Andries, Patrick, and Lauren Wood. “Converting typesetting codes to structured XML.” Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31, 2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Wood01.
Balisage: The Markup Conference 2020 July 27 - 31, 2020
Balisage Paper: Converting typesetting codes to structured XML
Patrick Andries
Xcential Corporation
Patrick Andries is a senior consultant with Xcential Legislative Technologies. He
is
the chief architect, designer, and developer of Xcential's software to convert legacy
typesetting data to XML, as well as one of Xcential's main developers of systems to
publish XML documents and edit Legislative XML documents. He has vast experience in
multilingual software, internationalization and Unicode support. He is a long-standing
member of the Unicode consortium.
Lauren Wood
Xcential Corporation
Textuality Services, Inc.
Lauren Wood is the principal consultant at Textuality Services Inc, with Xcential
Legislative Technologies as a major client. Her projects in legislative documents
for
Xcential focus on document analysis, modelling, and XSLT transformations. She is also
managing editor of XML.com and the course director at the XML Summer School. Lauren
has a
long history in standards committees for both OASIS and W3C, worked in healthcare
standards for Lantana Consulting Group, and was part of the privacy and identity standards
group at Sun Microsystems.
Before XML, the United States Government Publishing Office (GPO) created complex
typography using non-hierarchical, line-based typesetting systems characterized by
“locator” files which contain lines of typesetting instructions. Our mission
is to convert years of locator files that describe U.S. government bills, laws, and
statues
(etc.) into structural XML, valid to the United States Legislative Markup (USLM) XML
Schema.
This was and is complicated, as locator files, in addition to being completely
presentation-focused, use stylistic differences to communicate semantic significance.
Our
iterative analysis grew the mapping specification in stages. The conversion itself
is in two parts.
First, Java converts the locator files into hierarchical XML (the JAVA lexical, syntactical,
decomposition, and generational phases are the focus of this paper). Then XSLT improves
the
resulting XML. Quality control and testing required additional programming and the
creation
and maintenance of a large set of reference samples.
The authors wish to thank the reviewers for their questions and comments, which helped
improve the paper.
The authors further wish to thank Brad Chang for reviewing.
Motivation
This paper discusses part of the system used in a continuing set of projects at the
U.S.
Government Publishing Office that produce XML documents marked up to the United States
Legislative Markup (USLM) schema. Although many legislative documents are authored
in XML, others still use
locator files for some part of the processing. Because of this, the smooth transition
from locator- to XML-based tools
requires conversion from the presentation-focused typesetting-style locator codes
to semantically rich XML.
So what is MicroComp, the system that is still used to create the print and PDF for
legislative documents? The historical perspective at https://xml.house.gov/drafting.htm describes it thus:
MTP, as well as the current PC-based Microcomp software, used “locator” codes to
enable the specification of typesetting instructions to the phototypesetting equipment
and
was used to typeset legislation beginning in 1978. An example of a locator code is
bell-I22. The “bell” character is the hex 07 character which is used to signify the
beginning of a locator code. In this case, I22 represents the code used to generate
a
paragraph with a 2-em space indent and is used to generate the typesetting of subsections
in legislation.
In other words, it is a flat line-based typesetting system, where hex-07 (the
BEL character in ASCII, hence the bell terminology) is the
character used to prefix the typesetting instructions codes. The locator file is
presentation-focussed, and the many stylistic differences between parts of the documents
are
used to indicate semantic significance.
Note: there is a small glossary of terms in the appendix to this paper.
Locator files
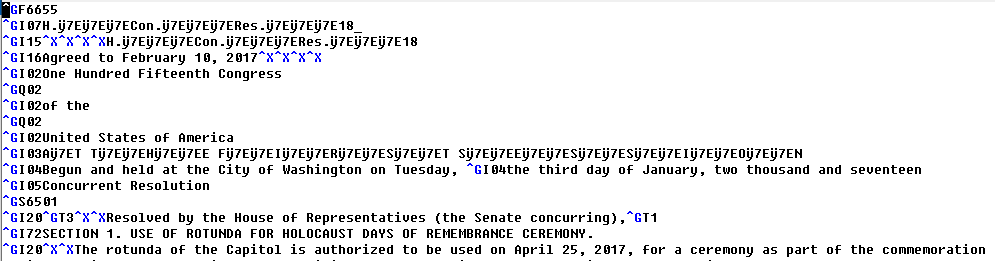
Figure 1: Sample locator code
This sample locator (typesetting) code file shows that each line starts with a
BEL (hex-07, which in this font with the buffer encoding set
to Latin-1 appears as ^G) character, followed by typesetting
instructions.
This sample makes it clear that MicroComp uses a custom character encoding. The standard
ASCII printable characters are all used as defined in ASCII, but the characters in
the
C0 range (0-31) and the range 128-255 are used for system-specific purposes. For example,
the character
displayed as a ^X character in the Latin-1 view in the screenshot above is the hex-18
or octal-030 (CAN) character and represents an EM space
in the rendered output.
The complications don't stop there. The first line of the locator file defines the
page
format code for the document. This number (F6655 in this sample) defines things
such as page sizes, and the rendering of the content directly after various locators,
such as
the I16 shown in the sample). The S6501 further down changes the
rendering of the locators again. The rendering of the locators is defined with font
grids (a
collection of typefaces) and the typeface within that grid, along with the font size,
leading,
and other relevant information. There are hundreds of grids, each of which has four
or five
typefaces associated with it. The format which applies to most of the content of the
document,
S6501, has four grids, each with five typefaces associated with it. The default
grid is grid 731, which uses the Century font in the typefaces Roman, Bold, Italic,
and two
versions of Roman with Caps and small caps.
You can see an example of switching the typeface within a particular grid at the line
that
starts ^GI20^GT3 — this indicates switching to typeface 3 in the default grid,
i.e. to the italic font. The ^GT1 at the end of the line switches the font
typeface back to the usual Roman value. I20 in this format is defined as font size
10pt, in
grid 731, typeface 1, justified text (if the line has more than a defined number of
characters), and other
information required by a sophisticated typesetting system.
Note: in this paper we will refer to the ^G as variously
<bell>, BEL, or bell. These are all equivalent
formulations.
There is an introduction to the MicroComp locator format online in two formats: (HTML,
best viewed in a browser where you can set the character encoding, such as Firefox)
and Word. There
are also more definitive documents at gpo.gov/vendors/composition.htm, for which you
have to
use the internet archive wayback machine (2009 was a good year).
Issues with conversion to XML
In summary, some of the issues we're faced with in the up-conversion to semantic,
structured XML are:
The custom character set.
The emphasis on presentation in the input file.
Variability of input to get the same output, for example there can be multiple ways
to
create a character outside the standard ASCII set. This includes switching grids and
typefaces to get particular characters.
Styling changes within documents, particularly when such documents are amending other
documents and those amended documents have different styling. These styling changes
have
semantic meaning - the type of legislation, for example.
Examples of such styling variations include using a section mark (§), the word 'Section',
or the
abbreviation 'Sec.' to indicate a section number. These are visual clues to the reader
that they are reading a particular type of document. The section mark indicates that
we are
referring to a section in the U.S. Code, while "Sec." hints that we are dealing with
a section in a
Bill, which may refer in its content to the U.S. Code Section.
Inferring the correct nested hierarchy, which is context-dependent, from a flat
structure. There can be several different levels of nested hierarchies, some of which
can
be quoted content blocks which each have their own level hierarchies.
Quote characters have many different semantic meanings. There can be three levels
of
quoted content, each with their own nested level hierarchy.
It would be tempting to infer that any given bell code always maps to the same USLM
element. Unfortunately, this is not the case. And, as a further complication, different
bell codes may map to the same USLM element.
Let's take a look at the start of two very simple sections to illustrate this issue.
First the locator file:
🔔I81SUBCHAPTER III_CONCILIATION OF LABOR DISPUTES; NATIONAL EMERGENCIES
🔔I80 ÿ1A171
🔔I89. Declaration of purpose and policy
🔔I11It is the policy of the United States that_
🔔I12(a) sound and stable industrial peace ...
Now the corresponding USLM output file:
<section style="-uslm-lc:I80">
<num value="171">§ 171.</num>
<heading> Declaration of purpose and policy</heading>
<chapeau style="-uslm-lc:I11" class="indent0">It is the policy of the United States that—</chapeau>
<subsection style="-uslm-lc:I12" class="indent1">
<num value="a">(a)</num>
<content> sound and stable industrial peace ...</content>
Note how I12 maps to a <subsection> here.
Let's now look at the bell codes of another section in the same document:
🔔I80 ÿ1A1413
🔔I89. Partitions of eligible multiemployer plans
🔔I19(a) Authority of corporation
🔔I11(1) Upon the application ...
and its USLM mapping
<section style="-uslm-lc:I80">
<num value="1413">§ 1413.</num>
<heading> Partitions of eligible multiemployer plans</heading>
<subsection style="-uslm-lc:I19" class="indent2 firstIndent-2">
<num value="a" class="bold">(a)</num>
<heading class="bold"> Authority of corporation</heading>
<paragraph style="-uslm-lc:I11" class="indent0">
<num value="1">(1)</num>
<content> Upon the application...</content>
</paragraph>
Here, the <subsection> is introduced by a I19 and I11 no longer maps to a <chapeau> but rather introduces a <paragraph>.
We use Java to build the basic document in XML, with as much hierarchy as can reasonably
be added by the parser. All input characters are converted to Unicode character sequences
in
this stage. All six major problems outlined earlier have been addressed by the end
of the first stage.
Then in a second stage we manipulate that XML document using XSLT, moving parts of
the document around, adding context-dependent semantic markup, fixing invalid constructions
etc.
Although we could have used different tools for the first stage, we chose Java for
two main
reasons.
First, we were familiar with Javacc, an efficient parsing engine that allows for the
separation of
lexical and syntactical phases, that we had used for previous conversion projects.
Second, a general purpose imperative language is an efficient and flexible tool to
use to
operate on this type of content. All content is converted first to internal
data-structures and processed in that form.
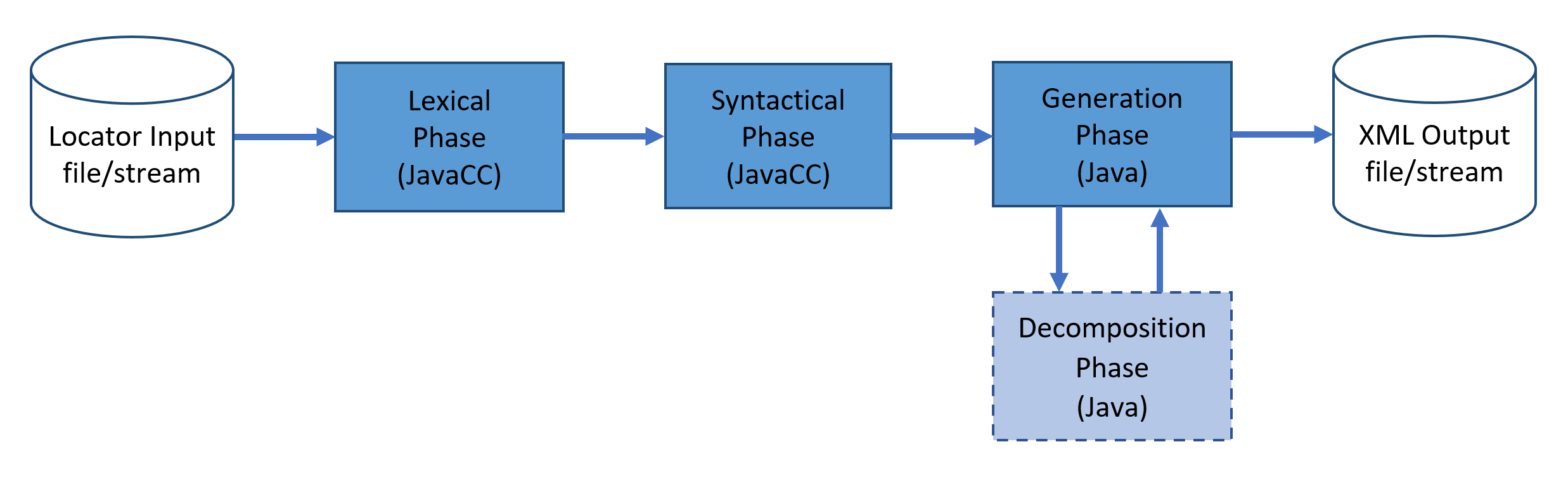
Stage One — Java
The program is implemented as a number of Java classes called by a JavaCC parser.
The
parser runs through a number of phases to create the XML from the typesetting locator
codes.
Figure 2: Process phases
Phase 1 — Lexical
The first phase is the lexical phase, which assigns distinct tokens to locators
(sometimes a set of locators), page breaks, comments, and text.
The < DEFAULT> or < ACT> part are what is called
the "lexical state" of the parser. A lexical state is usually set by the
<bell>F[0-9]+ or <bell>S[0-9]+ styles found in the
input, so that when the parser recognizes a <bell>S used in Public Laws
it sets the PUBL state.
Let us look at the first three lines of lexical definitions above:
< DEFAULT, STATE5804, ACT, TOCACT, PUBL, STATUTESATLARGE, PROX, INDEX,
IN_TABLE_BODY > are the states for which the following token is defined.
<PAGEBREAK> is the lexical token being defined, following the ":" is
a JavaCC regular expression matching the token. That is either a bell 0x07
followed by an ASCII "A"
or a sequence made from a 0x07 (a bell) followed by 0x0AE, itself
followed by the ASCII string "MD", then a series of bytes
containing neither a 0xAF nor a 0x07 byte and closed by a
0xAF byte followed by an ASCII "A".
The textual content of the token is available to further phases. We will see how this
is
done later.
Phase 2 — Syntactical
The second phase is the syntactical phase. It uses and analyzes the tokens produced
by the lexical phase according to a formal grammar defined in JavaCC. This grammar
is
defined by the syntactic specification of the input.
When a token specified in the lexical analysis is matched, it is returned into a Token
variable which may be used by the syntactical parser. The Token contains several fields,
notably:
int beginLine: beginning line position of the token as it appeared in the input stream
String image: the actual string which causes this token to be generated as it appeared in the
input stream.
So, in the syntactic specification, the code t = < I15STATS >
means that if the input stream matches the < I15STATS > lexical token,
t will contain a Token object containing the fields mentioned above. t.image will contain
"\u0007I15" since the token I15STATS was defined as:
< I15STATS : "\u0007I15" >.
A syntactical code snippet may look like the sample below which handles Front Matter
Notes in Statutes:
a note may be preceded by an optional PAGEBREAK token, if a
PAGEBREAK is encountered then the code between the braces
"{...}" is executed: an InlineProcessInstruction of type
"page" is created and immediately generated (added to the output file). Then
follows the note itself, which may contain I15/I20/I21/... locators (in the
STATS [statutes] state) as well as page numbers or F9787 format
codes, which are ignored.
Each of these IxxSTATS (where xx indicates a number such as
the 20 in the locator code I20) line may be followed by what is
known as a formattedLine() itself a set of rules. These
formattedLine contain text which maybe styled (include italics, bold
characters, etc.) A series of characters styled the same way is called a Text Run.
The
formattedLine() methods returns a set of text runs stored in a global
variable called ctrl (current text run list).
Each of these IxxSTATS will generate a <P> in the note
opened. The gen.genericP() method has three arguments: the locator saved in the
t variable, the line where the IxxStats locator was encountered
in the input file (for debugging purposes) and the set of Text Runs returned by the
formattedLine().
Some notes may also contain an image file, the parser then adds these lines in that
case:
t = < GRAPHICFILE > formattedLineNoQ() {
Graphic g = new Graphic(getCurrLoc(t), t.beginLine, t.image, ctrl);
g.generate(gen);
}
which can be read as follows: when a GRAPHICFILE token is encountered and followed
by a formattedLine containing no <bell>Q, save this token and its
associated data in the t variable. Then, execute the code between the braces
{...}, viz. create a Graphic object, where t.image corresponds to the
actual string which matches the GRAPHICFILE token defined as a regular
expression. Then the graphic object is generated in the output file. We will see how
this is
done in phase 4.
When an unexpected character is parsed, the parser will raise an error, complaining
of
an "illegal" sequence. This is almost always triggered by either an unknown locator
code, or
one that is unexpected in that particular context. Pure ASCII text is allowed
almost anywhere by the parser.
This "unexpected character" error was a deliberate design decision to ensure that
we properly analyzed the input
file and did not drop or ignore semantically important constructs. This creates a
strict
and rigorous parser, which is important since the locator files do not have a well-defined
grammar. In fact, since there are potentially many ways to create the same apparent
output
(whether print or PDF), it is important to catch any potential errors so that the
parser does
not miss any important structures. The approach chosen was one of slow refinement
of the
parser to remove successive "illegal" sequence exceptions. However, the parser may
handle
input we do not want to interpret in detail by using the "lexical state" mentioned
in the
lexical parser phase.
The lexical definition below states that in the STATE5804 state (typically,
this means the last <bell>S encountered was a S8504) any
unknown locator (<bell> I [0-9][0-9]) will be treated as a
S5804LOCATOR token.
The dumpLine() method consumes such S5804LOCATORs and the text
runs following them and simply adds them to a RawContent. These will later be
generated as a series of <P> elements each containing the text found after that
locator.
Let's look at another snippet of code from the syntactical phase: an extract of the
parser for Sections. The code snippet in {...} calls the generation phase using
the internal structures produced during the parsing
void section() throws ParserInternalException :
{
// local variables
Token format,headerTok;
List<TextRun> sectionTr;
SectionLevel s;
escapeNotes = false;
}
{
// grammar
format = < SECTIONLEVEL > formattedLineFN()
// a section starts with a section level token (🔔I80) followed by a formatted line (a list of Text Runs).
{
sectionTr = ctrl;
// if I80 was matched, execute this Java code. It saves the global current text run list
// to a local copy called sectionTr
}
headerTok = < SECTIONHEADER > formattedLineFN()
// a section header starts with (I89)
{
s = new SectionLevel(getCurrLoc(format), format.beginLine, sectionTr, getCurrLoc(headerTok), ctrl);
// create a new section Level object, pass it sectionTr, and the text runs after 🔔I89
s.generateBegin(gen);
// call the generation of start of the section (<section><num><heading>)
}
[
LOOKAHEAD(2) sectionContent(s)
// look ahead a couple of lexical tokens, to know if this section has content rather than only notes,
// if so call sectionContent() method which parses all the section content and stores it inside
// the SectionLevel s object.
{ s.generateSectionContent(gen); }
// at the end of the section content parsing, generate and thus decompose the section level's content
]
notesAndSourceCredit(s)
// gather notes and sourceCredit into s
{
s.generateEnd(gen); // generate end of section level
escapeNotes = false;
}
}
Phase 3 — Decomposition (optional)
The decomposition phase is an optional first step of the generation. It is only necessary
for structures which may be nested such as sections or quoted content which may itself
contain parts of sections. For other constructs such as images which may not be nested,
the XML output can be generated without any decomposition of the object being necessary.
Let's assume we have this locator input corresponding to the start of a section:
🔔I80 ÿ1A309
🔔I89. Application for license
🔔I19(a) Considerations in granting application
🔔I11Subject to the provisions...
🔔I19(b) Time of granting application
🔔I11Except as provided in subsection (c) of this section, no such application_
🔔I12(1) for an instrument of authorization in the case of a station in the broadcasting or common carrier services, or
🔔I12(2) for an instrument of authorization in the case of a station in any of the following categories:
🔔I13(A) industrial radio positioning stations for which frequencies are assigned on an exclusive basis,
🔔I13(B) aeronautical en route stations,
🔔I13(C) aeronautical advisory stations, ...
by the end of the syntactical phase (phase 2) we have produced an internal structure
equivalent to
<section style="-uslm-lc:I580080">
<num value="309">§ 309.</num>
<heading style="-uslm-lc:I580089"> Application for license</heading>
<content>
<p style="-uslm-lc:I580019" class="indent2 firstIndent-2">(a) Considerations in granting
application</p>
<p style="-uslm-lc:I580011" class="indent0">Subject to the provisions...</p>
<p style="-uslm-lc:I580019" class="indent2 firstIndent-2">(b) Time of granting
application</p>
<p style="-uslm-lc:I580011" class="indent0">Except as provided in subsection (c) of this
section, no such application—</p>
<p style="-uslm-lc:I580012" class="indent1">(1) for an instrument of authorization in the
case of a station in the broadcasting or common carrier services, or</p>
<p style="-uslm-lc:I580012" class="indent1">(2) for an instrument of authorization in the
case of a station in any of the following categories:</p>
<p style="-uslm-lc:I580013" class="indent2">(A) industrial radio positioning stations for
which frequencies are assigned on an exclusive basis,</p>
<p style="-uslm-lc:I580013" class="indent2">(B) aeronautical en route stations,</p>
<p style="-uslm-lc:I580013" class="indent2">(C) aeronautical advisory stations,</p>
... </content>
</section>
This is the XML output we would produce at this stage without any further processing.
But large constructs such as sections, quotedBlock, or tables are not immediately
generated.
The parser adds all the components of such constructs (usually as P's for sections)
to an
internal structure representing the said construct.
The raw internal structure of sections is then analyzed and the list of P's is
transformed into a hierarchy with internal structure (subsections, paragraphs, subparagraphs,
continuations, clauses, etc.) according to a set of rules mostly based on the leading
<num> of each such level but not exclusively since these may be
ambiguous, inconsistent or even incorrect.
This process is recursive since sections may contain quoted content (up to three levels)
which may themselves contain hierarchical levels.
The decomposition phase is usually called as an optional first step of the generation.
A
syntactical phase might for instance have between braces :
{
s.generateSectionContent(gen)
}
where s is a SectionLevel object (an instance of a Java
class).
SectionLevel.generateSectionContent() then calls the decomposition
phase.
Phase 4 — Generation
Finally, the generation phase is invoked to generate the XML. It always operates on
internal structures
created by the second or third phases.
Let's take the example of Graphic generation seen above. The generation phase is called
by g.generate(gen); where g is a Graphic object and
gen is the "generator" an object encapsulating the output style (USLM here,
it could in theory be HTML or XSL:FO) and the output destination (a file or output
stream in
this case).
a) So, if the input file contained
🔔gs,w318,d386,r1
🔔I25ED04JA07.005
the lexical token
< GRAPHICFILE :
"\u0007gs"(",il")?(",w"(["0"-"9"])+)?",d"(["0"-"9"])+(",rl")?("\r"|"\n")*"\u0007I9"("1"|"4"|"5")("
")*> matches this first line and the following 🔔I25.
b) The parser then consumes t = < GRAPHICFILE >
formattedLineNoQ()
As seen above we then instantiate a new Graphic object (new Graphic(getCurrLoc(t),
t.beginLine, t.image, ctrl);)
t.image contains 🔔gs,w318,d386,r1\n🔔I25 while
ctrl contains ED04JA07.005.
c) the generation phase then produces this in the output file, by calling
Graphic.generate() with these two parameters
Notice how the XML output produced preserves as much of the original input information
as possible in
the figure/@style attribute. This is useful for debugging and ensuring that no information
is inadvertently lost during the transformation from locator code to XML.
Stage Two — XSLT
Stage Two is the XSLT stage, which takes the XML file created by Stage One, and manipulates
it to
create the valid USLM 2 file.
The type of manipulations required vary according to the final document type (statutes
at large,
public and private laws, or enrolled bills). The results
can be seen on the govinfo website. Enrolled Bills from the 113th Congress to the
latest in
USLM 2 are at Congressional Bills, Public
and Private laws also from the 113th Congress to the latest at Public and Private Laws, and
the Statutes at Large from Volume 117 to the latest at United States Statutes at
Large.
Stage two for each document type:
Recognises references to standard types of documents, such as the U.S. Code, Public
Laws, or the Statutes at Large.
Recognises short titles, terminology, and other important constructs in various
contexts and adds the appropriate markup. It's important to note that this recognition
depends on reliable clues. The principle is that if the construct cannot be reliably
recognised, the tags are not added. For example, if standard language is used for
an amendment, such
as "is amended to add", then the matching instruction can be marked as an amending
instruction.
If some other language were to be used, a phrase that is not in the relevant style
guide, this would not be recognised.
Rearranges punctuation around and in quoted content blocks to meet the GPO Style
Guide requirements.
Rearranges elements as needed to make the document valid.
Quality control
The conversions are tested to make sure no text content is dropped or moved, and that
the
resulting XML is valid.
After that, spot checks are carried out to make sure the resulting XML
is as correct as is reasonable, given the starting point.
The check of textual content uses a version of the Library of Congress locator
processor, converting the input locator file to flat text instead of HTML, and adding
other characters as needed. The
flat text files created from this process ("locator text") are compared to those created
by
flattening the output USLM 2 file using XSLT "USLM text"). This is not the default
text
output, since characters outside the ASCII character set have to be converted into
the same
Unicode character as the locator text file for a true comparison.
Another issue with the text comparison is in tables and tables of content. The line-based
locator code and the table-cell based USLM do not a priori give the results in the
same order, so we needed to add a conversion step to line those up appropriately.
We compared those two versions of the complete sample set (multiple years of Enrolled
Bills, Public and Private Laws, and Statutes at Large, and allowing for differing
line breaks
in some files, which showed us missing and moved content.
To check the quality of the XML conversion, once the files are validated, we have
a
reference set of samples (chiefly Enrolled Bills and Public and Private Laws) that
are
compared each time the conversion is updated. These files were created over the main
development period of the project, and are known good samples.
Summary
Conversion is a crucial, painstaking, detailed and iterative process. Large legacy
systems
cannot realistically all be replaced and adopt the XML format in a short period. New
tools
have to be slowly upgraded. In large settings, old tools and new tools have to live
side-by-side for years.
To allow a smooth migration from the old technology, conversions between the old
format
and the new one often have to be supported for many years. Conversion has to be fast,
precise,
efficient, and preserve as much information as possible. We have focused in this paper
on the
conversion from the old presentation format to the new XML one, since it is the hardest
one.
However, the reverse process must usually be available to ensure the coexistence of
old and
new tools during the transition.
The approach presented above has allowed such a transition as the Congress of the
United
States is migrating its documents from a paper and presentation-focused format to
a richer
semantic and structured format that is better suited to a world where information
may be served in
many formats, both electronically and on paper.
Appendix A. Glossary
Bell code
A bell character (HEX 07) signals that a command immediately follows. The character that immediately follows
a bell indicates the type of command which may itself be followed by an argument.
<bell>I21, is a bell-I command with a parameter of 21.
The final official copy of the bill or joint resolution which both the House and the
Senate have passed in identical form. https://www.govinfo.gov/help/bills
Format
Formats are designated by a four- or five-digit number that follows a bell-F or bell-S.
Each format is associated with a set of definitions for 99 bell-I codes (bell-I01
to bell-I99). Each format number defines page layout and new set of bell-I codes.
GPO
The United States Government Publishing Office. The office produces and distributes
official publications, notably of the Supreme Court and the Congress. https://www.gpo.gov/
Grid
The rendering of the locators is defined with font grids (a collection of typefaces)
and the typeface within that grid, along with the font size, leading, and other relevant
information. Each locator code contains a default grid and typeface value. These
values can be overridden, however, using <bell>g codes followed by the new grid number.
Locator code
A synonym for Bell code.
MicroComp
Typesetting software developed in-house by GPO at the end of 1980s. Replaced the earlier
MTP software. https://xml.house.gov/drafting.htm
MTP
Multi-Typography Program was a typesetting software developed in-house by GPO in the
mid-1970s. It was replaced by MicroComp. https://xml.house.gov/drafting.htm
USLM 2
The second version of the United States Legislative Markup (USLM) schema, formally
describes legislative XML documents such as USC titles, bills and statutes. https://github.com/usgpo/uslm