Holstege, Mary. “Fast Bulk String Matching.” Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6, 2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Holstege01.
Balisage: The Markup Conference 2021 August 2 - 6, 2021
Mary Holstege spent decades developing software in Silicon Valley, in and around markup
technologies and information extraction. She has most recently been pursuing artistic
endeavours. She holds a Ph.D. from Stanford University in Computer Science, for a
thesis on document representation.
XQuery developers deserve to have access to libraries of implementations of useful
algorithms, just as developers in other languages do. This paper describes an implementation
of the Aho-Corasick algorithm and some applications of it, as part of an effort to
build up one such a library.
Although XQuery 3.1 is a fully capable programming language, well-suited to processing textual data,
it does suffer from a relatively small user community and a dearth of publicly available
libraries. Implementations of well-known algorithms or capabilities are simply not
readily available. Birnbaum2020 pointed out the issue with respect to statistical plotting and commenced an effort
to remedy that situation. This paper discusses an effort to do the same for some string
processing algorithms, starting with an implementation of the classic Aho-Corasick
string matching algorithm, together with some layered tools for using it for tagging
and information extraction.
The Aho-Corasick algorithm allows for finding all the matches of a large number of
keywords in a text in one go. It has good performance characteristics both for setting
up the data structures and for applying them once built.
The Aho-Corasick algorithm (AhoCorasick1975) is a fast, simple algorithm for matching a fixed set of keywords against an input
text. It returns all the matches in the text. It has a number of salutary properties.
The cost of matching, assuming the dictionary has been built, is independent of the
size of the dictionary. Matching performance is linear with the size of the input
and the number of matches: the algorithm requires a single scan through each symbol
in the input. Furthermore, the cost of building the dictionary is also linear with
respect to the size of the dictionary. Although the algorithm is building a finite
state machine, because we don't have to worry about general regular expressions and
state minimization (as we would, for example, with algorithms such as Brzozowski1964), the size of the state machine is also linear in the worst case with the size of
the dictionary, and is usually smaller, as we shall see.
The core data structure for the algorithm is a trie, or prefix tree. Each edge in the trie is labelled with a symbol, and each node represents
the concatenation of the symbols from the root leading to that point. Some nodes are
terminal in the sense that they have a matching keyword associated with them. In our case,
the symbols are Unicode codepoints. As we scan a string, codepoint by codepoint, we
traverse the corresponding edges in the trie, if any. If traversal reaches a terminal
node, that node's keyword is a match. If no edge from a node for the current codepoint
exists, the match for the string at that point fails.
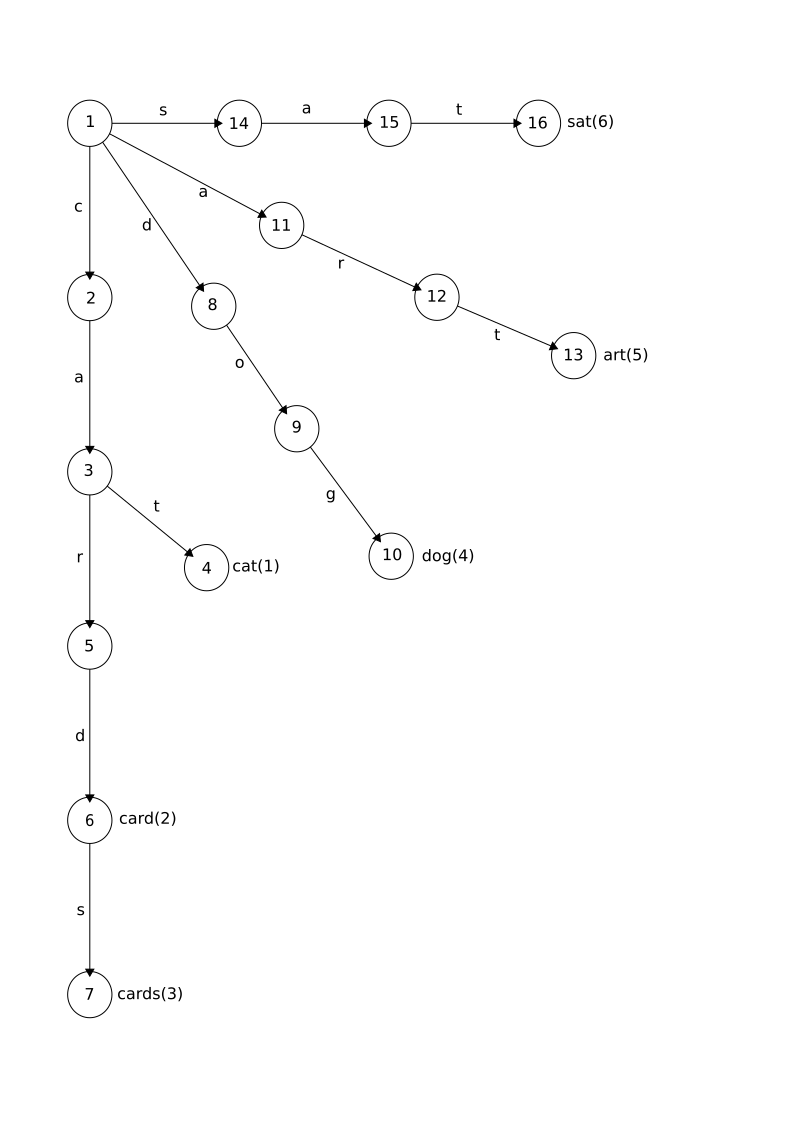
Trie 1 (Base) shows a trie constructed for a small dictionary consisting of the words cat, card, cards, dog, art, and sat. I use the convention of referring to a state xyz to mean the state representing the prefix xyz, that is, the state reached by following the edges labelled with the codepoints in
xyx in turn. State 5 (car) corresponds to the prefix car; state 6 (card) to the extended prefix card. As you can see, although the size of the dictionary is 21 (adding up the lengths
of all the words), the trie only requires 16 nodes and 15 edges, because there are
overlapping prefixes. This is typical, although in the worst case there will be as
many states as the concatenated size of the keyword set. There are six terminal nodes,
but notice how "terminal" nodes may yet have edges coming from them. An input string
cards would match both card and cards by traversing first state 6 and then state 7, returning the match from each terminal
node in turn.
Trie 1 (Base): Trie for words cat, card, cards, dog, art, and sat
Image description
The trie consists of 16 states arranged largely in four straight branches from the
root state. The root state is labelled state 1.
The main part of the left-hand branch consists of states 2, 3, 5, 6, and 7. State
1 links to state 2 with edge c, state 2 links to state 3 with edge a, state 3 links to state 5 with edge r, state 5 links to state 6 with edge d, and state 6 links to state 7 with edge s. State 6 has the output card associated with it and state 7 has the output cards associated with it. There is a side branch from state 3 to state 4 with the edge
t linking them. State 4 has the output cat associated with it.
The second branch from the root has the states 8, 9, and 10 linked with the edges
d, o, and g in turn. State 10 has the output dog associated with it.
The third branch from the root has the states 11, 12, and 13 linked with the edges
a, r, and t in turn. State 13 has the output art associated with it.
The final branch from the root has the states 14, 15, and 16 linked with the edges
s, a, and t in turn. State 16 has the output sat associated with it.
A prefix trie showing the states and edge relationships for the set of words.
To get all matches of an input string, conceptually we need to run the traversal from
the root starting at each position in the input string. Thus we rescan each character
in the string multiple times instead of only once. How many times will depend on the
length of partial matches at any given point in the input string. To avoid this rescanning,
the Aho-Corasick algorithm uses failure edges which are followed when there is no matching edge. You can think of the failure edge
as taking us to the state we would have been in had we restarted from the root to
get to the current failure point. They link to the state with the longest suffix of
the current prefix. The failure links allow us to skip the back-tracking and go directly
to the state we'd have got to by backtracking and restarting from the root.
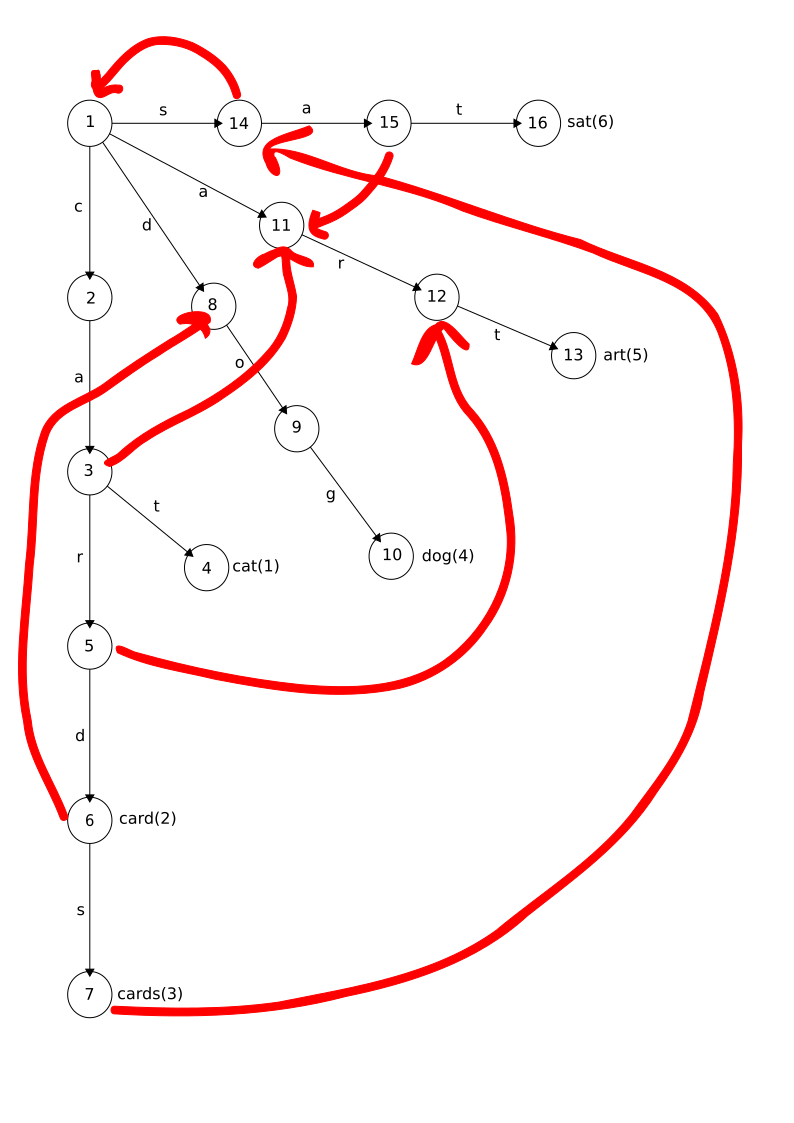
Trie 1 (Failure) shows failure edges added to the base trie of Trie 1 (Base). Most failure edges go straight back to the root (like the one from state 14) and
they have been elided for clarity. State 5 (car) has a failure link to state 12 (ar) because ar is the longest suffix of car that has a path from the root.
Trie 1 (Failure): Trie with failure links added
Image description
The trie is the same trie as before with some additional links of a different kind
drawn in. These failure links connect the following states:
State 14 (linked by edge s from the root) to state 1 (the root)
State 15 (sa) to state 11 (a)
State 3 (ca) to state 11 (a)
State 5 (car) to state 12 (ar)
State 6 (card) to state 8 (d)
State 7 (cards) to state 14 (s)
The same prefix trie showing the added failure links.
Now consider the task of matching all the keywords in this dictionary against the
input string cat and dog.
We start in state 1, see c and traverse to state 2 (c), then on to states 3 (ca) and 4 (cat), which is terminal so we emit a match for keyword number 1 (cat).
There is no edge for the space, so we take the failure edge back to state 1. Now we
follow the a edge to state 11 (a), where we fail back to state 1 again, as there is no edge for n.
That creates another failure, looping back to state 1, and we proceed with the d edge to state 8 (d).
Another failure (for the space) and we proceed along the d edge again to state 8 (d), then on to state 9 (do) along the o edge, and finally along the g edge to to state 10 (dog). State 10 is a terminal state so we emit a match for keyword number 4 (dog).
We have performed a single linear scan of the input, and matched all the keywords.
Let's take another example: cartography. We start at state 1, follow the c edge to state 2 (c), then the a edge to state 3 (ca) and the r edge to state 5 (car). Now something interesting happens. We fail not to the root, but to state 12 (ar). State 12 records the fact that we have already matched ar so there is no need to backtrack. Traversal continues to state 13 (art) which is terminal. Keyword 5 (art) is emitted. We'll discuss prevention of partial word matches in a bit. The rest
of the traversal is a litany of failure, which I will pass over in silence.
Building the basic trie is straightforward: scan through each keyword in the dictionary
and traverse the current trie from the root as we go, adding edges if they are missing,
and adding information about the keywords for terminal nodes when we get to the end
of a keyword.
Once all the keywords are added, we can compute failure edges. They are initialized
to the root and then updated with a breadth-first traversal. Once we know the failure
edge for a node, the failure edges for its children will depend on it in the following
way:
Let's consider a node x representing the prefix x, that is, it is the node reached by following the edges for the codepoints in x in turn. Suppose node x has a failure link to y. What should the failure link of x's child xa be?
If ya exists, then the failure link will be ya because the ya represents the continuation of the failure from x with a. Diagram 1 (Case 1) shows this case.
Diagram 1 (Case 1): Computing failure links
Context for xa
Image description
There are four states: x with an edge labelled a to xa and y with an edge labelled a to ya. There is a failure link from x to y.
Failure link for xa
Image description
The failure link for xa is added to the diagram, linking to ya.
Computing failure links when there is a continuation of the target failure node.
On the other hand, if there is no ya, recursively consider y's failure link, say, to z. If za exists, then that becomes the failure link for xa, because, again, it represents the continuation of the failure from x with a. And so on. Diagram 1 (Case 2) shows this case.
Diagram 1 (Case 2): Computing failure links
Context for xa
Image description
There are five states: x with an edge labelled a to xa, y with no edges, and z with an edge labelled a to za. There are failure links from x to y and from y to z.
Failure link for xa
Image description
The failure link for xa is added to the diagram, linking to za.
Computing failure links when there is a not a continuation of the target failure node.
It sounds more complicated than it is. These traversals for failure links are limited
by width of the tree in the worst case[1].
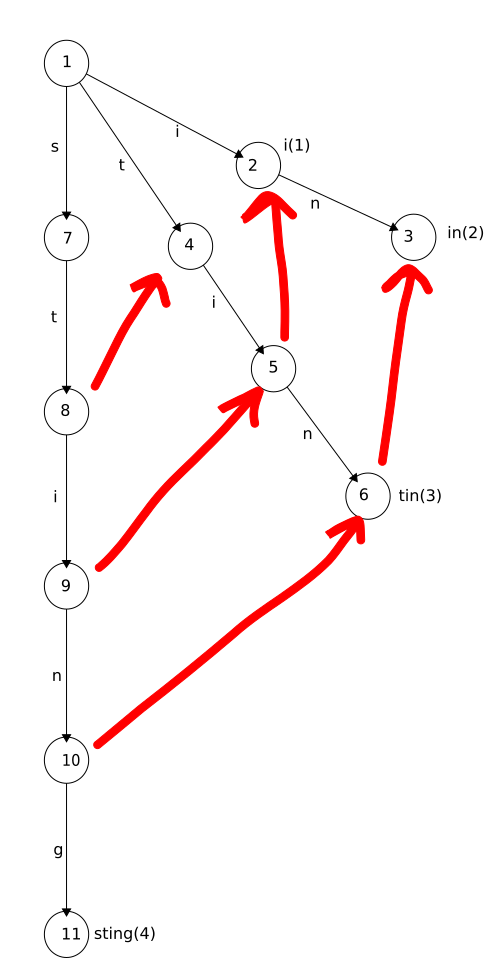
There is another slight issue to take care of, because of the highly optimized nature
of this data structure. Consider the trie in Trie 2 constructed from the keywords i, in, tin, and sting. The key failure links are shown in red. What happens when we match the string sting here? I won't take you through the entire blow by blow, but I hope it is plain that
we zoom straight down the leftmost branch of the trie, winding up at state 11, where
we emit keyword 4 (sting). Yet all the other keywords matched too! We missed them because we never followed
a failure link to get to them because they are proper suffixes of the path along the
way to sting. To fix this we need to do one more thing as we are constructing failure links, and
that is to construct output links as well.
Trie 2: Missing matches
Image description
The trie consists of 11 states arranged in three straight branches from the root.
The root state is labelled state 1.
The left-hand branch from the root has states 7, 8, 9, 10, and 11 linked with the
edges s, t, i, n, and g in turn. State 11 has the output sting associated with it.
The second branch from the root has states 4, 5, and 6 linked with the edges t, i, and n in turn. State 6 has the output tin associated with it.
The final branch from the root has states 2 and 3 linked with the edges i and n in turn. State 2 has the output i associated with it and state 3 has the output in associated with it.
There are also failure links between the following states:
State 8 (st) to state 4 (t)
State 9 (sti) to state 5 (ti)
State 10 (stin) to state 6 (tin)
State 5 (ti) to state 2 (i)
State 6 (tin) to state 3 (in)
A trie showing how matches that are proper suffixes can be missed.
Output links point to a node we need to visit to emit more matches. For a node w, the output link points to the node corresponding to the longest proper suffix of
w that also emits a keyword. To compute output links we initially set them to a null
value. As we construct failure links look at the node being set as the failure link.
If it represents a keyword in its own right or by virtue of its own output link, the
current node's output link points to that node (the end of the failure link). Otherwise
it copies the failure node's output link.
For matching, when we visit a node, we emit any keywords it has in its own right,
and if it has an output link, we collect keywords from the node at the end of the
output link as well (and recursively, if that node also has an output link).
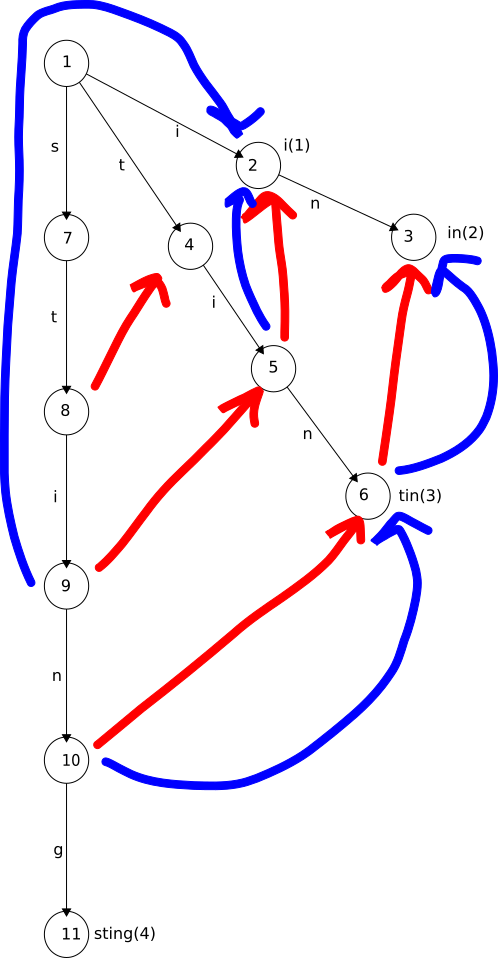
Trie 2 (Output) shows the added output links. Now when we look for matches to sting things proceed down the diagram as before, except we do a little extra work when
we come to states 9 (sti) and 10 (stin). At state 9 we look at the output node (state 2 (i)) and emit keyword 1 (i). At state 10 we look at the output node (state 6 (tin)) and emit keyword 3 (tin). State 6 also has an output link which leads us to emit keyword 2 (in). Finally, as before, we arrive at state 11 and emit keyword 4 (sting). In this way we get all the matches, still with a single pass through the input
string.
Trie 2 (Output): Output links
Image description
The trie is the same trie as before with additional links of a different kind drawn
in. These output links connect the following states:
State 9 (sti) to state 2 (i)
State 10 (stin) to state 6 (tin)
State 5 (ti) to state 2 (i)
State 6 (tin) to state 3 (in)
The same trie with output links added.
Notice that creation of failure states and output links assumes a complete dictionary.
There is no incremental addition of new keywords once the states have been computed.
There are related algorithms, such as Meyer1985, but in my experience the incremental use cases can often be solved by constructing
auxiliary dictionaries and running multiple matches.
There are a few additional points to consider:
Matching is codepoint-by-codepoint. What about case-insensitive matching?
The algorithm clearly allows for overlapping matches.
It also clearly does nothing about anchoring matches to words.
With respect to case-insensitive matching, we are already converting strings to codepoint
sequences in both the construction of the dictionary and the matching against it.
Case insensitive matching can be accomplished by applying the lower-case function to the strings before obtaining the codepoints. The case mapping should
be consistent between trie building and matching: for this reason the API takes case-sensitivity
as a configuration option on the trie, not as a match-time option. There are other
codepoint manipulations we might want to do, such as Unicode normalization. This is
also a configuration option to the trie.
Overlapping matches can be removed at match time by sorting and pruning. The API provides
a match option for this purpose, preferring longer matches over shorter ones, and
matches starting earlier in the input text to those starting later.
Anchoring matches to words is somewhat costly, the most costly aspect of matching
as implemented, in fact. Each match must be checked against the input text to verify
that it falls on a proper word boundary. The algorithm is geared to finding all the
matches in the string and all matches it finds. One can imagine various tricks to
avoid having to do the post-processing filtering, but they all essentially work by
subverting the optimizations of the algorithm in some way or by forcing a boundary
check on every character in the input sequence, and they are not promising.
Implementation
The core data structure is a graph with nodes that are linked together with a variety
of edges. These edges need to be updated when the graph is built. Let us be plain:
XQuery is not a language for building updatable linked data structures. What shall
we do?
The answer to the puzzle is to play the old C programmer's trick of putting everything
into an array and representing relationships with index numbers.[2] States hold their own index number, which makes operations somewhat more convenient
when we are traversing through the trie. To "update" a state means to create a new
state and put it into the appropriate place in the array, creating a new array. And
since the trie has some other information besides the state array, a third level of
update is required: that of the trie data structure itself. By flattening the trie
in this way, we only have to update a known fixed number of levels of structure instead
of doing a recursive bubbling of updates across the trie. All of these mechanics are
handled via an API over the trie for updating the state array. (The third level of
updating would be the change to the state itself.)
For example, here are the functions to fetch and update a state in the state array.
As you can see, there are two levels of updating: (1) updating the state array with
array-put and (2) updating the trie by replacing its old state array with the new one.
Listing 1: State getter and setter
declare %private function this:get-state(
$trie as map(xs:string,item()),
$i as xs:integer
) as map(xs:string,item())
{
$trie("states")=>this:array-get($i)
};
declare %private function this:put-state(
$trie as map(xs:string,item()),
$i as xs:integer,
$state as map(xs:string,item())
) as map(xs:string,item())
{
$trie=>map:put("states", $trie("states")=>this:array-put($i, $state))
};
Interactions with the state array.
I implemented most of the basic data structures here as XQuery 3.1 maps, including
the state array. An XQuery 3.1 array or even (with care) a plain sequence could be
used for the state array, but it makes the put-state function a little messier because it has to behave differently for the addition of
a new state versus the replacement of an existing state. Using a map for a sparse
or growing array is a useful trick.
Trie 1 (Data structure) shows what the completed data structure looks like, rendered as JSON. The state "array"
is a map from a state ID to a map representing the corresponding state. Each state
includes its own ID and depth, the map of transitions to successor states, output
and failure links, and the set of keywords to emit[3]. The trie has some additional properties that streamline some aspects of the implementation
(the empty 0 state is likewise used to simplify some of the code) which I will not dwell on further.
Trie 1 (Data structure): Data structure for true (as JSON)
JSON serialization of the data structure constructed for the trie in Trie 1 (Base) with failure edges and output links
To insert a keyword into the trie we must execute a fold, returning a new trie with
an updated state array for each codepoint in the keyword. A modestly tricky aspect
here is that we need to both update the trie and keep track of the current state because
we are creating child edges from the current state and advancing down the trie as
we go. Since neither the trie nor the state can be empty, I just return both in a
sequence: the caller needs to do a little unmarshalling of the result, as you can
see in the insert function in Listing 2.
Listing 2: Insert function
declare function this:insert(
$trie as map(xs:string,item()),
$word as xs:string
) as map(xs:string,item())
{
let $data :=
fold-left(
string-to-codepoints($word),
($trie, $trie=>this:get-state($trie("root"))), (: Marshalling :)
function($data as map(*)*, $codepoint as xs:integer) as map(*)* {
(: Unmarshalling :)
let $trie := $data[1]
let $cur-state := $data[2]
return (
(: add-state returns (updated trie + state) :)
$cur-state=>this:add-state($trie, $codepoint)
)
}
)
(: Unmarshalling :)
let $trie := $data[1]
let $cur-state := $data[2]
let $num-keywords := $trie("num-keywords") + 1
return (
$trie=>
this:put-state($cur-state("id"),
$cur-state=>this:add-emit($word, $num-keywords))=>
map:put("num-keywords", $num-keywords)
)
};
Marshalling and unmarshalling to update both trie and current state together.
Aho and Corasick's original paper describes the construction of the failure and output
links in entirely non-functional ways, as is typical for classic algorithms. The breadth-first
walk is described with a queue of nodes that gets processed in a while loop, nodes
added and removed as we go. I implemented this with recursion and folds instead.[4]
Case sensitivity and Unicode normalization are handled as configuration options when
the trie is built. A function that maps strings to codepoints based on these settings
is called for each word inserted into the trie and to scan the input string during
matching. In fact, an extended form of the basic API allows for the use of an arbitrary
codepoint function here, which can do things like transliteration or other kinds of
normalizations. Care must be taken, however, that the matching is done with a consistent
codepoint function.
Matches of partial words are pruned by testing the character (if any) in the input
string immediately before and after the match against a word boundary regular expression.
A configuration option controls what that expression should be: by default it matches
any non-letter non-number codepoint. This is not a terribly sophisticated word break
definition. Pruning based on the Unicode text break algorithm would produce more reliable
results, perhaps, if an implementation of that were available, by allowing partial-word
matches and pruning after the fact against word break positions. Alternatively, this
could be handled in a preprocessing step to insert a word break marker character into
the text at appropriate places and add the word break character at the appropriate
places in each word in the dictionary[5].
By default, overlapping matches are pruned, with longer, earlier matches preferred.
This is generally suitable for applications where the matches will be the basis for
markup. For information extraction applications, overlapping matches are desirable.
In some cases an application may want to make its own decisions about which of the
overlapping matches it wants, by pruning the matches after the fact.
API
The basic API has two main functions: one to construct a trie and one to return matches
for an input text.
The trie construction function, trie, takes a configuration map and a sequence of keywords to add to the trie. The configuration
has properties indicating whether case mapping and Unicode normalization should be
done when entering the words. The result is a populated trie with the failure states
and output links calculated.
A more advanced version of this part of the API allows for the basic trie to be constructed
separately from having words added. An explicit call to initialize the failure states
and output links is then required for the trie to be usable for matching.
The matching function, get-matches, takes a fully constructed trie and an input string plus an optional map of match
options, and returns a series of matches. The matches are themselves maps, it turns
out, but the API provides accessors to the important aspects, so they can be treated
as opaque objects consisting of the matching keyword, the index of the matching keyword,
and the start and end positions of the match in the text suitable for use by substring. The index is the position of the keyword in the original sequence of words used
to build the trie. It is useful for linking the keywords to richer entity information.
We'll see how this gets used in the layered API. Match options control how partial-word
matches and overlapping matches are handled.
Listing 3: Main API functions
(: Trie constructor :)
declare function trie(
[$config as map(xs:string,item()*),]
[$words as xs:string*]
) as map(xs:string,item())
(: Matcher :)
declare function get-matches(
$trie as map(xs:string,item()),
$text as xs:string,
[$options as map(xs:string,item())]
) as map(xs:string,item())*
Definitions of the main API functions. Square brackets indicate optional parameters[6].
Applications
Extraction
The basic use for the algorithm is to extract matches to perform some kind of analysis
of them. Set up the trie. Use it to get matches. Use the accessors to get whatever
information you need to process the matches. Example 1 shows a simple example of getting counts of how many times various people are mentioned
in Shakespeare's play Hamlet.
Example 1: Extracting and processing matches
let $people := (
"Claudius", "Hamlet", "Polonius", "Horatio", "Laertes",
"Lucianus", "Voltimand", "Cornelius", "Rosencrantz",
"Guildenstern", "Osric", "Marcellus", "Bernardo",
"Francisco", "Reynaldo", "Fortinbras", "Gertrude",
"Ophelia")
let $config := map {"case-insensitive": true()}
let $trie := aho:trie($config, $people)
let $hamlet := doc("hamlet.xml")//text()
let $matches :=
for $text in $hamlet return aho:get-matches($trie, $text)
let $zero :=
fold-left(
$people, map {},
function ($counts, $person) {
$counts=>map:put($person, 0)
}
)
let $counts :=
fold-left(
$matches, $zero,
function ($counts, $match) {
$counts=>
map:put(aho:keyword($match),
$counts(aho:keyword($match))+1
)
}
)
for $person in $people
order by $counts($person) descending
return $person||" mentioned "||$counts($person)||" times
"
Extracting names of people from a play to determine the number of mentions of them.
We set up the trie to use case-insensitive matching over the cast of characters with
the call to aho:trie, then perform matching with the default options over every text node in the play
using aho:get-matches. Finally we walk through the matches gathering counts, using the accessor aho:keyword.
Tagging
To use string matching to create markup, perform a recursive walk of the input node.
All the action falls in the text nodes, which get replaced with a series of text nodes
for non-matches and markup nodes for matches. We can accomplish this by folding over
the matches while also keeping track of the position of the last match, so:
let $matches := $trie=>aho:get-matches($text)
let $markup :=
fold-left(
$matches, (1),
function($markup, $match) {
(: Unmarshalling: first in sequence is position :)
let $pos := head($markup)
let $next := aho:start($match)
return (
aho:end($match)+1, tail($markup), (
(: Non-match part of text :)
if ($next > $pos) then (
text { substring($text, $pos, $next - $pos) }
) else (),
(: Match :)
element {"keyword"||aho:index($match)} {
substring($text, aho:start($match), aho:interval-size($match))
}
)
)
}
)
return (
(: Strip off position; emit final non-matching text :)
tail($markup), text { substring($text, head($markup)) }
)
Note the use of the accessor functions aho:start and aho:interval-size.
This code only works if matching prunes overlaps. Marking up text in the face of overlapping
matches requires some additional work well beyond the scope of this simple example.
Operations on Strings
XQuery provides additional functions that use regular expressions to operate over
strings matches, replace, tokenize, and analyze-string. Similar operations can be created for use with tries. The flags here do not make
sense: only case sensitivity is germane and we have that as a trie option. Group replacement
variables also don't make a whole lot of sense (except for $0) although we could choose to define $N to mean the Nth keyword in the trie.
The matches analogue is the most trivial to implement: just wrap a call to exists around the output of aho:get-matches. Of course, as a built-in function matches can stop as soon as it finds one match to provide a performance advantage. We would
have to provide a separate API on the trie to get the same kind of advantage here.
For long texts the advantage for matches is extreme and the more actual matches there are the worse it gets. I ran a little
experiment with the same smallish dictionary but where various words were tweaked
to enable or disable actual matches by appending an "x". Running this against the
concatenated text of Hamlet takes about the same time with matches regardless of the number of actual matches: a little over a second. Running it with
aho:get-matches with Saxon-HE 10.1 on my 4 core Intel(R) Xeon(R) CPU 3.5MHz desktop took over five
and a half minutes with 14 actual matches, about six minutes for 486 matches, and
about thirteen minutes for 826 matches:
Matches
Regex Time
Trie Time
14
1.3s
5m40s
486
1.1s
6m3s
825
1.1s
13m2s
It is interesting to note, however, that if we structure the code to process one text
node at a time the timings become comparable, taking about a second and a half regardless
of the number of matches, because aho:get-matches can stop at the first matching text node, even if it does take the time to process
all matches within that text node. So a chunking strategy can overcome most of the
advantage matches has. Varying the chunk size we can see the tradeoff: increasing the chunk size generally
increases the running time.[7]
Chunk size
Time (seconds)
50
1.4
500
1.5
5000
2.2
50000
56.0
100000
126.0
An implementation of tokenize looks a lot like the snippet of code in section “Tagging” except that instead of returning the node children for matches and non-matches we
return only the strings for the non-matches. The analogue to analyze-string operates similarly, but wrapping matches and non-matches into the appropriate fn:match and fn:non-match elements.
The replace analogue is only slightly more tricky because it also needs to do some processing
of the replacement string in order to handle replacement variables. Since replace cannot short-circuit like matches does, running time increases with the length of the string and number of actual matches.
Replacement generally requires pruning overlapping matches, so the analogue function
will need to pay for that.
We'll take a deeper look at analyze-string in another section, which raises some of the same considerations as replace as well as some of others its own.
Cute Pet Tricks
The advanced API provides a hook for an arbitrary codepoint extraction function. We
can use that to do cute things like match transliterated keywords:
let $trie :=
aho:trie()=>
aho:insert-all(("Ельцин","Каспаров","Путин"), local:romanize#2)=>
aho:initialize-states()
let $text := "Are Putin and Kasparov friends?"
for $match in aho:get-matches($trie, $text, local:romanize#2, map {})
return aho:keyword($match)
Here we construct a trie (aho:trie), insert a bunch of Russian words (aho:insert-all), and initialize the failure and output links (aho:initialize-states). The local function romanize is used to map codepoints.
Then we run a match against the sample text, making sure to use the same codepoint
function, and return all the matching keywords. Assuming the transliteration function
properly maps the Russian names to Latin characters, we would see the matches Путин and Каспаров returned.
Entity API
Things get more interesting when we make use of the keyword index in the trie to correlate
matches to a richer set of information about the match words.
The higher-level API built on top of the base string matching does this by defining
an entity table, or dictionary. Each entry in the entity table includes a unique identifier, the normalized form
of the matching word, the keyword to match, and a type designator. In addition to
constructors and accessors for entities and entity dictionaries, the API provides
two walker functions. One acts as a transformer, recursively walking through the input
node and its children, replacing text nodes with a series of text nodes for non-matches
and results of a callback function for each match. The other walks recursively through
the input node and its children and produces just the results of the callback function
for each match, acting as an extraction function.
Listing 4: Main Entity API functions
(: Entity entry constructor :)
declare function this:entity(
$id as xs:string,
$normalized as xs:string,
$word as xs:string,
$type as xs:string
) as map(xs:string,xs:string)
(: Entity table constructor :)
declare function this:dictionary(
$entities as map(xs:string,xs:string)*
) as map(xs:string,item()*)
(: Extractor :)
declare function this:extract(
$input as node()*,
$dictionary as map(xs:string,item()*),
$callback as
function((:text:)xs:string,
(:match:)map(xs:string,item()),
(:entity:)map(xs:string,xs:string)) as node()*,
[$match-options as map(xs:string,item()*)?]
) as node()*
(: Inline markup :)
declare function this:markup(
$input as node()*,
$dictionary as map(xs:string,item()*),
$callback as
function((:text:)xs:string,
(:match:)map(xs:string,item()),
(:entity:)map(xs:string,xs:string)) as node()*,
[$match-options as map(xs:string,item()*)?]
) as node()*
Definitions of the main API functions. Square brackets indicate optional parameters.
In addition a variety of sample callback functions is provided, such as one that wraps
the match in an element whose name is derived from the entity type.
Walking through node trees to do extraction or tagging in this way is so generally
useful, additional convenience functions are provided to do so at the lower level
as well, with callback functions for handling each match. The API is almost identical
to this one, with a extract and a markup function. The functions take a bare trie instead of an entity dictionary and the
callbacks only have two arguments instead of three (no entity).
Normalization
Imagine an entity dictionary where each entity has entries in the table for the variations
in spelling or longer or shorter forms of the word. For example: Nixon, Richard M. Nixon, President Nixon, Dick Nixon, Richard Milhouse Nixon, all mapped to the same normalized form President Nixon. Run the walker over the input with this dictionary with a callback function that
replaces the match with the normalized form, and we get consistent usage.
Imagine an entity dictionary with the British and American spellings of words as alternative
lemmas to the British form. Run that same play and we can have consistent British
spelling throughout.
Junk Elimination
A similar ploy to using the walker to normalize forms is to use it to eliminate them
entirely. Strip out the FIXMEs and TODOs. Strip out stop words. Strip out punctuation. Strip out spaces.
Query Enrichment
We often think of markup and matching as processes that apply to content, but it is
interesting to apply them to query strings. Stopwords can be removed. Terms can be
normalized. Known entities can be identified and linked to semantic information. Wrap
the string in a text node, and apply appropriate markup callback functions to rewrite
it.
Consider the query string: Does Hamlet stab Claudius?
Apply a walker with a callback that just removes matches, using a dictionary of stop
words and extraneous punctuation:
text { "Hamlet stab Claudius" }
Apply a walker that extracts marked up matches for proper nouns:
We now have some rich semantic information about our query, to which we can apply
some disambiguation logic or semantic inferences to get better responses.
Performance Notes
Building the trie is the most expensive operation. This is directly proportional to
the sum of the lengths of the keywords added to the trie. For small dictionaries the
cost of building a trie and using it for matching in the same query is modest and
acceptable. For bulk matching of strings against very large dictionaries, we can precompile
the trie, save it using serialize with the JSON output method, and load it back again using parse-json. That is still a linear operation, but a cheaper one. Annoyingly, parse-json turns all our codepoint and state integers into doubles. Since the code is strongly
typed, this creates issues unless the load function does a fixup pass to cast them
back to integers.[8]
Matching, by contrast, is proportional to the length of the input string plus the
amount of work done to process each match. So matching a very large dictionary against
a text is no more expensive than matching a small dictionary against it, if the number
of matches were the same.
It is worth pointing out that the API always returns the matches in order because
that it most useful most of the time. Technically a sort is not generally linear in
performance. However, the matches are mostly sorted already (only the matches from
output arcs appear out of order as we saw in sting example). The impact of this depends on the underlying sort algorithm, of course,
but for many likely algorithms this is a good case (e.g. quick sort, bubble sort,
insertion sort) so we can still get linear or close to linear in practice.
Overlap elimination depends on processing the matches in a different order, however,
so in that case we are paying the full cost of the sort (twice).
To get a sense of "how slow is slow", I ran some simple tests with Saxon-HE 10.1 on
my 4 core Intel(R) Xeon(R) CPU 3.5MHz desktop. These tests were run using an entity
dictionary consisting of all the nouns in WordNet 3.0® (WordNet)[9] written out into a tab-delimited file format. Each entity consisted of the synset
number used as an identifier, each lemma used as the keyword for matching (with the
first lemma taken as the normalized form), and a type plus subtype, which was the
concatenation of a "top" level hypernym and the immediate hypernym.
For example, the entity entries related to synset 00015388 are:
00015388 animal animal living thing:organism
00015388 animal animate being living thing:organism
00015388 animal beast living thing:organism
00015388 animal brute living thing:organism
00015388 animal creature living thing:organism
00015388 animal fauna living thing:organism
In all there are 146,346 entries.
Reading and parsing the entity table and using the lemmas to populate a trie took
56 seconds, with most of the time split fairly evenly between inserting the words
and building the failure states.[10]
Doing all of that and then using the dictionary to drive entity markup over Jon Bosak's
XML representation of Hamlet (Hamlet) took 63 seconds. That is, reading Hamlet from disk, walking over the data model, running the match over each text node and
rebuilding the tree to include XML markup representing the pruned non-overlapping,
whole-word matches (and therefore sorting the matches twice) and writing that result
to disk took an additional 7 seconds over the cost of building the dictionary. Three
quarters of the matching time was pruning matches of partial words.
For comparison, loading up (and fixing up the integers in) a precompiled dictionary
saved to disk and then running it over Hamlet took 34 seconds. So using the precompiled dictionary cut the cost of getting a dictionary
ready for use approximately in half.
Comparison with analyze-string
XQuery 3.1 includes a powerful string matching operation already: analyze-string. By converting a dictionary of words into a giant regular expression where each keyword
is an alternative, analyze-string can find all matches for that set of words in an input text. What are the pros and
cons of using that function against using the Aho-Corasick matcher with or without
the entity tables layered on top?
We have already seen, in detail, how to build a trie from an arbitrary set of strings.
Building a regular expression for an arbitrary set of strings is relatively straight-forward,
although we do need to exercise a little care to avoid problems with metacharacters:
they need to be escaped.
Listing 5: Building the regular expression
declare function this:escape(
$word as xs:string
) as xs:string
{
replace($word, "([\[\]\{\}\(\)\+\*\?\-\^\$\\\|\.])", "\\$1")
};
declare function this:regex(
$words as xs:string*
) as xs:string
{
string-join(
for $word in $words return "("||this:escape($word)||")",
"|"
)
};
Constructing a regular expression for use with analyze-string.
When we apply this regular expression to a string with analyze-string we will get the input string broken in to a sequence of match and non-match elements,
where each match will have a group with the group number corresponding to the index
number of the word in the input dictionary.
In most respects, what analyze-string and get-matches can do is very similar. There are convenience and performance tradeoffs depending
on the application. When it comes to mass string matching over large texts, the performance
advantage of the Aho-Corasick shines. When it comes to rich contextual matching over
short strings, regular expression matching brings the necessary power. There are a
number of differences, issues, and opportunities with this approach in comparison
to the trie-based approach:
Performance of matching for small versus large dictionaries
Provision of integrated context including word boundary regular expression
Difficulties with handling overlapping matches
Complexity of linkage to entities with groups of alternatives
Availability of positional information
Handling of normalization, case-sensitivity
Let's look at these in more detail.
Performance
analyze-string allows for arbitrary regular expressions and thus allows for more powerful matching
than just codepoint-by-codepoint matching, or even matching with some codepoint mapping.
Power comes with a cost: it is very unlikely that a generic regular expression matching
engine would optimize this string-only all-matches case as well.
If we consider the case of matching all the verbs in WordNet®, to pick up all the
regular verb forms, we'd need to expand the dictionary to include them all. That does
increase the cost of building the dictionary, but it wouldn't increase the cost of
matching, even if we over-generate verb forms.
Matching performance of the regular expression is slower than for the trie, however.
Although matching a simple regular expression against a single string can be linear
with the length of the input string, that is not the task at hand. We are matching
each proper suffix of the input string against the regular expression. For a generic
regular rexpression matcher the cost of matching is proportional to the length of
the input string times the number of matches, and it will take time. The more matches
we have, the worse it gets, and in a multiplicative way. At some point a dramatic
difference in performance amounts to a dramatic difference in capability: simple processes
executed quickly can often be more effective than more sophisticated processes executed
slowly.
Marking up Hamlet with all matches against all the verbs in WordNet® (23713 entries) with the Aho-Corasick
tooling took about 11 seconds. Building the dictionary was about 5 seconds. Building
the corresponding regular expression took about the same time, but performing just
a quick extraction of all the matches with the regular expression approach took 3403
seconds. (The best part of an hour, that is.)
I lacked the patience for doing full markup with the much larger noun set.
That said, for small numbers of matches, the analyze-string method performs well. Marking up the names of characters in the play against Hamlet took 3.1 seconds with the Aho-Corasick implementation where the simple extraction
with analyze-string took less than a second.
Integrated context
With the analyze-string approach, we are already have a full regular expression matcher on the case: to perform
word boundary detection we don't need to run a separate regular expression test to
prune matches. The word boundary regular expression can be included in the regular
expression directly so those matches don't arise at all with minimal additional cost.[11]
We can also use regular expressions to perhaps streamline the dictionary: instead
of generating regular morphological variations, for simple cases we can apply regular
expression to do the trick instead:
string-join(
for $noun in $nouns return "("||this:escape($noun)||"(s|es)?"||")",
"|"
)
Regular expressions can also provide richer contextual information to allow for better
matching. For example, a regular expression can match running as a verb, but only after is|are|am or running as a noun but only after the|a.
Overlapping matches
analyze-string picks the first alternative as the match. There is no feasible way to get multiple
overlapping matches in a generic way. Where the overlaps represent different entities
associated with the same keyword, for example different senses for the same lemma,
one way around this is to map the keyword to the full set of senses, and expand the
matches that way. For matches within matches, we're out of luck.
For example: We might want to match Prince of Denmark to all of Prince of Denmark (Hamlet), Prince (royalty), and Denmark (country). We might want to match burning eyes of heaven with both burning eyes and eyes of heaven. With analyze-string we'd have to perform multiple matching episodes with different regular expressions
constructed somehow to avoid interference. That construction is by no means trivial
or obvious.
Linkage to entities
With the entity API, the entity dictionary included an entity ID, which might be shared
across multiple alternatives. Each match provided the index of the word, and the entity
dictionary linked that index to the entity ID. If we construct the regular expression
so that each individual keyword is wrapped in a group (as we have seen already), the
group numbers returned from analyze-string correspond to keyword index numbers, so we can do the same mapping.
However, contextual augmentations generally introduce additional groups so we lose
the direct association between the group number and the index number of the word.
For simple matching that doesn't matter a lot, but if we want to use that index to
identify an entity, now we have a problem. As long as the contextual augmentations
are consistent (i.e. now every word has a word boundary regular expression sub-group)
we can still perform the mapping by applying some arithmetic. But if different words
have different contextual regular expressions, or rather (crucially) different numbers of contextual subgroups, we can no longer correctly map from group number to keyword
number to entity ID.
Positional information
analyze-string does not give positional information about the match but it does chop up the input
string into matches and non-matches. By contrast, get-matches does not chop up the input string, but does provide the positional information. When
the goal is inline markup, the analyze-string approach takes some of the work out of things. If the goal is to extract offline
entities, positional information is critical, and the analyze-string approach requires extra work to calculate offsets properly.
Normalization and case-sensitivity
For the trie matching, case insensitivity is a build-time option, as it affects which
states and edges we have in the trie. For analyze-string it is just a match-time flag. In theory we could make it into a match-time option
for trie matching as well by moving beyond codepoint equality for edge matching. Edges
are currently stored in a map for each state, so edge matching leverages map key access,
a well-optimized process rather than a series of equality comparisons. I haven't attempted
to implement this but I suspect that it would impact performance and make for more
complicated failure and output edge processing.
As far as codepoint transliterations and normalizations go, these can be handled in
a very similar way. The mapping functions would return strings rather than codepoints.
Final Thoughts and Future Directions
The Aho-Corasick string matching algorithm provides a useful tool for bulk matching
of keywords against a text, for analysis, markup, or information extraction. It makes
a useful companion to the built-in analyze-string function.
An implementation of this algorithm is provided under generous licensing terms, along
with a higher-level API geared towards linkage of multiple alternative strings to
a singular entity that allows for high performance information extraction or inline
markup using large dictionaries. Compilations of some of the WordNet® entity dictionaries
described in this paper are also available (subject to WordNet licensing).
There are additional extensions and enhancements to be made here: more than just codepoint-by-codepoint
matching for the transition arcs and some analogue to matches that can stop after the first match, for example. This is something of a foundational
algorithm, and there are many variations and related algorithms than can be built
based on, or inspired by, this implementation.
Going forwards, there are other string-related algorithms that it may be useful to
provide implementations for: string metrics such Jaro-Winkler and Damerau-Levenshtein,
phonetic algorithms such as double Metaphone and Soundex, sequence alignments, fuzzy
string comparison, and so forth. Transliteration functions such as that mentioned
in one of the examples are useful as well. A plethora of possibilities!
Appendix A. Terminology
trie
A tree data structure where each edge represents a symbol and each node represents
the sequence of symbols of the edges from the root. Each node therefore represents
the prefix sequence of all its children. Also known as a prefix tree.
terminal node
A node that represents a complete keyword in the trie.
failure edge/failure link
A special kind of edge that connects a node in the trie to the node representing the
longest suffix of the current node's prefix sequence.
failure node
The endpoint of a failure edge.
output edge/output link
A special kind of edge that connects a node in the trie to the node representing the
longest suffix of the current node's prefix sequence that is terminal (or that has
an output link to such a node, recursively).
state
The trie with failure and output links can be viewed as a finite state machine where
the nodes in the tree are the states we pass through in the matching operation.
entity table/dictionary
A collection of entities organized into a set of entries.
entity
A concept with an identifier, a normalized string form, a type, and a collection of
alternative word forms (or lemmas). Each alternative word form gives rise to a distinct
entry in the entity table.
References
[AhoCorasick1975]
Aho, Alfred V. and Corasick, Margaret J.
Efficient String Matching: An Aid to Bibliographic Search.Communications of the ACM, Volume 18 Number 6 (1975): 333-340. doi:https://doi.org/10.1145/360825.360855.
[Birnbaum2020]
Birnbaum, David J.
Toward a function library for statistical plotting with XSLT and SVG. Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31,
2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020).
doi:https://doi.org/10.4242/BalisageVol25.Birnbaum01.
[1] More precisely: it is limited by the number of distinct symbols in the keyword set.
[2] Hence the labelling of states and keywords with numbers in the diagrams.
[3] Why is emits property a compound value? Because case folding and codepoint normalization may lead
different keywords to the same state, and we wish to return all appropriate matches.
Why is it a map? Because it makes updating the data structure more convenient. What
is the value of the map entry? The keyword index for that particular match. Why is
it an array and not a single value? Because we allow for the same keyword to give
rise to different matches with a different keyword index. The discussion of the entity
API will make this clearer.
[4] Saxon "explain" has a great deal of trouble with the functions that compute the failure
states and give up before giving me a complete report. Saxon EE's output does make
clear this is not recognized as tail-recursion, however. Even so, I tried some very
perverse cases and have seen some worst-case performance, but not stack overflows.
[5] This will mean that there is an extra single-transition state in the trie that all
matches must pass through. It will also require post-processing step to remove the
word break characters from extracted keywords or marked up text. It should also be
noted that this does not mean that there will be no need for failure states or output links nor that there
will be no overlapping matches. They can arise if we allow for some words to be "phrases"
and some phrases in the dictionary overlap with words in the dictionary, or in the
face case-folding, codepoint normalizations, or out and out duplication in the dictionary.
This approach also removes some functionality: the ability to distinguish phrases
based on which word-break character they include internally, e.g. "large-scale" vs
"large scale".
[6] Implemented, in the XQuery way, by creating functions with the same name but a different
arity.
[7] For this test I used fixed size chunks, which means some potential matches may have
been chopped in half, so the number of matches here may not be consistent. A markup-sensitive
chunker (text node by text node or paragraph by paragraph) would be better. The average
text node size in Hamlet is 31 characters, the total concatenated length is 176K characters.
[8] I suppose I could strip out all the typing to avoid this, but I like strongly typed
code as it helps me find bugs. It would certainly cut down the cost of using precompiled
dictionaries substantially: fixing the WordNet noun dictionary is about 3/4 of the
time in loading it.
[9] Well, almost all. Some of the more abstract nouns I picked as top level "classes"
and didn't add them as entries in their own right. I also didn't run the lemma generation,
so you don't have plural forms.
[10] I'm relying on Saxon's profiling information for all these numbers.
[11] This point connects to the observations on performance in previous sections: the reason
the partial word match elimination phase takes a large part of the overall time is
precisely because it is a regular expression step iterated across the input string.
The fact that it is only performed against the places that already had a match (rather
than all possible word breaks) helps, but it is still fundamentally a multiplicative
process.
Aho, Alfred V. and Corasick, Margaret J.
Efficient String Matching: An Aid to Bibliographic Search.Communications of the ACM, Volume 18 Number 6 (1975): 333-340. doi:https://doi.org/10.1145/360825.360855.
Birnbaum, David J.
Toward a function library for statistical plotting with XSLT and SVG. Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31,
2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020).
doi:https://doi.org/10.4242/BalisageVol25.Birnbaum01.
Brzozowski, Janusz A.
Derivatives of Regular Expressions.Journal of the ACM, Volume 11 Number 4 (1964): 481-494. doi:https://doi.org/10.1145/321239.321249.
W3C: Jonathan Robie, Michael Dyck, Josh Spiegel, editors.
XQuery 3.1: An XML Query Language
Recommendation. W3C, 21 March 2017.
http://www.w3.org/TR/xquery-31/