Introduction
Link management, and more generally, hyperdocument management, is fundamentally about managing dependencies among the objects that contribute directly to something that gets published—a book, a Web site, etc.—in the context of development and publishing business processes. Linking involves addressing and thus the resolution of addresses to objects. The implication of "hyperdocument" is that two or more things link among themselves. This presents a general address management challenge in the face of changes to the components involved. If the components are re-used within a single hyperdocument or among distinct hyperdocuments, additional challenges in address management appear.
Of all the current XML-based standards for document repesentation: DocBook, JATS, TEI, S1000D, and DITA, only DITA defines the modularity, use-by-reference, and indirect addressing facilities that both expose the challenges inherent in the management of hyperdocument source and demand practical solutions to these management challenges.
This paper first describes the general hyperdocument management challenges inherent in hyperdocuments that involve reuse, as revealed by the modularity re-use patterns DITA provides. It then describes an abstract version management model that provides a general solution for versioned hyperdocument management. Finally, it describes an open-source implementation of this abstract model that provides the version and link management features required by authors of DITA documents in order to practically author, manage, and publish complex DITA-based publications to multiple deliverable types reflecting multiple conditional configurations of the same source content.
Hyperdocument Management Challenges
When the document being authored is a single XML document or a relatively small set of XML documents that link only among themselves and use relatively robust addresses then managing the links and addresses is not too hard: once a given link is authored it is unlikely to break unless the details of the target change (it is deleted, its identifier is changed for some reason, or it is moved to a new context that requires a new address).
However, if the document source is organized into objects that can be re-used in different documents (by which we really mean different publications) things get much more interesting.
This reuse can occur in any of three ways:
-
Two distinct publications both use (include) the same component.
-
A single publication uses the same component in two or more places, either two uses of the same version in time (e.g., a common subtask used from two or more different parent tasks) or two different versions in time of the same resource. For example, you might have a topic for Release 2 of a product that needs to have a link to the same topic for Release 1 of the product for some reason. The link is to the same logical object but to a different version in time of it.
As soon as you have reuse you have multiple use contexts for a single content object and the linking and addressing details for those different contexts may need to be different.
When a given resource is used two or more times within the same publication it establishes distinct use contexts for that resource. This then requires that references to the resource be to the appropriate use of the resource: a specific use, all the uses, or none of the uses.
When a given resource is used two or more times in different publications (different hyperdocuments), it again establishes distinct use contexts and presents the same choice: a specific use (within the context of a specific publication) or uses, all uses, or no uses.
When a given resource that has links to other resources is used in two or more contexts, it is necessary to be able to establish, for each distinct use of the resource, what the links from that resource should resolve to in each of the linking resource's uses. For example, a topic that links to the "installation" topic probably needs to link to the different installation topics in each of the different publications the linking topic is used in. However, a topic that links to the installation topic for a specific product probably needs to link to that topic in the context of the publication for that product regardless of what other publications the linking topic is used in.
Note too that the organization of publications for the same set of resouces may vary based on the deliverable type or delivery context. For example, the same topics might be published as per-product publications for print purposes but published as per-application or per-product-component publications for Web delivery. The deliverable-specific linking and addressing details will be very different for these different deliverables but the links as authored need to be invariant (meaning they do not, themselves, reflect any particular deliverable-specific details, as the deliverable details could change at any time as different delivery targets and publication organizations are developed). Any content with links directly authored in anticipation of a specific delivery target or publication organization scheme is broken as soon as it is authored because we know that the delivery targets and organization schemes will change over time.
The following example illustrates these general challenges through use of the DITA architecture. DITA provides a robust set of linking and reuse features that when used together can create all of the potential problems that one might face in any hyperdocument system.
DITA defines two types of document: maps and topics.
Topics are the atomic unit of content in DITA. Topics contain documentation content (e.g., paragraphs, lists, figures, etc.).
The DITA architecture only allows topic elements and map elements as the root elements of documents (ignoring the ditabase element type, which is primarily a convenience for legacy data conversion).
Topics can contain two basic types of link: use-by-reference links ("content references" or "conrefs" in DITA parlance) or navigation links (cross references, related information links, etc.).
Use-by-reference links establish the effective markup structure of a topic or map, with the implication that use-by-reference links are resolved and then final deliverable generation processing is applied to the resolved result.
Navigation links are intended to result in actionable links in deliverables. However, the processing and presentation details of these links are up to processors to determine. The only invariant in DITA is the meaning of the addresses used: two conforming DITA processors, presented with the same source documents and the same filtering condition sets, should resolve all the addresses to the same targets (at least for those targets that are DITA elements).
Maps are collections of links to topics, other maps, or non-DITA resources (anything that is not itself a DITA map or DITA topic). The links within maps are called "topic references" or "topicrefs" for short. Within a map topicrefs can be organized into sets, sequences, or hierarchies or into sets of n-ary links ("relationship tables") analogous to XLink extended links.
Starting with a given map (the "root map"), DITA defines rules for constructing the "effective map" using any maps referenced directly or indirectily from the root map. The result of this process is a single map with a single set of topicrefs and relationship tables. Conceptually, maps serve primarily to impose some sort of navigation structure onto topics (the topicrefs outside of relationship tables) and/or to impose some set of arbitrary set of topic-to-topic links. However, the DITA architecture does not require any particular interpretation of maps: fundamentally they are just bags of links: the semantics you apply to those links is up to you.
DITA defines two forms of address that links may use:
-
Direct URI references (@href, @conref). For references to elements within DITA topics, DITA defines the fragment identifier "topicid/elementID". The topicid component can be ".", meaning "this topic". For topic elements and elements within maps, the fragment identifier is just the ID of the element. Within topic documents, topic elements must have @id attribute values that are unique within the entire XML document (they are of type ID), while the IDs of elements within topics must be unique only within the scope of the topic that directly contains them. Thus, each topic defines a separate ID namespace for the elements it contains.
-
Key references, where keys are defined in DITA maps using topicref elements to bind key names to resources in the context of the map that contains the key definitions. A reference to a key is a reference to the resource ultimately addressed by the key definition. One key definition may point to another key, creating multiple levels of indirection.
A simple DITA map looks like this:
map-01.ditamap:
<map>
<title>Map 01</title>
<topicref href="topic-01.dita">
<topicref href="topic-01-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Within this map there are three links (the three <topicref> elements), each using a direct URI reference to a topic.
A simple topic looks like this:
topic-01.dita:
<topic id="topic_01">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02: <xref
href="topic-01-02.dita"/></p>
</body>
</topic>
This topic contains one link, a cross reference (<xref>) using a direct URI reference to another topic. Per the DITA standard, a reference to an XML document containing a topic is implicitly a reference to the root (or first) topic within that document. So this link is to the <topic> element that is the root of the XML document "topic-01-02.dita".
Even in this simple system of two documents there are already some potential problems:
-
The link from topic-01.dita to topic-01-02.dita does not, by itself establish any use context: if topic-01.dita is processed in isolation, what is the output implication for the link? That is, what should the deliverable-specific projection of the link be? Specifically, where (if at all) will topic-01-02.dita be published?
-
When topic-01.dita is processed in the context of the map, you can reasonably assume that topic-01-02.dita is available (because it's also referenced from the map) and therefore can implement some reliable business rules about what the deliverable address of each topic will be. However, the address is not, by itself, to a specific use of topic-01-02.dita. It just happens that the topic is only used once in this map, so there's only one context it could be in, this time.
There are two possible reuse cases for topics used from maps:
-
The same topic is used two or more times within the same map. For example, a common subtask used by many different main procedures[1]
-
The same topic is used in two different root maps. For example, a task that is the same for two different products or a glossary entry used in two different textbooks.
Case (1) is:
<map>
<title>Map 01</title>
<topicref href="topic-01.dita">
<topicref href="topic-01-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
<topicref href="topic-02.dita">
<topicref href="topic-02-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Here topic-01-02.dita is used twice in the map. Now there is an ambiguity for the reference to "topic-01-02.dita" from topic-01.dita: What is the presentation result? In a monolithic output like PDF or EPUB, topic-01-02.dita will be reflected twice in the deliverable: which of those reflections should the link from topic-01.dita go to? The first? The "nearest"? Both? Neither, it's an error condition? What was the author's intent? It is impossible to tell from the information in the link alone, because the address does not provide any use context: it's a direct URI reference to the topic outside of any context.
Case (2) results from adding a new map, map-02.ditamap:
map-02.ditamap:
<map>
<title>Map 02</title>
<topicref href="topic-03.dita">
<topicref href="topic-03-01.dita"/>
<topicref href="topic-01-02.dita"/>
</topicref>
</map>
Now topic-01-02.dita is used in two maps. From the standpoint of topic-01's link to topic topoic-01-02.dita, the context ambiguity is even greater: does the author intend this link to be to the topic as published in the context of map-01 or map-02? With a direct URL link there's no way to know: there is no use context information in the URL.
Based on these examples it should be clear that direct URI references (or any equivalent form of direct topic-to-topic address) will not work in the face of either of these two reuse cases: without use context information as part of the address there is ambiguity about how to resolve the link for a particular deliverable produced from a particular topic or map. The ambiguity could be resolved by a given processor by making some arbitrary choice in the face a specific ambiguity, but that is necessarily processor-specific. And in any case, certain use cases are simply not provided for, in particular, distinguishing the author's intent to link to the topic in the context of the same map or a different map. That is, there is no general solution that can resolve the ambiguity in a way that both satisfies all possible reasonable desired results and enables full author control over their intent for a given link in a given use context.
One possible option would be to address a topicref instead of the topic, e.g., by putting an ID on the topicref and then referencing that:
map-02.ditamap:
<map>
<title>Map 02</title>
<topicref href="topic-03.dita">
<topicref href="topic-03-01.dita"/>
<topicref id="tr-01" href="topic-01-02.dita"/>
</topicref>
</map>
topic-01.dita:
<topic id="topic_rxk_4pl_sr">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02 as used in map-02.dita:
<xref href="map-02.dita#tr-01"/></p>
</body>
</topic>Now the link is unambiguously to the topicref in map-02, establishing the use context.
But there is still a problem with re-use: what if you want to link to a different
use of topic-01-02 (or a completely different topic) when topic-01 is itself reused
in a different context? With the direct URI reference there is only one option: the
link points only to map 02.
So direct URI references to topicrefs only partially solve the problem.
Clearly, some form of indirection is required.
DITA's key and keyref facility provides the necessary indirection.
All of the preceding use cases can be resolved through the use of keys.
In each map a unique (within the map) key is added to each topicref. For links to topics as used in other root maps, the target root map is linked using a topicref with a scope of "peer" and a key scope name applied. The @scope value of "peer" signals that the target map is to be treated as a separate root map and references to keys in the attached scope are to be resolved in the context of the target map.
Adding keys, the maps become:
map-01.ditamap: <map> <title>Map 01</title> <topicref keys="key-01" href="topic-01.dita"> <topicref keys="key-02" href="topic-01-01.dita"/> <topicref keys="key-03" href="topic-01-02.dita"/> </topicref> <topicref keys="key-04" href="topic-02.dita"> <topicref keys="key-05" href="topic-02-01.dita"/> <topicref keys="key-06" href="topic-01-02.dita"/> </topicref> </map> map-02.ditamap: <map> <title>Map 02</title> <topicref keys="key-01" href="topic-03.dita"> <topicref keys="key-02" href="topic-03-01.dita"/> <topicref keys="key-03" href="topic-01-02.dita"/> </topicref> </map>
Note that topic-01-02.dita has been bound to the key "key-03" in both maps and also to the key "key-06" in map 01. The two keys in map 01 serve to distinguish the two use contexts for topic-01-02.dita and enable unambiguous references to one or the other (or both).
Within the topics, the direct URI references are replaced with references to the appropriate keys:
topic-01.dita:
<topic id="topic_rxk_4pl_sr">
<title>Topic 01</title>
<body>
<p>A link to topic 01-02: <xref
keyref="key-03"/></p>
</body>
</topic>
With use of keys the processing of topic-01.dita in the context of map-01.ditamap is unambiguous: the reference to key "key-03" is bound, in map 01, to the first use of the topic and not the second. In addition, because the key is bound in the context of the map that uses topic-01.dita, the link is explicitly not to any other use of topic-01-02.dita in other maps.
If map-02.ditamap decides to also use topic-01.dita the reference to key "key-03" in the context of map-02 will resolve to that map's use of topic-01-02.dita.
If a new map, map-03.ditamap, is created that uses topic-01.dita, that map must also provide a binding for the key name "key-03" in order to satisfy the requirement topic-01.dita has established by reference to the key.
The author of map-03.ditamap has three choices for how to bind the key:
-
Bind it to a topic used by the map (either topic-01-02.dita or a different topic, as appropriate for the publication map-03 represents)
-
Bind it to a topic as used by a different root map
-
Bind it to a "null key definition", effectively turning off the link. A key definition that does not address any resource or have any subelements that could be used as the effective value of the linking element "turns off" the link.
The author of map-03.ditamap decides to bind key name "key-03" to the use of topic-01-02 in map-01.ditamap. They do this by establishing a peer-map relationship to map-01.ditamap and then binding the key "key-03" to the appropriate key definition in map-01.ditamap:
map-03.ditamap:
<map>
<title>Map 03</title>
<topicref keyscope="map-01"
scope="peer"
href="map-01.ditamap"
format="ditamap"
/>
<topicref keys="key-03"
keyref="map-01.key-03"/>
<topicref keys="key-01" href="topic-01.dita">
...
</topicref>
</map>
The first topicref establishes map-01.ditamap as a "peer" to map-03.ditamap, meaning that map-01.ditamap is treated as a separate root map with its own key definitions. The topicref sets the key scope name "map-01" on this reference. With this scope name, all scope-qualified key references will be resolved from the set of keys defined by map-01.ditamap processed as root map.
The second topicref redirects the unqualified key name "key-03" to the scope-qualified key name "map-01.key-03", which is then resolved in the context of map-01.ditamap, which ultimately addresses the first use of topic-01-02.dita.
Note that because keys are defined in maps and because of DITA's top-down key-definition precedence rules, map authors have complete control over the effective bindings of all the keys referenced from any maps or topics used by a given root map.
Basic Hyperlinking Model
This paper uses the following general terminology to describe hyperdocuments and their change over time:[2]
-
document: An object that serves as the source for all or part of a publication, managed as a single storage object, e.g., an XML document.
-
storage object: An atomic unit of storage within some storage system, e.g. a file in a file system or an object in a database. For the purposes of this paper there is always a one-to-one correspondence between XML documents and storage objects. This means that the use of external parsed entities is not allowed. Likewise, the use of XInclude, which is functionally equivalent to external parsed entities, is not allowed.[3]
Note that storage objects are the unit of versioning within version control systems, such as git. That is, if a thing is versioned, it must be a storage object or have a storage object that represents it. For example, if one wanted to track the version history of an individual XML element within an XML document (which is, by definition, a single storage object), one could create a separate storage object, bound to the element (e.g., by an XPath stored within the storage object), for which a new version in time is created every time a new version of the XML document that contains the element is created such that the element itself has changed (not all updates to the XML document will cause a change to the element itself). Another approach would be to put the element in a separate storage object (that is, in another XML document) and use some use-by-reference mechanism from the original XML document to define the effective document (e.g., DITA's content reference facility).
-
link: An object that establishes a relationship among two or more objects. In the context of documents authored and managed primarily as XML documents, the objects of interest are: XML documents, XML nodes (e.g., XML elements, XML text nodes, etc.), and any non-XML thing that can be addressed by the addressing scheme being used (e.g., "resources" in the context of uniform resource identifiers (URIs)). The nature of the objects does not change the semantics of the links (that is, the meanings of the relationships) but does affect the addressing details used to express the relationships in some computer-processible form. To keep things simple, we tend to limit links to pairs of objects, but that limitation is not necessary to this model or to the practical implementation of link management. The DITA architecture provides a construct, relationship tables, the enables the creation of n-ary links.
-
hyperdocument: A document that has links to one or more other documents. The links may be established by any mechanism, including linking constructs embedded within a given document's source content and links imposed by some third party. Given a starting document there is a set of documents determined by recursively following all the link relationships understood to be within the scope of the hyperdocument until either all links have been followed or some processing limit has been reached.
The notion of "scope" distinguishes links to things intended to be part of the hyperdocument (and by implication, included as part of the direct processing used to produce deliverables from the hyperdocument) and links to things that are outside the scope of the hyperdocument, that is, objects considered to be part of another hyperdocument by the hyperdocument making the link. For example, a link from a document to a Web site published by some other organization would be an "out of scope" or "external scope" link. More generally, a distinction must be made, one way or another, between things that are part of "this hyperdocument" and things that are "outside of this hyperdocument". Within the context of a system of related hyperdocuments managed in a coordinated way, there is the further distinction between "this hyperdocument", "that hyperdocument that I can know everything I need to know about it, in particular, the objects within that hyperdocument that I'm allowed to link to and that hyperdocument's publication history (past, present, and future)", and "things that I know existed because they were there the last time I looked but over which I have no control or reliable knowledge of their publishing details". Informally: the hyperdocument I'm authoring, the hyperdocuments my colleagues are authoring, and stuff on the Web.
While a single document may have links to itself and is, technically, a hyperdocument, that case is not interesting by itself because it does not present any particular link management or re-use challenges. That is, a document that links only to itself will always satisfy all of its own dependencies regardless of the revision and publication workflows it goes through (as long as those links are not version-specific).
While a hyperdocument does not necessarily have a natural hierarchy or exclusive root document, because there is a necessary correspondence between documents and publications, in practice there is usually one document that serves as the exclusive root (and therefore identity) of the hyperdocument. In DITA terms, there is always a "root map" that serves as the root document of the publications produced from that map.
A single document may be a member of any number of hyperdocuments.
-
dependency: A relationship between two documents implied by the existence of links from one document to another document (the two documents involved may be the same object). A dependency has a dependency type, where the default type is "depends on". One document depends on another document if the first document has one or more links to the second document. For example, Document A could have 100 links to Document B, but those 100 links can be represented by a single dependency instance. How individual links map to dependency instances is a policy decision.
-
publication: A business object that represents a single unit of publication, e.g. a book, a Web site, an online help set, etc. The implication of being a publication is that the publication goes through its own publishing business process resulting in one or more deliverables for that publication. Being objects, publications have identity that distinguishes any two publications. A publication is produced from one or more documents. As a simplification, this paper assumes that for a given publication there is exactly one document that is the root document of the publication. That is, there is a subset of documents that serve as the sources of publications. Or more formally, for any given document there are zero or more publications produced from that document.
-
deliverable: An artifact produced from a publication intended for consumption by some agent (e.g., a human reader). (While in practice a single deliverable could reflect multiple publications, this model imposes a strict one-to-many correspondence between publications and deliverables. Any multi-publication deliverable can be refactored into a new publication represented by a new document that then uses the documents of the individual publications as subcomponents.)
Using this terminology we can say that authors create and modify documents in order to define publications from which they produce some number of deliverables.
For the purposes of this paper we are concerned specifically with hyperdocuments and the resolution of links to objects in the context of specific configurations (versions) of the hyperdocuments involved.
Storage Objects and Version Management
Version management applies to storage objects. That is, it is ultimately atomic sequences of bytes that get managed as versions in whatever versioning system is used. The details of how this management is implemented are unimportant to this discussion: the only concern is being able to reliably access any version of a given storage object.
A storage object is an object, meaning it has identity within the set of storage objects managed by the storage system that contains it, e.g., an absolute path or inode in a Linux-style file system, an object ID in an object database, or whatever.
Within a version management system there must be a way to refer to all possible versions of a given storage object as well as to specific versions of that storage object.
Abstract Version Management Model
For the purposes of discussing hyperdocument management the following abstract object model applies:
-
Repository: Contains a set of Resources.
-
Resource: Has zero or more Versions.
-
Version: A set of Properties, possibly including a "content" property (sequence of bytes). Properties of a version may be invariant or mutable. The content property of a Version that is not a Mutable Version is always immutable. This means that, once created, the content property of a Version cannot change. (Or, alternatively, there are two subclasses of Content Property, a mutable one and an immutable one.)
A Version has zero or more "previous versions" and zero or more "next versions".
A Version with a content property is a Storage Object. A Storage Object that serves, semantically, as a document in the abstract hyperdocument model is a Document in this model.
-
Property: A name/value pair. A Property is either mutable or immutable.
This model is the minimum model required to model versioning generally but it is not complete as it does not reflect branching or merging.
In addition, as will be made clear elsewhere, hyperdocument management requires the ability to manage sets of related versions as atomically-created units of versioning ("atomic commit of multiple versions") in order to ensure that the hyperdocuments involved can always be in a correct and consistent state as stored in the versioning repository.
To satisfy these requirements, the model adds the types Branch and Snapshot:
-
A Repository has one or more Branches.
-
Branch: A linear sequence of Snapshots, a set of zero or more Sandboxes, and a set of zero or more Properties.
By implication, a Branch reflects zero or more Resources. A Resource may be associated with zero or more Branches.
-
Snapshot: A set of Versions with the constraint that no two Versions have the same Resource. A Snapshot may have zero or more Properties. A Snapshot has zero or one previous Snapshots and zero or one next Snapshots with the constraint that only the first Snapshot on a branch has no previous Snapshots and only the last Snapshot on a branch has no next Snapshots. By implication of the previous/next relationships, a Snapshot has exactly one associated Branch.
Snapshots are invariant. Thus, a Snapshot represents a specific configuration of a set of Resources as reflected by the Versions of those resources directly referenced from the Snapshot.
The creation of a Snapshot is an atomic action, such that any Versions created as a result of creating the Snapshot have identical creation times.
A Version may be referenced by zero or more Snapshots or Sandboxes.
A Snapshot may be created in any of three ways:
-
The repository management system creates a new Snapshot without reference to any existing Snapshots or Sandboxes.
-
A Sandbox is committed, creating a new Snapshot that reflects the state of the Sandbox at the time it is committed. Committing a Sandbox results in the creation of new Versions from any Mutable Versions created in the Sandbox.
-
One or more Snapshots are synced onto a Branch to create a new Snapshot reflecting the result of the sync. The sync operation can be represented by a Sync object that relates one more source Snapshots to the result Snapshot and captures zero or more Properties (e.g., who performed the sync, sync policies applied, etc.). Note that this model only reflects the result of the sync operation. If the Sync involves two or more Snapshots then the Sync represents a merge operation that may require resolving conflicts between two different Versions of the same Resource into either a new Version reflecting the result of a literal merge of the Versions involved or a selection of one Version from among the available Versions. This might require the use of a Sandbox to manage the creation of new Versions.
By default, when two or more of the source Snapshots have different Versions of the same Resource and the Sync results in a new Version of that Resource (rather than a selection of one of the existing Versions) then the new Version will have as its previous versions all of the Versions from the source Snapshots.
-
-
Sandbox: A mutable Snapshot. Like a Snapshot, a Sandbox contains zero or more Versions or Mutable Versions, with the same unique resource constraint. Versions may be added or removed from the Sandbox at any time. A Sandbox may have a source Snapshot from which it was created.
Sandboxes are committed to a Branch in order to create a new Snapshot.
-
Mutable Version: A Version on which some or all of the properties may be changed, including the previous and next versions and the content property (if present).
Figure 1: Base Repository Model
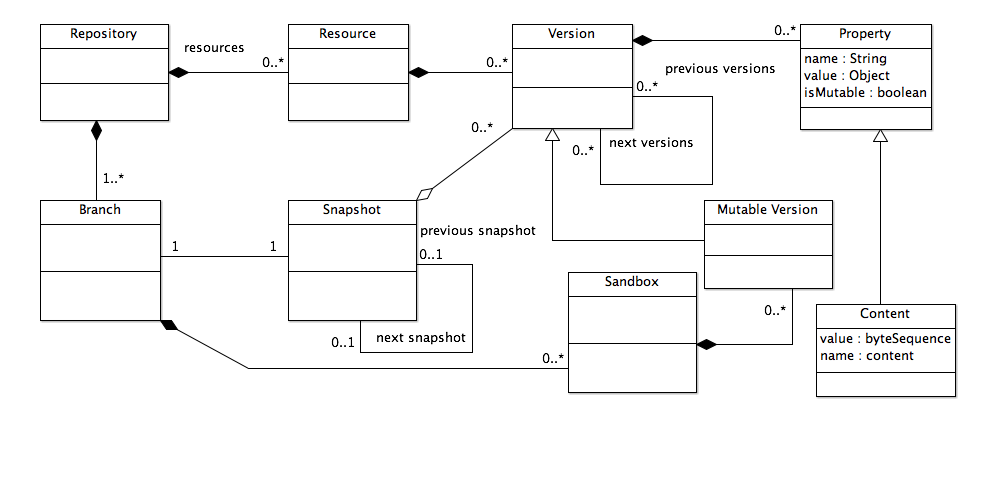
Figure 2: Version Types
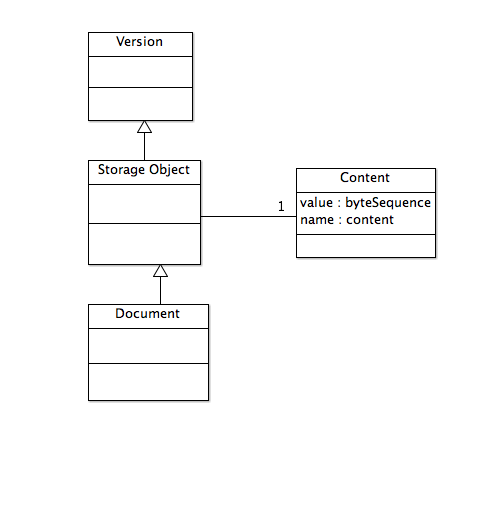
This model does not address the persistence over time of Versions, Branches, and Snapshots. That is, repository management systems could implement this model using write-once media or could allow destruction of Versions, Branches, and Snapshots.
This model does not preclude repository management systems that allow modification of nominally-invariant objects (Snapshots and Versions). For example, a git-based implementation of this model would inherently allow modification of previously-created snapshots and versions because git allows modification of the history of any object as well as pruning of versions within branches. There is nothing wrong in practice with allowing this modification but for the purposes of hyperdocument management it is useful to presume that the system state history persists over time and is thus reliable.
Because this model represents all history as pointers among objects, it is inherently possible to reflect any history desired simply by changing the pointers and objects. So while the model is presumably invariant it is not unalterably invariant. Likewise, because the version details are not dependent on any particular implementation details (diffs, time stamps captured in a particular way, etc.) it means that any desired history can be synthesized at any time by simply creating the objects that reflect the desired repository state. (In particular, it means that any given repository instance could be serialized in some way and reconstituted with complete fidelity as long as object IDs are preserved.)
There are some important implications of this model:
-
The version history of a given Version has a time component (in that every Version has a "created on" time) but the previous/next relationships among Versions are arbitrary and not limited to strict temporal sequence. For example, a new Version could use any existing Version or Versions as its previous or next versions.
-
Given access to a Version it is possible to get to any other Version of the same Resource by following the previous and next links or by going to the Version's Resource and then to any of its Versions. This model does not, by itself, impose any visibility or access control policies. This has important implications for link resolution.
-
Because a Snapshot reflects a set of unique Resources and Versions of those Resources, a Snapshot acts as a view that filters the directly-observable Versions of those Resources.
This allows Snapshots and Branches to act as anchors for access control or link resolution policies. Likewise, because a Branch reflects a finite set of Resources, it can serve to determine which Resources are visible for a given repository access instance. For example, the system could be configured such that a Branch defines explicitly what Resources are allowed to be used on that Branch and thus preclude access, through that Branch, to other Resources in the repository.
Typical access or link resolution policies include:
-
Only versions on snapshot: The user can only access those Versions directly referenced by the Snapshot they are accessing the repository through. The user has access to exactly one configuration of the Resources exposed through the Snapshot.
-
Only versions on branch: The user can only access those Versions directly referenced by any Snapshot on the branch through which they are viewing the system.
-
Only versions on branches I can see: The user can only access those Versions directly referenced by any Snapshot on any Branch to which the user has view access rights.
-
Only versions on snapshots of branches I can see that are not newer than the currently-selected snapshot: You can see older stuff but not newer stuff (e.g., you can't see things you couldn't have known about at the time the versions on the current Snapshot were created).
Note that in this model, the notion of "latest" is entirely context dependent: Different branches may expose different versions-in-time of a given Resource. While the system can know which Versions of a given Resource have the newest recorded creation time, there is no requirement that any those Versions be referenced by any Snapshot.
For the purposes of link resolution, Branches and Snapshots combined with access policies serve to define the possible configurations of a set of Versions a given link can be resolved in terms of and, in particular, to distinguish the "current configuration" from any previous, next, or alternative configurations, based on which Branches and Snapshots are available for a given link resolution instance.
-
This model can be mapped to any real system that manages storage objects:
-
A normal file system represents a repository of exactly one Branch where only the latest Snapshot and Versions are retained and every save of an individual file represents the commit of a Sandbox with exactly one Mutable Version, resulting in a new Snapshot reflecting a new Version for exactly one Resource, with the previous Snapshot destroyed (that is, all record of the previous state of the system is lost to history). The absolute path to a file represents the Resource while the Version indicator is implicit (because there is ever at most one available version, the current version, of a given resource).
-
A non-branching versioning system represents exactly one Branch but any number of Snapshots and Versions. In a file-system-based versioning system like CVS or Subversion, the absolute path within the versioned file system is the object ID of the Resource while the version-specific identifier of a given version identifies the Version. Each new commit creates a new Snapshot and the user's local working copy is the Sandbox.
-
A full-featured version control system such as git, Mercurial, Subversion, etc. has any number of Branches. In the case of git in particular, there is a very close correspondence between the git notion of "branch" and Branch in this model, in that in git a branch is just a set of pointers to specific "commits" and a commit reflects a distinct set of versions. Git has the notion of atomic commits of multiple objects such that all the versions on a given git commit have identical creation timestamps and can be reliably accessed as a unit without the need for additional user action. Each git commit/branch pair represents a new Snapshot. Git can also infer the previous/next relationships for versions based on their creation times and branching details. Git also has a notion of object identity separate from its file sytem location and so can track, for example, renaming of files where the bytes of the files did not change between two commits.
-
A system using something like DITA maps to represent the collections of resources into Branches and Snapshots. Because Snapshots are inherently invariant they can be represented just as easily by distinct DITA map documents as by any other implementation choice. By this approach one could represent an arbitrarily complex set of Resources, Branches, and Snapshots using nothing but files on a file system. This essentially pushes the version management concern from a system like git into the XML processing application. This could be interesting either as an interchange syntax for representing any repository that reflects this model or as a way of implementing this model using a system that manages XML documents well but does not itself have a built-in facility for storage object versioning or branching.
Branching and Merging
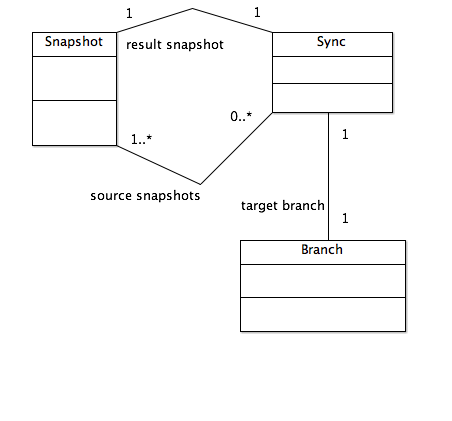
The general operations of branching and merging are modeled using the Sync object, which represents the result of performing a sync operation. A sync of two or more Snapshots represents a "merge".
A Sync relates one or more source Snapshots to a result Snapshot, created on some Branch.
The notion of "conflict" is implicit in the "unique resource" constraint for Snapshots: If two source Snapshots have different versions of the same Resource, the agent performing the sync operation must choose one or the other or create a new Version reflecting the resolution of any conflicts between the two versions. In the context of a real version management system, the system may be able to resolve conflicts automatically, as is done by all modern code control systems. The abstract Sync object does not define how to resolve conflicts, it merely allows for the determination that conflicts exist based solely on the Version and Resource configurations of the source Snapshots.
If a sync operation is from an existing Branch to a new Branch using only the latest Snapshot on the existing Branch, then it is analogous to the git "create branch" operation.
If a sync operation is from an existing Branch to another existing Branch, then it is analogous to a git "merge" operation.
Note that the existence of Sync objects creates a graph of Branch-to-Branch relationships within the version history.
Figure 3: Branching and Merging
The General Versioned Hyperdocument Management Problem
The general hyperdocument management problem is simply the management of addresses used by links within documents: when a new version of a target object is created, it may change the location of the object addressed, requiring all addresses to that object to be updated so that they continue to address the correct version of the object.
When a new version of an object is created one of two things is possible: the previous version is maintained and a new version is created or the previous version is destroyed, leaving only the new version. For example, when working with files on a non-journalled file system, every time you "save" a file you destroy the old version and create a new version. Journalled file systems can retain knowledge of every version in time of every storage object. Likewise, version control systems can maintain all relevant versions of a storage object.
Regardless of how versions are managed, the problem remains: when a new version of a target object is created, all references to that object must be evaluated to determine if and how they should be updated to reflect the new version:
-
No change: the reference continues to be correct, either because the reference should reflect the specific version it currently points to or because the new version is the appropriate target and the address of the target object did not change.
-
Update the reference to point to the new version, because the new version has a different address than the previous version and either the new version is the only available version or because the new version is the appropriate version to link to. The object's address could be different because the storage object identifier was changed or the location or property details of the element within the storage object was changed or both. Note that when the storage object is managed as a set of versions, the new version has a new storage object identifier that may or may not be used (that is, we assume you can either refer to the storage object by a version-independent identifier or a version-specific identifier—every version necessarily has identity within the set of all possible versions).
-
Remove or replace the link because the original target no longer exists or is no longer the appropriate target of the link.
Of these possibilities, options (2) and (3) both require creating new versions of the documents making the links, which in turn may require new versions of other documents, which may then require new versions of the documents that link to them, and so on.
In the worst case, a change to any one document may require a change to every other document in the repository, which in turn requires a change to every other document, and so on.
If a system does not provide atomic commits of multiple versions, then it is impossible to ensure that the repository is never in an inconsistent state in all cases. In particular, if two documents have embedded links to each other, such that Document A adds a link to a new anchor in Document B and Document B adds a link to a new anchor in Document A, if Document A is committed first, its link to Document B cannot be resolved until Document B is also committed, meaning there will be some period of time during which Document A has an unresolvable link. Likewise, if Document B is committed first there will be a period of time during which it has an unresolvable link to Document A. To avoid an inconsistent state you either have to create extra versions such that you create a version of A with the new anchor but no link to Document B, then commit Document B with the new anchor and a link to document A then create a new version of Document A with the link to B or you have to commit documents A and B as an atomic action that either succeeds completely or fails utterly, leaving the system in a consistent state in either case.
In terms of the abstract version management model, an address can be to a Resource or to a one or more Versions. Such an address can be resolved in the context of a Snapshot on a Branch or it can be resolved without regard to Branch or Snapshot context. In typical systems, there is always a "current snapshot" that determines the default resolution context.
The abstract version management model addresses the problem of creation of a new version causing ripples of change in two ways:
-
When addresses are to Resources then creation of new Versions of those Resources does not, by itself, require any change to existing Versions. That is, as long as some version of the target resource is visible in the current resolution context under the current resolution policies, the address can be resolved and no change is required simply to repair a broken address. The specific Version of the Resource the address will resolve to is a function of the current configuration, as defined by the Versions on the current Snapshot, and the resolution policy in effect for each address resolution instance (where the default policy is "on snapshot").
-
Because creation of a new Snapshot is an atomic commit of multiple Versions, the author of the new Snapshot has the opportunity to ensure that all addresses are resolvable, in the context of the Sandbox from which the Snapshot will be created, such that it is possible to never have the repository in an inconsistent state.
Use-context-specific indirection could be implemented in any number of ways. The DITA solution uses DITA-defined markup used within DITA documents, avoiding the need for any particular management system functionality (one of the basic design principles of DITA is that everything DITA defines should be implementable using normal non-versioned file systems). Another solution would be for the version management system to provide additional addressing and address resolution options, that is, providing the indirection within the repository, separate from the content of the Documents involved. This approach has the advantage of being general and the disadvantage of being proprietary, or at least non-standard. It also has the disadvantage of potentially being redundant with source formats that already provide the necessary indirection mechanisms, such as DITA.
An Abstract Hyperdocument Management Model: Branches, Snapshots, and Dependencies
To extend the base version management model to support address resolution and general link (dependency) management the following types are added:
-
Anchor: An addressable component of a Storage Object. The details of how an anchor is addressed are specific to the semantics of the data format of the Storage Object. For example, an XML storage object could be addressed using normal XML addressing methods (XPath, XPointer, IDREF, etc.) or as a sequence of lines, as a sequence of characters, as a sequence of bytes, or as some more abstract model for which the XML is a serialization. An Anchor is always addressed in the context of the Storage Object that contains the Anchor. That is, you cannot address an Anchor without first addressing the Storage Object. This rule is reflected in URIs, for example, where a distinction is made between the resource part of a URI and the fragment identifier or query part of the URI. The resource part of a URI addresses a Storage Object (that is, a sequence of bytes) and the fragment identifier or query part addresses the anchor within the Storage Object.
-
Address: A pointer to an Anchor, e.g., a URI reference, an XML ID reference, etc. Has an associated Address Resolution Policy.
-
Address Resolution Policy: A definition of the rules to apply when resolving an Address in the context of a Repository. The default Address Resolution Policy is "on snapshot", which is what you get, for example, if all the data involved are simply files on the file system (meaning there are no other versions available to which an address might be resolved in any case).
The details of Address Resolution Policies are necessarily implementation dependent. They could be simple, such as "on snapshot" and "specific version X" or they could embody complex business rules for selecting the appropriate Version or Versions based on whatever properties are available on the candidate targets and whatever conditions are in effect at resolution time. That is, resolution policies can be as static or dynamic as needed to meet business requirements. However, except where "surprise me" is the intended result, the application of resolution policies should be deterministic such that two resolution attempts with the same starting conditions should result in the same Anchors being addressed.
This model implies that repository managers should provide address resolution services but this is not required: address resolution might be done entirely in processors that are not, themselves, aware of the larger repository or version management system. E.g., using git to do version management and the DITA Open Toolkit to produce deliverables from DITA-based publications. In that case, the address resolution policies may be implemented indirectly through the way that files are made available to the processors.
In terms of the practical aspects of hyperdocument management, it is usually much more important for authoring tools (editors) to depend on repository managers to do address resolution so that editors are not required, for example, to make local copies of or bring into local memory all the storage objects involved in the hyperdocuments.
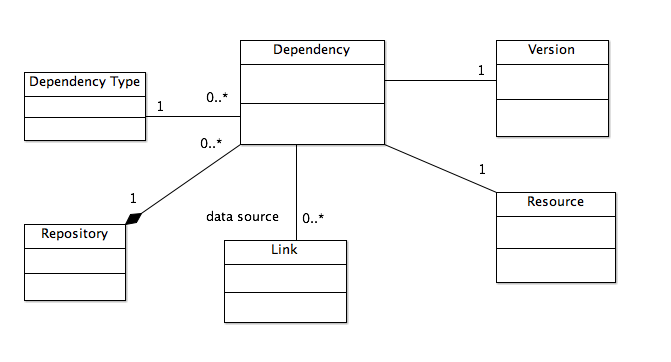
Given the Address object, it is then possible to model links and dependencies:
-
Link: A relationship among two or more Link Ends. A Link has a type, with the default type being "Is Linked To" and zero or more Properties. If a Link reflects semantic components within a Document the link may have a Data Source property that identifies the data from which the Link was generated.
-
Link End: One participant in the relationship defined by the Link. A Link End has zero or more Anchors. A Link End has a role, with the default role being "link end". A Link End has zero or more Properties.
-
Dependency: A relationship between a Version and a Resource. Has a type, where the default type is "depends on". Has zero or more source Links, representing the Link objects that imply the dependency (a Dependency may be explicilty created and not derived from Links). Has zero or more Properties.
Dependency objects serve three main purposes:
-
To simply capture the fact that Version-to-Resource dependencies exist for whatever reason. For example, a user of the system may need to simply assert a dependency that is not inherent in the content and does not warrant the creation of explicit links, such as to reflect some business-process-specific dependency, e.g., "must be published with" or "cannot be published before".
-
To optimize where-used queries by avoiding the need to examine all links for every where-used lookup. For this purpose, the Dependency object is not strictly required, but it seems to be useful as an object. For example, a system can create distinct Dependency objects for each kind of link within a given Version, making it quick to determine, for example, if a given DITA topic has any cross reference or content reference links to other topics, as those two types of links have different data processing and business rule implications.
-
To optimize the determination of the ability to satisfy dependencies in the context of a Branch or Snapshot. Because a Dependency is from a Version to a Resource, when evaluated in the context of a Branch or Snapshot, the system can determine whether or not the dependency can be satisfied without the need to resolve every Link in every Version on the Snapshot. For example, when adding a Version to a Sandbox, the system can quickly determine if that Version's dependencies can be satisfied on the Sandbox and, if not, what Resources need to be reflected in the Sandbox (the selection of specific Versions of those Resources is the job of the author or business rules).
-
Figure 4: Link and Anchor Model
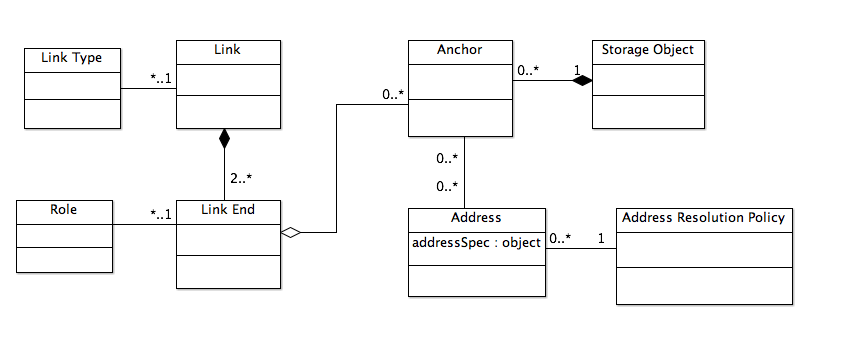
Figure 5: Dependency Model
A git-Based DITA Hyperdocument Management System
It's one thing to have an abstract model that appears to address all the cases or a filesystem-based XML vocabulary that lets you specify all the addressing and version details literally and quite another to have a usable system that implements the model and allows hyperdocument authors to be as effective and productive as possible. In practice authoring groups working on realistic hyperdocuments require some sort of authoring, versioning, and production management system. That system must provide some degree of link awareness.
Implementing a practical XML-aware, hyperdocument management system is a significant engineering challenge, as many people have discovered over the last 30 or more years.
The evolution of various open-source tools and their attendant infrastructure as well as enabling standards like XQuery, XSLT, and DITA, into mature and robust system components now makes it possible to implement remarkably robust hyperdocument management systems with relatively little effort or cash outlay.
In particular, git provides a robust version control system that maps very closely to the abstract versioning model. XQuery and XQuery databases, such as BaseX, eXist, and MarkLogic, make it practical to implement link management features to support authors and output processing tools. Continuous integration (CI) systems like Hudson and TravisCI provide easy-to-configure process automation that integrates well with content managed in git or comparable version control systems.
In the context of DITA-based content, the various DITA-aware processors, such as the DITA Open Toolkit, provide robust processing for the generation of deliverables from DITA-based publications.
Finally, the DITA 1.3 architecture itself provides several essential address representation features that make it possible to create hyperdocuments that satisfy the hyperdocument management challenges presented by reuse.
This paper presents one implementation of such a system, the open-source DITA for Small Teams (DFST) project, based, where possible, on open-source tools, with the intent of having the lowest overall cost while providing as much link management functionality as possible in the support of writing teams, from single authors to large distributed teams or even loosely-coordinated teams that have some requirement to share content or simply enable reliable linking among their various publications.
The solution is built around the following components:
-
Git as the version management system for all hyperdocument content (with the possible exception of media objects, which might be managed in some other system if necessary, as long as it can be coordinated with the main versioning system).
-
An XQuery-based DITA-specific link management system built on top of an XQuery database. The link management compoennt uses git hooks to reflect the authoritative XML source in the XQuery database to then provide link management services to authors, editing tools, and processing tools. The initial implementation uses the open-source BaseX database, but the bulk of the XQuery business logic will work in any XQuery 3.1-capable database.
-
Any DITA-aware editor. The choice of editor is unimportant as long as it provides the DITA awareness required by authors. All the major commercial XML editors provide robust DITA authoring features.
-
TravisCI (hosted) or Jenkins (local) and the DITA Open Toolkit for process automation and generation of deliverables from DITA-based publications. Any comparable continuous integration system will serve.
Git's Model Maps Closely to the Abstract Versioning Model
The abstract versioning model presented in this paper was first formalized and published between 1999 and 2001 by myself, John Heintz, Joshua Reynolds, and Brandon Jockman, all of Datachannel-ISOGEN. Thus, this work predates the development of git by at least 2 years. As far as we know, the git development team was not aware of our work or influenced by itSnapCM.
However, the git model turns out to be remarkably similar to the abstract model in many ways:
-
It treats objects as having identity separate from their particular file name, which is almost the same as the Resource/Version distinction. Git is still focused on the storage object nature of the data it manages, so it uses byte identity as the fundamental object identifier, rather than a more abstract "these things are versions of the same resource because I say they are", which is what the abstract model enables. In practice, git's approach is good enough for typical document authoring and management use cases. Because DITA itself provides indirect addresses from abstract names (keys) to resources, it is possible to use normal DITA maps to maintain an abstract Resource-to-Versions mapping in order to maintain a persistent identifier for resources as the storage object details of the Versions of those resources change (e.g., a filename is changed or git is, for some reason, unable to maintain the version history for what the authors of the resource consider to be the same resource).
-
It provides atomic commits of multiple objects. The git commit object is almost the same as a Snapshot, the difference being that two branches can reflect the same commit in git while in the abstract model, each Snapshot is specific to a Branch. But a git branch/commit pair is equivalent to a Snapshot and git can maintain the per-branch commit history for each branch, which gives you the effect of Snapshots (meaning that you can know what versions are visible on a given git branch by looking at the commits made on or merged into that branch).
-
Branches are simply pointers to versions and you can choose to bring versions from different commits into a branch. This is analogous to selecting a specific Version of a Resource when configuring a Snapshot (either through a Sync or through a Sandbox).
Branches in git provide essentially identical visibility and configuration management features as intended for Branch in the abstract model. Branches in git are lightweight, which means they can be created quickly and switched among quickly. In the context of hyperdocument management using git, it means that an author or processing system can use git branches to control the configuration of their hyperdocuments and control visibility of specific versions, at least for the purposes of link resolution, if not for general access control.
-
Git provides complete control over the history of versions and branches, allowing you to either change history, prune away unwanted history (unneeded versions), delete branches that are no longer needed, or, if necessary, completely reconstitute some historical record.
While I don't have any knowledge of or insight into the development of git I take the correspondence of features between our abstract version management model and git's model as evidence of the soundness of both designs, in that they reflect the most appropriate solution to the configuration management challenges that face both software developed by highly-distributed and loosely-coordinated teams and hyperdocuments developed through asynchronous and loosely-coordinated business processes. Git's developers were more focused on the practical implementation details of source code management while we were focused on defining a more formally-complete abstract model that could have any number of implementations, but the general characteristics of the solutions are the same.
This means that git, out of the box, provides many of the features that any implementation of the abstract version management model would require and does it quite well.
Git does not, of course, provide the hyperdocument-specific features required. Those must be provided by some combination of content link and address representation features, authoring tools, component content management systems, and deliverable-generation processors.
The DFST XQuery Link Management Support
The DFST Link Manager ("link manager") is a relatively-simple Web application implemented in XQuery and XSLT. It depends on XQuery 3.1 features, such as maps. The implementation consists of two main components: a generic library of DITA-specific link management and general DITA processing XQuery functions (and, where needed, XSLT transforms) and XQuery-database-specific Web applications that provide the necessary REST APIs and interactive user interfaces.
The system provides the following general services:
-
Access to the full set of maps, topics, and non-DITA resources referenced from the DITA XML content through one or more navigation structures (e.g., a reflection of source filesystem directory tree). The system maintains a complete catalog of all the Resources reflected in a given Snapshot and a (potentially incomplete) catalog of Branches and Snapshots (depending on what git repositories and branches a given user has actually accessed)
-
Full-text and XML-aware searching of the resources. This is essential for the user task of finding candidates for new links or simple exploration and analysis of the current corpus reflected in a given Branch or Snapshot.
-
Where-used lookup for all referenced things (topics and maps, individual XML elements, images, other non-DITA resources).
-
Dependency tracking using configurable business rules to infer Dependencies from Versions to Resources.
-
Inspection of the DITA-specific linking and addressing details of maps and topics: map trees, map navigation trees, key spaces, relationship table link graphics, and other details.
-
Visual previews of DITA maps and topics through configurable XQuery or XSLT transforms.
The system is not intended to be a general-purpose delivery system nor is it intended to be the primary repository of content. It serves simply as an aid for authors. Effectively it serves as a persistent cache of information that could be determined by brute-force processing of the original DITA content at any time. Any features it provides for creating new objects (for example, new Dependency objects that reflect arbitrary dependency relationships not inherent in the content) are written back to the appropriate git repository as DITA-based XML documents.
Core DITA Support Features
The core DITA support features provide XQuery functions that simplify and generalize the task of operating on DITA content.
The full DITA architecture imposes some challenging data processing requirements on processors that aim to implement architecture completely, including:
-
Filtering of content based on dynamically-defined filtering conditions.
Any element may be included or excluded from the final deliverable based on any number of different conditions (e.g., operating system, product, delivery target, etc.). When applied to maps, this filtering can in turn affect the effective values for resolved indirect addresses. In DITA 1.3, the "branch filtering" feature allows different filtering conditions to be applied to a single branch of a map (that is, a specific topicref), implying the existence of multiple copies of that branch, each copy reflecting a different set of filtering conditions and name augmentation rules. Thus indirect addresses must be resolved in the context of a specific branch of a map under a known set of filtering conditions. Because the link management system is reflecting the source XML content and not a particular rendition of it, it must be much more dynamic with regard to the application of filtering than is required for a sequential output processor such as the DITA Open Toolkit.
-
Scoped keys.
Starting with DITA 1.3, a single map may associate scope names with maps or topicrefs in order to establish new named key spaces within a larger map. These key scopes are then used to resolve key references such that an unqualified key reference is resolved in the context of a specific use of the topic from a map, that is, in the context of the key scope ancestry of the topicref that references the topic. If a topic is used in the context of different key scopes the same key reference can resolve to different resources. As for filtering, a link management system must be able to both know what key scopes a given topic or map is used in and what the effective key bindings are in each of those scopes.
-
Content references.
The DITA content reference facility allows any element to act as a use-by-reference link to any element of the same or more specialized type. These content references can be via key, meaning that the element used by reference can vary depending on the filtering and key scope details of the topic or map making the reference. This complicates the determination of how an element is used as whether or not a given element is used depends on how its containing topic or map is itself used.
In addition, DITA 1.3 introduces the "this topic" fragment identifier, which allows a reference to an element in a topic to replace the normal topic ID with a ".". When such a reference occurs within content that is used by reference via a content reference link the DITA rule is that "this topic" is the topic containing the use-by-reference link (that is, the using or referencing context), not the topic that contains the element used. This allows the re-use of elements that contain links to either other elements within the reused element itself or to elements that are expected to exist in the referencing topic.
-
Specialization.
All DITA element types are either base types defined in the DITA specification or "specializations" of one of the base types. All DITA processing can be defined in terms of the base types by using the DITA @class attribute to select elements, rather than the tag name. This makes DITA processing robust in the face of new specializations but complicates otherwise-normal XML processing where a simple tagname match would normally be used.
-
Topicref types with special rules
While the DITA architecture defines a single base type for topic references, <topicref>, the architecture also defines rules for specific configurations of topicref properties and special rules for specific specializations of topicref. Any general-purpose processing of DITA maps must be aware of the implications for different types of topicref. For example, the topicref specialization "topicgroup", which functions as a semanticless grouping element for other topicrefs, may have a title but that title is never to be reflected in any deliverables.
-
Metadata cascade within maps.
DITA maps and topicrefs may specify metadata, either as attributes or subelements. This metadata "cascades" (propagates) to descendant topicrefs and referenced topics according to both invariant rules defined in the DITA architecture and author-defined controls (the DITA 1.3 @cascade attribute). This metadata cannot affect address resolution but it can affect search. In particular, it is useful to be able to find topicrefs or topics based on metadata imposed on them because of their existence in or use from different map contexts.
The DITA support XQuery library generalizes this processing as much as possible and provides utility functions to make working with DITA content in the face these data processing requirements easier and more efficient.
Key Space Construction and Key Resolution Services
The focus of the link management challenge is the resolution of references to keys.
Resolving keys requires constructing the key spaces defined by a root map.
A given root map defines one or more key scopes. Each key scope defines a "key space," that is, a namespace of key names in which each key name defined in the key scope has exactly one effective binding based on the application of content references that use direct addressing, filtering conditions, and key definition precedence rules applied to the key definitions.
In the context of a fully filtering-aware link management system, a constructed key space must reflect each potential key definition for a given key name by maintaining the first definition, in precedence order, with a given unique set of filtering conditions, including the first unconditional key definition if it occurs after any conditional key definitions in precedence order.
The DITA precedence order for key definitions is:
-
Within a given map document, the first definition in normal depth-first traversal of the map, treating scope-qualified key names from child scopes as occurring within the parent scope at the point of occurrence of the child scope.
-
Within the tree of directly-addressed maps descending from the root map, the first definition of the key in a breadth-first traversal of the map tree. This rule ensures that higher-level (using) maps can always override keys defined in the lower-level (used) maps.
In addition to determining the effective (or potentially effective) key definition for a given key name, key space construction also requires copying, literally or effectively, key names from parent key scopes to child scopes, such that the child scope reflects the scope-qualified version of any keys defined in the child scope, as well as scope-qualified child key names to each of the parent scopes for the key. That is, the root (anonymous) key space for each root map implicity contains definitions of all the scope-qualified keys from all the key scopes defined in the map tree descending from the root map. Of course, a processor does not need to litterally create the key definition copies, but it might be the easiest thing to do from an implementation standpoint or provide the greatest performance, especially when the number of keys is very large.
There are two basic approaches to key space construction:
-
Process each root map and construct a separate index or data set that reflects the key spaces constructed from this map. For example, one might populate relational database tables or use a triple store to record the key spaces for speed of lookup by key or by resource used (the inverse of a key space table is a where-used-by-key-in-map index).
-
Process each root map to construct a single "resolved map" that reflects the application of all the map-specific preprocessing (branch filtering, content reference resolution, qualified key definition expansion for ancestor and descendant key spaces) while retaining knowledge of the original submap boundaries (which would otherwise be lost when the topicrefs within submaps replaced the topicref to the submap, which is the normal implication for a reference to a submap). This resolved map can then be used by XPath functions to determine effective keys and thus determine the resources to which a given key resolves in the context of a given key scope).
The approach used in this implementation is option (1), building standalone key space documents that capture the key scope hierarchy defined by a root map but making key lookup and application of precedence rules easier. It also makes inspecting the resulting key spaces and reporting on them easier. In order to construct the key space documents the system also builds the resolved map documents and stores them as well. Because key space construction involves copying qualified key definitions from children to parents and because key names defined in parent scopes override the same (unqualified) key name in child scopes, it is easier to implement and validate this processing by doing the copying literally rather than trying to do it virtually through functions that traverse the resovled map. It also avoids changing the initial resolved map in a way that distorts its original structure as authored.
The identity of a given key scope is the topicref that provides the scope names and its key scope ancestry within the root map. Note that it is not sufficient to simply know what topicref element made the reference, you must know what it's ancestry is within a specific root map. Because maps can themselves be used from other maps and because the same map could be used multiple times in the same map, it is not sufficient to know the just the topicref or just the topicref and root map. You must know what the full key scope hierarchy is for a given address resolution instance or, more generally, you must be able to find all uses of a given topicref in order to then report all possible resolutions of a given key reference.
Where Used Index Construction
The link manager must provide quick answers to the question "given this resource, where is it used within the hyperdocuments?".
While this question can always be answered by brute force queries applied to the documents involved, for any non-trivial amount of content it is necessary to maintain some form of where-used index.
The where-used index is fundamentally a single lookup table that maps known or addressible resources to the components that use them directly or indirectly. Of course, there is additional information that it is useful to maintain in this index, such as the element type or DITA class hierarchy of each reference, the map use context of each reference, type of reference (content reference pull, content reference push, cross reference, whether the resource is addressed by key or direct URI reference, etc.).
In this implementation, the where-used index is maintained as a set of XML documents, one for each use of a given resource, that uses a normalized "resource key" as the primary lookup key, where the resource key is a string reflecting one of the following:
-
The URI of the resource for resources that are addressed only by URI (non-DITA resources, e.g., images, external Web sites, etc.)
-
For topics, the absolute URI of the topic plus the topic ID fragment identifier ("{uri}#{topicid}. In DITA, every topic must have an ID and that ID is an XML ID and thus must be unique within the document that contains the topic. Thus the absolute URI/topic ID pair is reliable object ID for a topic on a given Snapshot (that is, as it exists as a file on the file system in a given git commit).
-
For elements within topics, the absolute URI of the topic plus the topic ID/element ID fragment identifier. The ID of every element within a topic must be unique within that topic, but not any ancestor or descendant topics.
-
For elements within maps, the absolute URI of the map plus the ID of the element. Each map document defines a unique ID namespace, although IDs on elements within map are not declared as type ID.
-
For elements that do not have IDs, the absolute URI of the document that contains it plus a "tree location" string reflecting the element's position from the root of the XML tree.
Note that because all addressing in DITA is by explicit or implicit ID reference, it is only necessary to maintain where-used information for elements that have values for their @id attribute. All other elements are not addressable by DITA-defined addressing.
The where-used index is constructed by processing every resolved root map to determine the resources used by that map. References to sub maps and non-DITA resources in the map are captured at this point. The resolved root map is then walked in order to process each reference to a topic. Each topic use from the map is recorded. Each referenced topic is then processed in each map use context in order to determine the resources that topic references and those entries are recorded.
The where-used records are stored in the BaseX repository in a separate "metadata" database whose name is determined from the name of the database that contains the content documents. The where-used documents are stored in a common directory. Each element used is represented by a directory where the name is a hash of the element's "resource key". These directories then contain use record documents, one for each use of the element. This approach keeps things organized and makes it easy to get a use count for a given element by simply seeing if there are any use records in its directory (if there is no directory then the use count is zero). Each use record captures details about the element used, the using element (the element that links to the used element) and also captures the title of the nearest containing map or topic for the using element. This information is sufficient to get back to the used and using elements in their source locations.
There is the usual cache management problem of recalculating the where-used records for a given Snapshot (new git commit on a branch). The where-used table manager can know whether anything that contains a reference has changed in the new Snapshot and therefore whether or not the current where-used table is invalid. If the reference container is a topic and the maps that reference it have not changed, only the entries that reflect the use by that topic require updating. If the reference container is a map, then the resolved map for each root map that uses the map (or that is the map) must be recalculated and the references in that map reprocessed. It is almost certainly possible to determine, for a given root map containing a reference to a map that has changed, what the changes are to the key spaces for that map and only process the parts that could have been affected. That level of sophistication is beyond the scope of the DFST project.
In the initial implementation, the link metadata is simply recalculated any time a branch is checked out or modified via commit or merge.
Dependency Tracking
The link manager maintains a separate pair of dependency indexes that relate each Resource to the Versions that depend on it in the current Branch and each Version to the Resources it depends on. The set of available dependency types is configurable as are the business rules for how links in the source content map to Dependencies.
REST APIs
The link manager service provides REST APIs for doing where-used lookup and resolving key references.
The REST APIs are implemented in BaseX using the RESTXQ support.
The RESTXQ specification defines annotations for XQuery functions that bind the function to a specific URL pattern. You can capture any part of the URL as parameters to the XQuery function as well as capture any form-provided parameters or query parameters.
Where-Used REST API
The where-used REST API uses the URL pattern:
/dfst/linkmgr/whereused/resourceURI? fragid=fragmentID &usecontext=useContextSpec &conditions=conditionSpec &options
Where:
|
resourceURI |
The absolute URI of the resource to get the where-used details for. |
|
fragmentID |
The fragment ID of the element to look up, either "topicid/elementID for elements within topics or elementID for topics and elements within maps. |
|
useContextSpec |
The specification of a use context to limit the where-used query to. The details of use context specs are yet to be determined as it requires either enumeration of the map and topicref ancestry of the topicref that uses a topic or map or requires reference to an ID generated in the context of a resolved map. |
|
conditionSpec |
The active conditions to use for filtering purposes. The details of the condition spec are yet to be determined. Conceptually a condition spec is a set of condition/value/action tuples, where the action is either "include" or "exclude". The condition spec may also require specifying one or more DITA subject scheme maps that define the taxonomies that govern interpretation of condition values. |
|
options |
Additional options to the where-used lookup. At a minimum the type of link (xref, topicref, conref, etc.). |
The where-used response is either an XML or JSON structure that details each use of the specified resource as well as details about the lookup, such as the options specified, the time taken to return the results, any error conditions. etc. For the initial implementation no consideration is given to paging of results, but that level of sophistication would required in a more robust implementation where scale is a design consideration.
Key Resolution REST API
The Key Resolution REST API uses the URL pattern:
/dfst/linkmgr/resolvekey/{keyname}?
&usecontext=useContextSpec
&conditions=conditionSpec
&options
Where
|
useContextSpec |
The topicref that establishes the key scope context the key reference is to be resolved against. If not specified, all effective bindings for the specified key are returned. |
|
conditions |
The active conditions to use for filtering purposes. The details of the condition spec are yet to be determined. Conceptually a condition spec is a set of condition/value/action tuples, where the action is either "include" or "exclude". The condition spec may also require specifying one or more DITA subject scheme maps that define the taxonomies that govern interpretation of condition values. |
|
options |
Additional options for the key reference resolution request, such as whether or not to recurse through intermediate key references. |
The service returns an XML or JSON structure containing the absolute URIs of each of the resources addressed by the key, if any. The response also contains details about the lookup request, such as the time taken, any error conditions, etc.
User Interface for Link Management
The link manager application provides a variety of user interfaces implemented through a RESTXQ-based Web application. This user interface is BaseX-specific and provides the following services:
-
Browse the set of known git repositories and branches
-
Browse the set of DITA topics and maps in a given branch
-
Do where-used lookups for potentially-used elements
-
Inspect the key spaces of root maps
-
Full-text and XPath searches against the content in a given branch or set of branches.
Conclusions and Future Work
The DFST project has demonstrated git works well as the underpinning of a hyperdocument management system for XML documents. The fairly direct mapping from git branches and commits to abstract model Branches and Snapshots made it relatively easy to implement a companion link management component by simply copying a given git repository and branch to a separate BaseX database, capturing the necessary git details to enable correlation back to the source git repository.
The RESTXQ support in BaseX made it remarkably easy to implement both REST APIs and a simple HTML-based user interface for use by authors.
The most serious implementation challenge has been construction of the DITA key spaces in the face of the general data processing complexity and the sometimes subtle details of the full DITA requirements.
Another implementation challenge is reporting details of link resolution and other processing done in order to construct the where-used, key space, and dependency records. Because these are stored in the XQuery repository using XQuery updating functions, which do not allow returning any value other than an empty sequence, there is no direct way to communicate messages to the user. The BaseX system provides an extension that allows returning data to the caller of the top-level updating function but as that is a RESTXQ function that responds to an HTTP request, there is no opportunity to handle the returned result before responding to the HTTP request. A more robust and general logging mechanism is required, both in the context of the RESTXQ Web application and in the context of the non-updating code that does the data processing to produce the link management records that are then stored.
Future enhancements and potential explorations include:
-
Improving cache management to avoid unnecessary reconstruction of key spaces and where-used indexes.
-
Visualization of links in interesting and useful ways such as graphs of relationships among components, re-use statistics, etc. The visualization technology required is readily available, it's merely a matter of the time required to implement the visualizations.
-
Tighter integration of the link management services with XML editors, removing the need for authors to switch between their authoring environment and the link management application.
-
Using the preprocessing work done to calculate resolved maps and key spaces to then serve output processors so that the preprocessing does not need to be repeated.
References
[HyTime] ISO/IEC 10744:1996, Information Technology -- Hypermedia/Time-based Structuring Language, http://www.hytime.org
[Literary Machines] Nelson, Theodor H. 1987. Literary Machines. South Bend, Indiana: The Distributors.
[RTD] Kimber, W. Eliot, Steven Newcomb, Peter Newcomb, Version Management as Hypertext Application: Referent Tracking Documents, Markup Technologies ’99
[SnapCM] Heintz, John, Joshua Reynolds, SnapCM, 2001, http://www.xiruss.org/xiruss-docs/snap_cm.pdf (Originally published as a white paper on the Innodata Isogen Web site.)
[Vitali] Vitali, Fabio, Versioning hypermedia, ACM Computing Surveys 31(4), December 1999, http://cs.brown.edu/memex/ACM_HypertextTestbed/papers/50.html, doi:https://doi.org/10.1145/345966.346019
[XInclude], Online from http://www.w3.org/XInclude
[XLink], Online from http://www.w3.org/XML/Linking
[XML], Online from http://www.w3.org/XML
[XPointer], Online from http://www.w3.org/XML/Linking
[1] In a Boeing aircraft manual there was the subtask "Put away your tools and clean up your work area" that happened to be used 666 times in the manual. We knew because the task document had a syntax error that resulted in an error message each time the task was used.
[2] This model uses lowercase names for the objects to distinguish them from the more formal version management model presented later.
[3] External parsed entities are evil and we should have never have preserved them in XML. XInclude merely perpetuates the evil of external parsed entities.