are classified as
divisible instructions representing the fact that their
push-mode execution can be split into two halves, realised by the entry points
processLeft() and processRight(). The drill-down action is one
of apply, copy-of, value-of, or skip,
and indicates what is to be done with the content of the matched element (the events
that
occur after the startElement that activates the template rule and before the
corresponding endElement). The value skip causes these events to
be skipped, and arises when the template rule contains no drill-down construct. The
value
copy-of indicates that a subtree is to be built from these events;
value-of indicates that a string is to be constructed by concatenating the
text nodes and ignoring everything else. Finally, the value apply indicates
that the events should be matched against template rules for the relevant mode; when
a match
occurs, the selected template rule will then receive the events until the matching
endElement event occurs.
This is all implemented using the a StreamingDespatcher that despatches events
to the relevant template rules. This functions in a very similar way to the
WatchManager described earlier, and in the current Saxon 9.3 code base the
two despatching classes have been combined into one.
Streamable Templates in Saxon 9.3
Saxon 9.3 (not yet released at the time of submitting this paper) extends streamable
templates to handle a much
larger subset of the XSLT language, while still falling a little short of the capabilities
defined in the XSLT 2.1 draft.
The first extension is in the area of match patterns for templates. Saxon 9.3 integrates
the two concepts of a match pattern
and a streamable XPath expression. This makes sense because both are implemented by
testing to see whether a given
node matches the pattern; the only difference is that with an XSLT match pattern in
non-streaming mode, the predicates can
contain XPath expressions that perform arbitrary tree navigation. For XSD selector
and field expressions, the parsing still
artificially restricts the path expression to conform to the XSD-defined XPath subset,
but the object that results from the parsing,
and that is used at run-time, is a Pattern object equivalent that used when starting from an XSLT match pattern.
The pattern used in a streamable template rule can be any XSLT pattern provided it
does not contain a predicate that is
positional (for example, is numeric or calls position() or last()) or that uses
the child, descendant, descendant-or-self, following, following-sibling, preceding,
or preceding-sibling axes.
The body of the template rule is inverted in the same way as with Saxon 9.2, but the
rules for what it may contain are less restrictive. There is still a rule that only
one
downward selection is allowed: more specifically, in the expression tree (abstract
syntax
tree) representing the body of the template rule, there must be only one leaf node
whose
path to the root of the expression tree contains a downwards selection. This path
through
the expression tree is referred to as the streaming route.
This rule is relaxed in the case where the template contains a conditional instruction
such
as xsl:choose; in this case each branch of the conditional may make downwards
selections. Unlike the XSLT 2.1 draft, Saxon does not currently allow a node in the
streamed
input document to be bound to a variable, or passed as a parameter to another template
or
function. A further rule is that the template must not return a node in the streamed
document (for example, <xsl:sequence select="."/>) - this is because there
is no way of analyzing what the caller attempts to do with such a node.
It is also possible, of course, for the template rule to make no downward selection
at all: this results in the subtree
below the matched node being skipped.
All the expressions that appear on the streaming route must be capable of push
evaluation, that is, they must have an implementation that is event-driven. Saxon
supports
push evaluation at two different levels of granularity (Kay2009),
parse-event granularity and item granularity; the corresponding event streams are
referred
to respectively as decomposed or composed streams. In the first case the expression
evaluator is notified every time a parse event occurs (for example, startElement and
endElement). In the second case, it is notified only for complete XDM items (nodes
or atomic
values). The sum() function supports push evaluation at the item level, which
means that given the expression sum(.//value), each descendant
value element is assembled as a complete node, which is then atomized, and
the resulting atomic values are notified one by one to the sum implementation, which
adds
each one in turn to the running total. By constrast, the functions count() and
exists() have implementations that work at the parse-event level, which means
that there is no need to build the nodes being counted as trees in memory: thus
count(.//employee) merely tallies the startElement events that match its
argument expression .//employee without ever building a tree representation of
an employee element.
A push component that takes a composed stream (XDM items) as input is referred to
as a feed; an evaluator
that works on a decomposed stream (parse events) is referred to as a watch. This classification
is based on the nature of the input stream. Orthogonally, the component may deliver
its result as either a composed or
decomposed stream: so there are four categories overall: a composing and decomposing
Watch, and a composing and decomposing Feed.
Examples of the four categories are shown in the table below:
Table I
Input/Output
Composed
Decomposed
Composed
remove($in, 3)
<e>{$in}</e>
Decomposed
data($in)
<xsl:for-each select="$in"/>
In general, the flow is that decomposed events arrive from the source XML parser.
After
some processing they are turned into composed items; these are then further processed,
and
eventually decomposed into events to be sent to the serializer. To make this more
concrete
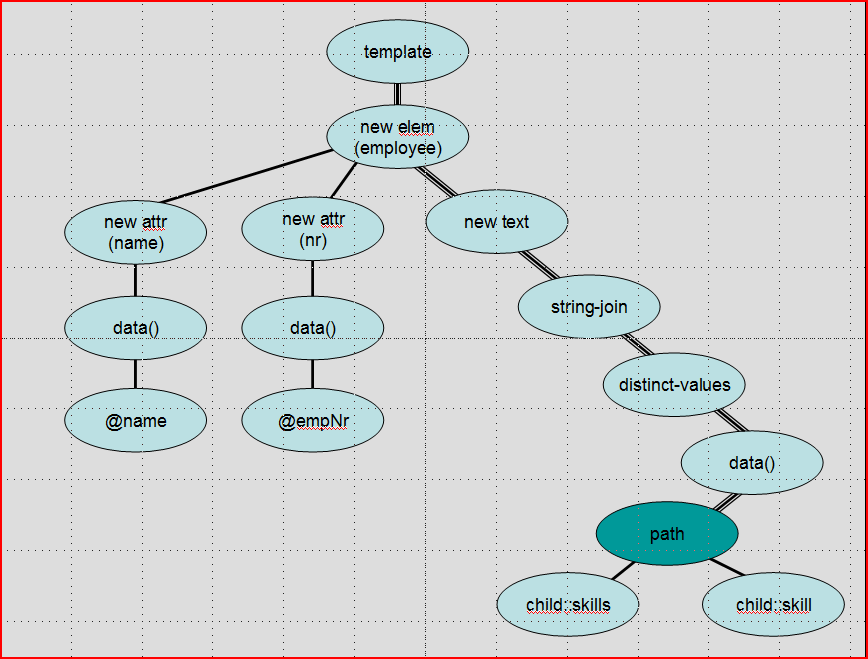
consider the streaming template:
The streaming route here contains a literal result element (employee), the
xsl:value-of instruction, the distinct-values() function call,
and the path expression skills/skill. It also contains expressions added by the
compiler, reflecting the implicit atomization and type checking performed by the
distinct-values() function, and the implicit call on
string-join() that is performed to insert separator spaces on behalf of the
xsl:value-of instruction. The full expression tree is shown in Figure 3, with
the streaming route highlighted.
Figure 3: Figure 3: The expression tree of a template, showing the streaming route
The expression tree omits some nodes, for example type-checking operators, for clarity.
The
highlighted "path" node acts as the Watch, looking for events coming from the parser
that match the
pattern skills/skill. The data() node composes these events into strings
representing the typed value of the skill elements; these are fed through the operators
found on the streaming route until they reach the <employee> element
constructor, which delivers a stream of events representing the newly constructed
element. Typically
these events go straight to the serializer. The parts of the expression tree that
are not on the streaming
route (the two attribute constructors) are evaluated in pull-mode as normal.
The distinct-values() function implicitly atomizes its input. So the first
thing that happens to the incoming data is that it is sent to a TypedValueWatch: this
takes
in a decomposed sequence of events and outputs a composed sequence of atomic values
representing the typed values of the skill elements. This is piped into a type
checker that checks that the values in this sequence are all strings. The type-checked
csequence is then piped into the component that evaluates the distinct-values()
function, which again outputs a composed stream (this being identical to its input
stream
except that values are removed from the stream if they have been encountered before).
The
xsl:value-of instruction is initially compiled into a pipeline of primitive
instructions that first joins adjacent text nodes, then atomizes, then inserts separators
between adjacent strings, then converts the resulting string to a text node; in this
case
the optimizer knows from type analysis that the first two steps are superfluous, so
we are
left with a pipeline that takes a composed sequence of strings as its input, and produces
a
composed sequence comprising a single text node as its output. Finally, the component
representing the literal result element employee takes this composed input, and
produces decomposed output consisting of a startElement event, two attribute events,
a text
node event, and an endElement event. Typically these events will be sent directly
to the
serializer.
An expression, of course, may have more than one sub-expression, and it may be capable
of push evaluation in respect of some of those sub-expressions but not others. All
expressions support push evaluation in respect of sub-expressions that are singletons
(cardinality zero-or-one). Thus, for example, the expression (sum(.//value) +
1) is streamable, because although there is no specific support for evaluating the
addition in push mode, the system is capable of constructing the two singleton arguments
and
using the conventional pull-mode addition. Many expressions also benefit from a generic
implementation in cases where an argument is a non-singleton sequence. This generic
implementation buffers the argument sequence in memory and then uses the pull-mode
implementation once the sequence is complete. This of course is not pure streaming,
but it
provides useful scaffolding to enable less commonly used expressions to appear in
a
streaming template while awaiting a pure streaming implementation. Currently this
mechanism
is used for comparison expressions such as .//value = 17 (recall that in XPath,
this returns true if at least one of the value elements is equal to 17); there
is no technical reason that prevents the creation of a pure push-mode implementation
of a
general comparison expression with respect to either argument, but it has not yet
been
implemented, and it is not a top priority because in the vast majority of cases the
arguments actually turn out to be singletons.
The compile-time template inversion process operates by means of a recursive walk
of the
expression tree. At every level there must be at most one branch that performs downward
selection; this branch is taken, and by this means the streaming route is identified.
The
process then attempts to identify the longest suffix of the streaming route that constitutes
a streamable pattern. For example, if the body of the template is <xsl:value-of
select="sum(.//value) + 1"/>, the streamable pattern is .//value. The
immediate parent of this pattern on the streaming route must always be an expression
that
can be evaluated as a Watch. The number of expressions implemented as a Watch is suprisingly
small:
TypedValueWatch handles all expressions that use the atomized value of the
selected nodes.
StringValueWatch handles all expressions that use the string value of the
selected nodes.
CountWatch handles the count(), exists(), and
empty() functions.
CopyWatch (the one we met earlier) handles xsl:copy-of.
VoidWatch is used for templates or branches of a conditional that make no
downwards selection.
SimpleContentWatch implements the rules for instructions such as
xsl:value-of and xsl:attribute; specifically, it
concatenates adjacent text nodes, removes empty text nodes, and reduces all other
nodes
to string values.
ApplyTemplatesWatch is used where the downwards selection appears in the select
expression of an xsl:apply-templates instruction, and also supports
xsl:apply-imports and xsl:next-match.
ForEachWatch is used where the downwards selection appears in the select
expression of an xsl:for-each instruction.
Most of these Watch implementations are composing: they emit a sequence of XDM items.
The two exceptions are the ForEachWatch and the ApplyTemplatesWatch, which
emit a sequence of parse events.
We have already seen the CopyWatch earlier in the paper: it is used for a
simple streaming copy, as well as for xsl:copy-of instructions appearing within
a streaming template. When it receives a startElement event representing an element
selected
by its controlling pattern (we'll assume to keep things simple that it is watching
for
elements), it starts building a tree. All subsequent parse events until the matching
endElement are directed to this tree builder. When the tree is complete, the node
at the
root of the tree is emitted to the Feed that implements the parent of the
xsl:copy-of instruction, that is, the parent expression in the streaming
route through the expression tree.
The StringValueWatch and TypedValueWatch work in a very
similar way, except that instead of building a tree from the incoming events, they
construct
the string value or typed value of the node by concatenating the values of those events
that
represent text nodes.
All these Watch implementations have a complication that has already been mentioned
for Streaming Copy: a startElement
event for a matching element might be notified while an existing matching element
is already being processed; that is, the
pattern that the Watch matches may select a node that is a descendant of another matched
node. For this reason, the Watch
does not actually construct the tree (or string value or typed value) directly; instead
it creates an event receiver
dedicated to this task, which it passes back to the WatchManager; the WatchManager
then notifies all events to all active
event receivers to do the necessary work, taking care of deactivating them when needed.
When the endElement event occurs,
the Watch passes the constructed tree to the next Feed in the streaming route only
if the matched element has no matching
ancestors; for an inner matched node, the tree is held in a queue until the outer
tree is complete, since the outer tree
comes first in document order and must therefore be notified to the waiting Feed before
the inner trees. This queue
again represents a departure from pure streaming; the XSLT 2.1 draft has an open issue
on this question.
The ApplyTemplatesWatch is similarly notified of the startElement event for
a node that matches the select expression of the xsl:apply-templates
instruction. It responds to this by searching for a matching template rule — this
is
possible because the constraints on match patterns in a streamable template ensure
that the
pattern can be evaluated when positioned at the startElement event (the object representing
the event, it should be mentioned, provides methods to get local properties of the
node such
as the name and type annotation, and also to navigate to the node's ancestors and
their
attributes). Having identified the template to be applied, which because it is in
a
streaming mode will always have been compiled with template inversion, it then gets
the
Watch expression identified during the analysis of the called template, and nominates
this
Watch expression to the WatchManager. All events up to the corresponding endElement
will
therefore be sent by the WatchManager to the called template, where the same process
continues recursively. At the same time, the same events are being sent to the calling
ApplyTemplatesWatch, because as with xsl:copy-of, it is entirely
possible for the select expression of xsl:apply-templates to
select an element that is a descendant of another element already being processed;
the
results of the processing of such nested elements will again be buffered.
The ForEachWatch operates in a very similar way to the
ApplyTemplatesWatch, except that there is no need to search for a matching
template. Rather, the body of the xsl:for-each instruction is compiled directly
as an inverted template and is invoked unconditionally for each startElement event
matching
a selected node.
A similar streaming implementation has been written for xsl:iterate; none
is yet available for xsl:for-each-group, but it is expected that it will follow
the same principles.
Conclusions
Streaming of XSLT transformations has long been an aspiration, and many partial solutions
have
been developed over the years. It has proved difficult or impossible to create streaming
implementations
of the full XSLT language as defined by W3C.
The draft XSLT 2.1 specification has been developed as a solution to this problem.
It
defines a subset of the full XSLT language that is intended to be streamable without
requiring
unknown magic on the part of the implementation, and at the same time it provides
extensions
to the language (such as xsl:iterate) that make it possible to write powerful
transformations without straying from the streamable subset. The design of the language
is
informed by experience with both XSLT 2.0 and STX, and by a large collection of use
cases
describing problems that benefit from a streamed implementation.
Successive releases of Saxon, some predating this work and some influenced by it,
have provided partial
solutions to the streaming challenge with increasing levels of sophistication. At
the time of writing, there are
many ideas in the specification that are not yet implemented in Saxon, and there are
some features in the Saxon
implementation that are not yet reflected in the specification. Nevertheless, development
of the language
standard and of an industrial implementation are proceeding in parallel, which is
always a promising indicator
that standards when they arrive will be timely and viable. Both the language and the
implementation, however,
still need a lot more work.
Saxon's approach to the problem is based on using a push architecture end-to-end,
to eliminate the
source tree as an intermediary between push-based XML parsing/validation and pull-based
XPath processing.
Implementing the entire repertoire of XPath expressions and XSLT instructions in an
event-based pipeline
is challenging, to say the least. However, enough has been completed to show that
the undertaking is viable,
and a large enough subset is already available to users to enable some serious large-scale
transformation
tasks to be performed.
References
[Barton2003] Charles Barton et al.
An Algorithm for Streaming XPath Processing with Forward and Backward Axes.
In Proc. 19 Int Conf Data Eng, Banagalore, India, 5-8 March 2003. ISBN: 0-7803-7665-X
http://www.research.ibm.com/xj/pubs/icde.pdf
[Dvirakova2008] Jana Dvořáková.
A Formal Framework for Streaming XML Transformations.
PhD Thesis, Comenius University, Bratislava, Slovenia, 2008.
[Dvorakova2009a] Jana Dvořáková.
Automatic Streaming Processing of XSLT Transformations Based on Tree Transducers.
Informatica: An International Journal of Computing and Informatics,
Special Issue - Intelligent and Distributed Computing, Slovene Society Informatika,
2009
[Dvorakova2009b] Jana Dvořáková and F Zavoral.
Using Input Buffers for Streaming XSLT Processing,
Proceedings of the International Conference on Advances in Databases - GlobeNet/DB
2009,
Gosier, IEEE Computer Society Press, 2009.
doi:https://doi.org/10.1109/DBKDA.2009.25.
[Guo2004] Zhimao Guo, Min Li, Xiaoling Wang, and Aoying Zhou.
Scalable XSLT Evaluation. In Proc 6 Asia-Pacific Web Conf, Hangzhou, China, 14-17
April 2004. ISBN 3-540-21371-6
http://arxiv.org/pdf/cs.DB/0408051
[Kay2009] Michael Kay.
You Pull, I’ll Push: on the Polarity of Pipelines.
Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14,
2009.
In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009).
doi:https://doi.org/10.4242/BalisageVol3.Kay01.
[STX] Streaming Transformations for XML (STX).
http://stx.sourceforge.net/ Retrieved 2010-07-10. Contains links to articles and presentations by Tobias Trapp,
Oliver Becker, and Petr Cimprich.
[1] Looking at this syntax, one might reasonably ask whether a pull pipeline would not
deliver the result with less complexity. For this example, it probably would. The
push
code was used primarily because it already existed and could be reused. But I think
this
is no accident: I tend to the view that components implemented with a push model are
likely to be reusable in a wider variety of configurations. For more details on push
versus pull pipelines, see Kay2009.
[2] In Saxon 9.2, the element is in the Saxon namespace as saxon:mode
Charles Barton et al.
An Algorithm for Streaming XPath Processing with Forward and Backward Axes.
In Proc. 19 Int Conf Data Eng, Banagalore, India, 5-8 March 2003. ISBN: 0-7803-7665-X
http://www.research.ibm.com/xj/pubs/icde.pdf
Jana Dvořáková.
Automatic Streaming Processing of XSLT Transformations Based on Tree Transducers.
Informatica: An International Journal of Computing and Informatics,
Special Issue - Intelligent and Distributed Computing, Slovene Society Informatika,
2009
Jana Dvořáková and F Zavoral.
Using Input Buffers for Streaming XSLT Processing,
Proceedings of the International Conference on Advances in Databases - GlobeNet/DB
2009,
Gosier, IEEE Computer Society Press, 2009.
doi:https://doi.org/10.1109/DBKDA.2009.25.
Zhimao Guo, Min Li, Xiaoling Wang, and Aoying Zhou.
Scalable XSLT Evaluation. In Proc 6 Asia-Pacific Web Conf, Hangzhou, China, 14-17
April 2004. ISBN 3-540-21371-6
http://arxiv.org/pdf/cs.DB/0408051
Michael Kay.
You Pull, I’ll Push: on the Polarity of Pipelines.
Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14,
2009.
In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009).
doi:https://doi.org/10.4242/BalisageVol3.Kay01.
Streaming Transformations for XML (STX).
http://stx.sourceforge.net/ Retrieved 2010-07-10. Contains links to articles and presentations by Tobias Trapp,
Oliver Becker, and Petr Cimprich.