Toman, Vojtěch. “XML Pipeline Processing in the Browser.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Toman01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Balisage Paper: XML Pipeline Processing in the Browser
Vojtěch Toman is a Consultant Software Engineer in the Information Intelligence Group
of EMC Corporation where he is involved in the development of XML content management
and delivery solutions. Previously, he worked for X-Hive Corporation B.V., a vendor
of native XML data management technologies, which was acquired by EMC in 2007.
Vojtěch is an active member of the W3C XML Processing Model Working Group and is the
main developer of EMC's XProc implementation. He studied Computer Science at the Charles
University in Prague, the Czech Republic, specializing in XML data compression and
optimized processing.
With the growing interest in end-to-end XML web application development models, many
web applications are becoming predominantly XML-based, requiring XML processing capabilities
not only on the-server-side, but often also on the client-side. This paper discusses
the potential benefits of using XProc for XML pipeline processing in the web browser
and describes the developments of a JavaScript-based XProc implementation.
Looking back at the past couple of years, it is clear that web browsers have come
a long way and have evolved tremendously. With increasing support for open standards
and rapid performance improvements, modern web browsers are no longer just tools for
viewing web content - they have become complete platforms for developing complex applications.
Traditionally, the programming model in the web browser environment has been based
primarily around HTML and JavaScript – and surprisingly, not much has changed in this
regard: we still use (more or less) the same markup language for describing the structure
and content of web pages, and implement the dynamic logic in the same scripting language.
What has changed, however, is how we combine these two technologies: from the first
static web pages with only a minimum of scripting to the highly dynamic and interactive
applications of today, often built on top of entire JavaScript frameworks and libraries.
With the major browsers gradually working out the performance and compatibility issues,
JavaScript has become powerful (and usable) enough not only for web pages scripting,
but also as an enabling tool for other web technologies for which there is no (or
very little) native browser support. So we now have, for instance, a number of JavaScript
XForms implementations[1], libraries for cross-browser rendering of SVG[2], or even a JavaScript implementation of Flash[3]; and many more.
JavaScript has also brought XML to the web applications world, in particular thanks
to the AJAX programming model that introduced an XML-based communication mechanism
between the client-side JavaScript and the server-side. Obviously, the ability to
deal with XML data relies on the availability of XML processing APIs: DOM-based access
has always been the standard in JavaScript, and most modern browsers also support
other technologies such as XSLT or XPath.
With the recent interest in the XRX (XForms/REST/XQuery XRX) architecture and native, end-to-end XML environments in general, web applications
(both on the server-side and client-side) are becoming more centered around the XML
data model; modern XForms-driven user interfaces are an example. However, JavaScript
is still often used to implement the client-side XML processing logic (parsing of
XML documents, extracting relevant information etc.) and to bind the various XML-based
components together (populating an XForms instance etc.). While this approach works,
it often requires hard-coding the processing logic in JavaScript and writing plumbing
code (often browser-specific). This can make the applications difficult to develop
and maintain, and to be interoperable with different web browsers.
But integrating and orchestrating XML processes is exactly what XProc: An XML Pipeline
Language W3C XProc is trying to address. The declarative, pipeline-oriented approach to XML processing
in XProc provides a flexible integration layer on top of other XML technologies (such
as XQuery, XSLT or, for instance, schema validation) that makes developing complex
XML processing flows easier and more transparent.
Although XProc is probably viewed as a primarily server-side technology, we believe
that it can have useful applications on the client-side, too. Based on our recent
experimentation with porting Calumet, EMC's XProc implementation to JavaScript, this
paper discusses some examples of using XProc in the web browser environment.
Calumet: Sharing the XML Peace Pipe with JavaScript
To our knowledge, all currently available XProc implementations are essentially server-side
applications. This is definitely the case with XML Calabash XML Calabash and EMC's Calumet EMC Calumet, which are both Java-based. Other projects that we are aware of also make use of
server-side technologies.
At EMC, when we started thinking about bringing Calumet to the browser, we were basically
facing two options: either re-implement the processor in JavaScript from scratch,
or port the existing code base to JavaScript somehow. (As our objective was a truly
cross-browser solution with no additional requirements on the client-side, we didn't
want to go the route of writing an XProc browser plug-in.) Eventually, we decided
for the latter option: porting existing Java sources to JavaScript.
This decision was motivated mainly by our previous experience with the Google Web
Toolkit, or GWT Google Web Toolkit, a framework for building dynamic web applications - in Java, without having to write
any JavaScript[4]. The central component of GWT is the GWT compiler that takes the application Java
sources and converts them into highly optimized JavaScript that runs in a variety
of browsers, without any need for extension plug-ins or presence of Java runtime on
the client machine. GWT supports only a subset of the JRE functionality as not everything
that Java provides can be mapped to JavaScript; however, the set of supported features
is still comprehensive enough to bring most of the power and benefits of Java to the
web application development context.
Porting Calumet to GWT turned out to be mostly a mechanical process: refactoring out
dependencies on features not supported by GWT from the original Java code, and implementing
adapters for accessing the browser DOM functionality. Especially the latter turned
out to be critical for the overall function of the XProc engine and its interoperability
with different browsers.
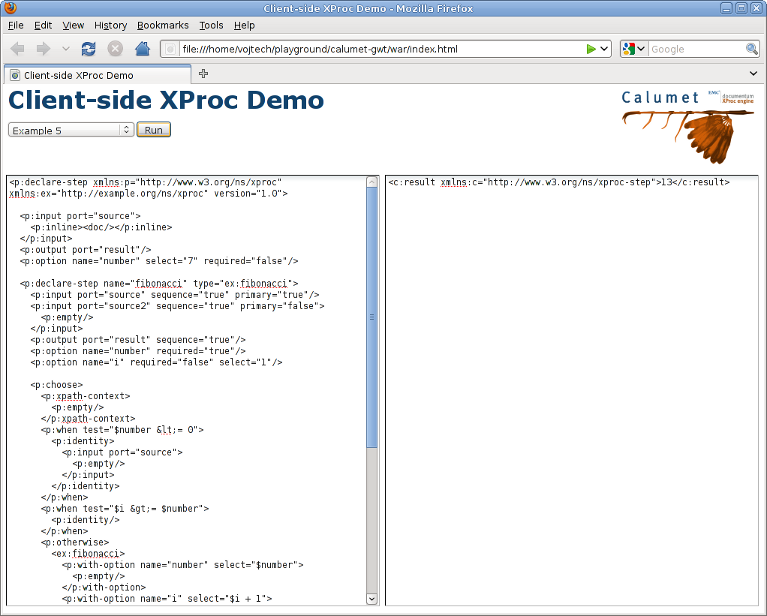
The result is an XProc processor with a standard server Java version and a JavaScript version that can run in a web browser. Figure 1 shows a screenshot of a simple demo application built on top of the GWT version of
Calumet. The demo was presented at the XML Prague '10 DemoJam event.
Figure 1: GWT Calumet Demo Application
XProc Compliance
A large part of the code base is shared between the Java and GWT versions. This not
only reduces code duplication, but also ensures that both versions of Calumet are
aligned in terms of functionality and the level of XProc support. As of July 2010,
the GWT version supports 34 out of the total 41 steps from the standard XProc step
library W3C XProc (the Java version supports all steps); Table I provides an overview of the missing functionality.
Table I
XProc Standard Step Library - Missing Functionality
Step
Supported
Remarks
p:directory-list
No
p:http-request
Yes
Only simple GET requests
p:load
Yes
DTD validation not supported
p:unescape-markup
No
p:xinclude
Yes
XPointer not supported
p:xslt
Yes
Only XSLT 1.0 supported (browser-native)
p:exec
No
p:hash
Yes
CRC32 not supported
p:validate-with-relax-ng
No
p:validate-with-xml-schema
No
p:xquery
No
p:xsl-formatter
No
The GWT version has most of the features of the original Java version: from high compliance
with the XProc specification to extensibility and customizability. For instance, it
is possible to register extension steps or custom URI handlers with both the Java
and GWT versions.
Table II below summarizes the current results of running the GWT version of Calumet against
the XProc Test Suite XProc Test Suite. The XProc Test Suite comprises four main categories of tests:
Required tests (that all conformant XProc processors must pass)
Optional tests (that conformant XProc processors are not required to pass)
Serialization tests (that test the XML Serialization W3C Serialization features)
Extension tests (that test the support for XProc extensibility)
Table II
GWT Calumet XProc Test Suite Results
Category
Percent passed
Required
81.85%
Optional
45.45%
Serialization
68.00%
Extension
100.00%
As can be seen from Table II, GWT Calumet scores relatively well with the required tests (passing over 80% of
the tests), as well as with the serialization and extension tests. The biggest gap
is in the optional tests that depend on functionality that is difficult to implement
in JavaScript (for instance, XQuery or schema validation) and some of which will probably
not be supported in the GWT version of Calumet any time soon. However, this limitation
can be overcome easily in the web browser environment by using the standard XProc
HTTP Request step and invoking a server-side service that provides the missing functionality.
Alternatively, the missing steps themselves can be implemented as callbacks to the
server-side if necessary.
Preliminary Performance Results
The GWT version of Calumet has been tested successfully with most of the major browsers.
Work is currently underway on implementing the gaps in the standard XProc step library
support and also on improving the performance and reducing the size of generated JavaScript.
The current size of the JavaScript code (without compression) is about 550 KiB, but
we are confident that this can be brought down - the original Java code was not written
with GWT in mind and many of the programming constructs used in the code are perhaps
too generic for efficient translation to JavaScript.
Regarding the performance of the GWT version of the processor, there are noticeable
(and expected) differences between different browsers, especially with more complex
pipelines that involve evaluating many XPath expressions or creating large numbers
of intermediate XML documents. But surprisingly, the most expensive part of running
an XProc pipeline turned out to be the initial phase: parsing the pipeline source,
resolving imports, performing the static analysis, and establishing the evaluation
order of the steps in the pipeline. While executing the pipeline itself generally
requires only milliseconds or tens of milliseconds (in Gecko- or WebKit-based browsers
on a 2.33 GHz dual-core workstation with 4 GB of RAM), preparing and statically checking
the pipeline often takes considerably more time (from 50 to 300 milliseconds depending
on the web browser and the complexity of the pipeline); a clear area for further performance
optimizations.
Having the possibility to run - and test - the same code base in two completely different
environments (Java and in-browser JavaScript) actually resulted in an interesting
synergistic effect between the two versions of the processor: code that performs reasonably
well in Java may prove to be a performance bottleneck in JavaScript (or the other
way around); but fixing the issue usually has a positive effect in both environments.
Applications of Client-side XProc
From the start, our work on the JavaScript port of Calumet was driven by a number
of use cases that we were trying to address to validate that the whole concept is
viable. This section describes some of these use cases.
AJAX and Dynamic Web Applications
Modern dynamic web applications often rely on heavy use of JavaScript and AJAX for
interacting with the server-side. In the XML-based model, the result of an AJAX request
is an XML document that needs to be processed in some way; most often by traversing
the XML structure using the DOM API. For example, in a web shop application, an AJAX
callback might be used to call a productlist service and to display the results in a dynamically constructed HTML table. This
would typically involve iterating over the result elements in the returned XML document
and creating a table row for each result.
While this approach works, hard-coding the AJAX XML response processing in JavaScript
may not always be the best option. First, it requires knowledge of the AJAX and DOM
APIs as well as awareness of various browser quirks, and second, the processing model
becomes set in stone, often hard to change or even understand. This may be critical
for larger-scale enterprise applications, or in any application in general that requires
a flexible (and maintanable) processing model the developers can build on.
The example below attempts to translate the usual AJAX request - process response - update host page pattern to XProc. The XProc pipeline starts with an HTTP request to the productlist service. The XML document returned by the service is then processed by creating an
HTML table row for each product element in the document. After that, all table rows are inserted into a table wrapper
which is then injected into the host page. In the example, a custom extension is used
that makes it possible to address elements of the host page using their ID. In our
case, the p:store step effectively replaces the element with the ID search-results by the generated HTML table.
XML is not the only format that can be used in AJAX environments. JSON, or JavaScript
Object Notation JSON, is an increasingly popular, text-based format for data interchange that is both
light-weight and very easy to work with in JavaScript (on the syntactic level, JSON
is just a subset of JavaScript). In the web applications world, JSON and XML can be
seen as competing formats where JSON is often presented as the simpler and more efficient
alternative to XML. Leaving aside the (often emotional) arguments between the JSON
and XML proponents as to which format is better, it is obvious that both JSON and
XML have much in common: they are both open formats, readable by machines and humans;
they are self-describing; and they are well supported by a wide variety of tools.
The strength of JSON lies mainly in representing simple data structures, where XML
is often seen as too heavy-weight; XML, on the other hand, is generally better suited
for semistructured data.
For the use case discussed in this section, one could argue that using AJAX and JSON
would be a much better fit than XProc. Indeed: the 40 lines of XProc code (plus the
necessary GWT or JavaScript code for actually executing the pipeline) could probably
be replaced with only a handful of lines of simple JavaScript. The overhead of an
XProc solution is also likely to be much higher compared to plain JavaScript: the
XProc pipeline needs to be parsed and analyzed first, and the data is then processed
using relatively expensive (at least in the browser) XML manipulations.
So is there a benefit in adopting the inherently heavier XProc approach where a simpler and more efficient alternative exists? We argue there
is, although it depends strongly on the particular use case. XProc is not a hammer
for everything: it is first and foremost an XML processing language, and it should
be used as such. Client-side XProc therefore makes most sense in user interfaces that
are XML-driven, consume or produce XML data, or require non-trivial XML processing.
In other situations, other approaches may be more appropriate.
The XProc pipeline above is admittedly very minimal, and from the dynamic web applications
perspective it does not show anything new that could not be done with existing approaches.
The interesting part lies in what XProc can offer beyond this point. While the example
pipeline may seem as unnecessary overhead for the simple problem (populating an HTML
table based on data returned from the server), the perspective begins to shift when
further processing of the server-side results is needed. The XProc pipeline can query
or transform the data easily, enrich it, or combine it with data obtained from other
services; all using a unified, declarative, and flexible XML processing model.
Client-side XML Presentation
A common task in XML-based web applications is presenting the XML data (either static
or dynamically generated) to the user. Typically, this is done by transforming the
XML data on the server-side to HTML or some other format understood by the browser.
Most of these transformations can be expressed in the form of XProc pipelines, and
with a reasonably compliant client-side XProc implementation, it should be possible
to move the processing to the client-side completely. Delegating the rendering to
the client-side can not only reduce the load on the server, but in many cases, it
can also simplify the server-side functionality in general and make it less coupled
with the front-end technology.
The pipeline below takes an XML document, resolves possible XInclude references, and
applies an XSLT stylesheet to the resolved document; all with standard XProc and completely
in the browser.
The previous pipeline is obviously a very simple one, but the potential of using XProc
as a client-side XML rendering tool is obvious: one can imagine using XProc for bringing
popular XML vocabularies like, for instance, DocBook DocBook or DITA DITA to the browser.
The example below shows a pipeline that takes a DITA topic and returns its HTML rendition.
While the pipeline itself is trivial, the dita:topic-to-xhtml step will most likely perform rather complex XML processing: from resolving the various
DITA link types to content filtering to applying an XSLT stylesheet. Or... maybe not:
the black-box nature of XProc steps provides great freedom by allowing different implementations
of the same step interface - which is not only convenient when writing (and testing) the pipelines, but it also
makes it possible to adapt the pipelines to the needs of a particular user audience
or to different browser environments. Thus, the pipeline below can, for instance,
do full-blown client-side DITA processing in web browsers that are known to be fast
(or compliant) enough, and delegate to the server-side in other cases.
An interesting application of XProc pipelines in web browser is using them as a driver
for interactive client-side procedures. In such an obvious user interface-oriented
platform as a web browser, it is possible to imagine XProc extension steps that would
add interaction with the end-user to the XML processing logic - for example, by displaying
dynamically generated dialogs or messages on the screen. This would make XProc a simple
(yet powerful) alternative to other approaches for representing interactive processes:
from simple data collection procedures to complex and often highly dynamic maintenance
and diagnostic procedures found, for instance, in the military and in the aerospace
industry.
In the area of interactive processing, client-side XForms is a technology that combines
exceptionally well with XProc: as an XML-based standard, it is very easy to load -
or even dynamically generate - XForms-based dialogs in XProc pipelines. Similarly,
the XForms submissions, which are XML documents as well, can be processed naturally
in XProc.
The pipeline below shows how XForms could be used with XProc in an imaginary aircraft
maintenance system; in this case, the example is a simple circuit breaker check procedure. The pipeline has two options, an aircraft model number and its variant.
Depending on a specific combination of the model and the variant, the maintenance
mechanic is presented with a dialog (an XForm) that allows him to enter information
about the state of the circuit breaker. When the mechanic submits the dialog, the
pipeline displays a message that tells the mechanic to switch on the breaker if it
was in the OFF position.
Although XProc is still a relatively new technology, it is already finding its way
into the XML application developers' tool set. Extending and complementing the family
of established XML processing languages such as XSLT and XQuery, XProc provides a
unifying and flexible integration layer that makes orchestration of XML processes
easier.
In the web applications world, XML processing has traditionally been done primarily
on the server-side. However, with the recent advances in modern web browsers and the
growing interest in end-to-end XML application architectures, we can see that more
and more XML processing is being done on the client-side. We believe that the problems
that XProc is attempting to address - the impedance mismatch between different XML
processing models, and the need to write plumbing code - apply equally to the server-side
and the client-side (although on the client-side this may not be that visible - yet).
This paper discussed some of the possibilities of using XProc pipelines in the web
browser environment, motivated by our recent work on porting EMC's Calumet XProc processor
to JavaScript (using the Google Web Toolkit). What initially started more as a proof-of-concept
effort has lead to some interesting outcomes. Not only did it prove that performing
complex XML processing in JavaScript in the web browser is possible, it also showed
that client-side XProc can have useful practical applications that are worth exploring.
The current GWT port of Calumet is still very much work-in-progress. While it is reasonably
stable already and supports a relatively large portion of the XProc specification,
the code still needs to be optimized and fine-tuned for different web browsers. Also,
work needs to be done on providing convenient XProc processing APIs in JavaScript.
In GWT-based applications, the native Java API of Calumet can be used, but for the case of traditional HTML/JavaScript
applications, a JavaScript interface will be necessary. An additional option that
we are considering is to support embedding XProc pipelines in the HTML script element; however, that direction still needs to be researched.
Future versions of the Calumet XProc processor will most likely be distributed as
a dual Java/JavaScript package; work is still ongoing on the JavaScript version, but
the progress with the development and the results achieved so far are encouraging.
[W3C XProc] Norman Walsh, Alex Milowski, and Henry S. Thompson, eds. XProc: An XML Pipeline Language.
W3C Proposed Recommendation. 9 March 2010. http://www.w3.org/TR/xproc/
[4] Of course, it is possible to combine JavaScript with GWT quite easily; GWT-based applications
can invoke external JavaScript functionality and vice versa.
Scott Boag, Michael Kay, Joanne Tong, Norman Walsh, and Henry Zongaro, eds. XSLT 2.0
and XQuery 1.0 Serialization. W3C Recommendation. 23 January 2007. http://www.w3.org/TR/xslt-xquery-serialization/
Norman Walsh, Alex Milowski, and Henry S. Thompson, eds. XProc: An XML Pipeline Language.
W3C Proposed Recommendation. 9 March 2010. http://www.w3.org/TR/xproc/