Nordström, Ari. “Using XML to Implement XML: Or, Since XProc Is XML, Shouldn't Everything Else Be,
Too?” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Nordstrom01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: Using XML to Implement XML
Or, Since XProc Is XML, Shouldn't Everything Else Be, Too?
Ari Nordström is the resident XML guy at Condesign AB in Göteborg, Sweden. His
information structures and solutions are used by Volvo Cars, Ericsson, and many
others, with more added every year. His favourite XML specification remains
XLink so quite a few of his frequent talks and presentations on XML focus on
linking.
Ari spends some of his spare time projecting films at the Draken Cinema in
Göteborg, which should explain why he wants to automate cinemas using XML. He
now realises it's too late, however.
This paper discusses implementing XProc-based publishing and processing in a
document management system that is currently very difficult to expand because
even
though it handles and processes XML, the system is currently implemented in a
way
that makes any changes to publishing and processing difficult. The author currently
depends on C# developers without XML knowledge for any changes.
The paper suggests using XML to implement the
XProc pipelines with, handling everything from the .bat files
for the XProc engine to the GUI that makes the pipelines available to the end
user.
This XML can be used to generate both, but is also useful as an abstraction layer
that black-boxes not only the XProc but everything surrounding it, providing a
blueprint for the processes, simplifying development and, for the author,
eliminating an unwanted dependency to C# developers.
My company develops and markets a document management system. It does what these
things do; there is an XML editor, there is a database, and there is middleware
for
version handling, workflows, modularisation, reuse, etc. Something we call the
Process Manager processes XML documents, for example, outputs
them in PDF. Unfortunately, it is currently difficult to add new processes for
new
formats or media, something that such a system should handle without difficulty.
The Process Manager
Overview
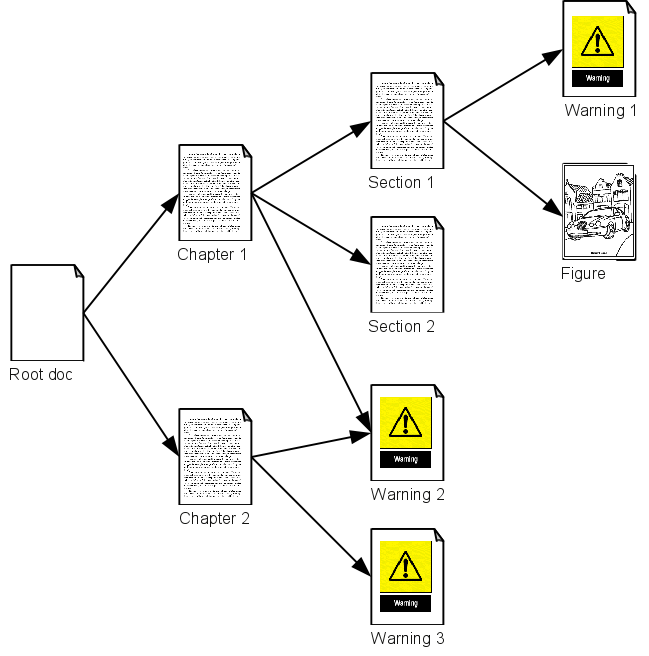
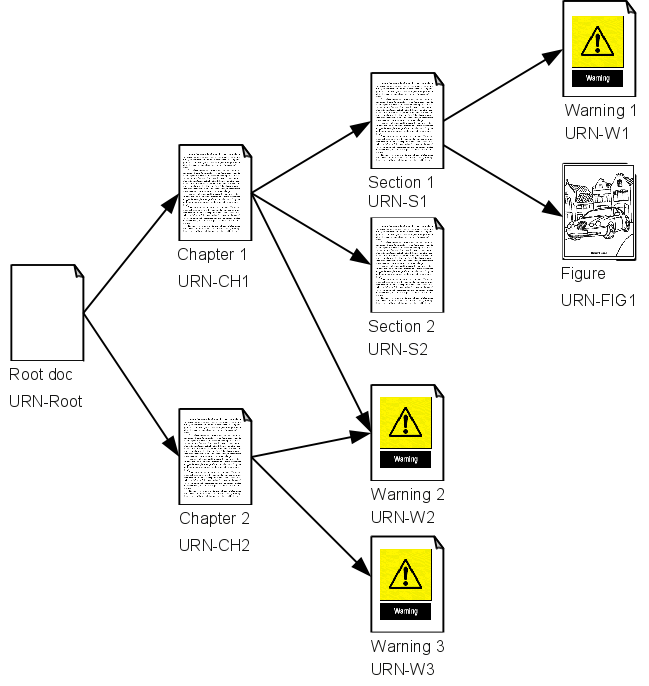
Most documents in the system are modularised, with a root XML file linking to
other XML and images. The linked XML, in turn, often link to further XML and
images, effectively creating a link tree.
Figure 1
A Link Tree
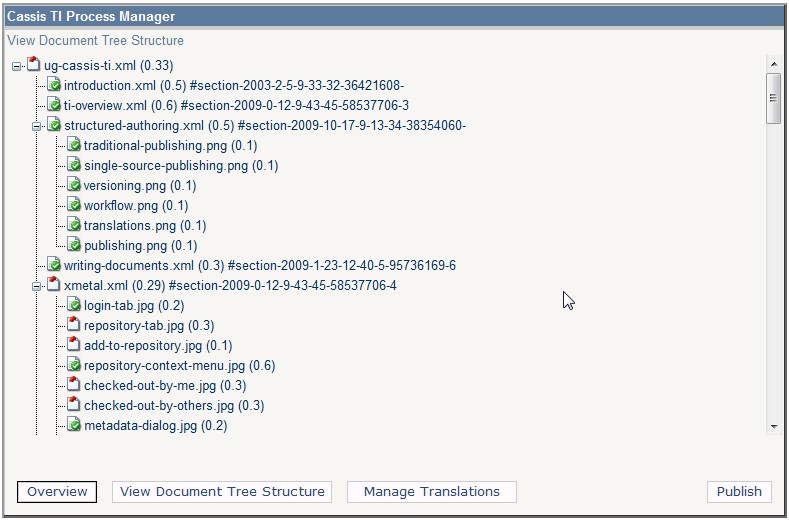
The Process Manager points out the root XML[1] and maps the linked resources in a link tree representation, with
status information, target IDs, versions, etc (see Figure 2). This info is stored in a
configuration.
Figure 2
A Tree View of the Master-Language Document
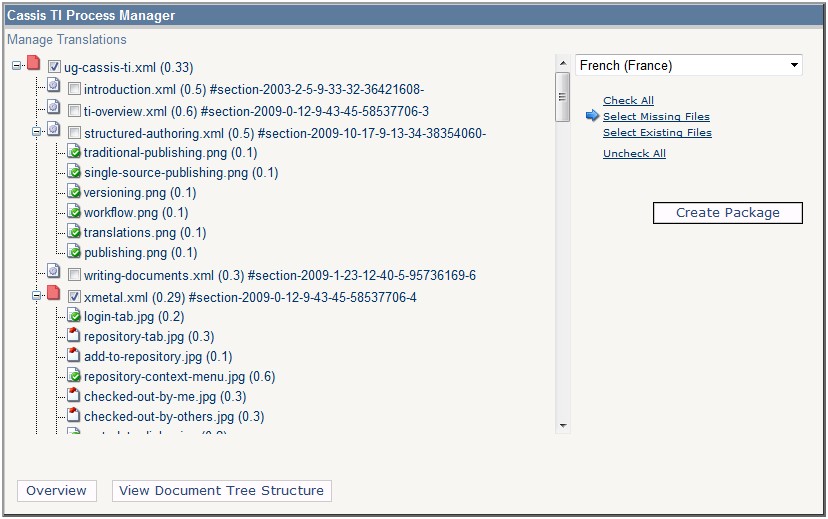
The link tree is the same, regardless of document language, and therefore
useful when handling translations. It can show what translations exist, help
create new translation packages, etc.
Figure 3
Managing Translations
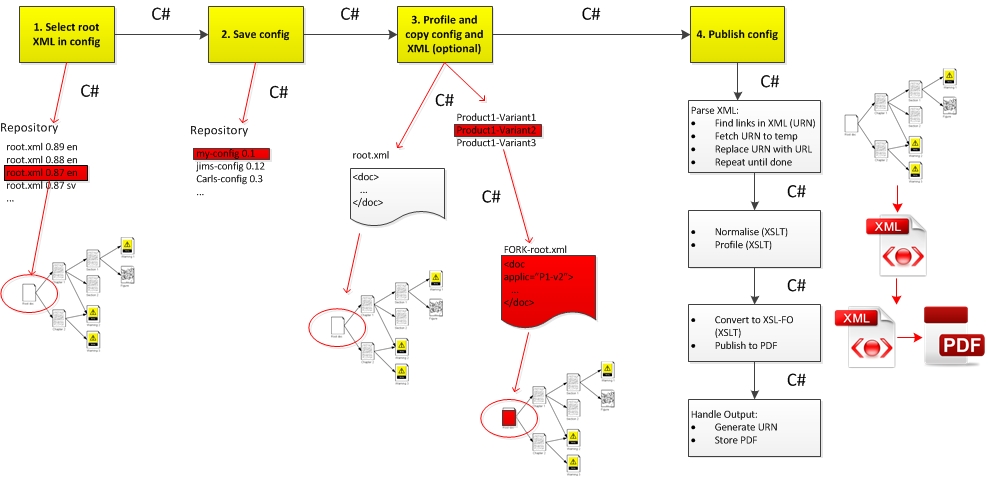
More importantly, the Process Manager uses
the configuration to publish the link tree. It starts a process that fetches
the
necessary XML and images, and normalises them to one big XML file. It then
applies a FO stylesheet to output PDF using Apache FOP. Here's the basic process
handled by the Process Manager today to publish
a modularised document.
Figure 4
Publishing Using the Current Process Manager
The four numbered steps at the top show what is actually exposed to the user.
They hide a lot of background processing, including several XSLT conversions,
DOM manipulation, etc. Everything is glued together using C#. The GUI itself
is
static and always more or less the same.
Other processes might output, say, HTML or ePUB, or simply a report, but
currently, only copying the original process, translation handling and PDF
publishing, all of which depend heavily on C# code, are supported.
URNs Rather Than URLs
Everything is identified, handled and linked to using URNs. Whether a link
points out XML or an image, the pointer is a URN. The URNs are unique and
include language/country and version information, so there's full traceability;
link trees can always be recreated later, regardless of what's been done to a
module or image since.
This works well. The URNs define basic semantic documents (with
base URNs), master language documents (base URN plus the
master language/country) and their translations (the base URNs plus the target
language/country)[2].
Figure 5
Everything Is Identified Using URNs
Stylesheet modules, while handled in the
system in the same way as any other XML, using URNs, are developed outside the system and use relative URLs to refence
each other. Thus, the current Process Manager
can only use them in the temp location when publishing, because otherwise the
relative URLs would break.
Process Details
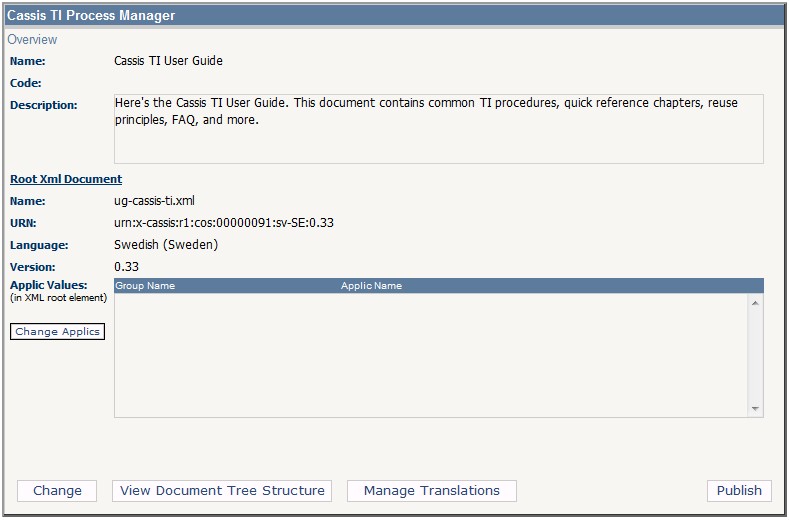
The Process Manager can currently do the following:
Create and save new configs, with titles, descriptions and other
metadata, and point out the exact version and language of a root XML
document using its URN.
Open and edit an existing config.
Copy an existing configuration and the root XML pointed out by it,
that is, create a fork of the XML[3].
Figure 6
A Saved Configuration
A configuration is used by the Process
Manager to process the document it identifies:
View the document as a link tree, including any linked
resources.
Create a translation package of the document, selecting the target
language and the modules to be included.
Publish the document. Currently, only PDF.
Profile[4] a copy (fork) of the document, setting
conditions that include or exclude content from the output[5].
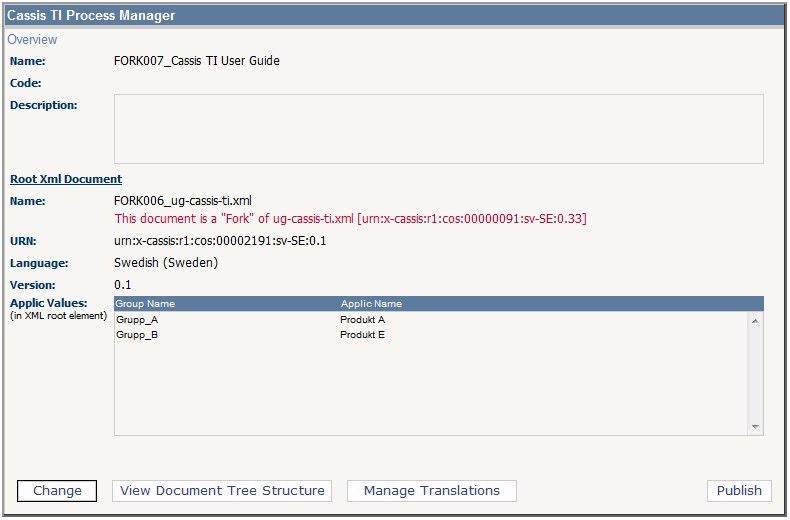
Copying Configurations and XML
In terms of pipeline processing, this is what happens when copying and
profiling a configuration:
Copy the configuration (copied config points to copied
XML).
Change the filenames of the copied XML and config.
Generate new URNs for the copied config and XML[7].
Profile the root XML copy using a GUI in the Process Manager, adding and removing values
controlled by the CMS.
Insert the selected profiles as attribute values in the copied
XML's root element.
Store both copies in the CMS.
Figure 7
A Forked Configuration
The copied XML is then processed.
Publishing Processes
Even with the limited processing available today, there are quite a few steps
involved, as shown in Figure 4,
above.
Here's how to start the actual process after pointing out a root XML and
possibly profiling a copy of it:
Select the workflow status of the publication (temp, preview,
delivery).
Add any mandatory metadata to the configuration[8].
Start the publishing itself.
The publishing process does this:
Use the root XML URN to fetch the file to a temp folder. Map the
URN to a temporary URL for later use.
Parse the root XML for links (URNs, possibly followed by fragment
IDs).
Fetch the URNs and place the files in the temp folder. Map the
URNs to temp URLs.
Parse every URN that is an XML file for further links and repeat
until there are no more links to parse.
Note
Currently, this is all written in C#, with whatever methods C#
provides to manipulate XML.
Replace every URN link with corresponding URLs in every
resource.
Use XSLT to normalise and profile the root XML, producing a single
large XML file. Name it for use in the .bat
file for FOP, below.
Copy the XSL-FO stylesheets from the CMS to the temp
folder.
Currently, the CMS can only identify and use one
main FO stylesheet file at a time[9]. The FO stylesheets use xsl:import and
xsl:include with relative URLs, but the system is
not aware of any of this. It simply copies all FO files in the same physical folder ID'd by the
CMS to the temp location.
Generate a .bat file to run the print engine
(Apache FOP).
Transform the large XML file to XSL-FO.
Convert the FO file to PDF.
Depending on the workflow status for the publishing job, name the
PDF file and generate a new URN for it, storing the file in the
database according to relevant workflow instructions.
Clearly, most if not all of the above steps would be far more effective to
express as XProc pipelines.
Problems
The Process Manager is written in a non-XML way
in C#, by developers who understand C# but not all that much XML. It uses XSLT
for
the transforms, but if I want to use more than one set of stylesheets, say for
HTML
or just a different-looking PDF, I need developers to write more C# to put it
all
together because I don't speak C#. I speak XML.
The GUI is static, too. While it is sufficient when presenting PDF publishing
options, any other processing, be it validation, HTML output or something else,
requires changing it, meaning more C# code and (for me) a dependency to
developers.
Any additional steps, for example, cross-reference validation of the normalised
XML document before publication, also require coding.
All sorts of things (XSLT, DOM APIs, etc) are used to manipulate XML, of course,
but all is glued together using C# code, called using C# code, and changed using
C#
code, with whatever methods there are in that language for manipulating XML.
Suffice to say, most changes require C#.
Some less obvious problems become apparent when handling XSLT:
The XSLT files are modularised and developed offline, outside the
system. They use import and include
instructions with relative URLs to reference each other. Obviously, they
are handled together, as packages.
The CMS can currently not identify them as packages, however. XSLT
files belong together in the system only by proxy, by being stored in
the same place.
A working set of stylesheets in (and outside) the CMS always consists
of specific versions of the included modules. One module might require
uploading a dozen versions before release while another only two (see
below; note the versions to the left).
Unfortunately the CMS can currently only use the latest versions of
the stylesheets, partly because of the above problems with identifying
packages, but also because the relative URLs in the import
and include instructions do not include version
information, URN or otherwise.
The relative URLs, of course, are only usable in the temp publishing
folder.
This applies to any set of XML files that needs to be handled as a package by a
process in the CMS.
A First Attempt at XProc
The Process Manager, of course, should be a
showcase for XProc. Replace the current functionality with an XProc engine that
runs
pipelines for publishing and an admin interface to add and manipulate pipelines
and
stylesheets with, without having to resort to more C# code. And, of course, a
GUI
for the end users to select pipelines from.
The developers agreed. Their lives would be easier, too. If XProc pipelines can
take care of any XML processing while leaving the non-XML stuff to the middleware,
everybody wins.
Manipulating pipelines efficiently was far more complex than we first thought,
however. We needed a GUI for the XProc engine, ways to add parameters and input
to
it, including pointing out modularised stylesheets and other XML, etc. This required
more C#, not less.
Also, XML pipelines are only as flexible as the user interfaces to run them with.
I could think of using and reusing pipelines in more ways than would be practical
to
present in any GUI. The time estimate for the admin functionality alone was far
bigger than our initial guesses, but the end user interface added enough hours
to
the point where the project was turned down.
So I started thinking about ways to generalise all this, to accomplish it all
without admin GUIs and a million lines of new C# code. This paper presents what
I
came up with.
Requirements
Let's take a brief look at my wish list:
Less need for C# development when manipulating XML.
For me, more C# means a more complex and less flexible solution. It makes
little sense to solve what is essentially an XML domain problem with
something else than XML, using C# developers without XML expertise.
Easier-to-implement XML-based processing.
To implement new XML-based processes without C#, I need to handle them in
some other way.
A more dynamic GUI for end users.
The publishing process is by nature flexible and changes with the task.
Therefore the GUI should change, too.
Describing Processes with XML
XProc is XML, of course, so I think the processes surrounding it should be XML, too:
The XProc engine command line, from input to output, parameters, options,
etc, would be useful to handle in XML.
The command line needs to reference packages in the CMS (sets of XSLT or XML modules) rather
than individual files, so the packages would be useful to express in
XML.
A pipeline can reference different packages and use different options,
parameters, etc, which means that a single pipeline can be used with
different sets of command line options by the engine. On the other hand, one
such set of options might be useful to several different pipelines. A
pipeline and its assciated command lines should therefore be separated in
the XML.
The pipeline is part of a process in the Process
Manager. It would make sense to express that whole process in
XML, because it would then be far easier for me to define such a
process.
A GUI presenting the processes to an end user should be as dynamic as the
processes themselves. With the processes expressed in XML,why not generate
the GUI from the XML?
XProc and Calabash Command Lines
Here's an example Calabash command line to handle a simple publishing process in
the CMS's temp location:
java com.xmlcalabash.drivers.Main
-isource=[runtime URN/URL]
-istylesheet-fo=[URN/URL for FO main stylesheet]
normalize-stylesheet=[URN/URL string for normalize]
pdf=[runtime PDF URN/URL]
[URN/URL for FO XPL]
Most inputs are URNs mapped to temp URLs as part of the publishing process, but
others are generated at runtime. Generating a .bat file
directly from today's system is doable, but since XProc allows writing pipelines
in
many ways, it is hard to do consistently. For example, input to the pipeline can
be
handled in several ways. Note how the normalize stylesheet is defined using an
XProc
option rather than the usual input port:
Taking this kind of variation into account when creating an admin interface for
handling pipelines would cause problems, as would, for example, optional parameters. User-selectable options (such as
stylesheets) would further complicate things. Etc.
If we expressed the command line options in XML, generating the
.bat file would be far more straight-forward:
<pipeline>
<!-- XProc script for PDF -->
<script href="[URN/URL for FO XPL]"/>
<!-- Calabash command line -->
<cmdlines>
<cmdline>
<inputs>
<input>
<port>source</port>
<value type="ti">[runtime URN/URL]</value>
</input>
<input>
<port>stylesheet-fo</port>
<value type="uri">[URN/URL for FO main stylesheet]</value>
</input>
</inputs>
<options>
<option>
<name>normalize</name>
<value type="uri">[URN/URL for normalize main stylesheet]</value>
</option>
<option>
<name>pdf</name>
<value type="ti">[runtime PDF URN/URL]</value>
</option>
</options>
</cmdline>
</cmdlines>
</pipeline>
This describes a single command line for one specific script. Other command lines
for that same script might use other stylesheets, optional input, XProc engine
options, etc. My basic DTD can easily include such variations:
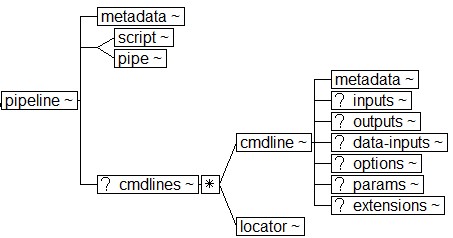
Figure 8
The Pipeline Structure
The pipeline element allows for different command line alternatives
to be inserted or linked to[10]. A GUI could easily present them as user-selectable options. Note the
extension mechanism to provide some support for changes to XProc (perhaps a step
imported from another namespace) and the engine (see Figure 9). The extension capabilities are
limited, however; any addition requiring preconfiguring or input beyond the basics
will cause problems (see section “Limitations and Other Considerations”.
Figure 9
Extensions
Here's an example with several command lines:
<pipeline>
<metadata>
<title>PDF Output</title>
<description>This process outputs PDF.</description>
</metadata>
<!-- XProc script for PDF -->
<script href="[URN/URL for FO XPL]"/>
<cmdlines>
<cmdline id="cmd1">
...
</cmdline>
<cmdline id="cmd2">
...
</cmdline>
<cmdline id="cmd3">
...
</cmdline>
</cmdlines>
</pipeline>
A command line alternative is easily expressed as
/pipeline//cmdline[@id='cmd1'] and so easily transformed to a
.bat file once selected. Also, the alternatives are easy to
represent in a GUI, for example, with check boxes[11] or a list of choices. The pipeline's metadata element
contents can be used to add labels and help texts to the GUI[12].
A pipeline structure instance with its associated command lines[13] is a blueprint for possible ways to use the
pipeline. There is no one-to-one correspondence with an actual XProc
script; rather, the XML represents the available choices. For example, several
command line alternatives might exist for a pipeline, a command line might include
several alternative input stylesheets, etc. A user would have to make choices
for
each option before running the pipeline.
The GUI needs to reflect this by only offering such choices once the prerequisite
choices have been made (for example, you'd have to select a command line before
selecting a stylesheet).
Note
Why not use the XProc script itself to generate the .bat
file and the GUI to handle the process with? First of all, XProc scripts do not
easily offer the kind of modularity suggested above, nor can one XProc script
express all possible variations. More importantly, XProc cannot handle
referencing packages (see the next section) or the kind of runtime naming we
need.
The input step in the below example points out the root XML, but the
value is not known until runtime. The attribute type="ti" means that
the system is expected to provide the content[14].
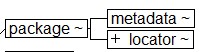
A package is a collection of resources (XML,
XSLT, etc) identified with URNs. As the URNs identify specific versions (and
languages), a package can identify an arbitrary but well-defined set of files
in the
database. Usually but not always[15], there will be a main file that links to the others. Here's an example
FO stylesheet package:
The package consists of URN-based links to the stylesheet files, plus some
metadata for the GUI. Also, the main stylesheet file is identified with a
type attribute with the value root.
Figure 10
A Package Is Basically A Set of Links
If the package XML is identified with
urn:x-example:packages:123456:en-GB:1 in the CMS (the last part
identifies the package version, 1), the relevant input
in the initial pipeline processing XML from the last section is this:
When generating the pipeline's .bat file, the whole package,
including the package XML, is copied to the temp location, with URNs in the package
XML replaced with corresponding URLs (for example,
urn:x-example:xslfo:0012:3 with main-fo.xsl) .
Each user-selectable stylesheet alternative in a pipeline's command line (see
section “XProc and Calabash Command Lines”) would reference a different
such package.
Packages, then, provide the necessary abstraction layer to define input from the CMS to XProc pipeline processes.
As we've seen, the XML that describes the packages is fairly static, easily
definable beforehand. With more frequent package updates, however, it might be
useful to call the package with a wildcard in place of the URN version
string:
urn:x-example:packages:123456:en-GB:*
The wildcard means use latest version with workflow status approved for a user with technical author
permissions, but use latest version with workflow status reviewing for someone with test privileges.
The permissions control how URNs are processed, significantly lessening the need
to
change or update system behaviour for small updates[16].
Finally, the package abstraction very neatly separates offline versioning (in
subversion, in my case) of the participating files from their online versioning.
The
latter are a conscious decision from the developer to release a set of files,
while
the former is simply work in progress.
Putting It All Together
The Process Manager is meant to handle processes (the name sort of gives it away). Normally, a
complete process and the primary action that process performs (such as outputting
a
PDF) are largely the same, but until now, it has not been possible to produce
variants of the process in any case.
It should be. For example, two different sites sharing the same CMS might use
almost the same basic process to publish
documents with, with the same basic pipeline and options, but use different
stylesheets for their respective brands. It would be useful to glue the pipelines
and packages together to describe such variations.
Here's a basic XML structure defining two processes A and B that use more or less
the same pipelines, command lines and packages:
<processes>
<!-- Process for A -->
<process id="id-process-A">
<metadata>
<!-- Metadata for A Process -->
</metadata>
<!-- Pipelines for A -->
<pipelines>
<pipeline>
<metadata>
<!-- Metadata for pipeline for A -->
</metadata>
<!-- XProc script for A FO -->
<script href="a.xpl"/>
<cmdlines>
<cmdline>
<!-- Command line for A FO -->
</cmdline>
<cmdline id="id-cmdline-fo-a-and-b">
<!-- Command line for A and B -->
</cmdline>
</cmdlines>
</pipeline>
</pipelines>
<!-- Packages available for A -->
<packages>
<!-- Normalize stylesheet reference -->
<locator href="packages.xml#id-norm"/>
<package id="id-fo-a">
<!-- FO stylesheet package for A -->
</package>
<!-- Link to A and B FO stylesheet package -->
<locator href="packages.xml#id-fo-a-b"/>
</packages>
</process>
<!-- Process for B -->
<process id="id-process-b">
<metadata>
<!-- Metadata for B Process -->
</metadata>
<!-- Pipelines available for B -->
<pipelines>
<pipeline>
<metadata>
<!-- Metadata for B pipeline -->
</metadata>
<!-- XProc script for B FO -->
<script href="b.xpl"/>
<!-- Links to command lines -->
<cmdlines>
<!-- Link to A and B FO cmdline (above) -->
<locator href="#id-cmdline-fo-a-and-b"/>
</cmdlines>
</pipeline>
</pipelines>
<!-- Packages available for B -->
<packages>
<!-- Normalize package ref -->
<locator href="#id-norm"/>
<!-- Link to A and B FO package -->
<locator href="packages.xml#id-fo-a-b"/>
</packages>
</process>
</processes>
Both A and B link to packages.xml that defines common
packages:
<packages>
<package id="id-norm">
<!-- Normalize stylesheet package -->
</package>
<package id="id-fo-a-b">
<!-- FO stylesheet package for A and B -->
</package>
</packages>
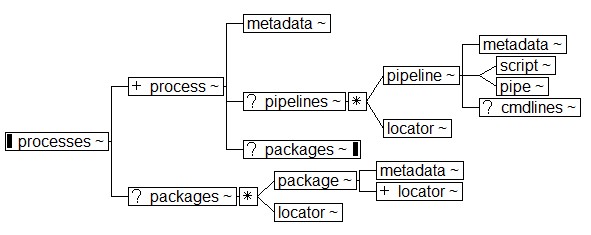
A processes instance is a blueprint for every possible
allowed process, each of which is associated with one or more
possible pipelines. The user has to select a process before selecting from the
pipelines for that process.
Figure 11
Putting It All Together
The design is modular, so everything from command lines to packages can be reused.
The modules are identified with URNs, just as everything else in the system,
offering traceability and allowing whole processes to be repeated when
required.
Implementation and Examples
The process XML is not a reality yet, partly because I have to deal with paying
customers and other inconveniences, but also because my XForms/HTML5 skills really
aren't on par with what I need. Nevertheless, below are some comments and ideas
about an
implementation.
Writing This Paper
This whitepaper, written in our system, provided me with further motivation:
The paper uses our basic XML format. It's straight-forward to convert
it to the conference XML[17], but currently I have to do it outside the system.
The conversion means replacing URN-based links (cross-references and
images) with relative URLs. Again, I have to do this outside the
system.
The paper and images are zipped together before they are sent to
Balisage. Yes, I have to do that outside the system, too.
The additional processes (URN/URL conversion, export to DocBook, zip) are simple
enough to implement, but right now I'd need a C# developer to do it. I'd have
to
explain what I want done and why, and the GUI would need changing. And it would
all
have to be done again if I wanted to add some other processing.
Generating GUIs
The processes structure is a blueprint describing every available
process to manipulate XML documents with. Every process is associated with one
or
more pipelines, run using one or more command lines, and each command line may
allow
for one or more stylesheets.
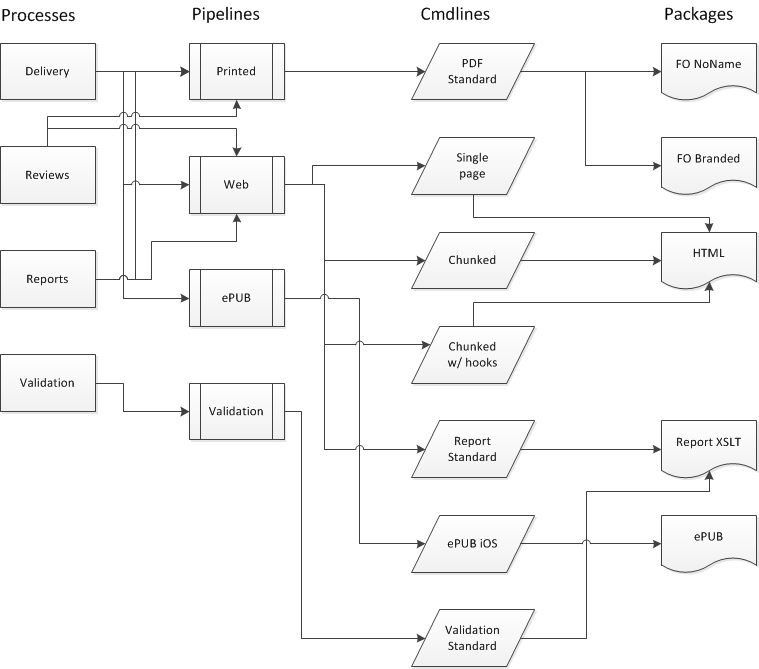
An XForms (or HTML5) GUI generated from the process XML blueprint can help a user
visualise these choices. Figure 12
provides a blueprint example. The Delivery process, for example, can use three
pipelines but Validation only one. The Printed
pipeline can only use one command line, but the Web
pipeline four. Etc.
Figure 12
Process Selection Relations
Using XSLT for GUI generation is the obvious choice as the underlying database is
relational, SQL rather than XML, and there's no XQuery implementation[18].
The process XML requires input from the system for pointing out the root XML
document to be processed. My knowledge of the JScript-based tree controls we use
to
select XML in a web browser is limited, but it is supposedly easy to query the
tree
and get lists of the XML (as URNs) and other resources, including translations
and
older versions of the listed XML.
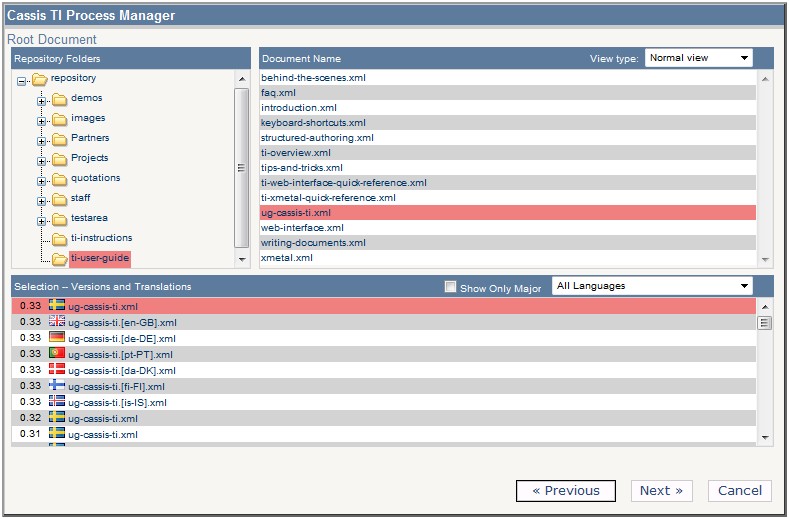
Figure 13
Selecting the Root XML Document
The root XML selection is used as a starting point for pipeline processing. The
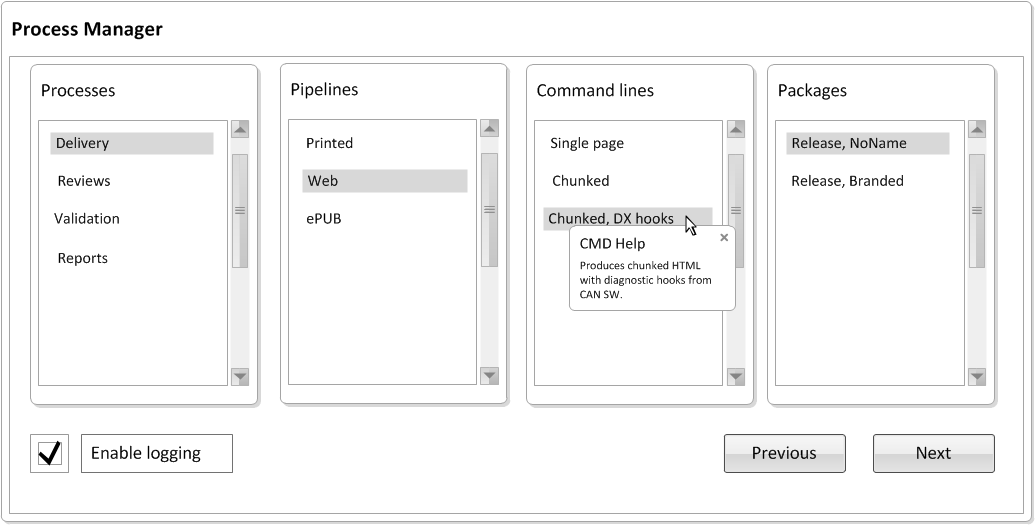
next step is to generate a GUI from the process XML blueprint. Figure 14 shows a GUI example that follows
the logic in Figure 12.
Figure 14
Process Selection Page Generated From XML
Apologies for the crude mock-up. Generating new selection lists based on a
previous selection can probably be represented better, but hopefully the principle
is clear. The labels are fetched from the process metadata, as are help texts.
Also,
note the checkbox to enable logging; this is a command line alternative[19].
The selections provide data to refine the process instance. I'm not enough of a
programmer, nor sufficiently familar with XForms, to tell you exactly how this
is
handled best. For example, the GUI needs to handle a Back or Previous button, Undo, and more, and I don't know what the best way to
implement those would be. Here, I work from the assumption that the user's choices
can be stored in a temporary process XML instance, used to generate the batch
file
to run the actual pipeline.
Generating .bat Files
Note
My current markup started life assuming that Calabash is used for XProc processing. It should handle other
XProc engines, but this is outside the scope of this paper.
Pipelines are run using batch files generated from the process XML using XSLT, but
first, the process XML must be narrowed down to an instance defining
only a specific pipeline and options, as described above.
Generating the batch file:
Select an XML root document URN from a list in the Process Manager GUI. Use it as input to the
pipeline command line input in the process XML blueprint[20].
Create a temp location for the process.
Convert the process XML blueprint into a GUI (see the previous
section) to handle the rest of the selection.
Select a process from the GUI.
Select a pipeline from the available choices for that process.
Select command line options for the pipeline.
Select an XSL package. The package is fetched from the system and
placed in the temp location. The main stylesheet temp URL is used as
further input.
Save the choices that are made in a process XML instance.
Convert that instance to a batch file.
The batch file then runs the selected pipeline and its options, parsing the root
XML document and any linked resources for URNs, downloads the associated resources,
eventually replacing URNs in links with temp URLs, and runs any XSL and other
processing as specified by the pipeline.
Writing Process XML
When writing a new pipeline script (or editing an existing one), it is useful to
simultaneously edit the process XML blueprint that will include the pipeline.
Command line options might require updating or a new XSLT stylesheet might be
needed
with the pipeline. It makes sense to put the new pipeline in context so whatever
options it has are handled.
The process XML is edited in the same authoring environment that is used to write
documents. The markup uses the same linking mechanism as the XML documents—XLink
with URN-based links—so only some additional CSS styling and macros for editing
are
required; the rest is already in place. The results can be checked into the CMS,
just as any other XML, with very few modifications[21].
Limitations and Other Considerations
Some notable problem areas:
Script style. Some decisions need to be made, such as
which options to support and which XProc script designs to allow (such
as what kinds of input to expect for stylesheets). These decisions need
to be documented in a style guide for writing process XML
to avoid breaking the conversions.
GUI design. A GUI that allows for the dynamics of the process XML,
including Undo, Back and such, requires
temporarily storing the choices made in the various stages during the
process, including identifying what Back means as opposed
to Undo, but also to use the temp information for
immediate feedback in the GUI during processing.
Other parts are easier:
The XSLT for the conversions, both to (and from) the GUI and to a
.bat file, should be fairly straight-forward,
once the above is clear.
Hooking the process XML functionality to the current root XML document
selection in the system should also be straight-forward. The queries to
handle and fetch URNs are already in place, as are creating and handling
temp locations[22].
Additions to the XML editor for the basic styling and handling of
process XML are needed, but also permissions and web services to allow
admins to write and check in the process XML. Both of these changes are
trivial to implement.
Many extensions (see XML Calabash (also known as Stop Censorship),
http://xmlcalabash.com/docs/reference/extensions.html) fall into
the engine domain as they happen completely behind the scenes; if the engine
supports it, the process XML will, too, if they can
be run transparently, without having to preconfigure the engine in some way. If
they
require engine configuration, setting system properties or specific input on the
command line, they will fail as anything depending on setting a Calabash system
property or configuration on the command line is currently not supported.
Educating Users
The final point I want to make is perhaps the most important one. The process XML
is very useful when educating users about a
process, without requiring detailed knowledge about XProc, XSLT, or some other
processing. It allows us to represent the process with just enough information
for
an overview because it black-boxes every component.
For example:
My developers today know a lot about C# and SQL, but processing XML
today requires a lot of effort, for them to understand what I want to do
and for me to understand what they can help me with, and how.
The process XML allows me to do the XML parts cleanly, without lengthy
explanations or compromises, but also for the developers to query the
process XML for their purposes, for example, to understand how to handle
process data in the database. The process XML is a clean interface
between me and them.
The process XML can be visualised as a tree mapping process choices
and options. If user permission handling is added to the process XML,
user category-specific descriptions can be included.
The process XML can be used to simulate a process without actually
processing anything. This is very useful when training new users.
Of course, the process XML can be converted to SVG or other formats
for more flexibility.
And More
I'm thinking about adding:
A more generic XProc engine cmdline structure. The
current one is not feature-complete.
Better support for reshaped or restyled GUIs for different
requirements. Some of these might be user-controlled while others might
result from the user's document types, product variants, etc.
Markup support for workflow status and user permission information,
providing workflow- or user-based conditionality when selecting
processes, pipelines, etc.
And, of course, I'm working on a demo implementation.
Conclusions
They say that there is nothing quite as practical as a good theory. I'm not a
programmer and cannot describe the specifics of a good XForms or HTML5 GUI integrated
in
the Process Manager, but I can describe the markup
handling the GUI's semantics. The process XML happened because of a practical problem,
namely that we had a static GUI and system, requiring coding for everything, but
I
wanted something more flexible, something I could change without having to ask
for help
all the time.
In other words, I created a theory that I believe is practical:
Expressing the processes, pipelines, etc as XML is a useful abstraction,
providing the black-boxing of feature sets. The XML provides a blueprint for
the total features available without having to go into specifics.
It's easy to add new output media and formats, extra steps, etc, just as
it should be with XProc, but it is also easy for me to write new processes
with new pipelines and options, thereby changing the whole feature set of
the Process Manager, and do this in XML,
using an XML editor.
The process XML solves the problem with identifying packages rather than single files for the pipelines, but
also handling URNs and URLs for online and offline use, respectively,
without compromising.
The process XML is dynamic so the GUI needs to be, too. Generating the GUI
from it offers the exact same dynamics.
The process XML can visualise and describe the feature sets for any user
category, without requiring detailed knowledge of the underlying
mechanics.
Acknowledgments
I'd like to thank Stefan Tisell and Daniel Jonsson, both at Condesign, for their
invaluable insights and input. Also, my thanks need to go to Henrik Mårtensson.
His
ideas on pipeline processing (see eXtensible Filter Objects (XFO)) have certainly affected mine.
Any errors and omissions in this paper, however, are purely mine.
[eXtensible Filter Objects (XFO)] eXtensible Filter
Objects (XFO). Whitepaper by Henrik Mårtensson about pipeline-based
processing of XML, presented at XML Scandinavia 2001. XFO was implemented in Perl
but
the black-boxing of arbitrary feature sets was a useful abstraction in any context.
Unfortunately, the paper no longer seems to be available online.
[5] Modules include pre-defined profiles in attribute values
inside them; a string comparison is made between these and a
profile context defined in the root element.
[6] Any descendants linked to from the root XML remain
unchanged.
[7] The database tracks the relations between the old and the
new URNs.
[8] This metadata is used to identify the configuration rather
than the XML, so that the process can be found and repeated
later.
[9] Admin-based system configuration is required to point out
another main FO file.
[10] Which means that they can be used by other pipelines.
[12] The command line alternatives also include metadata for the same
purpose.
[13] And the packages, as defined in the next section.
[14] Other possible values include uri to point out referenced
packages, described in the next section.
[15] Standard texts for stylesheets, for example, could be stored in separate
modules, without a main module.
[16] It also allows power users with specific privileges to test
new features without having access to a test setup or affecting the normal,
day-to-day work.
eXtensible Filter
Objects (XFO). Whitepaper by Henrik Mårtensson about pipeline-based
processing of XML, presented at XML Scandinavia 2001. XFO was implemented in Perl
but
the black-boxing of arbitrary feature sets was a useful abstraction in any context.
Unfortunately, the paper no longer seems to be available online.
Author's keywords for this paper:
Pipeline processing; XProc; Implementing XProc pipelines using XML; Black-boxing feature sets; XProc pipeline processes described in XML blueprints