How to cite this paper
La Fontaine, Robin. “Element order is always important in XML, except when it isn't.” Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6, 2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.LaFontaine01.
Balisage: The Markup Conference 2021
August 2 - 6, 2021
Balisage Paper: Element order is always important in XML, except when it isn't
Robin La Fontaine
Robin is the founder and CEO of DeltaXML. His background includes computer
aided design software and he has been addressing the challenges and
opportunities associated with information change for many years. DeltaXML tools
are now providing critical comparison and merge support for corporate and
commercial publishing systems around the world, and are integrated into content
management, financial and network management applications supplied by major
players. Robin studied Engineering Science at Worcester College, Oxford and
Computer Science at the University of Hertford. He is a Chartered Engineer and
member of the Institution of Mechanical Engineers. He has three adult children,
three and a half grandchildren, and never finds quite enough time for walking,
gardening and working with wood.
Copyright ©2021 DeltaXML Ltd. All Rights Reserved.
Abstract
"Which came first," begins an old joke. But the more interesting question might
be, "does it even matter?" There are many obvious and several not-so-obvious ways
in
which the order of items (be they XML elements or attributes, or JSON maps or
arrays) can be understood to be significant or insignificant. These are not new
questions and how they’re answered plays out across vocabulary design, schema
design, and individual documents. They are important questions when it comes
deciding if two documents are “the same” or “different” and to what extent.
This paper challenges the one-size-fits-all decree in XML that order needs to be
preserved and reviews the implications of 'order'. When ordered elements can be
moved then we have something that has some common ground with orderless. This paper
establishes a continuum between ordered information and orderless information and
proposes that these are not as far apart as they might at first appear.
Table of Contents
- Introduction and Background
- XML elements and attributes, JSON objects and arrays
- Comparison and moves - a focus for order
- Is order a binary choice?
- Schema Languages and Orderless
- Conclusions
Introduction and Background
What one community takes for granted and never even discusses, because it is
'obvious', another community sees as an important area for debate and discussion.
Order
in XML is certainly one of these areas. The community of those who use XML for
human-readable documents never questions the assumption that the order of elements
is
important, it is obvious to anyone that swapping a couple of paragraphs round can
have a
significant impact on the meaning of a document. Similarly the attributes of a paragraph
are just attributes and it is 'obvious' that declaring one before another is of no
consequence.
The data community, if we can be so bold as to make this distinction, will always
define whether or not a collection of data items constitute a set (where they can
appear
in any order) or a list (where order is important). As the Eskimo language has 50
words
for snow (and the Scots quite a few words for mist and fog) so the data community
has
many words for collections, including for ordered collections lists, arrays, vectors
and
for orderless collections maps (name/value pairs), set (where each object is unique),
and bag (where duplicates are allowed).
The document community makes a distinction between 'content', the words that appear
on
a page, and structure/formatting which affect where the words may appear or what font
they may be in. The data community does not have such a binary distinction between
what
constitutes data and what is meta-data, because the distinction may depend on the
type
of processing that is being performed. To put it another way, one person's meta-data
is
another person's data.
This vexed subject of order in XML was discussed at Balisage in 2002 by Tommie Usdin
[1]. There was clearly quite a discussion about it and the
title of her paper, "When 'It Doesn’t Matter' means 'It Matters' ", is uncannily similar
to the one for this paper. Tommie introduces that paper with a story about how order
that was 'obvious' to the document author was not so obvious to a programmer. Her
paper
proposed, and I am very much in agreement, that tight specifications and only one
way to
represent something is the best way forward for unambiguous information exchange,
and we
will return to that later.
So it is not surprising that we have issues around how best to handle order, though
it
is perhaps surprising that we had the same issue almost 20 years ago. As Tommie says
in
her paper, "please listen carefully when someone says 'it doesn’t matter'. Figure
out if
they mean 'there is not information to be conveyed here' or if they mean 'there is
a
great deal of information to be conveyed here'. Or if they don’t know which they mean
because they haven’t thought it through."
XML elements and attributes, JSON objects and arrays
It is worth considering how JSON [2] handles order, as it
has been adopted in place of XML by many in the data community because XML did not
work
well for some types of data. JSON objects with their members resemble XML attributes
in
that they are name/value pairs and they have unique names within their immediate
context. JSON object members are also not ordered, so this is a common feature with
XML
attributes and both implement the concept of a map. A lot of data is order independent
and unless each data item has a name the only JSON structure that can be used is the
array construct. However, JSON defines arrays as ordered collections, as in a list,
and
this reflects the significance of order in a sequence of XML elements.
If we look at XML Schema [3] and JSON Schema [4] we find the ability to define the type of items, minimum and
maximum numbers of items but not whether order is significant. It is for the author
or
provider of the information to decide on the order of the information but we cannot
specify whether or not this order conveys information. It is in one sense reasonable
that the significance of order depends on the information but it seems an omission
not
to be able to indicate one way or the other in a schema.
We find some distortions in the way that data is represented when either format is
adopted. For example, in SVG [5] the points of a polygon and the
line style could be defined in any order, and this seems to be one reason they are
defined as attributes as shown in this example. The representation of points within
an
attribute might be more compact than if elements were used, but all the power of markup
is lost because the attribute has no internal structure. Using attributes in this
way
precludes, for example, the addition of an attribute on a point.
<polygon points="220,10 300,210 170,250 123,234"
style="fill:lime;stroke:purple;stroke-width:1" />
Similarly, if we look at JSON data, and we want to represent data items that each
have
a unique key then the natural way to do this might be using an object where each unique
key is represented as the member name, as follows.
{"contacts": {
"324": {
"first_name": "AN",
"last_name": "Other"
},
"127": {
"first_name": "John",
"last_name": "Doe"
}
}}
However, it is much more usual to see such data represented in an array like
this.
{"contacts": [
{
"id": "324",
"first_name": "AN",
"last_name": "Other"
},
{
"id": "127",
"first_name": "John",
"last_name": "Doe"
}
]}
It could be argued that both XML and JSON have one way to represent ordered data
(elements and arrays) and one way to represent orderless data (attributes and objects).
But adopting these structures means that some uncomfortable consequences are
encountered. In both cases, each orderless data unit or item (it is not possible to
use
the term object or entity without causing confusion) must have a unique identifier,
i.e.
the XML attribute name or the JSON member name. The temptation is to assign an arbitrary
key if there is no key or if it is difficult to determine what the key should be,
but
that is not a sensible way forward. This is why in practice some XML elements can
appear
in any order without change of meaning, and the same is true for the content of some
JSON arrays. Therefore it is important as part of the definition of any data format
to
know whether or not the order is significant.
We can draw up a table to illustrate the characteristics of the two formats in this
area.
Table I
Order and Uniqueness in XML and JSON
|
XML |
JSON |
Comment |
| Order |
Elements ordered |
Array members ordered |
Both XML elements and JSON arrays commonly used for orderless data
especially if not keyed
|
| Orderless |
Attributes are name/value pairs and are orderless |
Object members are name/value pairs and are orderless |
Attribute values have no structure, so do not work for structured
information
|
| Keys |
Attributes keyed by name of attribute |
Object members keyed by name |
Implication is that orderless needs to be keyed, but this is not always
the case
|
| Uniqueness |
Powerful 'unique' concept in XML Schema that allows scope to be
defined
|
Provided in JSON Schema for arrays |
|
| ID |
ID attribute is unique across the whole document |
|
|
This table shows that according to the definitions, it is not possible to specify
XML
child elements or JSON array members where the order can be changed without changing
the
meaning.
In the XML world, XML Schema does not help here. It allows complex types to contain
'sequence', 'choice' or 'all'. A sequence or choice may occur more than once. Choice
is
just one of a list of elements and sequence is a defined order of elements, 'all'
is
unordered. This is certainly useful in that it allows us to validate the syntax of
an
instance file but the order of the instance data is always deemed to be significant.
Perhaps there is sometimes confusion between the ordering of elements that is defined
for validation of the structure and the significance of the order of elements as they
appear in the instance data. Our discussion is about the ordering of instance data
and
not the ordering of elements that constitute the structure. This might appear a subtle
distinction, but it is not!
When we look into the logic behind the above decisions about XML Schema, there is
an
interesting document that has no official standing but stems from discussions within
the
Web Services working group using XML Schema. This describes schema patterns [6]. Here there is the concept of a vector 'A vector is
an ordered sequence of repeated items of the same data type.' and map 'A map is an
unordered collection of repeated items of the same type... each item is accessible
by a
key value, unique within the scope of the collection.' So again we see unordered or
orderless data needing to have keys and there is no provision for orderless data without
keys.
Comparison and moves - a focus for order
Knowing whether or not order is important is essential to the process of determining
whether or not two XML documents are the same or different. This was noted as long
ago
as 2001 in 'A Delta Format for XML: Identifying changes in XML files and representing
the changes in XML' [7], where it states "some elements
may appear in any order and so a change to order should not be identified as a
change."
Determining if a document has been changed may be critically important, especially
if
that document is a legal or technical document. It is not possible to determine if
a
document has changed unless we can determine with certainly whether two documents
are
the same. This may seem simple and obvious but in practice equality is often not well
defined. The result is that a change to the order of elements is identified as a change
but may not be a 'real' change. Another example is change to white space, which could
simply be the result of pretty-printing, may often not be considered to constitute
a
change.
We know that a change in attribute order does not constitute a difference, but the
change in order of elements should by default be flagged as a difference. But if those
elements are simply elements that have attributes conveying some meta-data and have
no
content, then a change in order may not be significant. This suggests that the
significance of order may depend on other factors, e.g. whether or not there is text
content directly or indirectly within an element.
It is worth noting that Canonical XML [8] provides some
support in that "It is the goal of this specification to establish a method for
determining whether two documents are identical, or whether an application has not
changed a document, except for transformations permitted by XML 1.0 and Namespaces
in
XML 1.0." But of course this is based on the premise that order of elements is always
important so it does not help when a change in order is not a 'real' change.
XML element comparison by default preserves the order of elements in the two
documents. A change of order will therefore result in elements appearing as added
and
deleted. But the result of a change of order could also be represented as a poor match
between two paragraphs that are deemed to be in the same position, for example because
they have common paragraphs before and after them. It is not trivial to determine
what
has changed - have several paragraphs been modified or have one or more paragraphs
been
moved? This suggests that when considering order in the context of comparison one
factor is whether or not we are interested in identifying moves.
Is order a binary choice?
We have deliberately muddied the waters here by introducing the possible distinction
of elements with and without text content, and in considering moves. There appear
to be
binary alternatives: either the order of elements is significant or it is not. Therefore
to determine whether two documents are equal, we test this equality by an ordered
comparison, i.e. preserving the order of elements in both documents, or by ignoring
order and seeking to find pairs of equal elements. By 'equal' here we mean that the
full
content of the elements are equal, often known as 'tree-equal'. If the ordered alignment
shows no differences then by definition the orderless will also show no differences,
but
vice versa is not true.
It is always the case that an orderless alignment will be at least as good if not
better than an ordered alignment. The term 'better' here means that more information
is
aligned, taking into account the full tree structure of all the child elements. Two
elements that are tree-equal represent the 'best' alignment. We discuss later how
to
measure this quality of alignment, e.g. by determining how many words (or PCDATA
characters) and/or attributes are aligned as equal.
This implies that as we move from a strictly ordered alignment to an orderless
alignment, the quality of alignment is likely to improve. If 'nothing can move' then
we
cannot improve on the ordered alignment, but if 'anything can move' then we can use
the
orderless alignment as the best result.
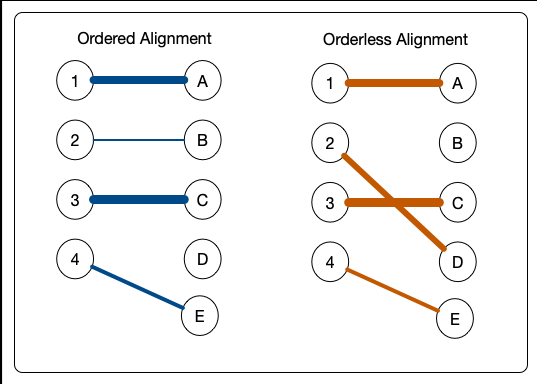
The diagram above illustrates two lists of child elements, denoted 1, 2, 3, 4 in one
XML document and A, B, C, D, E in the other. These labels are purely so that we can
identify them in this discussion. The lines between an element in one file and one
in
the other shows a possible alignment, where the left pairing denotes an alignment
that
preserves order and the right pairing shows an alignment that does not preserve order.
The width of the connecting lines shows the quality of the alignment, where wider
line
shows a better alignment. Note that here we are discussing element alignment rather
than
the alignment of individual words or text items which will either be treated as equal
or
not equal.
We can see here that although 2 is aligned with B when an ordered alignment is made,
the quality of this is not as good as between 2 and D. We can deduce that 2 was probably
moved to a new position, D, rather than modified to create B. The orderless alignment
here sheds some light on what has probably happened in moving from one document to
the
other. This example is very simple and has few items to be aligned, but for a large
number of items of different sizes the complexity rises very rapidly.
If we do not allow any moves, then we have the ordered alignment. If we allow any
moves anywhere then we end up with the orderless alignment. But what happens between
these two extremes? Is there anything meaningful in between them? It is interesting
to
explore this, and in developing algorithms to find 'optimum' alignment we find that
we
are obliged to explore this further.
The alignment will typically improve as we consider some elements as moved rather
than
added, deleted or changed. This suggests a continuum between ordered and orderless
that
is determined by how tolerant we might be to considering that an element has been
moved.
It is interesting to speculate whether we can find an optimum result. How might this
be defined? We would need to measure the quality of an alignment in some way and to
assign a cost to a move. A move would seem to be better always than an addition and
a
deletion, but we would need more detailed quality metrics to determine if an element
that could be aligned with its order preserved is a better or worse result than an
alternative alignment that is better but changes the order. When paragraphs are being
aligned it is normal to apply some threshold so that two paragraphs are deemed to
be
different rather than modified versions of one another if this threshold of common
words
is not met: it is nonsense to align two long paragraphs just because they both contain
a
similar sequence of common words such as 'and', 'but', 'the'. The same could also
be
applied to data though the definition of a good threshold metric is not trivial.
It would take a full paper to explore the metrics that could be applied to determine
the quality of an alignment. Counting the number of words or elements that are equal
versus the number that are not equal is one simple measure but for human readability
of
documents the degree of fragmentation is also important. For example, if the number
of
items aligned is the same in two possible alignments but in one of the two the items
are
in a contiguous sequence, then this would seem to be the better alignment because
it is
less fragmented. For this discussion, we will consider some measurement of Alignment
Quality as having a value between 1 (exact tree equality) and 0 (nothing is
aligned).
Let us consider an Order Metric as a value of 1 to denote fully ordered and a value
of
0 to denote fully orderless. What might 0.9 mean? It could mean, in our example above,
"if the Alignment Quality of 2 and D is greater than 0.9 and the Alignment Quality
of 2
and B is less than 0.9, then align 2 and D." As we slide our Order Metric down from
1
towards 0 we find the alignment changes and there are more moves.
Clearly if the order really does not matter, in other words it has no meaning at all,
then our Order Metric will be 0. But it is usually the case that even if order is
important, we would like to see when items have been moved. In the simplest case,
an
Order Metric of 0.999 would only discover a move if the moved item was more or less
equal to the item in the new position. Document authors would like to see moves even
when there are also changes and this becomes more complex to determine.
We also find a similar effect in data because the simple map model of orderless items,
where they each have a key, is limited when data is changing - not least because
sometimes the key itself is changed and all the other data remains the same! This
is
actually an important use case when comparing data between two different applications
where a key has been incorrectly set in one of the two. So with data even if the order
has some significance, it may be useful to determine where items have been moved.
Schema Languages and Orderless
Returning to schema languages, we have established that there is no way to indicate
that we have a sequence of items which do not have keys (so XML attribute or JSON
Object
members are not appropriate) and where the order in which they appear conveys no meaning
at all. Currently it is only possible to specify this in the documentation.
The simplest model for orderless is to indicate that all the child elements of an
element are orderless. A more complex model would be to specify that certain children
in
a sequence or choice are orderless but this would seem to introduce unnecessary
complexity because the orderless children can always be put in a wrapper element,
which
would seem to be good practice.
Returning to Tommie's paper, schema developers should take note of her comment, "But
if it means the same thing which ever sequence they come in, then pick one and require it!" This means that if elements A, B and C can
occur once each but the order they appear in has no meaning, then specify the order
and
then there is no ambiguity about whether or not it is important because it cannot
be
changed. It is counter-intuitive to require a certain order when the order does not
matter, but that is the correct way to do it, for the reasons articulated in that
paper.
We could avoid adding the burden of having to output information in a specific order
if
we were able to specify in the schema that the order was not significant.
If we can explore further the definition of an Order Metric then this would certainly
be useful in comparing information expressed as XML or JSON, but it does not seem
to
have a place in a schema language. The concept of a move belongs in the configuration
of
a comparison. This is because it might be local to one element, so a child element
can
be moved to another position in the same parent element, or it could be global so
an
element could be moved to somewhere else in the document. Again, there is a continuum
between these two extremes, e.g. a paragraph could be moved within a section but not
across sections.
Conclusions
This paper has considered how the significance of order within an XML document or
a
JSON data set cannot be fully specified in a schema. There seems to be an implication
that unordered or orderless data must have keys, as in a map structure. There may
also
be some confusion between the ordering of elements for structural validation and the
ordering of instances of these elements in a document.
The paper has also shown how looking at order and orderless as a continuum rather
than
a binary choice is helpful to understand change in the sense of moving an element
from
one position to another.
Any future update to XML Schema or JSON Schema should consider how to define the
significance of order, in instance data, for XML element children and JSON array
members.