Sperberg-McQueen, C. M. “An XML infrastructure: for spell checking with custom dictionaries.” Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31, 2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Sperberg-McQueen01.
Balisage: The Markup Conference 2020 July 27 - 31, 2020
Balisage Paper: An XML infrastructure
for spell checking with custom dictionaries
C. M. Sperberg-McQueen
Founder and principal
Black Mesa Technologies LLC
C. M. Sperberg-McQueen is the founder and
principal of Black Mesa Technologies, a consultancy
specializing in helping memory institutions improve
the long term preservation of and access to the
information for which they are responsible.
He served as editor in chief of the TEI
Guidelines from 1988 to 2000, and has also served
as co-editor of the World Wide Web Consortium's
XML 1.0 and XML Schema 1.1
specifications.
Spell checking has both practical and theoretical
significance. The practical connections seem obvious: spell
checking makes it easier to find some kinds of errors in
documents. But spell checking is sometimes harder and less
capable in XML than it could be. If a spell checker could
exploit markup instead of just ignoring it, could spell
checking be easier and more useful? The theoretical
foundations of spell checking may be less obvious, but every
spell checker operationalizes both a simple model of language
and a model of errors and error correction. The SCX (spell
checking for XML) framework is intended to support the author's
experimentation with different models of language and errors:
it uses XML technologies to tokenize documents, spell check
them, provide a user interface for acting on the flags raised
by the spell checker, and inserting the corrections into the
original text.
Spell-checking sometimes seems harder and less useful in XML
than it ought to be. Conventional open-source
spell-checkers like ispell, aspell, and hunspell have very
poor built-in support for XML markup: at best, they know how
to skip past tags; they don't do well with entity
references; they do not understand how to tell what
languages the document is in by consulting the
xml:lang attribute, let alone how to use the
markup intelligently to guide the spell-checker. Editing
software aimed specifically at XML sometimes does better,
but even those tools do not always make it as easy as
they might to customize the dictionary or apply specialized
dictionaries to specific parts of the document.
Users of XML in the digital humanities have additional
problems. Many digital humanities projects produce
transcriptions of pre-existing material (whether manuscript
or published), but few use spell-checking technology to
check their transcripts for transcription errors. This is
due partly to the factors already mentioned, but also partly
to the absence of appropriate dictionaries for
under-resourced languages and for older forms of languages,
and partly to a conceptual difficulty: many projects will
normally wish to reproduce misspellings in the exemplar, and
not to correct them, and it is not immediately obvious that
spell-checking software can be used in such contexts. With
some effort, however, both the practical and the conceptual
difficulties could be overcome and spell-checking tools
could usefully be deployed in DH projects Sperberg-McQueen / Huitfeldt 2019.
In seeking ways in which spell checking could be more
convenient and more useful to users of XML, it would be
helpful to be able to experiment simply with
alternative approaches to the task. This paper reports on
a framework for spell checking of XML documents developed
in order to support such experimentation. Its possible
interest to the document markup community is three-fold:
it makes it easier to experiment with ideas for improving
spell checking of XML documents; it provides a concrete
framework for illustrating the difference made by a change
in underlying models of language; and it illustrates some
applications of XML technologies that may be of interest
to practitioners of those technologies.
In the next section, a simple
abstract view of spell checking is presented; this view suggests
several areas in which experimentation could be fruitful, and
conversely several operations which every experimental spell
checker must support. The following
section describes the implementation of a framework
intended to separate the process of spell-checking into
model-dependent and model-independent parts, and provide a
reusable implementation of the model-independent parts. The
final two sections of the paper discuss related work and future developments of the framework.
An abstract view of spell checking
When the first computer-based spell checking programs were
developed, attention was focused primarily on the technical
challenges of managing word lists which were rather large by
contemporary standards; considerable ingenuity was spent on ways
to compress the word list (or dictionary, as it is typically
called in spell checking). Later, as interactive spell checkers
superseded batch operation and found ways to propose corrections
for misspelled words, attention was focused on the user interface
and pragmatic concerns. Very little overt attention went to any
theory underlying the process, and indeed some people have
expressed surprise at the idea that any theory is involved at
all.
At a first approximation, what are here referred to as
conventional spell checkers operate
roughly as described by Douglas McIlroy [McIlroy 1982]:
The modern spelling checker consists of a sequence
of processes:
Split out the words of the document, one per
line. ...
Cull the words for duplicates by sorting them,
preserving case distinctions.
Look up the words in the stop list. If a word,
or a stem obtained by stripping prefixes and suffixes, is
found on the stop list, attach a stop flag.
Look the words up in the spelling list. If
the word has a stop flag, accept (that is, discard) it
only if it appears verbatim in the spelling list.
Accept a word with no flag if it, or any stem obtained
by stripping prefixes and suffixes, appears in the
spelling list.
Print all remaining words as potential spelling
errors.
Although some things have changed, McIlroy's description
was until fairly recently not far from the state of the art,
and it remains a useful point of reference for understanding
spell checkers and identifying variations in practice.
Among the most important variations are these:
Most spell checkers today operate interactively,
not in batch mode. Step 2 is consequently
dropped.
Most spell checkers propose corrections for words
flagged as potential misspellings. Step 5 is consequently
replaced by interaction with the user. In the course of
this interaction, the user typically has the opportunity to
add word forms to a local dictionary so that repeated
occurrences will not be flagged.
Some modern spell checkers use more sophisticated
affix analysis than McIlroy describes; this affects how
steps 3 and 4 operate.
Some but not all contemporary programs use a more
sophisticated model of language for detecting potential
errors than dictionary lookup; for such programs, steps 2-5
will be replaced by other processes.
Some but not all contemporary programs do not ask
the user how to correct flagged forms but change them
automatically (and in some cases correctly).
It should be obvious that several kinds of malfunction are
in principle possible in such a system. A correctly spelled
word may be flagged because it is missing from the dictionary;
the obvious solution to this is to make the dictionary larger.
Or an incorrect spelling may not be flagged because it happens
to be the correct spelling of another word
(e.g. intension when
intention is meant); these are often
referred to as real-word errors. The obvious solution
to real-word errors is to make the dictionary smaller by
eliminating correct forms, when their appearance in the input
is more likely to be an error for a common word than a correct
spelling of a comparatively rare one. The tradeoff between
minimizing erroneous flags and minimizing unflagged errors has
been a concern for decades; McIlroy discusses the tradeoffs at
some length. Since users are apt to be irritated by erroneous
flags and may never notice unflagged errors, the general
tendency seems to favor larger and larger dictionaries.
But no adjustment in the size of the dictionary can help
programs built on the model described to deal with errors like
there for their
or they're; for that some understanding
of the grammar of the text appears to be necessary. Tools
with some grammatical awareness are often called grammar
checkers to distinguish them from spell checkers. Comparing
what grammar checkers do and how they resemble and differ from
conventional spell checkers, it is easier to see that both
kinds of software follow the same abstract pattern, differing
in how the pattern is instantiated.
The common abstract pattern seems to the author to involve
four salient parts:
A statistical theory of language, which assigns
probabilities to specific tokens or utterances.
Conventional spell checkers model language as a sequence
of equiprobable known word forms.[1] The probability of any word form not in
the dictionary is estimated at zero.
Other more complex statistical models are of course
possible (Charniak 1993). Grammar checkers, for
example, clearly have such a model, though the nature of
that model is not obvious. It might be a conceptually
straightforward Markov model on word forms or parts of
speech, or something very different.
A threshold value for reporting errors; tokens or
utterances whose probability falls below this threshold are
flagged as likely errors.
In conventional spell checkers, the rule is simple: flags
are thrown when p = 0.
If the language model assigns
different probabilities to different tokens, variations in
the threshold will allow a choice between a high threshold
(which should minimize erroneous flags) and a low one (which
should minimize unflagged errors).
A theory of errors which, given a pair of word
forms, provides an estimate of the probability that one is
an error for the other.
A common and easily understood model is that errors
consist in the omission or insertion of letters, the
substitution of one letter for another, or in the
transposition of letters. Damerau reports that in a
retrieval system, 80% of the descriptors rejected by the
system as unknown were misspellings were due to a single
insertion, deletion, substitution, or transposition of
letters (Damerau 1964). Accordingly, many spell
checkers use edit distance to measure similarity between the
input form and forms in the dictionary. Other checkers (for
example Aspell [Atkinson 2017]) translate the
input word into a phonetic representation in the style of
Soundex, and suggest words with similar phonetic
representations; the translation from orthography to a
representation of word sound of course makes the correction
model language-specific. It is clear on reflection that
edit distance will work fairly well when the most common
cause of errors is errant fingers on a keyboard (though a
model which accounted for adjacency on the keyboard might be
more helpful), while phonetic distance is likely to provide
more useful help for bad spellers. A different model based
on visual similarity of character sequences might be helpful
for detecting OCR errors.
A threshold value for reporting suggestions: if the
similarity between the input word and a dictionary word
exceeds the threshold, the dictionary word will be suggested
to the user as a possible correction.
Conventional spell checkers often provide suggestions
whose edit distance from the input word is one. Suggestions
based on an edit distance of two are also possible, with
sufficiently clever data structures (Garbe 2012, Garbe 2015).
It seems clear that by varying any of these four factors
one can change the behavior of a spell checking system. A
simple language model that pays attention to the preceding
and/or following word (an n-gram Markov model,
to give it a technical name) might be able to detect at least
some real-word errors. A language model based on character
sequences might be able to distinguish between word forms
which look normal for the language in question and word forms
which do not — though it cannot, of course, reliably
determine whether the statistically less probable word forms
are foreign words, intentionally deviant spelling, or the
result of a cat walking across an unattended keyboard.[2] And error models
based on the observed frequency of particular letter
substitutions might be able to do a better job of suggesting
corrections for OCR errors than current methods.
For these reasons, it seems that it might be interesting
and worthwhile to experiment with different language and error
models, with an eye toward finding ways to make spell checking
more helpful and more powerful in an XML context.
To experiment with different models, however, it does not
suffice to implement new ways to assign probabilities to
tokens and to calculate similarity measures for possible
corrections; it will be necessary to perform the other tasks
needed in a full spell checker: tokenize the text, present
flagged forms to the user for action, and follow the user's
instructions about what to do with the flagged form. For the
most part, these seem at this point unlikely to vary much with
different language and error models, and building a new user
interface for each experiment with a different language model
is likely to be an excellent way of bogging things down and
making experiment more difficult.
That is the motivation for the framework presented
here.
An XML framework for experimentation with spell checking
What is desired is an analysis of the spell-checking process
into a set of modules with clean interfaces, such that the
model-dependent modules can easily be swapped out and
replaced with modules based on different models, while the
model-independent modules continue working in the same way.
The first iteration of our design is simple. We are working
with small, arcane (or at least highly specialized), non-trivial
datasets encoded in XML (SANDs, to use the term introduced for
such datasets by Josh Lubell [Lubell 2014]), so it is
convenient to handle the user interaction through an XForm. A
suitable customization of an XML editor could also be used. At
this level of abstraction, our workflow looks like this:
Figure 1
XForms provide specialized user interfaces for interacting
with XML documents; in this case,
the interface presented to the user will show the spelling
error in context in a formatted display, with a distinct
user-interaction widget for every flagged word.
Figure 2
The only changes the user can make will be through interaction
with these widgets.
The user can correct the word, confirm that the word
is correct as it stands, or take other actions; details will
be given below.
Two limitations of the framework described here should be
borne in mind. First, its primary aim is to make it simpler
for the author and others to experiment with different models
of language, different thresholds for error signaling, and
different strategies for identifying possible corrections.
The framework is intended to make that experimentation more
convenient by separating user interface concerns from the
actual identification of errors and possible corrections, so
that the same interface can be used with different back ends.
In consequence, convenience for swapping out back ends has
been valued more highly than efficiency or polished user
interfaces. Simplicity of implementation has similarly been
decisive in many design choices.
Second, one class of users for whom alternative forms of
spell checking are expected to be useful are projects working
to transcribe a body of material, in which spell checking is a
distinct step in the quality assurance process, and in which
it is desirable to be very careful with the data.
In some cases (including the kinds of experiments the
author is interested in making), it may be desirable either to
keep a log of all changes made to the text, or to enable
review of proposed changes before they are made. In these
cases, it will be useful to have the XForm modify not the main
text but a separate list of proposed changes, which can be
checked, modified as necessary, and then applied to the XML in
a batch process. With this refinement, the workflow looks
like this:
Figure 3
The workflow shown makes sense in projects for which a
certain amount of overt process and record-keeping is
appropriate, and where keep a log of all spelling corrections
made sounds like possibly a good idea, rather than a crazy
notion of no imaginable interest. For casual use — if
for example one wants a quick spell check on the minutes of a
meeting, before sending them out — the process shown
would be far too cumbersome. It is possible, of course, that
experiments with this framework might show ways in which
spell-checking could be more effective and useful in XML
contexts, and that might motivate the development of more
convenient interfaces for lighter-weight spell checking. But
that is a faint possibility for the future, not something that
will appear on anyone's desk soon.
Implementation
To keep the implementation simple, and to allow manual
intervention at multiple points in the work flow, both the
path from native XML to the XForm and the path from the XForm
to the corrected native XML have been subdivided into
pipelines of relatively simple processes.
The initial refinement is to split the preparation of the
XForm into three steps:
A tokenizer identifies the tokens which should be
treated as words and spell-checked; it marks those
tokens for the use of later steps.
A batch spell-checker checks the tokens indicated in
the input, ignores everything else, and flags any tokens
it identifies as likely errors. It may optionally also
propose possible corrections and supply annotation of
various kinds (e.g. a probability that the token indicated
is in fact an error, or similarity scores for the possible
corrections).
A form generator translates the tokenized and flagged
text into an HTML+XForms document. If there is already a
stylesheet for rendering the input vocabulary into HTML,
it is convenient to import it so the document rendering in
the XForm is as much like the usual form as possible.
Some adjustments will of course be needed if the
introduction of new markup in the document causes problems
for the stylesheet. The form generator handles the markup
specific to spell checking and provides the required
XForms infrastructure.
This workflow is straightforward to implement and will suffice
for simple cases; for polyglot texts — or more
generally, any text in which some portions of the document
have specialized language or require a dictionary of their own
— further refinement may be useful.
Tokenizing
The task of the tokenizer is to identify each word of the
text, without disturbing any existing element markup.[3] Concretely, the
tokenizer should retain the existing markup as is, replacing
some or all text nodes with sequences of
application-specific elements denoting words and non-words,
interleaved with whitespace. It is a requirement that
information about the location of whitespace in the input be
retained, so that a de-tokenizer can
reverse the process and restore the original XML — or
rather, in view of the necessary disturbances to entity
structure, to create output equivalent to the input from
which the tokenizer started, except for any corrections and
related changes.
A generic tokenizer which breaks words at whitespace and
separates words from adjacent punctuation will work
reasonably well on documents written in conventional
alphabetic scripts, in which all words to be checked are in
the text nodes of the documents and all language shifts are
recorded using the xml:lang attribute; in many
cases, however, it will be desirable to make some
data-specific modifications to the tokenization algorithm.
Simply substituting a tokenizer written for a particular
body of material is a simple approach; less drastic methods
of customization would be desirable, but it is not currently
clear what they should be. Importing the default tokenizer
and overriding its variables and templates is of course an
obvious possibility.
The initial proof-of-concept tokenizer makes some
simplifying assumptions:
Any element boundary coincides with a word boundary.
Or equivalently: no word crosses any element
boundary, and no word contains word-internal markup.
All word tokens are delimited by whitespace or
element boundaries, and any whitespace constitutes a
token boundary. Equivalently: no words contain
whitespace, and no whitespace-free character sequence
contains multiple words.[4]
Any whitespace-delimited token containing only
punctuation characters is a non-word. For practical
purposes punctuation characters may be defined as
characters in the Unicode punctuation class, matched by
the XSD regular expression \p{P})
Equivalently: all words contain at least one
non-whitespace, non-punctuation character.[5]
In a token containing both punctuation and
non-punctuation characters, leading and trailing
punctuation is not part of the word but a word-adjacent
non-word. Internal punctuation, however, forms part of
the word to be spell-checked.[6]
Every text node may contain words to be checked;
every text node should be tokenized.
All words to be checked appear in text nodes; there
are no words in attribute values, comments, or
processing instructions that need to be checked.
Handling cases in which these assumptions do not hold will
be left for later refinements of the tokenizer.
The initial tokenizer replaces text nodes with sequences
of the following elements (the prefix scx is
assumed bound to the appropriate application-specific
namespace):
scx:w for words
scx:pc for sequences of punctuation characters
scx:pcw for words with internal punctuation
(this makes it very slightly simpler to provide special
handling for them in later steps)
scx:s for whitespace, translated using
string-to-codepoints() into a
whitespace-delimited sequence of decimal numerals
representing the sequence of Unicode code points in the
input
The code presented here makes an effort to preserve the
whitespace of the original, but in order to make it easier
to handle the data even if the whitespace is normalized in
some way (e.g. for easier reading of the XML, as in the
example output shown below), the join attribute
proposed by Bański, Haaf, and Mueller 2018 is used whenever
any of the elements listed abuts an adjacent token without
whitespace.
A simple example may be helpful. As test data, entries
from Liam Quin's web edition of Alexander Chalmers's
Biographic Dictionary of 1811-1817 are
used.[7]
In the source XML,
one article in the test data reads, in part:
<entry id="gainsborough-thomas"
born="1727"
died="1788"
vocation="an admirable English artist"
><title><csc>Gainsborough, Thomas</csc></title>
<body><p>, an admirable English
artist, was born in 1727, at Sudbury, in Suffolk, where
his father was a clothier. He very early discovered a <!--
-->propensity to painting. Nature was his teacher, and the
woods of Suffolk his academy, where he would pass in <!--
-->solitude his mornings, in making a sketch of an antiquated
tree, a marshy brook, a few cattle, a shepherd and his
flock, or any other accidental objects that were presented.
...
Finding the danger of his
situation, he settled his affairs, and composed himself to
meet the fatal moment, and expired Aug. 2, 1788. He
was buried, according to his own request, in Kew Churchyard.
</p>
<p>Mr. Gainsborough was a man of great generosity. If he
selected for the exercise of his pencil, an infant from a
cottage, all the tenants of the humble roof generally <!--
-->participated in the profits of the picture; and some of them
iVequently found in his habitation a permanent abode.
His liberality was not confined to this alone: needy <!--
-->relatives and unfortunate friends were further iucumbrances
on a spirit that could not deny; and. owing to this <!--
-->generosity of temper, that affluence was not left to his family
which so much merit might promise, and such real worth
deserve. ... </p>
...
</body></entry>
Here and elsewhere I have shortened some lines
to simplify the display, by introducing line
breaks inside tags and comments with line
breaks inside text nodes. After tokenization
with the simple tokenizer, the beginning of the article
has the following form:
Since the whitespace of the original has been
preserved using scx:s and the join
attribute, there is no information loss in indenting
this document to show the XML structure.
Checking word forms and proposing alternatives
The actual checking of words and the identification of
possible corrections depends crucially on the language and
error models chosen; for the framework to make
experimentation with different models possible, therefore,
it must be simple to swap out implementations of this step.
The only requirement is that they accept as input documents
in arbitrary XML vocabularies with embedded scx:w,
scx:s, and scx:pc elements, and produce as
output a near-identical copy of the input in which some
scx:w elements have been wrapped in
scx:flag elements, whose structure is described
below.
To ensure that models are relatively easy to swap in and
out, two different implementations of this step are being
prepared at the outset. (In the course of the planned
experimentation, of course, more should follow.) One uses a
pre-existing external spell checker, augmented with XSLT
steps; the other (full disclosure: not yet implemented at
paper submission time) uses XQuery and XSLT to do the same
job in a different way.
Using an external spell checker
To use an off-the-shelf spell checker like ispell (Kuenning 2018), aspell (Atkinson 2017), or
hunspell (Németh 2018), it is only necessary to
provide it with a stream of checkable tokens, and then to parse
its output and integrate it into the XML document.
From the tokenized text create an alpha text.
Following Huitfeldt 2006, an alpha-text is a
set of strings derived from a transcription
according to a language-specific procedure with
the expectation that each such string should be a
well formed and thus correctly spelled word in the
language. An XSLT stylesheet that reads the flagged
input document and dumps the contents of the
scx:w elements, one per line, is an
acceptable way to do this.
Use any off-the-shelf spell checker that can be
invoked in batch mode to identify the
not-in-dictionary forms and the corresponding
suggestions.
Hunspell, ispell, and aspell all have batch modes
in which they accept input and signal, for each
word, whether they believe it is correctly spelled
or not.[8]
Parse the report in XSLT / XQuery and
merge the information into the tokenized version
of the document.
For the Chalmers article on the painter Thomas
Gainsborough, the hunspell output includes the following
two flags (for the text shown above in the image of an
XForm):
The leading ampersand signals that the word is not
found in the dictionary, but some similar words are, so
hunspell has suggestions. The input word form is followed
by the number of suggestions made, the position of the
word in the input, a colon, and the suggestions found
by hunspell.[9]
After the hunspell report is parsed and integrated
into the XML document, the two words and their immediate
context have the following form.
It may be seen that the original word is retained
(scx:w) and has been augmented with
the full matching line of output from hunspell
(for debugging purposes),
the word form as reported by hunspell
(scx:bogon) — these will normally
be the same —
and hunspell's suggested alternatives
(sxc:alt).
Using an internal (XSLT / XQuery) spell checker
An alternative implementation of this step uses
XSLT and XQuery to perform the spell checking. To
implement a more or less standard word-out-of-context
check against a word list, the following steps
suffice:
Load one or more dictionaries; these can
take the form of simple whitespace-delimited
word lists and be dealt with in XDM 3.0 programming
as a sequence of xs:string*,
or they may be constructed more elaborately
to speed search.
Look up each scx:w token in the
dictionaries. If the word form is found,
move on; if not, flag it.
If it is desired to propose alternative
forms as possible corrections, search the
dictionary for similar forms. (This is likely
to require an index of some kind. See
Garbe 2012 and
Garbe 2015 for a helpful
approach.)
Emit the flags in the form shown above.
Building the XForm
Many variations are possible, but the initial version
of the SCX framework seeks to construct an XForm for
working with the flags thrown by the spell checker that
is as simple to use (and as simple to construct!) as
possible.
The basic display of the document should be an HTML
rendering with which the intended users are familiar and
comfortable; for that reason, where possible the form
generator should import a data-specific XSLT stylesheet
that produces appropriate HTML.
A sample entry in the test data, for example (the article
on Gainsborough), might look like this in a default HTML
rendering. (It should be noted however that this is not the
standard rendering in Quin's edition of the text.)
Figure 4
Within the XForm itself, the text of the document
(in the running example: the entry on Gainsborough)
is displayed read-only. The XML instance on which
the form operates contains a wrapper and the flags
found in the spell-checker output, as seen in the next
example.
As may be seen, the scx:flag elements in the
input all been given IDs for ease of reference and grouped
by word form. Both the word form and the individual flags
have an action attribute to record the user's
instructions about handling the case; two levels are
needed because user instructions may relate either to the
word type or to the individual tokens of that type.
In the running text, each flag in the input produces an
xf:output element that links to the appropriate
flag in the XForms instance document and displays the value
of the scx:w element there. CSS styling is used to
signal the presence of the flag, as shown above.
The flags also produce an XForms interaction widget
to allow the user to signal their wishes with respect to
each flagged token. As already shown, these widgets
have buttons labeled Accept and
Change.
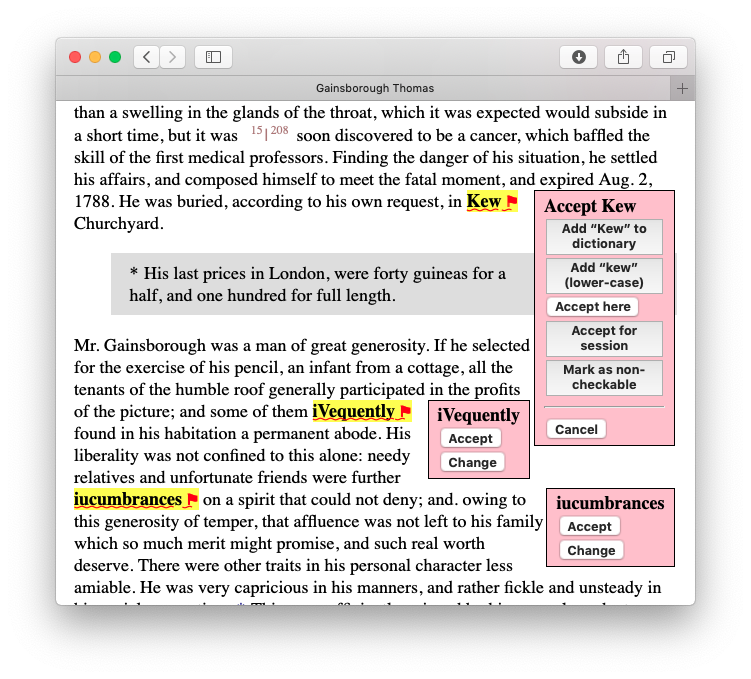
In the example shown, the place name
Kew
is correct, not a misspelling. When the user clicks on
Accept, several different actions are offered,
each of which accepts the form in a different way:
Figure 5
Add the form Kew to the
dictionary. Since the form is capitalized, only
capitalized occurrences of the form will be accepted.[10]
Add the lower-case form
kew to the dictionary. Both
lower-case and initial-capital forms will be
accepted.
Mark this token as not to be corrected but do not
add the word type to the dictionary.
Mark this word type as not to be corrected but
do not add it to the dictionary).
Mark this token as not to be corrected and also
as not to be spell checked in future. Do not add the word
type to the dictionary.
With the exception of the last, these options correspond
directly to the actions offered by conventional spell
checkers. If the user vocabulary allows it, the last
option allows the token to be marked with an appropriate
element (e.g. TEI sic) which will signal on
future runs of the spell checker that this form is not
expected to conform to conventional spelling and should
not be spell checked. (The de-tokenizer will be responsible
for taking appropriate action and producing appropriate
markup.)
Once the user has clicked the button to Add
Kew
to dictionary, the menu of options is closed (it may
be reopened by clicking on the remaining Reconsider
button) and the display of the word in the text changes
to show that it has been accepted as correctly spelled.
Figure 6
The words iVequently and
iucumbrances, on the other
hand, are OCR errors and should be corrected. Clicking
on Change opens a menu with a different set of options.
Figure 7
A text input area allows the user to specify
the correct spelling. As shown in the figure, it
initially has the current incorrect spelling.
The first button in the menu instructs the system
to accept the spelling currently in the text input
area.
Further buttons offer the corrections suggested
by the spell checker; in the example, the word
equivalently.
Again, these options correspond directly to the actions offered
by conventional spell checkers.
As the user types the correct spelling into the text
input area, the label on the first button changes to match:
Figure 8
Clicking on the appropriate button, and going through an
analogous process for the other flag[11]
produces a screen in which the corrections made are
recorded visually:
Figure 9
The result of these interface actions may be seen
in the corresponding scx:flag elements in the
XML instance being edited by the form:
Careful inspection will show the reader that the
only changes are to the action attribute,
where the value undecided has been
replaced by add (i.e. add to dictionary)
and replace (i.e. change the text),
and to the scx:w element, which now contains
the form to be inserted in the document to replace
the flagged form. (In case the flagged form must be
referred to, it is still present as the value of
scx:bogon.)
Making the corrections
The first electronic spell checkers were batch
programs: the user invokes the checker on a document, and
the checker produces a list of word forms that are likely in
error. Guided by this list, the user can then open the
document in the editor of choice, find the offending forms,
and correct them. But as soon as it was feasible, spell
checkers began working interactively, within text editors,
checking word forms, offering corrections interactively, and
making corrections immediately.
In the majority of cases, it would be technically
unproblematic to make changes interactively in the XForms
interface. But in any multi-year editorial project, the
moment will arrive when someone looks at some part of the
material and says How on earth did that get
into the data? At such times it is convenient to have
records of changes that have been made. And in order to
minimize the number of such what-on-earth moments, it may
be thought convenient to have the XForm produce not a
modified version of the input text but a list of changes to
be made, with enough contextual information to enable
systematic review by a second (or third, or
nth) pair of eyes. In such a case, it
will be only after such review that the changes are made.
So our XForm does not edit the document itself; it
edits a list of change proposals.
And the real work is done by a batch editor.
We make it easy for ourselves: we are not implementing a
generic batch editor along the lines of sed for text files,
but only an editor capable of reading (a) the XML document
with tokens marked (and supplied with IDs) and (b) a change
list that identifies which tokens to replace, and how.
Since the scx:flag elements in the change list have
IDs corresponding to specific scx:flag elements in
the output of the spell checker (from which they were, after
all, copied in the first place) it is easy to match
instructions in the edit list to flags in the document being
processed, and when appropriate to replace the
scx:w elements. At the same time, the corrector
can remove the flags, which have now served their purpose,
leaving only the corrected text, and in some cases an
attribute to signal that a particular token should be
tagged as non-checkable.
De-tokenizing
The output of the batch corrector is, except for the
corrections and the occasional attribute-value specification
scx:note="non-checkable", essentially the same
as the tokenized text used as input to the spell checker.
In order to produce a document in the original
markup with the desired corrections, then, all that remains
is to strip out the spell-checking markup, and optionally
to mark some tokens as non-checkable. This simple task
is performed by the de-tokenizer, which also strips out the
scx:pc elements marking punctuation and
reconstitutes the whitespace-only nodes of the original
input from the scx:s elements of the tokenized
document.
The technique of reifying the whitespace of the original,
in order to use conventional indentation in the intermediate
texts and make them more legible, before restoring the
original whitespace in this final step, may be
applicable in other tools as well. Certainly, it made it
much easier to preserve the whitespace of the original
at the same time as preserving the sanity of the programmer
deciphering intermediate document forms, than a constant
struggle with the whitespace-handling options of the
XSLT and XQuery processors would have been.
After the elaborations described, the workflow now
takes the following form:
Figure 10
Related work
On the earliest spell checkers, see Earnest 2011;
for the influential spell checker of the Unix system, see
McIlroy 1982.
A relatively early overview of the state of the art is given by
Peterson 1980.
Damerau 1964 introduced the Damerau/Levenshtein
measure of edit distance still widely used to find possible
corrections for misspelled words.
Accessible discussions of the basic ideas of spell checking
may be found in Bentley 1986 and
Norvig 2007.
For the notion of alpha-text used here,
see Huitfeldt 2006 (who developed the concept
in connection with spell checking work on the notebooks
of Wittgenstein).
Useful ways of quantifying the performance of spell checkers
are offered by
Van Huyssteen, Eiselen, and Puttkammer 2004 (though they are engaged in a
quixotic search for quantitative measures that will
remain constant across different texts, which means their
concrete measurements don't, for the most part, involve looking
at the specific errors and non-errors in any actual texts,
which gives the discussion a slightly surreal quality).
For many users, the current state of the art in conventional
(word out of context) spell checking is represented by the
venerable program ispell (internationalized spell,
a direct descendant of McIlroy's spell checker
[Kuenning 2018]),
the newer program aspell, intended as a drop-in replacement
for ispell (Atkinson 2017), and the competing
program hunspell (the hun signals that the original
motivation for its creation was to improve affix checking
and morphological analysis for Hungarian
[Németh 2018]).
In the immediate future, work on the framework will
focus on improving its capabilities and using it with
a wider variety of test material. Points of concern
include the following.
When shifts of language are signaled by the
xml:lang attribute, the spell checking step
must be able to use a dictionary for the appropriate
language. (This is already the way spell checking works
in Oxygen.)
More generally, different kinds of material may require
different dictionaries. A TEI encoding of an
eighteenth-century English text may want an
eighteenth-century dictionary for the transcribed text
(or, quite likely, a project-specific dictionary built
to track the author's spelling habits) and a dictionary
of current English for the notes and metadata. In the
case of Chalmers, it's clear that many abbreviated forms
are used in bibliographic references which do not appear
in the main text; it would probably be useful to build a
specialized dictionary for bibliographic references, to
avoid having entries for those specialized abbreviations
cluttering the main dictionary (and possibly causing
actual errors to be missed).
Conventional spell checkers allow the use of multiple
dictionaries for the same language: a main system
dictionary with common words, and specialized domain
dictionaries for words common in particular kinds of
document. The framework presented here should make that
practice similarly easy.
Some spell checkers (e.g. hunspell) allow the user's
personal dictionary to contain
negative entries, identifying forms
which should always be flagged. The framework should
support such entries.
A user might for example include the forms
use and
sue, or the form
manger; the latter is a perfectly
reasonable English word, but if the form occurs in
contemporary business documents it is likely to be a
typo and should be flagged. Individual forms which are
frequent errors for a particular typist or a particular
data flow can also be flagged in this way.
For projects whose goals are the accurate transcription
of a particular source text, as distinct from the
production of orthographically conventional texts, it
will be convenient to allow the user, when considering
what to do about a particular flag, to consult an image
of the page being transcribed. It would also be
convenient to be able to consult a list of passages
where the form in question, and competing forms, are
found in the current version of the text corpus. The
frequency of a particular form, and the relative
frequencies of its being a correct or an incorrect
transcription, can affect the decision on whether to add
it to the dictionary or not.
For long-running projects, examination of the change
logs may help show patterns of error in the uncorrected
data, which could in principle be used to guide the
assignment of probabilities to corrections: if (as in some
OCR) the sequence cl is a
common misreading for d (or
vice versa, or both ways), then a distance measure on word
forms could assign a smaller distance to that pair of
sequences than to others. Such
elaborate weightings may be too expensive for interactive
spell checkers, where response time is important, but in a
batch process a better ranking of proposals may be worth
the extra run time for the batch spell checker.
Tools for aggregating edit lists, gathering appropriate
statistics, and calculating such variant versions of edit
distance should be developed.
In spell checking aimed specifically at XML documents,
it would also make sense to consider possible errors in
markup. When a word in Chalmers's Biographical
Dictionary is not recognized as correctly spelled
English, the reason may be that it is in fact correctly
spelled Latin, French, or Italian. The correct way to
handle it may be a change to the markup: insertion of an
appropriate xml:lang value, and if necessary a
phrase-level element to carry it. Erroneous omission of
such markup for changes of language may mean, for example,
that a Latin phrase like Comtnentaria in Libros
Feudorum is checked against an English dictionary and
the correctly spelled words libros
and feudorum are wrongly flagged.
(For the word Comtnentaria,
meanwhile, a spell checker is more likely to find a
plausible correction in a Latin than in an English
dictionary.)
An XML-aware spell checker might be written to propose
such corrections. If for example an element has a high
rate of errors against the dictionary for the language of
the surrounding text, the spell checker might propose
supplying an xml:lang attribute-value pair on
the element. A sufficiently aggressive checker might try
the contents of the element against dictionaries for the
other languages known to be in the document and propose a
specific language value. (At the moment, this remains
speculation.)
Even if the spell checker does not make an appropriate
suggestion, it is desirable to provide the user with the
ability to make corresponding changes, or failing that to
add a note describing a change to be made manually.
It appears to be impossible to show a sufficiently
large quantity of text to a user in read-only form without
having the user notice something that needs correction.
For pragmatic reasons, therefore, it would be helpful if
the XForm included a way to attach arbitrary notes or
comments either to arbitrary locations in the text or to
individual paragraphs or text nodes.
The main point of the framework presented here is to make
it easier to experiment with alternative instantiations of the
spell checking process: alternative statistical models of
text, alternative thresholds for likely errors, alternative
ways of finding candidate correction proposals and measuring
their distance from the form present in the input, and
alternative distance thresholds for choosing which
alternatives to present.
So the most interesting future work is not the further
development of the framework, but its use in exploring
alternative language models (character n-grams,
word n-grams, part-of-speech tagging, ...)
and alternative word-similarity measures (for finding
plausible corrections: Levenshtein distance,
Damerau/Levenshtein distance, phonetic distance measures,
other distance measures).
[Bentley 1986]
Bentley, Jon.
1985.
A spelling checker.
In
Programming Pearls.
Reading, Mass.: Addison-Wesley, 1986, pp. 139-150.
Reprinted from
Communications of the ACM
May 1985.
[Charniak 1993]
Charniak, Eugene.
Statistical Language Learning.
Cambridge, Mass.: MIT Press, 1993.
[Choudhury et al. 2018]
Choudhury, Ranjan, Nabamita Deb, and Kishore Kashyap.
Context-Sensitive Spelling Checker
for Assamese Language.
2018.
In
Recent Developments in Machine Learning
and Data Analytics,
ed. Jugal Kalita, Valentina Emilia Balas, Samarjeet
Borah, Ratika Pradhan
(= Advances in Intelligent Systems and Computing 740).
New York, etc.: Springer, 2018, pp. 177-188.
[Dashti et al. 2018]
Dashti, Seyed MohammedSadegh,
Amid Khatibi Bardsiri,
and Vahid Khatibi Bardsiri.
Correcting real-word spelling errors:
A new hybrid approach.
2018.
Digital Scholarship in the Humanities
33.3 (2018): 488-499. doi:https://doi.org/10.1093/llc/fqx054.
[Gazdar/Mellish 1989a]
Gazdar, Gerald,
and
Chris Mellish.
1989.
Natural language processing in LISP:
An introduction to computational linguistics.
Wokingham, et al.: Addison-Wesley, 1989.
[Gazdar/Mellish 1989b]
Gazdar, Gerald,
and
Chris Mellish.
1989.
Natural language processing in PROLOG:
An introduction to computational linguistics.
Wokingham, et al.: Addison-Wesley, 1989.
[Huitfeldt 2006]
Huitfeldt, Claus.
2006.
Philosophy Case Study.
In
Electronic Textual Editing,
ed. Lou Burnard, Katherine O´Brien O´Keeffe, and John
Unsworth.
New York: MLA 2006, pp. 181-96.
[Van Huyssteen, Eiselen, and Puttkammer 2004]
Van Huyssteen, Gerhard B.,
E. Roald Eiselen, and
Martin J. Puttkammer.
2004.
Re-evaluating evaluation metrics
for spelling checker evaluations.
Proceedings of First Workshop
on International Proofing Tools and Language
Technologies.
Patras: University of Patras, 2004, pp. 91-99.
[Lubell 2014]
Lubell, Joshua.
2014.
XForms User Interfaces for Small Arcane
Nontrivial Datasets.
Presented at Balisage: The Markup Conference 2014,
Washington, DC, August 5 - 8, 2014.
In
Proceedings of Balisage: The Markup
Conference 2014.
Balisage Series on Markup
Technologies,
vol. 13 (2014). doi:https://doi.org/10.4242/BalisageVol13.Lubell01.
[Quin 2020]
Quin, Liam, ed.
2020.
The General Biographical Dictionary:
Containing an historical and critical account of
the lives and writings of the most eminent persons
in every nation; particularly the British and Irish;
from the earliest accounts to the present time.
A NEW EDITION,
Revised and enlarged by
Alexander Chalmers, F. S. A.
1812 - 1817.
A majority edition created by running
multiple OCR engines over the text, with fairly extensive
post-editing. On the web at
https://words.fromoldbooks.org/Chalmers-Biography/
[1] There are exceptions; hunspell offers to
flag rare words, which suggests that its internal model can
distinguish at least two levels of probability for known
forms.
[2] The idea of a spell checker based on the frequency of
different character sequences is not new; it was suggested as an
exercise in Gazdar/Mellish 1989a and Gazdar/Mellish 1989b.
[3] Since XSLT is used to implement the
tokenizer, any existing entity structure will be lost; this
would have horrified or at least disappointed many SGML
users, but XML users are so used to using XSLT that there is
rarely any non-trivial entity structure in the first place.
So we can sigh and move on.
[4] The
whitespace assumptions mentioned are usually true for
many languages including English and other widely spoken
languages written in alphabetic or syllabic scripts;
they do not, however, match reality perfectly. It is
well known, for example, that some widely spoken
languages, including Chinese, Japanese, and Korean, are
conventionally written without whitespace between
words.
Even English has some common
forms which violate these whitespace assumptions:
segments which serve linguistically as single words may
be written with segment-internal whitespace
(e.g. in spite of, which
does not accept otherwise normal transformations: the
superficially similar in lieu
of can incorporate its object, taking
the form in lieu thereof;
cf. *in spite thereof).
Conversely, multiple words may be written together
without whitespace (e.g. you're
outtasite, in which two tokens are used
to write five lexical words). Of course, for pragmatic
reason a spell checker may choose to treat
in spite of as three words
and outtasite as one, if
only because when words are written together in this way
their orthography often changes, so
outtasite will in any case
require its own entry in the word list.
[5] For some data, it may be preferable to
assume that all words contain at least one
letter (\p{L}); this
will matter for numerals and may matter for text
prepared by optical character recognition.
[6] The assumptions concerning leading, trailing, and
word-internal punctuation work reasonably well with most
punctuation, with contractions like
can't, and with words
with required word-internal hyphens; they work less well for
syntactically determined hyphens (like the hyphen between
word and
internal in the
preceding clause), and forms with required leading or
following punctuation (e.g. the leading apostrophe in
'tis for
it is, or the trailing
full stop in standard abbreviations like
e.g. and
i.e.). Spell checkers
may vary in how they treat forms like
Dr. or possessives,
though the ones consulted for this paper appear mostly to
strip trailing full stops and possessive forms.
One motivation for allowing internal punctuation is
that in the test data used here, internal punctuation is
often an OCR error for a letter; treating it as forcing
a word boundary, as standard spell-checkers often do,
will complicate the search for corrections.
[7]
The author is grateful to Liam
Quin for allowing the use of the data, for his help
understanding the data, and for many discussions on spell
checking and other topics.
[8] All three also have
run-time flags to make them ignore XML markup, which
will work reasonably well for monolingual texts but
offers no good way to exclude some elements from
spell checking.
[9] The example shows
clearly, for what it is worth, that hunspell does not
limit its suggestions to dictionary forms within an edit
distance of one from the input form.
[10] The rules for handling capitalization can
of course vary from spell checker to spell checker, but
the behavior described is common.
[11]
For the form iucumbrances,
hunspell not implausibly suggests
encumbrances. In this case,
however, Chalmers uses what is now regarded as an archaic
spelling:
incumbrances.
Bentley, Jon.
1985.
A spelling checker.
In
Programming Pearls.
Reading, Mass.: Addison-Wesley, 1986, pp. 139-150.
Reprinted from
Communications of the ACM
May 1985.
Choudhury, Ranjan, Nabamita Deb, and Kishore Kashyap.
Context-Sensitive Spelling Checker
for Assamese Language.
2018.
In
Recent Developments in Machine Learning
and Data Analytics,
ed. Jugal Kalita, Valentina Emilia Balas, Samarjeet
Borah, Ratika Pradhan
(= Advances in Intelligent Systems and Computing 740).
New York, etc.: Springer, 2018, pp. 177-188.
Damerau, Fred J.
1964.
A technique for computer detection and correction of spelling errors.
Communications of the ACM
7.3 (March 1964): 171-176. doi:https://doi.org/10.1145/363958.363994.
Dashti, Seyed MohammedSadegh,
Amid Khatibi Bardsiri,
and Vahid Khatibi Bardsiri.
Correcting real-word spelling errors:
A new hybrid approach.
2018.
Digital Scholarship in the Humanities
33.3 (2018): 488-499. doi:https://doi.org/10.1093/llc/fqx054.
Gazdar, Gerald,
and
Chris Mellish.
1989.
Natural language processing in LISP:
An introduction to computational linguistics.
Wokingham, et al.: Addison-Wesley, 1989.
Gazdar, Gerald,
and
Chris Mellish.
1989.
Natural language processing in PROLOG:
An introduction to computational linguistics.
Wokingham, et al.: Addison-Wesley, 1989.
Huitfeldt, Claus.
2006.
Philosophy Case Study.
In
Electronic Textual Editing,
ed. Lou Burnard, Katherine O´Brien O´Keeffe, and John
Unsworth.
New York: MLA 2006, pp. 181-96.
Van Huyssteen, Gerhard B.,
E. Roald Eiselen, and
Martin J. Puttkammer.
2004.
Re-evaluating evaluation metrics
for spelling checker evaluations.
Proceedings of First Workshop
on International Proofing Tools and Language
Technologies.
Patras: University of Patras, 2004, pp. 91-99.
Lubell, Joshua.
2014.
XForms User Interfaces for Small Arcane
Nontrivial Datasets.
Presented at Balisage: The Markup Conference 2014,
Washington, DC, August 5 - 8, 2014.
In
Proceedings of Balisage: The Markup
Conference 2014.
Balisage Series on Markup
Technologies,
vol. 13 (2014). doi:https://doi.org/10.4242/BalisageVol13.Lubell01.
Peterson, James L.
Computer programs for detecting and correcting
spelling errors.
Communications of the ACM
23.12 (December 1980): 676-687. doi:https://doi.org/10.1145/359038.359041.
Quin, Liam, ed.
2020.
The General Biographical Dictionary:
Containing an historical and critical account of
the lives and writings of the most eminent persons
in every nation; particularly the British and Irish;
from the earliest accounts to the present time.
A NEW EDITION,
Revised and enlarged by
Alexander Chalmers, F. S. A.
1812 - 1817.
A majority edition created by running
multiple OCR engines over the text, with fairly extensive
post-editing. On the web at
https://words.fromoldbooks.org/Chalmers-Biography/
Sperberg-McQueen, C. M., and
Claus Huitfeldt.
Bootstrapping Project-specific
Spell-checkers.
Talk given at DH 2019 Utrecht,
July 2019.
On the web at
https://dev.clariah.nl/files/dh2019/boa/0961.html