Durusau, Patrick. “Hypergraphs: Escaping the Surly Bonds of Syntax.” Presented at Balisage: The Markup Conference 2023, Washington, DC, July 31 - August 4, 2023. In Proceedings of Balisage: The Markup Conference 2023. Balisage Series on Markup Technologies, vol. 28 (2023). https://doi.org/10.4242/BalisageVol28.Durusau01.
Balisage: The Markup Conference 2023 July 31 - August 4, 2023
Balisage Paper: Hypergraphs, Escaping the Surly Bounds of Syntax
Patrick Durusau is the Co-Chair of the OASIS Open Document Format for Office Applications
(OpenDocument) TC and has been a member of that TC since its initial meeting on December
16, 2002. His employer/sponsor has changed several times over the years, and Patrick
has been a co-editor/editor of the OpenDocument Format (ODF) for the majority of that
time. Patrick is also the project editor for the ISO/IEC mirror of ODF as ISO/IEC
26300.
Patrick blogs about topic maps (being one of the co-editors of ISO 13250-5), other
semantic issues and of late, how irregular forces can leverage data for their causes
at Another Word for It.
Claus Huitfeldt responded to one of the many variants of What is a Text Really:
Finally, and most importantly, I am struck by the lack of imagination in this approach:
why on earth should texts by all means be hierarchies? No doubt, there are many hierarchical
structures, and no doubt this is important, but there are countless other relations
between text elements which are worth while finding and investigating- overlap, substitution,
discontinuity, parallel texts, cross-references, etc.
Huitfeldt and Sperberg-McQueen have labored for decades on the imaginative representation
of texts in markup. As have many others.
Humanities scholars are confronted with a bewildering array of markup languages and
techniques, should they not decide to invent their own for representing complex texts.
A number of those syntaxes are illustrated here, to lay the groundwork for this heretical
suggestion: Humanists should use any consistent method they choose for complex markup.
The burden of preparing texts for interchange, should rest on technologists who have
input those texts in a hypergraph database. Let scholars be about what scholars do
and technologists at aiding them in those tasks, not training them for new ones.
The Balisage archives have forty (40) papers since 2008, addressing overlapping markup.
(SeeAppendix 1.) The literature beyond Balisage is vast and deep; I had two filing cabinets full
of such papers more than a decade ago. But the Balisage collection represents a fair
sampling of approaches and are likely familiar to you both as authors and listeners.
If you have been to one or more Balisage conferences, you will no doubt have heard
our host, Tommie Usdin, admonish us to be good listeners! For those of you not familiar
with the concept, it means hearing what others are saying without polishing your response
or slides as the case may be. While I try to listen, to the extent that I have at
Balisage, have I been listening to the wrong people?
That’s not a slur on the Balisage presenters, all of who I value as friends and colleagues.
When I say the wrong people, I mean while I enjoy the complexities of rabbit-duck grammars, will that help me capture the native language of users in other domains? For all
of my use and appreciation for markup, I want to empower users, not myself.
Languages
Texts Are Not Discrete and Linear
A casual perusal of the previous Balisage papers on overlapping markup, leaves no
doubt, the tree model of texts is the exception rather than the rule for texts. If
you roll the clock back to Text Retrieval on a Microcomputer, we find a description of overlapping complexities in my domain, biblical texts:
The structure of spoken text has particular complexities which make it difficult to index with already available
software. Most computer-assisted indexing systems, including the recent ones, assume
that ideas are discrete and linear, hence sequentially indexable. In spoken text, however, ideas are rarely discrete and linear. Instead,
as interviewees recount a story or make a point, ideas and recollections are often
condensed and bundled. Often a block of text may contain a number of ideas that a
researcher would like to index. Just as often, a block of text containing a single
idea may overlap other blocks of text containing other ideas. Indeed, the taut structure
that one hopes find in formal written text rarely exists in spoken or informal text
because many speakers and writers think extemporaneously, without regard to structure
or polish.
When you think about either the Hebrew Bible or the New Testament, they are almost
completely spoken texts. People talk to each other, they talk to snakes, donkeys,
fig trees, rocks, divine beings, conspire to conceal adultery, and government officials,
to name only a few of the spoken interactions.
The Hebrew Bible and the New Testament were transmitted over thousands of years through
thousands of witnesses, composed by authors lost to history, authors who are known, maybe, and those witnesses
each contend for particular content at a given location. Another set of conversations.
Biblical commentators have not been silent about the text, being in conversation (shouting?)
with each other and each succeeding generation creating new conversations (more shouting?)
about the text.
Modern scholars have a variety of languages to talk about the biblical text.
What is surprising is despite thousands of years of careful study, prior to 1988,
no biblical scholar raises the issue of overlap. Not once. Whatever model of the text
they were using, the concept of overlap wasn’t an issue.
The Birth of and Solutions to Overlap
The problem of overlap came into being, at least for our purposes, with the publication of Standard Generalized
Markup Language (ISO 8879, SGML) in 1988. As was the default for software at the time,
SGML assumed text to be encoded, in the words of Giordano, was discrete and linear. To be fair, SGML did have an optional feature, CONCUR, which enabled different discrete
and linear views of the same text, but only one could be active at any time. Being
an optional feature, it was only occasionally implemented.
For reasons that remain unclear, at least to someone who learned SGML from the SGML
Handbook (Goldfarb 1991), programmers wanted a simpler to use markup language, which we now know as XML.
What was an optional feature of SGML, that is CONCUR, was discarded as too hard for
the weekend programmer. A defect in XML that persists to this day, despite many labors
to repair that defect. (SeeAppendix 1.)
Examining only a few of the proposals to solve the overlap problem, which is a standards defect and not a feature of texts, or conversations
about them, shows languages strange to scholars, invented to solve a problem with
our standards.
Near the beginning of addressing the complexity of texts with markup, is MECS - A MULTI-ELEMENT CODE SYSTEM. Its language isn’t as frightening as some we will see, but still daunting to scholars
who already possess languages to describe their texts:
MECS is a syntax for the design of text encoding systems. Documents which conform
to this syntax consist of text interspersed with codes, of which there may be seven
syntactically distinct types:
No-element codes: <s>
One-element codes: <a/ ... /a>
Poly-element codes: [a/2| ... /a| ... /a]
N-element codes: [s/2\ ... /s| ... /s]
Character representation codes: {a}
or {"---"\a}
Character disambiguation codes: {a\a}
or {"---"\a}
Comments: <| xxx |>
MECS and its successors were developed at The Wittgenstein Archives at the University
of Bergen (WAB), https://wab.uib.no/index.page, in a particularly fruitful collaboration between Claus Huitfeldt and Michael Sperberg-McQueen.
Another solution, championed by Henry Thompson for different markup systems for text
corpora, is standoff markup:
Adding markup from a distance
Consider marking sentence structure in a read-only corpus of text which is marked-up already with tags for words and punctuation, but nothing more:
. . .
<w id='w12'>Now</w><w id='w13'>is</w><w id='w14'>the</w>
. . .
<w id='w27'>the</w><w id='w28'>party</w><c id='c4'>.</c>
With an inclusion semantics, I can mark sentences in a separate document as follows:
. . .
<s xml-link='simple' href="#ID(w12)..ID(c4)"></s>
<s xml-link='simple' href="#ID(w29)..ID(c7)"></s>
. . .
which does support arbitrary markup (so long as each instance is well-formed XML)
views on a text, but remains subject to the linear requirements in each instance.
Subject to breaking should the target text change but escapes the one view of a text
mandated by XML. (http://xml.coverpages.org/thompson-sgmleu97.html)
While writing this paper I encountered a non-Balisage paper (it happens) on text and
hypergraphs: Texts as Hypergraphs: An Intuitive Representation of Interpretations of Text by Elli Bleeker, Ronald Haentjens Dekker, and Bram Buitendijk (https://doi.org/10.4000/jtei.3919). The abstract reads:
Over the past decades, the question of what text really is has been addressed by a
large number of conferences, workshops, articles, and blog posts. If there is one
thing that, taken together, those contributions illustrate, it is that our understanding
of text is—and has been—constantly in flux and open to many interpretations. Still,
there is often a gap between how an editor conceptualizes a source text and how this
text is encoded and stored on a computer: using TEI XML, editors are compelled to
model their text as a single tree (a hierarchy), whether this structure corresponds
with their intellectual understanding or not. Textual features that do not fit naturally
into the XML data model require additional layers of code, which hinders processing,
querying, and interchange.
The Text-As-Graph (TAG) data model and the associated syntax TAGML are developed to
express and store textual information as a network. To this end, TAG implements a
hypergraph model. In the present contribution, we illustrate the benefits of TAG’s
hypergraph for the modeling of features like nonlinearity, discontinuity, and overlap.
In contrast to a tree model, a hypergraph accommodates these nonhierarchical structures
naturally. By making them part of the data model and the syntax, a TAGML processor
can process the features without having to resort to workarounds or schema-aware tools.
This lowers the difficulty of working with digital editions and facilitates querying
and interchange.
That sounds like it answers all the questions for conversations in, about, and with
a text. Or does it?
Consider the formal grammar of TAGML:
1. document ::= documentHeader? richText*
2. documentHeader ::= namespaceDefinition*
3. namespaceDefinition ::= '[!ns ' namespaceIdentifier ' ' namespaceURI ']'
4. namespaceIdentifier ::= nameCharacter+
5. richText ::= ( textEnrichment | text )*
6. textEnrichment ::= ( markupStartTag | markupEndTag | markupMilestone | textVariation | comment )*
7. text ::= textCharacter*
8. textCharacter ::= [^[<\] | '\[' | '\<' | '\\' # For regular text, we only need to escape the 2 characters that start a markupStartTag, markupEndTag or markupMilestone, plus the escape character itself.
9. markupStartTag ::= '[' ( optional | resume )? tagIdentifier (' ' annotation)* '>'
10. markupEndTag ::= '<' ( optional | suspend )? tagIdentifier ']'
11. markupMilestone ::= '[' tagIdentifier (' ' annotation)* ']'
12. textVariation ::= '<|' richTextInTextVariation ( '|' richTextInTextVariation )+ '|>'
13. richTextInTextVariation ::= ( textEnrichment | textInTextVariation )*
14. textInTextVariation ::= textInTextVariationCharacter*
15. textInTextVariationCharacter ::= [^[<|\] | '\[' | '\<' | '\|' | '\\' # For text inside textVariation tags we also have to escape the variation divider character |
16. comment ::= '[!' commentCharacter* '!]'
17. commentCharacter ::= [^!\] | '\!' | '\\' # For text inside a comment we only have to escape te 2 characters that constitute the comment closing tag !], plus the escape character itself.
18. optional ::= '?'
19. resume ::= '+'
20. suspend ::= '-'
21. tagIdentifier ::= qualifiedMarkupName layerSuffix?
22. qualifiedMarkupName ::= ( namespaceIdentifier ':' )? localMarkupName
23. localMarkupName ::= nameCharacter+
24. layerSuffix ::= '|' layerInfo ( ',' layerInfo )*
25. layerInfo ::= ( parentLayerId? '+' )? layerId
26. parentLayerId ::= layerId
27. layerId ::= nameCharacter+
28. annotation ::= annotationName '=' annotationValue
29. annotationName ::= nameCharacter+
30. annotationValue ::= stringValue | numberValue | booleanValue | richTextValue | listValue | objectValue
31. stringValue ::= '"' doubleQuotedStringValueCharacter* '"' | "'" singleQuotedStringValueCharacter* "'"
32. singleQuotedStringValueCharacter ::= [^'] | "\'" '\\' # For text inside the stringValue delimiters, only the delimiter used needs to be escaped, plus the escape character itself.
33. doubleQuotedStringValueCharacter ::= [^"] | '\"' '\\'
34. numberValue ::= '-'? digits ('.' digits)? ([eE] [+-]? digits)?
35. booleanValue ::= 'true' | 'false'
36. richTextValue ::= '[>' richText '<]'
37. listValue ::= '[' annotationValue ( ',' ' '? annotationValue )* ']'
38. objectValue ::= '{' annotation+ '}'
39. digits ::= [0-9]+
40. nameCharacter ::= [a-zA-Z] | digits | '_' | '-'
Considering these three examples, or any reported in the appendix, what is the one
thing they have in common (aside from the subject of overlapping markup)? (Sit with
that for a moment.)
Have you ever seen a Bible, a commentary on any book of the Bible, a critical edition
of a Bible, that uses any of these languages for consumption by the reader? And yet,
those texts embody all the richness of texts, without resort to such mechanisms. That
is to say the languages of scholars aren’t broken, deficient, but we have rushed in
with repairs for our languages, instead of listening for theirs.
Note: Why this paper is a mess
Gentle reader, this is where my paper blew up while writing my slides. I discovered I was committing
the same error I caution against, that is I was offering my language for a text model, which is the same error we as digital humanists have been committing
for decades. Apologies for the hasty citations, all will be repaired in the final
version.
TypeDB
I encountered TypeDB during one of my irregular sweeps for hypergraph software. TypeDB
is of particular interest because of its use of an Entity-Relationship-Attribute model,
where attributes are first-class citizens, relationships have roles.
Entity
TypeDB has an impoverished definition of entity:
An entity may be defined as a thing capable of an independent existence that can be
uniquely identified. An entity is an abstraction from the complexities of a domain.
When we speak of an entity, we normally speak of some aspect of the real world that
can be distinguished from other aspects of the real world.
I prefer:
anything whatsoever, regardless of whether it exists or has any other specific characteristics,
about which anything whatsoever may be asserted by any means whatsoever (TMDM)
It doesn’t damage the model and does free up the use of entity-relationship modeling
for something more than the real world.
The focus in TypeDB development (and true for other hypergraph software) is on modeling
a domain using the language of users and not a language invented by developers, or even markup language specialists. That
is, we learn the language of the domain and use it to create labels for entities,
relationships between entities, along with attributes recognized by users for both.
Don’t be frightened; it has been done successfully in a number of domains.
Modeling the Greek New Testament, Without Syntax
My original demonstration was going to use a loader to take a CSV file with Greek
New Testament data and enter it into a TypeDB database. But unlike me, you have already
spotted the betrayal of the central theme of this paper. I don’t want to impose or
recommend a syntax, such as CSV, so much as advocate for abstract modeling of a text,
however it happens to be encoded. It’s the my language versus your language trap, the one that has kept so much information locked in free text form. (For consumption
by statistical idiots.)
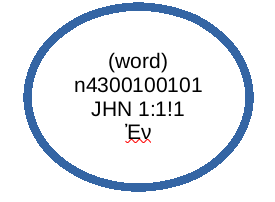
For example, here is the first line of the Gospel of John, at least according to the
Nestle 1904 text (in part, there are many other attributes):
One way to model that single word as an entity would be:
Figure 1: JHN 1:1!1
A single entity representation of the first word in the Gospel of John
While that figure captures the word and location of it in the Gospel of John, it doesn’t
enable us to represent variations on that text. What witnesses support that reading
of the text? What has been said about witnesses to that text? Or a host of other details.
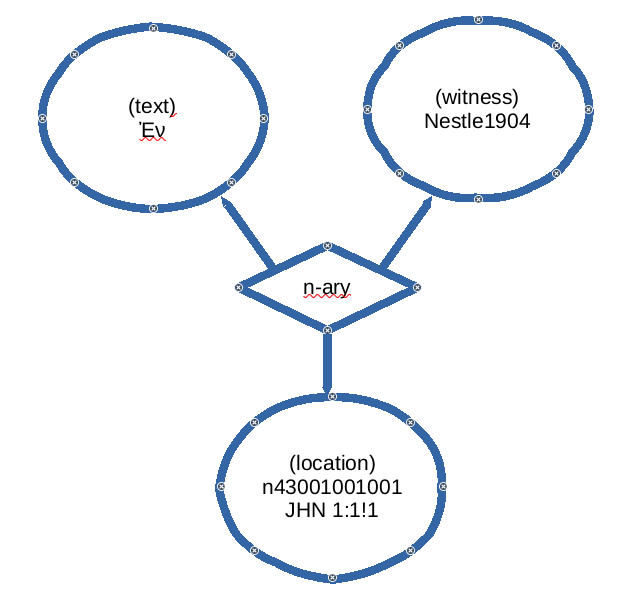
Compare the difference if we model the references to the biblical text, long held
standard by biblical scholars and then create an n-ary relationship (being permitted
in hypergraphs) to represent the text as:
Figure 2: JHN 1:1!1
An n-ary representation the first word in the Gospel of John, according to the Nestle1904
text
With the second representation, any number of n-ary relationships with distinct text
or witnesses components can all point at the entity representing the position of JHN
1:1!1. We can query for not only all the texts said to occur at that position, but
we can also find the witnesses for any particular text at that position. Or we can
ask for all the positions in the text where that term appears. To say nothing of other
relationships, being represented in the languages of other biblical disciplines, including
cognitive linguistics.
That is to say that hypergraphs enable us to harken back to the TEI adage that DTDs
represent some view of a text, but never the only true view of a text. We extend that
by capturing the language and models used by users, not as specified in the arcane
dialect of DTDs.
Listening to Users
Confronting users with yet another language, a language not their own, isn’t a solution.
So, why not take a different tack? Ask users what they want to talk about, what properties
(think attributes) they have, and the relationships they have to other subjects? Including
roles in those relationships.
While that sounds attractive, how does that move data from users into a hypergraph
database?
Conclusion
Rather than solving a problem of our own creation, overlap, we should be listening
to users to capture their vocabularies and models for texts. It’s at least as challenging
as overlap and to actually listen, contrary the the claims of some programming paradigms,
will be a novelty among users. Who know? Listening may catch on, even in the digital
humanities.
For future reference, this Appendix contains abstracts for Balisage papers addressing
overlapping markup, from Volume 1 (2008) to Volume 23 (2022). (Overlapping markup
papers start with the publication of SGML (ISO 8879: 1986). What follows is a sub-set
of convenience from that literature.)
The literature on overlapping markup spans decades and to be manageable, this appendix
is limited to the Balisage conference and its prior incarnation.
Adventures in Correcting XML Collation Problems with Python and XSLT: Untangling the
Frankenstein Variorum
Abstract
The process of instructing a computer to compare texts, known as computer-aided collation,
might resemble trying to fix a power loom when the threads it is supposed to weave
together become tangled. The power of the automated weaving continues, with the threads
improperly aligned and the pattern broken in a way that can make it difficult to isolate
the cause of the problem. Automating a tedious process magnifies the complexity of
error-correction, sometimes calling for new tooling to help us perfect the weaving
or collating process.
The authors are attempting to refine a collation algorithm to improve its alignment
of variant passages in the Frankenstein Variorum project. We have begun with a Python
script that tokenizes and normalizes the texts of the editions and delivers them to
collateX for processing the collation and delivering TEI-conformant output for our
project. In post-processing stages after running the collation, we apply a series
of XSLT transformations to the collation output. This post-collation XSLT pipeline
publishes the digital variorum edition, which prepares each output witness in TEI
XML to store information about its own variance from the other editions. We have discussed
that pipeline elsewhere, but our interest in this paper is in efforts to repair and
correct and improve the collation process.
We have applied Schematron and XSLT in post-processing to correct patterns of erroneous
alignments, but eventually realized that the problems we were trying to solve required
repairing the collation algorithm. We are now experimenting with revising the collation
algorithm in two ways: 1) by fine-tuning the text preparation algorithms we apply
in our Python file that delivers text to the collateX software, and 2) by attempting
to introduce those same text preparation algorithms entirely with XSLT using the Text
Alignment Network’s XSLT application of tan:diff() and tan:collate(), introduced by
Joel Kalvesmaki at the 2021 Balisage conference. In this paper we discuss the challenges
of figuring out where and how to intervene in the collation process, and what we are
learning about how far we can take XSLT and Schematron in helping to automate the
preparation, collation, and correction process.
How to cite this paper
Beshero-Bondar, Elisa E. Adventures in Correcting XML Collation Problems with Python and XSLT: Untangling the
Frankenstein Variorum. Presented at: Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5,
2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27 (2022). https://doi.org/10.4242/BalisageVol27.Beshero-Bondar01
Contemporary transformation of ancient documents for recording and retrieving maximum
information: when one form of markup is not enough
Abstract
This paper considers what we can gain from enhancing TEI-encoded texts with RDF. We
consider the use of Open Annotation Collaboration (OAC) annotations as part of our
work for the future. To illustrate our approach, we take as a case study the Sharing
Ancient Wisdoms (SAWS) project, which explores and analyses the tradition of wisdom
literatures in ancient Greek, Arabic and other languages. It aims to publish its texts
digitally in a manner that enables linking and comparisons within and between anthologies,
their source texts, and the texts that draw upon them.
How to cite this paper
Jordanous, Anna, Alan Stanley and Charlotte Tupman. Contemporary transformation of ancient documents for recording and retrieving maximum
information: when one form of markup is not enough. Presented at: Balisage: The Markup Conference 2012, Montréal, Canada, August 7 -
10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Jordanous01
Deferred Well-Formedness and Validity: Change.log, Collaboration, Immutability, XML,
UUIDs
Abstract
This proposal emerges out of conversations about introducting collaborative editing
into OpenDocument Format (ODF) applications, as a type of change tracking. Vis-a-vis
a document, a lone author is a lesser and included case of collaborative editing.
In either case, changes have to be captured, along with their metadata, and reconciled,
in the case of conflicting edits.
Despite progress on the software side of collaborative editing for a variety of formats,
there has been no visible progress on the capturing of changes, or their reconcilation
in OpenDocument Format documents. Being habituated, not to say addicted, to markup
approaches, it’s understandable I find the lack of format discussions disquieting.
It’s all well and good to have change tracking/collaborative editing, successfully
in software, but what the hell am I going to write down in ODF?
How to capture changes, from one or many authors, and how to capture reconciliations are the focus of this proposal. That requires unique identification
of changes (one or many authors), identifying where changes may be applied, and recording
the application of changes (the resulting document).
How to cite this paper
Durusau, Patrick. Deferred Well-Formedness and Validity: Change.log, Collaboration, Immutability, XML,
UUIDs. Presented at: Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6,
2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Durusau01
Document lattices: Equivalence, compatibility, and contradiction in document markup
Abstract
If the information conveyed by the markup in a document can be identified with the
set of inferences we can draw from that markup, as has been proposed in earlier work,
then the sets of inferences licensed by documents form an infinitely large lattice,
by means of which the relative information content of any two documents (equivalence,
subsumption, contradiction, consistency) can be displayed visually. The sets of inferences
licensed by markup can be used to test translations from one markup language to another
for equivalence or information loss; a simple example using XHTML and CALS table markup
illustrates the process.
How to cite this paper
Sperberg-McQueen, C. M., Yves Marcoux Yves Marcoux and Claus Huitfeldt. Document lattices: Equivalence, compatibility, and contradiction in document markup. Presented at: Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8,
2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Sperberg-McQueen01
Document similarity: Transcription, edit distances, vocabulary overlap, and the metaphysics
of documents
Abstract
In recent years, development of tools and methods for measuring document similarity
has become a thriving field in informatics, computer science, and digital humanities.
Historically, questions of document similarity have been (and still are) important
or even crucial in a large variety of situations. Typically, similarity is judged
by criteria which depend on context.
The move from traditional to digital text technology has not only provided new possibilities
for discovery and measurement of document similarity, it has also posed new challenges.
Some of these challenges are technical, others conceptual.
This paper argues that a particular, well-established, traditional way of starting
with an arbitrary document and constructing a document similar to it, namely transcription,
may fruitfully be brought to bear on questions concerning similarity criteria for
digital documents. Some simple similarity measures are presented and their application
to marked up documents are discussed. We conclude that when documents are encoded
in the same vocabulary, n-grams constructed to include markup can be used to recognize
structural similarities between documents.
How to cite this paper
Huitfeldt, Claus, and C. M. Sperberg-McQueen. Document similarity: Transcription, edit distances, vocabulary overlap, and the metaphysics
of documents. Presented at: Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31,
2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Huitfeldt01
Documents as Timed Abstract Objects
Abstract
At Balisage 2009 and 2010 Renear and Wickett discussed problems in reconciling the
view that documents are abstract objects with the fact that they can undergo change.
In this paper we present an account of documents which we believe is quite common,
but which was not discussed by Renear and Wickett.
According to this account documents are indeed abstract objects, but this is easily
reconciled with the fact that they are created and can undergo change. We then point
to a similarity between this account and the notion of so-called space-time slices.
We argue that the proposed account of documents as timed abstract objects may be subject
to the same kind of criticism that has been raised against the notion of space-time
slices.
We believe that our account fares no worse than the other accounts given of documents
as abstract objects. But it still fails, and we remain agnostic about the ontological
status of documents and their relation to abstract objects, as well as about the nature
of abstract objects. We conclude that either documents are not (or not related to)
abstract objects, or they are (or are related to) abstract objects of a kind which
does not correspond to the standard definition of what an abstract object is.
How to cite this paper
Huitfeldt, Claus, Fabio Vitali and Silvio Peroni. Documents as Timed Abstract Objects. Presented at: Balisage: The Markup Conference 2012, Montréal, Canada, August 7 -
10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Huitfeldt01
Encoding semantic relationships in literary texts: A methodological proposal for linking
networked entities into semantic relations
Abstract
Encoding meaningful semantic relationships in literary texts is almost as difficult
as defining and identifying them. Defining the types and the components of semantic
relationships that can be extracted from literary texts is a quite challenging task
because literature is full of implicit and oblique messages and references. Subsequently,
identifying and encoding semantic relationships in literature is even more challenging
because often relations do not have neither clear nor standard linguistic form and
usually they overlap each other. This paper discusses modeling and encoding issues
concerning the mapping of relationships of cultural content in literary and humanities
texts, highlighted by the case of the ECARLE project annotation campaign. On handling
these modeling and encoding issues the paper proposes a methodology of minimalistic
and flexible annotation techniques, combined in order to generate human annotated
training data for a Relation Extraction machine learning system. The proposed methodology
utilizes the available TEI tagset, and, without any further customizations, allows
the mapping of relations formed by named entities in a simple yet flexible way, open
to reuse, interchange, conversion and visualization.
How to cite this paper
Koidaki, Fotini, and Katerina Tiktopoulou. Encoding semantic relationships in literary texts: A methodological proposal for linking
networked entities into semantic relations. Presented at: Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6,
2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Koidaki01
An extensible API for documents with multiple annotation layers
Abstract
Both XML namespaces and standoff annotation are promising approaches to tackle possibly
overlapping multiple annotation layers in XML instances. The creation and processing
of standoff instances can be cumbersome – especially when the underlying textual primary
data is allowed to be modified after the annotation has been added. In this paper
we present a powerful API that is capable of dealing with these tasks by providing
an extension mechanism that allows for the easy creation of modules corresponding
to a certain namespace (and therefore markup language). We use XStandoff as a working
example since it is a standoff format that highly depends on XML namespaces for different
annotation layers.
How to cite this paper
Diewald, Nils, and Maik Stührenberg. An extensible API for documents with multiple annotation layers. Presented at: Balisage: The Markup Conference 2013, Montréal, Canada, August 6 -
9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Diewald01
Extension of the type/token distinction to document structure
Abstract
The type/token distinction introduced by C. S. Peirce and taken up by many others
is familiar when applied to individual symbols or characters in a writing system,
and also when applied at a higher level to words (and word-like objects).
Some writers apply the distinction not only at some basic or foundational level but
also as a description of higher levels of organization. This paper follows their example
by outlining a concrete extension of the type/token distinction to all levels of document
organization, specifying that higher-level types may contain sequences of lower-level
types, and similarly for higher- and lower-level tokens. We further extend the usual
model of types and tokens by allowing higher-level types to contain not just sequences
of (lower-level) types but also sets, bags, conjunctions and disjunctions of types.
This allows the system to deal gracefully both with indeterminate documents (e.g.,
a manuscript in which it is not clear whether a given mark on the page represents
a 'c' or a 't') and with intentionally polyvalent documents, in which some marks are
to be read as tokens of more than one type, as in the ambigram, a sort of combination
puzzle and calligraphic artwork in which the shapes on the page may be read in different
ways, or the same way, in different directions.
This account of document structure in terms of types and tokens is similar in many
ways to that offered by SGML, XML, and other systems of descriptive markup. On this
view, SGML and XML elements are, strictly speaking, types (and tokens) in Peirce’s
sense of those words. Some techniques developed in other areas to which the type/token
distinction is relevant may be useful in work on markup languages (and vice versa).
How to cite this paper
Huitfeldt, Claus, Yves Marcoux and C. M. Sperberg-McQueen. Extension of the type/token distinction to document structure. Presented at: Balisage: The Markup Conference 2010, Montréal, Canada, August 3 -
6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Huitfeldt01
Freestyle Markup Language: Specification of an intuitive, powerful, polyhierarchical
new extensible markup language
Abstract
This paper provides a new generation of a markup language by introducing the Freestyle Markup Language (FML). Demands placed on the language are elaborated, considering current standards and
discussions. Conception, a grammatical definition, a corresponding object graph and
the bi-directional unambiguous transformation between these two congruent representation
forms are set up. The result of this paper is a fundamental definition of a completely
new markup language, consolidating many deficiency-discourses and experiences into
one particular implementation concept, encouraging the evolution of markup.
How to cite this paper
Pondorf, Denis, and Andreas Witt. Freestyle Markup Language: Specification of an intuitive, powerful, polyhierarchical
new extensible markup language. Presented at: Balisage: The Markup Conference 2010, Montréal, Canada, August 3 -
6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Pondorf01
The FtanML Markup Language
Abstract
This paper presents a new markup language called FtanML, together with an associated
schema language called FtanGram, and a query/transformation language called FtanSkrit.
FtanML was originally designed by a group of students taught by the author, together
with Stephanie Haupt, at a summer school held in the Swiss village of Ftan in August
2012. It has since been taken forward by the author with some further involvement
by the students. The idea of FtanML is to rethink markup from the ground up: to imagine
what the world could be like if we didn’t have to carry forward the mistakes of the
past; to take what works well in current languages, and discard the features that
do little more than add complexity. More mundanely, FtanML can be seen as a blend
of ideas from XML and JSON: neither the union nor the intersection of the two, but
a new language that combines the best features of both.
How to cite this paper
Kay, Michael. The FtanML Markup Language. Presented at: Balisage: The Markup Conference 2013, Montréal, Canada, August 6 -
9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Kay01
Graph characterization of overlap-only TexMECS and other overlapping markup formalisms
Abstract
We establish a necessary and sufficient condition for a graph to correspond to the
structure of an overlapping markup document, such as a well-formed TexMECS document
(not using interrupted or virtual elements). This provides a test for determining
if any given graph can be serialized into a TexMECS document—or any other similar
language—using only overlapping markup. Such a test may prove useful in DOM-based
applications, to determine if an attempted modification operation would preserve the
overlap-only serializability of the document. For example, in a document editor using
a graph-oriented interface, the user could be warned when a requested operation would
prevent the document from being serializable with overlapping elements only. To our
knowledge, no such characterization has been given before.
How to cite this paper
Marcoux, Yves. Graph characterization of overlap-only TexMECS and other overlapping markup formalisms. Presented at: Balisage: The Markup Conference 2008, Montréal, Canada, August 12 -
15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Marcoux01.
Hierarchies within range space: From LMNL to OHCO
Abstract
LMNL provides a markup syntax for annotating arbitrary ranges, irrespective of hierarchical
relations, in text. A LMNL processor can parse this syntax (or any other syntax, if
mapped) into a generalized data model, which can be queried and processed. Among the
applications that LMNL supports readily is the creation of visual sketches of the markup on a document, e.g. using SVG. Such sketches can discover and depict
any range relations of interest. It turns out the overlap is often less interesting
than the hierarchies.
Examining texts showing overlapping hierarchies (MCH or multiple concurrent hierarchies)
suggests some interesting things about the evolution, purposes and uses of the OHCO
(ordered hierarchy of content objects) as a concept applied to documents or literary artifacts in general — and by implication of any hierarchical data model
such as XML.
How to cite this paper
Piez, Wendell. Hierarchies within range space: From LMNL to OHCO. Presented at: Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8,
2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Piez01
Hyper, Multi, or Single? Thinking about Text in Graphs and Trees
Abstract
This paper explores the potential of combining the Text-As-Graph (TAG) and the XML
data models. It proposes a digital editing workflow in which users can model, edit,
and store text in TAG, and subsequently export the data to XML for further analysis
or publication with XML-based tools. The conversion from TAGML to XML presents several
interesting challenges on a technical level as well as a philological level. Overall,
we argue that there may be many pragmatic reasons to encode cultural heritage texts
in XML, but we have to be mindful of the XML framework becoming synonymous with the
framework in which we conceptualize text. The paper therefore dives deep into the
translation from conceptual model to logical model(s) and argues in favor of understanding
the affordances and limitations of the text modeling technologies we use.
How to cite this paper
Bleeker, Elli, Ronald Haentjens Dekker and Bram Buitendijk. Hyper, Multi, or Single? Thinking about Text in Graphs and Trees. Presented at: Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6,
2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26 (2021). https://doi.org/10.4242/BalisageVol26.Bleeker01
Implementing TEI Standoff Annotation in the browser
Abstract
Proposes a method for encoding and visualizing arbitrary annotated segments of TEI
documents.
How to cite this paper
Cayless, Hugh. Implementing TEI Standoff Annotation in the browser. Presented at: Balisage: The Markup Conference 2019, Washington, DC, July 30 - August
2, 2019. In Proceedings of Balisage: The Markup Conference 2019. Balisage Series on Markup Technologies, vol. 23 (2019). https://doi.org/10.4242/BalisageVol23.Cayless01
It’s more than just overlap: Text As Graph: Refining our notion of what text really
is—this time for sure!
Abstract
The XML tree paradigm has several well-known limitations for document modeling and
processing. Some of these have received a lot of attention (especially overlap), and
some have received less (e.g., discontinuity, simultaneity, transposition, white space
as crypto-overlap). Many of these have work-arounds, also well known, but—as is implicit
in the term “work-around”—these work-arounds have disadvantages. Because they get
the job done, however, and because XML has a large user community with diverse levels
of technological expertise, it is difficult to overcome inertia and move to a technology
that might offer a more comprehensive fit with the full range of document structures
with which researchers need to interact both intellectually and programmatically.
A high-level analysis of why XML has the limitations it has can enable us to explore
how an alternative model of Text as Graph (TAG) might address these types of structures
and tasks in a more natural and idiomatic way than is available within an XML paradigm.
How to cite this paper
Haentjens Dekker, Ronald, and David J. Birnbaum. It’s more than just overlap: Text As Graph: Refining our notion of what text really
is—this time for sure! Presented at: Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4,
2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Dekker01
Luminescent: parsing LMNL by XSLT upconversion
Abstract
Among attempts to deal with the overlap problem, LMNL (Layered Markup and Annotation
Language) has attracted its share of attention but has also never grown much past
its origins as a thought experiment. LMNL’s conceptual model differs from XML’s, and
by design its notation also differs from XML’s. Nonetheless, a pipeline of XSLT transformations
can parse LMNL input and construct an XML representation of LMNL, with the resulting
benefit that further XML tools can be used to analyze and process documents originating
from the alien notation. The key is to regard the task as an upconversion: structural
induction performed over plain text.
How to cite this paper
Piez, Wendell. Luminescent: parsing LMNL by XSLT upconversion. Presented at: Balisage: The Markup Conference 2012, Montréal, Canada, August 7 -
10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Piez01
Marking up microrevisions with major implications: Non-linear text in TAG
Abstract
The article discusses how micro-level textual variation can be expressed in an idiomatic
manner using markup, and how the markup information is subsequently used by a digital
collation tool for a more refined analysis of the textual variation. We take examples
from the manuscript materials of Virginia Woolf’s To the Lighthouse (1927), which
bear the traces of the author’s struggles in the form of deletions, additions, and
rewrites. These in-text revisions typically constitute non-linear, discontinuous,
or multi-hierarchical information structures. While digital technology has been instrumental
in supporting manuscript research, the current data models for text provide only limited
support for co-existing hierarchies or non-linear text features. The hypergraph data
model of TAG is specifically designed to support and facilitate the study of complex
manuscript text by way of its syntax TAGML and the collation tool HyperCollate. The
article demonstrates how the study of textual variation can be augmented by designated
markup to express the in-text, micro-level revisions, and by computer-assisted collation
that takes into account that information.
How to cite this paper
Bleeker, Elli, Bram Buitendijk and Ronald Haentjens Dekker. Marking up microrevisions with major implications: Non-linear text in TAG. Presented at: Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31,
2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Bleeker01
Markup Discontinued: Discontinuity in TexMecs, Goddag structures, and rabbit/duck
grammars
Abstract
That the textual phenomena of interest for markup are not always hierarchically arranged
is well known and widely discussed. Less frequently discussed is the fact that they
are also not always contiguous, so that the units of our analysis cannot always correspond
to single elements in the document. Various notations for discontinuous elements exist,
but the mapping from those notations to data structures has not been well analysed
or understood. And as far as we know, there are no standard mechanisms for validating
discontinuous elements. We propose a data structure (a modification of the Goddag
structure) to better handle discontinuous elements: we relax the rule that every pair
of elements where one contains the other be related by a path of parent/child links.
Parent/child links are then not an automatic result of containment. We conclude with
a brief sketch of the issues involved in extending current validation mechanisms to
handle discontinuity.
How to cite this paper
Sperberg-McQueen, C. M., and Claus Huitfeldt. Markup Discontinued: Discontinuity in TexMecs, Goddag structures, and rabbit/duck
grammars. Presented at: Balisage: The Markup Conference 2008, Montréal, Canada, August 12 -
15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Sperberg-McQueen01
Markup Meaning and Mereology
Abstract
When marking up a document we chop it up into elements. Elements are parts of the
document, some of which contain further elements, i.e., have parts of their own. Thus,
the part-whole relation is central to the way markup works.
Mereology is precisely the theory of part-whole relationships, but has not yet found
much application in markup theory. In this paper we provide a sketch of how mereology,
in the form more specifically of Nelson Goodman’s Calculus of Individuals, might be
applied to markup.
We discuss ways of identifying the individuals of marked-up documents and of referencing
these individuals, and we sketch some ways of applying the calculus to the problem
of propagation of properties in documents.
How to cite this paper
Huitfeldt, Claus, C. M. Sperberg-McQueen and Yves Marcoux. Markup Meaning and Mereology. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Huitfeldt01
Merging Multi-Version Texts: a General Solution to the Overlap Problem
Abstract
Multi-Version Documents or MVDs, as described in Schmidt and Colomb (), provide a
simple format for representing overlapping structures in digital text. They permit
the reuse of existing technologies, such as XML, to encode the content of individual
versions, while allowing overlapping hierarchies (separate, partial or conditional)
and textual variation (insertions, deletions, alternatives and transpositions) to
exist within the same document. Most desired operations on MVDs may be performed by
simple algorithms in linear time. However, creating and editing MVDs is a much harder
and more complex operation that resembles the multiple-sequence alignment problem
in biology. The inclusion of the transposition operation into the alignment process
makes this a hard problem, with no solutions known to be both optimal and practical.
However, a suitable heuristic algorithm can be devised, based in part on the most
recent biological alignment programs, whose time complexity is quadratic in the worst
case, and is often much faster. The results are satisfactory both in terms of speed
and alignment quality. This means that MVDs can be considered as a practical and editable
format suitable for representing many cases of overlapping structure in digital text.
How to cite this paper
Schmidt, Desmond. Merging Multi-Version Texts: a General Solution to the Overlap Problem. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Schmidt01
Methodology for the construction of multi-structured documents
Abstract
We present the multi-structured documents problem and offer an overview of existing
solutions. We then notice that they do not consider the problem of constructing such
documents. In this context, we use our experience with philosophers who are building
a digital edition of the work of Jean-Toussaint Desanti, in order to present a methodology
for the construction of multi-structured documents. This methodology is based on the
MSDM model in order to represent such documents.
Moreover each step of the methodology has been implemented in the Haskell functional
programming language.
How to cite this paper
Portier, Pierre-Edouard, and Sylvie Calabretto. Methodology for the construction of multi-structured documents. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Portier01
The MLCD Overlap Corpus (MOC) Project report
Abstract
The MLCD Overlap Corpus (MOC) is a collection of samples of texts and text fragments
with overlapping structures. The main immediate goal of the MOC project is to build
a corpus of well understood and well documented examples of overlap, discontinuity,
alternate ordering, and related phenomena in various notations, for use in the investigation
of methods of recording such phenomena. The samples should be of use in documenting
the history of proposals for dealing with overlap and in evaluating existing and new
proposals.
How to cite this paper
Marcoux, Yves, Claus Huitfeldt and C. M. Sperberg-McQueen. The MLCD Overlap Corpus (MOC) Project report. Presented at: Balisage: The Markup Conference 2012, Montréal, Canada, August 7 -
10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Huitfeldt02
Modeling overlapping structures: Graphs and serializability
Abstract
The problem of overlapping structures has long been familiar to the structured document
community. In a poem, for example, the verse and line structures overlap, and having
them both available simultaneously is convenient, and sometimes necessary (for example
for automatic analyses). However, only structures that embed nicely can be represented
directly in XML. Proposals to address this problem include XML solutions (based essentially
on a layer of semantics) and non-XML ones. Among the latter is TexMecs , a markup
language that allows overlap (and many other features).
XML documents, when viewed as graphs, correspond to trees. Marcoux characterized overlap-only
TexMecs documents by showing that they correspond exactly to completion-acyclic node-ordered directed acyclic graphs. In this paper, we elaborate on that result in two ways.
First, we cast it in the setting of a strictly larger class of graphs, child-arc-ordered directed graphs, that includes multi-graphs and non-acyclic graphs, and show that — somewhat surprisingly
— it does not hold in general for graphs with multiple roots. Second, we formulate
a stronger condition, full-completion-acyclicity, that guarantees correspondence with an overlap-only document, even for graphs that
have multiple roots.
How to cite this paper
Marcoux, Yves, Michael Sperberg-McQueen and Claus Huitfeldt. Modeling overlapping structures: Graphs and serializability. Presented at: Balisage: The Markup Conference 2013, Montréal, Canada, August 6 -
9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Marcoux01
Multi-structured documents and the emergence of annotations vocabularies
Abstract
The construction of multi-structured documents often implies the definition of annotations
vocabularies. Moreover, in a multi-users context, the growth of these vocabularies
has to be controlled. Therefore, we propose using the trace of users activity to limit
this growth and to document the vocabularies. For example, a user will be able to
follow and annotate a term in the context of its surrounding actions from its creation
to the last time it was used. From a broader point of view, this work is grounded
on our Web based philological platform, DINAH, and is mainly motivated by our collaboration
with a group of philosophers studying the handwritten manuscripts of Jean-Toussaint
Desanti.
How to cite this paper
Portier, Pierre-Édouard, and Sylvie Calabretto. Multi-structured documents and the emergence of annotations vocabularies. Presented at: Balisage: The Markup Conference 2010, Montréal, Canada, August 3 -
6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Portier01
Overlapproaches in documents: a definitive classification (in OWL, 2!)
Abstract
everal different types of overlap exist and different strategies are needed to detect
them. In particular, there is a clear difference between ranges of text that overlap
and markup items that overlap (that is, elements and attributes), and how these types
of overlapping affect dominance and containment relations of nodes is of some relevance,
too. In order to provide a complete definition and description of these overlapping
patterns, we introduce the EARMARK Overlapping Ontology (EOO), i.e., an OWL 2 DL ontology
that extends EARMARK (an OWL-based markup meta-language compliant with extended GODDAGs)
to define properties describing dominance and containment relations as well as a complete
characterisation of the different kinds of overlap that can happen to nodes. In addition,
we also present some inference rules for the automatic retrieval (by means of a reasoner)
of all the overlapping instances in a given input markup document.
How to cite this paper
Peroni, Silvio, Francesco Poggi and Fabio Vitali. Overlapproaches in documents: a definitive classification (in OWL, 2!). Presented at: Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8,
2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Peroni01
Poio API and GraF-XML: A radical stand-off approach in language documentation and
language typology
Abstract
This paper presents an ongoing CLARIN project that implements a library and web application
for data management in language documentation and language typology. The project uses
annotation graphs as pivot format, as described by ISO 24612 "Language resource management
- Linguistic annotation framework (LAF)". The standard contains an XML representation
of annotation graphs. We will show hwo we map common file formats onto annotation
graphs and how this stand-off approach will improve linguistic workflows and data
management in language documentation and typology.
How to cite this paper
Blumtritt, Jonathan, Peter Bouda and Felix Rau. Poio API and GraF-XML: A radical stand-off approach in language documentation and
language typology. Presented at: Balisage: The Markup Conference 2013, Montréal, Canada, August 6 -
9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Bouda01
Representing concurrent document structures using Trojan Horse markup
Abstract
The need for markup to handle multiple concurrent document structures has been clear
at least since SGML introduced the CONCUR feature to support such markup. Few SGML
users found the use of CONCUR necessary, few products ever supported it, and the designers
of XML dropped it as an unnecessary complication. But those who need concurrent markup
really need it. Fortunately, the functionality of CONCUR can be recreated more or
less successfully in XML: one document structure can use conventional XML, while others
use Trojan-Horse markup (DeRose 2004). Rabbit/duck grammars can be used to validate
the document and to guide the creation of conventional schemas for use in editing
tools.
How to cite this paper
Sperberg-McQueen, C. M. Representing concurrent document structures using Trojan Horse markup. Presented at: Balisage: The Markup Conference 2018, Washington, DC, July 31 - August
3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Sperberg-McQueen01
Representing Overlapping Hierarchy as Change in XML
Abstract
Changes in an XML document may effect not only element and attribute content but,
more problematically, the markup hierarchy. Markup for tracking structural changes
must represent multiple, often overlapping, structures in the same document. Thus
the perennial problem of overlap becomes a subset of the problem of managing change
to structured documents, such as versions of documents amended over time. Our work
started with a delta format for two or more documents, which easily represents inline
changes, but handles hierarchy change by duplicating content. In order to avoid duplication,
we introduce a distinction between the name of the element (its tag) and the element
content, so that assertions can be made separately. We then introduce @dx (change)
and @dxTag (change tag) attributes to mark changes. This representation allows us
to define overlapping hierarchies in a completely XML way without declaring a dominant
hierarchy and while keeping element fragmentation to a minimum. While this solution
probably will not scale for large numbers of variants, it shows promise for many classes
of documents.
How to cite this paper
La Fontaine, Robin. Representing Overlapping Hierarchy as Change in XML. Presented at: Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5,
2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016).
https://doi.org/10.4242/BalisageVol17.LaFontaine01
Stand-off Bridges in the Frankenstein Variorum Project: Interchange and Interoperability
within TEI Markup Ecosystems
Abstract
Developing the Frankenstein Variorum Project has necessitated a reconciliation of
extremely divergent markup ecosystems supporting multiple editions of a single novel.
The reconciliation process involves breaking or flattening the original hierarchies
to prioritize units of low-level lateral intersection, points shared in common to
construct bridge or intermediary formats for processing with automated collation via
CollateX. The output from the automated collation process also serves as an intermediary
format that we transform into a TEI form of stand-off parallel segmentation, in which
stand-off pointing mechanisms operate like a switchboard for connecting the individual
editions which can remain (for the most part) undisturbed or unmarked from the collation
process. The TEI stand-off bridge negotiates the distinct markup ecosystems in ways
that can break the silo effect of isolating specially encoded editions. Far from an
ephemeral support structure, the stand-off bridge upholds the whole as the spine of
the variorum project because it improves the interoperability and interchangeability
of all the markup ecosystems involved. Building the stand-off bridge effectively reconstitutes
the hierarchies in a way that expresses intersections essentially as a graph structure
of nodes with edge pointers to comparable nodes.
Our experience on the Frankenstein Variorum is consistent with other TEI projects
that involve the curation of divergence, variance, and forking in text streams. Taken
together, such projects illuminate how the TEI can organize textual data in ways other
than an ordered hierarchy of content objects, and that the TEI can be turned to express
unordered lateral intersections in ways that serve long-standing goals of the TEI
community: interchangeability and interoperability of electronic texts. As Syd Bauman
in particular has discussed, where interchangeability reflects the capacity for humans
to negotiate and adapt to markup ecosystems from systematic navigation and documentation
without needing to contact the encoder for help, interoperability reflects the capacity
of software tools to process the markup without needing to change either it or the
tools. Although we usually consider the needs of software interoperability as at odds
with the richly expressive capacity of human-readable semantic interchange, this paper
suggests that the TEI can be designed to prioritize the interests of both, from facilitating
automated collation to generating an interlinking web interface that gives the user
means to choose and change directions in navigating multiple editions as desired.
How to cite this paper
Beshero-Bondar, Elisa E., and Raffaele Viglianti. Stand-off Bridges in the Frankenstein Variorum Project: Interchange and Interoperability
within TEI Markup Ecosystems. Presented at: Balisage: The Markup Conference 2018, Washington, DC, July 31 - August
3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Beshero-Bondar01
TagAl: A tag algebra for document markup
Abstract
This paper takes its point of departure in an overview of the overlap problem, and
of proposed solutions to that problem. We then look at some analogies between bracketed
markup notations and rules for well-formedness and structuring of simple parenthetical
expressions. We propose a method for building lattices from marked up documents with
and without overlap, and for generating, from these lattices, document models in the
form of trees for XML documents, and in the form of GODDAGs for documents with overlap.
It turns out that one and the same method can be used for generating both kinds of
models, and we argue that lattices can also be used to implement well-formedness constraints
for both kinds of documents. Finally, we discuss and compare some of the algebraic
features of the document models, and the relations between them.
How to cite this paper
Johnsen, Lars G, and Claus Huitfeldt. TagAl: A tag algebra for document markup. Presented at: Balisage: The Markup Conference 2011, Montréal, Canada, August 2 -
5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011).
https://doi.org/10.4242/BalisageVol7.Johnsen01
TAGML: A markup language of many dimensions
Abstract
This report presents new developments in three areas pertaining to Text As Graph (TAG),
a data model that conceptualizes what text really is as a property hypergraph, which
we first introduced at Balisage 2017. () In this new report 1) we propose a markup
language for TAG, which we call TAGML; 2) we discuss a workflow, implemented in our
Alexandria reference implementation of TAG, for editing TAG documents selectively,
so as to retain a legible interface; and 3) we introduce some modifications in the
TAG data model (principally the use of undirected edges to connect Text nodes).
How to cite this paper
Haentjens Dekker, Ronald, Elli Bleeker, Bram Buitendijk, Astrid Kulsdom and David
J. Birnbaum. TAGML: A markup language of many dimensions. Presented at: Balisage: The Markup Conference 2018, Washington, DC, July 31 - August
3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.HaentjensDekker01
TEI Feature Structures as a Representation Format for Multiple Annotation and Generic
XML Documents
Abstract
Feature structures are mathematical entities (rooted labeled directed acyclic graphs)
that can be represented as graph displays, attribute value matrices or as XML adhering
to the constraints of a specialized TEI tag set. We demonstrate that this latter ISO-standardized
format can be used as an integrative storage and exchange format for sets of multiple
annotation XML documents. This specific domain of application is rooted in the approach
of multiple annotations, which marks a possible solution for XML-compliant markup
in scenarios with conflicting annotation hierarchies. A more extreme proposal consists
in the possible use as a meta-representation format for generic XML documents. For
both scenarios our strategy concerning pertinent feature structure representations
is grounded on the XDM (XQuery 1.0 and XPath 2.0 Data Model). The ubiquitous hierarchical
and sequential relationships within XML documents are represented by specific features
that take ordered list values. The mapping to the TEI feature structure format has
been implemented in the form of an XSLT 2.0 stylesheet. It can be characterized as
exploiting aspects of both the push and pull processing paradigm as appropriate. An
indexing mechanism is provided with regard to the multiple annotation documents scenario.
Hence, implicit links concerning identical primary data are made explicit in the result
format. In comparison to alternative representations, the TEI-based format does well
in many respects, since it is both integrative and well-formed XML. However, the result
documents tend to grow very large depending on the size of the input documents and
their respective markup structure. This may also be considered as a downside regarding
the proposed use for generic XML documents. On the positive side, it may be possible
to achieve a hookup to methods and applications that have been developed for feature
structure representations in the fields of (computational) linguistics and knowledge
representation.
How to cite this paper
Stegmann, Jens, and Andreas Witt. TEI Feature Structures as a Representation Format for Multiple Annotation and Generic
XML Documents. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Stegmann01
A toolkit for multi-dimensional markup: The development of SGF to XStandoff
Abstract
In this paper we describe the extended standoff approach defined by XStandoff (the
successor of the Sekimo Generic Format, SGF), together with the accompanied collection
of XSLT stylesheets. SGF has undergone further developments after its first presentation
(cf. ) which resulted into the new development version called XStandoff containing
different changes addressed in this paper. In addition, refinements have been made
to the already available transformation scripts that help generating SGF and XStandoff
instances and newly developed stylesheets have been added for the deletion of single
XStandoff annotations and the conversion into inline representations.
How to cite this paper
Stührenberg, Maik, and Daniel Jettka. A toolkit for multi-dimensional markup: The development of SGF to XStandoff. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Stuhrenberg01
Towards markup support for full GODDAGs and beyond: the EARMARK approach
Abstract
One of the most evident tenets of the literature on overlapping markup is that the
philosophy of documents as trees (as dictated by meta-markup languages such as SGML
and XML) is a simplification that sometimes fails and requires corrections. These
corrections have been proposed at the markup level (e.g., milestones, segmentation),
at the meta-markup level (e.g., LMNL, TexMecs, XCONCUR, etc.) or at level of the abstract
model (e.g., GODDAG). Unfortunately full GODDAGs do not allow linearizations in general,
and as such a restricted version of GODDAG, r-GODDAG, has been proposed that is guaranteed
to be linearizable (in TexMecs) and still allows many nice features beyond trees.
In this paper we discuss that the problem of linearizing more-than-hierarchical structures
lies basically in the embedding of markup within content and that no such problem
arises with an appropriate standoff approach, that is able to represent full GODDAGs
without restrictions. This gives ample opportunities to deal with interesting markup
features that are describable with GODDAGs but not with r-GODDAGs, such as non-contiguous
elements and virtual elements.
Besides, we discuss whether a specific constraint of full GODDAGs is really necessary
once all residual hopes of embeddability are given up, and we further propose a minimal
extension to GODDAG, genially called "extended GODDAG" (e-GODDAG) that, by removing
the requirement for names in non-terminal nodes, adds support for additional interesting
markup features such as content repetitions. In truth, e-GODDAGs are even less embeddable
than full GODDAGs, but they are just as easily dealt with by using stand-off markup.
We further propose a meta-syntax for non-embedded markup, called EARMARK, that can
be used for stand-off annotations of textual content, and that naturally represents
e-GODDAGs with fully W3C-compliant technologies. EARMARK is based on an ontologically
precise definition of markup that instantiates the markup of a text document as an
OWL document, and through appropriate OWL and SWRL characterizations it can define
structures such as trees, r-GODDAGs, full GODDAGs and e-GODDAGs, and can be used to
generate validity constraints (including co-constraints), and to verify adherence
to content model patterns.
As mentioned, in general the embedding of a full EARMARK document is not straightforward,
but approaches can be taken in that direction: just like segmentation and fragmentation
are strategies to embed in a strictly-hierarchical language a r-GODDAG-specific feature
such as overlapping elements, similarly a number of strategies exist to provide embedding
of GODDAG and e-GODDAG features in less expressive syntaxes. In the final part of
the paper we discuss our wish to provide at the metalanguage level a series of embedding
strategies of the non-hierarchical features of EARMARK, i.e. a number of language-independent
mechanisms to express e-GODDAGs structures into XML (as well as in TexMecs and in
LMNL) and that can be recognized as such (i.e., as strategies, as tricks) by tools
and readers alike, especially for further uses of such documents.
How to cite this paper
Di Iorio, Angelo, Silvio Peroni and Fabio Vitali. Towards markup support for full GODDAGs and beyond: the EARMARK approach. Presented at: Balisage: The Markup Conference 2009, Montréal, Canada, August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Peroni01
UnderDok: XML Structured attributes, change tracking, and the metaphysics of documents
Abstract
UnderDok is an XML system for publishing, quality assurance, and change tracking of
higher education course descriptions. The documents have a fixed structure, numerous
cross-references, and prose interspersed with standard phrases. Each document exists
in a native language form, in an English translation, and sometimes in additional
languages. Changes must be tracked relative to the last authorized version. Up to
now, documents have been produced in Microsoft Word and manually copied to a database,
a process both labor-intensive and error-prone. UnderDok provides solutions to many
of these technical challenges, but may also inspire reflections on the metaphysical
status of documents. It is suggested that a course description, by which an institution
and its students are legally bound, is neither the source XML nor the presentation
XHTML, but a visual object containing linguistic information that occurs in certain
situations and contexts. The legal stability for these documents, which was traditionally
provided by printed pages, is now provided by the reproducibility (standardization)
of document representation and presentation technology.
How to cite this paper
Huitfeldt, Claus. UnderDok: XML Structured attributes, change tracking, and the metaphysics of documents. Presented at: Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14,
2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Huitfeldt01
Visualization of concurrent markup: From trees to graphs, from 2D to 3D
Abstract
The present paper deals with the visualization of concurrent markup. An initial discussion
of the underlying model of XML instances demonstrates that valid XML exceeds the expressive
power of trees. While some challenging features of concurrent markup, like overlaps,
can be captured by minimally extended trees, there are other phenomena which can be
adequately expressed in XML using constructs which instantiate advanced graph structures
(e.g. discontinuous elements or repetitive structures).
On the basis of two representation formats for concurrent markup, XStandoff and xLMNL,
two distinct approaches towards its visualization are presented. The first method
has been implemented in XSLT as an SVG-based 2D visualization strategy. Although it
can be shown that this first approach provides an adequate (though not optimal) solution
to overlapping structures, it is not capable of illustrating enhanced graph-based
phenomena like the ones mentioned above. Therefore, some remarks about possible 3D
visualizations are made which show how the adding of another dimension could contribute
to the appropriately expressive visualization of concurrent markup. In addition, a
prototypic implementation based on XSLT and X3D is discussed as first step towards
a three-dimensional illustration.
How to cite this paper
Jettka, Daniel, and Maik Stührenberg. Visualization of concurrent markup: From trees to graphs, from 2D to 3D. Presented at: Balisage: The Markup Conference 2011, Montréal, Canada, August 2 -
5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Jettka01
What, when, where? Spatial and temporal annotations with XStandoff
Abstract
Abstract We describe an extension for the generalized standoff approach XStandoff to describe
spatial information over non-textual primary data objects. A use case for this kind
of markup is the annotation of multimodal documents, that is text-image combinations.
How to cite this paper
Stührenberg, Maik. What, when, where? Spatial and temporal annotations with XStandoff. Presented at: Balisage: The Markup Conference 2013, Montréal, Canada, August 6 -
9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Stuhrenberg01
Why TEI stand-off annotation doesn’t quite work and why you might want to use it nevertheless
Abstract
The present submission focuses on the concept of stand-off annotation as it is implemented
in the current version of the TEI Guidelines. We look at the motivation for choosing
the stand-off approach to encoding Language Resources, briefly recount the history
of the concept within the broadly conceived TEI setting (since TEI P3 and the LT NSL
suite, through CES and XCES, ending in TEI P5), review the various kinds of hyperlink
semantics and identify three kinds of reasons for the poor uptake of the TEI-recommended
stand-off annotation approach to corpus encoding. We also suggest some solutions that
may contribute to a change in the current state of affairs.
How to cite this paper
Bański, Piotr. Why TEI stand-off annotation doesn’t quite work and why you might want to use it nevertheless. Presented at: Balisage: The Markup Conference 2010, Montréal, Canada, August 3 -
6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Banski01
An XML engine to model and query multimodal concurrent linguistic annotations: Application
to the OTIM Project
Abstract
This paper presents an XML engine defined to model and query multimodal concurrent
annotated data. This work stands in the context of the OTIM (Tools for Multimodal
Annotation) project which aims at developing conventions and tools for multimodal
annotation of a large conversational French speech corpus; it groups together Social
Science and Computer Science researchers. Within OTIM, our objective is to provide
linguists with a unique framework to encode and manipulate numerous linguistic domains:
morpho-syntax, prosody, phonetics, disfluencies, discourse, gesture and posture. For
that, it has to be possible to bring together and align all the different pieces of
information (called annotations) associated to a corpus.
We propose a complete pipeline from the annotation step to the management of the data
within an XML Information System. This pipeline first relies on the formalisation
of the linguistic knowledge and data within a OTIM specific XML format. A Java framework
is proposed for interfacing with both linguists specific annotation tools and XML
Information System. Finally, the querying of multimodal annotations within the XML
information system using XQuery is presented. As annotations are time aligned, an
extension of XQuery to Allen temporal relations is proposed.
How to cite this paper
Seinturier, Julien, Elisabeth Murisasco and Emmanuel Bruno. An XML engine to model and query multimodal concurrent linguistic annotations: Application
to the OTIM Project. Presented at: Balisage: The Markup Conference 2011, Montréal, Canada, August 2 -
5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Seinturier01
References
[Giordano et al., 1998] Giordano, Richard (Princeton), Jonathan R. Cole and Harriet Zuckerman (Columbia University).
Text Retrieval on a Microcomputer. 1988. Perspectives in Computing, Volume 8, Issue 1. International Business Machines Corporation.
[Goldfarb 1991] Goldfarb, Charles. The SMGL Handbook. 1991. Edited by Yuri Rubinsky. Oxford University Press.
Giordano, Richard (Princeton), Jonathan R. Cole and Harriet Zuckerman (Columbia University).
Text Retrieval on a Microcomputer. 1988. Perspectives in Computing, Volume 8, Issue 1. International Business Machines Corporation.