Nordström, Ari. “XML Solutions for Swedish Farmers: A Case Study.” Presented at Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14, 2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Nordstrom01.
Balisage: The Markup Conference 2015 August 11 - 14, 2015
Balisage Paper: XML Solutions for Swedish Farmers
A Case Study
Ari Nordström
Ari Nordström is a freelance markup
geek, based in Göteborg, Sweden, but offering his services across a number of
borders. His information structures and solutions are used by Volvo Cars,
Ericsson, and many others. His favourite XML specification remains XLink so
quite a few of his frequent talks and presentations on XML focus on or at least
touch on various aspects of linking.
Ari is the proud owner and head
projectionist of Western Sweden's last functioning 35/70mm cinema, situated in
his garage, which should explain why he once wrote a paper on automating
commercial cinemas using XML. He now realises it's too late, however.
The Federation of Swedish Farmers – LRF - provides its 170,000
members with a web-based service to check compliance with existing state and EU
farming regulations. These checklists are also made available as a nightly produced
generic checklist document with more than 130 pages, and individualised checklists
for registered members.
This paper is a case study describing
the XML-based system used to author, manage and publish content. The system consists
of the eXist-DB, coupled with oXygen Author, used for edit, store and process the
contents of the checklists and their related contents, including publishing them as
PDFs and exporting them to a SQL database in charge of member registration, feeding
the website, and various other tasks. The solution includes step-by-step processing
of the various types of information in eXist, based on XQuery and XSLT. The system
also uses XInclude modularisation, an extended XLink linkbase, as well as other
markup technologies. The system currently handles a yearly volume of more than
40,000 PDF documents and many more than that in the web-based forms.
While some of the images and examples in this paper include content in Swedish,
understanding the language is not a prerequisite. It might, however, be
interesting.
The Federation of Swedish Farmers – LRF – is an interest and business
organisation for the green industry with approximately 170 000 individual
members. Together they represent some 90 000 enterprises, which makes LRF the
largest organisation for small enterprises in Sweden.
The members' operations range from
small-scale farming to large operations handling crop, livestock, and more. They
frequently rely on state and EU funding to subsidise their operations; however, to
receive funding, they need to comply with any relevant regulations, requiring
inspection both by themselves and by appointed officials.
Checklists
To ease the compliance-related tasks
for its members, LRF provides a website (id-miljohusesyn-nu) with
regulatory audit schemes, checklists with questions intended to
highlight every relevant regulation, each of them accompanied by help texts that
offer more detail. Today, around 11,000 LRF members have registered on the website
to use the services. Their registration data is used to filter the checklists and
the associated facts to only include the relevant contents; for example, a dairy
farmer should not have to answer questions about beekeeping.
Both the checklists and their
associated facts are output in PDF files that are either filtered for the individual
member, excluding irrelevant questions and facts, or output as a total checklist
document, a 130+ page monster that includes everything.
Figure 1: Checklist Questions in the PDF...
For every checklist question, there are
three possible answers: Yes and N/A indicate
compliance and non-applicability, respectively, while no identify
areas where actions are required before approval. For these, members can add
comments, notes, expected completion dates and other information.
The questions always include help texts
to aid the members in completing the checklists. These help texts, called
facts in LRF parlance, appear on the web as pop-ups, and in
the PDF as separate sections.
Figure 2: ...And Their Matching Help Texts
Note
Why is the main output PDF rather than a personalised online form? Very
simple: the end users are farmers who spend most of their time far away from
computers and like it that way. They are not computer-savvy, not comfortable
with online formats, and a majority of them prefer PDFs as the main output[1].
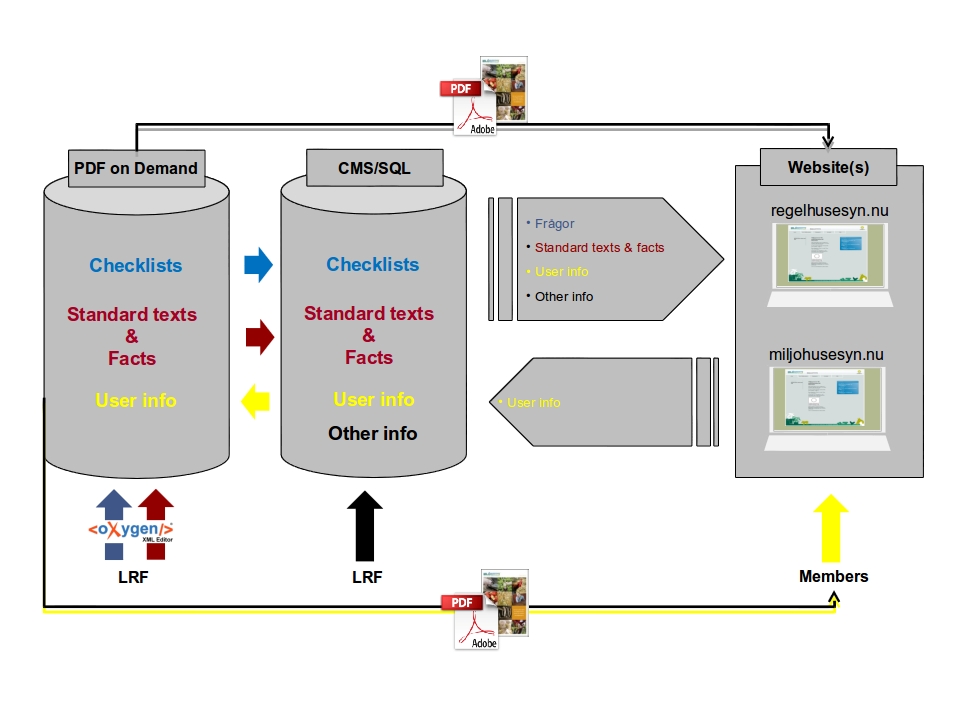
System Overview
The web checklist answers, including
the member partial or complete checklists and their personal and company
information, are handled by and stored in an SQL database. The checklists
themselves, as well as their associated facts and other auxiliary information
appearing in both the web and the PDFs, are fed from an eXist-DB XML database that
converts XML contents to the required output formats and supplies links to these
using an extended XLink linkbase when getting a request from the SQL database.
Figure 3: System Overview
The XML, split into roughly a thousand
modules, is written in a DocBook-based authoring environment in oXygen Author and
stored in a work area in the eXist database. Once new texts are ready, they are
copied to a publishing chain area in eXist, where they become part of
the content output to the web and to the PDFs.
The website also includes a large bank of reference information ranging from legal
texts to links, help texts for the site, news and more, all of which is related in
some way to the compliance process driving the checklists but that is not included
in the published checklists. This information is written in and fed by a Wordpress
CMS that seamlessly coexists with the SQL-DB and eXist DB feeds.
A Brief History
Originally, the checklists were a strictly paper-based publication, compiled and
edited in InDesign from a variety of sources about once a year and then published
in
thousands of copies. As rules and regulations change far more often than that, the
publication was out of date by the time it was printed.
Web-based versions of the checklists were then developed, with checklist questions,
facts and other texts compiled from a variety of sources including third party legalese
feeds and then updated through the admin pages of a SQL server and finally fed to
a
website. These texts were then copied, pasted and edited for the yearly InDesign
version.
This was just as cumbersome as creating the original paper version, and also caused
additional problems with multiple occurrences of the same information.
To handle the problem, we created an authoring and on demand publishing system (id-xmlprague2013-exist) for
the paper version[2], based on eXist and oXygen. Checklists and user data were still produced in
the SQL database while the associated facts and the standard texts were now handled
in
oXygen/eXist. The latest checklists were mirrored to eXist nightly and a total PDF
version of the checklists, facts and other material produced and output to the website,
while the user-specific checklists were imported on demand, when a user PDF needed
to be
produced.
The various eXist conversions (from the raw SQL-DB XML to the publishing XML, from
the
DocBook derivative used for authoring facts to the publishing XML, etc) and PDF
publishing were handled by a series of XProc pipelines on the server filesystem, not
in
eXist itself[3], and the results were either put back into eXist or fed to a XEP instance,
finally sending the resulting PDFs to the various recipients using an email
service.
This solution greatly improved on the old SQL-DB/InDesign combo, but since the
checklists were still authored in one place (SQL) and the associated facts in another
(oXygen/eXist), without the two being connected directly in any way because we had
no
control over the SQL-DB, the system was error-prone. A 600+ question checklist with
almost daily changes had to be exported to eXist and manually associated with 600+
corresponding fact modules. We needed a system that moved all
authoring of content (checklists, facts, etc) to one place, oXygen/eXist, and keeping
only user registration and checklist answer information in the SQL database[4], ensuring that the total checklist with all of the associated facts and
other related content was always up-to-date and valid before it was output to the
website and the PDFs.
This paper describes the resulting new system.
The System
This focusses mainly on the eXist/oXygen part; the Wordpress CMS and the SQL-DB are
both mostly output channels, even though the SQL-DB supplies member checklist answers,
member metadata and profiling information to eXist.
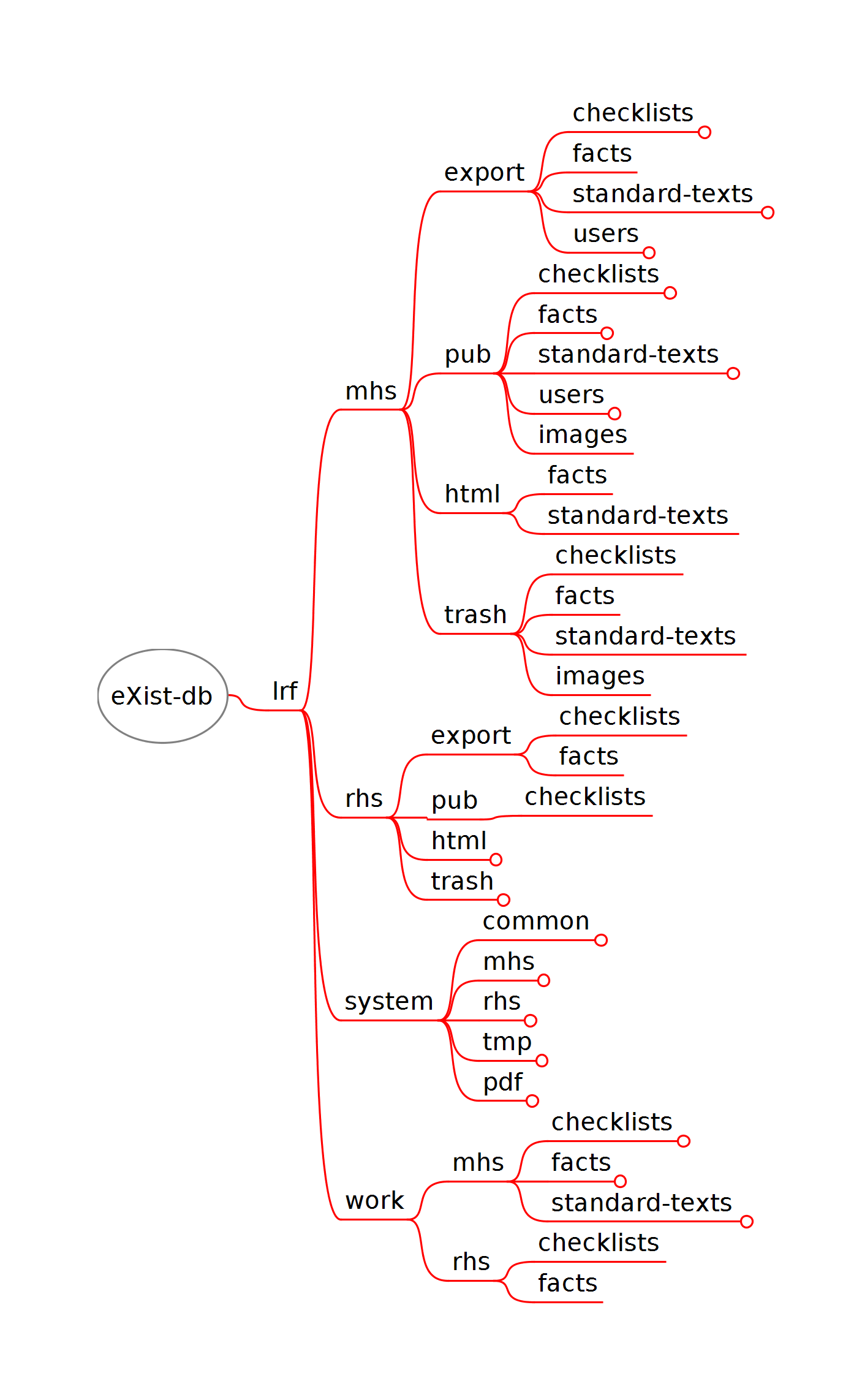
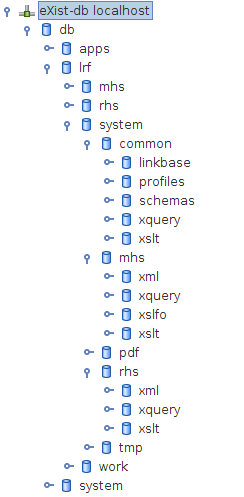
eXist Layout
The eXist database has the following collection layout:
Figure 4: eXist-db Collection Layout
The eXist layout is split into several parts:
There is a publishing chain, represented by the
mhs and rhs branches. MHS and
RHS are two separate regulatory areas requiring their own checklists, but
are handled identically by the system.
There is a work branch that is split into the two
regulatory checklist branches, MHS and RHS. These include collections for
storing checklists, facts and standard texts (auxiliary
information such as preface sections or appendices) not directly associated
with specific questions) while editing the contents in oXygen.
And finally, there is a system branch that contains
the XSLT stylesheets, XQuery scripts, XML linkbases, schemas, and so on,
used to manipulate and move the data in the other branches.
Note
There is also a separate eXist-DB web application, stored in eXist's
/db/apps structure. The app is used for various
administrative tasks.
The Publishing Chain
The principle of the publishing chain is simple enough. There is an
export map that contains the raw data to be published. The
data is stored in subcollections according to information type: Checklists, facts
and standard texts copied from the work area are stored in their own subcollections,
and the user data (metadata and their checklist answers) imported from the SQL
database are stored as combined files per user in users.
Each user is identified using a unique user ID generated by the SQL database. A
convention used everywhere in the system is that uid0 designates the
total checklist with all of the questions and facts, while uidXYZ
identifies the subset for some user with the uid XYZ.
In the older oXygen/eXist system as well as this one, the raw data in
export is then converted by a chain of steps, each
converting a specific type of information for a specific user, basically either the
total, uid0, or uidXYZ, and the results stored in corresponding subcollections in
pub. This is the basic process:
If publishing for a specific user, convert user metadata in
export/users to the publishing XML format and store
in pub/users.
Normalise the modularised checklists in
export/checklists (by default, this happens
automatically in eXist), convert the resulting XML to the publishing XML
format and store as
pub/checklists/pub-checklists-uid0.xml[5].
Convert every corresponding fact file for the total checklist
(uid0) in export/facts to the
publishing XML format, normalise them into a single XML file, and store the
results in pub/facts/pub-facts-uid0.xml. The conversion
is always based on the checklist in the previous step, so only the facts
that are required by it (see section “Node IDs”) are converted.
If publishing for a specific user uidXYZ, convert the user-specific
checklist answers from the user data files in
export/users to the publishing XML format and store
in pub/checklists/pub-checklists-uidXYZ.xml.
Using the converted user-specific checklist, filter the total converted
facts file for uid0 (step 3), removing any inapplicable facts, and store it
in pub/facts/pub-facts-uidXYZ.xml.
Convert any standard texts in export/standard-texts
to the publishing XML format and store them in
pub/standard-texts.
Using the root XML file linking to the other XML modules converted in
previous steps (the root file is a standard text converted in step 6),
normalise it into one big XML file and save the result as a temp
file.
Convert the normalised temp XML to FO format and feed the results to a XEP
formatting engine.
Store the PDF in an output collection that is then used by the SQL
database to fetch the PDF and send it to the recipient or publish it on the
website.
As mentioned, the uidXYZ process runs on demand, when a user logged
onto the checklist website orders a PDF version of his answers, while the
uid0 total checklist document is produced nightly and published
on the website for those members that have not yet registered for the online
checklist services.
Each step above consists of an XQuery wrapper, called by the SQL-DB as an http
request during the synchronisation and publishing processes, that in turn invokes
XSLT stylesheets that do the actual conversion. Frequently, the XQuery will prepare
the indata in some way, perhaps adding base URIs or filtering the indata according
to some criteria based on the regulatory checklist branch (mhs or
rhs; see above).
The facts and the standard texts are also converted to HTML for use by the SQL
database for the web versions of the checklists, where they are used as
context-sensitive help texts. The publishing process is similar to the above, using
one XQuery per step and information type, storing the results in their respective
subcollection inside the html collection. Since the facts and
standard texts are written using a DocBook derivative, the XSLT used is a very
slightly updated DocBook XSLT 2.0 package[6].
Whenever the website requires an HTML fragment, the SQL database sends an http
request to eXist, invoking an XQuery that reads a linkbase listing every resource
in
the system (see section “Node IDs and the Linkbase”), and gets a link to the converted HTML in
return.
Note
The RHS checklists branch is currently somewhat simpler than MHS, presently
requiring no PDF output, only HTML, but this is about to change as I write
this.
Node IDs and the Linkbase
Early on, it occurred to us that an extended XLink linkbase that listed the
resources in eXist would be useful. For example, to use a fact HTML file as a help
text on the web requires only the link to the HTML in eXist, so looking that link
up
in one place made sense. Similarly, when authoring a checklist question in oXygen,
locating the associated fact's URI in a single linkbase file rather than searching
a
number of collections inside the work area seemed like a sensible
alternative.
So, the most interesting resources (and relations between them) for lookup by the
SQL database or others are the checklists and their associated facts. , using
@node-id values as keys.
Node IDs
But how do we know that a question is indeed associated with a fact? We use a
simple attribute, @node-id, to identify a question. For a fact to
be associated with that question, it needs to include the same
@node-id value in its root element. Here is a checklist
fragment (the qandaentry element identifies questions, while
qandaset identifies groups of questions
(which are basically grouped questions according to some topic; groups also use
facts to provide further detail):
<?xml-model href="http://localhost:8080/exist/rest/db/lrf/system/common/schemas/lrfbook/lrfbook.rnc" type="application/relax-ng-compact-syntax"?>
<section
xmlns="http://docbook.org/ns/docbook"
text-type="checklist"
version="lrfbook"
operation="G">
<titleabbrev>G</titleabbrev>
<title>Allmänna Gårdskrav</title>
<qandaset
text-type="group"
xml:id="d1e17"
node-id="node-id-G1-2015-03-26-0100">
<title>Anmälnings- och tillståndsplikt</title>
<para>Reglerna nedan berör enbart anmälnings- och tillståndspliktiga företag. Syftet är att
minska risken för att miljön förorenas eller att andra betydande olägenheter för
människors hälsa eller miljön uppstår. </para>
<qandaentry
text-type="question"
xml:id="d1e31"
node-id="node-id-G1-1-2015-03-26-0100"
cc="true">
<question>
<para>Om verksamheten är anmälningspliktig, har anmälan gjorts till kommunen?
(Tvärvillkor att anmäla djurhållning)</para>
</question>
</qandaentry>
<qandaentry
text-type="question"
xml:id="d1e50"
node-id="node-id-G1-2-2015-03-26-0100"
cc="true">
<question>
<para>Om verksamheten är tillståndspliktig, har tillstånd lämnats av länsstyrelsen?
(Tvär villkor att anmäla djurhållning)</para>
</question>
</qandaentry>
...
</qandaset> ...
<qandaset
text-type="group"
xml:id="d1e1058"
node-id="node-id-G10-2015-03-26-0100">
...
</qandaset>
</section>
Your Swedish may be rusty, but the interesting bits here concern the
@node-id attributes. For example,
qandaentry[@node-id='node-id-G1-1-2015-03-26-0100] at the top,
highlighted above, is associated to this fact:
<?xml-model href="http://localhost:8080/exist/rest/db/lrf/system/common/schemas/lrfbook/lrfbook.rnc" type="application/relax-ng-compact-syntax"?>
<sect1
xmlns="http://docbook.org/ns/docbook"
cc="true"
node-id="node-id-G1-1-2015-03-26-0100"
text-type="fact"
version="lrfbook"
xml:id="d729e2">
<title>Anmälningspliktig verksamhet</title>
<para>(Tvärvillkor)</para>
<para>Djurhållning över 100 djurenheter kräver en anmälan till kommunen. Anmälan om t.ex. utökad
djurhållning ska göras minst 6 veckor före planerad start. Verksamheten bör invänta
kommunens beslut i ärendet, då beslutet kan innehålla särskilda villkor. Kommunens beslut
kan även överklagas av t.ex. närboende.</para>
...
</sect1>
A one-to-many relation is also possible: the same fact can be used with
several questions simply by adding the @node-id values to the fact,
each separated by whitespace: <sect1 node-id="node-id-1
node-id2"...>...</sect1>
Linkbase
An extended XLink linkbase at its simplest is basically a list of
points of interest, pointers to resources called locators.
They are pointed out using a URI and possibly some kind of fragment identifier
or pointer inside the resource, frequently to ID attributes. Optionally, the
linkbase may then define relationships between these locators, called arcs, and
there are also a number of other features having to do with giving the locators
and arcs roles as well as other information about their expected behaviour. For
a far better introduction to XLink, please read the specification (see id-xlink).
The linkbases (there is one for each regulatory branch of checklists) look
like this (the actual file in this case contains some 3500 locator
entries):
The example lists three checklist questions and their associated facts. Note
that the checklist locators include fragment identifiers to pinpoint the
question inside the checklist. Also note the @res-type attribute
that identifies the type of resource[7] that is listed.
Similarly, the linkbase lists every resource in the work area.
The linkbase does not currently include the converted versions of the
resources in html and its subcollections. Instead, it
relies on the nightly synchronising process to do the actual conversion and
simply rewrites the link that is returned to the SQL database to point at the
HTML equivalent, with the query returning a 404 if there is no HTML version at
the target location.
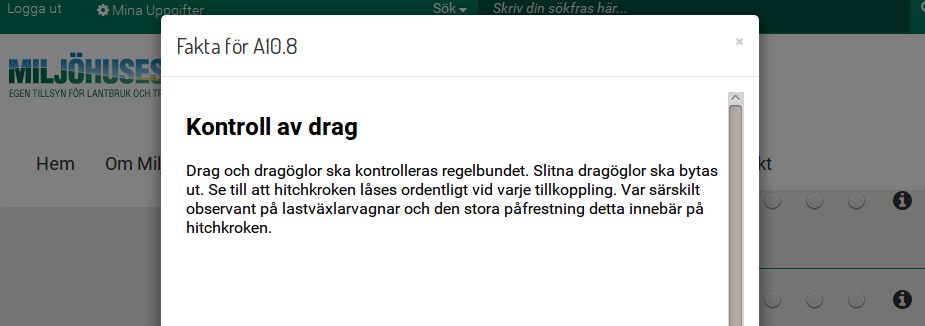
A query made by the SQL database for the HTML version of the fact file A10-8
(@node-id="node-id-A10-8-2015-04-16-0200"), highlighted above,
includes the domain (regulatory checklist branch), type and media, like
this:
It would, of course, be possible to implement the query functions in eXist
without gathering the @node-ids and their associated resources
inside a linkbase, and instead look for them directly in eXist, but we saw
several advantages with a linkbase:
Firstly, a linkbase does not have to list every
resource with a @node-id in eXist, only those that we consider
to be needed. That selection can easily be changed by rewriting the linkbase
generation code.
Second, the linkbase offers a single point of contact for outside systems;
it provides in itself a level of indirection. A query function that returns
content from it easier than something that deals with the entire
database.
Work
The work area replicates the general collection structure found in the publishing
chain, split into two regulatory branches:
Figure 6: The Work Area
The information is placed strictly after information type: checklists in
checklists, facts in facts, and so on.
This again makes it very easy to manipulate and move the data in well-defined
steps.
Writing Checklists and Facts
The checklist groups and questions control the process, so they are edited
first. If a new question is added, the fact text is written afterwards,
sometimes much later, when there is sufficient background information (for
example, regulatory or legal information, numbers, etc). This made the old
system fairly error-prone because the question and the fact were written apart
in time and in two separate systems. Frequently, there would be no matching fact
file for a question on the web.
The new system handles this by allowing the checklist to control the
publishing process (see section “Checklist Publishing”) and using the @node-id
attribute values to match facts.
The linkbase makes it easy to find out if there is already a matching fact in
the system (see section “Finding Matching Resources ”), and there is also a way to first write a
new fact file and then associate a question to the new fact, using an XQuery
that copies the question's @node-id value, allows the user to
browse for the target fact file, and finally adds the value to the fact[8].
Of course, there are also functions that generate new @node-id
values and replace existing ones, if the relationships between checklists and
facts need to be updated.
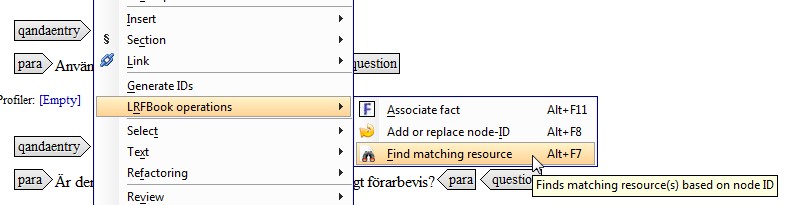
Finding Matching Resources
When authoring content in oXygen Author, the linkbase is used to locate
corresponding resource(s) for the one being edited. The function is available as
a context-sensitive menu item:
Figure 7: Find Matching
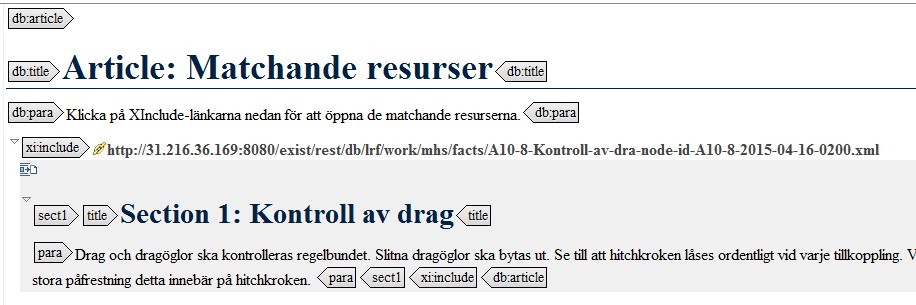
So, when editing, say, the checklist question A10-8, a query to find the
corresponding question (implemented as an oXygen action in the LRFBook
framework) would locate the A10-8 fact and open the query answers as XInclude
links in a wrapper document[9]:
<?xml version="1.0" encoding="UTF-8"?>
<db:article xmlns:db="http://docbook.org/ns/docbook" version="lrfbook">
<db:title>Matchande resurser</db:title>
<db:para>Klicka på XInclude-länkarna nedan för att öppna de matchande resurserna.</db:para>
<xi:include
xmlns:xi="http://www.w3.org/2001/XInclude"
href="http://31.216.36.169:8080/exist/rest/db/lrf/work/mhs/facts/A10-8-Kontroll-av-dra-node-id-A10-8-2015-04-16-0200.xml"/>
</db:article>
The fact that oXygen will automatically expand XIncludes makes this approach
even more useful:
Figure 8: matched-res-a10-8.jpg
If the matching fact needs to be edited, the author only has to click on the
XInclude link to open the file.
Checklist Publishing
The checklists control the process. Every time a checklist collection is
approved and copied into the publishing chain, the process (an XQuery
transformation run as an oXygen action) walks through the checklist groups and
questions in every linked checklist module, comparing each @node-id
value against @node-ids in fact XML files. When a matching file is
found, it is copied to export/facts. Any facts that do not
match a group or a question are left alone.
When a checklist module has been checked, it is also copied to the publishing
chain, and the process moves on to the next module, until there are no more
modules to check. Finally, the root checklist file (basically a DocBook file
containing XInclude links) is copied to the publishing chain.
Writing Standard Texts
As mentioned before, standard texts are auxiliary files related
to the checklists and facts but not dependent on them. They include appendices,
introductory texts, etc.
There is also a root file that binds the document parts together using
XInclude links. As the checklists and their associated facts are governed by
regulatory requirements, they are not linked into the root directly, but instead
inserted automatically by the publishing process when outputting PDF, beyond the
author's control. Thus, the author is only able to add, remove, and change the
order of the standard texts in the root XML.
Users, Selections and Profiling
The user registration information (name, address, telephone, email, etc) is
created and maintained in the SQL database, as is any information concerning their
respective operations. These include two somewhat generic areas with information on
the farm and the work environment, but also two more specific operational areas,
livestock and crop. All four are grouped in far more detail, however, and many of
them are interrelated across the operational areas. For example, a small farm with
only a few hens will have fewer regulatory requirements on the farm and the work
environment than a large, 400-cow plant. There are also geographical dependencies,
with some farms situated near protected water bodies and groundwater stocks and
therefore falling under other regulatory requirements.
The many relationships between the operational areas, the user information and the
user checklist answers was deemed to require a relational database, even in the new
system.
If left unfiltered, the sheer number of checklist questions (MHS alone contains
around 650 of them) has caused many members to shy away from the checklists and
understandably so. For this reason, the new system adds profiling capabilities when
authoring checklists.
The idea is as simple as it is common. A group or question is profiled using one
or more labels that describe when the group or question is applicable. Profile
values might include >400-hens or a county name, stating that the
question is only applicable if the member has more than 400 hens or operates in the
specified county. In the XML, the profiles are whitespace-separated attribute
values:
These questions, of course, become part of the total checklist that is exported to
the SQL database and used as the online checklist web form:
Figure 9: Checklist Questions on the Web
The profiles for each question are tracked by the SQL database, but additionally,
the SQL database also defines relations between separate
profiles. The >400-hens value, for example, might relate to a
question regarding the farm's size and facilities, meaning that answering
yes to the question about the number of hens being more than 400
might automatically cause other questions to be included and yet others to be
excluded. In any case, the member is directed only to relevant questions.
The profile values are created and edited in the SQL database[10], but converted to XML and exported to
system/common/profiles/xml/profiles.xml in eXist when
needed. This file is simply a list of profile values:
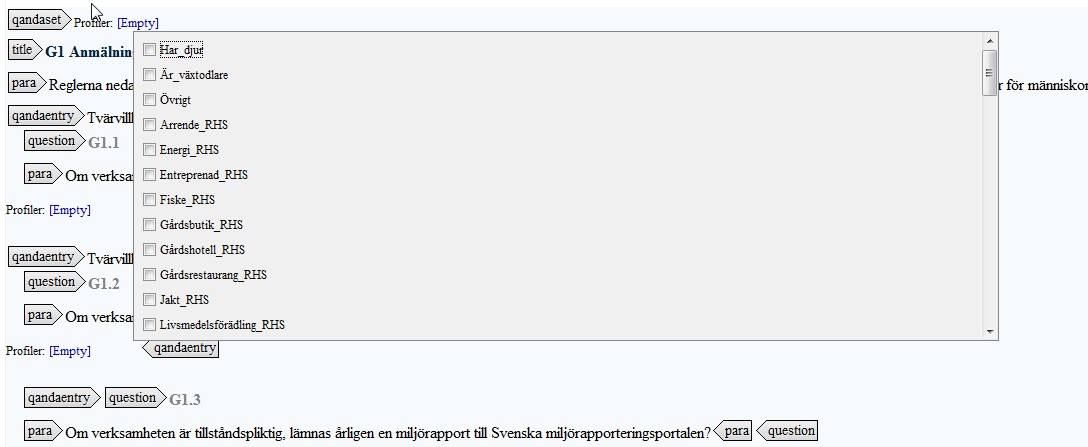
This file is then read by the Profiles pop-up dialog in
oXygen, used by the author to edit the profiles of a group or question:
Figure 10: Profiles Pop-up Dialog in oXygen
Here, the author selects any profile values that apply to the group or question.
If it is about beekeeping, for example, the author might probably want to check the
beekeeping profile value, as well as any physical locations that
are applicable.
The pop-up is implemented using oXygen's proprietary CSS extensions, making adding
a simple dialog such as this easy, using only a few lines:
The values property does most of the job fetching the profiles and
edit defines the attribute (@profiles).
System Collection Layout
The system collection layout reflects the same philosophy
that is used for the contents as described in the previous sections:
Figure 11: The System Layout
Here, the organisation is based on the differences between the regulatory
checklist branches, using a common collection for shared
resources and dividing the rest into branch-specific parts. Currently, the
mhs branch is more complex, with more than double the
amount of data than rhs and including PDF publishing in
addition to the web.
This might change but if so, this layout makes it easy to implement the change. It
is also easy to add a branch, something that is being discussed.
Schemas
The eXist/oXygen system uses a number of schemas, two of which deserve mentioning
here.
LRF-Pub
The old, XProc-based system (id-xmlprague2013-exist) started life as a PDF on demand
publishing system for the web-based checklists that were then fed from the SQL
database handling all content. The content was only to be exported to the PDF on
demand system when publishing a PDF. Therefore, the first schema made was a
Relax NG schema designed specifically to be used to generate the PDF checklist
document. It was unsuitable for actual authoring, since it included loose
content models and constructions designed to handle XML export data form the SQL
database.
So, when the requirements changed to include authoring, we needed to either
redo the publishing schema (and customise an editor) or add another specifically
for authoring. Enter DocBook 5.
LRFBook
The contents in the work area are written using a DocBook 5 variant called
LRFBook that excludes a lot of unneeded structures
(especially those used for technical content), and adds a few LRF-specific
attributes. The schema, done in Relax NG Compact Syntax, is close enough to
DocBook to be able to use oXygen's DocBook 5 customisation almost out of the
box, with only a few additions to help authors manage the LRF-specific
features.
Exports, Imports and Publishing
Every night, the server initiates an integration process, a
synchronisation of contents between the SQL database on one hand and the eXist database
on the other. It also starts a complete PDF output process for uid0 in eXist, converting
current export contents to pub and onwards to
a finished PDF, and to html.
The new total checklists for mhs and rhs are
then fetched by the SQL database from eXist, including not only edited question contents
but possibly also new profiles for them, causing the web contents to be updated and
the
selection process in the checklists to be refined.
User-specific checklists that include their comments and due dates, on the other hand,
are only produced on demand. in that case, the SQL database converts the user data
to
raw XML and exports it to eXist, then initiating the publishing chain for that user
only. Eventually, a link to the new PDF is returned by eXist, obfuscated by the server
and included in an email to the user.
The SQL database also includes search functionality for the web service, the Wordpress
contents, and eXist's HTML content. The latter is implemented as an http request to
an
XQuery that then returns the document URI and copies of every matching node. The latter
are presented as fragments in the search results.
When needed, the SQL database exports a new profiles XML file to eXist, instantly
updating the allowed profile values when editing checklists in oXygen.
Versioning and Rollbacks
None of the XML content is currently versioned in any way. While it has always
been an option to enable eXist's versioning module and to add similar content
management to the SQL database, so far the customer has been unwilling to pay for
that particular feature.
This does not mean that there is no way to go back to an earlier stage if
something goes wrong. eXist is backed up nightly, and the backups for the last week
(and, further back, once every month) are stored in case errors manage to find their
way to the published content. In that case, rollbacks will always be made to
work rather than the publishing chain and then republished,
as this ensures that the checklists will always be associated with the correct
facts.
Nevertheless it is usually easier and faster to fix the problem in oXygen and then
republish, as the backup is handled by developers rather than the writers; to date,
a rollback of one or more documents since the old system went live has happened on
a
handful of occasions, and once when the server itself failed. Nothing of the kind
has yet happened with the new version.
End Notes
The system went live in late April, around the Balisage paper submission deadline,
but
before that, we also had a test system running for several weeks, both with system
testers and real-life users, and can present some conclusions.
First of all, the end users find the system to be much faster than its predecessor,
and based on the rather small number of bug reports, the system is also more
reliable.
The improved reliability is confirmed by the writers, who can now publish checklists
and their associated facts with ease, knowing that the question/fact pairs will always
match.
For me as a developer, the oXygen/eXist-DB combo works like a charm. It's fast, it's
stable, and even though I'm a markup geek and don't know a thing about Java, writing
the
various functions for the conversions, linkbase queries, editor customisation, etc,
has
been a joy—most of them were written in XQuery and XSLT—and I only had to ask for
a
single JAR from the developers who were busy writing the SQL database and Wordpress
parts.
Also, while moving away from XProc was a disappointment for me, redoing the pipelines
in XQuery made a huge difference in terms of performance and reliability; the XProc
implementation was on the server filesystem rather than eXist itself, using James
Sulak's eXist XProc library (id-eXist-sulak) to send XML back and forth between eXist and the file
system, because XProc in eXist then (December 2012) was basically broken[11]. When preparing to upgrade the old system, I really wanted to move those
XProc pipelines into eXist, as a new Calabash XProc module for eXist was made available
about a year ago. My tests quickly proved it to be unreliable, unfortunately. It used
an
embedded old version of the Calabash JAR which caused some problems, but there were
also
limitations to what it could do. And, worst of all, it was mostly undocumented. The
state of XProc in eXist remains a sad affair.
Also, a couple of other points:
Yes, I know it is possible to handle the profiling functionality directly in
eXist rather than in the SQL database, including the relations between them. I
did consider implementing profiling in the linkbase, but this would have taken
more time while not adding enough; profiles are edited only rarely.
There are currently no arcs in the linkbase. There should have been; using
arcs rather than @node-id matching would be cool.
Last but not least, I would like to extend a heartfelt thank you to my colleagues
at
Condesign, but also to LRF who graciously agreed to let me write and submit this
paper.
[3] Because of limitations in the then-current eXist implementations of XProc and
Calabash.
[4] A relational database was seen as better suited for the kind of tasks that
relate user-specific metadata to checklist answers, limiting the relevant
questions from 600+ to less than a hundred.
[5] This file is fetched nightly by the SQL database and published on
the website, ensuring that the latest available checklists are
always used. The pub-checklists-uid0.xml file will frequently
contain updated or new questions that are identified using new node
IDs (see section “Node IDs”). The SQL database uses these to
pair questions with facts during the member registration and
checklist fill processes.
[6] The updates handle eXist-specific addressing and the XLink-based
cross-references used when authoring contents.
[7] This is actually not entirely necessary since every specific type of
information uses its own collection, making it easy to identify the
type. Using a dedicated attribute makes it easier to index the linkbase
in eXist, however.
[8] A solution we considered was to use extended XLink arcs in the
linkbase to define these relations, rather than creating explicit
relationships using the @node-id values. This might still
happen, but the current solution was faster to implement in the existing
XSLT from the XProc-based solution.
[9] A fact might be used by more than one question, which makes it more
practical to list the matches in a single XML document, as XInclude
links. It is also far easier to do for a non-programmer like yours
truly.
[10] We did consider allowing the author to edit the profiles in oXygen and
exporting that to SQL, but as the values are not edited often, an easier and
faster solution was to keep profiling in the SQL database for now.
[11] The XQuery-based xprocxq did not support enough of the
spec, and neither did the XML Calabash module; besides, it
was mostly broken with newer Calabash versions.