Malý, Jakub, and Martin Nečaský. “Utilizing new capabilities of XML languages to verify integrity constraints.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Maly01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: Utilizing new capabilities of XML languages to verify integrity constraints
Jakub Malý
XML and Web Engineering Research Group, Faculty of Mathematics and Physics, Charles
University, Prague, Czech Republic
Jakub Malý is a Ph.D. student at Charles University in Prague, Czech Republic.
His research areas involve conceptual modeling of XML data, integrity constraints,
evolution and adaptation
of XML applications.
Martin Nečaský
XML and Web Engineering Research Group, Faculty of Mathematics and Physics, Charles
University, Prague, Czech Republic
Martin Nečaský is an assistant professor at Charles University in Prague, Czech Republic.
His research areas involve XML data design, integration, evolution and linked open
data.
In this work, we show how integrity constraints expressed using Object Constraint
Language (OCL) can be verified using XML technologies - Schematron, XPath/XQuery and
XSLT -
and using Model Driven Architecture (MDA) principles. Some constructs typical for
OCL
constraints are different from the methods used in XPath/XQuery expressions. That
is why for
translating some OCL expressions, the standard XML toolset must be extended. We introduce
such extension for the 2.0 versions of the languages, but with the new features and
constructs proposed in drafts for XSLT 3.0, XPath 3.0 and XQuery 3.0, the transition
from
OCL is much more seamless and transparent. Higher-order functions, maps, error-recovery
instructions etc. provide us with necessary power to translate a general OCL expression
and
we discuss in detail their potential.
Unified Modeling Language (UML) has proved to be a powerful language for modeling
software
systems. Modeling is an important activity in the software development process. It
is a good
way of how to abstract from technical details of a software system and concentrate
on
structural, semantic and functional aspects of the system.
In connection with UML, a methodology called Model-Driven Architecture (MDA) has been
established. It proposes to start modeling a system at an abstract platform-independent level stripped from technical details and then specify the
model with more technical details at a platform-specific
level. From this level, actual executable code can be then generated (ideally)
automatically. In practice, the step from the platform-specific model (PSM) to executable
code
requires usually some level of the designer's interaction, but nonetheless, the presence
of
the layered model is a significant improvement both during initial formation of the
implementation and it's management in the future.
In our previous work (Nečaský 2012A, Nečaský 2012B), we have
shown how beneficial it can be to interconnect the world of UML and MDA with the world
of
designing XML schemas. Our premise was the fact that complex software systems are
often
modeled with UML diagrams at the platform-independent level. In particular, a UML
class
diagram is suitable for modeling a conceptual schema of the application domain. Such
schema is
called schema in a platform-independent model or simply
PIM schema in MDA terminology. The term model means a
modeling language (the language of UML class diagrams in our case). Our method allows
to
exploit the existing PIM schema to design XML schemas in the system. Each XML schema
is
modeled as so called schema in a platform-specific model or
simply PSM schema. A PSM schema is, again, a UML class
diagram. It represents a part of the PIM schema and shapes it to the form of the aimed
XML
schema. From the PSM schema, the XML schema expressed in a selected language (we currently
support XML Schema) can be derived automatically. We have implemented the method in
our CASE
tool eXolutio.
One advantage of such approach is that an XML schema designer takes an existing PIM
schema
and derives from it a PSM schema of the aimed XML schema. This is much easier then
writing the
XML schema manually even when the designer uses an XML schema visualization tool.
Another
advantage of using a PIM schema is that it prevents from inconsitencies between the
XML schema
and the conceptual schema.
Several UML/XML schema mapping approaches were proposed so far (Pagano 2009, Bauman 2009), the advantage of our approach is hidden in the fact that a
software system usually does not presume only one XML schema, but a whole family of
XML
schemas each representing a selected part of the application domain (e.g. in the domain
of
of e-commerce, the system might contain following XML schemas:
purchase order, product
catalogue or customer detail). Moreover, several
different XML schemas may overlap and share some part of the reality but may represent
it
differently (e.g., the concept of Customer in of
e-commerce is shared by different XML schemas which represent it with different
XML structures). Using our approach, the reality is modeled only once in the PIM schema
and
its different representations in different XML schemas are derived from the PIM schema
as PSM
schemas. When the designer examines a particular PSM schema, he can always track any
used
concept back to the common model and thanks to this fact never looses the "big picture".
The
management of a family of schemas is thus more efficient and error-proof. Moreover,
our
approach makes the XML schemas better readable - anyone can look up what real-world
concepts
modeled in the conceptual schema are represented with a selected part of a particular
XML
schema and, vice versa, how a selected real-world concept is represented in which
XML schemas.
In this work, we extend our previous work towards modeling complex integrity constraints
(ICs). ICs are a substantial part of every software system, equally important as a
conceptual
schema. However, most of them cannot be expressed with UML class diagrams and, therefore,
Object Constraint Language (OCL, see OCL specification) was introduced for this purpose.
OCL is a formal language which can be used to declare ICs over a UML model. The ICs
are in a
form of logical expressions and can check constraints such as "employee, who is a
division
manager, must have a collage degree" or "the store manager can get a bonus only when
the
profits have grow at least 10% compared to last year" (the following section contains
more
examples of integrity constraints and how they are expressed fromally in OCL) . Usaing
OCL has
two main benefits in comparison to the natural language:
unlike natural language, the formal expression is exact and unambiguous,
an expression in a formal modeling language can be used to generate code that
verifies the validity of the IC in actual data or running program.
The authors of Dresden OCL toolkit (see Dresden OCL) have demonstrated how
OCL ICs can be checked at runtime in Java (by translating OCL into Java code and adding
triggers that verify the constraints when objects are changed) and also in relational
databases (by translation of OCL expression into SQL statements, which allow to select
records
violating the IC).
When a system uses XML (e.g. for message exchange in communication or storing data),
the
ICs should be checked in the XML data and using XML technologies. In this work, we
show how
OCL ICs can be checked at runtime in XML documents using Schematron. The result of
our
research can be again profitably used by XML schema designers in cases when a PIM
schema
complemented with OCL ICs. Together with modeling the XML schemas as PSM schemas derived
from
the PIM schema, the designers can also easily convert OCL ICs from the PIM schema
to the PSM
schemas.
Having OCL ICs expressed at the platform-independent level the question is how they
can be
translated to the platform-specific level and from here to the XML schema level. The
conversion to the platform-specific level is not covered in this paper. Just let us
note that
we have already implemented several methods for this conversion in our tool eXolutio
but we do
not describe them in this paper. Instead, we focus on the actual conversion of OCL
ICs
expressed at the platform-specific level to their suitable XML conterpart, which are
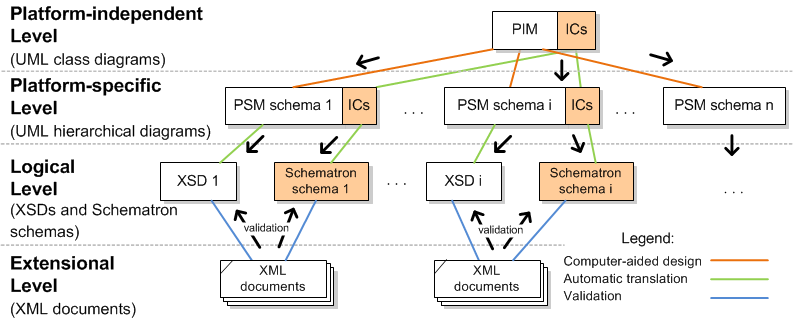
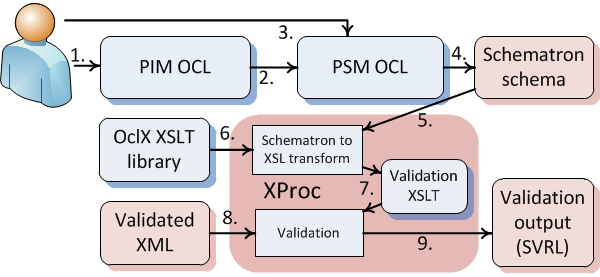
Schematron schemas. Figure 1 shows an overall architecture of the system.
Figure 1: eXolutio - architecture overview
Schematron is a rule-based XML schema language based on XPath expressions. It is often
used as a complement of grammar based schema languages (such as XML Schema, Relax
NG or DTD),
which define a proper vocabulary and validate the structure of the XML document, to
check data
and co-occurrence constraints - it serves a similar purpose, as does OCL in UML. Because
the
approach used in OCL to build expressions is rather different than the space of expression
provided by XPath, it is necessary to extend XPath to provide comparable expressive
power. We
implemented the required extensions in our XSLT functions library called OclX. Since Schematron validation is usually implemented as several steps of
XSLT processing, our extension will not require modification of the existing Schematron
validation tools, except referencing OclX library. We will examine different approaches,
how
the required functions can be implemented, and show how several of the new constructs
(such as
higher-order functions, maps, or error-recovery instructions) proposed
in the 3.0 drafts of XPath, XQuery and XSLT can serve our goal.
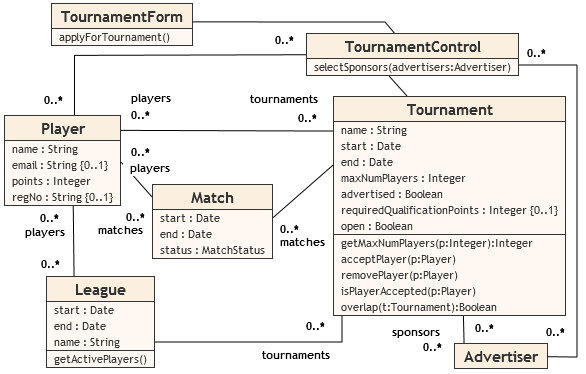
In this section, we will show on several examples the usage of OCL constraints.
Figure 2 shows a sample platform-independent schema of a chess leagues
information system. [1].
Figure 2: A sample platform-indpendent schema
Figure 3 shows some constraints defined for the PIM schema. We will not
elaborate the syntax of OCL in detail in this paper. Briefly: OCL script consists
of
declaration of blocks of integrity constraints, each block starts with the selection
of
context class and contains one or more invariants for this class. The invariants are
logical
expression refereing to the concepts defined in the PIM schema. Standard OCL does
not allow to
specify an error message describing the violated constraint. However, this is a valued
feature
of Schematron which we did not want to lose. That is why we extended OCL to allow
an optional
message after each invariant definition. The message can contain subexpression, as
is shown in
IC PIM1.
Figure 3: PIM ICs for chess leagues
context Tournament
/* PIM1 */
inv: start <= end
message: 'Dates inconsistent {start} is grater than {end} in {name}'
/* which is an abbreviation for: */
inv: self.start <= self.end
/* PIM2 */
inv: matches->forAll(m:Match | m.start >= start and m.end <= end)
message: 'All matches in a tournament occur within the tournament’s time frame'
/* PIM2 in the previus is in fact an abbreviation for: */
inv: self.matches->forAll(m:Match | m.start >= self.start and m.end <= self.end)
/* PIM3 */
inv: matches->forAll(m | m.players->forAll(mp | mp.tournaments->includes(self)))
message: 'A match can only involve players who are accepted in the tournament'
/* PIM4 */
inv: matches->exists(m:Match | m.start.equals(start))
message: 'Each tournament conducts at least one match on the first day'
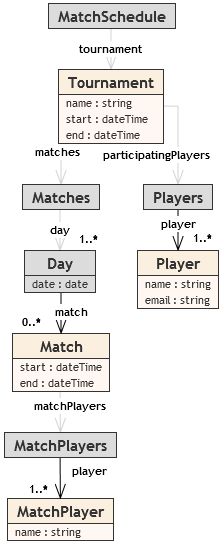
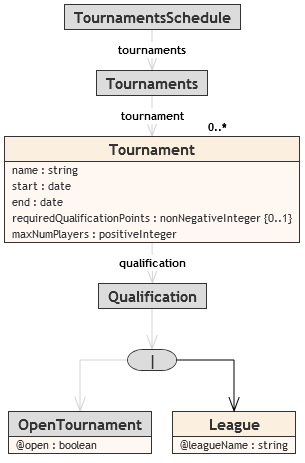
From this schema, two platform-specific schemas (Figure 4, Figure 5) were created, each using the classes from Figure 2,
but each for a different type of XML documents used in the system. XSDs obtained from
the PSM
schemas are shown alongside the figures.
Figure 4: A sample platform-specific schema modeling a type of XML documents for Matches and
Players involved in a Tournament
Figure 6 shows, how the constraints from Figure 3 can be applied in the PSM schemas, where they are relevant. For the purposes of using
OCL
at the PSM layer, we added additional ways of navigation (to those defined in the
standard) -
parent and child_N,
choice_N, set_N,
seq_N (navigate to the n-th child, choice set or sequence
in the content model of a class).
It is also possible to add additional constraints, which do not have a counterpart
PIM
constraint, for each PSM schema (e.g. constraint PSM5). In this paper, we will not
show, how
the relevant constraints are chosen for each PSM schema, but we will focus on how
they can be
verified in XML documents. (MARTIN: Tady ale zhruba rozved, jake jsou vyhody toho,
ze to je na
PIMu. Tj. odpovedi na otazku, proc si to nemuzu rovnou vyjadrit na PSM urovni?)
Figure 6: PSM ICs for chess leagues
/*** Match schedule schema constraints ***/
context Tournament
/* PSM1 */
inv: start <= end
/* which is an abbreviation for: */
inv: self.start <= self.end
message: 'Dates inconsistent, {start} is greater than {end} in {name}'
/* PSM2 */
inv: matches.day.match->forAll(m:Match | m.start.after(start) and m.end.before(end))
/* abbreviation for: */
inv: self.matches.day->collect(d:Day | d.match)->
forAll(m:Match | m.start.after(self.start) and m.end.before(self.end))
message: 'All matches in a tournament occur within the tournament\'s time frame'
context Match
/* PSM3: */
inv: matchPlayers.player->forAll(p | p.parent.parent.parent.parent.parent.
participatingPlayers.player->exists(px | px.name = p.name))
message: 'A match can only involve players who are accepted in the tournament'
context Tournament
/* PSM4 */
inv: matches.day.match->exists(m:Match | m.start.trunc() = start.trunc())
message: 'Each tournament conducts at least one match on the first day of the tournament'
/*** Tournaments schedule schema constraints ***/
context Tournament
/* PSM5 */
inv: qualification.choice_1.child_1.open = true or
qualification.choice_1.child_2.leagueName <> null
message: 'Tournament must be either open tournament or belong to a league'
From the nature of the excerpt Figure 6, it can be seen that
contexts and invariants in
OCL play the same role as rules' contexts and asserts in Schematron. The core of the transition from OCL to
Schematron thus lies in translating OCL expressions into XPath tests, preserving the
semantics. Some expressions (e.g. literals, if-then-else, variables, arithmetic, string
and
boolean operations, some collection operations) may be mapped directly to a corresponding
XPath expression or function.
For some operations, a corresponding function does not exists or has a different semantics
(e.g. OCL indexOf behaves just like XPath index-of when the searched
item occurs at most once in the searched sequence, but XPath version returns indexes
of all
occurrences, when there are more). For these cases, we created a set of functions
in OclX
library preserving the semantics.
Feature-call expressions are a fundamental part of OCL - starting at a variable, they
allow traversing the UML model along associations and accessing attributes. These
are mapped
to path expressions of XPath, which traverse the XML document. E.g. expressions
self.start or self.matches.day can be expressed as
$self/start and $self/matches/day respectively.
In the following sections, we will be dealing with those OCL constructs that cannot
be
expressed trivially - iterator expressions, tuples and nested sequences. We will also
analyse
the differences in error recovery in both languages.
Iterator expressions
In the examples above, a construct distinctive for OCL is used several times. It is
the
so-called iterator expression. An iterator expression is a certain kind of a function.
It is always
called on a collection object. It does not have ordinary parameters, instead each
usage
declares the iterator variable(s) it will use and a body
expression. OCL standard library contains several predefined iterator
expressions, the fundamental being iterate. Its most general form is:
iterate(i; acc = {acc-init} | {body})
The semantics of the expression is as follows:
Expression acc-init is evaluated (in the actual context, i.e. it may
reference any variables valid in the calling expression). The result is assigned to
variable acc, which, from now on, functions as an accumulator.
For each member of the source collection (for which iterate is called), the member
is assigned to variable i. Variables i and acc
(containing the value of accumulator from the previous iteration) are added to the
context.
Expression body is evaluated (the context now contains the variables
i and acc. The result is assigned to variable
acc and will be used in the next iteration.
After the last iteration, the value in the accumulator is returned as a result.
There are several facts regarding iterator expressions:
There are two fundamental iterator operations - closure and
iterate. From these two, iterate is not very often used
directly by the designers working with OCL. More often, another, more specific, iterator
expression is used. The importance of iterate lies in the fact that all other iterator
(with the exception of closure) expressions (and a majority of collection
operations) can be defined in terms of the fundamental operation iterate.
E.g. operation exists(it|{body}) is defined as iterate(it; acc=false|
{acc or {body}}).
Iterator expressions forAll and exists (serving as
quantifiers) together with not and implies make OCL
expressions at least as powerful as first order logic . Operation closure
increases the expressive power with the possibility to compute transitive closures.
Operation iterate allows to compute primitively recursive functions (for
more on the expressive power, see Mandel 1999.
Multiple iteration variables, such as in c->forAll(v1,v2|v1 <> v2),
are allowed for some expressions, but that is just a syntactic shortcut for nested
calls
(i.e. c->forAll(v1|c->forall(v2|v1<>v2))).
Collection operations define additional variables to self, which is
global in the scope of the invariant, and these
variables (iterators and accumulator) are local (they
are valid in the subexpression only).
When we want to translate OCL ICs for XML, property 1 guarantees that showing how
to
express iterate and closure proves that other iterator expressions
can be expressed as well, because they can be defined using these two (although the
actual
implementation would be often more efficient when implemented directly). Property
3 relieves
us of the necessity of considering expressions with multiple iterators. Property 4
requires
the translation to abide the rules for context and scope of variables. Every expression
can
refer to the global variable self and possibly other global variables declared
explicitly by the user. Iterator expressions define local variables.
There is no construct similar to iterator expression in XPath, which is used by
Schematron. In some special cases, iterate can be translated to XPath
for expression, but not in general - whereas iterate can in each
iteration refer to the result of the previous iterations (through acc variable),
in XPath for, computations of every iteration are strictly separated. Thus, XPath
must be extended to fully support iterator expressions and in this section, we will
show
several approaches, how it can be achieved. Since "iterate" is a name of a construct
in OCL, a
name of its implementation in our library OclX and also a name of an XSLT instruction,
we will
distinguish them by using iterate for the OCL construct,
oclX:iterate for its implementation in OclX and by refering to the XSLT
instruction as to xsl:iterate.
Iterators via generated functions
The principle of using accumulators in recursive calls is a routine practice in XSLT.
The expression from the integrity constraint PSM4 from Figure 6 can be
rewritten into an XPath expression and an accompanying XSLT function as follows:
Figure 7: Usage of exists translated to an XSLT function
The context of the expression (valid variables) is passed as parameters
(accumulator, self and iteration). The value of
accumulator is computed using the combination of the two expressions: expression from
the
definition of exists function (acc or (body)) and from the actual
call of the function (m.start = self.start), which is substituted for
body.
In this way, it is possible to translate every iterator expression (closure
function can be expressed similarly). The negative side is that for each usage (call)
of an
iterator expression, a separate function has to be generated and each Schematron schema
must
be equipped with a specific set of functions that handle iterator expressions. The
generated
functions for the same iterator expression (e.g. exists) would differ very
little (in the case of exists, only in the second argument of or computing the
value of newAcc). Our aim is to create a set of universal functions directly
corresponding to general iterator expresions, but for that, we will need some features
beyond the 2.0 versions of XPath and XSLT.
Iterators via dynamic evaluation
Function in Figure 7 can be looked upon as a template. As we
have pointed out in the previous paragraph, the generated functions for all iterator
expressions (except closure) would differ very little - only in the line
computing the next value of the accumulator. Moreover, the functions generated for
different
calls of the same predefined iterator (e.g. all calls of exists) would differ
even less - only in the body ($m/start eq $self/start in the
example). Thus, the whole generated function can be looked upon as a sort of template.
If
only it were possible to create such "templated function", we would be able to use
the same
template for all calls, parameterized by body .
One way to achieve this is by using dynamic evaluation. Each iterator expression can
then be mapped to a call of the same function, for which body is passed as a
string. The value of body is then computed dynamically. Figure 8 shows an implementation of iterate using
dynamic evaluation.
Figure 8: Generic oclX:iterate function implemented using dynamic
evaluation
Dynamic evaluation is a feature not present in standardized XSLT 2.0, but exists both
in
the form of cross-processor portable external libraries (such as EXSLT) or
vendor-specific extensions (e.g. in Saxon). Unfortunately, the semantics
of dynamic evaluation is not consistent in these cases, e.g. EXSLT allows to use free
variables in the evaluated expression (e.g. self, m and
acc in the example) and they are bound to values defined in the context where
the function is called. On the other hand, in Saxon, all free variables are bound
to the
parameters passed to the call of evaluate (as a consequence to this design
decision, the names of the free variables are coerced to be p1, p2
etc. and there is a limit on the maximal amount of free variables allowed).
W3C answered the call for dynamic evaluation in the draft of XSLT 3.0 and introduced
a
new instruction - xsl:evaluate. The semantics is closer to the one used by
Saxon, values of free variables are assigned using xsl:with-param instructions
(the names of the parameters are in this case up to the user to decide). As it turns
out,
there is no perfect solution with dynamic evaluation, because there are these obstacles:
There is no upper limit on the amount of both free and bound variables the user
can use in an OCL expression.
The names of the variables are also selected by the user.
The first one renders Saxon, with its limit on the number of free variables, not general
enough. All three approaches also share the same problem - the names of free variables
are
either coerced (Saxon) or they are defined statically (EXSLT, xsl:evaluate). If
xsl:evaluate allowed dynamic naming of the parameters, the following call
would be usable (the excerpt replaces the definition of newAcc in the template
from Figure 8:
Yet, even this solution works only when there are only three allowed free variables
in
body expression - accumulator, iterator, and self.
Figure 9 shows, how exists iterator expression
can be implemented (as function oclX:exists) according to its specification in
the terms of iterate (implemented as function oclX:iterate, Figure 8). The body expression is combined with the
expression defining exists iterator expression (acc or (body)) using simple
string manipulation.
Figure 9: Generic exists function implemented via call of
iterate
To conclude this discourse, we implemented a version of OclX library which uses dynamic
evaluation. We used the extension function provided by Saxon. We solved the second
problem
by passing the values of all free variables in one value (a sequence of values) and
replacing the references of free variables by expression indexing the sequence before
the
expression is evaluated. This solution works with XSLT 2.0 (+ Saxon extension). Passing
more
values in one sequence is a problem of itself, because empty values and values, which
are
sequences themselves, have to be encoded (more about this in section section “Tuples as maps”, the approach used there can also be applied for the encoding
problem here). However, XSLT 3.0 offers another approach to tackle iterator expressions
and
free variables satisfactorily and elegantly, and those are higher-order functions.
Higher-order functions
The drafts of XPath 3.0 and XQuery 3.0 define a new kind of item in the common data
model - function item. Funciton item is an item, that can be called. This makes functions in XPath and XQuery first-class citizens that can
be results of expressions and passed as arguments to function calls, making XPath/XQuery
full-fledged functional languages (technique for using higher-order functions also
in XSLT
2.0 was shown in Novatchev 2006, but that is far from native). A prototype
implementation of HOF is available in Saxon since version 9.3.
The OCL iterator expressions can be viewed as functions, which expect another function
as their parameter - i.e. higher-order functions[2]. In iterate expression, body can be looked upon as a
parameter, which expects a function. Figure 10 shows how
iterate is implemented in OclX. We also used the new instruction -
xsl:iterate - which is also proposed in the XSLT 3.0 draft and has a very
similar semantics to its OCL namesake.
Figure 10: Implementation of iterate as a higher-order function
oclX:iterate
The function's body parameter expects a function with two bound variables,
the first one representing the accumulator, the second one the member of the iterated
collection for this iteration. Also, the definition of function oclX:exists in
Figure 11 shows that this definition is general enough to be used
to define other functions in its terms. The implementation of closure is
similar to that of iterate, only it uses recursion.
Figure 11: Implementation of exists as a higher-order function
oclX:exists calling oclX:iterate
Now let us compare the higher-order function approach to the dynamic evaluation
approach. As in OCL, there is no limit on the number of free variables in XPath function
items, so the mapping is seamless in this respect. Furthermore, the semantics of free
variables in a higher-order function is that their values are obtained from the context
at the
place of the call - the same semantics OCL uses for free variables.
As an icing on the cake, we can utilize the reflection function
function-arity (supported for function items) to allow iterator expressions
with more than one iterators directly (not via replacing them by nested calls). Figure 12 shows a multiple-iterator version of exists
(which is one of the few iterator expressions, which allows multiple iterators by
OCL
specification). We use two helper functions: getIndices (which returns the n-th
number in a system with a given base in the form of a zero-filled sequence) and
functionItemCall, which assigns the values to the iterators and calls the
higher-order function. However, we are forced to fix the maximum amount of iterators
allowed, because a call of function item requires a fixed amount of parameters (of
course,
we could prolong the last if as we like).
Figure 12: Implementation of existsN - multiple iterators
The issue of local variables is closely related to iterator expressions, because they
are one of the two ways how local variables can be defined. Apart from iterator expressions
(which define local variables implicitly), OCL also contains let expression,
which defines a variable valid in the scope of the expression. The semantics of local
variables is similar to that of XPath - the value is assigned in the moment of declaration
and does not change from that place on.
In XPath 2.0, the same effect can be achieved using for, but only when the
value of the local variable is not a collection (for would only perform one
cycle). In other cases, we must descend to inlining the value (since it is immutable).
Alternatively, when the variable is defined in the scope of the invariant (making
it global
variable for the whole invariant), it can be translated into XSLT variable definition.
XPath 3.0 again makes the translation easier, because it allows let/return
expressions, with semantics eqivalent to OCL let.
Tuples as maps
In this section we propose how to deal with tuples (anonymous types) from OCL.
OCL allows the designer to combine values in expressions into tuples. Tuples can be
considered an anonymous type, which has a finite number of named parts. An example
of a tuple
may be Tuple { firstName = 'Jakub', lastName = 'Malý', age = 26 }. The values of
the parts may be of arbitrary type, including collections and other tuples. The names
of parts
(firstName, lastName, age in the example) must be
unique and are used to access the parts of the tuple in the expressions, similarly
to
attributes of classes, i.e. it is possible to write employees->collect( e | Tuple { name
= e.name, salary = e.salary })->select( t | t.salary > 2000), the result of this
expression would be a collection of tuples.
There is a noteworthy property coming with the possibility to create tuples: together
with
tuples, OCL was equipped with the operation product, defined as follows:
The result of product is a collection of type Collection(Tuple(first:
T1, second: T2)), which contains all possible pairs where the first compound comes
from collection c1 and the second collection c2. This operation thus
finalizes the suite of equivalents of the constructs required for a language to be
relationally complete (see Codd 1972):
Select - can be expressed using select
iterator expression,
Project - can be expressed using
collect iterator expression that creates a tuple with the projected
attributes (see the employees example above, which, in fact, performs
projection to attributes name and salary) ,
Union - OCL has union operation as well,
Set difference - OCL has operation '-'
working on sets,
Cartesian product - can be expressed using
product,
(Rename) - can be expressed using
collect in the same manner as project
operation.
Thus, not only tuples can be used to write more concise expressions, but, together
with
the operation product, they increase the expressive power of the language to relational
completeness.
As far as XPath 2.0 is concerned, there exists no construct that could be naturally
used
to represent tuples, they can only be partially simulated. One possibility is to use
sequences, where each item in the sequence corresponds to one part of the tuple, i.e.
Tuple { firstName = 'Jakub', lastName = 'Malý', age = 26 } would be represented
as a sequence ('Jakub', 'Malý', 26).
But this solution is not completely satisfactory from the following reasons:
We loose "safety" and clarity in the expression, because we have to write
$t[1] to represent the OCL expression t.firstName.
When some part is missing (which is in OCL indicated by null value), we
have to use some placeholder value to keep the length of the sequence constant (e.g.
('null', 'null', 26)).
A part of a tuple in OCL can be of any type, including other tuples and collections.
Here, this approach fails utterly, because all sequences are flattened in XPath. This
also makes implementing product operation impossible, because it should
return a collection of tuples, i.e. a collection of sequences.
Instead of representing tuples using sequences, an alternative would be to represent
them
using temporary documents, for example:
This approach would overcome the first issue (t.firstName would be
represented as $t/firstName), the second issue (an empty element could represent
a missing part) and also the third issue (nesting is no problem here and collections
could be
encoded into trees as well). However, it brings two problems of its own:
The value which is about to become a part of a tuple, is copied to a temporary XML
document. This would not hurt so much with atomic values, but would be a significant
overhead, when the value was a node or a sequence of nodes in the input document (whole
subtree would be copied in this case).
When a node is copied into the temporary document, its position in the document is
lost, it would not be possible to navigate outside its subtree (e.g. using
parent axis) and operations relying on node identity (such as the
is operator) would give unexpected results when applied on nodes from the
input tree and from the temporary tree.
To conclude, restrictions inherent in XPath 2.0 data model prevent from satisfactory
representation of tuples with semantics corresponding to OCL.
However, the possibility of extending the XPath/XQuery model with another item type
- map
- is being discussed and a prototype implementation is now available in Saxon (an alternative is to use XQuery implementation of maps using function items instead
of map
items, for details see Snelson 2011). The map type requires atomic values for
keys and allow items of any type as values. These properties of map type make it a
great
candidate for representing tuples, thus, we decided to create a version of OclX which
supports
tuples represented as maps. Strings containing the name of a tuple part can be used
as keys
(and the names of parts must be distinct in an OCL tuple as well). The tuple from
the example
would be represented as map{'firstName' := 'Jakub', 'lastName' := 'Malý', 'age' :=
26}, expression t.firstName would be represented as
$t('firstName'). A value in a map can also be another map or sequence, which is
consistent with semantics of OCL tuples. Operation product can be defined either
by translating the definition from specification (using two nested iterates) or
via a much more succinct expression:
for $e1 in $collection1 return for $e2 in $collection2
return map{'first' := $e1, 'second' := $e2}
Different kinds of collections, nested collections
OCL defines an abstract type Collection and 4 different types of collections - Set,
OrderedSet, Bag (in other languages sometimes called multiset) and Sequence. A member
of any
collection can be an arbitrary value, including another collection.
We treat all collections as sequences in OclX, yet it would be possible to represent
the
other kinds of collections using maps (or sequences as well).
Nested collections are a foreign concept to XPath data model. The disadvantages of
encoding collections into temporary documents were discussed in section section “Tuples as maps”.
With the introduction of maps, there is a, rather ugly, way of encoding nested sequences
-
thanks to the possibility of using maps as values and members
of sequences. A nested sequence ((1,2),(3),()) could be encoded to map{'s' := (map{'s'
:= (1,2)}, map{'s' := (3)}, map{'s' := ()})}, the expression returning number two
would be written as (map{'s' := (map{'s' := (1,2)}, map{'s' := (3)}, map{'s' :=
()})})('s')[1]('s')[2]. Using this approach also requires the functions which
concatenate sequences not to use XPath operator ,, because it flattens the
resulting sequence.
The double indexing (first to get the value from the map, second for getting the desired
member of the sequence) can seem confusing, but it can be in fact hidden behind a
library
function at(i) (which OCL uses instead of the operator [i] to get an
i-th member of a sequence). The wordy and a bit unclear way of creating a nested sequence
appears in those expression that create nested sequences using literals. This, however,
could
be eliminated by using preprocessing of the schemas before evaluating the expressions
(adding
another step to Schematron pipeline).
Error recovery
OCL as a language has a direct approach to "run-time" errors or exceptions. Errors
in
computation cause the result of the expression to be invalid - a sole instance of
type OclInvalid. It conforms to all other types and any further computation with
invalid results in invalid - except for operation
oclIsInvalid[3], which returns true, when the computations results in
invalid and false otherwise. This operation thus provides the
only, very coarse-grained error checking (there are no error codes or exception types)
available in OCL. Unlike OCL computation, XPath/XSLT 2.0 processor halts when it encounters
a
dynamic error and there is no equivalent of oclIsInvalid. It is also not possible
to instruct it to jump to the validation of the next IC when a validation of an IC
fails.
XSLT 3.0, however, introduces new instructions - xsl:try and
xsl:catch - which provide means of recovery from dynamic errors. With these
instructions, it is possible to implement oclIsInvalid as listed in Figure 13. We, again, utilize higher-order functions capabilities - the
expression is evaluated in a function call wrapped in try/catch. OCL expression
oclIsInvalid(1 / 0) can be translated to oclX:oclIsInvalid(function() { 1
/ 0 }). Optionally, our validation pipeline (fully introduced in section “Implementation”) allows to safe-guard the evaluation of each expression using
try/catch, so that the validation of another constraint may continue if a runtime
error occurs
and it is not contained by oclIsInvalid.
Figure 13: Implementation of oclIsInvalid using
xsl:try/xsl:catch
<xsl:function name="oclX:oclIsInvalid" as="xs:boolean">
<xsl:param name="func" as="function() as item()*" />
<!-- evaluate func and forget the result, return false -->
<xsl:try select="let $result := $func() return false()">
<xsl:catch>
<xsl:if test="$debug">
<xsl:message select="'Runtime error making the result ''invalid''. '"/>
<xsl:message select="' - code: ' || $err:code"/>
<xsl:message select="' - description: ' || $err:description"/>
<xsl:message select="' - value: ' || $err:value"/>
</xsl:if>
<!-- if function call fails, return true -->
<xsl:sequence select="true()" />
</xsl:catch>
</xsl:try>
</xsl:function>
Implementation
We implemented the work presented in this paper into our XML schema modeling tool
eXolutio, the workflow is depicted in Figure 14. The
tool incorporates a UML and OCL editor for both PIM and PSM schemas and implements
algorithm
for suggesting/translation of relevant constraints from PIM to PSM (steps 1-3, not
covered in
this paper) and translation from OCL (4) to Schematron schemas. The user may choose
between
schema-aware and non-schema-aware (which add data conversion for extracting typed
values from
the XML document) schema and between implementation of iterator expressions using
dynamic
evaluation or higher-order functions. The generated schema can be then used to validate
an XML
document. XProc pipeline is then used to perform the validation. It first executes
the
transformation steps from standard Schematron pipeline (5.), adds includes for OclX
library
(6.) and then validates the document (7.) with the resulting XSLT. The pipeline expects
the
schema (5.) and validated document (8.) on its input ports and writes validation result
- a
SVRL document - to its output port (9).
Figure 14: Schematron and OclX pipeline
The tool itself (incl. examples), OclX library and the XProc pipeline are all available
for free download on the tools website. Finally, Figure 15 depicts the
translation of integrity constraints from the examples in Figure 6
(schema-aware, iterators via higher-order functions). The error messages defined in
OCL
translated into schematron error messages and their subexpressions into value-of
instructions (see translation of PSM1).
Figure 15: Generated Schematron schemas
<!-- Match schedule schema -->
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:pattern>
<sch:rule context="/tournament">
<!-- PSM1 -->
<sch:assert test="start le end">
Dates inconsistent, <sch:value-of select="$self/start" />
is greater than <sch:value-of select="$self/end" />
in <sch:value-of select="$self/name" />
</sch:assert>
<!-- PSM2 -->
<sch:assert test="oclX:forAll(oclX:collect($self/matches/day, function($d) { $d/match }),
function($m) { $m/start ge $self/start and $m/end le $self/end })">
All matches in a tournament occur within the tournament's time frame
</sch:assert>
<!-- PSM4 -->
<sch:assert test="oclX:exists(
oclX:collect(matches/day, function($d) { $d/match }),
function($m) { oclDate:trunc($m/start) eq oclDate:trunc($self/start) })">
Each tournament conducts at least one match on the first day of the tournament
</sch:assert>
</sch:rule>
<!-- PSM3 -->
<sch:rule context="/tournament/matches/day/match">
<sch:assert test="oclX:forAll($self/matchPlayers/player,
function($p) { oclX:exists($p/../../../../../participatingPlayers/player,
function($px) { $px/name eq $p/name }) })">
A match can only involve players who are accepted in the tournament
</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
<!-- Tournaments schedule schema -->
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:pattern>
<!-- PSM5: either open tournament or belongs to some league -->
<sch:assert test="qualification/@open eq true() or exists(qualification/@leagueName)">
Tournament must be either open tournament or belong to a league
</sch:assert>
</sch:pattern>
</sch:schema>
Expression rewriting and syntactic sugar
In many cases, iterator expressions and functions, can be expressed using a native
XPath
construct, e.g. forAll can be expressed as every/satisfies, select
by application of a filter etc. The current version of the algorithm does not provide
any of
such rewritings, but in the following work, we plan to examine the possibilities of
such
rewritings and offer them to the user, where applicable.
OCL expressions have a useful property that they can be read from left to right thanks
to the arrow notation '->' for collections and dot
'.' for calling operations . When translated to XPath, the
readability decreases (the object before the arrow/dot corresponds to the first parameter
of
the function. Also, the notation of higher-order functions in XPath is not so transparent.
If
desirable, it would be possible to preserve OCL notation even for Schematron schemas
(and
change it to usual XPath notation in another preprocessing step).
A valued feature of Schematron is the possibility to specify human-friendly error
messages
for violated integrity constraints. However, OCL does not provide such functionality
in the
current version of the standard (2.3.1). Since custom error messages were strongly
advocated
(e.g. in Malaika 2009), we extended recognized OCL grammar to allow
specification of error messages.
Conclusion
In this paper, we inquired into the possibility of using OCL for modeling integrity
constraints over XML data. We have discussed several ways of how non-trivial OCL expressions
can be expressed using XPath with our proposed extension in a form of a XSLT function
library
OclX. The library itself contains a useful set of functions, which can be used on
their own
and provide a handy toolset with considerable expressive power. However, the main
contribution
is the possibility to check OCL integrity constraints in XML data. Our approach allows
using
the integrity constraints defined in the UML model also for XML, which supports consistency
of
the system as a whole (the constraints do not have to be rewritten by hand and managed
manually after each change). It helps to bridge the gap between the platform-independent
conceptual model and its applicability at runtime.
Since translated OclX constraints are, in structure, very simlar to OCL constraints,
they
will be easy to comprehend even for a modeller less familiar with XML technologies.
In the future, we want to thoroughly examine the possibilities of rewriting the
expressions in order to use native XPath constructs to express iterator expressions
where
possible and allow the user to choose from several ways of expressing a certain constraint.
As
another part the future work, we plan to extend our approach for schema evolution
and document
adaptation (see Maly 2011) by utilizing OCL integrity constraints.
Acknowledgement
This work was supported by GAČR grant no. P202/10/0573.
[EXSLT] C. Stewart, C. Bayes, J. Fuller, U. Ogbuji, D. Pawson, J. Tennison.
EXSLT - community initiative to provide extensions to XSLT.
http://www.exslt.org/
[Snelson 2011] J. Snelson. An implementation of a red/black tree built using XQuery 3.0
higher order functions, and an associative map library built on top of it.
https://github.com/jpcs/rbtree.xq
[Maly 2011] J. Malý, I. Mlýnková, M. Nečaský. XML Data Transformations as Schema Evolves.
Proceedings of ADBIS 2011: Advances in databases and infromation systems.
September 2011. Lecture Notes in Computer Science. Springer.
http://dl.acm.org/citation.cfm?id=2041783
[Codd 1972] E. F. Codd. Relational Completeness of Data Base Sublanguages. In: Database Systems, Prentice Hall and IBM Research Report RJ 987, San
Jose, California, 1972.
[2] Yet OCL does not have the full power of functional languages, since it does not
allow functions to be results of expressions.
[3] To be accurate, another operation - oclIsUndefined - behaves equally to
oclIsInvalid when the argument is invalid, but it also returns
true, when the result of the computation is null.
L. Mandel, M. Cengarle. On the
Expressive Power of OCL. In FM'99 Formal Methods, volume 1708 of LNCS.
Springer Berlin / Heidelberg, 1999.
http://dl.acm.org/citation.cfm?id=730476
J. Snelson. An implementation of a red/black tree built using XQuery 3.0
higher order functions, and an associative map library built on top of it.
https://github.com/jpcs/rbtree.xq
J. Malý, I. Mlýnková, M. Nečaský. XML Data Transformations as Schema Evolves.
Proceedings of ADBIS 2011: Advances in databases and infromation systems.
September 2011. Lecture Notes in Computer Science. Springer.
http://dl.acm.org/citation.cfm?id=2041783
E. F. Codd. Relational Completeness of Data Base Sublanguages. In: Database Systems, Prentice Hall and IBM Research Report RJ 987, San
Jose, California, 1972.