Birnbaum, David J., Elisa E. Beshero-Bondar and C. M. Sperberg-McQueen. “Flattening and unflattening XML markup: a Zen garden of XSLT and other tools.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Birnbaum01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: Flattening and unflattening XML markup:
a Zen garden of XSLT and other tools
David J. Birnbaum is Professor and Co-Chair of
the Department of Slavic Languages and Literatures at
the University of Pittsburgh. He has been involved in
the study of electronic text technology since the
mid-1980s, has delivered presentations at a variety of
electronic text technology conferences, and has served
on the board of the Association for Computers and the
Humanities, the editorial board of Markup languages: theory and
practice, and the Text Encoding Initiative
Council. Much of his electronic text work intersects
with his research in medieval Slavic manuscript
studies, but he also often writes about issues in the
philosophy of markup.
Elisa Beshero-Bondar is a member of the TEI
Technical Council, as well as an Associate Professor
of English and Director of the Center for the Digital
Text at the University of Pittsburgh at
Greensburg. Her projects investigate complex texts
such as epics, plays, and multi-volume voyage logs,
and involve her in experimentations with the TEI,
including refining methods for computer-assisted
collation of editions and probing questions of
interoperability to reconcile diplomatic and critical
edition encodings. She is the founder and organizer of
the Digital Mitford
project and its annual coding school.
C. M. Sperberg-McQueen is the founder and
principal of Black Mesa
Technologies, a consultancy specializing in
helping memory institutions improve the long term
preservation of and access to the information for
which they are responsible. He served as editor in
chief of the TEI Guidelines from 1988 to 2000, and has
also served as co-editor of the World Wide Web
Consortium’s XML 1.0 and XML Schema 1.1
specifications.
Copyright by the authors 2018 under a Creative Commons Attribution-ShareAlike 4.0
International (CC BY-SA 4.0) license.
Abstract
From time to time, it may be necessary or expedient
to flatten our XML documents by replacing the start- and
end-tags of conventional XML content elements with empty
place-marker elements (variously known as milestone elements or as
Trojan horse markup). When we do, we
will often wish, later, to restore the content elements we
flattened. The purpose of this late-breaking presentation
is to present a survey of ways to perform the task of
unflattening or of raising: restoring a conventional XML
element structure of content elements from a flattened XML
document instance (or part of one), and comparing
different solutions to see what we can learn from
them.
From time to time, it may be necessary or expedient to
flatten our XML documents by replacing the start- and end-tags
of conventional XML content elements with empty place-marker
elements. These place-markers are variously known as
milestone elements after
the milestone technique described in the TEI Guidelines for
page beginnings, column beginnings, line beginnings,
etc. [TEI P5], or Trojan horse
markup after the technique described by Steve
DeRose [DeRose 2004]. To avoid
over-stressing any particular syntax, we will
use a more general term, markers. When we do flatten
our documents, we will often wish, later, to convert markers back into their original
form as
content elements. The three co-authors discovered
recently that we had each had occasion to perform this task,
and that we had undertaken it using different
techniques.[1]
The purpose of this late-breaking presentation is to
survey multiple ways to perform the task of unflattening or
raising, that is, restoring a conventional XML element
structure of content elements from a flattened XML document
instance. We will compare different
solutions to see what we can learn from them. Nothing here is
profoundly difficult or new, but each of us found it
challenging and interesting enough that we think it may be
worth while to share what we have learned with others.
In the following sections, we describe first a concrete
instance of the task, with enough supporting detail to make
clear that this is not an academic exercise but one that
arose in a real project. We then present several
approaches to solving the problem, including some false
starts, which illustrate possible wrong turnings along the
way. We then discuss and compare the different solutions with
respect to coding difficulty and costs in space and
time.
In the discussions that follow, we adopt the following
terminology in an attempt to avoid unnecessary
confusion. First, we distinguish content elements (marked by
standard XML start- and end-tags) from virtual elements
(indicated by markers).
content element
a conventional XML element marked by start- and end-tags with
(possibly empty) content between them, or by a sole-tag. Cf. marker.
virtual element
a logical element indicated by start- and
end-markers.
marker
an empty XML element serving to mark the start or end of a virtual
element.
We are interested in two processes that convert between content elements and virtual
elements indicated by markers:
flattening
the process of replacing the start- and end-tags of content
elements with corresponding start- and end-markers.
raising (aka unflattening)
the process of replacing virtual elements with content elements by converting pairs
of start- and end-markers into corresponding start- and end-tags.
Our approaches for raising flattened XML may be categorized according to the following
parameters:
Whether they read their input as XML or as a string.
Whether they construct their output as XML or as a string.
For those that read the input as XML, the
order in which they raise the virtual elements.
The methods that work with the input and output as XML
are typically recursive (whether the recursion is implemented
through functions or templates), and the recursion follows one
of three patterns:
The input is handled in a single pass and
the virtual elements are raised left-to-right in
start-tag/end-tag order.
We refer to the order as left-to-right or tag-order,
rather than as depth-first, partly because in the input the markers and the
content of the virtual elements they mark are all siblings. That is, the
input document is typically a shallow hierarchy and there is no difference
between depth- and breadth-first traversal of the input tree. With respect
to the output tree, this pattern performs a depth-first pre- and
post-order traversal: that is, the processing of an element
starts before the processing of its children and ends afterwards.
We refer to the construction as tag-order
because the construction of the virtual elements
begins in the order of their start-markers and
ends in the order of their end-markers.
The input is processed in multiple passes;
on each pass the innermost or bottom-most virtual
element(s) are raised to become content
elements.
We refer to the construction as bottom-up
because in each parent-child pair of the output,
the construction of the child begins and ends
before the construction of the parent
begins.
As in the preceding case, because the input
has no meaningful depth, it is more appropriate to
describe the traversal without using hierarchical
terms, although bottom-up is an appropriate way to
refer to the order in which nodes of the final
output tree are completed.
The input is processed with a series of
recursive calls to a function or template to
operate on a sequence of nodes. On each call, the
left-most start-marker in the sequence and its
matching end-marker are selected. Material which
precedes the selected start-marker is returned
without change; material between the selected
markers is processed recursively as the content of
a newly raised element; material which follows the
selected end-marker is processed recursively as
the following siblings of the newly raised
element.[2]
We refer to the construction as outside-in
because on each call (one of) the outermost
element(s) in the parameter sequence is raised,
and a recursive call operates on elements
contained within that one.
With respect to those parameters, the methods discussed
below may be classified as follows:
Table I
Method
Input
Output
Raising Order
Passes / Calls
Overlap handling
Right-sibling traversal
XML
XML
Left to right
Single
Silent error
Inside-out recursion
XML
XML
Inside-out
Depth of tree
Partial raising, well formed
Outside-in recursion
XML
XML
Outside-in
Number of virtual elements
Partial raising, well formed
Accumulator
XML
XML
Left to right
Single
Silent error
Regex replacement
String
String
Left to right
Single or double
Full raising, ill formed
Python pull parser 1
XML
String
Left to right
Single
Full raising, ill formed
Python pull parser 2
XML
XML
Left to right
Single
Silent error
We have implemented the last three methods in
Python and the others in XSLT (and experimentally in
XQuery). The accumulator method requires XSLT 3.0; the
inside-out, and outside-in methods can all be
implemented with (recursive) function calls in XSLT
2.0 and 3.0 and with named templates in XSLT 1.0.
Right-sibling traversal has been implemented using
match templates; an experimental implementation using
a recursive function is also contemplated.
Input and Output refer to whether the input is read as XML or as a string,
and whether the output is constructed as a DOM tree or as a string.
Raising order
describes the order in which virtual elements in the
input are raised. Left to right,
Inside-out and
outside-in are as described
above.
Passes / Calls
describes how many passes over the input are made, or
how many recursive calls to the core function are
made.
Right-sibling traversal makes a single pass over the
input, but because it does so using recursive calls to
to apply-templates which select single
nodes, the template stack will in theory grow until it
has one template on the stack for each node in the
flattened sequence of nodes in the input. (Since the
calls are tail-recursive, implementations may optimize
the calls and perform the traversal in constant stack space.)
Regex replacement is easiest to implement in two
passes: we replace start-markers globally and then
end-markers globally in a pipeline (or vice
versa). Matching both types of marker with a single
regex is easy, but because the replacements are
different (start-markers may contain non-Trojan
attributes), the replacement logic may be more
complex.
The other left-to-right methods will use template
stack space proportional to the depth of the tree, as
is common in XSLT stylesheets.
The inside-out method makes one pass over the input
for each nesting level in the tree of virtual
elements being raised. On each pass, the entire
document is processed, although content elements can
typically be handled with copy-of,
which means their subtrees do not require template
matching.
In the outside-in method, each call to the function
raises one virtual element (unless the arguments are
all leaves, in which case it raises none), so the
total number of calls is proportional to the number
of virtual elements. Each node in the input is
passed as (part of) an argument n + m times, where n is 1 plus the number of
virtual ancestors the node has (for outermost
elements, n= 1, for
their children, 2, etc.), and m is 1 + the number of
preceding siblings the node has in the final output
tree.
Overlap handling
describes what happens when this method is used on
input with overlapping virtual elements, where an
attempt to raise every virtual element would produce
ill-formed output.
Partial raising, well
formed means that the method raises some
but not all virtual elements and produces well-formed
XML by leaving some markers unraised.
Full raising, ill
formed means that the method converts all
start- and end-markers to start- and end-tags without
any rearrangement or adjustment, even when the result
is not well formed.
Silent error means
that the method produces well formed XML output that
is semantically incorrect: in some cases the method
includes content within a raised element which does
not belong there, in other cases content is omitted.
In all three cases, the absence of any error signal is
a characteristic of our simple proof-of-concept
implementations, which were designed to handle input
without overlapping virtual elements. All of these
methods can be implemented with a more thorough
check of the input, to raise an error, and optionally
to recover from the situation, in cases involving
overlapping virtual elements.
The problem
Raising Frankenstein
As a concrete example, we can consider the form taken by this task in the
Variorum Frankenstein [Variorum Frankenstein]
project edited by the second author. In this project, we collate different encodings
of the novel deriving from five digital sources using the software CollateX [CollateX], which reads the input texts to locate their moments of
alignment and variation. The process of collation compares XML documents as text
files, which means that XML tags are treated as text so that strings of text that
compare structural boundaries like paragraph breaks in one version of a document can
be aligned with passages containing the same (or nearly the same) text lacking those
boundaries. CollateX provides XML output that represents in one file the collation
of all the variant input documents, and its output raises a new hierarchy made
up of a root element and a flat sequence of TEI critical apparatus elements designed
to mark
where the documents align in comparable and variant passages. When XML elements are
supplied in the input to the collation process, their tags are returned as text with
angle brackets escaped, as shown in Figure 1 below.
To prepare the editions for collation we began by flattening the original
structural markup, converting elements that wrapped volumes, chapters, paragraphs,
and lines (among others) into self-closed start and end markers. We flattened these
elements in anticipation of reconstructing them on the other side of the collation
process. Because we need to retain original markup information in the eventual
collation output for later use, flattening it allows us to preserve it without
letting it interfere with the alignment process or the new hierarchical output of
CollateX. The XML output produced by CollateX includes (as we expect and want) many
fragmented start and end tags, showing us not only places where paragraph breaks
occur in one witness to the text but not in the others, but also locations where
part (but not all) of a deleted passage in the manuscript draft aligns with material
in the published editions of the novel. In such situations, we wind up with an
original start-tag inside one container element and its corresponding original
end-tag inside another, and we cannot reconstruct that element without creating
overlap. Knowing that the collation process will generate (by design) a hierarchy
in
conflict with the structural markup of our input documents, we prepared the input
source documents in advance to flatten their hierarchies, because we intended to
reconstruct the elements later building on the collation output.
Here is an example from the output of CollateX representing a single divergent
reading in the Thomas copy of Frankenstein
before all witnesses align. (Some line breaks have
been introduced for legibility.)
Figure 1
<app>
<rdg wit="#fThomas">
contortions that ever and anon
con<del
sID="fThomas_C10-del_2"/>puls<del
eID="fThomas_C10-del_2"/>vulsed
& deformed his un-human features.
<p eID="novel1_letter4_chapter4_p133"/>
<p sID="novel1_letter4_chapter4_p134"/>
The
</rdg>
</app>
<app type="invariant">
<rdg wit="#f1818">different accidents of life are </rdg>
<rdg wit="#f1823">different accidents of life are </rdg>
<rdg wit="#f1831">different accidents of life are </rdg>
<rdg wit="#fMS">different accidents of life are </rdg>
<rdg wit="#fThomas">different accidents of life are </rdg>
</app>
Sample CollateX output
In the example above, there is only one <rdg> element inside
the first <app> because at this point the Thomas edition contains
an inserted passage not present in the other editions, which have no material to
compare with it. Following this point, the witnesses all agree, as shown in the next
<app> element. The output actually does not contain markers
for the virtual <del> and <p> elements but
rather these have been converted to a string carrying escape characters as a trace
of their prior existence as elements: <del/> and
<p/>.
Following the collation process, we use the XML output as the basis for
reconstructing the individual edition files so that they may individually indicate
hotspots, or passages that vary in the other editions. We wrote
XSLT to run over the collation XML output to produce a separate file representing
each reading
witness (not shown here for space reasons). In this first stage, we leave all the
original marker elements of the edition as escaped strings and we mark each witness’s
hotspots with <seg> elements.
Because these hotspots will sometimes overlap with structural markup from the input
editions, we must also insert these elements as flattened start and end markers.
In the next stage, shown in Figure 2, we apply an XSLT script with
<xsl:analyze-string> to reconstruct the source edition’s
element markers from the strings.
Figure 2
<xsl:template match="ab/text()"
<xsl:analyze-string select="." regex="<.[^/]+?[es]ID=[^/]+?/>">
<!--The value of the regex attribute is the string we isolate for conversion into a new element.
It begins and ends with a left and right angle bracket and
contains the pattern to isolate the original non-namespaced form of our Trojan markers. --<
<xsl:matching-substring>
<xsl:variable name="flattenedTagContents"
select="substring-before(., '/') ! substring-after(., '<')"/>
<xsl:variable name="elementName"
select="tokenize($flattenedTagContents, ' ')[1]"/>
<xsl:element name="{$elementName}">
<xsl:for-each select="tokenize($flattenedTagContents, ' ')[position() gt 1][contains(., '=')]">
<!--In defining the variable below, we apply the Trojan Horse (th:) namespace prefix
to the original forms of sID and eID in the input data. If the regular expression
matched by [se]ID is found in the string, we concatenate the prefix with the substring before the '=' sign
to form the attribute name. Otherwise, the substring before the '=' sign will be the attribute name. -->
<xsl:variable name="attName" as="xs:string">
<xsl:choose>
<xsl:when test="matches(current(), '[se]ID')">
<xsl:value-of select="concat('th:', substring-before(current(), '='))"/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="substring-before(current(), '=')"/>
</xsl:otherwise>
</xsl:choose>
</xsl:variable>
<xsl:attribute name="{$attName}">
<xsl:value-of select="substring-after(current(), '="') ! substring-before(., '"')"/>
</xsl:attribute>
</xsl:for-each>
</xsl:element>
</xsl:matching-substring>
<xsl:non-matching-substring>
<!--At this point, we run xsl:analyze-string again
to isolate other kinds of strings that represent other kinds of elements.
(For example, the Frankenstein project has a number of milestone-style elements
that are not intended to be Trojan markers.)
After running a series of "string-surgeries" to make new elements with xsl:analyze-string,
we conclude with <xsl:value-of select="."/> to output what remains as a string.-->
<xsl:value-of select="."/>
</xsl:non-matching-substring>
</xsl:analyze-string>
</xsl:template>
XSLT template to reconstruct element markers from escape-character strings [3]
The script above applies regular expressions to isolate the strings we need to reconstruct
the Trojan marker elements of the source edition that were reduced to text in the
collation process. Going into the collation none of our files contain namespaces,
but we apply them in the up-conversion process, so here we concatenate the th: namespace prefix as we reconstruct our Trojan horse attributes.
Following this element reconstruction, our next
task will be to find a way to raise both the original markup we flattened from the
source editions with the conflicting hierarchy posed by the seg
elements derived from the collation process. Figure 3
shows a sample passage from the
Thomas copy edition file with the reconstructed but
flattened elements (again, white space has been added for legibility):
Figure 3
<seg xml:id="C10_app90-fThomas_start"/>
contortions that ever and anon
con<del
th:sID="fThomas_C10-del_2"/>puls<del th:eID="fThomas_C10-del_2"/>vulsed
& deformed his un-human features.
<p loc="novel1_letter4_chapter4_p133" ana="end"/>
<p loc="novel1_letter4_chapter4_p134" ana="start"/>
The
<seg xml:id="C10_app90-fThomas_end"/>
Sample reconstruction of the Thomas file, with flattened markup
In the passage above, the empty <seg> elements indicate the
start and end points of the variant passage in the Thomas copy. Their partially
shared @xml:id values coindex them while also pointing to the collation
unit and numbered <app> element in the collation output; the
trailing underscore separator and the string start or end
distinguish start- from end-markers. In this example, <seg
xml:id="C10_app90-fThomas_start"/> means that this is the start of a
variant from apparatus unit 90, where the Thomas copy diverges from a reading shared
by all of the other editions (in this case, the type of variation is that the other
witnesses have no corresponding reading).
Within the <seg> virtual element, the first two
<del> markers (start- and end-) frame a deleted portion of a
word (puls), and the third marks the end of paragraph 133 in Chapter
4, followed by the beginning of paragraph 134 in the same chapter. The use of
attributes on <del> and <p> markers differs from
that with the <seg> elements; in the case of
<del> and <p>, the Trojan horse attributes point
to the location in the source and coindexes the start- and end-markers.[4]
While we wish to raise both hierarchies, the primary use case on which we concentrate
in this paper is to raise the structural elements from the original edition (such
as <p> and <del>), while leaving the <seg> elements flattened. The question of how best to accomplish this brought the three
co-authors together, and serves as a testing ground for the raising methods described
in this paper. The output will look something like Figure 4 for the end of paragraph 133 and the start of paragraph 134 in the Thomas edition:
Figure 4
<p xml:id="novel1_letter4_chapter4_p133">
…
<seg xml:id="C10_app90-fThomas_start"/>contortions
that ever and anon
con<del xml:id="fThomas_C10-del_2">puls</del>vulsed
& deformed his un-human features.
</p>
<p xml:id="novel1_letter4_chapter4_p134">
The <seg xml:id="C10_app90-fThomas_end"/>
different accidents of life are not so changeable as
the feelings of human nature
…
</p>
The sample passage above, after raising structural elements (and
reflowing)
A secondary use case is to raise the <seg/> elements. When,
later in the production process, we also raise the <seg>
elements, we avoid overlap, or, rather we mark a moment of intersecting hierarchy,
by fragmenting the one that spans a paragraph boundary
into two parts:
Figure 5
<p xml:id="novel1_letter4_chapter4_p133">
…
<seg xml:id="C10_app90-fThomas__Pt1">contortions
that ever and anon
con<del xml:id="fThomas_C10-del_2"
>puls</del>vulsed
& deformed his
un-human features.
</seg>
</p>
<p xml:id="novel1_letter4_chapter4_p134">
<seg xml:id="C10_app90-fThomas__Pt2">
The
</seg>
different accidents of life are
not so changeable as the feelings of human
nature
…
</p>
Because raising <seg> would create overlap, we split
the element into parts.
The split <seg> elements in the passage above now indicate
their association with each other with __Pt1 and __Pt2
appended to the original value of the apparatus and
reading witness location.
Our process of raising the new edition files thus entails the following steps:
Flatten all markup (prior to and following the collation
process)
Reconstruct (raise) the structural elements from the source edition
(e.g., <p>, <del>)
Raise the <seg> elements, which indicate moments of
variation in the collation, splitting the raised elements into parts
where that is required to avoid creating overlap
The experimental transformations tested and discussed in this report
focus primarily on the middle of these three steps, raising the structural markup.
Simplified sample data
In addition to exploring and reporting on the application of different raising
methods to authentic data from Variorum Frankenstein, described above, for
illustrative and development purposes when discussing program logic we use a small
contrived hierarchical XML sample extracted from a short passage of poetry, derived
from a quoted passage in the Frankenstein novel. The simplified
data comes in three forms, which we call basic,
extended, and overlap.[5]
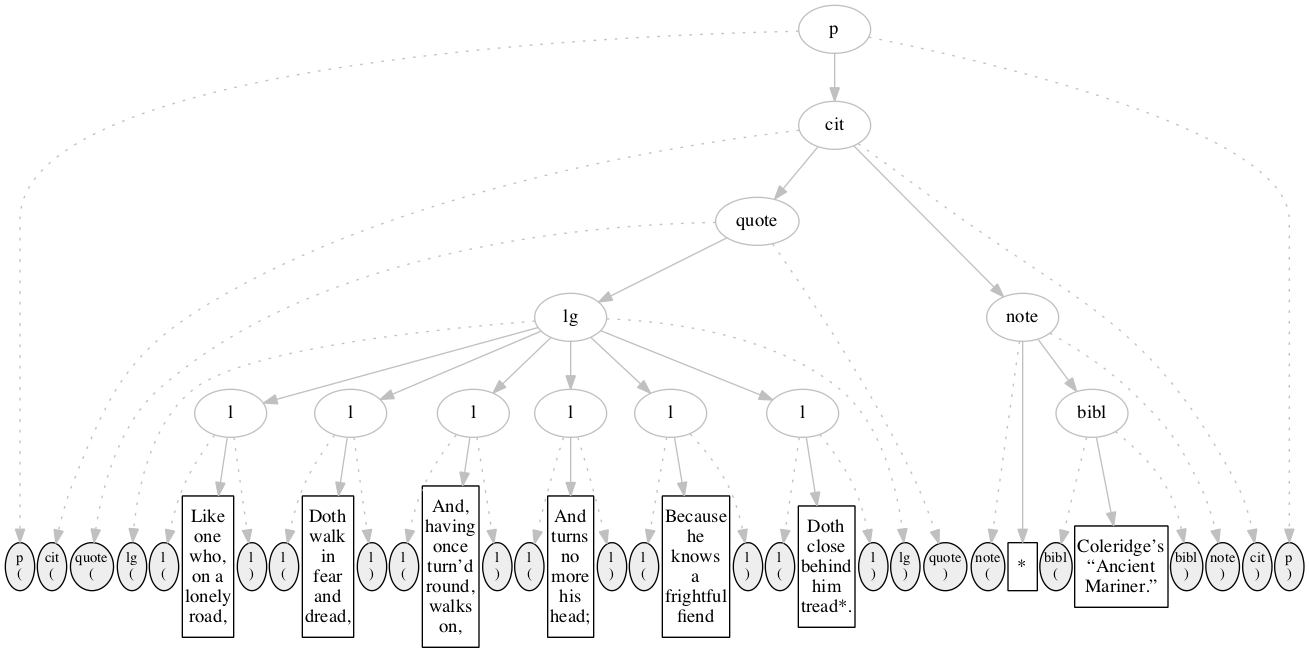
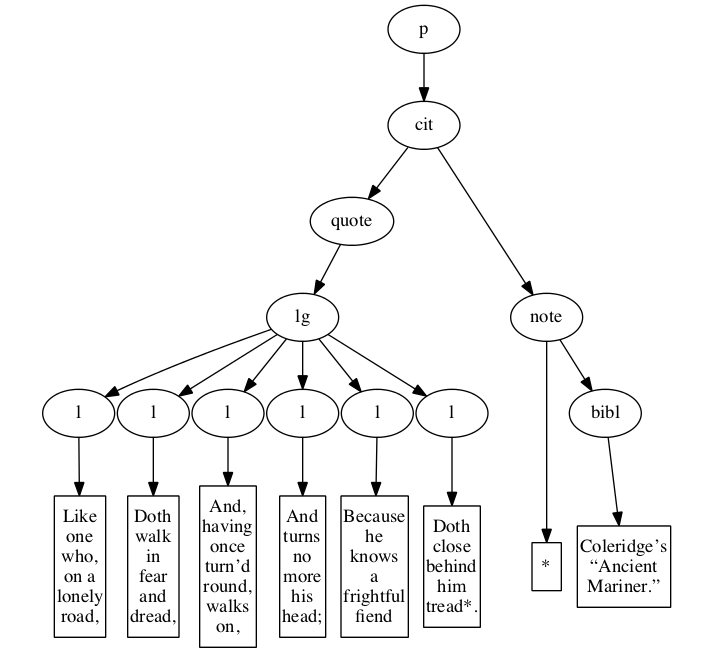
Basic sample
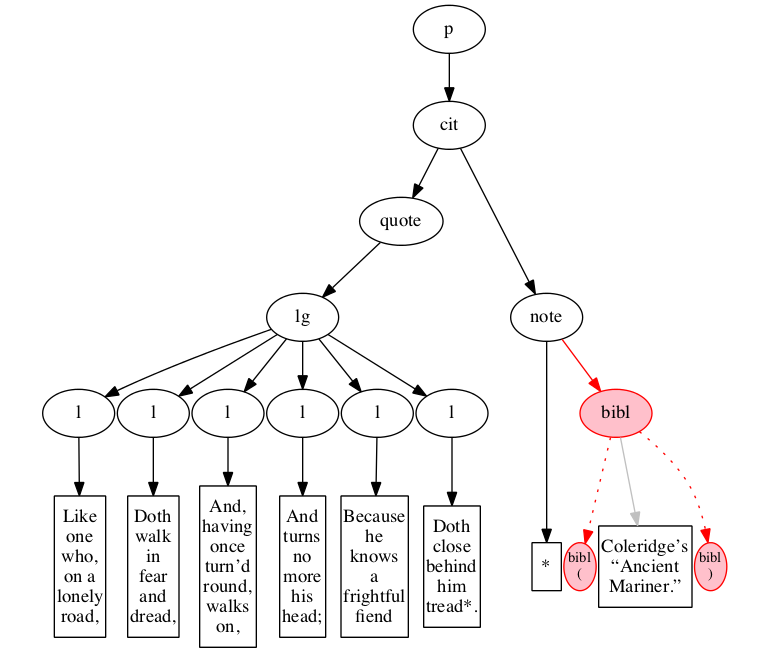
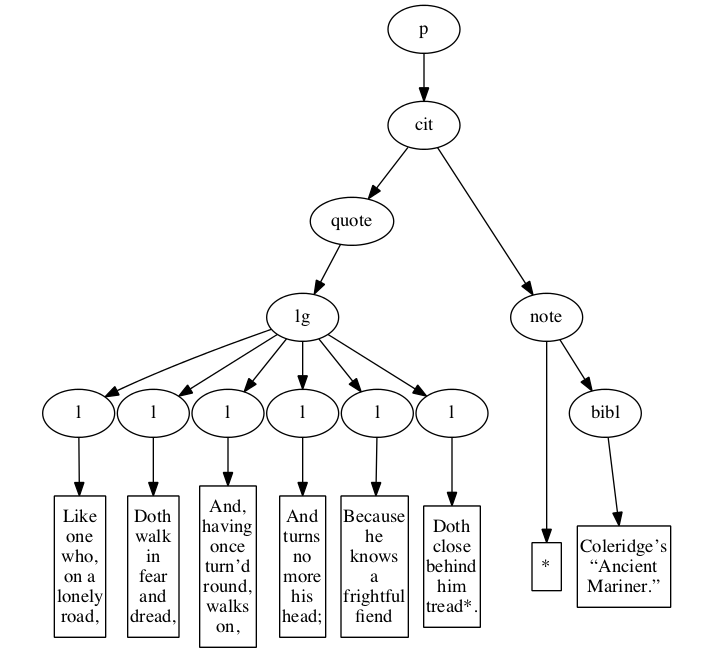
A sample of the basic input format in its
original form is:
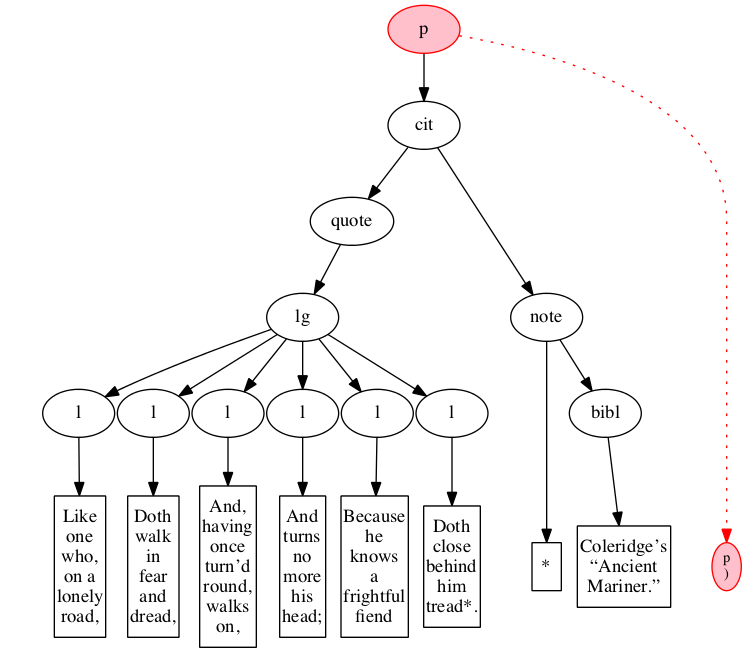
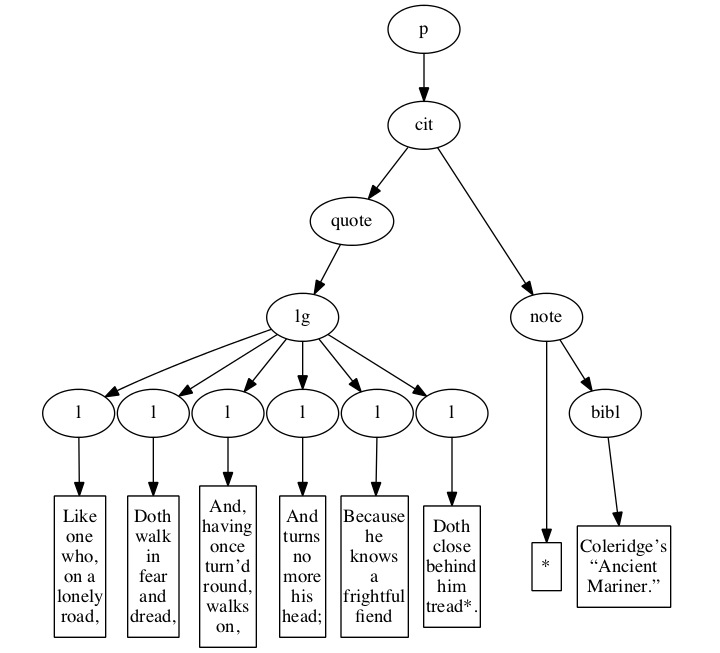
Figure 6
<p>
<cit>
<quote>
<lg>
<l> Like one who, on a lonely road, </l>
<l> Doth walk in fear and dread, </l>
<l> And, having once turn’d round, walks on, </l>
<l> And turns no more his head; </l>
<l> Because he knows a frightful fiend </l>
<l> Doth close behind him tread*. </l>
</lg>
</quote>
<note> *
<bibl>
Coleridge’s “Ancient Mariner.”
</bibl>
</note>
</cit>
</p>
Original hierarchical XML
Flattening
To test the method on our Simplified sample data, we first flatten the
original XML with the following XSLT, which converts all tags except the root
(which must be preserved as a container element to ensure that the XML is well
formed) to Trojan milestones. We modify the Trojan milestone markup method
described in DeRose 2004 by putting the @sID and
@eID attributes in a namespace, for which we bind the prefix
th: to the URI
http://www.blackmesatech.com/2017/nss/trojan-horse
(following Sperberg-McQueen 2018). The
original generic identifier is retained, the start-tag is replaced by an empty
element that adds a @th:sID attribute with a generated value, and
the end-tag is replaced by an empty element that adds a th:eID
attribute with the same generated value:
XSLT to flatten hierarchical XML to Trojan milestones
The flattened version looks roughly like the
following (line breaks have been added within tags
here, to shorten the lines:
Figure 8
<?xml version="1.0" encoding="UTF-8"?><p
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse">
<cit th:sID="d1e3"/>
<quote th:sID="d1e5"/>
<lg th:sID="d1e7"/>
<l th:sID="d1e9"
/> Like one who, on a lonely road, <l th:eID="d1e9"/>
<l th:sID="d1e12"
/> Doth walk in fear and dread, <l th:eID="d1e12"/>
<l th:sID="d1e15"
/> And, having once turn’d round, walks on, <l th:eID="d1e15"/>
<l th:sID="d1e18"
/> And turns no more his head; <l th:eID="d1e18"/>
<l th:sID="d1e21"
/> Because he knows a frightful fiend <l th:eID="d1e21"/>
<l th:sID="d1e25"
/> Doth close behind him tread*. <l th:eID="d1e25"/>
<lg th:eID="d1e7"/>
<quote th:eID="d1e5"/>
<note th:sID="d1e30"/> *
<bibl th:sID="d1e32"/>
Coleridge’s “Ancient Mariner.”
<bibl th:eID="d1e32"/>
<note th:eID="d1e30"/>
<cit th:eID="d1e3"/>
</p>
Original XML after flattening with Trojan milestones
The output of raising must match the original
XML.
Extended basic sample
The basic sample contains no non-Trojan empty elements and no non-Trojan
attributes. We can test whether those features are handled properly with the
following slightly more complicated sample:
Figure 9
<?xml version="1.0" encoding="UTF-8"?><p
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse">
<cit xml:id="fThomas_C10-cit_1" th:sID="d1e3"/>
<quote xml:id="fThomas_C10-quote_1" th:sID="d1e5"/>
<lg xml:id="fThomas_C10-lg_1" th:sID="d1e7"/>
<l xml:id="fThomas_C10-l_1" th:sID="d1e9"
/> Like one who, on a lonely road, <l th:eID="d1e9"/>
<l xml:id="fThomas_C10-l_2" th:sID="d1e12"
/> Doth walk in fear and dread, <l th:eID="d1e12"/>
<l xml:id="fThomas_C10-l_3" th:sID="d1e15"
/> And, having once turn’d round, walks on, <l th:eID="d1e15"/>
<l xml:id="fThomas_C10-l_4" th:sID="d1e18"
/> And turns no more his head; <l th:eID="d1e18"/>
<l xml:id="fThomas_C10-l_5" th:sID="d1e21"
/> Because he knows a frightful fiend <l th:eID="d1e21"/>
<l xml:id="fThomas_C10-l_6" th:sID="d1e25"
/> Doth close behind him tread*. <l th:eID="d1e25"/>
<lg th:eID="d1e7"/>
<quote th:eID="d1e5"/>
<note xml:id="fThomas_C10-note_1" th:sID="d1e30"/> *
<bibl xml:id="fThomas_C10-bibl_1">
Coleridge’s “Ancient Mariner.”
</bibl>
<note th:eID="d1e30"/>
<cit th:eID="d1e3"/>
</p>
Extended basic sample input
The extended basic sample adds the following features:
The bibl element a
non-Trojan element, without Trojan
attributes.
Most elements have, in addition to their Trojan attributes,
@xml:id attributes. The Trojan attributes must be
removed during raising, but the non-Trojan attributes must be
retained.
Overlapping markers
To test the behavior of the methods with input that cannot be fully raised
without creating overlap, we use the following
sample (some whitespace added for legibility):
Figure 10
<!--* Example adapted from LMNL sawtooth syntax
* at http://piez.org/wendell/LMNL/lmnl-page.html
*-->
<excerpt xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse">
<source th:sID="source"/>The Housekeeper<source th:eID="source"/>
<author th:sID="author"/>Robert Frost<author th:eID="author"/>
<s th:sID="s1"/>
<l th:sID="L144" n="144"/>
He manages to keep the upper hand
<l th:eID="L144"/>
<l n="145" th:sID="L145"/>
On his own farm.
<s th:eID="s1"/>
<s th:sID="s2"/>
He's boss.
<s th:eID="s2"/>
<s th:sID="s3"/>
But as to hens:
<l th:eID="L145"/>
<l n="146" th:sID="L146"/>
We fence our flowers in and the hens range.
<l th:eID="L146"/>
<s th:eID="s3"/>
</excerpt>
Flattened XML that cannot be raised without creating overlap
This consists of a few lines of verse, marked up
with both the metrical structure (verse lines) and the
division into sentences; both the first and third
sentences span verse boundaries.
Frankenstein
markers
The Frankenstein Variorum encoding represents an overlapping virtual hierarchy, so
we need a way of distinguishing one set of elements participating in one hierarchy
from the other set. The virtual elements participating in the first hierarchy hold
trojan markers with attributes in the form of @th:sID and @th:eID. The second hierarchy is signalled with an alternative marker style used only on
the <seg> elements. Here there is an @xml:id bearing a flag indicating the start or end position of a variant passage. These markers
cannot be raised in exactly the way they were placed, since in some cases a variant
passage may start inside a paragraph or chapter, and end in the next one. In this
project, the decision to raise the <seg> elements necessitates a process of splitting them into pieces within structural boundaries,
so that the original virtual element becomes two elements, with part one inside one
structural unit and part two inside the next. Different styles of markers here facilitates
handling these elements at different moments in the raising process.
Solutions to the problem
We describe several solutions to the problem, some
formulated in XSLT 3.0 and some using other tools.
Right-sibling traversal
One way to construct content elements from flattened
XML is to do roughly what a recursive-descent parser for
XML does: when a recursive-descent parser sees the
beginning of any construct, it calls a routine to handle
that construct; if the construct contains other
constructs, other routines are called recursively. The
function handling a parent element starts before any
function handling a child, and ends only after all
children have been processed.
The standard idiom of including
xsl:apply-templates similarly visits each
node in the input tree left to right, in order, but
provides no mechanism for passing results or state from
one sibling to the next. In order to perform the raising
task, we perform instead a right-sibling traversal of the
input tree, which proceeds one element at a time
processing along the following-sibling axis. Each marker
element calls <xsl:apply-templates>
only on its first child, and each template passes control
to its immediate right sibling.
Order of raising the elements
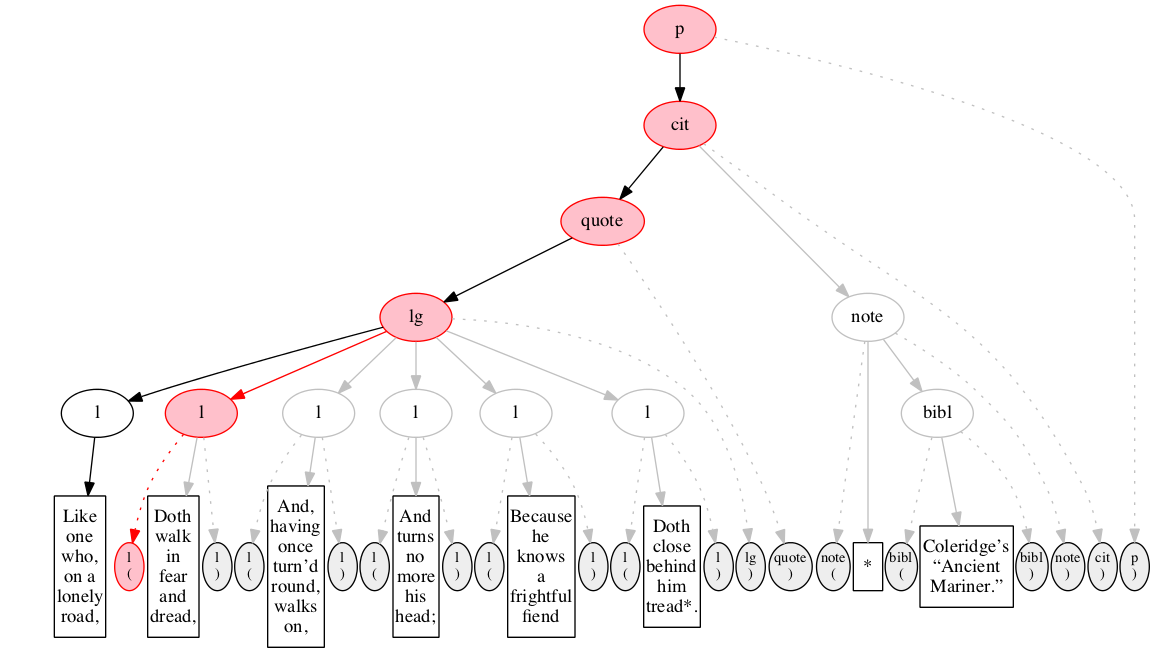
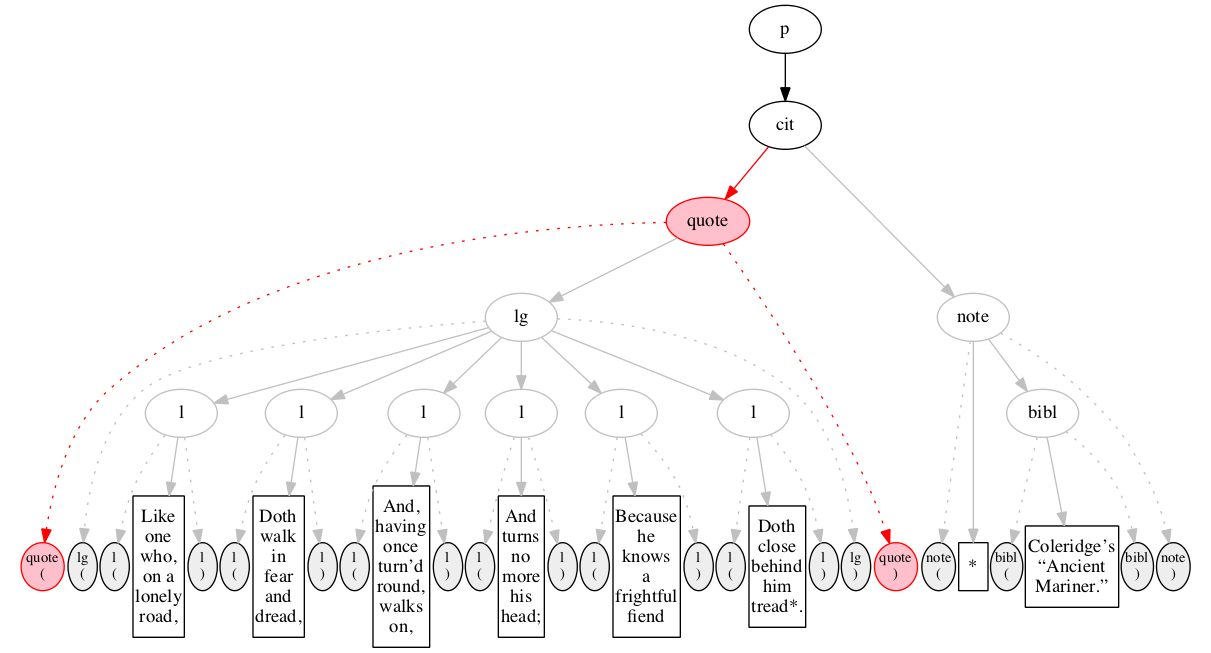
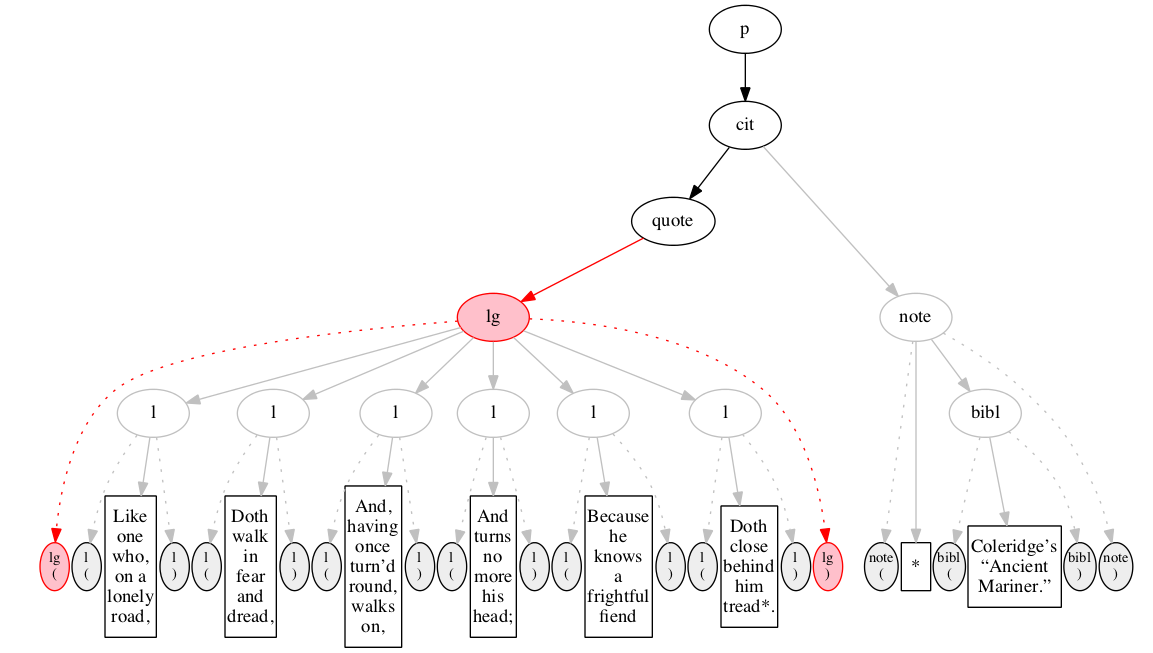
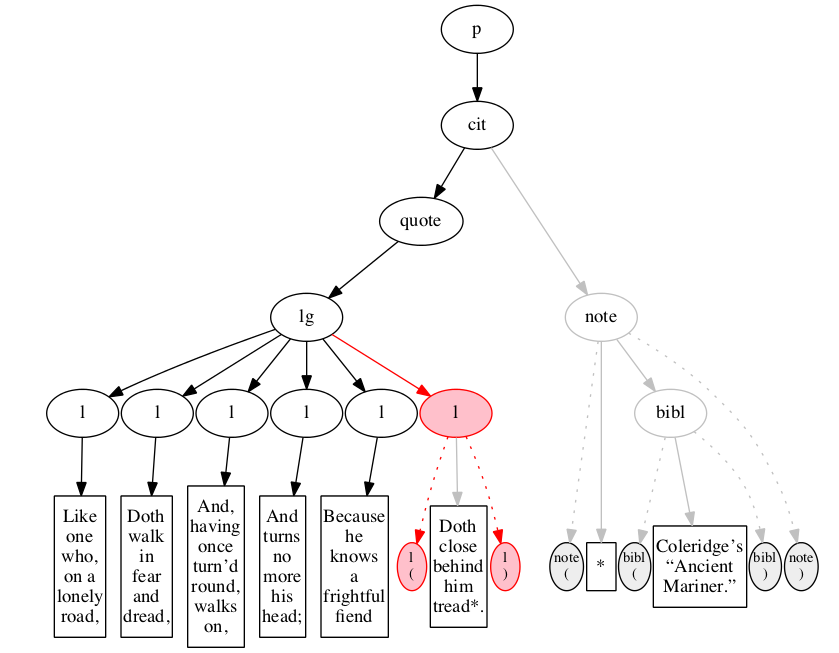
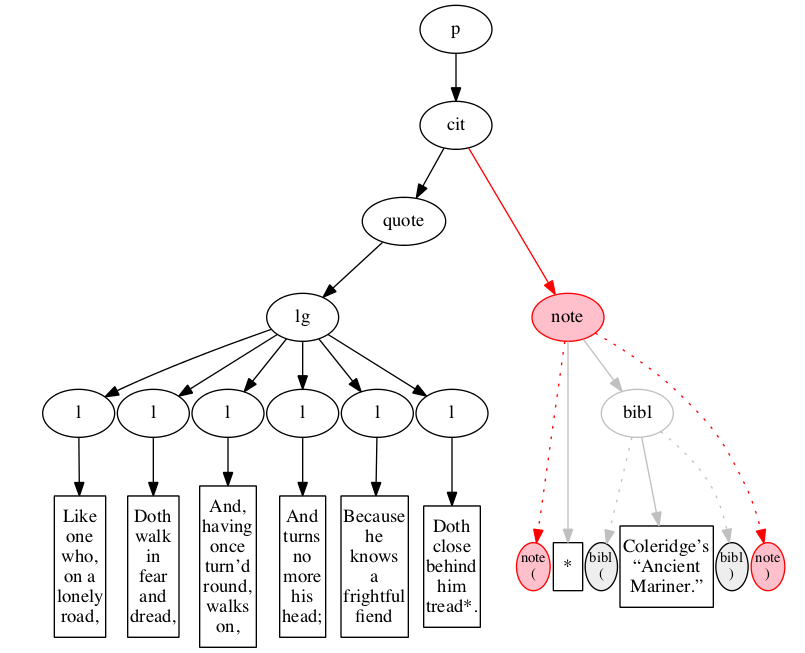
Figure 11 through Figure 20 illustrate some stages in the
process of raising the virtual elements in the sample
document by progressing through the flat sequence
of siblings which makes up most of the input.
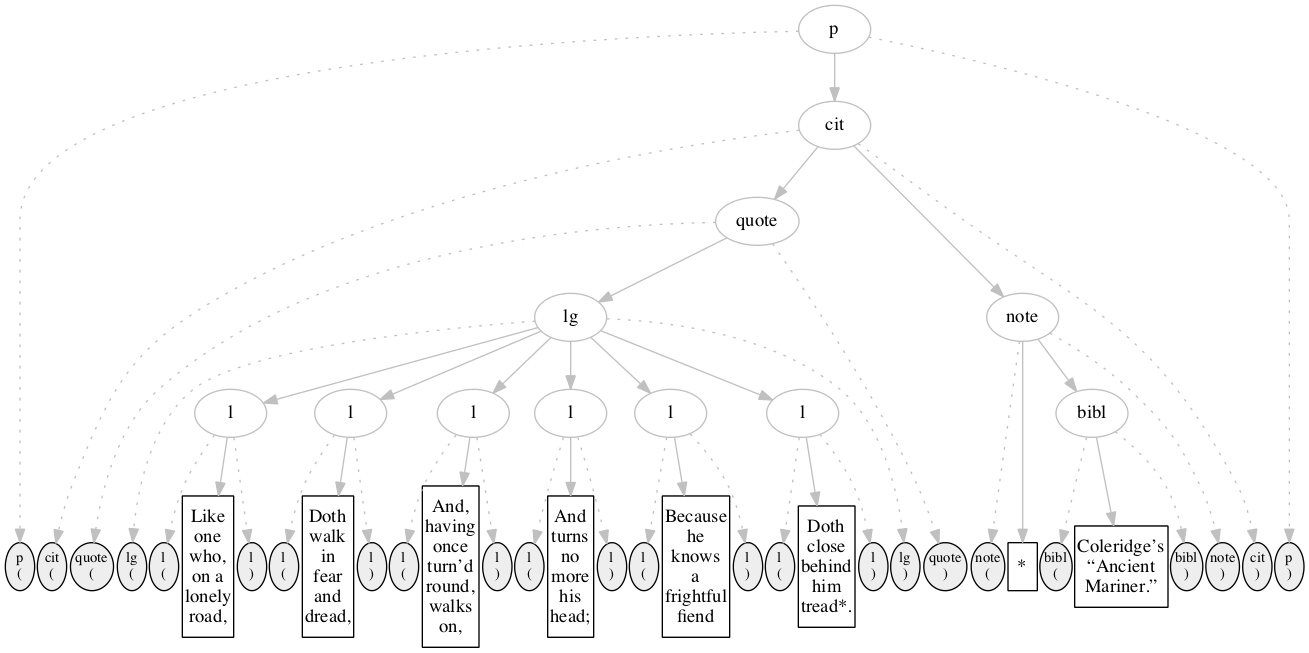
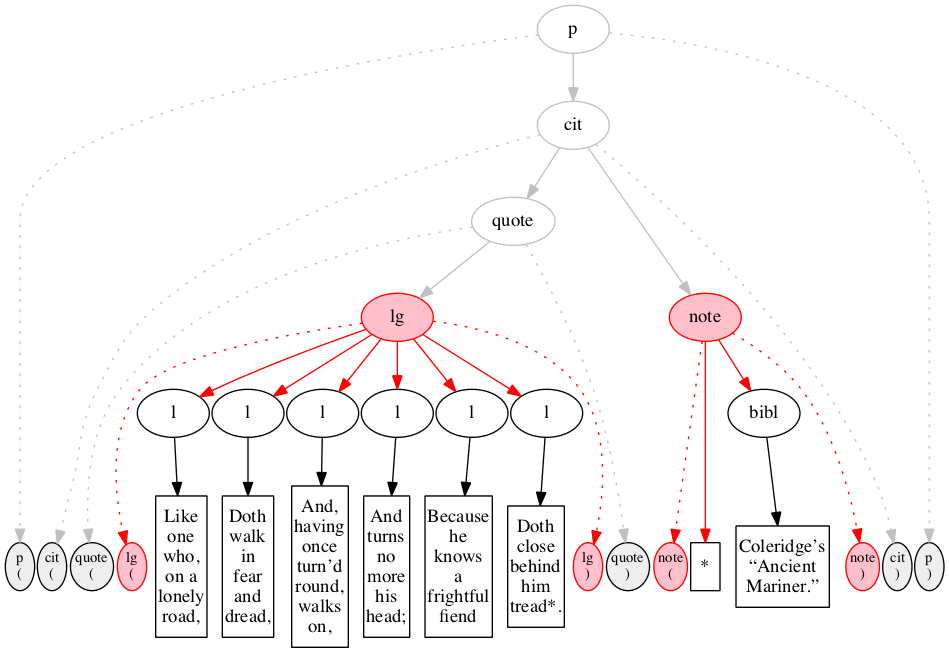
Figure 11
Illustration of left-right handling of input by
a recursive-descent parser or by the left-right method
described in the text. Initial state.
The input is shown arrayed along the bottom of
the diagram: ovals filled with gray denote start- and
end-markers, rectangles denote text nodes. The gray
ovals above denote the logical hierarchy which is to
be constructed (visible to human observers even if not
visible to the software).
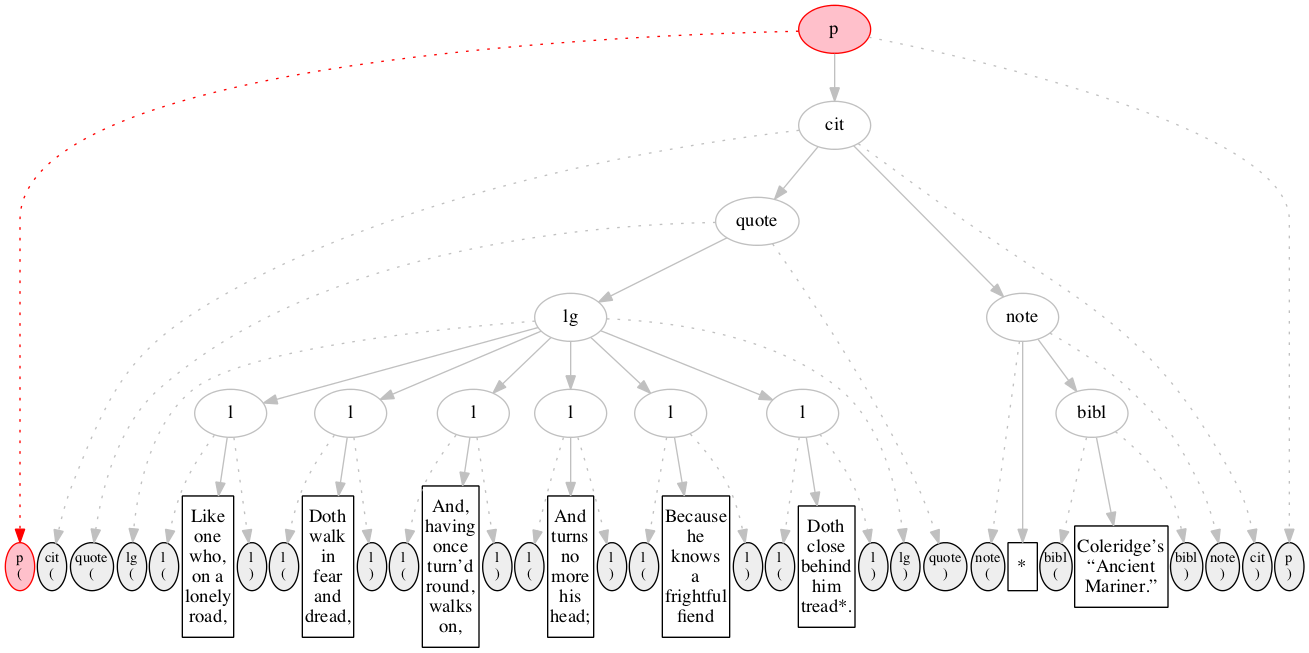
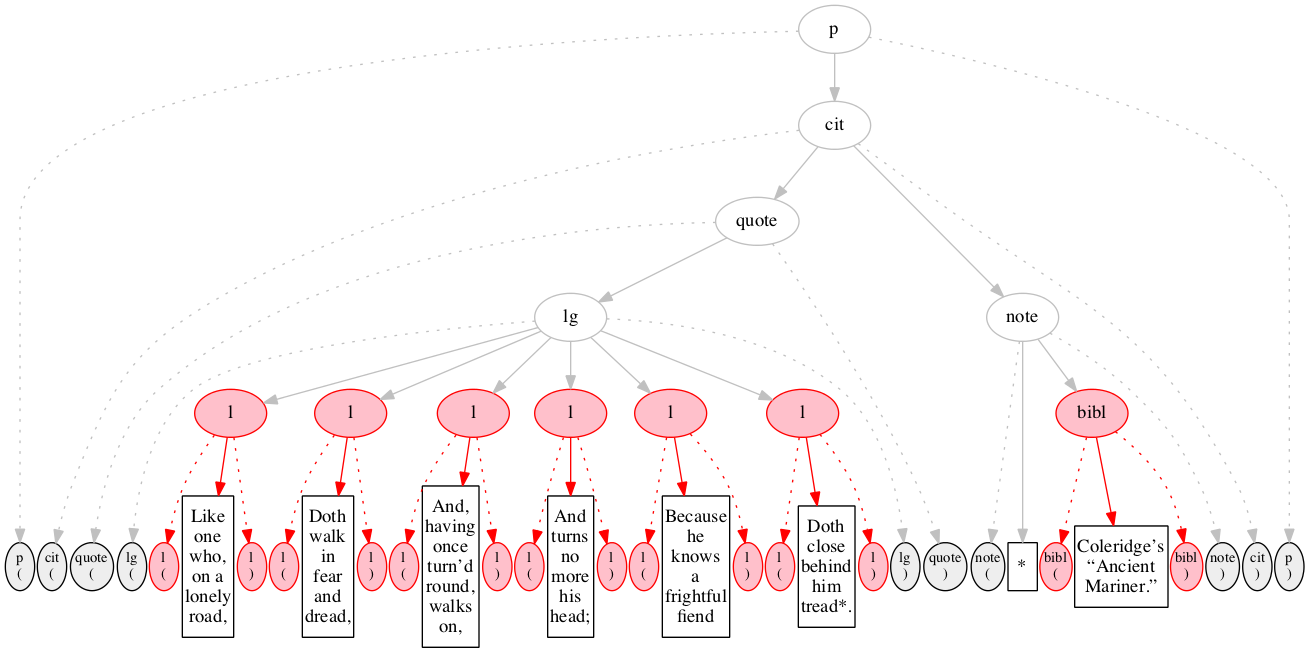
Figure 12
The first input node is read and recognized as
the start-marker for the p element.
Both the start-marker and the element node constructed
are shown in red, as is the arc connecting them.
Figure 13
The second input node is read and recognized as
the start-marker for the citation element cit.
The start-marker for the enclosing
p element has served its purpose and is omitted
from the diagram. The node for the p
element is still incomplete, as indicated by its
pink background.
Figure 14
The third input node is read and recognized as
the start-marker for the citation element cit.
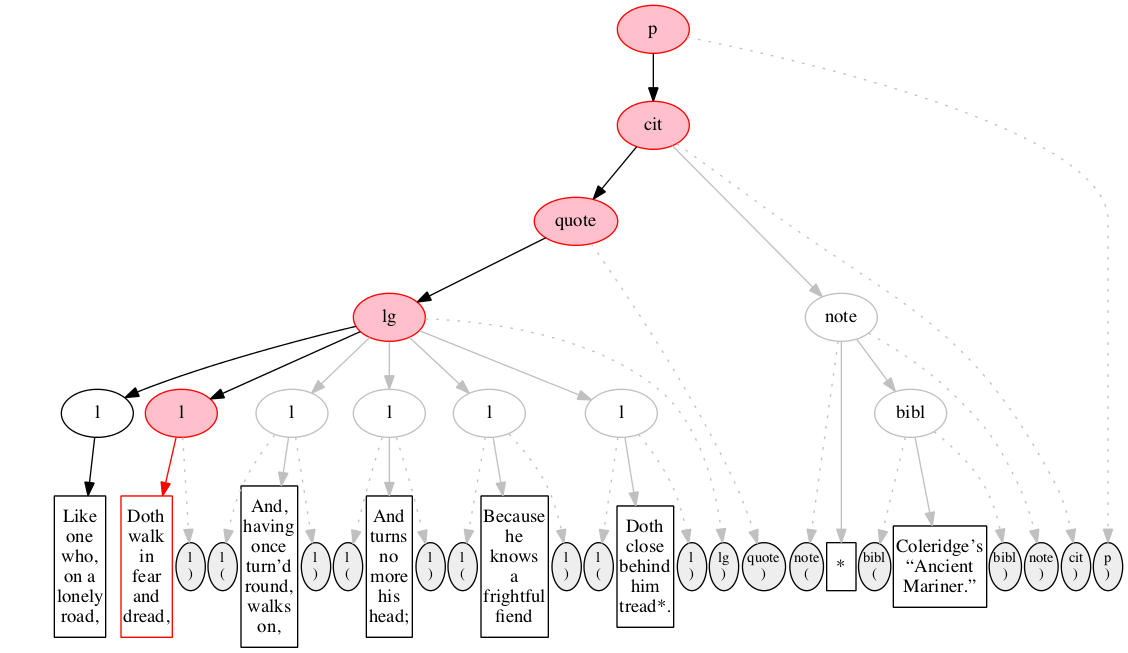
Between Figure 14
and Figure 15, we elide several
stages. Figure 15 through Figure 17 illustrate the
complete recognition of the second line of verse.
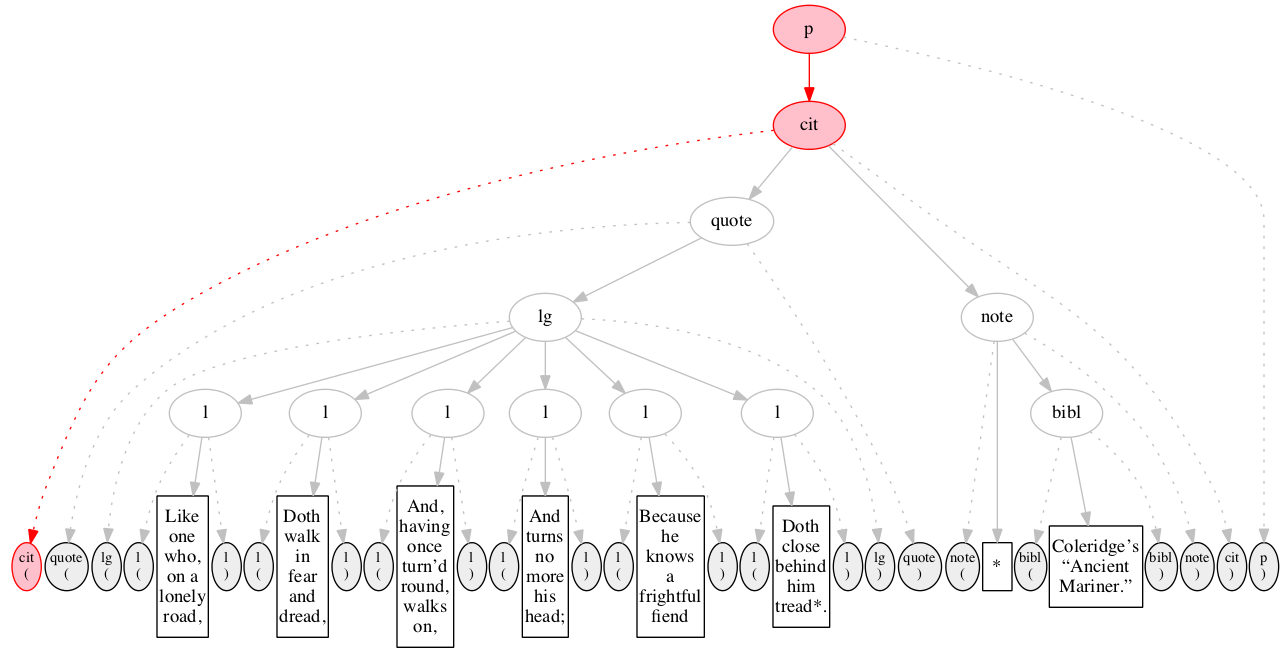
Figure 15
The eighth input node is read and recognized as
the start-marker for the second line of verse.
The first line of verse is now complete and its
node is now shown with black oval and white background
instead of pink.
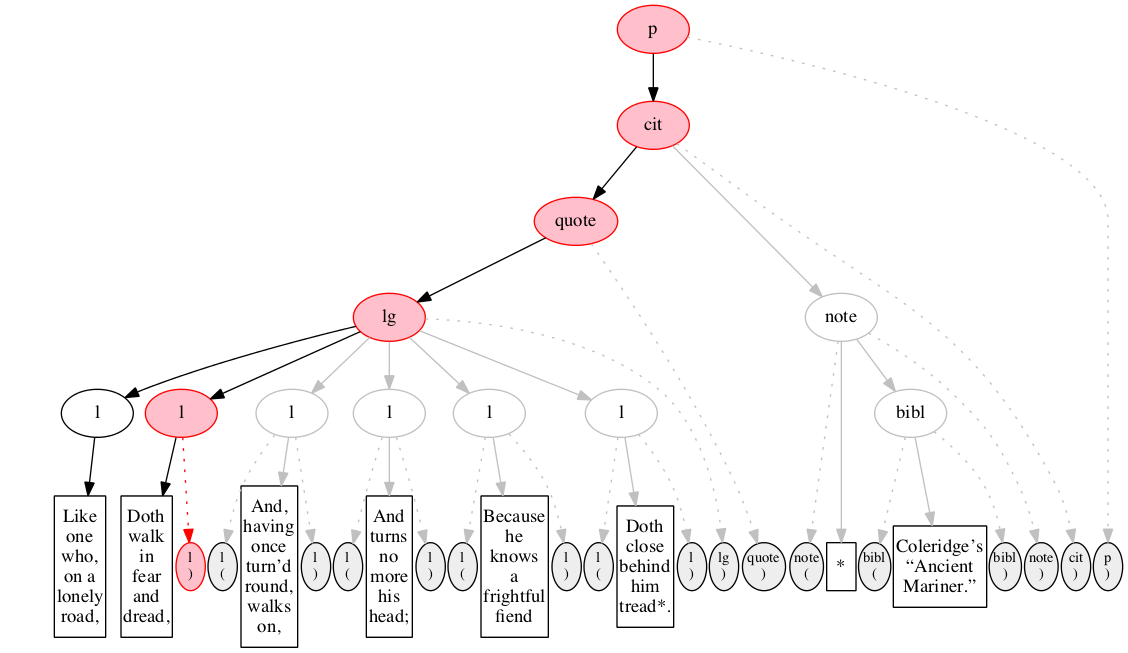
Figure 16
The ninth input node is the text
for the second line of verse.
Figure 17
End-marker for second line of verse.
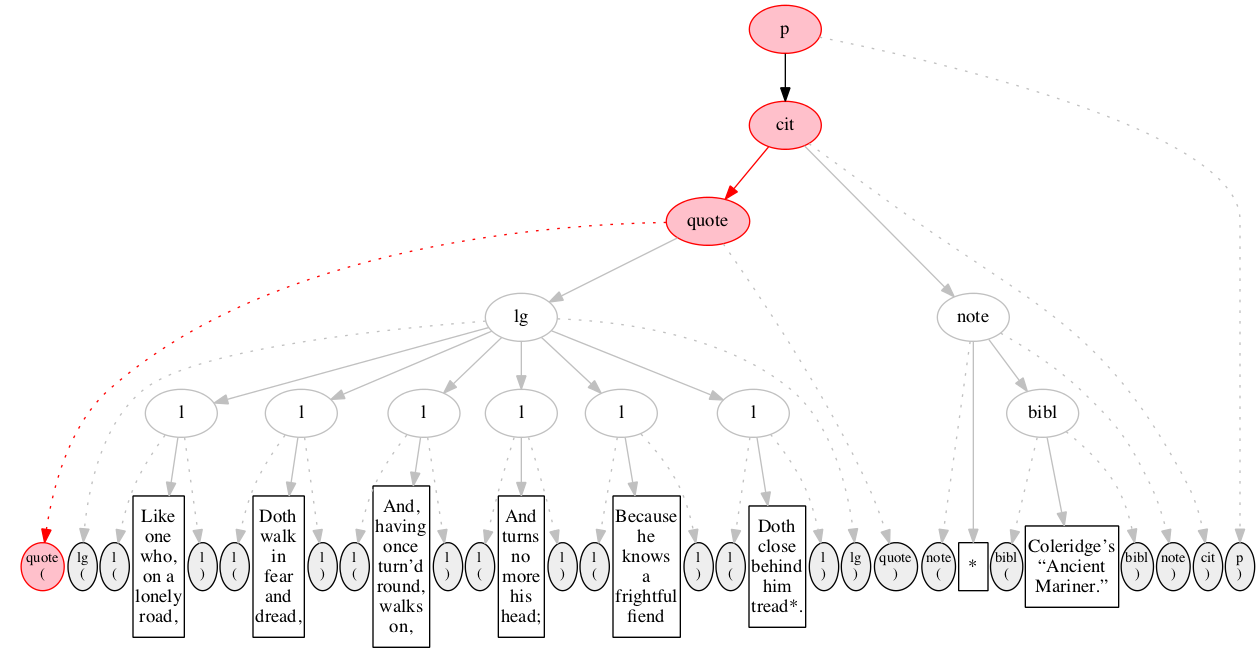
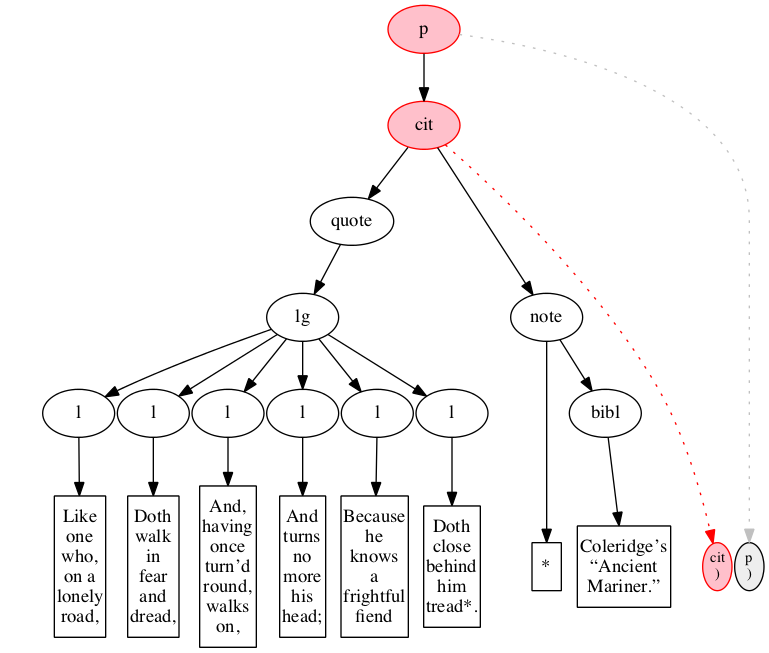
Figure 18 through Figure 20 illustrate the
recognition of the last two end-markers and the final
state of processing.
Figure 18
End-marker for cit element.
Figure 19
End-marker for paragraph.
Figure 20
Final state: all markers are gone, and all
elements have been raised.
Outline of XSLT code
As described above, the right-sibling traversal idiom
in XSLT proceeds one element at a time along the following-sibling axis. In the
general case, each template for a content element calls
<xsl:apply-templates> not on all its children but only on
its first child. Every template (for content elements, marker elements, text
nodes, comments, or processing instructions) concludes with a call to
<xsl:apply-templates
select="following-sibling::node()[1]"/>, thus passing control to the
template for its immediate right sibling. In the flattening case, the outermost
element of the document may be the only content element and its template the
only one that applies templates to its children.
For our simple test cases, processing begins
with the template for the outermost element.[6]
The template for start-markers constructs a content element
for the corresponding virtual element; it has the following
structure:
Figure 22
<xsl:template match="*[@th:sID]" mode="raising">
<!--* 1: handle this element *-->
<xsl:copy>
<xsl:copy-of select="@* except @th:sID"/>
<xsl:apply-templates select="following-sibling::node()[1]"
mode="raising">
</xsl:apply-templates>
</xsl:copy>
<!--* 2: continue after this element *-->
<xsl:apply-templates select="following-sibling::*
[@th:eID = $sID
and namespace-uri()=$ns
and local-name()=$ln]
/following-sibling::node()[1]"
mode="raising"/>
</xsl:template>
Template for start-marker
Note that there are two calls to <xsl:apply-templates>. The
first call to <xsl:apply-templates> occurs within an
<xsl:copy> element (which constructs an element with the
name and attributes given by the start-marker); it selects the immediately
following sibling node, which will in the normal run of things become the first
child node of the new content element. The second call to
<xsl:apply-templates> occurs after the new content
element and it does not select the start-marker’s immediately following sibling, but instead selects the
node immediately to the right of the end-marker.
Each child of the virtual element copies itself into the content element being
created. The templates for text() nodes, comments, processing
instructions, and any content elements present in the input all have essentially the
same structure:
Template for text() nodes, comments, processing instructions,
and content elements
If content elements can contain further markers at other levels of the tree, the
<xsl:copy-of> should be replaced by a shallow copy and a
recursive <xsl:apply-templates select="child::node()[1]>. That is
not the case with our test data.
When an end-marker is encountered, the contents of the virtual element whose end
it marks have now all been accumulated, and the right-sibling traversal of the
input should stop. The template for end-markers will thus look like this:
Figure 24
<xsl:template match="*[@th:eID]" mode="raising">
<!--* No action necessary *-->
<!--* We do NOT recur to our right.
* We leave it to our parent to do that.
*-->
</xsl:template>
Empty template to stop the processing of end-markers
The code shown here is simplified by assuming
that the start- and end-markers in its input correspond
to the start- and end-tags of a well-formed XML
document. The template for end-markers, for example,
does not check to see that the end-marker found is the
one that matches the element on the top of the current
element stack. When confonted with the overlapping
virtual elements of some of our sample input, therefore,
the code shown here will behave as if start- and
end-markers were paired up by position, without regard for
co-indexing or element type.
Better behavior in the presence of overlapping
virtual elements or errors in the input can be achieved
by passing parameters on each call to
apply-templates in mode raising,
which keep a stack of co-indexing IDs and element types.
Resource consumption
A few notes on resource consumption may be
in order.
The templates shown each handle a single node and then call
<xsl:apply-templates>, selecting the next node to be
processed. The template activation stack in the XSLT processor thus contains no
sets of nodes waiting to be processed, but the call stack may become rather
deep: in our sample data, the maximum depth of the template stack is the number
of nodes in the flattened portion of the input. An XSLT processor that does not
eliminate tail-recursive template calls may thus run out of stack space (at
least in theory—in practice, we have never seen a right-sibling recursion blow
the stack on real, well-formed input).
Because the right-sibling idiom visits each node
in the flattened input just once, the cost of the process
should be linear in the size of the input. (In practice,
preliminary measurements suggest that with the Saxon
HE processor, the rise in cost is sub-linear to the rise
in input size.)
Despite its virtues, the right-sibling traveral
idiom is needed rarely enough in XSLT programming
that many XSLT authors have never used it; some find it
difficult.[7]
The inside-out algorithm described below
(Inside-out recursion)
can be regarded as an alternative which
is closer to conventional XSLT usage. The
implementation using XSLT 3.0 accumulators
is another approach worth learning.
Raising
Frankenstein
For raising Frankenstein using right-sibling traversal,
we adapt the code lightly to apply to its project markup in the following
template rules:
Right sibling traversal method applied to
Frankenstein
Inside-out recursion
Inside-out recursion works by finding all innermost pairs of start- and
end-markers, that is, those that mark virtual elements that do not contain any
markers or other virtual elements. They may contain anything else, including
text() nodes, empty elements that are not markers, and container
elements. The transformation forms all innermost pairs that it finds into container
elements and passes the resulting new document back into the recursive function,
where the (new) innermost pairs of markers are now outside the newly created
container elements. The function recurs until there are no more markers. The maximum
possible depth of recursion is equal to the depth of the original (pre-flattening)
XML hierarchy.
The sequence in which virtual elements in our sample
document are raised in this method is illustrated by the
diagrams in Figure 26 to Figure 32.
Figure 26
Illustration of inside-out handling of input.
The input is shown arrayed along the bottom of
the diagram: ovals filled with gray denote start- and
end-markers, rectangles denote text nodes. The gray
ovals above denote the logical hierarchy which is to
be constructed (visible to human observers even if not
visible to the software).
Figure 27
On the first pass, the inside-out algorithm
raises all childless virtual elements.
Figure 28
On the second pass, inside-out raises elements
with children but no grandchildren.
Figure 29
On the third pass, elements of the third layer
from the leaves are raised.
Figure 30
The fourth pass raises the children of the
virtual root.
Figure 31
The fifth pass raises the p element.
Figure 32
In the final state, the inside-out algorithm has
raised all elements.
Raising
The output of the preceding transformation is included in the Simplified sample data section, above. We then reconstruct the hierarchy
using the inside-out recursive function th:raise() in the following
XSLT stylesheet:
Figure 33
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse"
exclude-result-prefixes="#all">
<xsl:output method="xml" indent="no"/>
<!--* Set $debug parameter to any non-null value to output messages *-->
<xsl:param name="debug" static="yes" required="no"/>
<xsl:key name="end-markers" match="*[@th:eID]" use="@th:eID"/>
<!--
Identity template of anything lower than grandchildren of the root
Just copy; they cannot contain markers
-->
<xsl:template match="/*/*/descendant::node()" mode="#all">
<xsl:sequence select="."/>
</xsl:template>
<!-- Traditional identity template for root and its children -->
<xsl:template match="@* | node()" mode="#all">
<xsl:copy copy-namespaces="no">
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
<!--
th:raise(.): raise all innermost elements within the document
messages controlled by $debug stylesheet parameter
-->
<xsl:function name="th:raise">
<xsl:param name="input" as="document-node()"/>
<xsl:message use-when="$debug">raise() called with
<xsl:value-of select="count($input//*)"/>-element document
(<xsl:value-of select="count($input//*[@th:sID])"
/> Trojan pairs)</xsl:message>
<xsl:choose>
<xsl:when test="exists($input//*
[@th:sID eq following-sibling::*[@th:eID][1]/@th:eID])">
<!-- If we have more work to do, do it -->
<xsl:variable name="result" as="document-node()">
<xsl:document>
<xsl:apply-templates select="$input" mode="loop"/>
</xsl:document>
</xsl:variable>
<xsl:sequence select="th:raise($result)"/>
</xsl:when>
<xsl:otherwise>
<!-- We have no more work to do, return the input unchanged. -->
<xsl:message use-when="$debug">raise() returning.</xsl:message>
<xsl:sequence select="$input"/>
</xsl:otherwise>
</xsl:choose>
</xsl:function>
<xsl:template match="/">
<xsl:sequence select="th:raise(.)"/>
</xsl:template>
<xsl:template match="/" mode="loop">
<xsl:apply-templates/>
</xsl:template>
<!--
Innermost start-markers
@priority needed here and below because otherwise ambiguous with identity templates
-->
<xsl:template match="*[@th:sID eq following-sibling::*[@th:eID][1]/@th:eID]" priority="1">
<xsl:copy copy-namespaces="no">
<xsl:copy-of select="@* except @th:sID"/>
<xsl:variable name="end-marker" as="element()" select="key('end-markers', @th:sID)"/>
<xsl:copy-of select="following-sibling::node()[. << $end-marker]"/>
</xsl:copy>
</xsl:template>
<!-- nodes inside new wrapper: suppress, since they have alredy been copied -->
<xsl:template
match="node()[preceding-sibling::*[@th:sID][1]/@th:sID eq following-sibling::*[@th:eID][1]/@th:eID]"
priority="1"/>
<!-- end-tag for new wrapper; suppress because it has already been copied -->
<xsl:template match="*[@th:eID eq preceding-sibling::*[@th:sID][1]/@th:sID]" priority="1"/>
</xsl:stylesheet>
XSLT to transform Trojan milestones into container elements
We turn off indentation (line 5) to avoid deforming the whitespace and set up
a debug option (line 8), controlled by a
$debug parameter.
The traditional identity template walks the entire tree, but because any
descendant nodes lower than children of the root are guaranteed not to be or
contain Trojan markers, we set up one identity template for those lower nodes,
which just copied them to the output (lines 16–18). The regular identity
template (lines 21–25) applies only to the root element and its children.
@exclude-result-prefixes="#all" is not enough to avoid writing
the th: namespace onto the root element of the output, even though
the namespace in question is not used in the output. An unused namespace
declaration is informationally harmless, but also needlessly distracting, so we
suppress it by specifying @copy-namespaces="no" on
<xsl:copy> in the identity template that deals with
Trojan markers (line 22).
Our recursive raising operation (the th:raise() function, lines
31–52) operates on document nodes, and we need to process the original document
node of the input file differently from the new document nodes that we create on
each pass through the recursive function. For that reason, we match the original
document node in no mode (<xsl:template match="/">, lines
54–56) and pass it into the raising function (<xsl:sequence
select="th:raise(.)"/>, line
55).
The raising function checks for the presence of @th:sID
attributes in the input that are candidates for raising (<xsl:when
test="exists($input//*[@th:sID eq
following-sibling::*[@th:eID][1]/@th:eID])">, line 137 see the
discussion of this test in Inside-out recursion challenges). If there
aren’t any (<xsl:otherwise>, lines 46–50), the recursion is
finished, and the function returns the result (<xsl:sequence
select="$input"/>, line 49). If there are still
@th:sID attributes that can be raised in the text, we create a
variable $result (lines 39–43) of type document and apply templates
inside the newly created document node (line 41). After the application of
templates is finished, we recur and pass the result into another invocation of
th:raise() (<xsl:sequence
select="th:raise($result)"/>, line
44).
The application of templates within the recursive function begins by applying
templates to the (newly created) document node in loop mode
(<xsl:apply-templates select="$input" mode="loop"/>, line
41). The matching template (lines 58–60) simply applies templates to its
children, unlike the template that matches the original document node (in no
mode, lines 54–56), which passes the document into the th:raise()
function (line 55), a difference in mode that is needed to avoid an endless
loop. All other processing is the same for both the original document and the
interim documents created inside th:raise(), so
<xsl:template match="/" mode="loop"> (lines 58–60) is the
only modal template, and it applies templates to
its children in no mode.
There are three templates that do the actual processing of the innermost
elements to be raised on each recursion: one that processes the start-marker,
one that processes the content of the newly raised container element, and one
that processes the corresponding end-marker. XSLT thinks that they have the same
priority as the identity templates, so we specify a higher priority explicitly
with priority="1".
start-marker: We match elements
with a @th:sID attribute that has a value equal to the
value of a @th:eID attribute on their first following
sibling element that has a @th:eID attribute (line 33).
This, then, matches only start-markers that contain nothing but
text() nodes, non-Trojan empty elements, and
container elements. In other words, it matches only the innermost
flattened elements, those that do not contain any other empty
flattened elements.[8] We process these hits by creating a container element
with the same generic identifier as the start-marker; we instruct it
not to copy unused namespaces, and we copy all non-Trojan
attributes. We create the element content by copying all
following-sibling nodes that precede the end-marker (which we find
with the help of the end-markers key) that matches the
start-marker we’re processing at the moment (lines 66–72). In other
words, we copy the content of the newly raised element into
it.
nodes inside the new wrapper: We
have already copied the content of the newly raised element inside
it, which means that we don’t want to process those nodes again,
since that would create duplicates. For that reason, we suppress all
nodes between the start- and end-markers that we’re processing at
the moment by matching them inside an empty
<xsl:template> element (lines 75–78).
end-marker: Since we create real
start- and end-tags when we match the flattened start-marker, we
have no more use for the flattened end-marker, so we suppress it by
matching it, too, inside an empty <xsl:template>
element (line 80).
When the simplified original document is flattened and then raised, as
described above, the output of the raising operation matches the original
input.
Raising Frankenstein
To raise the Frankenstein data, our process
is run recursively over a collection of 165 files in the Frankenstein Variorum.
The files have a TEI header that for project maintenance purposes needs to be updated
after a version change, and only a portion of the document is to be raised. Here the
most significant adaptation is that we supply an element node rather than a document
node as the input parameter for the th:raise function.
Figure 34
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
xpath-default-namespace="http://www.tei-c.org/ns/1.0"
xmlns="http://www.tei-c.org/ns/1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse"
exclude-result-prefixes="#all"
version="3.0">
<xsl:output method="xml" indent="no"/>
<!--* This stylesheet works to raise "trojan
elements" from the inside out, this time over a collection
of Frankenstein files output from collation. It also adapts
djb's function to process an element node rather than a
document node in memory to perform its recursive
processing. *-->
<xsl:variable name="novel-coll"
as="document-node()+"
select="collection('../input/frankenstein/novel-coll/')"/>
<!--* In all modes, do a shallow copy, suppress namespace nodes,
* and recur in default (unnamed) mode. *-->
<xsl:template match="@* | node()" mode="#all">
<xsl:copy copy-namespaces="no">
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
<!--* th:raise(.): raise all innermost elements within the container element this time passed as parameter *-->
<xsl:function name="th:raise">
<xsl:param name="input" as="element()"/>
<xsl:choose>
<xsl:when test="exists($input//*[@th:sID eq following-sibling::*[@th:eID][1]/@th:eID])">
<xsl:variable name="result" as="element()">
<div type="collation">
<xsl:apply-templates select="$input" mode="loop"/>
</div>
</xsl:variable>
<xsl:sequence select="th:raise($result)"/>
</xsl:when>
<xsl:otherwise>
<!--* We have no more work to do, return the input unchanged. *-->
<xsl:message>raise() returning.</xsl:message>
<xsl:sequence select="$input"/>
</xsl:otherwise>
</xsl:choose>
</xsl:function>
<xsl:template match="/">
<xsl:for-each select="$novel-coll//TEI">
<xsl:variable name="filename">
<xsl:text>raised_</xsl:text><xsl:value-of select="tokenize(base-uri(), '/')[last()]"/>
</xsl:variable>
<xsl:variable name="chunk"
as="xs:string"
select="substring-before(tokenize(base-uri(), '/')[last()], '.') ! substring-before(., '_')"/>
<xsl:result-document method="xml"
indent="yes"
href="output/frankenstein/novel-coll/{$filename}">
<TEI>
<xsl:apply-templates select="descendant::teiHeader"/>
<text>
<body>
<xsl:apply-templates select="descendant::div[@type='collation']"/>
</body>
</text>
</TEI>
</xsl:result-document>
</xsl:for-each>
</xsl:template>
<!--* Template rules for altering the TEI header, otherwise uninvolved in the raising process: *-->
<xsl:template match="teiHeader">
<teiHeader>
<fileDesc>
<titleStmt><xsl:apply-templates select="descendant::titleStmt/title"/></titleStmt>
<xsl:copy-of select="descendant::publicationStmt" copy-namespaces="no"/>
<xsl:copy-of select="descendant::sourceDesc" copy-namespaces="no"/>
</fileDesc>
</teiHeader>
</xsl:template>
<xsl:template match="titleStmt/title">
<title>
<xsl:text>Bridge Phase 4:</xsl:text><xsl:value-of select="tokenize(., ':')[last()]"/>
</title>
</xsl:template>
<!--* On the input container element node, call th:raise() *-->
<xsl:template match="div[@type='collation']">
<xsl:sequence select="th:raise(.)"/>
</xsl:template>
<!--* Loop mode (applies to container element only). *-->
<!--* Loop mode for container element: just apply templates in default unnamed mode. *-->
<xsl:template match="div[@type='collation']" mode="loop">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="*[@th:sID eq
following-sibling::*[@th:eID][1]/@th:eID]">
<xsl:variable name="currNode" select="current()" as="element()"/>
<xsl:variable name="currMarker" select="@th:sID" as="xs:string"/>
<xsl:element name="{name()}">
<xsl:copy-of select="@* except @th:sID"/>
<xsl:attribute name="xml:id">
<xsl:value-of select="@th:sID"/>
</xsl:attribute>
<xsl:variable name="end-marker" as="element()" select="following-sibling::*[@th:eID = current()/@th:sID]"/>
<xsl:copy-of select="following-sibling::node()[. << $end-marker]"/>
</xsl:element>
</xsl:template>
<!--suppressing nodes that are being reconstructed, including the old end marker. -->
<xsl:template
match="node()[preceding-sibling::*[@th:sID][1]/@th:sID eq following-sibling::*[@th:eID][1]/@th:eID]"/>
<xsl:template match="*[@th:eID eq preceding-sibling::*[@th:sID][1]/@th:sID]"/>
</xsl:stylesheet>
Inside-out raising of the Frankenstein Variorum collection
The adaptation to the raising function to process a container element node allows
for us to make changes to our TEI header. Beyond this, there are few differences between
our
generic inside-out raising example and the Frankenstein
stylesheet. One minor difference is that we use only one identity-transformation template,
and have not set a priority on the template rule to process the innermost elements.
We convert the Trojan marker attributes into an xml:id with an element constructor:
Element constructor to refactor @th:sID as
@xml:sid in Frankenstein
Outside-in processing
Once the inside-out algorithm has been defined and
understood, it is natural to wonder whether a mirror-image
version of the algorithm would be possible which works
from the outside in. Once the pairs of outermost start-
and end-markers have been identified, the function can be
called recursively not on the entire document but only on
the children of the outermost elements, in an
instantiation of a divide-and-conquer strategy; this
should (or so it seems) result in faster processing.
Our realization of this idea is imperfect
in that we have not found a way to find and raise
all outermost
elements in a sequence with a single call, the way
the template-matching rules of the inside-out
approach can raise multiple elements in a single
call to apply-templates. Instead,
we find the left-most start-marker and process it,
then recur to continue processing the remainder
of the sequence after the matching end-marker.
This results in two recursive calls for each virtual
element: one to handle the children of the newly
raised element, and one for its right-siblings.
The order in which elements are raised
is illustrated in the diagrams of
Figure 36
to
Figure 44.
Some steps are elided to save space.
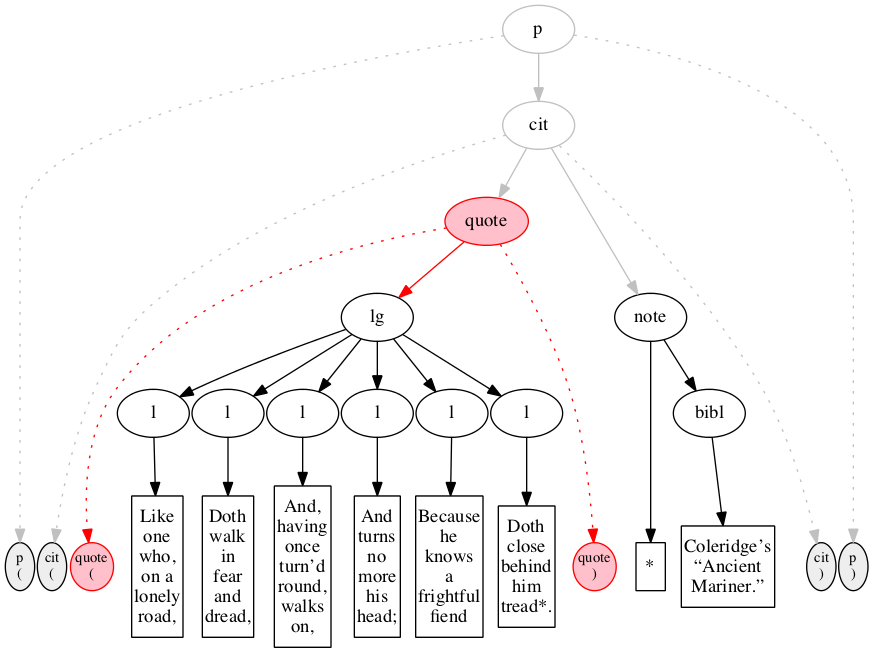
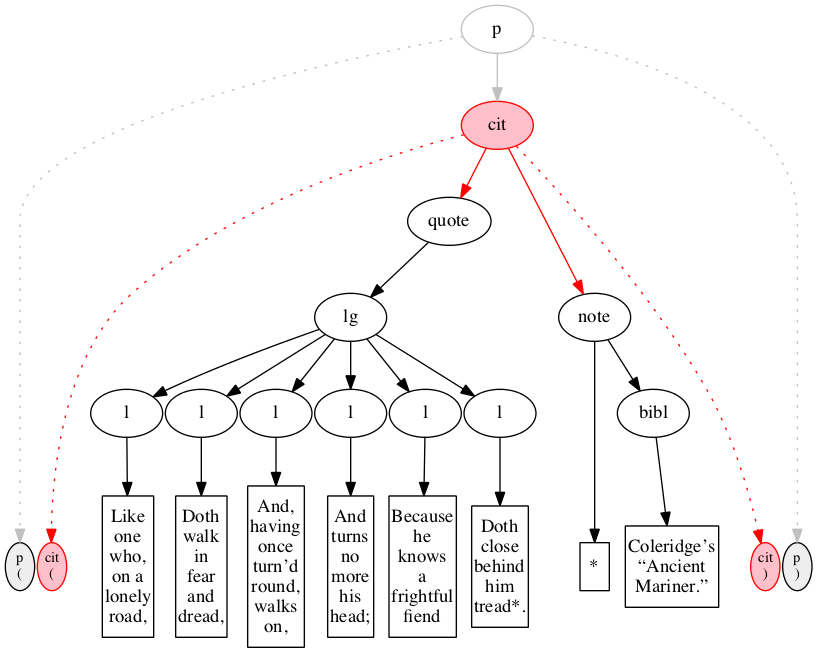
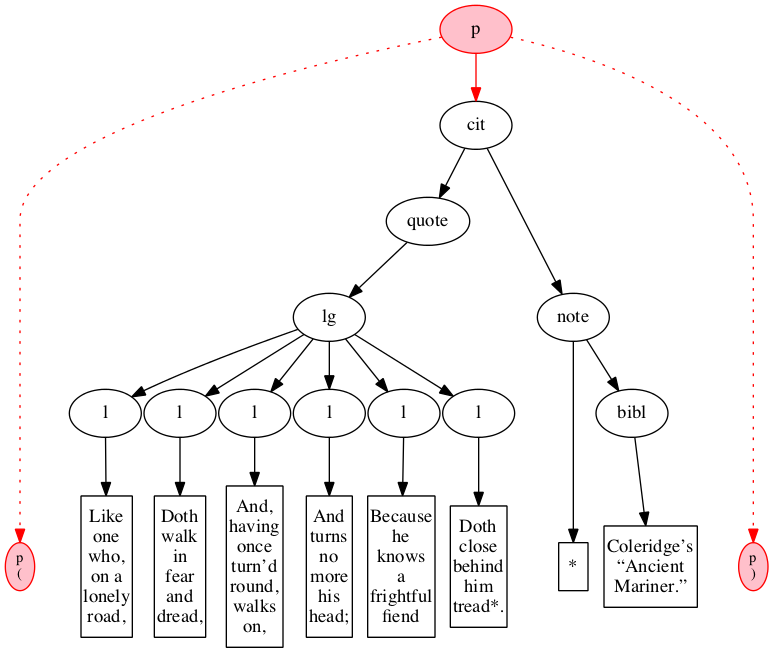
Figure 36
Illustration of outside-in handling of input.
The input is shown arrayed along the bottom of
the diagram: ovals filled with gray denote start- and
end-markers, rectangles denote text nodes. The gray
ovals above denote the logical hierarchy which is to
be constructed (visible to human observers even if not
visible to the software).
Figure 37
On the first pass, the outside-in algorithm
raises the leftmost outer element, here the paragraph.
Figure 38
On the first recursive call, outside-in raises elements
the citation (cit) element.
Figure 39
On the third call, an ideal outside-in algorithm
would raise both the quote element
and the note, but our implementation
raises just the leftmost of these.
Figure 40
The fourth call to outside-in continues the
depth-first traversal of the virtual tree.
Figure 41
The tenth call to the outside-in function raises the sixth and final verse line.
Figure 42
On the eleventh call, we reach the note element.
Figure 43
The final pass raises the bibl element.
Figure 44
In the final state, the outside-in algorithm has
raised all elements.
Code outline
The default handling for all nodes is
a shallow copy, as specified in the mode
declaration for the default mode:
Figure 45
<xsl:mode on-no-match="shallow-copy"/>
For content nodes, the function th:raise-sequence() is called on their
children. In the simple inputs we are dealing with, this template will match
only the document's outermost element; for the Frankenstein data, it will match
several others. At the time of this writing, we have not experimented to see
whether it would be faster to test for start- and end-marker children here.
The core of the implementation is the
th:raise-sequence function.
The function begins by creating lists of start- and end-markers (identified by their
co-indexing IDs), so that we can find not just the leftmost start-marker but the
leftmost start-marker with a matching end-marker in the
sequence. If there are no matching pairs in the sequence, the
sequence is returned without change. (This makes this implementation slightly
more robust in the presence of overlap than the implementation shown above of
the right-sibling traversal approach; we have not yet had time to update our
method of right-sibling traversal to rectify the inconsistency in implementation
philosophy.)
In the normal case, however, the function
will select the leftmost start-marker with a
matching end-marker, find the positions of the
start- and end-markers in the input, and then
partition the input sequence into three parts.
A call to apply-templates processes
nodes preceding the selected start-marker;
a recursive call to th:raise-sequence()
from within the raised elements processes the
nodes between the selected start- and end-markers;
a second recursive call processes the remainder
of the original sequence.
Figure 47
<xsl:function name="th:raise-sequence" as="node()*">
<xsl:param name="ln" as="node()*"/>
<!--* lidStarts, lidEnds: lists of IDs
* for start- and end-markers *-->
<xsl:variable name="lidStarts"
as="xs:string*"
select="for $n in $ln[th:start-marker(.)]
return th:id($n)"/>
<xsl:variable name="lidEnds"
as="xs:string*"
select="for $n in $ln[th:end-marker(.)]
return th:id($n)"/>
<xsl:choose>
<!--* base case: no start-marker / end-marker
* pairs present *-->
<xsl:when test="empty($lidStarts[. = $lidEnds])">
<!--* The sequence may contain elements
* with markers inside, so we apply
* templates, instead of just returning $ln *-->
<xsl:apply-templates select="$ln"/>
</xsl:when>
<!--* 'normal' case: take first start-marker
* with matching end-marker *-->
<xsl:otherwise>
<!--* find ID of first start-marker
* with matching end-marker *-->
<xsl:variable name="id"
as="xs:string"
select="$lidStarts[. = $lidEnds][1]"/>
<!--* find position of start- and
* end-markers with that ID *-->
<xsl:variable name="posStartEnd"
as="xs:integer+"
select="for $i in 1 to count($ln) return
if ($ln[$i]
[(th:start-marker(.)
or th:end-marker(.))
and th:id(.) eq $id])
then $i else ()"/>
<xsl:variable name="posStart"
as="xs:integer"
select="$posStartEnd[1]"/>
<xsl:variable name="posEnd"
as="xs:integer"
select="$posStartEnd[2]"/>
<!--* Apply templates to all items to
* left of start. These may include
* markers, but if so they are not
* matched and not raisable. They
* may also include elements which
* contain markers, so we need to apply
* templates, not just return them.
*-->
<xsl:apply-templates
select="$ln[position() lt $posStart]"/>
<!--* Raise the element and
* call raise-sequence() on its
* content. *-->
<xsl:copy select="$ln[$posStart]">
<!--* copy the attributes
* (filtering as needed) *-->
<xsl:sequence
select="$ln[$posStart]/(@* except @th:*)"/>
<!--* handle children *-->
<xsl:sequence
select="th:raise-sequence(
$ln[position() gt $posStart
and position() lt $posEnd])"/>
</xsl:copy>
<!--* call raise-sequence() on all items
* to right of end *-->
<xsl:sequence
select="th:raise-sequence(
$ln[position() gt $posEnd]
)"/>
</xsl:otherwise>
</xsl:choose>
</xsl:function>
A number of ancillary functions are
defined in the stylesheet and used in the
code shown above. They are shown
briefly here.
The th:start-marker()
and th:end-marker() functions
encapsulate the recognition criteria for
markers. (These forms are redundant with
those given elsewhere in this paper; we have
not yet eliminated the redundancy in our
demonstration code.)
The implementation shown calls the
th:raise-sequence() function
once for each virtual element. The cost of
the process should thus be roughly linear
in the number of virtual elements in the input;
that seems consistent with our timings of
XSLT processors.[9]
Each node in the original flattened sequence is
passed to the central as part of the argument sequence
once for each level of its distance from the root of the
virtual tree. In this, the outside-in approach is
indeed the mirror image of the inside-out approach.
The implementation of outside-in shown here is not, however, demonstrably faster than
our implementation of inside-out, despite the divide-and-conquer strategy. We
have not been able to perform measurements to explain the differences in run
time, but we can offer a couple of speculations. First, on our test data the
inside-out approach reduces the number of nodes faster than the outside-in
approach: in a typical XML tree there will be more leaf nodes than root nodes
(and more than that: in our test data the fanout increases with distance from
the root). Second, each call to the function traverses the input sequence
several times: once to find all start-marker IDs, once to find all end-marker
IDs, once to find the positions of the selected markers. Either or both of these
could explain a slow run-time.
Accumulators
Another approach to the problem avoids recursion by performing a single pass over
the input, maintaining a stack of partly-raised elements using the
accumulator construction
introduced in XSLT 3.0.
A bluffer's guide to accumulators
An accumulator is a sequence of values associated with the nodes of a tree. Each
node has two values:
a before value (calculated without
access to the values associated with any descendants, and thus calculable before
descendants are visited in a depth-first traversal of the tree)
an after value (which may depend on the values associated
with descendants and thus cannot be calculated until after they have been
visited).
The declaration of an accumulator specifies how to calculate the
before and after values to be associated with a node, given the after values
associated with the previous node and with the node’s last child. One simple way
to calculate all the values of an accumulator would be to visit each node in the
document in a pre-and-post-order traversal, determining the before value on the
first visit to a node and the after value on the second. When streaming
processing is requested, the calculation rules are not allowed to look ahead in
the document, but accumulators can be used whether or not streaming is
requested.
As a simple example, we can make an accumulator to keep track of the number of
open virtual elements at any given point in the flattened input document: when we
encounter a start-marker we will add one to the accumulated value, and when we
encounter an end-marker we will subtract one. An accumulator is declared using an
<xsl:accumulator> declaration, which contains a sequence of
<xsl:accumulator-rule> elements describing how the
accumulator’s values are calculated. Within an accumulator rule, the variable
$value gives the value of the accumulator assigned by the
immediately preceding node.
The pattern in the accumulator rules here assumes that start- and end-markers use
the @th:sID and @th:eID
attributes described above.
At any point in a tree to which this accumulator applies, we can refer to the
current node’s before value of the accumulator with the expression
accumulator-before('stack') and to the after value with
accumulator-after('stack').[10] Without accumulators, we could keep track of the relevant information by
replacing references to accumlator-before('stack') with references to
count(preceding::*[@th:sID]) -
count(preceding::[@th:eID]).
Implementation strategy
To solve the raising problem with accumulators, we declare an accumulator whose
value is an array (if the XPath 3.1 feature is supported) or a map, with which we
maintain a stack of virtual elements that have been started, but not finished. The
first member of the array will track the contents of the outermost element, the
second member will track the contents of a second-level virtual element, and so
forth. Each member of the array is a sequence of nodes containing a start marker
(the first item in the sequence) and all the nodes seen so far that should be
children of the raised content element.
The processing rules are relatively straightforward and may feel familiar to
anyone who has ever constructed an in-memory tree from a SAX event stream:
Each time we see a start-marker, we will push a new sequence onto the
stack.
Each time we see a text node, comment, processing instruction, or
content element, we will append it to the sequence on the top of the
stack.
Each time we see an end-marker, we will
Create a content element from the sequence on top of the
stack: the element type and attributes come from the
start-marker at $stack(array:size($stack))[1], and
the contents come from the rest of the sequence:
$stack(array:size($stack))[position() gt
1].
Pop the stack, i.e., discard the topmost member, whose purpose
has been served now it has been turned into a content
element.
Append the newly created content element to the sequence now
at the top of the stack.
Special handling is required for the case in which the element just
ending is at level 1 in the stack, because once the stack has been
popped there is no top level to which to append the new element, which
should be written to the output tree instead.
Some utility functions
In order to allow the stylesheet to be used with either the th:
attributes or with the ana="start|end" convention, we isolate the
definition of start- and end-markers in two functions we place in the
Trojan-Horse namespace:
Figure 51
<!--* th:trojan-start($e as element()): true iff $e is a Trojan
* start-tag we want to process.
*-->
<xsl:function name="th:trojan-start" as="xs:boolean">
<xsl:param name="e" as="element()"/>
<xsl:value-of use-when="$th-style = 'th' "
select="exists($e/@th:sID)"/>
<xsl:value-of use-when="$th-style = 'xmlid' "
select="ends-with($e/@xml:id,'_start')"/>
</xsl:function>
<!--* th:trojan-end($e as element()): true iff $e is a Trojan
* end-tag we want to process.
*-->
<xsl:function name="th:trojan-end" as="xs:boolean">
<xsl:param name="e" as="element()"/>
<xsl:value-of use-when="$th-style = 'th' "
select="exists($e/@th:eID)"/>
<xsl:value-of use-when="$th-style = 'xmlid' "
select="ends-with($e/@xml:id,'_end')"/>
</xsl:function>
Two functions to encapsulate the definition of markers
These functions rely on a static parameter that identifies the idiom in use
for markers.
A static parameter to control the definition of markers
Marking the parameter as static allows the choice among definitions to be made
during static analysis of the stylesheet (informally, at compile time) and not
with a dynamic (run-time) choose/when construction.
Another function constructs a content element from a sequence of nodes
beginning with a start-marker:
Figure 53
<!--* th:make-element($ln as node()+): make an element out of
* one stack entry *-->
<!--* We package this as a function because it's called from
* two different locations in the stylesheet *-->
<xsl:function name="th:make-element" as="element()">
<xsl:param name="ln" as="node()+"/>
<xsl:copy select="$ln[1]">
<!--* first copy (and filter) attributes *-->
<xsl:sequence select="$ln[1]/(@* except @th:*)"
use-when="$th-style = 'th' "/>
<xsl:sequence use-when="$th-style='xmlid'">
<xsl:sequence select="$ln[1]/@*"/>
<xsl:attribute name="xml:id"
select="replace($ln[1]/@xml:id, '_start$','')"/>
</xsl:sequence>
<!--* then copy children *-->
<xsl:sequence select="$ln[position() gt 1]"/>
</xsl:copy>
</xsl:function>
A function to construct a content element from a start marker and sequence
of nodes
The functions just presented are not specific to the use of
accumulators; they or analogous functions could be used in any of the XSLT
stylesheets described here. But most of the other code shown in the current
version of this paper does not use them; they are described here because the
other code in this section uses them and would be hard to understand if they
were not presented.
Declaring the accumulator and making it applicable
The overall pattern of accumulator declarations was shown above, and the
declaration for an accumulator to be used as a stack follows the same pattern,
though the rules are slightly more complex.
Figure 54
<!--* Declare stack accumulator to keep track of contents. *-->
<!--* Start with empty array. *-->
<xsl:accumulator name="stack" as="array(node()*)"
initial-value="[]"
streamable="yes"
>
<!--* On Trojan start-tag, push the start-tag onto the stack *-->
<xsl:accumulator-rule match="*[th:trojan-start(.)]"
select="array:append($value, .)"/>
<!--* On Trojan end-tag, make the currently pending element,
pop the stack, and insert the pending element at the
end of the new top item. *-->
<xsl:accumulator-rule match="*[th:trojan-end(.)]"
phase="end">
<xsl:variable name="level" as="xs:integer"
select="array:size($value)"/>
<xsl:variable name="e" as="element()"
select="th:make-element($value($level))"/>
<xsl:choose>
<xsl:when test="$level eq 1">
<!--* at outermost level, we have no previous
level to add anything to, so we just pop the
stack. *-->
<xsl:sequence select="[]"/>
</xsl:when>
<xsl:otherwise>
<xsl:sequence select="array:put(
array:remove($value, $level),
$level - 1,
($value($level - 1), $e))"/>
</xsl:otherwise>
</xsl:choose>
</xsl:accumulator-rule>
<!--* On any other node, append current node
* to the top sequence in the stack *-->
<xsl:accumulator-rule
match="node()[not(self::element())
or (not(th:trojan-start(.))
and not(th:trojan-end(.)))]"
select="for $level in array:size($value) return
if ($level eq 0)
then []
else array:put(
$value,
$level,
($value($level), .))"/>
</xsl:accumulator>
Declaration of an accumulator to be used as a stack
Since accumulators were introduced largely to support the streaming processing
of very large inputs, and since the pointless calculation of accumulator values
would make that processing unnecessarily difficult, XSLT 3.0 requires that any
accumulators be associated more or less explicitly with an input tree or a mode.
If the accumulator is not made applicable to a given tree in this way,
references to the accumulator-before() and
accumulator-after() functions will raise errors.
We handle that by declaring the default mode of the stylesheet and adding a
@use-accumulators attribute naming the accumulators to be
calculated:
Figure 55
<!--* declare default mode; we make it fail on no match
* because it turns out we need templates for all nodes.
*-->
<xsl:mode on-no-match="fail"
use-accumulators="stack"
streamable="yes"/>
Declaration of mode with @use-accumulators
Note that the streamable="yes" is not required unless streaming
processing is to be requested.[11]
Templates
The templates in this stylesheet have very little work to do: their primary
task is to override the default templates and ensure that nodes are not copied
unnecessarily to the output tree.
The template for start-markers does nothing; all the work is handled by the
declaration of the accumulator.
Figure 56
<!--************************************************
* 1. Virtual start-tags
************************************************-->
<xsl:template match="*[th:trojan-start(.)]" priority="10">
<!--* Nothing to do, all the work
* is done by the accumulator *-->
</xsl:template>
Template for start-markers
The template for end-markers is more complicated, because it must handle the
case where the end-marker marks the end of an outermost virtual element. The
normal accumulator rules cannot handle this case, because they write the newly
constructed element into the new top member of the stack. But after we pop the
stack at level one, the stack is empty and there is no top member. So we need to
make the element and write it to the output tree ourselves. In all other cases,
this template has no work to do.
Figure 57
<!--************************************************
* 2. Virtual end-tags
************************************************-->
<xsl:template match="*[th:trojan-end(.)]" priority="10">
<xsl:choose>
<xsl:when
test="array:size(accumulator-before('stack')) eq 1">
<!--* if this end-tag ends the outermost element,
* emit the element *-->
<xsl:sequence
select="th:make-element(accumulator-before('stack')(1))"/>
</xsl:when>
<xsl:otherwise>
<!--* Otherwise, nothing to do *-->
</xsl:otherwise>
</xsl:choose>
</xsl:template>
Template for end-markers
The template for the document node is identical to the default template; it is
made necessary by the specification on-no-match="fail" on the mode
declaration.
Figure 58
<!--************************************************
* 3. All other nodes
************************************************-->
<!--* 3.1 Document node *-->
<xsl:template match="/">
<xsl:apply-templates/>
</xsl:template>
Template for document node
The templates for other nodes make the same distinction as that for
end-markers: when the stack is empty, the node is copied to the output tree, and
otherwise all the work is left to the accumulator.
Figure 59
<!--* 3.2 Non-marker element nodes *-->
<xsl:template match="node()[self::element()
and not(th:trojan-start(.))
and not(th:trojan-end(.)) ]">
<!--* If we are outside the flattened area, copy the node;
* otherwise, do nothing and leave everything
* to the accumulator *-->
<xsl:choose>
<xsl:when
test="array:size(accumulator-before('stack')) eq 0">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:apply-templates/>
</xsl:copy>
</xsl:when>
<xsl:otherwise/>
</xsl:choose>
</xsl:template>
Template for content elements (or non-selected markers)
Figure 60
<!--* 3.3 Non-element nodes *-->
<xsl:template match="node()[not(self::element())]">
<!--* If we are outside the flattened area, copy the node;
* otherwise, do nothing and leave everything
* to the accumulator *-->
<xsl:choose>
<xsl:when
test="array:size(accumulator-before('stack')) eq 0">
<xsl:sequence select="."/>
</xsl:when>
<xsl:otherwise/>
</xsl:choose>
</xsl:template>
Template for non-element nodes
Regex
It is not, in general, advisable to attempt to process arbitrary XML solely with
regular expressions (regex), but it is not difficult to identify and process markers
of the kind we are concerned with here.[12]
The following regex matches start-markers:
Figure 61
(<[^>]+?)th:sID\s*=\s*['"]\w+?['"](.*?)\/(>)
Regex to match start-markers
The regex works as follows (in dot-all mode, that
is, where dot also matches \n):
The first capture group matches everything from the beginning of a tag
that contains a @th:sID attribute until that attribute
name. This necessarily includes the space that precedes the attribute
name, as well as any attributes that might also precede it.
We do not capture any part of the @th:sID attribute: the
attribute name, the equal sign (with optional whitespace before or
after), the quotation mark value delimiter (single or double), the
attribute value (all characters up to the closing value delimiter), and
the closing value delimiter. As long as the @th:sID and
@th:eID values are created with the XPath
generate-id() function, they cannot contain single or
double quotation marks (generate-id() creates only values
that are XML names), so we do not need to verify that the opening and
closing delimiters match each other lexically.[13]
The second capture group captures everything following the
@th:sID attribute up to the /> that
marks the end of the tag.
We replace all matches with the following
replacement pattern:
Figure 62
\1\2\3
Replacement pattern for start-markers
The regex to match end-markers is similar to the one for start-markers, and
because real end-tags cannot contain attributes, we do not need to match or copy
them. We capture the opening < separately from whatever follows it,
so that we can write a / into the replacement after it. The regex
is:
Figure 63
(<)(\S+?)\s+[^>]*?th:eID=['"]\w+['"][^>]*?\/(>)
Regex to match end-markers
and the replacement pattern is:
Figure 64
\1/\2\3
Replacement pattern for end-markers
This method will incorrectly apply the replacement to matching patterns within XML
comments and CDATA marked sections. With insincere apologies for disappointing Regex
Edge-Case Bounty Hunters, coping with matches in these contexts, which would not
naturally appear in our data, is not a goal in our work.[15]
A more serious limitation of this method is that because it is not XML-aware, it
can be used only in situations where raising is guaranteed not to create overlap.
For example, given input like:
Figure 65
<?xml version="1.0" encoding="UTF-8"?>
<root xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse">
<page th:sID="page1"/>
<para th:sID="para1"/>Content on page 1 in paragraph 1
<page th:eID="page1"/>
<page th:sID="page2"/>Content on page 2 in para 1
<para th:eID="para1"/>
<para th:sID="para2"/>Content on page 2 in para 2
<para th:eID="para2"/>
<page th:eID="page2"/>
</root>
XML that cannot be unflattened without creating overlap
the result of converting all markers to real start-
and end-tags would be:
Figure 66
<?xml version="1.0" encoding="UTF-8"?>
<root>
<page>
<para>Content on page 1 in paragraph 1
</page>
<page>Content on page 2 in para 1
</para>
<para>Content on page 2 in para 2</para>
</page>
</root>
Invalid (overlapping) result of converting all markers to real start- and
end-tags
The resulting document is not well-formed because the pages and paragraphs
overlap. It is, however, possible to raise just pages but not paragraphs, or just
paragraphs but not pages, without creating overlap, and the result would be
well-formed.
Pull parsing in Python
The Python xml.dom.pulldom module can be used to stream an XML
document past an event handler that can be instructed to raise a flattened hierarchy.[16] The result of pull parsing can be fashioned into output in two ways,
as a string or as XML. With string output, it passes all events through unchanged
except for markers, which it replaces with regular XML start- and end-tags. Because
the output construction is not XML-aware, it has the same limitations as the regex
approach: most significantly, it is capable of creating output that includes
overlap, and that therefore is not well formed XML. With XML output, though, we use
xml.dom.minidom to create XML elements within a DOM structure,
which means that the result is necessarily well-formed. Pull parsing operates as a
single traversal, which is to say that it begins at the document node and touches
each element only once. With string output, the procedure can create write output
as
it handles each event; with XML output it is necessary to maintain the current
context in a stack, which is similar to the use of a stack in the Accumulators method described above.[17] The maximum depth of the stack is equal to the maximum depth of nesting
in the hierarchical XML.
String output
The following Python 3 code replaces markers with strings equivalent to real
XML start- and end-tags:
Figure 67
import sys
from xml.dom.pulldom import CHARACTERS, START_ELEMENT, parseString, END_ELEMENT
def entities(input):
return input.replace('&', '&').replace('<', '<').replace('>', '>')
output = []
with open(sys.argv[1], 'r') if len(sys.argv) > 1 else sys.stdin as input:
for event, node in parseString(input.read()):
if event == START_ELEMENT:
if node.hasAttribute('th:eID'):
# Trojan end tag
output.append('</')
else:
# Trojan start tags and non-Trojan elements
output.append('<')
output.append(node.nodeName)
for attname, attvalue in node.attributes.items():
# remove Trojan attributes and namespace declaration
if not (attname.startswith('th:') or attname == 'xmlns:th'):
output.append(' ' + attname + '="' + attvalue + '"')
output.append('>')
if event == END_ELEMENT:
if not (node.hasAttribute('th:sID') or node.hasAttribute('th:eID')):
# non-Trojan only
output.append('</' + node.nodeName + '>')
elif event == CHARACTERS:
output.append(entities(node.data))
print("".join(output))
Python code that constructs the XML output as a string
We create an empty list to hold the output, read in the source, and examine
each event. In this simplified example, we process only
START_ELEMENT, END_ELEMENT, and
CHARACTERS, as follows:
START_ELEMENT. Markers with @th:eID
attributes are flattened end-tags, so when we encounter one, we output
</; for other START_ELEMENT events we
output only <. We follow this with the gi
(node.nodeName) and then iterate over the attributes.
For each non-Trojan attribute, we output a space, the attribute name, an
equal sign, and the attribute value in quotation marks. Finally, we
output the closing >.
END_ELEMENT. Although markers are sole-tags, they fire
both START_ELEMENT and END_ELEMENT events.
Since we process all markers at their START_ELEMENT events,
we ignore their END_ELEMENT events. For other
END_ELEMENT events, we create a regular end-tag.
CHARACTERS. We add character data content to the output,
explicitly replacing reserved characters with XML entities.
We are parsing the input XML in an XML-aware manner, which is reasonably
robust, but we are constructing the output XML as a string, which is not. See
below section “Pull parsing in Python” for a discussion of the limitations.
XML output
The general approach to parsing with pulldom and constructing
output with minidom is similar to the Accumulators method described above. Specifically, the flattened XML is traversed in a
single pass from left to right (technically a depth-first traversal, which is
how pulldom sees it) and events (we focus on
START_ELEMENT, END_ELEMENT, and
CHARACTERS) are handled as they occur. The output is assembled
in memory as a tree, using minidom to create and attach nodes as
needed. Open elements are stored on a stack, the maximum depth of which is,
therefore, equal to the maximum depth of the unflattened XML. The code
is:
Figure 68
from xml.dom.pulldom import CHARACTERS, START_ELEMENT, parseString, END_ELEMENT
from xml.dom.minidom import Document
class Stack(list):
def push(self, item):
self.append(item)
def peek(self):
return self[-1]
open_elements = Stack()
d = Document()
open_elements.push(d)
with open('flattened.xml') as input:
for event, node in parseString(input.read()):
if event == START_ELEMENT:
if not node.hasAttribute('th:eID'): # process pseudo-end-tags on END_ELEMENT event
open_elements.peek().appendChild(node)
open_elements.push(node)
elif event == END_ELEMENT:
if node.hasAttribute('xmlns:th'): # don't declare now-unused th: namespace
node.removeAttribute('xmlns:th')
if node.hasAttribute('th:sID'): # can't remove @start until we're done with the node
node.removeAttribute('th:sID')
else: # pop only on container elements and Trojan end-tags
open_elements.pop()
elif event == CHARACTERS:
t = d.createTextNode(node.data)
open_elements.peek().appendChild(t)
print(open_elements.pop().toxml())
Raising with python using pulldom
Parsing is the same as described above, so we import the same items from
pulldom. From minidom we import only the
Document class, which we use to initialize our output XML
document. Our Stack class is a Python list adorned with
stack-idiomatic terminology: we alias append() as
push() (lists already have a pop() method), and we
add peek() to provide access to the item at the top of the stack.
That top item is the most recently opened element, and we peek at it in order to
append child elements and child text() nodes as we encouter them.
We begin by pushing the document node onto the
stack.
We handle START_ELEMENT, END_ELEMENT, and
CHARACTERS events in an if/elif/elif structure,
silently ignoring other events. There are three types of elements whose start
and end events we need to process: start-markers, end-markers, and regular
elements (whether empty or not).
In the case of start-markers and regular elements, we append the new
node as a child of the item at the top of the stack (initially the
document node; thereafter an element node) and then push the node onto
the stack so that it becomes the new context element. The
appendChild() and push() operations serve
different but related purposes. Appending the new node to the current
context (whatever is at the top of the stack) adds it to the correct
location on the eventual output tree. Pushing it makes it the new
current context, so that subsequent nodes will be added to it as
children as long as it remains the current context. Nodes are
passed by reference, rather than by value, so after these operations we
point to the same new current node from three places:
the original input document,
the top of the stack
the location in the tree we are
assembling under the output document node, which is at the bottom of the
stack.
We ignore START_ELEMENT events for end-markers; all of
their processing happens on their END_ELEMENT event. This
is a somewhat arbitrary decision.
The three mutually exclusive clauses in the if/elif/elif
block that processes END_ELEMENT events work as
follows:
minidom treats namespace declarations as
attributes, so the presence of an attribute with the name
xmlns:th identifies the root note.[18] In our examples we are raising all markers, and
therefore removing all attributes in the Trojan namespace, so we
remove this declaration to avoid the clutter of an unneeded
namespace declaration in the output. Because we identify Trojan
attributes by their lexical shape (that is, by the presence of
an explicit th: prefix), removing the namespace
declaration early in the processing does not impinge on our
ability to identify attribute instances that use the prefix.
Because we never pop the root element, it will be at the top of
the stack when our processing concludes.
We remove the Trojan @th:sID attribute from the
start-marker. We want to remove it eventually because it is not
needed in the output, but we cannot remove it until the
END_ELEMENT event of the start-marker because
its presence tells us not to pop the stack at that
END_ELEMENT event. In this way we push the
element we are currently raising onto the top of the stack at
its start-marker, but we remove its Trojan attributes only when
we pop it at the END_ELEMENT event of the
end-marker.
The first two clauses process the root element and
start-markers, both of which we leave on the stack after their
END_ELEMENT events. In the remaining cases
(end-markers and regular elements, whether empty of not), we pop
the stack at the END_ELEMENT event, which makes its
parent in the output tree where we are constructing the current
context for the next event.
In the case of CHARACTERS, we create a
text() node and append it as a child of the current
context, that is, the element at the top of the stack. When we wrote
string output earlier we had to convert reserved characters to character
entities ourselves, but in this case we are writing XML output, so the
system automatically performs the entity encoding for us.
Conceptually, the entire start-marker functions as if it were the
START_ELEMENT event for a regular element, and the entire
corresponding end-marker functions as if it were the END_ELEMENT
event for the same regular element. This means that we push a start-marker on
its START_ELEMENT event (ignoring its END_ELEMENT
event, except to remove its Trojan attribute), and pop it on the corresponding
end-marker’s END_ELEMENT event (ignoring its
START_ELEMENT event). In tabular
form:
Table II
Element type
START_ELEMENT
END_ELEMENT
Regular
Push
Pop
Start-marker
Push
Remove @th:sID
End-marker
Ignore
Pop
Some things that can go wrong
Each of the methods described above comes with its own complications, and it was in
the discussion of these complications that this paper originated. Some of these are
challenges that can be overcome, others are limitations in what the method can manage,
and others are deal-breakers that show that the method is not ultimately suitable
for
realistic use cases. In this section we review briefly the complications for each
method.
Right-sibling traversal
Two elusive bugs in an initial implementation of the right-sibling traversal
algorithm took the better part of a day or two to identify:
It is remarkably easy to write
select="following-sibling::node()" instead of
select="following-sibling::node()[1]", and remarkably easy
to overlook the error when scanning the code looking for the reason that the
output is an order of magnitude larger than the input instead of
approximately the same size. The symptom is that single nodes in the input
appear more than once in the output.
Similarly, it is remarkably easy to write <xsl:apply-templates
select="..."/> instead of <xsl:apply-templates
select="..." mode="raising"/>. The symptom is the reverse
of the preceding: some nodes in the input drop out of the output.
[Fuller examination of the version-control history of the stylesheets will
probably reveal further errors, a discussion of which may be
illuminating.]
Inside-out recursion
The two principal pitfalls with inside-recursion are double
processing and endless
recursion.
Double processing
When a start-marker is matched and raised, the nodes that belong inside the
new container are copied into it inside the template that matches the
start-marker. Because the nodes being copied are also candidates for the
application of templates in the current pass through the function, we need to
match them (along with the end-marker) in an empty
<xsl:template> in order to avoid outputting them twice.
Otherwise they would be copied when the start-marker is matched and then
processed again when templates are applied to them in their own right.
Endless recursion
Recursion requires an exit condition to avoid falling into an endless loop. In
an early version of the code, the recursive function tested for the presence of
Trojan milestone attributes, and if there weren’t any, it concluded that all
raising had been completed and stopped the recursion. This test fails in
situations where there are Trojan elements that cannot be raised without
creating overlap. Avoiding the endless loop in such situations requires a more
complex test, not just for the presence of Trojan attributes, but for the
presence of those that can be raised without creating overlap. In our simplified
sample, instead of testing for exists($input//@th:sID), we test for
elements that can be raised without risk of overlap with:
Test for markers that can be raised without creating overlap
Endless recursion is not an issue in situations where complete raising would
not create overlap. This is the case with our original simplified sample, where
the XML with Trojan markup was created by flattening original hierarchical XML,
and since the original could not have had overlap, it can be reconstructed
safely. Endless recursion is also not a problem when we raise only a subset of
the markup that is guaranteed not to overlap. For example, if we have
tessellated page and paragraph hierarchies over a prose text, where both pages
and paragraphs have been flattened, we cannot fully raise all instances both
types of elements if doing so would create overlap. But if our markup convention
is that pages cannot overlap with pages and paragraphs cannot overlap with
paragraphs, we can modify the raising routine to raise only the pages or only
the paragraphs. See also Appendix A, where we discuss an
alternative approach to raising with data of this type.
Accumulators
The primary problems we encountered in our implementation using accumulators were:
Failure to use a fully implemented XSLT 3.0 processor. Initial tests
used Saxon HE 9.6.0.5, which does not complain or warn about
version="3.0", but which appears not to support all of
the 3.0 constructs used. The main symptom was an error message reporting
that XTSE0010: Element xsl:mode must not appear directly within
xsl:stylesheet (which led to a wild goose chase through the
3.0 spec trying to locate constraints on where mode declarations are
allowed), followed unobtrusively by the message XTSE0010: Unknown
XSLT element: mode. Upgrading to Saxon 9.8.0.12 solved this
problem.
Failure to specify @use-accumulators.
The next problem was the persistent repetition of the error message
Accumulator stack is not applicable to the current
document. Several attempts of increasing complexity (and, to
be honest, decreasing plausibility) to make it applicable failed, until
eventually it became clear that the only thing needed was to specify
use-accumulators="stack" on the mode declaration for
the default unnamed mode. (The mode declaration was already present; had
it not been, it would have needed to be introduced.)
Regex
The principal challenge to writing the regex (aside from the risk of inadvertently
creating XML that is not well-formed because of overlap, which is discussed above)
is anticipating variation in the markup. For example, an XML start-tag with a single
attribute looks like <gi attname="value">, but it allows optional
whitespace around the equal sign and before the closing >
delimiter—but not between the opening < delimiter and the generic
identifier, and not between the / and the > at the end
of a self-closing empty tag. Where it allows whitespace, it allows any amount of any
combination of whitespace characters.
Within the context of a single project, the easiest way to deal with the allowable
variation is not to allow it, that is, to enforce rigorous consistency even where
XML syntax does not require it. But because rigorous consistency is difficult to
achieve without computational validation, we opted for a more robust regex—that is,
one more accepting of variation, even though allowing for variation made the regex
harder to read and develop.
The regex expressions needed to raise Frankenstein are slightly more complex because they may or may not coexist with other attributes
on a given element node.
Pull parsing in Python
The Python pull parser reads the input XML as XML and responds to parse events. We
handle START_ELEMENT, END_ELEMENT, and
CHARACTERS, and ignore other events, and we use XML-aware methods
to access attributes. With respect to managing the input, then, this is a reasonably
robust strategy. The quality of the output handling depends on whether we create
output as a string or as an XML DOM.
String output
Creating XML output as a string is a brittle strategy. Not only is it
susceptible to writing overlapping tags for the same reason as the regex method
described earlier, but we also explicitly wrap attribute values in double-quote
characters ("), which will produce results that are not well-formed
if the attribute value happens to have contained the double-quote character
originally. Python has an escape mechanism that is capable of dealing with
awkwardly nested single- and double-quote characters in strings, as does XML,
but the Python escape strategy is different from the XML one, and the code to
perform the string manipulation needed to mediate between the two is difficult
to read and write. Furthermore, where output is created as a string, we have to
replace reserved characters with character entities explicitly ourselves, while
XML-aware output does that automatically. For those reasons, it is safer to use
XML methods to create the XML output as a (necessarily well-formed) DOM tree,
which can then be serialized, instead of creating the output directly as a
string. The use of pulldom to parse the input XML also requires
accommodations to the peculiarities of pulldom namespace handling,
which are discussed immediately below, under Python XML output challenges.
XML output
Generating XML output with Python minidom is reasonably robust
and straightforward, but potentially confusing for the following reasons:
The pull parser responds not to start- and end-tags, but to
START_ELEMENT and END_ELEMENT events.
Although markers are single tags (sole-tags), they fire both events, one
immediately after the other. Since a start-marker and an end-marker both
fire both types of events, dealing with the two different senses of
start and end (marker vs event) simultaneously is potentially
confusing for the developer. We also need to decide whether to process
the marker at the START_ELEMENT or END_ELEMENT
event, or to divide the processing of a marker over the two events.
Since the two events always follow each other immediately, it might seem
not to matter, but that assumption led us into error when dealing with
removing Trojan attributes, about which see the following issue.
Attributes in minidom are part of a dictionary-like
property of the element node. We had decided (somewhat arbitrarily) to
process start-markers at the START_ELEMENT event, and we
wanted to remove Trojan attributes from those elements when we raised
them. Initially we removed them when processing the
START_ELEMENT event without noticing that we use them
as part of the decision process on END_ELEMENT events.
Because minidom objects are mutable, once we had removed
the attribute at the START_ELEMENT event it was no longer
available when we needed to test for it at the END_ELEMENT
event, which led to errors in our stack management. We fixed the problem
by removing the Trojan attributes only at the END_ELEMENT
event. An alternative strategy, which also worked under testing, was to
clone the node at the START_ELEMENT event, remove the
Trojan attributes from the clone, and add the clone to the output tree
and the stack. Since this approach does not remove anything from the
original node, any original Trojan attribute is still available for
testing when the END_ELEMENT event fires.
The relationships among namespaces, namespace prefixes, and namespace
declarations in minidom are alien to the XML view of
namespaces. While minidom is namespace-aware at the level of the
model, that awareness is not integrated with the serialization
supported by the toxml() method (and some others). Here is
a partial summary of the details:
Whether minidom writes a namespace prefix into a
serialization depends only on whether the prefix was specified
when the element was created. It has nothing to do with whether
the element is really in a namespace. It is possible to create
and serialize an element with a namespace prefix that is not
really in the namespace. It is also possible to create an
element in a namespace without a prefix and when you serialize
it, it will emerge without a prefix even if the namespace is not
in scope, which means that when the serialization is parsed
downstream, the element will be in whatever the default
namespace is for its context.
minidom will not write namespace declarations
(default or prefix-binding) unless you create them explicitly as
attributes. This means that you can create an element with a
prefix and serialize output where the prefix is not actually
declared, which is not well-formed.
minidom will let you create and serialize an
element with a namespace prefix with
createElement() even though the element is not
really in a namespace. An element is in a namespace only if it
is created with createElementNS().
Because pulldom and minidom are essentially
blind to namespace declarations, this also means that when we remove the
declaration of the Trojan namespace while processing the root element
(which changes the in-memory tree because pulldom and
minidom objects are mutable), we can nonetheless still
find Trojan attributes by their lexical shape, that is, by their
explicit prefixes. It also means that our code is depending on those
lexical forms: we rely on the presence of an explicit declaration of the
Trojan namespace prefix only on the root element, and we rely on the use
of the string th: as the namespace prefix. This means that
XML that expresses the same namespace information in different ways
(e.g., by binding a different prefix to the namespace URI, or by using
namespace declarations on individual elements, instead of a prefix) will
not be processed correctly.
These pulldom and minidom behaviors are
far from XML-idiomatic, but except for the syntactic dependencies they
impose (where namespaces are declared, how the declarations are spelled,
how they are bound to prefixes), they prove not to be much of a
practical obstacle during processing. The required accommodation entails
writing namespace prefixes and namespace declarations (using
attribute-like syntax) explicitly where we want them in the output, and
matching namespaced elements and attributes with the prefix where it is
used in the serialized input and without the prefix where it is
not.
Comparison
The inside-out recursive approach (both the function-based XSLT 3.0 version and
named-template-based XSLT 1.0 one) is tail-recursive, which means that an XSLT processor
that performs tail-call optimization will not be at risk for running out of stack
space.
In cases where tail-call optimization is not available, the maximum depth of recursion
is equal to the depth of the deepest marker in the
input (pseudo-)hierarchy. The right-sibling traversal approach (both the XSLT 3.0
and
the XSLT 1.0 versions) is also tail-recursive, and with an XSLT parser that does not
perform tail-call optimization, it requires stack space equal to the maximum width of the widest
hierarchical level.
Insofar as an open-source XSLT 3.0 processor that performs tail-call optimization
is
freely available in the open-source, platform-independent Saxon-HE product [Saxon-HE], the difference in stack requirements between the two methods has
not been a consideration for our purposes. But insofar as XML documents of the sort
that
are of interest to digital humanists are typically wider than they are deep, users
who
are unable to employ an XSLT processor that performs tail-call optimization may favor
inside-out processing over right-sibling traversal because inside-out processing is
likely to require less stack space.
Developing the XSLT to reconstruct elements from the inside out may be more efficient
than to do so from the outside in. Attempts to write code that does not control the
order of processing must always account for the potential presence of intervening
nodes
to be reconstructed on the inside, that risk becoming duplicate (or triplicate, or
quadruplicate, etc) nodes in the output depending on the depth of the hierarchy to
be
reconstructed.
[Comparison of other methods to be added]
Conclusion
None of the methods described here is new, but their explicit juxtaposition,
comparison, and evaluation in a tutorial context based on real use cases has clarified
much about micropipelining for the author, and, it is hoped, for the reader, as
well.
Appendix A. Raising tessellated hierarchies
Raising tessellated hierarchies is a common requirement for hierarchy inversion.[19] Consider a simple printed document that can be understood as containing a
sequence of pages or a sequence of paragraphs, where each sequence fully covers the
content without self-overlap, but where the two different element types overlap in
a way
that makes it impossible to use container elements for both. One typical XML workflow
with such structures involves encoding one hierarchy with XML container elements and
the
other with milestones. For example, a novel transcribed from an original source and
encoded in TEI
might be structured with <div> elements for chapters, which contain
<head> elements for chapter titles and <p>
elements for paragraphs, with page beginnings encoded as empty <pb/>
elements. If it later becomes necessary to operate on the pages as units, we can
invert the markup by transforming the
page-beginning milestones into page container elements, while flattening the elements
that demarcate chapters, titles, and paragraphs.
The method described in this appendix differs from those described above because it
works only where the hierarchy being raised is tessellated. That outcome requirement
invites the use of <xsl:for-each-group>, which partitions its entire
domain exhaustively into groups. The same property that makes
<xsl:for-each-group> suitable for a situation where an entire
text may be partitioned into tessellated paragraphs or tessellated pages makes it
a poor
choice for the contexts described in the body of this report, where new container
elements must be created only around small islands of content.
[Sperberg-McQueen 2018]
Sperberg-McQueen,
C. M.
Representing concurrent document structures using Trojan Horse markup.
To be
presented at Balisage: The Markup Conference 2018,
Washington, DC.
On the Web in the preliminary proceedings.
[2] Ideally, all the outermost elements in the
input sequence would be recognized and processed
in a single call to the function, but we have not
found a way to achieve this.
[3] This particular kind of “raising” from text strings is slightly tangential to the
methods we concentrate on this paper, but we include some discussion of it because
it is part of the practical use-case prompting our work on this paper, and is likely
to be a stage in other projects that require elements to be flattened and raised.
The complete XSLT stylesheet for this process is in the Frankenstein Variorum GitHub repository, and the stylesheet itself is part three series of transformations in our raising process that may be found
in the parent directory, which also holds its input and output directories.
[4] Using different formats for the markup of different flattened elements
makes it easy to raise one group of flattened element types while leaving
another in its flattened stage. Alternatively, we could use the same
attributes for all flattened elements and specify which ones we wanted to
raise at the processing stage. Sperberg-McQueen 2018 proposes a
th:doc attribute for identifying a start- or end-marker as
belonging to a particular hierarchy.
[6] If the flat content is contained not in the outermost element but in some other container
element, all nodes outside the flattened region can be copied to the
output without change. In this case the template for the container
element will be responsible for shifting from the mode for identity
transformation to the mode for element raising, and will have a more
selective match pattern.
[7] And even those who don’t admit to finding it difficult may find it easy to slip up
in
the details when implementing a right-sibling traversal; see below
(section “Right-sibling traversal”).
[8] Attributes in the th: namespace are removed
from markers when they are converted to tags during
raising.
[9]
In an experimental implementation of
inside-out and outside-in using tumbling
windows in XQuery, on the other hand, the
two approaches differ dramatically in run
time, and the costs do not appear to be
linear. We do not currently have good
data on this or any explanation.
[10] In streaming processing, references to the after value can only be located
after any <xsl:apply-templates> or other expression that
requires that descendants be processed.
[11] Despite Saxon’s apparent belief to the contrary, the declarative
statement that the accumulator is streamable does not constitute a
request that the XSLT processor perform streaming processing of the
input. It is merely a claim that streaming processing is possible.
[12] In terms of the Chomsky hierarchy, XML is a Type 2 (context-free) grammar
and regular expressions are a Type 3 (regular) grammar. Parsing a
context-free grammar, which permits recursion, requires a stack, which is
not available in regular grammars. While some modern regular expression
implementations support back-referencing and recursion and thus go beyond
the limitations of a Chomsky regular grammar, whether methods that rely on
these extensions should be considered regular-expression parsing is unclear
(this is a theoretical issue), as is the role of legibility in evaluating
the suitability of the method to the task (this is a practical
concern).
[13] “The returned identifier must consist of ASCII alphanumeric
characters and must start with an alphabetic character. Thus,
the string is syntactically an XML name.” [XPath functions, §14.5.4]
[14] Forward slash has to be escaped in some regex implementations,
but not in others. Escaping where it is not required does no
harm.
[15] Similarly, we rely on the use of th: as the namespace prefix
and th:sID and th:eID as the attribute names for
our Trojan attributes. Changing these assumptions is not a problem as long
as the regex is changed to match.
[16] The authors are grateful to Ronald Haentjens Dekker for bringing this
method to our attention. The example at his
https://github.com/rhdekker/python_xml_pull_parser_example
GitHub repository is a partial model for the examples here, and we
appreciate his assistance in debugging the Trojan attribute pitfall
described below under Python XML output challenges.
[17] We buffer output by writing it to a list, which we stringify and write all
at once at the end, saving the overhead of repeated write operations. With
large documents and low memory, though, the method can easily be modified to
stream the output to the filesystem.
[18] It is legal to declare namespaces redundantly even
where their declarations are already in force because
they are inherited from a higher level in the tree. If
accommodating a redundant declaration of the
th: namespace is required, the code
could be modified to do that by revising the
if/elif/elif logic.
[19]Tessellated structures cover an entire domain
with the same pattern without gaps or self-overlap, much as mosaic tiles might
cover an entire floor.
DeRose, Steve. 2004. Markup
Overlap: a review and a horse. Presented at Extreme Markup Languages 2004. Montréal,
Québec, August 2-6, 2004.
http://xml.coverpages.org/DeRoseEML2004.pdf
Sperberg-McQueen,
C. M.
Representing concurrent document structures using Trojan Horse markup.
To be
presented at Balisage: The Markup Conference 2018,
Washington, DC.
On the Web in the preliminary proceedings.