Imsieke, Gerrit, and Nina Linn Reinhardt. “JATS Blue Lite: The Quest for a Compact Consensus Customization.” Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6, 2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Imsieke01.
Balisage: The Markup Conference 2021 August 2 - 6, 2021
Balisage Paper: JATS Blue Lite
The Quest for a Compact Consensus Customization
Gerrit Imsieke
Gerrit is managing director at le-tex publishing services, a mid-size preprint services,
data conversion,
and content management software company in Leipzig, Germany. A physicist by training,
he entered the field of
scientific publishing during his graduate studies. He is responsible for XML technologies
at le-tex. He is a
member of the NISO STS Standing Committee and of the XProc 3.0 working group.
Nina Linn Reinhardt
Nina holds a B.A. in production editing from Leipzig University of Applied Sciences
(HTWK). This paper
is a byproduct of her master’s thesis in the field of Media Management, also at HTWK
Leipzig.
A JATS customization with a restricted vocabulary that is suitable for publishing
metadata has
been a desideratum in the JATS community. For some members, the JATS publishing customization
(“Blue”)
has acquired too many JATS archiving (“Green”) vocabulary items over time. Others
want to have a straightforward
editing schema without too many alternatives, similar to the authoring (“Pumpkin”)
customization, but with
support for publishing metadata.
This work is an attempt to identify a commonly used subset of Blue (goal: 60% of its
elements and attributes)
that is able to support at least 90% of the JATS articles found in the wild, where
“wild” means several hundred thousand
articles sourced from publishers directly and from PubMed Central’s vast collections.
In addition, this subset should also support the elements and attributes that have
been added to JATS only
recently and that are therefore unlikely to be found in large numbers within the articles
analyzed. An attempt
has been made to scrutinize vocabulary items that have been adopted from Green: Is
the adoption merely a sign of
the creeping “aquafication” of Blue that some suspect, or have these items really
been missing in a more
prescriptive and widely applicable journal tag set? Items that are considered important
to modern publishing for
several reasons – accessibility, open access, machine processability – have been included
in this proposed
subset. Also items that were underrepresented in the analyzed set of articles, but
are considered fundamental to
JATS, have been retained.
The initial spark for this study was a discussion on the JATS mailing list [JATS-list 2020], when someone opposed the “watering down” of Blue, that is, vocabulary items that
have only been available in
Green are moving to Blue and there are multiple allowed ways to tag a given piece
of content. Typically the
requests to amend Blue go in the other direction, that is, to add items. But also
the JATS dogma of backwards
compatibility tends to favor additions as opposed to deletions of vocabulary items.
“We have bent over backwards
to be backward compatible for years!” [Lapeyre 2019]
Restricting choices for tagging content can be done by restricting the vocabulary
or by limiting choice and
optionality, depending on context. Apart from documenting allowed use and restrictions,
the latter can be achieved more
robustly by adapting the DTD itself or by superimposing Schematron rules [Schwarzman 2017],
as JATS4R [JATS4R] does, for example.
Although subsetting a DTD may also impose context-dependent restrictions such as which
elements may be present in
which order, which attributes may be present and which values they may assume, this
work views customizations only as a
restriction of the vocabulary, that is, the elements and attributes that are permitted
by the subset anywhere in the
document. Although this is a very coarse and limited approach to customizations, a
reduced vocabulary can be beneficial in
several ways; in particular it reduces the effort necessary to develop and maintain
renderers and editors for the given
vocabulary. The JATS authoring subset (“Pumpkin”) has a significantly reduced vocabulary,
but it is not designed for
publishing since it omits most of the metadata vocabulary. Quoting [Lapeyre 2019]:
My Favorite Proposed Change
Make a new simplified JATS subset
Specifically designed for schema-driven editing and tool use
Intended audience: journal production workers and editors
For example, it will include journal metadata
Such an attempt has already been made for the Texture editor [Texture 2017]. The
proposed customization removed 228 elements and 147 attributes from Green, among them
question/answers, index
terms, and MathML. As will be discussed later, the authors decided to treat the entirety
of MathML as a single
vocabulary item. Doing so will reduce the number of elements omitted by Texture to
36 and the number of attributes
to 30. This amounts to a vocabulary reduction of about 14%, far away from the stated
40% reduction target.
The authors decided to analyze the actual usage frequencies of the JATS vocabulary
items. They sent an email
to the mailing list [JATS-list 2021,Reinhardt 2021a], calling on
publishers to either supply representative full-text XML articles or to run an analysis
XSLT on their articles
that produces lists of distinct element and attribute names used in the publications.
For a given collection of articles, the names of the elements and attributes that
are used in the collection
constitute a “de-facto customization.” This way, the authors hoped to be able to identify
less popular vocabulary
items and consider them for omission in a future “community consensus customization,”
a synthetic customization
that is both compact and well suited as a schema for creating, editing, and validating
content,
or as a starting point to derive the other de-facto customizations from without the
nee to add many items.
How does one measure well-suitedness though? Not using available vocabulary items
will not hurt, therefore
customization A will be better suited as a starting point to derive
customization B from if A is a superset of B. So the
best synthetic customization will be the union of all element and attribute names
of all collections?
If all collected articles used in fact only the same 60% of the JATS vocabulary, the
stated goal would haven
been reached trivially. It turns out that the collected articles use approx. 82% of
the JATS vocabulary though.
In order to identify a smaller de-facto customization – for example the vocabulary
used by a
specific journal, a specific publisher or a specific subject area – that may serve
as starting point to derive many other
customizations from with as little vocabulary item additions as possible, the authors
established a metric for
the aptness of a given customization to serve as a starting point.
When considering vocabulary items on the basis of their popularity, one needs to be
aware of the fact
that items introduced in later JATS versions might not be widespread yet in published
articles, or that other
aspects such as promoting accessibility suggest that items be added to the consensus
customization despite
infrequent use in currently available articles. This is why the authors will suggest
a minimal customization
that comprises significantly more vocabulary items than the “naive minimal customization”
that was determined
as adequate for tagging many of the articles actually analyzed.
Sources
The authors have received or downloaded JATS articles from the following sources:
Table I
Article sources
Source
Subject Area
Article Count
de Gruyter
STEM/HUM/ECON
568
John Benjamins
HUM
n/a
Optical Society of America
STEM
n/a
Oxford University Press
n/a
n/a
PMC comm_use A–B
STEM
379.835
PMC non_comm_use O–Z
STEM
249.341
PsychOpen
STEM
45
Science Open
STEM/HUM
210
The articles have been tagged according to diverse versions of JATS Blue or Green,
sometimes with proprietary
extensions.
When there is n/a in a table cell this means that the authors didn’t have access to
full-text articles; therefore
they were unable to count the articles or to classify them.
The subject classification was only applied handwavingly to individual journals or
sources. The authors hoped
that such a rough classification will offer insights with respect to varying tagging
practices in the disciplines,
but the analysis didn’t reveal large discrepancies, except that STEM (science, technology,
engineering,
mathematics and/or medicine) uses more vocabulary items than HUM (humanities and social
sciences) or ECON
(economics), but this is primarily due to the much larger sample size of STEM articles,
and due to
the wholesale categorization as STEM of all articles from PMC, which might not be
vindicated.
The PubMed Central bulk packages have been downloaded from their FTP site [PMC].
The Science Open input consists of open-access articles that have been downloaded
randomly from scienceopen.com.
In the PMC archives, the authors ignored journals with 40 or fewer articles, which
only marginally decreased
the number of articles processed.
As schemas, the authors considered the JATS 1.3d2 Blue, Pumpkin, and Green customizations,
and also the Green
customization that provides OASIS tables. This DTD should be the ultimate superset,
unless a publisher uses
proprietary extensions. The authors did also include the aforementioned Texture customization.
In addition, a synthetic schema “minimal” is included. It represents the proposed
minimal Blue subset. It
was only conceived after analyzing the collections and schemas according to the metrics
and methods described
in the next section, and after identifying an existing de-facto customization as a
starting point.
A derivative of this minimal customization is the “naive minimal” customization that
was prepared by omitting
strategically important but infrequently used items from “minimal.”
Metrics and Methodology
“Supersetticity” and Aptness Metrics
A conceivable metric for the aptness of a given customization is to measure whether
its vocabulary is
sufficient to mark up 90% of all collected articles. Given that there are more than
1,000 de-facto
customizations (when considering the vocabulary of each PMC journal as a de-facto
customization on its own), the
computational effort necessary to compare each of these 1,000 lists (one per journal)
of several 100 items with
approximately 630,000 lists (one for each article) of several 100 items seemed prohibitive.
Therefore the authors looked for a metric that was a cheaper to apply while still
making the adequacy
of a customizing measurable.
The difference is that each of the more than 1,000 customizations will be compared
not to each article,
but to all other more than 1,000 customizations. If an item needs to be added to arrive
at the other customizing,
it needs to be penalized more than if an item may be removed.
After four attempts of defining such a metric, the authors arrived at the following
quantities and
computation rules:
s
The “supersetticity” defines the degree to which one customization is a superset of
another. The
maximum value here is 2.0, which means a customization is a complete superset of another.
The
supersetticity of a customization j with respect to a customization
i is calculated as follows:
sij =
(1+rji) /
(1+rij)
with rji = aji
/ dji,
rij =
aij,
aij: additions to j towards obtaining
i,
aji: additions to i towards obtaining
j,
dij = dji =
aji + aij =
edit distance between i and j.
Example 1
Green (j) contains 764 items, Blue (i) contains 755
items.
aij is 0,
aji is 9.
dij and
aji are both 9.
rij is 0,
rji is 9/9 = 1.
sij = (1 + 1) / (1 + 0) = 2.
A supersetticity sij of 2 means that
j is a superset of i.
Example 2
Swapping Green (now i) and Blue (now j) of the
previous example.
aij is 9,
aji is 0.
dij and
aji are both 9.
rij is 9,
rji is 0.
sij = (1 + 0) / (1 + 9) = 0.1.
The supersetticity of Blue with respect to Green is 0.1, which means that Blue is
not a superset
of Green (otherwise it would be equal to 2).
Note
rij was originally intended as the relative number
of items that needed to be added to j in order to move it closer
to i. The asymmetry between rij
and rji is due to the consideration that if something
needs to be added to j in order to get to i, it should
drag the supersetticity of j wrt i quickly down to zero.
On the other hand, an item that needs to be added to Blue on the way to Green doesn’t
affect Green’s
supersetticity wrt Blue since an increase by one in aji
are roughly compensated by the same increase of dji.
That is, if Blue lacks 10 items of Green and Green lacks none of Blue,
rji = 10 / 10 = 1. If we add a missing item to Blue,
rji = 9 / 9 = 1.
Example 3
Let i be a de-facto customizing (list of elements and attributes that
occur) as constituted by an issue of De Gruyter’s Journal New Crystal
Structures. Let j be a de-facto customizing as constituted by an
issue of De Gruyter’s Journal Nanophotonics.
i contains 122 items (elements and attributes with distinct names that
occur at least once), j contains 176 items.
There are 5 items in i (New Crystal Structures) that
are missing in j (Nanophotonics): The elements
<funding-statement> and <pub-id> and the attributes
@orientation, @publication-format, and @valign.
There are 59 items in j (Nanophotonics) that are
missing in i (New Crystal Structures), for example
<alternatives>, <mml:math>, @fig-type, and
@mathvariant.
aij is 5,
aji is 59.
dij and
dji are both 64.
rij is 5,
rji is 59 / 64 = 0.92.
sij = (1 + 0.92) / (1 + 5) = 0.32.
The supersetticity of j (Nanophotonics) wrt
i ( New Crystal Structures) is 0.32.
Swapping both customizations, let j be New Crystal Structures and i be Nanophotonics:
aij is 59,
aji is 5.
dij and
dji are both 64.
rij is 59,
rji is 5 / 64 = 0.078.
sij = (1 + 0.078) / (1 + 59) = 0.018.
The supersetticity of j (New Crystal Structures) wrt
i (Nanophotonics) is 0.018.
This exemplifies:
Even with the moderate amount of 5 additions necessary, the supersetticity of
Nanophotonics drops quickly from the optimal value of 2 (full superset) to 0.32.
The need to add almost 50% of the initial item count to New Crystal Structures in
order to
be able to arrive at Nanophotonics lets the supersetticity of New Crystal Structures
wrt
Nanophotonics drop to 0.018.
q
defines the aptness of a customization as a starting point for another customization.
Being a superset to another should favor a customization. But of two customizations
with the same
supersetticity wrt a third customization, the one that has the least edit distance
should be favored even
more. Therefore we define
qij := 100 *
sij /
dij
as the aptness of customization j to serve as the starting point for deriving customization
i.
Example 1 (as above)
qij = 100 * 2 / 9 = 22.2, that is, Green’s aptness
to serve as a starting point for Blue is 22.2.
Example 2 (as above)
qij = 100 * 0.1 / 9 = 1.11, that is, Blue’s aptness
to serve as a starting point for Green is 1.11.
Example 3 (as above)
Nanophotonics’ aptness to serve as a starting point for
New Crystal Structures is 100 * 0.32 /
64 = 0.5, while New Crystal Structures’ aptness to serve as a starting point for
Nanophotonics is
100 * 0.018 / 64 = 0.03.
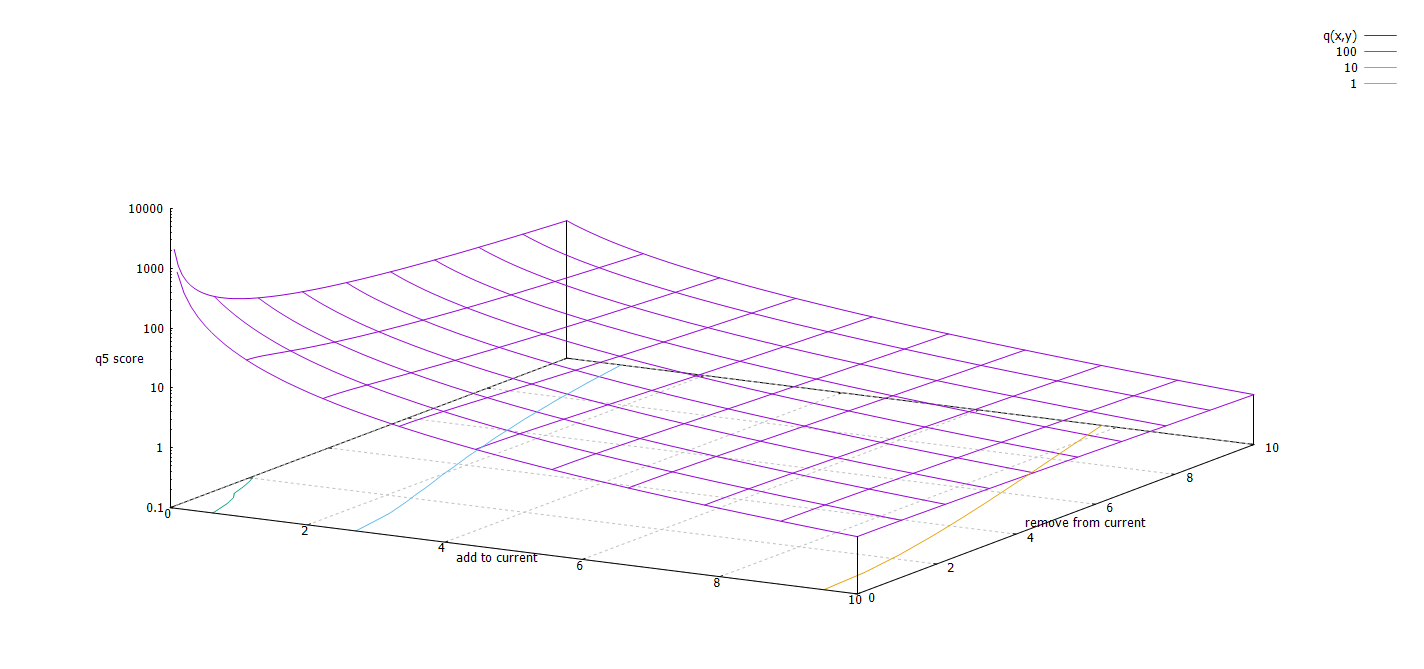
Figure 1 shows that qij will drop more quickly if items
need to be added to j than if items need to be removed from j
(= added to i in order to obtain j).
It needs to be stressed that the q metric does not claim absolute truth (“the higher, the better
starting point in all circumstances” is not necessarily true; it also depends on other
factors such as: It
is easier to add the whole of MathML than to add MathML partially). The q function was modeled after the
requirement that both a small editing distance and “subsetting over supersetting”
should be honored.
In some figures and tables q5 or q5 can be seen.
The 5 stems from the fact that the metric described here was the authors’ fifth attempt
at finding
appropriate supersetticity and aptness metrics.
p
defines the percentage of aptness of a customization j to serve as a starting point relative to the
best starting point’s aptness, which is arbitrarily set to 100.
Let qmax,i
be the maximum aptness of all other
customizations k to serve as the starting point for i. Then
the relative aptness of customization j wrt i is
pij =
100 * qij /
qmax,i
Example 1
With i Blue and j Green,
qmax,i
is 22.2 (that is, Green is the best starting point for Blue, see the green square
in the second
table row of the table sample-conf.details.xhtml), and
pij = 100 * 22.2 / 22.2 = 100.
Example 2
With i = Green and j = Blue,
qmax,i is 1.11
(third row in said table). In this case, pij
= 100 * 1.11 / 1.11 = 100, that is, Blue is the best starting point for deriving Green.
The other p values in the same row are lower than 100.
Example 3
With i = New Crystal Structures and
j = Nanophotonics, we need to identify the table row
that corresponds to New Crystal Structures and then spot the cell with the green background.
It is
in the column with the table head “DeGruyter”. That is, the de-facto customizing that
corresponds to
the collection of all ten De Gruyter journal issues that we examined is the best starting
point for
New Crystal Structures. Compared to its
p score of 100, the customization Nanophotonics only
receives a p score of 25.28 to serve as a starting point for
New Crystal Structures.
With i = Nanophotonics and j =
New Crystal Structures, DeGruyter is again the best starting point of
all. Compared to its p score of 100, the customization
New Crystal Structures only achieves a p
score of 0.66 to serve as a starting point for Nanophotonics.
Average p
This value is shown for each customization in the last column of the table at
sample-conf.xhtml. The individual p values for a given customization to
serve as a starting point for all the other customizations can be read column-wise
in the other, detailed
table. These p values are averaged. The customization with the highest score is deemed to be most
suitable
to derive the other customizations from.
Figure 1: Dependency of qij on the number of items to be added to
j or to be removed from j in order to arrive at i
The outcomes of these computation rules have been compared to what one would intuitively
think
is a good customization starting point, and the authors think they are appropriate
in helping identify
few candidate de-facto customizations that may serve as a basis for the synthetic
minimal customization.
For evaluating the true aptness of a given or putative customization, other factors
need to be considered,
too, such as compactness (small number of items), support for recent additions to
JATS, or subjective factors,
such as the conviction that <array> may never substituted with a caption-less
<table-wrap> or that <sans-serif> must never perish despite infrequent use
and the availability of styled-content/@style for literal CSS.
There is no objective truth in this metric; it is just a means to reward customizations
that may
act as a starting point for other customizations without the need to add many items.
Data Acquisition and Normalization
In order to make DTD-based customizations and de-facto customizations comparable,
all have been converted to
HTML files that contain essentially two unordered lists: one with the element names
and another one with the attribute
names.
For the DTDs, the transformation starts with the corresponding, equivalent Relax NG
versions. In a first
XSLT pass, the includes are resolved, then each define element will backtrace its
refs recursively until it ultimately reaches the start element. If it doesn’t reach
start, the define will be removed from the resulting transformed RNG. In a third
pass, the HTML lists will be populated from the remaining defines that define elements or
attributes.
Articles can be grouped in different ways. The granularity chosen for example 3 in
section ““Supersetticity” and Aptness Metrics” was: Articles are grouped with their respective journals for de Gruyter, but the
Science Open articles were put in three baskets, SO_Medicine, SO_Science, and
SO_Humanities_SocialSciences.
A third kind of input are precompiled HTML lists that publishers supplied if they
couldn’t send the actual
articles. These are grouped by publisher or by journal.
A configuration file points to the different Relax NG sources, article XML collections,
and precompiled HTML
files. A sample configuration file is at the Github
repository that also holds the transformation code and the pre-cooked HTML lists as supplied
by contributing publishers.
Virtual collections are created for each subject classification, that is, STEM, HUM,
and ECON.
Analysis Choices
In order for the analyzed data to be more useful towards the goal, several choices
have been made:
MathML
MathML is included in the schemas as a black box. Although its usage is limited to
a relatively
small number of elements and attributes throughout the collections, the authors decided
not to attempt
to identify a popular MathML subset. The reasoning is that it is easier to include
MathML wholesale in a
customization than to cherry-pick individual elements and attributes.
In order not to let the number of included or omitted MathML items influence scores,
the authors decided to include only <mml:math> if MathML is used in a collection,
or if it is available in a Schema, respectively.
Table model
A similar argument was made for the HTML-informed table model of JATS. As opposed
to MathML, the
vocabulary items will be considered individually and the rarely used attributes @abbr
and @headers will be included in the minimal customizing despite low frequencies.
Outlier Filtering
For most collections, only items with a frequency of more than 0.01, that is, one
occurrence in
100 articles, were considered.
Journal Permanence
Only journals with at least 40 articles were considered (where individual articles
were
available)
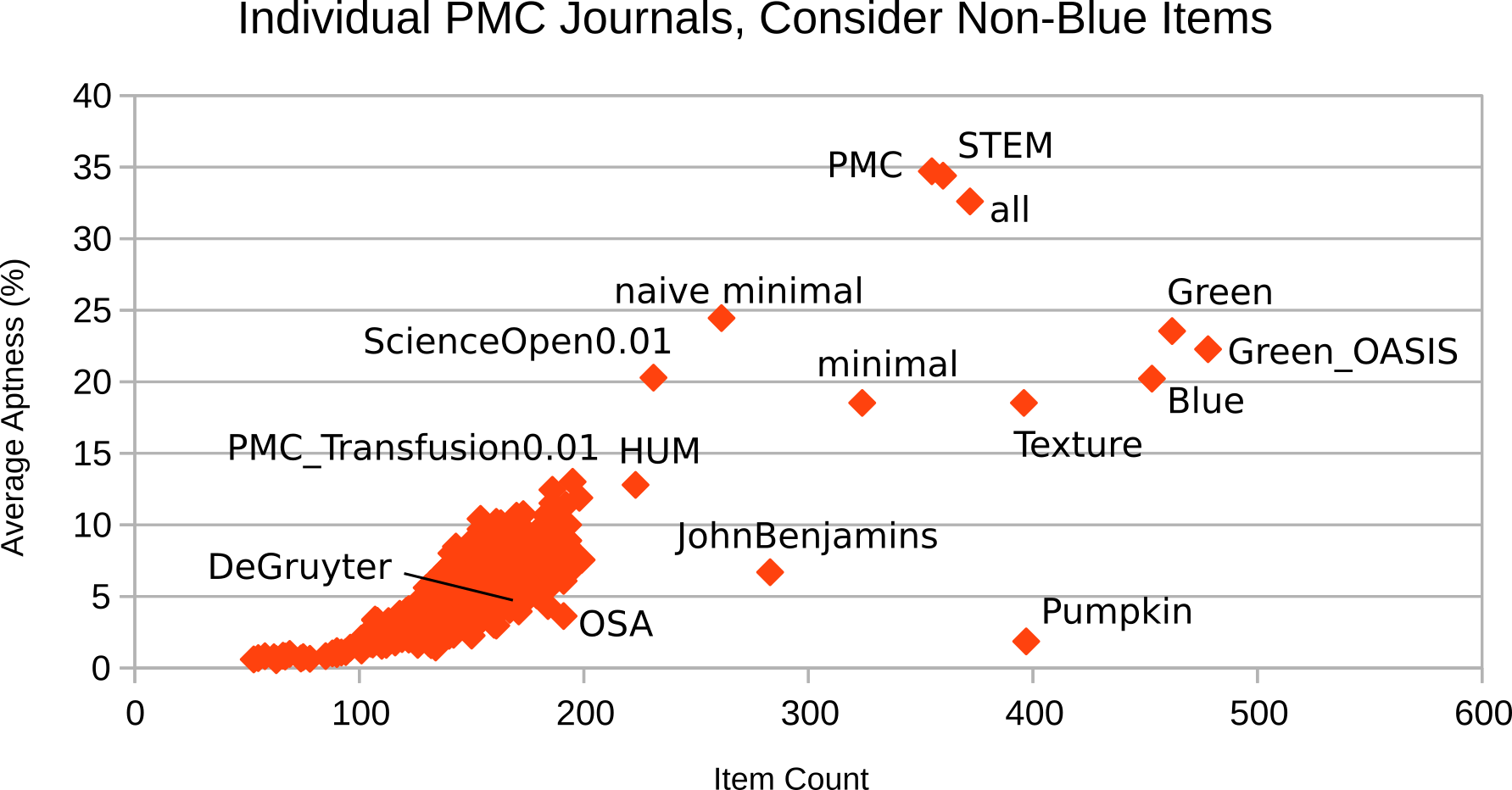
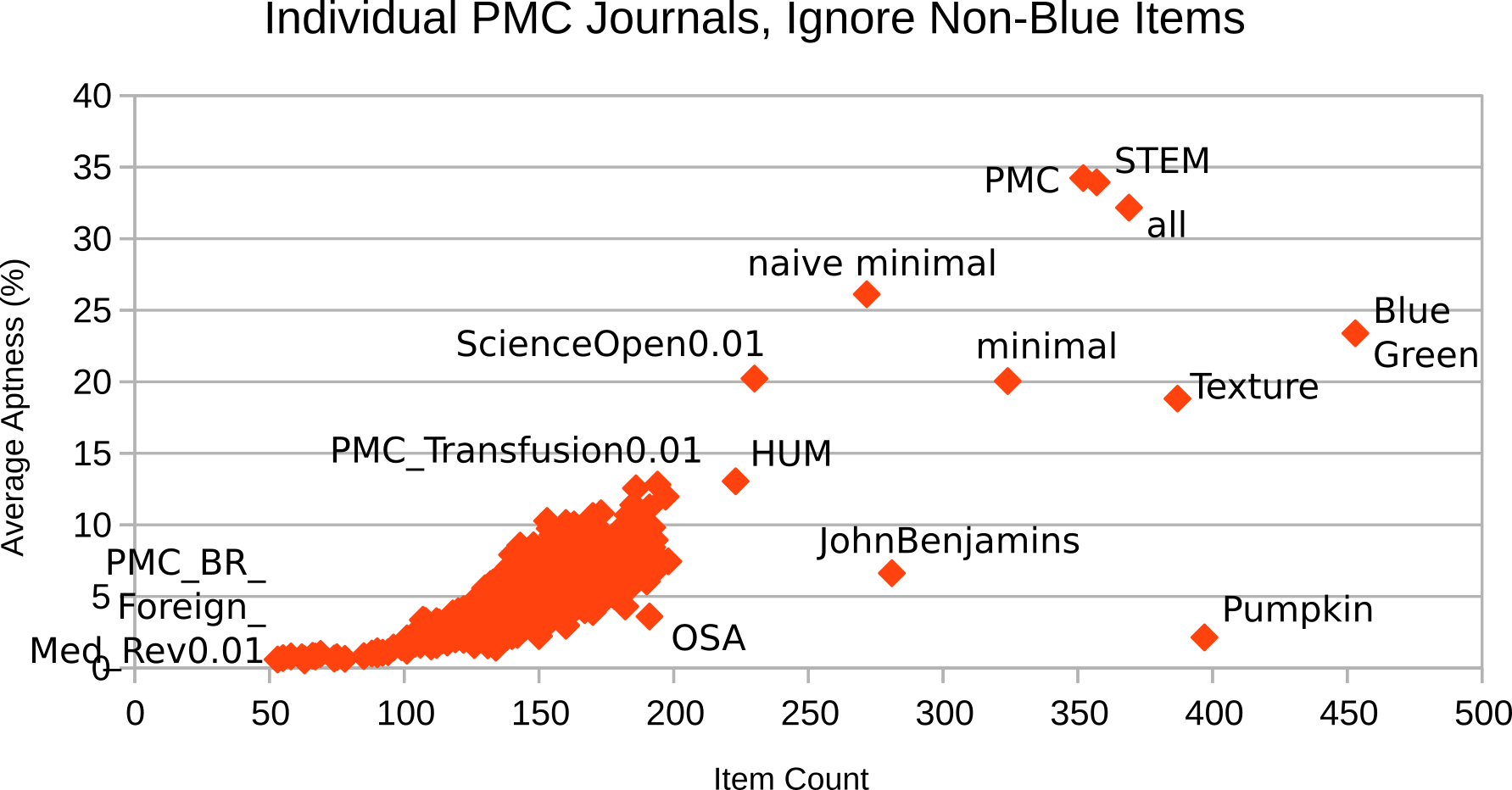
Non-Blue Items
Aptness analysis is carried out twice: Once with the original vocabulary of the schema
or
collection customization, and then with each vocabulary reduced to a subset of Blue.
The reason is
that customizations that also use Green or proprietary markup should have a chance
to compete with
their Blue subset.
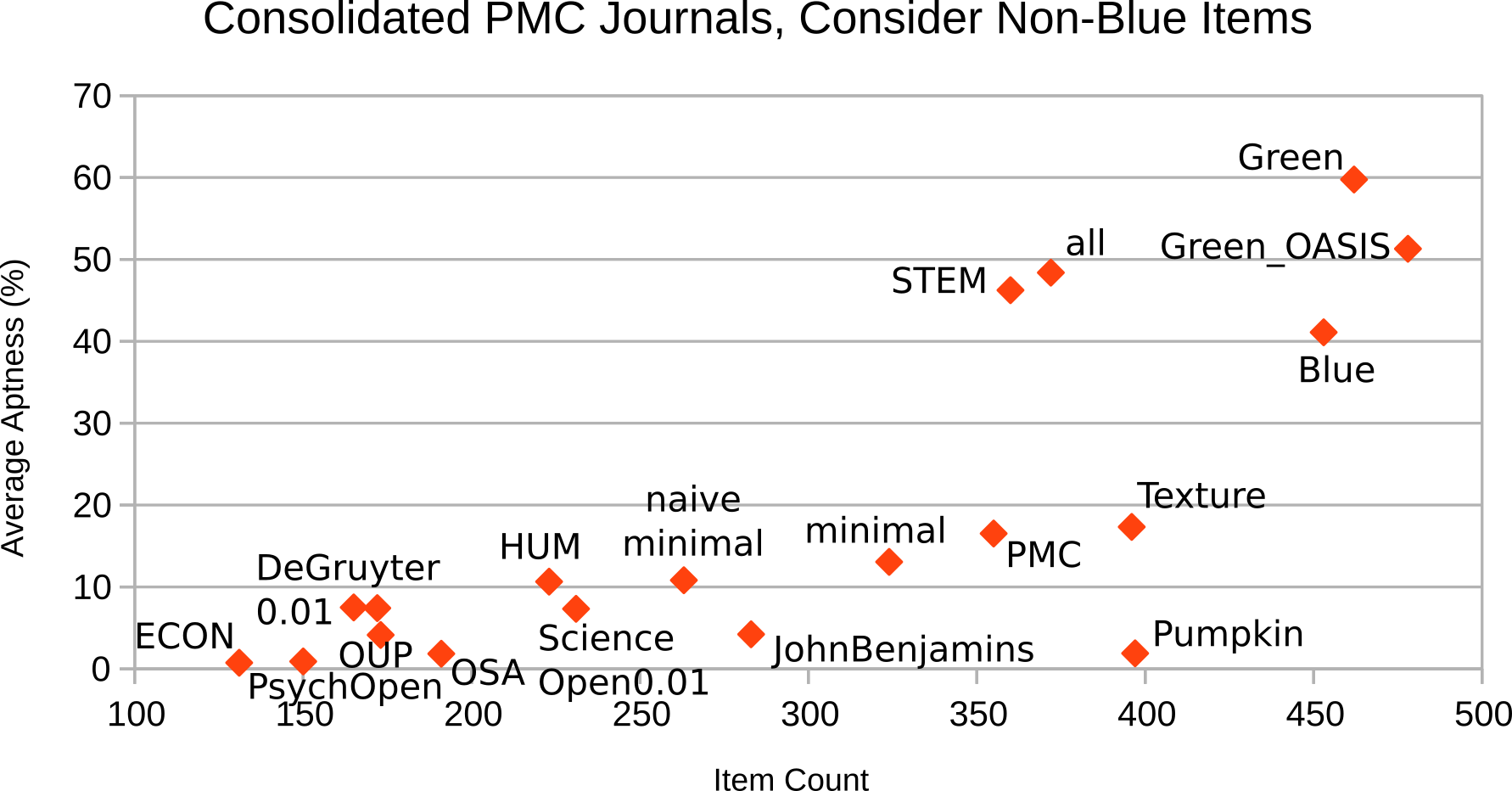
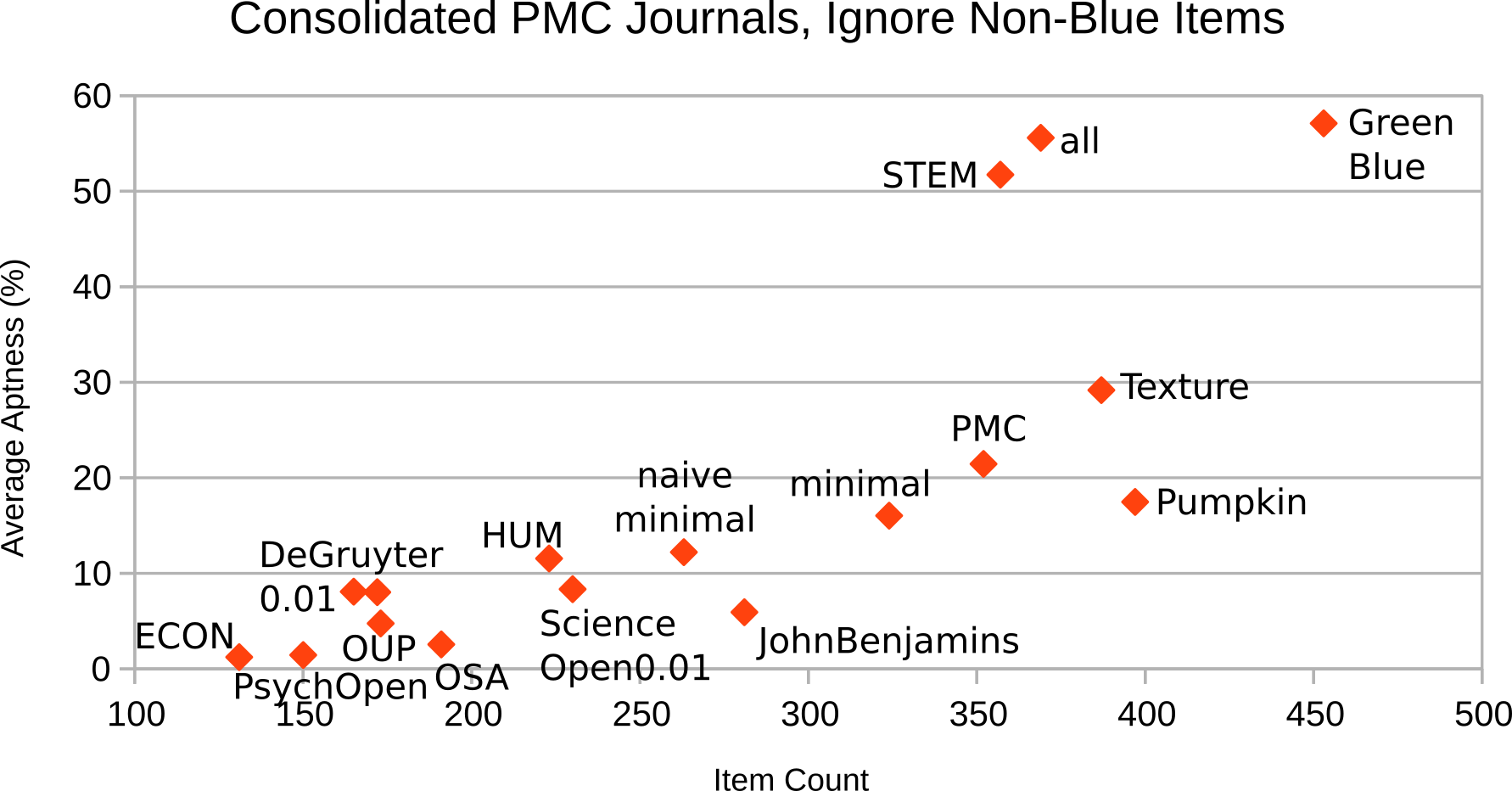
It turns out that the ignore-non-blue variants (Figure 12
and Figure 14) do not differ much from their peers
that consider non-blue items (Figure 11
and Figure 13).
PMC as individual journals or as a single collection
Considering PMC as a single collection instead of more than 1,000 per-journal collections
will
accelerate computing, but will skew the results. Aptness analysis is carried out twice
again,
yielding the two variants depicted in Figure 13 and
Figure 14 for single-collection PMC
and Figure 11, Figure 12 for
individual-journal PMC.
Applying each of the latter two alternatives, four different analysis tables are created:
all.xhtml,
its average p values (last column) are visualized in Figure 11
These linked tables and figures already contain the proposed minimal and the naive
minimal customizations.
The tables and figures that have been used for identifying promising candidates to
derive the minimal
customization from certainly lacked these data points. Because of the averaging over
the aptness to derive all
other customizations from a given customization, the numbers have been slightly different
before adding
minimal and naive minimal. The difference is not large though, in particular for the
datasets with individual
PMC journals. Therefore, because they look qualitatively and almost quantitatively
the same, the authors have
omitted tables and figures without the minimal and naive minimal customizations in
this paper
Minimal Subset Criteria and Choices
A candidate customization with a relatively low item count and a relatively high average
aptitude p will be selected as a starting point for the minimal customization.
For synthesizing the proposed minimal subset, these choices have been made:
“Strategic” vocabulary items
Although their frequency is low, vocabulary of certain important areas has been retained:
Recently added items (that are not considered aquafication symptoms – index terms
and questions/answers may be regarded as such), as shown in Table II;
Although they occur surprisingly unfrequently in the data set, <code> with several
attributes such as @language and <preformat> have been retained.
Frequency
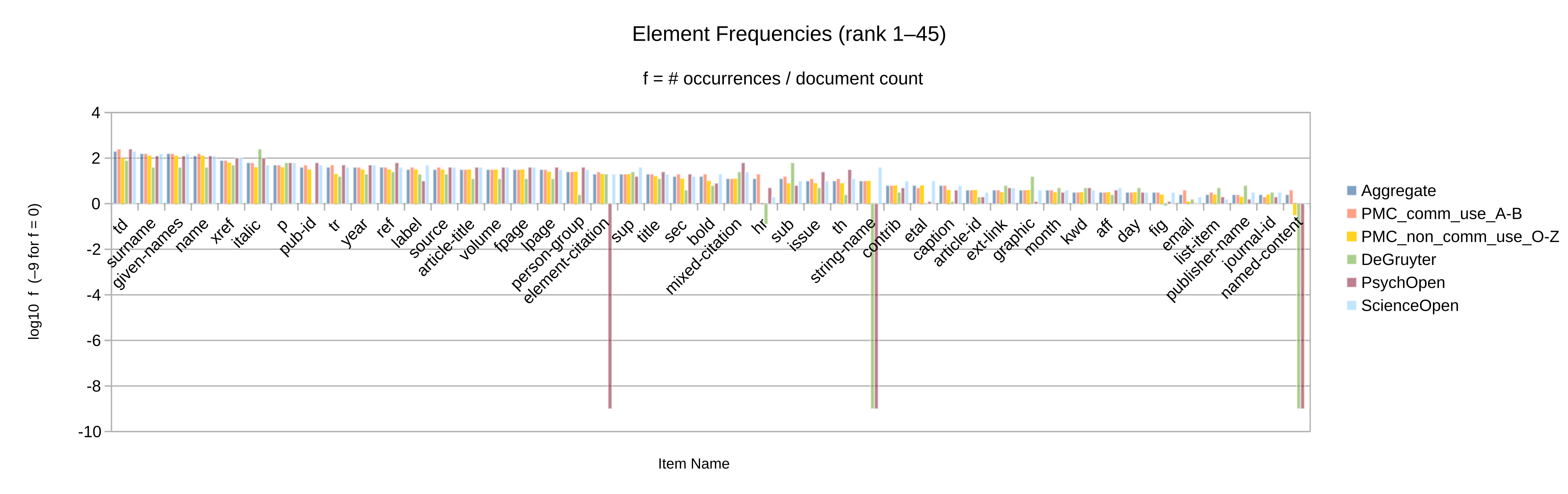
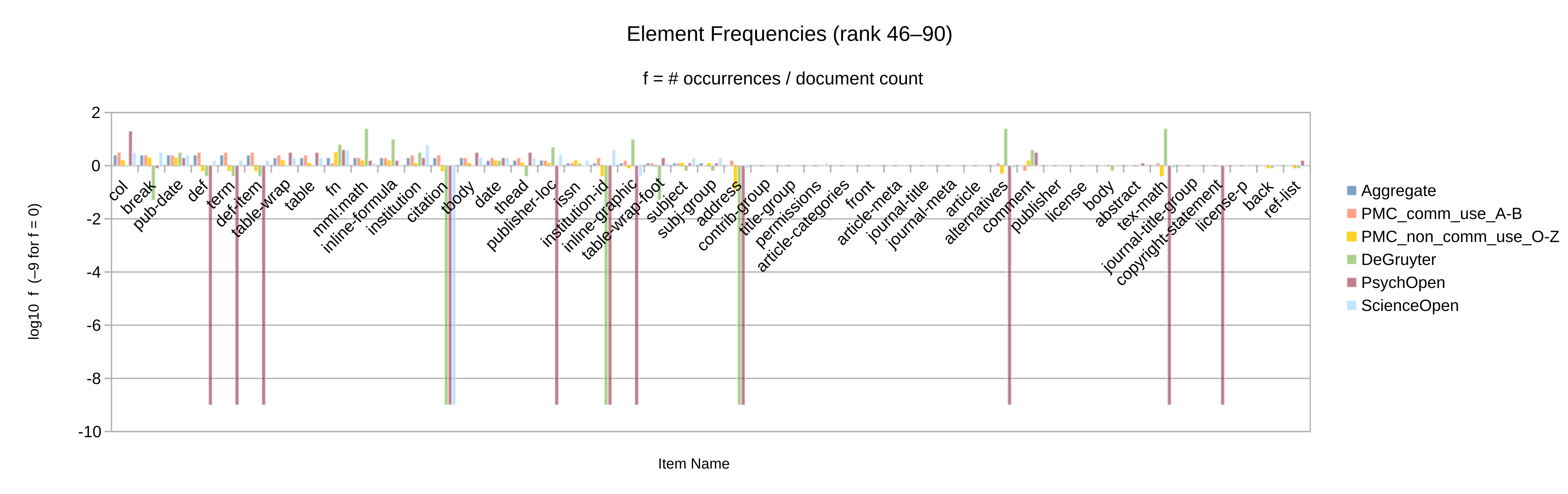
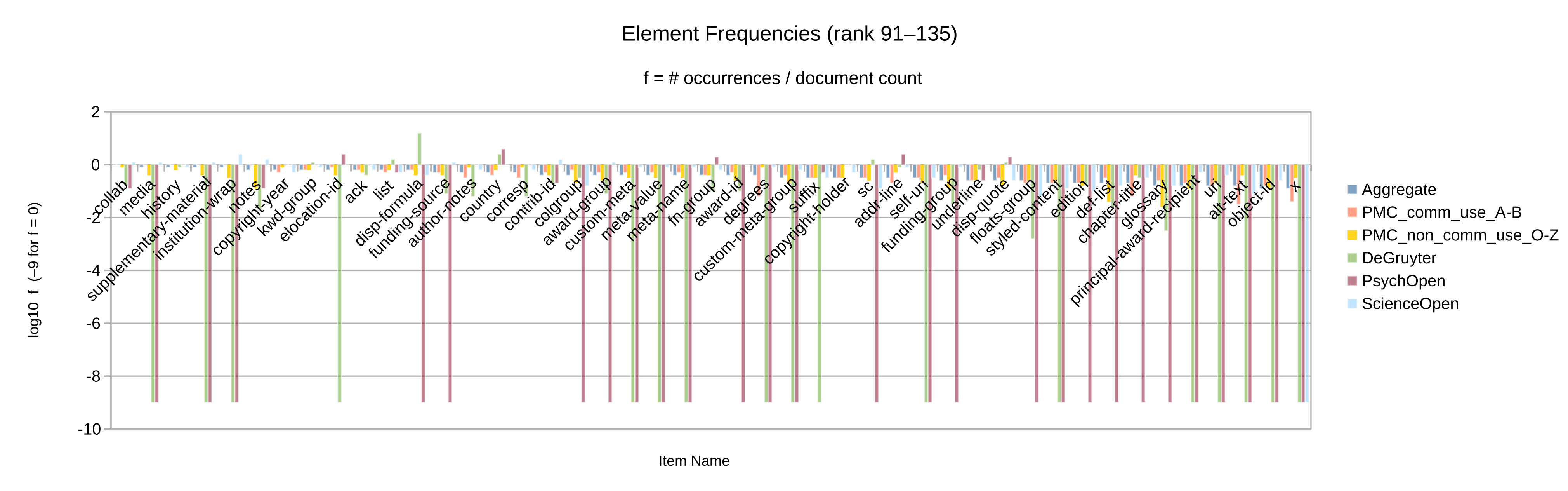
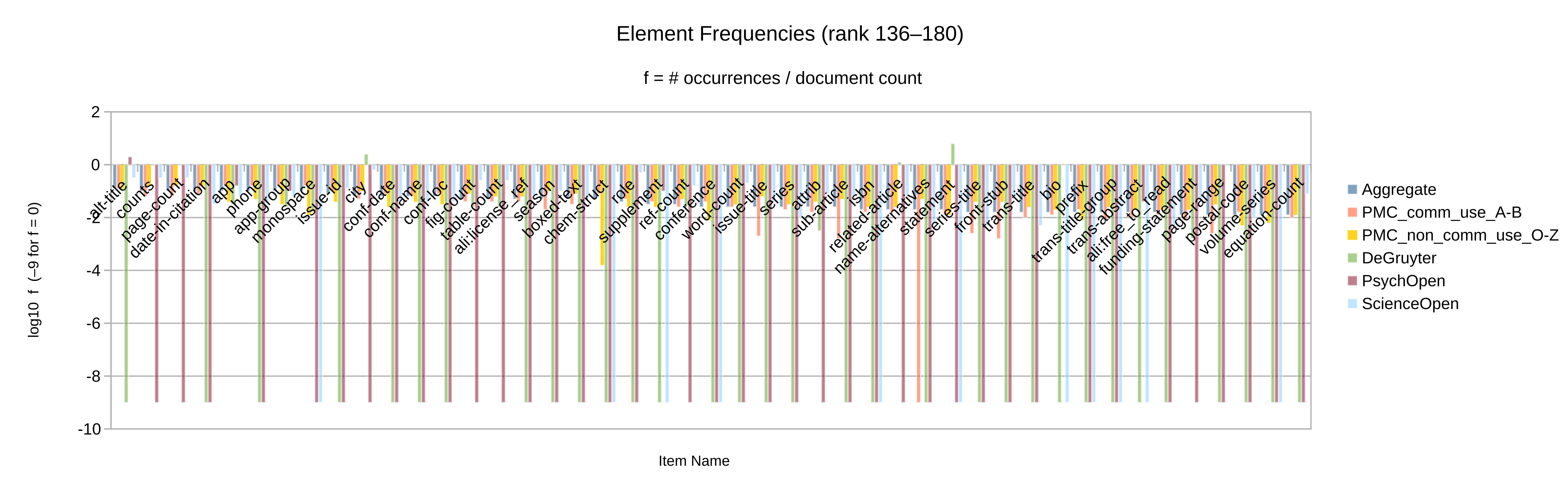
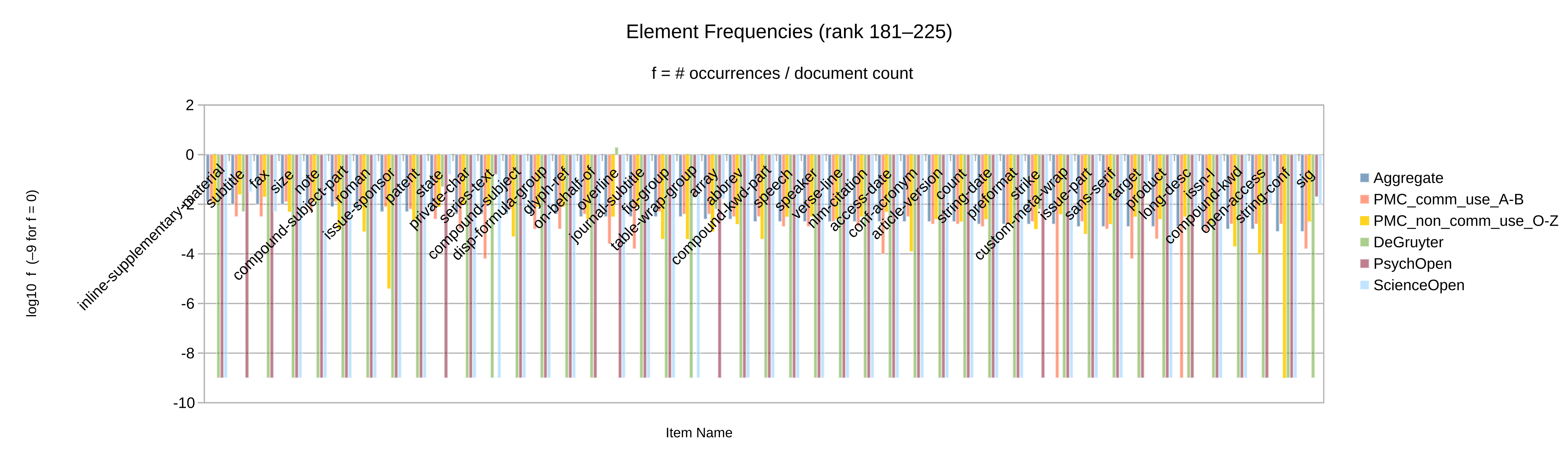
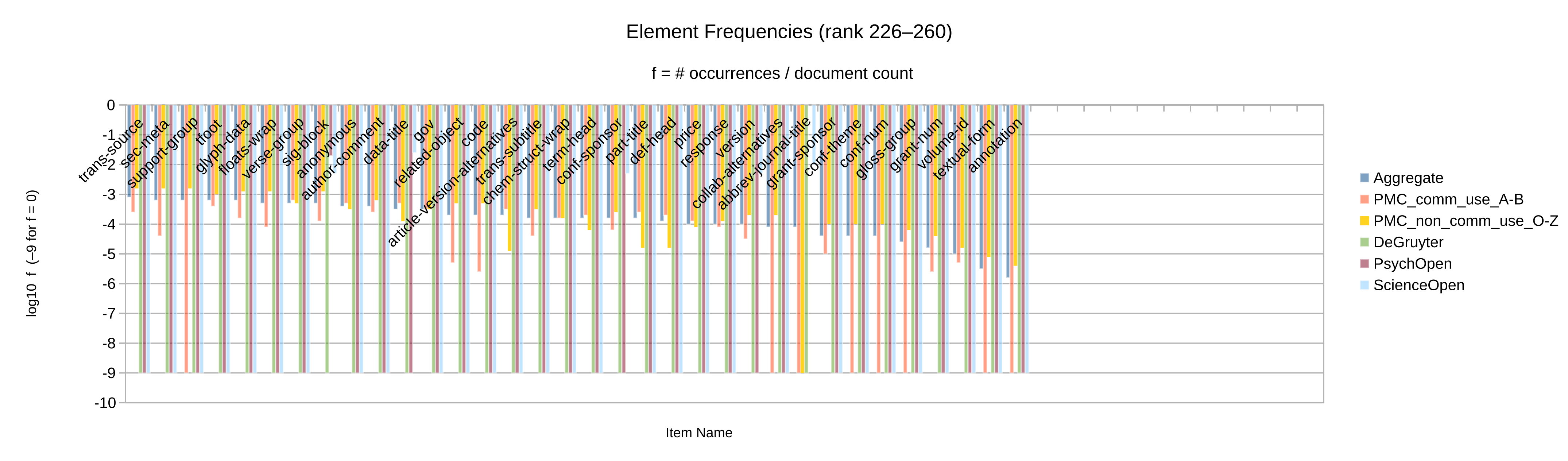
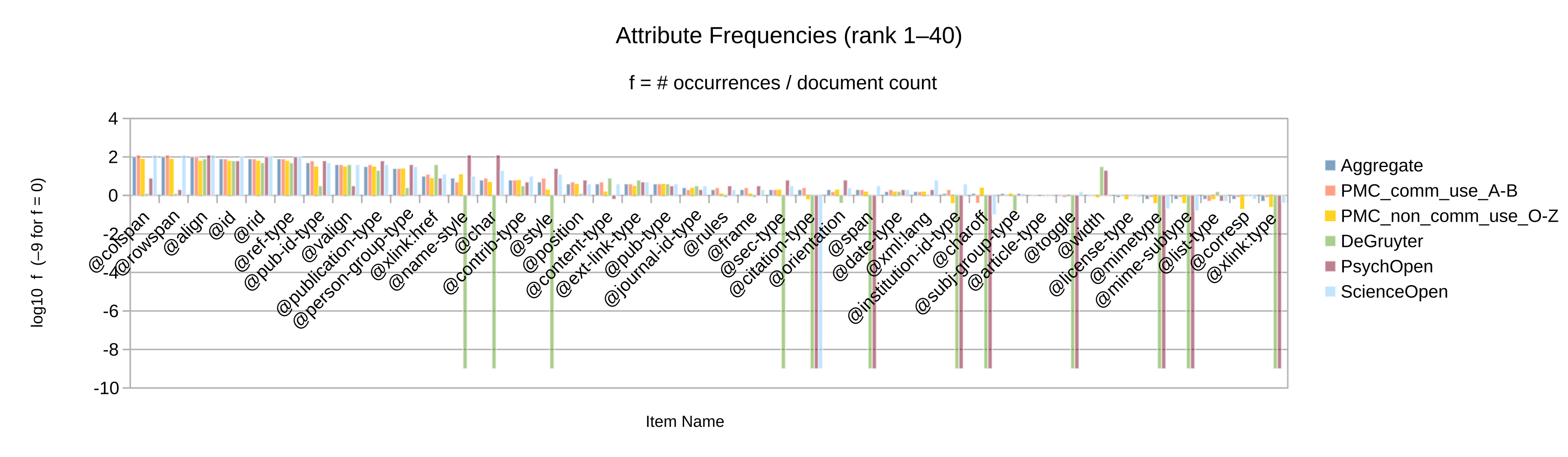
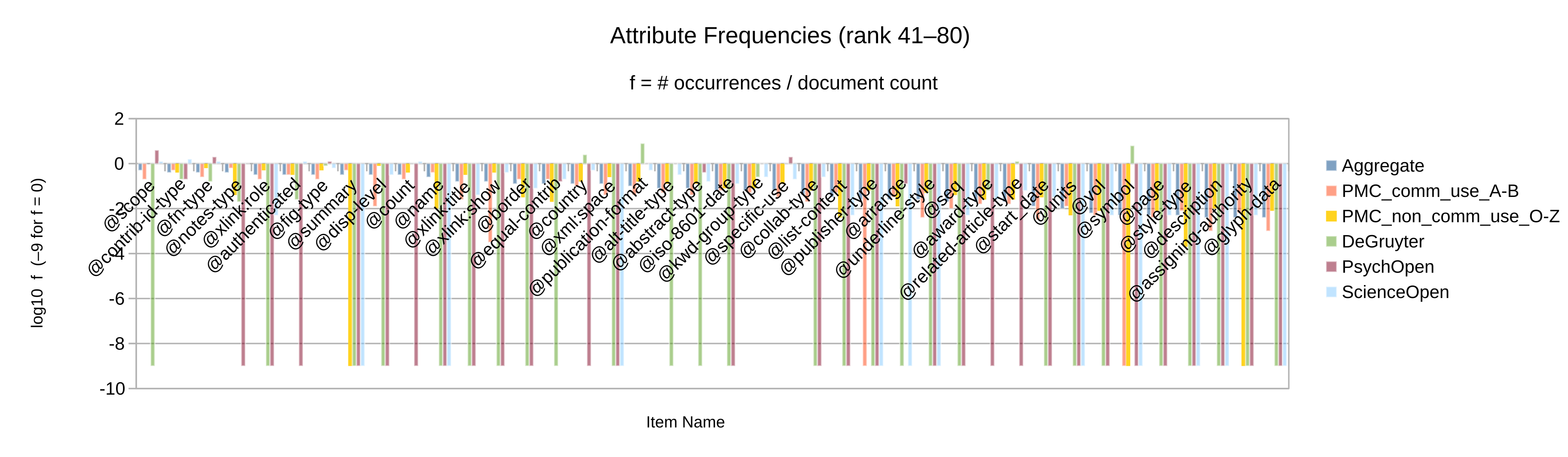
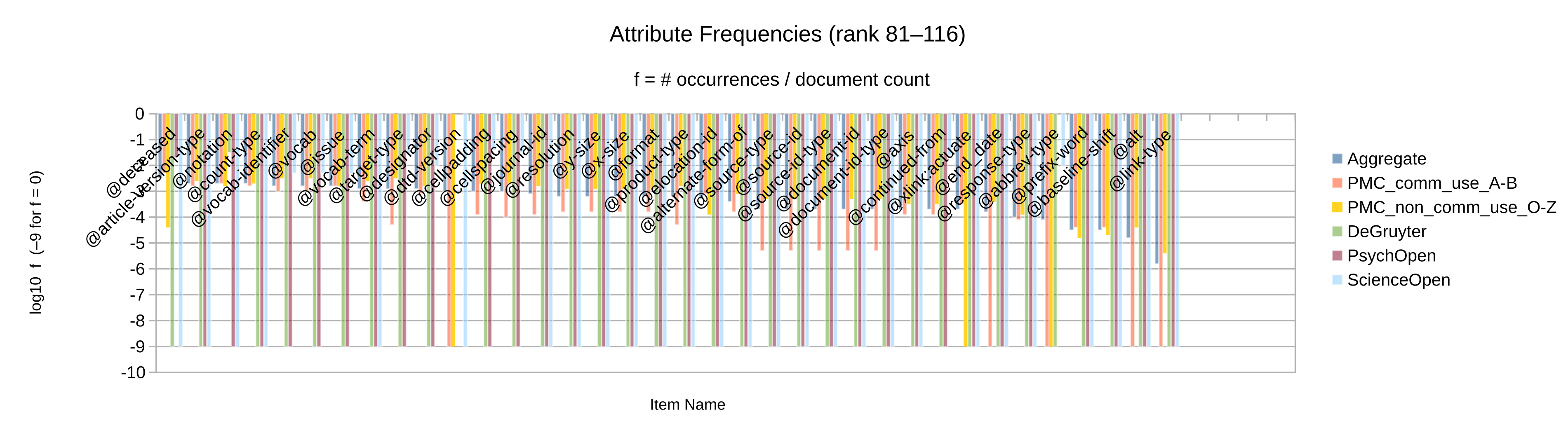
Otherwise, let the element and attribute frequencies (Figure 2 to
Figure 10) guide the decision whether an given Blue vocabulary item
is retained in the synthesized minimal customization.
Apart from the frequency itself, a secondary criterion may be whether the item’s frequency
is significant in more than one of the source collections considered. (Note that only
collections
for which full-text XML articles have been obtained could be analyzed by item frequency.)
Table II
Vocabulary items added to Blue in recent JATS versions
The analysis results presented in this section already contain the proposed minimal
subset
and its derivative, the naive minimal subset.
Figure 11: Individual PMC journals, consider vocabulary items not in Blue
Figure 12: Individual PMC journals, ignore vocabulary items not in Blue
Figure 13: PMC as a single de-facto customization, consider vocabulary items not in Blue
Figure 14: PMC as a single de-facto customization, ignore vocabulary items not in Blue
The authors selected a compact yet high-scoring de-facto customizing of PMC Transfusion
(items with less than
1% frequency ignored) as a starting point. Items that met the criteria presented in
section “Minimal Subset Criteria and Choices” have been included. This led to a significantly larger and lower-scoring
“minimal” customization. This customization still contains fewer items that the union
of all items found in the
collections. This is achieved by dropping more unpopular items than adopting strategic
items. The item count (324)
is still significantly lower than Blue’s (453), and the average aptness is not much
worse than that of other
collection-based or schema customizations. The reduction goal of 60% couldn’t be reached
though. And it is
questionable whether 90% of the analyzed articles are covered by this customization.
This minimal customization is
a superset of 38% of the de-facto customizations in the “Individual PMC journals,
ignore vocabulary items not in Blue”
scenario. Unless the use of the vocabulary is distributed very unevenly among a collection’s
articles, this
means that the goal of 90% article coverage is also missed by a high margin.
The situation looks different if the strategic additions are not considered. This
is called the “naive
minimal” customization and it comprises only 58% of Blue items. It is a superset to
only 27% of the de-facto
customizations, therefore the 90% goal is also missed significantly.
While the minimal subset has been prepared as a
proper DTD customization, the naive minimal customization has been prepared manually by using
the
HTML vocabulary lists and commenting out strategically important yet empirically unpopular items again.
This
boosts the average aptness of minimal, in particular in the per-journal PMC case,
to heights that
only the all-used-vocabulary union customizations can reach, yet with about 25% less
vocabulary.
Conclusion
Empirical JATS usage statistics have been analyzed. There is no clear-cut set of universally
unpopular
vocabulary items though. It is therefore arbitrary where to cut off the long tail.
A thing that the authors
consider not arbitrary at all is the question whether newly-added or otherwise strategically
important
items may be left out in a consensus customization; they may not. Only few items have
been considered as
maybe a sign of aquafication: index terms and questions/answers. These have also been
left out in a previous
effort by the Texture team.
More restrictions with respect to canonical usage of the tags within the vocabulary
that the proposed
minimal customizing provides may be done by fine-tuning the schema or by adding Schematron
constraints, including
existing ones from JATS4R.
The authors are not sure whether the proposed minimal customizing, together with these
Schematron rules, may
develop into a valid alternative to mainstream Blue. This probably needs to be field-tested
by production staff
at publishing houses.
A longer-form version of this paper, that is, Nina Reinhardt’s master’s thesis
Reinhardt 2021 will be
available for download from HTWK Leipzig in August, 2021.
[Schwarzman 2017] Schwarzman, Alexander B.
JATS Subset and Schematron: Achieving the Right Balance. In: Journal Article Tag Suite Conference (JATS-Con)
Proceedings 2017. Bethesda (MD): National Center for Biotechnology Information (US);
2017.
https://www.ncbi.nlm.nih.gov/books/NBK425543/
Schwarzman, Alexander B.
JATS Subset and Schematron: Achieving the Right Balance. In: Journal Article Tag Suite Conference (JATS-Con)
Proceedings 2017. Bethesda (MD): National Center for Biotechnology Information (US);
2017.
https://www.ncbi.nlm.nih.gov/books/NBK425543/