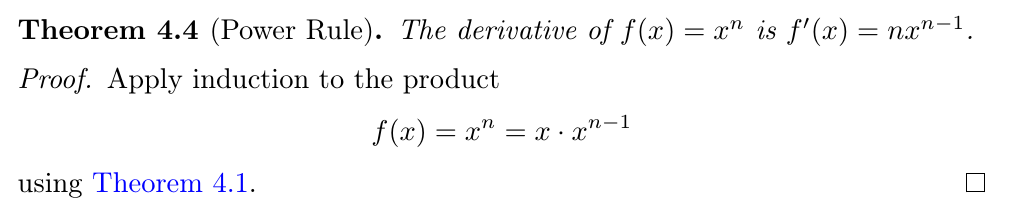Beezer, Robert A. “PreTeXt: An XML vocabulary for scholarly documents.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Beezer01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: PreTeXt
An XML vocabulary for scholarly documents
Robert A. Beezer
Professor, Department of Mathematics and Computer Science
Robert Beezer combined his long-time interest in programming (since 1970) with his
long-time interest in teaching university mathematics (since 1978) to author in 2004
an open source linear algebra textbook featuring live embedded computational examples.
A structured approach to the material, and numerous technical experiments, led him
to start work on PreTeXt in 2013.
PreTeXt is an XML vocabulary for scholarly documents. A key feature is the rigorous
separation of presentation and content. This results in conversions to a variety
of outputs, including print, PDF, HTML, EPUB, and Jupyter.
While still under heavy and rapid development, it is stable enough to have been used
for numerous textbook projects. We are also in a position to be able to report on
aspects of its design and implementation.
PreTeXt [PreTeXt] is an XML vocabulary to describe the content and structure of a scholarly textbook,
monograph, or article. The aim of the project is to make it easy for (academic) authors
to create highly-capable versions of their work, ideally provided with open licenses.
The initial focus has been on the particular demands of mathematics, with its specialized
layouts and symbols, and other sciences with similar requirements. We are also interested
in embedding computational examples, and producing output for use within computational
systems, so documents addressing computer science and technology are well-supported.
Not surprisingly, the most interest has come from authors of openly-licensed (or low-cost)
undergraduate mathematics textbooks, such as [Boelkins 2018]. However, there are also textbooks authored in PreTeXt on physics, computer science
[Plantz 2018], music theory [Hutchinson 2018], and even a handbook on writing for entering university students [Chun 2018].
Why not use an existing markup vocabulary? The short answer is that we want to walk
a fine line between making it easy for authors to write, while also capturing the
complete structure of a scholarly document. We looked hard at vocabularies such as
DocBook [DocBook], TEI [TEI], DITA [DITA], BITS [BITS], and JATS [JATS], but were unsuccessful in grafting on the features needed for disciplines like mathematics
and computer science in a work as big as an entire textbook. Maybe today, with greater
skills working with XSLT, we would be able to get further. But still, DocBook has
an emphasis on documentation, and TEI has an emphasis on textual analysis, and neither
is consistent with our purpose. No system seems to have robust enough support for
mathematics, such as numbering multi-line displays of equations. Some have explicit
tags for presentation, such as bold or italic fonts, which we do not want to make
available to authors.
According to the Scholarly Publishing and Academic Resources Coalition (SPARC) [SPARC 2017], mathematics is the discipline with the greatest open educational resources traction. LaTeX [LaTeX] has been the de-facto markup language for mathematics for 35 years. It was designed
for print and its base system, TeX [TeX], contains a Turing-complete language. LaTeX has some shortcomings in describing
document structure, though TeX itself does a very good job of typesetting mathematical
expressions. Conversions to PDF [PDF] have evolved nicely, but conversion to HTML [HTML] has been problematic. TeX4ht [TeX4ht] is one good system, as it uses the TeX executable, other attempts include [TtH] and [LaTeX2HTML]. The web is full of nicely-produced lecture notes, authored in LaTeX, and distributed
as one PDF per chapter. Authored in PreTeXt, it would take very little effort to
collect these notes into book form, and make available in web browsers with capabilities
well beyond those offered by PDF.
With markup that rigorously captures structure and intent, without allowing any preference
for presentation, it becomes possible for software to create output formats with disparate
technical formats, making encouraging multiple styles where supported (e.g. CSS for
HTML). As a demonstration of the power and utility of these ideas, we have as targets
five output formats:
PDF for print-on-demand publishing
PDF for electronic distribution and reading
HTML with semantic CSS
EPUB for offline electronic use
Jupyter notebooks for laboratory notebooks with embedded code [Jupyter]
The conversions to PDF are accomplished via LaTeX (rather than, say, XSL-FO [XSL-FO]) and are very mature. Future work will enable easy design and specification of
styling elements, similar in some ways to CSS. The HTML output sees the most work,
is very mature now, and continues to gain new features, given the possibilities of
an open standard and browser development. EPUB and Jupyter conversions are largely
functional, but need more development. We hope to obtain a Kindle version from the
EPUB output.
Why would an academic author abandon a tool like LaTeX, or a WYSIWYG word-processor
for a scholarly writing project? Stated simply, the HTML output is so far superior
to the electronic PDF output, while also a faithful and accurate representation of
the print version. PreTeXt authors who come from LaTeX say that PreTeXt is no more
complicated conceptually, it is just a new language to learn.
Community
Discussions within a diverse community have been critical for developing a system
that can meet the competing demands of a variety of authors, disciplines, and document
styles.
PreTeXt was initiated in May 2013. There are now roughly 35 books authored in PreTeXt.
The RELAX-NG schema and XSLT stylesheets are distributed as a git repository with an open license (GPL), so development is an open and transparent
process. There are three Google Groups for discussion and announcements [Announce, Support, Dev], involving 200 members, and there is an issue tracker on GitHub [GitHub]. There have been 21 contributors to the code and 70 forks.
More important than numerical measures of interest, and reports of bugs, the discussion
groups have seen lively and civil discussions ranging from pedagogical aspects of
textbook design and use, though to the nitty-gritty of what XML and XSLT can accomplish,
and how. The evolution of the PreTeXt schema has been strongly influenced by these
discussions involving authors and teachers with interests in technology, while also
maintaining the consistency that ultimately comes from a single designer.
Only recently, we realized that academic authors of openly-licensed materials often
play three roles simultaneously: author, publisher, and instructor. This realization
led to a split of the documentation into an Author's Guide [Author's Guide] and a Publisher's Guide [Publisher's Guide]. This also clarifies certain technical decisions: should an option be hard-coded
into an author's source as a result of a decision that properly rests with the author,
or should it be a command-line switch that is a publisher's decision about the form
of a particular output or rendering of the author's content? Work to support instructor's
needs (such as indicating which exercises are part of collected homework) is just
starting. So the discussion of language features includes decisions about which actor
makes the decision.
Below we discuss the features, design decisions, and technical decisions, that have
resulted from this community process.
Features
In this section, we describe a number of key features of PreTeXt.
Content versus Presentation
Every attempt is made to rigorously separate content from presentation. This can
be a hard argument to make to authors from a WYSIWYG background, and can even be hard
to make for authors experienced with LaTeX, since they think LaTeX already does this
(it could, but there are few facilities to enforce it). The obvious payoff is the
ability to produce many (dissimilar) output formats from one source, with no editing.
And it has been a long time since anybody asked for a bold tag.
Multiple Output Formats
PreTeXt has excellent support, via XSLT stylesheets, for conversion to the following
output formats based on other markup languages: online HTML, PDF for viewing on a
screen, and PDF for print-on-demand physical versions. There are good, but not complete,
conversions to EPUB and Jupyter notebooks. The EPUB conversion renders well in iBooks,
and work is in-progress to convert further to Kindle format. Jupyter notebooks are
online computational notebooks [Jupyter], allowing editing in a web browser with embedded code executed by connections to
modular computational kernels. Their underlying format is JSON [JSON] holding a mix of Markdown [Markdown] and HTML.
Cross-Referencing
The ID/IDREF system provides the basis for a robust and unified system for cross-referencing.
Many elements in PreTeXt can be the target of a cross-reference, and the cross-reference
produced can take many forms (display number, display number plus type-prefix, title,
etc.). By contrast LaTeX uses \label to mark objects, and then \ref produces display numbers for cross-references, but there is also \pageref to generate page numbers, \cite for citations, and \eqref for equations. Further, certain natural parts of a document are not easy to cross-reference
in LaTeX, such as a proof, or a case within a proof, since they do not earn a display
number. In HTML output a cross-reference can be implemented with a knowl [Knowl], which is a form of transclusion [Wikipedia]. So when a reader clicks on a cross-reference to definition, the page splits and
a box opens containing the text of the definition. Clicking again on the knowl puts
the box away. Readers rapidly come to expect a citation to open up with the bibliographic
information, rather than spiriting them away to a division of the back matter. Rather
than having page numbers in the index, a knowl works much better. Every knowl contains
a traditional in-context link if the reader wishes to migrate away to another location.
Extensive and Flexible Numbering
A textbook or monograph is not a novel. Readers may sample, authors will cross-reference
previous material, and a textbook may later serve as reference material. So items
that need to be identified unambiguously are automatically assigned numbers (which
are, of course, the same in each output format). There are six numbering schemes
in use (divisions, blocks/environments, equations, exercises, citations, and footnotes)
and the form of the number can be configured to follow the document hierarchy to a
specified level. So the same theorem in the source could be Theorem 7.3.4 or Theorem 7.17 or Theorem 105, depending on an author's document-wide choice. Almost everything that is not unique
(e.g. the Acknowledgments division) is automatically numbered, with no provision for
turning it off, either document-wide nor one-off. Equations are the one notable exception,
allowing numbers optionally.
Online Output (HTML)
Our HTML output is the most capable. We can embed interactive components such as
video, and activities expecting more reader interaction through sliders, checkboxes
and text fields. Anything that can live on a standard web page becomes a candidate
for a component of a book, including current support for HTML5 canvas element with Javascript libraries. Extensive work by David Farmer and others has
led to CSS designed to meet the needs of serious readers. Rich navigational devices,
knowls (information hiding and cross-referencing), integrated search, and other features
further aid the reader.
We aim to find the best mix of the old and new. Centuries of book design have given
us a hierarchical organization, an optimal number of characters per line, and navigational
devices like an index. Web browsers allow extensive hyper-linking, a copious margin
for tangential material, and integrated search. We are careful to not throw out the
baby with the bathwater.
Accessibility
The accessibility of online materials for students with physical limitations is a
huge concern at many universities, and enhancing the opportunities for those with
disabilities should be part of the promise of electronic formats. Because we do not
presume electronic outputs are housed in proprietary systems, we can employ open standards
and best practices wherever possible. For example, the MathJax library [MathJax] gives every mathematical expression a textual representation that a screen reader
can read in sync with the expression tree. Presently, the HTML markup is being fine-tuned
to validate completely and roles from the Accessible Rich Internet Applications [ARIA] standard will then be added.
Diagrams Authored in Source
Graphic images, created with other tools, often get disassociated from their final
resting place in a finished document, and then reside only in uneditable formats.
We encourage authors to use graphics languages, such as LaTeX's tikz, or Asymptote,
to include the source code of graphics within their PreTeXt source. An XSLT stylesheet
and a Python script, with other executables, then manage a conversion from source
to final image format. SVG is the ideal for online output, since it scales uniformly
along with surrounding text.
Documentation
As mentioned earlier, we have an Author's Guide, which explains the elements and attributes,
and partially serves as an implementer's guide. The Publisher's Guide is more concerned
with aspects of particular conversions, and topics like choosing an open license.
We have formatted a style guide for source, so that contributors will feel comfortable
working with another author's material, and so material can be shared and remixed
across different projects. This should remind Python programmers of the infamous
PEP 8 [PEP8].
Design Decisions
In this section, we describe fundamental decisions which have influenced the construction
of the PreTeXt vocabulary. Many of these decisions are important to an author, but
are not always readily apparent to a reader.
Book Design
A printed book delivers information in a format that has evolved over hundreds of
years. Some aspects of a book fail miserably in an electronic medium. For example,
page numbers. We believe others are still important, like a hierarchical organization
expressed through chapters, sections, subsections, and so on. Not unlike this article.
So a decision to use XML syntax is natural.
There are many more examples of our fourth Principle: PreTeXt respects the good design practices which have been developed over the past
centuries. Such as, we limit the width of text in HTML output to fall within the optimal number
of characters for the mechanical and mental aspects of reading.
LaTeX and MathJax
Mathematics is complicated. And complicated typographically. The simplest fraction
becomes a two-dimensional exercise rather than a linear exercise (which is not to
really imply that regular typography is not two-dimensional). A sequence of complicated
expressions (aligned on an equal sign) or a matrix with three rows and five columns,
where entries contain symbols, quickly becomes challenging.
MathML would seem an obvious choice. However we want authors to be able to write
and edit their source directly at this point. So requiring MathML would suggest another
tool to compose expressions. Instead we rely on MathJax [MathJax], a Javascript library to interpret and render mathematical expressions expressed
in LaTeX syntax. It could be said that MathJax really is the enabling technology
for this entire project. TeX is great between the dollar signs (its math delimiter), and MathJax supports a broad enough subset of symbols and constructions
to satisfy almost any technical author.
So an author constructs their mathematical expressions with tools and techniques they
may already know. A conversion to HTML puts the right Javascript on the page along
with the raw LaTeX in the right wrapping. Features, such as screen-reading of mathematics
are simply a consequence of employing the MathJax library. For a conversion to LaTeX/PDF/print
the raw LaTeX is similarly dropped into the right place, and the resulting PDF output
leverages the thirty years of development of TeX.
Lists and Display Mathematics
The logical placement of lists and display mathematics (runs of centered equations)
was a difficult decision. Rightly or wrongly, we decided that these items are parts
of paragraphs (rather than siblings of paragraphs). A fortunate consequence is that
the conversion of deeply-nested lists became less difficult. An unfortunate consequence
is that this decision is contrary to the HTML specification, so we must frequently
explode a PreTeXt paragraph into a sequence of mixed HTML paragraphs, lists, and display
mathematics.
Print Representation of Interactive Content
Including interactive components in the online version of a text begs the question
of what to do for a print representation. Our solution is to include in print a screenshot
and a link, accessible through a matrix barcode, specifically a Quick Response (QR)
code.
Horizontal Flow
Normal text is linear across the page as a sequence of characters, but is then stacked
vertically as a sequence of lines, paragraphs, figures, lists, etc. as you move down
the page or screen. But sometimes you want to go horizontal. Maybe you have three
images from a science experiment, and a comparison will work best if you line them
up side-by-side. Or, because width always seems to be at a premium, you do not want
to leave large amounts of whitespace, and so want to place a table and some text next
to each other.
We accomplish this with a container named sidebyside, which suggests that it is specifying layout. Carrying crude controls for widths,
margins, and vertical alignment, it probably is a layout device. But it is incredibly
useful, and important enough to get an annual refactor every summer.
Short Names, Long Names, Attributes, IDs
XML does not have to look like it was machine-generated. We have tried very hard
to make the vocabulary easy to remember, easy to use, intuitive to read, and not overly
verbose. To this end, we use full names (not abbreviations) for elements used infrequently,
such as introduction, proposition, and subsection. For frequently used elements, we have kept the names short, often borrowing from
HTML, such as p, em, ol, and li. And we have added our own, such as c (code), q (quotes), and sq (single quotes).
We have tried to keep attributes to a minimum, especially by providing sensible default
behavior in their absence. Boolean attributes are named to work well with only the
values yes or no (not true/false, nor 0/1). The xml:id attribute is used as more of an author-provided short-identifier. It is the basis of the cross-referencing system, and migrates to other identifiers,
such as URLs in the HTML output.
We try to recycle element names as much as possible, when resulting behavior will
be predictable. The best example is title, which is ubiquitous. Sometimes this backfires and makes constructing XSL templates
difficult. Some of the places an introduction can appear are in a chapter, prior to a list of objectives, at the start of a project, and at the start of an exercisegroup. This works well for authors, but requires some care in processing.
Technical Considerations
In this section we describe some technical aspects of PreTeXt, and some common templates
used in every conversion. Generally these considerations are not immediately apparent
to an author, though they do have some effect on their work.
Escaping Escape-Character Hell
With many different markup languages in play there can be considerable confusion moving
from one to another. Thankfully, XML has very few special characters. LaTeX has
at least ten, JSON has several, Markdown has a multitude, including combinations.
In technical documents there is often a need to express every single character literally.
PreTeXt aims to insulate an author from all this. An interesting exercise is to give
examples of a markup language, authored using that same language. But of course,
for us, the author needs to write in XML!
Consider the ampersand, &. (How was that just authored?) In LaTeX this symbol is
used to separate cells of a table, or separate entries of a matrix, or provide alignment points in a sequence of displayed equations. And in XML is the the escape character. So
PreTeXt provides an ampersand element for normal text use, which can be output properly into a given markup language.
For use in mathematics, PreTeXt makes available the \amp TeX macro (which is actually built-in as part of MathJax, and a simple addition for
LaTeX output itself). For verbatim text (such as a logical or bit-wise and-operator
in a programming listing) we provide education and advise authoring & (how was
that just authored?). The conversion then handles literal characters according to
the expectations of the target language. We very assiduously avoid instructing authors
in the use of a CDATA section.
Coordinating LaTeX and XSLT Numbering
LaTeX provides automatic hierarchical numbering of divisions (chapters, etc.) and
their contents (theorems, figures, etc.) through a system of counters which increment
as used and reset as boundaries are crossed. The depth of the numbering, the number
of different counters, and the boundaries where they reset, can all be configured
by a knowledgeable user of LaTeX.
In PreTeXt we implement a significant and flexible subset of this behavior through
the use of the xsl:number instruction. Remarkably, we are able to provide authors with a wide range of options
for customizing numbering, write hard-coded numbers into HTML output, create preamble
instructions for LaTeX, and have the automatic numbers produced by LaTeX match the
numbers created by counting nodes in the XML tree.
Whitespace Handling
LaTeX is fairly permissive about whitespace, though not as much so as HTML. For example,
two consecutive newlines indicates the start of a new paragraph. And there are some
instances where a blank line will cause a fatal error (e.g. the align environment for multi-line mathematics). Sometimes excess space at the end of a
line will cause subtle additions of unwanted vertical space.
Authors have been conditioned to expect to a lot of freedom in using whitespace liberally.
Further, authors accustomed to programming and revision control like to think of text
in 80-character chunks, so want to be very liberal with newlines. Fortunately, xsl:strip-space solves the problem of whitespace interspersed with the elements of structured content,
but mixed content proved more delicate. At least we know where that is, and where
it should go. So we can effectively sanitize normal text and LaTeX mathematics without
doing any harm and meeting the expectations of the output format.
A happy consequence of sanitizing the mixed content is that we have a good handle
on what that version looks like. We can then provide services like the following.
Recall that we decided that display mathematics belongs in a paragraph. When several
equations in a row are displayed, and end a sentence, then the period should be rendered
in the display, at the end of the last equation (which could have a number pushed
to the right margin). The author places the period after the closing tag of the element containing the mathematics, where it logically belongs,
and the stylesheet wraps it properly for its automatic insertion into the display
at the right place.
Conversion of Legacy LaTeX
There is a wealth of valuable material authored in LaTeX. There is no converter that
reliably does a good job converting it to a structured form, since the extensibility
of LaTeX and the numerous consequent add-on packages, give an author freedom to accomplish
many variations. (Remember that Tex has a Turing-complete language.) However, David
Farmer maintains a Python script, based on the use of regular expressions, to break
apart a LaTeX document, throw away formatting information, deduce intent and purpose
based on previous experience, and then reassemble the content in a structured way,
using PreTeXt as the language. His script is not perfect, and never will be, but
with each conversion it improves. An author needs to do a careful review, and a little
bit of tedious editing, but quickly gains new output formats beyond a PDF.
Duplicated Content
Some content migrates to new places, like titles going to a Table of Contents. Other
content gets duplicated, like the statement of an exercise being reprised in the back
of a textbook. We implement cross-references to all but the largest chunks of a book
via knowls, which duplicate content.
So it is important to recognize when content is being born, and so is the original version, and should have a unique identifier, such as an
HTML id attribute, or when it is a duplicate version and none of its components should have
a repeated version of an identifier. This is simply a matter of careful programming,
and passing a flag (original versus duplicate) to templates.
Verbatim Text
When writing about computer code, either for a text in computer science, or in a discipline
that is enhanced by computation, there is the need to use verbatim text that can display
any character (including reserved, special, or escape characters). And a typical
presentation is a fixed-width font of slightly heavier weight, meant to remind one
of typewriters, teletypes, and primitive consoles.
This simply becomes a tedious and tricky exercise to let authors write without concern
for the various output formats and let the stylesheets and templates perform the necessary
manipulations. We have empty elements for many such characters. Some are necessary,
such as ampersand described above, others are a convenience, such as copyright for the circled-c symbol.
Scaling Images
We do not believe the size of images should be given in explicit units by an author,
nor do we think it is the job of PreTeXt to manipulate the aspect ratio. But the
natural size of an image is not a reliable indicator. So we have authors specify desired width as a percentage of available width. This works well, especially since width is a scarce resource. However, it lacks
precise control, and some authors desire to have the font-size of their diagrams exactly
match the font-size of the surrounding text, in all possible formats. We do need
to make this approach more robust, but do not yet have a concrete plan.
Styling and Themes
The CSS used in our HTML relies on extensive use of semantic class names, with sensible
HTML elements for fallback styling when the CSS is not available. We have begun to
improve the CSS by refactoring to provide greater modularity and extensibility. So
providing alternative styling through additional CSS should see excellent support
soon.
A strong suit of LaTeX is its customizability, though that is also one of its weaknesses.
We have some good ideas on how to mimic the versatility of CSS to style LaTeX output
via a system of hooks in existing templates and simple imported stylesheets.
Example PreTeXt Markup
We finish with a small, but representative, example of PreTeXt markup. When shown
to mathematicians with no prior experience with XML, they are quick to understand
the content of this snippet, to the point where they may even comment on the novelty of the proof.
There is a cross-reference to a previous theorem, the Product Rule, which is not shown,
but would have an xml:id attribute with value product-rule. Note the inline mathematics in LaTeX syntax, authored with the m element, and the single displayed equation in LaTeX syntax, authored with the me element.
Figure 1: PreTeXt Source
<theorem xml:id="power-rule">
<title>Power Rule</title>
<idx>power rule</idx>
<statement>
<p>The derivative of <m>f(x)=x^n</m>
is <m>f'(x)=nx^{n-1}</m>.</p>
</statement>
<proof>
<p>Apply induction to the product
<me>f(x)=x^n=x\cdot x^{n-1}</me>
using <xref ref="product-rule"/>.</p>
</proof>
</theorem>
PreTeXt markup of the Power Rule and its proof
Figure 2: PDF Output
Presentation of the Power Rule Theorem via LaTeX to PDF output
Figure 3: HTML Output
Presentation of the Power Rule Theorem in HTML output, with Proof knowl revealed
Conclusion
PreTeXt has demonstrated that technically-minded authors, and even those from less
technical disciplines, can, and will, author using a carefully-designed vocabulary
based on an underlying XML syntax. Long-term, PreTeXt may attract front-ends perceived
to be more friendly. However, for now, the utility of highly-capable output formats,
obtained without additional editing, is enough to win over new authors and projects.
The benefits, once properly understood, are hard to deny.
The PreTeXt language is fairly stable today, to where deprecations are infrequent,
and planned new elements are few. A robust system for bibliographies, built on Citation
Style Language (CSL) [CSL] is the only glaring omission for serious scholarly writing. Work will continue
on the vocabulary and schema, while existing and new output formats also improve in
parallel.
Acknowledgment
Partial support for this work was provided by the National Science Foundation's Improving
Undergraduate STEM Education (IUSE) program under Award No. 1626455. Any opinions,
findings, and conclusions or recommendations expressed in this material are those
of the author(s) and do not necessarily reflect the views of the National Science
Foundation.
Chun, C., O'Neil, K., Young, K., Nelson-Christoph, J., Anderson, I., Risner, J. Sound Writing. [online]. [cited 22 Apr 2018]. https://soundwriting.pugetsound.edu/.