Becker, Abraham, and Jeff Beck. “XML Essence Testing.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Becker01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Balisage Paper: XML Essence Testing
Abraham Becker
XML Translation Specialist
National Center for Biotechnology Information (NCBI), National Library of
Medicine (NLM), National Institutes of Heath (NIH)
Abraham is currently working as a Contractor with the National Center for Biotechnology
Information. He started in print production, document management, and has
been working with XML based technologies for the past seven years.
Jeff Beck
Technical Information Specialist
National Center for Biotechnology Information (NCBI), National Library of
Medicine (NLM), National Institutes of Heath (NIH)
Jeff Beck has been involved in the PubMed Central project at NLM since 2000. He
has been working in journal publishing since the early 1990s.
Authors' contribution to the Work was done as part of the Authors' official duties
as NIH employees and is a Work of the United States Government. Therefore, copyright
may not be established in the United States. 17 U.S.C. § 105. If Publisher intends
to disseminate the Work outside the U.S., Publisher may secure copyright to the extent
authorized under the domestic laws of the relevant country, subject to a paid-up,
nonexclusive, irrevocable worldwide license to the United States in such copyrighted
work to reproduce, prepare derivative works, distribute copies to the public and perform
publicly and display publicly the work, and to permit others to do so.
Abstract
SYNOPSIS:PubMed Central (PMC) is the
U.S. National Institutes
of Health free digital archive, gathering together biomedical and life
sciences journal literature from diverse sources. When an article arrives at PMC,
it
conforms to one of over 40 evolving DTDs. An ingestion process applies appropriate
"Modified Local" and "Production" XSLT style sheets to produce two instances of the
common NLM
Archiving and Interchange DTD. In the "Essence Testing" phase, the essential
nodes of these XML instances, as specified by some 60 XPath expressions, are compared.
This method allows the reliable detection of unintentional changes to an XSLT style
sheet that can have negative impacts on product quality.
OBJECTIVE: Create an easy-to-use tool that allows
tracking, reporting, and qualitative analysis to monitor the effects of changes to
existing XSLT style sheets on the content of XML articles. The tool should have the
ability to look beyond differences in the XML structures of those articles, focusing
on
essential data and its semantics (the document’s Essence).
RESULTS: A Guided User Interface was created using
CGI, which invokes 2 PERL scripts (sampler [SQL, UNIX], and converter [Saxon 9.1.0.5J]).
A test and a control NXML document are created. The Essence is extracted from those documents using XPath expressions, and a
JAVA program compares and formulates a report of the differences in the Essence documents.
SIGNIFICANCE: Quality control reports on XSLT style
sheets are now run on a weekly basis, or any time significant changes are made to
the
XSLT style sheets. The level of control and the granularity of tracking has increased,
and has had a very positive effect on quality of the XML output.
PMC processes approximately 500 full-text XML articles per day, and 16,000 full-text
articles per month, in over 40 evolving DTDs. The frequency of updates to the DTDs,
and new
versions of the NLM
Archiving and Interchange DTD itself, force the XSLT style sheets that process
those documents to also evolve rapidly. This continuous metamorphosis brought about
a need
to track the way changes to production XSLT style sheets affect XML result documents.
A
regression system was originally put into place which utilized the UNIX diff function.
Its
method was to check for textual differences between sample articles converted with
"Production" XSLT style sheets, and those same sample articles converted with "Modified
Local" XSLT style sheets (a basic regression test).
PMC must maintain content in different versions of the NLM Archiving and Interchange DTD. Since the
release of version 3.0 in the fall of 2008, the PMC Conversion Group has been methodically
upgrading our XSLT style sheets to XSLT2. This upgrade adds a level of confusion to
our
existing regression testing, since some of the changes from version 2.3 to version
3.0 are
backwards incompatible, and some of the XML nesting structures have changed.
How can we verify that an article originally created in DTD version 2.3, is now
correctly represented by the new DTD version 3.0 coding?
Upgrading or migrating the sample set to DTD 3.0 is an obvious answer, but in order
to
migrate the data, we need an XSLT conversion. It is the very XSLT style sheet that
would
perform this conversion which we aim to check. We needed a way to verify that the
article
written in DTD 3.0 is semantically the same as the 2.3 version. We needed to check
that the
test XML instance has the same content, even if the content is nested in a different
structure, or captured using new named elements. We need to check the article's Essence.
Our solution was to define a set of XPaths that would extract essential nodes in the
document, allowing us to compare a small subset of the most important nodes between
a test
and a control XML instance. The goal was to go beyond simple text comparison, to managing
consistency of XML documents’ data and semantics across updates to the XSLT
Converters.
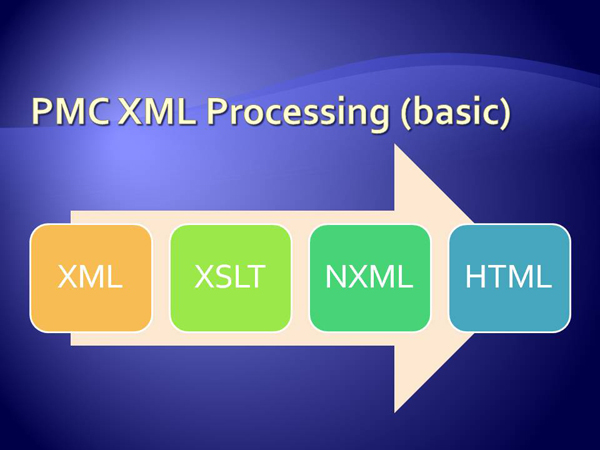
Overview of the PMC XML Processing Model
Some background information is necessary for a good understanding of how the Essence
Testing system works. As stated earlier, PubMed Central accepts XML in just over 40
different DTDs. Articles from each DTD are processed as follows:
XML is submitted to the PMC FTP site, and ingested into the file system.
OASIS XML Catalogs resolve source XML PUBLIC and SYSTEM identifiers, which map
validation to the appropriate DTD.
A configuration file determines which production XSLT style sheet to apply,
based on the source XML DTD name and version.
The newly created NXML and its associated files (Images, PDFs, Supplementary
files) are loaded to a common database for rendering and indexing.
Changes to the XSLT style sheets have an impact not only on the normalized
NXML, but also on the HTML rendering. It is therefore important to ensure that changes
to
the XSLT style sheets do not negatively affect those downstream data products.
regr-pmc-proc
Methods
The Essence Testing Process
The Essence Testing Software uses a single XML
source instance (submitted by the external data provider), the user's "Modified local"
copy of the appropriate XSLT style sheet, and the quality assured production NXML
to
test if the changes in the user's "Modified local" XSLT style sheet produce adverse
effects in the test NXML output, when compared to the quality assured NXML.
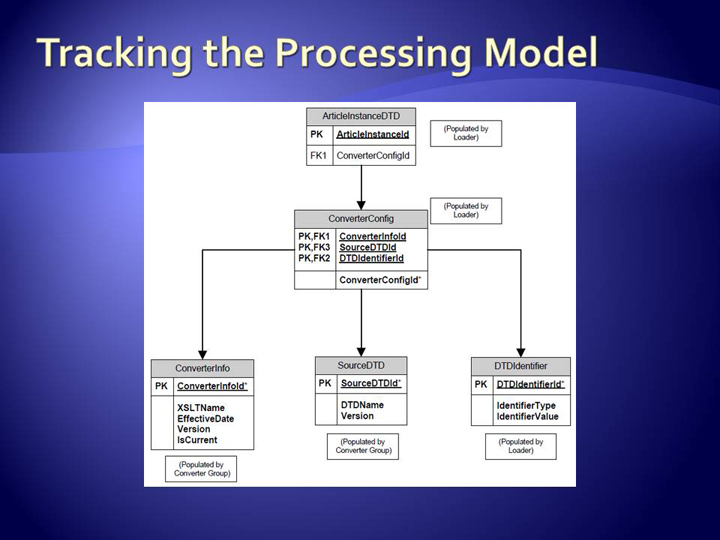
Tracking
Tracking the configuration used to convert each XML instance gives us the freedom
to take completely random sample sets based on a given set of parameters. XML
processing instructions are added to the NXML instances to facilitate tracking of
the
processing model applied. In the PMC system, the following information is written
to PIs:
DTD Identifier Value (DOCTYPE string used to resolve DTD)
DTD Identifier Type (PUBLIC or SYSTEM)
DTD Name
DTD Version
XSLT Name
XSLT Version
XSLT Effective Date
If XSLT is Currently in production
These PIs are used to populate a tracking database in which each article's
processing model is stored. Aside from generating sample sets, we have the added
benefit of targeted reconversion when bugs are found. Each article instance is
assigned to a specific processing configuration, and all articles processed with a
given configuration can be queried for reconversion.
regr-database-model
Defining the Document's Essence
Familiarity with the XML model should guide which nodes in the XML test instances
are the most important to monitor. The PMC Conversion Group created tests that fall
into one of two categories: system critical or content related. System critical
issues are those that directly impact the way an article is processed. For example,
the Open Access Status registers inclusion in the PMC Open Access
Subset. These articles are generally made available immediately to the
public under a creative commons license. It is critical that this property is set
correctly, because many non-Open Access articles are contractually bound to be hidden
until an embargo period expires. Content related issues are those that pertain to
the
quality of the data, such as the count of paragraphs, sections, references, and figures.
System Critical: Open Access Status,
Release Delays, Publication Dates, Journal Meta data, Article Meta
data
Content Related: Presence of Abstract,
Body, Paragraph Element counts, Back Matter, Article Type, Author counts,
Language(s), Figure Table and Math counts, Bibliographic References,
Citation counts
Example: Research articles are always
associated with a journal in the PMC context, so this test is system critical. The
element <journal-title> is a child of <journal-meta> in NLM DTD version
2.3. With the release of NLM DTD 3.0, the <journal-title-group> wrapper was
added to group the optional elements <trans-title-group>,
<abbrev-journal-title>, and <journal-subtitle>. A simple text comparison of
these two structures would yield a mismatch. By using XPath, we facilitate comparison
of the content from two separate DTD models, overlooking the differences in
structure, focusing on consistency and meaning of the data.
regr-2.3-3.0
Essence XML Extractor Style Sheet
Each Essence Test is placed inside a literal
result element in the Essence XML Extractor Style
Sheet. This method of identifying the essential nodes via XPath can
be applied to XML documents in two analogous, or two completely different DTDs. By
creating a list of XPaths that point to the essential nodes in the result
documents, we can extract the Essence from both
the (test) NXML and from the quality assured production (control) NXML, using
these extracted documents as a basis for comparison.
regr-ess-extractor
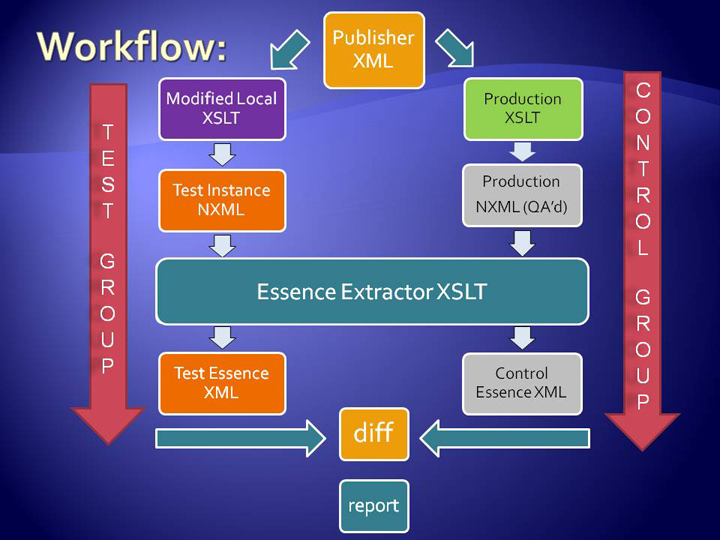
Essence Testing Work flow
The Essence testing process is aimed at creating two Essence XML documents that
can be compared to expose anomalies resulting from changes to the "Modified Local"
XSLT. We start with the publisher XML file (source). Using the production XSLT(shown
in green), a production NXML (gray) is converted, to be used as the control instance.
Quality assurance on these documents is handled by the PMC data group. They report
variations in rendering and processing, and verify that content is acceptable based
on a set of approximately 90 quality checks. A test NXML instance is also created
by
applying the user's "Modified Local" XSLT style sheet (shown in purple) to the
original source XML.
regr-ess-wkflw
Comparing Essence XML Documents
As mentioned earlier, the Essence XML Extractor
XSLT is used to extract the Essence of
both the test and control instances, creating a Test Essence XML and a Control
Essence XML. These two documents are compared element-by-element, and any differences
in structure or content are aggregated into a report.
Example: Below is an example of Essence XML
documents from an article of the journal BMC Microbiology. Note that some of the
tests are counts, and some are string comparisons. In this particular case, while
running a weekly regression test, I noticed that the report showed a MathML formula
was present in the test Essence XML, but not in the control Essence XML. After some
investigation, I found that a bug was fixed in the XSLT converter a few weeks
previous to this Essence Test, but there were still some lingering articles that
needed to be reconverted. Because the processing configuration was stored in our
tracking database, I was able to easily locate and reprocess all articles affected
by
the bug, without reprocessing the entire journal data set.
regr-ess-xml1
regr-ess-xml2
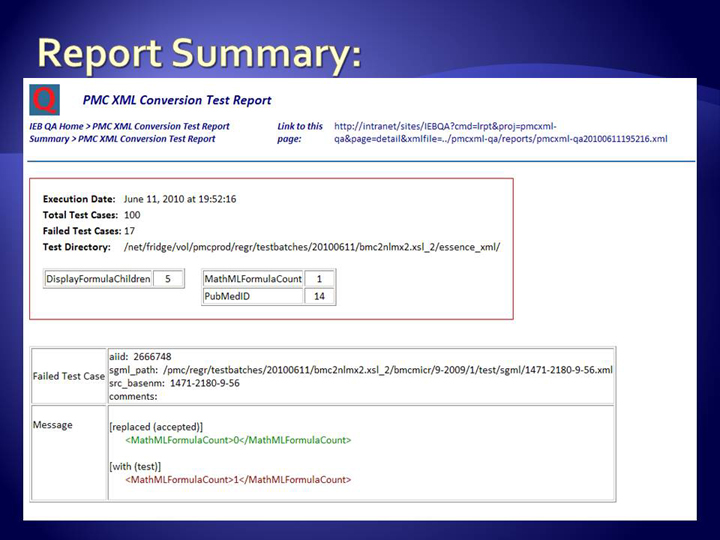
Essence Report
The Essence report summary lists the number of differences by test category in the
red box, showing a macro view of how the changes to the "Modified Local" XSLT are
adding up in a more general sense. For each difference detected between the test and
the control instances, a failure is reported below, aggregated by XML instance.
"[added (test)]" means the test case has additional information when compared to the
Control Essence XML. "[replaced (accepted)]" followed by "[with (test)]" means that
the test case does not match the Control Essence XML, and the test instance contains
something additional to what was found in the test instance.
regr-ess-report
Results
Using the Essence of an XML document as a basis for
quality control is a viable solution for verifying that documents tagged in different
versions of a schema or DTD represent the same semantic. Large data sets are time
consuming
to process, but random sampling maximizes the effects of testing, while limiting the
time
to run a given test. Controlling XSLT regression over large XML data sets is not trivial,
and this system allows an acceptable means of monitoring the effects of those modifications
over time.
Discussion
How did we do at meeting the objectives?
The Essence Testing GUI has proven to be an effective and useful tool after several
months in production. It ensures changes to XSLT style sheets do not have adverse
effects
on the quality of XML output. Using XPath to test the Essence of XML output allows comparisons between different DTD versions of
the same article in an organized and reliable way.
Were there implementation problems?
Processing large data sets, especially those over 100 full-text articles, takes longer
than what we would ideally want. Converting full-text XML articles, applying the Essence transformation, then comparing the output of those
processes could be handled more efficiently with a modular, object oriented approach,
involving several parallel processes converting XML simultaneously.
What future directions might the project take?
The configuration of this tool is specific to PubMed Central's data directory structures
and database models. Modularizing the code for a more generic software API could be
a
direction for future improvement.
What are the greatest benefits of this system?
When an XSLT bug was found in the past, large portions of the entire XML data set
would
have been reconverted to fix it. Tracking the processing model information for each
XML
article instance significantly reduces the reprocessing overhead associated with such
bugs,
and allows more specificity when identifying affected articles. Negative impacts on
NXML
output due to changes in the XSLT style sheets have been significantly reduced. Automatic
weekly regression tests continually reinforce the quality and integrity of the data
stored
in our system.
Acknowledgements
Jeff Beck, Sergey Krasnov, Vladimir Sarkisov, Andrei Kolotev, Anh Nguyen, and Laura
Kelly provided a great deal of guidance in the design of this project. Their input,
as
always, has proven to be wise, insightful, and is very much appreciated. The comparison
and
reporting segment of the system was written by Jane Rall and Byungsoo Kim. This research
was supported by the Intramural Research Program of the NIH, National Library of
Medicine.
Wall, Larry; Christiansen, Tom; Orwant, Jon
Programming Perl, Third Edition. Sebastopol, California: O'Reilly & Associates,
Inc.; 2000
Author's keywords for this paper:
XML Essence Testing; Regression; XML Conformance Testing; XML Quality Control; Computer Science; Information Storage and Retrieval; Document Management; XML Testing