Delpratt, O'Neil Davion, and Michael Kay. “The Effects of Bytecode Generation in XSLT and XQuery.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Delpratt01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
Balisage Paper: The Effects of Bytecode Generation in XSLT and XQuery
Dr Delpratt is a software developer at Saxonica. Before joining Saxonica, he
completed his post-graduate studies at the University of Leicester. His thesis
title was 'In-memory Representations of XML documents', which coincided with a
C++ software development of a memory efficient DOM implementation, called
Succinct DOM.
Michael Kay has been developing the Saxon product since 1998, initially as a
spare-time activity at ICL and then Software AG, but since 2004 within the
Saxonica company which he founded. He holds a Ph.D from the University of
Cambridge where he studied under the late Maurice Wilkes, and spent 24 years
with ICL, mainly on development of database software. He is the editor of the
W3C XSLT specification.
This paper attempts to analyze the performance benefits that are achievable by
adding a code generation phase to an XSLT or XQuery engine. This is not done in
isolation, but in comparison with the benefits delivered by high-level query
rewriting. The two techniques are complementary and independent, but can compete for
resources in the development team, so it is useful to understand their relative
importance. We use the Saxon XSLT/XQuery processor as a case study, where we can now
translate the logic of queries into Java bytecode. We provide an experimental
evaluation of the performance of Saxon with the addition of this feature compared
to
the existing Saxon product. Saxon's Enterprise Edition already delivers a
performance benefit over the open source product using the join optimizer and other
features. What can we learn from these to achieve further performance gains through
direct byte code generation?
Many modern compilers generate code in an intermediate representation which is then
interpreted by a virtual machine. One of the best known examples is Java: its
intermediate code (known simply as bytecode) has proved flexible enough to be used
as a
target by many other high-level languages, allowing these languages to be mixed in
the
same Java Virtual Machine (JVM). XSLT and XQuery are no different from other languages
in this respect, and a number of processors for these languages have used code
generation to boost performance. There are few reports, however, that enable the
effectiveness of this technique to be assessed, largely because of the difficulty
in
attributing performance differences to one particular optimization technique. This
paper
attempts to evaluate the impact of introducing code generation into the Saxon processor,
enabling such a comparison to be made.
One well-known XSLT processor that compiles queries to Java bytecode is XSLTC [XSLTC]. [XSLTC] at a superficial level works by
parsing the XSLT into an Abstract Syntax Tree (AST) which then goes through a
type-checking phase before being compiled into Java bytecode. The output is a so-called
translet class which can be used for
transformations or saved to disk for re-use later. For XSLTC (which is distributed
as
part of the Apache Xalan-J package), the aim is not only to deliver enhanced performance
in the runtime execution of queries, but also to produce a compact executable (the
translet) which can be readily shipped around the network and executed anywhere.
Code generation is also believed to be used in a number of proprietary XSLT
processors, such as the Datapower processor [DataPower] and
Microsoft's .NET processor. However, no technical details of these products have been
published in the literature.
Saxon first introduced Java code generation as long ago as version 4.2 [Kay1999] (some six months before XSLT 1.0 was published in 1999).
However, this proved to be something of a blind alley, since it became clear that
much
greater performance gains could be realized through other optimization techniques,
and
that the existence of a code generator actually made these techniques more difficult
to
introduce. The architecture of Saxon at this time was to interpret the DOM of the
source
stylesheet directly instead of building an expression tree. This design made it
impossible to do any extensive optimisation rewrites, as it is done now. One of the
present authors [Kay2006a] argued that high-level
optimizations are more important, and that compiling expressions to bytecode might
reduce the scope for high-level optimizations, if only by making them more complex
to implement and debug.As a result, the code generation was "shelved" while
the architecture was changed to introduce tree rewriting.
Eventually code generation re-emerged in version 8.9 (Feb 2007), supporting XQuery
only. It still took the form of Java source code generation, rather than bytecode
generation. But it cannot be counted a great success: we are aware of very little
usage.
This is for several reasons:
From a user perspective the generation of java source code is cumbersome,
requiring three phases: firstly they must generate the Java source code to a
file, then the Java source must be compiled, and finally the query can be
executed.
The performance gains are modest (typically 25% improvement).
There are numerous restrictions concerning the subset of the language that
is supported in this mode.
This paper describes a new approach in which we hope to eliminate these problems.
In
particular, we believe that a 25% speed-up is not enough to encourage users to go
to a
great deal of effort in the way they execute their stylesheets and queries, but it
will
be much appreciated if it comes with no effort. There is a commercial factor which
motivates this: Saxon is distributed in two versions, a free open-source product and
a
commercial paid-for version. While the commercial Enterprise Edition already has many
features that users value, including features that can be used to deliver improved
performance, users are sometimes disappointed to find it does not always run faster
"out
of the box". Code generation is an obvious way to remedy this, and ensure that users
who
pay their dues get some immediate benefit, with no need to change a single line of
code.
Our objectives in adding code generation to Saxon are rather different from those
for
XSLTC, and this affects the approach we have adopted. In particular, we are not
primarily interested in producing an executable that can be saved to disk or sent
around
the network. Rather, we want to integrate code generation and interpretation closely,
so
that we only generate code where there is a performance benefit to be gained, and
continue to interpret otherwise. This should ensure that there are no language
restrictions or differences when using code generation; it allows development effort
to
be focused where the potential gains are largest; and it limits the extent to which
the
existence of a code generation phase working off the expression tree limits our freedom
to evolve the design of the expression tree itself when implementing new rewrite
optimizations.
The remainder of this paper is organized as follows. Firstly, we discuss the
high-level optimization of Saxon. Secondly, we discuss the bytecode generation feature
of Saxon. Then we give an experimental evalaution of the running time performance
of
bytecode generation compared to Saxon interpreted mode. We base our experiments on
the
XMark benchmark queries, and conclude our findings.
High-level Optimization
The Saxon XSLT/XQuery processor includes a number of internal processes to compile,
simplify and execute queries or stylesheets efficiently. In our discussion we will
only
make reference to XQuery, however in the Saxon internals very similar processes apply
to
XSLT.
Queries are parsed by a XSLT/XQuery compiler into a Abstract Syntax Tree (AST), which
is a in-memory expression tree structure representing the logical structure of the
query. In the case of XSLT, this tree combines the two sublanguages, XSLT and XPath,
into a single integrated structure. References to variables and functions are largely
resolved during parsing, an operation that is only slightly complicated by the fact
that
forwards references are permitted. Saxon then perfoms three optimization steps to
produce the final AST that is interpreted at runtime. The first step is the
normalisation of the AST, the second step is the type checking of the sub-expressions,
and the third is expression rewriting. Detail of these are provided in the literature
[Kay2008], [Kay2006b] and [Kay2005]. We summarize these steps below.
The optimizations require several depth-first traversals of the tree. In Saxon a
visitor object provides a depth-first navigation of the expression tree. This class
supports the various optimization steps involved in the processing of an expression
tree, as it requires a recursive walk visiting each node in turn. A stack is also
maintained as each node is visited, which holds the current ancestor nodes. The
expression tree consists of many kinds of expression nodes, each of which implement
the
Expression interface. (This is the classic Interpreter design pattern.) The Expression
class contains three important methods: simplify,
typeCheck and optimize.
Normalisation. As in databases this is an important
step, where we minimize redundancies in queries. In Saxon the expression
visitor is used to walk the tree. At each expression node the simplify method is called on its child
sub-expressions before normalisation is applied if required. It is possible
that at each node the simplify method may be called
several times after the re-writing of sub-expressions. For example, the
XPath a/b/c is rewritten to docOrder(a!b!c), where
docOrder is an operator that eliminates duplicates and sorts into document
order, and ! is a simple mapping operator which evaluates
c once for each item in b, which in turn is
evaluated once for each item in a.
Type Check. As we traverse the expression tree each
sub-expression node is type checked. Here checks are performed on the
operands of the expression, whether the static types of the operands are
known to be subtypes of the required type. [Kay2006b]
details several possible outcomes in the process: The static type is a
subtype of the required type, then no further check is required, or some
instances only are instances of the required type, here a node is inserted
in the tree to indicate run-time type check required. The other possiblility
is that the static type and the required type are disjoint, therefore Saxon
generates a type error at compile time. Saxon also performs atomization
conversions, such as casting of untypedAtomic values. It also removes any
redundant conversions, such as casts written by the user.
Expression Rewriting (Optimization). The optimizing
of XSLT stylesheets, XQuery and XPath expressions is a well studied area,
which has provided implementations significant performance gains. In [Kay2007] and [Snelson2011] there is a
detailed study of the main optimization techniques, some of which are used
in Saxon. The rewrite of expressions is achieved in the
optimize method, requiring a third pass of the
expression tree. Saxon performs join optimization (familar in database
languages), by replacing predicate expressions with key indexes. There are
other techniques such as function inlining and the optimization of tail
recursion, which is familar in functional programming languages. This is
another area where Saxon differentiates the commercial product from the free
open-source product: many of the more advanced optimizations are available
in the Enterprise Edition only.
Each of these phases adds information to the tree. The most obvious information is
the
inferred static type of each expression, but there are many other properties that
play
an equally important role: for example the dependencies of an expression on variables
or
on the dynamic context, and properties of node-sets such as whether they are known
to be
sorted and whether they can contain duplicates.
Bytecode Generation
We now discuss a new Java bytecode generation feature in Saxon, which we consider
as a
fourth step in the optimization processes discussed in Section 2. It directly replaces
the java source code generation feature provided in Saxon up to version 9.3. Here
we are
now generating the Java bytecode directly when compiling a query after it has been
optimized. Our approach is different to that in XSLTC because we are generating bytecode
selectively for expressions that are considered to have potential performance
improvements, so that interpreted code and compiled code interact freely. The fact
that
compiled code exists only transiently in memory means that it can refer to data
structures on the expression tree, rather than regenerating them at initialization
time.
In the longer term, this architecture also leaves the door open to just-in-time
compilation (or hotspot compilation) based on observed execution patterns at
run-time.
There are a number of Java class manipulation tools available (see Bruneton2002). One of the most widely used of these tools is BCEL [Dahm1999, Bruneton2002]. In this tool the class
modification is achieved in a three part process: The bytecode representing the class
is
deserialized into a constructed class structure in memory, with a object created for
each node, right down to the bytecode instructions. This structure is then manipulated
in the second phase. The third phase is to serialize the modified object structure
into
a new byte array.
We chose instead to use the ASM [Bruneton2002] framework library
tool to generate bytecode for queries. ASM [Bruneton2002] claims to be
smaller and to give better performance than other tools. Where BCEL builds a DOM-like
tree representation of the code, ASM works using a series of SAX-like streaming passes
over it. There are other Java class manipulation tools which we only mention here
such
as SERP, JIOE: these are described in [Bruneton2002]. We have not done
any experimental anaylsis of the Java class manipulation tools nor is there scope
in
this paper to provide an anaysis of these tools. Nevertheless, we have chosen the
ASM
library based upon [Bruneton2002], due to the simplicity of the tool
and our requirement which only relied upon a small part of the library to dynamically
generate bytecode in the runtime of queries.
The bytecode generation process has as input an AST, optimized to a greater or lesser
extent in earlier phases depending on the Saxon product that is used. The top-level
expression in each function or XSLT template is compiled into an equivalent Java
bytecode class. We call this a CompiledExpression: it is
constructed as we traverse the AST and can be evaluated at runtime. If the expression
cannot be compiled, perhaps because it uses unusual language constructs, it is simply
interpreted instead: but its subexpressions can still be compiled. The structure of
the
CompiledExpression is as follows: Firstly we generate static
variables which have been initialised. As mentioned above, we are generating transient
bytecode that works interchangably with interpreted code. The static variables in
the
generated code contain references to data on the expression tree: either whole
expressions, or helper classes such as node tests, comparators, converters, and the
like. For example, the NodeTest object, which provides XSLT pattern
matching, acts as a predicate in axis steps, and also acts as an item type for type
matching, is stored as a static variable available for use in the bytecode generated.
As discussed in [Kay2009] and [Kay2010], Saxon can
execute internally in both pull and push mode.
In pull mode, an expression iterates over the data supplied by its child expressions;
child expressions therefore implement an iterate()
method which delivers results incrementally to the caller. In push mode, an expression
writes SAX-like events to an output destination (a Receiver). Choosing between pull and push mode can make a substantial
difference to performance: during development, when we have observed situations where
compiled code was outperformed by interpreted code, it was generally because the
interpreter was making better decisions on when to pull and when to push. The compiled
code therefore needs to work in both modes, so each
CompiledExpression has two methods: an
iterate method to deliver results to its caller, and a
process method to write events to a Receiver. A third method,
evaluateItem(), is provided for single-shot
evaluation of expressions that always return a singleton result. Of course in many
cases
these methods will share common logic.
Architecture of Java bytecode generator
The ExpressionCompiler is an abstract class which represents
the compiler (that is, Java bytecode generator) for a particular kind of expression
on the expression tree. The ExpressionCompiler classes are used
to build the CompiledExpression class in bytecode, traversing
the expression tree in depth-first manner: there is a one-to-one correspondence
between the classes implementing the expression on the expression tree and the
compiler object used to generate Java code fragments[1]. The following methods are supplied to compile expressions; exactly one
of them is called, depending on the context in which the expression appears:
compileToItem - Generate bytecode to evaluate the expression as an Item
compileToIterator - Generate bytecode to evaluate the expression as an Iterator.
compileToBoolean - Generate bytecode to evaluate the expression as a boolean.
compileToPush - Generate bytecode to evaluate the expression in push mode.
compileToLoop - Generate bytecode to evaluate the expression in such a way that
the supplied loop body argument is executed once for each Item.
compileToPrimitive - Generate bytecode to evaluate the expression as a plain Java value
(e.g. int, double, String). This method must only be called if the
target type of the expression is known statically.
Within each kind of expression one or more of the methods above is implemented.
For example, the exists() function delivers a
boolean value so we implement the compileToBoolean
method. To understand why compiled code is sometimes faster than interpreted code,
it is useful to examine this example in some detail. Essentially, compiled code will
only be faster than the interpreter if decisions can be made at compile-time than
would otherwise be made at execution time. There are many cases where this is simply
not possible: for example, code that is dominated by string-to-number conversion
will gain no speed-up from compilation, because the actual code executed is
identical whether it is compiled or interpreted. Making decisions at compile time
is
only possible where the information needed to make those decisions is present in the
expression tree. For example, for the exists()
function we compare its compileToBoolean method to
the interpreted code and the Java source generation below. The simple query
exists(.) generates the following bytecode in push mode (simplified
only to remove diagnostic information used by the debugger):
public process(Lnet/sf/saxon/expr/XPathContext;)V
L0
// Get the Receiver to which output will be sent
ALOAD 1 // the XPathContext object
INVOKEINTERFACE net/sf/saxon/expr/XPathContext.getReceiver ()Lnet/sf/saxon/event/SequenceReceiver;
ASTORE 2 // local variable holding the current Receiver
ALOAD 2
L1
L2
// Get the context item (evaluate ".")
ALOAD 1 // the XPathContext object
INVOKEINTERFACE net/sf/saxon/expr/XPathContext.getContextItem ()Lnet/sf/saxon/om/Item;
DUP
// Generate an error if no context item is defined
IFNONNULL L3
NEW net/sf/saxon/trans/XPathException
DUP
LDC "Context item for '.' is undefined"
LDC "XPDY0002"
INVOKESPECIAL net/sf/saxon/trans/XPathException.<init> (Ljava/lang/String;Ljava/lang/String;)V
DUP
GETSTATIC CE_main_671511612.nContextItemExpression0 : Lnet/sf/saxon/expr/ContextItemExpression;
INVOKEVIRTUAL javax/xml/transform/TransformerException.setLocator (Ljavax/xml/transform/SourceLocator;)V
ATHROW
// Load "true" (1) or "false" (0) depending on whether the value is null
L3
IFNULL L4_returnFalse
ICONST_1 //Load true (1)
GOTO L5
L4_returnFalse
ICONST_0 //Load false (0)
L5_endExists
// Convert the result to a Saxon BooleanValue object and send it to the Receiver
INVOKESTATIC net/sf/saxon/value/BooleanValue.get (Z)Lnet/sf/saxon/value/BooleanValue;
INVOKEVIRTUAL net/sf/saxon/event/SequenceReceiver.append (Lnet/sf/saxon/om/Item;)V
RETURN
}
It is interesting to compare this with the java source code generated for the same
query exists(.) using Saxon 9.3:
public void process(final XPathContext context) throws XPathException {
SequenceReceiver out = context.getReceiver();
if (context.getContextItem() == null) {
dynamicError("The context item is undefined", "XPDY0002", context);
}
final boolean b0 = (context.getContextItem() != null);
out.append(BooleanValue.get(b0), 0, NodeInfo.ALL_NAMESPACES);
}
The
logic is very similar, and in fact the bytecode generated when this Java source code
is compiled is very similar too (just fractionally less efficient because of the
unnecessary boolean variable b0). See the bytecode of the Java
source code in Appendix A, which can be compared with the generated
bytcode above. Thus for a typical query, the new bytecode generation feature does
not provide noticeable performance benefits over the generated java source from
Saxon 9.3. However from a usability point-of-view, the advantage is that there is
no
need to compile and run the java program source code, which makes all the difference
for a typical user.
It's also worth noting that the logic in Saxon to generate the bytecode is not
significantly more complex than the logic that was used to generate Java bytecode.
All the complexity is in the ASM library. Debugging the logic when it is incorrect
can be a little harder however (diagnostics are not ASM's strongest feature).
Experimental Evaluation
In this section we draw comparisons of the running time performance between
interpreted code and generated bytecode. An important aim is to compare the impact
of
code generation with the impact of high-level rewrite optimizations: to this end we
run
with four configurations, both features being switched on or off. (In the released
product, neither feature will be available in the open source Saxon-HE, and by default
both will be enabled in Saxon-EE).
Setup
We used Saxon 9.3.0.4 as the baseline. The test machine was a Intel Core i5
processor 430M laptop with 4GB memory, 2.26Ghz CPU and 3MB L3 cache, running Ubuntu
10.04LTS Linux. The compiler was Sun/Oracle Java 1.6.0.2. The experiments are based
on the XMark benchmark [XMark]. We use the XMark XQuery queries
numbered q1 to q20, and synthetically generate several XML data files from [XMark], these being of sizes in the range 1MB to 64MB.
Running Times
The 20 XMark queries are run repeatedly up to 1000 times or until 30 seconds
have elapsed, and we record the average time spent to complete the runs, using
the system clock in Java. [Appendix B] shows the complete
running times. We show these for Saxon-HE, Saxon-Bytecode, Saxon-EE and
Saxon-EE-Bytecode (that is, with weak optimization and no code generation; with
weak optimization plus code generation, with strong optimization and no code
generation, and with strong optimization followed by code generation). We
compare the running times of the Saxon-EE product for the interpreted code and
bytecode. We found on average over all files that bytecode generation gave
between 14% and 27% improvement.
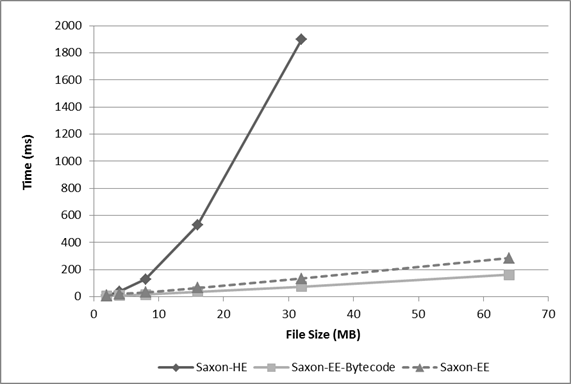
Figure 1: Scalability test. Running time performance for different file sizes on
query 10
Scalability test: For Saxon-HE, Saxon-EE and Saxon-EE-Bytecode the
timing results of running the XMark benchmark query 10 on XMark
generated data files of sizes 2MB, 4MB, 8MB, 16MB, 32MB and 64MB. For
Saxon-HE the running time for the 64MB data file is omitted as it goes
off the graph.
In Figure 1, we show a graph of the scalability of running
the query 10 on the XMark data files of sizes ranging from 2MB to 64MB with
Saxon-HE, Saxon-EE and Saxon-EE-Bytecode. In Saxon-EE and Saxon-EE-bytecode the
timing results show a linear growth as files become larger in size. For Saxon-HE
we observe a quadratic growth: this shows up the absence of join optimization in
the Saxon-HE product.
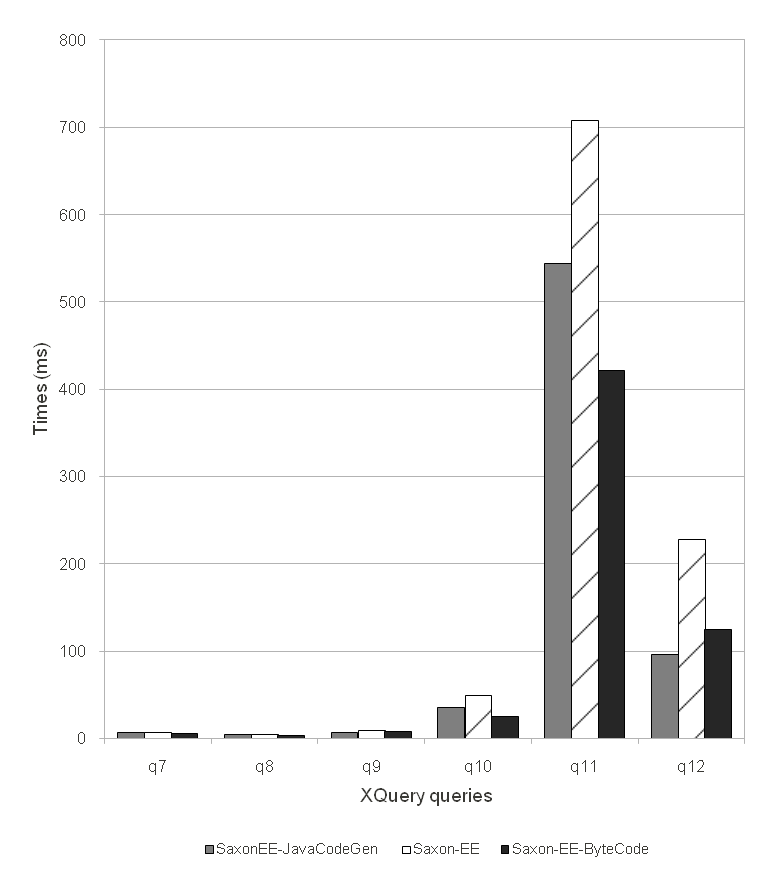
In Figure 2 and in Table III in Appendix B we observe that for certain queries the performance of
bytecode generation is well above average. Queries 8, 10, 11 and 12 gave
improvements between 35% and 50%. We compare the Saxon-EE products with the
feature of Java code generation (Saxon-EE-JavaGen, featured in Saxon 9.3), the
interpreted code and bytecode. Again we see an overall improvement over the
intepreted code, but we observe similar results for Java code generation and
bytecode generation, the difference being approximately 10% on average over all
queries.
Effect of Optimization Rewrites
Comparison of the timings for different data sizes shows that with weak
optimization, queries 8, 9, 10, 11 and 12 have performance that is quadratic in
the data size; with strong optimization, only query 11 is quadratic. This is
because queries 8, 9, 10 and 12 are equijoins, whereas query 11 is a
non-equijoin which the Saxon optimizer cannot handle well.
Figure 2: XQuery Queries Running Times (10MB data file)
For Saxon-EE-JavaGen (Java Generation in Saxon 9.3), Saxon-EE
and Saxon-EE-Bytecode the timing results of running XMark benchmark
query 7, 8, 9, 10, 11 and 12 on a 10MB XMark generated data
file.
Using Hand-written Code as a Benchmark
In the previous sections we've concentrated on comparing the performance of compiled
queries and stylesheets with the same queries and stylesheets run under the interpreter.
But there's another technique we have found useful, which is to compare the performance
of a compiled query with hand-written Java code performing the same task. The
performance of the hand-written code sets a target to aim for, and provides a measure
of
how much room for improvement is available.
The results show great variation between different queries, which is useful
information in itself. Here we'll consider two simple queries.
The first computes the average income of buyers recorded in the XMark dataset: we're
running the query
avg(//profile/@income)
against the
10Mb version of the dataset.
The Saxon interpreter runs this in an average of 792ms. Currently, when compiling
to
bytecode, the improvement is quite modest: average time is 768ms.
The same query coded in Java looks like this:
NodeInfo root = doc.getUnderlyingNode();
AxisIterator descendants = root.iterateAxis
(net.sf.saxon.om.Axis.DESCENDANT,
new NameTest(Type.ELEMENT, profileNC, pool));
NodeInfo profile;
double total = 0;
int count = 0;
while ((profile = descendants.next()) != null) {
String income = Navigator.getAttributeValue(profile, "", "income");
if (income != null) {
total += Double.valueOf(income);
count++;
}
}
The execution time for this code is 690ms. So we see that the interpreter is already
almost as fast as the hand-written Java code. On the assumption that generated bytecode
will rarely be better than hand-written Java code, there is little headroom available
for the code generator to make a significant impact. It's easy to see why this should
be
the case: the query is spending nearly all its time (a) searching the descendant axis
for <profile> elements, and (b) converting
attribute values from strings to numbers. These two operations are done by library
routines that execute exactly the same code whether it is run under the XQuery
interpreter, the XQuery code generator, or the hand-written Java code. Both routines
have been carefully tuned over the years and there is little scope for improvement;
neither is doing any work that doesn't absolutely need to be done.
Our second query is rather different. This one doesn't in fact process any XML, so
one
could argue that it is atypical; but as a fragment within a larger query it is code
that
one might well encounter:
sum(for $i in 1 to $p return xs:double($i)*xs:double($i))
Here, with $p set to 100000, the XQuery interpreter executes the query in 29.4ms.
The
equivalent hand-written Java code is
and
this executes much faster, in just 1.2ms. So this time there is a lot more headroom,
a
lot more scope for the code generator to make a difference. Our first version of the
code generator in fact made no difference at all to the execution time of this query
(a
mere 1% improvement, which is within the range of experimental error). It's not
difficult to see why: the generated code was essentially an inlined version of the
same
instructions that the interpreter was executing, except for a very small amount of
control logic to walk the expression tree. Comparing this with the hand-written code
in
this case shows us that we can do a lot better. There is no reason in principle why
the
XQuery code should not run just as fast as the Java code. We're not quite there yet,
but
we have improved it to around 12ms. One technique that proved useful in achieving
this
was to write a Java program that executed the same logic as the XQuery-generated
bytecode, and to measure the effect of making a variety of improvements to it: this
exercise showed where it would be worthwhile to invest effort. The two areas that
account for the improvement are:
Removal of unnecessary boxing and unboxing operations. Saxon generally
wraps simple values such as integers, strings, and booleans in a wrapper
(IntegerValue, StringValue, and BooleanValue, all subclasses of AtomicValue)
so they can all be manipulated using polymorphic methods. This means that
multiplying two doubles to produce another double involves not only the
multiplication, but two unboxing steps and one boxing step. Eliminating
these operations accounted for around half the improvement.
Removal of unnecessary mapping iterators. The way this query is executed
in the interpreter is to create an iterator over the integers 1 to 100000;
the results of this iterator are piped into a mapping iterator which applies
a mapping function to each value, this being the expression xs:double($i)*xs:double($i); and the resulting
doubles are then piped to the sum() function, which reads through the
iterator and totals the values. Inverting this structure to a loop where a
running total is incremented in the body of the loop, as in the hand-written
Java solution, accounts for the other half of the improvement.
The lessons from this exercise are firstly, that there are some execution paths where
it is very hard to improve performance because it is already very close to optimal;
but
that there are other operations that still leave much room for improvement, and one
good
way to identify this is to compare the system-generated code with hand-written Java
code
that performs the same task.
Conclusion
The purpose of this paper was to study the performance benefits that can be achieved
by adding a code-generation phase to an XSLT or XQuery processor. To do so, we examined
these side-by-side with the benefits achieved by high level optimization rewrites.
The
two techniques are orthogonal to each other, in that one can do either or both, but
it
is interesting to analyze which delivers better improvements in relation to the
cost.
In the best case (or the worst case, depending on how you look at it), optimization
rewrites can turn a query with quadratic performance into one with linear performance.
This is something code generation can never aspire to. This therefore vindicates the
approach that has been taken in Saxon of putting aside work on code generation until
the
high-level optimizer had achieved a sufficient level of maturity.
The conclusion of our study is that compiled code can be expected to run about 25%
faster than code executed under an optimal interpreter, but the improvements can be
greater (up to 50% in our case) when the interpreter is less than optimal or when
the
individual expressions on the expression tree are performing tasks such as arithmetic
operations or numeric comparisons whose execution time is small in comparison to the
overhead of the control logic for invoking them.
For Saxon, the extra 25% is well worth achieving, since there are many users with
demanding workloads, and since the business model for the product relies on the
development being funded by revenue from the small number of users with the most
demanding requirements. For other products, the trade-off might be different: in
particular the message from this study is that code-generation is something you should
do only when all other opportunities for performance improvement have been
exhausted.
Appendix A. Bytecode of generated Java source code
Using Saxon 9.3.0.4 generated Java code for the simple query exists(.) we
show its byte code using the tool javap with option
-c:
Appendix B. Running times of the 20 XMark XQuery queries
The following three tables show running times of the 20 XMark XQuery queries. Each
query is executed 1000 or until 30 seconds have elapsed, whichever comes first. The
average is time reported in micro-seconds. We show results for Saxon-HE (no
optimization), Saxon-Bytecode (no optimization, with bytecode generation), Saxon-EE
(with optimization), Saxon-EE-JavaCode (with optimization and java source code
generation) and Saxon-EE-Bytecode (with optimization and bytecode generation). We
also
show the Saxon-EE-Bytecode speedup as percentages with respect to Saxon-EE times.
The
fastest Saxon configuration for each result is set in bold font.
Table I
Running Times, with 1MB data file
Query
Saxon-HE
Saxon-Bytecode
Saxon-EE
Saxon-EE-Bytecode
Bytecode speedup (%)
q1
0.363
0.394
0.095
0.080
NEG
q2
0.456
0.452
0.473
0.432
9%
q3
0.547
0.450
0.606
0.416
31%
q4
0.308
0.296
0.443
0.380
14%
q5
0.183
0.127
0.176
0.144
18%
q6
0.181
0.208
0.177
0.166
6%
q7
0.773
0.717
0.773
0.626
19%
q8
15.468
12.630
0.491
0.458
7%
q9
19.401
15.833
1.313
1.058
19%
q10
4.639
4.128
4.180
2.329
44%
q11
7.688
5.984
7.533
4.957
34%
q12
2.926
2.226
2.918
1.812
38%
q13
0.138
0.137
0.146
0.152
-4%
q14
1.740
1.710
1.698
1.654
3%
q15
0.108
0.149
0.123
0.170
-39%
q16
0.162
0.161
0.262
0.274
-5%
q17
0.175
0.140
0.176
0.160
9%
q18
0.343
0.303
0.231
0.219
5%
q19
1.774
1.549
1.633
1.483
9%
q20
0.371
0.403
0.454
0.452
NEG
Table II
Running Times, with 4MB data file
Query
Saxon-HE
Saxon-Bytecode
Saxon-EE
Saxon-EE-Bytecode
Bytecode speedup (%)
q1
0.210
0.209
0.011
0.012
-7%
q2
0.408
0.329
0.416
0.417
NEG
q3
1.143
0.845
1.238
0.962
22%
q4
1.005
0.926
1.257
0.922
27%
q5
0.418
0.268
0.428
0.305
29%
q6
0.371
0.362
0.369
0.306
17%
q7
2.930
2.908
2.941
2.354
20%
q8
293.398
207.416
1.605
1.107
31%
q9
333.601
257.565
2.992
2.750
8%
q10
52.349
41.815
19.142
9.514
50%
q11
119.141
90.013
118.535
71.100
39%
q12
37.280
26.328
37.029
20.050
46%
q13
0.254
0.216
0.262
0.261
NEG
q14
6.531
6.181
6.489
6.011
7%
q15
0.325
0.294
0.382
0.434
-14%
q16
0.536
0.453
0.597
0.627
-5%
q17
0.632
0.501
0.700
0.537
23%
q18
0.692
0.601
0.577
0.517
10%
q19
4.613
4.164
4.517
3.638
19%
q20
1.428
1.397
1.689
1.449
14%
Table III
Running Times, with 10MB data file
Query
Saxon-HE
Saxon-Bytecode
Saxon-EE
Saxon-EE-Bytecode
Bytecode speedup (%)
q1
0.597
0.519
0.010
0.015
NEG
q2
1.067
0.820
1.130
0.880
22%
q3
3.415
2.505
3.63
2.54
30%
q4
2.8824
2.5606
3.66
2.43
34%
q5
1.0686
0.6742
1.08
0.76
30%
q6
0.9080
0.8893
0.90
0.76
16%
q7
7.487
7.403
7.55
6.03
20%
q8
1725.13
1295.78
5.00
3.26
35%
q9
2081.03
1534.66
10.1
8.168
19%
q10
325.35
276.57
49.74
25.16
49%
q11
701.79
539.59
708.45
421.38
41%
q12
228.34
162.37
228.38
124.48
45%
q13
0.66
0.58
0.70
0.59
16%
q14
15.57
15.23
16.03
14.73
8%
q15
0.77
0.72
0.94
1.05
-12%
q16
1.28
1.11
1.50
1.39
7%
q17
1.59
1.26
1.77
1.27
28%
q18
1.86
1.62
1.57
1.29
18%
q19
12.85
12.12
12.64
10.90
14%
q20
5.32
3.64
5.92
3.74
37%
References
[Bruneton2002] E. Bruneton et al. ASM: A code
manipulation tool to implement adaptable systems. In Proceedings Adaptable and
extensible component systems, November 2002, Grenoble, France. http://asm.ow2.org/current/asm-eng.pdf
[1] It would have been possible to use the same class for both purposes: This
is a rare example of a distortion to the design caused by Saxon's need to
divide open-source from proprietary code.
E. Bruneton et al. ASM: A code
manipulation tool to implement adaptable systems. In Proceedings Adaptable and
extensible component systems, November 2002, Grenoble, France. http://asm.ow2.org/current/asm-eng.pdf
Snelson, John. Declarative XQuery
Rewrites for Profit or Pleasure. An optimization meta language for implementers and
users alike. In Proceeding XMLPrague 2011, March 2011, Prague,
Czech Republic. http://www.xmlprague.cz/2011/files/xmlprague-2011-proceedings.pdf