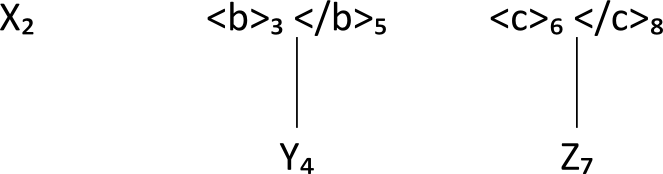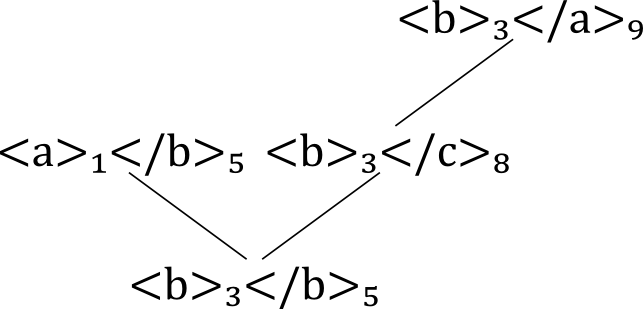Johnsen, Lars G., and Claus Huitfeldt. “TagAl: A tag algebra for document markup.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Johnsen01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
This paper takes its point of departure in an overview of the overlap problem, and
of
proposed solutions to that problem. We then look at some analogies between bracketed
markup
notations and rules for well-formedness and structuring of simple parenthetical expressions.
We propose a method for building lattices from marked up documents with and without
overlap,
and for generating, from these lattices, document models in the form of trees for
XML
documents, and in the form of GODDAGs for documents with overlap. It turns out that
one and
the same method can be used for generating both kinds of models, and we argue that
lattices
can also be used to implement well-formedness constraints for both kinds of documents.
Finally, we discuss and compare some of the algebraic features of the document models,
and
the relations between them.
Digital documents: Representational forms and operations
When computers were first used for purposes of text processing, documents were typically
represented as linear sequences of characters. This format lends reasonable support
to basic
operations on documents, such as visual presentation, editing, retrieval, content
extraction,
linguistic and quantitative analysis, and various forms of transformation.
However, the objects of such operations are not always most naturally thought of,
or not
easily identified, in terms of character sequences. Some operations are performed
on
structural partitions of documents such as sections, paragraphs, or sentences. Objects
defined
in terms of their thematic, linguistic, rhetorical or other properties, such as names,
foreign
words, high-lighted phrases etc. may also be the target of operations to be performed.
Sometimes such objects can be identified at least indirectly in terms of properties
of
character sequences, but seldom reliably, [1] and often not at all.
Document markup can be seen as a response to these problems: when candidate objects
of
operations are explicitly marked, text processing applications are relieved of the
burden of
identifying them, and developers of such applications may concentrate on the operations
to be
performed rather than on the identification of the objects to be processed. Thus,
marked up
documents provide improved support for text processing, compared to documents without
markup.
Therefore, it is perhaps only natural that with the introduction of document markup,
the
number and kinds of document objects that became subject of interest for processing
increased.
Markup languages and tools were developed not only for general purpose document publication
and analysis, but also for more specialized purposes and document types.
For a number of reasons, the markup languages which became most widely used, and the
grammars which ultimately acquired the status of international standards for those
languages,
such as SGML and XML, [2] were based on context-free grammars. One obvious reason was that representations
based on context-free grammars were processable according to well known and computationally
efficient algorithms. Over the years a plethora of general as well as special-purpose
software
for XML document processing has become available.
Such markup languages invite an abstract view of document structure and content,
in which
the "artifacts" of markup in the document in its serial form are represented in a
more
conspicuous way. Many or most XML processors do not actually perform operations on
the
document in its serialized form, but only (or largely) on a model of the document,
usually in
the form of a labeled directed acyclic graph. The graph is constructed from the serialized
form of the document, and reserialized only for purposes of storage and exchange.
Since one
and the same graph may be represented in the form of more than one serialization,
focus tends
to be transferred on the graph (or, in XML terms, the document object model), rather
than the
serial form of the document.
The Overlap Problem
The coincidence of the two factors mentioned above (i.e. the increasing interest
in
marking up more and more aspects of documents, and the fact that available systems
were based
on context-free grammars) lead to a number of closely related problems which are now
commonly
referred to as "the overlap problem". [3] On the one hand, the obvious advantages of markup lead to interest in marking up
a
wide variety of aspects of document structure, often necessitating different segmentations
of
one and the same document. On the other hand, standard markup systems did not provide
a
straight-forward and natural way of representing such competing or conflicting segmentations.
[4] So although marked up documents provide better support for a broad range of
processing purposes than documents without markup, the introduction of markup also
lead to a
number of problems one did not have much means or motivation to identify or formulate
before
the introduction of markup.
The so-called overlap problem was identified fairly early, and the literature of proposed
solutions goes more than 30 years back in time. [5] The responses to the problem may be said to fall largely in four groups: 1)
Alternate linear forms, 2) Alternate document models, 3) Stand-off markup, and 4)
Transformation algorithms.
Alternate linear forms
Since the syntax of XML enforces a strict hierarchical nesting of XML elements, it
seems like a tempting solution simply to lift or soften this restriction. A large
number of
such proposals have been made.
The advantages of most of these proposals is that they provide what for human readers
seems like a more natural and easily readable linear representation of overlapping
elements
than is provided by alternative proposals adhering to XML syntax. They may also provide
better support for certain operations on overlapping elements. However, for the most
part it
is unclear how to perform anything like a full range of standard operations on their
markup
constructs, and there are unresolved issues of processability, expressive power etc.
Alternate document models
Some proposals provide alternatives to what is commonly perceived as the XML document
model, i.e. tree-shaped graphs like XDM or XML DOM, either in combination with or
independently of proposals for alternative linear forms.
Although these solutions in general provide better support for at least certain
operations on overlapping elements, the question of how to perform other standard
operations
is mostly unclear or not systematically addressed. For some of the proposals it is
also
unclear whether, or to what extent, it is possible to support roundtripping between
the
proposed document model and its form, or even what such roundtripping would amount
to. (This
is the case, for example, concerning the relation between Goddag and TexMecs.) Again,
there
are in general unresolved issues of processability, expressive power etc.
Stand-off markup
Quite early on, it was suggested that many or most of the problems related to overlap
can be seen as a result of the general limitations of embedded markup. [Raymond et al. 1992, Raymond et al. 1995] Thus, the idea
of separating the markup from the document to be marked up, in the form of so-called
"stand-off" markup has received considerable attention and adoption.
Stand-off markup does indeed provide potentially very strong expressive power and
might
seem to be the one sweeping solution to all problems related to overlap. And perhaps
it is. [6] We note, however, that standoff markup either has been used, or could be used,
in combination with any or all of the linear formats and document models referred
to above.
Thus, all the unclarities that pertain to those, and to the relationships between
them,
pertain also to stand-off markup.
Transformation algorithms
Since there is such a multitude of proposals for alternate linear forms and document
models, since they all have their pros and cons, and since no universal agreement
on a
unified solution seems to be forthcoming, it has been proposed that one should instead
try
to provide a common framework of algorithms for transformation between different linear
forms and/or document models. [7]
The advantages of this approach may be as obvious as its disadvantages: A major
advantage is that, to the extent that transformations may be performed without loss
of
information, it makes all the strengths of all of the solutions above available to
the
users. Major disadvantages are: First, for every alternate serial form and/or document
model
introduced, the number of required transformation algorithms increases exponentially.
Second
(and perhaps most importantly), there seems to be no established and agreed-upon way
of
deciding whether or not any given transformation algorithm introduces information
loss.
The idea of a tag algebra
There seems to be no consensus neither on whether the basic elements of marked up
documents are most suitably regarded as partitions of a character stream (tags, elements
etc.)
or nodes of a graph of some kind, nor on what the basic operations on these elements
are and
how they are to be defined. As long as these issues are not clear, it is hard to compare
and
evaluate the various approaches to the overlap problem.
Elementary algebra assumes that numbers are the same whether written in Arabic or
Roman
notation, or, for that matter, whether we use a decimal, a digital or a hexadecimal
numeral
system, and that the sum of two numbers is the same irrespective of which algorithm
we employ
to calculate it. Certainly, some notations may seem less intuitive than others, and
some
notations require the use of more complex algorithms than others in order to perform
certain
operations. However, while important enough, such issues have no bearing on the question
of
what the correct result of an operation is. There is one and only one answer to the
question
of what the sum of two numbers are, irrespective of which notation and algorithm one
might
choose to use in computing that sum.
Similarly, a tag algebra should be able to tell us whether two representations of
a
document marked up using different notations are representations of the same document
or not,
and what the result of adding or subtracting a specific element to or from that document
should be. In what follows, we hope to establish at common basis for the solution
of at least
the first of these problems. We believe this basis will also be useful for defining
operations
on marked up documents, although we do not get that far in this paper.
Bracketed notations and matching
In the rest of this paper, we will explore the relationship between markup without
overlap and markup with overlap by way of comparing XML to another, imaginary markup
language.
This other markup language, which we may call O-XML, is exactly like XML, except that
in O-XML
overlap is allowed. [8] So whereas nesting structures like
<a>...<b>...</b>...</a>
are well-formed in both
XML and O-XML, overlapping structures like
<a>...<b>...</a>...</b>
are ill-formed in XML,
but well-formed in O-XML. As we are concerned exclusively with element structure,
we ignore
all other features or mechanisms of XML such as attributes, entities, comments, declarations,
cdata sections, processing instructions, etc.
We may start with the observation that in XML all elements nest, while in documents
with
overlap not all of them do. [9] We may also observe that the element structure of XML documents can be deduced
without looking at the generic identifiers of end tags, [10] whereas in notations allowing overlap this information is essential. We might
summarize this by saying that in XML the start and end tags of nesting elements always
match,
whereas in other notations they do not always match.
But there is something puzzling about this way of putting the matter. Exactly what
do we
mean by the terms nesting, element, and match? We
observe that whereas there is no overlap in
<a>...<b>...</b>...</a>
and there is overlap in
<a>...<b>...</a>...</b>
the difference between
them disappears if we leave out the generic identifiers:
< >...< >...</ >...</ >
Our guess is that it
probably seems natural to most readers to assume that the element structure of the
last
example above is identical to the first, rather than the second. But is this necessarily
so,
and if so, why? Let us pursue the similarities between the nesting of start and end
tags and
the nesting of simple parentheses a bit further.
Consider any string consisting of left (i.e. start, or open) and right (i.e. end,
or
close) parentheses. One common assumption is that there should be a one to one correspondence
between left and right parentheses, so that they are equal in number. This ensures
that the
string ((())) is to be regarded as well-formed, while the string
((()) is not. Another common assumption is that for every left parenthesis there
is a succeeding right parenthesis. This ensures that the string )()( is not to be
regarded as well-formed. In the following, we will refer to these two assumptions
as "basic".
The two basic assumptions do not by themselves imply any specific answer to the question
which of the left parentheses correspond to which of the right parentheses in the
well-formed
cases. The intuitively most plausible (or common) reading of the string (()) may
be in accordance with a "nesting" convention, to the effect that the first left parenthesis
corresponds to the last right parenthesis. According to this convention, the structure
of the
expression ()(()) looks like this, where subscripts indicate correspondence:
(1 )1 (2
(3 )3 )2
However, nothing in the two basic assumptions as stated stops us from adopting
other conventions. We might imagine a "mirroring" convention, where the first left
parenthesis
corresponds to the first right, the second left parenthesis to the second right, and
so on. A
"mirroring" convention for the same expression may look like this:
(1 )1 (2
(3 )2 )3
(Note the "overlap" between parentheses subscripted 2 and
3 here. [11])
Other conventions may be imagined in which some parentheses are selected according
to
specific rules, while the rest follow some general scheme like nesting or mirroring.
[12]
Thus, the two basic assumptions concerning the well-formedness of parenthetical
expressions are compatible with alternate ways of assigning structure to those expressions.
This important fact is easy to overlook, because one common method of testing for
well-formedness, namely the use of rewrite grammars, also lends itself very easily
to the
assignment of a structure in accordance with the "nesting" convention above. The following
example will illustrate this.
A rewrite grammar for generating strings of parentheses which obey the two basic
assumptions may look like this:
Base step
P→()
Subordination step
P→(P)
Coordination step
P→PP
A string is well-formed, in accordance with the two basic assumptions, if and
only if it can be generated by this grammar, which generates strings like (),
()(()()) and ((()))[13]
As mentioned, this grammar may also be used in order to assign a structure to the
expressions in accordance with the "nesting" convention. This may be done by associating
with
each other the two parentheses that are generated together in each of the subordination
or
base steps. Selecting an index from the sequence number of rule application, the string
(()()) could be derived with indicated associations as follows, where each rule
selects a P in the string coming from the immediately preceding rule application,
and substitutes it with the right hand side of the →:
0th step, start symbol
P
1st step, subordination
(1 P )1
2nd step, coordination step
(1 P P )1
3rd step, base step
(1 (3 )3 P )1
4th step, base step
(1 (3 )3(4 )4 )1
After the fourth step, there are no non-terminals left in the expression, and
the process halts. As can be seen from the last line, the structure that has been
assigned to
the expression is in exact accordance with the "nesting" convention.
This confirms that rewrite grammars may be used for assigning structure as well as
for
checking well-formedness. However, one may very well use a rewrite grammar to check
for
well-formedness without using that same grammar for assigning
structure. Moreover, there are other ways both of checking well-formedness and of
assigning
structure than using rewrite grammars.
This should make clear that well-formedness is separate from structure. In the appendix
we
prove that well-formedness is preserved even when inserting randomly any left parenthesis,
succeeded by another randomly inserted right parenthesis, into a well-formed string.
We observe that the rule for matching of start and end tags in XML is identical to
what we
called a "nesting" convention for simple parenthetical expressions above. We also
observe that
this seems to be the "default" rule for matching of start and end tags in markup languages
which allow overlap, such as O-XML. In such languages, however, deviations from the
default
rule are allowed, and they are signaled by the selection of generic identifiers for
end tags.
This explains why, as we noted above, the element structure of XML documents can be
identified independently of information about the generic identifiers of start and
end tags,
whereas in O-XML this information is essential. In the following sections we will
exploit
these observations in order to look at alternate ways of describing the difference
between
nesting and overlap.
Document lattices
We believe that lattice theory [Grätser 1971] may usefully be
applied to the construction of document models from marked-up documents. Lattice theory,
like
graph theory, is a way of reasoning over ordering relations. The theory has two components,
one is a theory of order, the other of algebraic operations defined in terms of that
order. In
this section we will consider the order aspect, while algebraic operations will be
discussed
in the next section ("Algebraic characterization").
A lattice is a partially ordered set of objects, here referred to as nodes, which
will
provide the elements of document models. Not all nodes will find their way into a
document
model, only those that do may also be referred to as elements, in agreement with the
use of
this term in XML and XSLT. A key requirement for an ordered collection of nodes to
constitute
a lattice, is that there should be one unique largest and one unique smallest node
in the
collection. If there is only a largest (or smallest) node, it is what is called a
semi-lattice. [14] Examples of lattices so constructed abound. Any society ordered by social rank (or
constitutional order) is a semi-lattice, with e.g president or monarch at the top.
XML trees
are semi lattices, with a root node on the top and text nodes at the bottom.
We analyze the stream of characters making up a document morphologically into a series
of
typed objects consisting of start tags, end tags, and simples.[15] The terms "start tag" and "end tag" should require no further explanation. We will
used XML notation in specifying them.
The term "simples" refers to PCDATA. Informally, we might say that a simple is whatever
occurs between two tags. [16]
Empty elements are treated as a start tag followed by an end tag, without any intervening
simple.
We assume a linear order on the morphological constituents. This order is derived
directly
from the serialized form of the document.
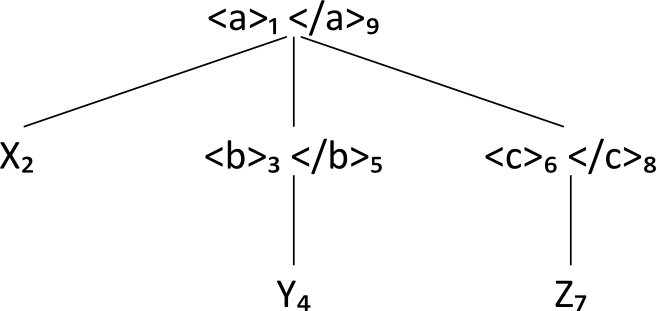
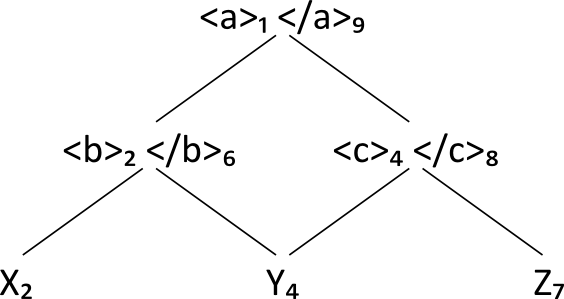
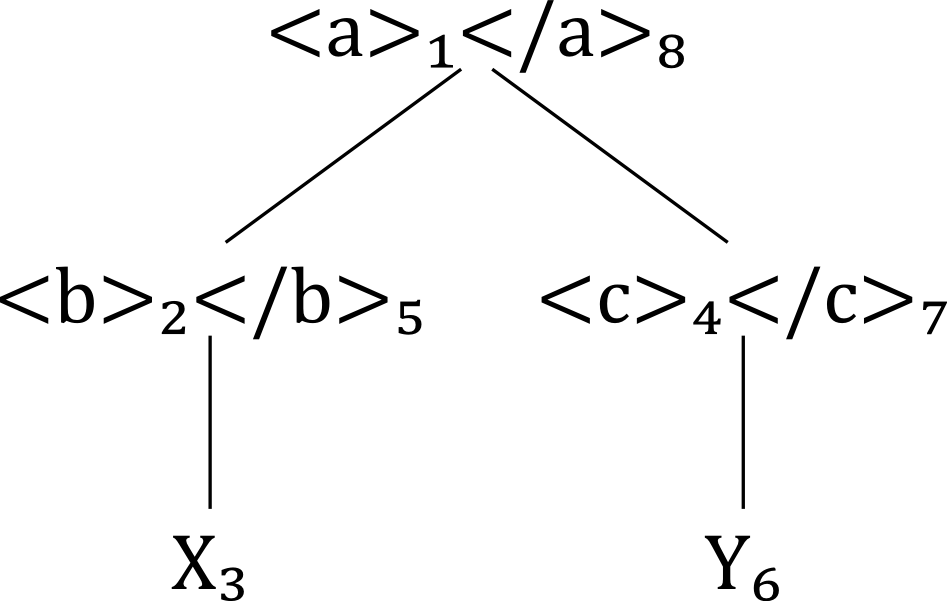
Consider the following XML sample document, D1:
Figure 1: Sample document 1 (D1)
<a>X<b>Y</b><c>Z</c></a>
According to the definitions just given, this document is a linearly ordered set
of
token objects, consisting of the following morphological constituents with the properties
indicated in this table, along with position indexes which, for our purpose, serve
as token
indexes for the types:
Table I
Constituent
<a>
X
<b>
Y
</b>
<c>
Z
</c>
</a>
Type
start
simple
start
simple
end
start
simple
end
end
N
1
2
3
4
5
6
7
8
9
For any document D, let S be the set of all start tag tokens and E the set of all
end tag
tokens in the document. Take the Cartesian product (all possible combinations) of
S and E, and
subtract all pairs for which the position of the end tag does not succeed the start
tag. This
object then represents all the possibilities for a start tag to match up with an end
tag. Add
the simples, and name the result L(D).
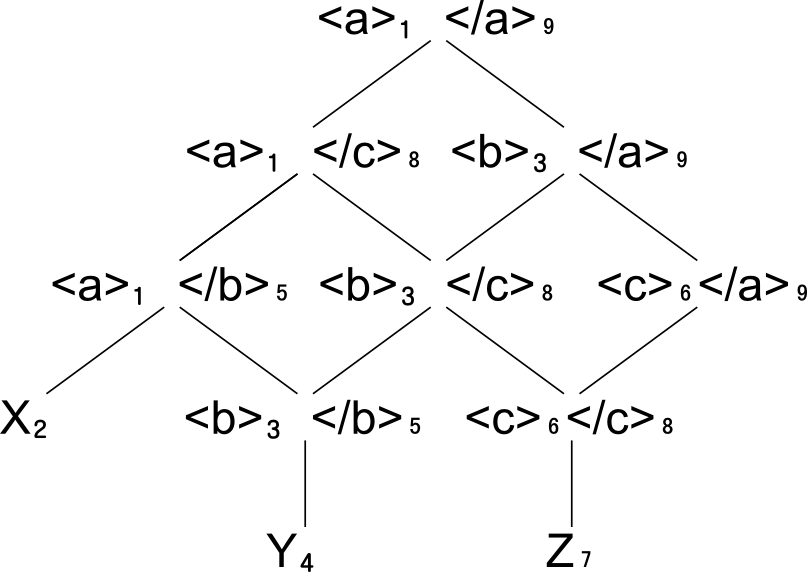
L(D1) now consists of the following nodes:
Table II
<a>
</b>
1
5
<a>
</c>
1
8
<a>
</a>
1
9
<b>
</b>
3
5
<b>
</c>
3
8
<b>
</a>
3
9
<c>
</c>
6
8
<c>
</a>
6
9
X
2
2
Y
4
4
Z
7
7
The reader may be puzzled by the fact that we include non-matching pairs of tags,
i.e.
nodes with start and end tags with different generic identifiers (GIs), among the
nodes of the
lattice. This is simply because the point of the exercise at this stage is to see
how far we
are able to build document models without taking the generic identifiers of tags into
consideration.
We define a hierarchical order relation between nodes in terms of
containment as follows: A node x is larger than a node y if and only if
the start position of x is smaller or equal to that of y, and the end position of
x is greater
or equal to that of y (viewed as strings the larger, or higher, node contains the
other). [17] This relation is asymmetric and transitive, so it is a partial order. [18]
With this order in place, L(D1) as given in the table above is a semi-lattice. It
has a top node, namely the pair consisting of the first start tag and last end tag
<a>₁</a>₉. It also has a set of minimal nodes, the
simples. Each pair of tag tokens is a node in the semilattice. Lattice structures
are
displayed using Hasse-diagrams (familiar from tree structures).
Nodes are positioned vertically according to their position in the hierarchy, with
the more inclusive nodes at the top and the less inclusive further down.
Nodes at the same vertical level are positioned from left to right according to
their linear order in the document.
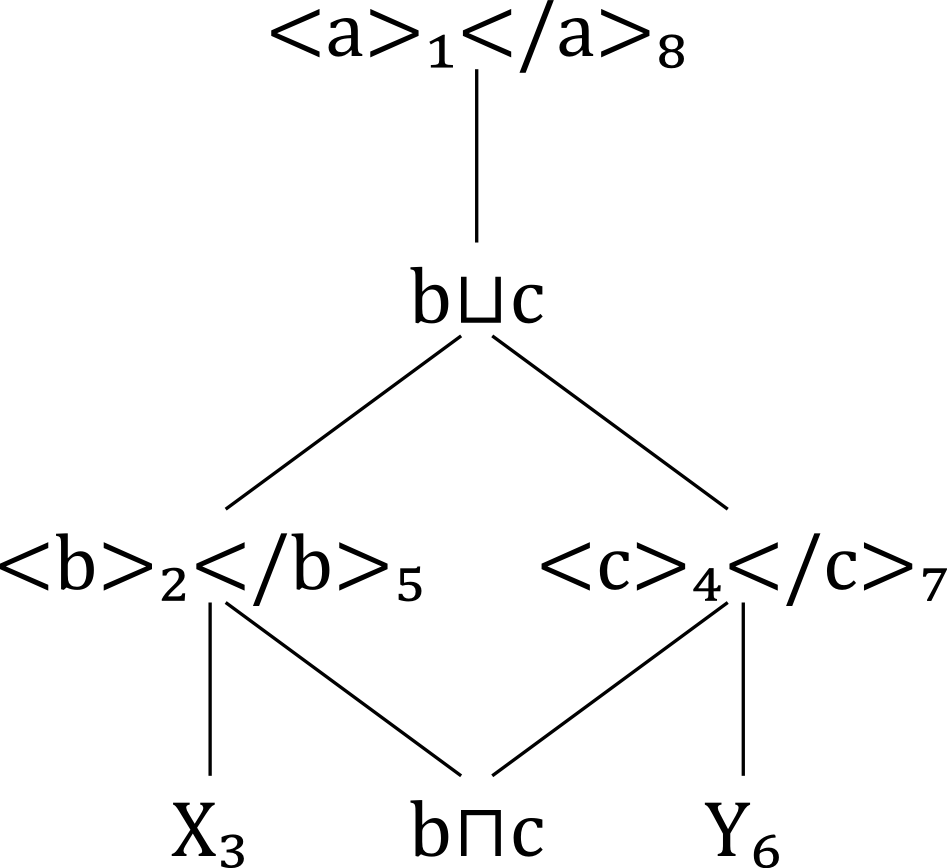
The lattice structure for L(D1):
Lattice L(D₁): Lattice L
As mentioned, the hierarchical order is transitive. According to the conventions of
diagrams like these, however, lines are drawn only between nodes immediately ordered.
Before we proceed, we need to define a relation we call relatives: Two nodes are relatives if they share a token start or end tag. This is
a reflexive, symmetric and non-transitive relation.
We also need to define a concept which has already been introduced implicitly, the
concept
of a minimal node: A node is minimal if it is lowest in the
hierarchy, i.e. if it contains no other node.
Building document models from lattices
Modeling documents without overlap
In what follows, we will show how what we may call a "standard" document model can
be
built on the basis of the lattice. In building this model, we will rely on distinguishing
between nodes only in terms of the morphology introduced earlier, i.e. on the basis
of which
start tags, end tags, or simple tokens they contain. In particular, we do not take the GIs of tags into consideration in the building of this
model.
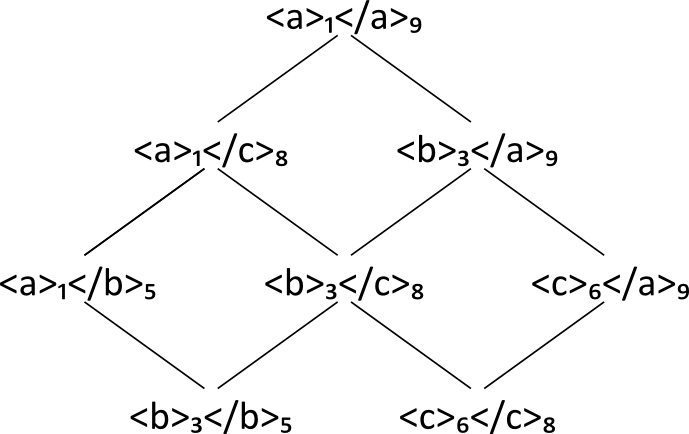
A document model for D1 from the lattice L(D1) is built through a
number of steps by selecting subsets from L(D1). Hence, the model building process
can be viewed as a filtering process. We start from the bottom of the lattice and
identify
all the lowest-level minimal nodes. We copy these minimal nodes, i.e. the nodes labeled
X₂, Y₄ and Z₇, from L and transfer them to a subset of L(D1)
which we call S0.
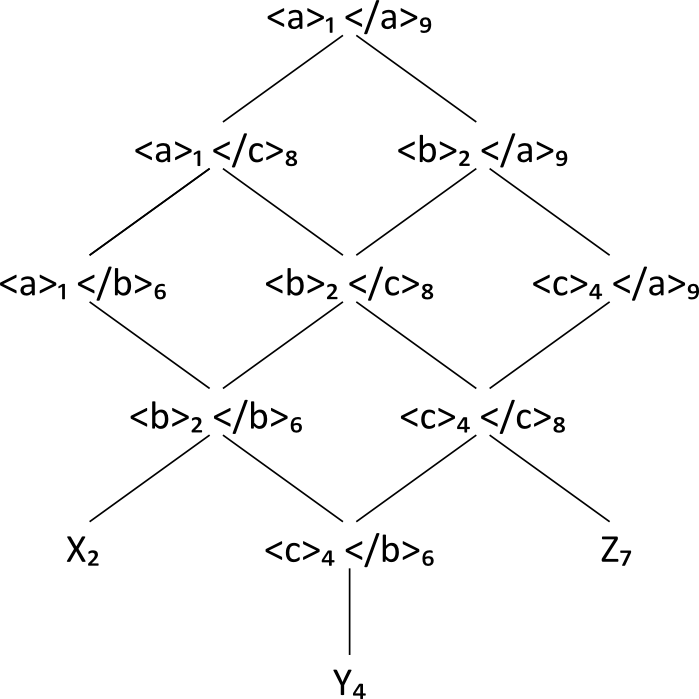
subset S₀: Subset S0
X₂ Y₄ Z₇
We then delete these minimal nodes from L(D1), [19] and call the result L0.
Lattice L0: Subset L0
We repeat the process of selecting minimal nodes, now from L0,
and add them to S0, naming the result S1. In
this case the minimal nodes are those labeled <b>₃</b>₅ and
<c>₆</c>₈. S1 inherits the order from L, and looks like
this:
Lattice S1: Subset S1
Next, we delete these minimal nodes, as well as all their
relatives, from L0, and call the result
L1.
Removal of the relatives assures that a tag can only enter into a relationship once.
As
soon as a node is selected for the model, neither the start nor the end tag of that
node can
enter into another node of the model. The relatives of <b>₃</b>₅
in L(D1) are the following nodes
As L1 only contains the single node
<a>₁</a>₉ a repetition of the step above, which copies this
minimal node to S1 resulting in S2, will
terminate the process. [21] There are now no more nodes to select, and the process stops with the following
candidate model M of D1:
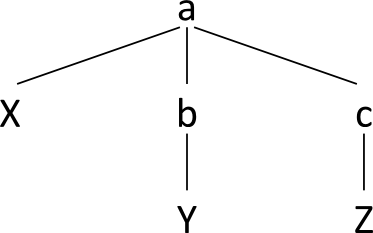
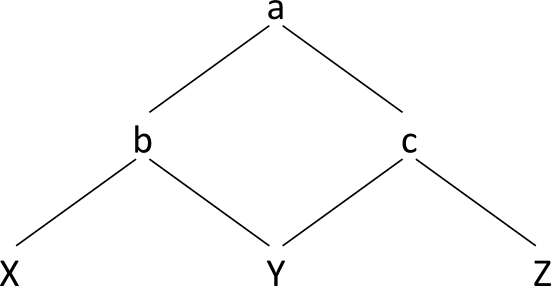
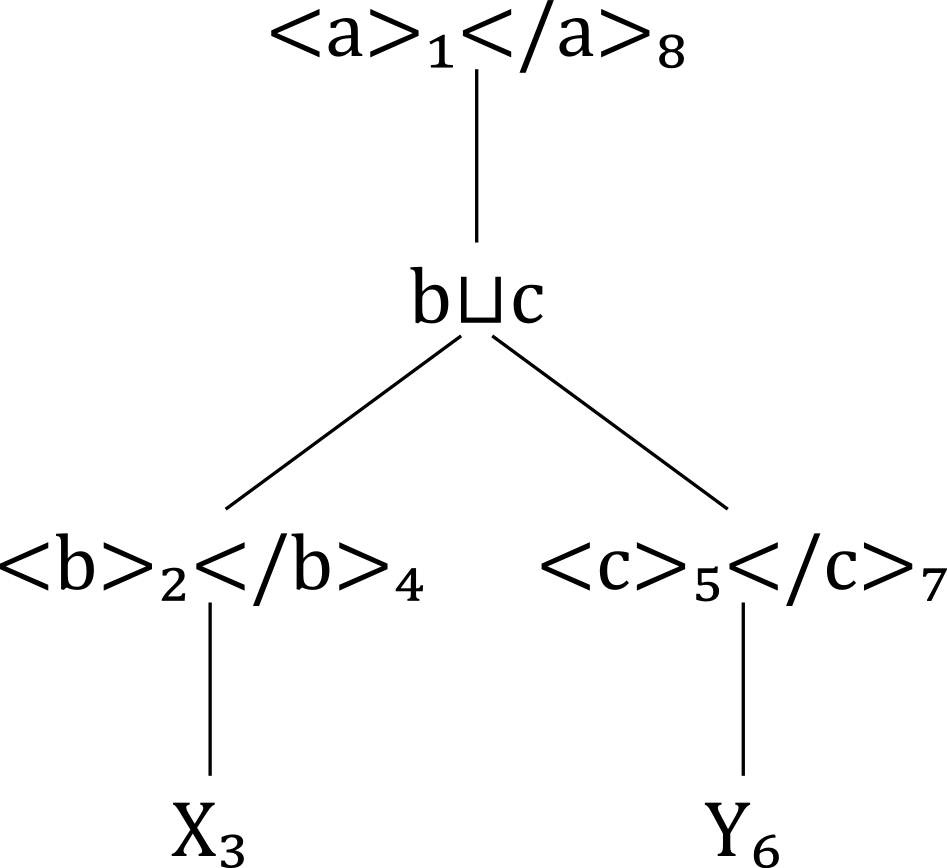
Lattice D2: subset S2=M(D1)
What we find in S2 is, mutatis mutandis, identical to the
"standard" XML document tree for the document we started with:
Lattice D3: Standard document model of D1
While GIs have been left out of consideration during the building, the candidate
model
will also be subjected to a well-formedness check: For each node in the model, the
GI of the start tag must be identical to the GI of the end tag.. For this
model, this is the case.
We conclude that with the method described here, lattices can be used to generate
"standard" models of XML documents in the form of conventional XML document trees.
Recall
that we may also refer to nodes that are members of the model as elements. The claim
that these constitue trees will be
substantiated below, where we will show that the model building procedure indeed
guarantees production of tree structures only.
Modeling documents with overlap
In this section, we will show that lattices can also be used in order to generate
models
of O-XML documents in the form of GODDAGs [Sperberg-McQueen and Huitfeldt 2000]. Consider the following O-XML sample document, D2:
Figure 10: Sample document 2 (D2)
<a><b>X<c>Y</b>Z</c></a>
The lattice L(D2) for this document is as follows (while we have used capital M
to designate document models for XML documents, we will use capital O to designate
document
models for O-XML models):
Lattice O: Lattice L(D2)
An application of the method described in the previous section to this lattice, yields
the following candidate model:
Lattice P: Candidate model of D2, M(D2)
It easy enough to see that something must have gone wrong here, as there is disagreement
between the GIs of the start and end tags for the nodes <b>₂</c>₈ and
<c>₄</b>₆. Now D2 is not a well-formed XML document, and we have used the
same procedure for generating M(D2) from D2 (which is a well-formed O-XML document
with overlap, but not a well-formed XML document) as we did for building M(D1) from
D1 (which is a well-formed XML document). The method will build document models for
well-formed as well as ill-formed documents. However, the ill-formedness of D2 will be
captured by the well-formedness condition introduced above.
In constructing O(D2), it suffices to introduce one single modification to the
procedure described in the previous section: Before performing any other operations
on
L(D2), we remove all nodes that have start and end tags with different GIs. Once
this rule is introduced, the application of the procedure produces the following candidate
model:
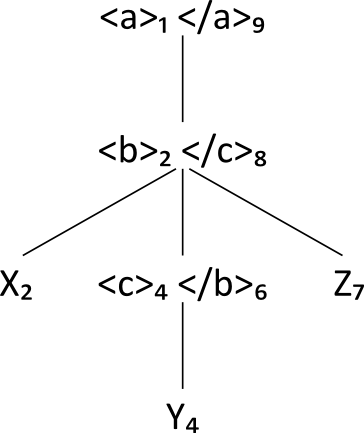
Lattice Q: Subset O(D2)
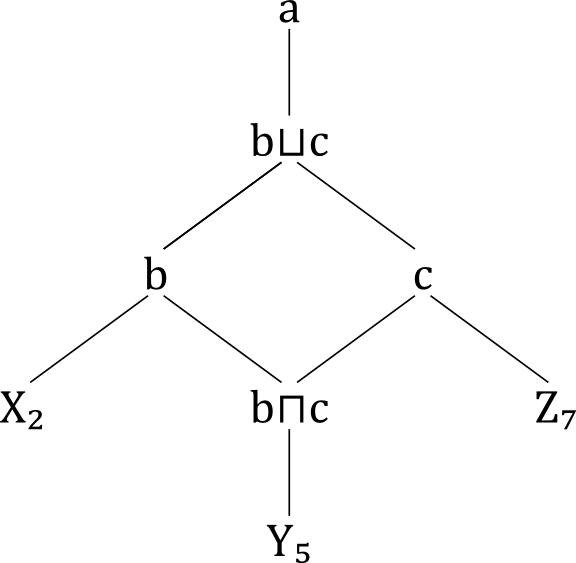
What we find here is, mutatis mutandis, identical to the GODDAG document model of
the
document:
Lattice R: GODDAG model of D2
We conclude that with the method described here, lattices can also be used for
generating document models of O-XML documents with overlap in the form of GODDAGs.
Since the
extra rule that we introduced in this section does not affect the result for XML documents,
one and the same method can be used for generating XML trees from XML documents and
GODDAGs
from O-XML documents. In other words, if D is a well-formed XML document M(D)=O(D).
However,
O(D) does not have any built-in well-formedness check.
Well-formedness
In the previous section we noticed, in passing, that of the proposed method for building
models from XML and O-XML documents, only M-models carry a well-formedness constraint.
By
introducing the rule that all nodes with different GIs on start and end tags should
be
deleted from the lattice, we effectively made sure that O(D) fulfills one well-formedness
constraint on documents. The difference between the M- and O-constructions is subtle:
The
M-construction will always produce trees, while the O-construction will not necessarily
produce trees. That issue is discussed in a subsequent section. The question to be
asked
here is: Can document lattices be used to capture the full set of well-formedness
constraints?
The model building in itself may work even if document D starts with and end tag or
ends
with a start tag. The process will just ignore them. If they are taken into account
as e.g.
simples, the requirement that L(D) is a lattice will rule them out, since they will
be
ordered on the same level as the widest start tag/end tag pair.
Another source of ill-formedness stems from unbalanced parenthesis. For M(D) this
is
taken care of by requiring that the top node of L(D) is also the top node of M(D).
The
reason for this is that the top node of L(D) will be the widest start/end tag pair.
If that
pair is not a node it will be because all the tags are used up, so to speak, before
it is
reached, as the model building moves inside out. Consider this ill-formed document
<a>₁<b>₂</b>₃
The top node for L(D) is <a>₁</b>₃
but this node will be removed from M(D) as a relative of the minimal
<b>₂</b>₃.
For O(D) this doesn't work since the removal process looks at tag GI, so if the document
is this
<a>₁<b>₂</a>₃
it is <b>₂</a>₃ which is left out. So we cannot
pin the requirement on the top node. However, we take it that for any document, including
O-XML,
that each tag should find a partner. Clearly <b>₂ in this document does
not have one.
We conjecture that, in addition to the already introduced rule of deleting nodes with
non-matching GIs on start and end tags, the following rule should suffice to capture
all
remaining well-formedness constraints on O-XML:
For any x.start or x.end in L(D) there must be an element E in M(D) or O(D) such
that
E.start=x.start or E.end=x.end.
This should make sure that every tag in L(D) finds a match in M(D) or O(D). Moreover,
ff
M(D) is constructed without first removing non macthin GIs, the GI agreement constraint
mentioned above will rule out any overlap.
If this conjecture is correct, it means that checking for well-formedness as well
as
asignment of document structure can be accomplished by using document lattices, and
without
the use of rewrite grammars.
Concluding remarks
We believe that the proposed use of document lattices for building document models
from
marked up documents provides a unified account of the assignment of structure to documents
with and without overlap. If our conjecture about well-formedness is correct, this
account
is also able to capture all well-formedness constraints on both types of markup.
The proposed method exploits the observations made about possible alternative
conventions for the assignment of structure to simple parenthetical expressions made
earlier. In building models for both kinds of documents, XML and O-XML, we rely on
the
"nesting" convention. The difference is that for XML documents, information about
the GIs of
tags may be ignored, whereas for O-XML documents this information is essential.
In introducing O-XML, we said that the only difference between XML and O-XML is that
O-XML allows overlapping elements, whereas XML does not. What about so-called self-overlap,
discontinuous elements and virtual elements, mechanisms which have been proposed in
for
example TexMECS, LMNL and other alternative markup languages? We believe that the
handling
of self-overlap with document lattices is just a question of adjusting the basic morphology.
Whether, or to what extent, document lattices can also be used for markup languages
with
discontinuous or virtual elements we simply do not know.
Algebraic characterization
Meet and join
The meet and join operations are a central part of lattice theory. In our context,
they
may serve to characterize the difference between the models for XML and O-XML, and
their
relationship to the lattice L.
The meet operation selects the largest node below its operands, while join selects
the
smallest above its operands. A requirement for lattices is that any two nodes have
a meet
and a join.
Since we are dealing not primarily with lattices in the strict sense, but mostly with
semi-lattices, we need to lighten this requirement for the meet operation: two nodes
are
allowed not to have any meet if they do not have any common nodes below them at all.
We indicate the vertical ordering of nodes in a lattice by using the symbols ⊒
and ⊑, so that the opening is faced towards the larger node. In other words,
x⊒y means that x is higher in the lattice than y, while x⊑y means that y
is higher than x.
We can now define the meet operation, indicated by the operator ⊓, and the
join operation, indicated by the operator ⊔, as follows:
meet:
x⊓y=z iff, for all u, whenever u⊑x and u⊑y then
u⊑z.
join:
x⊔y=z iff, for all u, whenever u⊒x and u⊒y then
u⊒z.
The meet and join operations can also be characterized in terms of tag configurations.
Let the start and end tag for a node x be written as x.start and x.end. The meet operation
can be captured by saying that whenever z=x⊓y then z.start=max(x.start, y.start)
and z.end=min(x.end,y.end). Similarly, the join operation can be captured by saying
that
whenever z=x⊔y then z.start=min(x.start,y.start) and z.end=max(x.end, y.end). [22]
Are M(D) and O(D) lattices?
The first step of the method we have proposed consists in constructing, on the basis
of
a marked up document D, a lattice L(D). The construction method ensures that L(D)
always is
a lattice, i.e. that it has a unique largest node, that every pair of nodes has a
join, and
that every pair of non-minimal nodes has a meet. The document models, M(D) for XML
documents
and O(D) for O-XML documents, however, are derived from L(D) through a filtering process.
Therefore, it is appropriate to ask whether M(D) and O(D) are also lattices, or not.
In this section we will argue that M(D) is not only guaranteed to be a lattice, it
is
also guaranteed to be a tree. O(D), however, is obviously not guaranteed to be a tree,
but
it is also not guaranteed to be a lattice.
We have earlier observed the similarity between the document model M(D) and XML trees.
The following argument will show that this is necessarily the case for any model M(D).
In
XML, whenever both x.start<y.start and y.start<x.end is true, it is safe to conclude
that y.end<x.end (in other words, there is no overlap). This is also true for the
relationships in M(D).
To see why, consider x and y, both elements of a model M(D), with the assumption
that
x.start<y.start and y.start<x.end. We want to show that it will always be the case
that y.end<x.end under these circumstances. So suppose for contradiction that this
is not
so, and that x.end<y.end. Then there exists a node z=(y.start,x.end) in L(D), since
y.start<x.end (recall that L(D) contains all pairs of start tags followed by end tags).
It is also clear that z is not a member of M(D). Further, from z's definition, we
note that
z is smaller than both x and y, and also a relative of both. This is enough to contradict
the selection assumption for M(D): if z is smaller than x, then, since z=(y.start,
x.end), z
cannot have been removed in the model building process as a candidate for x, because
any
node is below all the relatives it removes, and by assumption z<x . So z must then
have
been removed as candidate for M(D) considered as a relative of y. But this contradicts
the
assumption that z<y, since y<z for z to be removed. We can therefore conclude that
assuming that x.end<y.end is not tenable, and therefore that y.end<x.end. This means
that if ⊓ is confined to elements of M(D), u⊓v is either one of u or v (if it
has a value at all); if u strictly comes after v, they would not share any nodes.
A
consequence of this is that any element x must have a unique parent (if it has one
at all):
if both u and v where distinct parents in M(D) (i.e. smallest nodes above x), x⊑u
and
x⊑v, which would mean that x⊑u⊓v=u (or v). We can therefore conclude that
M(D) is a tree.
The above argument does not hold for O(D) which models overlap structures. The example
GODDAG in Lattice R shows that the structure is not a tree, as the simple Y has
two parents. Also, the join may be undefined when restricted to O(D) (that is, redefined
within O(D) and not computed within L(D)). In O(D) two elemnts do not necessarily
have a
unique smallest dominating element, even if there are elements above them. For example,
two
elements x and y may be dominated by elementss a and b, and neither of these dominate
the
other if they overlap. In this example it is therefore impossible to select a smallest
dominating element to serve as the join of x and y.
Closure
In this section and the ones that follow, we will look at the differences between
O-
and M-models in terms of meet and join. This also brings us to regard M(D) and O(D)
as
subsets of L(D), and consider ways of adding nodes to them in order to make them satisfy
certain requirements.
When M(D) and O(D) are seen as subsets of L(D), with meet and join computed in L(D),
there are a number of differences between them that were not captured above, when
we limited
ourselves to look at their structures only. Our first question is whether the meet
and join
operations are closed in M(D) and O(D). (An operation is closed in a subset A if the
result
of the operation stays in A when operating on elements of A.)
One defining difference between O(D) and M(D) in terms of closure is that while the
meet
operation is closed in M(D), it is not in O(D). As we saw above, given two elements
x and y
in M(D), their meet is either x or y, which is still in M(D). If u and v in O(D) are
distinct and overlapping, which means that u.start<v.start while u.end<v.end, their
meet is w=(v.start,u.end), which is not an element of O(D). (It is a node in L(D),
but since
it is a relative of both u and v, it is not a member of O(D)).
The join operation will not always be closed, neither in M(D) nor in O(D). If x precedes
y with both tags of x before y.start, their join is (x.start,y.end). This node cannot
be any
element neither of M(D) nor of O(D), since it is a relative of both x and y, but not
identical to any of them.
An observation concerning M(D) is that there are nested documents that are closed
under
both join and meet. Documents where no node precedes another are of that type, like
for
example <r><a>X</a><r>. In a document like this, where ⊑ is a
total order, it is the case that if x⊔y=x then x⊓y=y and vice versa. A
document with overlap will in general leak into L(D) for both meet and join.
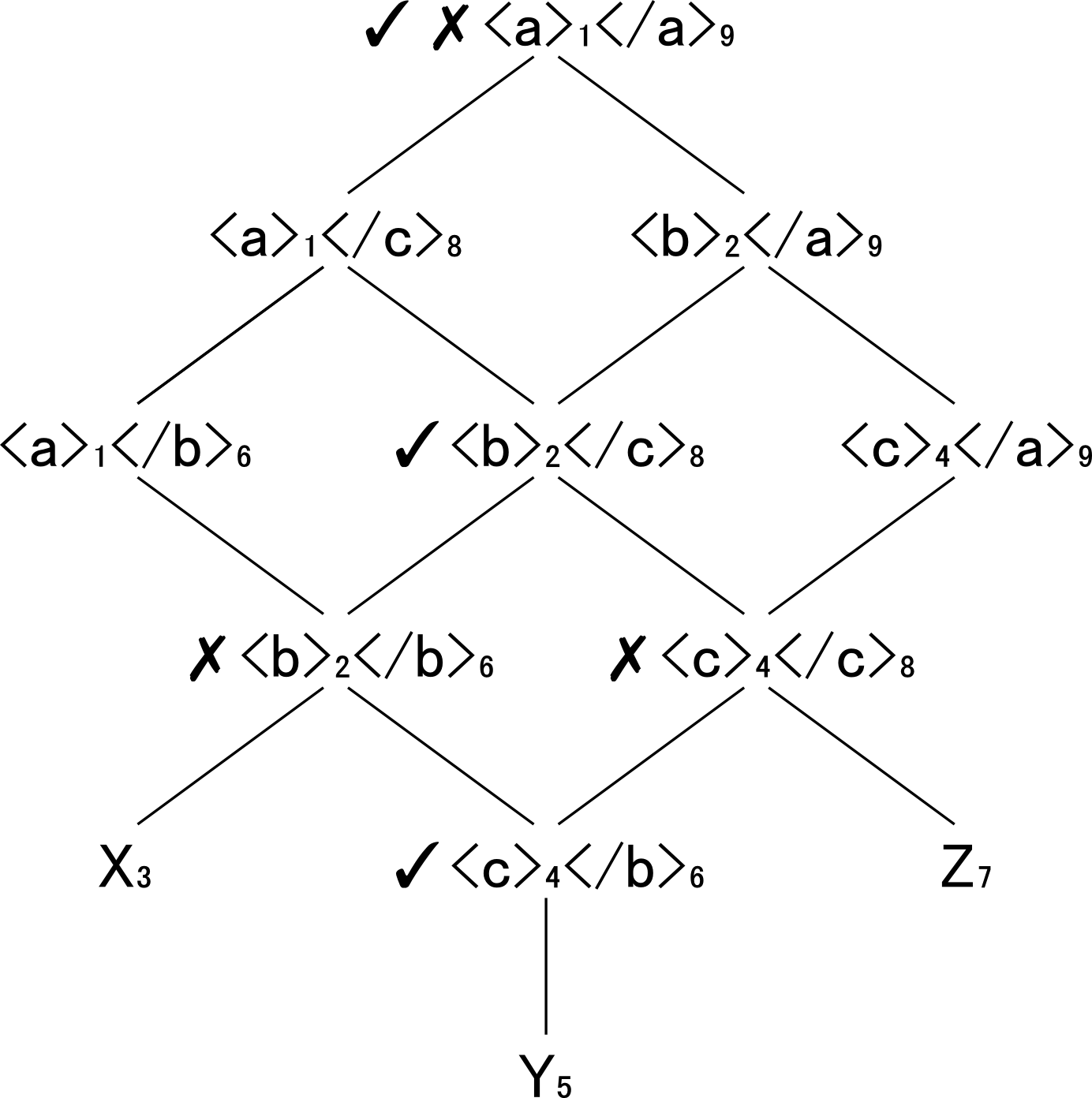
Consider D2 from the previous section. The lattice L(D2) may be used to
represent M(D2) as well as O(D2). D2 is an O-XML document with overlap, so
M(D2) will be ill-formed, but that is not of relevance at this point; M(D2) will
simply exhibit the nested view of the document. In the figure below, showing the lattice
L(2), the elements of M(D2) are indicated with a ✓, while the elements of
O(D2) are indicated with a ✗; the simples are members of both models.
Lattice OMD2: L(D2) with subsets ✓M(D2) and ✗O(D2)
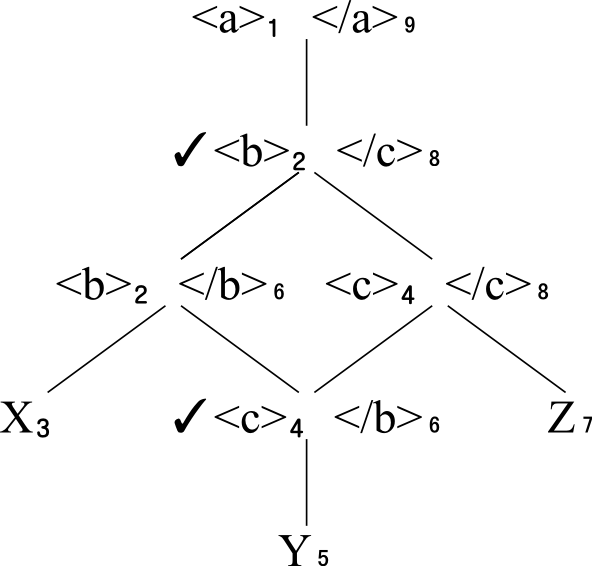
We write M(D)* for the closure of M(D). It is obtained by collecting all nodes
x⊓y and x⊔y in L(D) where x, y are elements of M(D), with recombinations.
Similarly, we write O(D)* for the closure of O(D). The new nodes that are added in
this way
are called semi-elements, distinct from the elements of M(D) or O(D).
Here is what the O-XML document D2 with overlap looks like with semi-elements
added. The semi-elements are indicated with a check mark, ✓. Note that the
semi-elements are precisely the candidate elements for M(D2), an observation we return
to below.
Lattice oOMD2: O(D2)* with semi-elements check marked.
The semi-elements are considered nameless, they may be annotated with an algebraic
formula having that node as value.
Lattice oOMD2s: O(D2)*
The reader may check that the above diagram represents the closure of O(D2). Here
are all possible combinations alongside their value, not including combinations involving
elements x and y such that x≤y.
Table III
All possible meet and join combinations for O(D2)
X₃⊔Y₅ = b = <b>₂</b>₆
X₃⊔Z₇ = b⊔c = <b>₂</c>₈
Z₇⊔Y₅ = c = <c>₄</c>₈
b⊓c = <c>₄</b>₆
It was noted above that M(D2) was a subset of O(D2)*. We want to demonstrate
that it holds for any document D that M(D) is a subset of O(D)*, even though M(D)
and O(D)
need only have the top element in common. The converse does not hold. A consequence
of this
is that O-XML documents with overlap cannot be reached from algebraic manipulations
on M(D),
but that the corresponding XML document without overlap can be reached from O(D)*.
For this to make sense, D must be a well-formed overlapping O-XML document. If D
has no
overlap, it will also be a well-formed XML document for which we have already established
that O(D)=M(D). Hence, in that case M(D) will automatically be a subset of O(D)* (=M(D)*).
Further, we take it without argument that if O(D) contains an element x that does
not
overlap with any other element y in O(D), x will also be a member of M(D). It doesn't
matter
if x contains, or is contained, in an overlap configuration as long x does not itself
overlap with another element. To illustrate, the a and b elements of the following
document
D4 will be elements of both M(D4) and O(D4), even though c and d overlaps.
The latter two will obviously not be members of M(D4):
<a><d>X<c><b>Y</b></d>Z</c></a>
In
addition to the simples, the elements of M(D4) will be these (token indexes are skipped
since the GIs serve to uniquely identify token tags), where the linear order of the
elements
also reflects the hierarchical order:
(<a>,</a>) (<d>,</c>) (<c>,</d>) (<b>,</b>)
So the odd elements here, which are not elements of O(D4), are these two
(<d>,</c>) (<c>,</d>)
It can be seen that these
two nodes are semi-elements of O(D4)* given the equations
(<d>,</c>)=(<d>,</d>)⊔(<c>,</c>)
(<c>,</d>)=(<d>,</d>)⊓(<c>,</c>)
The above equations hold also in the general case. Consider an O-XML document D, and
an
element m in M(D), so m may possibly not have matching tags. Then it will be the case
that either m
is in O(D), or else there will be elements in O(D) so that m is their join, their
meet or a
combination of join and meet. To see this, note that m will either be well-formed
according
to XML (checked through the GI-identity constraint) or it will not, but still well-formed
according to O-XML. So it is like either (<a>,</a>) or
(<d>,</c>) of M(D4). If m is a member of O(D), it will also be in
O(D)*. So consider the case where m is not an element in O(D). Then there must be
distinct
elements a and b in O(D) so that a.start=m.start and b.end=m.end, this because of
the
constraint which says all tag tokens must be part of an element. Now there are three
cases
to consider:
a.start<b.start and a.end<b.end (this subsumes overlap and
sequencing)
b.start<a.start and b.end<a.end (overlap only)
a.start<b.start and b.end<a.end (nesting)
In the first case m=a⊔b, while in the second, m=a⊓b, parallel to the case
for D4.The third case, the nesting case is a bit trickier. The tag configuration for a and
b is now
...<a>...<b>....</b>...
where
m=(<a>,</b>), another way of stating that m=(a.start, b.end). Recall
that the M-models are constructed without looking at GIs, so for m to be an element
of M(D),
all the tags between a.start(=m.start) and b.end(=m.end) must match up. In particular
there
must be an equal number of start tags and end tags between a.start and b.end. Since
we
already have b.start in there, we know there must be at least one extra end tag between
a.start and b.end. That end tag must be matched in O(D) by a start tag outside of
the
(a.start, b.end) configuration. Which means that there must be an element c of O(D)
such
that c.end is between a.start and b.end and such that c.start is outside of the pair,
that
is c.start<a.start. Now m can be written on the form m=a⊓c⊔b, and so is a
semi-element of O(D)*. [23]
This result, that M(D) is a subset of O(D)*, but not vice versa, pinpoints an asymmetry
between overlapping and nesting documents. Nested documents can be recovered, so to
speak,
from overlapping documents, but there are overlapping documents that cannot be described
algebraicly in terms of nested documents.
Spurious overlap
Closure models may be help in representing certain cases so-called spurious overlap
as discussed in [Huitfeldt and Sperberg-McQueen 2003]. Roughly, spurious overlap occurs
whenever two elements a and b overlap, and there is no PCDATA either between the two
start
tags, or between the two end tags, or between the start tag of a and the end tag of
b. The
following O-XML document D3 may illustrate.
<a><b>X<c></b>Y</c><a>
Its document model is this
Spurious model: O(D3)
Except for token indexes, it is identical to the document model for the following
XML document:
<a><b>X</b><c>Y</c><a>
The closures of the two document models are slightly different, though. The
document with spurious overlap has this closure:
Spurious closure: O(D3)*
while the document without overlap has this closure:
Nested closure: M(D3a)*
This may serve to illustrate the close relationship between the lattice model and
the
serial form of the marked up document. By the use of closure models with semi-elements,
documents with spurious overlap can be distinguished from other documents which share
the
same document model.
Conclusion
We have described a method for building lattices from marked up documents with and
without overlap, and for generating, from these lattices, document models in the form
of trees
for XML documents, and in the form of GODDAGs for documents with overlap. We have
shown that
one and the same method can be used for generating both kinds of models, and we have
given
reasons to believe that lattices can also be used to implement well-formedness constraints
for
both kinds of documents. In this sense, this is also a step away from relying on context
free
grammars and the like in analyzing documents. As presented here, model building is
kept
separate from grammar, but we leave open the question of how this bears on document
validation.
We have discussed and compared some of the algebraic features of the document models
and
the relations between them, and pointed out some interesting results. For example,
that the
algebraic operations provide a link between nested documents and overlapping documents.
The
former can be computed by algebraic means from the latter, but not the other way around.
We
have also disussed how the algebraically closed models can be used to distinguish
models of
spurious overlap from nested models, via the introduction of semi-elements.
Therefore, although many of the details in the work presented here probably are in
need
of correction and revision, we believe that the application of lattices to marked
up documents
may provide a unified account of markup languages with and without overlap.
Appendix
In the section called "Bracketed notations and matching" we defined the grammar P.
We will
formally prove that any two parentheses (a left then a right) can be added to a well-formed
parenthetical expression according to this grammar, while preserving well-formedness.
We start
with the following lemma
Lemma on string splitting
Let the string S over left and right parentheses be derived according to P,
and decomposed into S=XYZ. Then X, Y and Z
can be reduced, by removing non-terminal Ps
from each of them into X', Y', and Z', such that
X'=(n and
Y'=)m(p and
Z'=)q, so that S' is well-formed.
Proof: Since X is the leftmost string of S, any right
parenthesis, ), in X must occur in the pattern (p), and
such a pattern can safely be removed without destroying the well-formedness of the
expression.
Thus, X will in the end be reduced to X' as a consecutive string of
left parentheses. A parallel argument goes for Z and its reduction to
Z' as a string of right parentheses. For Y the story is a bit
different, since a left or right parenthesis may be generated with a corresponding
parenthesis
in X or Z. However, we can safely conclude that if all
Ps are removed from Y, then there can be no string of the form (W)
in Y, since either ) is derived with a corresponding (
in W, or ( is derived with a corresponding ) in
W. Thus, Y' must be a string of )'s followed by ('s.
Since removing a P from a well-formed string won't affect its well-formedness,
the string S'=X'Y'Z' is well-formed.
This lemma will be used to show that any pair of left and right parentheses can be
inserted into a well-formed string without affecting its well-formedness.
Well-formedness of additional parentheses
Let the string S be a well-formed parenthetical expression according to P. Inserting
a
left parenthesis anywhere in S followed by a right parenthesis anywhere after the
left, will result in a well-formed string according to P.
Proof: Split the string S into three substrings XYZ at the
positions where ( and ) are to be inserted, so that The new string is
S1=X(Y)Z.
Now according to lemma, X Y and Z can be reduced and re-concatenated into the well-formed
expression
(n)m(p)q
Inserting the new left-( and right-) into their respective positions, results in
(n()m(p))q
Now, all that is left to do is just to shift the superscripts to the right and
left; this expression can be written as
((n)m(p)q)
But this is just the expression (X'Y'Z'), and since the X'Y'Z',
can be reduced to a sequence of Ps, the resulting
expression is also well-formed, being then on the form (P*).
This proposition guarantees that the intended matching of the parentheses is of no
concern to the well-formedness of the expression.
References
[Abney 1997] Abney, Steven, Partial Parsing via
Finite-State Cascades. Journal of Natural Language Engineering
2:337-344.
[Barnard et al. 1995] Barnard, David; Burnard,
Lou; Gaspart, Jean-Pierre; Price, Lynne A.; Sperberg-McQueen, C. M.; Varile, Giovanni
Battista, Hierarchical Encoding of Text: Technical Problems and SGML Solutions,
Computers and the Humanities, The Text Encoding Initiative:
Background and Contents, Guest Editors Nancy Ide and Jean Vèronis, 29/3, 211-231.
http://www.springerlink.com/content/p7775247276v88h3/
[Jagadish et al. 2004] Jagadish, H.V.; Laks V.
S. Lakshmanan; Monica Scannapieco; Divesh Srivastava; and Nuwee Wiwatwattana, Colorful
XML: one hierarchy isn't enough, Proceedings of the 2004 ACM
SIGMOD international conference on Management of data, Paris, France: 251-262.
doi:https://doi.org/10.1145/1007568.1007598
[Schonefeld 2007] Schonefeld, Oliver Georg Rehm,
Andreas Witt, Lothar Lemnitzer (eds.), XCONCUR and XCONCUR-CL: A constraint-based
approach for the validation of concurrent markup, Datenstrukturen für linguistische Ressourcen und ihre Anwendungen / Data structures
for
linguistic resources and applications: Proceedings of the Biennial GLDV Conference
2007, Tübingen: Gunter Narr Verlag. Pp. 347-356.
[Sperberg-McQueen and Huitfeldt 2000] Sperberg-McQueen, C. M., and Claus
Huitfeldt Peter R. King and Ethan V. Munson (eds.), GODDAG: A Data Structure for
Overlapping Hierarchies, Digital documents: systems and
principles. Lecture Notes in Computer Science 2023, Berlin: Springer, 2004, pp.
139-160. Paper given at Digital Documents: Systems and Principles. 8th International
Conference on Digital Documents and Electronic Publishing, DDEP 2000, 5th International
Workshop on the Principles of Digital Document Processing, PODDP 2000, Munich, Germany,
September 13-15, 2000.. http://www.w3.org/People/cmsmcq/2000/poddp2000.html
[Witt 2005] Andreas Witt Stefanie Dipper, Michael
Götze, and Manfred Stede (eds.), Multiple Hierarchies: New Aspects of an Old
Solution, Heterogeneity in Focus: Creating and and Using
Linguistic Databases, volume 2 of Interdisciplinary Studies on Information
Structure (ISIS), Working Papers of the SFB 632. University of Potsdam, Germany. (Corrected
reprint of an Extreme Markup 2004 paper). http://en.scientificcommons.org/42597903
[1] Simple examples in point are sentences, quotations, and proper names
[2] For convenience, we will allow ourselves to use the term "XML" in the rest of this
paper, also when for historical or other reasons the correct reference would be either
to
XML, or to SGML, or to both.
[3] The one problem which has received most attention in the literature is the difficulty
or inconvenience of representing overlapping elements in XML. There are related problems
pertaining to the representation of discontinuous elements and alternate ordering
of
elements, which we do not address in this paper. We do believe, however, that the
general
strategy outlined here could also be adopted in order to get a better grip on these
problems.
[4] An important exception on this point is the SGML CONCUR feature, which did provide
a
mechanism for the encoding of concurrent hierarchies. Unfortunately, CONCUR was never
widely supported by SGML implementations, and was not carried over to XML. However
see
[Schonefeld 2007].
[5] See e.g. [Barnard et al. 1988], [Barnard et al. 1995], [DeRose 2004], and [Witt 2005].
We cannot and do not attempt a full overview of the literature in this paper, but
only to
point to some of the main courses among various approaches to the problem.
[6] In addition, stand-off markup may provide solutions to problems related to the
representation of document change histories, of multi-versioned documents, and to
dynamic document editing. These problems often coincide with, but are in our view
distinct from, the overlap problem. Common objections to stand-off markup concern
data
integrity under document editing. This is indeed a serious concern, but one which
lies
outside the scope of this paper.
[7] Requests and proposals for transformation tools are abundant in the literature, but
we know of only one proposal which recommends the establishment of a common framework
of
transformation algorithms as a general solution: [Marinelli et al. 2008].
[8] For all relevant purposes, therefore, O-XML is equivalent to what Yves Marcoux termed
"overlap-only TexMECS" in [Marcoux2008]. Note that, like
"overlap-only TexMECS" and some other notations, but unlike yet other notations allowing
for overlap, O-XML does not allow for self-overlap.
[9] The latter may seem like a tautology, as it merely says that in documents with overlap
some elements overlap. Note that in the sense we are using the term overlap here,
XML
documents do not have overlap, whereas documents in notations like O-XML, such as
MECS,
TexMecs, LMNL, xConcur etc. may have.
[10] This may be one of the reasons for the complaints about the verbosity of XML as
compared to e.g. SGML, which allows for the omission of generic identifiers on end
tags.
[11] Nesting and mirroring agrees on single level coordinate structures, for example
()().
[12] Imagine speakers of two dialects Nest and Mirr of the language Parenthesian, a
language forming subsets of well-formed parentheses. In dialect Nest the semantics
follows
nested brackets, in Mirr matches are a mix of mirrored and nested parenthesis. In
both
dialects the word for walk is "()" and the word for dog is "(())". The rule
for forming "verb+subject" sentences in dialect Nest is to wrap the verb inside the
first
parenthesis of the noun, so that "dog walks" becomes "(()())". Using
subscripted d's to indicate "dog" the structure is:
(d()(d)d)d.
Dialect Mirr has a different rule for forming sentences (verb+subject): wrap the
last parenthesis of the verb around the first parenthesis of the noun, resulting in
the
configuration "(()())". Surprisingly, this is exactly the same expression as
above, although it now has a different structure:
((d)(d)d)d.
[13] If we allow for the use of regular expressions in grammar rules, the base and
coordination steps can be merged to: P→P*
[14] In the following, this distinction will not always be important, and we may
occasionally refer to lattices and semi-lattices indiscriminately as "lattices".
[15] As noted above, the only difference between XML and O-XML is that O-XML allows
overlapping elements. Therefore, element structures of some other markup languages,
such
as the suspend and resume tags of TexMecs, are not taken into consideration.
[16] Excluding other markup constructs, such as comments, processing instructions or
declarations, cf. the remark above. It does not matter whether the tags separating
two
simples are start tags, end tags, or a combination of start and end tags.
[17] This would mean that nodes contain each other if their start and end positions are
identical, -- however this situation cannot occur in the current context, since a
position
index functions as token index.
[18] We observe that these concepts are parallel to the concepts of sequence and range
of
Core Range Algebra [Nicol 2002a]. There is a connection between the
approach adopted here, and Core Range Algebra, but we leave a discussion of that
connection for future work.
[19] These minimal nodes happen to have no relatives, otherwise we would have had to
delete those as well. See next step.
[20] Remember that the relatives of a node are defined as the set of other nodes with the
same start or end tag token. If there had been further
nodes with tokens of the start tag <b> or the end tag </b> in the lattice,
they would still not have been relatives of <b>₃</b>₅. In
other words, we are still ignoring information derivable from GIs.
[21] The above process can be defined inductively using the functions
min that selects the minimal nodes from a lattice, and
rel which selects the relatives of its argument. Recall that the
latter relation is reflexive, which means that rel(S) has S as a subset. The induction
stops when Li is empty.
Base step for S:
S0 =
min(L)
Base step for L:
L0 = L -
rel(S0)
Induction step for S:
Si+1 =
min(Li)
∪ Si
Induction step for L:
Li+1 =
Li -
rel(Di)
This method bears a resemblance to cascaded finite state transducers, used in
natural language processing Abney 1997. A finite state transducer
F, may scan a string over the symbols "(" and ")" replacing each occurrence of "()"
(i.e
the innermost, or minimal elements) with the empty string. Then repeat the process
on
the output (the cascading). When nothing is left, the process stops and the parentheses
that are removed together can be taken to match. Even though the language over
parentheses itself is context free, a cascaded approach using finite state transducers
can in principle analyze it.
[22] To see that this is so, consider first the case of ⊓. Any node that is
below x must have a start tag occurring after or at x.start and an end tag at or before
x.end, and similarly for any node below y. Thus, any node u, such that u⊑x and
u⊑y, must satisfy that u.start ≥ x.start and that u.start ≥
y.start, and both of u.end ≤ x.end and u.end ≤y.end. Consequently, any
such u will therefore also satisfy u⊑z so z must be equal to x⊓y in
accordance with the definition for ⊓. A similar argument can be applied to
⊔. As simples are minimal, they cannot have a meet, while their join will be
discussed below.
[23] Note in passing that there must be an end tag positioned between b.start and b.end.
This is so because m as a member of M(D) do not allow overlap, and with b.start between
its start and end tags, b.start must match up with a tag in M(D) that comes before
b.end
itself. If c does not serve this purpose, there will be additional tags between a.start
and b.end
Barnard, David, Ron
Hayter, Maria Karababa, George Logan, and John McFadden, SGML-based markup for literary
texts: Two problems and some solutions, Computers and the
Humanities, 22: 265-276. http://www.springerlink.com/content/r1p6t63627663436/
Barnard, David; Burnard,
Lou; Gaspart, Jean-Pierre; Price, Lynne A.; Sperberg-McQueen, C. M.; Varile, Giovanni
Battista, Hierarchical Encoding of Text: Technical Problems and SGML Solutions,
Computers and the Humanities, The Text Encoding Initiative:
Background and Contents, Guest Editors Nancy Ide and Jean Vèronis, 29/3, 211-231.
http://www.springerlink.com/content/p7775247276v88h3/
Huitfeldt C, MECS - A
Multi-Element Code System, Working Papers from the
Wittgenstein Archives at the University of Bergen, No 3, Version October 1998.
http://helmer.aksis.uib.no/claus/mecs/mecs.htm
Huitfeldt, Claus; and C. M.
Sperberg-McQueen, TexMECS: An experimental markup meta-language for complex
documents, Working paper of the project Markup Languages for
Complex Documents (MLCD), University of Bergen. http://decentius.aksis.uib.no/mlcd/2003/Papers/texmecs.html
Jagadish, H.V.; Laks V.
S. Lakshmanan; Monica Scannapieco; Divesh Srivastava; and Nuwee Wiwatwattana, Colorful
XML: one hierarchy isn't enough, Proceedings of the 2004 ACM
SIGMOD international conference on Management of data, Paris, France: 251-262.
doi:https://doi.org/10.1145/1007568.1007598
Schonefeld, Oliver Georg Rehm,
Andreas Witt, Lothar Lemnitzer (eds.), XCONCUR and XCONCUR-CL: A constraint-based
approach for the validation of concurrent markup, Datenstrukturen für linguistische Ressourcen und ihre Anwendungen / Data structures
for
linguistic resources and applications: Proceedings of the Biennial GLDV Conference
2007, Tübingen: Gunter Narr Verlag. Pp. 347-356.
Schmidt, D.,
Colomb, R., A data structure for representing multi-version texts online,
International Journal of Human-Computer Studies, . http://portal.acm.org/citation.cfm?id=1523966
Sperberg-McQueen, C. M., and Claus
Huitfeldt Peter R. King and Ethan V. Munson (eds.), GODDAG: A Data Structure for
Overlapping Hierarchies, Digital documents: systems and
principles. Lecture Notes in Computer Science 2023, Berlin: Springer, 2004, pp.
139-160. Paper given at Digital Documents: Systems and Principles. 8th International
Conference on Digital Documents and Electronic Publishing, DDEP 2000, 5th International
Workshop on the Principles of Digital Document Processing, PODDP 2000, Munich, Germany,
September 13-15, 2000.. http://www.w3.org/People/cmsmcq/2000/poddp2000.html
Andreas Witt Stefanie Dipper, Michael
Götze, and Manfred Stede (eds.), Multiple Hierarchies: New Aspects of an Old
Solution, Heterogeneity in Focus: Creating and and Using
Linguistic Databases, volume 2 of Interdisciplinary Studies on Information
Structure (ISIS), Working Papers of the SFB 632. University of Potsdam, Germany. (Corrected
reprint of an Extreme Markup 2004 paper). http://en.scientificcommons.org/42597903