Balisage Paper: Copy-fitting for Fun and Profit
Tony Graham
Antenna House, Inc.
<tony@antennahouse.com>
<tgraham@antenna.co.jp>
Tony Graham is a Senior Architect with Antenna House, where he works on their XSL-FO and CSS formatter, cloud-based authoring solution, and related products. He also provides XSL-FO and XSLT consulting and training services on behalf of Antenna House.
Tony has been working with markup since 1991, with XML since 1996, and with XSLT/XSL-FO since 1998. He is Chair of the Print and Page Layout Community Group at the W3C and previously an invited expert on the W3C XML Print and Page Layout Working Group (XPPL) defining the XSL-FO specification, as well as an acknowledged expert in XSLT. Tony is the developer of the ‘stf’ Schematron testing framework and also Antenna House’s ‘focheck’ XSL-FO validation tool, a committer to both the XSpec and Juxy XSLT testing frameworks, the author of “Unicode: A Primer”, and a qualified trainer.
Tony’s career in XML and SGML spans Japan, USA, UK, and Ireland. Before joining Antenna House, he had previously been an independent consultant, a Staff Engineer with Sun Microsystems, a Senior Consultant with Mulberry Technologies, and a Document Analyst with Uniscope. He has worked with data in English, Chinese, Japanese, and Korean, and with academic, automotive, publishing, software, and telecommunications applications. He has also spoken about XML, XSLT, XSL-FO, EPUB, and related technologies to clients and conferences in North America, Europe, Japan, and Australia.
Copyright ©2018 Antenna House, Inc.
Abstract
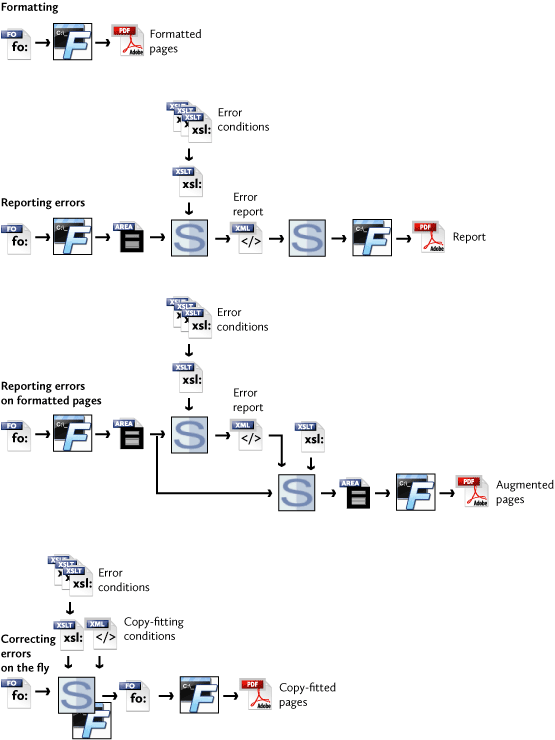
Copy-fitting is the fitting of words into the space available for them or, sometimes, adjusting the space available to fit the words. Copy-fitting is included in “Extensible Stylesheet Language (XSL) Requirements Version 2.0” and is a common feature of making real-world documents. This talk describes an ongoing internal project for automatically finding and fixing problems that can be fixed by copy fitting in XSL-FO.