Seinturier, Julien, Elisabeth Murisasco and Emmanuel Bruno. “An XML engine to model and query multimodal concurrent linguistic annotations: Application
to the OTIM Project.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Seinturier01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
Balisage Paper: An XML engine to model and query multimodal concurrent linguistic annotations
Application to the OTIM Project
Julien Seinturier
Post-Doctorate
Laboratoire LSIS UMR CNRS 6168, Université du Sud Toulon et Var
Julien Seinturier is a PhD in Computer Sciences at the
University of Sud Toulon-Var (South of France) since 2007. He is
post doctorate at the CNRS Laboratory of Information Science and systems(LSIS)
within the computer science teaching department.
His fields of research covers Knowledge Representation, Semantic Web, XML data
management.
His research activities have been supported
by French National and European pluridisciplinary research projects.
Elisabeth Murisasco
Professor
Laboratoire LSIS UMR CNRS 6168, Université du Sud Toulon et Var
Elisabeth Murisasco is Professor in Computer Sciences at
the University of Sud Toulon-Var (South of France) since 2007.
She is researcher at the CNRS Laboratory of Information Science
and systems (LSIS) and she is member of the computer science
teaching department .
Her main research experience and scientific expertise covers databases,
XML-based data, semantic web technologies. Her research activities
have been supported by French National research projects.
Emmanuel Bruno
Lecturer
Laboratoire LSIS UMR CNRS 6168, Université du Sud Toulon et Var
Emmanuel Bruno is Assistant Professor in Computer Sciences at the
University of Sud Toulon-Var (South of France) since 2001. He is
researcher at the CNRS Laboratory of Information Science and systems(LSIS)
and he is member of the computer science teaching department.
His main fields of research covers databases, XML data management,
semantic web technologies. His research activities have been supported
by French National research projects.
This paper presents an XML engine defined to model and query multimodal concurrent
annotated data.
This work stands in the context of the OTIM (Tools for Multimodal Annotation)
project which aims at developing conventions and tools
for multimodal annotation of a large conversational French speech corpus; it
groups together Social Science and Computer Science researchers.
Within OTIM, our objective is to provide linguists with a unique framework
to encode and manipulate numerous linguistic domains: morpho-syntax, prosody,
phonetics, disfluencies, discourse, gesture and posture.
For that, it has to be possible to bring together and align all the different
pieces of information (called annotations) associated to a corpus.
We propose a complete pipeline from the annotation step to the management of
the data within an XML Information System. This pipeline first relies on
the formalisation of the linguistic knowledge and data within a OTIM specific XML
format. A Java framework is proposed for interfacing with both linguists specific
annotation tools and XML Information System. Finally, the querying of multimodal
annotations within the XML information system using XQuery is presented.
As annotations are time aligned, an extension of XQuery to Allen temporal relations
is proposed.
The paper conclude on a discussion about the interest of a pure XML approach
for linguistic annotations information system and the question of the
integration of the semantic within the pipeline.
In this paper, our intention is to present an XML engine defined to model and query
multimodal concurrent annotated data.
This work stands in the context of the OTIM (Tools for Multimodal Annotation) project
which aims at developing conventions and tools
for multimodal annotation of a large conversational French speech corpus (http://aune.lpl.univ-aix.fr/~otim/) [Blache 2010b]. This interdisciplinary project
is funded by the French ANR agency; it groups together Social Science and Computer
Science researchers. Within OTIM, our objective is to provide linguists with a unique
framework
to encode and manipulate numerous linguistic domains: morpho-syntax, prosody, phonetics,
disfluencies, discourse, gesture and posture [Blache 2010]. For that, it has
to be possible to bring together and align all the different pieces of information
(called annotations) associated to a corpus.
Since some years, several works have studied concurrent markups/annotations associated
to the same data, in particular in the context of XML documents. These
documents are usually called multistructured. Indeed, XML documents are mainly
hierarchical. The hierarchy, captured in a tree-like structure corresponds to
one level of analysis of the data contained in the document. Concurrent markup
opens a way for dynamically linking and aggregating documents with different
structures associated to the same data. The CONCUR feature of SGML [Goldfarb 1990] first pointed out this need in the nineties in context of
document-centric encoding where some applications needed to consider more than
one hierarchy over the same text.
The main problem with concurrent structures is that merging every hierarchy in
an unique XML document implies overlapping: structures
cannot be merged in order to get a well-formed XML document without using a flat
representation or hyperlinks that make the structure difficult to query with
standards XML languages like XPath (http://www.w3.org/TR/xpath/), XQuery (http://www.w3.org/TR/xquery/) or XSLT (http://www.w3.org/TR/xslt/).
See [Witt 2004][DeRose 2004] for a review about the problem of overlapping and about multiple hierarchies. Another
approach
is to keep one document by hierarchy and to solve the problem of the concurrent
querying. We stand our work in this last approach: we want to keep each structure
safe to use available XML tools and languages for its manipulation.
Historical solutions which propose syntactic solutions for the representation of
multiple hierarchies in the same text, like the CONCUR feature [Hilbert 2005]
of SGML or TEI specifications [TEI P4] (e.g. a flat representation or a main (hierarchical) structure and the use references
(ID/IDREF) for
the description of the other structures). These solutions make impossible querying
by means of standards XML languages.
Proprietary graph based-model (and possible alternative syntax to XML) like LNML
[Tennison 2002], TexMecs[http://decentius.aksis.uib.no/mlcd/2003/Papers/texmecs.html],
XCONCUR [http://www.xconcur.org/], Annotation graphs [Bird 2001] (coming from the linguistic domain coupled to specific extension of XPath) or
MVDM [Djemal 2008]. They allow the concurrent markup relying on a granule of data common to all the
structures. Nevertheless, hierarchical structures
are easier to exploit compared to the graph structure which remain complex when a
large number of structures exist. XML syntax for serialization or import/export XML
syntax do
not make easy their querying by XML standard languages.
Finally, the third category is XML compatible contributions; they generally propose
extensions of XML data model (XDM) (http://www.w3.org/XML/Datamodel.html) to consider a set of XML trees
[Le Maitre 2006][Jagadish et al. 2004] or several trees sharing their leaves [Dekhtyar 2005][Bruno 2007][Bruno 2007b]
[Chatti 2007]. For querying, these proposals define extensions of XPath or XQuery in order to
navigate between different structures either by extending the notion
of step in XPath [Jagadish et al. 2004] or by adding new axis [Dekhtyar 2005]. Another solution is to extend the semantics of the XQuery filter [Bruno 2006]
to use as much as possible an unchanged XQuery structure. Adding Allen’s relations
[Allen 1991] by means of function definitions enable to deal with overlapping [Bruno 2006][Chatti 2007].
Besides, some linguistic projects have a similar objective than OTIM, for instance
NITE (http://groups.inf.ed.ac.uk/nxt/),
AGTK (http://weblex.ens-lsh.fr/projects/xitools/logiciels/AGTK/agtk.htm), ATLAS [Bird et al. 2000],
PAULA (http://www.sfb632.uni-potsdam.de/~d1/paula/doc/), XStandoff [Sperberg-McQueen 2000].
These projects rely on graph-based model. They generally propose toolkits for multi-level
annotation by means of libraries of data and annotation management. The
multiplication of annotation schemes and coding formats is a severe limitation
for interoperability. One solution consists in developing higher level approaches
(e.g. GrAF [Ide 2007])
or annotation graphs based formats on top of which conversion routines between
tools can be developed (see the Atlas Interchange Format [Sthrenberg 2009]).
However, these experiments still remain very programmatic.
Interoperability of linguistic annotated resources requires over all to be independent
from the coding format. This means to specify and organize the information to be encoded
independently from the constraints or restriction of the format (or the annotation
tool), then to encode the information into an standard XML format, readable whatever
the edition or
annotation system. Moreover we have made the choice not to provide new anootation
tools for linguists as they have a long experience and they are efficient with their
own tools.
This paper is organised as follows: the context and motivations are presented, then
we describe the project objectives and its functional architecture. A visual UML representation
of
the linguistic knowledge is proposed before the OTIM XML representation and Java
framework are explicited. The end of the work shows the methods for querying and managing
linguistic annotations
within the XML engine and the implementation of the whole corpus construction and
management before a conclusion.
Context and motivations
The OTIM project can be summarized in two main steps.
The first step concerns the multimodal annotation of a conversational speech between
two persons. It is under the responsibility of linguists;
annotation is done according to different levels of linguistic analysis. Each
expert has to annotate the same data flow according to its knowledge
domain and the nature of the signal on which he annotates (signal transcription
or signal). Experts generally use dedicated tools like PRAAT
http://www.fon.hum.uva.nl/praat/, ANVIL http://www.anvil-software.de/ or ELAN http://www.lat-mpi.eu/tools/elan/.
The qualifier multimodal is due to the nature of the studied corpus which is composed
of text, sound, video.
Within the project OTIM, linguists propose an encoding for annotating spoken language
data, with the acoustic signal as well as its orthographic
transcription. They have chosen to use Typed Feature Structures [Carpenter 1992][Copestake 2003] (TFS) to represent in an unified view the knowledge and the information
they need for annotation. TFS representation is usual for linguists: it aims at
normalizing, sharing and exchanging annotation schemas between experts.
Linguistic annotation tools rely on native and not often open formats which are
not directly interoperable. TFS provides an abstract description using a
high level formalism independent from coding languages and tools.
The second step concerns the representation and manipulation of multimodal annotation.
To analyze and find correlations between annotated linguistic
domains, it is necessary to consider them grouped together: it implies the definition
of a formal model for describing and manipulating them in a concurrent
way. The main difficulty in defining a data model comes from the heterogeneity
and the distribution of the resources. Concurrent manipulation consists in
querying annotations belonging to two or more modalities or in querying the relationships
between modalities. For instance, we need to be able to express queries
over gestures and intonation contours (what kind of intonation contour does the
speaker use when he looks at the listener?) and to query temporal relationships
(in terms of anticipation, synchronization or delay) between both gesture strokes
and lexical affiliates. The results of queries could be useful to help in constructing
new annotations or to extend existing ones.
The paper focuses on the second step. It describes an XML engine based on an architecture
dedicated to the construction and the exploitation of multimodal annotated
linguistic corpus. Our theoretical standpoint being to share data and resources,
we will use open standards from the XML universe (see http://www.w3.org).
Linguistic knowledge is captured by means of three types of information:
Properties: the set of characteristics of an object. An object is a type of information
to be annotated in the corpus ,
Relations: the set of relations that an object has with other objects,
Constituents: complex objects are composed of other objects called constituents.
Typed Feature Structures proposes a formal presentation of each object in terms of
feature structures and type hierarchies: properties are encoded by features,
constituency is implemented with complex features, and relations make use feature
structure indexing; each linguistic domain is represented as a hierarchical model.
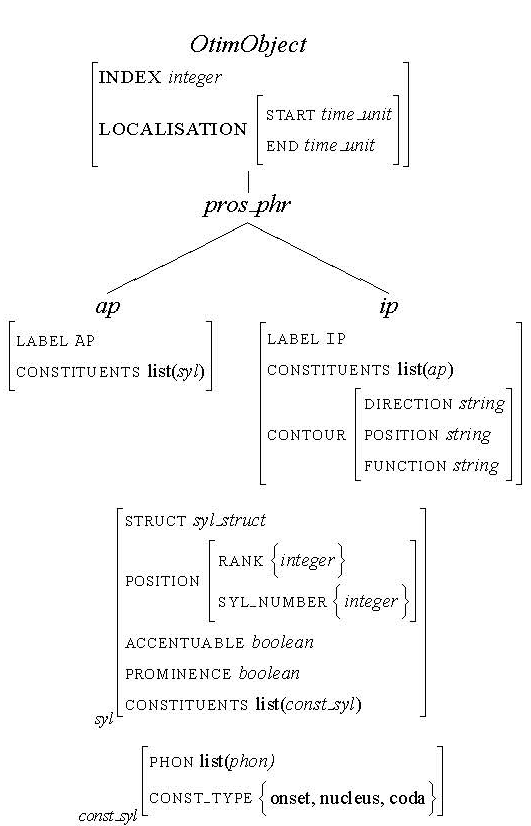
Figure 1: TFS of the prosodic domain
TFS description of the prosodic domain within the OTIM project.
For example, Figure 1 graphically describes TFS representation of the prosodic domain. Notice that every
feature of the domain related to
signal is a sub-feature of the OtimObject that is constituted of an INDEX feature in order to be referred
and a LOCALISATION feature that represents an interval,
which boundaries are defined by the features START and END, with temporal value (usually milliseconds).
Prosodic phrases are of two different types: ap (accentual phrases)
and ip (intonation phrases). Accentual phrases are constituted of two appropriate features:
the LABEL,
which value is simply the name of the corresponding type, and the list of CONSTITUENTS, in this case a list of syllables. The features of
type ip contain the list of its CONSTITUENTS (a set of ap) as well as the
description of its CONTOUR which is a prosodic event, situated at the end of the ip and is usually associated to
an ap. The prosodic phrases are formally defined as set of syllables. A syllable (syl) is constituted of features:
STRUCT that describes the syllable structure (for example CVC, CCVC, etc.), the
position of the syllable in the word (POSITION), its possibility to be accented or prominent (resp. ACCENTUABLE,
PROMINENCE). Features of type const_syl, contains two different features: a set of phonemes, denoted
PHON, and the type of the constituent (onset, nucleus and
coda), denoted CONST_TYPE. Note that each syllable constituent can contain a set of phonemes.
Objectives and functional architecture
TFS is well suited to take into account the heterogeneous characteristics of annotated
data. TFS provides an abstract
description using a high level formalism independent from coding languages and tools.
Nevertheless, due to its theoretical
nature, such a representation cannot be used within an applicative framework and
has to be implemented into other formalisms.
In this context, our contributions are the following:
The representation of the knowledge expressed by means of TFS in an XML formalism.
We base our proposal on XDM (XML data model, http://www.w3.org/XML/Datamodel.html),
The automatic construction of XML annotated multimodal linguistic corpus. We
define an operational multimodal data processing
from TFS and (semi) automatic procedures to convert legacy data and annotations
to the XML formalism,
The concurrent querying of multilevel annotated linguistic data represented
in the XML formalism. We use the XML
Query Language XQuery that we have extended to multistructured XML documents
[Bruno 2006], in particular in order to take
into account Allen’s temporal relations.
In summary, from the organization of annotations in terms of TFS, we automatically
generate a XML schema [http://www.w3.org/XML/Schema] for each linguistic domain.
All the annotations are then encoded following this schema and data are represented
in standard XML document. This representation provides a
high level of modularity for applicative requirements and enables to modify only
the structure / schema needed and it can be queried by our XQuery
extension which supports Allen’s relations. Notice that the TEI consortium has
proposed guidelines for implementing feature structures in XML (http://www.tei-c.org/Guidelines/P5/)
however, we have decided not to encode TFS this way because type hierarchies and
inheritance are not easily and directly represented and no querying support
has be defined. This engine, from TFS to XML data, based on formalisms independent
from linguistic coding languages and tools is an element of answer to
the question of interoperability.
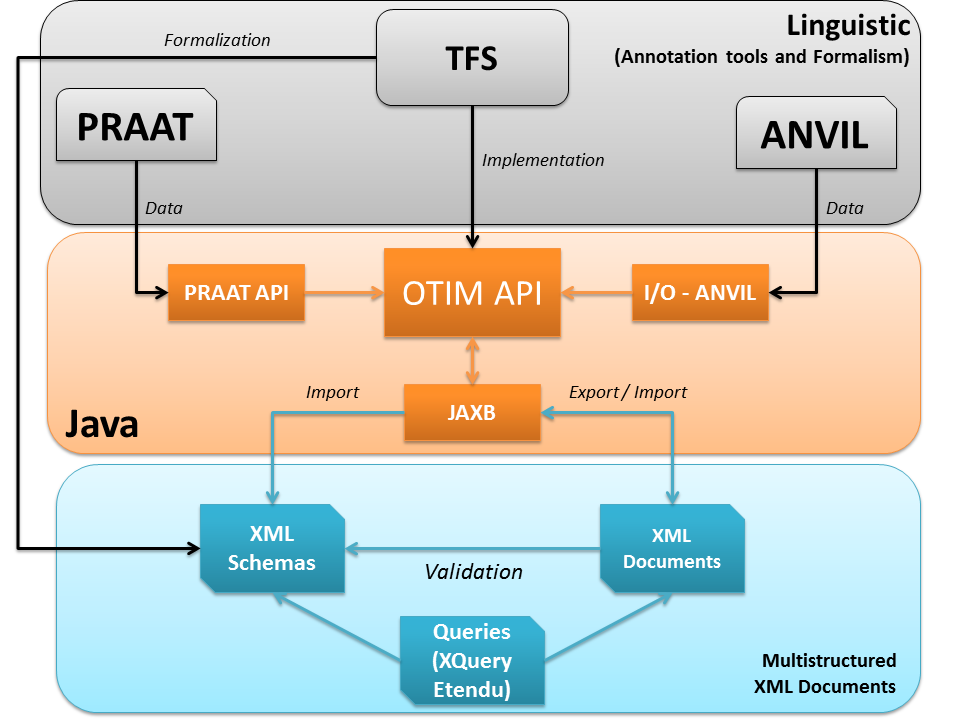
Figure 2: The OTIM Framework
The OTIM project applicative framework.
Figure 2 shows the functional architecture of our XML engine. It is composed of three parts:
Linguistics tools and formalisms chosen by linguists in the OTIM project,
An XML information system dedicated to the representation and querying of XML annotated
multimodal corpus,
A Java API that interfaces with both XML information system and linguistic specific
annotation tools.
Our approach guarantees that no information is lost when translating one format
into the target formalism. However, the Java / XML framework does not provide
linguists with a visual representation equivalent to the graphical representation
of TFS. Therefore, we have chosen to make a preliminary work within the representation
process
that leads to XML / Java. This work is the representations of TFS by means of UML
diagrams. This representation has two advantages: first it is standard, secondly there
is many
friendly and ergonomic tools that enable to build UML diagrams like Omondo (http://www.omondo.com/) or Poseidon (http://www.gentleware.com/).
UML Representation
As we have already said, TEI consortium proposes guidelines for implementing TFS in
XML (http://www.tei-c.org/Guidelines/P5/). However, OTIM consortium has decided
not to encode TFS this way for several reasons [Blache 2010]. First,
there is a need of representation for type hierarchies and inheritance. Secondly,
it is not realistic, or even possible, to encode all information by means of a TFS,
that rapidly becomes huge and intractable. This last argument is important in
the perspective of interoperability: annotation tools mainly focus on properties annotation
(the
encoding of object characteristics). Only some of them propose solution for constituency
representation (e.g. in terms of primary/secondary tracks). None implement typing
machinery.
We think then preferable a decentralized representation in which objects are represented
separately, their organization in hierarchy being encoded independently from their
properties.
Such an encoding offers the advantage to be close to the traditional way of encoding
annotations without losing the richness of TFS representation.
OTIM UML representation relies on two different views. Static one describes the static
structure in terms of objects, attributes, operations and relationships. This view
includes class diagrams. Dynamic view emphasizes the dynamic behavior of a
system. One of its advantages is that the language includes a set of graphical notation
techniques to create and share intuitive visual models. We can represent a TFS
description by a set of UML class diagrams by means of the following mapping:
to each complex TFS corresponds a class,
to each TFS atomic attribute corresponds a class attribute,
the inheritance relationship defined on the TFS is represented by an inheritance relationship
between classes,
the constituency relationships between TFS are represented by aggregation relationships
between classes,
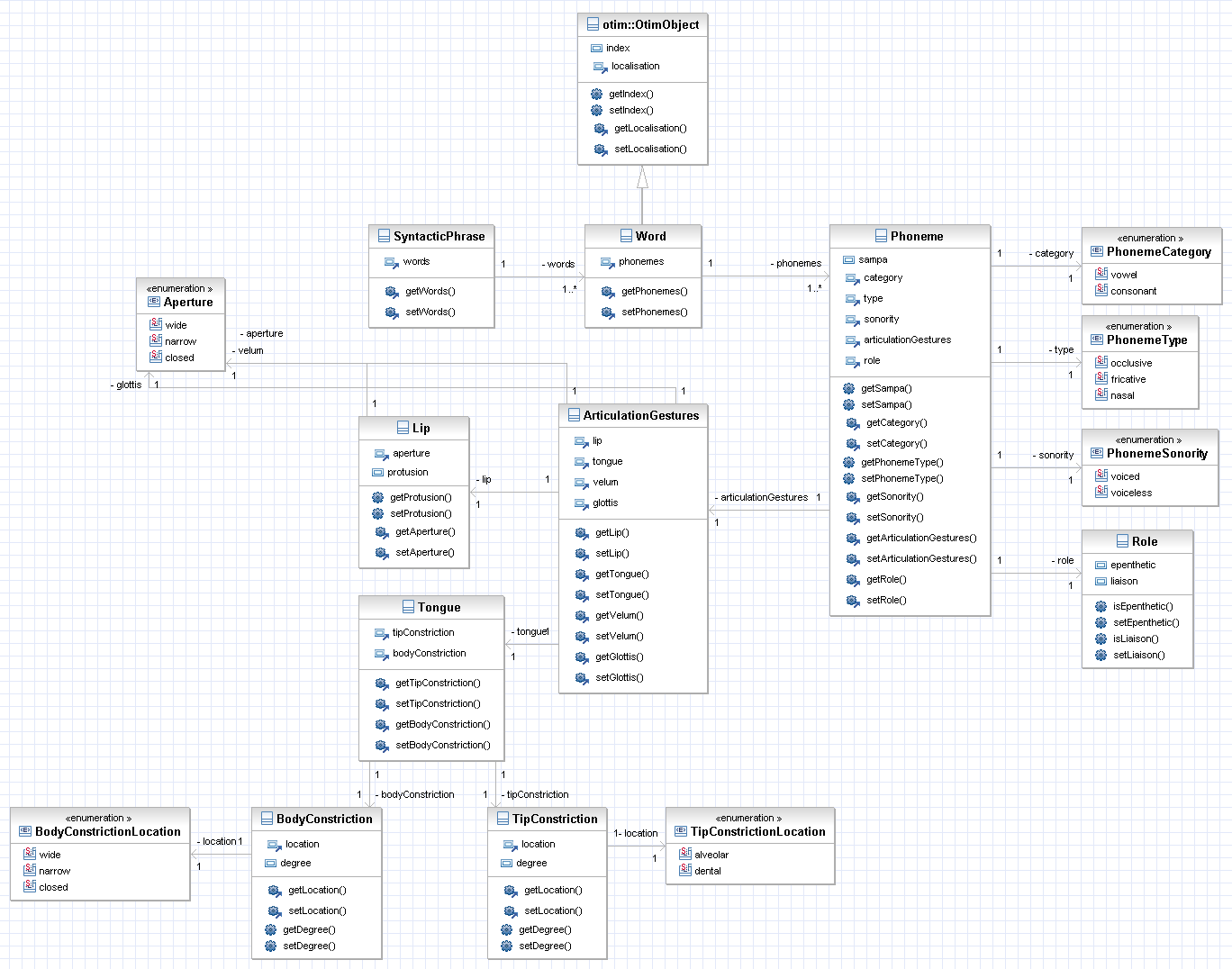
Figure 3: The phonetics domain
UML representation of phonetics domain.
Figure 3 shows the UML representation of phonetics and prosody domains. This graphical representation
provides a global standard view of the two domains and a suitable way for experts
to share
their knowledge.
XML / Java representation
From TFS to XSchema
XML representation of the knowledge and data within the OTIM framework relies on XSchema.
We generate an XSchema for each linguistic domain
(for example phonetics and prosody). Data are then represented in different documents
validated by the associated XSchemas. This method is motivated
by two important points already said:
this representation provides a high level of modularity for applicative requirements
and enables to modify only the structure / schema needed
recents works on multistructured documents open a way for dynamically linking and
aggregating various documents with different structure [Bruno 2006].
Within such a framework, it is possible to deal with a TFS-like XML representation
and to process data as standard XML documents.
For the sake of simplicity, we call OTIM XML our set of XML schemas constructed from
TFS. From a linguistic point of view, this set can be seen as the third component mentioned as a perspective
in [Schmidt et al. 2009]. This component, besides a basic encoding of data exportable into linguistic standard
AIF (Atlas Interchange Format)
[1], encodes every information concerning the organization as well as the constraints
on the structures. In the same way, as TFS are used as a tree description language
in theories such as HPSG (Head-Driven Phrase Structure Grammar, http://hpsg.stanford.edu/), the
XML schema generated from our TFS representation also plays the same role with
respect to the XML annotation data file. On the one hand, basic data can be encoded
with AIF, on the other hand, the
XML schema encodes all higher level information. Both components (basic data +
structural constraints) guarantee against information lost that otherwise occurs when
translating from one coding
format to another (for example from Anvil to Praat).
The creation of the XSchema from the linguistic knowledge is done from the TFS
or the UML representation if it is available. The first step consists in representing
all the information available within TFS. Each feature of a TFS appears in the
associated XSchema:
feature types encoding atomic type are represented with a simple type (integer, string,
...),
composite feature types are represented with complex types.
From type definitions, a feature is represented by an XML element. The two relations
of the TFS formalism (hierarchy and constituency) are represented respectively by
type
hierarchy and element aggregation. This representation guarantees that every information
described within OTIM XML formalism can be represented by XML documents.
Appendix A shows the complete XSchema of the prosodic domain. It shows all required components
for annotating the prosody of a
dialog within the OTIM project.
The choice of constructing one XSchema by linguistic domain is motivated by two
reasons. The OTIM project crosses several domains but a significant part of the data
processing is
made within each domain. Independence between schemas implies that expert only
has to work with XML documents containing the needed information. Moreover, as the
knowledge
on the domains evolves, a modular approach of the formal representation enables
to be more reactive and efficient for updating or revising the XSchemas according
to the
TFS updating.
From raw annotations to XML documents
XSchemas enable to represent the knowledge of the linguistic domains and to describe
the complex structure of data but linguists work with specific tools (like PRAAT or
ELAN) that provide
data as raw text files or specific XML documents that are not valid with our
schemas. Generating valid OTIM XML documents relies on a transformation from the outputs
of linguistic tools to
the OTIM XML representation.
Documents generation relies on the expression of the link between the data present
within the annotation tool outputs and the value of the elements of the OTIM XML documents.
This link is called Annotation Scheme and describes what kind of information is contained within raw annotation files and
what element is attached to within the
OTIM XML document. The annotation scheme also describes good practices to experts
for a consistent and repeatable annotation. The construction of a set of valid XML
documents is made by processing
the raw annotation files with the annotation scheme.
A Java framework for managing linguistic data
The OTIM project aims to fully annotate an 8 hours long corpus of recorded dialog.
The raw annotation outputs from linguists' specific tools have to be processed in
an efficient way
with respect to the OTIM XML description proposed. As linguists are very familiar
with their annotation tools (PRAAT, ANVIL, ...), it was not an option to provide new
tools from scratch
to directly make annotations within OTIM XML representation. Moreover, the diversity
of the tools would make difficult to provide and maintain extensions for them in order
to conform with
the OTIM XML. A solution for providing data processing capability that can deal
with both raw annotation files and OTIM XML document is an applicative framework composed
of specific modules.
We made the choice of developing a Java framework for OTIM that is composed of
two main parts (see Figure 2):
an implementation of the OTIM XSchemas within Object paradigm,
a set of modules that can interface with both raw annotation files and XML documents.
The first part of the framework is distributed as OTIM API and enables to deal with linguistic annotations with respect to OTIM XSchemas
(and also TFS). The link between XML schemas and Java implementation is guaranteed
by using the Java Architecture For XML Binding (JAXB)
[2]. This technology provides method for automatically generating Java classes from a
set of XSchemas.
Using JAXB makes implicit and always consistent the link between XSchemas and
their Java representation. When a schema is modified, the associated Java classes
are automatically regenerated.
In most case, a minor change within XSchemas only involves an automatic update
of the Java classes (changing an element name, changing a value, ...). When the changes
are important:
the structure of an XSchema or the annotation scheme are modified, the update
of the Java classes need to be manually performed as implementation can be heavily
modified. This can be seen as a limit but this
kind of changes are rare in a standardidation context.
The second part of the framework is a set of I/O modules that provide data exchange
capabilities between OTIM XML documents and raw annotations files. The most important
work of these
modules is to generate OTIM XML documents from raw annotations. This work is done
by parsing annotations and interpreting them against the annotation scheme. Another
important need is to reinsert
annotations that are expressed within OTIM XML format into a specific annotation
tool. The I/O modules enable to export from XML documents to PRAAT or ANVIL tools
and so, linguists can see
annotations performed by other teams on other domains within their own tools. This
capability can be seen as a partial response to interoperability between different
annotation tools and enable to
make a full pipeline from the annotation step to information system.
Querying and managing annotations in XML
The OTIM project aims to provide a fully annotated corpus represented in XML which
can be queried by the standard XQuery language. Annotations can be used in various
ways: simple viewing, domain crossing or reinsertion within standard tools.
Every need of access to annotations relies on a query on the corpus. We first present
general queries on the corpus and then the OTIM specific queries related to time and
temporal relations between
annotations. These last queries need an extention of XQuery with temporal capabilities.
General queries
Queries are classified into two groups: those involving only a single domain and
those taking into account several domains. In addition, for each group we distinguish
between filtering queries and queries
requiring the construction of new XML documents.
Filtering queries enables to extract a subset of data in the corpus. Filtering on
a single domain produces a subset of the involved OTIM XML documents.
For example, the following query filters the phonemes from the phonetic annotations
(described within the document phonetics.xml) by getting only those
that are tagged with the label "A":
for $phoneme in fn:doc("phonetics.xml")/SyntacticPhrase/words/word/phonemes/phoneme[@label="A"]
return $phoneme
Such a quite simple query is very important for linguists as it enables to target
only annotations with specific characteristics. One another example of query is the
filtering of phonemes according to their
temporal anchoring. The following query extracts each phoneme that verifies a condition
on its temporal bounds:
for $phoneme in fn:doc("phonetics.xml")/SyntacticPhrase/words/word/phonemes/phoneme
where ($phoneme/TimeInterval/start/@time > 250) and ($phoneme/TimeInterval/end/@time < 500)
return $phoneme
Filtered fragments can be reorganised in the return clause specifying the structure of the result to match linguistic specific needs.
For example, the following query builds an empty element
A (searched label) for each filtered phoneme computing its duration:
for $phoneme in fn:doc("phonetics.xml")/SyntacticPhrase/words/word/phonemes/phoneme
where ($phoneme/TimeInterval/start/@time > 250) and ($phoneme/TimeInterval/end/@time < 500)
return <A duration='{$phoneme/TimeInterval/end/@time - $phoneme/TimeInterval/start/@time}'/>
Finally, the following query shows an example of concurent querying based on phonetics
and prosody domains. For each accentual phrase (ap) with at least 6 syllables the query builds an
element phoneme which is the first phoneme of the phrase as their share same start
time (see inner where clause).
for $ap in fn:doc("prosody-IP_AP.xml")/TurnConversationalUnit/phrases/ip/constituents/ap
where count($ap/syllables/syllable) > 6
return
<phoneme id='{$ap/@id}'>{$ap/label}
{for $phoneme in fn:doc("phonemes.xml")/phonemes/phoneme
where $phoneme/TimeInterval/start/@time = $ap/TimeInterval/start/@time return $phoneme}
</phoneme>
Time related queries
Among the queries shown above, some take into account the notion of time. For a corpus
of annotations aligned with a signal such as video, time is indeed the dimension with
which
the studied objects are related. However, even if the time can be taken in account
in an absolute way without extending XQuery, the use of temporal relation (such as
relations described
within Allen algebra) cannot be expressed. A relative expression of time position
(before, after, during, ...) is a critical need when linguists process the corpus
for determining some
complex object (before,
meets, overlaps, starts, during,
finishes and equal and symetrics).
We have extended XQuery by adding functions that implement Allen's relations within
the OTIM XML representation. By inheritance, every object description contains the
following structure that enables
temporal anchoring:
Allen's function are binaries boolean functions that take in parameter a TimeInterval or a
TimePoint XML fragment and that return true if the given relation is verified or false otherwise.
Extending XQuery with specific time functions for OTIM XML representation is a solution
that satisfies linguists need for expressiveness. However, due to TFS initial representation,
OTIM XML
representation is not optimized for processing queries that are significantly based
on time. Their use cannot be made on an entire corpus. Among the possible solutions
to solve this problem, an explicit representation of time relationships in separate
XML documents or an ontological approach (OWL) can be considered.
Implementation
The OTIM framework is implemented within a Java / XML framework. The JAXB technology
provides a strong and consistent link between XML Schema and Java representations.
The XML management and querying is
hosted within one eXist (http://exist.sourceforge.net/) server for web application or within an embedded eXist module for a standalone utilization.
At this time, 15 minutes of the corpus
have been annotated for 4 domains (phonetics, prosody, syntax, disfluency). The size
of an XML document representing the 15 minutes can vary from 150 up to 500 Mo.
Conclusion
In this paper, our intention was to describe an XML engine dedicated to the representation
and the concurrent querying of multimodal linguistic
annotations implying to analyze and to find correlations between annotated linguistic
domains.
From the signal and the signal transcription of a conversational speech between
two persons, experts annotate data according to different linguistics domains
like prosody, phonetics, morpho-syntax, discourse or gesture/posture. From the
TFS provided by linguists that describe the knowledge of the studied domains,
from legacy data and annotations, we automatically build an XML corpus which can
be queried by means of an extension of XQuery, in a concurrent way. A java framework
has been provided
and enables to interface with both linguistic tools and OTIM XML information system.
With this framework, the problem of the interoperability
is solved for all the involved tools (PRAAT, ANVIL, ELAN) and domains within the
OTIM project. Moreover, our proposal is based on XML standards.
Nevertheless, we can notice that our XML solution cannot capture the semantics
of linguistic knowledge. Moreover, TFS expressivity is limited, for example for temporal
relations. Object anchoring
is absolute: interval boundaries are represented by the features start and end, with temporal value (an object can also be situated
by means of a point). It would be useful to have a relative anchoring. Another
limit is due to the underlying model of TFS which is a Directed Acyclic Graph (DAG).
When linguists need to annotate
co-references or disfluencies which are organized around objects, it would be
useful to have an object anchoring which is conflicting with the acyclic graph.
We currently work to propose a knowledge representation formalism which be an alternative
to TFS: an ontological approach based on Description Logics [Baader et al. 2003] (DL)
and on semantic web technologies for the development of a linguistic Knowledge-based
Information System. We have already defined a linguistic ontology from the TFS provided
by linguists for prosody, phonetics, lexical and disfluency domains. An applicative
framework is under development, it is based on semantic web proposals such as OWL
DL
(Ontology Web Language5) for the representation of this ontology and SPARQL [Prud’hommeaux 2007] the querying language of semantic web for its manipulation.
[Bruno 2007b]
Bruno E., Calabretto S., Murisasco E.
Documents textuels multistructurés : un état de l’art, Revue en Sciences du Traitement
de l'Information
in I3 (Information - Interaction – Intelligence) , Vol. 7 (1).
2007
[Bruno 2007]
Bruno, E. and Murisasco, E.
An xml environment for multistructured textual documents.
in Proceedings of the Second International Conference on Digital Information Management
(ICDIM’07), pages 230–235.
Lyon, France, October 2007.
[Bruno 2006]
Bruno, E. and Murisasco, E.
Describing and querying hierarchical structures defined over the same textual data
in Proceedings of the ACM Symposium on Document Engineering (DocEng 2006), pages 147–154.
Amsterdam, The Netherlands, October 2006
[Le Maitre 2006]
Le Maitre, J.
Describing multistructured xml documents by means of delay nodes.
in Proceedings of the 2006 ACM symposium on Document engineering (DocEng ’06), pp 155–164.
Amsterdam, The Netherlands, oct 2006.
[Baader et al. 2003]
Baader F., Calvanese D., McGuinness D.L., Nardi D., P. F., Patel-Schneider P.F.
The Description Logic Handbook: Theory, Implementation, Applications.
Cambridge University Press, Cambridge, UK, 2003. ISBN 0-521-78176-0
[Portier 2010]
Portier, P.-E. and Calabretto S.
Multi-structured documents and the emergence of annotations vocabularies.
in Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies,
vol. 5.
Montréal, Canada, August 3 - 6, 2010. doi:https://doi.org/10.4242/BalisageVol5.Portier01.
[Bird 2001]
Bird S. and Liberman M.
A formal framework for linguistic annotation.
in Speech Communication 33(1,2), pages 23–60.
september 2001.
[Bird et al. 2000]
Bird, S., Day, D., Garofolo, J., Henderson, J., Laprun, C., and Liberman, M.
ATLAS: A flexible and extensible architecture for linguistic annotation
2000
[Dekhtyar 2005]
Dekhtyar A. and Iacob I.E.
A framework for management of concurrent xml markup.
in Data and Knowledge Engineering, 52(2):185–208,
2005
[Chatti 2007]
Chatti, N., Kaouk, S., Calabretto, S. and Pinon J.M..
Multix: an xml based formalism to encode multi-structured documents.
in Proceedings of Extreme Markup Languages Conference.
August 6-10 2007.
[Djemal 2008]
Djemal K., Soule-Dupuy and Valles-Parlangeau, C.
Modeling and exploitation of multistructured documents.
in Proceedings of the IEEE 3rd International Conference on Information and Communication
Technologies: From Theory to Applications (ICTTA’ 08).
Damascus, Syria, April 2008.
[Goldfarb 1990]
Goldfarb, C.-F. and Rubinsky Y.
The SGML handbook.Clarendon Press,
Oxford, 1990.
[Hilbert 2005]
Hilbert M., Schonefeld O. and Witt A.
Making concur work.
in Proceedings of The Extreme Markup Languages Conference.
August 2005.
[DeRose 2004]
DeRose, S.
Markup overlap : a review and a horse.
in In Proceedings of The Extreme markup language Conference.
2004
[Jagadish et al. 2004]
Jagadish, H.-V., Lakshmanan, L.-V.-S., Scannapieco, M., Srivastava, D. and Wiwatwattana
N.
Colorful XML: One Hierarchy Isn’t Enough.
in Proceedings of The International Conference on Management of Data (SIGMOD’04), pages
251–262.
2004
[TEI P4]
Sperberg-McQueen, C.-M. and Burnard, L.
Tei p4 guidelines for electronic text encoding and interchange.
2001
[Sperberg-McQueen 2000]
Sperberg-McQueen, C-M and Huitfeldt, C.
Goddag: A data structure for overlapping hierarchies.
in Proceedings of The Principles of Digital Document and electronic publishing (DDEP/PODDP’00),
pages 139–160.
2000
[Tennison 2002]
Tennison, J. and Wendell, P.
Layered markup and annotation language (lmnl)
in Proceedongs of The Extreme Markup Languages Conference.
2002
[Witt 2004]
Witt, A.
Multiple hierarchies : news aspects of an old solution.
in Proceedings of The Extreme markup language Conference.
2004
[Blache 2010b]
Blache, P., Bertrand, R., Bigi, B., Bruno, E., Cela, E., Esperrer, R., Ferre, G.,
Guardiola, M., Hirst, D., Magro, E., JC, M., C, M., Ma, M., Murisasco, E., I, N.,
P, N., B, P., Laurent, P., J, P.-V., Seinturier, J., N, T., Marion, T., and Stephane,
R.
Multimodal annotation of conversational data.
in In Proceedings of the fourth linguistic annotation workwhop (LAW), pages 186–191.
Assocation for computational Lunguistics (ACL). 2010
[Copestake 2003]
Copestake, A.
Definitions of Typed Feature Structures.
in Collaborative Language Engineering: A Case Study in Efficient Grammar-based Processing
CSLI Publications, Ventura Hall, Stanford University, Stanford, CA 94305-4115, 2003.
[Schmidt et al. 2009] Schmidt, T., Duncan, S., Ehmer, O., Hoyt, J., Kipp, M., Loehr, D., Magnusson, M.,
Rose, T., and Sloetjes, H.
chapter An exchange format for multimodal annotations
in Multimodal corpora.
pages 207–221. Springer-Verlag, Berlin, Heidelberg, 2009
[Blache 2010] Blache, Philippe and Bigi, Brigitte and Prévot, Laurent and Rauzy, Stéphane and Seinturier,
JulienAnnotation schemes, annotation tools and the question of interoperability: from Typed
Feature Structures to XML Schemas
in Proceedings of the 2nd International Conférence on Global Interoperability for Language
Resources
(compiled under Act of Congress of 18-20 January, 2010). City University of Hong
Kong
http://www.yale.edu/lawweb/avalon/raleigh.htm.
[Carpenter 1992]
Carpenter, R. L.
The Logic of Typed Feature Structures.
in volume 32 of Cambridge Tracts in Theoretical Computer Science
Cambridge University Press, The Edinburgh Building, Shaftesbury Road, Cambridge
CB2 8RU, United Kingdom. 1992
Bruno E., Calabretto S., Murisasco E.
Documents textuels multistructurés : un état de l’art, Revue en Sciences du Traitement
de l'Information
in I3 (Information - Interaction – Intelligence) , Vol. 7 (1).
2007
Bruno, E. and Murisasco, E.
An xml environment for multistructured textual documents.
in Proceedings of the Second International Conference on Digital Information Management
(ICDIM’07), pages 230–235.
Lyon, France, October 2007.
Bruno, E. and Murisasco, E.
Describing and querying hierarchical structures defined over the same textual data
in Proceedings of the ACM Symposium on Document Engineering (DocEng 2006), pages 147–154.
Amsterdam, The Netherlands, October 2006
Le Maitre, J.
Describing multistructured xml documents by means of delay nodes.
in Proceedings of the 2006 ACM symposium on Document engineering (DocEng ’06), pp 155–164.
Amsterdam, The Netherlands, oct 2006.
Allen, J.Time and time again : The many ways represent time
in International Journal of Intelligent Systems
6(4):341–355, july 1991. doi:https://doi.org/10.1002/int.4550060403.
Baader F., Calvanese D., McGuinness D.L., Nardi D., P. F., Patel-Schneider P.F.
The Description Logic Handbook: Theory, Implementation, Applications.
Cambridge University Press, Cambridge, UK, 2003. ISBN 0-521-78176-0
Portier, P.-E. and Calabretto S.
Multi-structured documents and the emergence of annotations vocabularies.
in Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies,
vol. 5.
Montréal, Canada, August 3 - 6, 2010. doi:https://doi.org/10.4242/BalisageVol5.Portier01.
Bird, S., Day, D., Garofolo, J., Henderson, J., Laprun, C., and Liberman, M.
ATLAS: A flexible and extensible architecture for linguistic annotation
2000
Ide, N., Suderman, K.
GrAF: A Graph-based Format for Linguistic Annotations
in Proceedings of the Linguistic Annotation Workshop LAW'07.
2007. doi:https://doi.org/10.3115/1642059.1642060.
Chatti, N., Kaouk, S., Calabretto, S. and Pinon J.M..
Multix: an xml based formalism to encode multi-structured documents.
in Proceedings of Extreme Markup Languages Conference.
August 6-10 2007.
Djemal K., Soule-Dupuy and Valles-Parlangeau, C.
Modeling and exploitation of multistructured documents.
in Proceedings of the IEEE 3rd International Conference on Information and Communication
Technologies: From Theory to Applications (ICTTA’ 08).
Damascus, Syria, April 2008.
Jagadish, H.-V., Lakshmanan, L.-V.-S., Scannapieco, M., Srivastava, D. and Wiwatwattana
N.
Colorful XML: One Hierarchy Isn’t Enough.
in Proceedings of The International Conference on Management of Data (SIGMOD’04), pages
251–262.
2004
Sperberg-McQueen, C-M and Huitfeldt, C.
Goddag: A data structure for overlapping hierarchies.
in Proceedings of The Principles of Digital Document and electronic publishing (DDEP/PODDP’00),
pages 139–160.
2000
Blache, P., Bertrand, R., Bigi, B., Bruno, E., Cela, E., Esperrer, R., Ferre, G.,
Guardiola, M., Hirst, D., Magro, E., JC, M., C, M., Ma, M., Murisasco, E., I, N.,
P, N., B, P., Laurent, P., J, P.-V., Seinturier, J., N, T., Marion, T., and Stephane,
R.
Multimodal annotation of conversational data.
in In Proceedings of the fourth linguistic annotation workwhop (LAW), pages 186–191.
Assocation for computational Lunguistics (ACL). 2010
Copestake, A.
Definitions of Typed Feature Structures.
in Collaborative Language Engineering: A Case Study in Efficient Grammar-based Processing
CSLI Publications, Ventura Hall, Stanford University, Stanford, CA 94305-4115, 2003.
Schmidt, T., Duncan, S., Ehmer, O., Hoyt, J., Kipp, M., Loehr, D., Magnusson, M.,
Rose, T., and Sloetjes, H.
chapter An exchange format for multimodal annotations
in Multimodal corpora.
pages 207–221. Springer-Verlag, Berlin, Heidelberg, 2009
Sthrenberg, M. and Jettka, D.A toolkit for multidimensional markup - the development of sgf to xstandoff
in Proceedings of Balisage: The Markup Conference 2009
Assocation for computational Lunguistics(ACL), Balisage Series on Markup Technologies,
vol. 3.
http://www.xstandoff.net/. doi:https://doi.org/10.4242/BalisageVol3.Stuhrenberg01.
Blache, Philippe and Bigi, Brigitte and Prévot, Laurent and Rauzy, Stéphane and Seinturier,
JulienAnnotation schemes, annotation tools and the question of interoperability: from Typed
Feature Structures to XML Schemas
in Proceedings of the 2nd International Conférence on Global Interoperability for Language
Resources
(compiled under Act of Congress of 18-20 January, 2010). City University of Hong
Kong
http://www.yale.edu/lawweb/avalon/raleigh.htm.
Carpenter, R. L.
The Logic of Typed Feature Structures.
in volume 32 of Cambridge Tracts in Theoretical Computer Science
Cambridge University Press, The Edinburgh Building, Shaftesbury Road, Cambridge
CB2 8RU, United Kingdom. 1992
Author's keywords for this paper:
Knowledge Engineering; XML Information System; Application