Harvey, Betty. “Using Excel Spreadsheets to Communicate XML Analysis.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Harvey01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: Using Excel Spreadsheets to Communicate XML Analysis
Betty Harvey
As President of Electronic Commerce Connection, Inc. since 1995, Ms. Harvey
has led many federal government and commercial enterprises in planning and
executing their migration to the use of structured information for their
critical functions. She has helped develop strategic XML solutions for her
clients. Ms. Harvey has been instrumental in developing industry XML standards.
She is the co-author of "Professional ebXML Foundations" published by Wrox. Ms.
Harvey founded the Washington, DC Area SGML/XML Users Group. Ms. Harvey is a
member of "The XML Guild" and was a coauthor of the book "Advanced XML
Applications From the Experts at The XML Guild" published by Thomson.
What is the best approach for analyzing large XML datasets? Reading thousands (or
possibly millions) of pages of raw XML to fully understand the markup constructs?
This approach is just not feasible. CSS stylesheets are useful for displaying a few
files of XML data but is not really efficient. I have found creating analysis
information in Excel spreadsheets is a very useful tool for understanding the full
XML data constructs. This approach is also understandable to stakeholders when
trying to convey useful information about their datasets. This paper will describe
an approach for creating document analysis Excel spreadsheets using XSLT and
XML.
Consider you are handed hundreds or thousands of XML files in order to process them.
You may be required to:
Convert from original SGML or XML to another XML format
Convert to HTML
Create PDF files
Create new datasets or products from the original data
Populate database(s) with the data
etc.
Performing data analysis on XML files can be a daunting task. As a data analyst you
need to pull every trick in your in your bag of tricks
out. One of the tricks that I almost always use is to create Excel spreadsheets in
order
to accomplish in-depth analysis of the data and tagging in an easy and understandable
way. The spreadsheets provide quick snapshots of the whole dataset or a slice of
the
dataset.
Depending on what is uncovered by looking at different views of the data, new
spreadsheets can be created to help delve deeper into the data.
Spreadsheets are also a good way to present data analysis issues for subject matter
experts (SME). SMEs who may or may not be XML savvy and spreadsheets is an easily
consumable format to convey information. Almost everyone has dealt with spreadsheets.
Anomalies are easily uncovered with this approach. It is a good way to see how
prevasive a data problem may be.
For the purposes of this presentation I am going to describe how to create the
spreadsheet using Excel 2003 XML format. You can also create the same spreadsheets
using
Excel 2007 and beyond. I wrote a paper entitled Convert Excel
2007 XML to OASIS code lists that describes how to create a 2007 format
spreadsheet if you are interested. Excel 2007 XML is a more complicated approach to
creating Excel. It involves multiple XML files and the necessity to create a zip
file
in order to Excel to consume the database. An Excel .xslt file is actually a zip archive file. If you are curious you can
unzip a file and look through the file structure and look at all the XML files it
contains.
The Balisage committee has been kind enough to allow me to use papers from the current
and past Balisage conferences for doing a simple analysis for this paper.
Initial Analysis Spreadsheet
The first spreadsheet that I always run on a new dataset is to create a 3
worksheet (tab) spreadsheet of all elements and attributes used in the dataset. The
rationale for creating this spreadsheet is to accurately determine what elements and
attributes and attribute values are in the entire or subset of the data. I create
the
following worksheets in the spreadsheet. Worksheets are the tabs in spreadsheet.
List of unique elements and unique attributes for each element
List of all unique attributes
List of all unique attributes and attribute values.
This spreadsheet provides information the data that you need to look further into.
For
example, let's say you are working with files from Docbook or DITA. We know that
both
standards have hundreds of elements and attributes and attribute values. Most datasets
only use a subset of the entire standard. For instance if your dataset doesn't use
the
element <procedure> then you can ignore doing any analysis or
downstream processes on this element.
Also, both DocBook and DITA use the role attribute to
further define many elements. The role attribute is
defined in the schema as text which means that there can be many role values and
some may be misspelled. Unless the authoring system restricts the values of the this
and other attributes it would be impossible to accurately accomplish downstream
processes based on each value.
The Balisage paper data is about the cleanest data I have had the honor to look at.
However, the element/attribute analysis did provide a few interesting facts. There
are 2
elements in the data that are currently not in the latest version (1.2) of the Balisage
schema (lineage and para.level). This probably means that these elements have been
eliminated from the schema but we still need to know about these elements in order
to
process them.
The second worksheet is used to get a list of all attribute name. This is useful
to
determine which attributes should be looked at further for their unique values.
Obviously you don't want to get a list of attribute values for attributes such as
identifiers, table and figure dimensions because that would be to much data and not
useful to the analysis. Attributes such as 'role', 'class', 'type', etc. will provide
important insight into the data.
The Balisage papers contain a total of 38 unique attributes. I chose the following
attributes to look further at.
Table I
Attribute
Attribute Value
align
center left right
role
author bital bold ital rom under
numeration
arabic loweralpha lowerroman
spacing
compact
There isn't anything that jumps out with these values except that the 'upperalpha'
and
'upperroman' values are not used for the 'numeration' attribute, 'justify' and 'char'
are not used for 'align' attribute and finally, the 'spacing' attribute is no longer
in
the schema. This means that we don't have to take these values into account with
the
current dataset.
Developing the XSLT for Analysis
Creating an XSLT for data analysis is really relatively easy. Looking at the code
it might seem a little 'daunting' at first but the most difficult part is accurately
iterating through the data to extract the information that is helpful.
Creating a Template
If this is the first time that you will be creating an Excel spreadsheet using
XSLT, the easiest way to start is to create a template in the Excel application.
The template should include all the columns that you will need and a single row
of dummy data. You can also create multiple worksheets (tabs) in your template.
Below is sample of what the template looks like.
Figure 1: Sample Excel Template
If you want to be able to filter the data or freeze the columns set this
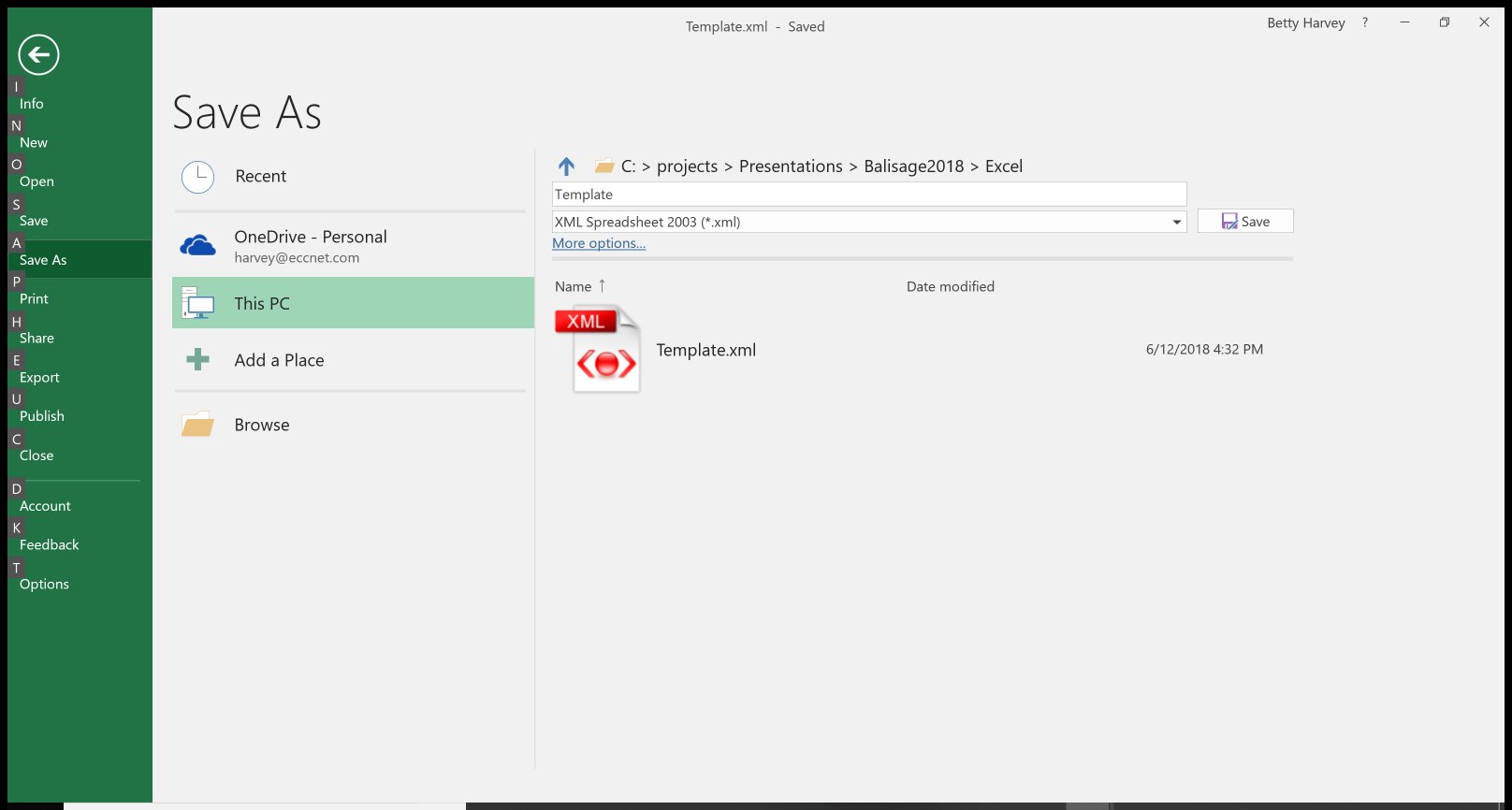
capability inside the template. Once the template is completed save the template
as Excel 2003 XML.
Figure 2: Save Template
That is all there is to it. Now you are ready to create your XSLT around the
template you just created. Open the template in your favorite XSLT
editor.
Excel 2003 XML Structure
There are some modifications to the template that will be required because
Excel. First, let's talk about the different sections in the XML. Below is XML
file for the template created by Excel. For the most part you will only need to
care about the second row because this is where the data will be populated.
You shouldn't need to modify the style section. However, if you decide
that you want to add columns to your spreadsheet and you copy and paste the
new cell parameters from a temporary template, the style identifier may not
be the same as the style in your original template. Excel is sneaky about
changing style identifiers.
There is always a default style. If the <Cell> element has no style
attribute then it uses the default style or no style. A cell that has styling
uses the ss:StyleID, "<Cell
ss:StyleID="s68">". The value associates with a style in the
<Style> section. You can modify the styles in the XML file, if
necessary.
Table Section
If you are familiar with either the OASIS-Open (previously CALS) or HTML
table models, the table structure of the Excel XML will look pretty familiar
to you.
You will need to remove the 'x:FullRows'
and 'ss:ExpandedRowCount' attributes in the
table. Excel uses these attributes to determine the size of the
spreadsheet. Excel uses these to determine the number of rows of the
spreadsheet. If the sizes don't match then Excel will throw an error.
However, if the attributes are not there Excel calculates the size of the
table automatically and Excel will open successfully and place these
attributes into the spreadsheet.
I also remove the 'ss:ExpandedColumnCount' and x:FullColumns even though you don't need to if you don't
increase the number of columns. I will often add columns to the spreadsheet
after I have created the template based on information I get when I run the
initial spreadsheet. Sometimes it is difficult to know where your analysis
will lead you once you start looking at the data in-depth.
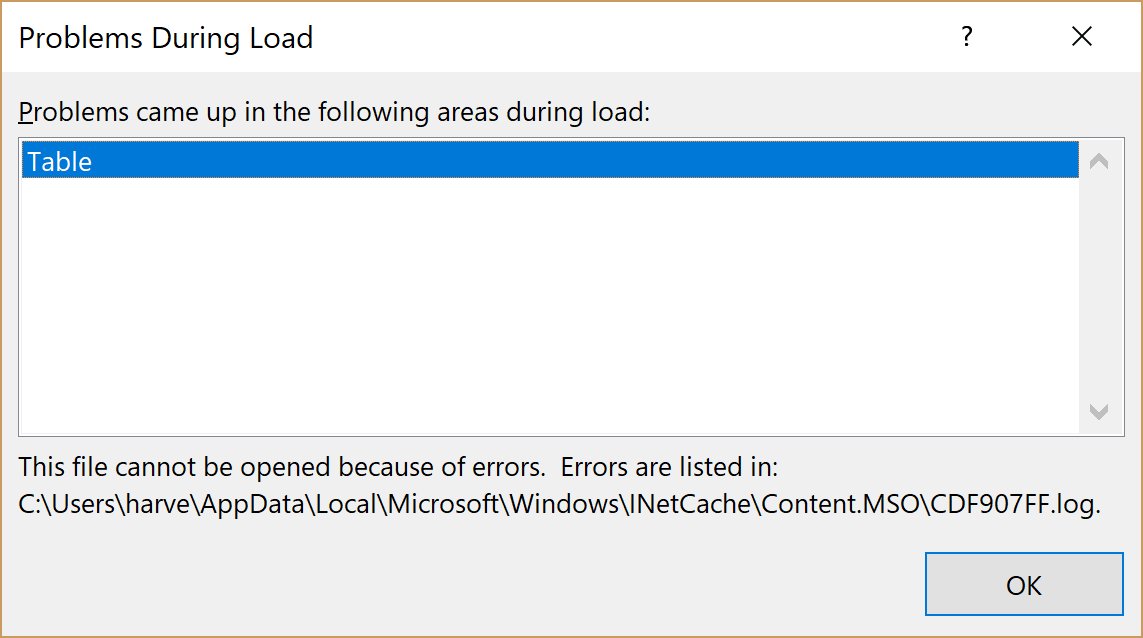
If you do get an error when opening the spreadsheet up after you create
your XSLT. Microsoft will point you to a log file. The log file doesn't
provide a lot of information but should provide some clues about what the
error is.
Figure 3: Microsoft Error Notice
Row Section
The first row in our template is the table header row. You should leave
this row 'as is'. There is no need to modify this row. The second row in the
template is the row that you should wrap your XSLT around to create your
data rows. The <NamedCell> element is
used for filtering the data.
Header Row
<Row>
<Cell ss:StyleID="s68">
<Data ss:Type="String">List of Elements</Data>
<NamedCell ss:Name="_FilterDatabase"/>
</Cell>
<Cell ss:StyleID="s68">
<Data ss:Type="String">List of Attributes</Data>
<NamedCell ss:Name="_FilterDatabase"/></Cell>
</Row>
Data Row That Gets Modified
The second row is where your data will be created. Below is the original
output from the template. You will want to remove the 'dummy' data from the
<Data> element.
<Row>
<Cell><Data ss:Type="String">element1</Data></Cell>
<Cell><Data ss:Type="String">attributes for element1</Data></Cell>
</Row>
At this point we can create the logic for creating the spreadsheet. There
are 2 ways to process the data using XSLT. One way of accessing the data is
using the 'collection()' function. The
other way of accessing the data is by using 'xinclude'. For the example above I used 'xinclude' in order to look at the data as a whole
because I want to get unique values. Below is an example of accessing the
document is put together using xinclude'
file. Later in this paper I will show an example using the collection() function.
<files xmlns:xi="http://www.w3.org/2001/XInclude">
<file><filename>vol1/xml/Altheim01/BalisageVol1-Altheim01.xml</filename><xi:include href="C:/projects/Presentations/Balisage2018/Papers/vol1/xml/Altheim01/BalisageVol1-Altheim01.xml"><xi:fallback>File not found</xi:fallback></xi:include></file>
<file><filename>vol1/xml/Bauman01/BalisageVol1-Bauman01.xml</filename><xi:include href="C:/projects/Presentations/Balisage2018/Papers/vol1/xml/Bauman01/BalisageVol1-Bauman01.xml"><xi:fallback>File not found</xi:fallback></xi:include></file>
...
</files>
Below is the XSLT snippet that creates the Rows of the Excel
spreadsheet:
The last 2 sections of the template setup information for the worksheet.
The WorksheetOptions section contains standard information about the
worksheet. You will also find information about freeze panes.
The Autofilter section defines the filtering of the columns. Filtering
columns provide the capability of having a drop down menu to pick specific
values in a column.
If you add more columns to your spreadsheet increment the 'R1C2' by how
many columns are in your spreadsheet.
Figure 4: Filtering Example
More Analysis
Now that you have the building blocks for creating analysis spreadsheets the sky is
the limit on what you can gleen from your data. For example, using the Balisage data
we
might want to get a list of all authors. The logic is pretty simple:
At some point you may be required to perform data cleanup. This is a common
occurrence when dealing with large amounts of data that are coming from different
sources. You may want to normalize the data especially where attributes such as
role and class
are concerned. In order to perform the data cleanup it is important to understand
what the data looks like and what you may encounter.
If you are cleaning up the data you may want to create a before and after
spreadsheet just to make sure that your modifications didn't have unexpected
consequences.
For this paper and demonstration purposes I did a search on the Balisage papers
for all superscript and subscript elements. I got the value of each superscript and subscript, as well
as before and after text to provide textual context. For the most part the data that
came back looked reasonable. However, some values jumped out that may not be valid
superscript or subscript content. There were 1744 instances of superscript and subscript elements
in the complete dataset. Below are examples of where I thought the superscript or
subscript values were problematic.
Figure 5: Suspicious Superscript/Subscript Values
Having the ability to filter values in the spreadsheet allows you to drill down into
problem areas pretty quickly. In a matter of minutes you are able to create a
spreadsheet, find any problems and come up with the plan for fixing any problems
that are in the data.
In the first entry above, the closing parenthesis is part of the subscript.
In the other entries, it looks like the superscript is not closed after before the
para but is closed at the end of the block. It turns out that this data is actually
a footnote in a table and in order to get the smaller font the author has used
superscript.
Again, the logic to create this spreadsheet is relatively simple. In this example
I
am using the collection() function to iterate
through the data.
I hope that I have been able to convey how useful spreadsheets can be in the analysis
of large (or small) data sets. It can provide clarity into the data and help every
person who is touching the data to understand useful pieces of information. Along
with
other analysis processes the spreadsheet can be an amazing tool.
This approach is not limited to XSLT. The same analysis can be done using XQuery
and
databases. I have created spreadsheets using both technologies.