McCay, Charlie, Michael Odling-Smee, Joseph Waller and Ann Wrightson. “Graciously handling a level of change in a complex specification: Configuration management
for community-scale implementation of an HL7v3 messaging
specification.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Wrightson01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Balisage Paper: Graciously handling a level of change in a complex specification
Configuration management for community-scale implementation of an HL7v3 messaging
specification
Charlie McCay
Ramsey Systems Ltd
Charlie McCay has been closely involved in defining how XML is used in the HL7
healthcare interoperability specifications for ten years. He is Chair of the HL7
Technical Steering Committee and on the HL7 international board. As well as
international standards work, he has been responsible for specifying the way XML
is used in many English national projects including the transfer of primary care
records (GP2GP), Electronic Prescribing, and the Retinal Screening Program. He
is currently working on Standards conformance methods for the NHS in England,
and convergence between international standards groups in the healthcare
sector.
Michael Odling-Smee
XML Solutions Ltd
With a background in Experimental Atomic & Molecular Physics Dr.
Michael Odling-Smee switched to IT in 2000 where he started his career in a
small Java software consultancy start-up before moving on to Integration
architecture in both B2B and Health care arenas. As is the nature with
integration Michael has been involved in XML message integration design using
many XML based technologies - XSD, XSL, SOAP, WS-*, ebXML, BPEL and XML
Acceleration appliances. Michael also started an XML based requirements
management system (http://www.xml-solutions.com/products.html) that uses XSD to
define an XML data model for requirements and use-cases with XSL and XSL:FO to
derive multiple views on the data. In May 2007 Michael co-founded XML Solutions
Ltd. - a specialist XML and Systems Integration Consultancy.
Joseph Waller
XML Solutions Ltd
Joseph is co-owner and Director of the Integration Consultancy XML Solutions
ltd (http://www.xml-solutions.com). He started his career developing hedge
derivative systems for Halifax Bank before moving onto architectual consultancy
work and eventually specializing in XML and Healthcare integration. Developing
integration strategies across finance and UK government systems, recent work has
focussed on England's NHS Spine and related parts of the National Programme for
IT.
Ann Wrightson
IT Consultant - Technical Architecture
Informing Healthcare (NHS Wales)
Ann Wrightson has been working with markup since 1978, from typesetting
languages & fielded records through generic coding to SGML &
XML. She has experience of using markup for interoperability and
platform-independence across a wide range of content including published
reference works, technical publications, e-learning, legal codes &
materials, and semantic interoperability standards for information systems.
Since 2004 Ann has worked principally with interoperability in healthcare,
initially on the information systems supplier side and more recently in NHS
Wales. She has a particular concern for usability of interoperability standards
within a diverse implementation community, and has pursued that concern in the
international HL7 community through involvement in innovations to introduce
service-oriented integration and an adaptable enterprise architecture framework.
Ann has been a member of the Board of HL7 UK since 2007, from 2009 as HL7 UK
Technical Committee Chair.
The concept of a flexible and yet also breakable interface is central to
successful configuration and version management for a messaging specification.
Changes which are made to a message or message definition should not affect systems
or design teams that are not concerned with the subject of the change. However,
changes causing unexpected behaviour or misinterpretation of a message should ‘break
the interface’ thus making it impossible for systems to unknowingly use a changed
message in a way which may hold clinical safety or other risks. Achieving these
features in a complex specification with a diverse implementation community is not
a
simple matter. However, there are several measures that could be beneficial.
Applying the kind of configuration management discipline that is well known for
complex software artefacts to the development of a complex specification is likely
to be cost-effective, even though the tools available are less mature. A combined
strategy of representing key aspects of design configuration not only within the
specification artefacts published to the implementation community, but also as a
matrix documenting expected impacts, and within message instances in live operation,
is also promising as a way to enable gracious handling of change.
Version and configuration management is an important area both in computing generally
and in the management of XML artefacts of many kinds (see Versioning Symposium ). This paper is about version and configuration management issues arising
for a closely related collection of HL7v3 (Health Level Seven Version 3) healthcare
messaging specifications. Although this is a specialist area, the overall challenges,
approach and conclusions are expected to be of interest to a wider community. This
paper
is therefore divided into two sections, an introduction for background and a main
body
describing the method of analysis and resulting recommendations for improving management
of configurable artefacts on a large programme.
This Introduction provides background on the underlying principles of HL7v3 and a
general description of the structure and internal dependencies of an HL7v3
specification.
The main body of the paper describes an approach developed in order to enable a
substantial HL7v3 messaging specification to change "graciously", that
is, accommodating change whilst restricting the introduction of interface-breaking
changes to a necessary minimum. The principal recommendations of this approach are
first, developing an overall dependency map and corresponding configuration matrix;
and
second, identifying specific dependencies in message instances through profiles
referenced by name (that is, by profile-id).
HL7v3 from RIM to XML - a quick tour
HL7 as a standards development organization (generally known as
"HL7.org") has been engaged recently in extending and adapting the
HL7v3 framework to accommodate a wider range of system integration approaches, in
particular adopting an enterprise architecture framework based on RM-ODP (Reference
Model – Open Distributed Processing, ISO/IEC 10746), and developing a suite of
service-oriented specifications. The interested reader can follow these recent
developments on the HL7 wiki , however this
section focusses on the traditional core of HL7v3, that is, messaging specifications
designed to enable information flow between disparate information systems within a
healthcare organization. The account that follows draws on the HL7v3 Guide and
Foundation sections of the HL7v3 Normative Edition 2008 (see HL7v3 Normative ), intentionally following their style and phraseology so as to give an
accurate sketch. However, this is only a sketch, and a thorough and accessible
introduction to HL7v3 can be found in Hinchley's HL7v3 Primer (see HL7v3 Primer).
The heart of HL7v3 is a hierarchy of three levels of information modelling:
Reference Information Model (RIM)- The RIM encompasses the HL7 domain of
interest as a whole, and provides an underlying relatively simple yet
comprehensive model for the data content of all HL7 messages. The RIM is a
static model of health and health care information as viewed within the
scope of HL7 standards development activities. The RIM is a class-based
model that can be expressed in UML (the Object Management Group's Unified
Modelling Language, ISO/IEC 19505).
Domain Message Information Model (D-MIM)- A D-MIM is a specialization of
the RIM that models the subject matter of a domain (a particular area of
interest in healthcare). For example, there is a Clinical Statement Pattern
D-MIM that provides a standard, high-level structure for clinical
information as it appears in messages supporting specific business
functions. A characteristic feature of the HL7v3 modelling style is that one
RIM class may appear many times in different specializations in one D-MIM.
Another feature is that association classes (in UML terms) are heavily used,
and often carry substantive attributes of the domain being modelled.
Refined Message Information Model (R-MIM)- An R-MIM is a subset or
refinement of a D-MIM that expresses the information content for a
particular message or closely related set of messages.
Complementing the structural models in the above hierarchy is a comprehensive
repertoire of data types for class attributes and vocabulary domains for attributes
with coded values.
The elaboration of complex and detailed D-MIMs and R-MIMs from a single,
relatively simple RIM is supported by methodical use of class attributes to express
structural relationships and dependencies across the model stack. For example, the
classCode attribute is used to classify derivatives of RIM classes, so that Acts
that are Observations all have a common coded attribute expressing that fact.
Another example of methodical use of class attributes is to express state values
that are defined for a RIM class, so that the status of an Act could be active,
suspended, cancelled, completed, or aborted - and the semantics of these status
values is described in a state machine that forms part of the HL7v3 normative
publication.
The diagrammatic representation of an R-MIM is accompanied by structured tabular
documentation that typically contains usage constraints and implementation guidance.
This is called a "Tabular view" in the HL7v3 community.
The HL7v3 Clinical Document Architecture (CDA) is of particular interest, not just
because it has been adopted for clinical messaging in the NHS Connecting for Health
Messaging Implementation Manual (MIM), but also because it has been implemented in a range of contexts
worldwide. The base CDA clinical document includes marked up text intended for human
readers together with structured, coded data following the Clinical Statement
Pattern, and is customarily specialized for a particular context of use by means of
Implementation Guides providing precise guidance on usage. This is a further layer
of specification, in particular involving Templates, (a rather generic name for) a
specific HL7v3 way of constraining a region of an R-MIM. Typical constraints added
to the underlying R-MIM by a Template would be forbidding or making compulsory some
attributes that are optional, and providing specified value sets for attributes that
have general datatypes such as strings or integers in the underlying R-MIM.
CDA has an R-MIM, and like all HL7v3 R-MIMs there is a defined, tool-supported
automation that generates the XML implementation. R-MIMs (in an XML model
representation known as the MIF (Model Interchange Format)) are transformed by
standardized tools into a set of W3C schema documents conforming to the XML
Implementation Technology Specification (ITS) for HL7v3. The role of datatypes in
this context illustrates very well the interdependency of computable and human
readable aspects of HL7v3 specifications, as described in the section on CDA in
HL7v3 2008 Normative Edition:
HL7v3 defines both an abstract data type specification, which is the
definitive reference, and an XML-specific data type representation.
Data types define the structural format of the data carried within a RIM
attribute and influence the set of allowable values an attribute may assume.
Some data types have very little intrinsic semantic content. However HL7 also
defines more extensive data types such as the one for an entity's name. Every
attribute in the RIM is associated with one and only one data type.
A reader will often find that the XML-specific description of a data type is
sufficient for implementation, but at times will want to refer to the abstract
data type specification for a more comprehensive discussion.
A further factor is that although the principles and specification developement
practice are strongly model driven, the majority of implementations work purely with
the XML artefacts technically, treating the models as documentation rather than
computable artefacts. The XML style adopted in the HL7v3 XML ITS is more suited to
taking object instances unharmed from one object model into another (i.e as a
serialization of instances of RIM classes), than for conventional XML processing
based on XPath and XSLT. Much of the meaning that would be conveyed by element
naming in other XML styles is provided through attribute values belonging to
maintained value sets such as template identifiers. This makes these value sets -
which can get quite numerous - a key dependency item for implementers, especially
if
value sets need to have (for business reasons) a maintenance cycle that is different
from the maintenance cycle for the message models and thence the XML schemas.
The manifold interdependencies within a sizeable HL7v3 specification, especially
where a number of clinical communications are implemented using a common repertoire
of templates, can be seen even from this brief summary. Simple version management
is
built into the available HL7v3 tools, however the potential complexity is greater
than can be handled by simple means. Conversely, it is difficult to see how the kind
of technology and practice used to control complex software products together with
their specification dependencies (see Software Product Lines) can be put in place across a diverse user community - and a diverse
user community is inherent to the need for a rigorously modelled interoperability
standard.
Sustaining an HL7v3 Messaging Specification
A particular challenge in sustaining a complex interoperability specification for
the
long term is to enable it to change "graciously", that is, to
accommodate change with the minimum necessary impact on established users. This is
a
problem arising from success: being able to handle change graciously is a requirement
that emerges for interoperability specifications when they achieve a significant level
of acceptance and implementation, and need to continue to evolve in response to changes
in business requirements.
Development and maintenance process for a community-level specification
A published specification designed for adoption by a substantial community is
necessarily the output of a multi-stage process that crosses organizational
boundaries. Changes to specification artefacts need to make sense in the context of
this process as well as technically. This section outlines a typical development
process (in the authors' experience across several such activities) using HL7v3
tools.
The logical unit in which new content is created, or within which maintenance
changes are introduced, is called a specification domain in HL7v3. Domains organize
a large specification into sections containing a suite of interactions with common
subject matter. For example, domains in the HL7v3 Normative 2008 package published
by HL7.org include Patient Administration, Public Health Reporting and Clinical
Genomics. Domains in the NHS Connecting for Health Messaging Implementation Manual
(MIM) include Alerts and Diagnostic Image Reporting. From an implementation
perspective, a domain usually (but not always) also corresponds to a logical service
interface for interoperability.
A typical process for introducing change in a specification domain is as
follows:
Requirements for new interactions or changes to current interactions are
elaborated and documented in a business analysis artefact, for example a
narrative document plus analysis-level UML models showing information
structures and message flows.
This analysis (a combination of process analysis and high level
information modelling) is generally undertaken within the specification
modelling process, either blended in or as an initial phase of work, in
HL7.org working groups. In HL7v3 implementation programmes it is more likely
in the authors' experience to be separated out into a distinct business
analysis team, partly by design and partly because subject matter knowledge
and technical HL7v3 knowledge and skills are more likely to be developed by
different individuals.
A specification design team analyses the requirements into HL7v3
information models with accompanying implementation guidance, mostly
embedded in the specification's Tabular Views. Any required changes to
locally maintained datatypes and value sets are made, then the XML schemas
for the new or amended messages are generated from the HL7v3 information
models using HL7v3 tools.
Alongside the XML schemas, an XML representation of the whole domain model
is generated, which is particularly useful from an implementer's point of
view since computational difference checking can be used to verify presence
or absence of changes eg in the guidance wording. Example messages are
constructed by a semi-automated process, and the whole domain content is
formatted into a publication package. The publication package is designed to
be human-readable in a Web browser, and also to have a uniform directory
structure so that the XML schemas, for example, can be extracted easily for
deployment into an implementer's test environment.
The revised specification is published to the implementation community,
and a review and comment process follows leading to formal adoption of the
new and changed content. The new content and changes are then introduced
into live use through the implementation community's agreed implementation
and testing processes.
In practice, in the authors' experience, such a development process becomes more
variable once a family of specifications has become established in use. For example,
once such interfaces become a normal way of doing business, requirements and
analysis level models are more likely to come in from different sources, and a
greater quantity of development relating to live business requirements leads to a
greater likelihood of high priority late requirements changes. In general there will
be changes and new content in hand for more than one domain, and the review cycles
and publication schedules for different domains need to be aligned as far as
possible to facilitate scheduling of review and testing activities. This added
complexity is the price of success and needs to be expected and managed rather than
- as sometimes occurs - just being regarded as anomalous and
"incorrect".
A framework for gracious handling of change is expected to deliver its main
benefit by reducing the overall cost of the activities outlined above.
Representative change scenarios
In order to identify the nature of the changes that needed to be handled
graciously, a systematic analysis of an established specification was undertaken.
Representative change scenarios were used to ground the analysis in implementation
experience. Actual past change scenarios were collected from developers and
implementers alongside probable future scenarios for change. The resulting
collection was cut down to a representative selection through a preliminary analysis
of similarity, ensuring coverage of the main types of change within a manageable
selection for detailed analysis. All the selected scenarios were analysed as if they
were isolated requirements for change against an assumed baseline, that is, it was
assumed that the changes were independent, and actual past changes and other
scenarios selected were analysed in the same way.
A sample of the types of scenarios encountered is given below.
Extension to a value set due to organizational change
A vocabulary (a value set specifying valid values for an attribute) used in a
message (call it a type A message) needs an additional term (value) due to the
addition of a new organizational unit. The structure of the message has not
changed, however the change in allowed values is significant for a central
service point that receives type A messages, and also to information systems
needing to issue type A messages including the new value.
However, any systems that send type A messages and have no need to mention the
new organizational unit are unaffected. Their old-style type A messages continue
to be accepted by the central service point.
Introducing structured representation of medication dose
Initially, medication dosage instructions were contained in a text field.
Whilst this is meaningful for a human, it is not machine processable for example
to enable decision support for prescribing. A new message component is
introduced to enable endpoints able to provide fully structured dosage
instructions to do so. The new component replaces the old component wherever
possible, and the old component will eventually become deprecated. Because of
the long retention period of clinical records the old component may still appear
in older information, even when contained in new messages. This results in
systematic change to the representation of a prescription, affecting a number of
messages across a number of different interactions.
Extemporaneous Preparations
Although most prescriptions involve manufactured products (such as packs of
tablets) that are identified using codes from a nationally managed terminology,
occasionally a pharmacist creates a one-off preparation for an individual
patient, and such an extemporaneous preparation needs to be recorded
differently, including its ingredients. A new message component is introduced to
represent these extemporaneous preparations. This structure would be used
instead of the standard prescription item structure when required (i.e. there
would be a choice about which structure is used). This results in systematic
change to the representation of a prescription, affecting a number of messages
across a number of different interactions.
Increased validation leading to new error codes
To increase data quality, additional specific validation is introduced on
certain interfaces. New error codes will be introduced to indicate the cause
when a message fails the new validation. The new error codes will need to be
recognized by sending systems, and implementers' testing processes will also
need to cope with new errors emerging in previously tested interfaces.
Changes to Tabular Views to clarify interpretation
Documentation in Tabular Views provides authoritative guidance to
implementers. In this scenario, a defect raised during testing is attributed on
analysis to misinterpretation of poor wording in the guidance. The wording is
revised. This is a literal change in the specification that does not include any
technical change, yet does constitute a significant change for implementers with
respect to conformance.
Schema change as a result of an integration defect
During testing process an integration defect is encountered which is traced to
an inconsistency between guidance wording in the Tabular View and the XML schema
for the associated message. On analysis, the guidance is found to be correct,
and the schema is corrected and re-issued (using the normal HL7v3 model-driven
schema generation process).
A complication for this scenario would be if the defect corrected is in the
datatypes schema document, which is used as a common resource by all schemas in
a published specification package.
Specification artefacts and the HL7v3 specification change process
The development of a substantial HL7v3 specification package involves many artefacts,
and an important early activity was to identify amongst these the key items for
configuration management and change control. Candidate configuration items were gathered
from the combined knowledge and experience of implementers and developers of the
specification in workshop-style meetings, in parallel with gathering scenarios as
described above.
This activity, especially considered in the light of the authors' knowledge
of other HL7v3 specification developments, brought out clearly the applicability of
Software Product Line concepts and techniques (see Software Product Lines )to the development of complex specifications.
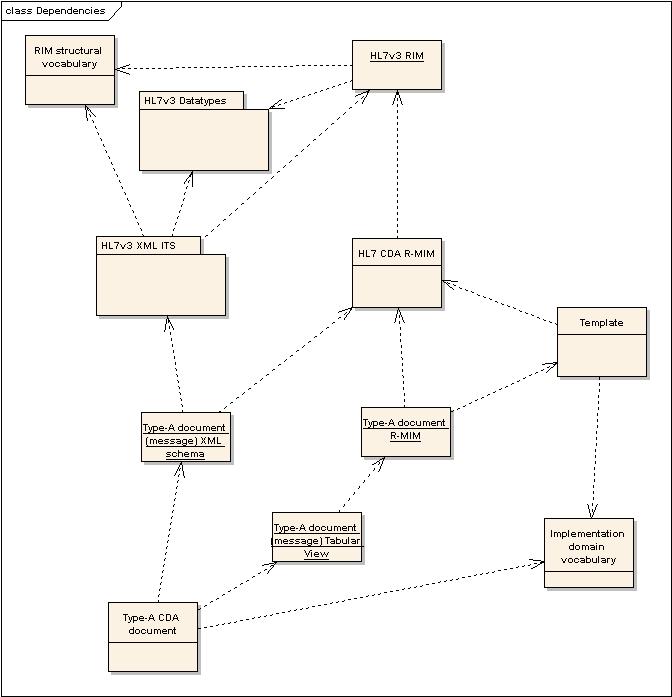
The full dependency model was too large to reproduce here. The following diagram shows
the main dependencies in practice.
Figure 1: A simplified diagram of dependencies
Further analysis adopted Walter Tichy's principle (see Tichy94 ) of a variant being anything that is the same from some point of view. That
is, instead of starting out with a particular model of change (eg temporal sequence),
start by identifying sources and kinds of variation encountered "in the
wild" and refine from that gathered knowledge a model of variation and change
that suits this particular situation. An important advantage of this approach was
the
ability to identify sources of difference as such without necessarily characterizing
them immediately as sequential versions or alternates.
An interesting feature emerging from this analysis was that in practice many changes
acted as sequential versions from one perspective, and parallel alternates from another.
A simple example of this situation would be where additional interactions including
one
that substitutes for an existing interaction are added to the specification. The one
that substitutes for an existing interaction is naturally regarded as a sequential
update by those implementers that require it, and as an alternate by implementers
that
either have no need for the new capabilities, or now handle both variants equally.
Similar patterns also emerge at finer levels of detail. This general pattern appears
to
be an important aspect of graceful handling of change.
Configuration issues for key specification artefacts
This section describes typical issues that arise during review and testing of a
new or changed specification domain. These issues are summarized from a longer list
identified through systematic review of the reference change scenarios with a group
of experienced implementers.
Consistency between XML schemas and guidance wording (Tabular Views)
The schema and tabular views in a specification package are sometimes
found to conflict. While this is an issue in of itself, interoperability
could at least be achieved if all implementers followed the same
approach where there is a conflict, i.e. there was an agreed principle
of either following the guidance or following the schema in case of
conflict. However, examples were found of situations where each approach
was clearly "right", so that a simple rule was not
appropriate.
Embedding detailed version history in schema documents
The schemas and examples (sample instances) generated by the HL7v3
tools contain embedded version information including information about
the versions of the tools used. The practical issue here is the
identification of a significant change. Because all the schema documents
in particular are regenerated from the model when a domain is
maintained, embedded version information may change, even where there is
no change to the content, when the tooling is updated. Since in general
any change may trigger extgensie testing in a clinical information
system, this was a matter of concern and needed a formalized consensus
approach.
Omitting the tool-version information from the generated schema
documents was not an attractive option, however, since a tooling version
upgrade had once introduced an unintended breaking change by changing
the order in which certain elements in the model (where classes, and the
attributes of each class, are essentially unordered) were represented in
a generated schema.
The conclusion was that full version information should be included in
schemas and example files, and that implementation guidance should make
it clear that versioning and provenance metadata could be ignored when
evaluating whether there has been a change in a configuration item for
testing purposes.
Usage of CMETs (Common Message Element Types) and Templates
CMETs and Templates are both ways of specifying component structure on
a scale in between a whole message and a single class. CMETs are
embedded components with a predefined structure, whereas HL7v3 Templates
provide a mechanism for a looser XML structure to be constrained in a
particular context. Changes to a CMET necessarily result in changes to
the message schema, whereas a Template can be changed without changing
the underlying elements in a message, thus providing some built-in
resilience to change.
Templates are used in particular to support detailed business
requirements for clinical data within a generic message pattern. For
example, in the MIM, the HL7v3 Clinical Document Architecture (CDA)
underlies a range of specific messages such as a Discharge summary and
an Emergency department report. In fact, the base CDAv2 standard has
been specialized to a common pattern for MIM messages (removing some
optional aspects of the base CDA2 standard); this generic MIM CDA is
further specialized to provide specific documents for each clinical
domain such as Discharge. The value of Templates in this context is the
ability to create additional specialized clincial domain messages, and
increase the repertoire of clinical subject matter supported,
independent of the overall structure and data format of the MIM CDA
document. This enables technical interfaces to be built generically for
MIM CDA clinical messages, with the detail represented by Templates only
taken into account by system components that are concerned with the
detailed subject matter.
A possible approach is for Template changes to be deployed in a way
that ensures that significant change to a message is necessarily
communicated to a user (implementer) of the specification. That is, a
change to a template should be a
"breaking"change in an interface, re-introducing one –
though not all – of the original limitations of a CMET.
However, this misses the original objective that system components
that do not care about Templates must be able to ignore Template level
changes, whereas system components dealing with the detailed clincal
information need to be maintained and tested in line with the changes
made.
It was recommended that Templates should be used in situations where
the underlying structure – in absence of the template – is expected to
be used as a valid scenario. The ability for all MIM CDA messages to be
understood using the generic MIM CDA pattern is a good example of this,
with the practical benefit of providing a basic level of
interoperability for all MIM-governed clinical content.
Where a common message component structure is needed but there is no
need for the underlying message to be understood without that structure,
a CMET may be used, and for "breaking" change should
be used in preference to a Templates.
Vocabulary changes
Vocabularies in an HL7v3 specification are controlled sets of allowed
values for class attributes in the model, represented in the generated
XML either as values of XML attributes or as enumerated values of XML
elements.
The uniform designation "vocabulary" for all value
sets used in a message is somewhat misleading, since they range widely
in significance and usage, including for example clincial terms,
repertoires of names for types of organizations, and values that
indicate the status of a business transaction. Vocabulary changes tend
to be more frequent than data structure changes, so maintaining
vocabularies separately is attractive, and is essential for those
vocabularies such as clinical terminologies that are maintained on an
independent timescale. However, although separate change management is
very appropriate for many vocabularies, it also introduces potential
problems since changes to required processing on receipt of a message
can in principle be made by this route without necessarily being clear
to implementers.
So, although some vocabularies are obviously better maintained
outside the HL7v3 specification itself, there are also risks associated
with this approach. It was recommended that if a significant functional
or conformance interpretation of an element or attribute is changed,
then this should not be done without simultaneously breaking the
technical interface - even if this requires an apparently unnecessary
artifice to force the break.
A framework for implementing specification change
Artefacts within specifications for system interoperability describe behaviours,
interactions, messages, models, templates, vocabularies, schemas etc. that change
over
time. These changes may be triggered by many factors including new business
requirements, enhancement/expansion to address new business needs or domains, fault
or
issue resolution, changes to underlying standards, and changes to vocabularies as
discussed above.
Sizeable specifications generally start small, for example growing from a relatively
simple set of messages to a complex specification with multiple kinds of dependencies.
Eventually it is a good idea to take a checkpoint, re-evaluate the whole picture and
consider how best to support both current implementers and future plans.
The following key recommendations emerged from the work underlying this paper, to
enable effective configuration management whilst supporting appropriate -
"gracious" - responses to change in the implementer community.
Creating and maintaining a fully detailed dependency model that not only shows
the expected impact of changes but also states where configuration changes
should create changes in other entities and where they should not.
Using a Configuration Matrix to manage the impact of change, and to
communicate an authoritative view of the expected impact of a published or
intended change.
Using a Version Profile, Profile ID and Profile Manifest as a central
resource for versioning all of the ‘configuration items’ of a message.
Additions to XML Schemas in the published specification to support more
flexible, configurable change.
The first of these may seem obvious, however previously the number of configuration
items and the relationships between them, and the practical benefit to be gained from
the considerable effort involved to create and maintain a configuration control model
for an HL7v3 interoperability specification, had not been
clear.
The other recommendations are presented in more detail below.
Configuration Matrix
The configuration matrix is intended to communicate expectations of change impact
and dependencies between principal configuration items, to both developers and
implementers. For all parties, this will help in assessing the impact of upcoming
changes, and support prioritization of changes in terms of development cost, service
impact and benefit. In addition, the use of the matrix as a communication tool will
support the development of a shared understanding of the impact of new requirements,
and of the level of change that is expected to be handled by information systems
performing different roles within the implementation community.
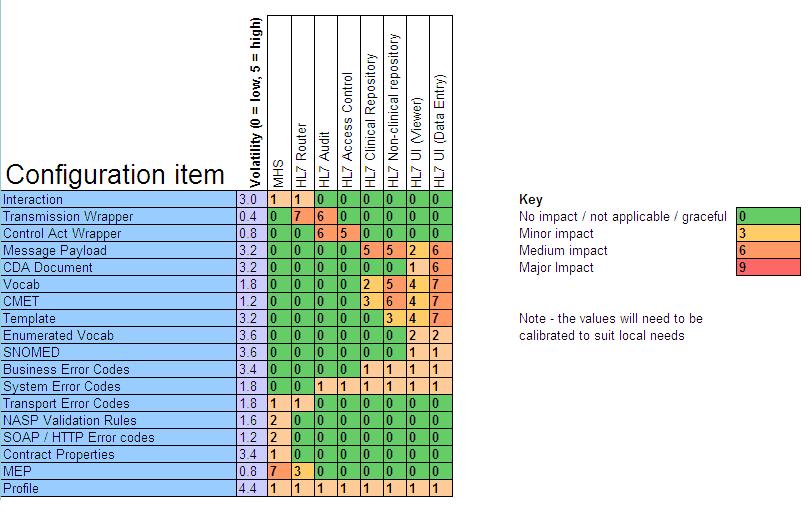
The following shows a simplified view of a configuration matrix for the MIM,
showing the various versioned configuration items matched against implementation
areas in which specification changes may cause change (note values shown are
illustrative and do not represent real findings). The list of items on the left
shows configuration items, including some MIM components and related artefacts not
discussed in this paper. The list along the top shows the main areas of
implementation affected by specification change.
Figure 2: An example matrix
The example above shows a simple scale of severity of impact. Depending on the
overall system architecture and the kinds of impact most relevant to an
implementation community, a configuration matrix could show for example:
Levels of impact against a predefined scale indicating the extent and
nature of testing required before entering live operation
Categorization against a range of predefined timescales for withdrawal of
"old" interfaces
Version Profile, Profile ID and Profile Manifest
The main technical innovation proposed to support configuration management
together with gracious response to change is that all MIM-specified messages will
carry a Profile ID that references a corresponding
profile manifest published to the implementation community.
A particular profile manifest will contain a version identifier for every
configuration item relevant to an instance message. Thus a particular permutation
of
artefact versions can be referenced at run time in a message and at design time by
suppliers.
The profile manifest will be the key singular reference for version control that
is maintained by specification developers. In other words, if any item that affects
a message is changed then the profile manifest for that message must be updated.
This will allow most other versioning constraints to be liberated. For example,
parts of a message can be changed without having to change the formal identifier of
the interaction but in the confidence that the change will be known to any user via
reference to the profile.
A example of a (very short) profile manifest follows, showing references to a code
set for error codes together with two items of supporting documentation.
Since some content may be sent onward some time after initial receipt, and message
wrappers will in general be regenerated for each sending, then for most messages it
is actually necessary to have two profiles:
Transport-profile-ID: Represents layers of the
instance message that are necessary for transport, security and audit. In
general this information is only relevant whilst the message is in flight,
and most systems discard the information (bar audit) once the message has
reached its destination. At any one time there will be relatively few
different transport-profile-IDs in use to exchange messages between
endpoints.
Payload-profile-ID: Represents the business payload
of the message. In general the business payload contains information that is
displayed to the end user or otherwise acted upon by the receiving system.
Depending on the application this information (in some cases the raw XML)
may have a long lifetime (from days, weeks, to many years) and hence we
should expect to have an ever-growing list of profile IDs over time. For the
same reason, it is expected that (copies of) the same payload will be
transmitted at different times in messages with different
Transport-profile-IDs.
Additions to XML Schemas to support more flexible, configurable change.
The full analysis contained a number of recommendations specific to the HL7v3 XML
ITS. Amongst these are some more general recommendations more likely to be of
interest to the wider markup community, as follows.
Treat even small value sets as separately maintained vocabularies
A number of small value sets were accumulated into a single schema document,
that in time gradually became a common dependency point for a large number of
message schemas.
It is recommended that this single common schema be split into multiple
vocabulary files, managed as parts of specific domains. Some vocabularies will
be used by interactions from multiple domains. Where this occurs one domain
should be considered ‘owner’ of that vocabulary. Other domain interactions using
that vocabulary will use that domain’s vocabulary schema. This recommendation
would also allow versioning of the vocabulary schema document filenames,
supporting direct control of schema "breakage" in implementation contexts
without configuration management support.
Embed versioning in names of complex and simple types to control breaking
change
Changing the filename in order to break an interface is one possible approach.
However a finer grained mechanism for selectively breaking the interface is to
version the type name in a schema. For example, instead of a type name such as
<xs:simpleType name="AdministrationType_code">,
use <xs:simpleType
name="AdministrationType_code_v1.1">
Designers are thus able to add a new version of a type without changing the
filename of the schema document. Legacy schemas will be able to use the new
schema document but instances of the legacy schema will not be able to use the
new version of the type without allowing for the update. Again, this feels
somewhat crude compared to automated configuration control, however is likely to
deliver appreciable benefit across a diverse implementation community where
common tools & approaches cannot be assumed.
Support for fallback processing?
A range of possibilities were discussed for establishing uniform strategies
for handling messages where the sending and receiving system are out of step in
version support. This is especially relevant in the longer term for dealing with
older electronic records of clinical information that are still relevant for a
patient's care. No consensus was reached for a definite recommendation, however,
since the balance between losing some information by rejecting messages, and
potentially misinterpreting some information by applying fallback processing to
poorly supported messages, is difficult to weigh. The main strategy in this
regard remains the overall conformance of all MIM clinical documents to a
generic HL7v3 CDA format, with defined minimum processing for such generic
documents that ensures the human-readable information at least will be able to be
displayed.
Validating the recommended framework
The full recommended framework for change, which we have only sampled here, was
validated by working through all the change scenarios identified at the start of the
project. In each case, the current process for managing such a change was elaborated
in detail, followed by elaboration of a recommended process using the new framework,
and testing of these recommendations by an independent panel.
This validation process was used informally with key scenarios during development
of the framework, then documented formally for each change scenario in the final
report as evidence for the viability and efficacy of the recommendations.
In conclusion
The concept of a flexible and yet also breakable interface is central to successful
configuration and version management. A well-planned configuration management strategy
allows interfaces to be both flexible and breakable depending on the circumstance.
Changes made to a messaging specification should not affect systems or system
creators that are not concerned with the subject of the change. However, changes to
a
message or message definition that could cause unexpected behaviour or misinterpretation
of a message should "break the interface" thus making it impossible for systems to
unknowingly use a changed message in a way which may hold clinical safety or other
risks.
In other words, in any particular configuration change, people and systems which need
to know MUST know and people and systems who don’t need to know, SHOULD NOT have to
know.
Achieving these features in a complex specification is not a simple matter. Applying
the kind of configuration management discipline that is well known for complex software
artefacts to the development of a complex specification is likely to be cost-effective,
even though the tools available are less mature. Representing key aspects of design
configuration within the specification artefacts published to the implementation
community, in documentation as a matrix documenting expected impacts, and as profiles
within message instances in live operation, is also promising as a strategy to enable
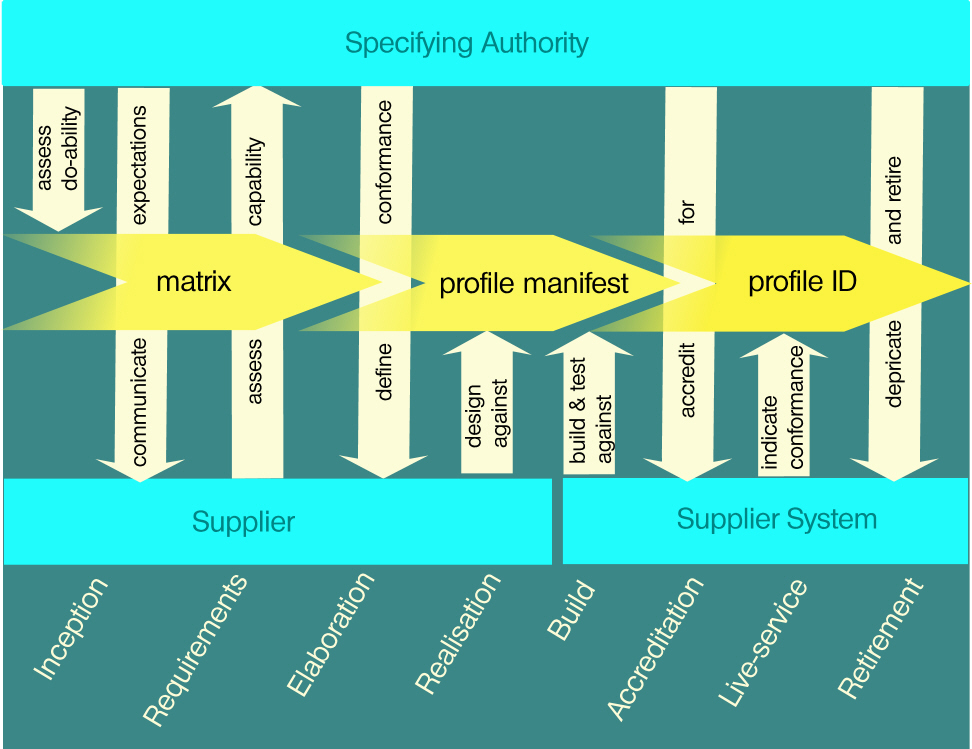
gracious handling of change. The way in which these artefacts support activities and
relationships
across the implementation community is summarized in the following diagram.
Figure 3: Overview
A final conclusion was that validation of the actual benefit of these recommendations
should be undertaken in a structured, evidence-based manner after a period of live
use.
Acknowledgements
Thanks to Keith Naylor of NHS CFH for reviewing the paper and sponsoring it for
publication.
The authors are indebted to the CFH Spine programme as an indirect means of forming
the team. During 2006-7 Ann, Joe & Mike were colleagues at the "sharp
end" of implementing the MIM in the National Care Records Service. Charlie was
involved in developing some parts of the MIM itself, and also, within HL7.org, in
designing the overall approach and XML formats used in the HL7v3 development
tools.
References
[Tichy94] W F Tichy (ed), [Trends in] Configuration Management, Wiley 1994 (ISBN
0471942456)
[Software Product Lines] F J van der Linden, K Schmid and E Rommes, Software Product Lines in Action: The Best Industrial Practice in
Product Line Engineering, Springer 2007 (ISBN 3540714367)
[HL7v3 Primer] A Hinchley, Understanding Version 3 - A Primer on the HL7 Version 3 Interoperability
Standard - Normative Edition, 4th edition, Alexander Mönch 2007 (ISBN
3-933819-21-0)
[Versioning Symposium] Balisage Series on Markup Technologies (ISSN
1947-2609) Vol. 2 International Symposium on Versioning XML Vocabularies and Systems
(ISBN-13 978-0-9824344-1-3 ISBN-10
0-9824344-1-3)
[1] Note that a number of the sources for this paper are unpublished internal
documents, in particular the MIM itself, & the Modelling Configuration
Management Investigation report, by McCay, Oldling-Smee & Waller 2009. The MIM
is made available to members of HL7.
F J van der Linden, K Schmid and E Rommes, Software Product Lines in Action: The Best Industrial Practice in
Product Line Engineering, Springer 2007 (ISBN 3540714367)
A Hinchley, Understanding Version 3 - A Primer on the HL7 Version 3 Interoperability
Standard - Normative Edition, 4th edition, Alexander Mönch 2007 (ISBN
3-933819-21-0)
Balisage Series on Markup Technologies (ISSN
1947-2609) Vol. 2 International Symposium on Versioning XML Vocabularies and Systems
(ISBN-13 978-0-9824344-1-3 ISBN-10
0-9824344-1-3)
Author's keywords for this paper:
Interoperability Standard; HL7v3; Configuration Management; Version Management; Health Informatics; Electronic Health Record