Ford, Katherine, and Will Thompson. “An Adventure with Client-Side XSLT to an Architecture for Building Bridges with
Javascript.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Thompson01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: An Adventure with Client-Side XSLT to an Architecture for Building Bridges with
Javascript
Will Thompson leads software development on core technologies for O’Connor’s Online,
the web-based legal research platform that complements the company’s expanding library
of
mostly home-grown (and mostly Texas-based) legal books. Will works on a wide array
of
software, from back-end editorial toolchains to customer-facing search engines.
This paper describes the development process we undertook to extend the capabilities
of
an XML-based authoring and publishing system. Originally designed to deliver content
for
print and the web, we transformed it into one that delivers fully interactive web-based
wizards whose steps are generated automatically based on logic encoded into the source
documents. To meet our requirements for the application, we rejected conventional
top-down
XML or JavaScript frameworks and instead sought to unite JavaScript and XSLT to leverage
the
strengths of each.
Despite being underutilized as a client-side technology, XSLT is still a valuable
tool
in the development of modern web applications. Its expressive nature, continuing support
in
browsers, and ability to integrate with a modern virtual DOM-based user interface
framework
allowed us to build a complex legal forms application that was simpler and more productive
than more conventional approaches. Our application demonstrates opportunities for
symbiosis
with client-side XSLT that has potential beyond legal forms and for an architecture
with
implications beyond XSLT.
Two decades ago, XSLT was a rising client-side star. XSLT, Java applets, and a array
of
other client-side technologies held great promise to fulfill dreams for the Web that
then-nascent HTML and JavaScript were unfit to deliver. Unlikely as it seemed at the
time
given the broad enthusiasm, not one of these technologies prevailed—none even survived!
In the intervening years, HTML and JavaScript have grown into much more powerful
technologies, but it should be at least somewhat surprising that everything else simply
evaporated, and the only thing to fill the void was more JavaScript. For a moment,
we seemed
headed for a polyglot client development environment, but a monoculture evolved—and
even
thrives—nonetheless.
Like Java, XSLT has lived on as a server-side technology, albeit in more specialized
environments. Unlike Java, however, client-side XSLT is not forbidden, just forgotten.
Remarkably, browser-native XSLT implementations have survived decades of rapid technological
change, leaving traces of a future unrealized.
XSLT in the client is of course not entirely forgotten. The vital necessity of XML
motivates an ecosystem of XML-centric tools that extend into the browser, including
modern
versions of XSLT written in JavaScript. But an unmistakable separation exists between
the XML
community using these tools and the larger web community—the JavaScript and HTML community—as
a whole.
Certainly something must have been lost in siloing these innovative communities. We
can
look back two decades and imagine a different future, one where multiple languages
and
technologies survived, stimulating virtuous cycles of interaction. Two decades in
tech is an
especially long time, but are we really that far from that possibility now, and were
we
ever?
Throughout the long and somewhat winding road to implementing a complex new feature,
we
present justification, both practically and philosophically, not only for client-side
XSLT,
but for an architectural pattern that reconciles a division between XSLT and JavaScript.
And
we demonstrate, generally, the benefits of pursuing bridges across these divides.
Improving an application
Interactive documents
As a legal publisher, one of our main product categories is template-style forms for
attorneys, which have undergone a limited evolution in their path to electronic delivery.
We
have traditionally delivered forms to customers as printed books of forms and subordinate
forms for the customer to fill in and manually assemble into a complete document.
More
recently, we launched a subscription-based online service to deliver all of our content
from
the web. A departure from a book-oriented concept, the online service joins all of
our
content together, so users can search across the complete corpus, browse content organized
by topic or practice area, annotate, and download forms.
Despite the improved convenience in finding and using digitized forms, the fundamental
format of the forms themselves remains print-oriented. The forms include several variations
for each section, from which the user selects the most relevant. They are modular,
with
written instructions describing conditions under which to include other relevant subforms.
It is up to the user to find and fill in blank fields, many of which repeat throughout
the
form, select the appropriate sections, and assemble all of the necessary subforms
into a
master document. As users generate collections of practice-specific forms, they are
also
responsible for maintaining their personal collection of forms for future reference
or
reuse.
Unlike our other content types, with forms we aim to provide to the user not just
relevant information, but a path to a completed document. Our goal in improving our
online
forms application was to bring the user further down that path, shifting the overhead
of
managing field data and conditional form structures into the software. We wanted to
offer a
streamlined, interactive experience.
User interface
Of the many systems already built for assembling documents interactively, we observed
two common concepts. The first is a document-centric user interface, in which interactive
elements are inserted or overlaid to help the user identify what to complete in a
WYSIWYG
view. The second, known as the wizard (or assistant) pattern is an abstraction from
the
document that transforms it into an ordered sequence of steps.
Simpler documents are easily presented in WYSIWYG views, similar to our print documents,
replacing empty fields in the print document with interactive fields on screen. Entering
information into one field automatically updates corresponding fields throughout the
document.
This approach is simple and elegant; however, it fails to scale as the rules for
generating a document become more complex. Specifically, as the amount of conditionally
included content increases, changes to variables with dependencies may have broad,
cascading
effects across a document. The simplicity of the document-centric user interface begins
to
break down as it becomes harder to visually convey these cascading effects or their
underlying dependencies. The document is interactive, but unstable and cluttered.
Figure 1: Cascading updates: WYSIWYG
Changes may occur anywhere in document (above or below), and without visual cues or
directives to compensate for the volatility, reasoning from one change to the next
becomes
more nebulous, manifesting as cognitive overhead for the user.
Using a wizard, the larger task is simplified by automating the work of breaking down
a
complex decision tree into linear ordered steps. Changes resulting in cascading effects
are
simple to handle and in most cases are completely hidden from the user. Because the
interface only presents a single step at a time, inputs resulting in drastic structural
changes to the document are not automatically thrust upon the user.
Figure 2: Cascading updates: Wizard
If changes suddenly reveal new incomplete content, the new content is processed into
new
steps, which can be appended to the active sequence without disturbing the user. The
ability
to maintain linear user interface complexity as the underlying problem grows non-linear
is a
profound improvement.
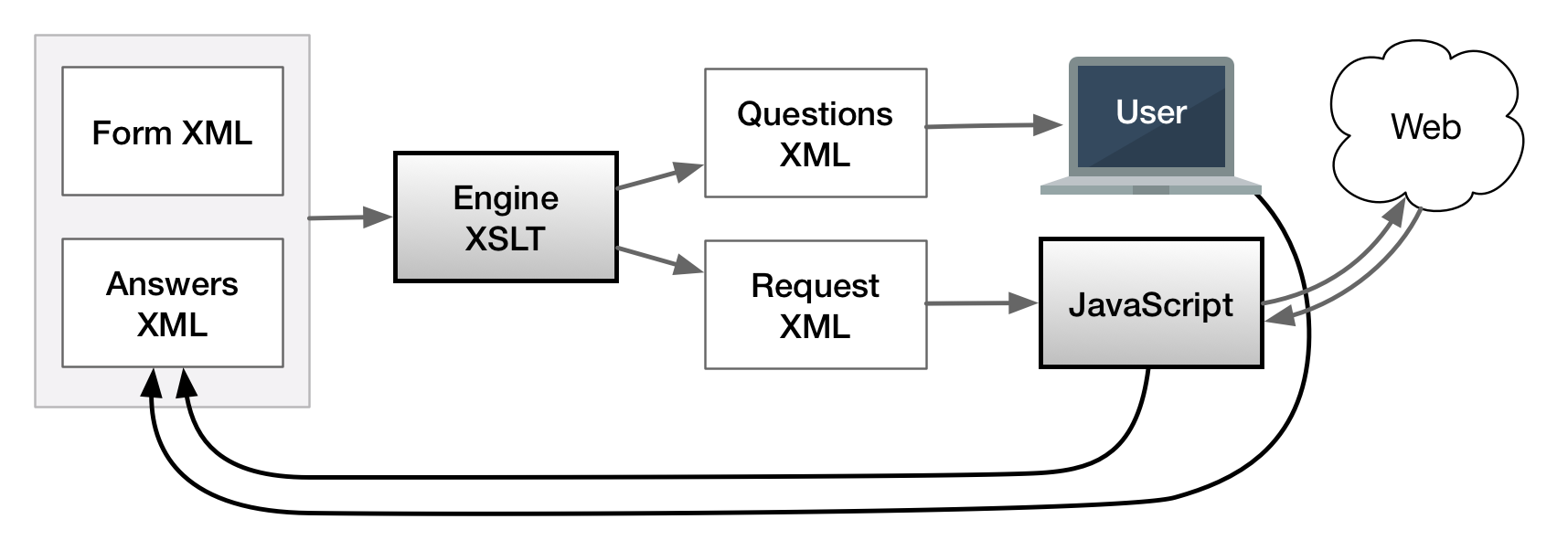
Providing this interface for documents, however, subdivides the problem of generating
a
user interface into two problems. Before the graphical part of the interface can be
built
from steps, it must first be possible to automatically generate steps from an incomplete
document. The complexity problem manifesting in the user-interface in the WYSIWYG
GUI is
hidden, but not eliminated. A software component is needed to transform incomplete
documents
into steps.
Figure 3: Wizard application architecture
Faced with the trade-off between building this new component or dealing with the
inadequacies of a document-centric UI, there was very little to consider. Many of
our forms
are dozens of pages long and highly variable, and it was clear that only the wizard
interface would be able to scale to meet our needs.
Requirements
Authoring system integration: We had already heavily customized Arbortext Editor to
author our complete library of products, each of which is marked up using an in-house
schema. Our authors would be responsible for encoding the data required by the form
and
defining relationships between the data and the structure of the forms, so it was
crucial that the authoring for automation integrated well into our existing authoring
and publishing workflow. The solution must use our existing authoring tools and a
print-compatible schema.
Online product integration: The solution must integrate with our existing online
content platform and with any new features for managing user data. The customer
experience of interacting with forms should be streamlined, but none of the existing
functionality should be removed. The full text of the forms must still be viewable
and
searchable online. The fully assembled, filled-in forms must be downloadable in editable
word processor formats. Additionally, data entered by the user in other applications
must be available to use in forms.
UI/UX consistency: The user interface and user experience should fall in line with
the conventions set by our existing applications. It should be fast, responsive, and
look and feel modern to customers.
Sensible: It must be feasible for our small team to implement and maintain the
entire system. The responsibilities of the software would be broad and complex,
including extensions to authoring tools, the automation engine backend, a sophisticated
user interface, and integration with our other applications. Its scale was daunting
from
the beginning.
A third-party solution
The scope of work to build the system we envisioned was immense, so we looked to
third-party products that might reduce that scope to something more suitable for our
team. Our
research led us to a product that provided an end-to-end solution, from document authoring
application to web server. It was modular and customizable enough to supply the components
that we did not already have, and its documents were XML, so it seemed feasible to
integrate
its automation and UI components with our own authoring tools.
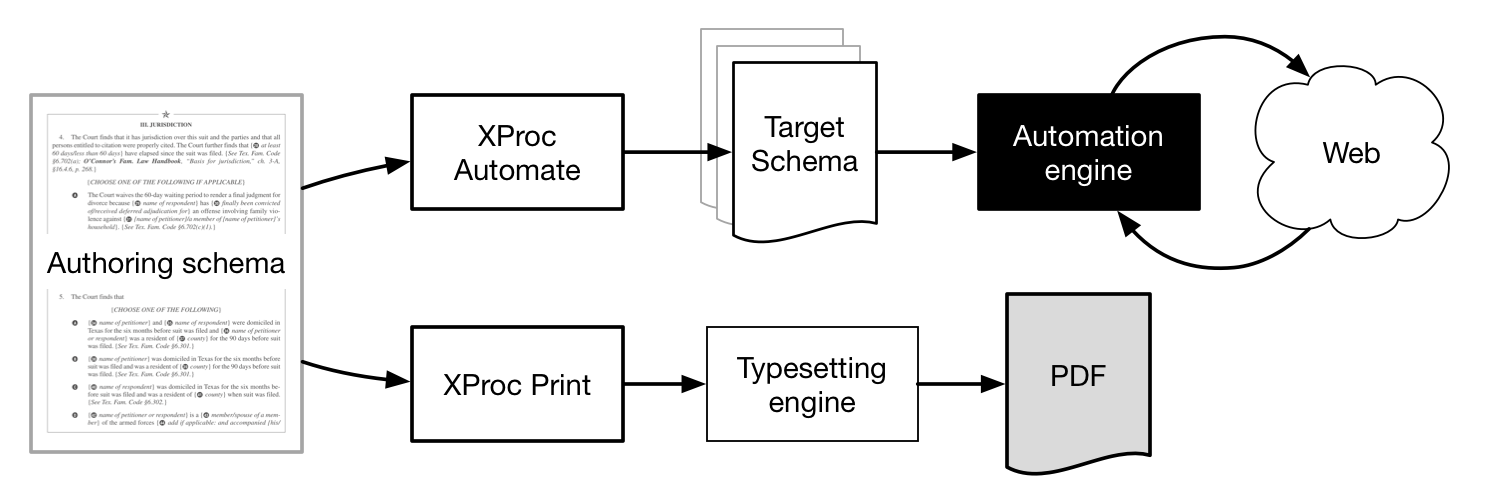
The authoring environment became the first focus of our integration effort, and we
set out
with the goal of substituting their editor, designed specifically to work in their
schema,
with ours, using an in-house composite schema that overlays automation logic over
our original
print-oriented markup.
Figure 4: Authoring/automation hybrid schema
The composite schema became the canonical format for these documents. Where in our
previous system print and authoring shared the same schema, now print would become
more like
our online application, treating it as an intermediate format and relying on pipelines
to
transform documents from the canonical source to its application-specific target schema.
We
also built an entirely new pipeline for the automation workflow, executed in XProc,
to
generate documents needed by the third-party automation engine.
Figure 5: Authoring and publishing pipeline
The integration added extra steps and rough edges to the authoring and publishing
workflow, but it was successful to the extent that we were able to work using our
native tools
and automate a wizard using the third party application. With the authoring back-end
up and
running, we began encoding documents and testing automation, and our software development
efforts shifted focus to integrating the wizard into our vision for the customer-facing
application.
The automation engine was well equipped to accommodate extension and customization
through
APIs and extensibility hooks, and we intended to augment the wizard with new features
to
integrate it into an array of tools that would make up the complete document automation
and
data management system. This meant writing a number of software extensions to manage
connections between the wizard system and our tools and database. We advanced quickly
toward a
prototype; however, as we transitioned from application plumbing to refining details,
a
serious flaw in our plan became clear. Out of the box, the wizard’s features were
deceptively
close to what we needed, but we found ourselves pushing the limits of the software’s
extensibility interfaces past their intended use case.
As the integration advanced, it accumulated layers around the wizard engine, which
itself
was mostly opaque as our insight was limited to verbose and unfamiliar log files.
Our team had
grown accustomed to an agile process of quick iterations, but as we moved from one
change to
the next, each step became more of a slog. We found ourselves, in effect, trying to
treat a
fully-featured application as if it were a software library. The result was that ordinary
refactoring and design updates snowballed in difficulty as the connective components
sprawled,
causing debugging to become unwieldy, and productivity dwindled.
This led to a significant shift in our expectations. The benefit of using the third-party
engine became uncertain, and it was conceivable that we could build our own engine
in the time
it might take to complete the integration. We made a hard decision to shift course
and set the
integration project aside to develop our own engine.
We sunk many hours into the integration process, but discarding the automation engine
did
not send us back to the drawing board. The Arbortext customizations, composite schema,
and
pipelines would all be useful scaffolding for the development of our own system, and
the
experience led us to shift our priorities towards minimalist architecture and faster,
iterative development.
Unifying XSLT and JavaScript
While we were happy to unburden ourselves of the responsibility for both working around
and integrating a third party engine into our existing system, in its place was the
imposing
task of green-fielding an entirely new replacement. However, it was an opportunity
to rectify
many aspects of the previous system with which we were dissatisfied.
Despite the fact that we were pushing the previous system beyond its limits, the process
left us squeamish about the prospect of building yet another ungainly system. We therefore
felt it was important to prioritize certain high level design goals to safeguard against
that.
In an effort to reduce dependencies and maximize flexibility as we developed the system,
we
chose to emphasize loose coupling across major components and to build the automation
engine
specifically with a focus on efficiency and portability. Practically speaking, we
aimed to
avoid redoing work, so it seemed prudent to protect the parts of the system with the
most
exposure to changes.
Thinking about designs for a wizard engine, its overall task had a state machine feel:
form documents would contain references to missing data—some inline, some as the result
of
satisfying a condition—and given new data, a document would be transformed to either
reveal
references to data that needed to be requested, or it would be complete.
Considering that our documents were already XML and that generating wizard steps from
a
document would frequently require walking document trees, the problem seemed like
a natural
fit for XSLT. We were hesitant to rule out JavaScript, however. Modern JS is not only
highly
optimized to run in web browsers, but through Node.js and other similar implementations
it has
grown into a very capable cross-platform server environment, and it has even permeated
some
databases as a native scripting language, including MarkLogic Server. JavaScript’s
ubiquity
has expanded to the point that it would be hard to imagine a more portable language.
However, this component would be the bedrock of our overall application, so it was
especially important that the language we chose align well with the task we needed
it to
accomplish, and we shared the opinion that “... in the areas where XSLT is strong,
Javascript
is at its weakest. Simple document transformation tasks … are painfully tortuous.”
[Delpratt and Kay 2013a]. In fact, not only is XSLT widely supported in server environments, but
also in web browsers, natively if XSLT 1.0 is sufficient, or by way of JavaScript
and Saxon if
XSLT 2.0 or 3.0 is needed. We therefore sought to develop our new engine using XSLT,
to
capitalize on its idiomatic approach to XML processing and because it satisfied our
need for
portability.
The three environments in our technology stack, MarkLogic Server, Microsoft .NET,
and
client-side JavaScript, could all run XSLT natively. Because the application would
be highly
interactive, we preferred a client-side solution to reduce architectural complexity
and
network chattiness. Running the automation engine in the browser would reduce the
need for
round-trip requests to the server, increasing the responsiveness of the application
and
reducing server load. We did not yet know whether that would be feasible, either using
browser-native or third-party XSLT processors, but we thought the advantages made
it worth
exploring.
Next, this application would be one of several that make up our online platform, and
we
had to consider how it would fit into our development and maintenance process. It
is a
universal priority that our product UIs look and feel modern to customers, so despite
our vast
reliance on XML technologies to deliver most of the functionality in our products,
we continue
to develop our UIs using modern JavaScript frameworks and libraries to maintain a
level of
polish that we think is commensurate with the quality of our editorial content and
print
formatting. Although a small but useful ecosystem of web frameworks and libraries
for building
interactive UIs with XML exists, including Saxon-JS, XForms, and more, we predicted
that in
light of our existing software stack, the conveniences gained from developing a new
UI using
native XML technologies would probably be overwhelmed by the burden of managing an
additional
and more esoteric library. So we added another constraint: the XSLT implementation
must also
play nice in a modern JavaScript UI environment.
Finally, one can only evaluate the suitability of a design to the extent that it is
possible to know the scope of its requirements, and throughout the development of
this
application we discovered new requirements and unforeseen complications. What initially
seemed
like a straightforward and intuitive document-oriented design gradually increased
in
complexity. Far into development, this led us to question the suitability of our design
and of
our choice to use XSLT to implement it. We will demonstrate how we eventually determined
that
the best way to overcome our complexity barrier was by rethinking our approach to
the problem,
rather than by changing the technology.
XSLT implementation
Our ideal solution would run in XSLT in the browser, but we did not know whether the
native implementations or even third-party JavaScript-based XSLT processors would
be able to
meet our requirements. To our surprise, we discovered that developing for browser-native
XSLT 1.0 processors was not only feasible but much less difficult than expected, and
added
significant performance benefits.
Client-side options
We first researched the state of browser XSLT processors and found mostly old or
conflicting information, but there were only three third-party XSLT implementations
to
consider: frameless.io, Saxon-CE, and Saxon-JS. We could not confirm that the frameless.io
processor was still actively being maintained, so it was ruled out. We were concerned
that
Saxon-CE’s large library size would result in slow loading times [Delpratt and Kay 2013b] or that it may not perform adequately for our stylesheets[1][2], and its replacement, Saxon-JS, had not yet had its first major release. Given
our imperfect options, we theorized that native XSLT 1.0 processors should be simple
to
adopt, considering they were already native to every component in our stack, fast,
and
adequate functionally to build a prototype. Though we were not convinced it would
be
possible to fully implement our application using only browser-native XSLT
implementations, we decided that because little work would need to be redone if we
failed,
it was worth exploring, keeping Saxon-JS in mind as a fallback if we discovered browsers’
implementations were too broken, or if the limitations of XSLT 1.0 made it too difficult
to continue.
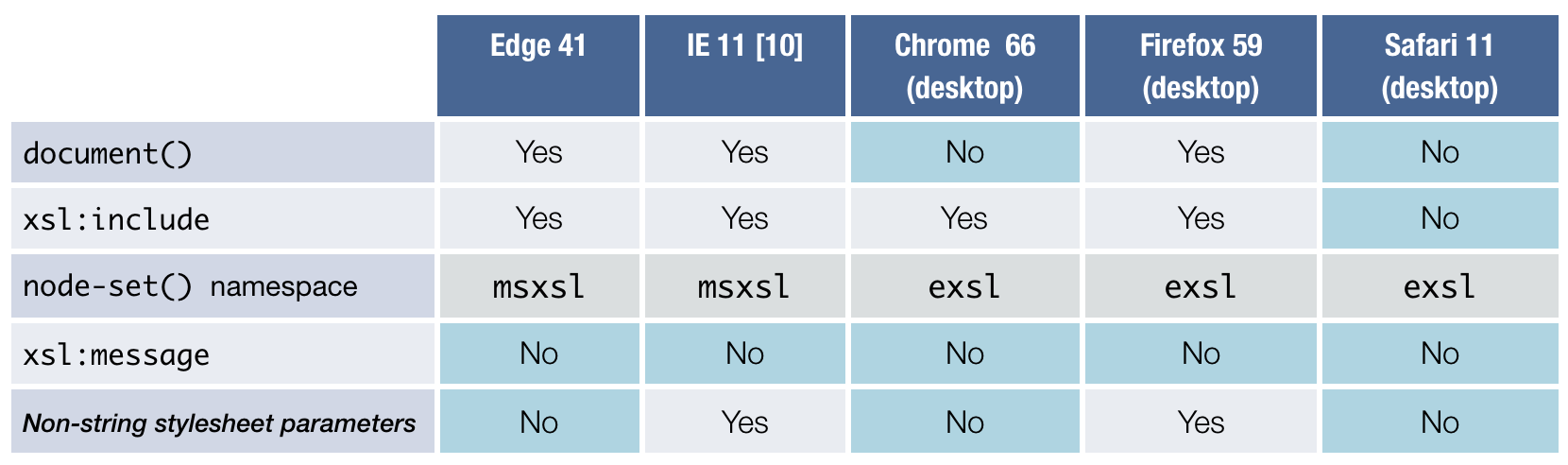
XSLT 1.0 support
When we started the project in December 2016 we were not even sure if all desktop
browsers still included fully working native XSLT processors. We found results of
testing
as recent as 2015 [Reschke 2015], and our own testing verified that the results
had not changed in current releases. Since the level of support had been stable for
almost
a decade (despite an effort to remove XSLT support from Google’s Blink browser engine
in
2013 [Barth 2013], we felt cautiously confident in the stability of
browser-native XSLT processors going forward.
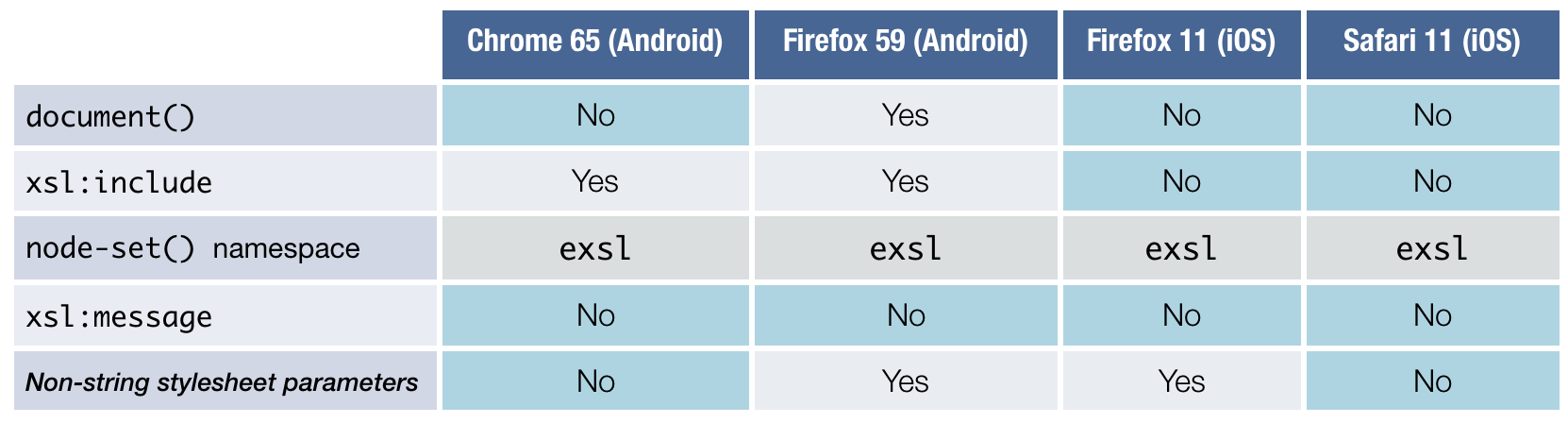
Desktop browsers would not be the end of the road for this project, however. While
we
view mobile phones as an inadequate form factor for an application like ours, we think
tablets have the potential to be as productive as desktop computers. On Apple’s iOS
and
Google’s Android platforms, mobile and tablet devices share essentially the same browser,
and it was important that we build on technology supported by both of those platforms
to
avoid a dead end. We confirmed through our own testing that mobile versions of Chrome,
Firefox, and Safari have indeed reached the same standard of XSLT support as their
desktop
counterparts.
Having established XSLT 1.0 processor support in every major desktop and mobile
browser, we back-ported our prototype to XSLT 1.0 and set out to test the level of
completeness for each. None of the missing features in the browser processors were
severe
enough to scuttle our experiment, and the same proved true of XSLT 1.0 itself. Though
1.0
lacks the expressiveness and the convenience of later XSLT versions, we produced a
functional implementation of our design with minimal frustration.
Figure 6: Desktop browser XSLT compatibility
Figure 7: Mobile browser XSLT compatibility
Adjusting to limitations
Two specific limitations of the browser XSLT implementations necessitated adjustments
to module boundaries and responsibilities within our design. Ostensibly due to vendor
concerns about security, browser XSLT environments have been heavily restricted in
their
ability to (1) make requests for external resources and (2) receive external input,
prompting us to shift those responsibilities from XSLT to JavaScript using a simple
message-passing system.
The first limitation stemmed from incomplete support for document() in
Apple’s WebKit and Google’s Blink XSLT processors. The Chrome security model does
not
allow its XSLT processor to access any local or external resources[3], but we required our application to request external data and to submit user
progress to our server. We moved responsibility for executing these requests and
processing their results to the JavaScript application, which had the additional benefit
of easier request handling for JSON data.
The second limitation, due to another years-old WebKit bug[4] (pre-dating Blink and therefore still present in both Chrome and Safari),
prevented us from supplying external parameters to the XSLT processor in any type
other
than a string. Without support in XSLT 1.0 for sequences or advanced string processing
functions to deserialize string input, submitting new information to the application
via
stylesheet parameters became untenable. To compensate, we allowed our JavaScript
application to submit new data by storing inputs directly in the source XML document,
further extending the message-passing system.
Figure 8: XSLT/JS message passing
The request messages returned in the XSLT output contain a description of an
HTTP request and instructions for processing it. The instructions include an ID,
expected response type, and if the type was JSON, a JSPath expression [9].
JavaScript checks for these request descriptors and executes them, evaluating a
JSPath expression against the response when applicable, and returned results to the
document processor as ID/result key-value pairs.
Other, smaller limitations were resolved by preprocessing our stylesheets. To work
around a broken xsl:import/xsl:include implementation in Safari, we created a new
stylesheet to merge the main stylesheet and its included modules into a single
file[5]. Though Microsoft browsers support node-set(), their
implementation is in the msxsl (urn:schemas-microsoft-com:xslt) namespace instead
of the
otherwise universal ext (http://exslt.org/common) namespace, so when the engine stylesheet
was requested by a Microsoft browser, we replaced it with the msxml namespace, also
using
a stylesheet to perform the transformation.
Unfortunately, browsers are not friendly environments for debugging. Lack of support
for the only standard debugging feature in XSLT, xsl:message, was universal across the
browsers we tested. Microsoft Edge was the only browser that output any error logging
to
the console at all. All other browsers failed silently.
Though the lack of certain XSLT 2.0 features was inconvenient, they were mostly
ergonomic, and we found reasonable alternatives. The most conspicuously absent features
relevant to the needs of our application were string-join(),
tokenize(), case-insensitive comparisons, range expressions, regular
expressions, and xsl:for-each-group. Examples of our XSLT 1.0 alternatives to
these functions are listed below:
<!-- returns a set of N <n/> elements to replace [1 to N] -->
<xsl:template name="range-expression">
<xsl:param name="n"/>
<xsl:param name="counter" select="1"/>
<xsl:choose>
<xsl:when test="$counter > $n"/>
<xsl:when test="$counter = $n">
<n><xsl:number value="$counter"/></n>
</xsl:when></code>
<xsl:otherwise>
<n><xsl:number value="$counter"/></n>
<xsl:call-template name="range-expression">
<xsl:with-param name="n" select="$n"/>
<xsl:with-param name="counter" select="$counter + 1"/>
</xsl:call-template>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
Regular expressions
Process server-side and replace with more template-friendly XML. Some simpler
regexes can be approximated using contains(),
substring-before(), and substring-after(), but we do not
advise that approach generally.
xsl:for-each-group
Double Muenchian grouping with a second, compound key[6]
In our initial design, we considered the ordering of questions displayed by the wizard
to be a grouping problem, prompting a serious discussion about switching to an XSLT
2.0+
implementation for its superior grouping support. The double Muenchian grouping technique
with compound keys, noted above, had become increasingly elaborate and difficult to
maintain, as we needed to order questions on several different levels.
This led us to step back and question assumptions we made about the problem we were
solving generally, and we determined that we needed to revisit our data model. As
we
explain in more detail later in this paper, instead of focusing solely on the form
documents that were mostly pertinent as input and output to the interview process,
we
changed the model to center around the interview process itself. In our new model,
we
could more easily manage relationships between data, which allowed us maintain questions
in the correct order throughout processing and incidentally avoid the need for grouping
entirely. Working in XSLT 1.0’s more constrained environment forced us to acknowledge
and
address flaws in our initial design that the added conveniences of XSLT 2.0 might
have
allowed us to work around, and we arrived at a more robust solution sooner than if
we had
pressed on with band-aid fixes.
The workarounds needed to achieve anything useful in multiple environments are real
impediments, but our judgment is that relative to the work required to set up nearly
any
modern programming environment, the scale is small. With awareness of these issues
upfront, getting up and running should take a matter of hours, not days. One
disappointment throughout this experiment, however, was the consistency with which
browser
vendors have apparently de-prioritized fixing XSLT bugs. Most of the bugs have lain
dormant in issue trackers for years, many including the tag “WontFix." However, that
was
not universally true. From the time we started this project to the time we began drafting
charts for this paper, Microsoft fixed the Edge bug[7] preventing the use of xsl:import. Progress is possible.
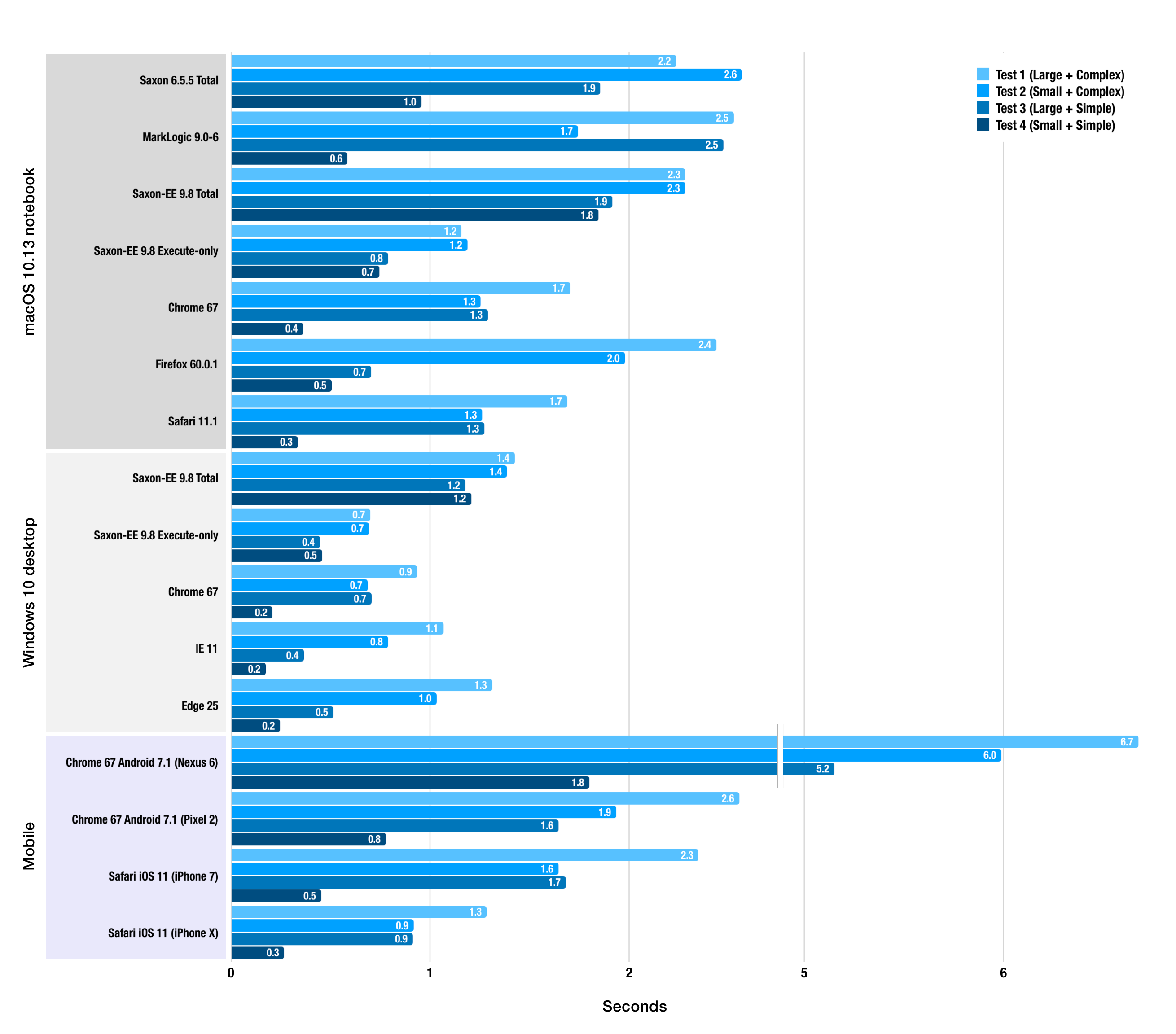
Performance
The results of our performance testing strongly affirmed our decision to stick with
browser-native XSLT processors, to a remarkable degree. We had not expected desktop
browser processors to perform comparably to Saxon-EE, but they did and even reliably
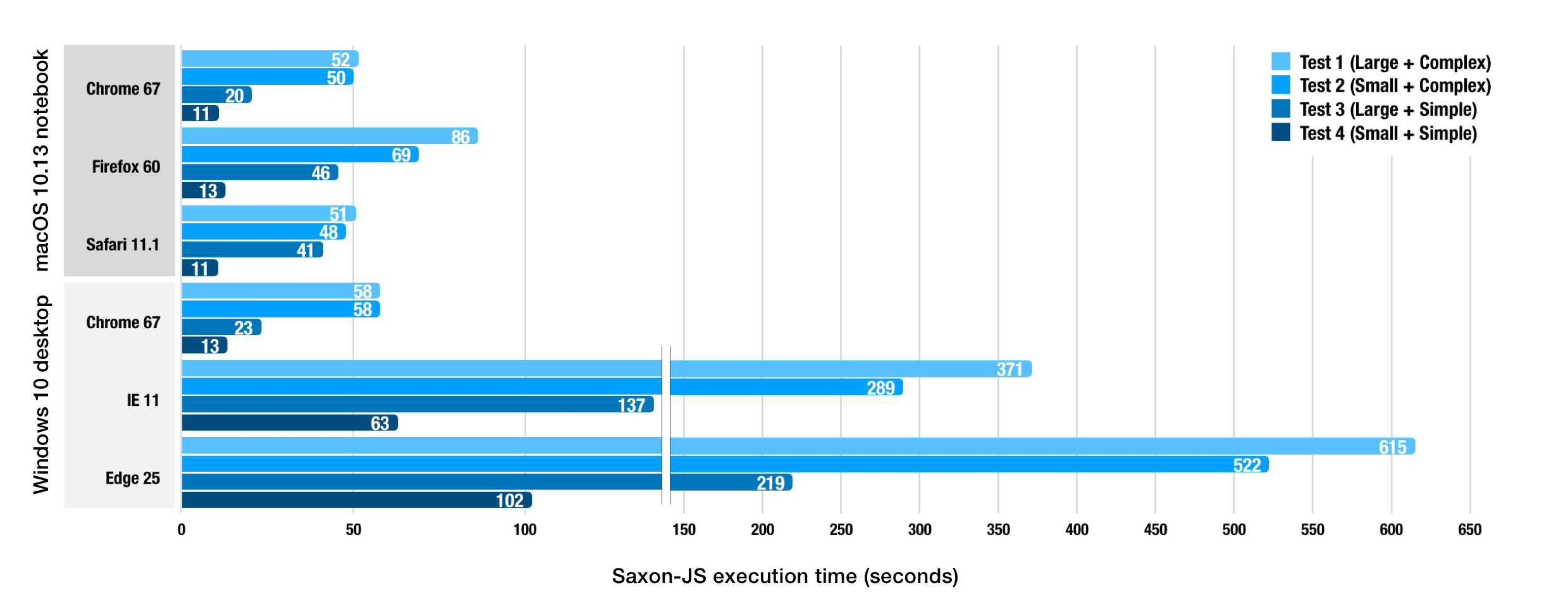
outperformed Saxon-EE for one of our test cases. We tested Saxon-JS with SEFs generated
using Saxon 9.8 and found that it was at best an order of magnitude slower than the
built-in processors.
Note: Saxon-JS Update
Before publication, we shared our tests and results with Saxonica. After investigating
our
workload, they attributed the disparity in XSLT evaluation times primarily to repeated
copying of
DOM subtrees and assured us that they are working to address this in future versions
of Saxon-JS.
Even mobile browsers’ native XSLT processors returned results that,
while slower than desktop equivalents, were acceptable for our application. Using
native
client-side XSLT 1.0 provided not only more minimal architecture and lower server
load and
round-trip latencies but comparable and sometimes much faster processing times than
any
other solution we considered.
Figure 9: Browser-native and Saxon-EE XSLT Peformance
Figure 10: Saxon-JS XSLT Performance
Note: Testing environments
"macOS 10.13 notebook" hardware: MacBook Pro (Retina, 13-inch, Early 2015), 16GB
RAM. "Windows 10 desktop" hardware: Dell OptiPlex 7040, 3.4 GHz Intel Core i7 (4-core),
16 GB RAM. Saxon-EE tests were run using Java 1.8.0. Test documents: Test 1: 980 kB
& complex XML, Test 2: 588 kB & simple XML, Test 3: 700 kB & complex XML,
Test 4: 189 kB & simple XML.
We had not expected our experiment using browser-native XSLT processors to be
ultimately successful. It would have been easy to assume that the combination of XSLT
1.0's limited feature set and an accumulation of browser processor bugs was enough
disqualify the browser-native XSLT environment for any serious project, and that
perception is certainly real. But the breadth and complexity of our application and
our
ability to achieve better performance with more minimal architecture is strong evidence
to
counter that perception.
JavaScript implementation
An all-XSLT or an all-JavaScript client development environment would lead to additional
complexity, either in the management of the UI or in the development of the automation
engine, so we sought a solution that could unify XSLT with a modern JavaScript UI.
Defining
modern in the context of JS technologies is a contentious subject and one with a moving
target. We attempt to define it as simply as possible, based on the observation that
a new
pattern has emerged in web development. Most recently, front-end web development was
dominated by monolithic two-way data binding frameworks like AngularJS or EmberJS
[Allen 2018]. Now, those large frameworks are giving way to preferences for a looser
mix-and-match approach to assembling tailor-made frameworks centering around a virtual
DOM-based view library like React or Vue.
Modern architecture
The virtual DOM is an abstraction of the browser DOM, and its key innovation is its
ability to very quickly compare an updated virtual DOM to the current one, then calculate
optimal steps to update the browser DOM based on the computed difference. This unburdens
a
front end developer in at least two important ways. First, it completely abstracts
away
the problem of managing explicit browser DOM updates—a revolution for front end developers
and its primary appeal. Second, and most relevant to our application, it enables us
to
build UIs with functional architectures.
Virtual DOM libraries are intentionally narrowly focused architecturally on only the
view component, whereas the previous frameworks provided a full architecture like
MVC[8] or MVVM[9]. Several popular functional reference architectures have emerged to fill the
void, available as minimalist frameworks that wrap a virtual DOM library and manage
application state. They all share a common theme: strict unidirectional data flow,
a
significant departure from the bidirectional data flow of the previous generation
of
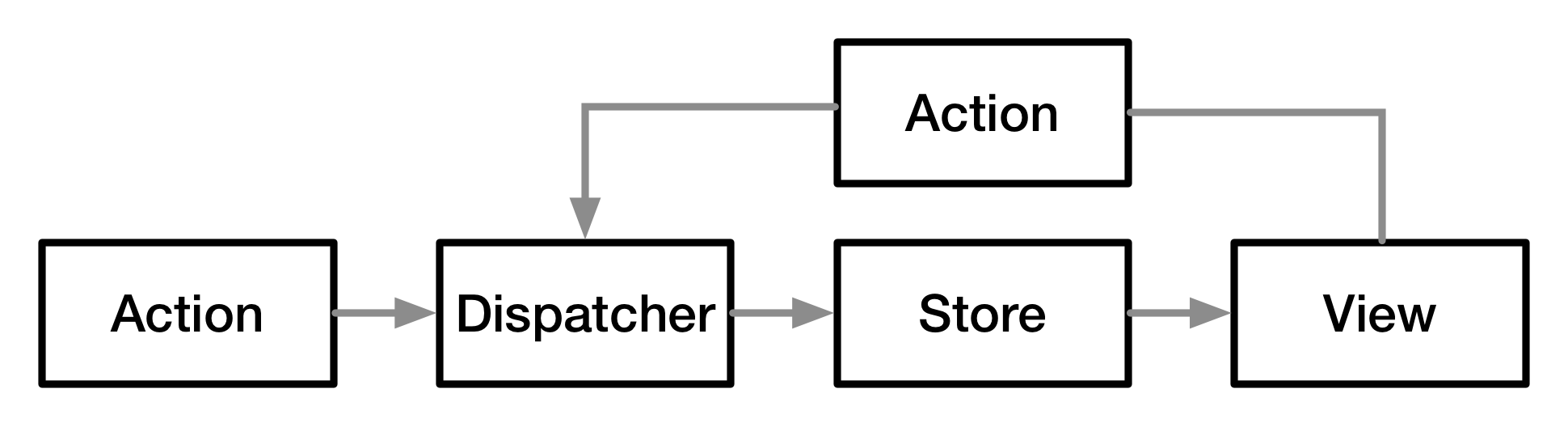
frameworks. The first such framework from the creators of ReactJS, Flux, demonstrates
an
architecture that separates concerns using this new idea.
Figure 11: Flux architecture
Because the virtual DOM engine will automatically apply surgical updates to the
browser DOM based only on what has changed in the view, developers are free to reason
about a view as if the page is being completely re-rendered every time. For some,
suddenly
this design may seem familiar. If you go back to the early Web, pre-Web 2.0, this
is
essentially how page interaction worked. A form was submitted, sending a payload of
parameters describing the action to the server, and the server built a complete webpage
and returned it to the user. Unidirectional flow was enforced automatically by the
limitations of the technology. Now, most of this process occurs in the client instead
of
on the server, and it is designed to update the view at 60 fps, but the architecture
is
similar because the fundamental assumptions we can make about rendering a view is
similar.
What’s old is new again.
XSLT symbiosis
The Flux pattern, using a virtual DOM-based view, provides a functional pipeline for
rendering views in the browser in JavaScript. In our application, we also needed to
include a functional pipeline for processing XML data based in XSLT. The architectural
equivalence gives us a bridge to unify these two-year-old and two-decade-old
technologies.
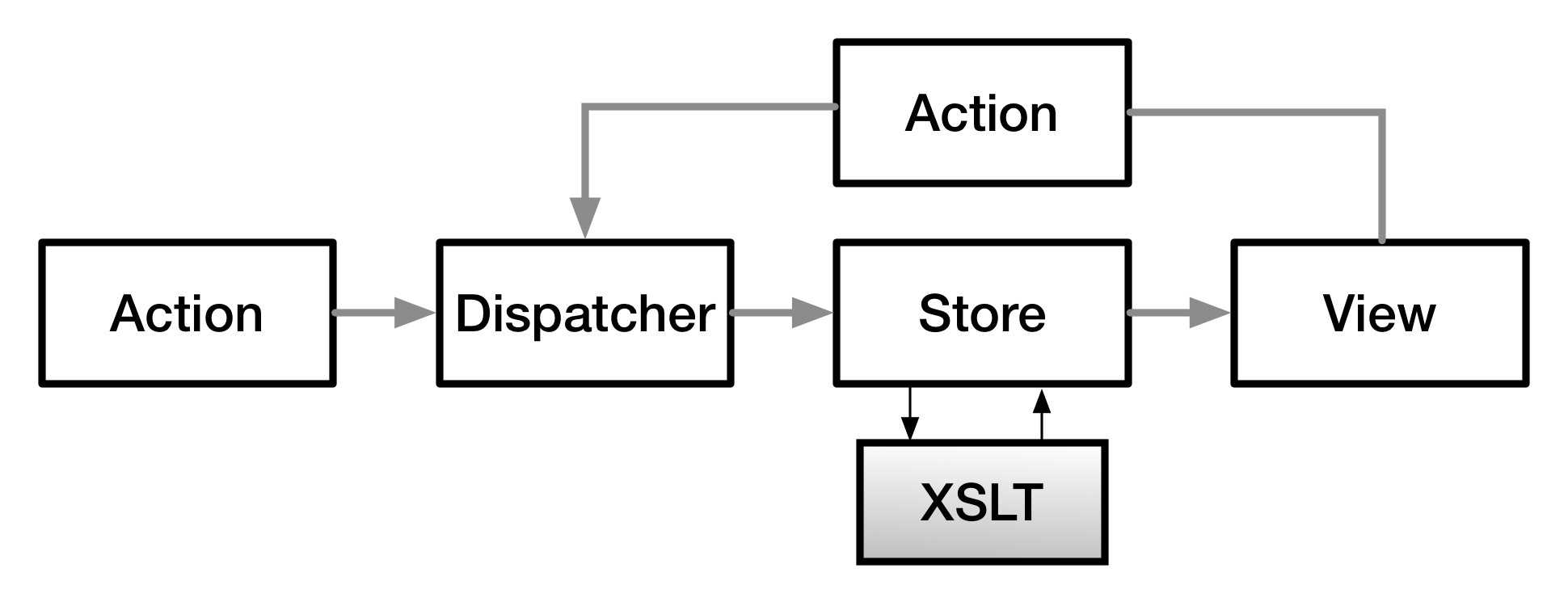
Under the Flux pattern, Stores are responsible for the application state and logic,
performing updates and transformations in response to Action inputs from the view
or from
external actions. Our XML documents represent the state of the document automation
process, a subset of the application state, and the XSLT engine is our logic for
transitioning from one state to the next, so Stores were the most appropriate injection
point.
Figure 12: FluXSLT architecture
XML-centric pattern
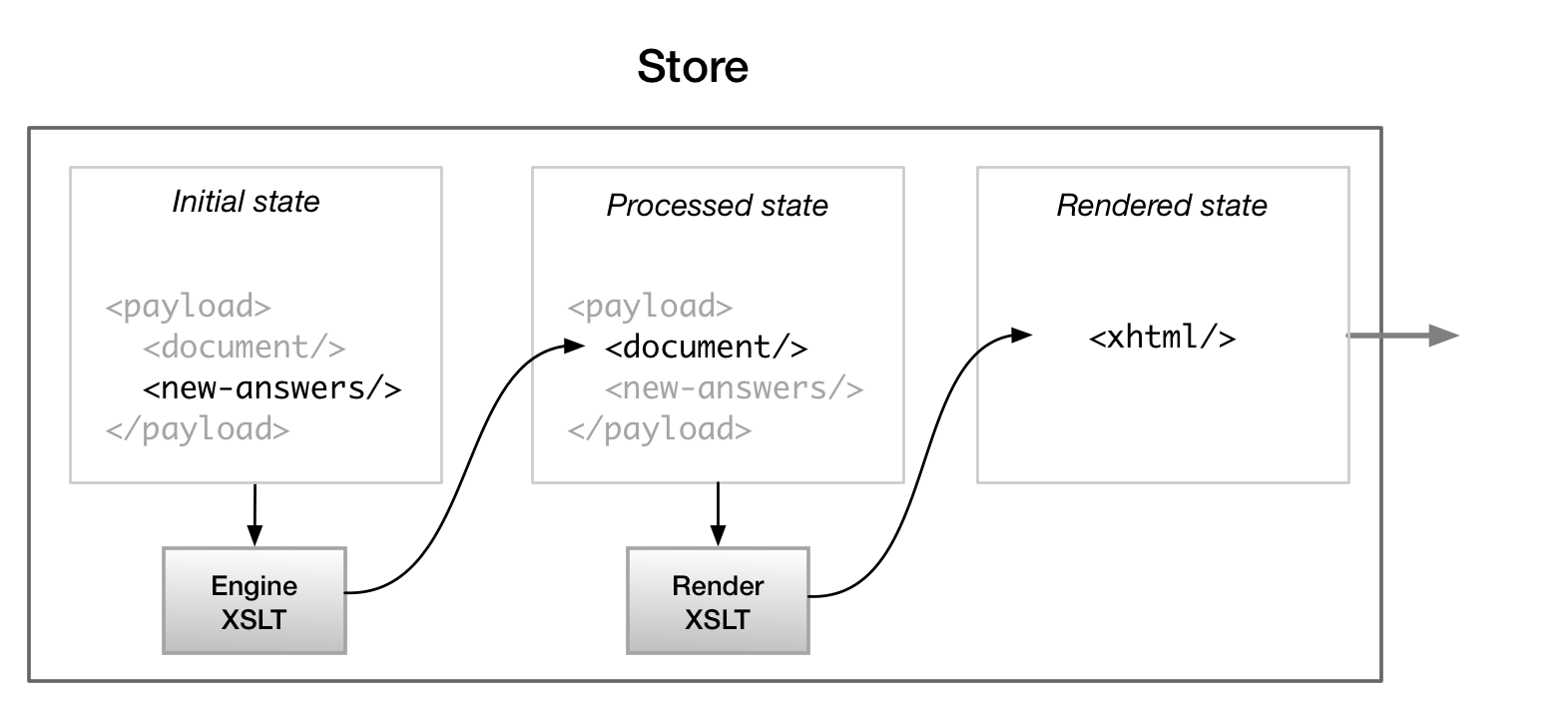
We established a pattern for working with XSLT within a Store. The application
initializes by requesting a payload from the server that contains the document to
be
automated and a set of initial user data. On the initial page load, the engine XSLT
transforms the document, using the user-supplied data, into a new state. Then the
render
XSLT transforms the updated document into an XHTML element, which is appended to the
virtual DOM. Subsequent actions are handled by the framework, and upon re-entering
the
store, changes to user data captured by the UI are marshaled into the user data XML
element, followed again by the XSLT pipeline.
Figure 13: Store returning XHTML
Within the overarching JavaScript framework, we are able to leverage XSLT in a
couple of important ways. We use it as a drop-in replacement for JavaScript to natively
processes application state on XML data in a JS-based framework without much ceremony,
and we use it to transform from hard-to-use (in the JS environment) generic XML to
XHTML, which is useable directly in the view.
In a traditional implementation of the Flux pattern, however, no components of a
view would be rendered in a store, so one could argue that our design leaks abstractions
between the store and the view. Our justifications for this are practical. This
application will be responsible for rendering large preview documents, and XSLT is
simply much better suited for performing that work. Abstractions are imperfect, and
sometimes allowing a leak is the only sensible solution to prevent overcomplicating
code
or bad performance.
JSON-centric pattern
Before coming to this conclusion, we considered another pattern to give complete
control over rendering to the virtual DOM for tighter integration into the traditional
virtual DOM architecture, but we rejected it because it added complexity with only
marginal benefit. However, the trade-off may be appropriate or necessary when composable
component hierarchies using combinations of XSLT-generated and virtual DOM-native
components are needed—not possible with XHTML-rendered components—or where it is
important to take advantage of virtual DOM-rendering performance optimizations.
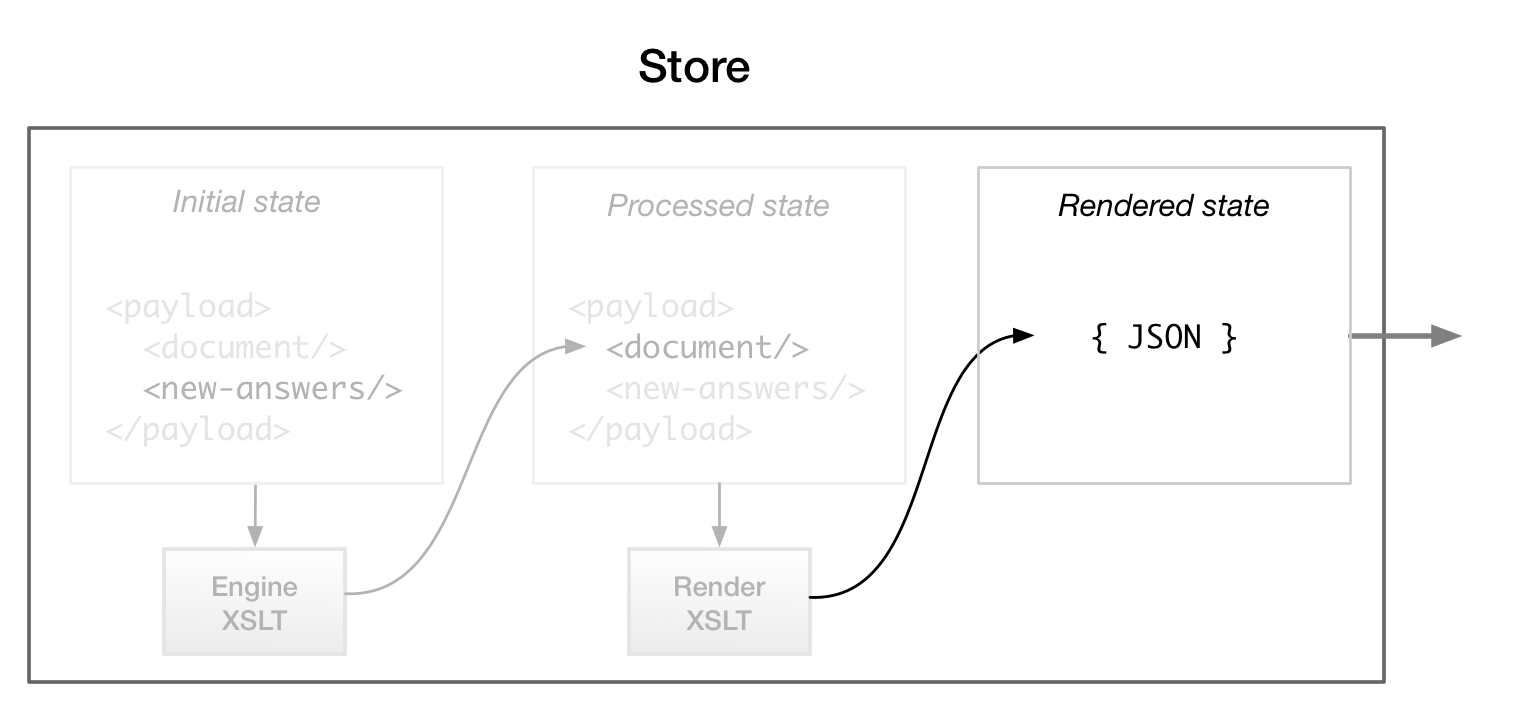
Figure 14: Store returning JSON
The goal of this pattern is to render the view using only virtual DOM-native
components, so the XHTML-rendering step is replaced by a step that transforms
view-relevant XML data into JSON[10]. Each virtual DOM library has a slightly different approach to rendering,
but they have in common supplying JSON properties as input to a functional
transformation that renders a component. Compared to an XSLT transformation, properties
are analogous to an input document, and the component (in some virtual DOM
implementations, literally a function) is analogous to the XSLT. The JSON output can
either be used wholesale to render the component, or it can be further reorganized
by JS
to maintain a greater separation between data models and view models.
A polyglot web
Modern client-side JavaScript development appears to be converging on functional
patterns resembling early web architecture, and we found it useful as a bridge to
another artifact of the early web, client-side XSLT. Using this architecture, we had
the
benefit of leveraging both JavaScript and XSLT for their strengths without being forced
to break boundaries between the two environments in ways that would complicate overall
application development and maintenance. But we see implications for its use beyond
XSLT.
With the recent adoption of the WebAssembly standard[11] by major browsers, we are hopeful for a future where language symbiosis[12] resembling server-side polyglot environments, like the Oracle JVM[13] and the Microsoft CLR[14], can flourish in the browser.
Redesign
Many of the difficulties we encountered working with native client-side XSLT were
not
from limitations of the language or the environment, but the result of a fundamental
design
problem. We assumed that processing documents in their canonical form would be the
simplest
and most idiomatic solution, and successfully working under that assumption in early
stages
of prototyping led us to establish a design centered on the wizard’s final output,
the
completed form, rather than the information needed to process the wizard itself. As
our
application and its requirements expanded, those assumptions failed, and it eventually
became clear we needed a different model. After overhauling the design to reflect
this
insight, we were finally confident that we had arrived at the appropriate idiom for
modeling
our document transformation problem, affirming our choice to implement the engine
in
XSLT.
The canonical documents were isomorphic to our initial conception of document processing
—walk the document tree, applying known information from other documents, and stop
when more
information is needed, just as a human would—and we were satisfied using them to manage
the
state of the interview through our first stages of requirements. But these documents
did not
explicitly model relationships between data—the form, questions, and their answers
were
separate self-contained data structures—and those relationships had to be reestablished
at
every iteration of the processor. As a direct consequence of this separated design,
we
employed increasingly complicated strategies to avoid repeating significant amounts
of
processing at every step. But the engine ultimately wasn't transforming a incomplete
form
into a completed form; it was transforming an incomplete form into an interview, and
we
needed sensible and distinct data models for each.
We understood from the outset what problems could arise from applying a document-centric
model to a UI, but it wasn't until much later into development that we understood
what was
fundamentally the same problem inside our engine. As we needed to support higher variability
within a form document, it became harder to step from one final form state to another.
The
bulk of the time spent processing each answer was for handling cascading effects,
and the
approach scaled poorly with the complexity of the forms. We needed to shift the work
upfront, transforming our data into a structure that would allow quick handling of
new
information and keeping all related data in one place.
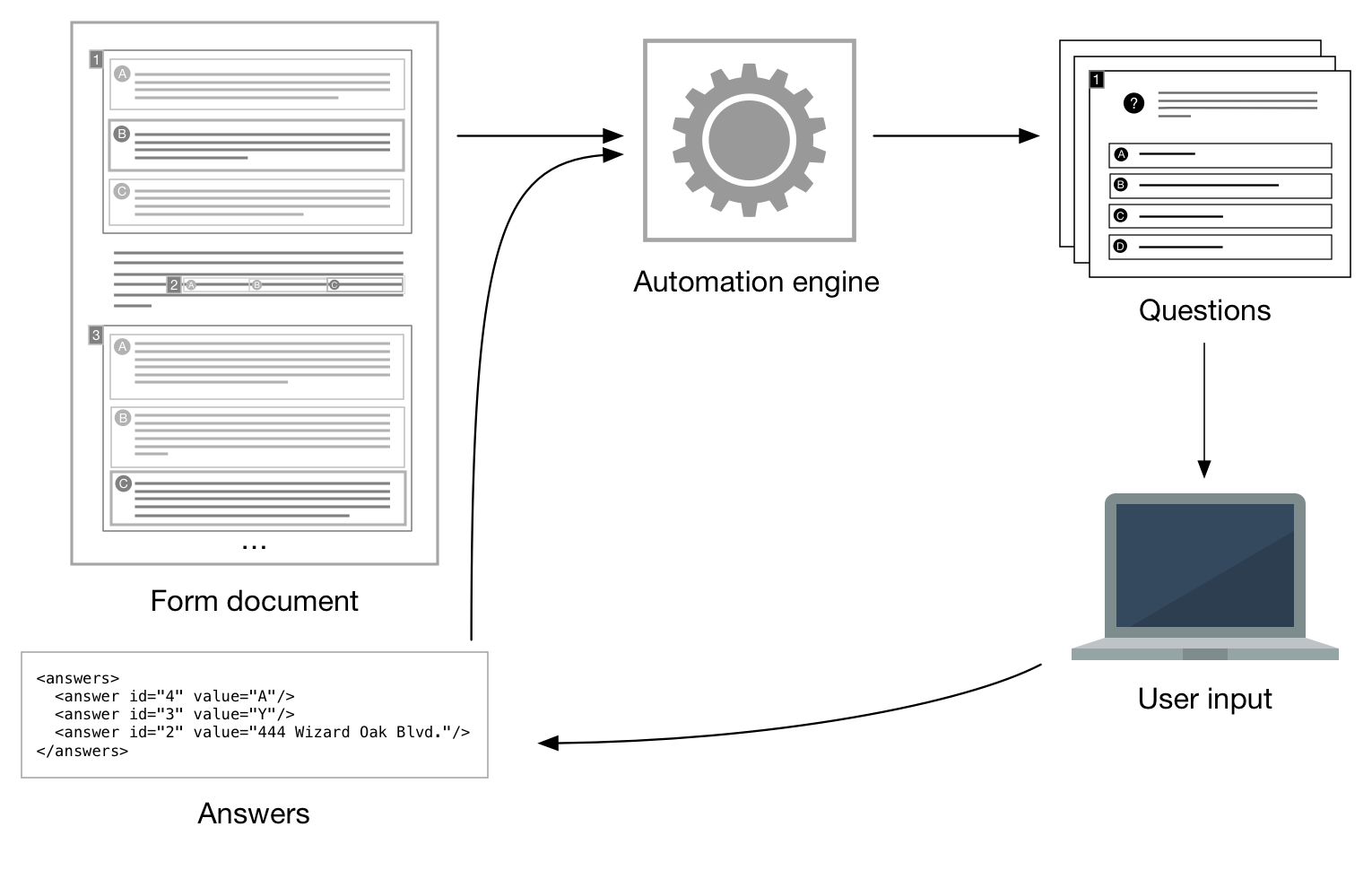
Our document processor is supplied three types of input: a form document, questions,
and
answers. The engine assumes the form document includes all conditional content and
any
questions needed to satisfy them. As the interview progresses, answers are added to
the set
of documents, and the form document is reevaluated to discover new references to fields
and
conditionals. The central objective of the form processor is to identify and resolve
these
references.
Figure 15: Document-centric data model
In the original design of our application, these inputs doubled as the data model,
but
they were a poor reflection of that central objective. As the processor walked the
form
document tree, it needed to re-evaluate conditions and identify form references to
determine
what content was included.
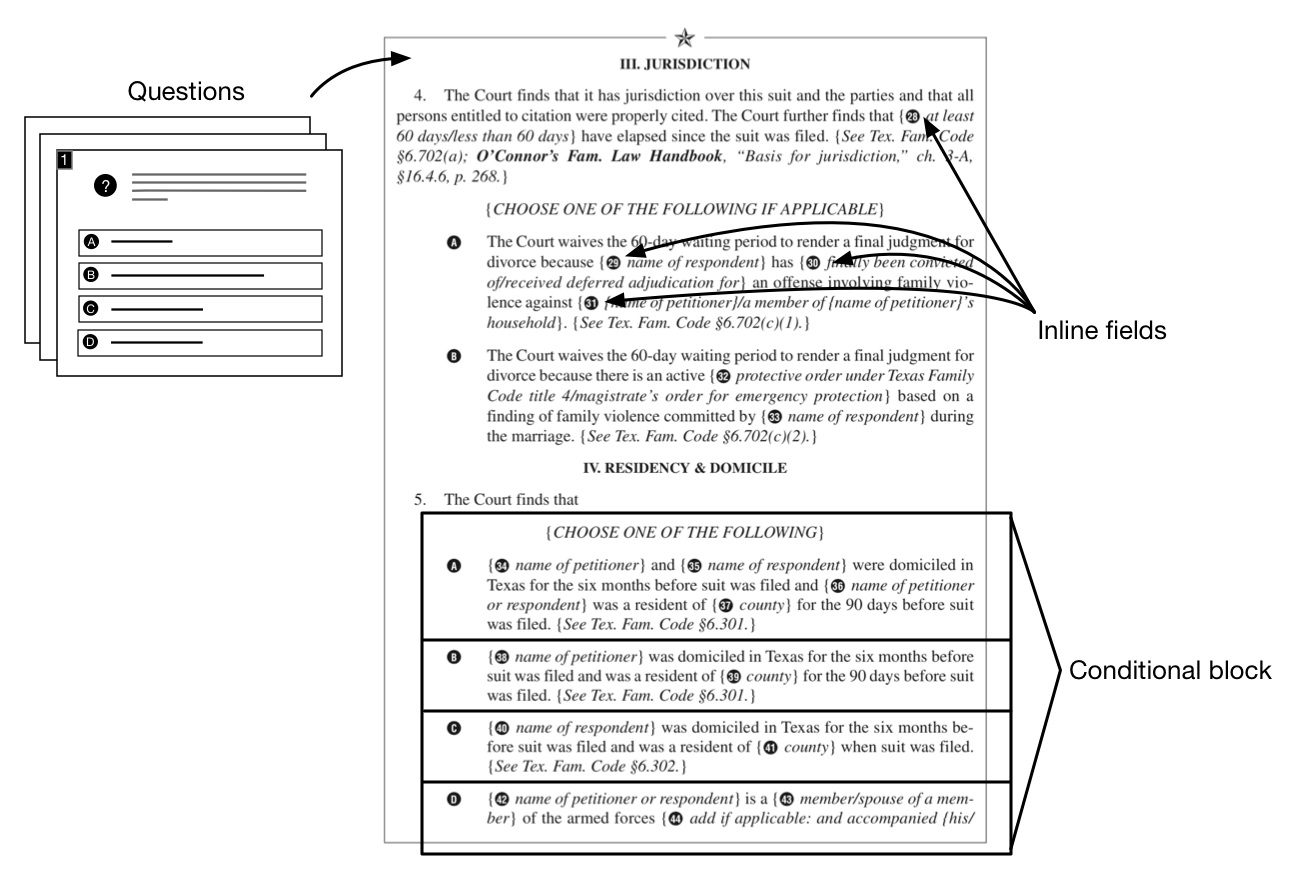
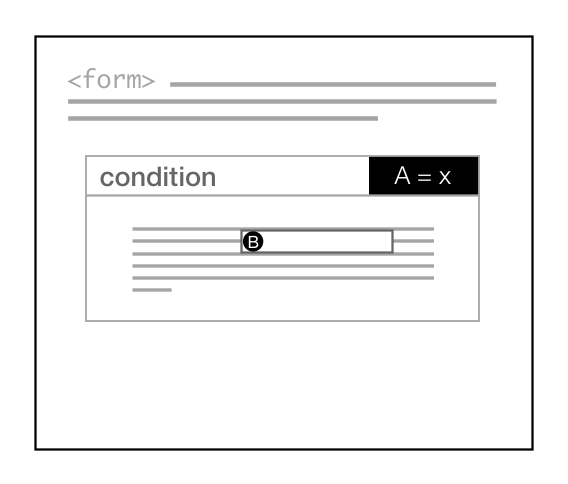
Figure 16: A visibility dependency
The inclusion of the reference to B depends on the value of A, so the visibility
of B is not known until A is resolved.
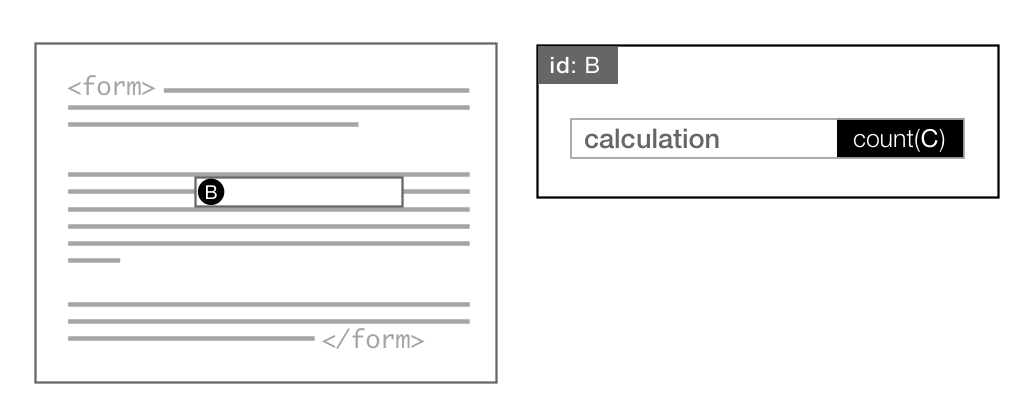
Figure 17: An evaluation dependency
The value of B depends on the value of C, so B cannot be resolved until C is
resolved. Also, another visibility dependency: the visibility of the reference to
C
depends on the visibility of the reference to B.
The dependency relationships between the references, or which references controlled
the
visibility or evaluation of what other references, were not explicit. As a direct
consequence, the information needed to respond to each reference's discovery or resolution
required tracing recursively through three three different data structures, a level
of
indirection that was painful to manage at run-time.
As we expanded our prototype to meet the demands of more sophisticated documents,
our
application became unwieldy, and implementing new features became disproportionately
difficult. The design had become hard to understand, sluggish, and we still had more
features to implement. Significant changes required carefully working around several
elaborate features, such as the grouping problem described above. The need to trace
cascading changes after new answers were provided to previously answered questions
was the
last straw.
The change would have required building a new dependency-tracking layer on top of
an
implementation already suffering from complex layers of indirection. Suddenly we were
experiencing deja vu. What had begun as a liberating and productive process, without
the
baggage of a third-party system, declined into a slow and frustrating affair. Our
approach,
again, needed to change. It was clear that the dependency-tracking information we
knew we
needed for tracing changes was so fundamental to the objective of the processor that
the
data and processing model should be redesigned instead of expanding the run-time patchwork
of indirection built on top of our current one. The data model should target an idiom
centered around the information-gathering process, not the form document.
To redesign the data model around references, we inverted the documents in a
post-authoring step. The new data structure formed a sort of stack, with elements
that could
be processed sequentially to trace their dependencies, inserting new dependencies
following
their references in the stack.
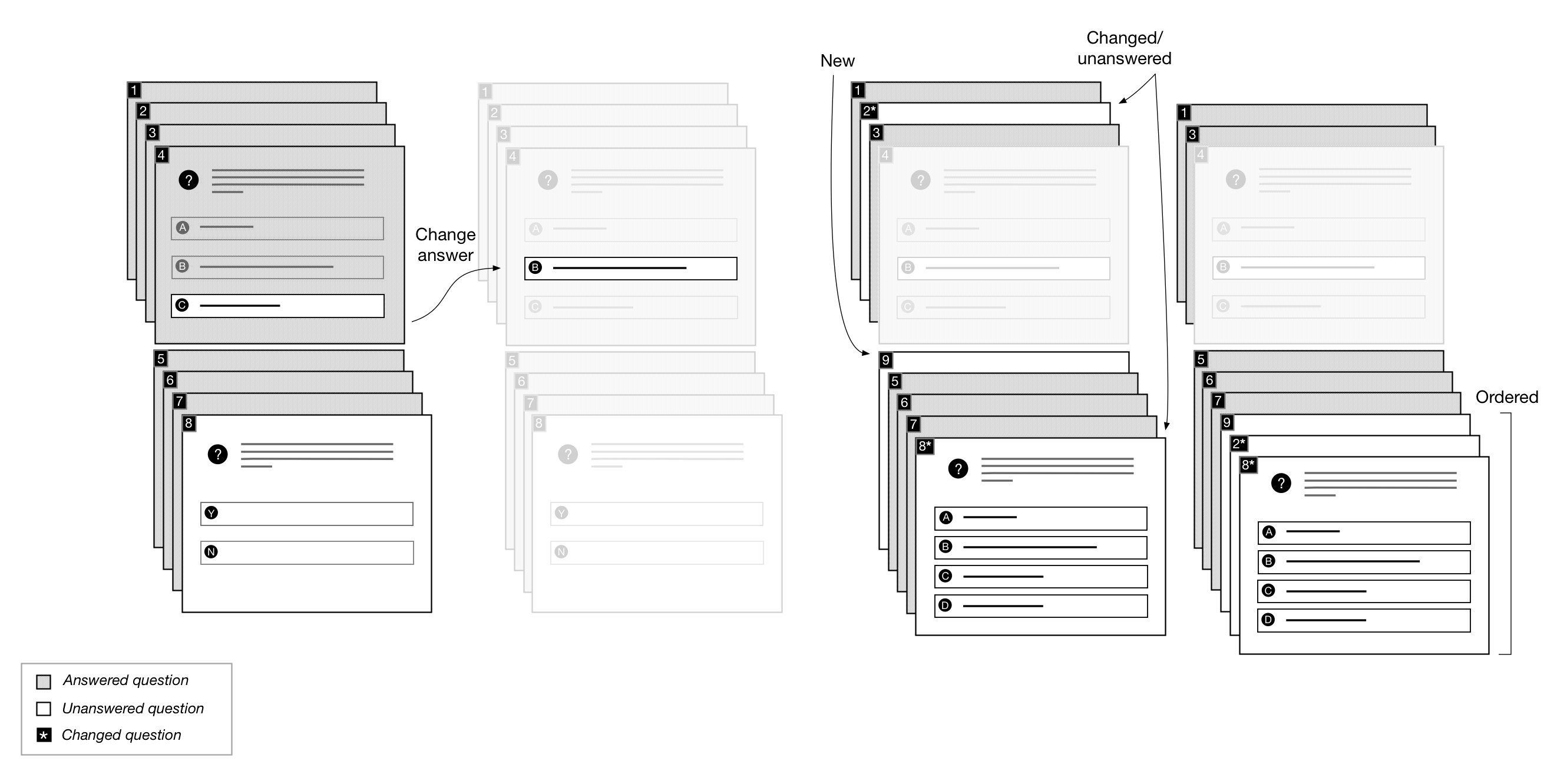
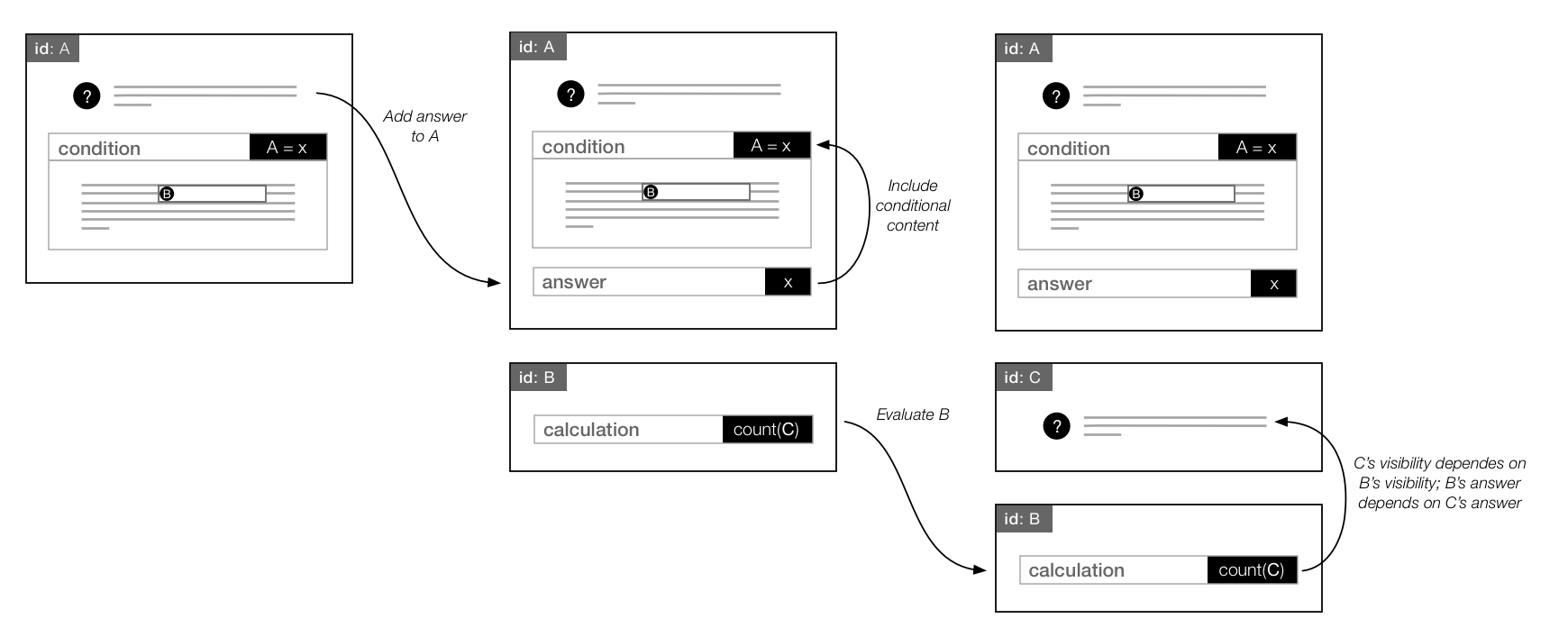
Figure 18: Stack-based data model
Figure 18 illustrates the issue that finally motivated the redesign of our data model:
cascading effects handling changed answers. Working with our original data model,
if a user
changes their answer to A to value y, there is no way to determine that B and C are
no
longer required without reprocessing the entire form. By focusing only on the relevant
parts
of the document, the problem becomes simpler and avoids repeating a great deal of
work. The
ordering requirement on the reference stack ensures that preceding siblings of reference
A
will not be affected by A's changed answer. Only the references between A and the
next
unconditional reference need to be reevaluated.
One of our early stated principles was to maintain simplicity in our design for the
document engine, but we had misjudged the implications of avoiding a transformation
from the
canonical document format into an engine-specific document. This was quite ironic,
considering that document transformation is the most powerful aspect of the language
we had
chosen to work in. Compounding the irony, our missing insight about data modeling
was
something that had been obvious to us about the UI all along: the structure of the
final
document was only incidental in the problem we needed to solve. Focusing on the progression
of information, rather than its consequences to the final document, eliminated the
layer of
complexity that led us to question our choice to write the engine in XSLT, and
post-redesign, we had an even stronger case for its use.
Conclusion
Over the last twenty years, the Web has grown increasingly separated from its early
XML
influences. Despite its evolution into a towering JavaScript monoculture, its ecosystems
are
now converging on architectures that are fundamentally capable of bridging the gap
to other
languages. Out of a desire to test that theory, and having a suitable use case for
XSLT,
emerged a great opportunity to put browser XSLT engines through their paces—and we
found them
nearly as capable as ever!
Truly unified with a modern JavaScript UI, we built an XSLT-based application on our
terms, uncompromised by the gravity of top-down XML and JavaScript frameworks, and
we believe
there are strong incentives for combining technologies, each with their best foot
forward. But
our unlikely love story between JavaScript and XSLT is just a single example of what
is
possible. The emerging WebAssembly standard is being adopted quickly by browsers and
promises
to bring dozens of new languages and ecosystems into the fray. Years of virtuous growth
may
have been lost by separating the XML and Web communities, but it seems possible the
silos are
only temporary.
The prospect of a future unconstrained by browser technology also underscores the
need for
a lucid understanding of the problems we are trying to solve. We are taught to empathize
with
the end users of technology who blame themselves for its flaws. But maybe as developers
we
should be more hesitant to adopt that perspective. The problem might not be the
technology.
Denicola, Domenic. “Non-Extensible Markup Language.” Presented at Symposium on
HTML5 and XML: Mending Fences, Washington, DC, August 4, 2014. In Proceedings of the Symposium
on HTML5 and XML: Mending Fences. Balisage Series on Markup Technologies, vol. 14 (2014). doi:https://doi.org/10.4242/BalisageVol14.Denicola01.
[Delpratt and Kay 2013b] Delpratt, O'Neil, and Kay,
Michael. “Interactive XSLT in the browser.” Presented at Balisage: The Markup Conference
2013,
Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013.
Balisage Series on Markup Technologies, vol. 10 (2013). doi:https://doi.org/10.4242/BalisageVol10.Delpratt01.
[10] Several convenient methods exist to generate JSON from XML. Badgerfish is a
convention for converting XML into JSON for which JavaScript and XSLT 1.0 libraries
are available, giving you the choice to decide on which side of the fence the
conversion is best suited. Similarly, the JsonML format is designed for round trip
conversions of XML and JSON, supported by libraries in JavaScript and XSLT 1.0 (and
other languages). The conversion can also be done in XSLT 3.0 natively, without the
need for any libraries [Kay 2016].
Denicola, Domenic. “Non-Extensible Markup Language.” Presented at Symposium on
HTML5 and XML: Mending Fences, Washington, DC, August 4, 2014. In Proceedings of the Symposium
on HTML5 and XML: Mending Fences. Balisage Series on Markup Technologies, vol. 14 (2014). doi:https://doi.org/10.4242/BalisageVol14.Denicola01.
Delpratt, O'Neil, and Kay,
Michael. “Interactive XSLT in the browser.” Presented at Balisage: The Markup Conference
2013,
Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013.
Balisage Series on Markup Technologies, vol. 10 (2013). doi:https://doi.org/10.4242/BalisageVol10.Delpratt01.