Clark, Ash. “Meta-stylesheets: Exploring the Provenance of XSL Transformations.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Clark01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: Meta-stylesheets: Exploring the Provenance of XSL Transformations
Ashley Clark
Ashley Clark recently received her M.S. from the Graduate School of Library and Information
Science at the University of Illinois at Urbana-Champaign, where she specialized in
data curation and worked as a research assistant and hourly academic. Her interests
include data curation and data provenance in the humanities.
When documents are transformed with XSLT, what methods can be used to understand and
record those transformations? Though they aren't specifically meant for provenance
capture, existing tools and informal practices can be used to manually piece together
the provenance of XSLTs. However, a meta-stylesheet approach has the potential to
generate provenance information by creating a copy of XSLT stylesheets with provenance-specific
instructions. This method is currently being implemented, using the strategies and
workflows detailed here. Even with the complications and limitations of the method,
XSLT itself enables a surprising amount of provenance capture.
Provenance records are records for trust and authenticity, records to prove that the
object is what it is claimed to be. Provenance has its roots in the archival world,
where the goal is to see objects survive with minimal weathering as they pass from
one caretaker to the next (Sweeney, 2008). Similarly, data provenance answers the question "How did this come to be here,
in this state?", and it does so by identifying the agents, transformation events,
and other artifacts associated with that object.
Computer usage is so prevalent in humanities and sciences research that it is all
but guaranteed that data will be changed in some way during its lifetime. This has
the advantage that tools can automatically generate provenance information, recording
important details about the transformation process. Later, a provenance record of
this sort may be used for error-checking, to independently reproduce a result, or
simply for results verification (Küster, Ludwig, Al-Hajj, & Selig, 2011). Few e-humanities software tools offer provenance capabilities, likely due to time
constraints and a lack of common practice. However, one reason may be in terms of
nomenclature. Humanities research often involves documents, and humanists may bristle
to think of their documents as the 'data' part of data provenance (Fear, 2011).[1]
Still, more and more documents are becoming - or are born as - data, thanks to mark-up
languages (Buneman, Khanna, & Tan, 2000). XSLT is one possible step in document transformation, and as such, is subject to
the same provenance needs as other processes. XSL transformations can be examined
and, with a little effort, used to generate provenance information about the creation
of documents. The goal of this project is to examine methods of gathering provenance
information about XSL transformations, and to explore the possibilities of automatically
generating such records.
Provenance terminology
A handful of provenance ontologies exist, and each identifies three basic classes
of provenance: information about processes, or transformation events; about agents,
or the people (or software) which catalyze or carry out the event; and artifacts,
or 'things' which may be acted on, generated by, or otherwise associated with a transformation
event. The below figure gives the terminology of two such ontologies, the Open Provenance
Model (Moreau et al., 2010) and the W3C PROV-O (Belhajjame et al., 2012).
Figure 1: Provenance classes of OPM and W3C PROV-O
Table I
Ontology
'Thing'
Transformation Event
Person/Software
Open Provenance Model (OPM)
Artifact
Process
Agent
W3C PROV
Entity
Action
Agent
My first attempts at provenance documentation were founded on the XML binding of OPM.
OPM was designed primarily to capture information about scientific data workflows,
and loosely fit the information needed to document XSLT provenance. Current work makes
use of the Open Provenance Model Vocabulary, a modified version of OPM which includes
a module for XSLT provenance (Zhao, 2010). As such, this paper makes use of OPM and OPMV XSLT module terminology.[2]
What can we glean from an XSL transformation?
Gathering XSLT provenance information is already possible through a number of methods.
The simplest method (though not necessarily the easiest for understanding) is to simply
examine the artifacts associated with an XSL transformation - mainly the input, output,
and stylesheets involved in the transformation. In particular, comments left on a
stylesheet could reveal the author agent's identity, thought process, and understanding
of what the XSLT code does or is supposed to do. One might be able to determine the
templates' firing order, but the process may just as well be laborious in terms of
piecing together provenance.
A better method is to use a debugger to step through a transformation, which grants
an in-depth look at the way an output document is constructed from input and stylesheet.
Parameter and variable values may also be shown, which may explain choices made by
the XSLT processor. This step-through method is aimed for human understanding, but
no record of the steps is available for consultation. Provenance information would
be easier to identify with this method as opposed to the first, but it would still
have to be documented by hand.
In contrast, the Saxon processor has a trace function[3] which provides a tree view of the steps within an XSL transformation. It shows what
input nodes are matched to templates, and includes the file name and line numbers
of each processed node. The trace log cannot reference the specific elements in the
output that came into existence due to any one transformation step. Instead, one must
infer the structure of the output from the steps taken. Still, when used as a roadmap
to examining the input documents and stylesheets, the trace log is explicit and exact
in its references - a good representation of the transformation which created the
output, so long as one has access to the files referenced.
XSLT itself also provides the capability to capture some provenance information, through
functions such as system-property() and base-uri(). With these functions, the output of a stylesheet could include information on the
XSLT version used; the processor agent which controlled the XSL transformation; and
the file names of an input document and the primary stylesheet. However, the use of
this method is dependent on those who created or who maintain the stylesheet.[4]
The oXygen XML Editor has a documentation generation tool for XSLT stylesheets. The
tool creates a log giving information about the stylesheet and children of the xsl:stylesheet node (most notably, templates). Interestingly enough, the documentation tool also
assumes that if a node has a comment placed immediately before it, then the comment
is documentation for the contents of that node. While this assumption could be wrong,
it certainly rewards those who provide descriptions of stylesheets and templates through
comments. It is worth noting that the documentation tool may not contain any provenance
information at all, since it only describes the stylesheet artifact and does not guarantee
any references to agents, process instances, or other artifacts. On the other hand,
the documentation is an excellent example of the types of information that should
be included when a provenance record references a stylesheet or template artifact.
What kinds of information, then, can we find about an XSL transformation?
XSLT version
XSLT processor name, version, vendor
input document URI
stylesheet URI
template matches or calls
literal result element (LRE) insertion
input node transformation steps
authorship (dependent on programmer)
copyright information (dependent on programmer)
explanation of coding choices (dependent on programmer)
Although we have a number of methods for piecing together the provenance of an XSL
transformation, there are a number of limitations, the foremost of which is the fact
that these methods offer only a portion of the provenance information available for
XSLT processes. To gather all of the above information would require using each method
and manually piecing together the results to form comprehensive provenance documentation.
A general provenance tool for XSLT should include as much of this information as possible,
recording it during XSLT processes at a user's behest.
The meta-stylesheet method
Assumptions and approach
When I started looking at XSLT provenance, I hoped to find a method that would be:
comprehensive, combining as many types of the above provenance information as possible;
easy to use - either fitting right into existing workflows, or able to be run and
used with minimum fuss; and
in a format built for shareable provenance.
I also hoped for a method that would be reliant on neither a specific type of XSLT
processor (as helpful as the Saxon trace has been), nor on a specific program such
as oXygen.
Wendell Piez suggested a possible solution - to build a "meta-stylesheet." The meta-stylesheet
will take stylesheet A as input, and output a stylesheet B, which in turn will approximate
the XSLT processes of running stylesheet A with the same input document. Instead of
the output expected from stylesheet A, the "meta'd" transformation scenario will output
an OPMV-based RDF graph, providing provenance information on multiple levels of granularity.
Currently, only two levels of provenance are captured: first, the file-level transformation
process; second, the firing of templates as they are matched or called.
A workflow for provenance reporting
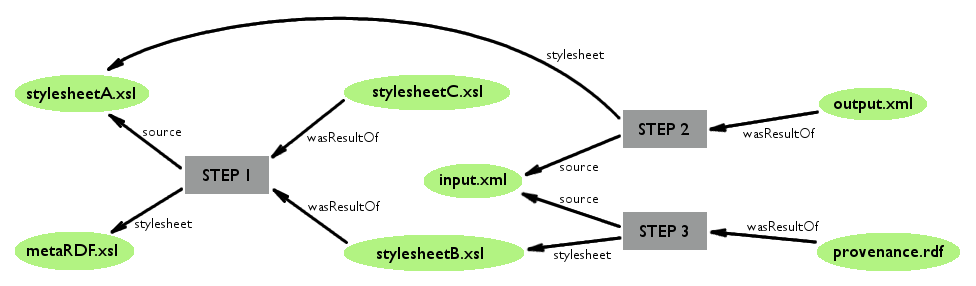
The steps of the XSLT provenance workflow are currently as follows:
Use the meta-stylesheet to create stylesheet B (for generating provenance) and, optionally,
stylesheet C (for assigning rdf:IDs to template code)
Use stylesheet A or C[5] and input.xml to create output.xml[6].
Use stylesheet B on input.xml to create an OPMV RDF graph representing the provenance
of step 2.
Figure 3: An overview of the meta-stylesheet method
The workflow is meant to capture the provenance of step 2, on two levels of granularity:
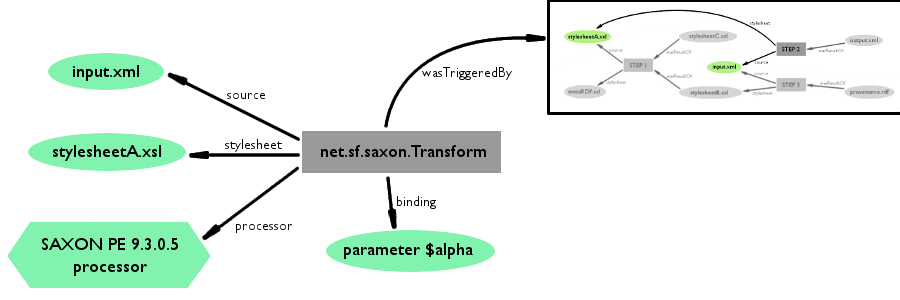
file-level and template-level. The file-level XSL transformation process references
the input document, as well as the stylesheet(s) used. The process is controlled by
the XSLT processor, and generates an output document. As with the Saxon trace, this
method can only give the provenance information of the transformation process which
created the output.xml.
<!-- Provenance for the transformation of file:/C:/Users/Ashley/Desktop/global_001/input.xml
using stylesheetC.xsl: -->
<xslt:Stylesheet rdf:about="stylesheetC.xsl">
<xslt:version>1.0</xslt:version>
</xslt:Stylesheet>
<xslt:Processor rdf:ID="proc01">
<xslt:vendor rdf:resource="http://www.saxonica.com/"/>
<xslt:productName>SAXON</xslt:productName>
<xslt:productVersion>PE 9.3.0.5</xslt:productVersion>
</xslt:Processor>
<xslt:Binding rdf:ID="alpha">
<xslt:value>Y</xslt:value>
</xslt:Binding>
<xslt:Transformation rdf:ID="overall">
<xslt:source rdf:resource="file:/C:/Users/Ashley/Desktop/global_001/input.xml"/>
<xslt:stylesheet rdf:resource="stylesheetC.xsl"/>
<xslt:processor rdf:resource="#proc01"/>
<xslt:binding rdf:resource="#alpha"/>
</xslt:Transformation>
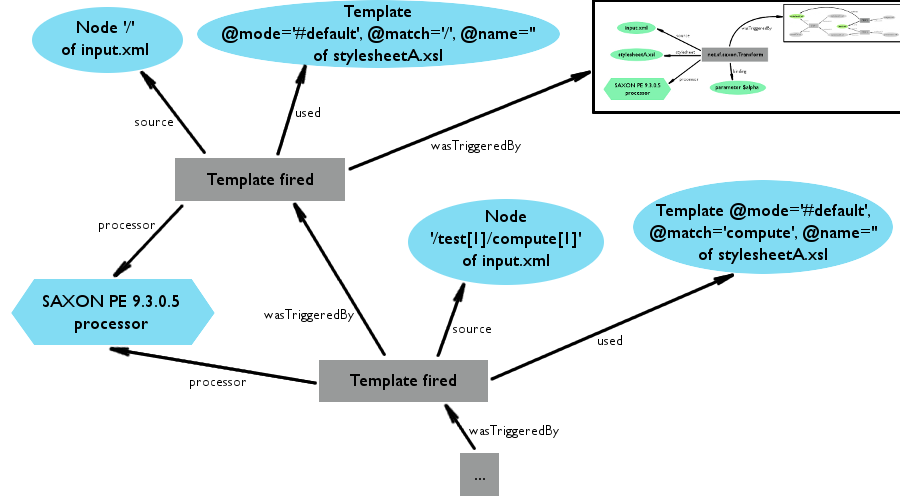
Like the overall transformation process, template-level provenance heavily uses the
XSLT module for OPMV. Here, each xslt:Transformation points to an xslt:Template artifact, which could be of either subtype xslt:MatchedTemplate or xslt:NamedTemplate. The edge between the two is xslt:used. If the template firing was triggered by xsl:apply-templates, then it also contains a reference to the source node to which the template was matched.
Any template, and thus any transformation, might contain parameters or variables,
and thus, bindings. Unlike stylesheet bindings, a template parameter of the same name
- but different rdf:ID! - can carry a different value every time the template is run.
The job of stylesheet B is to carry the same structure as stylesheet A, so that for
any input document, an XSLT processor will choose the same transformation step for
either stylesheet. However, the structure needed to accurately mirror stylesheet A
depends on the granularity expectations. If stylesheet B only needs to capture file-level
granularity, the XSLT code only requires information about the input document artifact
and the processor agent. On the other hand, template-level granularity would require
stylesheet B to maintain the same templates with the same attributes and the same
template calls or matches. Currently, the stylesheet B keeps only those elements from
stylesheet A which are essential to the structure of the stylesheet (such as xsl:template), or which are needed to determine parameter or variable bindings. The more provenance
required, the more stylesheet B will come to resemble stylesheet A. However, stylesheet
B keeps this structure only to accurately represent the process of obtaining output.xml
in step 2.[7]
The meta-stylesheet is simply a means to create stylesheet B. The meta-stylesheet
passes the OPMV base structures to the meta'd stylesheet. The stylesheet artifact,
and template artifacts must be generated at this step. The meta-stylesheet also sets
up the XSLT code for the transformation processes and artifacts which must be generated
when stylesheet B is used with input, so as to accurately represent the transformation
at step 2.
As an example, the next figure shows a simple comment taken from the beginning of
the provenance output. The two figures after that show the XSLT code needed to generate
that comment. The meta-stylesheet must layer xsl:comment within an xsl:element so that the comment appears in provenance.rdf and not stylesheet B. The meta-stylesheet
also passes the name of stylesheet A to stylesheet B, since stylesheet B otherwise
would have no knowledge of the parallel stylesheet. Stylesheet B, however, must find
the base-uri() of the input document and generate the comment for provenance.rdf.
Figure 8: Selection from provenance.rdf
<!-- Provenance for the transformation of file:/C:/Users/Ashley/Desktop/global_001/input.xml
using stylesheetC.xsl: -->
Figure 9: Selection from stylesheet B.xsl
<xsl:comment> Provenance for the transformation of <xsl:value-of select="base-uri()"/>
using stylesheetC.xsl: </xsl:comment>
Figure 10: Selection from the meta-stylesheet (metaRDF.xsl)
<xsl:element name="xsl:comment">
<xsl:text> Provenance for the transformation of </xsl:text>
<xsl:element name="xsl:value-of">
<xsl:attribute name="select">base-uri()</xsl:attribute>
</xsl:element>
<xsl:text> using </xsl:text>
<xsl:value-of select="$regularStylesheet"/>
<xsl:text>: </xsl:text>
</xsl:element>
Essentially, the meta-stylesheet has knowledge of stylesheet A; the version of XSLT
and the files it uses; and the number of and identifying information regarding the
templates. The stylesheet B will be able to grab information about the input document,
the specifics of an individual transformation, and the XSLT processor. The meta-stylesheet
sets up stylesheet B to take that kind of information and funnel it into the provenance
output.
Requirements for a meta-stylesheet
Before it does anything else, the meta-stylesheet matches the root of its input and
creates an copy of stylesheet A, only with rdf:IDs attached to the templates. "Stylesheet C" is unnecessary for the provenance workflow
above, but it may be useful for linking relevant template code to the provenance template
artifacts.
After stylesheet C is taken care of, the meta-stylesheet starts on stylesheet B. However,
stylesheet A might fall into one of three categories:
there is no template matching root (default template rules apply);
there is a template which matches root and only root;
or, there is a template which matches root as well as other nodes.
Since the meta-stylesheet must keep the structure of stylesheet A as well as preparing
for eventual RDF/XML output, the rdf:Graph container element must be carefully placed. In the first case, a root template is
created. In the second case, stylesheet A's root template can be reduced to provenance-ready
structure, but with the template node's descendants wrapped in the rdf:Graph. The third case is slightly more difficult. The original template must have the root
node stripped from @match before it can be copied forward into stylesheet B, and a new template created to
match only root, with the same instructions wrapped in the rdf:Graph. It's also worth noting that each template in stylesheet B will be prepared with
an rdf:about with a link to a template in stylesheet C. In the third case, both template artifacts
derived from the original will point to the same template in stylesheet C.
Placing the root element is also important because there is no better place to record
the file-level provenance. When the processor matches the root node to any template
(or built-in rule, as the case may be), the stylesheet and input file artifacts are
already known, as are the processor agent and stylesheet-level parameters and variables.
Figure 11: Code for the overall transformation process (metaRDF.xsl)
<!-- Set up the xslt:Transformation for $regularStylesheet and its input. -->
<xslt:Transformation rdf:ID="overall">
<xslt:source>
<xsl:element name="xsl:attribute">
<xsl:attribute name="name">rdf:resource</xsl:attribute>
<xsl:element name="xsl:value-of">
<xsl:attribute name="select">base-uri()</xsl:attribute>
</xsl:element>
</xsl:element>
</xslt:source>
<xslt:stylesheet>
<xsl:attribute name="rdf:resource">
<xsl:value-of select="$regularStylesheet"/>
</xsl:attribute>
</xslt:stylesheet>
<xslt:processor>
<xsl:attribute name="rdf:resource">
<xsl:text>#proc01</xsl:text>
</xsl:attribute>
</xslt:processor>
<xsl:for-each select="/(xsl:transform | xsl:stylesheet)/xsl:param">
<xslt:binding>
<xsl:attribute name="rdf:resource">
<xsl:text>#</xsl:text>
<xsl:value-of select="@name"/>
</xsl:attribute>
</xslt:binding>
</xsl:for-each>
</xslt:Transformation>
The template artifacts can be generated here by using xsl:for-each, so long as one is willing to accept that template artifacts may be listed that are
not referenced in any transformation.
The processes for templates firing should be generated during the transformation of
stylesheet B, thus guaranteeing a chain of template-level processes. A template-level
process is triggered by another process - either the file-level process, or by an
xsl:apply-templates or xsl:call-template during another template's firing. If a template is called or matched, OPMV contains
two Template subclasses - xslt:MatchedTemplate and xslt:CalledTemplate. For a process to correctly reference the use of a template artifact, the meta-stylesheet
must set up stylesheet B to pass along information about the 'parent' template. I
used tunneled parameters to accomplish this - each template in stylesheet B gains
two parameters, called 'provTemplate' and 'provTrigger'. 'provTemplate' identifies
the XSLT instruction which initiated the current template process, and 'provTrigger'
passes along the identifier for the 'parent' template. The meta-stylesheet must assign
xsl:with-param instructions to each xsl:apply-templates and xsl:call-template.
Figure 12: Code to track template parentage with xsl:call-template (metaRDF.xsl)
The meta-stylesheet has been successfully created, and it can provide file- and template-level
provenance documentation for XSL transformations, as shown in the examples above.
Still, there are a number of questions still left to explore regarding the meta-stylesheet
method and XSLT provenance documentation. For example, how much provenance collection
is too much? Further work can be done to include finer levels of granularity, but
it probably isn't necessary to document every XSLT instruction. What about coarser
granularity? If XSLTs are used in a workflow, what kinds of provenance documentation
can be generated, and what should it look like?
Unfortunately, the meta-stylesheet method does not entirely fulfill the assumptions
listed previously, especially in ease of use. No matter what version of XSLT is used
by stylesheet A, both the meta-stylesheet and stylesheet B currently require the use
of an XSLT 2.0 processor. This certainly limits the number of processors able to make
use of this method without fuss. Further, the meta-stylesheet has only undergone testing
using the Saxon HE and PE processors shipped with oXygen. More testing is needed to
ensure that the approach works in broader contexts, with other tools and XSLT 2.0
processors.
But the biggest problem with this approach is the meta-stylesheet's inability to say
anything concrete about the output of stylesheet A. Neither the meta-stylesheet nor
stylesheet B has knowledge of the actual contents of output.xml, although a good estimation
can probably be made by modifying the structure of stylesheet B. It is unclear whether
this is a beneficial side-effect (as in workflows where intermediate outputs may not
be available) or something that should be fixed.
Besides attempting to solve these questions, I continue to test the meta-stylesheet
against a greater number of input stylesheets, and to include other types of provenance
information, such as the template descriptions given by the oXygen Editor. Even at
this date, this project shows that an impressive amount of provenance information
can be generated with just XSLT.
Acknowledgements
Many, many thanks to Wendell Piez for coming up with the idea for a meta-stylesheet,
as well as providing guidance and technical help along the way. Thanks also to Allen
Renear, Megan Senseney, and my colleagues at CIRSS for their advice and unflagging
support.
This project was supported by DCEP-H, an initiative to extend the Data Curation Education
Program to the humanities. Funded by IMLS Grant RE-05-08-0062-08, DCEP-H was based
at the Center for Informatics Research in Science and Scholarship at the University
of Illinois at Urbana-Champaign.
[Küster, Ludwig, Al-Hajj, & Selig, 2011] Küster, M., Ludwig, C., Al-Hajj, Y. & Selig, T. (2011). TextGrid provenance tools
for digital humanities ecosystems. Proceedings of the 5th IEEE International Conference on Digital Ecosystems and Technologies
2011. (pp. 317-323). Daejeon, Korea: IEEE. doi:https://doi.org/10.1109/DEST.2011.5936615
[Sweeney, 2008] Sweeney, S. (2008). The ambiguous origins of the archival principle of "provenance".
Libraries & the Cultural Record 43(2), 193-213. University of Texas Press. doi:https://doi.org/10.1353/lac.0.0017
[1] See Babeu, 2011 for an in-depth look at digital humanists and the challenges of creating "ecosystems"
to suit their needs.
[2] Currently a work in progress, the W3C PROV is an attempt at a provenance ontology
general enough to be used for many fields, but flexible enough to handle the specific
provenance needs of any organization or community. Once completed, it will likely
prove more useful than OPM for provenance markup. For example, OPM has no versioning
capabilities, while PROV does.
[3] Append "-T" when transforming via Java platform.
[4] Read: those who likely already know the files and processor being used, and who may
not see the use in including such information.
[5] Since A and C have the same output, I refer to "A" when talking about the characteristics
of both, and "C" when specifically talking about stylesheet C.
[6] The input and output can, of course, be in formats other than XML.
[7] As provenance becomes increasingly fine-grained, other elements will be left in as
well.
Babeu, A. (2011). "Rome wasn't digitized in a day": Building a cyberinfrastructure
for digital classics. Washington, D.C.: Council on Library and Information Resources.
Accessed at http://www.clir.org/pubs/reports/pub150/pub150.pdf
Belhajjame, K., Deus, H., Garijo, D., Klyne, G., Missier, P., Soiland-Reyes, S., Zednik,
S. (2012). PROV Model Primer, W3C Working Draft 03 May 2012. Accessed at http://www.w3.org/TR/2012/WD-prov-primer-20120503/
Küster, M., Ludwig, C., Al-Hajj, Y. & Selig, T. (2011). TextGrid provenance tools
for digital humanities ecosystems. Proceedings of the 5th IEEE International Conference on Digital Ecosystems and Technologies
2011. (pp. 317-323). Daejeon, Korea: IEEE. doi:https://doi.org/10.1109/DEST.2011.5936615
Moreau, L., Clifford, B., Freire, J., Futrelle, J., Gil, Y., Groth, P., ..., Van den
Bussche, J. (2010). The Open Provenance Model core specification (v1.1). Accessed
at http://eprints.ecs.soton.ac.uk/21449/
Sweeney, S. (2008). The ambiguous origins of the archival principle of "provenance".
Libraries & the Cultural Record 43(2), 193-213. University of Texas Press. doi:https://doi.org/10.1353/lac.0.0017