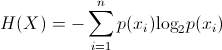Ruellan, Hervé. “XML Entropy Study.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Ruellan01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Hervé Ruellan holds an engineering degree from the École
Centrale des Arts et Manufactures (1993) and a Ph.D. in
computer science from Université Paris XI (1998). Since
2000, he has been working at Canon Research Centre France
first in the domain of Web Services, then in the domain of
XML technologies.
Reducing the impact of XML documents both in term of size
and in term of processing speed has been the goal of many
studies and research efforts, but never in a very formal or
comprehensive manner. To strengthen the foundations of those
works, we present here a comprehensive formal study of the
quantity of information contained in XML documents. We then
compare those theoretical results to the effective compactness
obtained by some existing binary XML formats.
XML (Extensible Markup Language) is now used in
many applications on many devices for storing a large variety of
data in a common format. XML being a verbose format, several
solutions have been developed to reduce the size of XML documents.
First, XML documents can be compressed using general-purpose
compressors (e.g., gzip).
However, taking advantage of the XML structure, it is possible to
achieve better compression ratio. For this reason, many binary
formats for XML documents have been developed and a few have even
been standardized, such as Fast Infoset which is
an ISO/IEC and ITU-T standard and EXI (Efficient
XML Interchange) which is a W3C Recommendation.
Binary XML formats have been studied experimentally to compare
both their compression ratio and their processing speeds. Augeri
et al. have compared general-purpose compressors, binary XML
formats, and schema-aware XML compressors (see Augeri 2007). Their efficiency measure, combining the
compression ratio and the compression speed, showed that the best
binary XML format they tested (XMill, see Liefke 2000) was equivalent to the best
general-purpose compressors (gzip,
WinZip®, and bzip2). In another study,
Sakr used several efficiency measures, combining the compression
ratio with both the compression and decompression speed, and
obtained similar results (see Sakr 2009). Last, Ng,
Lam and Cheng compared several binary XML formats, taking into
account whether they supported queries (see Ng 2006). They showed that the advantage of
supporting queries over the XML content was achieved at the cost
of decreasing the compression ratio.
In addition to these experimental comparisons, it would be
interesting to evaluate the theoretical efficiency of binary XML
formats at the compression ratio level. We therefore propose to
study the entropy of XML documents, first roughly as textual
documents, then more precisely by taking into account the
different aspects of their structure. Using this entropy study, we
will evaluate the theoretical efficiency of Fast Infoset and EXI.
To the best of our knowledge, this is the first and only such
study available.
In section “Testing Corpus”, we describe the set of XML
documents used as a testing corpus. In section “Entropy measurement”, we describe several methods
for measuring the quantity of information contained in an XML
document, using different representations of this XML document.
Last, in section “File format evaluation”, we use those results to
evaluate the theoretical capacities of several formats: textual
XML, Fast Infoset, and EXI.
Testing Corpus
XML document sources
To provide reliable results, the testing corpus used in this
study needed to cover a wide spectrum of XML documents. In
order to achieve this goal, the selected set of documents is
the testing corpus from the W3C EXI working group [EXI WG], which is large and representative.
Indeed, one of the tasks of the EXI working group was to
evaluate several technologies for encoding XML documents
[EXI Measurements]. This evaluation had to be
relevant for most of the usages of XML. Therefore, they had
to build a representative set of XML documents.
Our testing corpus contains 870 XML documents. This testing
corpus covers many usage of XML documents, including
scientific information, financial information, electronic
documents, web services, military information, broadcast
metadata, data storage and sensor information.
XML document classification
XML has many usages and therefore there is a wide variety of
XML documents. To engage in a deeper analysis of the different
XML documents, it is interesting to define some criteria for
classifying them.
Qureshi and Samadzadeh, in Determining
the Complexity of XML Documents [Qureshi 2005], have described several ways for
determining the complexity of XML documents using different
syntactic and structural aspects of those documents. They
start by observing that several measures can be extracted from
an XML document, such as the number of elements, the number of
distinct element, the size of the document, and the depth of
the document.
As these measures only reflect a part of an XML document
complexity, they propose several metrics for addressing this
problem. A first metric measures the complexity of XML
documents by analyzing their DTD (Document Type Definition).
However, this metric only takes into account the definition of
the document and not the document itself. Therefore, they
define a second metric, based on a weighted counting of the
elements contained in the documents: the weight associated to
an element is its depth inside the XML tree. This second
metric is found to be more representative of the complexity of
the XML documents.
Basci and Misra, in Entropy Metric for
XML DTD Documents [Basci 2008],
have proposed a new metric for measuring the complexity of DTD
based on an entropy-like computation. Compared to other
metrics for DTD or XML Schemas, this metric takes into account
the similarities in the different structures defined by a DTD.
Of the several measures above, we retained the following
three: the document size, its information density and its
structure regularity. These measures were selected for
representing several aspects of an XML document. No XML
Schema-based metric was selected as some documents of the
testing corpus did not have any associated XML Schema.
Size
The size of the XML document is the size in bytes of its
serialization (textual or binary). However, to have a
coherent measurement for all XML documents in the testing
corpus, we computed the size by serializing the parsed XML
document. This enabled to remove some variations such as
the presence or absence of the XML declaration, the
presence or absence of DTD, the presence of superfluous
white-spaces, and the use of DTD to include external
content in the document. In the rest of this document, we
will call this process ‘normalization’.
The size of the XML documents in our testing corpus
varies from 133 bytes to 62,750,078 bytes, with an average
of 364,620 bytes and a standard deviation of 2,790,290
bytes.
To use the size as a criterion, three classes of
document were considered. Small documents have a size
smaller than or equal to 1,000 bytes. Medium documents
have a size between 1,000 bytes and 10,000 bytes. Large
documents have a size greater than 10,000 bytes.
Information density
The second measurement used is information density:
information density represents the part of content in the
XML document relative to the part of structure in the XML
document. The content size of an XML document is computed
by summing the size of all character data (the “value” of
elements) and attribute values present in the XML
document, in bytes. The information density is computed as
the ratio between the content size and the size, in bytes,
of the XML document.
A low information density means that the document
contains mainly structural information, while a high value
means that the document contains mainly actual contents
(non-element and non-value definition contents).
The information density of the XML documents in the
testing corpus varies from 0 to 1, with an average of 0.39
and a standard deviation of 0.23.
While there is a variety of XML documents with low
information density values in our corpus, XML documents
with large information density values are mainly SVG
(Scalable Vector Graphics), with some X3D (Extensible 3D)
documents and scientific information documents.
The limit between structure-rich XML documents and
information-rich XML documents was chosen to be the value
of 0.33 for the information density parameter. This means
that a document is considered as structure-rich when the
part of content in it is less than one third of the total
document.
Structure regularity
The third measurement represents the regularity of the
structure of the XML document. We chose the following
simple definition: the structure regularity is computed as
one minus the ratio of the total number of distinct
elements over the total number of elements in the XML
document.
High structure regularity means that the document is
very regular, using only a few number of distinct
elements, while low structure regularity means that the
document is irregular, using many different elements.
The structure regularity of the XML documents in our
testing corpus varies from 0 to 1, with an average of 0.56
and a standard deviation of 0.36.
We chose 0.9 as the limit to separate regular from
irregular XML documents. XML documents with a higher
regularity are considered as regulars, while XML documents
with a lower regularity are considered as irregulars.
This limit means that for a regular XML document, each
element, in average, is repeated at least 10 times. Ten
times may be considered large, but is indeed small
compared to typical large regular documents, which can
contain hundreds or thousands of repetitions (e.g., an address book).
Entropy measurement
Introduction
The purpose of this study is to measure the quantity of
information contained in XML documents in order to gain a
better understanding of the possibilities of compacting them.
Since the paper from Claude Shannon, A
Mathematical Theory of Communication [Shannon 1948], the quantity of information
contained in a document is evaluated with the entropy measure he defined. The
entropy of a document represents the smallest encoded size
that can be obtained by a lossless compression of the
document. The document can be compressed to a size close to
its entropy, but never smaller than its entropy.
For a random variable X with n possible outcomes xi,
1 ≤ i ≤ n, Shannon
defined the entropy measure
as:
Equation (a)
In this definition, p is
the probability mass function of X. This means that p(xi) is the
probability that the random variable X takes the value xi.
Shannon proved in his source coding theorem that this
entropy measure is
the minimum number of bits necessary to represent an
outcome of the random variable.
Taking for example a random variable with
only one possible outcome, the entropy measure is 0. This means that there is no
information conveyed by the value of this variable. Indeed,
its outcome is always known in advance.
As another example, when tossing a coin,
there are two possible outcomes, heads and tails, with equal
probabilities of 1/2. In this
case, the entropy measure is 1. This means that the minimum
number of bits necessary to represent the result of tossing a
coin is 1 bit, which is achieved by a naïve coding using a
Boolean value.
To compute the entropy of a whole document,
Shannon considered that a document is a sequence of
statistically independent symbols corresponding to identically
distributed random variables. The entropy of the document is
computed as the sum of the entropies of the variables
constituting it. This entropy is called the first-order entropy.
For a given document, the first-order entropy
can be computed by extracting all the different symbols
composing it, and then computing the probability of occurrence
for each symbol. This enables to compute the entropy for the
random variable corresponding to these symbols, using
Shannon's definition, and from this the entropy of the whole
document.
However, in many documents, a symbol is not independent of the
other symbols. To represent this, nth-order
entropy values can be computed. For the entropy of order
n, the random variable
associated to a symbol is dependent on the n-1 symbols preceding it.
Naïve evaluation
A naïve evaluation of the quantity of information
contained in an XML document is to use the first-order entropy of this
document considered as a set of characters.
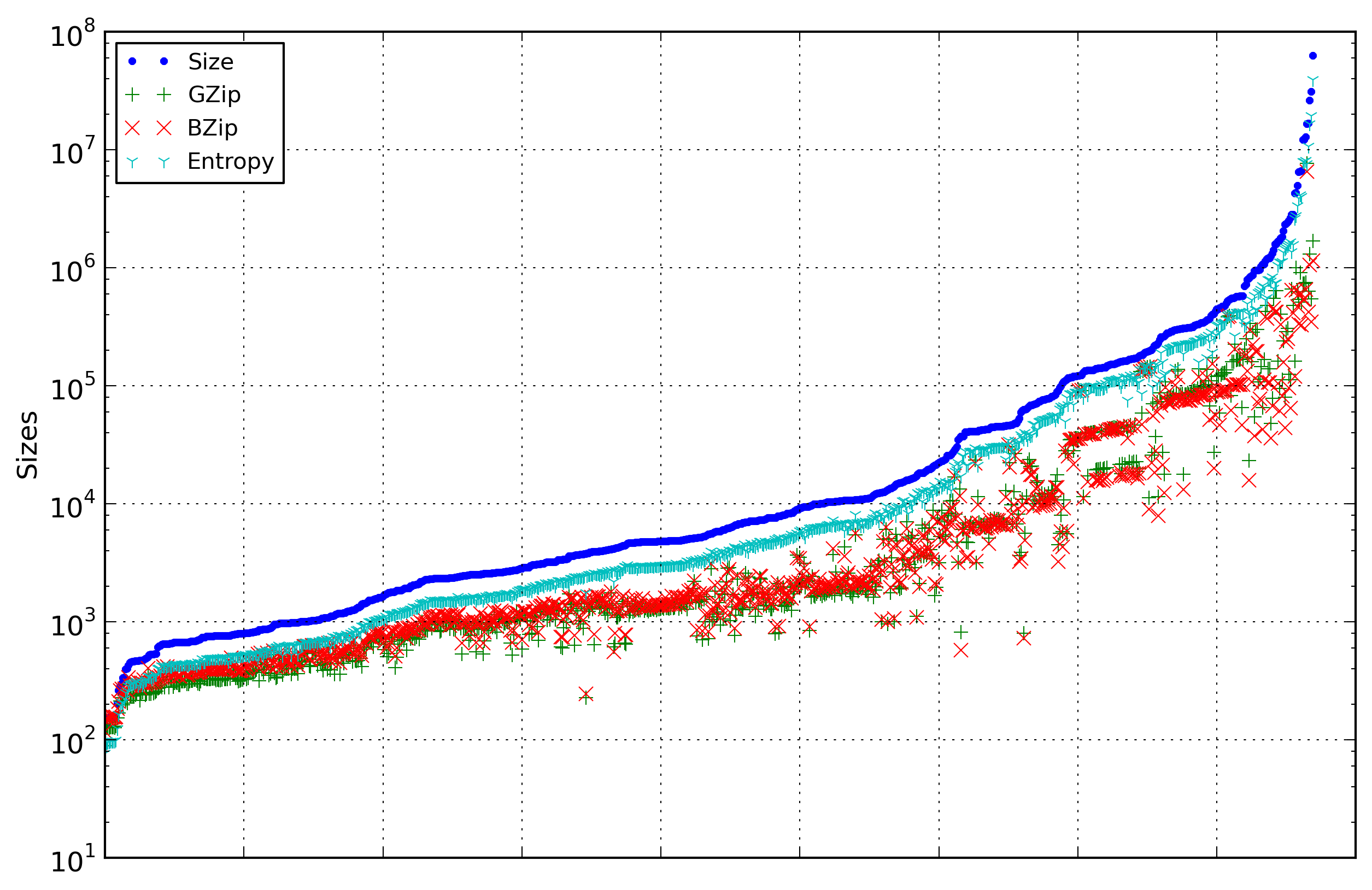
Figure 1 displays this first-order
entropy value, in the form of the cost in bytes of the
whole document, and compares it to several values. The
first comparison value is the size of the XML document.
The two other comparison values are the size of the XML
document compressed with gzip or bzip2.
Figure 1: XML Document Sizes
Comparison of four size-related measures for the
documents from the testing corpus: the base
document size, the compressed size using gzip, the
compressed size using bzip2, and the first-order
entropy cost.
In addition, the results are sorted by increasing
document size to enable a more meaningful comparison.
The results show that for all documents, the first-order
entropy, as expected, is lower than the document’s size.
However, in most cases, the compressed size (both with
gzip and bzip2) is lower than this first-order entropy.
These apparently surprising results are due to the fact
that the hypothesis of independence between the symbols
used to compute the first-order entropy does not hold.
This entropy value does not represent accurately the
quantity of information contained in an XML document.
For example, for someone quite knowledgeable of the XML
specification, the name of an element contained in a
closing-tag carries no informative value.
For it to become be useful, the quantity of information
contained in an XML document must be evaluated by also
taking into account the structure of this document. This
evaluation is presented in the remaining of this section.
It was realized by splitting the different sources of
information comprised in an XML document, and evaluating
the quantity of information for each source using its
first-order entropy measure.
XML structure
An XML document is a tree-like structure mostly composed
of elements, attributes (definition and values) and
textual data. For the purpose of this study, it is useful
to represent an XML document as a sequence of events, in a
manner similar to SAX (Simple API for
XML) or StAX (Streaming API for XML).
In such a representation, an XML document is represented
by a list of events, each event being described by its
type and content. For example, the start-tag of an
element is described by an event of type start-element,
whose value is the name of the element. Table I lists all the types of events used
to represent an XML document, and succinctly describes
each of them.
Table I
Description of the different events used to
represent an XML document. Each event is descried
by its event type and its content.
Event
Event type
Content
Start-tag
SE
name
End-tag
EE
Namespace definition
NS
URI, prefix
Attribute
AT
name, value
Character data
CH
value
Comment
CO
value
Processing instruction
PI
target, data
Structure-based evaluation
Using the event representation of an XML document, a
fine-grained evaluation of the entropy of XML documents
can be computed. It is a general principle to split a
piece of data to be compressed, such as a picture, a
movie, or a textual document, into several independent
sources of information. Each source of information can
then be compressed more efficiently. Similarly, an XML
document is split into several sources of information.
First, a list of event types describes the type of each
event contained in the representation of the XML document.
Then several other sources of information are used to
describe the content of these events: the list of element
names, the list of attributes, the list of character
contents, the list of comments and the list of processing
instructions. The list of attributes is further divided
into a list of attribute names and a list of attribute
values, or considered as a whole.
The rest of this section contains the evaluation of each
of these sources of information using several
representations. Indeed, each source of information can be
structured or further divided with several methods. For
each source of information, the main methods used by
binary XML encodings and variations thereof have been
studied.
The documents of the testing corpus contain only few
occurrences of comments or processing instructions.
Therefore, the results obtained for those pieces of
information were not deemed significant and are not
presented here.
Example XML Document
For a better understanding of the different types of
representations described afterwards, the following XML
document will be used as an example.
Event types form the backbone of the XML document
representation: by describing the type of each event, they
describe the base structure of the XML document, and point
at the source of information to use for completing this
structure for each event.
The set of events used here is close to those used in
SAX or StAX. Compared
to those APIs, we kept only the main events, removed
events related to the document’s start and end (which, in
themselves, provide no meaningful information), and events
related to DTD and entities. In addition, we chose to be
closer to the StAX model by separating attributes from
their owning element.
Representations
Two different methods for representing the list of event
types have been studied from the entropy point of view. It
should be noted that the set of all possible event types
is defined by the XML specification. Therefore, event
types can be represented by tokens defined beforehand and
no indexing mechanism is needed for them.
First, the list of event types can be considered as a
sequential list (list
representation). This is a representation used by most
binary XML technologies.
Using this representation, for the example document, the
event types to be encoded are represented by the following
list. In this list, // is used for delimiting
comments.
SE // article
SE // section
SE // title
CH
EE // title
SE // para
CH
EE // para
EE // section
SE // section
SE // title
CH
EE // title
SE // section
SE // title
CH
EE // title
SE // para
CH
EE // para
EE // section
EE // section
EE // article
Second, the list of event types can be partitioned
according to the name of their containing element
(part representation).
That means that the list of event types is split into
sub-lists corresponding to the content of each element.
Then, those sub-lists are grouped according to their
element names. Such a representation further splits the
list of event types into several sources of information.
There is no cost associated to this separation, as for
each event type its containing element can be
reconstructed from the list of event types and of element
names: it is the latest element for which a “Start-tag”
event was encountered without a matching “End-tag” event.
Such a representation is used by the EXI format.
In this representation, the same event types are to be
coded, but they are spread over five different partitions,
depending on their enclosing element:
document, article,
section, title, and
para. The document partition is
used for the root element. In the following description,
the partition for each event is given in curly brackets.
There is no need to encode this partition, as the current
element can be retrieved from what was previously parsed.
{document} SE // article
{article} SE // section
{section} SE // title
{title} CH
{title} EE // title
{section} SE // para
{para} CH
{para} EE // para
{section} EE // section
{article} SE // section
{section} SE // title
{title} CH
{title} EE // title
{section} SE // section
{section} SE // title
{title} CH
{title} EE // title
{section} SE // para
{para} CH
{para} EE // para
{section} EE // section
{section} EE // section
{article} EE // article
Results
For each document, the entropy associated to encoding
event types was computed using as unit the number of bytes
to represent an event type.
As there are 7 different types of events (see Table I), the entropy for representing them
as a list corresponding to a uniform distribution can be
computed by the formula:
Equation (b)
log2(7) / 8 = 0.35
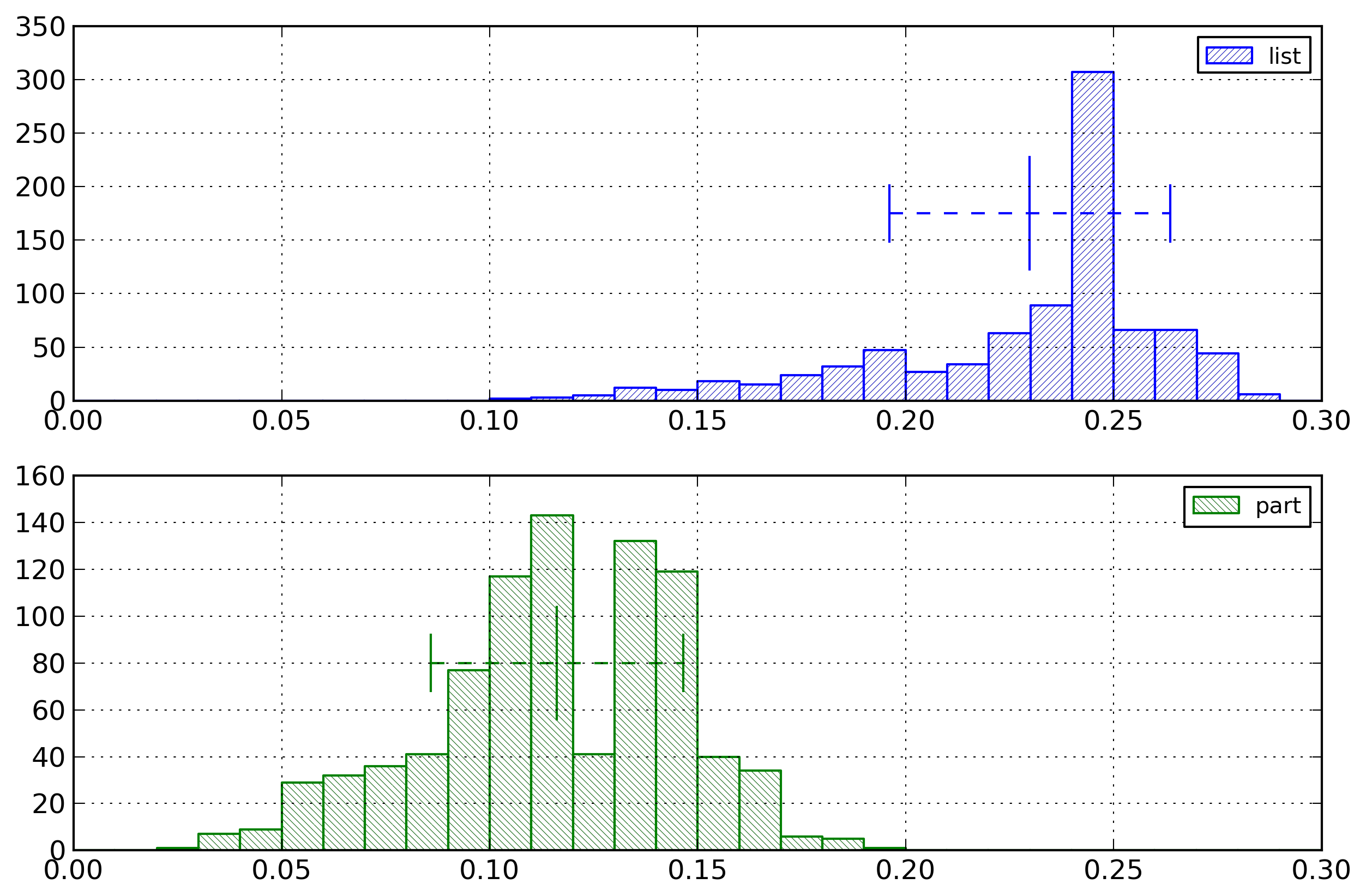
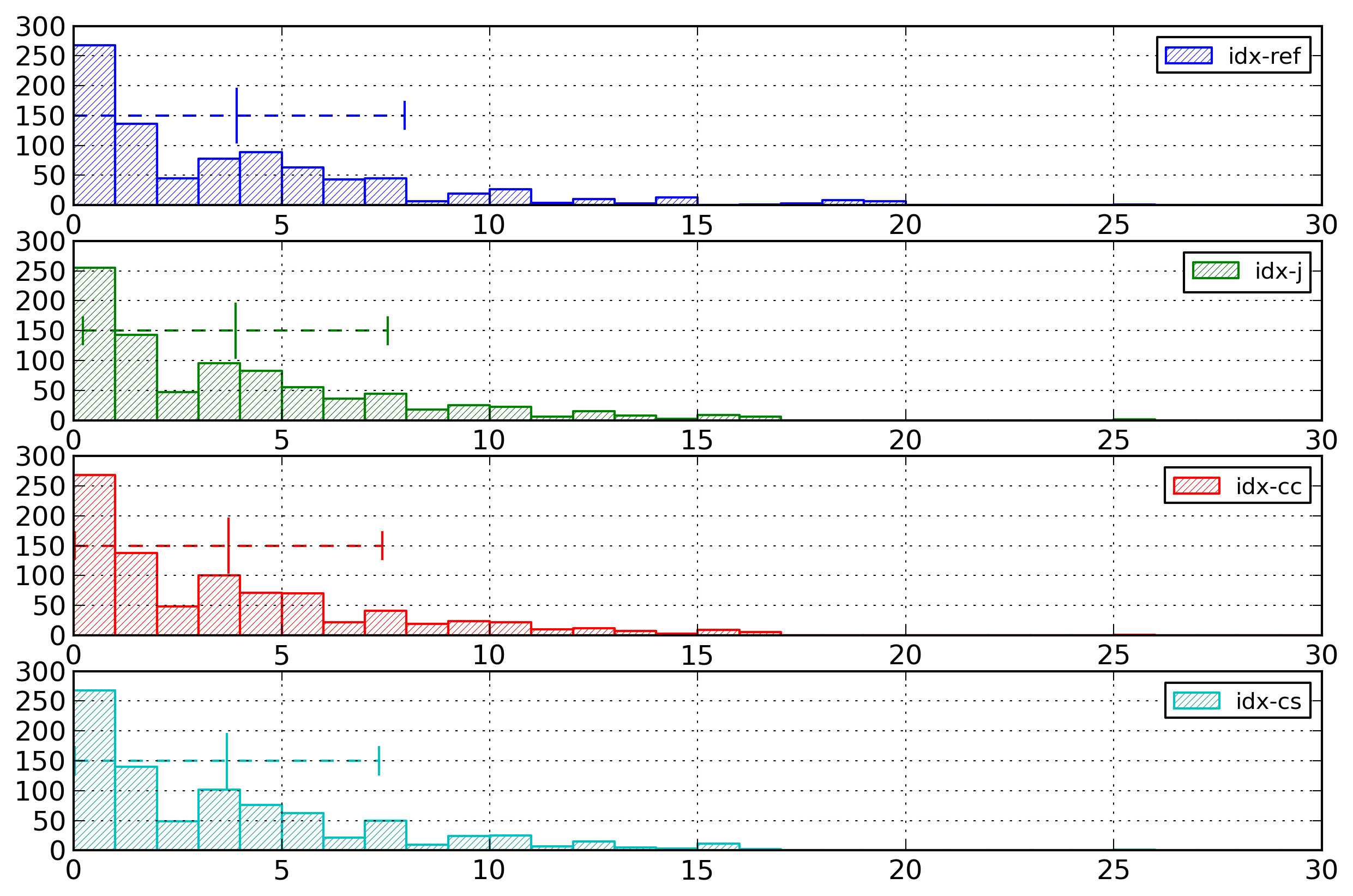
Figure 2 represents the repartition of
the entropy values for both the list representation and
the partitioned representation.
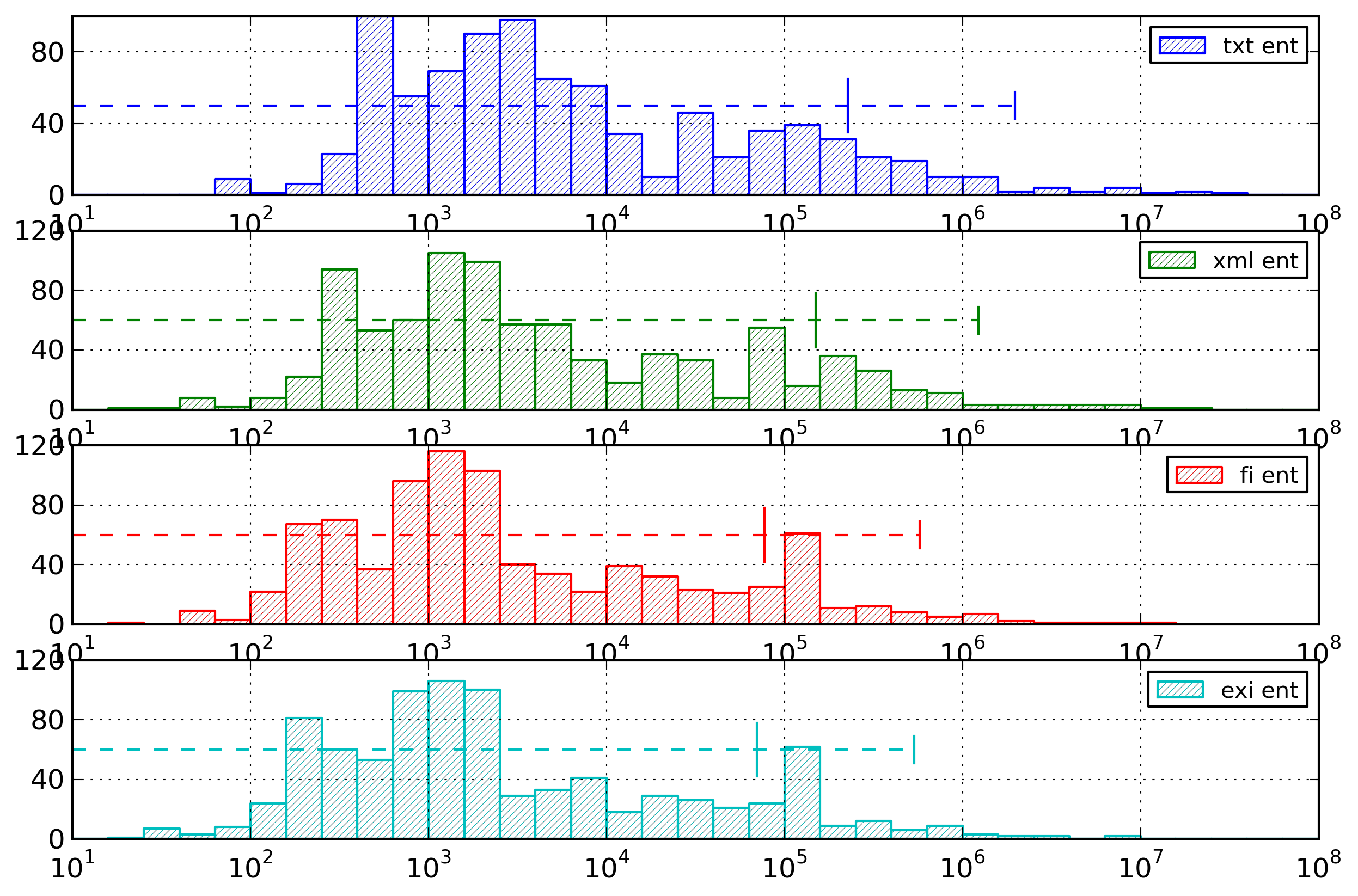
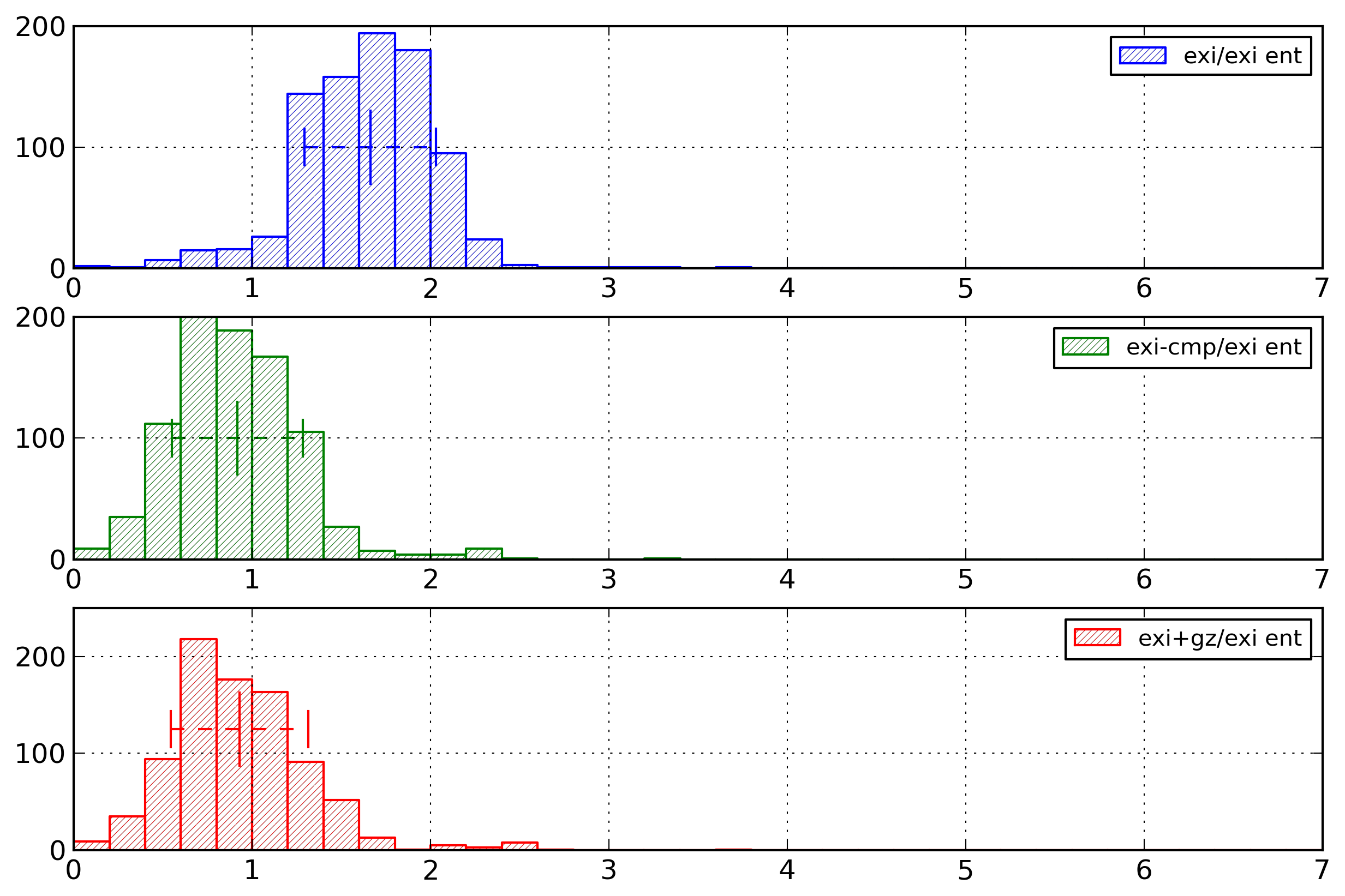
Figure 2: Event Type Histogram
Distribution of the entropy for event types,
computed in byte per event type, for the list
representation and the partitioned representation.
For the list representation, the average entropy is 0.23
byte per event, with a standard deviation of 0.03. For the
partitioned representation, the average entropy is 0.12
byte per event, with a standard deviation of 0.03.
It can be noted that the partitioned representation has
lower entropy values than the list representation, which
is what we expected.
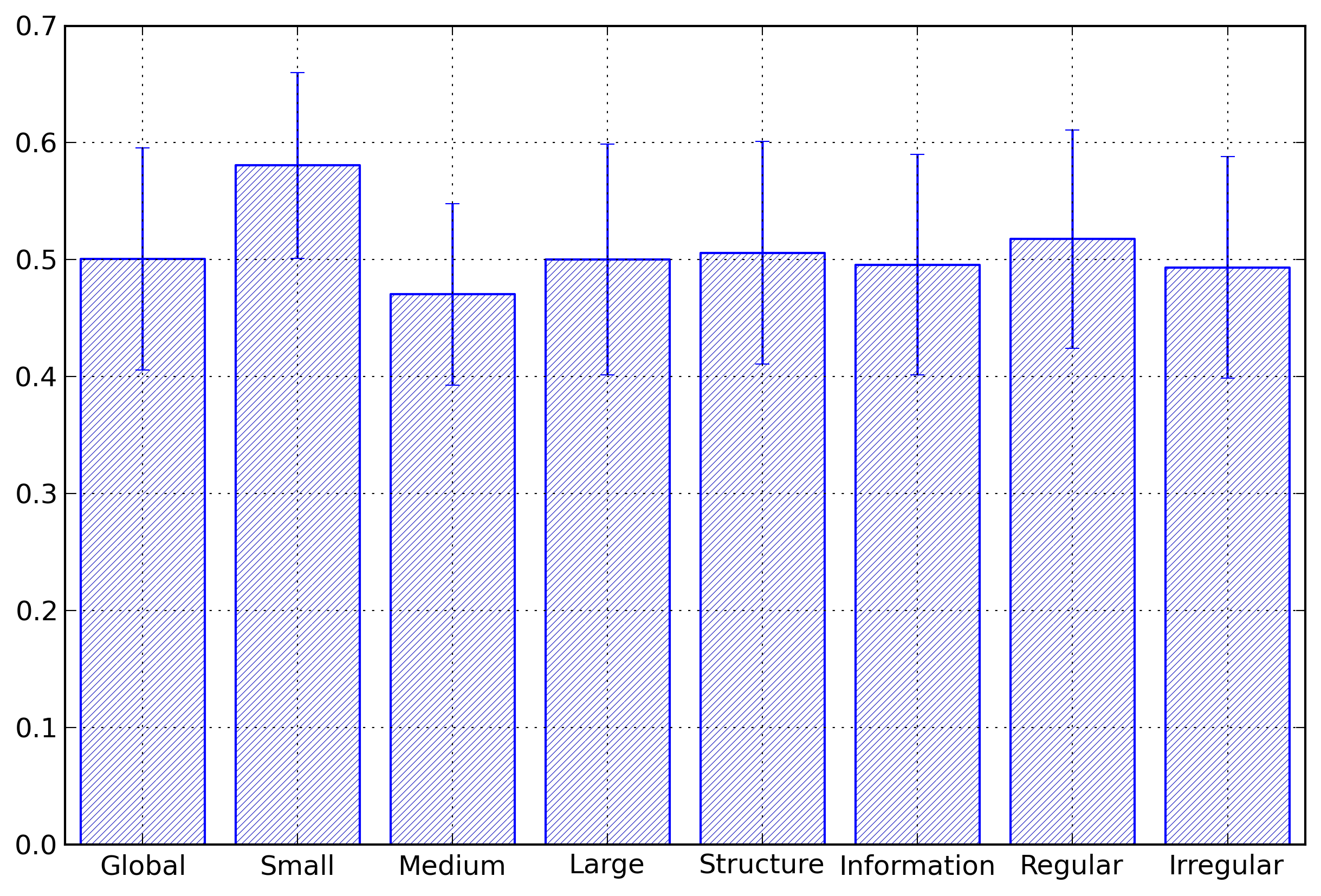
Figure 3 shows the ratio between the
entropy for the partitioned representation and for the
list representation for the different categories of XML
documents. On average, this ratio is 0.50, with a standard
deviation of 0.10. The differences amongst the categories
of documents remain small. The only exception is for the
small document category for which the ratio is greater
than for the other representations. This comes from the
fact that small documents contain only a limited number of
elements and therefore provide fewer opportunities for
partitioning to be efficient.
Figure 3: Event Type Entropy Ratio
Ratio of the event type entropy between the
partitioned representation and the list
representation for the different categories of
documents.
As a conclusion, the partitioned representation has
much lower entropy than the basic list representation,
with an average entropy cost of half the average entropy
cost of the list representation.
Element names
Introduction
Start element events are described by their type and the
name of the element. There is no name associated to the
description of end element events, as this name can be
determined by finding the corresponding start element
event. Therefore, the name contained in the end-tag
construct of the XML markup is redundant information.
The useful information about an element’s name is the
URI of its namespace and its local name. However, this
information can be represented in several ways. Indeed, it
was foreseen during the writing of the Namespaces in XML 1.0 [XML Namespaces] specification that using the URI in
each element’s name would be too verbose for XML
documents. Therefore, a shortcut mechanism was designed
from the start to represent an element’s name using a
prefix associated to its namespace.
While in XML the usage of the prefix is important for
reducing the size of the XML document (and also for
syntactic reasons), in many cases the prefix in itself has
no other usage and can be discarded by binary XML formats.
Therefore, this study ignores in most cases the cost
associated to encoding prefixes. In any event, this cost
is often very low compared to the rest of the XML
document.
Representations
Several representations can be used to encode element
names.
First, element names can be encoded as null-terminated
strings. There are two options for specifying the
namespace of the element: either using the URI of the
namespace (lst-URI
representation), or using a prefix (lst-pr representation)
associated to this URI.
Using the lst-pr representation, the
element names of the example document would be represented
as follows.
A second possibility is to use indexes for the namespace
and the local name. For evaluating the entropy cost, the
cost of the definition of those indexes must be taken into
account. An index definition can be represented by an
ordered list of its values. For local names, the index can
be either global (idx
representation), or it can be partitioned by namespace
(idx-part
representation).
For the example document, the idx representation would be the
following.
// Namespace list
http://docbook.org/ns/docbook
// Local name list
article
section
title
para
// Element names
1,1 // article
1,2 // section
1,3 // title
1,4 // para
1,2 // section
1,3 // title
1,2 // section
1,3 // title
1,4 // para
The idx-part
representation would be very similar for the example
document, as it uses only one namespace. In the general
case, there is one Local name list for each
namespace. Here, there would be only one Local name
list for the
http://docbook.org/ns/docbook namespace.
A third possibility is to use surrogates to represent
the element names. A surrogate is an index representing a
whole element name, that is both its namespace and its
local name. A surrogate can be defined in several ways.
The namespace corresponding to a surrogate is best
specified using an index. The local name corresponding to
a surrogate can be specified as a string (sur-lst representation), as an
index (sur-idx
representation), or as an index partitioned by URI
(sur-idx-part
representation).
For example document, the sur-idx surrogate
representation would be the following.
// Namespace list
http://docbook.org/ns/docbook
// Surrogate list
1,article
1,section
1,title
1,para
// Element names
1 // article
2 // section
3 // title
4 // para
2 // section
3 // title
2 // section
3 // title
4 // para
A last possibility is to partition the representation of
element names according to their enclosing element. Inside
a partition, an element name can be represented as a set
of strings, using either a URI or a prefix for the
namespace (part-lst-URI
and part-lst-pr
representations), as a set of indexes (part-idx and part-idx-part representations),
or as a surrogate, the surrogate being either defined
locally for each partition (part-sur-lst, part-sur-idx, and part-sur-idx-part
representations) or globally for all the partitions
(part-sur-glob-lst,
part-sur-glob-idx, and
part-sur-glob-idx-part
representations).
For the part-idx
representation, the element names of the example document
would be encoded as follows. The partitions are given in
curly brackets for clarity, but don't need to be encoded.
// Namespace list
http://docbook.org/ns/docbook
// Element name lists
// Document partition
article
// article element partition
section
// section element partition
title
para
section
// Element names
{document} 1 // article
{article} 1 // section
{section} 1 // title
{section} 2 // para
{article} 1 // section
{section} 1 // title
{section} 3 // section
{section} 1 // title
{section} 2 // para
Results
For each document, the entropy associated to encoding
element names was computed using as unit the number of
bytes needed to represent an element name.
Figure 4 shows a summary of those results
by displaying, for each representation, the average
entropy associated to element names, and the standard
deviation.
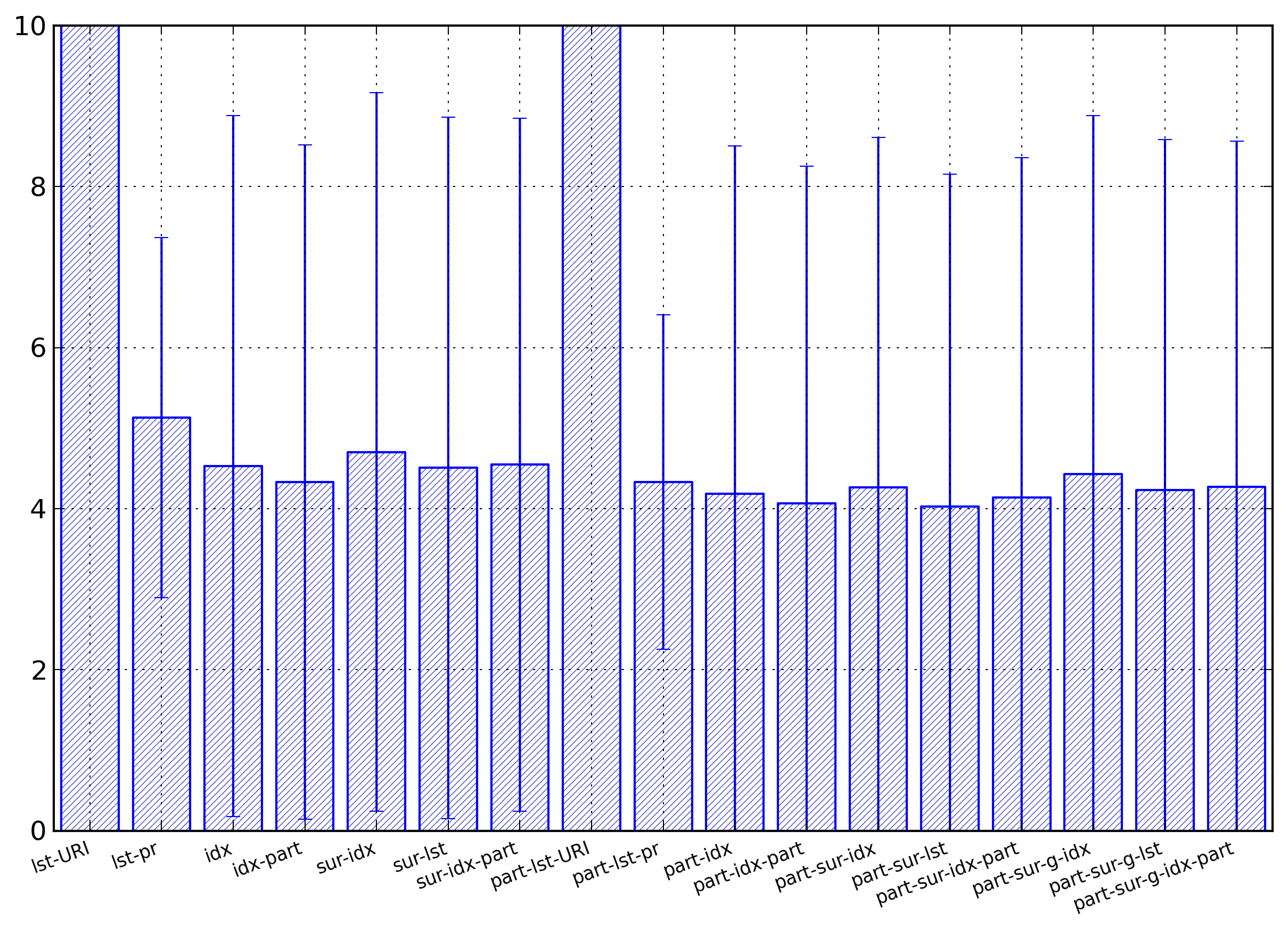
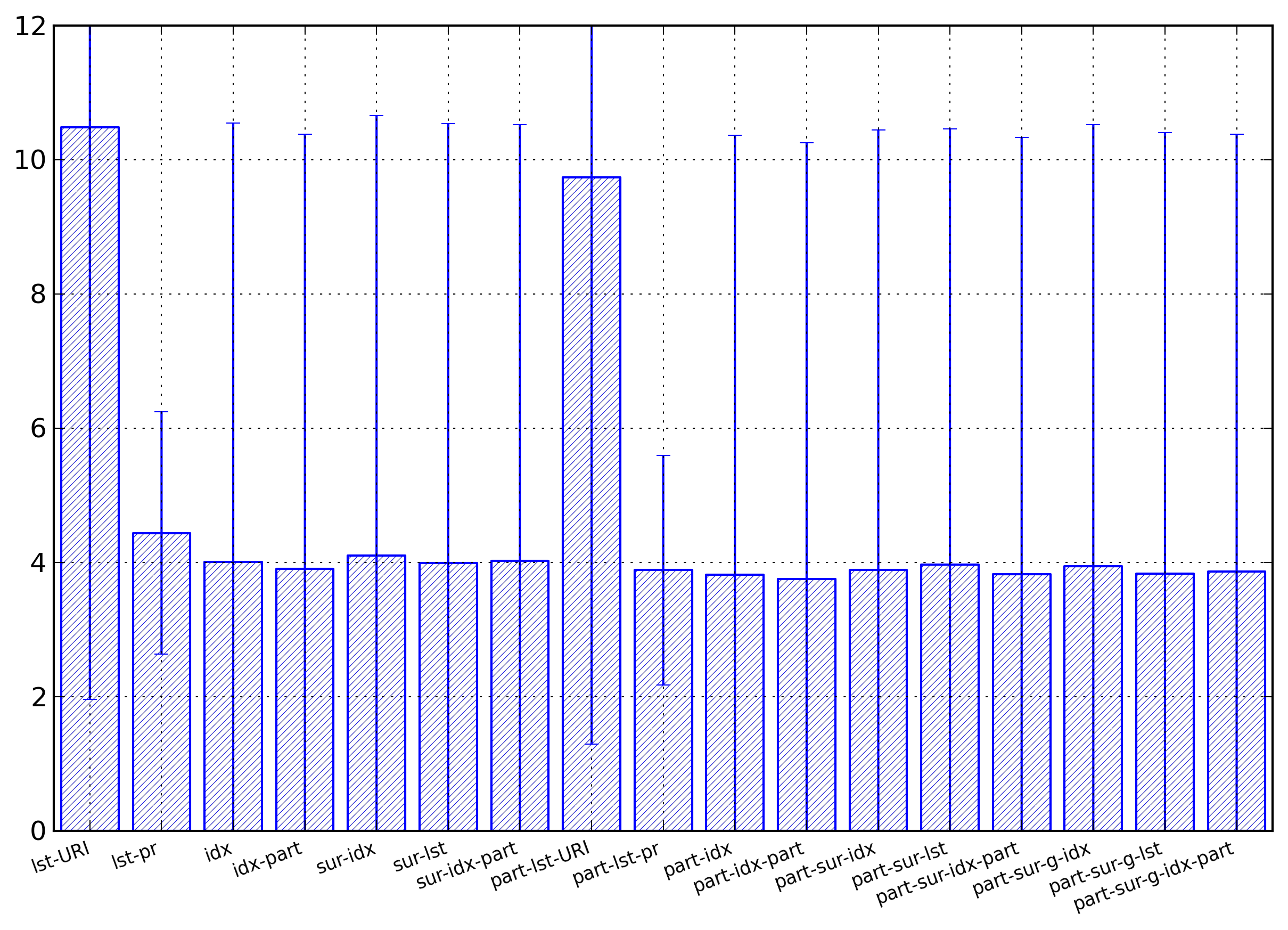
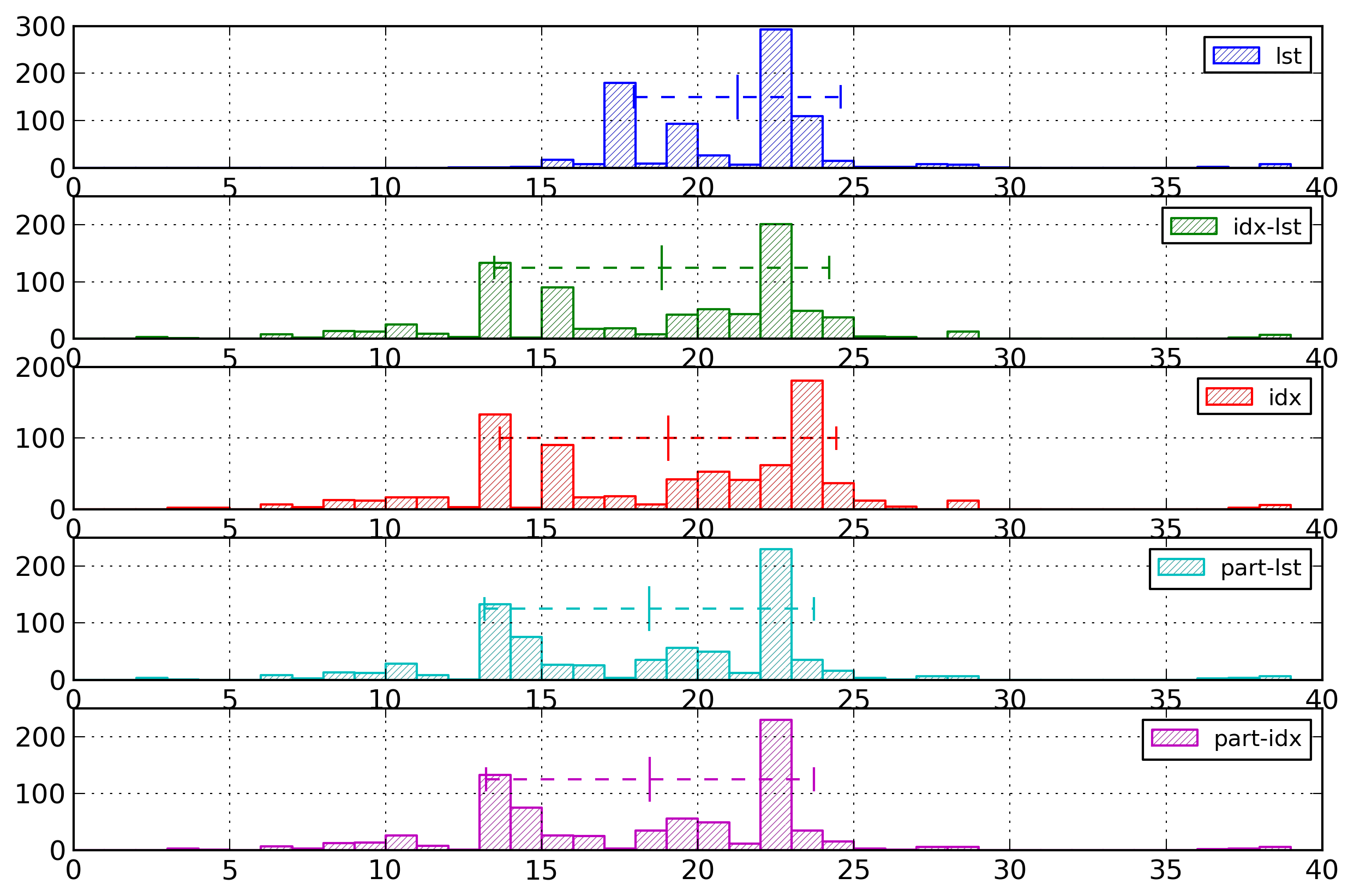
Figure 4: Element Name Summary
Average entropies, computed in bytes per name,
of the different representations for element
names. The lst-URI and the
part-lst-URI
columns have been willingly cut as their values
are far above the other values.
The first result is that representations using strings
for representing the namespace’s URI have entropies much
higher than all the other representations (the vertical
scale of Figure 4 was willingly chosen to
cut those numbers in order to better show the differences
between the other values). The lst-URI representation has an
average of 18.64 bytes per element name, with a standard
deviation of 6.76, and the part-lst-URI representation has
an average of 17.41 bytes per element name, with a
standard deviation of 7.02.
Figure 5 and Figure 6 show
the distribution of entropy values for a selection of
representations. Some features of these distributions can
be linked to documents with specific characteristics.
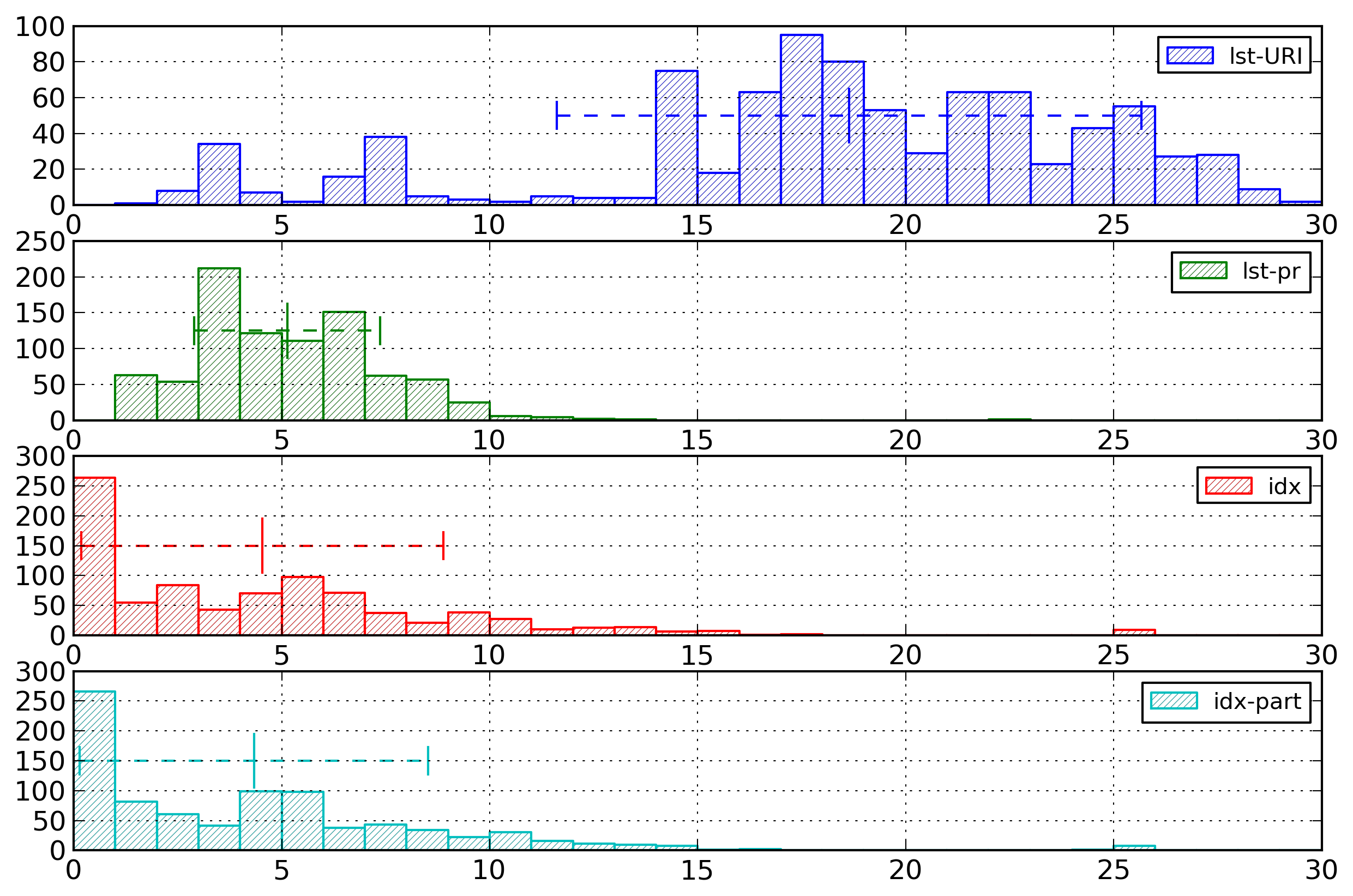
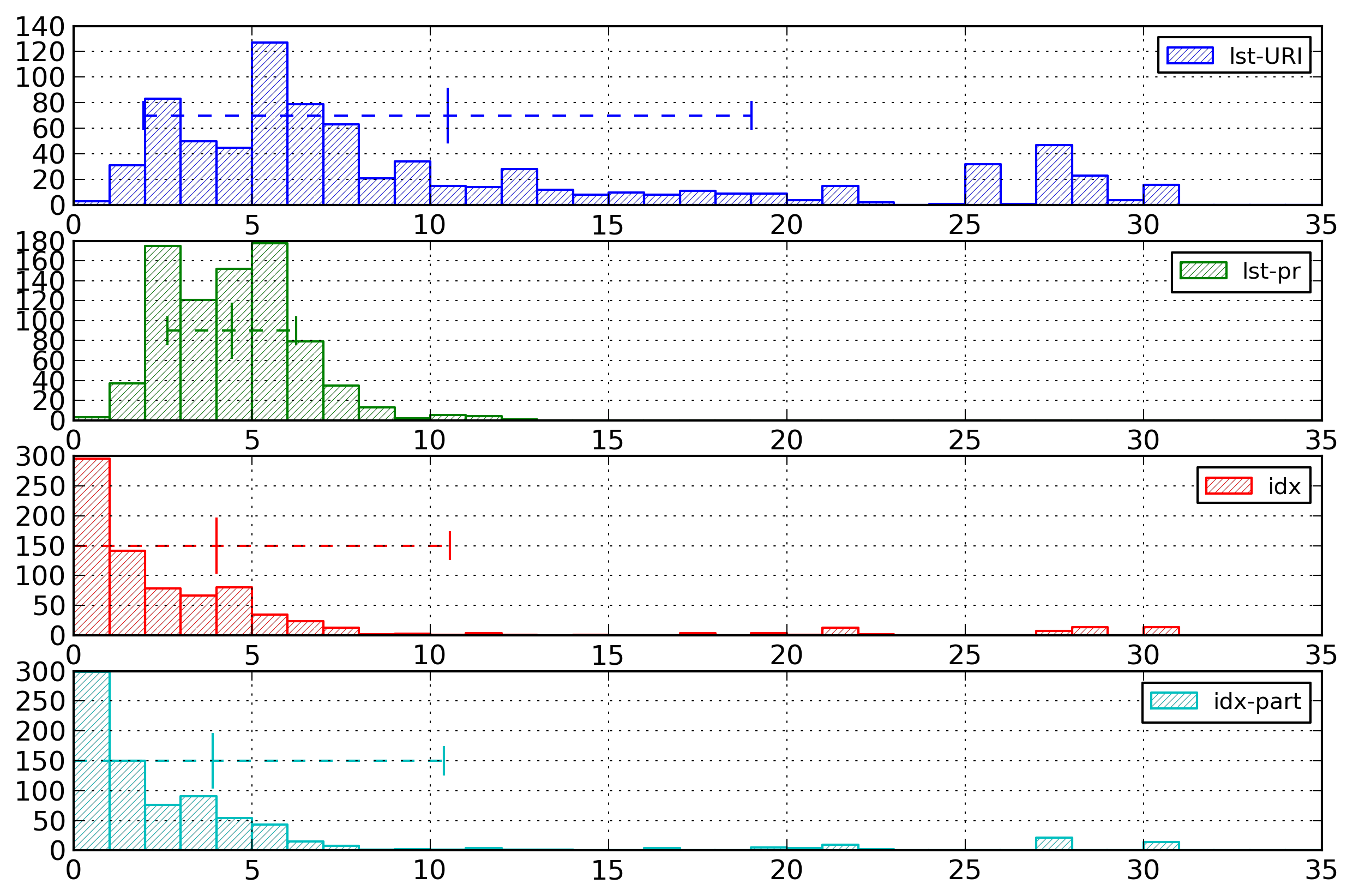
Figure 5: Element Name Histogram - Lists
Distribution of entropies for selected
representations of element names based on list of
strings or on indexes. The lst-URI histogram has
been willingly cut.
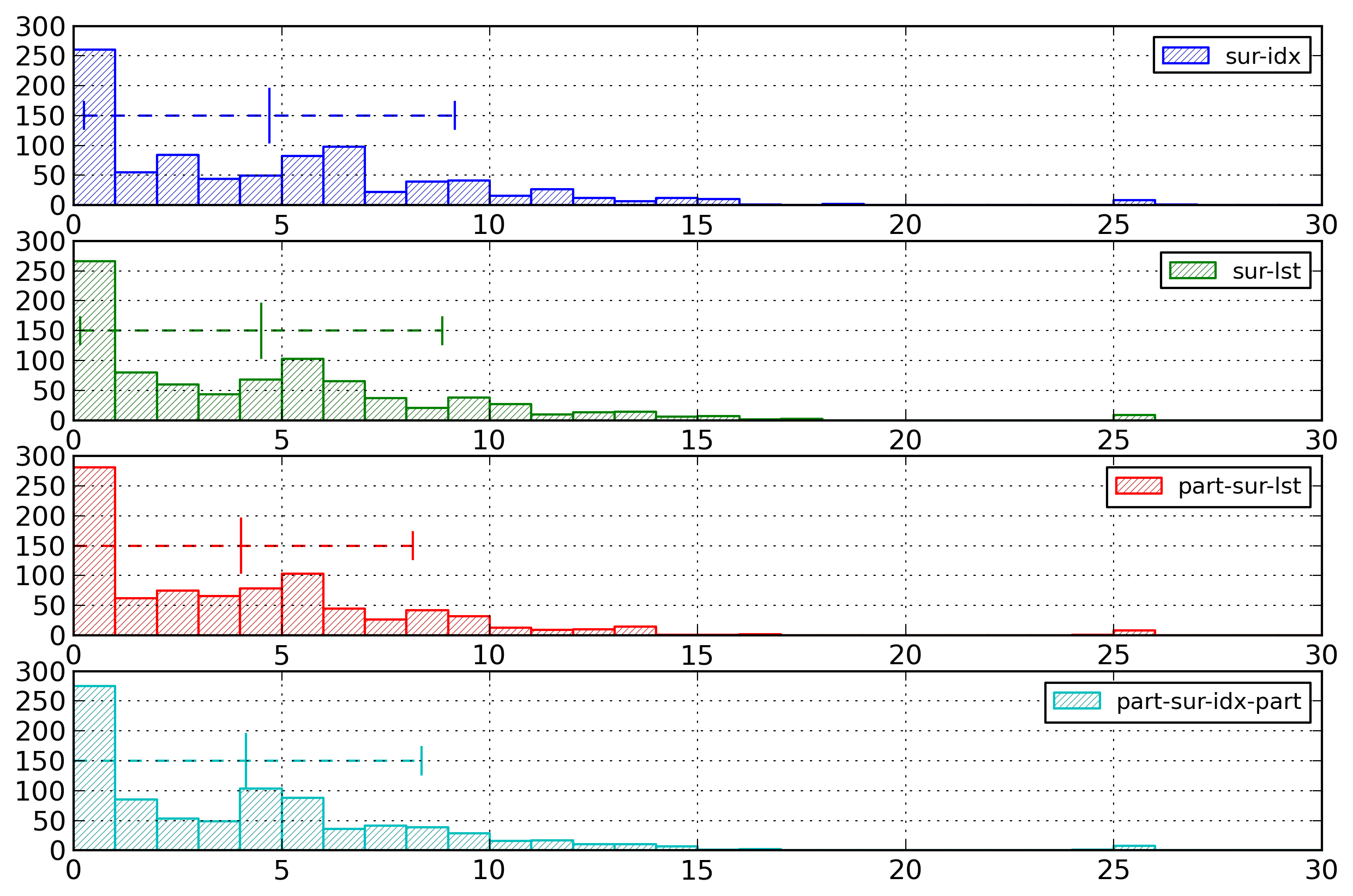
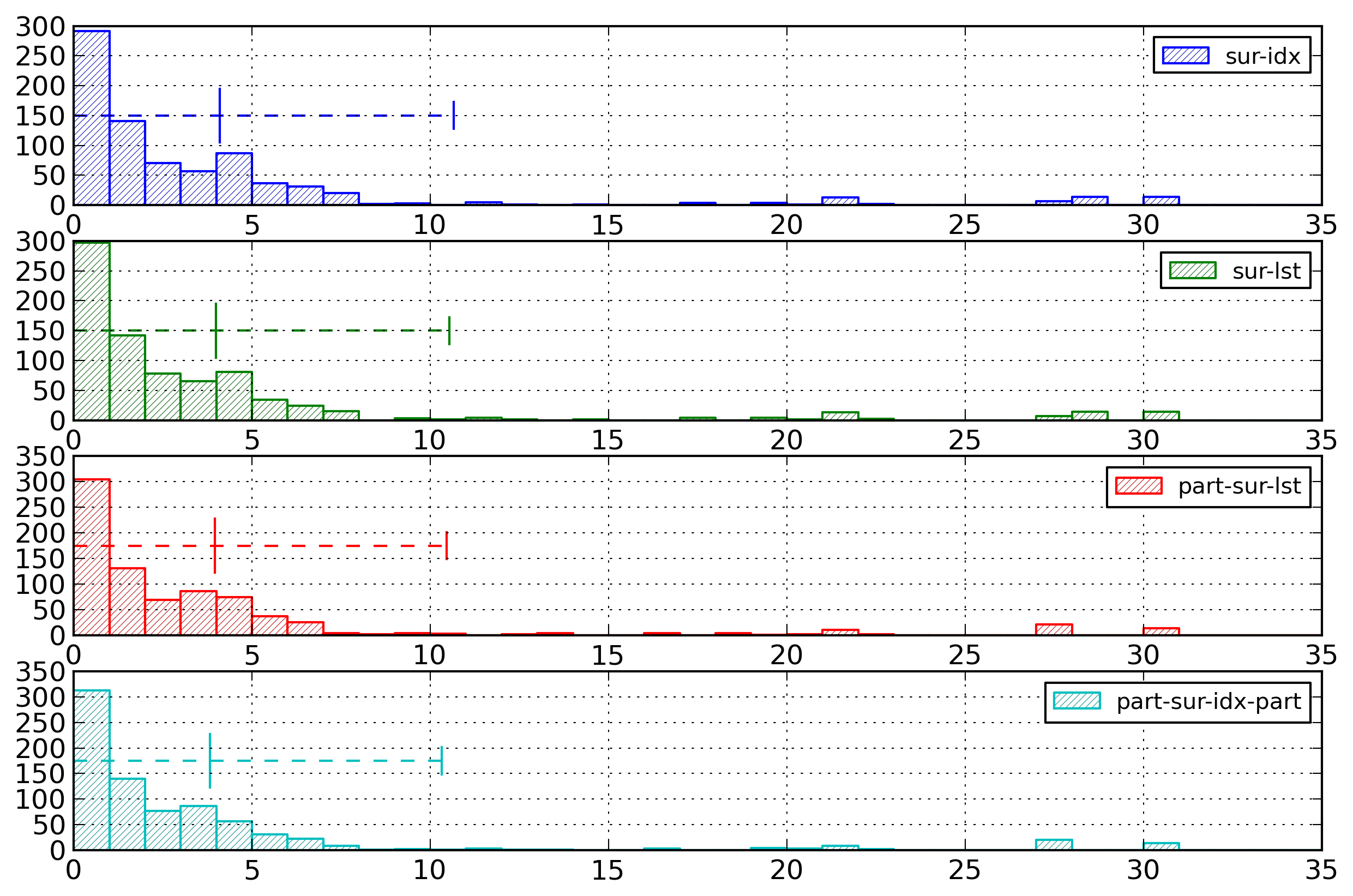
Figure 6: Element Name Histogram - Surrogates
Distribution of entropies for selected
representations of element names based on
surrogates.
The documents with high entropy (around 45 bytes per
element name, not displayed on the histogram) for the
URI-based representations correspond to medium-sized
documents containing several different URIs (from 5 to 7).
The few documents with high entropy (greater than 20
bytes per element name) for the prefix-based
representations correspond to documents with very long
element names (40 or 50 characters).
For all index-based representations, the documents with
a high entropy value (around 25 bytes per element name)
are documents containing only one element.
On a more global level, Figure 4 showed
that prefix-based representations are much closer to
index-based representations than to URI-based
representations in terms of entropy values. However, Figure 5 shows that the distributions of
those entropy values are very different for prefix-based
and index-based representations. Whereas for prefix-based
representations, the entropy values roughly follow a
normal distribution, for index-based representations, the
entropy values roughly follow a geometric distribution.
Those differences are directly linked to the kind of
representation used.
Several conclusions can be drawn from the results
obtained. First, using local-name indexes partitioned
according to the namespace decrease the entropy.
Second, partitioning the representation according to the
parent element also decrease the entropy.
Third, while using surrogates, the best representation
for a surrogate definition is to use an index for the URI,
but a string for the local name. Indexing the URI is
efficient, as a URI is reused for several surrogate
definitions. But indexing a local name is usually not
efficient, as a local name is often only used for one
surrogate definition.
In addition, the best surrogate-based representation
usually has a slightly lower entropy value than the
corresponding index-based representation. This is the case
for sur-lst compared to
idx and for part-sur-lst compared to
part-idx. This is however
not the case for part-sur-g-lst compared to
part-idx.
Lastly, for representations using surrogates partitioned
according to the parent element, those using a global
surrogate definition have higher entropy than those using
a local surrogate definition.
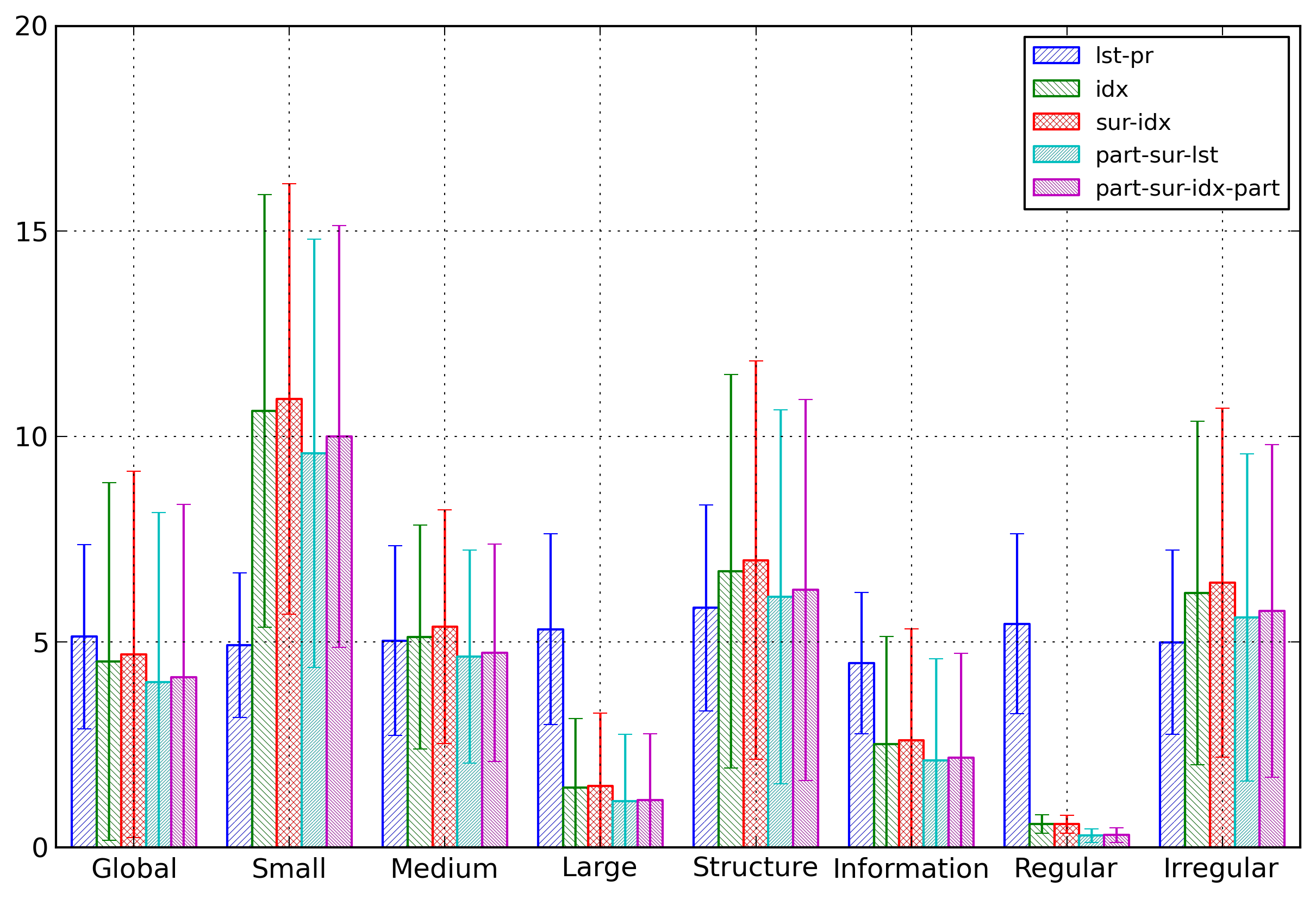
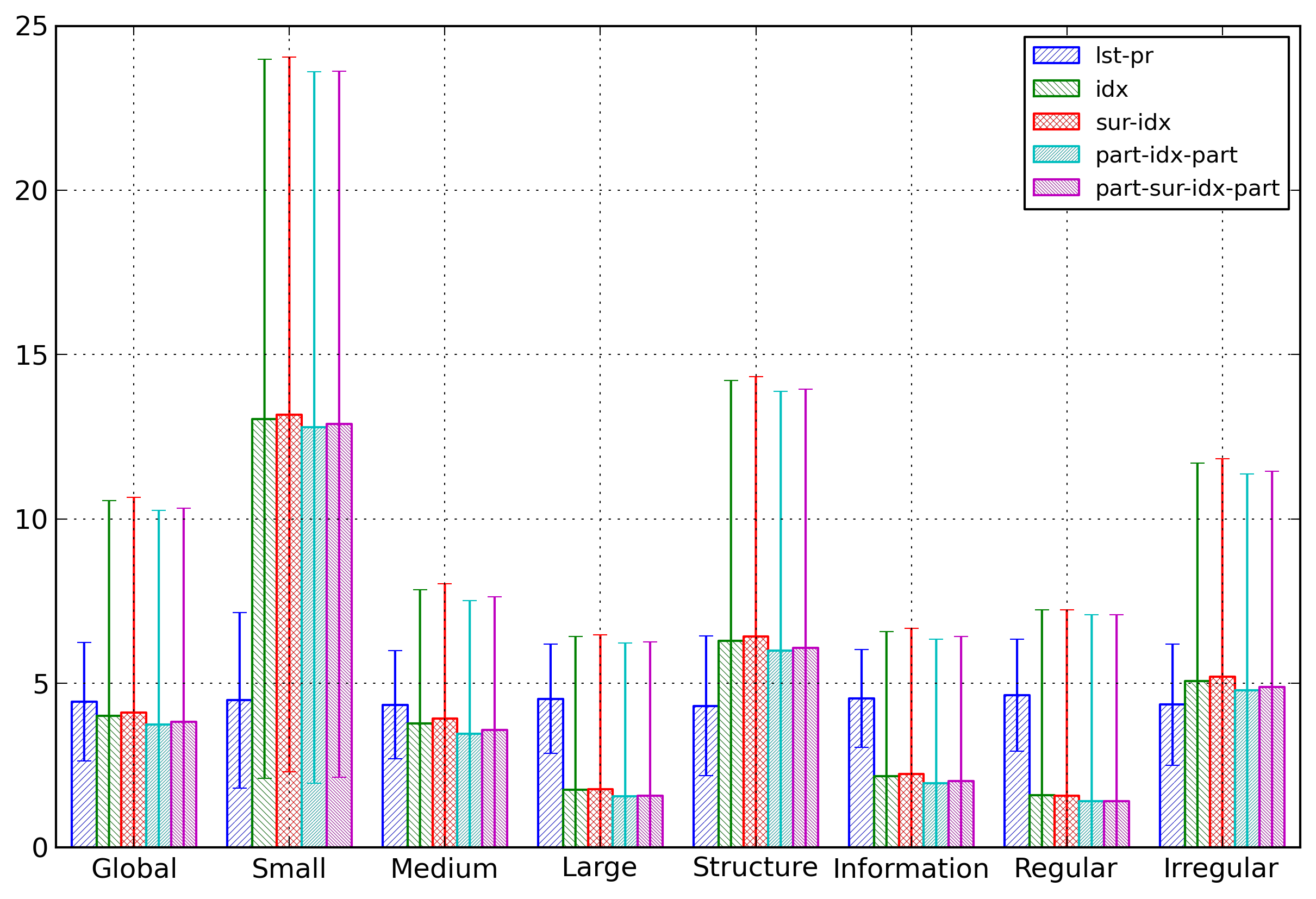
Figure 7 compares the entropies for some
selected representations for the different categories of
documents. The main result is that while the lst-pr representation has only
small entropy variations across the different categories,
the four other representations, all index-based
representations, have much more important variations. But
the relations between those four representations stay
similar across all categories.
Figure 7: Element Name Categories
Comparison of average entropies depending on the
category of documents for some selected
representations of element names.
This figure shows expected results: for index-based
representation, the entropy is lower for larger documents.
It is also lower for regular documents.
The conclusion for element names is that the lowest
entropy results are obtained by the combination of
indexing, partitioning and surrogate usage. On average,
the best combination is to use partitioned surrogates,
where surrogate definitions use indexes for the URIs and
strings for the local names. However, for some document
categories, a simple listing of the prefix and local name
has lower entropy values.
Attribute names
Introduction
Attributes can be considered either as a whole, or by
separating names and values. However, in most cases when
an attribute is used several times in a document, it will
have different values. Therefore, a join representation of
element names and values is not an attractive option and
we selected to study only independent representations. In
this section, we consider the representations of attribute
names. The representations of attribute values are studied
in a later section.
Representations
As attribute names and element names are very similar,
the same representations were used for attribute names as
for element names.
Results
Similarly to element names, for each document, the
entropy associated to attribute names was computed using
as unit the number of bytes needed to represent an
attribute name.
Figure 8 shows a summary of those results
by displaying, for each representation, the average
entropy associated to attribute names and the standard
deviation.
Figure 8: Attribute Name Summary
Average entropies, computed in bytes per name,
of the different representations for attribute
names.
A first result is that the representations for attribute
names have lower entropies than the corresponding
representations for element names. This is due to the fact
that in many cases, attribute names have no namespace.
This is especially true for URI-based representations.
However, for most representations, the standard
deviation is higher than for element names. This comes
from the fact that in a few cases the attribute names have
a namespace, and therefore higher entropy cost.
Figure 9 and Figure 10 show
the distributions of entropy values for a selection of
representations.
Figure 9: Attribute Name Histogram - Lists
Distribution of entropies for selected
representations of attribute names based on list
of strings or on indexes. The lst-URI histogram has
been willingly cut.
Figure 10: Attribute Name Histogram - Surrogates
Distribution of entropies for selected
representations of attribute names based on
surrogates.
For most representations, the distribution of entropy
values contains a group of documents with entropy values
higher than the main group of documents. This group
contains the documents containing attributes with a
defined namespace.
Apart from this point, the results are quite similar to
those obtained for the representations of element names.
The last difference is that using a surrogate increases
the entropy. This is also due to the fact that many
attributes have no specific namespace.
Figure 11 compares the entropies for some
selected representations for the different categories of
documents. The results are similar to those obtained for
element names apart for the differences already noted.
Figure 11: Attribute Name Categories
Comparison of average entropies depending on the
category of documents for some selected
representations of attribute names.
As a conclusion, for attribute names, the lowest entropy
values are obtained by combining indexing and
partitioning. Here, surrogate usage does not decrease the
entropy values. On average, the best combination is to use
partitioned indexing, with local names indexes being
partitioned according to their URI. However, as for
element names, for some document categories, a simple
listing of the prefix and local name has a lower entropy
value.
Element and attribute names
Introduction
While the two previous sections considered element and
attribute names separately, they can also be considered
jointly. In particular, element and attribute names may
share the same namespace, even if many attributes have no
namespace value.
Representations
Several representations can be used to encode jointly
element and attribute names. Those representations are
similar to those used for element names or attribute
names, but can vary in the degree of separation used
between element names and attribute names.
First, the names can be encoded as null-terminated
strings, specifying the namespace either through its URI
(lst-URI representation)
or through its prefix (lst-pr representation).
A second possibility is to use indexes for the
namespaces and the local names. When using an index, two
components can be shared: the definition of the indexes
from the string values, and the list of items, expressed
as index values. Element names and attribute names can be
indexed jointly, sharing both the index definitions and
the listing of indexed values (idx-j representation). They can
share a common index for namespaces and local names, but
with separated lists of indexes (idx-cc representation). Last,
they can have a common index for namespaces with separated
lists of indexes, and separated indexes and lists for
local-names (idx-cs
representation). As an option, the indexing of local names
can be partitioned according to their namespace (idx-j-part, idx-cc-part, and idx-cs-part representations).
For the idx-j
representation, the structure of the representation would
be the following.
// Namespace list
...
// Local name list
...
// Element and attribute names
...
For the idx-cc
representation, the structure would be as follows.
// Namespace list
...
// Local name list
...
// Element names
...
// Attribute names
...
For the idx-cs
representation, it would be the following.
// Namespace list
...
// Element local name list
...
// Attribute local name list
...
// Element names
...
// Attribute names
...
A third possibility is to use a partitioned
representation according to the enclosing element. All the
possibilities of the previous index-based representations
were reused with partitioned representations (part-idx-j, part-idx-cc, part-idx-cs, part-idx-j-part, part-idx-cc-part, and part-idx-cs-part
representations).
The possibility of using surrogates was not studied
here, as the previous results showed that they were very
close to the simple index-based representations.
Results
As for the analysis of separate representations of
element and attribute names, the entropy associated to
combined representations of element and attribute names
was computed using as unit the number of bytes needed to
represent one of those names.
In addition to all the representations combining element
and attribute names, some representations separating
element and attribute names were included for comparison
purpose. Those references are using string representations
(lst-URI-ref and
lst-pr-ref
representation), index-based representations (idx-ref and idx-ref-part representations),
and partitioned representations (part-idx-ref and part-idx-ref-part
representations). The entropy values for those reference
representations were computed by combining the values of
the corresponding independent representations.
Figure 12 shows a summary of those
results, displaying the average entropy and the standard
deviation for each representation. As for element names,
the chosen scale has been willingly selected to cut the
values of the string-based representations using URIs as
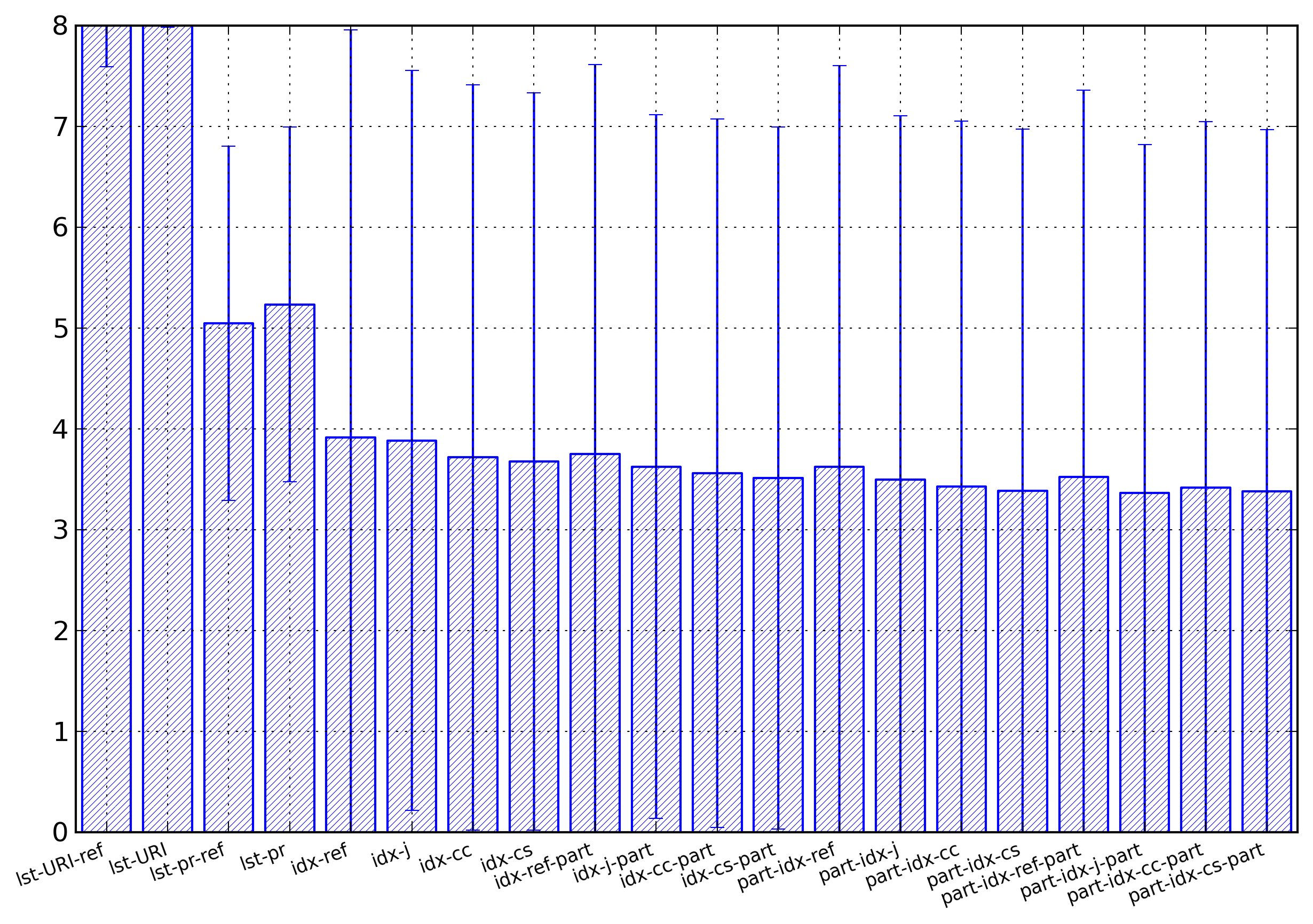
they were far greater than the other values. For lst-URI-ref representation, the
average entropy is of 15.00 bytes per name, with a
standard deviation of 7.41, while for the lst-URI representation, the
average entropy is of 15.40 bytes per name, with a
standard deviation of 7.41.
Figure 12: Name Summary
Average entropies, computed in bytes per name,
of the different representations for element and
attribute names. The lst-URI-ref and the
lst-URI columns
have been willingly cut as their values are far
above the other values.
The main result is that while a join representation
increases the entropy for string-based representations, it
decreases the entropy for index-based representations.
Figure 13 and Figure 14 show
the distributions of entropy values for selected
string-based and simple index-based representations.
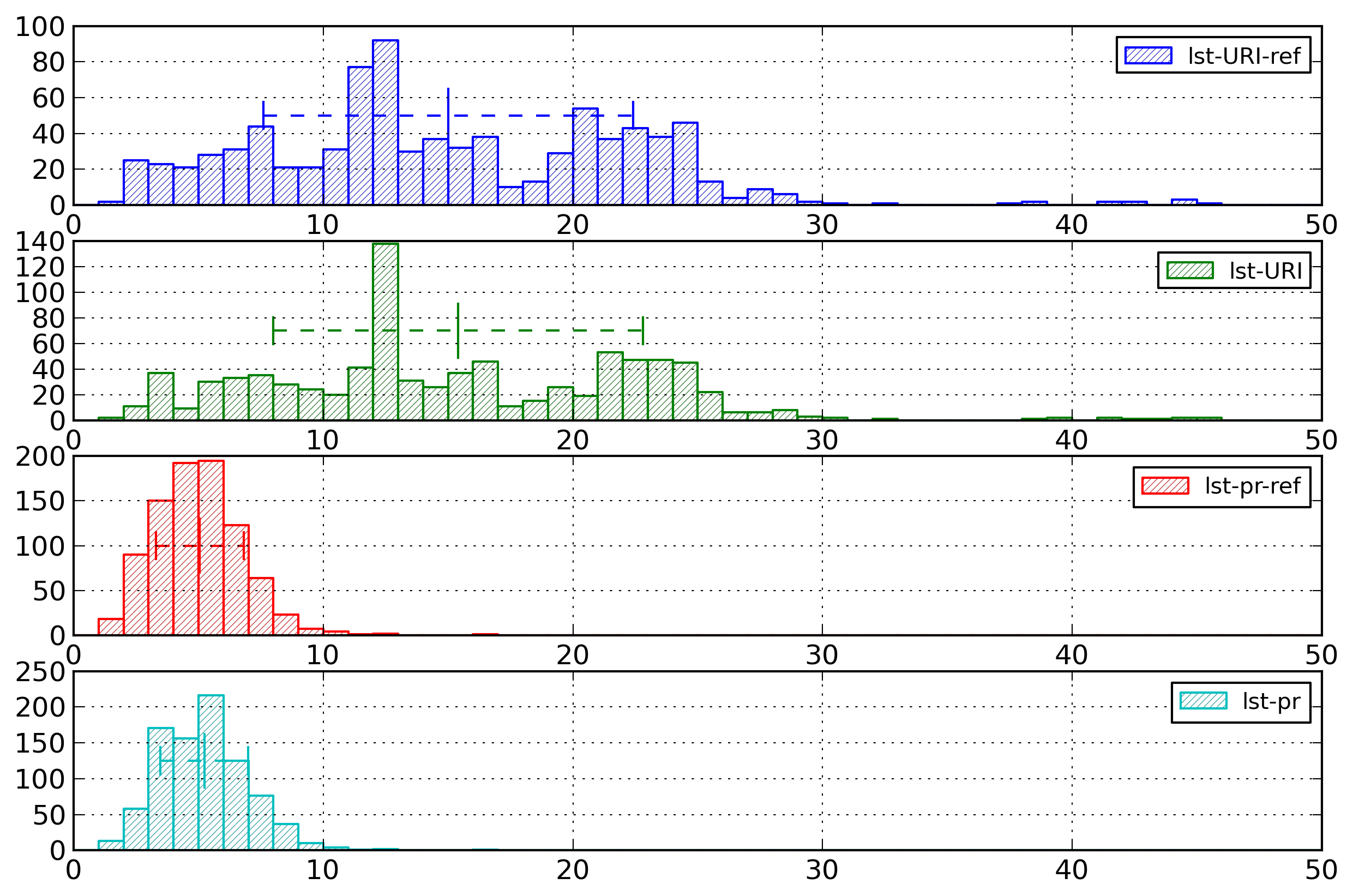
Figure 13: Name Histogram - List
Distribution of entropies for selected
representations of element and attribute names
based on list of strings.
Figure 14: Name Histogram - Index
Distribution of entropies for selected
representations of element and attribute names
based on indexes.
The main result is that for simple index-based
representations, the lowest entropy values are obtained
for the idx-cs
representation. This corresponds to the fact that element
and attribute names generally share the same set of URIs,
but with different usages, while they have different sets
of local names.
This result mostly holds for more complex index-based
representation. The exception is for representations
partitioned according to the containing element and with
local name indexes partitioned by namespace. For these
representations, the lowest entropy values are obtained
for the part-idx-j-part
representation.
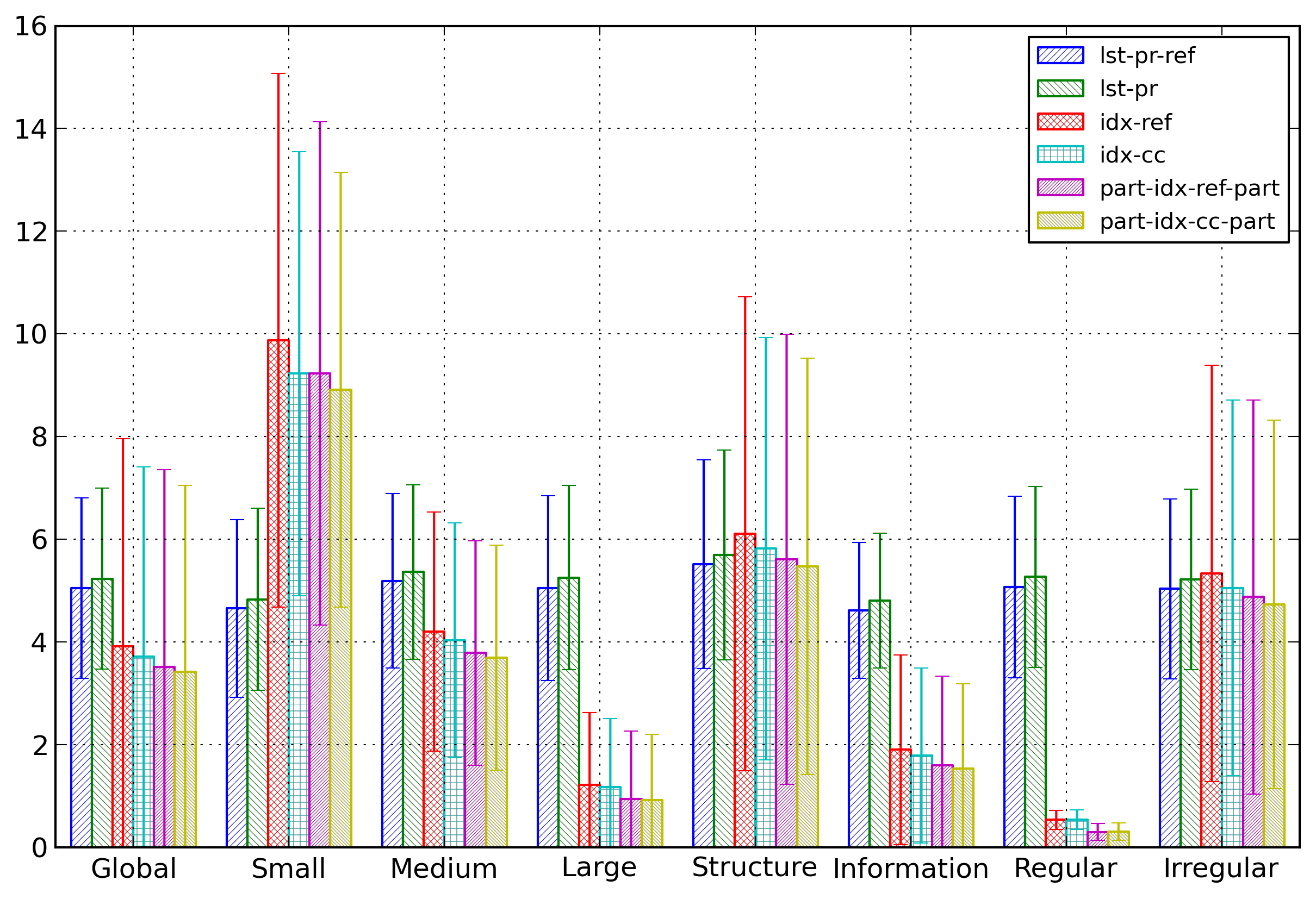
Figure 15 compares the entropies for some
selected representations for the different categories of
documents. The main results from this figure is that the
relationships found between the index-based
representations are maintained for all categories, and
that the relationships found previously between
string-based and index-based representations depending on
the category of documents are also maintained.
Figure 15: Name Categories
Comparison of average entropies depending on the
categories of documents for some selected
representations of element and attribute names.
The conclusion that can be drawn from these results is
that for index-based representations, the lowest entropy
is obtained by a partial joining of the representations of
element names and attribute names.
Namespace declarations
Introduction
Namespace declarations are used to associate a prefix to
a URI representing a namespace. As previously stated in
the section for element names, in many cases the prefixes
can be discarded by binary XML formats. However, in some
cases, prefixes are used in attribute values for
specifying a qualified name (for example, in XML Schema to
associate a type to an element or to an attribute). In
such cases, the namespace declarations must be preserved.
A namespace declaration is constituted of two
components: the URI of the namespace and the prefix
associated to it.
Representations
Several representations can be used to encode a
namespace declaration.
First, both the URI and the prefix can be encoded as
null-terminated strings (lst representation).
A second possibility is to use indexes. As URI are long
and can be used in several declarations, while prefix tend
to be short and not reused, a first option is to index the
URIs and simply list the prefixes (idx-lst representation). A
second option is to index both the URIs and the prefixes
(idx representation).
A third possibility is to partition the prefix
definition according to their URIs. The URIs are indexed,
and in each partition, the prefixes can either be
represented with a string (part-lst representation) or as
an indexed value (part-idx representation).
Results
For the documents of the testing corpus, the entropy
associated to namespace declaration is computed using as
unit the number of bytes needed to represent a namespace
declaration.
Figure 16 displays the distribution of the
entropy values for the different representations.
Figure 16: Namespace Histogram
Distribution of entropies for the representation
of namespace declarations.
These results show that using indexing reduces the
entropy. However, indexing only the URI is slightly
better than indexing both the URI and the prefix. This is
explained by the fact that prefixes are usually short and
not repeated.
Partitioning has a somewhat stronger effect than
indexing. For the prefix definition in partitioned
representations, both direct string and indexed
representation have the same entropy values.
It should be noted that in most cases, a document
contains only a few or no namespace declarations. However,
a few sample documents from the testing corpus contained a
lot of namespace declarations (from 150 to 3000). Those
documents are automatically generated documents with
repetition of namespace declarations for each separately
generated element. For such documents, indexing reduces
significantly the entropy value.
As a conclusion, in most cases, where only a few
namespace declarations are used and no redundancies are
present in those declarations, all the representations
have almost the same entropy. However, when taking into
account all the cases, using a partitioned representation
gives the best results.
Attribute values
Introduction
In addition to their name, attributes are also defined
by their value. In this section, we consider the
representation of attribute values independently of their
names.
Representations
A few different representations can be used for
attribute values.
First, the attribute values can be represented as
null-terminated strings (lst representation).
Second, the attribute values can be indexed (idx representation). As for the
element names, the cost of the index definition must be
taken into account.
Third, the attribute value representation can be
partitioned according to the attribute name. This can be
done either for a string-based representation (part-lst representation) or for
an index-based representation (part-idx representation).
Last, in a partitioned representation, the attribute
values can be represented by using a global index instead
of local ones (part-idx-glob representation).
Results
The results for attribute values were obtained by
measuring the entropy associated to them, using as unit
the number of bytes needed to represent an attribute
value.
The first thing of note is that there is a huge
variation in the results obtained depending on the
document. While most documents have entropies ranging from
0 to 100 bytes per attribute value, there are a few
documents with much greater entropies (up to about 12,000
bytes per attribute value).
Those documents with very high entropies for attribute
values are either SVG or X3D documents containing large
graphical information in one (or more) attribute values.
Taking into account those documents skew the results and
do not provide many insights on the different
representations. In particular, the average entropy value
is almost the same for all the representations.
Therefore, to enable a better analysis of the attribute
value representations, those documents were removed from
the testing corpus. Specifically, all documents for which
the average attribute value entropy was greater than 100
bytes per attribute value for the lst representation were
discarded. There were 33 such documents.
Figure 17 shows the distributions of
entropies for the reduced testing corpus. These
distributions show that indexing and partitioning reduce
the entropy. Indexing has a somewhat stronger effect. In
addition, indexing and partitioning can be combined,
enabling their respective entropy reductions to partly
combine. Using a global index and a partitioned list of
value is slightly less efficient than using a partitioned
index.
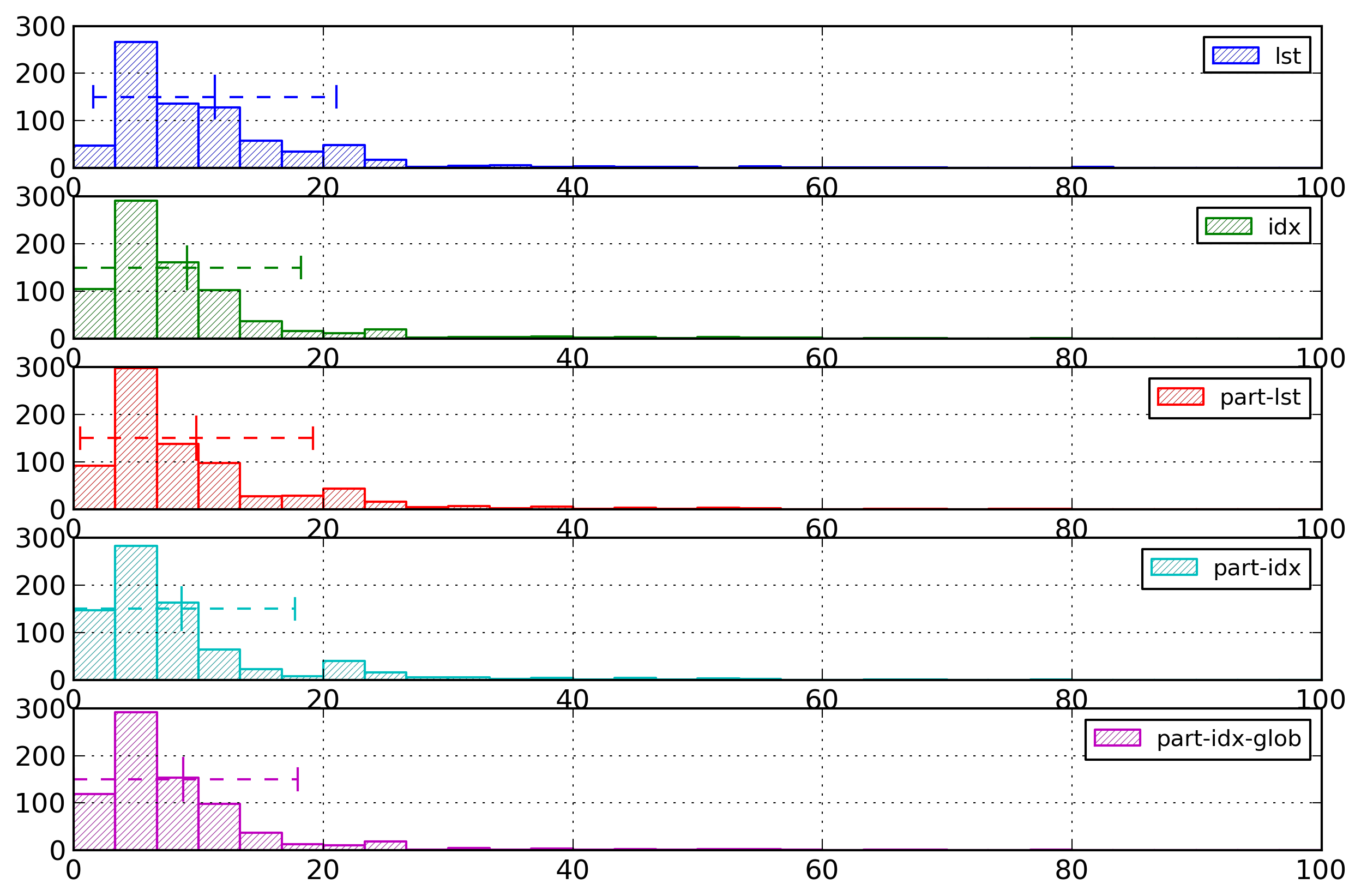
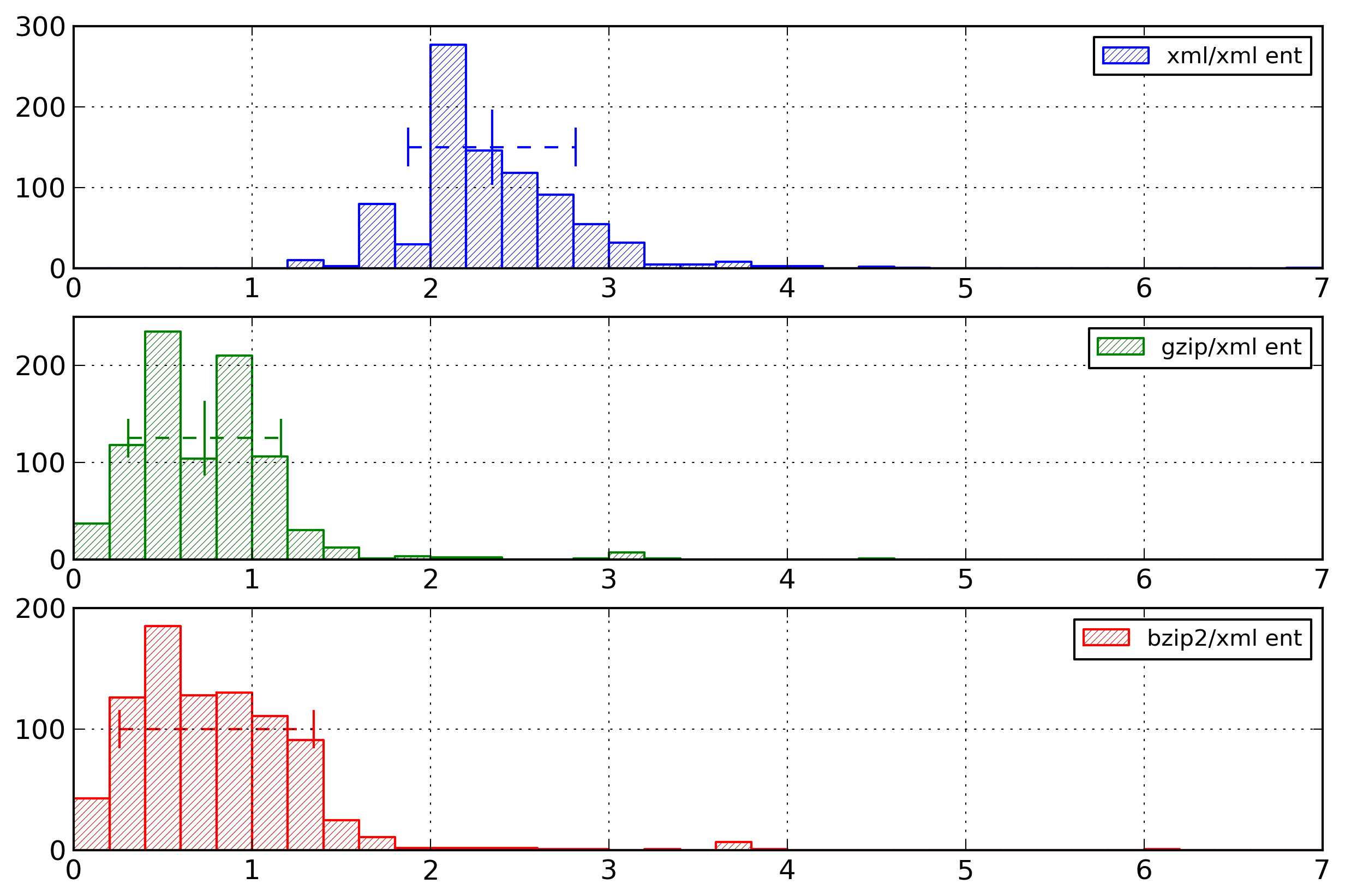
Figure 17: Attribute Value Histogram
Distribution of entropies for the
representations of attribute values, on the
reduced testing corpus (i.e., without documents
with entropy values greater than 100 bytes).
A more detailed analysis was conducted by analyzing the
results for each category of documents on this reduced
testing corpus. It should be noted that the removed
documents mostly belong to the large, information-rich,
and irregular categories.
The main result obtained is that partitioning is more
effective than indexing for small documents. On the other
hand, indexing is more effective than partitioning, for
large documents, for information-rich documents, and for
regular documents.
In all case the combination of indexing and partitioning
leads to lower entropy results than using only one of
those mechanisms. Joining the two mechanisms has a
greater impact for the medium, structure-rich and
irregular documents.
In addition, in most cases, using a global index gives
slightly higher entropy values than using partitioned
indexes. The main exceptions are the information-rich and
irregular documents.
As a conclusion, the representation with the lowest
entropy for attribute values is the one using partitioning
according to the attribute name and locally indexed
values.
Character contents
Introduction
Character contents representation is very similar to
attribute values representation. Both represent textual
information contained in an XML document. Where an
attribute value is related to an attribute, a character
content item is related to an element.
However, character contents and attribute values have
different natures and therefore, it is expected that some
differences will appear in the results.
Representations
For character contents, the same representations were
used as for attribute values (lst, idx, part-lst, part-idx, and part-idx-glob representations)
Results
The results for character contents were obtained from
the testing corpus and are expressed using for unit the
number of bytes needed to represent a character content
item.
It should be noted that the documents from the testing
corpus were pruned of any whitespace character content,
and that all contiguous character contents were joined
together (i.e., removing
newlines).
A second thing to note is that, as for attribute values,
there are a few documents with much larger entropy values
than the others (up to about 500,000 bytes per character
content). These documents with very high entropy values
are either SVG documents containing application specific
additions, or some scientific data files.
To enable a better analysis of the character content
representations, documents with average character content
entropy greater than 100 bytes per character content item
for the lst
representation were pruned from the testing corpus. There
were 25 such documents.
Figure 18 shows the distribution of the
entropy values for the reduced testing corpus. Those
results show that both indexing and partitioning reduce
the entropy. On average, indexing enables a somewhat more
important reduction than partitioning. Combining indexing
with partitioning enables combining part of their
respective reductions of entropy. Last, using a global
index with partitioned list of values representation leads
to greater entropy values than a fully partitioned indexed
representation.
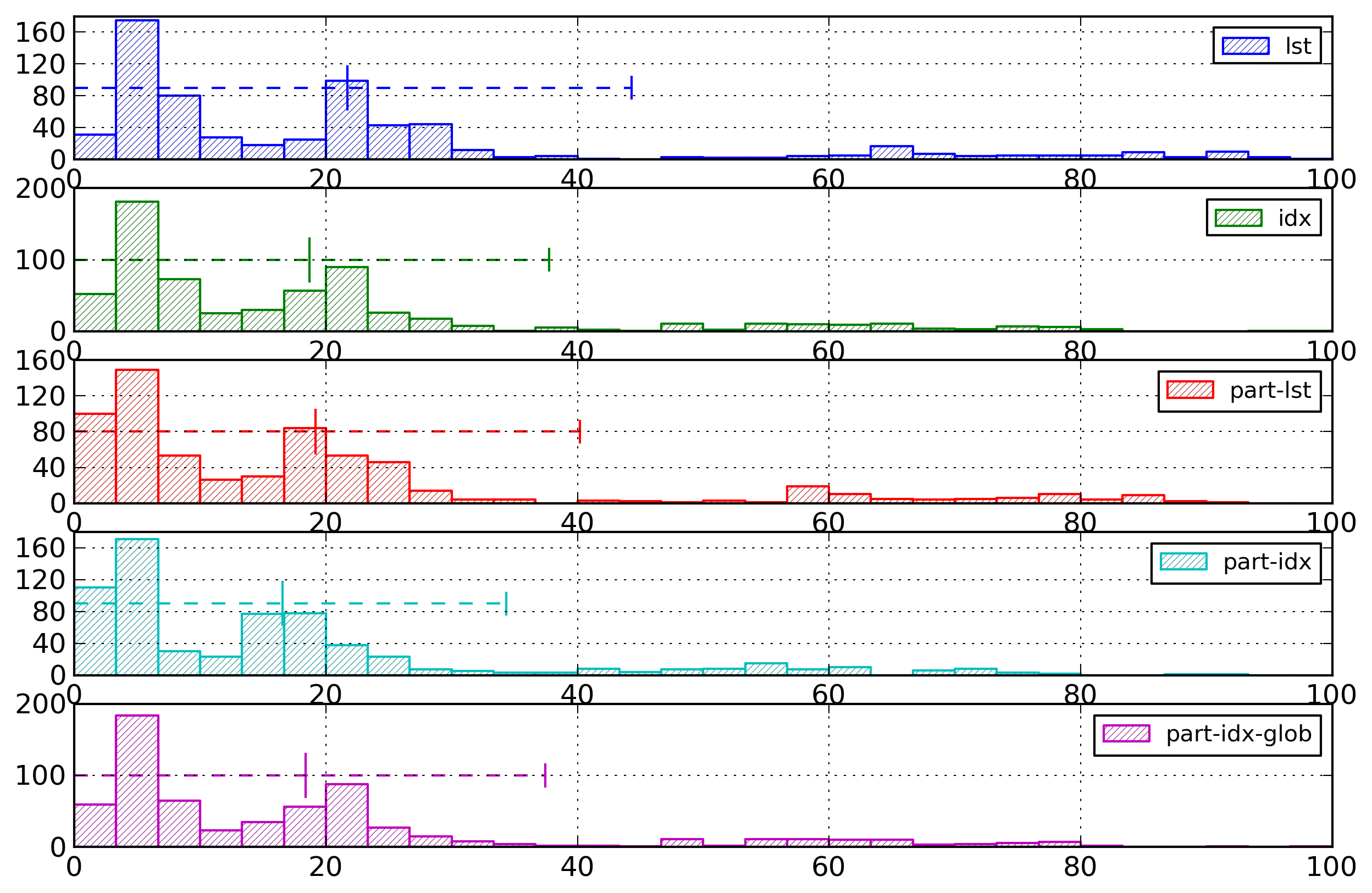
Figure 18: Character Histogram
Distribution of entropies for the
representations of character contents on the
reduced testing corpus (i.e., without documents
with entropy values larger than 100 bytes).
A more detailed analysis was conducted on the different
categories of documents. The removed documents mostly
belong to the large, information-rich and irregular
categories.
The first result is that indexing is more effective than
partitioning for large documents, for information-rich
documents, and for regular documents. On the contrary,
partitioning is more effective than indexing for small
documents, for medium documents, for structure-rich
documents, and for irregular documents.
Secondly, the combination of indexing and partitioning
has lower entropy values than using only one of those
mechanisms.
Last, using a global index leads in all cases to higher
entropy values than using partitioned indexes.
As a conclusion, the general observations found for the
attribute values are also relevant for the character
contents. However, the difference of usage between
attribute values and character contents is reflected in
the details of the results.
File format evaluation
Introduction
In the previous section, we obtained results related to the
evaluation of several representations for the different parts
of an XML document using entropy measurements. In this
section, we reuse those results to study several encoding
formats for XML documents.
Three formats have been studied here: textual XML XML, the Fast Infoset format Fast Infoset, and the EXI format EXI.
File format description
XML
Textual XML is the default format for XML document. We
considered here XML documents as defined by the XML 1.0 [XML]
and the Namespaces in XML
1.0 [XML Namespaces]
specifications (XML 1.1 introduces only marginal changes
and the results of our study mostly apply).
We have shown previously some entropy results obtained
when considering an XML document as a textual document.
However, more precise results can be obtained by splitting
the XML document into its different components and
considering each of them individually.
In XML, event types are not specified explicitly, but
rather implicitly through the XML syntax. However, those
event types can be considered as being represented as a
list.
Element names are represented as strings, using prefixes
to specify their namespaces.
Attribute names are also represented as strings, as well
as the attribute values.
Namespace declarations are represented as strings,
associating a prefix to a URI.
Character contents are also represented as strings, as
well as comments and processing instructions.
Globally, textual XML uses a basic string representation
for all the components. The only optimization is to use
prefixes as shortcuts for namespace’s URIs.
Fast Infoset
Fast Infoset is a binary XML format, specified by the
ITU-T rec. X.891 | ISO/IEC
24824-1 standard [Fast Infoset]. This format drops the textual
representation of XML documents to replace it by a binary
representation, enabling a more compact encoding of XML
documents.
In Fast Infoset, event types are explicitly coded in a
binary form, and their representation corresponds to a
list.
Element names and attribute names are represented as
surrogates, a surrogate being defined from the index of
the namespace’s URI and the index of the local name.
Namespace declarations are represented using indexed
values for both the URI and the prefix. As prefix
preservation has been ignored in this study, namespace
declarations have not been taken into account here.
Attribute values, character contents, comments, and
processing instructions are represented as indexed
strings.
It should be noted that for Fast Infoset, the indexes
for attribute values, character contents, comments, and
processing instructions are all separated.
The representation used for Fast Infoset was slightly
simplified for the purpose of this study. However, these
simplifications should have only a minimal impact on the
results.
Fast Infoset is a rather straightforward binary XML
format, taking advantage of replacing the textual
description of the XML structure by a binary description
of it, and providing indexes for most items. In addition,
Fast Infoset uses various encoding techniques for reducing
the size of the encoded documents.
EXI
Efficient XML Interchange
(EXI) [EXI] is a binary
XML format standardized by the W3C. This format was
selected amongst several propositions (one of them was
Fast Infoset) and therefore contains some somewhat complex
mechanisms for obtaining a compact encoding of XML
documents.
In EXI, event types are explicitly coded in a binary
form, and are in addition partitioned according to their
enclosing element. Therefore their representation is a
partitioned list.
Element and attribute names are represented as
surrogates, a surrogate being defined from the index of
the namespace’s URI and the index of the local name
partitioned according to its URI. In addition, surrogates
are partitioned according to the parent element. The
element and attribute name representations corresponds
therefore to partitioned surrogates, with surrogate
definition based on URI indexes and local name partitioned
indexes.
Namespace declarations are represented as indexed
strings for URIs and indexed strings, partitioned
according to the URI, for prefixes. As for Fast Infoset,
prefix preservation has been ignored here.
Attribute values are represented as indexed strings
partitioned according to the attribute name.
In a similar manner, character contents are represented
as indexed strings partitioned according to the element
name.
Comments and processing instructions are represented as
strings.
As for Fast Infoset, the representation used for EXI was
slightly simplified for the purpose of this study.
EXI is a binary XML format more complex than Fast
Infoset, using partitioning in many places to improve the
compactness of the encoding.
Summary
Table II shows a summary of the
representations used by each of the three studied formats.
This table is representative of the differences between
the formats. XML is mostly list-based, Fast Infoset is
mostly index-based, and EXI is mostly
partitioned-index-based.
Table II
Summary of the representations used by the three
formats for XML documents analyzed here.
XML
Fast Infoset
EXI
Event type
List
List
Partitioned list
Element name
List
Surrogate
Partitioned surrogate
Attribute name
List
Surrogate
Partitioned surrogate
Attribute value
List
Index
Partitioned index
Namespace declaration
List
Index
Index
Character content
List
Index
Partitioned index
Comment
List
Index
List
Processing instruction
List
Index
List
Results
Formats overview
The different formats for XML documents can be first
compared using their encoding size. Figure 19 shows the distribution of encoded
file size for the three formats considered, and also for
textual XML compressed with gzip.
Figure 19: Size Summary
Distribution of file sizes for the different
formats.
This figure shows that on average, Fast Infoset encoded
document size is 39% of the original XML document size,
while EXI encoded document size is 34% of the original XML
document size. However, gzip achieves much better results,
as compressed XML document size is 12% of the original
size.
While Fast Infoset and EXI provide better encoding for
the XML structure and for repeated content, they leave
other aspects of the XML documents uncompressed. On the
other hand, gzip compresses the full XML document, both
structure and content and is therefore able to achieve
better results.
However, gzip has no information on the structure of XML
and therefore compressed Fast Infoset or EXI documents are
more compact that compressed XML documents.
Entropy values were computed for those three formats and
their distributions are shown by Figure 20,
alongside with the basic entropy of textual XML documents
(that is the entropy of the text constituting the XML
documents).
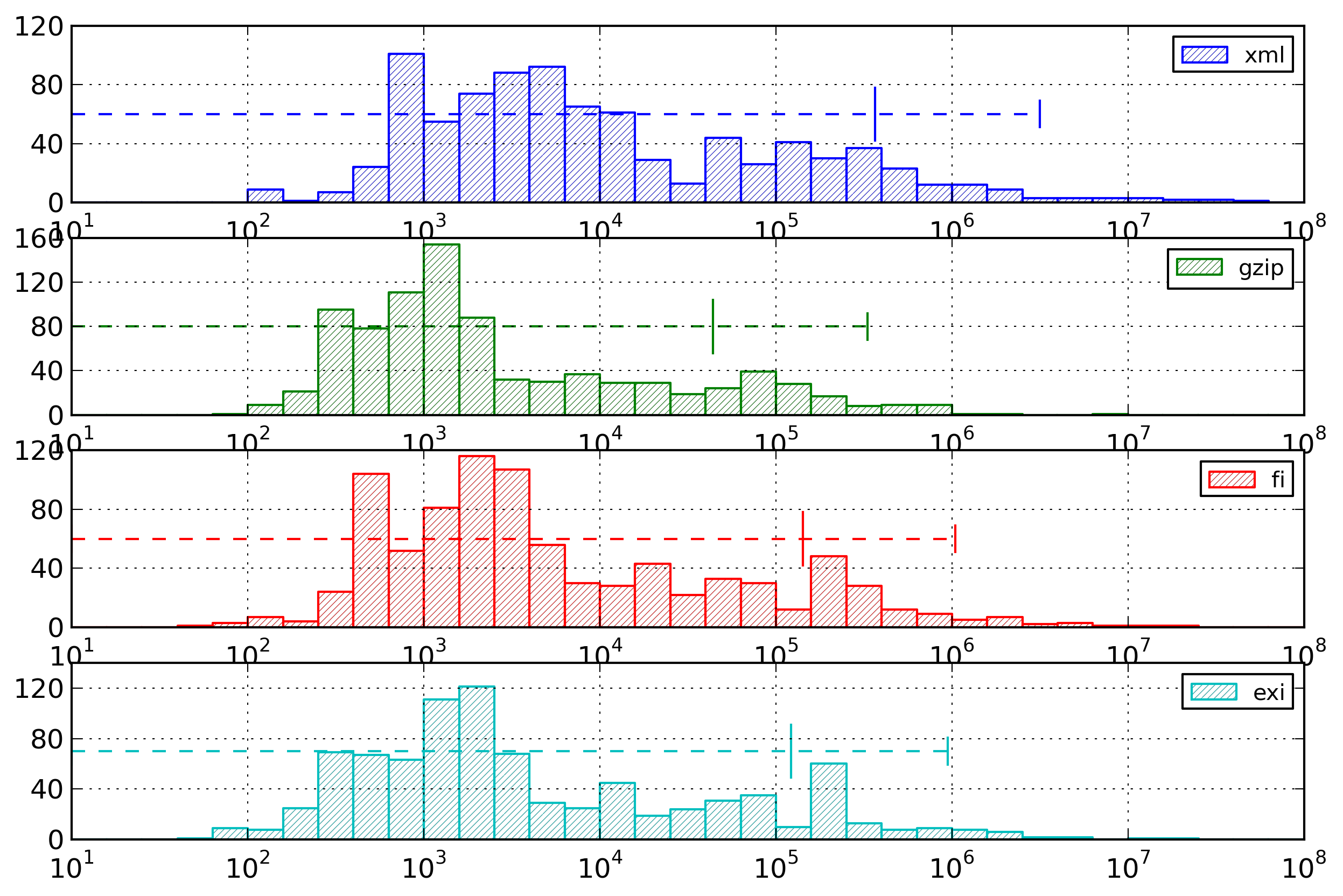
Figure 20: Entropy Summary
Distribution of total entropy values for the
different formats.
The relations observed for the encoding sizes still hold
for the entropies, meaning that the effective encoding
chosen for Fast Infoset and EXI are correct. The average
entropy of Fast Infoset documents is 51% of the average
entropy of XML documents, and the average entropy of EXI
documents is 46% of the average entropy of XML documents.
In addition, the average textual entropy of XML documents
is 151% of the average XML entropy of XML documents.
The first observation is that the better results
obtained by EXI compared to Fast Infoset (as measured by
the document sizes) are due to the choice of more
efficient representations (as measured by the entropy
values).
Second, those results show that the average entropy
values for the three formats are closer than the average
document sizes for these same formats. This means that the
EXI encoding is closer to its theoretical minimum than the
Fast Infoset encoding, and that the Fast Infoset encoding
is closer to its theoretical minimum than textual XML.
XML
Figure 21 shows the distribution of the
ratio of document size over entropy value for textual XML,
using either no compression, gzip compression or bzip2
compression.
Figure 21: XML Results
Distribution of ratio between document size and
XML entropy value for textual XML under different
compression options.
This figure shows that on average, an XML document size
is 2.34 times its entropy value. However, compressed
document sizes are lower than the entropy values, being on
average 0.73 times the entropy value for gzip, and 0.80
times the entropy value for bzip2.
These results mean that the entropy value we computed is
more representative of the quantity of information
contained in an XML document than the text-based entropy
we computed initially. However, this entropy value is
still overestimated. In particular, it should better take
into account the possible repetition of element or
attribute names.
Figure 22 shows the detailed distribution
of entropy costs for XML documents among the different
sources of information. This distribution is given for
the whole testing corpus and also for the different
categories of documents.
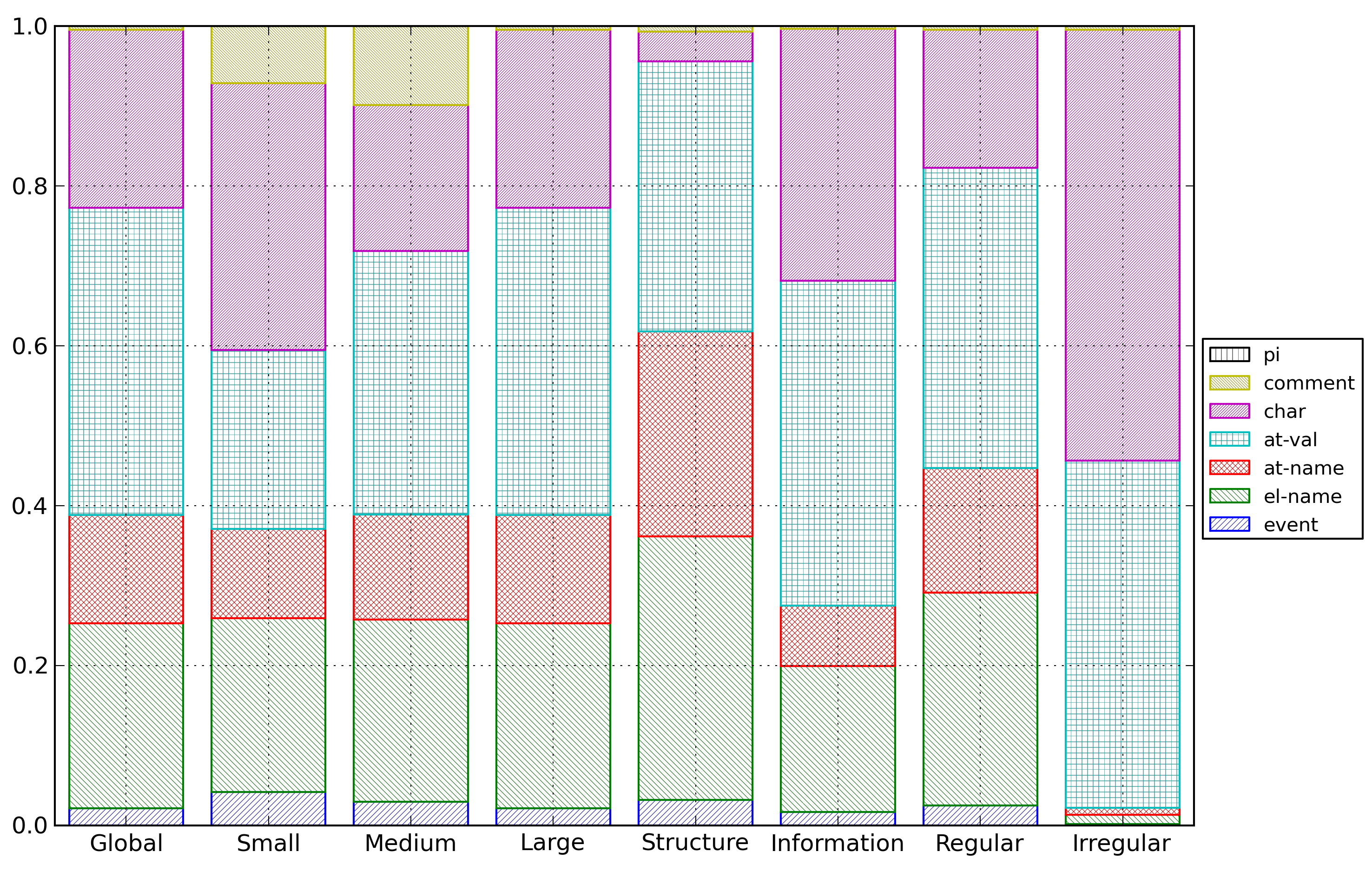
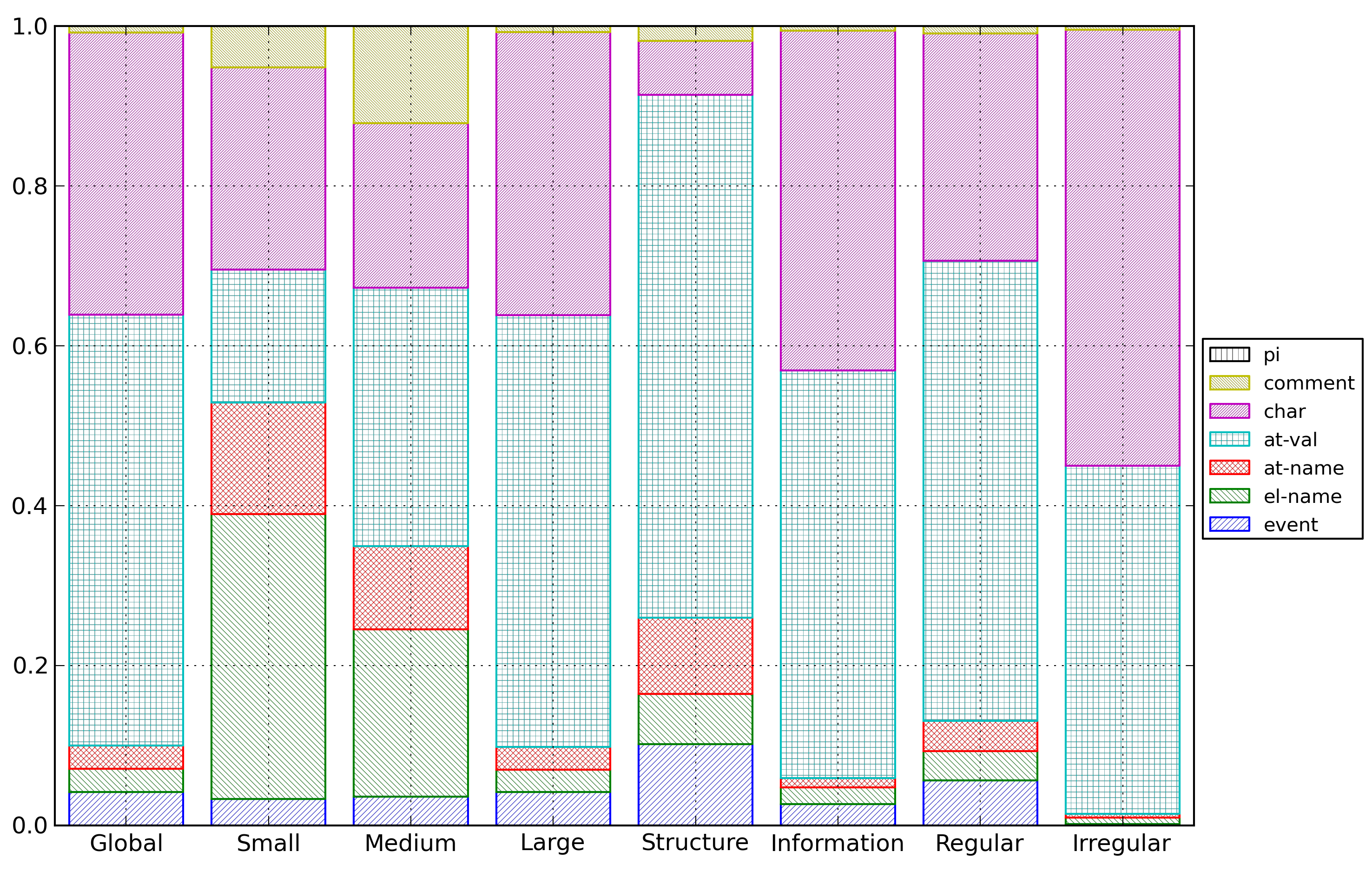
Figure 22: XML Cost Repartition
Distribution of entropy costs for XML documents
for the different categories of documents.
The entropy cost for each source of information was
computed as an average of the entropy cost for this source
of information for all documents in the category, and
then, for comparison purpose, those entropy costs were
normalized so as their total value is one.
First, it should be noted that the cost of the structure
(represented by the event list, the element names and the
attribute names) is independent of the file size, staying
around 40% for the small, medium and large document
categories.
However structural cost is higher for structure-rich
documents than for information-rich documents. Last, while
it is somewhat above the average for regular documents, it
is almost negligible for irregular documents (around
2%).
Fast Infoset
Figure 23 shows the distribution of the
ratio of document size over entropy value for Fast Infoset
documents. A first set of results uses the base Fast
Infoset document, while a second set of results uses the
Fast Infoset document compressed with gzip.
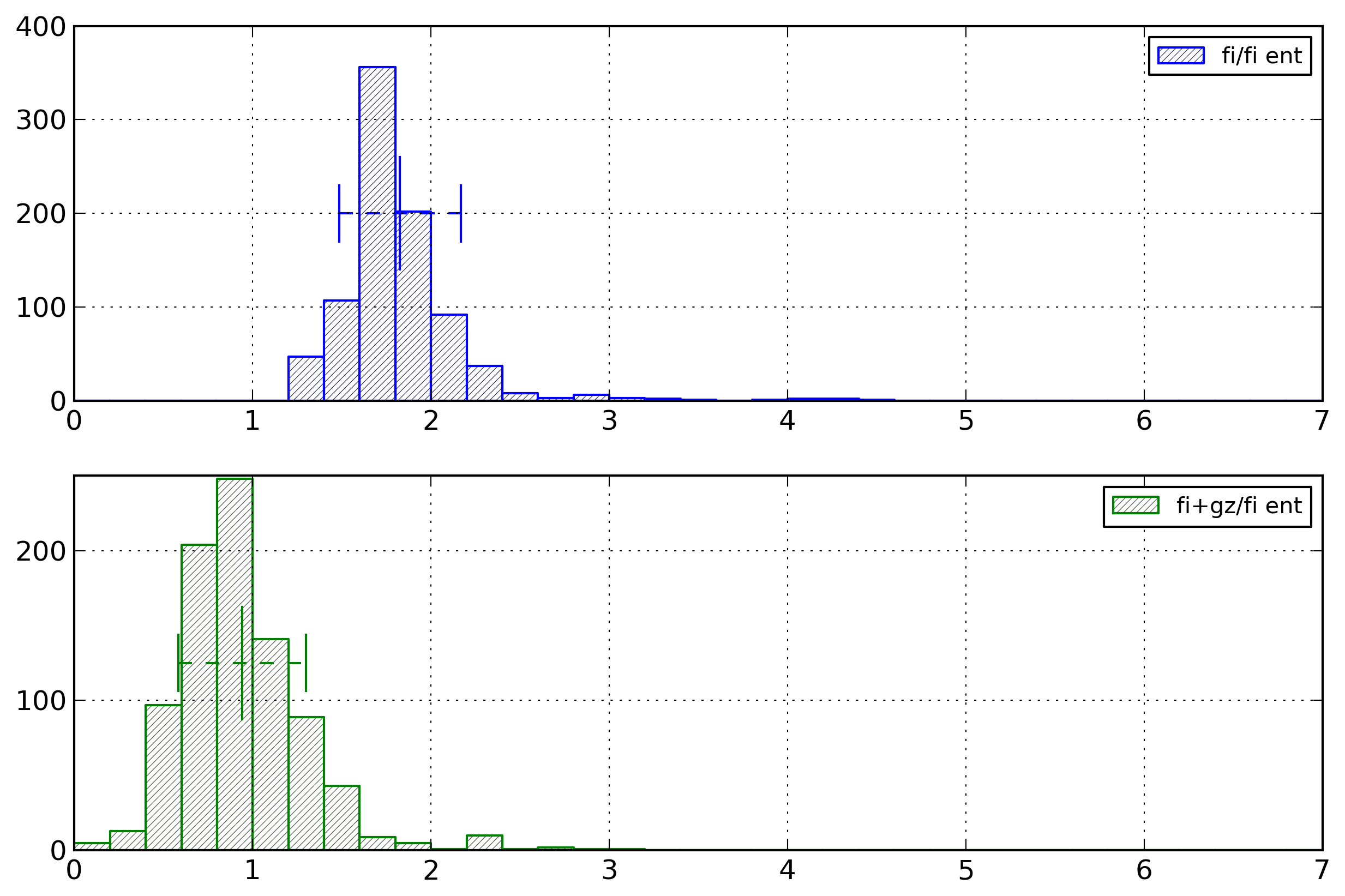
Figure 23: Fast Infoset Results
Distribution of ratio between document size and
Fast Infoset entropy value for Fast Infoset
documents with different compression options.
On average, the size of a Fast Infoset document is 1.83
times its entropy, and the size of a compressed Fast
Infoset document is 0.94 times its entropy.
Those results first corroborate that on average Fast
Infoset documents have a size closer to their entropy
values than textual XML documents.
However, as compressed Fast Infoset documents still have
on average a size lower than the entropy value, the
entropy value computed for Fast Infoset still overestimate
the quantity of information contained in an XML document.
Nevertheless, the difference is lower for Fast Infoset
than for textual XML.
Figure 24 shows the detailed distribution
of entropy costs for Fast Infoset documents among the
different event types.
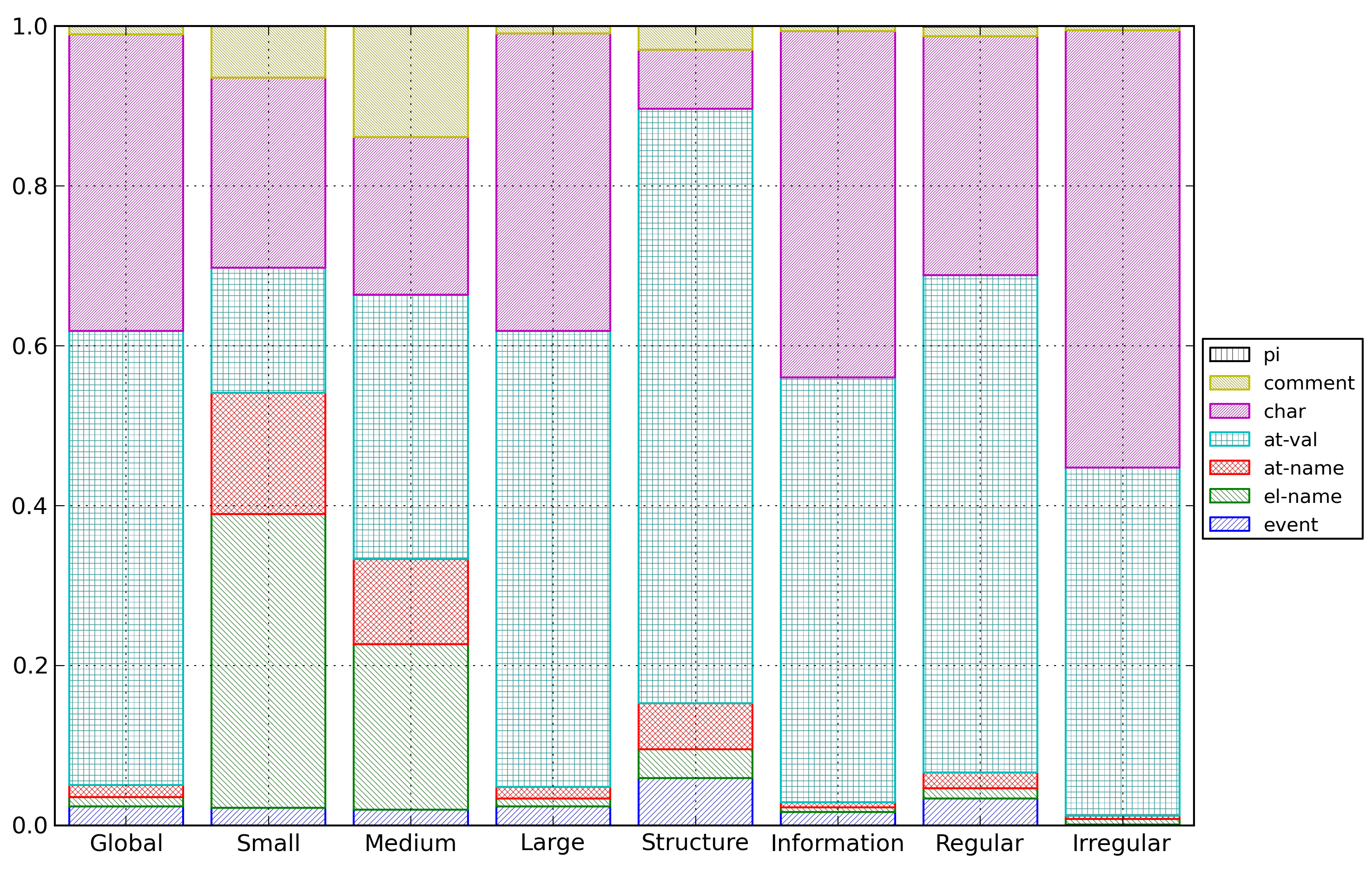
Figure 24: Fast Infoset Cost Repartition
Distribution of entropy costs for Fast Infoset
documents for the different categories of
documents.
These distributions show that the behavior of Fast
Infoset is clearly different from the behavior of textual
XML.
A first observation is that, globally, the entropy cost
of the structure represents a smaller part of the total
entropy cost for Fast Infoset documents than for textual
XML documents. This means that the representations used
by Fast Infoset are more efficient for reducing the
entropy of the structure than for reducing the entropy of
the content.
Moreover, the part of entropy cost related to the
structure decreases as the size of the document increase.
EXI
Figure 25 displays the distribution of the
ratio of document size over entropy value for EXI
documents.
Figure 25: EXI Results
Distribution of ratio between document size and
EXI entropy value for EXI documents with different
compression options.
Three types of documents are shown there. First, EXI
documents encoded with the options close to the default
ones (bit-packed, no schema, no compression, preservation
options only for comments and processing instructions),
second, EXI documents using the compression mechanism
built-in in EXI, third, EXI documents further compressed
with gzip (these documents use the pre-compress option as
this gives more compact documents than compressing
documents encoded with the default options).
On average, the size of an EXI document is 1.66 times
its entropy, the size of an EXI document using the
compression option is 0.92 times its entropy, and the size
of an EXI document compressed with gzip is 0.93 times its
entropy.
A first observation is that the built-in compression
mechanism of EXI is on par with a generic compression
mechanism (with a slight advantage for the built-in
mechanism).
These results also corroborate that on average EXI
document sizes are closer to their entropy values than
Fast Infoset document sizes from their entropy values.
However, compressed EXI document sizes are still smaller
than the EXI entropy values, showing that this entropy
value is also an overestimation of the quantity of
information contained in XML documents.
Figure 26 shows the detailed distribution
of entropy costs for EXI documents among the different
types of events.
Figure 26: EXI Cost Repartition
Distribution of entropy costs for EXI documents
for the different categories of documents.
These distributions are very similar to the ones
obtained by Fast Infoset.
In most cases, the entropy cost of the structure is a
smaller part of the total cost for EXI than for Fast
Infoset. The only exception is for the small document
category.
Summary
The results obtained here show that binary XML formats
reduce the size of XML documents both theoretically and in
practice. Moreover, while indexing mechanisms, as used by
Fast Infoset, are efficient for the compactness of the
representation, including in addition partitioning
mechanisms, as done by EXI, further improves this
compactness.
It should also be noted that as EXI is closer to its
theoretical minimum than Fast Infoset. This suggests that
the practical techniques used by EXI are more efficient
than those used by Fast Infoset.
Last, the distribution of the entropy costs among event
types show that binary XML formats globally reduce the
entropy cost of structure relatively to the entropy cost
of content. This means that XML language designers should
reflect as much as possible the structure of their data
into the XML structure to take a full advantage of these
encodings.
Conclusion
In this study, we analyzed the theoretical performances of
several representations for XML documents. First, our theoretical
results are in line with the experimental results obtained for the
different formats. This was an expected result, but is
nevertheless welcome news.
We showed that the compaction advantage of EXI over Fast
Infoset is due to the usage of partitioning mechanisms. In
addition, the practical implementation of EXI seems somewhat
better than the one of Fast Infoset, enabling compaction
performances for EXI closer to their theoretical minimum than for
Fast Infoset.
Further investigations could be undertaken to complete this
study. First, the usage of generic compression showed that the
first-order entropy results computed were overestimating the
quantity of information contained in the documents. For XML
documents, the hypothesis of independence between the symbols does
not hold, and therefore the entropy results obtained are not
correct. This hypothesis does not hold either for attribute values
and character contents. These items are often English text, for
which consecutive letters are not independent. A detailed analysis
of these items could be undertaken to find a better entropy
measure for them.
Second, both Fast Infoset and EXI provide mechanisms for a
partial indexing of content-related values. Some quick experiments
showed that the minimum entropy value is usually obtained
somewhere between a full indexing of those values and no indexing
of those values. More investigations could be realized on this
topic. Such investigations should be backed-up by experimental
measurements to check that theoretical results are in line with
practical implementations.
Last, EXI is able to take advantage of an XML Schema to
better encode an XML document. More specifically, EXI can extract
both the structure of the XML document and the type of the
content. It would be of interest to compute entropy values for XML
documents while considering their XML Schema as well. A reduced
experiment could focus on the type of the content, by computing
the entropy values while taking into account the type of each
content item.
References
[Augeri 2007]
Christopher J. Augeri, Dursun A. Bulutoglu, Barry E. Mullins, Rusty
O. Baldwin, Leemon C. Baird, III, An Analysis of XML
Compression Efficiency, ExpCS'07.
[Basci 2008] Dilek Basci,
Sanjay Misra, Entropy Metric for XML DTD Documents,
in ACM SIGSOFT Software Engineering
Notes, vol. 33, Issue 4, July 2008.
[XML] Tim Bray, Jean Paoli, C. M.
Sperberg-McQueen, Eve Maler, and François Yergeau,
Extensible Markup Language (XML) 1.0 (Fifth
Edition). W3C Recommendation,
26th November
2008. Retrieved
27th September
2010 from http://www.w3.org/TR/xml/.
[XML Namespaces] Tim Bray, Dave
Hollander, Andrew Layman, Richard Tobin, Henry S. Thompson,
Namespaces in XML 1.0 (Third Edition). W3C
Recommendation,
8th December 2009.
Retrieved 27th
September 2010 from http://www.w3.org/TR/xml-names/.
[EXI WG] Michael Cokus, Takuki
Kamiya, Carine Bournez, Efficient XML Interchange Working
Group. 5th May 2010. Retrieved
4th August 2010
from http://www.w3.org/XML/EXI/.
[Liefke 2000] H. Liefke and
D. Suciu, XMill: an efficient compressor for XML
data, in Proceedings of the
International Conference on Management of Data
(SIGMOD), pages 153-164, 2000.
[EXI] John Schneider, Takuki
Kamiya, Efficient XML Interchange (EXI) Format 1.0.
W3C Recommendation, 10 March 2011. Retrieved
2nd April 2012
from http://www.w3.org/TR/exi/.
[Shannon 1948] Claude E.
Shannon, A Mathematical Theory of Communication,
Bell System Technical Journal,
vol. 27, pp. 379-423 and 623-656, July and October, 1948.
Christopher J. Augeri, Dursun A. Bulutoglu, Barry E. Mullins, Rusty
O. Baldwin, Leemon C. Baird, III, An Analysis of XML
Compression Efficiency, ExpCS'07.
Tim Bray, Jean Paoli, C. M.
Sperberg-McQueen, Eve Maler, and François Yergeau,
Extensible Markup Language (XML) 1.0 (Fifth
Edition). W3C Recommendation,
26th November
2008. Retrieved
27th September
2010 from http://www.w3.org/TR/xml/.
Tim Bray, Dave
Hollander, Andrew Layman, Richard Tobin, Henry S. Thompson,
Namespaces in XML 1.0 (Third Edition). W3C
Recommendation,
8th December 2009.
Retrieved 27th
September 2010 from http://www.w3.org/TR/xml-names/.
Michael Cokus, Takuki
Kamiya, Carine Bournez, Efficient XML Interchange Working
Group. 5th May 2010. Retrieved
4th August 2010
from http://www.w3.org/XML/EXI/.
H. Liefke and
D. Suciu, XMill: an efficient compressor for XML
data, in Proceedings of the
International Conference on Management of Data
(SIGMOD), pages 153-164, 2000.
Wilfred Ng, Lam Wai Yeung, James Cheng, Comparative
Analysis of XML Compression Technologies, World Wide Web, pp. 5-33, 2006. doi:https://doi.org/10.1007/s11280-005-1435-2.
S. Sakr, XML
Compression Techniques: A Survey and Comparison,
Journal of Computer and System Sciences
(JCSS), 75(5), pp. 303-322, 2009. doi:https://doi.org/10.1016/j.jcss.2009.01.004.
John Schneider, Takuki
Kamiya, Efficient XML Interchange (EXI) Format 1.0.
W3C Recommendation, 10 March 2011. Retrieved
2nd April 2012
from http://www.w3.org/TR/exi/.
Greg White,
Don Brutzman, Stephen Williams, Jaakko Kangasharju,
Efficient XML Interchange Measurements Note.
30th June 2007.
Retrieved 2nd
April 2012 from
http://www.w3.org/TR/exi-measurements/.
ITU-T Rec. X.891 | ISO/IEC 24824-1 (Fast
Infoset). International Telecommunication Union
(ITU), May 2005. Retrieved
27th September
2010 from http://www.itu.int/rec/T-REC-X.891/.