For Want of a Proper CMS
This paper started life around fifteen years ago, when I was spending my professional life designing a document management system based on a then-popular XML editor and a SQL database. The system had a document management layer with full integration between the editor and the database, exact versioning and traceability, translation handling, and, of course, XSL for publishing.
It had all kinds of bells and whistles — and yet, adding any kind of new processing capabilities, be it editor functionality or additional publishing targets, was a nightmare because the system was based on technologies and languages far removed from XML. As a markup person, I relied on programmers specialising on .net for even the slightest change.
XML First
That all changed with XProc 1.0. As long as I had something in the DMS calling an XProc engine and a pipeline of my choice, adding a new publishing format or an import function was a matter of writing the stylesheets and an associated pipeline. It was brilliant!
And it was to get even better — not only was I able to write an XProc pipeline for the processing but I could also generate a matching user interface in XForms using XProc! [Using XML to Implement XML]
Some time later, I helped design another content management and (web-based)
publishing system to produce regulatory checklists for farmers seeking national and
EU funding, this time using oXygen and eXist-db [XML Solutions for Swedish Farmers: A Case Study].
Importantly, beyond a few web technologies and design choices outside of my control,
it was all implemented using XML technologies — XProc, XSL, XLink, XQuery, and a few
other things beginning with X
— so rather than having to deal with
binary blobs in a SQL database, I could query and process the XML directly.
My next step was to test the waters by combining the aforementioned XProc and XForms publishing approach with eXist-db [ProXist]. It was a bit clunky but it worked; I was able to output a UI, published by an XProc pipeline and associated framework, based on the type of output pipeline I had.
I still missed version management and full traceability — what I had in that SQL server-based system — but implemented in an XML database using XML technologies. I came up with VML [Multilevel Versioning], an XML vocabulary for version management, and an outline suggesting how to implement it in eXist-db.
A Question and a Devious Plan
The XML first
content management approach stayed with me. I would
occasionally suggest solutions along those lines for my clients while keeping busy
with migration pipelines, publishing stylesheets, and DITA customisations, but
surprisingly no-one wanted to sponsor my XML-first system. I did write another
eXist-db and XForms project, a registration app for Balisage's sister conference,
Markup UK [Eating Your Own Dog Food],
but that was about as close I got.
But then, in 2022, a client asked me how I would go about implementing a portal for publishing DITA and S1000D content. The portal would publish the service documentation of a car manufacturer about to launch their very first model, but also fit into my client's larger strategy of providing an entire service lifecycle management chain, from 3D CAD data to service and end user documentation, parts catalogues, and so on.
I proposed a system where the XML content is stored in an XML database as-is, without pre-converting anything, filtered and queried as-is, and finally published to HTML on the fly. I had a devious plan.
The Portal
The portal happened in a specific context, namely in the publishing of web-based documentation within automotive and aerospace industries — user guides, workshop manuals, bulletins, parts catalogues, etc, much of which is accompanied by 3D graphics and animations produced directly from the product CAD data — using XML vocabularies such as DITA and S1000D.
It's just a portal, though; the content is authored elsewhere, in an unrelated system that doesn't know about the portal's existence. Similarly, the portal does not care where the content comes from.
Content
DITA [DITA Specification] and
S1000D [S1000D Specifications],
while very different on markup level, have similar approaches to content: firstly,
there are the topics, that is, the reusable blocks of information where the actual
content lives, and secondly, there are the publications or structure descriptions
(maps
in DITA, publication modules
in S1000D) that
combine the topics into actual documents with chapter and section hierarchies.[1]
The portal had to be able to display both — individual topics would be enough for, say, a disassembly task or a function description for a single component, while the structures would be needed to browse through the full publications.
A structure view
helps illustrate the overall document structure
and functions as a table of contents, but it also helps highlight the reuse of
common components — for example, see the arrows pointing to Warning 2
in Figure 1.
Figure 1: Reusing Topics
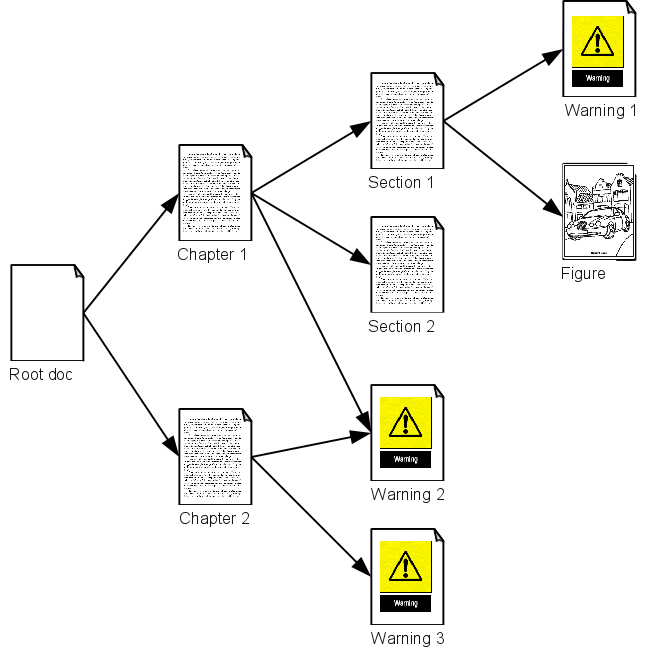
Both vocabularies employ what is known as conditional
processing (some vocabularies, including DITA, call it profiling),
basically declaring applicabilities (which is really S1000D
terminology) for the content: this topic applies to products A and B
,
this applies to regions APAC and EU
, and so on. By profiling
content from individual paragraphs to entire topics, reusing becomes easier; a
single topic can be reused in multiple contexts, spanning multiple products, product
variants, audiences, and so on.
The filtering is, of course, also useful when searching for content, but also for publishing on the fly; an end user can select the exact model and variant to only include relevant information when publishing to HTML.
Browsing and Filtering
In the portal, we store the source content as-is, and that content needs to drive everything. For example, we only list the topic types and profile values actually in use in the database, not everything that is possible. The UI should always reflect the actual content.
While XML databases use XML as their primary format, we still want to generate basic resource lists only once, when initialising, rather than every time those resources are queried.[2] This makes most operations far quicker, especially with a large enough database.
The initialise operation generates several lists, all in XML format:
-
A list of profiling attributes and values in use.
-
Elements in use.
-
Resources considered to be part of the portal content.
The resource list is especially interesting. It is currently limited to
content
and structure
XML only, so while there are
plenty of other files, XML and binary both, they are not used directly by the main
UI. For each listed XML, we add a basic information such as a database URI and a
title (extracted from the file contents), but also profiling and topic/resource type
information. The result is a (very long) list of file elements:
<file xmlns:exist="http://exist.sourceforge.net/NS/exist" uid="d97e1" depth="-1" selected=""
type="topic" uri="/db/test/content/dita-examples/01/my_first_portal_topic.dita"
name="my_first_portal_topic.dita" created="2023-04-09T19:29:19.867+02:00"
last-modified="2023-04-09T19:29:19.867+02:00" id="my_first_portal_topic"
dita-content-type="content" product="A" audience="C D E"
root-profiles="product(A) audience(C D E)" outputclass="" excluded="false">
<title xmlns:ditac="http://cadituk.com/xquery/ditac">My First Portal Topic</title>
</file>
<file xmlns:exist="http://exist.sourceforge.net/NS/exist" uid="d98e1" depth="-1" selected=""
type="topic" uri="/db/test/content/dita-examples/01/second_portal_topic.dita"
name="second_portal_topic.dita" created="2023-04-09T19:29:19.9+02:00"
last-modified="2023-04-09T19:29:19.9+02:00" id="my_second_portal_topic"
dita-content-type="content" product="A B" audience="D E"
root-profiles="product(A B) audience(D E)" outputclass="" excluded="false">
<title xmlns:ditac="http://cadituk.com/xquery/ditac">Second Portal Topic</title>
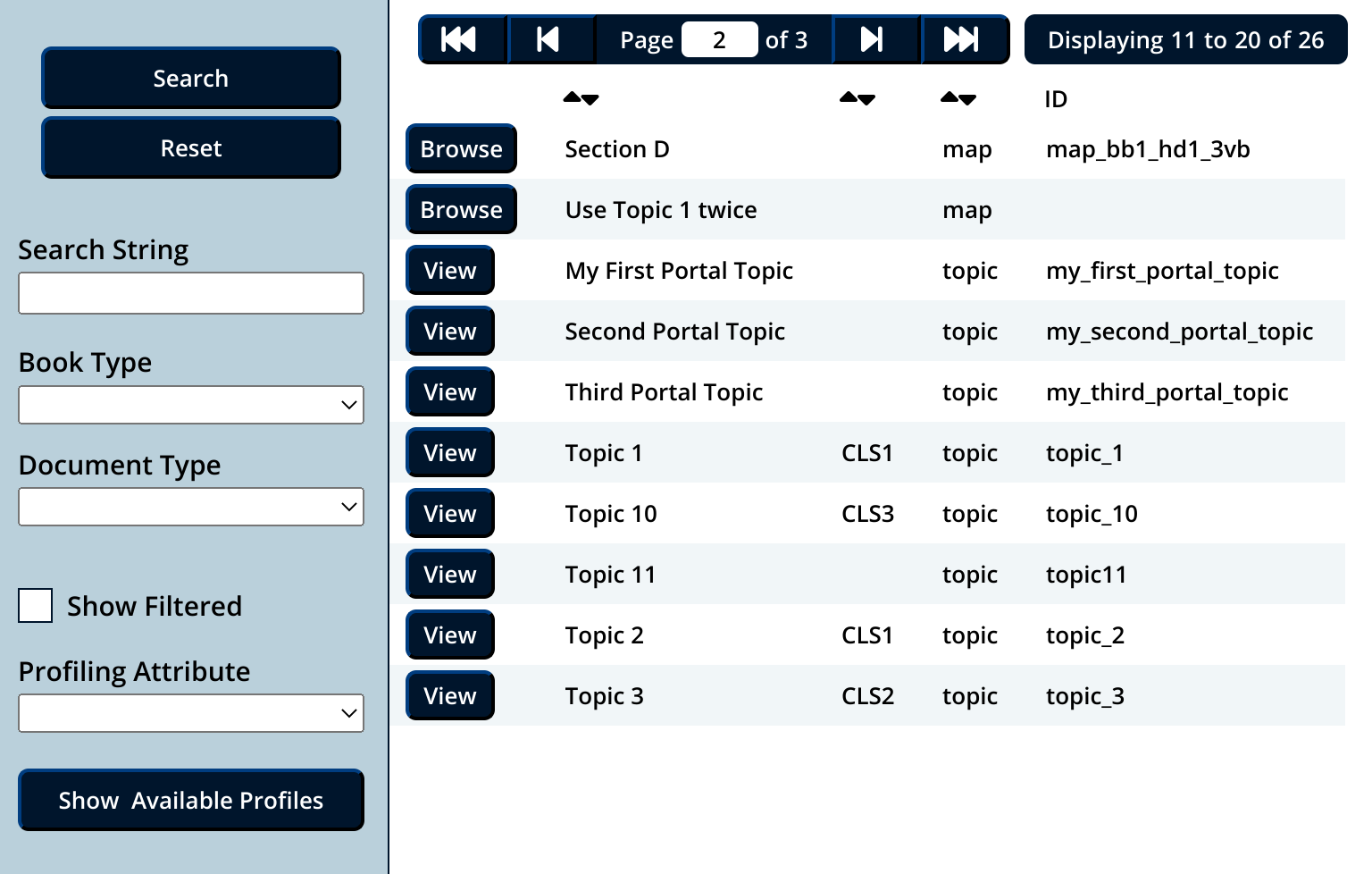
</file>The file list is read by an XForm and presented as a file browser with various controls:
Figure 2: File List
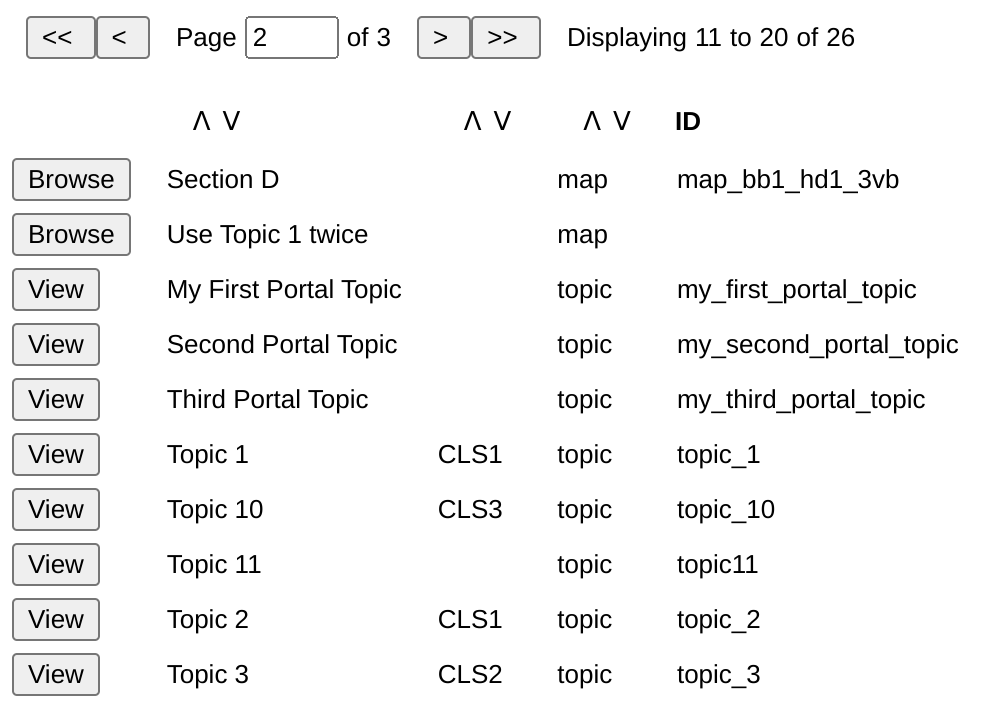
For structures
(maps) we add nested file elements
representing linked resources. Here's a DITA map structure:
<file xmlns:exist="http://exist.sourceforge.net/NS/exist" uid="d89e1" depth="-1" selected=""
type="map" uri="/db/test/content/dita-examples/02/section_d.ditamap"
name="section_d.ditamap" created="2023-04-09T19:29:19.791+02:00"
last-modified="2023-04-09T19:29:19.791+02:00" id="map_bb1_hd1_3vb"
dita-content-type="structure" outputclass="" excluded="false" expanded="false">
<title xmlns:ditac="http://cadituk.com/xquery/ditac">Section D</title>
<file uid="d90e1" depth="0" selected="" type="topic"
uri="/db/test/content/dita-examples/02/topic_8.dita" name="topic_8.dita"
created="2023-04-09T19:29:19.519+02:00" last-modified="2023-04-09T19:29:19.519+02:00"
id="topic_8" dita-content-type="content" outputclass="CLS2" excluded="false">
<title xmlns:ditac="http://cadituk.com/xquery/ditac">Topic 8</title>
</file>
</file>The View button starts a publishing process that converts the selected topic to HTML and opens it in a separate tab. For DITA maps, that button becomes a Browse button and presents the structure as a tree, with expandable subtrees and, of course, viewable topics:
Figure 3: Map View

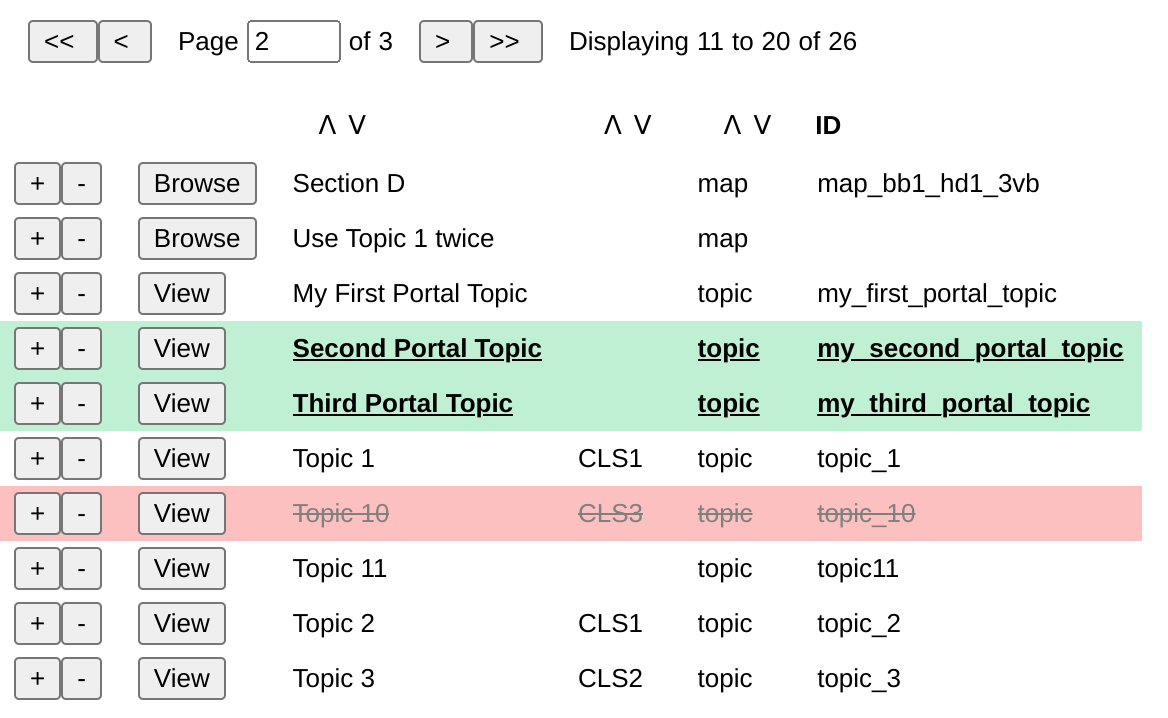
The UI is generated from the file list XML using an initial XQuery script that calls some XSLT, allowing us to not only localise the UI (all UI labels and text are stored in language- and country-specific XML files) but also configure how the UI is presented, using a configuration XML file to define what features are being used. For example, one setting allow us to select one or more resources for later processing or filtering:
Figure 4: Select/Unselect Buttons
Additional controls allow us to filter the file list by applying profiling information:
Figure 5: Profiling Controls
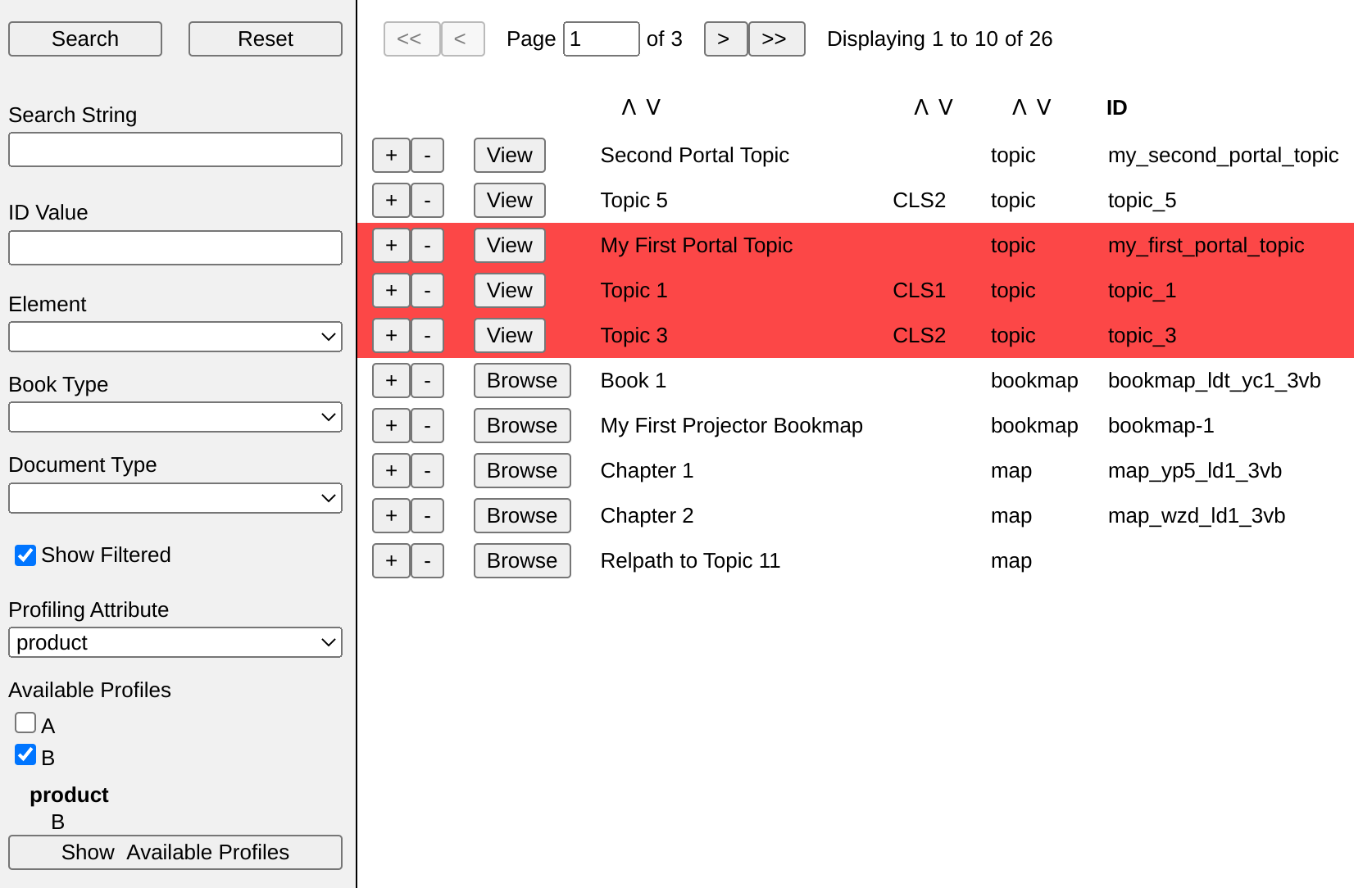
When applying filters, we simply add the currently selected values to the file list XML:
<profiles>
<product>
<value>B</value>
</product>
<platform/>
<audience/>
</profiles>This is used by the XForm controls, of course, but also for publishing. When a
topic is published (see section “Publishing”), the profiles element is converted to a
DITAVAL filter [TBA ref] and sent to the publishing process as a parameter.
Most of the file browsing and filtering features are implemented with XForm controls that either act on the file list XML directly or call XQuery functions.
A configuration XML file controls most aspects of the UI, including styling, scripts, and so on, so changing the appearance of the UI is a matter of tweaking the CSS stylesheet(s) and updating the UI configuration:
Figure 6: Alternative UI Layout
Finally, note that the file list XML acts as an XForms instance, so in addition to
the resource metadata, we frequently set attribute values for XForms-related
processing. For example, in the nested file elements shown above, there
is an @expanded attribute to expand and collapse the tree
representation. Other processing includes the resource type and the DITA
outputclass, both of which are useful when filtering and publishing.
Publishing
The first portal version ended up being a DITA implementation because that's what the customer, an automotive manufacturer, is using. DITA isn't without its advantages; most aspects of DITA, from authoring to publishing, are well supported today, meaning that we wouldn't have to write publishing stylesheets from scratch. Rather than using the DITA Open Toolkit, a first choice for many implementers, we chose XMLMind's DITAC framework [XMLmind DITA Converter] because it was far better suited to being integrated with eXist-db.
Standard DITA functionality, from profiling using DITAVAL filters to conref links,
is provided by DITAC out-of-the-box, which is a huge help: DITAC includes default
stylesheets for HTML, PDF, and a few other formats. This means that a DITAC
stylesheet to output a specific layout, known as a plugin
, is really
just an extension and therefore much faster to write.
The portal DITAC implementation brings the functionality to eXist-db and deals mostly with database URIs and packaging, but also JavaScript code to handle 3D[3]:
Figure 7: 3D in an Illustrated Parts Catalogue

Most aspects of the portal are XML technologies that the author feels quite comfortable with; this is not one of them.
What's in a CMS? Asking for a Friend.
What's in a CMS, really? What does it take? And mind, while I am a proponent of open-source software[4], this exercise is not about that; rather, it's about yours truly arriving at a point where document (content) management can be had without a year-long project[5] or an expensive third-party system offered by consulting firms who really want to make money from additional services and support[6], or both. Some people build boats or cars from scratch just because they can, even though money can buy both. Me, I want to build a document (content) management system and then take it for a spin.
So, again, what does it take?
-
Storage. Being a pointy brackets person[7], I'm partial to XML databases, and there are several alternatives out there.
-
Authoring. There are plenty of alternatives, from open-source editors to commercial products with everything supported out-of-the-box.
-
Publishing. Again, plenty of alternatives. XSLT and FO are no-brainers if you want to write the stylesheets yourself.
-
Management. This is the heart of the matter, really, isn't it? It's about listing whatever resources you store and author and publish, about searching and filtering their contents, and about keeping track of them.
Do-It-Yourself Document Management
The alert reader will have noticed where this is going, of course. The portal is half-way to a CMS:
-
Storage? Yes, we already store the content in an XML database so all kinds of things become possible.
-
Authoring? No, we don't have that per se but read on.
-
Publishing? Check.
-
Management? Yes, we have some of it. Read on.
Authoring
Adding authoring is easy, and easiest by far is to connect oXygen XML Editor to eXist-db[8], with the connector available out-of-the-box. Other editors require more work. If all you want is an integration to the (XML) database without versioning, then we're done.
Note
Obviously, if you're integrating Emacs, you'll have more to do.
Actually, even with versioning, I'd argue we're only ever going to edit the latest version of any document. If you check out an earlier one, you still don't actually edit that version, you create a fork and edit that instead.[9]
In a proper version management with check-out and check-in, your editor integration will require additions to do that.[10] I'd argue that the check-out function is a matter of locking the file and reasonably easy to achieve. There are probably also a number of convenience functions, but for a bare-bones authoring environment, this should be enough.
A reviewer rightly pointed out that the editor is frequently a stumbling block for non-markup people. While I do agree, addressing that particular problem must come later. oXygen, for example, makes an excellent effort towards user-friendliness for many types of authors[11], with or without an associated CMS, and so I would argue that a well-designed CMS (which this one aims to be) can only help.
Document Management
And we arrive at the heart of the matter. You'll note that we already have browsing and filtering capabilities; I'd argue that the portal's browsing UI isn't needed for basic editing when using oXygen (see section “Authoring”) since we'll always edit the latest version and the whole versioning business is handled in the CMS.
Other editors might have to either implement proper in-editor integration — which to me sounds a fairly difficult thing to do — or add a UI trigger to open a selected resource in the XForm, much like the buttons shown in Figure 4. That function, of course, would be a little something written in XQuery, perhaps made slightly more complex with check-out/check-in functionality.
The check-out/check-in functionality requires a suitable flag, of course, but it's is easy enough to add one to the file list XML as an attribute (with the flag controlled by XQuery functions behind the scenes):
<file checkout="true">...</file>
Other flags (and associated XQuery functions) are easily implemented, of course.
Versions and Workflow
This is not a paper on versions or workflow (which, by the way, are not the same or even close), but I do believe that the portal's basic approach to file listing and browsing is well suited to being expanded for the purpose.
I've long advocated an approach that centers on identifying resources using URNs (Uniform Resource Names). That URN identifies a resource on multiple levels, a base identifier followed by a point in time and a rendition, something like this:
urn:x-example:thing:123456:<version>:<xmllang>
If all you want is to identify an abstract notion of that resource, without a point in time (version) or a specific rendition (language and locale), you are left with a base identifier:
urn:x-example:thing:123456
Again, this is a base identifier, identifying the resource in its purest and most abstract form. My paper on versioning [Multilevel Versioning] explains how it all works and suggests how to handle versioning and workflows, so what is left here is to connect that with the portal's file list XML:
<file urn="urn:x-example:thing:123456">...</file>
This means that the base resource is identified by @urn but
that's it; any decisions on what version that should be used is left to other
business logic. Of course, given the nature of the file list XML, we might
reasonably expect it to use the latest version (and perhaps whatever language
and locale we're displaying at the moment). Alternatively, we might just provide
a specific value when publishing[12]:
<file urn="urn:x-example:thing:123456" version="15">...</file>
We can also use this approach to generate a list of versions of a single resource:
<file urn="urn:x-example:thing:123456" version="15">...</file> <file urn="urn:x-example:thing:123456" version="14">...</file> <file urn="urn:x-example:thing:123456" version="13">...</file> ...
Or include translations to show what versions have them:
<file urn="urn:x-example:thing:123456" version="15">...</file> <file urn="urn:x-example:thing:123456" version="14">...</file> <file urn="urn:x-example:thing:123456" version="14" xml:lang="sv-SE">...</file> <file urn="urn:x-example:thing:123456" version="14" xml:lang="fi-FI">...</file> <file urn="urn:x-example:thing:123456" version="13">...</file> ...
Notably, though, the file list XML is in no way a master list. It's for presentational and editing purposes only, and the actual master is a VML XML instance, with XQuery code keeping track of the two using the base URNs as keys.
In Closing
There is some way to go still, but I do think that an XML-first CMS based on the portal and some other bits and pieces is a distinct possibility. Some of it may happen well before Balisage[13], but I doubt I'll have full-blown versioning before the end of this year.
But What About...?
While I've thought about the subject for years[14], this paper simply cannot reflect everything. Also, I could be missing something obvious. The latter I can't do much about, but here's to addressing at least some of the outstanding questions:
-
Yes, the portal does handle localised content. Think of it as profiling — we're filtering on
@xml:langidentifying 4-position language/country codes. -
Version management is a really big subject and impossible to fully address here. You'll need to read the paper[15] I wrote on the subject [Multilevel Versioning]. It's certainly not definitive but I will be more than happy to argue my points.
-
Workflow management in a CMS, similarly, is not possible to address here.
-
Binary (non-XML) files are manageable in the same way as the XML files. The reason the portal limits the file list to XML is simply that we don't currently support doing anything with the non-XML files beyond what we do now, namely to display them if linked to from the XML.
This is easy enough to change because there is currently a function to specifically remove non-XML (and a few XML files, too, because not all XML is content) files from the file list. We'll need to decide what to do with them first.
-
The first implementation is somewhat DITA-centric, yes. Later versions will generalise much of the code to handle other vocabularies (S1000D and ATA XML to start with, but I'd assume DocBook will also follow).
As for schema languages, S1000D is on top of the list so we'll have at least one XML Schema implementation. The current DITA implementation uses DTDs, although Relax NG can be added with very minor updates.
The First Live Version
The portal went live before Christmas 2022 in what the author does regard as an unqualified success. The database contains 100+ GB of data, much of it 3D content but also thousands of XML resources, and the performance is surprisingly good. The XForms UI, in particular, works amazingly well.
References
[Using XML to Implement XML] Using XML to
implement XML
[online, fetched on 10 April 2023]. https://www.balisage.net/Proceedings/vol8/html/Nordstrom01/BalisageVol8-Nordstrom01.html. doi:https://doi.org/10.4242/BalisageVol8.Nordstrom01
[ProXist] ProXist - XProc Processes in
eXist
[online, fetched on 10 April 2023]. http://archive.xmlprague.cz/2014/files/xmlprague-2014-proceedings.pdf
[Multilevel Versioning] Multilevel
Versioning
[online, fetched on 10 April 2023]. https://www.balisage.net/Proceedings/vol13/html/Nordstrom01/BalisageVol13-Nordstrom01.html. doi:https://doi.org/10.4242/BalisageVol13.Nordstrom01
[XML Solutions for Swedish Farmers: A Case Study]
XML Solutions for Swedish Farmers: A Case Study
[online, fetched on 10
April 2023]. https://www.balisage.net/Proceedings/vol15/html/Nordstrom01/BalisageVol15-Nordstrom01.html. doi:https://doi.org/10.4242/BalisageVol15.Nordstrom01
[Eating Your Own Dog Food] Eating Your Own Dog
Food
[online, fetched on 10 April 2023]. https://www.balisage.net/Proceedings/vol23/html/Nordstrom01/BalisageVol23-Nordstrom01.html. doi:https://doi.org/10.4242/BalisageVol23.Nordstrom01
[DITA Specification] Darwin Information
Typing Architecture (DITA) Version 1.3 Part 3: All-Inclusive Edition
[online, fetched on 11 April 2023]. http://docs.oasis-open.org/dita/dita/v1.3/dita-v1.3-part3-all-inclusive.html
[S1000D Specifications] S1000D
Specifications
[online, fetched on 11 April 2023]. https://users.s1000d.org/Default.aspx
[XMLmind DITA Converter] XMLmind DITA
Converter
[online, fetched on 10 April 2023]. https://www.xmlmind.com/ditac/
[1] Neither DITA topics
nor S1000D data modules
have a section hierarchy. They describe a single, well, topic.
[2] And update those lists when content is added or removed.
[3] The heavy lifting for the 3D is handled by a proprietary library provided by a software vendor, Cortona 3D.
[4] I am writing this on a Linux laptop, after all.
[5] Back in the SGML days, two; the first year you'd design something that didn't work, the second you'd do it all over again but better.
[6] This is not in any way to condemn that approach; the author does it for a living.
[7] And because I had a bad experience with a SQL database.
[8] Which is what I did to author the rather simplistic DITA examples for this paper.
[9] Happy to discuss.
[10] I once worked on a DMS project without explicit check-ins and check-outs.
They called it optimistic check-out
, and essentially they
relied on being able to manage conflicts when two authors were editing the
same file at the same time.
[11] I've been involved in a number of projects where the aim was to make structured authoring available and easy for non-markup authors. We've come a very long way.
[12] Or opening a specific version in an editor.
[13] This is written in April.
[14] Apologies for the presumptuous phrasing; I have, but it does sound cocky.
[15] Actually I've written several, for Balisage and elsewhere.