Piez, Wendell. “Fractal information is.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Piez01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: Fractal information is
Wendell Piez
Wendell Piez is an independent consultant specializing in XML and XSLT, based in
Rockville MD.
We wrestle often with the granularity of data formats, object models, interfaces,
and
APIs: their strengths, their weaknesses, and the supports they provide to creators
and
consumers. Opinion is often muddled or extrapolated from limited experience: “X is
lightweight”, “Y is ‘self-describing’”, “everyone prefers Z”. This is a fractal experience;
there is self-similarity across scales. Issues that arise at one level of the system
have
weird echoes elsewhere. Indeed, one way of discriminating among options (XML, HTML,
Markdown, JSON, YAML, SAX, DOM, etc.) is to consider their different approaches to
the
problem of managing the chaos and representing (ir)regularity. This examination leads
to a
better understanding of how to exploit their differences to make them work better
together.
Fractals are defined mathematically, and phenomena with fractal properties are ubiquitous
in nature. Postpone for a moment the question of whether to consider fractal
here in a literal, or in an analogical and metaphorical (loose) sense — whether, that
is, we
should consider the phenomena we witness (in technologies of text encoding) as fractals,
or
only fractal-like. What are fractals like? One does not need to be a mathematician
to
observe:
Self-similarity across scales
Disparate parts are similar (alike) but also different
Boundaries become shaggy whenever we zoom in
There are rules, and there are also apparent anomalies, exceptions or
variations
(Or, more strictly: there are rules; but how the rules apply in the given context,
must be determined dynamically; it cannot be known ahead.)
Another way to put it: regular, but also irregular
Or, regularity punctuated by irregularity – even while anomalies point to deeper
orderings or wider contexts
Fractal phenomena turn up where there is some kind of recursion in the neighborhood. This includes those special recursive forms
we call indefinite iteration or periodicity.
Scales of resolution
Examples of fractal-like phenomena might be given at any of a number of layers or
levels
of scale. Looking only at the realm of human culture and economy (that is, to say
nothing of
physics or any of the natural sciences), we might pause to consider any of:
Cultural production
The archive!
Documentary production (or: the written word)
Electronic/documentary media
Non-proprietary, open, standards-based media
Text-based formats
Formalisms, formal languages, programming languages
Markup languages and data description syntaxes
This paper is concerned with only the most minute and low-level of these. The intention
here is to offer text encoding technologies as a synecdoche, a part representing the
whole.
From what we recognize in the problems we face as developers and users of text technologies,
we might extrapolate to other realms not considered here.
At the same time the effort here is given not so much to arguing that fractal phenomena
exist, but rather in exploring the consequences of recognizing fractal phenomena,
when we see
them, as such — at various levels of this scale but most particularly at the most
minute and
granular: markup technologies and text encoding technologies, looked at up close.
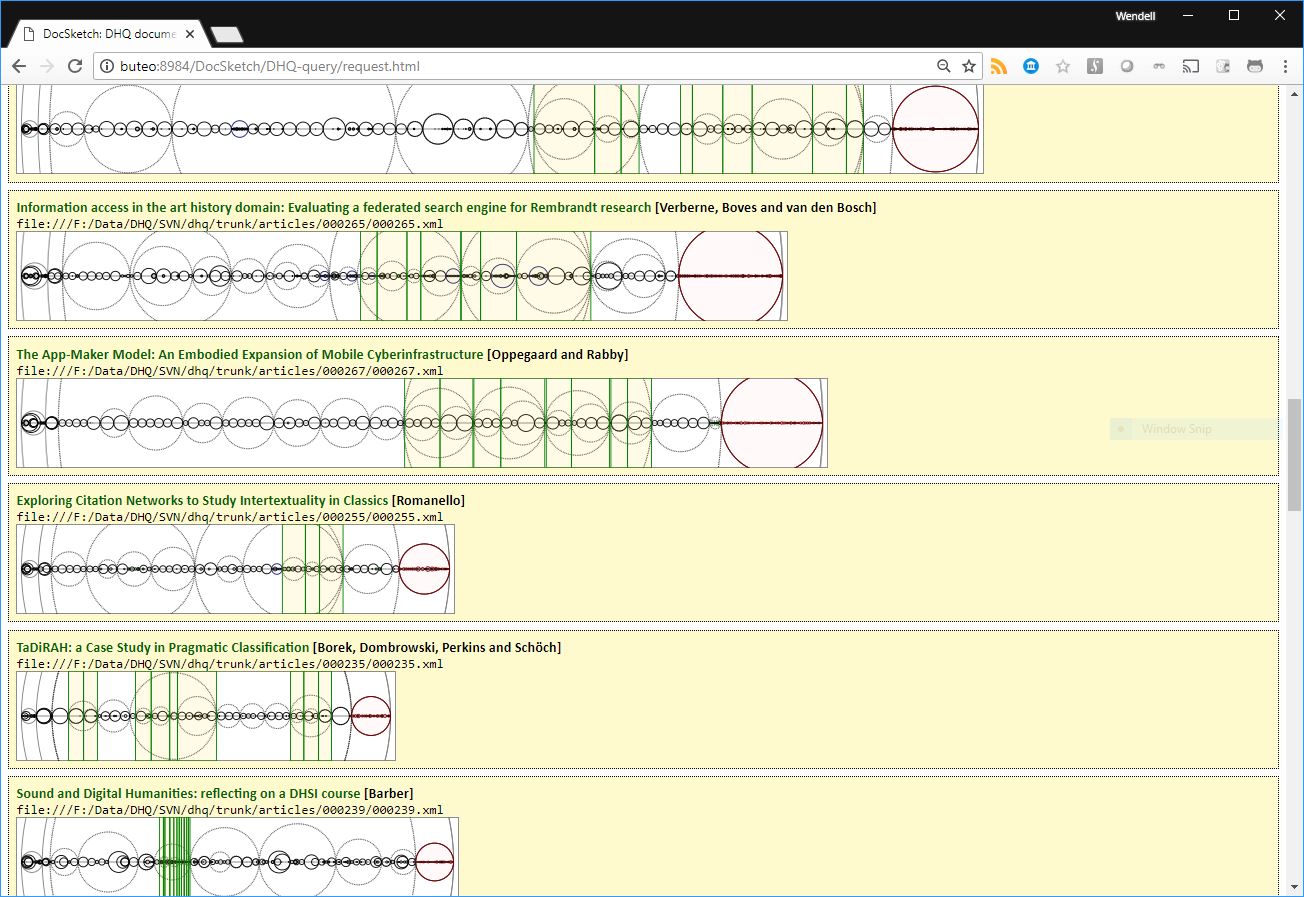
Figure 1
Some XML data, viewed graphically.
In other words, this paper asks the reader to set aside the literal in favor of the
metaphorical; instead of looking at what is, we look at what (it) is like (what).
This is
intentional, strategic and necessary, since we don't all know everything already.
(To be more
generous to ourselves we might imagine we know everything, but details remain to be
filled
in.) Indeed, it is something of a metaphystical mystery why, for example, we might
be so
assured that natural phenomena such as mountains and clouds are fractal: we only know
that
describing them as such, has explanatory power and even predictive capability, if
not in
absolute terms, then at least as or in the aggregate.
The dissolve into detail
This is an interesting and possibly strange angle of approach to considering where
markup
technologies, in particular (in the minutest particular), are in this moment. Yet
the very
local is like the very general: in both cases, the puzzle is in how one is able to
maintain
the requisite attitude of uncertainty, in the face of the need to amass incredible
levels of
detail and contextual information from any new situation (which we have stipulated,
is both
like and unlike any other situation). One way we can do this, is by plotting how to
do so. To
learn how to make and follow such plots, is the essence of technical knowledge and
expertise.
Here, my meta-plot begins with the recognition of a particular moment, which I call
the
dissolve into detail. The word dissolve here
is a noun, as in a cinematographer's dissolve, a dissolution. I am using the term
to describe
a moment that follows the shock of seeing something new and recognizing both its newness,
and
its likeness-yet-unlikeness to what one knows. It is a moment that may never happen:
indeed,
most of our lives are spent with the complexities of the world we face every day,
carefully
masked from us.
Note
In another paper I have called this latter attitude the semantic
collapse, namely the state of knowledge that one is invited to inhabit by
designers. It is when the database does not look like a database, but like a
calendar.
When the dissolve into detail does happen, it can be debilitating and discouraging
(one reason we do not like it). Yet it is important and salutary. It is a dissolve
or
dissolution not because the detail disappears, but because the witnessing and intentional
self
does, if only for a moment, into confusion or wonder. Indeed, to be able to proceed
from the
dissolve or dissolution into detail, to a later state of relative understanding and
mastery
(resolution) is precisely what makes a person an expert in some domain - that
they have enough relevant experience, to be able to judge something new, moving from
the
dissolve more or less quickly (in a way that may entail discovery of some nature)
to some
other attitude (in which, presumably, an intentional self is rehabilitated).
Whether this occurs or not, the dissolve itself is a commonplace experience, at least
for
some of us. Maybe one is faced with debugging a faulty thermostat or installing an
app on a
smartphone – when one is suddenly faced with the fact that one is presented with relevant
and
consequential detail. The detail is not understood: it is seen precisely, yet without
making
sense, its parts in view but not yet connected in an organic meaningful whole, so
rich and
pregnant with potential (with detail). It is either thrilling, or intimidating,
or both. In order to master the detail – this is why it is a moment of dissolution
– one
faces, first, a momentous choice: to turn away (perhaps finding and cede the problem
to an
expert – someone capable of resolving the detail) – or take on the burden of being
such an
expert, oneself.
In the face of technological change, the reason we so often face blind men and
elephant problems (the inescapable parable here) is that we are all experts, but in
something somewhat different, and gathered together to discover and delineate something
new,
we have yet to master the details of the elephant. Interestingly, the parable also
suggests
that to understand the detail of the elephant one must understand it as a whole. We
will come
back to this.
What's not so plain about plain text
No surprise that when posed with technical questions, the most important and salient
issues turn out to be technical ones: what makes them determinedly "fractal" is the
(repeated)
experience of more questions in every new anchoring context. It should not require
demonstration that our domain is a domain of domains, as well as a domain among many
others.
Stated in this way, we should well consider, what is a domain? For purposes of these
conversations, consider domains to be defined by rules and characterized by languages.
(Thus
we loosely encompass both technology, and culture.)
If (as) a domain is defined to a great extent by its language, the domain of text
encoding
technologies is a domain in which a term such as plain text has a specific,
technical meaning, referring to some sort of (categorical) entity that nonetheless
(however
abstract it is) becomes reified in the imagination as a "thing". So there is a set
of abstract
criteria by which (someone familiar the domain) can determine or measure, whether
something is
or is not plain text.
Yet at the very same time, we also acknowledge (even while using the language of our
domain) that even here, around the edges, we may occasionally have to clarify or
qualify.
In other words, there is a moment when we say plain text, followed by a
moment in which we ask but what do mean by that? and are confronted by the fact that,
well,
things are complicated. There is history … err.… this is the dissolve into detail.
(For many
or most attendees at this conference, the dissolve into the detail of plain text first
happened long ago. We may even remember when.) After longer familiarily with the topic,
things
start to make sense – there is resolution. The dissolve into detail does not stop,
and the
details do not disappear or change; but once more familiar, they become both clearer
and
possibly, less scary.
So it is with plain text. We can note a few examples of strings that might, or might
not –
subject to qualifications – qualify as plain text. The dissolve in detail takes
us into competing definitions and contexts, within each of which, meanings will be
slightly
different, to different effects. So it is, for example, that the meaning of plain
text shifts – or the questions around its meanings shift – with the widespread
adoption of Unicode.
Figure 2
Example of plain text
Example of "plain text"
Example of *plain text*
Example of “plain text”
“plain text”
<p>Example of <q>plain text</q></p>
<p>Example of <i>plain text</i></p>
Some examples of plain text or of nominal plain text. Even as such, however, the
most basic categories are debatable around the edges. We can only surmise what is
meant,
based on what we know.
So – we might observe that in itself, even for a data object to constitute plain
text might be necessary, but not likely sufficient. It is all about what and how much
we
know in advance.
In the case of plain text, we call it so (not to get into too much detail)
because we mean to distinguish it from formatted text, at least as it
presupposes that the format of text is something other than text itself,
moreover not represented directly by it (perhaps not even in Unicode) and thus
to be expressed as more text, except now not as (the presumptive) text itself
but, paradoxically, as the text-that-is-not-a-text. (Code or
markup. The irony and arbitrariness of this distinction implies another
paper. Nonetheless it is worth remarking how commonplace and ordinary it eventually
seems that
we can so easily
distinguish:
This is a text
from
{\*\ftnsep\chftnsep}\pgndec\pard\plain \s0\widctlpar\hyphpar0\cf0\kerning1\dbch\af5\langfe2052\dbch\af6\afs24\alang1081\loch\f3\fs24\lang1033{\rtlch \ltrch\loch
This is a text}
\par }
Many Balisage readers will recognize the second of these as This is a text
embedded in a (piece of) an RTF document, that is to say Microsoft's Rich Text
Format. (This is lines 15-17 of a 17-line file for this line of writing.) But this
audience is exceptional, as most people on being presented with this are not likely
to know
what this is, much less that this is RTF (or what RTF is or even that there is or
necessarily
should be such a thing). They do, however, as literate readers – indeed, demonstrating
a
sophisticated kind of pattern matching which might be taken to define literacy
– can readily separate the text from the encoding. And due to
this fact only, they might agree that this chunk of text taken (in toto) is not quite
plain subject to some definition of that term.
And this comes up despite how (what is also paradoxical, as well as known to this
audience) both these examples are plain text, as distinguished from some other
sort of encoded information (which would not, indeed, submit readily to transcription
here), a
(so-called) binary format. (Which here, means only not text,
since all digital electronic formats are binary.) The point here is that plain
text is hard to define – as is text. (We start talking about
encodings of alphanumeric characters and their histories and definitions, as well
as of the
histories of computer and text processing platforms on which these various schemes
and
protocols have been implemented.)
The definition of the term itself is relative to the point of definition. What do
you mean by plain text is a reasonable question to ask. (What seems like a clear
boundary, on getting closer, shows further detail.)
For rough purposes of the discussion to follow, we might provisionally define plain
text
as an arbitrary but finite sequence (string) of Unicode characters (or of an
analogous abstraction we can call a character), fully aware that this is both
too broad and too narrow. As experts – as members of a community of practice that
both does,
and does not (ever entirely, subject to qualifications) agree, on what plain text,
we can do
this.
At the same time, it is important to keep in mind that even the relative narrow domain
of
"plain text" or "plain text-based formats", is very broad. Not only are there more
than one
working definition for plain text itself, but also (given such a definition) there
is an
extreme broad and diverse kinds and applications of plain text.
Indeed, it is the muddle of discriminations that one can then begin to make, that
the
problems start. The kinds and uses of plain text.
There is something fractal about this too? What we consider plain, normal,
or unadorned - vs what we consider to be superfluous, additive, enhancement - is relative.
Even within what we might (otherwise) consider to be an extremely narrow category
of being –
encoded electronic text – we find a great variability and dependency, in detail, on
local
circumstance. In other words, further occasions of dissolution into further detail,
and
possibly confusion and vexation.
Nonetheless, those circumstances having been defined, plain text is
nonetheless a (relatively) stable thing, a controllable thing – so stable and so controllable,
even, that entire infrastructures can be built over and around it. We take plain text
so much
for granted, that mostly it can just disappear. So we are on a knife's edge: on the
one side,
plain text never means only plain text: there always has to be some narrower definition.
On
the other side: having settled on what plain text is, what we can do with it is entirely
open
ended.
Semantic staircase: from stream, to structure
Step in closer and things get complicated again.
Among sorts of varieties of applications of plain text is an extremely wide range
of
different formats, including everything from what we might call raw - that is,
text without markup or inline encoding of any sort, through a spectrum up through
rather
complex organizations optimized for certain kinds of processing, data mining, and
execution.
One might indeed draw a map showing the tradeoff space between different
approaches to plain text, with two axes representing (a) readily accessible processibility
(that is, the explicit, overt and ready capabilities of the text for automated data
processing
operations), vs (b) the necessary up front commitment in the form of constraints over
the text
- that is, the rules of its use, including the use of embedded encodings, invocations
of
spirits and powers, and all sorts of magical incantations. For these to be operational
and
effective, they have to be done right.
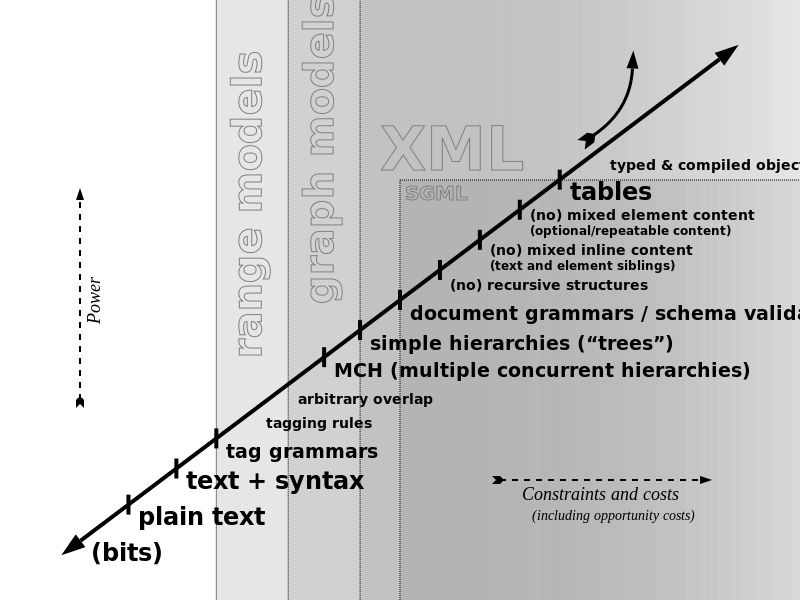
I drew such a map as a speculative exercise in my 2012 paper, Three Questions
and an Experiment, in opening a symposium on data modeling at Brown
University:
A slope of optimization, as described in 2012
Reassessed in 2018
Rendered as a staircase with some more examples projected onto it
(2018)
A few years later, it becomes possible to reflect on this further. The picture has
not
changed much in basic outline, which is reassuring. I have made a correction (as I
now see it)
the order between rules no mixed element content and no
recursion, in part since, at least in principle, JSON shows that it is possible to
support recursive structures, without being tolerant of arbitrary mixed content.
Note
A JSON array can be used to simulate arbitrary ordered (mixed) content, but array
items must be unlabeled. The tradeoff is thus, either contents can be significantly
ordered, or labeled, but not both at the same time.
Other than that, the diagram has only been fleshed out. In 2018 we can see how HTML
remains entrenched, with its more mature models (to say nothing of the binding of
model to
syntax represented in HTML5). Markdown especially among bespoke syntaxes has
become more prevalent, especially given its evident utility for tight-cycle documentation.
(For posting Issues on Github, it offers much to like.)
At the high end of the stairway, we see the emergence of structured data formats such
as
YAML, which would indeed show how encoding this high on the commitments ladder
becomes both hugely powerful (especially when aggregated), yet at the same time rather
inflexible as a reflection of its focus. It is important to note here that non-proprietary,
openly specified serializations may not do anything functionally superior to what
is provided
by earlier technologies – it is only that what is proprietary, is doomed to die away.
In any
case, the activity at the top of the scale (where indeed, application binding tends
to
happen), perhaps distracts us from developments at lower levels, that happen concurrently.
There, at lower layers, the design problems are much more intractable – largely because
real-world data sets are so rich and flawed at the same time,
and requirements are so exigent, and its generality so relevant – so sensitive
to context, to initial conditions.
As an illustration of the kind of progress we have made, consider how, as a source
format
for (say) a static web publication, it is clear enough why markdown and YAML make
such a nice
pairing – if only for simple sorts of texts whose structures will never get very
deep, only broad (such as, for example, a personal blog with subject
tagging). By the same token, it will also be clear where this architecture will have
its
limits.
What is clearer in 2018 that this graduation might better be called a staircase, because
what is important here is not the slope, or whether the slope is curved, or indeed
whether two
dimensions is adequate to the problem, but rather the incremental nature of the sorts
of
commitments that can be made. Note that since each step represents a new commitment,
it
entails a narrowing: an achievement of expressive power in
one domain, at the cost of expression in others. This is true whether the commitment
be made
at the level of syntax (reserved tokens and rules for combining them) but also when,
how and
by whom, names are given to things. A generalized tagging syntax like XML, for example,
settles one set of rules while allowing others to set other sets of rules, at higher
levels.
In turn, this reflects how commitments at lower levels of the staircase become the
basis for
new commitments at higher levels. It becomes a stack.
The suggestion of 2012, however, remains valid: what is needed is not any particular
format on any point of the staircase, but rather, capable technologies working at
any and all
of them, plus tools that enable us to move data up and down the stairway –which is
to say,
into and out of environments where control and regulation - where our capability of
imposing
full control and regulation - may be (in some important ways) sometimes be more the
exception
than the rule. This is the world of real data and information. Not everything all
nicely
organized up front. But organization is there, amidst the mix and mess. And organization,
once
resolved, can also underlie architectures.
Living in a JSON world
The simple fact is that while there may be fashions and trends, most decisions regarding
architecture and platforms are not made on the basis of technical considerations.
Nor should
they be - this is not intended as a critique, and for various reasons, an imperative
might
not be, that a technology is well suited to a task or
use.
Nonetheless the fact remains that (at least these days) JSON appears
to a certain (common) class of users and
developers to be the obvious first choice for a serialization format. To them, it
must often
seem mysterious why an architecture might be built around anything else. The benefits
of XML
in contrast, are not at all clear to them.
Yet, they are not all that clear to us either, often; indeed perhaps the bigger mistake
is
to see the choice in exclusive terms. Indeed, this has already been shown (for example
by
Robin LaFontaine at Balisage 2017) to be unnecessary, inasmuch as JSON syntax can
readily be
"adopted" into a family of supported syntaxes for serialization, in an XML based system.
Over
and above, that is, the more flexible modeling capabilities of a syntax that easily
supports
arbitrary mixed content, XML offers string features for modeling and manipulating
even
"naturally" JSON data, whatever they it be.
In itself this is a major achievement for which we have to thank the developers of
the
most recent XPath, XQuery and XSLT versions, who by describing means for both manipulation
of
map objects, and a serialization model between XPath and JSON syntax, have ensured
that they
are available even in commodity toolkits. Capabilities first described at conferences
like
this one (for example, Jonathan Robie at Balisage 2012) are now part of the toolkit
off the
shelf.
As Robin showed last year, once such a mapping (in effect, a tag description) of the
basic
JSON data model, with its objects, properties and values, into an XML-compatible
representation, is established, the rest becomes a matter of using our transformation
and
query tools as designed. Indeed, the most recent versions of the standards provide
not one but
two ways to do this – either via an XPath/XDM map object, or by means of an XML
vocabulary-and-model describing such a thing. Using either of these approaches, XML
tools can
see and handle JSON data in the same way as they see XML – that is, as
already parsed and rendered into an addressable form. Effectively, this means that
JSON can be
integrated freely as either an input, or an output (result) of an XML-based transformation
or
pipeline.
What is especially of interest is how, indeed, such a capability exposes the issues
of
working across the data format divide. As soon as there is no syntactic barrier, the
actual
modeling mismatches between (typical) XML-based document formats or data description
formats,
and analogous JSON formats, become exposed as problems of transformation.
As this happens, the complexity of the problem does not change – but it shifts. By
stabilizing a relationship – defining a clear boundary – at one level, by providing
a
technical bridge between XML and JSON representations of data, we reveal and highlight
the
challenges that remain potential blockers, or hindrances, at another closer level
of
detail.
Mappings and metamappings
It is not difficult to demonstrate the weaknesses of JSON for documentary data: on
line,
there are several tools offered for free use, which offer this functionality, readily
demonstrating the challenges and issues. Just paste a bit of well-formed XML and see
what an
analogous JSON might be, following the mapping implemented by the tool. Inevitably
exposed to
view are also the lapses that occur, inasmuch as the JSON object models fail to honor
the
organization of data in the original.
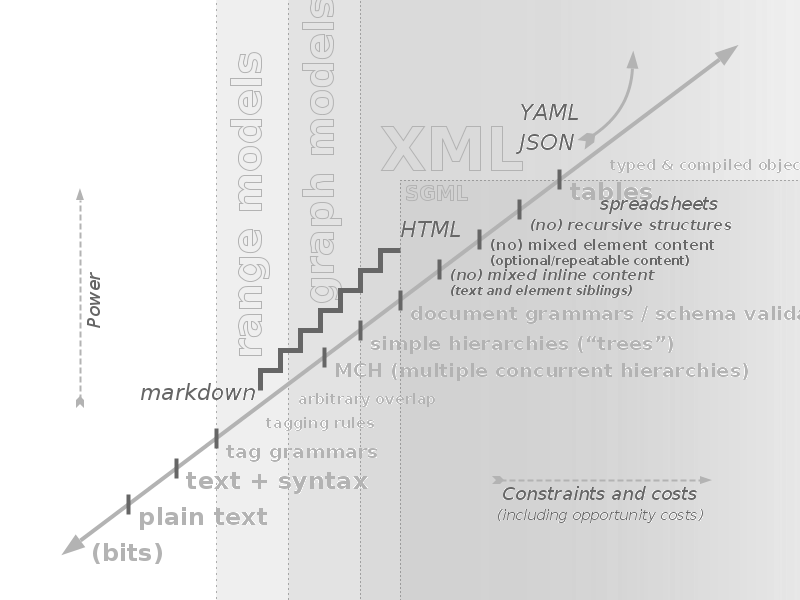
Figure 3
<p>P content may include <a>A</a> and <b>B</b> and <a>more A</a>.</p>
{
"p": {
"a": [
"A",
"more A"
],
"b": "B",
"__text": "P content may include \n and \n and \n."
}
}
This lapse happens because XML elements are more permissive than either of the possible
analogue data objects, available in JSON. This is because the reflection of JSON's
power as a
data format (its glovelike fit to Javascript) is also its weakness in this respect,
that it
cannot represent the (nominal) contents of any Javascript object, as anything
but another Javascript object. What in XML is the straightforward, literal occurrence
of a
sequence of labeled items, in JSON must be twisted and tortured, simply because it
has no
object type whose cardinality, ordering and naming is as unconstrained in its context
as are
XML elements.
While it has not escaped the notice of commenters (Kurt Cagle, Ken Holman) that this
makes
JSON inappropriate for certain kinds of data set, there is a contrary point that is
not often
emphasized. Evidently JSON (or Javascript-like object modeling more generally, even
in other
OO languages) does have its uses, or application designers would not be using them.
The
question is not only, when not to use JSON, but also, when to use it and how to use
it in such
a way that it can complement – not merely complicate – the workings of more fluid
and flexible
(markup-based) approaches.
Regarding the two technologies' different affordances, in other words, is critical
to
understanding how each can be exploited in its own way. Fortunately, while this field
is
complex, it is not unchartable nor even uncharted (including at this conference).
For example,
one approach specifically to managing the points of alignment between XML and JSON
representations of similar data, is by means of a unifying schema or more properly
metaschema.
This helps to control the costs of working in XML and JSON together by reducing the
technical
overhead of coordinating them to the overhead of implementing and maintaining a single
higher-level specification. In this arrangement, schemas (XSDs and JSON Schemas) like
documentation and tooling become products of the single metaschema.
Metaschemas are not a new idea; indeed most mature schemas under maintenance, have
some
sort of metaschema technology maintained below or alongside them. Nor is the idea
of amending
XML schemas to support mapping into JSON new (having been proposed at this conference
by David
Lee in 2011). Using a metaschema rather than an annotated RNG, however, abstracts
the modeling
of the document artifact (as an abstraction) all the way, even, from XML syntax and
content
models, to permit a parallel projection of any serialized instance using XML tags,
into an
analogous and equivalent JSON instance, capable indeed of automated (blind) conversion
back
again into XML, without loss of information.
In the specific case of aligning XML with JSON, the most concerning points of friction
are
typically where object/content models show (in XML terms) (a | b)*. Such a
structure, in which both arbitrary ordering, and type naming, occurs together, has
no precise
analog in JSON terms. Elements in XML are both named (typed) and ordered with respect
to their
siblings, while in JSON, properties on (or "members of") a JSON object must be singular,
while
their relative ordering with relation to one another (on a single object) is undefined,
and
JSON has nothing by which to order anything beyond arrays, whose items are unlabelled.…
the
dissolve into detail that occurs here, typically requires an element-to-object mapping
of some
sort, with an ad hoc (syntax marking) convention of some kind.
In other words - a generalized XML->JSON mapping is possible, but not pretty. If it
is
ungainly, however, this is not because of any lack of grace in the syntax – it is
because the
processing model to which JSON is ordinarily subjected, does not readily adapt to
the kind of
handling required by the data (especially with respect to recursive descent of tree
structures
to arbitrary levels of depth).
Moreover, in the instance, better results can always be gotten by putting in a bit
more
effort and mapping the data across, not with a generalized rule for handling any XML,
but with
particular rules for casting this particular kind of XML – and a metaschema can be
designed to
provide precisely the information set we need to effect this.
A metaschema can make it relatively trivial to head off mapping problems by simply
constraining models to prevent them from occurring to begin with. Its language (that
is, the
language of the metaschema) can stipulate and implicitly enforce (by a conformant
processor)
an organization over the data, that maps (more) cleanly to both XML and JSON, effectively
declaring the mappings between XML and JSON with the same expressions as it uses to
declare
the models themselves. In return for managing (by excluding or sequestering) problematic
XML
features such as arbitrary mixed content, wild XML can be tamed
for a JSON world.
Where this approach will not work is when you really do need mixed-repeatable ( a |
b )* content models. Of course, this is useful clarification in itself, since these
are precisely the sort of data sets that are not going to work very well in JSON syntax
– as
is easily demonstrable by dropping any of them into an auto-converter.
If you have followed this far, there are two things to note. First, we have now (whether
you agree with me or not about the particulars of all this) long ago passed the threshold
of
the dissolve into detail. We may or may not be along the way to resolution. Yet at
the same
time, it is also noteworthy the extent to which this landscape has actually already
been
charted before, for example by contributors to this conference and others.
Aligning XML with YAML presents not dissimilar problems as aligning XML with JSON:
because
it is higher on the slope, an arbitrary YAML instance can be cast without loss
into a semantically equivalent XML, while coming the other way may (or may not!) entail
restricting the XML (or ad-hoc annotating/extending the YAML target) so as to avoid
certain
problematic features. Like JSON (and unlike more tabular serialization formats,
such as CSV), YAML supports recursive structures: but this does not mean just any
XML will map
cleanly to YAML. Again, arbitrary mixed content is going to be a challenge, for example.
(So
it is forbidden in the canonical XML-YAML mapping as described at http://yaml.org/xml.html.)
So we are faced with a similar-but-different set of tradeoffs.
These are because JSON and YAML (serving as serializations of abstract data models)
sit
higher on the semantic staircase than many kinds of XML, including (most significantly)
the
major documentary formats with their arbitrary mixed (inline) content.
Who doesn't want their own syntax?
Markdown syntax has also emerged more prominently even since the early 2000s, when
markdown syntaxes first appeared on wiki platforms. For certain operations – hand
authoring,
even maintenance of documentation if/as it is firmly embedded as file system READMEs
– it has
apparently found a lasting place.
There is much to like about the essential approach to encoding represented by markdown.
Especially if they can help design the mappings themselves, some authors seem to enjoy
the
exercise of mapping inline character combinations, to encoding practices. For some
people
getting used to markdown, it feels a little like language design or even like a cat-and-mouse
game with the interpreter (can I get it to make this). This facility is important
to keep in
mind.
However, Markdown presents a set of problems of its own. Presumably, markdown works
by
masking in an attractive, amenable text-based syntax, the complexities
otherwise requiring the cumbersome overhead of tagging, with its pointy angle
brackets:
Who doesn't like *donuts*?
<p>Who doesn't like <em>donuts</em>?</p>
In
doing this, markdown does indeed offer an interface that makes it suitable for a range
of
tasks. But it gets you only so far. It gets you this distance rapidly and cleanly,
but one you
are there, you are subject to its constraints of expression: you can go no further
with it
because there is nowhere further to go.
For example, here it is only arbitrary and conventional that a line of text such as
this
should become a p? Equally plausible (at least in the general case, or in
some alternate world), one might suppose, it should be mapped to a q not
a p, or anything else. More importantly, however, once having mapped an
unmarked line to p, the markdown version has forsaken any possibility of mapping lines
to
anything else but p in the future. There will never be any mixing of p elements with
q
elements. As XML practitioners know, this limitation on the sorts of things you can
do with
blocks and lines, simply doesn't scale to real-world complexities. Markdown-based
static site
generators, accordingly (just to offer one example), will tend to do a lot of postprocessing
and working with not just the raw markdown itself, but its HTML analog. i.e., no longer
markdown, at all. Markdown by itself, simply cannot support the semantic for even
the kinds of
processing (navigation etc.) that are routinely supported on the platforms for which
it is
intended: markdown is no replacement for HTML (or anything else) simply because it
is unusable
without HTML (or some analogue) along with it and supporting it.
This is turn reveals markdown's fatal flaw, namely that there really isn't any such
thing.
(Look at markdown, and things dissolve into detail.) Notwithstanding several attempts
(some
valiant) to formalize it, markdown as a general class (and a very diverse one)
works because it is actually not a syntax at all, but merely a mask (in the form of
a mapping
convention) on top of another set of constraints as expressed in its target language,
not
stricly syntactic, but with regard to content models and structures imposed on top
of or in
accordance with (other) syntactic contracts. (That is, the downstream consumer of
the markdown
processor presumably doesn't care whether its HTML has double or single quotes as
attribute
delimiters as long as they parse in an HTML parser; but it depends on HTML to represent
the
contents as "paragraphs", "preformatted", "lists", "headers", and all the other
HTML-affordances that make a markdown representation might offer).
Consequently, there is no real need or even utility in treating markdown like a properly
specified language, rather than (what it is) a clever utilitarian hack to make the
work of
encoding certain kinds of semantics, less onerous for the
technically-uninclined user. In other words, we should not even bother trying to parse
markdown properly (by which, I mean in reference to some formal grammar and specification
of
its syntax) – since the question in any case is not, does it parse or not, but what
do we do
when it fails? In other words, what sort of information do we get from a successful
parse of a
markdown structure? If the answer is, whether it will map cleanly into our preferred
target
format – well, we can do that anyway, without a grammar for the markdown at all, given
only
the mapping conventions to follow – which either will, or will not, produce a syntax
that we
can parse.
Meanwhile, markdown parsers (really processors) are various and sundry, but
one thing they mostly have in common is, they aren't finished.
Given all this sleight of hand, getting into and out of markdown on an XML stack is
not
more challenging than working with markdown in other contexts. Producing markdown
from any XML
tool chain is straightforward: a clean approach is to produce HTML, then use a general
utility
(such as a second XSLT) to produce a markdown syntax "rendition" of this HTML.
To come the other way, it should be sufficient to map the markdown into XML or HTML
tagging, then attempting to parse that (literal markup). Upon a successful parse,
an XDM (or
functional equivalent) can be returned. Mathematically and practically, this is equivalent
to
parsing the markdown to begin with (according, presumably, to a sufficient grammar
of its own)
– and for systems that already have HTML and XML parsers, considerably easier.
While the failure point with JSON tends to be arbitrary sequencing of element types
and
especially mixed content, the failure point for markdown is in its inability to support
structures beyond the HTML soup that one infers from a sequence of represented
"paragraphs", "lists", "tables" and the rest. Consequently, markdown as a primary
platform for
content production and editing might be expected to work best in systems where such
authoring
and editing comes already "pre-fragmented", rather than representing full text or
rich
semantic contents.
Nonetheless the success and appeal of markdown syntaxes is very revealing, suggesting
that
they do in fact play a role, and indeed one complimentary to the role of either generalized
markup syntaxes, or more structured data formats. The question is, getting the data
across the
boundaries. Only when we can parse and map markdown syntaxes as easily as we can XML
document
models (or indeed JSON objects), will we be able to take full advantage of them.
Such capabilities are nearly in our hands. While it is an open secret that markdown
syntaxes typically have no grammar and thus no formal, validable parse – there is
also an
opportunity here, to streamline these systems. A further question is whether the strengths
of
markdown might be even better exploited in systems that knew about and supported some
deeper
level of semantic description. Semantic markdown – the way to something like
this, might be in a markdown syntax that supported both (some sort of) semantic annotation,
and some level of on-the-fly declaration of syntax constructs.
Approaches to chaos
The main reason we see questions such as "XML or JSON" or (in another context) "Java
or
Python" as either/or, is that any one of these demands so much attention and dedication
(of
effort and resources), that we can hardly imagine (as either individuals or on behalf
of
institutions) committing to any other (at least within the scope of the task or problem).
One
solution to this problem is to become tribalistic: this has the virtue at least of
seeming the easiest and most obvious way to approach things. If
mastering XML and everything related to it (schemas and transformations and queries)
were to
take only a week, and mastering JSON and Javascript and browser event handling and
interface
design and transaction handling, took only one more – this might seem more like having
one box
of toys (the blocks) out one week, and another (the screw-and-girders set) the next.
The
realities of sunk costs, however, make it such that once Java or Python or Ruby has
been
chosen, it is very hard to unchoose it or even to choose something else for the next
thing
(while mixed environments have their own risks and costs!); and once one has become
an expert
in XML (just for example) it may seem gratuitous that one should then have to become
expert in
something else. It is useful to keep in mind that the reason it takes more than a
week to
master XSLT or XQuery or Javascript or Python is that any single one of these languages
– seen
as what they really are, raw materials for creation – is endless and has no bottom.
Spend a
week and you discover how much more you have to learn. Dissolve into detail, then
spend years
resolving it.
Yet at the same time, this landscape of languages, whatever its metaphysical status
as a
"thing", and however it changes and grows from year to year, is nevertheless objective,
something that can be observed and studied. (A JSON object has properties of type
string,
boolean, numeric, array, etc. etc. I cannot add a new type to this list while my JSON
remains
JSON. As long as JSON is JSON, I can talk about strings and booleans with JSON developers.
The
JSON tools I know, if JSON is any good, just work this way. So much the better: what
this
means in effect is, the terms of discussion between me and the JSON developers, is
stable even
when our interchange problems, are very much not.
In other words, it may be that text-encoding technologies are fractal not in the way
that
a Julia set is fractal (that is, a mathematical function that is shown to be
fractal according to a mathematical principle) but rather, the way the coast
of Scotland (an actual place) is fractal or fractal. It turns out that thinking
analogically is of the essence – this is basically the only way we have of dealing
with what
we haven't surveyed yet – while at the same time, science and objective study are
just as
important as art.
So for example, using a metaschemas as an approach – not a solution, but a site for
negotiation – to reconciling XML-based and Javascript-based (JSON) serialization formats
for
appropriate datasets, is an idea that can only emerge on the basis of not only a particular
mapping (of a particular XML to a particular JSON or the reverse), but a generalized
one,
subject to codification by the metaschema. The particular powers and capabilities
of the
particular metaschema format – how effectively it manages to bridge between disparate
representations of the same data – will depend entirely on this generalized
analysis.
The same thing is true of the idea of a generalized local markdown – we can only get
to
such a thing after we have pondered, not only the problem of parsing markdown into
systems
where it can be processed and rendered (in ways we are used to doing with markup),
but also
the problem of how and where the semantics of a particular markdown syntax (and application)
are actually defined. When it turns out, that a markdown instance has no formal validity
at
all, but only a purported or presumed relation to another (valid) entity in another
syntax
(HTML or other) – at that point, it becomes clearer that we do not, in markdown, have
any
single thing at all, but merely a commonality in a certain strategy of representation
(of
inline encoding as "ASCII artish" embellishment), which can be readily applied in
other
domains, or generalized. In turn, such an insight can liberate us to take many more
liberties
with this idea.
Such capabilities may prove to be vital and essential features of technologies to
come, or
they may prove not to be worth the overhead. The important thing is that they now
begin to be
thinkable. There was a time when every parser had to be, effectively, hand made. Now
with
standards and generalized syntaxes (both those one finds "friendly" and those one
finds
strange or inimical), these pressures have eased.
To put it another way, we are developing both the experience and tools (which are,
indeed,
codifications of experience), that will alleviate all these problems considerably.
(See also
the work of Hans Juergen Rennau.) The detail does not disappear, but it becomes more
casual
and familiar, the inevitable variation more thinkable, and not only because we are
now jaded,
but because we actually means and methods for dealing with it. So for example, just
as we now
have ways of dealing with overlap problems – having seen them before – similarly,
the problems
of casting information across syntactic boundaries will become more familiar as we
come to
recognize their commonalities. And while the landscape shifts and develops over time
– as new
heights are explored and the territories expand – in the basic outlines of its domains,
and in
many of its patterns, it is likely to remain consistent.
Making peace with complexity
One of the interesting things about elephants is that their size, their skin, their
massive legs and ears, their trunks and even their tusks make more sense when the
animal is
considered as a whole organism – an extremely large herbivore, very social (hence
the tusks,
essential for marking and signaling status), who communicates with her kin using low-frequency
sound over miles. (Hence the trunk, the ears, and the sensitive feet.) In other words,
the
detail makes sense only in the context of the whole.
XML, JSON, YAML, declarative and procedural languages are in this picture, not exactly
things, but properties of things, characteristics or regularities within the systems
where we
find them. Like an elephant, such a system (maybe it's a publishing system, web site
or
transcation processor) can only really be understood as an operational whole within
its
context. But since our elephants are so different from one another, we simplify our
conversations about them by distinguishing them by type. My elephant reads XML
or my hippo uses markdown injected into a hosting platform with CSS for its page
layout.
This suggests that we should hold our judgments lightly – there is a big difference
(for
example) between asking how we will exchange arbitrary mixed content, given the constraints
and commitments of the facing systems (actual or likely), and judging an entire technology
stack to be unworthy of attention – and not only, that the latter judgement involves
a kind of
layer violation (since we are judging the type not considering the instance).
They also differ in their attitude and approach – a more limited and provisional observation
is simply more likely to be accurate. It is exactly when we think we have answers,
that we
find there is another dissolve into detail to face.
Given such reasons for humility, also, it helps also to keep in mind that the most
effective world-changing technologies are those that show what is possible, that imagine
altogether new abilities and insights. We only participate in this, however, if we
fully
engage with it. Adapting to a world of multifarious data exchange may require that
we be
ecumenical in our tolerance of formats. Again, the semantic staircase suggests why.
XML and
its kindred standards/technologies are designed and built to address some very general
problems of data description; they do this by means of the twin features of (a) the
built-in
tree design, and (b) the capability of the application designer to provide names to
XML
elements and attributes (so names are not privileged or reserved by the language),
making XML
a metalanguage capable of application (via one expression or another) to a huge variety
of
kinds of information sets – most especially those that come naturally as
hierarchies. (Certain other features such as attributes and inline mixed content are
also
helpful for dealing with such an open-ended problem set.) On top of these two very
simple
ideas, a very complex architecture is built supporting open-ended processing models,
which
must commonly support (in part but not only because they are documentary production
or
publishing formats, not just structured dataset) a broad range of transformation capabilities.
Over and over again, the resulting set of technologies (especially XSLT, XQuery and
both
together) have been shown to work well, not only at the lower end of weaker control
and data
description, but also higher up the stack, where we would expect object-oriented and
other
(supposedly more highly optimized) serializations should rule.
Just as the bumpy field called plain text provides a foundation, so also does this
set of
rules (rules upon rules) provide a next level of infrastructure to build on. It is
complex and
has its complexities; but it is stable and reliable.
In great part this is because of everything that markup syntaxes such as XML do not set out to do, the complexities they choose not to address, leaving them to be addressed elsewhere, by other means. That is
because these are essentially tools for naming and managing whatever complexities
we may be
faced with, at some level of resolution, not necessarily
high, but detailed enough to give us some purchase – thus the complexity of the solution,
does
not exceed the complexity of the problem. XML's affordances in particular seem to
dramatize
how any language (and most certainly a machine readable one) is an early optimization,
while
at the same time the only way to master a thing is to represent it. In this context,
one of
the more interesting things to me about the ideas proposed here for advancing the
use of XML
for modeling – by helping it to get along with non-XML competitors, its current neighbors
in
the space – is that they could all be implemented using XSLT. The field is open.
La Fontaine, Robin. “Making a difference by processing JSON as XML.” Presented at
Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of
Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). doi:https://doi.org/10.4242/BalisageVol19.LaFontaine01
Lee, David A. “JXON: an Architecture for Schema and Annotation Driven JSON/XML
Bidirectional Transformations.” Presented at Balisage: The Markup Conference 2011,
Montréal,
Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage
Series on Markup Technologies, vol. 7 (2011). doi:https://doi.org/10.4242/BalisageVol7.Lee01
Rennau, Hans-Jürgen. “From XML to UDL: a unified document language, supporting
multiple markup languages.” Presented at Balisage: The Markup Conference 2012, Montréal,
Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage
Series on Markup Technologies, vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Rennau01
Robie, Jonathan. “XQuery, XSLT and JSON: Adapting the XML stack for a world of XML,
HTML, JSON and JavaScript.” Presented at Balisage: The Markup Conference 2012, Montréal,
Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage
Series on Markup Technologies, vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Robie01
La Fontaine, Robin. “Making a difference by processing JSON as XML.” Presented at
Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of
Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). doi:https://doi.org/10.4242/BalisageVol19.LaFontaine01
Lee, David A. “JXON: an Architecture for Schema and Annotation Driven JSON/XML
Bidirectional Transformations.” Presented at Balisage: The Markup Conference 2011,
Montréal,
Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage
Series on Markup Technologies, vol. 7 (2011). doi:https://doi.org/10.4242/BalisageVol7.Lee01
Rennau, Hans-Jürgen. “From XML to UDL: a unified document language, supporting
multiple markup languages.” Presented at Balisage: The Markup Conference 2012, Montréal,
Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage
Series on Markup Technologies, vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Rennau01
Robie, Jonathan. “XQuery, XSLT and JSON: Adapting the XML stack for a world of XML,
HTML, JSON and JavaScript.” Presented at Balisage: The Markup Conference 2012, Montréal,
Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage
Series on Markup Technologies, vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Robie01