Portier, Pierre-Édouard, and Sylvie Calabretto. “Methodology for the construction of multi-structured documents.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Portier01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Balisage Paper: Methodology for the construction of multi-structured documents
Pierre-Edouard Portier
Université de Lyon, CNRS, INSA-Lyon, LIRIS, UMR5205, F-69621
Pierre-Edouard Portier is a computer science engineer. He has graduated in September
2007 from INSA-Lyon school with a Master degree in computer science. He is continuing
his studies at INSA-Lyon as a Ph.D student. He is working in the DRIM team of the
LIRIS laboratory under the supervision of Sylvie Calabretto.
Sylvie Calabretto
Université de Lyon, CNRS, INSA-Lyon, LIRIS, UMR5205, F-69621
Sylvie Calabretto : Doctor in Computer Sciences of the « Institut National des Sciences
Appliquées de Lyon » in 1993. Presently, Associate professor at the Institut National
des Sciences Appliquées de Lyon (INSA-Lyon) and Researcher at the Laboratory of Images
and Information Systems Engineering (LIRIS). Co-superviser of nine PhD dissertation.
Has published one collective book and about 100 papers on various computing subjects
among which Structured Document, Information Retrieval and Digital Libraries.
We present the multi-structured documents problem and offer an overview of existing
solutions. We then notice that they do not consider the problem of constructing such
documents. In this context, we use our experience with philosophers who are building
a digital edition of the work of Jean-Toussaint Desanti, in order to present a methodology
for the construction of multi-structured documents. This methodology is based on the
MSDM model in order to represent such documents. Moreover each step of the methodology
has been implemented in the Haskell functional programming language.
We introduce a new problem: the construction of multi-structured documents. The multiple
uses of a same document have led to a proliferation of documentary structures (physical,
logical, semantic, …). The definition of multiple structures for a same document introduced
the problem of multi-structured documents [Bruno2007]. It has to be analysed in his historical context where the most used formalisms
for documents representation (first SGML then XML) implied tree structures. That is
why this problem is often known as the overlapping hierarchies problem [Iacob2005].
By studying the construction of multi-structured documents we are close to the daily
practices of users who are writing documents. Our work is based on experience gained
working with philosophers who are building a digital edition of the handwritten archives
of French philosopher Jean-Toussaint Desanti (1914-2002). Desanti is known for his
epistemological work on the development of the mathematical theory of real variables
functions. Digital edition covers the whole editorial, scientific and critical process
that leads to the publication of an electronic resource. In the case of manuscripts,
it mainly consists in the transcription and critical analysis of digital facsimiles.
Exchanging with managers of other similar digital edition projects, we found that
the construction of multi-structured documents was at the heart of their work. A multiplicity
of structures is needed in order to access a document according to many points of
view. As we can see, our work does not only consist in the conception of a model for
the representation of multi-structured documents, but must of all in the development
of a methodology that promotes the emergence of multiple structures in a multi-users
context.
We illustrate our purpose with the Figure 1 that represents a double page from some Desanti's notebook. On this image, the region
named ZI represents a meaningful fragment of textual content that spans the two pages.
So we face two concurrent hierarchies (that is to say two structures that cannot be
represented through a single tree): the pages and the "regions of interest". We can
also see equations (E1 and E2) that, even though they do not raise the technical issue
of concurrent hierarchies, could belong to a third structure, the one of mathematical
expressions. Thus, we not only have to offer a solution to the multiple hierarchies
problem but also to conceive a methodology for the creation of multi-structured documents
so as to assist the user in his modeling choices.
Figure 1
Two pages from some Desanti's notebook
We propose a description of existing work for the representation of multi-structured
documents. Then, we introduce with some details a peculiar model: MultiX². Finally,
we use this model to propose a methodology for the construction of multi-structured
documents.
Existing solutions for managing multi-structured documents
Approach
We divide into four classes the set of existing solutions for the
representation of multi-structured documents. First, an historical
solution: CONCUR, then ad-hoc solutions as proposed by the TEI (Text
Encoding Initiative) consortium, next models that are not compatible with
the XML language, finally those that are compatible with XML. This XML
criterion, even though strictly technical, is very important since most
communities working on the construction of documents and who could benefit
from the new perspectives we introduce, are already using XML vocabularies
and tools (they will, for example, follow the TEI recommendations).
Finally, each solution is analysed according to six dimensions:
Expressiveness of the model determines if there is an explicitly
defined model for the static representation of multi-structured documents.
Genericity of the model determines, when a model exists, if
it can be modified in order to manage problems outside of the initial scope of
multi-structured documents representation.
Quality of the implementation takes account of the care taken to develop an
effective implementation
Compatibility with XML tools determines if it is possible to integrate
the solution with the numerous existing XML tools used to manage XML
documents (especially typing tools such as XML Schemas, ...)
Query mechanisms for multi-structured documents
Change management in data or structures, determines if the model is
robust to change
An historical solution
CONCUR [Goldfarb1990] is an SGML option that allows multiple DTDs for the same
content. In such an SGML document, every structure lives in a same file. In
this file, a first structure is encoded in a standard way. For each
additional structure, a prefix is added to opening tags, in order to
determine which DTD defines this tag.
However, with the CONCUR option, we cannot establish relations
between structures. Moreover, as stated in [Hilbert2005], if two
elements from different DTDs describe the same region, tags order is
indeterminable. That is why this solution is rarely implemented, and even
Charles Goldfarb [Hilbert2005], the main architect of the SGML
standard, recommends to avoid its use.
The CONCUR option answers most of the problems raised by multi-structured
documents, but cannot establish relations between structures.
However, as an SGML integrated option, it doesn't meet the genericity
criterion. Moreover, there is no query mechanism. It should be noted, that
since there is only one document, changes in structures or data are
possible.
Ad-hoc solutions
The TEI (Text Encoding Initiative) [Burnard2007] is a consortium developing
and maintaining a standard for the representation of electronic texts.
These recommendations are expressed as an extensible and well documented
XML Schema. Inside the recommendations, for each instance of the
multi-structured document problem, a local solution is proposed. Moreover,
in the last version of the recommendations, an entire chapter is devoted to a synthesis
of
the ad-hoc solutions. They are four [Rose2004] [Bruno2007]:
It is possible to duplicate the content for each tree structures … Poor
solution that prevents evolutions of the document.
Empty tags can be used (line break, page break, etc.). But
they prohibit us from using standard XML validation tools, or building a
schema that specifies the structure with empty elements.
For two concurrent structures that do not form a tree, we can divide one of
them into elements small enough to avoid overlapping with other
structures. The original structure can be rebuilt through well-chosen
attributes. As for the previous solutions, this one needs specific operations in
order to rebuild the original structures and does not allow us to use XML
typing tools.
Finally, we can isolate the content inside a so called base structure,
and build the documentary structures on top of it. This solution is
probably the most generic.
XML incompatible models
TexMECS
Instead of using existing languages, new syntaxes can be defined. MECS
(Multi-Element Code System) [Huitfeldt1998] was the first language to allow
overlapping of structures. TexMECS [Huitfeldt2003], based on MECS,
is much more expressive. It allows us to define complex structures where
an element can have multiple parents. The MECS model is expressive enough
to answer the classic problems raised by multi-structured
documents, but is too complex in order to satisfy the genericity criterion.
Moreover, it does not come with query mechanisms.
LMNL
LMNL (Layered Markup and aNnotation Language) [Tennison2002] defines a
specific syntax based on a notion of interval that allows the encoding of
multiple structures with overlapping elements. This is only a syntactic
solution that does not propose query mechanisms. As for the previous
solution, since the structures are encoded inside a single document, change in
data or structures is possible. These two solutions are quite complex
and not compatible with the XML tools and remained at an experimental
stage.
Annotation graphs
Annotation graphs [Maeda2002] has been developed in order to
model linguistics phenomena (phonetic, prosody, morphology, syntax, ...).
If we consider these domains as distinct structures, then annotation graphs
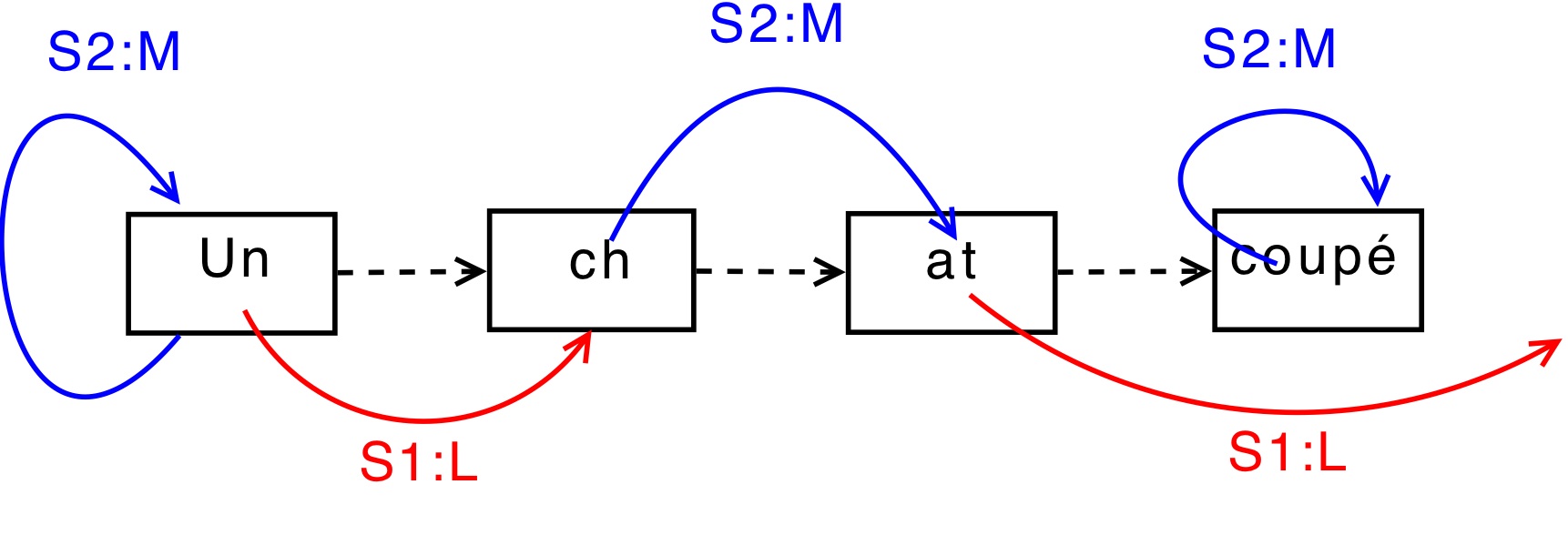
are a valid solution to the multi-structured documents problem. As shown on
Figure 2, the same textual fragment can be annotated
by elements from different structures.
Figure 2
Annotation Graph
Nodes granularity is the word, or even the character if necessary. Labels on edges
indicate the structure (eg S2:M for the words, S1:L for the lines).
Since structures share the same graph, their update is not a problem.
Moreover, a minimal query language has been developed for this kind of graph
[Bird2000]. The underlying model being a graph, it is
expressive enough to answer the multi-structured documents problem. But, strongly
oriented toward linguistic, it lacks genericity.
RDF graphs
The RDF (Resource Description Framework) graph formalism is able to
represent multi-structured documents [Tummarello2005]. This method is similar to
the previous one, but relies on a generic graph model.
Standard query tools for RDF graphs (eg SPARQL) can be used, but complex
queries can be difficult to formulate. Although RDF is serializable in XML,
the use of standard XML tools is problematic because they work on tree
structures. Finally, change management is possible since structures and
data share the same graph.
XML compatible models
MuLaX
MuLaX [Hilbert2005] is the adaptation of the SGML CONCUR option to
the XML formalism. This is a documentary format that allows to unify XML
documents sharing the same content in a single document. In order to
differentiate annotations levels, the tags are prefixed by a structure
identifier. This solution lacks genericity since a specific editor is
needed in order to interpret the produced documents. As for the CONCUR
option, changes in structures or data are possible since there is one
single document. No query operators has been defined, but the authors
explain that it should be possible to build path expressions similar to
those found in XPath.
GODDAG
[Sperberg-McQueen2000] presents a solution based on the GODDAGs (General Order
Descendant Directed Acyclic Graph) to represent multi-structured
documents. This graph model is a solution to the overlapping hierarchies
problem. In order to query those documents, the author developed an XPath
extension. This extension takes into account new kinds of relations between
elements of distinct structures. This model cannot manage generic relations
between structures. It is possible to import (or export) from (or to) the
XML formalism. With this model it is possible to manage change in
structures.
MCT
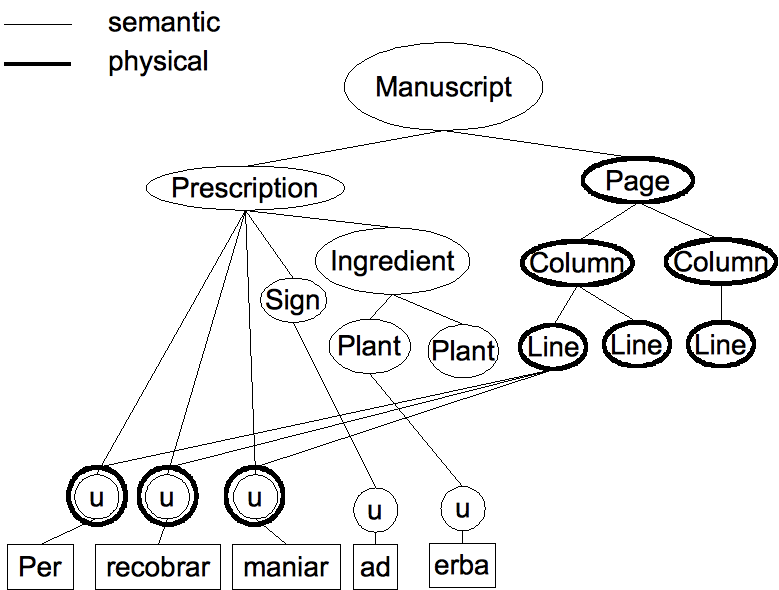
The MCT (Multi-Colored Trees) model [Jagadish2004] is an extension of the XML
model that allows us to represent multiple trees sharing the same
content. It relies on the tree coloring technique. A color is associated with
each tree. A node may have multiple colors: the color of the main tree to which
it belongs and colors for other trees. Figure 3 illustrates this model with an example of manuscript transcription. We see that three
of the units nodes share two colors: one for the semantic structure and another one
for the physical structure.
Figure 3
Colored Trees
The navigation in the multihierarchy is possible by means of the
multicolored nodes. To navigate between colors, the authors extend the
notion of step in XPath. An extension of
XQuery is also proposed for the creation of nodes.
Concerning updates, the authors explain that the extension of a
language such as XUpdate is possible by using the XPath extension that they propose.
The
underlying model is neither expressive nor generic enough since it imposes
an isomorphism of data segments (data segments must be of the same type:
word, character, etc.).
MSXD
MSXD (Multi-Structured XML Documents) [Bruno2006] is a representation model
for multi-structured documents that comes along with an XQuery extension. It allows
users to annotate the structures. Moreover a draft of a multi-structured
documents schema is introduced. However the need to define a large number
of relations between structures makes the model difficult to use.
Furthermore, it is not possible to manage changes in data or structures.
Delay Nodes
Jacques LeMaître [LeMaitre2006] proposed to add a new type of node to the
XDM model on which are based XPath and XQuery. Those nodes are a virtual
representation as an XQuery query of some of the child nodes of their
parent node (see Figure 4). The underlying multi-structured documents model is very similar to the one
of Multi Colored Trees (see Figure 5) where documents
are considered as a set of XML trees. But no
XPath or XQuery extensions are necessary in order to navigate inside these
structures. However, with this approach, it is not possible to reach the
parents of a delay node but only to navigate among the descendants.
Figure 4
Delay nodes
Figure 5
Delay nodes underlying MSD model
MonetDB/XQuery
MonetDB/Xquery is a XML SGBD. It has an extension [Alink2006] for managing
multi-structured documents thanks to the stand-off markup technique.
Optimized query operators has been developed, but no model is truly
defined, only an informal description is proposed (as for the TEI
solutions).
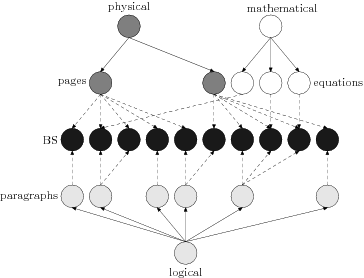
MSDM, MultiX
MSDM [Chatti2007] is a model used for the representation of
multi-structured documents written by N.Chatti. An instance of this model,
called MultiX, is expressed in the XML formalism. It belongs to the category of
stand-off markup solutions where content is isolated
in a base structure, and documentary structures are built by references
to the base structure.
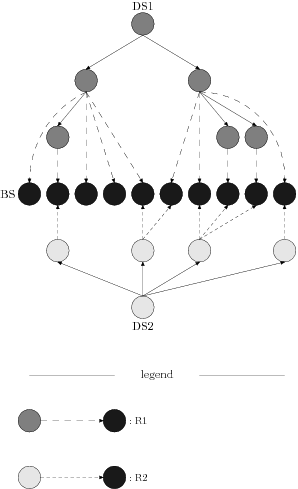
In this model, a document is a graph D composed of:
a set of nodes BS also called the base structure
a family (DSj) j ∈ J of trees also called documentary structures
Moreover, ∀ j ∈ J, there is a relationship Rj that associates
each node of DSj with a subset of BS ; for each leaf of DSj
this subset must be non empty. Figure 6 illustrates each element
of the model.
Figure 6
Illustration of the MSDM model
Finally, it should be noted that only nodes from the base structure have an
associated content and depend on the data types (text, movies, etc.). In
the case of textual data, a string of characters, called fragment,
is associated with each node of the base structure.
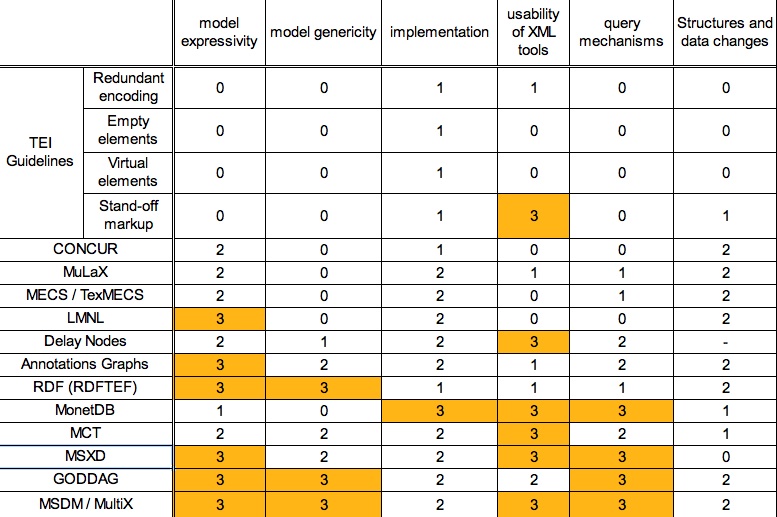
Summary
Figure 7 summarises the analysis by affecting, as objectively as
possible, a score from 0 to
3 to each criterion (model expressivity, quality of implementation, use of
standard XML tools, query mechanisms, management of changes in data and
structures) and for each solution. For readability, maximum scores have
been underlined.
Figure 7
Rating of existing solutions to the multi-structured documents problem
We now introduce a new instance of MSDM, called MultiX² that
will allow us to represent multi-structured documents.
MultiX², a model for the representation of multi-structured documents
MultiX² is an instance of MSDM that favors the W3C recommendations (we
make use of the XInclude Standard for linking documentary structures and
the base structure) to the specific mechanisms used by MultiX. We chose MSDM as the
representation model on which we built our methodology since, based on the stand-off
markup technique, it was simple enough and yet well defined (moreover, it is referenced
by the
fifth edition of the TEI guidelines).
We illustrate this instance of the MSDM model on an example taken from the Jean-Toussaint
Desanti's
Archive (see Figure 1). We see two pages from a notebook with
a region of text that overlaps the two pages. Moreover it should be
noted that mathematical equations appear inside this philosophical text. We distinguish
two structures. First, the physical structure of pages:
<s1>
<page>Autrement dit la distinction signe-signifie ...
Remarque,
</page>
<page>ce discours, ...
par ex le discours 3 + 2 = 0 - 1 est-il un texte ? ...
</page>
</s1>
Then, a logical structure of regions of interest:
<s2>
<p>Autrement dit la distinction signe-signifie ...</p>
<p>Remarque, ce discours, ...</p>
<p>par ex le discours
<eq>3 + 2 = 0 - 1</eq> est-il un texte ? ...</p>
</s2>
We build the base structure by identifying the shared fragments from the
two documentary structures:
<seg xml:id="F1">Autrement dit la distinction signe-signifie ...
</seg>
<seg xml:id="F2">Remarque, </seg>
<seg xml:id="F3">ce discours, ...</seg>
<seg xml:id="F4">par ex le discours </seg>
<seg xml:id="F5">3 + 2 = 0 - 1</seg>
<seg xml:id="F6"> est-il un texte ? ...</seg>
We use the XInclude standard in order to replace the content inside
documentary structures by references to the base structure. First, the
physical structure:
We can use standard XML tools in order to validate the documentary
structures. We build queries thanks to specific XQuery functions originally
built for the MultiX formalism. Below, a query that finds regions of
interest overlapping on two pages:
let $physique := doc("physique.xml")
let $logique := doc("logique.xml")
for $page in $physique//page,
$para in $logique//p
where multix:share-fragments($page,$para) and
not(multix:include-content-of($page,$para))
return $para
And the result will be:
<p>Remarque, ce discours, ...</p>
The share-fragments(a,b) function checks if elements a and b have at least
one fragment in common. The include-content(a,b) function checks if every
fragment composing element b also compose element a.
A methodology for the construction of multi-structured documents
We will use the MSDM model in order to introduce the construction of
multi-structured documents. We claim that the study of the construction of documentary
structures is a way to approach the user interpretation of a document. For example,
numerous critical edition
projects begin with manuscripts images they then transcribe and annotate.
During these operations, the documents will be manipulated by numerous users
and under a multiplicity of perspectives that mostly depend on how the
documents are used. However, within the limits of today systems dedicated to the
creation of documents, most of these diversified perspectives will remain
inaccessible, buried in users minds. We claim that, in the
context of the creation and annotation of documents, most of these hidden
perspectives can be revealed by the differentiation of structures. This
differentiation is an operation that splits an annotation vocabulary into
sub-vocabularies, thus adding a new structure to the document. Thereby, the
methodology we now present promotes the construction of a multiplicity of
structures that should reflect the perspectives adopted by the users while
accessing the documents. This methodology consists of three categories of
methods:
detection of needed restructuring and automatic
differentiation of structures. As we will see, the overlapping hierarchies
problem becomes an element of this category of methods.
execution of the dynamical interpretant of the confrontation of
a user with the results of automatic restructuring. Dynamical
interpretant is a term belonging to C.S. Peirce's terminology that will be
explained in a next section.
creation of a social network of documents authors
in order to encourage argument about and sharing of annotation vocabularies
Restructuring stage
We analyse the conditions under which it is necessary to build a new
documentary structure and we define the underlying functions performing
this task.
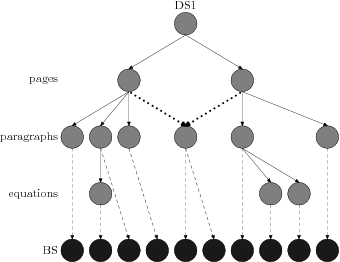
Illustration
For clarity, and since we know the field, we use an example taken from
critical electronic edition of manuscripts. We suppose that for the
transcription of a manuscript the researchers have on hand the elements defined by
the TEI. From the previous
example: pages, region of interest and equations have been correctly tagged until
a region overlaps two pages
(see dotted edges of Figure 8).
Figure 8
Restructuring is necessary (a paragraph overlaps two pages)
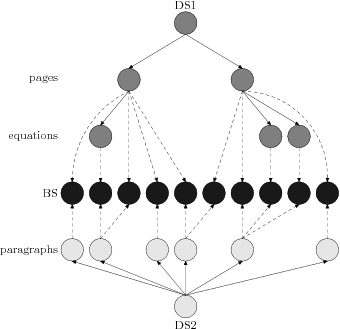
It is then necessary to distinguish two
structures. The creation of a new structure is a purely formal operation
(see Figure 9) consisting in the
transformation of a graph into two trees.
Figure 9
Automatic restructuring (two structures are distinguished)
Functions for restructuring
We now describe the functions that perform these restructuring operations.
We are using the Haskell pure and statically typed functional programming language
[PeytonJones2002]. As a pure language, Haskell keeps side effects under the control of a class of
type constructor called Monad, in practice this allows us to ensure that a valid document
will always be transformed into a valid document. Since our methodology introduces
numerous document transformations, this property is very interesting. All the
necessary notions for the understanding of the code will be provided. But not all
functions definitions will be given.
Moreover the main purpose of showing these functions is to give a proof of the
feasibility of our methodology.
We need two helper functions, if' for boolean conditions and add for
the addition of a new element at the end of a Map. A Map a b is a
structure of elements of type b indexed by element of type a.
From the signature of if' we learn that the function takes
three arguments, the first argument being a Boolean value. if'
True is a two arguments function that evaluates its first argument (the second argument
will never be evaluated), while if' False is a two arguments function that evaluates its second argument (the first argument
will never be evaluated).
-- This is a comment
-- A function is described by its type signature: the list of the types of its
-- arguments and of thereturned value separated by the symbol: '->'.
-- For example, the addIntegers function would have the signature:
addIntegers :: Int -> Int -> Int
-- and the definition:
addIntegers a b = a + b
-- Moreover, functions are curried, so (addInteger 2) is a function of type:
(addInteger 2) :: Int -> Int
-- Finally, we will:
-- * use some primitive types :
-- - Bool (with the only two constructors True and False)
-- - Int
-- * use the list constructor:
-- [Int] is the type of a list of values of type Int
-- * define data types:
data Interval = Interval {
start :: Int
,end :: Int
}
-- now Interval is a function (also called a constructor) of type:
Interval :: Int -> Int -> Interval
-- start is a function of type:
start :: Interval -> Int
-- end is a function of type:
end :: Interval -> Int
-- * define shortcuts for existing types:
type Tags = [Tags]
-- Tags is now a synonym for [Tags] (list of Tags)
if' :: Bool -> a -> a -> a
if' True x _ = x
if' False _ y = y
add :: a -> Map Int a -> Map Int a
We first define our main data types. A Tag is composed of an identifier
and a list of attributes. We also have a data structure associating
each tag identifier with a name and a list of default attributes. A
Taggee is the application of a Tag to an interval of characters of the
studied text. A Structure is a named map of taggees. A Document is the
association of a text and a map of structures.
data Interval = Interval {
start :: Int
,end :: Int
}
data Taggee = Taggee {
tag :: Tag
,interval :: Interval
}
data Structure = Structure {
name :: String
,taggees :: Map Int Taggee
}
type TagId = Int
data Tag = Tag {
tagId :: TagId
,atts :: Map Int String
}
type Tags = [Tag]
type Text = String
data Doc = Doc {
text :: Text
,structures :: Map Int Structure
}
We also need functions for simple interval algebra.
The addTag function tries to add a tag to a structure, if the addition
does not imply overlapping then the modified structure is returned, else a
pair of structures is returned: the first structure is the original one
except that every instances of the added tag have been
transfered to the second structure. In a similar way, the $delTag$ function
removes the instance of a given tag from a selected interval and may imply
overlapping thus the type signature.
-- partition the map according to a predicate:
partition :: Ord k => (a -> Bool ) -> Map k a -> (Map k a, Map k a)
elems :: Map k a -> [a]
-- function application:
$ :: (a -> b) -> a -> b
-- function composition:
. :: (b -> c) -> (a -> b) -> a -> c
-- map f xs is the list obtained by applying f to each element of xs:
-- map f [x1,x2,...,xn] == [f x1, f x2, ..., f xn]
map :: (a -> b) -> [a] -> [b]
-- foldl, applied to a binary operator, a starting value, and a list, reduces
-- the list using the binary operator, from left to right:
-- foldl f z [x1,x2,...,xn] == f (f (f (f z x1) x2) ...) xn
foldl :: (a -> b -> a) -> a -> [b] -> a
-- The Either type represents values with two
-- possibilities: a value of type Either a b is
-- either Left a or Right b
addTag :: Taggee -> Structure -> Either (Structure,Structure) Structure
addTag t (Structure n s) =
let (s1,s2) = partition ( ( (tagId $ tag t)== ) . tagId . tag ) s in
if' ( foldl (||) False $ map (overlaps (interval t) . interval) $ elems s )
( Left ( Structure n $ add t s1, Structure n s2 ) )
( Right ( Structure n $ add t s ) )
delTag :: Interval -> TagId -> Structure -> Either (Structure,Structure) Structure
Finally, the user must be able to add or remove textual data. This is the
purpose of the addText and delText functions.
-- split a list in two:
splitAt :: Int -> [a] -> ([a], [a])
fst :: (a, b) -> a
snd :: (a, b) -> b
addText :: Int -> String -> Doc -> Doc
addText i s d =
let t = text d
split = splitAt (i-1) t
t' = fst split ++ s ++ snd split
sts = structures d
sts' = map ( addCharInS i (length s) ) sts
in Doc t' sts'
addCharInS :: Int -> Int -> Structure -> Structure
addCharInS i size (Structure n s) =
Structure n $ map ( \t ->
if' ( i `inside` (interval t) )
t{interval = Interval (start $ interval t) $
(end $ interval t) + size}
t ) s
delText :: Int -> Int -> Doc -> Doc
Integration of the user in the restructuring process
Illustration
The automatic restructuring introduced above can be the occasion for a
user to make modeling choices. For example, he can ask for the
creation of a new mathematical structure for the equations and rename the
structures (see Figure 10).
Figure 10
Intervention of a user (Three structures are named and distinguished)
Functions for user integration
moveTag is the main function offered to the user for reacting to the automatic
restructuring, it allows him to move all the instances of a tag from one
structure to another. The function may fail if it introduces
overlapping hierarchies.
-- case analysis for the Either type
either :: (a -> c) -> (b -> c) -> Either a b -> c
-- the constant function
const :: a -> b -> a
-- foldr, applied to a binary operator, a starting value, and a list, reduces
-- the list using the binary operator, from right to left:
-- foldr f z [x1,x2,...,xn] == f x1 (f x2 (... (f xn z)))
foldr :: (a -> b -> b) -> b -> [a] -> b
moveTag :: TagId -> Structure -> Structure -> Maybe (Structure, Structure)
moveTag id s1 s2 =
let (ts',ts'') = partition ( (==id) . tagId . tag ) ( taggees s1 )
f :: Taggee -> Either (Structure, Structure) Structure ->
Either (Structure, Structure) Structure
f t ( Right s ) = addTag t s
f t ( Left (s1, s2) ) = Left (s1, s2) in
if' ( null ts' || null ts'' ) Nothing $
either ( const Nothing )
( Just . (,) ( Structure (name s1) ts' ) ) $
foldr f (Right s2) $ elems ts''
Recommendation system for documents authors
We now try to involve even more the author of a document in the process of
maintaining a coherent multiplicity of structures. This is why we promote the
emergence of a social network of documents authors. The recommendation
mechanism that allows us to build this network define two users
as closed, insofar as they are editing specific documents, if the implied
tags trees of their structures are similar. We first give an example of
this process and then define the structures and functions used to implement
it.
Illustration
We imagine three users who create documents containing
mathematical notations. For each of them, a mathematical structure emerged
from their operations of annotation (as described in the previous sections).
Users 1 and 2 have already decided to merge their tag hierarchies. The tag
hierarchies are given below:
Users 1 and 2
User 3
theorem
statement
proof
lemma
statement
proof
cocycle
cobordism
proposition
proof
operators
cohomology
cocycle
If these two hierarchies were detected as similar enough, each user would
be proposed to ask the other users the authorization to merge their
hierarchies. Thus, communities of users appear, centered on their
annotation practices. In this previous example, users seem to
work on the same kind of documents, but the perspective of user 3 may be formal logic
whereas users 1 and 2 refer to a more traditional vocabulary for the
description of proofs. Since the tips the
users receive while annotating a document come from the hierarchy of tags
associated with the current structure, once the merge is accepted, the users may align
their
annotation vocabularies or at least question their practices.
Functions for promoting users interactions
We define a new data type (TagStruct) in order to link each tag used for
the annotation of a document with its possible descendants. Thus, while a user is
annotating a document we can give him hints about the
next tag to choose, based on this new structure and its current position in the text.
We also
update the Structure data type to link to the corresponding
implied tag structure. For this linking to be possible, we maintain a map
(of type TagStructs) of the implied tag structures.
type TagStruct = Map TagId [TagId]
type TagStructId = Int
type TagStructs = Map TagStructId TagStruct
data Structure = Structure {
name :: String
,taggees :: Map Int Taggee
,tagStructId :: TagStructId
} deriving (Show)
We have to modify the addTag function in order to update the linked structures of
tags:
addTag :: Taggee -> Structure -> TagStructs -> Either (Structure,Structure, TagStructs) (Structure, TagStructs)
addTag t (Structure n s tagStructId) tagStructs =
let tId = tagId $ tag t
(s1,s2) = partition ( (tId==) . tagId . tag ) s
s' = Structure n (add t s) tagStructId
(tagStructIdS2, newTagStructs) = addTagStruct tagStructs in
if' (
foldl (||) False $
map (overlaps (interval t) . interval) $
elems s
)
(
Left ( Structure n (add t s1) tagStructId,
Structure "" s2 tagStructIdS2,
delTagFromTagStruct tId tagStructId newTagStructs )
) $
Right ( s', addTagToTagStruct tId (parentId t s') tagStructId tagStructs )
addTagStruct :: TagStructs -> (TagStructId, TagStructs)
delTagFromTagStruct :: TagId -> TagStructId -> TagStructs -> TagStructs
addTagToTagStruct :: TagId -> Maybe TagId -> TagStructId -> TagStructs -> TagStructs
parentId :: Taggee -> Structure -> Maybe TagId
parentId t s = maybe Nothing (Just . tagId . tag) $ parent t s
parent :: Taggee -> Structure -> Maybe Taggee
Note that Haskell is a pure functional programming language and as such does not allow side effects. That is
why, in the previous functions when we had to manage some kind of shared data structure
of type TagStructs, we passed it between functions by the way of an extra parameter.
Haskell has a data type design pattern called monad that offers a much nicer solution, but we kept with the basics so that the link between
the two previous sections remained obvious.
We finally have to compute the distance between every pair of implied tag
structures. We choose a very straightforward editing distance equals to the
number of "add" and "delete" operations needed to transform one set of tags
into another. It does not take into account the structure of the tags and
has for only purpose to guide the user towards other possibly similar
tagging practices. In our current implementation, the distances computation is a
daily batch process.
We now present the theoretical ideas that gave us the
opportunity to develop our methodology. Indeed, in order to explore the
dynamical aspects of multi-structured documents creation, and not only the
static problem of representing such documents, we needed new tools that
could allow us to think of a maintained multiplicity of structures. We
found them in C.S. Peirce. The
introduction of the dynamical interpretant as part of the notion of sign
received our full attention. In order to define this notion, we quote
Peirce [Peirce1909]:
…suppose I awake in the morning before my wife, and that afterwards she
wakes up and inquires, "What sort of a day is it?" This is a sign, whose
Object, as expressed, is the weather at that time, but whose Dynamical
Object is the impression which I have presumably derived from peeping
between the window-curtains. Whose Interpretant, as expressed, is the
quality of the weather, but whose Dynamical Interpretant, is my answering
her question. But beyond that, there is a third Interpretant. The Immediate
Interpretant is what the Question expresses, all that it immediately
expresses, which I have imperfectly restated above. The Dynamical
Interpretant is the actual effect that it has upon me, its interpreter. But
the Significance of it, the Ultimate, or Final, Interpretant is her purpose
in asking it, what effect its answer will have as to her plans for the
ensuing day. I reply, let us suppose: "It is a stormy day." Here is another
sign. Its Immediate Object is the notion of the present weather so far as
this is common to her mind and mine - not the character of it, but the
identity of it. The Dynamical Object is the identity of the actual or Real
meteorological conditions at the moment. The Immediate Interpretant is the
schema in her imagination, i.e. the vague Image or what there is in common
to the different Images of a stormy day. The Dynamical Interpretant is the
disappointment or whatever actual effect it at once has upon her. The Final
Interpretant is the sum of the Lessons of the reply, Moral, Scientific,
etc.
Elsewhere [Peirce], we find this definition of the sign: By a sign I mean any thing
which is in any way, direct or indirect, so influenced by any thing (which
I term its object) and which in turn influence a mind that this mind is
thereby influenced by the Object ; and I term that which is called forth in
the mind the Interpretant of the sign.
That being said, we take as a sign the presentation to the user of a
restructuring, and try to analyze it thanks to Peirce's categories :
immediate object: the actual presentation of an automatic
restructuring
dynamical object: the impression the user may have derived from
looking at the automatic restructuring presentation
immediate interpretant: validity of the restructuring
dynamical interpretant: user answer to the restructuring
presentation in terms of the operations (and the ways to combine them)
offered by the computer
final interpretant: effect of the operations engaged by the
user
We can replay this analysis but this time taking as a sign the previous dynamical
interpretant (we are allowed to take this step by the very nature of the
sign: every sign is linking to another one ad libitum:
immediate object: the multiple structures of the document
dynamical object: the operations to be applied on the
multi-structured document
immediate interpretant: execution of the operations
dynamical interpretant: effect of this particular choice of
operations in this particular context
final interpretant: effect the presentation of the computer
analysis of the user interactions will have on the user
First of all, the linked nature of the sign gave us the idea of introducing the user
at
the heart of the restructuring process. Moreover, being able to see the dynamical
interpretant as a producer of new signs gave us the idea of the
construction of a social network of documents authors, the documentary
structures being used as a social glue.
A prototype implementation of the methodology
We provide all the functions introduced above as a Web service that follows
the REST [Fielding2000] design pattern. In the context of this paper we cannot
fully describe this Web service. We only give as an example the HTTP
operation used for tagging a new "equation" in the mathematical structure
of a notebook. All we have to do is send a POST request to the resource
identified by the URL http://desanti.org/cahiers/148/structures/math/taggees with a body of:
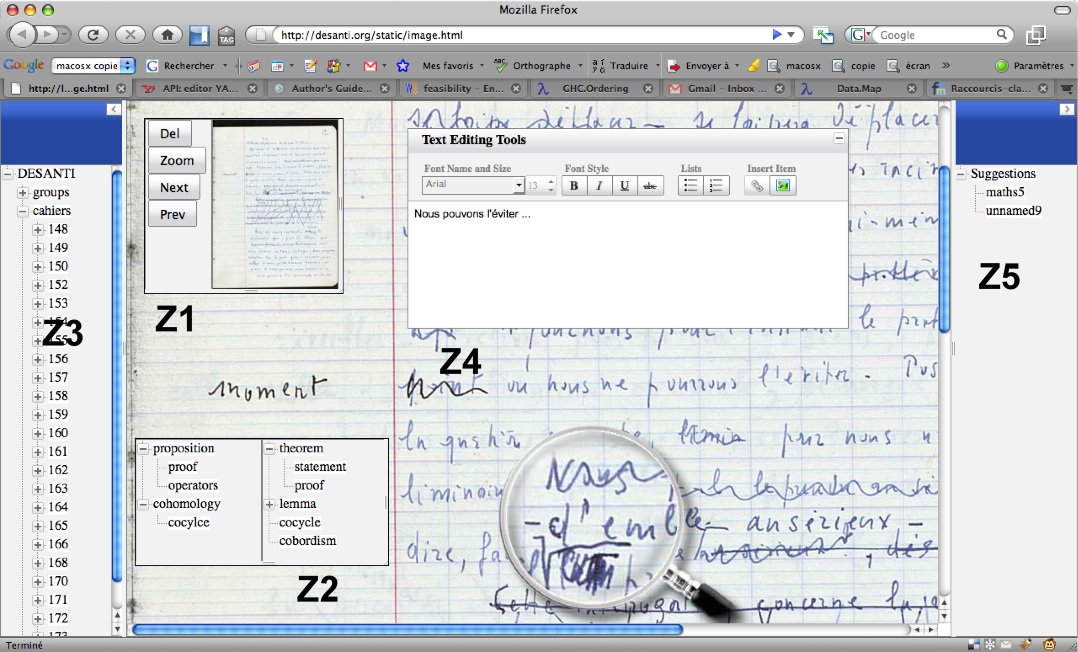
Figure 11 is a screenshot of the client application running inside a Web browser. The region
Z3 is a hierarchy
of all the documents of the archive, it gives the researchers the synoptic
view they need. The region Z1 is a draggable navigator obtained by clicking
on an element of the hierarchy Z3, it allows to navigate among the images
of the pages of a collection. The region Z4 is an editor for the
transcription. The region Z5 is the set of recommendations for tag
hierarchies similar to the one implied by the current documentary
structure. Region Z2 is the comparison frame obtained when the user click
on one of the recommendations, it allows him to decide if he wants to merge
his tags structure with the one suggested.
Figure 11
Prototype
Conclusions
We have identified a new problem: how to build multi-structured
documents? This allowed us to take over the old issue of multi-structured
documents as we pulled away from its technical formulation and bring
ourselves closer to the daily practices of those building documents. We have shown
that, although the enforcement of tree structures was for a long time
considered as the crux of the problem, we could place it at the heart of a
new solution where the emergence of overlapping hierarchies triggers the
creation of a new structure that has to be validated by the user. In fact, our methodology
places the users in a central position and we managed to lighten the cognitive load
that results from the interactions with the system by bordering the reflexive activities
on small and well defined periods. Thus we
managed to provide a methodology that addresses the needs of humanities
researchers by promoting and maintaining a multiplicity of stuctures.
Moreover, we developed a prototype that implements the algebraic operations
described in the article. These operations are provided through a Web
interface using the HTTP protocol in accordance with the REST design
pattern.
[Chatti2007] Noureddine Chatti, Souha Kaouk, Sylvie Calabretto and Jean-Marie Pinon, MultiX: an XML-based formalism to encode multi-structured documents in "Proceedings of Extreme Markup Languages'2007"
[Simeon2003] Jerome Simeon and Philip Wadler, The essence of XML, 2003 in "POPL '03: Proceedings of the 30th ACM SIGPLAN-SIGACT symposium on Principles
of programming languages", doi:https://doi.org/10.1145/604131.604132
[Bird1999] Steven Bird and Mark Liberman, Annotation Graphs as a Framework for Multidimensional Linguistic Data Analysis, 1999 in "Towards Standards and Tools for Discourse Tagging: Proceedings of the Workshop",
http://citeseer.ist.psu.edu/bird99annotation.html
[Tummarello2005] Giovanni Tummarello, Christian Morbidoni and E. Pierazzo, Toward Textual Encoding Based on RDF, in "From Author to Reader: Challenges for the Digital Content Chain: Proceedings
of the 9th ICCC International Conference on Electronic Publishing held at Katholieke
Universiteit Leuven - ELPUB 2005, Leuven-Heverlee, Belgium, June 8-10, 2005. Proceedings",
p. 57-63
[Alink2006] Wouter Alink, R. A. F. Bhoedjang, Arjen P. de Vries and Peter A. Boncz, Efficient XQuery Support for Stand-Off Annotation, in "Proceedings of the 3rd International Workshop on XQuery Implementation, Experience
and Perspectives, in cooperation with ACM SIGMOD, June 30, 2006, Chicago, USA. 2006",
http://www.ximep-2006.org/papers/Paper-Alink-Boncz.pdf
[Bruno2006] E. Bruno and E. Murisasco, Multistructured XML textual documents, 2006, in "GESTS International Transactions on Computer Science and Engineering",
vol. 34 n. 1, p. 200-211
[Sperberg-McQueen2000] C. M. Sperberg-McQueen and Claus Huitfeldt, GODDAG: A Data Structure for Overlapping Hierarchies, in "Digital Documents: Systems and Principles, 8th International Conference on Digital
Documents and Electronic Publishing, DDEP 2000, 5th International Workshop on the
Principles of Digital Document Processing, PODDP 2000, Munich, Germany, September
13-15, 2000, Revised Papers", vol. 2023, p. 139-160
[Hilbert2005] Mirco Hilbert, Andreas Witt and Oliver Schonefeld, Making CONCUR work, 2005, in "Extreme Markup Languages"
[Huitfeldt1998] Claus Huitfeldt, MECS - a Multi-Element Code System, 1998, in "Working Papers from the Wittgenstein Archives at the University of Bergen",
vol. 3
[Maeda2002] Kazuaki Maeda, Steven Bird, Xiaoyi Ma and Haejoong Lee, Creating Annotation Tools with the Annotation Graph Toolkit, 2002, in "Proceedings of the Third International Conference on Language Resources
and Evaluation", http://arxiv.org/abs/cs/0204005
[Bird2000] Steven Bird, Peter Buneman and Wang-chiew Tan, Towards a Query Language for Annotation Graphs, 2000, in "Proceedings of the Second International Conference on Language Resources
and Evaluation", p. 807-814
[Jagadish2004] H. V. Jagadish, Laks V. S. Lakshmanan, Monica Scannapieco, Divesh Srivastava, and
Nuwee Wiwatwattana, Colorful XML: one hierarchy isn't enough, 2004, in "SIGMOD '04: Proceedings of the 2004 ACM SIGMOD international conference
on Management of data", p. 251-262, doi:https://doi.org/10.1145/1007568.1007598
[LeMaitre2006] Jacques Le Maître, Describing multistructured XML documents by means of delay nodes, 2006, in "DocEng '06: Proceedings of the 2006 ACM symposium on Document engineering",
New York, NY, USA, p. 155-164, doi:https://doi.org/10.1145/1166160.1166200
[Iacob2005] Ionut E. Iacob and Alex Dekhtyar, Processing XML documents with overlapping hierarchies, 2005, in "JCDL '05: Proceedings of the 5th ACM/IEEE-CS joint conference on Digital
libraries", New York, NY, USA, p. 409-409, doi:https://doi.org/10.1145/1065385.1065513
[Goldfarb1990] Charles F. Goldfarb, The SGML handbook, 1990, Oxford University Press, Inc.
Emmanuel Bruno, Sylvie Calabretto and Elisabeth Murisasco, Documents textuels multi structurés : un état de l'art. in "Revue i3" 2007, http://liris.cnrs.fr/publis/?id=2708
Noureddine Chatti, Souha Kaouk, Sylvie Calabretto and Jean-Marie Pinon, MultiX: an XML-based formalism to encode multi-structured documents in "Proceedings of Extreme Markup Languages'2007"
Jerome Simeon and Philip Wadler, The essence of XML, 2003 in "POPL '03: Proceedings of the 30th ACM SIGPLAN-SIGACT symposium on Principles
of programming languages", doi:https://doi.org/10.1145/604131.604132
Steven Bird and Mark Liberman, Annotation Graphs as a Framework for Multidimensional Linguistic Data Analysis, 1999 in "Towards Standards and Tools for Discourse Tagging: Proceedings of the Workshop",
http://citeseer.ist.psu.edu/bird99annotation.html
Giovanni Tummarello, Christian Morbidoni and E. Pierazzo, Toward Textual Encoding Based on RDF, in "From Author to Reader: Challenges for the Digital Content Chain: Proceedings
of the 9th ICCC International Conference on Electronic Publishing held at Katholieke
Universiteit Leuven - ELPUB 2005, Leuven-Heverlee, Belgium, June 8-10, 2005. Proceedings",
p. 57-63
Wouter Alink, R. A. F. Bhoedjang, Arjen P. de Vries and Peter A. Boncz, Efficient XQuery Support for Stand-Off Annotation, in "Proceedings of the 3rd International Workshop on XQuery Implementation, Experience
and Perspectives, in cooperation with ACM SIGMOD, June 30, 2006, Chicago, USA. 2006",
http://www.ximep-2006.org/papers/Paper-Alink-Boncz.pdf
E. Bruno and E. Murisasco, Multistructured XML textual documents, 2006, in "GESTS International Transactions on Computer Science and Engineering",
vol. 34 n. 1, p. 200-211
C. M. Sperberg-McQueen and Claus Huitfeldt, GODDAG: A Data Structure for Overlapping Hierarchies, in "Digital Documents: Systems and Principles, 8th International Conference on Digital
Documents and Electronic Publishing, DDEP 2000, 5th International Workshop on the
Principles of Digital Document Processing, PODDP 2000, Munich, Germany, September
13-15, 2000, Revised Papers", vol. 2023, p. 139-160
Claus Huitfeldt and Michael Sperberg-McQueen, TexMECS: An experimental markup meta-language for complex documents, 2003, in "Working paper of the project Markup Languages for Complex Documents (MLCD),
University of Bergen", http://decentius.aksis.uib.no/mlcd/2003/Papers/texmecs.html
Kazuaki Maeda, Steven Bird, Xiaoyi Ma and Haejoong Lee, Creating Annotation Tools with the Annotation Graph Toolkit, 2002, in "Proceedings of the Third International Conference on Language Resources
and Evaluation", http://arxiv.org/abs/cs/0204005
Steven Bird, Peter Buneman and Wang-chiew Tan, Towards a Query Language for Annotation Graphs, 2000, in "Proceedings of the Second International Conference on Language Resources
and Evaluation", p. 807-814
H. V. Jagadish, Laks V. S. Lakshmanan, Monica Scannapieco, Divesh Srivastava, and
Nuwee Wiwatwattana, Colorful XML: one hierarchy isn't enough, 2004, in "SIGMOD '04: Proceedings of the 2004 ACM SIGMOD international conference
on Management of data", p. 251-262, doi:https://doi.org/10.1145/1007568.1007598
Jacques Le Maître, Describing multistructured XML documents by means of delay nodes, 2006, in "DocEng '06: Proceedings of the 2006 ACM symposium on Document engineering",
New York, NY, USA, p. 155-164, doi:https://doi.org/10.1145/1166160.1166200
Ionut E. Iacob and Alex Dekhtyar, Processing XML documents with overlapping hierarchies, 2005, in "JCDL '05: Proceedings of the 5th ACM/IEEE-CS joint conference on Digital
libraries", New York, NY, USA, p. 409-409, doi:https://doi.org/10.1145/1065385.1065513