Diewald, Nils, and Maik Stührenberg. “An extensible API for documents with multiple annotation layers.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Diewald01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: An extensible API for documents with multiple annotation layers
Nils Diewald received a B.A. in German philology and Text Technology and an M.A. in
Linguistics (with a focus on Computational Linguistics) from Bielefeld University.
Currently he is employed as a research assistant in the KorAP project at the IDS Mannheim
(Institute for the German Language) and is a Ph.D. candidate in Computer Science.
His Doctorate Studies focus on communication in social networks,
originating from his work as a research assistant in the
Linguistic Networks project of the BMBF (Federal Ministry of Education and Research).
Before that, he was a research and graduate assistant in the Sekimo project, part
of the
DFG Research Group on Text-Technological Modelling of Information.
Maik Stührenberg received his Ph.D. in Computational Linguistics and Text Technology
from Bielefeld University in 2012. After graduating in 2001 he worked in different
text-technological projects at Gießen University, Bielefeld University and the Institut
für Deutsche Sprache (IDS, Institute for the German Language) in Mannheim. He is currently
employed as research assistant at Bielefeld University.
His main research interests include specifications for structuring multiple annotated
data, schema languages, and query processing.
Both XML namespaces and standoff annotation are promising approaches to tackle possibly
overlapping multiple annotation layers in XML instances. The creation and processing
of
standoff instances can be cumbersome – especially when the underlying textual primary
data
is allowed to be modified after the annotation has been added. In this paper we present
a
powerful API that is capable of dealing with these tasks by providing an extension
mechanism
that allows for the easy creation of modules corresponding to a certain namespace
(and
therefore markup language). We use XStandoff as a working example since it is a standoff
format that highly depends on XML namespaces for different annotation layers.
Markup languages are often defined for structuring the information of a specific text
type, such as web pages (HTML), technical articles or books (DocBook), or a set of
information
items, such as vector graphics (SVG) or protocol information (SOAP). Therefore, their
structure is (in limits) determined by a document grammar that allows for specific
elements
and attributes. In addition, the different XML-based document grammar formalisms allow
to a
certain degree the combination of elements (and attributes) from different markup
languages –
usually by means of XML namespaces (Bray et al., 2009). In practice, one host
language can include islands of foreign markup (guest languages). There are different
examples
for the combination of host and guest markup languages (apart from the already mentioned
SOAP). A certain XHTML driver (Ishikawa, 2002) allows for the combination of
XHTML (as a host language), MathML and SVG (as guest languages), and the Atom Syndication
Format (Nottingham and Sayre, 2005) can be used in conjunction with a wide range of
extensions (e.g. for Threading, see Snell, 2006, or Activity Streams, see
Atkins et al., 2011) while it is also meant to be embedded in parts in the RSS
format (Winer, 2009).
Although XML namespaces support the combination of elements derived from different
markup languages, they do not change XML's formal model that prohibits overlapping
markup.
However, standoff markup (instead of inline annotation) may be used to circumvent
this
problem. The meta markup language XStandoff (Stührenberg and Jettka, 2009) embeds
(slightly transformed) islands of guest languages (with respective XML namespaces)
in
combination with a standardized standoff approach as key feature for the storage of
multiple
(and possibly overlapping) hierarchies.
In addition, the namespace attribute may be used to control the allowed
namespaces. While XSD 1.0 allows the values ##any, ##other or a list
of namespaces only (including the preserved values ##targetNamespace and
##local, see Thompson et al., 2004), RELAX NG supports the exclusion
of namespaces (by using the except pattern in combination with
nsName). XSD 1.1 (Gao et al., 2012) introduced the
notNamespace and notQName attributes.
The production of multiple annotated documents is typically the result of the combination
of formerly stand-alone documents (or their parts), such as the inclusion of externally
created SVG graphics in an XHTML host document, or the outcome of a mostly automated
process
(see Stührenberg and Jettka, 2009 for a discussion on the production of XStandoff
instances). What is still lacking is an API (Application Programming Interface)
that is flexible enough to support the production
and processing of multiple annotated instances, even if annotations are referring
to the same
primary data by means of standoff annotation. We will demonstrate such an API in the
reminder
of this article.
Creating an extensible API
XML::Loy (Diewald, 2011) is a Perl library, that
provides a simple programming interface for the creation of XML documents with multiple
namespaces. It is based on Mojo::DOM, an HTML/XML DOM parser that is part
of the Mojolicious framework (Riedel, 2008).
Mojo::DOM povides CSS selector based methods for DOM traversal (van Kesteren and Hunt, 2013), similar to Javascript's querySelector() and
querySelectorAll() methods.
The basic methods for the manipulation of the XML Document Object Model provided by
XML::Loy are add() and set(). By applying
these methods new nodes can be introduced as children to every node in the document.
While
add() always appends additional nodes to the document, set() only
appends nodes in case no child of the given type exists. Both methods are invoked
by a chosen
node in the document tree (acting as the parent node of the newly introduced node).
They
accept the element name as a string parameter, followed by an optional hash reference
containing attributes and a string containing optional textual content of the element.
A final
string can be used to put a comment in front of the element.
Figure 2: Using XML::Loy to create a document
use XML::Loy;
my $doc = XML::Loy->new('document');
$doc->set(title => 'My Title');
$doc->set(title => 'My New Title');
$doc->add(paragraph => { id => 'p-1' } => 'First Paragraph');
$doc->add(paragraph => { id => 'p-2' } => 'Second Paragraph');
print $doc->to_pretty_xml;
In the example presented in Figure 2 a new XML::Loy
document instance is created with a root element document. Applying the
set() method, a new title element is introduced as a child of the
root element. The second call of set() overwrites the content of the
title element. By using the add() method we insert multiple
paragraph elements without overwriting existing ones. These elements are
defined with both an id attribute and textual content.
By applying the to_pretty_xml() method, the result can be printed as XML.
The strength of this simple approach for document manipulation is the ability to pass
these methods to new extension modules that can represent APIs for specific XML namespaces,
as
both host and guest languages. The example given in Figure 3 is
meant to illustrate these capabilities by creating a simple XML::Loy extension
for morpheme annotations.
Figure 3: Creating XML::Loy extensions
package XML::Loy::Example::Morphemes;
use XML::Loy with => (
namespace => 'http://www.xstandoff.net/morphemes',
prefix => 'morph'
);
# Add morphemes root
sub morphemes {
my $self = shift;
return $self->add(morphemes => @_);
};
# Add morphemes
sub morpheme {
my $self = shift;
return unless $self->type =~ /^(?:morph:)?morphemes$/;
return $self->add(morpheme => @_);
};
The class inherits all XML creation methods from XML::Loy and thus
all XML traversal methods from Mojo::DOM. When defining the base class,
an optional namespace http://www.xstandoff.net/morphemes is bound to the
morph prefix, which means, all invocations of set() and
add() from this class will be bound to the morph namespace. The
newly created morphemes() method appends a morphemes element bound
to the given namespace as a child of the invoking node.
To implement simple grammar rules to the API the methods can check the invoking context,
for
example by constraining the introduction of morpheme elements to
morphemes parent nodes only (see the regular expression check
/^(?:morph:)?morphemes$/).
This newly created API for the http://www.xstandoff.net/morphemes namespace
can now be used to create new document instances (see Figure 4
and the output shown in Figure 5).
Figure 4: Creating a document by using XML::Loy::Example::Morphemes
use XML::Loy::Example::Morphemes;
my $doc = XML::Loy::Example::Morphemes->new('document');
my $m = $doc->morphemes;
$m->morpheme('The');
$m->morpheme('sun');
$m->morpheme('shine');
$m->morpheme('s');
$m->morpheme('bright');
$m->morpheme('er');
print $doc->to_pretty_xml;
Figure 5: The output instance created with
XML::Loy::Example::Morphemes
By using the generic methods add() and set() provided by
XML::Loy, the class can easily be used for extending an existing
XML::Loy based class (i.e. as a guest language inside another host
language). In the example shown in Figure 6 a simplified HTML
instance is read and instantiated. Elements from the
http://www.xstandoff.net/morphemes namespace are appended using the API
described above (the output is shown in Figure 7).
Figure 6: Using extensions with XML::Loy
use XML::Loy;
my $doc = XML::Loy->new(<<'XML');
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<html>
<head><title>The sun</title></head>
<body />
</html>
XML
$doc->extension(-Example::Morphemes);
my $p = $doc->at('body')->add('p' => 'The sun shines');
my $m = $p->morphemes;
$m->morpheme('bright');
$m->morpheme('er');
print $doc->to_pretty_xml;
Figure 7: The output instance created with XML::Loy and the
XML::Loy::Example::Morphemes extension
By extending the XML::Loy base object with the newly created class using
the extension()[1] method, all method calls from the extension class are available for namespace aware
traversal and manipulation. In general, using such an extensible API provides at least
some
functionality usually made available by document grammars (the nesting of elements
for
example) and adds methods to create and manipulate the respective class of instances.
XStandoff as an example application
XStandoff's predecessor SGF (Sekimo Generic Format) was developed in 2008 (see Stührenberg and Goecke, 2008) as a meta format for storing and analyzing multiple annotated
instances as part of a linguistic corpus. In 2009 the format was generalized and enhanced.
Since then, XStandoff combines standoff notation with the formal model of General
Ordered-Descendant Directed Acyclic Graphs (GODDAG, introduced in Sperberg-McQueen and Huitfeldt, 2004; see Sperberg-McQueen and Huitfeldt, 2008 for a more
recent discussion). The format as such is capable of representing multiple hierarchies
and
specifically challenging structures such as overlaps, discontinuous elements and virtual
elements. The basic structure of an XStandoff instance consists of the root element
corpusData underneath which the child elements meta (optional),
resources (optional), primaryData (optional in the proposed
release 2.0, see Stührenberg, 2013), segmentation and
annotation are subsumed. Figure 8 shows an example
XStandoff document.[2]
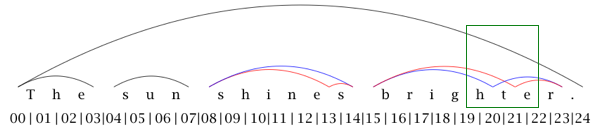
In this example, the sentence The sun shines brighter. is annotated with
two linguistic levels (and respective layers): morphemes and syllables. We cannot
combine both
annotation layers in an inline annotation, since there is an overlap between the two
syllables
brigh and ter and the two morphemes bright and
er (see Figure 9 for a visualization of the
overlap).
Figure 9: Graphical representation of overlapping hierarchies
Each annotation is encapsulated underneath a layer element (which in turn is
a child element of a level element, since it is possible to have more than one
serialization, that is, layer, for a conceptual level).[3] The xsf:segment attribute is used to link the annotation with the
respective part of the primary data. Similar to other standoff approaches, XStandoff
uses
character positions for defining segments over textual primary data. Changes of the
input text
result in an out-of-sync situation between primary data and annotation. Processing
XStandoff
instances requires dealing with at least n+1 XML namespaces: one for
XStandoff itself and one for each of the n annotation layers.
Up to now, these instances are created by transforming inline annotations via a set
of
XSLT 2.0 stylesheets (see Stührenberg and Jettka, 2009 for a detailed discussion). We
will outline an example API for XStandoff based on XML::Loy that makes it
easy to deal with the dynamic creation of multi-layered annotations in the following
section[4].
Creating and processing XStandoff instances using XML::Loy
As presented in the previous section, XStandoff associates annotations to primary
data by
defining segment spans[5] to which the annotations are linked to via XML ID/IDREF integrity features. There
are multiple ways to cope with standoff annotation: Compared to the XStandoff-Toolkit
discussed in Stührenberg and Jettka, 2009, our API will provide an additional
way to access and manipulate both annotations and primary data directly.
Figure 10: Creating XStandoff instances with XML::Loy::XStandoff
use XML::Loy::XStandoff;
# Create new corpusData
my $cd = XML::Loy::XStandoff->new('corpusData');
# Set textual content embedded
$cd->textual_content('The sun shines brighter.');
# Create segmentation
my $seg = $cd->segmentation;
# Create segments manually
my $seg1 = $seg->segment(0,24);
my $seg2 = $seg->segment(0, 3);
my $seg3 = $seg->segment(4, 7);
my $seg4 = $seg->segment(8, 13);
my $seg5 = $seg->segment(13, 14);
my $seg6 = $seg->segment(15, 21);
my $seg7 = $seg->segment(21, 23);
print $cd->to_pretty_xml;
In Figure 10 a new corpusData element is created.
Next, a textualContent element is added
(below an automatically introduced primaryData element with a unique xml:id).
Seven manually defined
segment elements are appended for selecting spans over the textual primary data
aligned to the words and the sentence as a whole. Figure 11 shows
the output.
Figure 11: The XStandoff instance created with XML::Loy::XStandoff
The document creation is simple, as most elements such as corpusData,
textualContent and segment have corresponding API methods for
finding, appending, updating and removing elements of the document. Segments are appended
by
defining their scope.
The manipulation of the primary data is possible by applying the
segment_content() method, that associates primary data with segment spans (see
Figure 12).
Figure 12: Using the XML::Loy::XStandoff API
# Get segment content
say $seg->segment($seg3)->segment_content;
# 'sun'
# Replace segment content
$seg->segment($seg3)->segment_content('moon');
# Interactively replace segment content
$seg->segment($seg7)->segment_content(sub {
my $t = shift;
# Remove a sequence of 'er' from the string
$t =~ s/er//;
return $t;
});
# Show updated textual content
say $cd->textual_content;
# The moon shines bright.
# Segment positions are updated automatically
for ($seg->segment($seg6)) {
say $_->attrs('start'); # 16
say $_->attrs('end'); # 22
};
The textual content virtually delimited by a segment can be retrieved, replaced and
manipulated, while all other segments stay intact and update their according start
and end
position values by calculating the new offsets in case they change.
This addresses one of the key problems
with standoff annotation: Usually, if one alters the primary data without updating
the
corresponding segments, association of annotations and corresponding primary data
will break.
Due to the dynamic access of primary data information provided by this API,
work with standoff annotations can
be nearly as flexible as with inline annotations, without the limitations these annotation
formats have, for example to represent overlapping (see Figure 9).
The morpheme extension created in section “Creating an extensible API” can be simply adopted
to represent an annotation layer with overlapping segment spans with an annotation
of
syllables (see Figure 13).
Figure 13: Extending XML::Loy::XStandoff
use XML::Loy::XStandoff;
# Create new corpusData
my $cd = XML::Loy::XStandoff->new('corpusData');
# Load extensions for Morphemes and Syllables
$cd->extension(-Example::Morphemes, -Example::Syllables);
# Set textual content embedded
$cd->textual_content('The sun shines brighter.');
# Start segmentation
my $seg = $cd->segmentation;
my $all = $seg->segment(0, 24);
# Create new annotation layer for morphemes
my $m = $cd->layer->morphemes;
# Create and associate all necessary segments for all morphemes
$m->seg($all);
foreach ([0,3], [4,7], [8,13], [13,14], [15,21], [21,23]) {
$m->morpheme->seg($seg->segment($_->[0], $_->[1]));
};
# Create new annotation layer for syllables
my $s = $cd->layer->syllables;
# Create and associate all necessary segments for all syllables
# independently, so overlaps are supported
$s->seg($all);
foreach ([0,3], [4,7], [8,14], [15,20], [20,23]) {
$s->syllable->seg($seg->segment($_->[0], $_->[1]));
};
# Change the primary data of the second morpheme 'sun' to 'moon'
$cd->find('morpheme')->[1]->segment_content('moon');
The resulting document is similar to listing Figure 8 but with a modified
primary data of The moon shines brighter. and updated segment spans.
Another problem with some standoff formats is the association with decoupled primary
data
content. In XStandoff the primary data can be included in the XSF instance (as seen
in the
previous examples) or stored in a separate file and referenced via the
primaryDataRef element (in case of larger textual primary data, multimedia-based or
multiple primary data files). If this file is on a local storage, the API will take
care
of updating the external textual content as well. Trying to modify files that are
not
modifiable (e.g. accessible online only) will result in a
warning.
Since metadata in XStandoff can be either included inline or referenced in the same
way, the handling of
metadata in our API can be treated alike, with a slight difference
if the metadata itself is a well-formed XML document. The example given in Figure 15 assumes a simple metadata document in RDF with a Dublin Core
namespace at the location files/meta.xml in the local file system (shown in Figure 14).
Figure 14: RDF metadata instance
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description>
<dc:creator>Nils Diewald</dc:creator>
<dc:creator>Maik Stührenberg</dc:creator>
<dc:title>An extensible API for documents with multiple annotation layers</dc:title>
<dc:language>EN</dc:language>
</rdf:Description>
</rdf:RDF>
Figure 15: Accessing external metadata
# Define the metadata as an external file
$cd->meta(uri => 'files/meta.xml');
# Retrieve the metadata, resulting in a new XML::Loy object
my $meta = $cd->meta(as => [-Loy, -DublinCore]);
# The extension is available in the newly defined object
print $meta->at('Description')->dc('title');
# 'An extensible API for documents with multiple annotation layers'
The API enables the reference to the external document and supports the access by
defining
a new XML::Loy object with an extension for dealing with Dublin Core data.[6] As a result, the Dublin Core annotated title element can be accessed
directly, although the data is not embedded in the document.
Conclusion and future work
We have demonstrated the XML::Loy API that can be used as a framework
for development of extensible modules for given namespaces (and therefore markup
languages). Modules created as extensions can then be used in a simple but yet powerful
way to
create and process multiple annotated instances, even with standoff markup and referenced
documents for primary and metadata information.
The current implementation of XML::Loy is written in pure Perl, with
the focus on demonstrating the flexibility and extensibility of our approach, rather
than
creating a performance optimized system. Since the whole API (including the extension
modules
and examples described in this paper) is available under a free license at http://github.com/Akron/XML-Loy-XStandoff further possible steps could include
performance optimizations and the creation of an extension repository for popular
standardized
markup languages (such as OLAC, DocBook and TEI).
Acknowledgements
We would like to thank the anonymous reviewers of this paper for their helpful comments
and ideas.
[Goecke et al., 2010] Daniela Goecke, Harald Lüngen,
Dieter Metzing, Maik Stührenberg, and Andreas Witt (2010). Different
views on markup. Distinguishing Levels and Layers. In: Witt, A. and Metzing, D.
(eds.), Linguistic Modeling of Information and Markup Languages. Dordrecht:
Springer. doi:https://doi.org/10.1007/978-90-481-3331-4_1.
[Sperberg-McQueen and Huitfeldt, 2004] C.
M. Sperberg-McQueen and Claus Huitfeldt (2004). GODDAG: A Data
Structure for Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.),
Proceedings of the 5th International Workshop on the Principles of Digital Document
Processing
(PODDP 2000), volume 2023 of Lecture Notes in Computer Science, Springer
[Sperberg-McQueen and Huitfeldt, 2008] C.
M. Sperberg-McQueen and Claus Huitfeldt (2008). GODDAG. Presented at the Goddag workshop,
Amsterdam, 1-5 December 2008
[Stührenberg and Goecke, 2008] Maik
Stührenberg and Daniela Goecke (2008). SGF – An integrated model for multiple
annotations and its application in a linguistic domain. Presented at Balisage: The
Markup
Conference 2008, Montréal, Canada, August 12 - 15, 2008. In: Proceedings of Balisage:
The
Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01
[1] The leading minus symbol is a shortcut for the XML::Loy module namespace,
meaning, that the qualified name is
XML::Loy::Example::Morphemes. More than one extension can be passed
at once.
[5] In the following example we will limit our view on segments defined by character
positions. See Stührenberg, 2013 for examples for other segmentation
methods supported by XStandoff.
[6] This extension is not described in this article.
Tim Bray, Dave Hollander, Andrew
Layman, Richard Tobin, and Henry S. Thompson (2009). Namespaces in XML 1.0 (Third
Edition).
W3C Recommendation, World Wide Web Consortium (W3C). http://www.w3.org/TR/2009/REC-xml-names-20091208/
Shudi (Sandy) Gao, C. M.
Sperberg-McQueen, and Henry S. Thompson (2012). W3C XML Schema Definition Language
(XSD) 1.1
Part 1: Structures. W3C Recommendation, World Wide Web Consortium (W3C). http://www.w3.org/TR/2012/REC-xmlschema11-1-20120405/
Daniela Goecke, Harald Lüngen,
Dieter Metzing, Maik Stührenberg, and Andreas Witt (2010). Different
views on markup. Distinguishing Levels and Layers. In: Witt, A. and Metzing, D.
(eds.), Linguistic Modeling of Information and Markup Languages. Dordrecht:
Springer. doi:https://doi.org/10.1007/978-90-481-3331-4_1.
C.
M. Sperberg-McQueen and Claus Huitfeldt (2004). GODDAG: A Data
Structure for Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.),
Proceedings of the 5th International Workshop on the Principles of Digital Document
Processing
(PODDP 2000), volume 2023 of Lecture Notes in Computer Science, Springer
Maik
Stührenberg and Daniela Goecke (2008). SGF – An integrated model for multiple
annotations and its application in a linguistic domain. Presented at Balisage: The
Markup
Conference 2008, Montréal, Canada, August 12 - 15, 2008. In: Proceedings of Balisage:
The
Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01
Maik
Stührenberg and Daniel Jettka (2009). A toolkit for multi-dimensional markup: The
development
of SGF to XStandoff. In Proceedings of Balisage: The Markup Conference 2009. Balisage
Series
on Markup Technologies, vol. 3. doi:https://doi.org/10.4242/BalisageVol3.Stuhrenberg01.
Henry S. Thompson, David
Beech, Murray Maloney, and Noah Mendelsohn (2004). XML Schema Part 1: Structures Second
Edition. W3C Recommendation, World Wide Web Consortium (W3C). http://www.w3.org/TR/2004/REC-xmlschema-1-20041028/