Holstege, Mary. “Type Introspection in XQuery.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Holstege01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Mary Holstege is Principal Engineer at MarkLogic
Corporation. She has worked as a software engineer in and around markup
technologies for over 20 years. She is a member of the W3C XML Schema and XML
Query working groups, and an editor of the W3C XML Schema Component Designators
and the XML Query Full Text specifications. Mary Holstege holds a Ph.D. from
Stanford University in Computer Science, for a thesis on document
representation.
Type introspection gives a program the ability to determine the
type of object at runtime and manipulate the type of the object as an object
in its own right. It can be used as a basis for generic and flexible services,
meta-programming, runtime adaptation, and data exploration and discovery. This
paper explores providing some type introspection capabilities to XQuery,
looking at some design and implementation issues, and demonstrating the
application of type introspection in various ways.
Type introspection gives a program the ability to determine the
type of data item at runtime and manipulate the type as a data item in
its own right. It allows the creation of more generic and flexible
data-processing frameworks, and allows operations to be constructed in a
more data-driven way. Type introspection also enables data exploration and
discovery. This paper explores one way of providing type introspection
capabilities to XQuery, looks at some design and implementation issues, and
shows the application of type introspection in various ways.
It may seem odd to talk about type introspection in the context of
XQuery, given that it is not an object-oriented language, and meta-classes and
type introspection are object-oriented concepts. However, XQuery does have the
concept of a type hierarchy with subtypes and supertypes. Instance variables
can be statically identified as being of one type, while being
dynamically instances of some subtype. Instead of
classic objects and base types, XQuery has XML nodes and base (atomic) types.
Adding structural type introspection to XQuery brings powerful
meta-programming patterns to XML.
Many programming languages offer some kind of reflection or
introspection. These terms are frequently used somewhat
interchangeably. Gabriel
et al Gabriel91 define reflection as "the ability of a program
to manipulate as data something representing the state of the program during
its own execution", and divide it into two parts: introspection and
effectuation. Introspection is the observational aspect of reflection;
effectuation is the active aspect, the making of changes to the program state.
Singh Singh04 usefully distinguishes between
type identification, structural introspection, and behavioural introspection.
Type identification allows a program to determine whether an object is an
instance of a particular class (or type). Structural introspection provides the
programmatic means to examine attributes of the class, such as its
base class and members. Behavioural introspection allows for the examination of
the runtime operations of a program. In this paper, we are concerned with type
introspection, and so we will not address behavioural introspection further.
Some form of type identification is common
to many programming languages. For example, the Java or PHP
instanceof, the C++ dynamic_cast, the Perl
isa all provide for type identification, where
the reference type is named statically and must be known at compile time.
XQuery XQuery30 provides for this form of type
identification too, through the instance of keyword pair.
Figure 1: Type Identification Examples
/* C++ example */
QName* name = dynamic_cast<QName*>(&value);
if (name != 0) {
cout << name->namespaceURI();
}
/* Java example */
if (value instanceof QName) {
QName qn = (QName)value;
System.out.println(qn.namespaceURI());
}
(: XQuery example :)
if ($value instance of xs:QName) {
fn:namespace-uri-from-QName($value)
}
Examples of type identification in several languages.
XQuery allows for named types to be applied in several ways:
through the use of the instance of, cast as,
treat as, and (in XQuery 3.0) validate as
constructs, and through the use of sequence type matching in
typeswitch and argument or variable binding constructs. A program
can use the constructs to ensure that data is properly typed in accordance with
the assumptions of processing and dispatch to the appropriate processing for
the type.
Consider, for example, writing some code to analyze dates in
documents of various kinds, where the documents may use different kinds of
dates. Suppose further the documents come in a variety of forms and we do not
necessarily have schemas for every document, although we do have schemas
defining each date format. If a document has a schema, then a
typeswitch or instance of test could be used to
determine which analysis function to apply, and type sequence matching could be
used to ensure that the analysis code is applied properly to ensure
correctness. In other cases castable as and cast as
can be used to perform this job.
Figure 2 shows a fragment of XQuery dispatching to the
appropriate analysis code along these lines.
Figure 2: XQuery Type-Based Dispatch
import module iso="http://example.com/dates/iso";
import module vat="http://example.com/dates/vatican";
...
declare function my:process-date($date)
{
if ($date castable as iso:date)
then iso:process-date($date cast as iso:date)
else if ($date castable as vat:date)
then vat:process-date($date cast as vat:date)
(: etc. one for each format :)
...
};
XQuery fragment for dispatching based on hard-coded type
tests and functions.
In all the XQuery constructs, the type must be a named type,
and its properties cannot be inspected, compared, or reapplied. In particular,
any annotations or facets associated with the type are not accessible to the
program directly. One cannot ask
for the type of one item and use it in any way to construct a new instance of
that type. The code must explicitly reference the names of any types it needs.
Many languages also provide for structural introspection as well as
type identification. Java's Class class and the reflection API
Java and Perl 6's Perl6 class traits
and methods allow for structural reflection.
Use of a meta-class in this way is the common pattern
for providing structural introspection. It generally also allows for more
dynamic type introspection, as well as dynamic instance construction.
XQuery does not provide for this kind of type introspection. The rest of this
paper explores adding structural type introspection to XQuery.
Figure 3: Structural Introspection Examples
Class myClass = value.class;
Class paramTypes[] new Class[1];
paramTypes[0] = String.TYPE;
Constructor ct = myClass.getConstructor(paramTypes);
Object args[] = new Object[1];
args[0] = new String("Hello World");
Object newObject ct.newInstance(args);
Example of Java structural introspection. We get the class
of a particular value, find a constructor that takes a string argument, and
construct a new instance of the class.
XQuery 3.0 introduces a couple of new features that interact well
with type introspection: function items and the simple mapping operator
(represented with the ! character). Function items allow functions to be
treated as values, assigned to variables, and passed as arguments to
functions. As we will see below, in some cases we will treat types as function
items for some purposes. Beyond that, however, putting function names in schema
annotations makes it possible to write generic data-driven processing
frameworks, by using the introspection API to obtain the name of the function
to perform some particular operation, and the function lookup and function
application features to execute that operation. The simple mapping operator
allows for mapping of non-node values in streamlined path-like
expressions. Many of the examples that follow use one or the other of these
constructs. Expressions involving the simple mapping operator could be
rewritten in other ways, but use of function items cannot be readily
replaced in an XQuery 1.0 setting. I will point out alternatives where they
exist.
Types as Values
Where should XQuery meta-classes fit into the existing classes in
the type hierarchy? What do the classes look like?
XQuery has a complex type system, integrating simple and complex types from
XML Schema XSD11.2, node kinds from the XQuery and XPath
data model DM30, as well as special item
types such as function items.
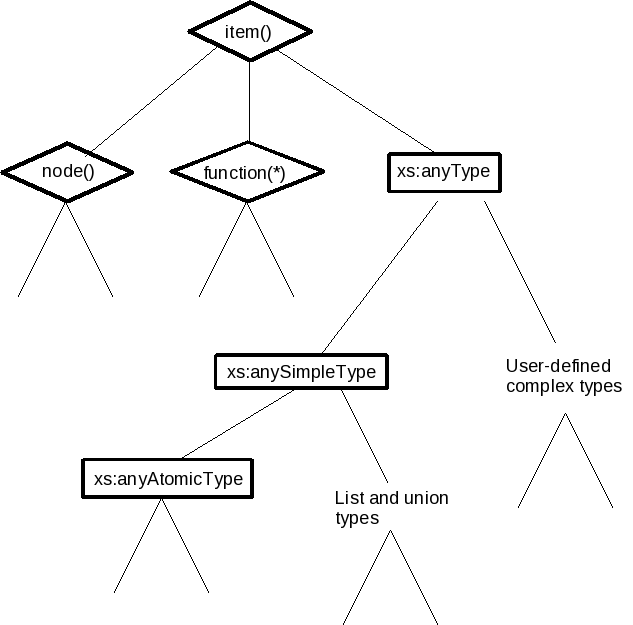
Figure 4: XQuery 3.0 Type Hierarchy
The diagram shows the main branches in the XQuery 3.0 type
hierarchy. Diamonds represent abstract types. See the XPath data model DM30 for more details.
XML Schema XSD11.1 defines a complex set of
schema component types. Each schema component has its own collection of
properties, some of which are components themselves. For example, among the
properties on a simple type definition are its name, a base type definition, a
primitive type definition, an indicator of constraints on deriving new
subtypes, whether it is a list or union type, and a variety of facets
indicating additional constraints such as the maximum permitted value.
For our purposes, adding richer type introspection to XQuery
amounts to creating values that represent schema components and providing
mechanisms for accessing those components and their their properties.
Values representing types have some similarities with nodes
and function items. Like nodes, schema components are complex objects with many
properties, such as names. However, most of the accessors for nodes do not
apply to schema components and most operations on nodes do not apply to schema
components. In XQuery, every simple type also creates an implicit constructor
function. In this sense, simple types act as function items. We could perhaps
make type values a kind of function item. However, type values are different
from function items in every other way, and other schema components are not
like functions at all. Values representing key schema components will be placed
in the XQuery type hierarchy as a new kind of item.
There are two kinds of type definition component: simple type definitions and
complex type definitions. Corresponding to each of these components is a
component value, one for simple type definitions and one for complex type
definitions. Since the distinction
between a simple type and a complex type matters in some cases (values can
only be cast to simple types, for example), but not in others (when we don't
know whether a particular element has a simple type definition or a complex
type definition, but we want to know its name, regardless), we introduce a
superclass "type definition" that encompasses both simple type definitions and
complex type definitions.
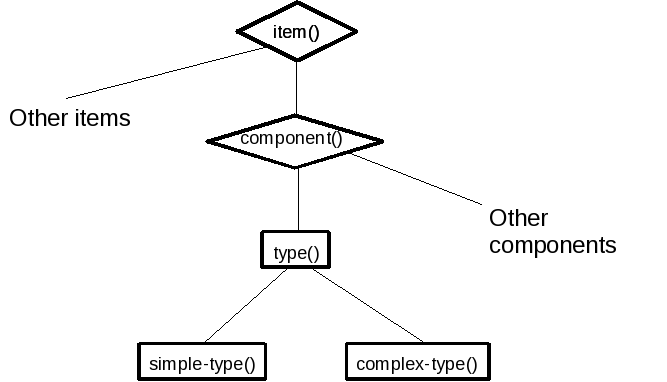
Figure 5: Type Values
Type values as component values, a new kind of item()
Integrating these new value types into XQuery involves:
Defining sequence type tests
Defining the means to obtain type values from other values
Determining how existing functions and operators apply to type values
Defining useful functions and operators over type values
Defining accessors on type values
Let's look at each of these steps in turn.
Type Tests for Type Values
For each kind of component value there is a sequence type test that
matches values of that kind. Since types might have names, sequence type tests
for type values can have a QName and will match if either the type has that
name or it has a base type that matches.
Figure 6: Sequence Type Tests: Types
component()
Matches any component value.
type() or type(*)
Matches any type component value.
type(q:name)
Matches any type component whose name matches the
given QName, or which is a subtype of a component with that type.
simple-type() or simple-type(*)
Matches any simple type component value.
simple-type(q:name)
Matches any simple type component whose name matches the
given QName, or which is a subtype of a component with that type.
complex-type() or complex-type(*)
Matches any complex type component value.
complex-type(q:name)
Matches any complex type component whose name matches the
given QName, or which is a subtype of a component with that type.
Obtaining Type Values
Linkage functions get component values from various kinds of
items. They are defined over all kinds of items, returning the empty sequence
if necessary. These functions all take any item as a parameter and have a
zero-argument form that applies to the context item. This is a small usability
feature, but makes such expressions as
/root/child/sc:simple-type() possible.
In this paper, the schema component linkage and accessor functions
are all defined as being in the namespace bound to the prefix sc
which the examples assume to be predefined. The specific namespace chosen is
not important. The experimental implementation used
http://marklogic.com/xdmp/schema-components.
Figure 7: Accessors Linking from Items to Component Values
sc:type([$context as item()]) as type()?
Get the type of the item as a value.
sc:simple-type([$context as item()]) as simple-type()?
Get the simple type of the item as a value.
sc:complex-type([$context as item()]) as complex-type()?
Get the complex type of the item as a value.
XQuery introduces an interesting wrinkle that is not found in most
other programming language type systems: some data may be untyped. The special
types xs:untyped and xs:untypedAtomic represent such
untyped complex and simple content.
For atomic values that are instances of a particular simple type,
the sc:simple-type linkage function returns that simple type as a
component value. If the atomic type is untyped, then a simple type definition value
for xs:untypedAtomic is returned. The accessor
sc:simple-type operates on attribute nodes in a similar fashion.
The operation on element nodes is similar, except that if
the element is an instance of a complex type, sc:simple-type
returns the empty sequence. For other kinds of items, the empty sequence is returned.
The linkage function sc:complex-type works analogously
like sc:simple-type except atomic values and attributes can never
be instances of a complex type, so sc:complex-type is only useful
for element nodes. If an element node is an instance of a specific
complex type, the value will be that complex type as a component value. If the
element node is untyped, xs:untyped will be returned as a complex type
component value. When an element is an instance of a simple type,
sc:complex-type returns xs:anyType as a complex type component
value. For other items, the empty sequence is returned.
The sc:type accessor combines certain aspects of the
sc:simple-type and sc:complex-type accessors. It
returns a type definition of the appropriate kind. For untyped element nodes,
xs:anyType is returned as a type definition value.
Functions and Operators on Type Values
Obtaining types as values is well and good, but what can we do with
them other than perform sequence type tests on them? At a minimum, equality
operators should work on these values: equals, =, and
!=. It is also useful to be able to test whether one type is a
subtype of another.
Figure 8: Operators
equals, =, !=
Test component equality.
subtype of
Returns true if the first type is a subtype of the second.
declare function my:spaceship-operator ($t1 as type(), $t2 as type())
{
if ($t1 subtype of $t2) then -1
else if ($t1 = $t2) then 0
else if ($t1 subtype of $t2) then 1
else xs:double("NaN")
};
XQuery F&O30 defines a large number of
functions. However, only a few
apply to all items. The sequence functions, such as fn:subsequence
can work on sequences of component values with no problem.
The general functions fn:string,
fn:boolean and fn:not don't really apply and will
raise errors if applied to component values.
If we have equality on type component values, then not only can we
define fn:deep-equal over them, we can define
fn:deep-equal with them. Figure 9 shows a
version of deep-equal that is stronger than that defined by
XQuery: it requires type equality as well as structural equality.
Figure 9: Implementing deep-equal with Type Values
declare function my:deep-equal ($p1 as item()*, $p2 as item()*, $coll as xs:string)
as xs:boolean
{
let $c1 := count($p1)
let $c2 := count($p2)
return
if ($c1 != $c2) then false()
else if ($c1 != 1) then
every $i1 at $i in $p1 satisfies my:deep-equal($i1, $p2[$i], $coll)
else if (exists(sc:simple-type($p1)) and exists(sc:simple-type($p2))) then
sc:simple-type($p1) eq sc:simple-type($p2) and
if (($p1 instance of xs:string) and ($p2 instance of xs:string))
then compare($p1, $p2, $coll) eq 0
else
try {
let $v := $p1 eq $p2
return ($p1 eq $p1) or (($p1 ne $p1) and ($p2 ne $p2)) (: NaN :)
} catch * {
false()
}
else typeswitch ($p1)
case document-node() return
(typeswitch ($p2)
case document-node() return true() default return false()) and
my:deep-equal($p1/(*|text()), $p2/(*|text()), $coll)
case element() return
(typeswitch ($p2)
case element() return true() default return false()) and
node-name($p1) eq node-name($p2) and
exists(sc:type($p1)) and exists(sc:type($p2)) and
sc:type($p1) eq sc:type($p2) and
my:deep-equal( for $a1 in $p1/@* order by name($a1),
for $a2 in $p1/@* order by name($a2), $coll ) and
if (exists(sc:simple-type($p1)))
then my:deep-equal(data($p1), data($p2), $coll)
else my:deep-equal($p1/(*|text()), $p2/(*|text()), $coll)
case attribute() return
(typeswitch ($p2)
case attribute() return true() default return false()) and
node-name($p1) eq node-name($p2) and
my:deep-equal(data($p1),data($p2),$coll)
case processing-instruction() return
(typeswitch ($p2)
case processing-instruction() return true() default return false()) and
node-name($p1) eq node-name($p2) and
compare(string($p1), string($p2), $coll)
case namespace-node() return
(typeswitch ($p2)
case namespace-node() return true() default return false()) and
my:deep-equal(node-name($p1), node-name($p2), $coll) and
compare( string($p1), string($p2), $coll ) eq 0
case text() return
(typeswitch ($p2) case text() return true() default return false()) and
compare( string($p1), string($p2), $coll ) eq 0
case comment() return
(typeswitch ($p2) case comment() return true() default return false()) and
compare(string($p1), string($p2), $coll)
case function() return error("err:FOTY0015")
case component() return $p1 eq $p2
default return false()
};
Once types are available as values, they can be returned in place
of type names to perform introspection on functions, for example.
Figure 10: Miscellaneous Introspection Functions
sc:type-named($qname as xs:QName) as type()
Return a type value for type with the given name, if
any. Raises an undefined type error otherwise.
sc:function-return-type([$f as function(*)]) as type()
Return a type value for the declared return type of
the given function.
sc:function-parameter-type([$f as function(*)],[$argNum as numeric]) as type()
Return a type value for the declared type of
indicated parameter of the given function. Raises an error if there is no such parameter.
Type Values as Functions
In XQuery, there is a constructor function for each in-scope (named)
atomic type derived from a primitive type, whether the type is user-defined or
built-in. This excludes list and union types. Given that we have a schema
component value in our hands, there is no particular reason to require the type
to have a name, or even be atomic. Indeed, if one generalizes the concept of
the "constructor" function to mean obtaining a typed value of the given type
or raising an error if that is not possible, there is no particular reason
not to define functions for complex types as as well, where the "constructor"
function for a complex type validates an item against that type. The
only types where this doesn't make sense is the "untyped" types
(xs:untyped and xs:untypedAtomic), which can be
applied as no-ops. A function can be defined to perform this typed-value
fabrication operation:
Figure 11: Types as functions
sc:type-apply($t as type(), $item as item()*) as item()*
Apply the type to the item, to obtain a typed value
or an error.
Figure 12: Example of applying a Type
declare function local:check($old as item(), $new as item())
{
let $f := $old/sc:type()
return sc:type-apply($f,$new)
};
local:check(doc("config.xml")/config/language, "en"),
local:check(doc("config.xml")/config/encoding, "utf-8")
With the XQuery 3.0 data model, we can go further, as function
items are defined as values. Then we can just treat types as function items and
apply them directly, as shown in Figure 13. Note that
this might be an anonymous type just as well as a named
type, unlike the type identification features that are part of standard XQuery.
Figure 13: Example of applying a type as an XQuery 3.0 function item
declare function local:check($old as item(), $new as item())
{
let $f := $old/sc:type()
return $f($new)
};
local:check(doc("config.xml")/config/language, "en"),
local:check(doc("config.xml")/config/encoding, "utf-8")
Combined with some of the introspection functions, we can get even
more powerful and flexible effects. The function run-plugin can
guarantee that a plugin function executed for some particular piece of the
framework has the expected type, without having to know a priori what that type
is.
Figure 14: Using Type Introspection in Plugin Framework
declare my:run-plugin($config as element(), $plugin as function(*), $args as item()*)
{
let $expected := sc:type-named(data($config))
if (sc:return-type($plugin) = $expected)
$plugin($args)
else
$expected($plugin($args))
};
Component Accessors
For true meta-programming, being able to access some of the details
of the type components is important. Schema components are complex and have many
interconnections and properties. Attempting to provide a clean API to access
all these properties is beyond the scope of this paper. We will content
ourselves with defining a few basic accessors.
Component accessors work analogously to accessors for nodes in the
data model: they apply to all component types, returning the
empty sequence where necessary. As with the linkage functions, these functions
have a zero-argument form that applies to the context item. This will make
chaining them together a little more usable.
Figure 15: Basic Component Accessors
sc:name([$context as component()]) as xs:QName?
Return the name of the component, if any.
sc:annotations([$context as component()]) as element()*
Return annotations on the component as a sequence
of xs:annotation element information items.
sc:base-type([$context as component()]) as type()
Return the base type of the component, if any.
Getting at schema annotations from instances has many applications.
For example, schema annotations can be used to define business rules, widget bindings
for
generic UI generation, associating help text with input components, defining
special indexing for certain content, defining XML mapping rules, and so on.
Figure 16: Some Schema Annotations
<xs:simpleType name="address">
<xs:annotation>
<xs:documentation>
A numeric internet address.
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:token">
<xs:pattern value="[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+"/>
</xs:restriction>
</xs:simpleType>
<xs:element name="address" type="address">
<xs:annotation>
<xs:documentation>
The server socket bind numeric internet address.
</xs:documentation>
<xs:appinfo>
<admin:default>"0.0.0.0"</admin:default>
<admin:cold-restart/>
<admin:help xmlns="http://www.w3.org/1999/xhtml">
<span class="help-text"><span style="color:#800000">address</span>
specifies the IP address for the App Server.</span>
</admin:help>
</xs:appinfo>
</xs:annotation>
</xs:element>
Schema annotations from a real product.
One key difference between XML types and classes in an
object-oriented programming language is that classes have methods as well as
data. Combining function items with annotation accessors can bring methods to
XML types as well, in a way.
Figure 17: Function Items Named in Annotations as Methods
declare function base:format-metadata ($metadata as element())
{
for $meta in $metadata/*
let $methods := $meta/sc:element-decl()!sc:annotations()/xs:appinfo
let $formatter := function-lookup($methods/base:formatter, 1)
return $formatter($meta)
};
Other Schema Component Values
Facets
Accessing facet information is important for working with simple
types. Figure 18 summarizes the additional type tests
and accessors for working with facets. The sc:facets accessor
returns sequences of facet component values when applied to simple type
components; it returns the empty sequence otherwise. The accessors already
defined apply to facet component values as well. The sc:name
accessor returns the name of the element used to define the facet
(e.g. xs:enumeration for the enumeration facet), and the standard accessor
fn:data returns the value of the facet.
Figure 18: Additions for Facet Values
facet() or facet(*)
Type test matching any facet value.
facet(q:name)
Type test matching any facet value whose name
matches the given QName. For example, a pattern facet matches 'facet(xs:pattern)'.
sc:facets([$context as item()]) as facet()*
Get all the facets of the item, if any. Only simple
types have facets.
Let's return to the date example from the introduction
(Figure 2). With access to types and their facets, as
well as function lookup and function application, we can create a generic
framework for processing dates without having to hardcode any type or function
names. A fragment of this framework is shown in
Figure 19.
Figure 19: Generic XQuery Type-Based Dispatch
...
declare function my:process-date($date)
{
for $date-type in fn:collection("templates")/date/sc:simple-type()
let $date-pattern := sc:facets($date-type)[. instance of facet(xs:pattern)]
let $process-func :=
fn:function-lookup(fn:data(sc:annotations($date-type)//my:date-func), 1)
where fn:exists($date-pattern) and
fn:exists($process-func) and
fn:matches($date, fn:data($date-pattern))
return $process-func($date-type($date))
};
XQuery fragment using schema annotations and function
lookup to create a generic date-processing framework.
Element and Attribute Declarations
As the example in Figure 16 shows,
it is frequently more natural to obtain the annotations from element and
attribute declarations rather than from the types associated with those
declarations, Annotations often have more to do with the use of a type in a
particular context than with the type itself. Adding accessors to obtain element and
attribute
declarations from element and attribute nodes, and defining the component
accessors over these new component types allows for these use cases.
Figure 20 summarizes the additional type tests and
accessors for working with element and attribute declarations. The
sc:element-decl and sc:attribute-decl
accessors return component values when applied to element and attribute nodes,
respectively; otherwise they return empty sequence. In addition, the accessors
already defined apply to these new declaration component values as well. The
sc:type, sc:complex-type, and
sc:simple-type accessors return the type associated with the declaration.
Figure 20: Additions for Element and Attribute Declaration Values
element-decl() or element-decl(*)
Type test matching any element declaration value.
element-decl(q:name)
Type test matching any element declaration value
whose name matches the given QName, or which is in the substitution group with
an element with the given QName as its head.
attribute-decl() or attribute-decl(*)
Type test matching any attribute declaration value.
attribute-decl(q:name)
Type test matching any attribute declaration value
whose name matches the given QName.
sc:element-decl([$context as item()]) as element-decl()?
Get the element declaration of the item, if any.
sc:attribute-decl([$context as item()]) as attribute-decl()?
Get the attribute declaration of the item, if any.
Fitting element declaration values into the type hierarchy leads us
to go still further: element declarations are but one kind of term in a content
model, along with wildcards and model groups. Given that we already have
element declaration values, it makes sense to expose the content model of a
type in general. Given that we already have attribute declaration values, it
makes sense to expose the attributes declared on a complex type.
The XML Schema component model creates some complexity in this area
and we need to decide how to expose the information in the a usable way.
That model makes a distinction between particles and terms,
where the particle carries occurrence information.
It also makes an analogous distinction between attribute uses and attribute
declarations, where attribute uses carry value constraints. Attribute uses and
particles also can be used to carry local context-specific annotations.
Figure 21: More Accessors
sc:particles([$context as component()]) as particle()*
Return the particles within a model group or complex
type's content type as values.
sc:term([$context as component()]) as term()
Get the term for a particle.
sc:attributes([$context as component()]) as attribute-use()*
Return the attributes uses from a complex type.
In addition to the new accessors listed in Figure 20,
the sc:attribute-decl accessor applies to attribute use component
values.
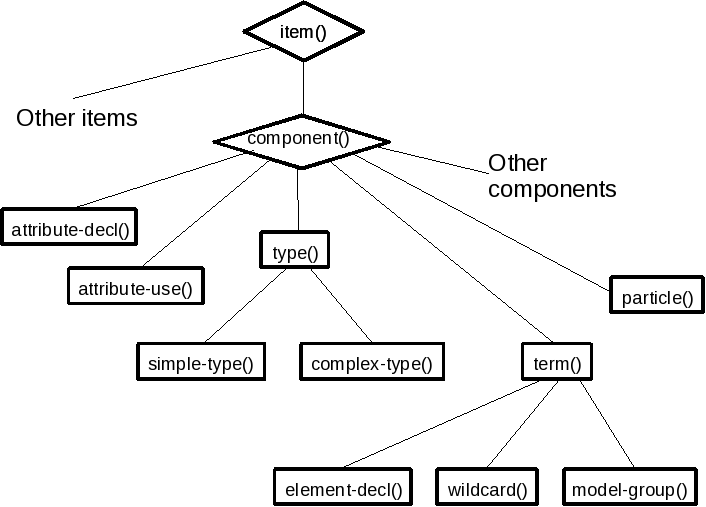
Figure 22: Declaration and Particle Values
Implementation Considerations
It is difficult to generalize about different
implementations of a language. Overall implementing the accessors, type
tests and operators discussed here on top of an existing XQuery implementation
was not difficult.
XQuery is notoriously sensitive to syntactic extensions.
The use of functional syntax made the integration with an existing
XQuery lexer and parser more straight-forward than it would have been if new
syntactic constructs had been required. The new sequence type tests and the
subtype of operator did require additions to the lexer and parser
rules. The subtype of operator was added as an additional kind of
comparison expression; the new sequence type tests were added in parallel to
XPath kind tests. Adding the component kind tests required the same kind of
special handling already required for other names that appear in a similar
context, such as element or document-node.
The values themselves were implemented as classes providing
faÇades over existing data structures used to implement XML Schema
components. These data structures were already present to support validation
and type assignment. An implementation that lacked such data structures would
clearly find exposing types as values more challenging. It is unclear, however,
whether a direct reflection of the schema component model is the right
approach. It may be better to step back and design a cleaner API, and provide
values over that model instead. Such a strategy would bring a higher
implementation burden.
Applying types as functions depended on a prior foundation
of XQuery 3.0 function items, and would be much more difficult to accomplish
without that foundation. Given that foundation, applying simple types as
functions is trivial, and applying complex types as functions only slightly
more so. The existing infrastructure to support schema validation was a
necessary prerequisite to applying complex types as functions, however.
The most challenging part of the implementation was
providing access to annotations. The existing data structures did not preserve
annotations as data model instances, as they were irrelevant for validation and
type assignment and there was no existing API that provided access to the
schema components. A surprising amount of work needed to be
done in order to preserve annotations and expose them as nodes.
Finally, the experimental implementation actually did allow schema
component values to be added as children to data model instances, primarily for
debugging purposes. Adding a schema component value as a child added it as the
XML Schema serialization. In addition, fn:string was also
implemented over these values to provide a terse representation of them, again,
for debugging purposes. About half the implementation code went into these
debugging APIs.
Future Directions
More Accessors, Functions, and Operators
This paper has focused mainly on exposing types as values in
XQuery with a few basic accessors, with some forays into some related
schema components. Some meta-programming techniques rely on being able to
examine the full richness of the schema component model — terms,
particles, attribute uses, schema component affiliations, abstractness, and so
on. The program to provide such full access is similar to what was outlined
here: define type tests for the component, define linkage functions or
accessors to get to that component, define accessors to get at the component
properties, and define whatever other useful functions and operators seem
appropriate.
More extensive additions to the syntax of XQuery to allow
variables to be used as the operand of instance of and cast
as expressions would improve usability further:
declare function my:filter-by-type($t as type(), $nodes as node()*)
{
for $n in $nodes where $n instance of $t return $n
};
Relationship to Schema Component Paths
Once we embark on the program of providing full access to all the
schema components and their properties, the use of schema component paths
arises. Schema component paths define an
XPath-like syntax for describing and navigating W3C XML Schema XSD11.1 component models. Abbreviated syntax is defined
for some path steps, and certain axes that skip over intermediate components
can provide effective ways of navigating through content models, or selecting
multiple components with a since path.
Schema component paths navigate through the schema component graph
of an assembled schema. As with XPath, each step in the path consists of an
axis combined with some kind of test and perhaps with a predicate. In schema
component paths, the test is a name test (possibly a wildcarded name test, and
possibly a test for an anonymous component), and the only predicate defined is
a positional predicate (selecting the Nth of like components). There are no
accessors for non-component properties: the axes act as accessor for component
properties, just like in XPath. About two dozen axes are defined, for each of
the component-to-component relationships in the graph. For example, the
annotation:: axis corresponds to the sc:annotations
accessor.
Figure 23 shows some schema component paths
rooted at the component for the schema as a whole. The first path starts
at the root of the assembled schema (/). It then traverses the
schemaElement axis (schemaElement::) with a name test
(p:outer), selecting a global
element declaration with the name outer. The path continues
through the type axis (type::) with a name test (0)
that in this case matches a type definition with no name (0 being
the indicator for this case). The path to this point will select the locally
declared anonymous type of the element declaration 'outer'. Finally the path
concludes by traversing the schemaAttribute axis
(schemaAttribute::) with a name test (p:inner),
selecting an attribute declaration whose name is 'inner' within the anonymous
type definition. As a whole then, this path selects a particular attribute
declaration of a particular element declaration. The second path means the same
thing, but uses abbreviated syntax.
The third path again starts at the root of the assembled schema
(/). This time it traverses through the type axis
(type::) with a name test (p:second), thus selecting
a global type definition with the name 'second'. The path then traverses the
model axis (model::) with a name test (sequence),
thus selecting the model group in the content model of the type,
but only if it is a sequence. The path continues along the schemaElement axis
(schemaElement::) with a name test (p:duplicate) and
a positional constraint ([2]), thus selecting an element
declaration within the sequence that has a name of 'duplicate', but referring
to the second such element within the content model. Finally, the path
traverses the type axis (type::) with a
wildcard (*), selecting the type of the given element declaration,
whatever it might be. The fourth path means the same thing, but uses
abbreviated syntax.
How does this compare to the accessors we have
defined above?
The accessors operate not on components but on
XQuery values. For example, sc:element-decl applies to nodes.
Some accessors, such as sc:type, apply to component values
also, and so behave somewhat like the schema component axes.
To get the full range of axes available in schema component paths, it would be
necessary to define an accessor function corresponding to each axis, and allow
it to apply to component values. To get the effect of the name tests, XPath
predicates must be applied to the results of the accessor. Some accessors
return simple properties of the components, such as its name. Schema component
paths do not provide for access to the non-component properties. Finally,
schema component paths use the slash (/) as a syntactic separator
between steps. Since schema components are not nodes, XQuery forbids using them
inside a path (although they can be the last step of a path). A FLWOR
expression, nested function call, or the XQuery 3.0 simple mapping operator
(!) must be used instead.
Table I
Summary of Comparison of Schema Component Accessors and Schema Component Paths
Schema Component Paths
Schema Component Accessors
operate on schema components
operate on XQuery values
apply to schema in isolation
can link between date model
items and schema component values
start at particular schema component, either root of schema or contextually supplied
schema component
apply to particular item(), not rooted at top of schema
path step selects component-valued component properties only
acccessor selects various kinds of properties
steps combine axis with name test directly
component or name test separate from accessor
steps combined with slash
chains of accessors cannot be
combined with slash: must nest function calls, use FLWOR expressions, or use
XQuery 3.0 simple mapping operator instead
path syntax and semantics similar to XPath, but is not XPath
syntax and semantics are standard XPath
Since schema component accessors do not apply to schemas in
isolation, it is not possible to construct XQuery expressions that are exactly
equivalent to the schema component paths given previously. However, we can give
some expressions that are roughly equivalent, to give some sense of how they
compare.
Figure 24: Rough Equivalents to Schema Component Paths
Figure 24 shows XQuery expressions using the
accessors that are roughly equivalent to the schema component paths shown in
Figure 23. These
expressions have to be grounded on some XQuery item ($context),
and it was necessary to invent a new accessor to link to the root of the
assembled schema governing the type information for that item
(sc:schema).
Schema component paths clearly express traversal
through a schema component graph more compactly than the accessor and linkage
functions do, in that they combine the accessor and the type test in one path
step. In addition, schema component paths generally elide the distinction
between terms and particles, which the chained accessors do not.
On the other hand, schema component paths do not provide a complete
answer, however. They do not provide access to non-component
information, nor do they bridge the boundary between schema components and
nodes or other item types.
We could imagine allowing schema component paths to mix directly
with normal XPath paths to provide that linkage. Then a path such as
/book/chapter/title/type::*/annotation::*/xs:appinfo/my:special-stuff/@my:type
would switch back and forth between XPaths and schema component paths. Under
this scheme the type axis in the fourth step of the path would start a relative
schema component path with some component as the default. In this case,
the context is the element declaration component for the title
element.
Mixing schema component paths with normal XPaths directly in this
way is apt to be very confusing, however. The rules governing the slash are
very different. In addition, abbreviated schema component paths in this mixed
context confuses interpretation tremendously. Is the @my:type at
the end of the path a normal attribute node on the
my:special-stuff element or is it an attribute declaration?
Careful specification of the switching rules may eliminate ambiguities,
but it won't eliminate confusion for humans reading and writing such
paths. The similarity of schema component paths to XPaths that helps make them
more intuitive in isolation causes difficulty when used in the same context as
XPath. This confusion also makes implementation more difficult: higher levels
of analysis would be required to determine what kinds of operations are
allowable, or to optimize node paths properly.
Keeping schema component paths and XPaths clearly separated
provides the power of both, without the confusion. Wrapping schema component
paths within some kind of scoping expression and providing the rich set of
accessor functions seems the best way to achieve this.
Figure 25: Example Integration of Schema Component Paths and Type Values
Schema component paths are wrapped inside special
syntactic for to keep them clearly separated from normal XPaths.
In summary, both schema component paths and the XQuery linkage and
accessor functions both have their place. Schema component paths are suited to
navigating through schema component graphs or pointing to specific schema
components for schema analysis or reporting. The accessor functions are more
useful to exposing the schema information relevant to a particular XQuery item
in the context of some operations over data.
Summary and Conclusions
This paper has explored adding schema types as values into XQuery,
providing some measure of structural type introspection. In an XQuery context,
a type is an XML Schema type, and to provide even basic structural type
introspection requires pulling in quite a bit of the complexity of the XML
schema component model. Nevertheless, implementation need not be too
challenging, and only modest changes to the XQuery data model and existing
syntax are required. It is possible to take an incremental approach to adding additional
capabilities, but even some basic abilities can provide significant
coding power and flexibility.
Schema component paths can be used in combination with linkage
function if they are integrated with care, to avoid confusion. Schema component
paths satisfy use cases where deep analysis of the schema is required, while
simple accessor and linkage functions work well for getting at basic metadata
about the types of the data being operated on.
References
[C++]
American National Standards Institute, 1430 Broadway, New York, NY 10018, USA.
The ANSI C++ Standard (ISO/IEC 14882), 2002.
[Gabriel91]
Richard P. Gabriel, Jon L. White, and Daniel G. Bobrow.
Clos: Integrating Object-Oriented and Functional Programming.
Communications of the ACM, 34(9):29–38, 1991. doi:https://doi.org/10.1145/114669.114671.
[XSD11.1]
W3C: Shudi (Sandy) Gao 高殊镝, C.M. Sperberg-McQueen, and
Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures .
W3C, April 2012.
http://www.w3.org/TR/xmlschema-11-1/
[SCD]
W3C: Mary Holstege and Asir S. Vedamuthu, editors.
W3C XML Schema Definition Language (XSD): Component Designators.
Candidate Recommendation. W3C, January 2010.
http://www.w3.org/TR/2010/CR-xmlschema-ref-20100119/
[XSD11.2]
W3C: David Peterson, Shudi (Sandy) Gao 高殊镝, Ashok Malhotra,
C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes.
W3C. April 2012.
http://www.w3.org/TR/xmlschema11-2/
[XQuery30]
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Last Call Working Draft. W3C, December 2011.
http://www.w3.org/TR/xquery-30/
[Singh04]
Hermanpreet Singh.
Introspective C++.
Masters Thesis, Virginia Polytechnic Institute, 2004.
Richard P. Gabriel, Jon L. White, and Daniel G. Bobrow.
Clos: Integrating Object-Oriented and Functional Programming.
Communications of the ACM, 34(9):29–38, 1991. doi:https://doi.org/10.1145/114669.114671.
W3C: Shudi (Sandy) Gao 高殊镝, C.M. Sperberg-McQueen, and
Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures .
W3C, April 2012.
http://www.w3.org/TR/xmlschema-11-1/
W3C: Mary Holstege and Asir S. Vedamuthu, editors.
W3C XML Schema Definition Language (XSD): Component Designators.
Candidate Recommendation. W3C, January 2010.
http://www.w3.org/TR/2010/CR-xmlschema-ref-20100119/
W3C: David Peterson, Shudi (Sandy) Gao 高殊镝, Ashok Malhotra,
C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes.
W3C. April 2012.
http://www.w3.org/TR/xmlschema11-2/
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Last Call Working Draft. W3C, December 2011.
http://www.w3.org/TR/xquery-30/
W3C: Norman Walsh, Anders Berglund, and John Snelson, editors.
XQuery and XPath Data Model 3.0
Last Call Working Draft. W3C, December 2011.
http://www.w3.org/TR/xpath-datamodel-30/