Kimber, Eliot. “High-Quality Microsoft Word documents from XML: The Wordinator.” Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31, 2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Kimber01.
Balisage: The Markup Conference 2020 July 27 - 31, 2020
Balisage Paper: High-Quality Microsoft Word documents from XML: The Wordinator
Eliot Kimber is an XML practitioner currently working with a U.S. government agency
on
a new report authoring, management, and delivery system. He has been involved with
SGML
and XML for more than 30 years. Eliot has contributed to a number of standards, including
SGML, HyTime, XML, XSLT, DSSSL, and DITA. While Eliot's focus has been managing large
scale hyperdocuments for authoring and delivery, most of his day-to-day work involves
producing online and paged (or pageable) media from XML documents. Eliot maintains
a
number of open-source projects including DITA for Publishers, The Wordinator, and
the DITA
Community collection of DITA-related tools and other aids. Eliot is author of
DITA for Practitioners, Vol 1: Architecture and Technology, from
XML Press. When not trying to retire the technical debt in his various open-source
projects, Eliot lives with his family in Austin, Texas, where he practices Aikido
and
bakes bread.
Many products make XML from Microsoft Word, but consider the reverse: making Word
versions of your XML documents, thus using MS Word as a document composition engine.
The
Wordinator enables automatic creation of high-quality Word documents from XML source.
It
uses an extension of the Word2DITA project’s SimpleWP (Simple Word Processing markup
language) as the input to an Apache POI-based Java application that generates Word
documents. XSLT generates the SimpleWP XML, managing the mapping of source XML elements
to
Word constructs and styles. I consider, in particular, the separation of concerns
between
the XSLT that generates the SimpleWP XML and the Java code that generates the Word
documents.
The Wordinator is a Java processor the takes as input a simplified XML representation
of a
word processing document and produces as output a Microsoft Word DOCX document. The
key
requirements for The Wordinator are:
Accurately and completely reflect the page layout details and visual rendering
required for non-trivial documents, initially codified municipal code as published
by
Municode, Inc., including complex tables with horizontal and vertical spans and embedded
graphics.
Support the creation of multiple page sequences with different page geometries and
different running heads and feet.
Minimize the effort required to configure the mapping from source elements to named
styles.
Support local formatting overrides (that is, do not limit styling only to the use
of
named styles)
Enable the automatic creation of DOCX files for different components of the source
document as authored ("chunking"), including the ability to create both a single DOCX
for the complete document as well as individual DOCX files for subcomponents of the
document in a single processing run.
Enable ease of integration into a larger XML-based publishing pipeline
The Wordinator also integrates with Saxon in order to provide a one-command process
that
takes as input the document source as authored, generates the intermediate word processing
XML
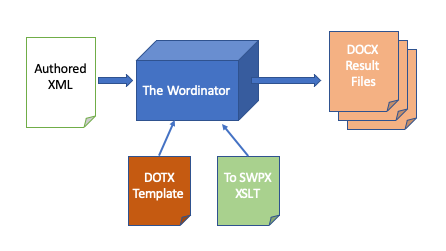
in memory, and produces the DOCX files as output. See Figure 1.
Figure 1
The Wordinator process schematic
The driving requirements for The Wordinator WORDINATOR come from
Municode, Inc's need to provide Microsoft Word versions of the municipal codes they
publish to
HTML such that for any chosen section of a municipality's code, the user of the HTML
can
download a high-quality Word version of what they are reading. The Word documents
may be
statically generated as part of the HTML publishing process or generated on demand
by the web
server that provides the HTML versions of the code.[1]
This requirement stems from the fact that the people working on municipal code almost
invariably do their work in Microsoft Word. Almost without exception, reviews of and
revisions
to muncipal code that are not done on printed paper are done in Word.
More generally, Microsoft Word is a de facto standard for
document viewing and printing in many organizations and for many private individuals.
For
example, the U.S. Government Accountability Office uses Microsoft Word for all the
drafts of
its reports (the reports are either published directly from their Word drafts or imported
into
the GAO's authoring management system as XML generated from the Word documents). GAO
also uses
Word as an intermediate format for producing accessible PDFs of their reports.
In many commercial publishing contexts Word is likewise used as the primary or only
format
for drafts of publications as they are developed, even when the publications themselves
will
be put into an XML format for final pre-publication preparation and publishing.
Another general requirement is using Word as a page composition engine. For example,
in
the DITA community the ability to print DITA documents using Microsoft Word would
serve the
needs of many small organizations that do not have the time or resources to customize
the DITA
community’s main open-source pagination tool or cannot afford other commercial tools.
While it is not difficult to generate Microsoft's DOCX format using typical XML processing
tools, it is a challenge to generate it correctly and with high quality such that
the Word
documents accurately reflect all of the structures and layout features required for
a given
document (to the degree that Word can support those layout requirements).
DOCX is an XML-based format optimized for the representation of the internal structures
used by word processors, spread sheets, and so on. The XML files are packaged into
a Zip file
that then forms the working DOCX file. DOCX is standardized as ECMA International
standard
ECMA-376 Office Open XML File Formats ECMA-376-1.
As an XML format, it is of course possible to generate Office Open XML directly using
XSLT
and a number of tools do that, including a plug-in for the DITA Open Toolkit ELOVIRTA. However, the markup generated is highly detailed and requires
managing a number of low-level concerns, such as ID-based references among different
files,
the detailed rules for the construction of specific components, and so on. It is easy
to get
this markup wrong due to the complexity of the markup itself and the vagaries of how
it is
processed by Microsoft Word.
In the context of Municode's requirements, the need was for Word documents that matched,
as closely as possible, the visual layout of the municipal code as published in HTML
and PDF,
as well as ensuring that all content was correctly reflected, enabling working hyperlinks,
generated tables of contents, and so on. In addition, the visual style of the generated
Word
documents could potentially vary from municipality to municipality, indicating the
need for
easy-to-configure styling and content organization details.
Municode, like many publishers, was putting in place a general XML-based system for
producing multiple outputs from a single XML source, meaning that the core XML processing
tools (in particular the Saxon XSLT engine) were available for use for Word generation
as
well.
In addition to meeting Municode's immediate requirements, I wanted to develop a
general-purpose XML-to-DOCX tool that could be quickly adapted to other documentation
formats,
in particular DITA. Municode agreed to allow me to develop The Wordinator as an open-source
project.
Solution: Separate The XML Transform from The DOCX Generation
Transforming directly from arbitrary XML for published documents (DocBook, JATS, DITA,
HTML5) to DOCX, while possible, does not provide a general solution that could be
easily
adapted to other formats.
As a general design principle, I like to use multi-phase processes that separate different
concerns as much as possible and as appropriate.
In this case, there are three main concerns:
Defining the visual styling and page layout of the generated Word documents.
Mapping of source document elements to the appropriate Word structures: paragraphs
and character runs with specific visual effects or named styles, tables, placed images,
and other page constructs, such as running heads and feet.
Generating the DOCX files themselves.
These three concerns are reflected more generally in any XML-based publishing process:
How should the content as published look? (layout and
styling)
How is the content as authored mapped to the input to the
publishing engine? (transformation mapping)
How are the published artifacts generated? (publishing automation that replaces
manual artifact creation such as manual page layout)
Commonly-used XML-based publishing technologies such as XSL Formatting Objects (XSL-FO)
present the challenge that the layout and styling concern is not easily separable
from the
transformation mapping concern, which makes XSL-FO a challenge to use and more expensive
to
implement and maintain than approaches that keep the design concern separate (for
example,
using CSS pagination).
As a general observation, the more that layout and styling are defined in the
transformation logic, the harder they are to both develop initially and adapt to new
requirements, because it usually requires a software engineer to implement any required
stylistic changes. That is, the styling concern is not in the hands of those who could
or
would otherwise define the styling.
In the case of Word documents, the styling concern is best implemented using Word
styles,
which provide a fairly complete mechanism for defining the visual look and feel of
the
resulting document, including page layout definitions (page geometry, running heads
and feet,
etc.). In addition, Word's existing features for generating tables of contents and
reflecting
layout-specific data (page numbers, paragraph numbers, automatic list numbers, etc.)
satisfy
most, if not all layout definition requirements.
Given a template with a complete set of styles for paragraphs, text runs, tables,
and
objects, as well as page design definitions (page geometry and page headers and footers),
the
mapping from source document elements to their appropriate visual renderings is mostly
a
matter of mapping elements in context to Word component types and style names. This
makes the
source-to-layout transform about as simple as it can be, significantly reducing the
engineering cost needed to implement the transformation for any given input XML source.
The
mapping is simple enough that it could be mostly or entirely defined through a declarative
configuration or defined using an interactive mapping tool.
That leaves the generation of the DOCX data itself.
The Apache POI library POI provides a robust open-source Java API
for reading and writing Office Open documents. This API handles most of the details
of the
Office Open XML format (OOXML) and thus makes the actual generation task both easier
to
implement and more reliable than the equivalent direct OOXML generation using XSLT
would be.
The Apache POI project is actively maintained and provides reasonably frequent updates.
I had prior experience using the POI library to generate Office documents in the context
of The Slidinator SLIDINATOR, a tool for generating PowerPoint documents from
DITA-based XML source, so I knew that POI would provide a quick and robust solution
for
generating Word documents.
That left only the question of how to get from the source XML to POI. This requires
a Java
processor that interprets some input source and calls the POI API to produce the result
DOCX
files. In addition, the processor must be able to read a Word template (DOTX) that
defines the
styles and page layouts to which the source XML is mapped.
My solution was to adapt the Simple Word Processing (SimpleWP) markup I originally
developed for the Word2DITA transformation framework WORD2DITA, which goes
from DOCX documents to XML for document authoring,
by adding the information needed to also go from arbitrary XML to DOCX.
The SimpleWP XML is then processed in Java to generate the DOCX content via the POI
library, which handles generating both the individual XML files that make up a DOCX
file as
well as doing the Zip processing to create the final working DOCX file.
In terms of the above three concerns, the solution is:
Use Microsoft Word to define a normal template document that provides all the named
styles needed to implement the desired published look and feel, as well as the necessary
page layout and section definitions.
Implement an XSLT transform that generates SimpleWP XML from the authored source
XML. Municode authors in HTML5 so the initial implementation of this concern was a
relatively simple HTML-to-SimpleWP transform.
A general-purpose Java component that reads SimpleWP input documents and generates
the DOCX results using the POI library.
This separation of concerns keeps the styling task in the hands of Microsoft Word
experts,
minimizes the source-to-style mapping XSLT implementation effort, and largely encapsulates
the
details of the DOCX generation in the SimpleWP-to-POI process, which can be treated
as a black
box.
In addition, because The Wordinator comes out of the box with an HTML-to-SimpleWP
mapping,
it means that other documentation source vocabularies can use Wordinator by generating
HTML
rather than going all the way to SimpleWP. As most, if not all, such vocabularies
already have
robust HTML generation transforms, the cost of adapting those to generate HTML for
use with
The Wordinator should be low.
SimpleWP to DOCX via POI
The Simple Word Processing XML vocabulary (SimpleWP) is a simplified representation
of
typical Word processing formats, but specifically Words structures: paragraphs, inline
runs,
tables, objects (image references, other embedded objects), etc. It provides the minimum
information need to either capture or generate the essential content and properties
of Word
document content.
The SimpleWP vocabulary was originally developed to enable the transformation of Word
documents into DITA XML and as such did not reflect layout-specific details such as
page
sequences and what Word calls "sections", which are sequences of pages with the same
page
geometry and running head and foot definitions (what would be page sequences in
XSL-FO).
To adapt SimpleWP to the needs of DOCX generation I added markup to represent page
masters, page sequence masters, and page sequences, that is Office Open sections and
section-specific components. I used terminology that is more reflective of XSL Formatting
Objects because that is what I'm most familiar with and will also likely be most familiar
to
other XML practitioners who might work with The Wordinator.
The full SimpleWP grammar is available from The Wordinator project. It's design is
purely
utilitarian, with the goal of keeping it as simple as possible in order to enable
generation
of all required Word features. In particular, it is not (yet) a full representation
of
everything you could do in a Word document. For example, it does not provide a way
to
represent arbitrarily-placed text boxes.
The Java code that processes SimpleWP XML is implemented as single Java class,
DocxGenerator, of about 2300 lines, that implements the overall business logic, supported
by a
number of utility classes that abstract some fundamental components, such as measurements
and
table column definitions.
The DocxGenerator class has three inputs:
A SimpleWP XML document.
The Word template (DOTX) that provides the style and page layout definitions to use
in the result document.
The DOCX file to write to.
The code as implemented assumes that all DOCX files are written to the file system--there
was no requirement to be able to stream the DOCX for output, although of course that
could be
added easily enough.
The DOCX generation process operates on the SimpleWP XML using Apache's XML beans
XmlCursor object, which parses an XML document into an XmlObject
instance:
XmlObject xml = XmlObject.Factory.parse(inFile);
XmlObject uses a cursor model to step through the XML, including moving up and down
the
document hierarchy. This is the same approach used in the POI code itself to read
and write
the DOCX XML files.
For example, the top-level constructDoc() method looks like
this:
private void constructDoc(XWPFDocument doc, XmlObject xml) throws DocxGenerationException {
XmlCursor cursor = xml.newCursor();
cursor.toFirstChild(); // Put us on the root element of the document
cursor.push();
XmlObject pageSequenceProperties = null;
if (cursor.toChild(new QName(DocxConstants.SIMPLE_WP_NS, "page-sequence-properties"))) {
// Set up document-level headers. These will apply to the whole
// document if there are no sections, or to the last section if
// there are sections. Results in a w:sectPr as the last child
// of w:body.
setupPageSequence(doc, cursor.getObject());
pageSequenceProperties = cursor.getObject();
}
cursor.pop();
cursor.toChild(new QName(DocxConstants.SIMPLE_WP_NS, "body"));
handleBody(doc, cursor.getObject(), pageSequenceProperties);
}
This provides a reasonably simple and natural way to process the XML. The main challenge
is ensuring that pushes and pops on the cursor stack are balanced.
The main output processing is handled by the handleBody() method, which processes
the
content of the <body> element to which it is applied and returns the last paragraph
in the
section or complete document to which the body
applies:
private XWPFParagraph handleBody(
XWPFDocument doc,
XmlObject xml,
XmlObject pageSequenceProperties)
throws DocxGenerationException {
XmlCursor cursor = xml.newCursor();
if (cursor.toFirstChild()) {
do {
String tagName = cursor.getName().getLocalPart();
String namespace = cursor.getName().getNamespaceURI();
if ("p".equals(tagName)) {
XWPFParagraph p = doc.createParagraph();
makeParagraph(p, cursor);
} else if ("section".equals(tagName)) {
handleSection(doc, cursor.getObject(), pageSequenceProperties);
} else if ("table".equals(tagName)) {
XWPFTable table = doc.createTable();
makeTable(table, cursor.getObject());
} else if ("object".equals(tagName)) {
// FIXME: This is currently unimplemented.
makeObject(doc, cursor);
} else {
log.warn("handleBody(): Unexpected element {" + namespace + "}:'" + tagName + "' in <body>. Ignored.");
}
} while (cursor.toNextSibling());
}
// The section properties always go on an empty paragraph.
XWPFParagraph lastPara = doc.createParagraph();
lastPara.setSpacingBefore(0);
lastPara.setSpacingAfter(0);
return lastPara;
}
This method simply iterates over the children of <body> and dispatches each child
to
the appropriate handler.
The XWPF objects are the top-level POI classes that abstract fundamental Office Open
constructs for Word documents, hide the details of how the actual Office Open XML
is
constructed, and provide appropriate methods for constructing the objects in terms
of their
semantics rather than in terms of the underlying Office Open details. This makes the
API about
as easy to use as it could be for this task.
Where the XWPF classes do not support generation of the Office Open XML details, it
is
(usually) possible construct the underlying XML structures directly using the lower
level POI
APIs.
In a few cases I found places where I needed to extend the XWPF API to meet the needs
of
The Wordinator. In all of those cases I was able to contribute the enhancement back
to the POI
project for release in the time frame that I needed them for Municode's use of The
Wordinator
or simply produce my own local build of POI, as needed.
In general, it was clear that most users of POI are reading, but not writing, Word
documents.
Construction of individual elements, such as paragraphs, gets a little more involved
(some
details omitted for
brevity):
private XWPFParagraph makeParagraph(
XWPFParagraph para,
XmlCursor cursor,
Map<String, String> additionalProperties)
throws DocxGenerationException {
cursor.push();
String styleName = cursor.getAttributeText(DocxConstants.QNAME_STYLE_ATT);
String styleId = cursor.getAttributeText(DocxConstants.QNAME_STYLEID_ATT);
if (null != styleName && null == styleId) {
// Look up the style by name:
XWPFStyle style = para.getDocument().getStyles().getStyleWithName(styleName);
if (null != style) {
styleId = style.getStyleId();
}
}
if (null != styleId) {
para.setStyle(styleId);
}
// Explicit page break on a paragraph should override the section-level break I would think.
String pageBreakBefore = cursor.getAttributeText(DocxConstants.QNAME_PAGE_BREAK_BEFORE_ATT);
if (pageBreakBefore != null) {
boolean breakValue = Boolean.valueOf(pageBreakBefore);
para.setPageBreak(breakValue);
}
if (cursor.toFirstChild()) {
do {
String tagName = cursor.getName().getLocalPart();
String namespace = cursor.getName().getNamespaceURI();
if ("run".equals(tagName)) {
makeRun(para, cursor.getObject());
} else if ("bookmarkStart".equals(tagName)) {
makeBookmarkStart(para, cursor);
} else if ("bookmarkEnd".equals(tagName)) {
makeBookmarkEnd(para, cursor);
} else if ("fn".equals(tagName)) {
makeFootnote(para, cursor.getObject());
} else if ("hyperlink".equals(tagName)) {
makeHyperlink(para, cursor);
} else if ("image".equals(tagName)) {
makeImage(para, cursor);
} else if ("object".equals(tagName)) {
makeObject(para, cursor);
} else if ("page-number-ref".equals(tagName)) {
makePageNumberRef(para, cursor);
} else {
log.warn("Unexpected element {" + namespace + "}:" + tagName + " in <p>. Ignored.");
}
} while(cursor.toNextSibling());
}
cursor.pop();
return para;
}
Again, an iteration over the contents of the incoming paragraphs to dispatch the
appropriate construction handlers.
The main implementation challenge with paragraphs is applying the appropriate styles.
When
an input SimpleWP paragraph, run, or table specifies a style name the style must be
present in
the input template or there is no way to correctly style the document.
In addition, Office Open XML has the concept of "latent styles", which are styles
where
the style definition is defined entirely in the processing application, i.e., Microsoft
Word,
and is not otherwise defined in the Office Open XML anywhere. References to latent
styles are
thus not resolvable to anything in a general way because they are by definition
application-defined. The DOCX file lists the names of all latent styles, so you can
know if a
style name is the name of a latent style, but you have no general way of knowing what
the
definition of that style is.
For example, in Microsoft Word, when you select the option to view All Styles, you
are
seeing both styles that are explicitly defined in the document's style catalog as
well as all
latent styles. If you subsequently selected a latent style for use on content in the
document
the latent style is copied into your document's local style catalog. This ensures
that a given
document's style catalog is a small as possible but makes it hard to know, a-priori,
what the
actual definition of a given latent style is as there's no generally-available definition
of
the latent styles that I'm aware of, short of creating a document that uses every
latent style
and then capturing its style catalog.
One missing feature in the XWPF API is access to the list of latent styles to know
if a
given style name is in fact a latent style--the API simply never considered the need
because
it has no relevance to reading DOCX files, only to writing them (or working with styles
in
some way). The challenge for The Wordinator is distinguishing between a style name
that does
not exist at all and a style name that is a latent style so that the user can be accurately
informed about a bad style name as distinct from a reference to a latent style.
As in all publishing processes, tables are the most challenging structure to generate,
mostly because of the challenge of handling vertical spans. However, because the SimpleWP
table markup is already a close match to the Office Open XML table model, the actual
processing is not that complicated.
Another table generation challenge is relative column widths where relative widths
are
mixed with absolute widths.
Office Open has a mechanism for specifying relative widths as a percentage of the
total
table width but the SimpleWP markup usually will not specify the absolute width of
the table
because that is normally a function of the output rendering.
Without knowing the width of the table there is no way to determine what fraction
of the
total a given relative-width column is when any other columns have explicit widths.
If all the columns have relative widths then you can calculate the percentage each
column
uses.
The SimpleWP table element provides an attribute for specifying the explicit width
of the
table but most authoring formats to not provide a reliable or general way to know
what the
rendered width of the table should be.
Thus, when the width of the table is not specified, The Wordinator effectively requires
either all explicit widths or all relative widths and issues a warning if this is
not the
case.
As with similar single-pass composition processes, the DOCX generation process does
not
have access to the formatted DOCX document, so it cannot know what the final rendered
size of
any component is.
Authored XML to DOCX Process
While the core DOCX generation processor takes as input SimpleWP documents, the normal
use
case for The Wordinator starts with the authored XML as input, producing one or more
DOCX
files as output with all intermediate processing done in memory, as opposed to first
generating a set of SimpleWP documents and then processing them to DOCX as separate
process
invocations.
To facilitate this use case, The Wordinator integrates Saxon to do the
authored-XML-to-SimpleWP transform and then immediately generate DOCX from the resulting
SimpleWP XML.
The Wordinator provides a command-line application that be invoked by specifying the
authored XML source, the XSLT transform to apply to that source, the DOTX template
to use for
the result DOCX files, and the directory to write the DOCX files to.
The connection from the Saxon result to the DOCX generator is done using a Saxon-specific
output URI
resolver:
Processor processor = new Processor(false);
DocxGeneratingOutputUriResolver outputResolver =
new DocxGeneratingOutputUriResolver(outDir, templateDoc, log);
processor.setConfigurationProperty(Feature.OUTPUT_URI_RESOLVER, outputResolver);
...
XdmValue result = transformer.applyTemplates(docSource);
The output URI resolver is then used by Saxon for xsl:result-document instructions,
effectively providing the result SimpleXP output of the XSLT transform to the DOCX
builder,
here from the HTML-to-SimpleWP transform provided with The Wordinator, where $result-uri
is
the URI of the result DOCX
file:
The DocxGeneratingoutputUriResolver's resolve() method sets up the Result object,
which
simply provides the result URI to use for the generated DOCX
file:
public Result resolve(String href, String base) throws TransformerException {
saxHandler = XmlObject.Factory.newXmlSaxHandler();
Result result = new SAXResult(saxHandler.getContentHandler());
result.setSystemId(href);
return result;
}
The resolver's close() method does the actual DOCX
generation:
public void close(Result result) throws TransformerException {
// Do the DOCX building
try {
XmlObject xml = saxHandler.getObject();
String outFilepath = URLDecoder.decode(result.getSystemId(), "UTF-8");
String filename = FilenameUtils.getBaseName(outFilepath) + ".docx";
File outFile = new File(outDir, filename);
File inFile = new File(new URL(result.getSystemId()).toURI());
log.info("Generating DOCX file \"" + outFile.getAbsolutePath() + "\"");
DocxGenerator generator = new DocxGenerator(inFile, outFile, templateDoc);
generator.setDotsPerInch(dotsPerInch);
generator.generate(xml);
} catch (Exception e) {
throw new TransformerException(e);
}
}
Note that this approach puts the decision of how to chunk the result DOCX files in
the
authoring-to-SimpleWP transform.
The connection between Saxon itself and the DOCX generator is completely generic.
This use of an output URI resolver to manage the generation of the DOCX files makes
the
use of the DOCX generator as natural as using Saxon to generate XML files and does
not require
any special consideration on the part of the XSLT implementor other than specifying
the name
of the result DOCX file at the result document URI.
Authored XML to SimpleWP XML
The generation of SimpleWP XML involves mapping the authored structures to the appropriate
word processing structure and mapping content elements in context to the appropriate
named
style or specific formatting effect.
The HTML-to-SimpleWP transform provided with the The Wordinator demonstrates the general
technique:
A main processor maps the source XML to the appropriate general SimpleWP structures:
document, section, paragraph, run, table, etc.
A "get style name" mode module provides the element-in-context to style name
mappings.
The main processor is fairly generic for a given input vocabulary because for most
authoring vocabularies the structural mapping will be the same regardless of the content
details. For example, for DocBook, each top-level division would probably result in
a new
result section and <para> will almost always result in a SimpleWP paragraph.
For example, the base template for HTML paragraphs and similar block elements
is:
The "get style name" module provides the more variable, and easier-to-code, mapping
of
elements in context to style names.
The get style name module provides three main services:
A literal class- or tag-name-to-style map using an XSLT map.
A base mapping to Word's default styles for headings, lists, and other common
structures for which Word provides built-in styles or dedicated OOXML structures.
Explicit element-in-context mapping to arbitrary style names or format
overrides.
The design goal is to make the mapping from the authored source (or the HTML generated
from the authored source) to Word styles as simple as possible to specify so that
the easy
cases are easy, obvious default mappings just work, and special cases can be implemented
without unnecessary overhead.
The class or tag name mapping is simply a literal XSLT
map:
This syntax is simple enough that anyone should be able to modify it, but of course
it
could be moved to a separate configuration file if that was useful. That level of
flexibility
and convenience was not a requirement for Municode.
One could imagine, for example, an interactive application that reads the style
definitions from a DOTX or DOCX file and the @class values from an HTML document or
the set of
element type names from an XML document and enables specifying the mapping from class
to
style.
The default "obvious" mappings include mapping hierarchical titles to Word's built-in
Heading N styles and styles for lists,
e.g.:
Even this template, while full XSLT, is simple enough that people who understand XPath
well enough to construct the correct match expression but are not otherwise XSLT programmers
could implement this kind of special case mapping.
While the simplicity of this template suggests that there should be a way to capture
the
same mapping in some kind of configuration file, in my thinking on this issue to date
(which
started more than 10 years ago with work I did to implement a similar DITA-to-InDesign
transformation DITA2ICML), it has always seemed that any such
configuration file would not be significantly easier to create than this style of
simple XSLT
template and the cost of implementing the processing of such a configuration file
would be
significant, especially if the target audience is not expected to be XML or XSLT experts,
meaning the configuration file processing has to provide robust error handling with
clear
messages, appropriate convenience features, and so on.
However, that work and thinking was done with XSLT 1 and 2. Newer features in XSLT
3, such
as the ability to dynamically evaluate XPath expressions and better facilities for
error
handling, might lower the cost of such a configuration mechanism to make the added
convenience
worth the implementation effort if that level of configuration convenience is otherwise
a
requirement.
Conclusions and Future Work
The Wordinator achieves it's original requirement of producing high-quality Word
documents, including support for multiple page sequences with different page geometries,
headers, and footers, complex tables, embedded graphics, and multi-column content.
By leveraging the Apache POI library the implementation cost was kept to a minimum,
within
Municode's limited budget. In addition, the use of POI, with its robust and mature
implementation of the Office Open XML format, limits the risk of producing bad DOCX
data.
The implementation demonstrates the utility of separating the three concerns of style
and
layout, authored-content-to-style mapping, and deliverable generation. It also demonstrates
a
useful technique of using Saxon output URI resolvers to post-process the direct output
of an
XSLT transformation into some non-XML format that cannot be generated (or easily generated)
using XSLT alone.
By using a simple-as-possible intermediate format (Simple Word Processing XML) as
the
input to the DOCX generation process, the complexity of the
authored-content-to-deliverable-structure is minimized.
The current Wordinator release, 1.0.2, is sufficiently complete to meets the needs
of most
documents that do not require page layouts and typographic effects that can only be
produced
in more sophisticated page layout systems or through manual construction of pages.
At this
level of completeness it is limited mostly by the inherent limitations in Microsoft
Word
itself.
However, Wordinator does not implement all layout features of Word, so there is room
for
improvement, for example, generation of content in floating text boxes.
Another area for investigation is the generation of Word documents with accessibility
features to be used as input to existing tools that generate accessible PDFs from
Word
documents. The U.S. GAO currently uses Word to create accessible versions of GAO reports
but
the Word is created manually as part of the publishing process. It is likely that
Wordinator
could be used to generate Word documents with the necessary accessibility features,
removing a
manual process without completely rearchitecting the current GAO publishing process.
Additional possible extensions include using CSS to define the Word style details,
enabling automatic generation of the Word styles from CSS style sheets, enabling the
reuse of
existing CSS style sheets used for web or paged delivery.
The Wordinator could easily be adapted to take non-XML data as input, in particular
JSON,
using XSLT 3's JSON processing features.
While part of my personal motivation for building The Wordinator was to enable the
easy
publishing of DITA content to PDF via Word, I have not actually implemented that process.
It
should be a relatively simple task to extend the existing DITA Open Toolkit HTML
transformation to produce HTML optimized for use with The Wordinator, along with DITA-specific
Word Templates that provide named styles corresponding to DITA content elements.