Latterner, Martin, Dax Bamberger, Kelly Peters and Jeffrey D. Beck. “Attempts to modernize XML conversion at PubMed Central.” Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6, 2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Latterner01.
Balisage: The Markup Conference 2021 August 2 - 6, 2021
Balisage Paper: Attempts to modernize XML conversion at PubMed Central
Martin Latterner
National Center for Biotechnology Information, National Library of Medicine, National
Institutes of Health, Bethesda, MD 20894, USA.
Martin Latterner is a Technical Information Specialist at the National Center for
Biotechnology Information at the US National Library of Medicine. He has been involved
in XML conversion for NCBI literature databases since 2008. Prior to coming to NCBI,
he worked at Alexander Street Press, an electronic publisher in the humanities.
Dax Bamberger
National Center for Biotechnology Information, National Library of Medicine, National
Institutes of Health, Bethesda, MD 20894, USA.
Dax Bamberger is a Technical Information Specialist at the National Center for Biotechnology
Information at the US National Library of Medicine. He just recently joined NCBI’s
XML conversion team, but has been working on XML conversion in the online scholarly
publishing field since 2000, with 19 of those years at HighWire Press.
Kelly Peters
National Center for Biotechnology Information, National Library of Medicine, National
Institutes of Health, Bethesda, MD 20894, USA.
Kelly Peters is a Technical Information Specialist at the National Center for Biotechnology
Information at the US National Library of Medicine. She joined NCBI as a journal manager
for PubMed Central in 2012. She then moved to working in XML conversion for NCBI literature
databases in 2014. Prior to coming to NCBI, she worked at CVPath Institute, Inc.,
as the head archivist.
Jeffrey D. Beck
National Center for Biotechnology Information, National Library of Medicine, National
Institutes of Health, Bethesda, MD 20894, USA.
Jeffrey Beck is a Technical Information Specialist at the National Center for Biotechnology
Information at the US National Library of Medicine. He has been involved in the PubMed
Central project since it began in 2000. He has been working in print and then electronic
journal publishing since the early 1990s. Currently he is co-chair of the NISO Z39.96
JATS Standing Committee and is a BELS-certified Editor in the Life Sciences.
Author’s contribution to the Work was done as part of the Author’s official duties
as an NIH employee and is a Work of the United States Government. Therefore, copyright
may not be established in the United States. 17 U.S.C. § 105. If Publisher intends
to disseminate the Work outside the U.S., Publisher may secure copyright to the extent
authorized under the domestic laws of the relevant country, subject to a paid-up,
nonexclusive, irrevocable worldwide license to the United States in such copyrighted
work to reproduce, prepare derivative works, distribute copies to the public and perform
publicly and display publicly the work, and to permit others to do so.
Abstract
PubMed Central® (PMC) is a free full-text archive of biomedical and life sciences
journal literature at the U.S. National Institutes of Health's National Library of
Medicine. PMC receives about 70,000 XML articles every month and uses XSLT to convert
them into its preferred format. In 2021, PMC started to explore options to modernize
its extensive conversion codebase leveraging XSLT 3.0. This paper describes XML conversion
and its challenges at PMC. It then outlines the first approach that PMC is evaluating:
breaking a single conversion operation into multiple, dynamic transformations using
fn:transform, one of the powerful new tools available with XSLT 3.0.
PubMed Central® (PMC) is a free full-text archive of biomedical and life sciences
journal literature at the U.S. National Institutes of Health's National Library of
Medicine (NLM). PMC converts about 70,000 full text XML articles per month. Over 750
submitters supply the source data in varying XML formats. Data providers are primarily
journal publishers, but also government organizations, non-governmental organizations,
or publishing vendors. The submitters deposit data packages to a dedicated FTP site.
The packages contain the full text article XML as well as corresponding PDFs, images,
and supplementary data files. PMC’s automated ingest process picks up the packages
and processes them into the PMC database. The process entails content repackaging
and validation as well as XML and image conversion. Once in a standard format, the
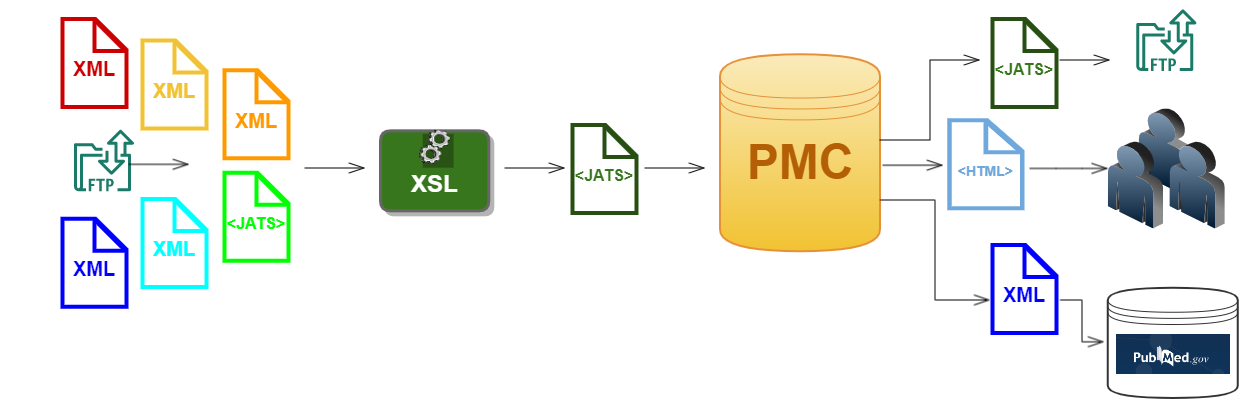
article XML can be made useful in multiple ways. First and foremost, PMC renders the
articles to HTML for its users to read. A subset of the XML, or derivations of it,
is also shared with other databases at the NLM and with the public.[1]
Figure 1
The PMC dataflow
Schema conversion
Over the years, PMC has received content in over 50 different SGML and XML DTDs and
schemas. In total, they amount to more than 250 different DTD versions. PMC converts
all incoming articles into its preferred format, the latest version of the Journal
Archiving and Interchange Tag Set, ANSI/NISO Z39.96 (JATS).[2] Transforming non-JATS articles into JATS is referred to here as “schema conversion”.
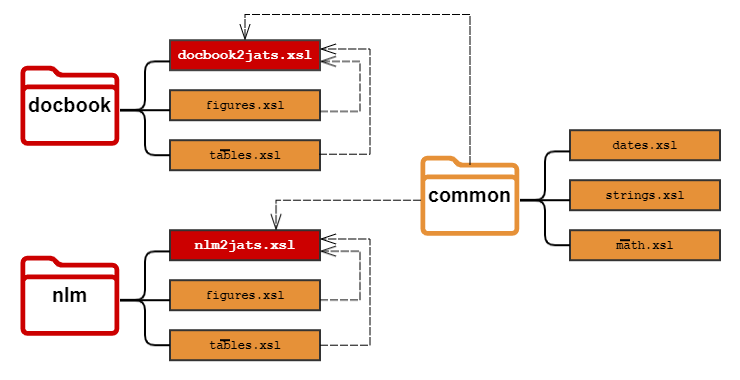
The main conversion work is performed by XSLT 2.0 stylesheets. The codebase is of
significant size, including about 200,000 lines of XSL in over 400 stylesheets. The
code is primarily organized by source XML schema. There is a repository for each major
submission DTD. It is supported by a set of “common modules”, a library of helper
templates and functions that are used across multiple conversions. A repository for
a specific DTD is itself broken down into several stylesheets. PMC organizes the stylesheets
by the major JATS elements that make up the conversion, for example front.xsl for all metadata, and body.xsl, figures.xsl, math.xsl, or xref.xsl for the main narrative. A main stylesheet includes all the modules and serves as
an entry point for the conversion.
Figure 2
Sketch of the current conversion infrastructure.
All XSLT converters are run by a single script. It starts by resolving the source
DTD or schema of an XML instance. This is done with the help of PMC’s XML catalog.
Knowing the source format, the script can then pick the appropriate XSLT to run. DTD
and XSLT are linked in a configuration file that contains other settings such as which
XSLT processor to run.
Example snippet from a PMC conversion configuration.
Converter maintenance consumes significant resources. A team of three to four XML
developers maintains the XSLT codebase, among other tasks. This includes bug fixes
as well as improvements necessary to accommodate new data suppliers or new DTD versions.
Changes are, of course, also necessary to address the evolving needs of PMC as a product,
its users, and its stakeholders. The codebase receives on average 70 updates per month.
The team operates at the intersection of production and development; reported bugs
and issues are addressed quickly. The team works against a rapidly rising and ebbing
backlog.
Frequent updates to a large codebase always pose the risk of bugs and regression.
A conversion testing framework helps to minimize this risk. For unit testing, PMC
has integrated XSpec into its development workflow.[3] To avoid regression, PMC employs a simple article testing mechanism. A baseline
test set of articles exhibiting varying features is converted with the production
version of the XSLT and with the modified XSLT. The converter output is then normalized
to remove insignificant differences such as the order of attributes or irrelevant
whitespace. A simple text diff compares the production version with the development
version. The differences are then made available for review in an HTML report. If
the changes are expected, then the developer accepts them into a new baseline. If
they look wrong, then the developer needs to fix the code. All tests run automatically
again prior to deployment of the updated XSLT. At this stage, any differences will
count as an error, just like any failed XSpec test. Deployment will be aborted, and
the development group will be notified of the problem.
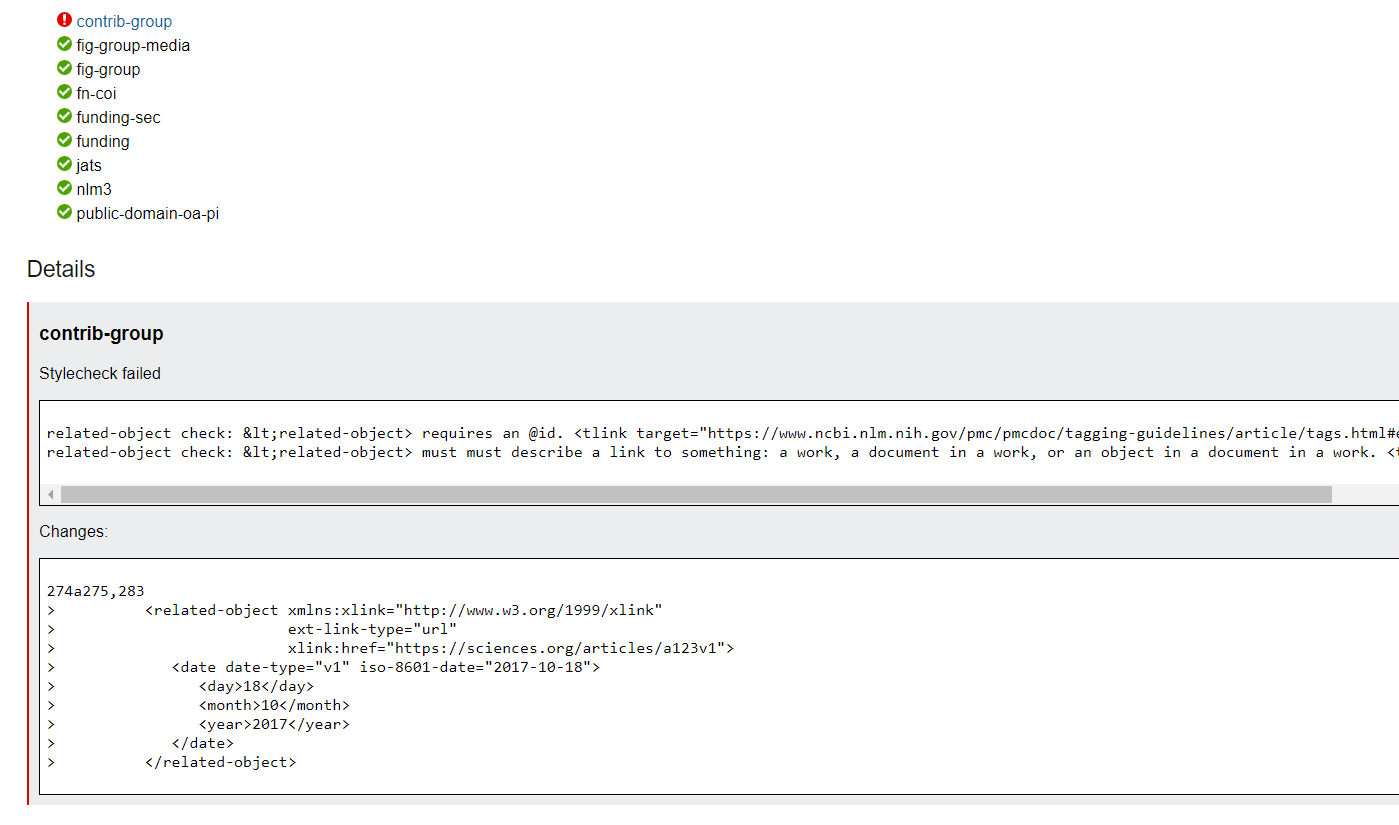
Figure 4
Sample of a PMC regression test report. The report shows that a converter change produced an extra <related-object> element. It also alerts to the fact that the markup is not PMC-style compliant.
Data normalization
The output XML must conform not only to JATS, but also to PMC’s own markup rules,
documented in the PMC tagging guidelines and enforced by the PMC style-checker.[4, 5] The latter is an XSL-based validation tool. It checks for poor markup and “common
sense” quality issues, such as empty formatting elements or links without pointers.
It also enforces PMC-specific restrictions on markup such as attribute values or JATS
element structures. XML conversion at PMC is, to a large degree, data normalization.[6]
The high volume of incoming content means a great variety of tagging flavors, conventions,
and styles. Different publishers may maintain proprietary lists of attribute values
such as for article types or link types. PMC needs to map each of these to its own
supported list. Article publication dates are another area that requires a lot of
work. Different publishers use different elements and qualifiers to describe their
publication models. PMC needs to standardize all these dialects so that the downstream
systems can understand the dates. Variations may even exist within a single publisher;
for example, one large data supplier has tagged license statements in 13 different
places over the years.
The converters also spend a lot of effort standardizing core metadata and objects
that are of elevated interest to PMC stakeholders and users. These may include license
statements, supplementary material, or data availability statements. For downstream
applications to make good use of the content, it is essential to standardize markup
and reduce variability. A good example is conflict of interest statements (COIs).
In 2016, prominent voices in the research community highlighted the importance of
proper disclosure of conflicts in research papers.[7] This culminated in a letter by five U.S. senators urging the inclusion and display
of COIs in PubMed, NLM’s citation database. PMC submits a subset of citations to PubMed.[8] Therefore, it was necessary to identify and standardize the varying methods of tagging
COIs in conversion. Unsurprisingly, different publishers use many ways to mark up
COIs. They may come as footnotes, article notes, sections, or dedicated elements.
Generic elements are typed with varying qualifiers, such as “conflict”, “COI”, “coi-statement”, “disclosure”, etc. XML conversion at PMC means identifying these variations and reducing the
complexity to a more manageable way of handling markup options.
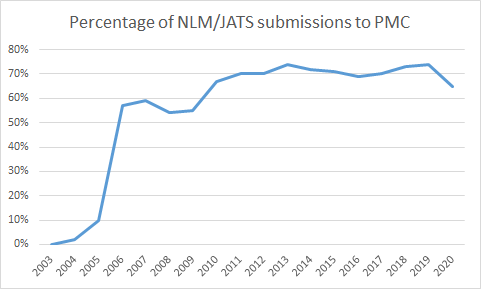
Data normalization has become increasingly important as PMC has evolved. This is also
related to an ongoing trend: the adoption of JATS as the de facto industry standard
in scholarly publishing. Publishers are increasingly abandoning their proprietary
journal article DTDs and switching to JATS. For PMC, this means that the converter
for the JATS DTD family needs to handle an ever-increasing volume of submitters and
tagging flavors while other converters go dormant. Not having to deal with a multitude
of vocabularies is naturally a welcome development. PMC finds it much easier to deal
with an article tagged in JATS than to deal with a DOCBOOK article. The former is,
however, not simply ready for ingest. Getting it into the PMC tagging style still
requires conversion work. The shift to JATS means a shift in focus from strict “schema
conversion”, meaning the translation of one vocabulary into another, to data normalization.
Figure 5
Percentage of articles submitted in the JATS DTD family and its predecessor, the NLM
Journal Archiving and Interchange Tag Suite.
Challenges
PMC’s approach to XML conversion has remained remarkably stable over the years. In
many respects, the transforms work just like in the early days of PMC, even though
the volume is many times what it used to be. PMC undertook the last significant modernization
project beginning in 2009, when all converters were upgraded from XSLT 1.0 to XSLT
2.0. This mammoth project was a game changer, as the capabilities of XSLT 2.0 far
outdo those of its predecessor. In 2019, PMC implemented a new framework for automatic
testing of all changes as described above. This helped minimize bugs and regression,
but it did not reform the codebase itself.
The stability of PMC’s approach to XML conversion is certainly a sign of success.
It has worked well for almost 20 years, as PMC grew from two journals to over 7 million
articles. However, XML conversion at PMC is not without challenges. To a large degree,
it exposes the typical problems of any large, aging, and still-growing codebase. Over
the years, many conversion templates have grown increasingly complex. Staff turnover
has also had an impact. Contributions of developers with different skill levels and
varying coding styles naturally led to inconsistencies and, over time, impacted readability.
As a result, it is not always possible to code a bug fix or an improvement in the
most efficient manner, as this would require refactoring larger related swathes of
XSLT. Challenges like this, sometimes referred to as “code rot” or “software entropy”,
are not particular to XML conversion at PMC.[9] Any development shop will eventually experience them in one form or another.
A more PMC-specific problem is the shift from schema conversion to data normalization
as described above. The converter that handles JATS submissions needs to account for
an ever-increasing number of new suppliers. XML conversion at PMC has been set up
for “schema conversion”, but by now it is doing much more than this. To understand
the challenges PMC faces, consider the following template which illustrates the kind
of data normalization the PMC codebase performs:
<xsl:template match="DOI">
<xsl:choose>
<xsl:when test="$publisher = 'Publisher A'">
<!-- Skip it: They use <DOI> to capture the DOI of the whole journal,
the actual article DOI is in <ArtID> -->
</xsl:when>
<xsl:when test="$publisher = 'Publisher B' and
$article-type = 'book-review'">
<!-- They issue one DOI for all book reviews, but send us each
individual review as a separate article
do not capture as "doi" to avoid duplicates in the PMC system
-->
<article-id pub-id-type="publisher-id">
<xsl:value-of select="."/>
</article-id>
/xsl:when>
<xsl:when test="normalize-space(.) = ''">
<!-- Empty: ignore -->
</xsl:when>
<xsl:when test="starts-with(., 'http://dx.doi.org/')">
<!-- Do not capture the URL portion -->
<article-id pub-id-type="doi">
<xsl:value-of select="substring-after(.,'http://dx.doi.org/')"/>
</article-id>
</xsl:when>
<xsl:otherwise>
<!-- All good! -->
<article-id pub-id-type="doi">
<xsl:value-of select="."/>
</article-id>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
This template performs several functions in one:
It converts the source <DOI> element into JATS, thus performing strict “schema conversion”.
Additionally, it normalizes output to comply with PMC tagging style by removing empty
DOI elements. Additionally, the article-id element for DOIs must contain only the
identifier string and not a full URL.
Lastly, it takes care of publisher-specific idiosyncrasies addressing usage that is
uncommon or that will present problems in the PMC system.
The above template does not contain difficult XSLT. PMC’s challenge, however, is the
growing volume and variability: these four tests could easily grow to 40 tests. Over
time, this leads to a complexity that becomes harder and harder to maintain.
A new approach with XSLT 3.0
The increased complexities of many converters and the shift from schema conversion
to data normalization coincided with the release of XSLT 3.0 in 2017. These factors
led PMC to explore options for modernizing the conversion codebase. Before weighing
approaches, a few basic requirements were formulated:
The conversion group did not want to embark on a complex and linear modernization
project fully consuming all resources. Rather, it envisioned a gradual transition
in many small steps.
One goal was to disentangle the different tasks that the converters perform (schema
conversion and data normalization). To make the converters simpler and more scalable,
it was deemed especially valuable to separate conversion rules for just a subset of
publishers or journals from the general rules applying to all the source documents.
It was recognized that intense, continuing maintenance is a reality that needed to
be factored in. XSLTs at PMC are not written once and then run with minimal intervention.
Rather, they undergo continuous updates. Therefore, easy maintenance is a primary
goal. When dealing with a bug, for example, the developer should be able to quickly
find and understand the problematic piece of code.
XSLT 3.0 exhibits many great new features. One function, however, is particularly
well-suited for achieving these goals: fn:transform allows a stylesheet to invoke another, dynamically loaded conversion. The ability
to call one XSLT from within another XSLT makes it very easy to separate concerns
and build a more modular conversion architecture.
Importantly, fn:transform can easily wrap around the legacy converters. As described above, PMC picks converters
by source DTD. Switching all JATS articles at once to a new codebase would constitute
a dramatic change and require a long period of prior testing. With fn:transform, however, it is possible to define smaller collections of articles on the fly and
to choose whether to simply convert them with the “old” XSLTs, or whether to use a
new conversion approach. It is possible, for example, to start “switching” only articles
from data suppliers who provide simple, high quality tagging. More complicated or
problematic article collections can be addressed when the codebase has matured.
fn:transform is also very appealing because all updates are strictly limited to the XSLT layer.
It enables PMC to take a substantially different approach to article conversion. Yet
the software that runs the XSLT does not need to know anything about these changes.
This makes transitioning significantly easier, since no coordination between XSLT
and other software components is required. The project would be a lot more involved
and expensive if PMC were to build a wholly new method to run transformation pipelines,
for example by adopting XProc. Encapsulating all changes at the XSLT layer reduces
complexity and friction.
Dynamic transformations with fn:transform can also contribute to the goal of separating general conversion from publisher-
or journal-specific modifications. PMC can define respective article collections and
run dedicated XSLTs for them, like publisher-a.xsl, publisher-b.xsl, or journal-c.xsl.
PMC thus breaks up the single legacy conversion into multiple discrete transformations.
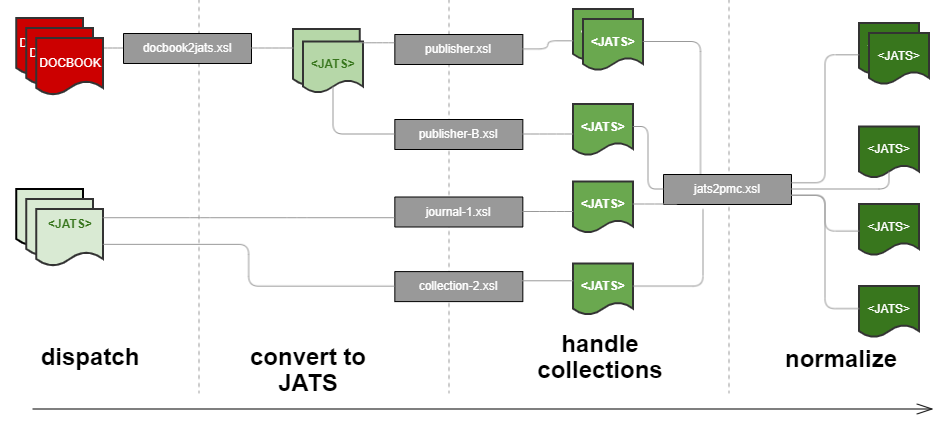
For each source schema or DTD, conversion starts by sending the articles to a “dispatcher”
stylesheet which serves as the main entry point. The dispatcher establishes article
collections by publisher, by journal, or possibly also by other convenient criteria
such as article type. The dispatcher concurrently determines whether the collection
is “ready for XSL3” or whether to invoke the legacy transformation.
If the article is ready for the new conversion approach, then the first step is to
convert it to the current version of JATS. The only goal of this pass is to produce
valid JATS. The output does not need to conform to PMC style nor address tagging idiosyncrasies.
This makes the transformation much simpler, as many complicated normalizing operations
do not need to be performed at this stage. If the source article is already tagged
per the current JATS version, then this step is skipped.
The second transformation then addresses collection-specific needs. The dispatcher
invokes a stylesheet dedicated exclusively to the article collection. This is where
issues like publisher-specific article types or very particular tagging structures
get addressed. Articles that are not in the collection are not impacted by this transformation.
Some articles may not need to undergo this step at all. If the markup is already very
close to the PMC standard and requires no special handling, then this step can also
be skipped.
The last conversion is a general normalization step to produce PMC-style compliant
JATS as the final output. Many supplier-specific problems and variations have already
been addressed in the previous pass. All articles now undergo a final polishing. Poor
tagging such as empty formatting elements gets removed. Restricted attribute values
undergo a final standardization. ID attributes are added where necessary.
Figure 6
Sketch of the new PMC conversion flow.
PMC’s hope is that separating out the different conversion concerns makes the actual
templates easier to find and maintain. Having piloted the approach on some article
collections, there are many promising signs. To illustrate the benefit, consider the
following conversion scenario:
Here we have a (fictional) source DTD that uses the <MediaObject> element both for images and for supplementary data files. There is no corresponding
element in JATS; images need to be captured as <graphic>, often in <fig>. Supplementary data files get tagged as <supplementary-material>. To determine the JATS output element, the converter has no choice but to check the
file extension and use <graphic>, for example, for jpg, png, tiff, etc. There is an additional complication because
the objects are cited. The <link> becomes an <xref> element in JATS. PMC tagging style requires that links to images carry the ref-type “fig”, whereas links to supplementary material get typed accordingly with “supplementary-material”.
This means the converters also need to check the extension of the <MediaObject> when writing the <xref>, from a different context. However, Publisher B introduces an additional wrinkle
– its tagging omits any file extension. Publisher B uses <MediaObject> exclusively for images and ships TIFFs to PMC. The converter is aware of this general
business rule and adds the missing extension.
This scenario is typical for XML conversion at PMC. None of the problems are particularly
difficult to solve with XSLT. However, when dealing with not two but 200 publishers,
the XSLTs can easily grow very complex. Let us further assume that years after talking
to PMC about its images, Publisher B now quietly decides that it was a bad idea to
omit image extensions all this time. PMC may now begin to find image callouts with
duplicated “.tif.tif” extensions in its output. It may not only take quite a while to determine where
in the code these duplicated extensions originate, but PMC also now needs to account
for two different methods by which Publisher B tags its images. Again, in isolation
this is not a difficult fix. However, when multiplied many times, such updates create
a complexity that becomes hard to maintain over time.
PMC’s hope is that separating conversion into different passes will make this easier.
Publisher B, with its distinct image extension rules, will be afforded a dedicated
transformation, publisher-b.xsl. Whatever changes this publisher ultimately makes will not impact the conversion
of articles from other publishers. The difference between “schema conversion” and
“data normalization” can also reduce complexity of the above transformation scenario.
The first pass, DTD conversion, can choose to simply ignore setting the xref @ref-type per PMC style. This can be done during normalization when the appropriate elements
are already written, and the conversion only needs to map the referenced target element
to a ref-type. This approach reduces complexity and increases consistency. Articles tagged in other
source DTDs can undergo the same standardization, and there is one single maintenance
point for normalizing the XML.
Conclusion
PMC’s current XML conversion architecture is simple – there is one transformation
for each source DTD. This simplicity, however, leads to complexity within the stylesheets
themselves. The converters perform different tasks as they deal with a very large
volume and variable tagging styles: schema conversion, data normalization, and collection-specific
customizations. The new architecture employing fn:transform is more complex; multiple transformations get dispatched dynamically. The hope is
that this will make the actual stylesheets simpler. Maintainers should be able to
quickly identify code sections of interest and easily fix or modify them. Whether
this promise will come true remains to be seen. As of July 2021, converters covering
about 1.2 million articles, or 17% of the total, have been updated to XSLT 3.0. So
far, the upgrade has proceeded smoothly. PMC has not encountered situations that made
it seriously question the validity of the new approach to conversion. In fact, many
transformations became much simpler when split over multiple conversion passes. However,
the new conversion has required very little maintenance so far, so there are still
many lessons to learn as implementation proceeds. Thankfully fn:transform makes it possible to take many small steps toward the greater goal.
Acknowledgments
This work was supported by the Intramural Research Program of the National Library
of Medicine, National Institutes of Health.
References
[1] Beck, Jeff. “Report from the Field: PubMed Central, an XML-based Archive of Life Sciences
Journal Articles.” Presented at International Symposium on XML for the Long Haul:
Issues in the Long-term Preservation of XML, Montréal, Canada, August 2, 2010. In
Proceedings of the International Symposium on XML for the Long Haul: Issues in the
Long-term Preservation of XML. Balisage Series on Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Beck01.
[6] Elbow A, Krick B, Kelly L. “PMC Tagging Guidelines: A case study in normalization.”
In: Journal Article Tag Suite Conference (JATS-Con) Proceedings 2011 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2011.
Available from: https://www.ncbi.nlm.nih.gov/books/NBK62090/
Beck, Jeff. “Report from the Field: PubMed Central, an XML-based Archive of Life Sciences
Journal Articles.” Presented at International Symposium on XML for the Long Haul:
Issues in the Long-term Preservation of XML, Montréal, Canada, August 2, 2010. In
Proceedings of the International Symposium on XML for the Long Haul: Issues in the
Long-term Preservation of XML. Balisage Series on Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Beck01.
Elbow A, Krick B, Kelly L. “PMC Tagging Guidelines: A case study in normalization.”
In: Journal Article Tag Suite Conference (JATS-Con) Proceedings 2011 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2011.
Available from: https://www.ncbi.nlm.nih.gov/books/NBK62090/