Feldman, Damon. “Message Format Persistence in Large Enterprise Systems.” Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington, DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18 (2016). https://doi.org/10.4242/BalisageVol18.Feldman01.
XML In, Web Out: International Symposium on sub rosa XML August 1, 2016
Balisage Paper: Message Format Persistence in Large Enterprise Systems
Damon Feldman
Solutions Director
MarkLogic Corporation
Damon Feldman is a passionate “Mark-Logician,” having been with the company
for over 7 years as it has evolved into the company it is today. He has worked
on or led some of the largest MarkLogic projects in terms of both volume of data
and complexity of implementation, for customers ranging from the US Intelligence
Community to HealthCare.gov to private insurance companies.
It is more efficient to store messages as-is or with minimal modification than it
is to develop a new (typically relational) schema to re-map and store the data in
the messages. Yet, persistent models and message models have different needs, so
naïve message persistence may not be ideal. We review the approach used in two
enterprise integration efforts where XML message formats are directly or
nearly-directly used to persist data and enable functions in the enterprise,
avoiding costly and fragile mapping layers and the associated impedance
mismatch.
We also make the general case that the message model is more critical to
enterprise architecture (as distinct from system architecture) and should therefore
be preeminent during enterprise design.
Actual integration efforts on the HealthCare.gov Data Services Hub and a large
insurance provider are discussed, and simplified, non-proprietary example documents
are used to illustrate the concepts concretely. We also review and define the Data
Hub pattern for integrating data in the service of real-time, transactional loads
that support service oriented communication across systems via messages.
The architectural implications of sharing message and persistent document
structures, rather than using a separate persistence model, is far-reaching and
affects multiple layers or “tiers” in the overall architecture. The extent of this
change illustrates that NoSQL technology, which can store message-like persistent
forms, drives a fundamentally different architectural approach rather than merely
being another persistence option.
Messages are preeminent in enterprise architecture
We assert here that defining message formats (typically XML and JSON in today’s
systems) are the most critical design decision of enterprise integration, and this
emphasis puts the overall enterprise architecture in tension with the needs of
individual (sub-) system design, where other concerns are paramount.
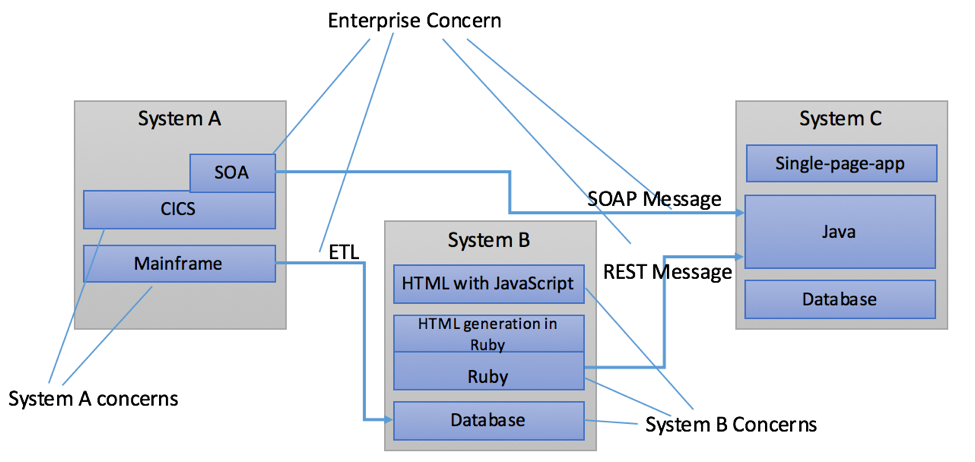
Consider the following diagram of three systems being integrated.
Figure 1
Multiple systems integrated by Messages. Each system has internal
architectural concerns separate from the overall enterprise architectural
concerns.
Each system individually has its own design and concerns, ranging from relational
schema design, to a good modular organization of the CICS code, to having a good object
model for the Ruby or Java tiers. The overall enterprise (the resulting system of
systems depicted by the entire diagram) however, is substantially unaffected by these
per-system concerns, as each system is or should be a black box accessible only through
APIs that are built around Message Formats. Therefore, Message Formats and the model
they are based on are far more of an enterprise concern, as distinct from individual
systems concerns, and in fact, enterprise and system design may be in conflict.
Given that enterprise and per-system concerns will sometimes be in conflict, which
should be privileged? In a larger enterprise, the Message Model is more difficult
to
change and has a broader impact, as it is used by many or even all systems to
communicate. The software re-work involved in changing many systems may be prohibitive
in itself, and the cross-team coordination needed to change many systems at once is
far
more prohibitive than the software work itself .
In fact, one expects most individual systems to be replaced over time. Clean
integration via well-defined messages (APIs) eases the task of replacing these
individual (sub-) systems. In essence, Message Formats and the APIs built on them
enable
and impose a componentization on the total enterprise with clean interfaces among
them.
This feature of an Enterprise cannot be overstated, as the ability to divide large,
complex tasks into manageable components is a fundamental tenant of computer science
.
The domain model representing core business entities within the API messages, in
contrast, is difficult to change, shared across multiple systems and involved most
directly in enterprise-wide integration between the component sub-systems.
The preceding aspects of Message Models, their role in enterprise architectures and
their larger importance relative to individual system concerns all suggest that
architects start with Message Models, and then adapt our systems to use them effectively
rather than the converse.
This then leads to the techniques in this paper – how to focus first and primarily
on
enterprise models for communication, and then use the resulting Message Models as
the
persistent model, or store a persistent model as close to it as possible.
In particular, this makes document modeling more important, and suggests that our
document modeling practices and tools should be used for enterprise architecture,
rather
than legacy tools.
Alternate approaches to Message Modeling
Unfortunately, much of our enterprise modeling is focused on entity-relational
modeling and related logical models, which are closely tied to relational modeling
practices, or is focused on UML modeling which arises from object oriented modeling.
Logical Models are a work around that can address this mismatch to some extent,
forming the basis of a Message Model with reduced baggage from E-R or OOP modeling,
but
logical modeling practices are still grounded in the other technologies they spring
from, including use of E-R and OOP tools, an (arguable) over-emphasis on cardinalities
(which drive relational models but not message models) and other baggage.
Below are two subtle ways in which current modeling practices privilege and focus
implicitly on relational models, to the detriment of the more important document models.
Focus on cardinality
Typical enterprise models focus on cardinality. In markup such as XML and JSON,
as well as in RDF, cardinality is not typically important. XML representing someone
with one address may look like this:
<person>
<name>bob jones</name>
<address> 123 Wall St, New York, NY </address>
<person>
and a relational model can also represent the same data:
Table I
PERSON_ID
NAME
ADDRESS
5538
bob jones
123 Wall St, New York, NY
The XML model is easily amended to hold an arbitrary number of addresses:
<person>
<name>bob jones</name>
<address> 123 Wall St, New York, NY</address>
<address> 76 Seaside Terrace, The Hamptons, NY</address>
<person>
Where in a relational model, changing cardinalities from 1:1 to 1:N requires
additional tables and a join key to be in third normal form.
Table II
PERSON_ID
NAME
5538
bob jones
Table III
ADDRESS_ID
PERSON _ID_FK
ADDRESS
22
5538
123 Wall St, New York, NY
23
5538
76 Seaside Terrace, The Hamptons, NY
Clearly, cardinality is of critical importance to relational modeling as getting
that wrong requires a disruptive change, and cardinality drives third normal form
modeling, E-R diagramming and related practices. In contrast, cardinality is less
important for XML or JSON message modeling.
Other modeling approaches such as UML are similarly infected with a concern for
cardinality, as cardinality determines the data structure (Array vs. single value)
needed in object-oriented code, so it must be called out on models that drive
functions, classes and method implementation.
Readability and intelligibility
Documents are human readable, where E-R diagrams and related models are machine
readable. This is because of hierarchy and the need to follow pointers or links.
The evidence for this is informal but compelling. Documents emerged organically
from human societies – insurance applications, messages, contracts, bills of
material, articles and books (including this one) have been organized hierarchically
for centuries, and such organization suits the human mind well.
Pointers and tables, however, are confusing and difficult to follow for a human.
One must often literally follow the lines on a complex E-R diagram to understand
what is related to what. Many readers of this paper will recall the experience of
walking up to a huge E-R diagram on plotter paper or taped together from many
smaller sheets and attempting to trace the various connections to the tables and
entities in an attempt to understand what is related to what.
Often, the maintainer of the diagram will try (with limited success) to group
related tables into particular areas of the diagram, thus imposing one level of
hierarchical organization on a spaghetti bowl diagram of inter-connected tables or
entities. This minimal hierarchy is helpful, but illustrates that the fundamental
approach is suited to relational modeling or object-oriented programming rather than
document modeling.
Beware conventional modeling tools
We include this discussion here to suggest that we, as an industry, need to
re-examination our typical modeling practices, and that document modeling should be
elevated as the primary goal of modeling in a large enterprise, tools such as schema
editors, UML, or new approaches should be considered that ease the development of
document models, and each practitioner should be clear if they are building a “good
model” informed by decades of relational modeling, or a “good model” based on how
the document model and derived Message Models will function.
Persisting document and message models
The above is to make the case that document models should be considered first and
with
increased priority in a moderate sized or large enterprise, that tooling should
primarily be evaluated by its ability to support document models, that architects
should
consider document models primarily as they create data models.
But what about the relational and other models? Creating a model that works for both
relational and message models is difficult and requires extensive transforms to
implement. Object models further complicate the situation, but as graphs they are
more
similar to documents (which are trees) so here we confine ourselves to the issue of
having relational and message models coexist.
Below, we describe two enterprises that were simplified and improved by focusing
first on the message models, and then using those same message models as a persistent
model to the extent practical. Specific issues and techniques are listed that helped
make this approach work well.
HealthCare.gov Data Services Hub
In the HealthCare.gov Data Services Hub (DSH), all message traffic flowing into,
out
of, and through the hub is (almost-) directly stored to enable traceability and other
business functions for the overall system. The data in message payloads is modified
prior to storage only to the extent needed to de-identify personal information, drop
irrelevant data and add standardized metadata such as timestamps, message type and
uniform success/error codes. This was implemented using NoSQL transform and storage,
so
the persistence was achieved with minimal additional data modeling or schema development
– only the additional metadata and decisions of what to redact was modeled – and the
overall effort was simple and rapid to develop.
As always, the key was that the data was already modeled (in the message model) so
there was substantial benefit in not re-modeling the bulk of the data, and only modeling
differences.
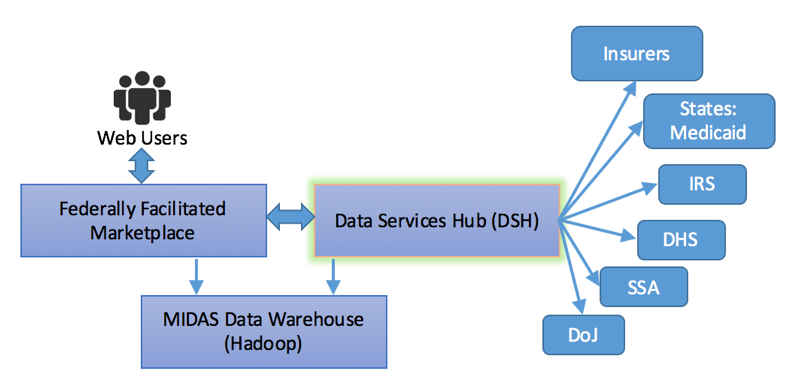
For context, HealthCare.gov has three major components. The first component is the
Federally Facilitated Marketplace (FFM) which is the web site that consumers interact
with to apply for and choose insurance plans. Second is the Data Services Hub (DSH)
which is a message service that proxies and coordinates requests to various government
and private entities, providing a clean, uniform API to the FFM and state exchanges,
while hiding the complexities of communication with myriad other systems. The third
is
the MIDAS data warehouse, which performs analytics and other downstream processing.
Figure 2
Overall Affordable Care Act systems, showing DSH which provides consistent
messaging to the overall enterprise
Numerous articles have been written about the lack of monitoring, infrastructure
issues, and general rockiness of the overall HealthCare.gov launch
(https://www.advisory.com/daily-briefing/2014/03/03/time-inside-the-nightmare-launch-of-healthcaregov
), but less well known is the success of the Data Services Hub component, which was
developed under the same tight time constraints as FFM. DSH integrates services from
the
Internal Revenue Service, Department of Homeland Security, Social Security
Administration, Department of Justice, Peace Corps, Office of Personnel Management,
as
well as many insurance providers. These data sources are used to verify income, check
prison status, validate social security numbers and other tasks. Some of the data
sources are stored as copies of US Federal Government data within the DSH system,
but
most are accessed in real time from source systems outside DSH, through APIs hosted
by
the data-owning government agency.
Processing
The process of calling the DSH and processing a request is conceived of as having
four “legs.”
The first leg is an incoming web service request to DSH containing an XML
body.
The second leg is a request to an authoritative data source – typically a
REST endpoint using XML payloads – hosted by an external Federal agency.
The third leg is the response from that authoritative data source.
Finally, the fourth leg is the return of an XML service response to the
caller.
As one may imagine, there are other complexities such as multi-step processes
where a message is split into many sub-requests which are combined using internal
workflow and state persistence, deferred due to outage windows, routed to a
multi-day, human-in-the-loop review processes, translated to REST, X12 or other
formats and the like, but these four legs constitute the essential workflow of every
call in the system.
How DSH stores message data directly
As noted above, messages flowing through DSH are stored with minimal modification
as persistent data. Each of these four legs transmits and processes different data,
but all are XML message formats and all a record of all messages for all legs are
stored by the DSH.
If this data were stored, say, in relational form, a complex XML to relational
mapping process would be needed for each and every message. Some designers would
even introduce a third model – an object oriented model – in a Java tier in between
the messages and relational persistence to parse the XML to POJOs only to then
transform the data to tabular.
This additional mapping and modeling would have been cost and time prohibitive
because of the modeling, the mapping, and the overhead and delay needed for every
message or API change. Any change to an API or message format would require a new
relational model, new mappings, new DDL to provision the model, and upgrade scripts
and coordination to change existing data if the system was already in production.
Instead, saving the message with minimal modification has proven to be efficient
and powerful. The business benefits include: enabling historic auditing and data
lineage, monitoring the system for issues in real time, support of forensic
investigations into data or system problems, and helping correct any consumer issues
that may be found.
The portion of DSH that stores message traffic in this manner was designed and
implemented in the final few months of the DSH development. The component of DSH is
called the Event Management Framework, from the notion that receiving, processing
and sending events are “events” within the DSH system. The bulk of system
development prior to this feature also used documents as the primary persistent
mechanism (for state management, workflow and other functions) but is beyond the
scope of this paper.
Message format persistence
As described above, the persistent format leveraged and closely resembled the
message model, and a NoSQL storage product was used that natively stores and
transforms XML. The benefit was to use as much of the message model as possible,
specifying only differences – how was this accomplished?
The design goal was to use existing structures to the extent possible, and
specify only additional data and removed data relative to the message model. This
is
somewhat in the spirit of object-oriented modeling, where the differences between
a
subclass and superclass are specified in the subclass, and common structure and
functionality is “inherited.”
Additional data
Additional data was added by creating a wrapper schema to capture key metadata
such as message type, success vs. error result, timestamp and other metadata.
The actual message payloads are not re-modeled for persistence and the schema
allows for the full (or partial) message to be stored as an xs:any with only
these minimal tracking and reporting fields added. For this reason, the schema
is considered a wrapper schema where very little data is specified and the bulk
of the data is whatever message was flowing through the system (subject to a
de-identification transform).
Instead of xs:any, one could us the message schema as the payload inside of
the <result> element. However, one would then need to manage one wrapper
schema per message type and update it whenever a message format or service API
changes.
Note that the message-event, timestamp, success flag, and <result>
element are in the “http://cms.gov/dsh/EMF” namespace as they are defined by DSH
and used for internal storage, but the child element of <result> is a
(notional ) OPM message describing whether someone is already insured via a
federal program. The messages from external services are typically much larger
than the minimal metadata elements defined by DSH, so the bulk of the persistent
format is being used as-is.
The example shows the <opm:ssn> element as “REDACTED.” In reality,
personally identifiable information (PII) elements that pose a privacy risk are
completely removed at DSH, but it is shown as redacted in this synthetic
document for clarity. The de-identification process was implemented because, per
policy, the DSH cannot store personally identifiable information, personal
health information, or federal tax information (PII, PHI or FTI).
The message uses the powerful “envelope pattern” where some raw or useful
data is stored separately from additional data or metadata. Here the additional
data is message metadata and is in the <metadata> element at the top of
the document.
Rapid application development and flexibility
A “dashboard” capability was developed within the DSH atop this model to aggregate
and filter system activity based on event types, destinations, times, success and
error codes, and other information (primarily the <metadata> information
illustrated above). These dashboards can answer questions such as: how many
enrollment request to Kaiser Health were rejected (based on metadata holding error
codes) for the state of Texas during the disk failover period from 1:15am to 1:37am
on December 17th? Were they retried?
Direct search and query of the persisted message model
Text search is enabled on the entire record inside the <result> section,
which is particularly useful when an ID is available. IDs may be shared across
disparate messages, but tend to be unique allowing an analyst to quickly narrow
down all traffic for a particular identifier. Certain readable codes or
descriptions in messages may also be searched as text.
XQuery and XPath can also be used to search the stored data by building
queries and path expressions that access one specific message format, such as a
certain IRS response format used for income verification. The NoSQL product used
supported text and XQuery on XML without additional systems integration, making
this appealing.
Agility
New message formats were simple to add to the system. The developers merely
wrapped any new SOAP or REST request to be captured with the metadata elements
above, wrote a de-identification XSLT transform, and sent the resulting
structure (now with metadata and without PII) to a tracing endpoint. While DSH
applied this de-identifying transform to filter out PII to comply with specific
DSH regulations, another project using this approach would likely store the
entire record as a child of the <result> element.
As very little data is considered PII, PHI or FTI, the de-identification
transforms were simple (names, social security numbers, addresses and the like)
and were based on a known list of elements that may represent PII or other
sensitive data.
where the select attribute holds a list of XML local-names of elements to
redact.
This is a “blacklist” approach, where the elements to be removed are
explicitly listed either in code or some configuration file. A “whitelist”
approach is also possible, where only fields known to not be sensitive are
retained. A whitelist approach is more complex, slower, and requires at least
some comprehensive examination of all schemas involved. For those reasons,
specific removal of known “blacklisted” elements was chosen for DSH.
The DSH use of messages illustrates how modeling, translation and code are
reduced by re-using message data directly as a persistent format, and storing
data in a form that is as close to the message format as possible.
Storing data “as-is”
Because the message formats did (and as agued above, should) exist prior to the
persistence need, we can call this storing data “as-is” which emphasizes the benefit
of aligning message and persistent models and storing documents.
DSH as enterprise integration using a message model
Conceptually, a portion of the US Federal Government spanning multiple agencies
is functioning as a single enterprise by virtue of their integration with the DSH.
Messages built on a uniform data model integrate all these systems, with the primary
data consumer being the Department of Health and Human Services’ HealthCare.gov
program.
This is therefore architecturally an Enterprise Integration effort based on
design and use of a coherent message model, despite the systems involved being
maintained and operated by different Federal and state agencies as well as private
companies.
This is a version of enterprise integration where existing systems are integrated
by a new model, but not an example of a system where a new model is pushed down by
governance to existing systems, to be used internally across the enterprise. That
is, the overall enterprise is integrated by a common message model, and the new
analytics/tracking component then leveraged this message model for persistence.
However legacy and externally-managed systems continued to use their own internal
object and persistence models, and in fact continued to use their own message
models, which were converted to a common model within DSH.
We now turn to an example where the message model is built a priori and used more
extensively to support interoperability across the enterprise.
Large, Commercial Insurance Provider
A large insurance provider also built a system that stores message formats with
minimal modification. This system uses a “Data Hub” architectural pattern where data
from many disparate systems are stored and integrated data into a consolidated Data
Hub.
This Data Hub then provides actionable, real-time information and services across
the
enterprise.
What is a Data Hub?
A Data Hub is a centralized persistent store that gathers data from numerous
(disparate) systems of record or data silos, on a periodic basis or in real-time,
and stores all data in one place and one form.
The Data Hub then becomes the preferred source for various kinds of data, and
likely the only source for integrated, cross-line-of-business data. The Data Hub
becomes the ideal place to access data due to its scalability, convenience and
de-coupling from transactional systems, and upstream transactional systems typically
remain the systems of record and handle new data capture, workflow, and end-user
interactions.
Note that the prior example was the CMS “Data Services Hub” which is a specific
computer system that loosely conforms to the Data Hub pattern; but here we have an
insurance provider using a more generic “Data Hub” architectural pattern to build
a
central repository. The insurance provider Data Hub stores but the core business
data for the insurer using message formats for efficiency (both computational and
software delivery efficiency). In contrast the DSH stored a record of messages
flowing into and through the DSH for analytics and monitoring.
The primary difference is that the DSH is for downstream analysis and forensics,
where this Data Hub implementation provides real-time APIs that expose consolidated
data to the rest of the enterprise to support service-oriented architecture (SOA)
patterns and transactional workloads. This real-time, transactional support of a SOA
is in contrast to a Data Lake or Data Warehouse which are typically analytic, and
cannot support real-time,, transactional loads.
High-level architecture
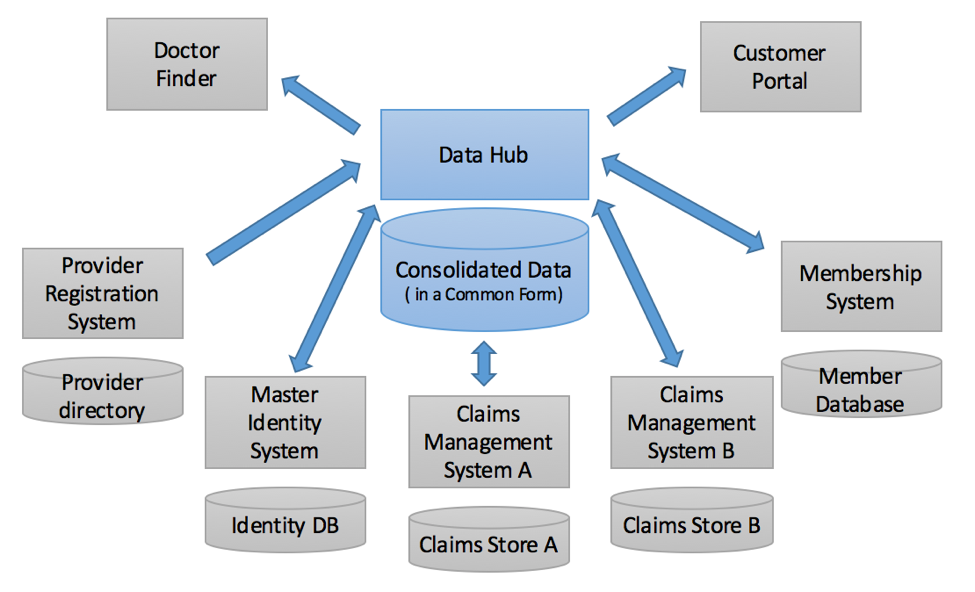
Figure 3
Data Hub interaction with systems of record, systems of interaction, and
one MDM system
The diagram above illustrates the insurance company’s Data Hub enterprise
ecosystem, including four systems of record – one for Providers (doctors,
pharmacists, dentists and labs), two for claims processing, and one for membership.
In addition to these systems of record, it also includes a legacy Master Data
Management (MDM) system that manages the merging and splitting of identities, and
two interaction systems that consume data but do not store much of their own data.
The interaction systems need access to consolidated data to provide accurate,
up-to-date information, and the systems of record also have a (lesser) need for
enterprise data. For example, the membership system may need to evaluate a member’s
risk or claims history by accessing a member’s consolidated claims history.
This pattern allows for both operational isolation and increased functionality in
the Data Hub. E.g. the Doctor Finder application includes geospatial and text
searching, where the providers system of record does not. Some of the systems of
record did not support online transaction loads that are supported by the more
robust Data Hub infrastructure and software.
Not shown are bulk exports to a downstream analytic Data Lake based on Hadoop
that performs most reporting and analytic functions. Since the data is exported to
the Data Hub and the data hub has larger processing capacity than the systems of
record, the Data Hub then exports data to the Data Lake without incurring an
additional bulk read from the various systems of record.
Data Hubs are distinguished from ESBs and virtual databases in that they store
data and index it in one place, rather than coordinating many queries and transforms
in real time, provide unique indexing and analytics, and allow operational
separation from source systems via separate disks and servers.
Core business objects used in message formats
The insurer’s Data Hub provides services using a consistent message format within
well-defined APIs to the entire the enterprise. These messages may combine data from
multiple data domains (such as membership, claims and payment). The messages have
simple request/response headers wrapping a core Business Entity model, which is
coherently designed – meaning naming conventions and overall style are consistent
across all business entities, regardless of the services or business domain for a
particular message.
Here is a notional response message which we see has some elements near the top
that are generic to all requests returning lists of items (<total-results>,
<page> and <page-size>), and the <result-item> element then holds
a Business Entity or list of Entities – in this case medical claims.
Physically, this Data Hub runs on a clustered, distributed database, is easier to
scale up with massively-parallel or elastic infrastructure, has less frequent and
more predictable outage windows, is fully highly-available (HA) and has other
advantages as a system explicitly built for this kind of high-volume, consolidated
data access.
As with the HealthCare.gov DSH, the insurer Data Hub runs on an enterprise-class
NoSQL distributed database comprising multiple primary nodes and a similar number
of
standby nodes at a remote disaster recovery site, synchronized by database
replication. This level of disaster recovery and clustering are not available for
all the upstream, transactional systems, making the Data Hub more robust and
available and also more easy to administer than a federation of the disparate
upstream products and systems.
Common Messaging Formats
To provide common services using common messaging formats, the insurer’s Data Hub
implementation also stores data in the messaging formats themselves. The above data
structure has a clear delineation between message management data (in the
http://insurer.com/response namespace) and business data (in per-domain namespaces
such as http://insurer.com/claims).
However, there are two minor changes to the overall messaging format used to
persist it, with specific motivations for each.
Flexible messages - but canonical persistent forms
First, persistent document formats must, curiously, be less flexible than
message document formats. Messages vary from caller to caller and service to
service, but the persistent format must be uniform across all instances to be
easily queried. Therefore, the Data Hub had to choose and specify one particular
form of the messaging format for persistence.
The example above returns a list of claims at a summary level, but others
will return a complete insurance claim together with associated data about the
provider giving care and the member filing the claim (that is: non-claim
membership and provider data from another data domain).
To achieve this aim, the Data Hub stores data in one, predictable format, but
serves it in many formats, requiring the persistent model to be transformed and
re-packaged when needed to satisfy various services and APIs. The primary
difference among the different message formats is one of what we will call “data
extent” – how many related elements are packaged together into one document.
Therefore the data modeling challenge is to support re-packaging of re-usable
data building blocks.
Here is an example persistent document showing the larger persistent data
extent which includes another data chunk beyond that which is in the claim
message above.
This persistent document differs from the above message form in that the
message header data about pagination and similar is not present, there is one
claim per document rather than many, and that in the <claim> business
entity there is an additional <claim-payment> data chunk which is not in
the message. (This notional XML document is substantially simpler than the
actual data to allow it to be easily shown here.)
Data chunks as building blocks
Rather than have arbitrary additions, re-groupings and transformations when
building messages from the persistent documents, the data model identifies such
“data chunks” which are preferentially deleted, added or re-combined. In the
example above the <claim-payment> element and its child elements are an
information a “chunk” so it was in keeping with the design philosophy to remove
it as a unit when determining the message format from the persistent format.
Removing a completely arbitrary set of elements or running an arbitrary data
transform is possible and used in some instances, but avoided in favor of adding
or removing at the chunk level where possible.
These data chunks are therefore the units of use and re-use in the data
model, particularly as the message model is re-used to construct the persistent
model.
The Data Chunk approach seen in the above example is covered in more detail
below.
Database optimization
The second change from the message format to the persistent document format
is the addition of database-specific information such as ingest dates, data
lineage (traceability to original source system), join keys, RDF data added to
support automated reasoning and semantic integration, and the like.
This addition of internal data is similar to the DSH addition of message
metadata, and is also accomplished using the envelope pattern.
The added internal data is typically used to optimize queries and support
database functions, auditing, data quality and governance and is not used in the
message formats. When the persistent document is converted to a message, this
additional data is dropped.
Here is a notional persistent document that also includes database-specific
information in a <header> element:
In this persistent message both changes are shown – the additional data chunk
of <payments> that was excluded from the message form, and the
<header> element with the following internal database information:
A list of IDs. These were added in this system to provide a
guaranteed numeric form despite some IDs being alphanumeric, which
allows faster numeric key joins between records when querying the
Data Hub.
A set of related medical concepts coded in SNOMED terminology.
This is notional for simplicity. The ICD9 and HCPCS systems have
incompatible codes, so to provide semantic interoperability and
simple querying, it is useful to convert all medical concepts into
one terminology set.
Semantic triples (typically in RDF format). The particular NoSQL
product used combines document storage with RDF storage, and
supports SPARQL queries over the claim data to the extent that some
information is stored in the header as triples.
Data Chunking for re-use
The data chunk approach provided substantial, but not completely arbitrary,
flexibility in building different data extents. E.g. for the insurance company, the
data chunks can be re-combined to support both a small Claim Summary message and
also a larger, detailed Claim description message.
Data Chunks vs Basic Types
Determining the size of a data chunk is a key design choice. In Chessell15 atomic, re-usable entities are called “Basic Types.” Basic Types, in Chessell,
et al, are exactly the un-changed smaller pieces of information that do not
change from place to place in the model. They may be addresses, effective date
ranges, telephone contact information and the like.
However, when substantively re-using a Message Model throughout the
technology stack and persisting it (nearly) as-is, much larger chunks can be
re-used and standardized than envisioned by Chessell et al. This is because in
traditional systems, the models must be radically re-modeled (because
traditional systems use a relational persistent model, a hierarchical XML
messaging model and a graph-shaped Object Model – all of which are incompatible
to some extent). The Data Hub approach uses the same fundamental model – a
hierarchical document model – at all layers, therefore re-use can be far higher,
with hierarchy being preserved across layers.
Re-use of the preeminent or pre-existing Message Model allows the chunk size
and granularity of re-use to be much larger. Certainly tens or hundreds of data
fields is acceptable in many cases for a chunk, rather than only a few. For the
insurer, Data Chunks represented a “core” claim with vital claim information
together with additional data chunks for conceptually separate claim processing
information, claim lines, provider information, historic information, claim
review information and so on.
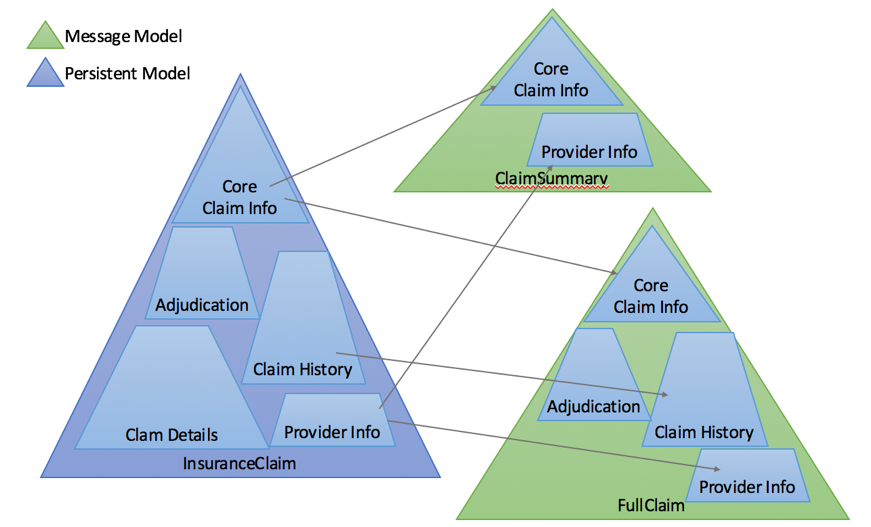
This diagram illustrates that the persistent model data chunks are recombined
to form different message formats, allowing re-use at the chunk level, but also
flexibility in message formats.
Figure 4
This diagram illustrates that the persistent model data chunks are
recombined to form different message formats, allowing re-use at the
chunk level, but also flexibility in message formats.
These chunks are not the persistent documents, but rather are the building
blocks of both persistent and message documents (the insurer used XML, so the
messages and persisted entities were “documents.” If JSON were used they would
be called objects or entities). This insurer was using XML Schema for modeling,
so the chunks were defined as types and various master schemas imported these
types to include them in the overall schemas.
Ideally, many messages will correspond exactly to the persistent form, with
no additional chunks added, or extraneous chunks removed. That is, the
persistent form should be chosen to include a set of chunks that is the most
natural and commonly served message form. This way, message formation at runtime
is as fast and simple as possible, and coding of transforms is minimized.
This is easiest when there is one well-known and expected Message format –
e.g. healthcare systems use HL7 CCD documents to transmit patient summaries.
Other message formats will require some re-combination of the chunks and will
incur at least minimal performance overhead, though still far less than a
wholesale transformation from relational to message formats, or even
field-by-field transformation between disparate document formats.
Data Chunks as dynamic message construction
One typical form of combination is to create summary records, such as a Member
summaries. The Member summary may contain some Member data chunks, and also have
non-member data such as payment and recent claim activity. This cross-domain message
is intuitively not ideal for persistence because it crosses domains and is very
particular to a summarization use case.
By gathering the chunks of related entities into a summary message, the system is
effectively summarizing and providing related information (e.g. last 20 claims) with
core information (e.g. basic member information).
Relationships among data chunks can be represented with RDF (semantic triples) or
other graph technologies. Documents + graphs combine to form a powerful data
representation approach as documents represent trees well (but not graphs) and
graphs model relationships naturally (but don’t highlight natural hierarchies as
found in trees).
This approach is actually quite similar to Dynamic Semantic Publishing (DSP -such
as implemented at the BBC and described in Rayfield12
http://www.bbc.co.uk/blogs/bbcinternet/2012/04/sports_dynamic_semantic.html) where
documents are statically stored as XML or HTML and then dynamically assembled based
on semantic rules and ontologies. Here we are dynamically “publishing” the message
format needed rather than an article, e-book or web page. While a detailed analysis
of similarities between dynamic message construction and DSP are beyond the scope
of
this paper, note that the DSP approach often uses RDF and ontologies to assemble
information as needed.
Common Message Models
Both the HealthCare.gov DSH and the insurer rely on a common message model. The model
was the single Message Model for DSH, and was the set of flexible Message Formats
built
from reusable data chunks for the insurer.
As with many things in computer science, such a hub-and-spoke model is needed to
simplify communications among many components. The number of translations needed to
implement point-to-point communications among N components is famously N(N-1)/2, but
the
number of translations needed to implement a hub/spoke model is N. Therefore, common
message models simplify enterprise integration.
Using the common message model as a persistent format continues and extends the cost
savings and agility of the common model. It is enabled by the rise of non-relational
(aka NoSQL) databases and data management techniques which can directly accept either
XML or JSON data, store it, index it, and query it.
Architecture implications
Using data chunks as the building blocks of documents provides re-use between the
persistent model and the message models in an enterprise. Only the differences need
be additionally modeled once the enterprise message model is complete.
To summarize how differences are specified in examples above, these differences
include:
Message metadata added to DSH persistent documents, such as dates,
types and success codes
PII removal from DSH messages before persistence per policy
Message header addition to messages in the Insurance Provider data
hub
Data chunk repackaging, combining, and removal in the insurer Data
Hub
Database-only fields for optimizations, auditing and data governance
in the insurer Data Hub
The key advantage being that the actual domain models comprising all business
data did not need to be re-modeled or mapped in either system.
This architecture allowed development efficiencies where an additional model was
not created, and computational efficiencies where messages in the Insurance Provider
case were largely de-normalized and ready to serve via APIs and services.
This is a substantial conceptual shift from the traditional approach. Typically,
and for decades, message models have been XML, JSON, EDI or similar, and persisted
data has been relational as defined by an entity-relation (E-R) model. Often an
object model is added to the mix (as though someone thought that when two models are
good, three must be better). These models are all fundamentally incompatible and
enterprise modeling techniques (such as Model-driven Architecture and logical
modeling) formed to ease the mapping and impedance mismatch problems inherent in the
formerly-ubiquitous underlying technologies.
In the DSH and insurance provider systems described above, where message models
drive the architecture the goal was no longer to work around the model
incompatibilities, but rather to manage the re-packaging and chunking of re-usable
data. Arguably, this focus is more critical to the business and directly calls out
areas of commonality and re-use, rather than having architecture and data modeling
focused on remediating mapping problems.
Message Models as Primary Drivers of Architecture
Both the DSH and insurer systems were large systems-of-systems, where pre-existing,
independent systems were being pulled together into an enterprise-wide whole. For
DSH,
that whole spanned HealthCare.gov and multiple involved US Federal Government systems.
For the insurance provider, the whole spanned various Membership, Claim, Identity,
Provider (doctor) systems, and other COTS or legacy products.
Each sub-system may have its own internal data formats, separate from the common
enterprise message model. It may have its own relational schema, separate from other
components schema and from the common formats used across the enterprise. These become
implementation details that are irrelevant to the way the sub-systems participate
in the
overall enterprise. The overall enterprise is connected and made to function as a
whole
using a common message model and the APIs that include those messages. This is perhaps
the core idea behind a service-oriented architecture for enterprise integration.
This integration approach is useful in all contexts, but is particularly enabled
by
direct persistence of XML, JSON or other message formats to make the entire enterprise
more agile and efficient, in addition to being integrated.
Efficiencies from persisting message model components
The efficiency and agility of persisting message data comes from the two shifts
implicit in the approaches described above.
First, there is no need to re-model the bulk of the data. Since integration is
the primary concern in combining a number of systems into a coherent enterprise, the
message formats can come first. The advantages of a hub-and-spoke approach dictate
that a single common model is developed (modulo data chunks where different messages
include more or less data as composed of different data chunks). Avoiding
re-modeling the data is a large savings vis the typical approach, and also speeds
up
application development, mitigates risk and reduces complexity.
Second, the insurer’s approach, in particular, allows architecture to re-focus on
the concerns of identifying re-usable data chunks and packaging and re-packaging
them into a variety of messages. This packaging and re-packaging is more fundamental
to the business than simple translations among incompatible formats, and is amenable
to semantic technology that describes links and collections among chunks.
Summary
Two major initiatives are described above where a message model was developed first,
to provide an efficient hub-and-spoke integration among disparate systems or data
silos.
In both cases, these messages are a key element of overall enterprise integration,
whereby data from many sub-systems are made available across lines of business and
enterprise silos. In addition, “sub-rosa” (under the table), these same interchange
formats are persisted with minimal changes and repackaging, in these two cases as
XML
using NoSQL persistent stores that process XML and JSON natively.
Agility was achieved by the insurer by re-using their core messaging model, focusing
on how to define re-usable chunks of data, and modeling a wide variety of related
messages as combinations of those chunks.
Agility was achieved by the DSH by defining singular (less flexible) messages first
and directly storing those, with only minimal modifications to tag them with additional
service data and remove personal information.
NoSQL technology alters the overall architecture
A key observation from this work is that NoSQL technology does not “plug in” to
an existing architecture as a persistence alternative in place of a relational
database. Instead, the overall nature of the architecture - starting with data
architecture and system architecture but extending also to enterprise architecture
–
must change when NoSQL technologies are used.
The author’s experience is that this shift is challenging to navigate, and
ideally these examples illustrate the different concerns and approaches that become
paramount when the data models can naturally and easily cross “layer cake”
boundaries – that is, when XML or JSON are used for messaging and can also be
persisted (approximately) as-is. “Standard” techniques such as logical models and
complex transforms or mapping technologies among relational, object and message
formats no longer need to be the focus of architecture, and data re-use and
re-packaging of existing XML or JSON structures rise to the fore.
[1]
References
[Hunt14] Your API versioning is wrong, which
is why I decided to do it 3 different wrong ways. (2014) From blog post.
[Rayfield12] Sports Refresh: Dynamic Semantic Publishing.
(2012) From BBC blog post.
[Yourdon79] Edward Yourdon, Larry Constantine. (1979) ISBN:0138544719. Prentice-Hall, Inc. Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design.
[Chessell15] Mandy Chessell, Gandhi Sivakumar, Dan Wolfson, Kerard Hogg, Ray Harishankar. (2015).
ISBN:0-13-336634-0. IBM Press. Common Information Models for an Open, Analytical, and Agile World.
[Time14] Steven Brill. (2014) 183(9). Time Magazine. Obama's Trauma Team.
[1] Note that workarounds and re-mappings can be introduced, where older
message formats are supported even as new formats are created. Troy Hunt discusses
some
issues with trying to manage multiple formats simultaneously in a blog post on API
Versioning at Hunt14. See Yourdon
and Constantine: Yourdon79 with full chapters on coupling and
cohesion, respectively. We are using simplified, “notional” documents in this paper,
meaning the
documents have the same basic structure as actual documents in the described systems,
but the exact structure, element names and namespaces are not used.
Edward Yourdon, Larry Constantine. (1979) ISBN:0138544719. Prentice-Hall, Inc. Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design.
Mandy Chessell, Gandhi Sivakumar, Dan Wolfson, Kerard Hogg, Ray Harishankar. (2015).
ISBN:0-13-336634-0. IBM Press. Common Information Models for an Open, Analytical, and Agile World.