Robinson, James A. “Performance of XML-based applications: a case-study.” Presented at International Symposium on Processing XML Efficiently: Overcoming Limits on Space,
Time, or Bandwidth, Montréal, Canada, August 10, 2009. In Proceedings of the International Symposium on Processing XML Efficiently: Overcoming
Limits on Space, Time, or Bandwidth. Balisage Series on Markup Technologies, vol. 4 (2009). https://doi.org/10.4242/BalisageVol4.Robinson01.
International Symposium on Processing XML Efficiently: Overcoming Limits on Space,
Time, or Bandwidth August 10, 2009
Balisage Paper: Performance of XML-based applications: a case-study
Jim Robinson has been a systems developer at Stanford University HighWire Press for
over ten years. He's been interested in XML-based technology since 2005.
HighWire Press is the online publishing operation of the Stanford University Libraries,
and currently hosts online journals for over 140 separate publishers. HighWire has
developed
and deployed a new XML-based publishing platform, codenamed H2O, and is in the process
of
migrating all of its publishers to this new platform.
This paper describes four XML-based systems developed for our new H2O platform, and
describes some of the performance characteristics of each. We describe some limitations
encountered with these systems, and conclude with thoughts about our experience migrating
to
an XML-based platform.
In late 2006 HighWire had started internal discussions over whether or not we needed
to
implement a radical overhaul of our publishing, parsing and content delivery system.
We wanted
the system to be much more flexible when it came to incorporating new data, sharing
data
between systems, and delivering new features.
At that time our system, which had been built up over the past decade, followed a
fairly
traditional model consisting of a display layer, a business logic layer, and a
metadata/storage layer. Specifically, our original system could be described as a
combination
of:
Perl and Nsgmls based tools to process data supplied by file providers.
NFS servers to hold derivatives (e.g., SHTML or similar files).
Relational database servers, accessed via SQL, to hold metadata.
Java Mediators talking to the NFS and database servers.
Java Servlets with a custom templating language similar to JSP, named DTL, to build
pages for the browser.
While this system has served us well, and continues to do so, there were some basic
problems we were finding difficult to overcome:
The translation from the relational databases model into Java Objects, and then into
DTL objects for use in the final display layer, often forced the writing of new
application features to become a senior developer task. In order to handle new metadata,
the developer had to determine whether or not the existing relational tables were
flexible
enough for the new data, or whether new tables were needed. Next would be the job
of
extending, or creating, appropriate stored procedures to access the new metadata.
Finally,
work would be needed in the Java layer to add object mapping support, including routines
to map the metadata into DTL.
Beyond the problem of mapping new metadata from the relational layer of the system
to
the DTL layer, the introduction of completely new models was daunting. The original
database had been built to support journals whose primary components were modeled
as
issues with articles, and articles with figures and tables. The original design of
the
system had intended that we support new models by creating new relational tables,
or
entire databases, and then building new Java mediators to handle the translation from
the
database to the display layer. Unfortunately, the reality was that it was more difficult
than we would have liked to support customers who wanted different, non-traditional
(to
us), models.
The original system hadn't been built with either XML or Unicode in mind. Much of
the
core system had been developed in the late 1990s, around the same time XML 1.0 was
published, and before it was widely adopted. By the same token, the DTL system was
developed before Unicode was supported in mainstream browsers. These shortcomings
meant it
was very difficult for us to properly ingest XML and produce valid XHTML with Unicode
support on the display side. Attempting to add Unicode support alone was a daunting
task,
as it required careful vetting of all code which worked at the character level, beginning
with the Perl system, moving through to the database systems and filesystems, and
ending
in the Java layers.
What we decided to build:
An end-to-end XML-based system. We would accept incoming XML, transform it into
different XML representations, store it as XML, query it as XML, and generate XML
for the
end user.
We would encode certain types of oft-used relationship data up front, trying as much
as possible to compute it only once.
We decided to build everything following a RESTful [Fielding2000] model,
with the idea that using a simple set of operators (GET/HEAD, POST, PUT, and DELETE),
using unique URIs (vs. SOAP documents submitted to a single URI shared by all resources),
and embedding hyperlink metadata into our documents would make it easier to spin off
new
services.
After about six months of discussions and prototyping, we had an outline of what we
would
be building and which new software technologies we would be using. By January of 2007
we had
built a demonstration system which made use of XSLT and XQuery to transform incoming
XML into
metadata and XHTML, and to deliver dynamically built XHTML pages.
After about fifteen months of work following this prototyping, HighWire had a beta
site
operating, and was ready to announce its new platform, dubbed H2O. In the first week
of July
of 2008 we launched our first migrated site, Proceedings of the National Academy of
Sciences
of the United States of America (PNAS). Since that time we've launched 57 additional
sites,
consisting of a mixture of new launches and migrations.
There are three primary tiers of XML-based technology in the H2O system:
Firenze, a HighWire-developed XSLT 2.0 pipeline execution system used to build both
front-end sites and back-end data services.
Schema, Addressing, and Storage System (SASS), a data store implementing an internally
developed protocol, the HighWire Publishing Protocol (HPP) built on top of the Atom
Publishing Protocol (APP) [AtomPub2007] and Atom Syndication Format (ASF)
[Atom2005]. SASS is used to manage and serve content, implemented in two
different technologies: XSLT 2.0 using Saxon-SA (read-only) and XQuery using MarkLogic
Server 3.x (read/write).
Babel XSLT, a HighWire-developed vector processing engine which we use to drive XSLT
2.0 transformations.
In this paper we'll discuss how these systems work, and will examine their different
performance characteristics.
Firenze
The first layer of the H2O system we'll describe is the Firenze application framework.
The
Firenze framework, written in 87,000 lines of code across 526 Java classes, is the
core piece
of technology we run that services all dynamic page generation requests in our public-facing
H2O web servers. All of the dynamically generated content served by the public-facing
sites
flows through this framework.
The bulk of Firenze is a vendor-agnostic set of classes which rely on various public
standard APIs, e.g., the Java Servlet API, JAXP, and HTTP handlers. An additional
set of
classes are then needed to provide a vendor-specific service-provider to execute XSLT
Transformations, and to provide custom URI Resolver implementations. We've written
about 30
additional Java classes which use Saxon-SA 9.x to implement this service-provider
functionality. The original implementation of Firenze used Saxon-SA 8.x APIs directly,
but in
a subsequent rewrite we decided that we would benefit from abstracting the smaller
vendor-specific parts away from the larger, more general, framework.
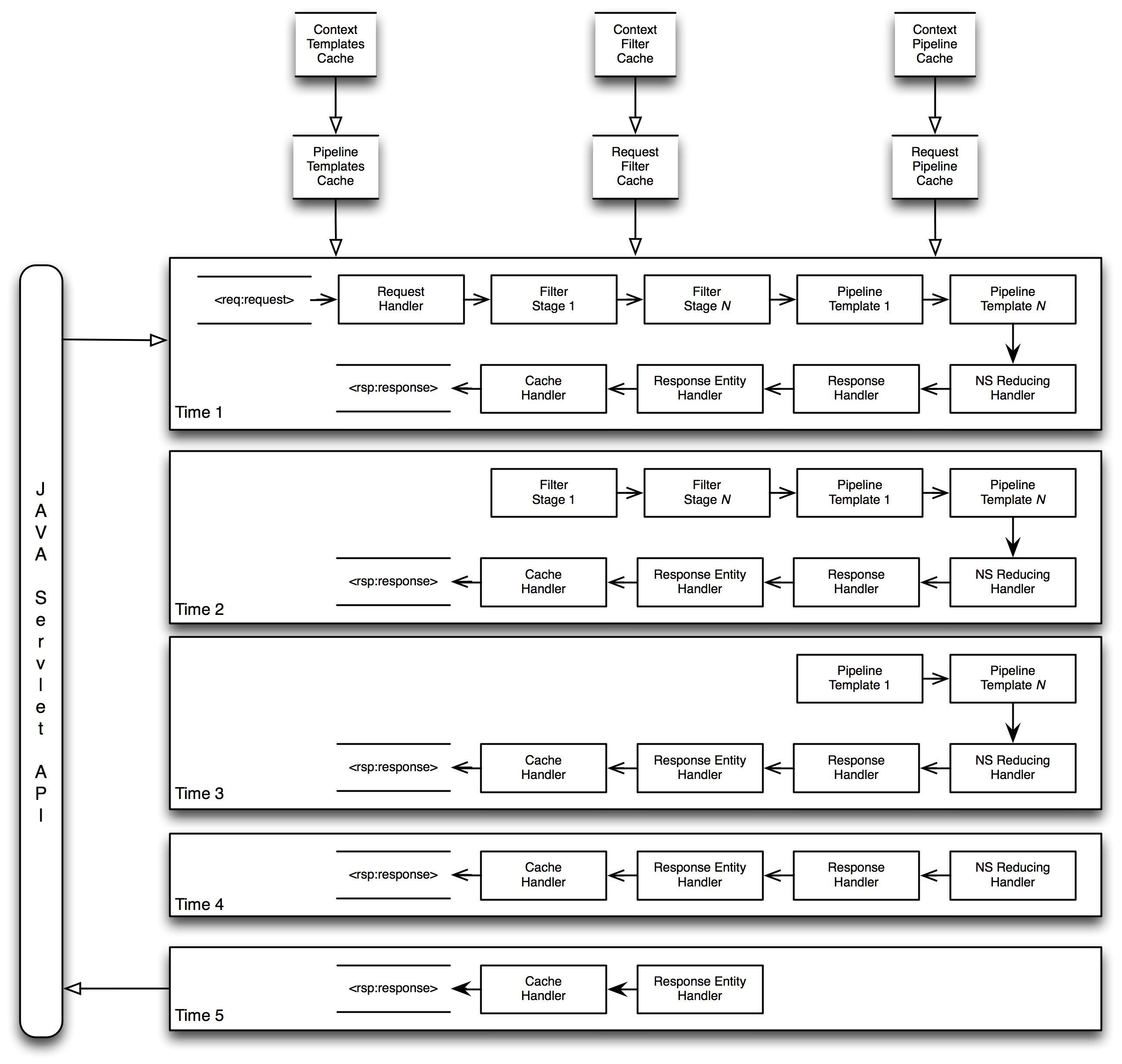
A Firenze application pushes an incoming request through four basic stages to produce
an
outgoing response:
It transforms an incoming HTTP request from the Java Servlet API into an XML
representation, req:request, based on an internal schema.
Firenze pushes the req:request through zero or more Filters which may
amend the req:request document, adding or removing data from the
body.
Next, Firenze pushes the amended req:request through a chain of one or
more XSLT Templates to produce an XML response representation,
rsp:response, which is also based on an internal schema.
Finally, Firenze transforms the rsp:response into appropriate calls
against the Java Servlet API to output an HTTP response to the client
The process of pushing these documents through the pipeline is handled via SAX2 events,
implemented by various event-handlers. As each event-handler is invoked it has a chance
to
operate on parts of the req:request or rsp:response as the documents
flow through the pipeline. Once each handler completes its area of responsibility
it is
removed from the execution stack, thereby reducing the number of SAX2 events fired
across the
length of the pipeline.
Firenze Application Pipeline
Note
From Time 1 through Time 5, various handlers for Filters and Transforms complete
their tasks and are removed from the pipeline, reducing the number of SAX2 events
which
have to be fired.
The demarcation of responsibilities between Filters and Templates is fuzzy: both may
amend
req:request documents in any fashion, and the decision whether to make the
process a specific Filter or part of the Template chain is up to the author. The Template
pipeline is then responsible for transforming the req:request into a final
rsp:response document. It may be interesting to note that almost all of the
Filters we've implemented are XSLT stylesheets. Only a few of the Filters have been
implemented directly in Java.
As an example of a pipeline operation, a request flowing through the pipeline might
start
its life as a req:request document as built via the Java Servlet API:
The initial req:request document describe the HTTP request in its entirety.
The first Filter handler which processes this req:request may then, for example,
add additional information about the resource being requested, shown here as an additional
msg:attribute element added to the end of the req:request
document:
The msg:attribute element in this case, given a name
content-peek, provides detailed information about how to retrieve the requested
resource from the central data store, in this case via the URL
http://sass.highwire.org/pnas/106/27/10877.atom?with-ancestors=yes. A second
Filter may then consume this msg:attribute and use it to fill in the contents of that
URL, in
this case a full text article with metadata about its ancestry (the issue it is in,
its
volume, etc.) expanded in-line, by adding another msg:attribute to the end of the
req:request document:
In this fashion, Filters and Templates aggregate data from multiple sources until
enough
information has been accumulated to produce the final response. It is probably obvious
that
the amount of data produced within the pipeline over the lifetime of a request may
greatly
exceed the final size of the response document sent to the client. For the example
above, the
final req:request document produced by the pipeline exceeds 375 kilobytes of
serialized XML, while the final XHTML document sent to the user is a mere 60 kilobytes.
The public-facing H2O sites run almost entirely off of Firenze, executing a codebase
consisting of a little under 50,000 lines of XSLT 2.0 code (including comments and
whitespace), spread across a set of 160 stylesheets. This codebase is maintained under
a
shared repository, with each site then applying overriding stylesheets for any site-specific
functionality. Currently each site has between 10 and 23 site-specific stylesheets,
though
some of these only consist of a single include statement referencing a shared stylesheet.
When
a context is deployed, a copy of the shared and local stylesheets are pushed out to
its Tomcat
server, and the context compiles and caches a private set of Templates objects for
execution.
This means that the shared development model for stylesheets doesn't get carried all
the way
through to the runtime, and each site must allocate memory to compile and store a
private copy
of all the stylesheets.
Firenze implements two levels of caching. The first is context-wide caching. Each
context-wide cache records all retrieved documents, e.g., JAXP Source and Templates
objects,
as well as any documents generated and cached on-the-fly by the pipeline. These cached
items
are available for any subsequent requests that execute in the context. Each context-wide
cache
may have a specific cache-retention policy and algorithm associated with it, as well
as its
own implementation of a backing store. Currently a memory-based store is used, but
we are in
the processing of implementing a disk-based store as well (our intent is to create
a two-tier
memory and disk cache).
Each context-wide cache then serves as a provider for request-specific caches. These
request-specific caches store items in memory for the duration of a given request.
The
request-specific caches were originally developed to fulfill a contract implied by
the XSLT
specification, which requires that a document, once read via functions like doc
or doc-available, remain immutable for the duration of the transformation. We've
extended this policy to require that any document read during the execution of a pipeline
remain unchanged for the duration of that request.
Currently the sites implement a very straightforward context-wide caching policy.
Any
Templates object survives for the lifetime of the context, while most Source objects
will
survive for a lifetime of 30 minutes, or until the cache size has reached a 1,000
item size
limit. Once the cache has reached its size limit, the addition of any new entries
force the
oldest Source objects to be evicted. In some cases we fine-tune the policy for Source
objects,
ensuring they will survive for the lifetime of the context, or by increasing or decreasing
the
size of the cache. This level of caching has proved to be sufficient, if not ideal,
for our
current level of traffic. The default cache policy is most effective for the scenario
of a
user who is looking at an abstract and then the full text of the article, or the scenario
of a
user scanning the abstracts of an Issue in sequential order, clicking from one abstract
to the
next within a fairly short period of time.
To determine the response times for requests handled by Firenze, we examined 78 days'
worth of Apache access logs, consisting of 727 million requests. These requests cover
all
types of requests, meaning it includes static file requests as well as dynamic page
requests.
We found that 214 million requests were dynamic, meaning that Firenze would have handled
them.
Examining the response times for those Firenze requests, we found the following response
times:
Table I
Response Times for Firenze requests
Seconds
Percent
< 1
84%
1 - 2
8%
2 - 3
3%
3 - 4
2%
> 4
3%
This means that 92% of Firenze requests took less than 2 seconds to complete, 5% took
from
2 to 4 seconds to complete, and 3% took more than 4 seconds to complete. Our performance
goal
is to be able to serve all dynamic page requests, and any associated static content,
within
1.5 seconds, so we have not yet met our performance goals.
We've been hosting sets of 15 to 20 sites per load-balanced cluster, with each cluster
consisting of either two or five servers. Each server has 32 gigabytes of memory and
between
four and eight CPU cores operating between 2.3 and 2.5 GHz. CPU on the clusters is
not heavily
taxed; we routinely record only 15% to 25% CPU usage per server, even during peak
traffic
periods.
By far the least efficient part of the Firenze system we've seen is its memory footprint.
What we've seen is that each 32-gigabyte server may use 9 gigabytes of memory during
the
lowest traffic periods, up to 15 gigabytes of memory in normal traffic periods, and
30
gigabytes during very high traffic periods. During normal traffic periods, memory
use can
cycle between 9 and 15 gigabytes within the space of a minute, with all the activity
occurring
in the Eden and Survivor spaces of the JVM. The need to allocate between one and two
gigabytes
of memory per site is a serious impediment to packing enough sites onto a machine
to fully
utilize the CPUs.
In order to improve the response time of the Firenze layer, we are currently building
Cache-Channel [Nottingham2007] support into Firenze, and are building a disk-based cache
implementation. The disk-based cache will allow us to store dynamically generated
components
of pages for a longer period of time, and will be paired with the in-memory caches
to take
advantage of optimized Source representations.
We also plan to implement an Adaptive Replacement Cache (ARC) [Megiddo2003]
algorithm to replace the Least Recently Used (LRU) algorithm currently used by the
in-memory
cache. The HighWire sites receive a steady stream of traffic from indexing web-crawlers,
and
we've found that these crawlers tend to push highly-used resources out of cache when
they
start crawling large amounts of archival content.
SASS
Firenze can be thought of as a framework designed to aggregate data from multiple
sources,
and then to manipulate that aggregate data into a final form. We currently aggregate
data from
many different services, gathering information for access control, running search
requests,
gathering reference data, etc. One of the primary services that the sites use is the
Schema,
Addressing, and Storage System (SASS). A SASS service is a data store that provides
a unified
view of metadata and content for publications we host.
One of the first decisions we needed to make when we were building the replacement
system
was how we would store metadata and related resources. Early on we mocked up a file-system
based set of XML files along with an XQuery prototype that combined these files dynamically,
feeding the combined resources to an XSLT-based display layer. These experiments proved
to us
that the fairly simple concept of using a hierarchy of XML files could actually provide
enough
flexibility and functionality for our needs. We decided we could replace some of the
relational databases of our original system with a hierarchy of XML files. Our implementation
of this, SASS, is the result of that decision.
A SASS service uses an HTTP-based protocol we've defined, named HighWire Publishing
Protocol (HPP), to handle requests. HPP is built on top of the Atom Publishing Protocol
(APP),
which specifies much of the basic functionality we needed for a database system:
It specifies how resources are created, retrieved, updated, and deleted.
It specifies the format of introspection documents, which provide configuration
information.
It specifies the output format for an aggregation of resources, using feeds of
entries.
It offers a flexible data model, allowing foreign namespaced elements and
attributes.
After examining APP in detail, we decided we needed a little more functionality, and
we
concluded that we would adopt APP and then extend it in three ways. Our extensions
give us the
ability to:
Add Atom entries with hierarchical parent/child relationships.
Create multiple alternative representations of an Atom entry, called variants.
Create relationship links between Atom entries.
As with APP, we have defined a form of XML-based introspection document, similar to
an APP
Service Document. These introspection documents define which collections exist and
the types
of resources the collections will accept. Because our HPP system allows every single
Atom
entry to potentially act as a service point to which new resources may be attached,
every Atom
entry references a unique introspection document. Each introspection document describes
which
content types and roles may be used for variant representations of the entry, and
defines zero
or more collections for sub-entries, with constraints regarding the types and roles
of
resources that may be added to each collection.
Both client and server examine the introspection document, the client being responsible
for evaluating which collection should best be used for a new resource it wishes to
create,
and the server to evaluate whether or not to allow a particular operation. Once the
server has
decided that a client's request to create a new resource is allowed, it further examines
the
introspection document to:
Determine how to name the new resource.
Determine what, if any, modifications need to be made to the new resource, e.g.,
creating server-managed hyperlinks to its parent.
Determine what other resources might need to be created or modified, e.g., creating
reciprocal hyperlinks between resources or creating a new Atom sub-entry for a media
resource.
An example slice of resource paths in our data store shows a top level entry, a journal
entry (pnas), a volume (number 106) entry, an issue (number 27) entry and an article
(page
10879) entry, and a child (Figure 1) of the article.
Examining the extensions of the paths above, you will see a number of media types
represented. The .atom files are metadata resources, while the .xml,
.html, .gif, .jpg, and .pdf files allow
us to serve alternative representations (variants) of those resources. SASS therefore
provides a
unified system for serving metadata paired with an array of alternative
representations.
The system is intended to be flexible enough that we can model new relationships
relatively quickly, and once those relationships are defined we can immediately start
creating
and serving the new resources and relationships. As an example, the hierarchy of relationships
we originally designed was, in part:
Initial SASS Journal Model
This model allows one or more Journals, each Journal may have one or more Volumes,
each
Volume may have one or more Issues, etc. When we encountered a journal whose hierarchy
didn't
match this model, we simply edited the templates for the introspection documents.
In this
case, we edited it to allow for an Issue to be attached directly to a Journal:
Updated SASS Journal Model
When deciding how to implement SASS, we concluded early-on that we needed to provide
both
a read-only and a read/write service. The read-only SASS services would be used by
the
public-facing sites, and the read/write service would be used by our back-end publishing
system. Splitting the services this way would allow us to optimize each service for
its
primary use-case: transactions and complicated searching would be needed in the read/write
SASS service, but would not be needed in the read-only SASS service.
Read-Only SASS
Based on our early prototyping work, we were confident that we could develop a
filesystem-based read-only implementation of the HPP protocol that would serve the
needs of
the public-facing sites. Currently we've implemented a read-only version of SASS using
Firenze.
The description of SASS to this point has only described the basic hierarchical layout
of resources. To take advantage of this hierarchy, HPP defines ways to request an
aggregated
view of the metadata and content representations for a resource. Specifically, a set
of
parameters may be provided when requesting an Atom entry:
These parameters may be combined in variations and some may be repeated. Taken together,
the parameters serve as a way to drive the expansion of a resource along its parent,
child,
and variant axes, returning a compound document consisting of an appropriate slice
of the
hierarchy. As an example, requesting
http://sass.highwire.org/pnas/106/27/10877.atom will retrieve the Atom entry
associated with PNAS Volume 106, Issue 27, Page 10877:
while adding the parameter to expand its ancestry axis in full,
http://sass.highwire.org/pnas/106/27/10877.atom?with-ancestors=yes,
additionally expands the Atom entries for the article's Issue, its Volume, etc:
<atom:entry xml:base="http://sass.highwire.org/pnas/106/27/10877.atom?with-ancestors=yes"
nlm:article-type="article-commentary" ...>
<c:parent xml:base="/pnas/106/27.atom">
<c:parent xml:base="/pnas/106.atom">
<c:parent xml:base="/pnas.atom">
<c:parent xml:base="/svc.atom">
<atom:category
scheme="http://schema.highwire.org/Publishing#role"
term="http://schema.highwire.org/Publishing/Service"/>
<atom:id>http://atom.highwire.org/</atom:id>
<atom:title>HighWire Atom Store</atom:title>
...
</c:parent>
<atom:category
scheme="http://schema.highwire.org/Publishing#role"
term="http://schema.highwire.org/Journal"/>
<atom:id>doi:10.1073/pnas</atom:id>
<atom:title>Proceedings of the National Academy of Sciences</atom:title>
<atom:author>
<atom:name>National Academy of Sciences</atom:name>
</atom:author>
...
</c:parent>
<atom:category
scheme="http://schema.highwire.org/Publishing#role"
term="http://schema.highwire.org/Journal/Volume"/>
<atom:id>tag:pnas@highwire.org,2009-01-06:106</atom:id>
<atom:title>106</atom:title>
<atom:author nlm:contrib-type="publisher">
<atom:name>National Academy of Sciences</atom:name>
</atom:author>
...
</c:parent>
<atom:category
scheme="http://schema.highwire.org/Publishing#role"
term="http://schema.highwire.org/Journal/Issue"/>
<atom:id>tag:pnas@highwire.org,2009-06-11:106/27</atom:id>
<atom:title>106 (27)</atom:title>
<atom:author nlm:contrib-type="publisher">
<atom:name>National Academy of Sciences</atom:name>
</atom:author>
...
</c:parent>
<atom:category
scheme="http://schema.highwire.org/Publishing#role"
term="http://schema.highwire.org/Journal/Article"/>
<atom:category
scheme="http://schema.highwire.org/Journal/Article#has-earlier-version"
term="yes"/>
<atom:id>tag:pnas@highwire.org,2009-07-02:0905722106</atom:id>
<atom:title>Should Social Security numbers be replaced by modern, more secure identifiers?</atom:title>
<atom:author nlm:contrib-type="author">
<atom:name>William E. Winkler</atom:name>
<atom:email>william.e.winkler@census.gov</atom:email>
<nlm:name name-style="western" hwp:sortable="Winkler William E.">
<nlm:surname>Winkler</nlm:surname>
<nlm:given-names>William E.</nlm:given-names>
</nlm:name>
</atom:author>
...
<atom:link rel="alternate"
href="/pnas/106/27/10877.full.pdf" type="application/pdf"
c:role="http://schema.highwire.org/variant/full-text"/>
<atom:link rel="http://schema.highwire.org/Publishing#edit-variant"
href="/pnas/106/27/10877.full.pdf"
c:role="http://schema.highwire.org/variant/full-text" type="application/pdf"/>
<atom:link rel="alternate"
href="/pnas/106/27/10877.full.html"
c:role="http://schema.highwire.org/variant/full-text" type="application/xhtml+xml"/>
<atom:link rel="http://schema.highwire.org/Publishing#edit-variant"
href="/pnas/106/27/10877.full.html"
c:role="http://schema.highwire.org/variant/full-text" type="application/xhtml+xml"/>
...
</atom:entry>
The difference between the two documents is that the parent link in the entry:
Because the with-ancestors value was yes, each entry has had its parent
link expanded into a c:parent element, pulling in metadata all the way up to
the root of the hierarchy.
Likewise, a client may also request with-descendants, and a common request
sent by the sites is for a Journal Issue with its ancestors expanded completely, and
its
descendants expanded to a depth of one. This in effect gives them the metadata for
the Issue
and its Article children, from which they may do things like build a Table of Contents
page.
In effect, these parameters allow us to perform operations somewhat like a join
operation in a relational database. If you think of the Atom entries as relational
tables,
and atom:link elements as foreign keys, we have a limited ability to join documents
together on those keys.
The read-only SASS service hosts an Apache front-end, load-balancing requests to a
set
of four Tomcat servers. Each Tomcat server uses two AMD 1210 cores, 8 gigabytes of
memory,
and two local SATA disks. Each Tomcat server runs Firenze to execute the read-only
SASS
service stylesheets. The stylesheets in turn pull data from a service named SASSFS,
running
on an Apache-only server using four AMD 2218 CPU cores, 32 gigabytes of memory, and
3.7
terabytes of FC attached SATA storage. The SASSFS service holds a synchronized clone
of the
read/write SASS service. The SASSFS system is, in effect, a network-based storage
system for
SASS, accessed over HTTP instead of a more traditional NFS protocol.
The XSLT implementation of read-only SASS consists just under 5,000 lines of XSLT
2.0
code (including whitespace and comments), spread across a set of 13 stylesheets. About
2,000
of those lines of code are an interim prototype for disk-based caching.
Our initial version of the read-only SASS service used the default in-memory caching
available in Firenze. This default would store the most recent 1,000 resources requested
from SASSFS in memory as Source document (the underlying representation being a Saxon
TinyTree). This caching proved to be effective, and the service performed very well
under
high load. While we were satisfied with the performance, we knew that we wanted to
implement
a more effective caching algorithm for Firenze as a whole, and we decided to use the
read-only SASS service as a test-bed for prototyping part of this work.
Because HighWire hosts a great deal of material that does not change very often, we
wanted to implement a caching system that could take advantage of the fact that most
of our
material is for all intents and purposes written once and then read many times. Our
research
turned up the Cache-Channel specification, describing a method where clients could
poll an
efficient service to detect when cached items were stale. If we implemented this system,
we
could cache responses built by the SASS service and, for the most part, never have
to update
them again. Thus, we could trade disk space for time, allowing us to short circuit
almost
all processing within the Firenze system when we had a cached response available
To prototype this work, we implemented a set of extensions for Saxon that allowed
us to
write serialized XML to a local disk partition. When an incoming request could be
fulfilled
by the cache, we could simply stream the data from disk, bypassing the bulk of the
XSLT
processing we would otherwise have to perform.
In the XSLT prototype, the req:request representation of the HTTP request
is processed via the following steps:
Examine the HTTP PATH of the req:request and check that the resource
is available on SASSFS; if it is not, return a not-found error code.
If the media type of the requested resource is not XML, stream the resource from
SASSFS to the client.
If the resource is not in cache, build the response. SASS reads resources from
SASSFS, storing the resources in local cache. Using the resources fetched from SASSFS,
the SASS service builds an XML rsp:response, and stores that response in
cache. Each resource written to the cache is accompanied by a corresponding XML
metadata file.
If the resource was in cache, check the metadata and perform HTTP HEAD requests
against SASSFS to see whether or not the item needs to be rebuilt. The rebuild would
be needed if any one of the constituent resources on SASSFS have changed. If nothing
has changed, stream the response from disk to the client. Otherwise a
rsp:response is built as in step #3.
For the XSLT-based prototype work, we decided not to implement the actual Cache-Channel
client or to hook into the in-memory cache of frequently used Source objects. We would
tackle these items later, when we implemented the caching logic in Java.
We expected this prototype to be slower than the original implementation, both because
Firenze would now need to be parsing XML from disk for every request, instead of simply
reusing cached Source objects, and because we would be polling SASSFS to see if a
resource
had changed.
Our initial analysis of the prototype's performance simply examined the average response
time across all requests. We were very unpleasantly surprised to find that for single
Atom
entries the average response time jumped from 0.031 seconds to 0.21 seconds. The average
response times for compound entries jumped from 0.05 seconds to 0.26 seconds. Looking
at
those averages, we decided we needed to know whether or not the slowdown was across
the
board, or whether the averages reflected large outliers.
We examined response times for a day's worth of requests using each of the two caching
implementations, and sorted the requests into two categories. One category was for
requests
that would return a single resource, effectively a transfer of a file from SASSFS
to the
client via SASS, with some cleanup processing applied. The second category was for
requests
that returned compound resources. These were resources built by SASS, using component
resources fetched from SASSFS. We examined the response time for these requests, and
sorted
them into percentiles:
Table III
SASS Response Times in Seconds per Cache implementation
Native Firenze Cache
XSLT Prototype Disk Cache
Percentile
Single
Compound
Single
Compound
25%
0.0181
0.0212
0.0262
0.0266
50%
0.0228
0.0346
0.0385
0.0616
75%
0.0299
0.0609
0.0785
0.1121
95%
0.0562
0.0956
0.7691
1.0838
99%
0.1434
0.2134
4.3750
4.7483
This analysis shows that the disk-caching prototype was 1-2.5 times slower than the
memory-based cache for about 75% of the requests, but that performance was significantly
worse for the remaining 25% of the requests.
What we discovered were two bottlenecks occurring with the prototype. The first, and
most significant, bottleneck was the IO subsystem. The hardware on our machines couldn't
keep up with the level of read/write activity being asked of them. When measuring
the disk
activity, we found it was operating at around 700 block writes per second and around
100
block reads per second. This level of activity was overwhelming the 7,200 rpm SATA
disks
used by the servers, causing high IO wait times.
The second bottleneck turned out to be the portion of XSLT code responsible for
executing HTTP HEAD requests to determine whether or not a resource had changed. When
we
profiled the application on a stand-alone machine (eliminating disk contention), we
found
that the following snippet of code was responsible for 30% of the execution time:
<xsl:sequence select="
some $m in $cache:metadata
satisfies cache:is-stale($m)" />
The cache:is-stale function takes as an argument a small XML metadata
element storing a URL, a timestamp, and an HTTP ETag value. The function executes
an HTTP
HEAD request against the URL to determine whether or not the resource has been modified.
As Saxon does not take heavy advantage of multi-threading, this XPath expression
ends up running serially. Because underlying resources don't change very often, the
algorithm usually ends up running through every metadata element only to find nothing
has
changed.
These discoveries were actually good news to us, as we knew that we could both reduce
disk contention and parallelize the check for stale resources when we implemented
the code
in Java as a native Firenze service. We're in the process of completing this work,
and in
the meantime we have rolled the XSLT prototype code into active service.
Performance of the prototype has proven to be adequate. Examining 12 days of access
logs
from read-only SASS, the service is handling an average of 5.9 million requests per
day,
ranging from a low of 3.3 million requests to a high of 7.8 million requests. On average
the
service is processing 70 requests per second, writing 3.5 megabytes per second to
its
clients.
Overall the read-only SASS service is serving an average of 266 gigabytes per day.
Because SASS serves both XML markup and binary data, and because binary data may be
streamed
directly from the SASSFS system without any intermediate processing by SASS, only
a subset
of those 266 gigabytes is XML processed via Firenze. A breakdown of the two types
of content
shows we serve an average of 166 gigabytes of XML data per day, and an average of
100
gigabytes of binary data:
Table IV
Gigabytes served per day by read-only SASS
Date
XML
Binary
Total
2009-07-01
193.05
122.33
315.38
2009-07-02
179.54
114.36
293.90
2009-07-03
132.53
87.73
220.26
2009-07-04
88.69
60.18
148.87
2009-07-05
111.07
69.61
180.68
2009-07-06
197.56
124.15
321.71
2009-07-07
221.43
141.19
362.61
2009-07-08
228.73
142.96
371.69
2009-07-09
215.75
123.90
339.65
2009-07-10
178.74
97.77
276.51
2009-07-11
115.11
48.31
163.42
2009-07-12
134.76
67.93
202.68
It has proven difficult to compare these numbers against our older system because
the
SASS service combines services that are spread out across multiple database and NFS
servers
in the older system.
Read/Write SASS
In order to implement the read/write SASS service, we knew we needed to build a
transactional system. We had to be able to know that we could roll back any operation
that
met with an error condition. In addition, we wanted a system that would allow us to
search
the XML documents without needing to write custom code or build new indexes for every
new
query we might come up with.
After exploring the available systems, we decided to license the XML server provided
by
Mark Logic Corporation. In addition, since both the MarkLogic Server and its underlying
XQuery technology were new to us, we contracted with Mark Logic for consultants to
work with
us to build an implementation of our HPP specification. HighWire staff provided details
regarding the specification and Mark Logic consultants wrote an implementation in
XQuery.
The implementation was written in just under 7,600 lines of XQuery code, spread across
24
modules.
We're currently running MarkLogic Server version 3.2, which is a few years old, and
which uses a draft version of XQuery. Newer releases of MarkLogic implement the XQuery
1.0
specification, and we plan to eventually modify the XQuery implementation to take
advantage
of the newer releases.
We are currently running the MarkLogic implementation on one dedicated production
server
using four AMD 2218 CPU cores, 32 gigabytes of memory, and 3.7 terabytes of FC attached
SATA
storage. This server is currently handling between 7 to 8 million requests per month,
and is
used as the system of record for our production processing system. The break-down
of those
requests for the months of April, May, and Jun in 2009 were:
Table V
Number of requests to SASS read/write service
Type
April
May
Jun
GET (non-search)
7,199,235
5,852,764
5,900,093
GET (search)
642,681
521,106
751,463
GET (report)
23,308
10,461
16,919
POST
1,097,209
730,489
913,385
PUT
21,214
10,284
26,905
DELETE
9,989
4,652
35,143
Total Requests
8,993,636
7,129,756
7,643,908
GET (non-search) reflects the retrieval of a single Atom entry or variant
GET (search) reflects the execution of a search
GET (report) reflects the execution of custom reporting modules we've
written
What these numbers translate to is the loading of between 40,000 to 50,000 articles
per
month, though in our first month of operations, when we were migrating PNAS, we loaded
93,829 articles that month alone.
As of Jun 18th 2009, the read/write SASS service held the following counts of resource
types (there are others, but these are the ones whose counts may be of general interest):
Table VI
read/write SASS service resource counts
Resource Type
Count
Journal/Volume
2,735
Journal/Issue
17,734
Journal/Article
421,375
Journal/Fragment
485,792
Adjunct
99,121
All variants
3,511,002
In the table above, Journal/Volume, Journal/Issue, and Journal/Article resources
correspond to the obvious parts of a journal. Journal/Fragment resources indicate
resources
extracted from an article to create a sub-resource, in this case they are representations
of
figures and tables. Adjuncts are media resources that provide supplemental data to
article
(e.g., raw data sets submitted along with an article). All variants consist of alternative
representations, including XHTML files, PDFs, images, etc.
In general we've found the performance of MarkLogic to be very good, and have not
yet
reached the level of use that would require us to add additional servers. When we
do reach
that point, an important advantage we see in MarkLogic was that we ought be able to
increase
capacity by simply creating a MarkLogic cluster of multiple servers.
There are two areas where MarkLogic has had some trouble with our particular application:
Complex DELETE operations are slow
Some ad-hoc XQuery reporting may be resource intensive depending on the
expressions used.
In MarkLogic, individual delete transactions are very efficient, but to properly
implement a DELETE operation in SASS the application executes an expensive traversal
algorithm, building a list of resources, including:
Resources that are children of the targeted resource.
Resources that refer to the resource targeted for deletion or to any of its child
resources.
The application then needs to delete all the descendant resources and remove
all references to those deleted resources. Deleting a single article could require
that the
application perform a dozen searches, delete fifty resources, and then update all
Atom
entries that refer to those deleted resources. This algorithm is costly to execute,
and it
makes DELETE far slower than the other operations.
For each type of HTTP operation a selection for 5,000 log entries were examined for
their execution times:
Table VII
Seconds to complete a request
Percentiles
Type
Mean
Minimum
Maximum
50%
75%
99%
GET (non-search)
0.0397
0.0073
3.6032
0.0133
0.0328
0.2670
GET (search)
0.4611
0.0098
23.9744
0.2342
0.3818
3.9794
POST
0.0775
0.0259
0.5822
0.0592
0.0977
0.1750
PUT
0.1304
0.0159
4.3666
0.0897
0.1487
0.6931
DELETE
6.1802
0.0084
628.9670
3.4020
4.1776
33.2024
GET (non-search) reflects the retrieval of a single Atom entry or a variant
GET (search) reflects the execution of a search
Performance is excellent for the GET (non-search), POST, and PUT operations, and fairly
good for GET (search), but DELETE operations are far slower than any other operation.
The
intrinsic problem with handling a DELETE is the complexity of the algorithm and the
number
of documents that need to be searched and modified. In theory we ought to be able
to
optimize how the searches are performed, implementing a more efficient algorithm,
thereby
speeding up the execution. Because DELETE operations make up such a small number of
the
requests we execute, we have not yet seriously investigated implementing such an
optimization.
The other problem area we've had with MarkLogic is constructing efficient ad-hoc
queries. MarkLogic automatically creates indexes for any XML that it stores, and while
these
indexes cover many types of possible queries, it is possible to construct queries
that do
not take advantage of these indexes. At various times we want to run ad-hoc reports
against
the database, and we've found that some of these queries can time out if they are
written
without applying some knowledge of how the server's query optimizer work. Given the
structure of our XML, for some of our ad-hoc queries, a challenge has been that our
version
of MarkLogic Server will not use an index if the expression is within nested predicates.
As
an example, if we have an index built on the two attributes @scheme and
@term for atom:category in an Atom entry, which together
function as a key/value pair:
/atom:entry/atom:category/@scheme
/atom:entry/atom:category/@term
as well as on the element:
/atom:entry/nlm:issue-id
then if we wanted to find those entries with the values represented by the
variables $scheme, $term, and $issue-id, the XPath
expression must be written along the lines of
for $cat in /atom:entry[nlm:issue-id = $issue-id]/atom:category[@scheme eq $scheme and @term eq $term]
return $cat/parent::atom:entry
Writing it in an alternative way, using nested predicates,
/atom:entry[atom:category[@scheme eq $scheme and @term eq $term] and nlm:issue-id = $issue-id]
results in the server's not using the @scheme and @term indexes,
resulting in longer execution times. As more predicates are added to a query, it can
become
very difficult to figure out how best to structure the query to take full advantage
of the
indexes.
As an example, the following XQuery expression searches for Atom entries under a
specified $journal-root location, and identifies those Atom entries that match particular
atom:link and atom:category criteria. The nested predicates listed are required to
ensure no
false positives are returned:
xdmp:directory($journal-root, "infinity")/hw:doc
/atom:entry
[atom:link[@rel eq $hpp:rel.parent and @c:role = $hpp:model.journal]]
[atom:category[@scheme eq $hpp:role.scheme and @term eq $hpp:model.adjunct]]
[not(atom:link[@rel eq 'related' and @c:role = $hpp:model.adjunct.related])]
This query takes some 472 seconds to run against a $journal-root which
contains a little over 1.8 million resources. Rewriting the query to first look for
one half
of the criteria for each nested predicate listed above, thereby allowing the server
to use
more indexes, reduces the execution time to around 4.6 seconds:
for $entry in
xdmp:directory($journal-root, "infinity")/hw:doc
/atom:entry
[atom:link/@c:role = $hpp:model.journal]
[atom:category/@term = $hpp:model.adjunct]
[not(atom:link/@c:role = $hpp:model.adjunct.related)]
where
$entry/atom:category[@scheme eq $hpp:role.scheme and @term eq $hpp:model.adjunct]
and $entry/atom:link[@rel eq $hpp:rel.parent and @c:role = $hpp:model.journal]
and not($entry/atom:link[@rel eq 'related' and @c:role = $hpp:model.adjunct.related])
return
$entry
Both
queries produce the correct results; it's just a matter of how quickly those results
are
computed. Another way we could improve the performance of this query is to change
the
structure of our XML to be better aligned with MarkLogic's indexes. For this application,
that was not an option.
MarkLogic Server is able to provide detailed information about which parts of a query
are using an index, and is able to provide very detailed statistics regarding cache
hit
rates for a query. Many queries in MarkLogic can be fully evaluated out of the indexes,
and
these queries are very efficient, usually returning in sub-second time. However, as
queries
become more complex, the developer needs to understand the impact of the query's conditions
and the way they interact with the indexes. MarkLogic provides accurate responses
to
queries, and as the query is made to make more use of the indexes, response times
are
typically reduced.
As an example, the following query makes full uses of the indexes to identify those
resources that contain a given DOI value $doi, and MarkLogic can return results for
this
type of query in less than 0.1
seconds:
for $doc in
xdmp:directory("/pnas/", "infinity")/hw:doc/
atom:entry/nlm:article-id[@pub-id-type eq "doi"][. eq $doi]
return
base-uri($doc)
Babel XSLT
The final component of the XML-based systems used in H2O is the Babel XSLT processing
engine. Babel XSLT is a batch processing engine that we use to transform incoming
source XML
into resources for loading into the read/write SASS service. We've implemented an
HPP aware
client in XSLT 2.0 (using Java extensions to allow XSLT programs to act as an HTTP
client),
and we perform the bulk of our content loading using the Babel XSLT engine to POST
the content
into the read/write SASS service.
Babel XSLT is an HTTP service that accepts XML documents describing a batch operation
to
perform. A batch consists of an XSLT stylesheet to run, an optional set of XSLT parameters
(these parameters may be complex content, meaning they may contain document fragments
or node
sequences), and one or more input sources to process, along with corresponding output
targets.
When a batch is submitted, it is queued for processing until the server has free
capacity.
Once the server begins processing a batch, it draws from a pool of threads to apply
the
specified stylesheet to each specified input source in parallel. Upon completion,
a batch log
report is produced that indicates the start and stop time of each transformation,
as well as
any xsl:message log events captured during the execution of the individual
transformations. As with the input parameters, the xsl:message log events may be
complex content.
The Babel XSLT service keeps a permanent cache of compiled Templates for the stylesheets
it is asked to execute. Because a batch requires the uniform application of any XSLT
parameters to every input source in a batch, the server is then able to set up its
processing
workflow once and then apply that workflow en masse to all the inputs listed in the
batch.
We currently use Babel XSLT to produce and, via its HTTP and HPP client extensions,
to
load and update almost all H2O content. The production process includes tasks such
as applying
Schematron assertions to produce reports on the content, applying normalization routines
to
the article source XML, enriching the article source XML to include extra metadata,
and
converting those article source files into Atom entries and variant representations
(e.g.,
XHTML). HighWire has written about 48,000 lines of XSLT 2.0 code (including comments
and
whitespace), spread across 318 stylesheets, to perform this work.
We are currently running Babel XSLT on two servers. Each server uses two AMD 1210
cores, 8
gigabytes of memory, and various NFS mounted storage arrays. Across both servers we
are
executing an average of 3,839 transformations per hour. At peak times we've run anywhere
from
23,000 to 57,000 transformations in an hour. Transformation execution times range
from a low
0.20 seconds to a high of 20.0 seconds, with 95% of transformations taking less than
7.0
seconds to complete.
The biggest efficiency headache we've encountered with the Babel XSLT service has
been
related to its memory requirements. A large enough batch job can run into memory limits
as it
converts the incoming batch into a JDOM object, runs its XSLT transformations, and
uses JDOM
to produce the batch log report. The Babel XSLT servers have a minimum memory footprint
ranging from 200 to 300 megabytes, but can easily use up to 5 gigabytes of memory
to process
their workloads. In the space of one minute, a server might jump from needing 500
megabytes to
needing 2.5 gigabytes of memory.
Currently HighWire uses a Perl-based framework to submit Babel XSLT jobs. The Perl
code is
responsible for identifying which stylesheet and which input and output files need
to be
submitted for a given batch, based on the phase of processing in a workflow. The Perl
code is
responsible for producing a batch, submitting it to the Babel XSLT system, and then
examining
the batch log report to determine whether or not the job was completed successfully,
and to
report any messages emitted by the stylesheet.
Conclusion
By far our most challenging experience has been that of educating everyone within
our
organization. Our developers are faced with new systems that make use of a bewildering
array
of specifications and standards, and it has not been easy for everyone involved to
come up to
speed on everything; our developers have demanded better documentation and clearer
explanations of how the new systems work.
In terms of performance, we've found the XML-based technologies to be adequate, if
not
stellar. When we've needed to improve performance we've applied traditional techniques:
Don't perform work if you don't need to (e.g., Firenze's ability to remove handlers
from the stack when the handler has completed its task).
Take advantage of optimized representations of your data, if available (e.g., using
compiled Templates, making use of optimized Source implementations).
Develop caching techniques at multiple layers, trading space for time.
Examine your algorithms to determine if they are the best fit for the
application.
Applying these techniques, the XML-based technologies we've discussed here can be
made
fast enough for most of our needs.
The advantages we see to using a unified, RESTful, XML data store paired with high-level
declarative programming languages like XSLT and XQuery are:
It is easier to introduce changes to our data models.
There's no need to spend time writing code that converts data from one data model
into another (e.g., from relational form to an object-oriented form and back).
Acknowledgements
I would like to thank Craig Jurney <cjurney@stanford.edu>, the architect and
developer of the Firenze system, and Jules Milner-Brage <jules@adakara.com>, the
primary architect of the SASS specification and the architect and developer of the
Babel XSLT
system, for their comments and advice during the preparation of this paper.
Roy Thomas Fielding,
Architectural Styles and the Design of Network-based Software
Architectures, Ph.D. Thesis, University of California, Irvine, Irvine,
California, 2000. [online]. [cited July 2009].
http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm.
Joe Gregorio, ed. and Bill de
Hóra, ed. The Atom Publishing Protocol, Internet RFC 2053,
October 2007. [online]. [cited July 2009].
http://tools.ietf.org/html/rfc5023.
M. Nottingham, ed. and R. Sayre, ed.
The Atom Syndication Format, Internet RFC 4287, December 2005 [online].
[cited July 2009]. http://tools.ietf.org/html/rfc4287.
Nimrod Megiddo and Dharmendra S. Modha,
ARC: A Self-Tuning, Low Overhead Replacement Cache, USENIX File and
Storage Technologies (FAST), March 31, 2003, San Francisco, CA. [online]. [cited July
2009].
http://www.almaden.ibm.com/StorageSystems/projects/arc/arcfast.pdf.
Author's keywords for this paper:
XML; XSLT; XQuery; Atom Publishing Protocol; publishing platform; performance case-study