David, Ravit H., Shahin Ezzat Sahebi, Bartek Kawula and Dileshni Jayasinghe. “Challenges and Potential of Local Loading of XML Ebooks.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.David01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
Balisage Paper: Challenges and Potential of Local Loading of XML Ebooks
Dr. Ravit H. David is the Digital Content Production Manager of the E-book project
at
Scholars Portal, University of Toronto. She also collaborates in various Digital
Humanities projects across Canada
Shahin works as a Computer engineer at Scholars Portal. Prior to joinging to Scholars
Portal Shain worked as a Software Developer for Amazon, Seattle, US.
Bartek has been working for Scholars Portal since early 2009, first as a Client
Services Librarian and more recently as an Information Architect. His primary role
has
been to design the user experience of Scholars Portal’s in-house services and to develop
new applications for OCUL members. Prior to this, he worked as a Digital Projects
Librarian for York University Libraries.
This paper is a summary of the experience of local loading of XML Ebooks on the Scholars
Portal Ebook platform. It discusses the problems and potential of local loading that
emerged
from a pilot loading of over 500 titles; the first stage of this pilot was completed
in
February 2011. More specifically, the paper will review the difficulties encountered
during
the various stages of the loading, starting from loading files on our MarkLogic server,
then
the presentation of content via XSLT and ending with transforming the table of contents
to
achieve functionalities, such as lone-chapter downloading. We will also touch upon
our web
reader and the features developed to enhance the reading experience of XML Ebooks.
Our conclusion is that with the gradual increase in publishers’ switching from PDF
to
XML format, the need to have a standard for XML Ebooks increases, as well; local loading
of
XML Ebooks in their current format suggests that much programming work will be called
for in
order to arrive at the best presentation of the content.
Finally, we will suggest that once a satisfying web-based presentation of XML Ebooks
is
achieved, there will still be an urgent need to develop good readers in order to provide
a
friendly reading experience.
This paper will describe the local loading process of XML book collections on the
Scholars
Portal Ebook platform. Scholars Portal (SP), a service of the Ontario Council of University
Libraries (OCUL), provides the technological infrastructure that preserves and allows
access
to information resources collected and shared by Ontario’s 21 university libraries.
The Scholars Portal books platform is designed to provide a single interface for accessing
digital texts from the world’s most important scholarly publishers and public domain
books
that have been scanned and digitized for online reading and downloading. Our PDF-based
reading
interface offers multiple- page view options, including a grid view to help users
easily
navigate in and among books. User accounts allow users to save searches, bookmarks
and notes,
as well as to cut and paste small sections of text. The service runs on the ebrary
ISIS and
MarkLogic technology— a special-purpose, document-centered database management system
that
uses the XML data model and XQuery query language and is optimized for large collections
of
both semi-structured and unstructured information.
As the Ebook is becoming more popular and as we see more reading devices, publishers
are
moving from PDF to XML formats. My talk describes the challenges we encountered during
a pilot
local loading of XML Ebooks and the potential uses of XML format versus PDF. Before
proceeding, we should define “XML Ebooks”; this refers to the many different ways
in which the
content of Ebooks is structured in markup. Currently, there is no standard for Ebooks
that
publishers follow; as a result, when the Scholars Portal receives content from more
than one
publisher, we have to solve the unique problems of each Ebook collection separately.
As well,
we cannot apply the same loader—the program we write to put Ebooks on our platform—to
different collections.
2. Local Loading Explained
The various university libraries in Ontario have built a service that will house and
archive content so that future generations of scholars may continue to access the
same content
regardless of changes in subscription policies, which take place so often in the publishing
industry. By “local loading,” we mean the delivery of data files from the publisher/vendor
for
presentation via SP software platforms. Local loading of Ebooks has provided Ontario
university libraries with the flexibility and control to create Web-based archival,
search and
delivery interfaces that are vendor independent. Furthermore, SP search tools reduce
the
complexity of multiple-vendor interfaces and provide our researchers with a common
search
interface for millions of journal articles and book chapters. The objectives of SP
local
loading are mainly long-term preservation and enhanced discovery.
From the publishers’ point of view, the most important advantage to local loading
is
stability. SP is in the process of being recognized as a trusted digital archive by
the Center
for Research Libraries - CRL. Moreover, security measures ensure that a publisher’s
data will
not be corrupted in the long-term and will be incorporated within new technologies
as needed.
The SP platform is also designed to ensure appropriate levels of access to authorized
users
because subscriptions vary with each member library. SP staff provides technical support
that
would otherwise be directed to publishers. Finally, SP search interfaces are heavily
used by
Ontario researchers, and SP metadata is indexed by Google; thus, SP can guarantee
high
visibility.
3. Scholars Portal’s Ebooks Platform
Currently, Scholars Portal Books numbers more than 350,000 Ebooks, which until recently,
were received from publishers mostly in PDF format. The local loading procedure for
PDF using
ebrary’s ISIS Toolkit comprises several stages. The first stage is preparing the PDF
file:
Some publishers deliver us Ebooks as individual chapters, and therefore we need to
create a
unified PDF Ebook by merging all those files together. The second stage is finding
MARC
records for each book: from the MARC records, we extract the metadata required for
loading and
later, also for publishing, so that other libraries can load the records on their
OPACs.
During the loading, we modify the MARC to contain a link to our platform (the 856
field). At
the third stage, we generate a MODS file from the MARC record. Research and bibliographic
management tools, such as Zotero, use MODS files.
Once we have matched the PDF with its MARC record, we submit the PDF and a set of
key-value metadata to ISIS through a service API. Each book on the Ebook platform
has a
book-i.d. that defines its URL (http://books2.scholarsportal.info/viewdoc.html?id=371372)
and
a permalink that contains one of the ISBN numbers from its MARC record
(http://books1.scholarsportal.info/viewdoc.html?id=/ebooks/ebooks1/lww/2010-10-18/1/01382858).
4. Ebooks Format Change: PDF to XML
The workflow involved in loading XML books is different from that with PDF books,
but
still shares some common practices: (1) Matching: pairing each book with a MARC file;
(2)
Generating a PDF file by extracting each book’s text and feeding the PDF, along with
the
metadata from the MARC file into our ISIS platform (this is a workaround to make the
books
searchable on our PDF-based platform); (3) Loading the XML books into Marklogic (after
cleanup). In order to display the books on our platform, we use a collection-specific
XSLT
transformer to convert the book into html. Consequently, each time someone tries to
read an
XML book on our platform instead of calling the rasterization service (which we normally
use
for PDF content), an XML service will be triggered that fetches the requested section
of the
book from Marklogic and transforms it into HTML (server side) and before serving it
to
browser.
a. Processing Instructions in the Markup
Our pilot loading of XML books included over 500 titles of Lippincott Williams &
Wilkins (LWW). Although LWW gave us schema files, since each publisher uses a different
schema, we were forced to pretty much ignore it.
Our pilot loading of XML books included over 500 titles published by Lippincott Williams
& Wilkins (LWW). Although LWW gave us schema files, we were forced pretty much to
ignore
them, since each publisher uses a different schema. The first step was to add the
XML files to
our MarkLogic server; however, doing so returned invalid XML errors, which required
our
programmers to fix the processing instructions for the data. For instance, pages appeared
as
follows: <?PG 155> and then <?PG 156>. Thus one of the tasks was to replace each such
error with, say, <<PG>155</PG>> and so on. It should be noted that even if we write
a
program to clean up this type of instruction, we cannot use it for other XML Ebooks.
For
instance, Oxford University Press—which we plan on loading next—created its instruction
for
pages as follows: <?Page pageId="2"?>. The difference in the instructions also demonstrates
the inconsistency in using Markup for Ebooks.
b. Generating TOC Table of content (TOC) and thumbnail
Generations are rather long processes and must be done asynchronously. After loading
each
batch of books, we used ActiveMQ to create and run tasks for each process. In order
to build a
TOC, we used a chapter’s ID to provide anchor points for linking. With the Lippincott
Williams
& Wilkins collection, however, we ran into a problem with chapter hierarchy. The LWW
Ebooks’ organizational structure includes sections nested within other sections. For
instance,
an I.D. such as “B00139907-DA1-DB1-C1” was not usable for us, since the machine could
not tell
the difference between C1 when stored under DB1 or its being the first chapter of
the book.
This screenshot shows a typical TOC structure for the LWW books TOC.
Figure 1: TOC
c. Structuring the Content via XSLT
Once the XML was cleaned and successfully loaded onto MarkLogic, we had to face problems
associated with the XSLT transformation. The XSLT file that came with the LWW Ebooks
was
created by Ovid technologies. Although it is a legitimate XSLT, it made for a poor
reading
experience when trying to use it as is, thus necessitating a major adaptation to fit
our
web-based reader. Among the prominent problems of this XSLT model is the size of tables.
Their
size always exceeds the viewport, thus making it very difficult for users to see the
text or
to navigate back to the page. Resizing the tables and adding frames to tables and
images
solved this problem. For instance: <div style="height: 100px; overflow: scroll">
Table…
</div> The following screenshot illustrate the problem, and represent a page before
we applied the changes to the XSLT.
Figure 2: Structuring Tables for the browser default behavior
Another major problem has to do with references and footnote linking. If users click
on
the footnote marker to return to the text, they will not be taken back to the same
place at
the page; or if this reference also appears elsewhere in the text, it will, by default,
take
them to where it first appeared. In some instances, references are also not linked.
This
structure is highly challenging for a reader’s orientation in that it forces the person
to go
back and forth while reading. A possible solution might be to highlight the reference
number
both on the way to the note and back in the body text. Since this solution involves
a great
amount of coding, we are still investigating alternative solutions. The challenge
is that
solutions need to be discreet and not depend on redesigning the book, which would
involve
copyright issues, a subject that is beyond the scope of this paper.
Additionally, we were forced to turn off some of the functionalities that arrived
in LWW’s
XSLT sheet. For instance, for cross-chapter links, LWW has included CGI calls in its
stylesheets; as a result, the XSLT file cannot readily be reused in other platforms
without
modification. We changed some calls, then, to local CGI and others we ignored. At
the same
time, we were able to turn on the in-chapter links. Another major problem was the
display of
images. This required us to write an image controller that finds images based on ID’s
and
serves them to the browser. We also had to modify the XSLT to correct the address
of the
images to point to our controller (handler).
d. Scholars Portal’s Reader: PDF versus XML
The SP reader originally developed for the platform was based on ebrary’s model of
converting PDF vector information into a raster format. We use the ebrary rasterization
engine, but opted to develop our own interface in order to create a more seamless
user
experience. We also provide a number of enhancements that were lacking in ebrary’s
web reader
at the time. These include a two-page view and a grid view for augmented navigation.
Additional features that we added include text clipping from the rasterized page,
exporting a
limited number of pages to PDF and the enabling of text searching. Recently we implemented
user accounts that allow users to save and sort books, bookmark pages, highlight text
and
write page notes.
With XML Ebooks, the most significant difference is that we no longer need to provide
a
“reader,” because the browser itself becomes the reader: what was once the static
image of a
printed page is now an HTML page. This also means that traditional reading tools,
such as page
magnification, bookmarking, multiple page views, text clipping and PDF page exporting,
are no
longer relevant features to worry about, because most of these tools are now included
in the
default behavior of most web browsers. Our initial version of the HTML page for XML
Ebooks
offered users the ability to view a table of contents, to search text across chapters,
to link
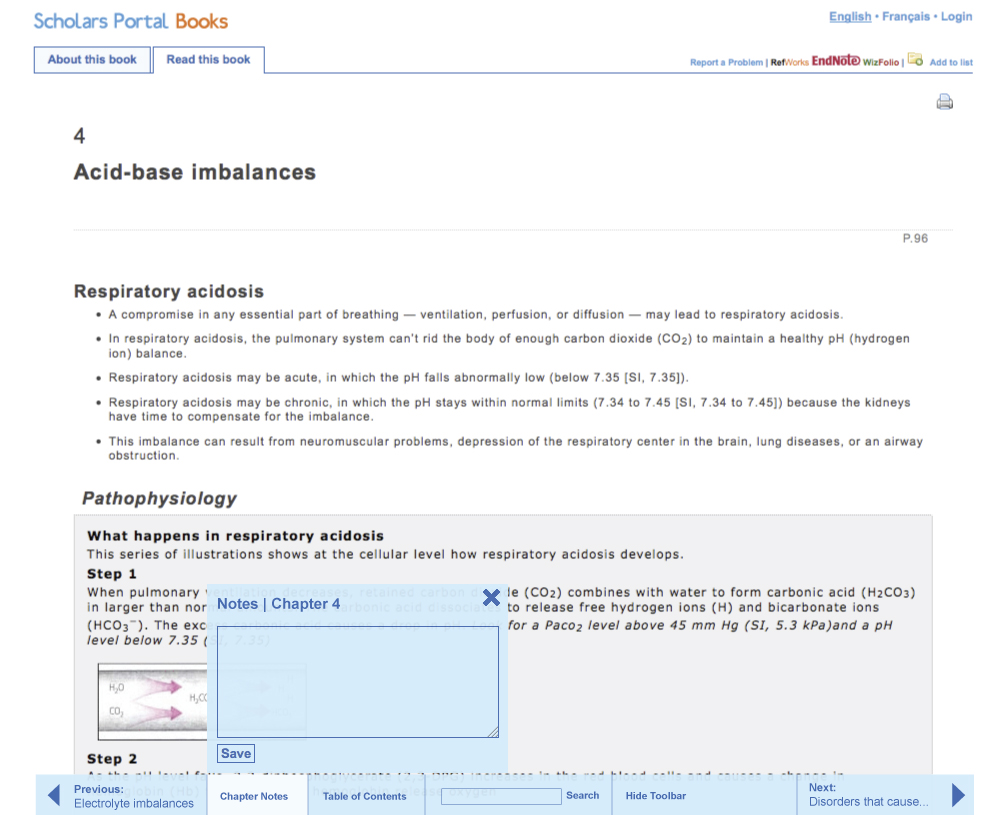
to endnotes or bibliographies and to write chapter notes. For instance, screen shot
4 shows
how we are planning to facilitate chapter-based annotation.
Since MarkLogic indexes all XML data, we took advantage of its Search API, using
the
namespace module to perform full-text searching. Up to now, we have dealt with only
one type
of XML books. However, after viewing other collections that we plan to load, it became
clear
that the structuring of sections or chapters varied from collection to collection,
and that we
will have to write a custom query collection-specific xquery in order to enable searches
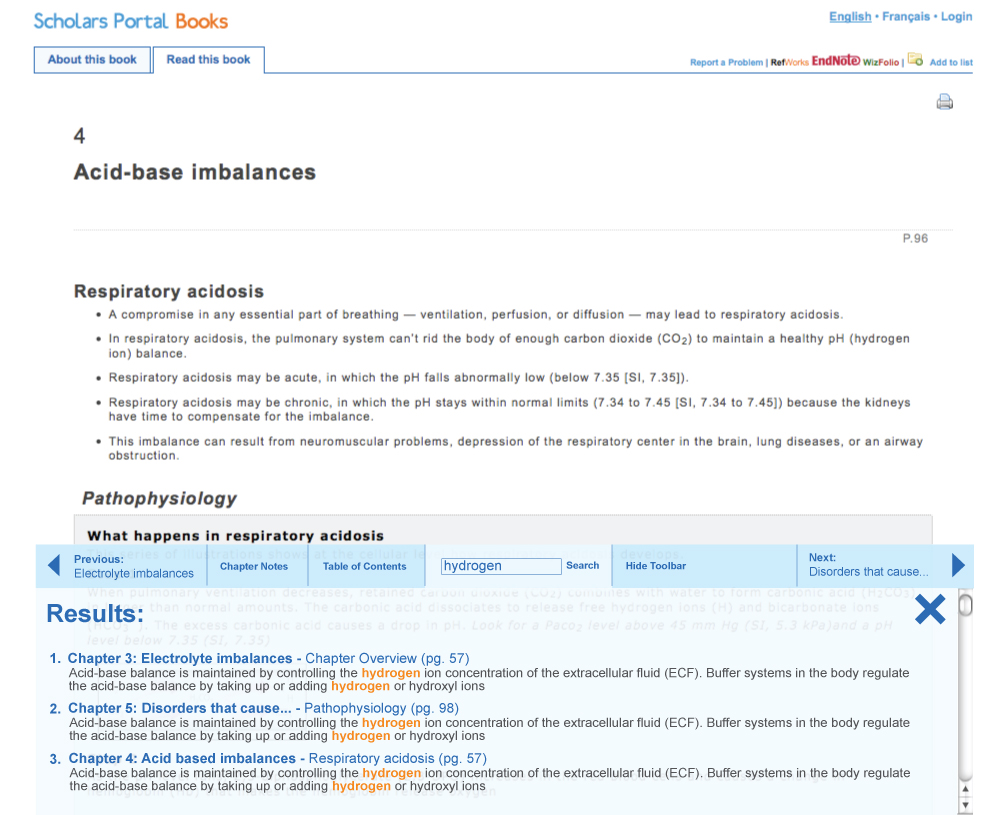
within each section or chapter. The presentation of relevance-scoring is also under
construction. Screen shot 4 shows the search results using ML Search API. In this
example we
used “chapters” as the definition of which parts of a document should be searched,
based on
our indexes in XQuerty. Once a user enters a search term, the results open up on the
bottom
like a drawer and are listed with an excerpt of the phrase surrounding the search
term, which
is highlighted. A user can then click on a result and be taken to that section of
the text.
Figure 3: Reader's Functionalities
Figure 4: Search Results Presentation
e. In the Land of EPUB3
EPUB is a specification intended to provide a standard way in which to interchange
and
deliver reflowable content to reading system. If EPUB3, the new generation of the
EPUB
specification recently issued by the International Digital Publishing Forum (IDPF),
is adopted
rapidly by publishers, it certainly will enable more control over knowing what it
is that we
are receiving from the publishers. This development, in turn, may bring back the comfort
associated with receiving PDFs from publishers, however limited a format that may
be. Yet,
unlike the PDF format, EPUB has functions called "media queries" that enable the layout
design
to adapt easily to the files' new "home," be it a laptop or an iphone. When treating
Ebooks
that contain many images, such as do the LWW books, EPUB3 will hopefully relieve us
of the
need to take control of the graphic design. It will be left to EPUB, because of its
vertical
writing capacity, to help images to adapt to the size and resolution of their rendering
environment.
Also, we will need to write an EPUB reader for MarkLogic, and hopefully, since EPUB3
accommodates more extensive metadata at all levels, even to the level of the single
paragraph,
we will also be able to take advantage of EBPUB3 support of new semantic markup features.
5. Conclusion
The local loading of XML Ebooks has created new challenges and opportunities previously
unavailable for Ebooks in PDF formats. As for processing instructions for XML data,
we did not
find instructions; and if we did, they were rarely complete. We attribute the minimal
and
often incomplete existence of processing instructions for XML files to the fact that
local
loading is not yet common practice. Thus, publishers still do not think about their
files as
needing processing by others or as having to perform in other environments. In most
cases, the
libraries simply point to the publisher’s website.
While problems with enriched metadata, such as TOC, can be challenging for all types
and
formats of Ebooks, the metadata for XML Ebooks can be found either in the XSLT sheets
or in
the XML schema (for instance, breaking up the book into pages). There are, then, various
strategies for creating administrative metadata, all with their own advantages and
drawbacks.
Because of copyright concerns, we do not want to touch the data; consequently, modifications
are done mostly at an XSLT level and in accordance with a browser’s default behavior.
In the
case of the LWW Ebooks, for instance, we found that a more detailed XML schema might
result in
a better presentation of the content.
With no acceptable format adopted by publishers for Ebooks, such as ePub, the optimization
of XML Ebooks is dependent on human resources and coding invested by the hosting platform.
In
the case of Scholars Portal Books, the local loading of Ebooks received from various
publishers has taken the technological burden off the publishers’ shoulders; at the
same time,
it has given us the freedom to experiment with the best available text-display formats
and
practices. That said, cleaning XML and applying extensive modifications to the XSLT
sheets act
to slow down the production line on our platform and to create a long time lag between
the
time the OCUL schools bought the books and the time they are available on our platform.
In
addition, since the advantage of MarkLogic is that any type of xml can be stored on
it, using
our limited number of software developers to create one format for all the publishers
with
which we work does not make sense.
Furthermore, some XSLT modifications may lead to the redesign of a book and, therefore,
possibly cause licensing difficulties for the hosting platform. Thus, in addition
to
standardization, it is important for both publishers and libraries to start thinking
about new
content management strategies for Ebooks that will include format and presentation
models.
Moving beyond PDF readers, XML Ebooks take advantage of web browser functionality
and
provide enhanced reading utilities, such as full-text searching. With MarkLogic’s
indexing
capabilities, search functionalities in XML Ebooks can be limited to chapters or sub-sections.
As each publisher may present content differently, however, the solutions found for
LWW Ebooks
may not be serviceable for other publishers. The Scholars Portal technical team would
then be
required to start anew with each collection or publisher. It is little wonder, then,
that the
current still- early-development state of XML Ebooks demands a great deal of resources
at the
hosting platform’s end. The success of Ebooks is affected by such factors as the cost
of
content and the feel of reading. It is possible that as the publishing industry moves
further
into XML Ebooks, new standards for displaying content will be adopted, allowing platforms
such
as Scholars Portal to receive Ebooks in a ready-for-production state and to concentrate
on
developing reading utilities.
References
Baumann, Michael. “Ebooks: A New School of Thought.” Information Today 27.5 (2010):
1-48.
Freese, Eric. “Multi-Channel eBook Production as a Function of Diverse Target
Device Capabilities.” In Proceedings of Balisage: The Markup Conference 2010. Balisage
Series
on Markup Technologies 5, Montreal, 2010. doi:https://doi.org/10.4242/BalisageVol5.Freese01.
Kyong-Ho Lee, Nicholas Guttenberg and Victor McCrary, “Standardization Aspects of
eBook Content Formats.” Computer Standards and Interfaces 24 (2002): 227-239. doi:https://doi.org/10.1016/S0920-5489(02)00032-6.
McDermott, Rene E. “Ebooks and Libraries.” Internet Express (March 2011): 7-11,
55.
Freese, Eric. “Multi-Channel eBook Production as a Function of Diverse Target
Device Capabilities.” In Proceedings of Balisage: The Markup Conference 2010. Balisage
Series
on Markup Technologies 5, Montreal, 2010. doi:https://doi.org/10.4242/BalisageVol5.Freese01.
Kyong-Ho Lee, Nicholas Guttenberg and Victor McCrary, “Standardization Aspects of
eBook Content Formats.” Computer Standards and Interfaces 24 (2002): 227-239. doi:https://doi.org/10.1016/S0920-5489(02)00032-6.