Sperberg-McQueen, C. M. “XiBIT: XML-in-the-browser interoperability tests.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Sperberg-McQueen01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: XiBIT
XML-in-the-browser interoperability tests
C. M. Sperberg-McQueen
Black Mesa Technologies LLC
C. M. Sperberg-McQueen is the founder of Black Mesa Technologies LLC,
a consultancy specializing in the use of descriptive markup to help
memory institutions preserve cultural heritage information for the
long haul. He has served as co-editor of the XML 1.0 specification,
the Guidelines of the Text Encoding Initiative, and the XML Schema
Definition Language (XSD) 1.1 specification. He holds a doctorate in
comparative literature.
The XiBIT (XML-in-the-browser interoperability tests) Project seeks
to provide a systematic collection of interoperability tests to
characterize the behavior of current Web browsers in the display and
processing of XML. It is not a collection of conformance tests;
conformance tests must cover an entire specification and must not
address behaviors not constrained by the specification, while
interoperability tests will tend to focus on areas where different
implementations behave differently, whether those behaviors are
constrained by any specification or not. Conformance tests have
right and wrong answers; interoperability tests do not. XiBIT
will produce both a collection of test cases and documentation of
the results of running those test cases on a selection of current
browsers.
Most current Web browsers support the retrieval of XML from Web
hosts, the application of CSS and XSLT stylesheets to that XML, and
the display of XML documents in the browser. But publication of XML
on the Web is not always a straightforward task. Does the browser
validate the document? If the document is invalid, will the browser
display it anyway or display only an error message? Will the browser
expand entity references? Will it process the DTD? Will it process
the internal DTD subset but not the external subset? Will it refuse
under certain circumstances to fetch the appropriate stylesheet or DTD
files?
These are not questions of specification conformance: the XML
specification does not impose answers to these or similar questions as
requirements of XML conformance. But they and others like them are
important questions for anyone who would like to publish XML documents
on the Web in a way that works with a broad variety of current
browsers.
The XiBIT project aims to help. The name XiBIT (pronounced like
the English word exhibit) stands for
XML-in-the-browser interoperability tests; the goal of the
project is to investigate and document the behavior of current Web
browsers in the processing and display of XML. It is hoped that the
results of XiBIT will be helpful to anyone who wishes to use XML on
the Web, by tabulating usages that work consistently across browsers
(or conversely by identifying usages or constructs which lead to
different behavior in different browsers).
This paper describes the current state and plans of XiBIT. An
introductory section includes some remarks on related work, a
discussion of the difference between interoperability testing and
conformance testing, and a brief discussion of some relevant
historical background. This is followed by a description of the
project, covering aims, expected work products, and work methods, and
by some sample test cases and results. A list of tasks for future
work and a brief conclusion complete the paper.
Introduction
Related work
Much of the obviously related work consists of
confomance tests.
Conformance and other test suites already exist for many of
the technologies involved in displaying XML on the Web.
Shortly after the XML specification was published, the
Organization for Organization for the Advancement of Structured
Information Standards (OASIS) chartered a technical committee
to develop an XML conformance test suite on the basis of a
earlier efforts by XML implementors and others; the committee's
report mentions contributions from James Clark, Fuji Xerox,
Sun Microsystems, IBM, and a joint effort by OASIS and the U.S.
National Institute of Standards and Technology (NIST)
[OASIS 2001]. After a revision
of the test suite for XML 1.0 Second Edition, the Oasis work
was transferred to the XML Core working group of W3C (the World
Wide Web Consortium); the current version of the test suite,
released in 2008,
covers XML 1.0 Fifth Edition, XML 1.1, and the corresponding
editions of the Namespaces in XML recommendation
[W3C 2008[?]].
A test suite for XSLT 1.0 was developed by the W3C XSL
working group and used to provide evidence of implementation
(which is required by the W3C process before specifications
are published as W3C Recommendations), but it is accessible
to W3C members only and has not been made publicly available.
(The same is true of the W3C's test suite for XSLT 2.0.)
Another strain of related endeavor includes the work done by the
W3C's HTML 5 and Web Applications working groups, which has done a
great deal to clarify the behavior of existing server and browser
software. XiBIT differs from that work partly in its exclusive focus
on XML rather than HTML, partly in its current focus on serving
human-readable documents directly and styling them using XSLT rather
than on serving XML data for use by Javascript code running in the
browser and manipulating it via the DOM; and partly in that XiBIT is
aimed solely at documentation of existing practice and not at the
development of any new specifications.
As the XiBIT project develops, it may integrate or adapt material
both from conformance test suites for the relevant specifications
and from test collections like those used by the HTML5 and Web
Applications working groups to document existing practice.
A third line of related work may be found in the investigations of
Alex Milowski over the last few years into the possibilities for
augmenting and improving XML support in Web browsers [Milowski 2009], [Milowski 2011]. Milowski's work overlaps with XiBIT in part; at
least, like XiBIT, he records some interoperability issues with recent
and current browsers. He raises those issues, however, as a way of
making rhetorical points about the need for more aggressive action by
the XML community; XiBIT's aims are less hortatory and more
systematic. Milowski is interested in possiblities for extending Web
browsers and improving their XML support; XiBIT restricts itself for
the moment to recording their status quo behavior.
Interoperability testing vs. conformance testing
The collection of tests developed by the XiBIT project differs
from conformance test suites in several ways.
First and foremost, XiBIT focuses on interoperability
testing or documentation of behavior, not conformance.
Note that strictly speaking,
interoperability denotes the ability of client-
and server-side implementations of network protocols to communicate
successfully with each other. Its application to specifications like
XML and XSLT, which define data formats or operations on data which
can be and usually are performed by individual implementations acting
alone, requires that the term be given a different meaning. In the
implementation of communications protocols, interoperability helps to
establish both that the specification is clearly enough defined to be
implemented consistently (thus providing a quality check on the
specification itself) and also that users of the technology can switch
from one implementation to another without (excessive) loss of
functionality.
As [ISO/IEC 2381-01] defines the term,
interoperability is
The capability to communicate, execute programs, or transfer data
among various functional units in a manner that requires the user to
have little or no knowledge of the unique characteristics of those
units.
In the case of single-processor specifications like XML and XSLT, it
is consistency among independent implementations that helps establish
these properties.[1]
XiBIT's focus on interoperability testing rather than conformance
testing means it differs from conformance tests in several ways:
Serious conformance tests need thorough coverage of the
specification(s) being implemented; they often include thousands or
tens of thousands of tests. At least in its initial versions,
XiBIT does not aim at that kind of coverage.
Conformance tests have right and wrong answers; XiBIT tests do
not have right or wrong answers. They seek only to find out what
processors actually do under the tested circumstances. (If the
behavior in question is clearly governed by a particular specification
which clearly prescribes a particular behavior, then the demands
of the specification are of some interest to most users interested
in open standards, as well as to most implementors. But strictly
speaking the relation of XiBIT tests to conformance is a side
issue.)
Almost all specifications leave some aspects of behavior
unspecified, to avoid over-constraining implementations, to leave some
conceptual space clear for implementations to compete against each
other, and/or to leave flexibility for implementations to adapt to
their expected users and operating environments.
Conformance tests should not, and typically do not, test behavior
in these areas, which stands to reason: testing behaviors not
constrained by a specification cannot in principle provide information
about the conformance or non-conformance of the software under
test. For interoperability as defined here, however, behaviors not
constrained by the controlling specifications can be just as
interesting and relevant as behaviors that are constrained. Indeed,
whenever most implementations are reasonably conformant,
interoperability testing is likely to focus all the more on behaviors
which are not constrained by conformance to the specifications,
because that is where variation among implementations will be found.
And for the same reasons, when not all implementations are reasonably
conformant, interoperability testing will in practice need to devote
more attention to areas where conformance is weak in some
implementations.
Those who want to publish XML on the web will need to attend
to browser and server behavior which is not in fact governed by any de
jure or de facto standard, or sometimes by any written specification
at all.
Historical background
When in the early 1990s the World Wide Web exploded in popularity,
it placed the SGML community in a delicate, slightly awkward position.
HTML was manifestly an application of descriptive markup: its syntax
was the reference concrete syntax of SGML, its element set clearly
modeled on (and in part identical with) the starter
set of IBM DCF, Waterloo Script, and Annexe E.1 of ISO
8879. The HTML spec paid lip service to the ideas of descriptive
markup. So the success of HTML and the World Wide Web could, with
a little effort, be interpreted as reflecting well on descriptive
markup and SGML.
But at the same time, the Web had characteristics which many SGML
users found troubling, even distasteful. Web browsers were
limited to a single vocabulary which few SGML users much liked,
they did not follow the standard rules of SGML parsing, and
the HTML specification prescribed behavior in
the presence of invalid input which was foreign to SGML practice.
Some SGML users found it hard to like an application which
deviated so markedly from what they regarded as good practice,
and some found it frustrating that the Web found
wider uptake than other SGML applications they regarded as better
designed.
It did not take very long for some in the SGML community to
conceive of a World Wide Web that accommodated their SGML data
without requiring a down-translation into HTML. Through a history
that does not need to be rehearsed in detail here, this idea led
to the formation of a working group at the World Wide Web Consortium
(W3C) chartered to formulate a version of SGML that would be
suitable for use on the Web. The end result of this SGML on the Web
Working Group was
a subset of SGML called (so as to differentiate it from any
markup system with a fixed single vocabulary, like HTML) the
Extensible Markup Language, XML.
One stated goal of the SGML on the Web working group was to
make it possible to deploy XML documents on the Web; this
intended application led in turn to the development of some other
specifications (e.g. for the XML stylesheet instruction
W3C 2010) and affected
the direction taken by others: Cascading Stylesheets (CSS)
was reformulated to enable CSS to work with any vocabulary, not
only with HTML, and XSLT 1.0 was designed to be lightweight enough
to be implementable in a Web browser.
If one of the goals of the work that led to XML was to
make it possible to deploy XML documents on the Web, then it
makes sense to ask how far that goal has been achieved, and
under what circumstances it's possible. That is one of
the rationales for XiBIT.
Project description
Aims
The goal of XiBIT is to investigate and document
the behavior of existing Web browsers in the processing
and display of XML.
Expected work products
XiBIT will generate several work products:
a set of tests, available from a Web server
a tabulation of browser behavior on those tests
a public interface to allow volunteers to submit
data recording behavior of specific browsers in specific
environments
prose documentation of XML browser behaviors
a diagnostic tool to read XML documents and issue
warnings of potential interoperability issues
Some of these exist now (samples and screen shots below); others
will be developed as the project continues. All materials developed
by XiBIT will be made publicly available under the GNU Public License
at the project's Web site, http://xibit.blackmesatech.com/.
Methods
Identifying axes of variation
XiBIT tests are written to explore browser behaviors that may
affect interoperability.
Each set of tests explores one or more dimensions along which XML
documents can vary, so as to see how that variation affects browser
behavior. The set of dimensions explored by a test set may be
referred to as a space of variation.
The dimensions or axes of variation to be tested are found
in several ways.
The project will perform a systematic search of the Web for documents
describing pitfalls of XML publication and techniques for avoiding
them.
Even without a survey of existing literature on the
subject, some axes suggest themselves to introspection based
on practical experience serving XML documents on the Web. For
example: browser behavior has in the past been affected by the
validity or invalidity of the XML document, by the location of DTD
files and stylesheets, by the presence or absence of document-type
declarations in XSLT stylesheets, etc., etc. Some failures of
interoperability among browser-based XSLT implementations reflect
conformance issues in the browsers' implementations of XSLT:
Mozilla-based browsers do not support the namespace axis, several
browsers have (different) bugs in their handling of the XSLT
unparsed-entity-uri() function, and so on.
Once the first version of XiBIT is made public, the project site will
solicit input from the public. Any problem that arises for anyone in
publishing XML documents on the Web may point to some relevant
variations in browser behavior, so any war story about things going
wrong in XML publishing may help XiBIT improve its coverage.
Other areas of variation can be identified by systematic examination
of the relevant specifications: XML, Namespaces in XML, XSLT 1.0, XML
Base, Associating Style Sheets with XML documents, Cross-origin
resource sharing, the Document Object Model, etc. For the reasons
described earlier, particular attention will be paid to areas left
unconstrained by the relevant specifications.
Finally, the project will (time permitting) review relevant conformance
test suites and the work of relevant working groups; many questions
addressed for HTML documents by the HTML5 work may also arise with
respect to XML documents. Because of the way current browsers are
constructed, they may behave differently for HTML and XML documents.
Size of the space of variation
Each axis of variation will have at least two possible values
and may have more. For example, processor variation in the handling
of DTDs may be affected by:
whether the document is valid or invalid;
whether the document type definition has an internal
subset (declarations in the document entity itself),
an external subset (declarations in other resources), or
both;
whether any external document type definition resources
are pointed to in a way that violates the browser's
same-origin policy; in different contexts, browsers
may behave differently for relative references that
point downward in the virtual directory structure of
URIs, relative references that point upward in that
structure, relative references that appear to point upward
(i.e. they begin with ..) but in
fact do not (they re-descend to the original location),
absolute references that refer to the same
host, absolute references that refer to a different host,
and references which use a different URI scheme, different
port number, etc. For purposes of the examples below,
it is supposed that there are six relevant variants
for the form of the URI.
The retrieval of stylesheets may be affected by the same
variations in location of the stylesheet.
In principle, these variables can interact in a browser, so a
complete survey will require testing all possible combinations.
In simple cases, the number of test cases required
is the product of the number of possible values on each
dimension, and the set of test cases to be constructed
for a given space of variation is the Cartesian product
of the dimensions. In most cases, however, not all combinations
of values are logically possible, so the actual number of
cases will be lower (and may be difficult to calculate
a priori). An example may serve to
illustrate the point.
In the case of XML documents with and without a DTD and
with and without a single CSS or XSLT stylesheet, the
exhaustive approach would require all combinations of
validity, DTD composition, external DTD location, CSS
location, and XSLT location, for
2 (valid vs. invalid)
× 2 (external subset with or without and internal subset)
× 6 (variations in relative and absolute URIs for the DTD)
× 6 (variations in relative and absolute URIs for the stylesheet)
× 2 (CSS vs. XSLT stylesheet)
or 288 cases for documents with an external DTD and one stylesheet,
plus another
36 (= 2 forms of validity × 2 forms of DTD structure × 6
forms of URI) for those with an external DTD and no stylesheet,
plus 24 (= 2 forms of validity × 6 forms of URI × 2 kinds
of stylesheet)
for those with no DTD and one stylesheet,
plus 1 for those with neither DTD nor stylesheet,
for a total of 349 tests.
In practice, many of the theoretically possible interactions among
variables do not arise. If a browser shows the user an error message
instead of the document, when the document is invalid and has no
stylesheet, it is unlikely though not impossible that the browser will
show the invalid document to the user if only the document has an XSLT
or CSS stylesheet. To reduce the overall number of tests, then,
and make it easier to examine the behavior of a browser on all tests,
the XiBIT project works on the assumption that different axes of
variation should be assumed to be independent unless evidence arises
that suggests that they interact.
Browser behavior with respect to location of DTDs and
browser behavior with respect to location of CSS and XSLT stylesheets
are tested independently, with 39 tests, rather than 349:
24 documents with external DTDs (= 2 forms of validity × 6 forms
of URI × 2 for the presence or absence of an internal subset),
2 with internal DTDs only (valid and invalid),
1 with no DTD at all and no stylesheet,
plus 6 tests each for various forms of URI pointing to an XSLT
or CSS stylesheet.[2]
Generating tests
For a given space of variation, XiBIT tests are generated
automatically using a two-step process: first a program generates an
XML description of the set of test cases, and then a second program
generates from this description both the individual files needed for
the test cases and a list of the tests in the form of a catalog. (In
the current version of XiBIT, the first program is written in XQuery
and the second in XSLT.)
Samples of the test-case generator code and test cases are given
below.
Testing browsers
Test cases take the form of XML documents which may have references
to a DTD and/or stylesheets. The simplest way to run a given test
case in a given browser is just to dereference that test case using
that browser, and see what the browser does with it. Possible
behaviors include styling the document with the given stylesheet,
displaying the document in tagged form (as most browsers now do with
data recognized as XML that has no XML stylesheet processing
instruction), treating the document as if it were HTML (i.e. ignoring
all tags unless they have the same names as HTML elements and
displaying the #PCDATA content of the document), displaying a blank
screen, and displaying an error message.
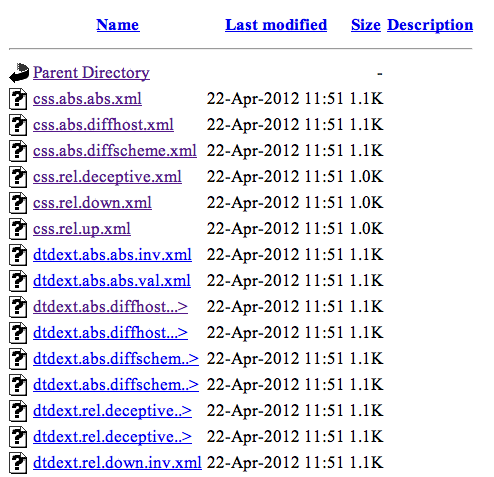
For this kind of testing, the simplest presentation of a
set of test cases is just a directory listing, as shown in figure
1.
Figure 1
If a set of tests has more than a handful of test cases, however,
dereferencing each test case individually is tedious (one click to
navigate to the test case, one click to navigate back or to
close the separate tab or window), and the temptation to skip a few
tests rapidly becomes overpowering.
For some kinds of software and test suite, it's possible to build a
test harness to run all the tests automatically and record the
results, comparing them automatically to the expected result of the
test. For interactive software, however, the result of the test often
consists not in output that could be written to a file and checked
automatically, but in this or that rendering of the XML document on
the screen; a human is required to evaluate the result. (The browser
window could in principle be captured in an image file and then
analysed automatically, but that kind of automated image analysis goes
far beyond the resources available to XiBIT.) So there is a limit
to the possible automation.
It's possible, however, to use the HTML iframe
and object elements to embed test cases in another
document; within some limits, this makes it possible to inspect
the results of many tests in a single page, as shown in
figure 2.[3]
Figure 2
Tabulation of results
The raw results will be stored in an XML database and
made available via a search interface so that the set of
results can be filtered by operating system, browser, and
test case. Details are not yet worked out.
Some sample tests
The more complicated a test case, the more different things there
are that might conceivably affect the way it is treated by a browser.
To simplify interpretation of the results, therefore, XiBIT tries
where possible to keep the test cases as simple as possible.
To test the effect of DTD location and validity, for example,
test cases of the following form are used. The external DTD has
a single declaration:
<!ELEMENT valid-document (#PCDATA) >
Valid documents take the following form; the form of the
system identifier is the only thing that varies.
<!DOCTYPE valid-document SYSTEM "lib/wabash.dtd">
<valid-document>
This test document is part of XiBIT:
XML in the browser interface tests.
</valid-document>
Invalid documents differ only in the element's generic identifier:
<!DOCTYPE valid-document SYSTEM "lib/wabash.dtd">
<invalid-document>
This test document is part of XiBIT:
XML in the browser interface tests.
</invalid-document>
Tests involving stylesheets are similarly simple
in structure and have no DTD (on the assumption described
above that DTD processing and stylesheet processing
can be described independently, unless we encounter
evidence that they interact). The following test
applies a stylesheet whose URI is a downward-pointing
relative reference:
<?xml-stylesheet type="text/xsl" href="lib/down.xsl" ?>
<wf-document>
This test document is part of XiBIT:
XML in the browser interface tests.
</wf-document>
As mentioned earlier, the tests are produced systematically
by an XQuery module, which defines a function for each
space of variation. An example may illustrate the construction
of these functions.
For testing the effect of location and stylesheet language
on stylesheet processing, the relevant function begins by
defining the relevant axes of variation: XSL vs. CSS,
(: define yesno so we can iterate over it conveniently :)
let $yesno := (true(), false())
(: Define the major axes so we can iterate over them :)
(: Axis 1: XSL or CSS? :)
for $lang in ('xsl', 'css')
(: Axis 2: location of the stylesheet:
absolute or relative?
Same host or different? same scheme?
Downward path? Upward? Deceptive path?
:)
for
(: Is the URI absolute or relative? :)
$uritype in ('relative', 'absolute'),
$reltype in ('', 'down', 'up', 'deceptive'),
$abstype in ('', 'abs', 'diffhost', 'diffscheme')
These axes are not orthogonal; a where clause
is used to filter out tuples[4] whose values form a
nonsensical combination (like a relative URI reference
pointing to a different host).[5]
(: Specify consistency constraints :)
where (: only relative URIs have relative types :)
($uritype eq 'relative' or not($reltype))
and (: only absolute URIs can have abstype :)
($uritype eq 'absolute' or not($abstype))
and (: one or the other, please :)
( ($reltype) or ($abstype) or not($uritype))
For each tuple of bindings satisfying the where
clause, the function then returns a test case description
element. (It would be possible to generate the test
case directly, but it proved simpler to separate the
tasks of formulating a description and actually writing
out the test case.)
return element test-case {
attribute id {
concat($lang, '.',
if ($uritype) then
concat(substring($uritype,1,3), '.',
$reltype, $abstype)
else '')
},
element stylesheet-link {
attribute type {$lang},
if ($uritype eq 'relative') then
attribute uri {$reltype}
else
attribute uri {$abstype}
},
<wf-document/>
}
The query produces elements like the following two,
which describe test cases which call an XSLT stylesheet
with two forms of relative URI:
In the next step, these descriptions are processed
to produce the actual test cases; the first of these
two descriptions produces the XSLT test case shown
above.
For testing the effect of DTD location and validity on
processing, the relevant function has the same
structure, though there are more axes of variation:
whether an internal subset exists,
whether an external subset exists, the nature of the URI
for an external subset, and validity:
(: define yesno so we can iterate over it conveniently :)
let $yesno := (true(), false())
(: Define the major axes so we can iterate over them :)
(: Axis 1: internal DTD? external DTD? :)
for $intdtd in $yesno,
$extdtd in $yesno,
(: Subvariation: if $extdtd,
then URI is absolute or relative :)
$uritype in ('', 'relative', 'absolute'),
$reltype in ('', 'down', 'up', 'deceptive'),
$abstype in ('', 'abs', 'diffhost', 'diffscheme'),
(: Axis 2: valid or invalid :)
$valid in $yesno
The consistency constraints are also more complex:
(: Specify consistency constraints :)
where (: only documents with DTDs can be valid or invalid :)
(($extdtd or $intdtd) or not($valid))
and (: only documents with external DTDs have URIs
for their DTDs :)
(($extdtd and ($uritype))
or (not($extdtd) and not($uritype)) )
and (: only relative URIs have relative types :)
($uritype eq 'relative' or not($reltype))
and (: only absolute URIs can have abstype :)
($uritype eq 'absolute' or not($abstype))
and (: one or the other, please :)
( ($reltype) or ($abstype) or not($uritype))
Preliminary results
The initial version of the XiBIT includes three
test sets. The first set tests a space of variation
concerned with document validity and DTD location;
its axes are:
location of the DTD: internal subset, external
subset, both, or none
location of the external DTD subset, if any:
relative URI pointing down (e.g.
lib/test.dtd)
relative URI pointing up (e.g.
../lib/test.dtd)
relative URI pointing first up then down (e.g.
../tests/lib/test.dtd, for a test case which is itself
located in the tests directory)
absolute URI with the same host name (etc.) as the test
case
The second and third test sets concern the effect of
stylesheet location on processing, for XSLT and for CSS
stylesheets. The same variations on relative and absolute
URIs are tested for stylesheets as are listed above
for DTDs.
As may be seen, this initial version of XiBIT tests simple situations
and the results are unlikely to surprise readers familiar
with developing and deploying Web sites.
(But the author confesses to being surprised by
some of them, despite having been deploying XML
on the Web successfully for several years.)
All browsers tested displayed XML documents without regard to
the validity of the document. (Most browsers, of course, do not
validate XML documents in any case and so are not in a position to
make any distinction. Internet Explorer did once issue error messages
instead of displaying invalid documents, but this appears not to be
true for current versions of IE, at least since IE 7.)
All browsers tested displayed XML documents without regard to
the location of the DTD. That is, none of them enforced a same-origin
policy against the DTD. Since non-validating browsers typically do
not read the external DTD subset at all, this may have a certain
logic. Only one browser tested (Internet Explorer) issued an
error message of the DTD referred to was unavailable.
For documents retrieved using HTTP, all browsers tested enforced
the same-origin policy on XSLT stylesheets: stylesheets were
retrieved and applied when they were pointed to using relative
references or using absolute URIs pointing to the host from which the
test case was obtained. Stylesheets located on a different host were
not retrieved; some browsers (IE, Firefox) gave error messages for
those test cases, others simply displayed a blank screen (as shown
for the final case in the screen shot above).
Stylesheets located in fact on the same host but referred to
using a variant name (e.g. example.org
instead of www.example.org, or vice versa) were
treated (as is usual for the same-origin policy) as coming from
a different domain.
For documents retrieved from the file system (i.e. using a
file:/// URI), some browsers enforced the same-origin
policy on XSLT stylesheets and some did not. Some that did
enforce a same-origin policy (e.g. Opera) retrieved and applied any stylesheet
available in the file system, while others (e.g. Firefox) retrieved
only stylesheets located in the same directory as the test case, or
in a subdirectory. (Firefox also refused to retrieve documents
by following symbolic links, which makes it extremely difficult to
use stylesheets located in a common library directory.) Chrome
did not apply XSLT stylesheets to any XML document retrieved
from the file system.
None of the browsers tested enforced a same-origin policy
on CSS stylesheets.[7]
Some practical implications for users of XML may be inferred from
these facts. Referring to URIs by way of relative references is more
likely to work than referring to them by means of absolute URIs (for
the browsers tested so far). Users of Firefox and Chrome, however,
will find it impossible to view XML documents from the file system in
those browsers, if the documents use stylesheets located outside the
directory holding the XML document (and thus referred to using URIs of
the form ../lib/house-style.xsl).[8]
Further work
XiBIT is still in an early stage of its development. The main work
to be done in the immediate future is to make its core set of tests
and test results bigger and better: more test cases, exploring more
axes of variation, more test results from more versions of browsers on
more operating systems, and better tabulation of the raw results.
After a larger core set of tests and test results has been
gathered, it should be possible to perform deeper analysis and gain
better understanding of the results, resulting in better practical
advice for users of XML who would like to publish XML on the Web.
A diagnostic tool to test for and warn about interoperability
issues will be built to make the information gained by testing
practically useful to individual XML publishers.
References
[ISO/IEC 2381-01]
ISO (International Organization for Standardization),
IEC (International Electro-technical Commission).
ISO/IEC 2382-1:1993
Information technology — Vocabulary — Part 1: Fundamental
terms.
Geneva: ISO, 1993.
(Cited from Wikipedia article on
Interoperability at
http://en.wikipedia.org/wiki/Interoperability.)
[W3C 2001]
World Wide Web Consortium. XSL Working Group.
XSL 1.0 Test Suite.
[Ed. Max Froumentin.]
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, 28 August 2001.
http://www.w3.org/Style/XSL/TestSuite/.
[W3C 2008[?]]
World Wide Web Consortium. XML Core Working Group.
Extensible Markup Language (XML) Conformance Test
Suites.
[Ed. Henry S. Thompson.]
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, [n.d.; 2008?].
http://www.w3.org/XML/Test/.
[W3C 2010]
World Wide Web Consortium. XML Core Working Group.
Associating Style Sheets with XML documents 1.0 (Second
Edition).
W3C Proposed Edited Recommendation 09 September 2010.
Ed. James Clark (First Edition),
Simon Pieters (Second Edition),
Henry S. Thompson (Second Edition).
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, 2010.
http://www.w3.org/TR/2010/PER-xml-stylesheet-20100909/.
[1]
In the light of the concern with the user's ability to exchange one
imlementation for another, perhaps the area of concern should be
called interchangeability testing, but this
paper stays with the conventional term interoperability
testing.
[2] Actually, even this reduced set
of test cases is probably more than is needed: browsers which do not
read the DTD at all do not check to see whether the DTD is served
from the same origin as the document instance, and in practice it
is not necessary to test them for each of the possible forms that
a violation of the same-source policy can take. To keep the size
of the active test suite within bounds and make it feasible to
run at least a core portion of the test suite casually and without a
large investment of time, the core part of the test suite really
should be restricted to axes of variation which actually exhibit
some variation among some defined set of browsers. Tests on which
all browsers behave identically produce relatively little information
when run; axes of variation that do not distinguish among browsers
will be recorded and documented (after all, the axis might become
important if some new browser breaks the pattern), but will not be
part of the core of XiBIT.
[3] The figure shows stylesheets with
various forms of relative-reference URI and absolute URI
successfully applied, and a blank screen for the test
xsl.abs.diffhost.xml, which has in its XML stylesheet
processing instruction a URI for a stylesheet on a different host.
As may be seen, each stylesheet produces different text and
has a different color scheme to make it easier to see at a glance
which stylesheet applies to which test case. This is less
important in a test of different URI forms than in a test
investigating which stylesheet is used by a browser when several
XML stylesheet instructions are included.
[4] I.e.,
sets of bindings for the variables $lang,
$uritype, $reltype,
and $abstype.
[5] This
is nonsensical because by definition a relative reference
omits the host name and it defaults to the host of
the base URI, in this case that of the test case
itself.
[6] In
principle, the test set should also test
the effect of using a different URI scheme (e.g. ftp or
https instead of http). The
test-case generation code shown above includes
diffscheme as a value, but that line of
testing has run into technical difficulties.
[7] The level of CSS
conformance turned out to vary dramatically among the browsers
tested, but no one interested in CSS needs XiBIT to document
that fact.
[8] This
problem can be avoided by running an HTTP server on one's personal
computer and retrieving a document using an
http://localhost URI instead of a file: URI,
for those willing to set up a Web server on their local
machine.
ISO (International Organization for Standardization),
IEC (International Electro-technical Commission).
ISO/IEC 2382-1:1993
Information technology — Vocabulary — Part 1: Fundamental
terms.
Geneva: ISO, 1993.
(Cited from Wikipedia article on
Interoperability at
http://en.wikipedia.org/wiki/Interoperability.)
Milowski, R. Alexander.
XML in the Browser: the Next Decade.
Presented at
Balisage: The Markup Conference 2009 (Montréal, Canada, 11-14 August 2009).
In Proceedings of Balisage:
The Markup Conference 2009.
Balisage Series on Markup Technologies, vol. 3 (2009).
doi:10.4242/BalisageVol3.Milowski01.
doi:https://doi.org/10.4242/BalisageVol3.Milowski01.
World Wide Web Consortium. XSL Working Group.
XSL 1.0 Test Suite.
[Ed. Max Froumentin.]
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, 28 August 2001.
http://www.w3.org/Style/XSL/TestSuite/.
World Wide Web Consortium. XML Core Working Group.
Extensible Markup Language (XML) Conformance Test
Suites.
[Ed. Henry S. Thompson.]
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, [n.d.; 2008?].
http://www.w3.org/XML/Test/.
World Wide Web Consortium. XML Core Working Group.
Associating Style Sheets with XML documents 1.0 (Second
Edition).
W3C Proposed Edited Recommendation 09 September 2010.
Ed. James Clark (First Edition),
Simon Pieters (Second Edition),
Henry S. Thompson (Second Edition).
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, 2010.
http://www.w3.org/TR/2010/PER-xml-stylesheet-20100909/.