How to cite this paper
Georges, Florent. “The EXPath Packaging System: A framework to package libraries and applications for
core XML technologies.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Georges01.
Balisage: The Markup Conference 2010
August 3 - 6, 2010
Balisage Paper: The EXPath Packaging System
A framework to package libraries and applications for core XML technologies
Florent Georges
XML Architect
H2O Consulting
Florent Georges is a freelance IT consultant in Brussels who has been involved in
the XML world for 10 years, especially within the XSLT and XQuery communities. His
main interests are in the field of XSLT and XQuery extensions and libraries,
packaging, unit and functional testing, and portability between several processors.
Since the beginning of 2009, he has worked on EXPath, to define "standard" extension
function libraries that can be used in XPath (so in XSLT, XQuery and XProc as
well).
Copyright ©Florent Georges
Abstract
This paper introduces the EXPath Packaging System. It describes the problems
addressed by application and library packaging, and the current lack of existing
solutions for XML technologies, before describing the Packaging System itself, its
structure, its usages and its implementations. It introduces briefly other systems
built
(or that could be built) on top of this system, like a packaging for web applications
written using only XML technologies, an online repository of libraries and applications,
or standard structures for XML projects.
Table of Contents
- Introduction
- The problem
- The Packaging System
- Integration
- Going further
-
- Standard project structure
- CXAN
- Webapp packaging
- Conclusion
Note: Quote
You're supposed (in the new order) to give everything (stylesheets,
you, your fridge) an absolute URI and just use that; then the URI used to refer to
your stylesheet never need to change.
--David Carlisle, on XSL List
Introduction
EXPath has been launched in early 2009. Its goal is to go behind the standards for
core
XML technologies by specifying extensions to those technologies in a consistent and
standard way across different processors, collaboratively by the relevant
communities.
Most of these core XML technologies are based on XPath, hence the decision to focus
principally on XPath. The whole project is divided into small parts, the
modules, more or less independent on each others. A specific
processor can thus chose to implement only some of those modules, regarding what is
relevant to the technologies it supports or what is relevant to its users.
Even though the idea is to provide the several vendors with a set of
(de-facto) standard modules to implement themselves, people may
chose to implement a module as a commercial or open-source product for a specific
processor
(given this processor provides the appropriate extension mechanism). Actually some
modules
are currently directly supported by some processors while other implementations exist
as
third-party products. The EXPath community itself provides several open-source
implementations, as well as support for such projects.
This paper focuses especially on the Packaging System defined by EXPath as a way to
package and deliver XML libraries or applications and to allow a user to rely on tools to automatically install (or deploy) such
packages.
The problem
To introduce the packaging system, let's try to answer the initial question:
what is such a system useful for? Let's try to do so by using a
specific example.
You are in charge of an XQuery application which, very imaginatively, you called MyApp.
As several other XQuery applications, MyApp uses the FunctX library (an XQuery and
XSLT
library providing general-purpose functions, like date and string manipulation functions).
In order to ease the integration of FunctX into MyApp, you decided to simply copy
the
source file into your own code base. You then use the same rules to import the library
as
for the import statements for your own XQuery modules:
import module namespace f = "http://www.functx.com"
at "../../lib/functx.xq";
So far, so good. Later on, you decide to use another library providing support for
XBRL
(a standard language for business reporting). It turns out that this library actually
uses
also FunctX. So you install the library into your code base, and you modify its source
code
to adapt the import statements related to FunctX to follow your own rules for import
statements. Indeed, you feel guilty to modify the source code of a third-party library
just
to be able to use it (as in the first place you did feel guilty to copy the source
code of
a third-party library into your own code base). But you don't have any other choice,
have
you?
You then use yet another library. You follow the install instructions. Manually of
course. Anyway those instructions are more or less: Copy the files "somewhere"
and use whatever mechanism your processor provides you with to import the library
modules. So once again, you copy the whole source code into your own code
base. You don't know it, but actually that library also uses FunctX (yes, FunctX is
really
useful) and you end up with two FunctX implementations into your own code base (hopefully
the same implementations).
We could continue this example for ever, with troubles updating FunctX or any of the
libraries using it, or by describing the pain of manually installing or updating any
new
library. And yet, those are only the issues a library user can find on his way. Let's
now
pretend your are a library author. You are in a maze, struggling with dependency management
and installation instructions. You feel there should be a simple solution. You are
getting
sleepy. Very sleepy. Your eyelids are heavy. Very heavy...
To make the long story short, dependency management is a complex problem and has always
been. And there is no standard addressing this problem accross several XML technologies.
Typically, each standard get rid of this problem by making it an implementation-defined,
optional feature. This is a reasonable decision at the level of each independent standard.
But having a specification addressing those issues accross several standards allows
to
address the most common use cases and to build packaging tools compatible with several
processors. From the above example, we can list the following issues, that the Packaging
System tries to address:
-
to solve the common problem of installing a third-party library, we always have to
think about similar technical solutions;
-
the way to install a library is always slightly different, because of differences
in the way the libraries themselves are packaged, whilst the concepts are always the
same;
-
library packaging (i.e. the other end of the delivery cycle) has the same
problems: no standards, no tools, and at the end of the day we always end up with
something different whilst the concepts are the same;
-
this situation prevents writing tools to help the developer to automate the build,
delivery and install cycle (for other languages, some tools provide a way to create
automatically a new project, from which they can automate the build process, and at
the other end systems provide the user with a way to automatically install those
packages).
The Packaging System
To address this problem, EXPath defines a packaging system to help library and
application authors to package and deliver their products without having to take care
of
specific install procedures and of every possible existing processors, now or in the
future.
The basic idea is simple. A package is a set of components, and contains enough
informations about those components for a processor to install them properly, and
to let a
user refer to them within his own applications or libraries by using always the same
absolute URI, resolved by the processor at compile-time. As soon as a library is packaged
using this format, it is usable in all processors supporting the packaging system,
without
the need for any further instructions for the users.
So a package is a set of components. A component is any piece of code of a supported
XML
technology, e.g. an XSLT stylesheet, an XQuery module, an XProc pipeline, or a schema
(XSD,
Relax NG, NVDL, Schematron, etc.) The packaging system has been designed to be extensible,
and an implementation can support other kinds of component: a standard not supported
yet
like BPEL, or even processor-specific components like a Java implementation of extensions
for Saxon (several implementations for Saxon of EXPath modules are actually delivered
this
way).
The several components are packaged as a single file by creating a ZIP file. In order
to
provide enough information to the installer, the structure of this ZIP file must follow
a
few simple rules, and contains in addition a package descriptor. The package descriptor
is
a simple XML file defined in the specification, providing informations about the components
and the package.
A central concept in the packaging system is the concept of public URIs. Each component
is associated with such a URI. In turn, this URI can be used to access the component.
For
instance, if a library contains an XSLT stylesheet, a public URI for this stylesheet
is
defined in the package descriptor. The user can then use this URI in an
xsl:import instruction to import this stylesheet:
<!-- the user's stylesheet can import the library's stylesheet -->
<xsl:import href="http://example.org/the/public/uri/of/the-stylesheet"/>
The package structure (i.e. the structure of the files and directories in the ZIP
file)
is simple. It must contain the file descriptor at the top-level of the ZIP file (an
XML
file named expath-pkg.xml) and a sub-directory with the actual components. The
library author is free to organize this sub-directory as he/she wants. If we take
again the
example of FunctX, which contains an implementation of the functions both as an XQuery
module and as an XSLT stylesheet, it could have the following structure:
- expath-pkg.xml
- functx/
- functx.xq
- functx.xslThe package descriptor itself (i.e. the file expath-pkg.xml) provides a few
informations about the library itself (a name, a version number, etc.) and associates
a
public URI to each component in the package:
<package xmlns="http://expath.org/ns/pkg"
name="http://www.functx.com"
version="1.0">
<title>FunctX library</title>
<desc>The FunctX library, both for XQuery 1.0 and XSLT 2.0.</desc>
<xquery>
<namespace>http://www.functx.com</namespace>
<file>functx.xq</file>
</xquery>
<xslt>
<import-uri>http://www.functx.com/functx.xsl</import-uri>
<file>functx.xsl</file>
</xslt>
</package>This is a simple package descriptor. It describes both components in the FunctX package:
the XSLT stylesheet and the XQuery module. The file element points to the
actual source code within the package, while the elements import-uri and
namespace set the public URI of each component. There are elements to
configure other kind of components like XProc, RNG, RNC, XSD, Schematron and NVDL.
An
implementation can also define its own elements (in its own namespace). For instance,
the
package for the Java implementation for Saxon of the EXPath HTTP Client contains the
following:
<java xmlns="http://expath.org/ns/pkg/saxon">
<jar>saxon/jar/expath-http-client-saxon.jar</jar>
<function>org.expath.httpclient.saxon.SendRequestFunction</function>
...
<saxon>
The Packaging System specification defines the format of the packages. That is required
to ensure compatibility accross different implementations. So while everything else
is
implementation-defined, an implementation will typically use the following components:
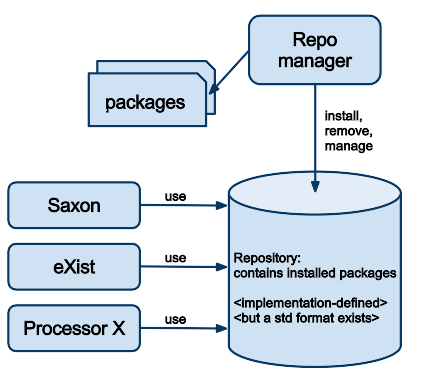
The central piece is the repository, where the packages are
installed. It can be dedicated to one product (or even one instance of a product,
e.g. for
a database), or be shared accross several products. The processors are
the products you want to be able to use the packages with (that is, your usual XQuery
or
XSLT or XProc processors). A manager (part of the processor or
provided as a separate program) is used to actually install the packages into the
repository (or remove them, list them, etc.)
Integration
As for other modules, and even more for the packaging system, the goal is to have
to
implemented directly by the several processors. This is the case for eXist for instance.
Third-party implementations have been written for Saxon and Calabash too.
Even though a processor is allowed to implement the packaging system in any way, the
specification defines a standard on-disk repository layout. If such an on-disk repository
makes sense for a specific processor, it can then benefit from standard tools to manage
the
repository (install new packages, remove existing one, install directly from the Internet,
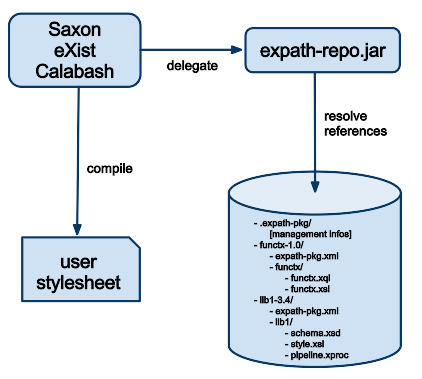
etc.) The packaging support in Saxon and Calabash for instance are open-source third-party
implementations. Those implementations resolve at compile-time the URIs within the
user
stylesheets and pipelines to the imported components in the repository:
The repository itself is managed by a standalone application, dedicated to that purpose.
Because this repository format is defined in the specification, if an implementation
chose
to support it, it does not have to take care at all about repository management, and
the
user can then use one single tool to manage repositories, even for several processors.
But
for some processors, such an on-disk repository just does not make sense, or is not
the
best design choice (e.g. for embedded systems or processors that can pre-compile packages
on a distributed environment).
Let us look at a concrete example. A stylesheet uses FunctX to build a date from three
integers (the year, the month and the day). Note that it uses an absolute URI to import
the
FunctX stylesheet, and this URI does not point to an actual location. This is just
a name,
and will be used to resolved the FunctX stylesheet from the repository:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:f="http://www.functx.com"
exclude-result-prefixes="f"
version="2.0">
<xsl:import href="http://www.functx.com/functx.xsl"/>
<xsl:output indent="yes"/>
<xsl:template name="main">
<result>
<xsl:sequence select="f:date(1979, 9, 1)"/>
</result>
</xsl:template>
</xsl:stylesheet>This stylesheet is also used in an XProc pipeline:
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:f="http://www.functx.com"
version="1.0">
<p:input port="parameters" kind="parameter"/>
<p:input port="source"/>
<p:output port="result"/>
<p:xslt template-name="main">
<p:input port="stylesheet">
<p:document href="user.xsl"/>
</p:input>
</p:xslt>
</p:declare-step>We have to install FunctX in the repository in order for those components to run
properly. The command xrepo is the standalone repository manager. It can
manage several repositories, list the content of a specific repository, install and
remove
packages. In a first time, FunctX is not installed yet, so the transform fails. Then
we
install the package, and run the transform again:
> saxon -xsl:user.xsl -it:main
Error at xsl:import on line 6 column 56 of user.xsl:
XTSE0165: java.io.FileNotFoundException: http://www.functx.com/functx.xsl
Failed to compile stylesheet. 1 error detected.
> calabash user.xproc
Apr 18, 2010 3:02:05 AM com.xmlcalabash.core.XProcRuntime error
SEVERE: Pipeline failed: [...]: Failed to compile stylesheet. 1 error detected.
Apr 18, 2010 3:02:05 AM com.xmlcalabash.core.XProcRuntime error
SEVERE: Underlying exception: [...]: Failed to compile stylesheet. 1 error detected.
> xrepo install functx.xar
Install module FunctX library? [true]:
Install it to dir [functx]:
> saxon -xsl:user.xsl -it:main
<result>1979-09-01</result>
> calabash user.xproc
<result>1979-09-01</result>
The format of the repository itself is simplistic. This is a directory on the
filesystem, which contains one sub-directory per installed library. Each of those
sub-directory has the same structure as the XAR file it was created with, with possibly
a
few informations generated during the install process in order to simplify the resolving
mechanism at runtime. For instance, if the package contains extension functions written
in
Java for either Saxon or eXist, a simple file is generated containing the classpath
needed
by this module in order for an application to find it:
/usr/share/expath/repo/
.expath-pkg/
...
[management infos, to help building efficient implementations]
...
functx-1.0/
expath-pkg.xml
functx/
functx.xql
functx.xsl
google-apis-0.2/
expath-pkg.xml
google-apis/
xq/
gdata.xql
gdata-impl.xql
xsl/
gcontacts.xsl
gdata.xsl
gdata-impl.xsl
gdocs.xsl
gcode.xsl
gmaps.xsl
expath-http-client-0.6/
expath-pkg.xml
.exist/
classpath.txt
.saxon/
classpath.txt
expath-http-client/
exist/
expath-http-client-exist.jar
saxon/
expath-http-client-saxon.jar
expath-http-client-saxon.xql
expath-http-client-saxon.xsl
lib/
apache-mime4j-0.6.jar
commons-codec-1.4.jar
commons-logging-1.1.1.jar
httpclient-4.0.1.jar
httpcore-4.0.1.jar
tagsoup-1.2.jarLet us have a closer look at this particular repository. Three libraries have been
installed: FunctX 1.0, the Google APIs 0.2 and the EXPath HTTP Client for Saxon and
eXist
0.6, an implementation in Java of the EXPath HTTP Client module. The first directory,
.expath-pkg, contains internal informations about what is installed, and
how to use it. It is not used already, but its first usage will probably be to record
for
each package the longest URI prefix common to all its components. This in turn can
be used
by the runtime resolvers to know in which package look for a particular component,
given
its public URI. This is important for standalone processors like Saxon which during
one
execution will typically use only a few components from the repository, as this enable
it
to only parse the package descriptors for those packages, and not for the whole repository.
In general, the directory .expath-pkg is a place to put management data about
the repository as a whole.
The second directory, functx-0.1, contains the FunctX library. This
directory has exactly the same structure as the XAR package. Put another way, this
directory is the result of unzipping the XAR file. The package descriptor, that is
expath-pkg.xml, contains all the information to resolve a public URI to an
actual component at runtime. The third directory, google-apis-0.2, contains
another example of a package, just a bit more complex. Especially, we can see the
package
directory internal structure is preserved (the subdirectories xq and
xsl). This is important for relative import statements to work.
The last directory, expath-http-client-0.6, shows a library implemented in
Java. It contains an implementation for both Saxon and eXist. In addition to the usual
content of the package (the package descriptor and the package directory), we can
see we
have two subdirectories, containing additional infos about the package for different
implementations (here, Saxon and eXist). The classpath.txt file, in both cases, contains
a
line-separated list of JAR files that must be added to the classpath in order to use
the
extension. Simply speaking, this contains the JAR within which the extension has been
compiled, and a list of the libraries it depends on. Those files are generated at
install-time by the installer, based on the package descriptor. They are used by the
launchers to properly set the classpath, because this must be done at launch time,
when we
don't know yet which libraries we will use, and we don't want to parse every package
descriptor every time we launch the application (and typically a few libraries only
will
define Java extensions).
One of the advantages of having such a standard layout for the repositories is to
be
able to share the implementation (as it is actually shared between Saxon, eXist and
Calabash), which means better maintained and up-to-date software. It is also very
lightweight, and it is possible to create several repositories for dedicated purposes.
Typically a general repository will be created on a machine to be used by interactive
tools
like Saxon and Calabash, and maybe IDEs like oXygen. Then specific repositories can
be
created for large projects like a Java Enterprise application, for which we want to
control
precisely the set of dependencies.
Going further
The Packaging System specification tries to be extensible and generic enough to allow
different kind of tools as well as other specification to be built on top of it. We
introduce here three of those related projects: a standard structure for XML projects
and
its associated tools to automatically build the packages, an online directory of packages
a
la CPAN, and an extended version of the packaging system itself for web applications
written only with XML technologies (as defined in the EXPath Webapp module).
Standard project structure
The packaging system specification is a low-level specification. It is interesting
for a user to understand how this system works and how it has been designed, but ideally
he/she should never need to read it in order to use it. The user should never be
bothered with the low-level details of the package's ZIP file structure nor even by
the
package descriptor. How many Java developer do really build their JAR files using
the
UNIX tar command, and write the JAR Manifest file by hand? In some case that can be
useful, but usually a Java developer just rely on its IDE to create a (more or less)
adapted project structure, and to provide the action build to
automatically build the JAR file.
Java is indeed only an example, but all mainstream languages do have such tools. And
that is a good thing as this allows the developer to focus on what is really important:
the business logic. The packaging is of course important as well. But usually the
packaging, and more generally the build system of a project, involve always the same
steps and can be handled automatically by a program.
This idea is to create a well-defined directory structure for a new project, so a
packaging program can use be used to package the project as a XAR file. Different
kinds
of structure can be defined, or different flavors for different needs (e.g. a plain
XProc library, a web application, or an extension for eXist written in Java).
This is only a research area for now, but a simple structure has been defined for
plain libraries (i.e. packages of standard components), and a tool has been created
that
use this structure to automatically build the XAR file. This tool is called
packager. The directory structure of a new project must have a
build/ subdirectory for the build infos, as well as a src/
subdirectory for the actual sources of the components. Here is the structure of an
hypothetical project hello-world:
hello-world/
build/
project.xml
src/
hello-world.xq
hello.xql
hello.xslThe build/ dir is used by the build process, and contains a file
project.xml provided by the user. This file give the packager all the
infos it needs and that it cannot infer from the directory structure and from the
source
files themselves. Principally, those are the infos like the name and the version number
of the package to build:
<package xmlns="http://expath.org/ns/packager"
name="http://example.org/hello-world"
version="1.0">
<title>Hello, world!: an example project</title>
</package>In order to build the package, the packager needs to know which files to include as
components. Those are simply the files in the src/ directory with a
specific extension (like *.xql, *.xproc, *.xsl, etc.) And for each of them, it also
needs to know the public URI to associate to the component. Instead of requiring the
developer to maintain an external document with this information (like the package
descriptor), those public URIs are directly set into each component. That makes more
sense as this public URI can be seen as the name of the component, and there is no
better place for this name than within the component itself.
The exact way a URI is associated to a component depends on the kind of component.
For components that are also XML documents, like XProc pipelines and XSLT stylesheet,
this is done by adding an element pkg:import-uri. For XQuery, the component
is either a library module and thus already has a target namespace, or it is a main
module and the public URI is set as the value of the global variable
$pkg:import. For instance, this is an excerpt of these kind of
components:
(:~
: an XQuery main module, sets $pkg:import-uri
:)
declare namespace pkg = "http://expath.org/ns/pkg";
declare variable $pkg:import-uri := 'http://example.org/hello-world/hello-world.xq';
...
(:~
: an XQuery library module, already contains enough information
:)
module namespace hw = "http://example.org/hello-world";
...
<!--
an XSLT stylesheet, uses a user element pkg:import-uri
-->
<xsl:stylesheet ...>
<pkg:import-uri>http://example.org/hello-world/hello.xsl</pkg:import-uri>
...
<!--
an XProc pipeline, uses an element pkg:import-uri
-->
<p:pipeline ...>
<pkg:import-uri>http://example.org/hello-world/hello.xproc</pkg:import-uri>
...
With the public URIs set directly within the component, with the well-known directory
structure, and with the few infos in build/project.xml, the packager tool
has all it needs to create automatically the package. The developer does not have
neither to maintain the package descriptor when adding new components, he/she just
has
to set properly the public URI within the component.
The packager itself is an XSLT stylesheet using the EXPath Files and ZIP modules to
navigate the file system and create the actual package in build/ (either
for a library or a web application). This is all the packager does for now. But it
will
be extended to support XSpec (to automatically run unit tests), deployment of a web
application on a Webapp container, documentation generation, and other tasks we usually
find in project managers and IDEs.
CXAN
The Packaging System defines the format and the structure of one package. So it can
be built from sources by a packager tool, and be installed in a processor or a local
repository by the user. It contains also meta informations like a name and a version
number. This provides the needed mechanisms to create a global directory of known
libraries and applications in and for XSLT, XQuery, XProc, etc.
Like CTAN for TeX and LaTeX, CPAN for Perl, or also the APT system for Linux
programs, the Packaging System makes it possible to create CXAN, the
Comprehensive XML Archive Network (or the
Comprehensive X* Archive Network if you prefer a stronger
difference between XML and the XML technologies we are discussing here).
CXAN (pronounce it c-zan) is composed of two parts. First a
website which contains all the uploaded packages and provides a way to navigate through
them, search for them and download them. And second a client program to retrieve a
package over the Internet and install it locally. This is a good example of the benefit
of using the standard repository layout for a processor implementing the Packaging
System, because there is an open-source implementation of a CXAN client that supports
local on-disk repositories with the standard layout. Other implementations can of
course
support CXAN as well, but then they have to implement this support themselves.
The client part is similar to the programs cpan or apt-get.
It provides the ability to look into the package database and directly install the
package on a local repository. In the example about the standard repository manager,
xrepo, in the above section, we shaw how to install the FunctX package,
provided it has already downloaded somehow:
xrepo install functx.xar
If this package has been uploaded to CXAN, under the name functx, we can
easily adapt this example to CXAN by using the following command instead:
cxan install functx
In this case, there is nothing on the local hard drive (except the local repository
of course), and the CXAN manager will automatically retrieve the FunctX package on
http://cxan.org/ and install it in the local repository.
CXAN is only a prototype at this stage, but the concepts are quite simple and the
technical part almost trivial once we have a packaging system. The crucial work will
be
the amount of libraries uploaded, their quality and the quality of their meta-data.
But
there are plenty of talented X* developers out there with a lot of interesting ideas
of
libraries. Reaching a large audience with an XML library is quite difficult for now,
because of the differences between the processors, and the lack of automatic install
processes even for one single processor. But with the help of a proper packaging system
and a system like CXAN, it is finally possible to write a general-purpose library
and
diffuse it over the whole community.
Webapp packaging
EXPath contains several modules for several needs. A typical EXPath module is a set
of XPath functions, defined in a specification. The Packaging System is a bit different
as it defines instead a whole system and a file format to package XML libraries. There
is another EXPath module which defines a system rather than a library of functions:
the
Webapp module. Its goal is to make it possible to write web applications entirely
with
XML technologies. The Webapp module defines an abstract web application container,
the
services it provides to the deployed web applications, and the way it maps HTTP requests
and responses to and from those applications (as well as a mechanism to package such
applications). This is a well-known abstraction used by several major frameworks for
web
applications, like the Java Servlet technology.
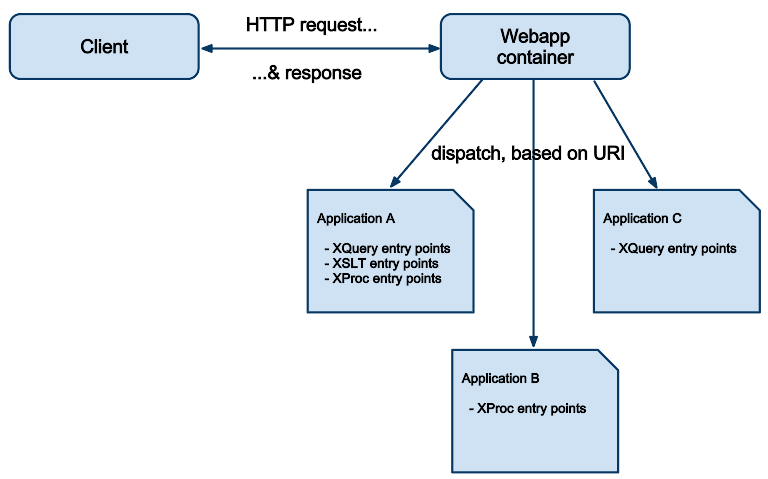
Basically, a web application based on this module is written in plain XSLT, XQuery
or
XProc, with some entry points respecting an interface defined by the Webapp module.
Those entry points (function, template, pipeline...) receive a representation of the
HTTP request as input and return a representation of the HTTP response as output.
They
are configured in a web application descriptor to be mapped to some URIs or URI
patterns. When the server receives a request on a URI, it looks for a matching
component, calls it with the proper input and return its result as the coresponding
HTTP
response, as shown on the following diagram:
The packaging of those web applications is based on the Packaging System. The Webapp
module specification does refer to the specification of the Packaging System, and
extends it by adding the web descriptor. The web descriptor maps URI patterns to
specific components in the package, or to specific functions, templates or steps within
those components. But all the packaging machinery itself is already defined. Just
to get
an idea, here is an excerpt of such a web descriptor:
<webapp name="http://h2oconsulting.be/ns/website"
...>
<title>H2O Consulting website</title>
<!--
The Freedom page.
-->
<servlet name="freedom">
<xslt function="free:backup-servlet">
<import-uri>http://h2oconsulting.be/ns/website/freedom.xsl</import-uri>
</xslt>
<url pattern="/freedom"/>
</servlet>
<!--
Serve main pages, transformed from XML files to XHTML.
-->
<servlet name="pages">
<xslt function="h2o:pages-servlet">
<import-uri>http://h2oconsulting.be/ns/website/servlets.xsl</import-uri>
</xslt>
<url pattern="/([-a-z0-9]+)?">
<match group="1" name="page"/>
</url>
</servlet>
...
</webapp>You can see that the principal role of this web descriptor is to map URIs (or URI
patterns) to entry points (functions, templates, pipelines, etc.) Note in particular
that those entry points, behind their name, are identified by an import URI (and not
by
a file name for instance). This import URI is the one defined by the Packaging System
and is set in the package descriptor. The Webapp module does not have to worry about
such a mechanism to resolve stylesheets or XQuery modules. It can simply reuse the
Packaging System mechanism, by extending it with entry points name in order to point
to
specific functions, templates or pipelines within those components.
Servlex is an open-source implementation of Webapp, using Saxon and Calabash as the
processors to execute the components. It uses the same standard on-disk repository
layout to deploy the web applications on the server. Thanks to this, it can reuse
the
existing open-source implementation of the Packaging System, and its integrations
within
both Saxon and Calabash, and needs just to process the webapp descriptor to initialize
a
map between URIs and components.
Because the Packaging System specification has been designed to be extensible, it
is
possible to use it in other specifications, and to reuse some existing tools for more
specific needs.
Conclusion
The lack of a proper packaging format to publish XML libraries has prevented people
to
write and publish such libraries in an implementation agnostic way (implementations
usually
do not provide such a facility anyway). The EXPath Packaging System aims to solve
this
problem, by defining an implementation-independent packaging format. This format is
extensible and can be reused for other needs, like the web application packaging.
This
system is not only a way to distribute packages, but can also be the missing piece
for a
lot of different applications, like CXAN and the project structures. And other ideas
we
have not thought about yet...