Morrissey, Sheila M., John Meyer, Sushil Bhattarai, Gautham Kalwala, Sachin Kurdikar, Jie Ling, Matt Stoeffler and Umadevi Thanneeru. “Beyond Well-Formed and Valid: QA for XML Configuration Files.” Presented at International Symposium on Quality Assurance and Quality Control in XML, Montréal, Canada, August 6, 2012. In Proceedings of the International Symposium on Quality Assurance and Quality Control
in XML. Balisage Series on Markup Technologies, vol. 9 (2012). https://doi.org/10.4242/BalisageVol9.Morrissey01.
International Symposium on Quality Assurance and Quality Control in XML August 6, 2012
One of the consequences of the rapid development and dissemination of the ecosystem
of XML technologies was the widespread adoption of XML as a meta-format for the specification
of application configuration information. The validation of these rich configuration
files with standard XML validation tools, however, is often not sufficient for error-free
deployment of applications. This paper considers how to categorize some of the constraints
that cannot be enforced by such tools, and discusses some XML-based approaches to
enforcing such constraints before, or as part of, deployment.
One of the consequences of the rapid development and dissemination of an ecosystem
of XML technologies, including free and open source XML parsers, XSLT engines, and
binding tools for various programming languages, was the widespread adoption of XML
as a meta-format for the specification of application configuration information.
The XML ecosystem obviated the need to write custom parsers for one-off configuration
formats. This was true in part because, at least at the syntactic level, there was
a tool-chain at hand to warrant the well-formedness and validity of those files.
XML also facilitated the use of richly structured configuration information. Coincident
with an increasing community of practice in architectural idioms such as abstract
factories (see [gamma et al]), this capacity for rich configuration made XML the norm for configuration of such
applications as Apache’s Tomcat server for Java servlets and Java Server Pages (JSP),
Hibernate’s object/relational mapping framework, the Ant build tool, and the Spring
application framework and inversion-of-control (IOC) container.
These rich configuration files forward many diverse ends, ranging from (at least the
possibility of) more cleanly engineered code, to hot-swappable web applications.
However, as even a cursory view of these projects’ listservs indicates, configuration
files often are the cause of hiccups in application deployment. Some of these problems
can be alleviated by the application of standard XML validating parsers in the deployment
process. Other problems however do not yield themselves to the standard XML tool
chain.
Widely used applications such as the ones mentioned here often have interactive development
environment (IDE) support for the creation of configuration files. The IDE might
make use of template files, for example, and provide hints when creating and populating
configuration instances. Such IDE support however is not typically robust in validating
the content entered, whether or not the hints are taken.
The information models of which these XML configuration files are instantiations (see
[abrams]) entail constraints more complex than those enforced by XML
well-formedness and validity. These constraints are not expressed, and are perhaps
inexpressible, in a configuration file’s document type definition, whether that
definition is a DTD, or an XSD schema, or a RelaxNG specification. How might we
categorize at least some of these constraints? What techniques can we employ to enforce
them before, or as part of, deployment?
XML for Configuration at Portico: Issues
What is Portico?
Portico is a digital preservation service for electronic journals, books, and other content.
Portico is a service of ITHAKA, a not-for-profit organization dedicated to helping the academic community use digital
technologies to preserve the scholarly record and to advance research and teaching
in sustainable ways. As of April 2012, Portico is preserving more than 17.7 million
journal articles, nearly 17,000 books, and nearly 1.5 million items from digitized
historical collections (for example digitized newspapers of the 18th century).
Content comes to Portico in approximately 300 different XML and SGML vocabularies.
These XML and SGML documents are accompanied by page image (PDF) and other
supporting files such as still and moving images, spreadsheets, audio files, and
others. Typically content providers do not have any sort of manifest or other
explicit description of how files are related (which ones make up an article, an
issue of a journal, a chapter of a book). This content is batched and fed into a
Java workflow that is driven by XML configuration files, which Portico calls
profiles (about 190, one for each publisher content stream), and
registries (shared across all content streams).
The Portico workflow maps the publisher-provided miscellany of files into bundles
that comprise an article or book or other content item.
Figure 1
Figure 1: Mapping Files to Content Units
Publisher-provided XML and SGML files are normalized to the Portico profile of the
National Library of Medicine’s Journal Archiving DTD. The workflow identifies the
format of each of the component files, and, where a format specification and
validation tool is available, validates each file against its format specification.
It generates metadata considered important for preservation (descriptive, or
bibliographic, metadata; technical metadata about files and their formats;
provenance and event metadata, detailing the tool chain, including hardware and
software information, used in processing the content). These metadata are formatted
as XML, and are stored with the preserved digital object.
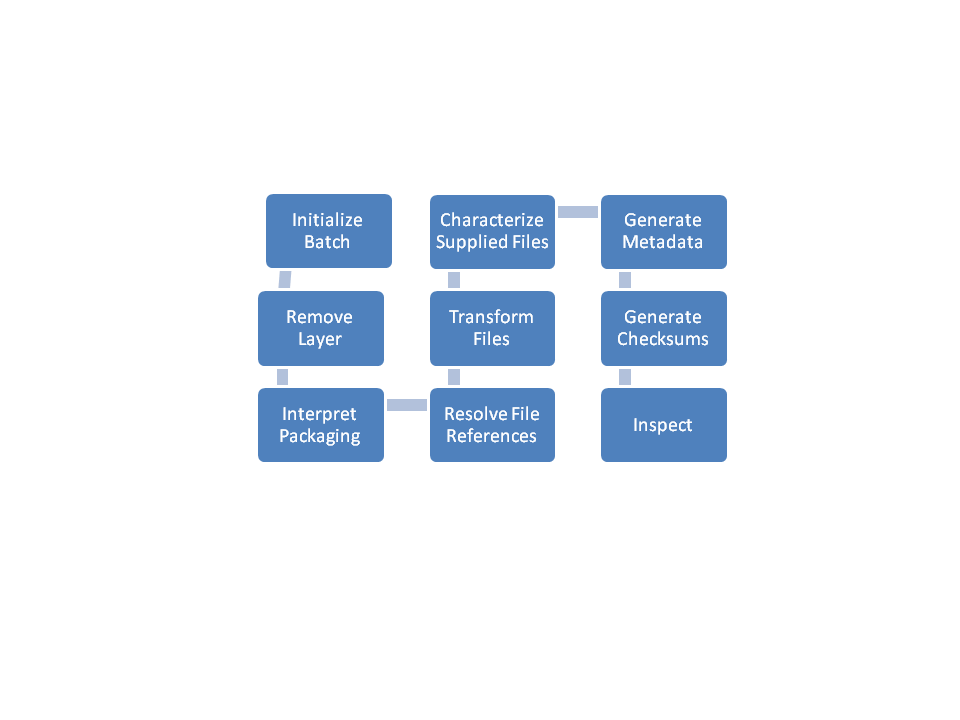
Figure 2
Figure 2: Portico High-Level Workflow
Some of the sub-steps in this workflow are explicit QA checks of the XML content –
both that provided by the publishers, and that produced by Portico in the workflow
itself. This QA includes XML validation, the assertion (via Schematron) of other
constraints on content values, and visual inspection of sample content. We have
written about some of the QA techniques and challenges associated with these content
files for Balisage and other venues (see, for example, [morrissey et al] and
[morrissey 2011]). In this paper we would like to focus on the QA
challenges associated with those XML registry files that drive our workflow.
Portico XML Configuration Files: A Description
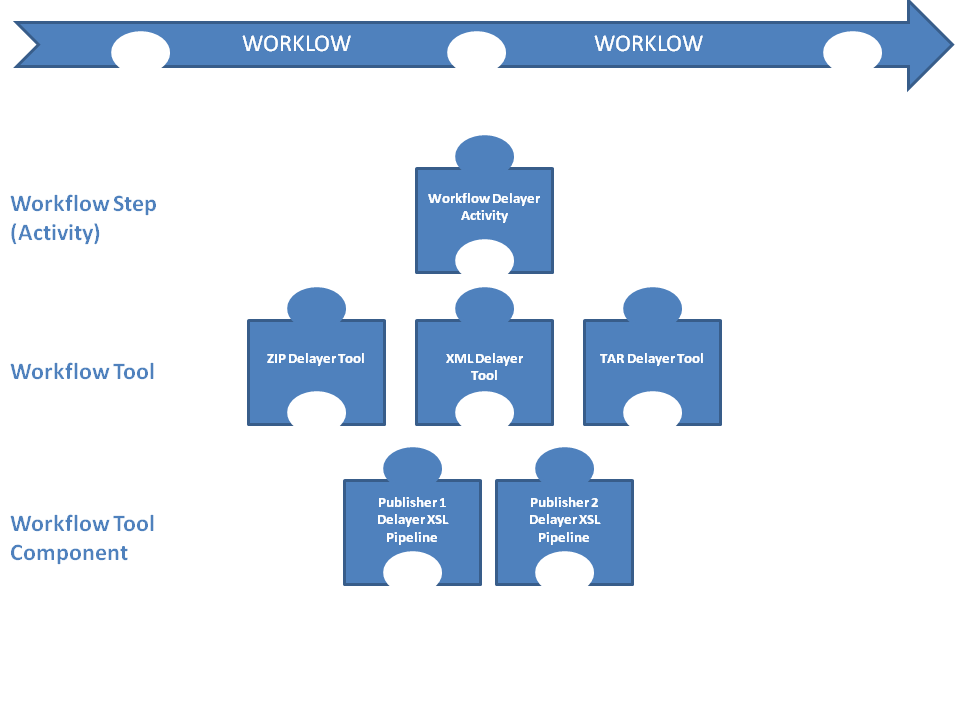
The Portico workflow is a pluggable framework. At each step, or activity, in the
workflow, the particular tool to be employed is dynamically selected, based on the
format or mime type of the file or files being processed at that step. Thus, for
example, the “de-layer” activity would invoke standard tar, gzip, or zip tools to
expand and separate out the content of .tar, .gzip, or .zip files. The same activity
would invoke an XSL transform to split a publisher XML file containing bibliographic
metadata for all the articles in an issue of a journal into separate XML files for
each article (and would invoke a different XSL transform for each different publisher
XML format).
Figure 3
Figure 3: Format-driven Tool and Tool Component Plugins for WorkFlow
Step
So, at the root of all the XML configuration files that drive and parameterize the
Portico workflow is the format registry file: FormatRegistry.xml. There is a <Format> element for each distinct format for which the archive contains at least one instance.
This, for example, is part of the <Format> element for one publisher’s profile of one version of the NLM Journal Publishing
DTD:
For each workflow step or activity, the tool registry file, ToolRegistry.xml, maps
each format to the Java class to be plugged in, configured, and executed at that step.
So, for example, in the tool registry, we have entries such as:
This entry indicates that in the workflow Transform Files step, if
the Portico identifier (defined in the format registry) for the format of the file
to be transformed is XXX_NLM_Journal_Publishing_DTD_2.1, then we should
look for plug-in information about what tool to employ, and how to parameterize it,
in a subsequent ScriptInfo element with a ScriptID
attribute value of scrxxx. In that element, we will see specified such
things as a list of relative file paths to XSL transforms that comprise the
transformation pipeline for instances of this format, along with (relative)
directory names where those files are located; the Portico identifier for the format
of the output of this transformation (also defined in the format registry); a
fully-qualified Java class name for a filter through which the input file is to be
passed; and an Rid attribute referring to yet another subsequent
element containing full information about the Java tool class that will invoke the
filters and the XSL pipeline.
Later in the tool registry, information about the BaseTransform_1.0 tool is specified, including its Java class name, and information about the parameters
to be passed when instantiating that class (as we did in the ScriptInfo element above), including whether or not the parameter is required, and what its
type should be:
<ToolInfoSet>
<ToolInfo Id="BaseTransform_1.0">
<Name>BaseTransformTool:1.0:2007-05-01</Name>
<Description>
Tool for transformation of XML files via XSL stylesheets.
</Description>
<Status>ACTIVE</Status>
<ClassName>
org.portico.threadedtool.tool.transform.BaseTransformTool
</ClassName>
<ToolParameters>
<ToolParameter Name="StyleSheetList"
Required="true"
ParameterType="ValueOrderedList">
<Description>
This is the list of XSL stylesheets that are to be processed and the
order in which they should be processed.
</Description>
</ToolParameter>
<ToolParameter Name="outputFormatId"
Required="true"
ParameterType="Value">
<Description>
This identifies the output format ID of this set of transforms.
</Description>
</ToolParameter>
<ToolParameter Name="InputFilterClass"
Required="false"
ParameterType="Value">
<Description>
This identifies the filter to be applied to the file before transforms.
It should contain the fully qualified class name of the filter.
If this Parameter is not supplied, the default BaseFilter
class is used. Legal values come from package
org.portico.threadedtool.tool.transform.filter.
</Description>
</ToolParameter>
...
</ToolParameters>
</ToolInfo>
...
<ToolInfoSet>
Portico XML Configuration Files: Categories of Configuration Issues
There are a lot of moving parts in even this condensed description of the semantics of these two configuration files.
As more and more publisher streams were added to Portico’s workflow, more and more
configuration information was added to these files, by more and more developers working
at the same time to add new content streams and their accompanying Java tool and filter
classes, and associated XSL transformations. And these additions had to be made in
several different workflow environments: a developer environment; an integration
environment where profiles and registries for new publisher streams are first worked
out; a QA environment for regression testing of tool, transform, workflow, and configuration
changes; and, finally, to the production environment.
Perhaps to no one’s surprise, Portico began to experience deployment glitches. None
of these glitches occurred because the XML registry files were either not well formed
or invalid, as developers consistently validated the files against their respective
schemas before committing to Portico’s source control system, and the deployment scripts
also invoked a parser to validate the files. The workflow was paused; new configuration
files and other resources were deployed; the workflow was cranked back up. Then it
would hum along through several workflow steps, before encountering what effectively
was a configuration error that would bring one or more batches to a halt.
So the first question we asked ourselves was, what is it about the semantics of the
content of the elements in these files – and the relationship among elements in the
same and in different XML configuration files, and the relationship between the content in those elements and other components of the
workflow software and other resource files – that enabled configuration errors to
pass undetected through the sieve of standard XML validation tools?
Consistency Issues
At run time, every tool specified in the tool registry verifies the presence
or absence of various required and optional parameters, and checks to see, when
present, that they are of the required type before proceeding to execute the
tool. Just as the workflow that invokes the tools is a pluggable framework, so
too are the individual tools themselves pluggable (See Figure 3). This enables Portico to
use a single generic XML transformation Java tool on input that requires
slightly varying processing.
Since the tool is in some sense generic, some parameters for the tool are
optional. However, it can be the case that if one of these optional parameters
is present, and if the parameter has a particular value, then other optional
parameters must be provided as well. For example, the
InputFilterClass parameter is optional, but if it is present, and if its value is
org.portico.threadedtool.tool.transform.filter.ExternalEntityReplacerFilter,
then the tool registry must also provide the additional otherwise optional
parameters AttributeValueSeparator, AttributeName,
ElementQNames, MatchString, and
ReplacementString. 1
If these constraints are not met, the tool registry file will pass schema validation,
but the workflow step attempting to transform an instance of this file format will
fail at runtime, because the tool it invokes requires more configuration information
to perform the transformation. So we have a need to check for consistency between
the (variable, and complexly dependent) input expectations of the Java tool, and the
configuration values provided in the XML registry.
Referential Integrity Issues
As mentioned above, the Portico workflow is "format driven.” The choice of
tool to be plugged in at different steps in the workflow is determined by the
format of the object to be processed at the step (indeed, the sequence of
workflow steps itself is driven by the expected collection of format instances
in a content stream). And, as noted, we encounter many formats – the
FormatRegistry.xml file contains, at the time of writing, 545
Format elements.
Various constructs for defining an XML vocabulary (DTD, Schema, and RelaxNG) have
provisions for specifying a constrained list of values for, for example, attributes.
These provisions typically are employed for a smaller number of values than would
be required to cover the ever-growing list of formats Portico encounters. Nor would
such a constrained list of identifiers include the other information about the format
that is associated with the identifier in the format registry. For our purposes, we
would categorize that list of format identifiers (along with associated format information)
as “data” rather than “structure”. Further, if the list of constrained values were
to be maintained in the document type definition itself – at “compile time”, so to
speak, – we would be injecting what would be for us an unwanted level of complexity
in the versioning of our schema.
Nevertheless, we have the requirement to ensure a sort of “referential integrity check”
among XML files – that is, between the unique Portico format identifiers in the format
registry, and the format identifiers employed in the tool registry and other Portico
configuration files – to ensure successful runtime interaction between the workflow
tools and the registries that drive them.
Existence Issues
As seen above, the tool registry refers to many objects that are assumed to
exist at run time: Java tool and filter classes, XSL files, and other supporting
files. The existence or non-existence of such objects, even if their names are
specified in a document type definition, is extrinsic to the kind of structural
information a document type definition can provide, and which standard parsers
can validate. Yet a successful deployment of these XML configuration files
depends on verifying the actual existence of these objects in the total
deployment package. This was in fact the most frequent cause of
configuration-file-dependent deployment errors. An updated tool registry would
be deployed, but the new XSL files, or a new JAR file containing new Java tool
or filter classes specified in the updated registry, or the DTD or XSD files
associated with an XML or SGML format, were not deployed along with the new
tool registry. When the workflow was restarted, a (Java) workflow step would
look to the tool registry to determine which Java tool or filter class it should
employ, or, if the workflow step was an XSL transformation, what list of XSL
makes up the transformation pipelene, or against which DTD or schema a format
instance was to be validated. If the classes or files specified in the tool
registry had not also been deployed, the workflow step would raise a fatal error
and halt processing.
XML for Configuration at Portico: Solutions
The second question we asked ourselves was whether we could devise some automated
solutions to these consistency, referential integrity, and existence issues in order
to avoid, or at least minimize, costly cycles of stop/deploy/restart/fail/stop/correct/redeploy/restart
in our release deployments. We found that we could, and that we could do so fairly
simply with XSL transforms, assisted, in some cases, with Java extension functions.
We run these transform as part of deployment script before the stop/restart of the
workflow.
Consistency Checker
The tool registry’s ToolInfo element documents all the possible calling parameters that can be passed to the Java
tool class it specifies, indicating whether they are required or optional, and specifying
the type of each parameter. Assuming correct documentation (for ensuring which, to
probably no one’s surprise, we have not yet invented a completely automated tool),
this meant that we had sufficient information in the tool registry itself to perform
consistency checks. We use an XSL transform (Schematron is another obvious candidate
for this) to compare the various Paramter elements in the ScriptInfo element that configures each invocation of a particular tool for a particular format,
with the information in the ToolInfo elements. If an error message is created, the registry is not deployed until it
is repaired.
“Referential Integrity” Checker
Again, we used an XSL transform. The transform extracts format and mime type information
from the format registry being deployed with the tool registry, and uses that extracted
information to verify that any referenced format id or mime type in the tool registry
has been declared in the format registry.
Existence Checker
Our existence checker also uses XSL, aided by extension functions, to look outside
the XML box to determine that expected directories and XSL and other files exist in
the target deployment directories, and that classes referenced in the tool registry
exist in the .jar files also on the deployment path. In the case of XSL and other
XML files, it would of course be possible to use xsl-document to check
for the existence of necessary resources. For non-XML file resources whose existence
we wished to confirm, we could have used the unparsed-text() function,
interpreting an empty string result as a non-existent file. As we were using Java
extension functions to confirm the existence (i.e. deployment) of Java classes on
what would be the workflow's runtime Java classpath, and as the workflow uses the
classpath to resolve the location of XSL and other file resources, we used Java
extension functions to confirm the existence of these resources at deployment.
Not all configuration files -- not even all Portico workflow configuration files --
are XML files, of course, and not all are likely to be amenable to an XML-based QA
solution. XML would be overkill for the sort of name-value pairs of configuration
information more compactly expressed in conventional properties files. As the category
name of one class of deployment issues suggests, a different implementation choice
(relational database in lieu of XML registry files for configuration) would provide
a
different mechanism for enforcing at least one sort of consistency in deployment.
There are some limitations to these tools, even as applied to XML configuration files.
Our consistency checker, which validates the number, name, type, and compulsoriness
of
parameters passed to our Java tools, depends on a manual process of updating the
ToolRegisty.xml file's ToolInfo section whenever we update our Java tools.
We could conceivably employ Java annotations, and a meta-process to generate appropriate
ToolInfo elements, and test to see if those generated elements matched
the actual elements in the ToolRegistry.xml file (though this approach perhaps only
pushes back our "manual" dependency on developer discipline to ensuring consistent
annotation in the Java code).
A warrant of existence of a resource at deployment time, while reassuring, is not
necessarily a warrant of existence at run time, particularly for resources outside
of
one's institutional domain or control (though this has not been an issue in Portico's
deployment process). We have found a simple syntactic surrogate (a non-empty return
from
a method call) that reliably signifies the existence or non-existence of an artifact
"out there" in the world extrinsic to the XML document we are interrogating. That
surrogate is satisfactory for our purposes, but it might not be sufficient for all
purposes. And it is certainly no magical solution to the general ontological problem
of
assessing an XML document's assertion about external reality.
As mentioned above in the Background section, users of other applications with rich
XML configuration files experience deployment problems. Many of these are caused by
these same consistency, referential integrity, and existence issues experienced by
Portico with its registry files. Spring, Hibernate, and Tomcat configuration files
all
contain elements whose contents are intended to be fully-qualified Java class names,
for
classes that are presumed to be on the application’s classpath at runtime, and hence
available for instantiation via inversion of control. The XML configuration files
for
any of the applications mentioned above can contain elements whose content refers
to
files and directories, both local and non-local, assumed to exist at runtime (for
example, the location for JSP files used by Apache, as well as “welcome” files and
login
pages, can be specified). Nothing in the schema for Ant files ensures that a developer
using Ant to build and deploy a Java servlet populates the Ant configuration file
so as
to follow the Java servlet conventions for relative deployment location for servlet
and
other files. A Tomcat web.xml file specifying both type and values for JNDI can be
well-formed and valid, and yet specify a value that cannot be instantiated as an
instance of the specified type, or specify a type that in fact does not exist.
What we have found is that, for our XML configuration files, where standard XML
validation tools will not resolve these deployment issues, we can use XML-based tools
for at least these categories of non-structural, “extrinsic” validation requirements.
Further, because they are XML based, they can be employed in both in simple deployment
scripts and in continuous integration tools, reducing many common deployment problems.
XML-based tools, though not the only possible solution for solving XML configuration
file-related deployment issues, were a natural choice for Portico. In part this was
a
pragmatic choice: such XSL and Java-based solutions were well-supported by the skill
set
in our programming team, and the categories of deployment problems we experienced
where
amenable to solution by the means described. Standard XML parsers and XSL transform
engines made it easy to "get at" the content of XML elements and attributes to test
assertions about that content beyond the document's well-formedness and validity (Do
certains things exist "out there" on the file system? Have we provided all the
parameters that an optional Java filter plugin to a Java plugin tool to a Java framework
requires at runtime?) . And they made it easy to "get at" them in different contexts
--both a manual context (a developer updating an XML registry in Oxygen, for example)
and an automated one (a deployment script that is part of a configuration management
system).
In part however this was also an aesthetic choice: there is a certain "turtles all
the
way down" appeal to applying XML-based QA tools to XML configuration files that drive
a
workflow for processing digital artifacts whose key components are XML files. The
aesthetic shaded into the pragmatic, as it so often does in software engineering.
The
consistent, conventional reuse of large-scale structure and coding idioms across such
a
large application as the Portico workflow system helps in making that system
comprehensible to the developers who support and extend it -- an approach, so to speak,
toward the possibly asymptotic, reader-centric rather than process- or processor-centric
goal of "Read once, understand everywhere" [reflection] in complex
systems.
What precisely comprises the "beauty" or aesthetic appeal of a piece of software (both
data structures and algorithms, and their instantiation in concrete formalisms such
as
languages) is a topic of much discussion. To what extent does a software instance
provide, as mathematicians might say of a proof, an "elegant" or "economical" solution
to the problem it was created to solve? The extent to which the XML community has
grappled with the ways in which, and the degree to which, an XML document type
definition can or might comprise a model homomorphic to some domain, suggests that
such
homomorphism is a key criterion. It might be argued that the choice of XML as a
configuration language for these large-scale frameworks was in some sense opportunistic,
or "merely pragmatic." The ecosystem of XML parsers provided a "good enough" solution
to
the expression of richly hierarchical configuration information, even if it did not
provide a solution to the problem of the more complex relationships among components
of
these hierarchies, and to extrinsic realities. The necessity of performing QA on these
files can be viewed as an indicator of the limits of the economy of XML as a solution
to
the original problem. Whether other software constructs would provide a more "beautiful"
solution is an open question. That a partial solution to the limits of XML as a
configuration language can be found in XML-based tools has, at least for Portico,
its
own economical appeal.
[gamma et al] Gamma, Erich, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software.Reading, MA: Addison-Wesley, 1995.
[morrissey et al] Morrissey, Sheila, John Meyer,
Sushil Bhattarai, Sachin Kurdikar, Jie Ling, Matthew Stoeffler and Umadevi Thanneeru.
"Portico: A Case Study in the Use of XML for the Long-Term Preservation of
Digital Artifacts." Presented at International Symposium on XML for the Long
Haul: Issues in the Long-term Preservation of XML, Montréal, Canada, August 2, 2010.
In
Proceedings of the International Symposium on XML for the Long
Haul: Issues in the Long-term Preservation of XML Balisage Series on
Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Morrissey01. Retrieved April 20, 2012, from
http://www.balisage.net/Proceedings/vol6/html/Morrissey01/BalisageVol6-Morrissey01.html.
1 Portico filters incoming XML and SGML files for a variety of reasons.
The format validation step, for example, makes use of the JHOVE tool,
which is not able to make use of catalogs. The DOCTYPE statement will
therefore sometimes require filtering to cause the parser to resolve to
a local copy of the DTD or schema. Sometimes a filter is used to correct
syntactic errors in the DOCTYPE statement, such as white space or
comments before the XML declaration, encoding declarations inconsistent
with actual encoding used by the publisher (see morrissey et al
for other examples)
Gamma, Erich, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software.Reading, MA: Addison-Wesley, 1995.
Morrissey, Sheila, John Meyer,
Sushil Bhattarai, Sachin Kurdikar, Jie Ling, Matthew Stoeffler and Umadevi Thanneeru.
"Portico: A Case Study in the Use of XML for the Long-Term Preservation of
Digital Artifacts." Presented at International Symposium on XML for the Long
Haul: Issues in the Long-term Preservation of XML, Montréal, Canada, August 2, 2010.
In
Proceedings of the International Symposium on XML for the Long
Haul: Issues in the Long-term Preservation of XML Balisage Series on
Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Morrissey01. Retrieved April 20, 2012, from
http://www.balisage.net/Proceedings/vol6/html/Morrissey01/BalisageVol6-Morrissey01.html.