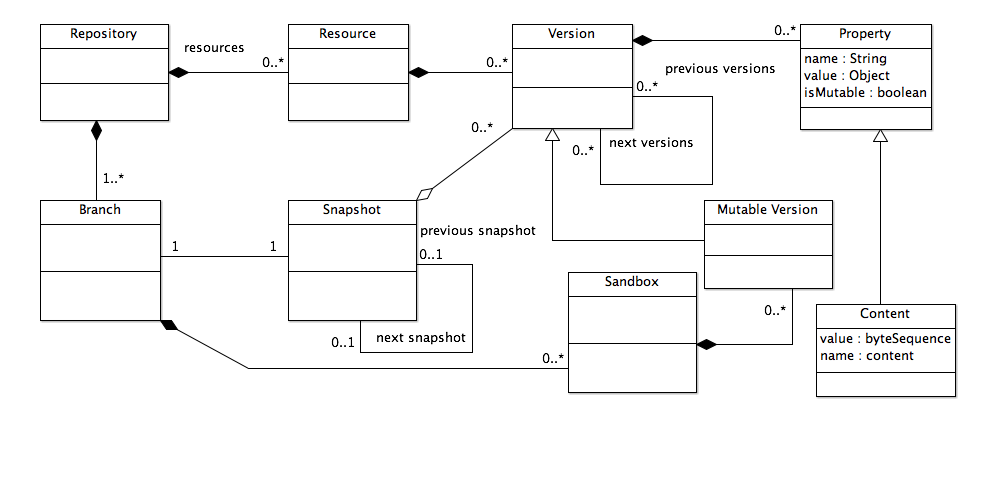
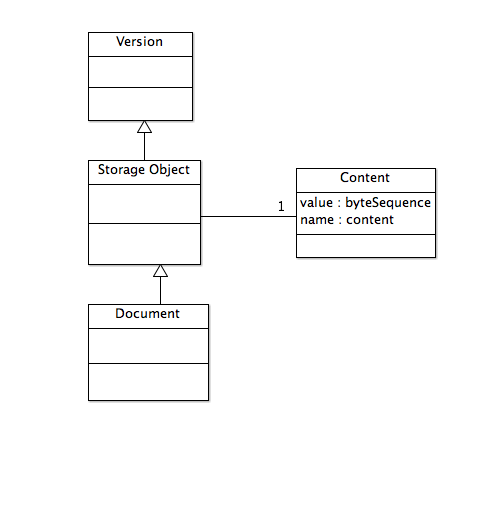
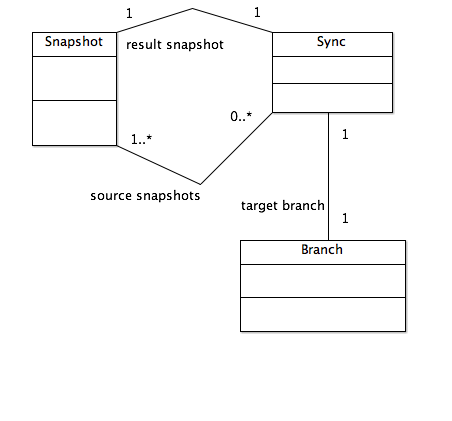
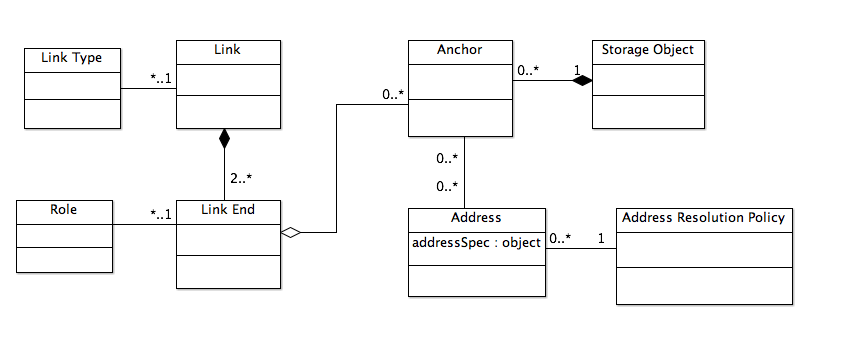
Link management, and more generally, hyperdocument management, is fundamentally about
managing dependencies among the objects that contribute directly to something that
gets published—a book, a Web site, etc.—in the context of development and publishing
business processes. Linking involves addressing and thus the resolution of addresses
to objects. The implication of "hyperdocument" is that two or more things link among
themselves. This presents a general address management challenge in the face of changes
to the components involved. If the components are re-used within a single hyperdocument
or among distinct hyperdocuments, additional challenges in address management appear.
Of all the current XML-based standards for document repesentation: DocBook, JATS,
TEI, S1000D, and DITA, only DITA defines the modularity, use-by-reference, and indirect
addressing facilities that both expose the challenges inherent in the management of
hyperdocument source and demand practical solutions to these management challenges.
This paper first describes the general hyperdocument management challenges inherent
in hyperdocuments that involve reuse, as revealed by the modularity re-use patterns
DITA provides. It then describes an abstract version management model that provides
a general solution for versioned hyperdocument management. Finally, it describes an
open-source implementation of this abstract model that provides the version and link
management features required by authors of DITA documents in order to practically
author, manage, and publish complex DITA-based publications to multiple deliverable
types reflecting multiple conditional configurations of the same source content.
Hyperdocument Management Challenges
When the document being authored is a single XML document or a relatively small set
of XML documents that link only among themselves and use relatively robust addresses
then managing the links and addresses is not too hard: once a given link is authored
it is unlikely to break unless the details of the target change (it is deleted, its
identifier is changed for some reason, or it is moved to a new context that requires
a new address).
However, if the document source is organized into objects that can be re-used in different
documents (by which we really mean different publications) things get much more interesting.
This reuse can occur in any of three ways:
-
Two distinct publications both use (include) the same component.
-
A single publication uses the same component in two or more places, either two uses
of the same version in time (e.g., a common subtask used from two or more different
parent tasks) or two different versions in time of the same resource. For example,
you might have a topic for Release 2 of a product that needs to have a link to the
same topic for Release 1 of the product for some reason. The link is to the same logical
object but to a different version in time of it.
As soon as you have reuse you have multiple use contexts for a single content object and the linking and addressing details for those different
contexts may need to be different.
When a given resource is used two or more times within the same publication it establishes
distinct use contexts for that resource. This then requires that references to the
resource be to the appropriate use of the resource: a specific use, all the uses,
or none of the uses.
When a given resource is used two or more times in different publications (different
hyperdocuments), it again establishes distinct use contexts and presents the same
choice: a specific use (within the context of a specific publication) or uses, all
uses, or no uses.
When a given resource that has links to other resources is used in two or more contexts,
it is necessary to be able to establish, for each distinct use of the resource, what
the links from that resource should resolve to in each of the linking resource's uses.
For example, a topic that links to the "installation" topic probably needs to link
to the different installation topics in each of the different publications the linking
topic is used in. However, a topic that links to the installation topic for a specific
product probably needs to link to that topic in the context of the publication for
that product regardless of what other publications the linking topic is used in.
Note too that the organization of publications for the same set of resouces may vary
based on the deliverable type or delivery context. For example, the same topics might
be published as per-product publications for print purposes but published as per-application
or per-product-component publications for Web delivery. The deliverable-specific linking
and addressing details will be very different for these different deliverables but
the links as authored need to be invariant (meaning they do not, themselves, reflect
any particular deliverable-specific details, as the deliverable details could change
at any time as different delivery targets and publication organizations are developed).
Any content with links directly authored in anticipation of a specific delivery target
or publication organization scheme is broken as soon as it is authored because we
know that the delivery targets and organization schemes will change over time.
The following example illustrates these general challenges through use of the DITA
architecture. DITA provides a robust set of linking and reuse features that when used
together can create all of the potential problems that one might face in any hyperdocument
system.
DITA defines two types of document: maps and topics.
Topics are the atomic unit of content in DITA. Topics contain documentation content
(e.g., paragraphs, lists, figures, etc.).
The DITA architecture only allows topic elements and map elements as the root elements
of documents (ignoring the ditabase element type, which is primarily a convenience
for legacy data conversion).
Topics can contain two basic types of link: use-by-reference links ("content references"
or "conrefs" in DITA parlance) or navigation links (cross references, related information
links, etc.).
Use-by-reference links establish the effective markup structure of a topic or map,
with the implication that use-by-reference links are resolved and then final deliverable
generation processing is applied to the resolved result.
Navigation links are intended to result in actionable links in deliverables. However,
the processing and presentation details of these links are up to processors to determine.
The only invariant in DITA is the meaning of the addresses used: two conforming DITA
processors, presented with the same source documents and the same filtering condition
sets, should resolve all the addresses to the same targets (at least for those targets
that are DITA elements).
Maps are collections of links to topics, other maps, or non-DITA resources (anything
that is not itself a DITA map or DITA topic). The links within maps are called "topic
references" or "topicrefs" for short. Within a map topicrefs can be organized into
sets, sequences, or hierarchies or into sets of n-ary links ("relationship tables")
analogous to XLink extended links.
Starting with a given map (the "root map"), DITA defines rules for constructing the
"effective map" using any maps referenced directly or indirectily from the root map.
The result of this process is a single map with a single set of topicrefs and relationship
tables. Conceptually, maps serve primarily to impose some sort of navigation structure
onto topics (the topicrefs outside of relationship tables) and/or to impose some set
of arbitrary set of topic-to-topic links. However, the DITA architecture does not
require any particular interpretation of maps: fundamentally they are just bags of
links: the semantics you apply to those links is up to you.
DITA defines two forms of address that links may use:
-
Direct URI references (@href, @conref). For references to elements within DITA topics,
DITA defines the fragment identifier "topicid/elementID". The topicid component can be ".", meaning "this topic". For topic elements and elements within
maps, the fragment identifier is just the ID of the element. Within topic documents,
topic elements must have @id attribute values that are unique within the entire XML
document (they are of type ID), while the IDs of elements within topics must be unique
only within the scope of the topic that directly contains them. Thus, each topic defines
a separate ID namespace for the elements it contains.
-
Key references, where keys are defined in DITA maps using topicref elements to bind
key names to resources in the context of the map that contains the key definitions.
A reference to a key is a reference to the resource ultimately addressed by the key
definition. One key definition may point to another key, creating multiple levels
of indirection.
A simple DITA map looks like this:
map-01.ditamap:
<map>
<title>Map 01</title>
<topicref href="topic-01.dita">
<topicref href="topic-01-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Within this map there are three links (the three <topicref> elements), each using
a direct URI reference to a topic.
A simple topic looks like this:
topic-01.dita:
<topic id="topic_01">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02: <xref
href="topic-01-02.dita"/></p>
</body>
</topic>
This topic contains one link, a cross reference (<xref>) using a direct URI reference
to another topic. Per the DITA standard, a reference to an XML document containing
a topic is implicitly a reference to the root (or first) topic within that document.
So this link is to the <topic> element that is the root of the XML document "topic-01-02.dita".
Even in this simple system of two documents there are already some potential problems:
-
The link from topic-01.dita to topic-01-02.dita does not, by itself establish any
use context: if topic-01.dita is processed in isolation, what is the output implication
for the link? That is, what should the deliverable-specific projection of the link
be? Specifically, where (if at all) will topic-01-02.dita be published?
-
When topic-01.dita is processed in the context of the map, you can reasonably assume
that topic-01-02.dita is available (because it's also referenced from the map) and
therefore can implement some reliable business rules about what the deliverable address
of each topic will be. However, the address is not, by itself, to a specific use of
topic-01-02.dita. It just happens that the topic is only used once in this map, so
there's only one context it could be in, this time.
There are two possible reuse cases for topics used from maps:
-
The same topic is used two or more times within the same map. For example, a common
subtask used by many different main procedures
-
The same topic is used in two different root maps. For example, a task that is the
same for two different products or a glossary entry used in two different textbooks.
Case (1) is:
<map>
<title>Map 01</title>
<topicref href="topic-01.dita">
<topicref href="topic-01-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
<topicref href="topic-02.dita">
<topicref href="topic-02-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Here topic-01-02.dita is used twice in the map. Now there is an ambiguity for the
reference to "topic-01-02.dita" from topic-01.dita: What is the presentation result?
In a monolithic output like PDF or EPUB, topic-01-02.dita will be reflected twice
in the deliverable: which of those reflections should the link from topic-01.dita
go to? The first? The "nearest"? Both? Neither, it's an error condition? What was
the author's intent? It is impossible to tell from the information in the link alone,
because the address does not provide any use context: it's a direct URI reference
to the topic outside of any context.
Case (2) results from adding a new map, map-02.ditamap:
map-02.ditamap:
<map>
<title>Map 02</title>
<topicref href="topic-03.dita">
<topicref href="topic-03-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Now topic-01-02.dita is used in two maps. From the standpoint of topic-01's link to
topic topoic-01-02.dita, the context ambiguity is even greater: does the author intend
this link to be to the topic as published in the context of map-01 or map-02? With
a direct URL link there's no way to know: there is no use context information in the
URL.
Based on these examples it should be clear that direct URI references (or any equivalent
form of direct topic-to-topic address) will not work in the face of either of these
two reuse cases: without use context information as part of the address there is ambiguity
about how to resolve the link for a particular deliverable produced from a particular
topic or map. The ambiguity could be resolved by a given processor by making some
arbitrary choice in the face a specific ambiguity, but that is necessarily processor-specific.
And in any case, certain use cases are simply not provided for, in particular, distinguishing
the author's intent to link to the topic in the context of the same map or a different
map. That is, there is no general solution that can resolve the ambiguity in a way that both satisfies all possible
reasonable desired results and enables full author control over their intent for a
given link in a given use context.
One possible option would be to address a topicref instead of the topic, e.g., by
putting an ID on the topicref and then referencing that:
map-02.ditamap:
<map>
<title>Map 02</title>
<topicref href="topic-03.dita">
<topicref href="topic-03-01.dita"/>
<topicref id="tr-01" href="topic-01-02.dita"/>
</topicref>
</map>
topic-01.dita:
<topic id="topic_rxk_4pl_sr">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02 as used in map-02.dita:
<xref href="map-02.dita#tr-01"/></p>
</body>
</topic>Now the link is unambiguously to the topicref in map-02, establishing the use context.
But there is still a problem with re-use: what if you want to link to a different
use of topic-01-02 (or a completely different topic) when topic-01 is itself reused
in a different context? With the direct URI reference there is only one option: the
link points only to map 02.
So direct URI references to topicrefs only partially solve the problem.
Clearly, some form of indirection is required.
DITA's key and keyref facility provides the necessary indirection.
All of the preceding use cases can be resolved through the use of keys.
In each map a unique (within the map) key is added to each topicref. For links to
topics as used in other root maps, the target root map is linked using a topicref
with a scope of "peer" and a key scope name applied. The @scope value of "peer" signals
that the target map is to be treated as a separate root map and references to keys
in the attached scope are to be resolved in the context of the target map.
Adding keys, the maps become:
map-01.ditamap:
<map>
<title>Map 01</title>
<topicref keys="key-01" href="topic-01.dita">
<topicref keys="key-02" href="topic-01-01.dita"/>
<topicref keys="key-03" href="topic-01-02.dita"/>
</topicref>
<topicref keys="key-04" href="topic-02.dita">
<topicref keys="key-05" href="topic-02-01.dita"/>
<topicref keys="key-06" href="topic-01-02.dita"/>
</topicref>
</map>
map-02.ditamap:
<map>
<title>Map 02</title>
<topicref keys="key-01" href="topic-03.dita">
<topicref keys="key-02" href="topic-03-01.dita"/>
<topicref keys="key-03" href="topic-01-02.dita"/>
</topicref>
</map>
Note that topic-01-02.dita has been bound to the key "key-03" in both maps and also
to the key "key-06" in map 01. The two keys in map 01 serve to distinguish the two
use contexts for topic-01-02.dita and enable unambiguous references to one or the
other (or both).
Within the topics, the direct URI references are replaced with references to the appropriate
keys:
topic-01.dita:
<topic id="topic_rxk_4pl_sr">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02: <xref
keyref="key-03"/></p>
</body>
</topic>
With use of keys the processing of topic-01.dita in the context of map-01.ditamap
is unambiguous: the reference to key "key-03" is bound, in map 01, to the first use
of the topic and not the second. In addition, because the key is bound in the context
of the map that uses topic-01.dita, the link is explicitly not to any other use of
topic-01-02.dita in other maps.
If map-02.ditamap decides to also use topic-01.dita the reference to key "key-03"
in the context of map-02 will resolve to that map's use of topic-01-02.dita.
If a new map, map-03.ditamap, is created that uses topic-01.dita, that map must also
provide a binding for the key name "key-03" in order to satisfy the requirement topic-01.dita
has established by reference to the key.
The author of map-03.ditamap has three choices for how to bind the key:
-
Bind it to a topic used by the map (either topic-01-02.dita or a different topic,
as appropriate for the publication map-03 represents)
-
Bind it to a topic as used by a different root map
-
Bind it to a "null key definition", effectively turning off the link. A key definition
that does not address any resource or have any subelements that could be used as the
effective value of the linking element "turns off" the link.
The author of map-03.ditamap decides to bind key name "key-03" to the use of topic-01-02
in map-01.ditamap. They do this by establishing a peer-map relationship to map-01.ditamap
and then binding the key "key-03" to the appropriate key definition in map-01.ditamap:
map-03.ditamap:
<map>
<title>Map 03</title>
<topicref keyscope="map-01"
scope="peer"
href="map-01.ditamap"
format="ditamap"
/>
<topicref keys="key-03"
keyref="map-01.key-03"/>
<topicref keys="key-01" href="topic-01.dita">
...
</topicref>
</map>
The first topicref establishes map-01.ditamap as a "peer" to map-03.ditamap, meaning
that map-01.ditamap is treated as a separate root map with its own key definitions.
The topicref sets the key scope name "map-01" on this reference. With this scope name,
all scope-qualified key references will be resolved from the set of keys defined by
map-01.ditamap processed as root map.
The second topicref redirects the unqualified key name "key-03" to the scope-qualified
key name "map-01.key-03", which is then resolved in the context of map-01.ditamap,
which ultimately addresses the first use of topic-01-02.dita.
Note that because keys are defined in maps and because of DITA's top-down key-definition
precedence rules, map authors have complete control over the effective bindings of
all the keys referenced from any maps or topics used by a given root map.