Clark, Ash. “A Wonderful Historie of Intertextual Networks: Or, How Not to Index Your Data.” Presented at Balisage: The Markup Conference 2023, Washington, DC, July 31 - August 4, 2023. In Proceedings of Balisage: The Markup Conference 2023. Balisage Series on Markup Technologies, vol. 28 (2023). https://doi.org/10.4242/BalisageVol28.Clark01.
Balisage: The Markup Conference 2023 July 31 - August 4, 2023
Balisage Paper: A Wonderful Historie of Intertextual Networks: Or, How Not to Index Your Data
Ash Clark
Ash Clark (e/em/eir) is the XML Applications Developer for the Northeastern University
Women Writers Project. Ash has studied Writing, Computer Science, and Library and
Information Science. Now, e is part web developer, part metadata consultant, part
XQuery
enthusiast, and all focused on thoughtful data design and accessible tech. Eir specialties
are drawing data from TEI-encoded documents; using XML databases to power websites;
and
creating exploratory interfaces out of compiled metadata. A genderqueer individual
and a
casual gamer, Ash lives in Massachusetts with eir magnificently floofy Pomeranian,
Frisk.
In 2022, the Women Writers Project (WWP) published Women Writers: Intertextual Networks
(WWIN), an EXPath web application served out of eXist-db. However, the site was quickly
plagued with connection issues: a page might take a long time to load, or the connection
would drop, or the site might be entirely inaccessible. In this paper, the author
will
describe the WWIN’s initial development, analyzing the design decisions and pitfalls.
Finally, e will describe the process of making the application much more stable and
efficient.
In 2022, the Women Writers Project (WWP) published Women Writers: Intertextual
Networks, an EXPath web application served out of eXist-db. However, the site was
quickly plagued with connection issues: a page might take a long time to load, or
the connection
would drop, or the site might be entirely inaccessible. In this paper, the author
will describe
the WWIN’s initial development, analyzing the design decisions and pitfalls. Finally,
e will
describe the process of making the application much more stable and efficient.
Intertextual gestures in Women Writers Online
In October 2016, the WWP set out to explore intertextuality as found within the Women
Writers Online (WWO) corpus. WWO is a collection of over 400 works by women: originally
published before 1850, now encoded in TEI and published online for subscribing institutions.
In a grant proposal to the National Endowment for the Humanities, WWP staff reasoned
that the
breadth and complexity of the existing WWO markup would allow us to work towards a much
clearer and more textured picture of the rhetoric of intertextuality: what female
authors
read, what they felt it important to quote, paraphrase, or cite, and what other subtler
mechanisms of allusion or unintentional echo were at work that connect their writing
to that
of other authors.[1]
Soon enough, a team of the WWP’s encoders and staff[2] examined, researched, and refined a great deal of rich, dense bibliographic and
intertextual data. Much later, in 2022, the WWP prepared to release a web interface
for
exploring this data — Women Writers: Intertextual Networks (WWIN).
The WWP’s goal was to create an interface which would let people view aggregated trends
in
intertextuality throughout Women Writers Online, but which would also let them drill
down to
interesting facets.
All together, WWIN melds data from:
WWO documents, which contain
Encoded intertextual gestures; and
A separate XML bibliography, which contains
An informal taxonomy of topic and genre keywords, and
Individual bibliography entries.
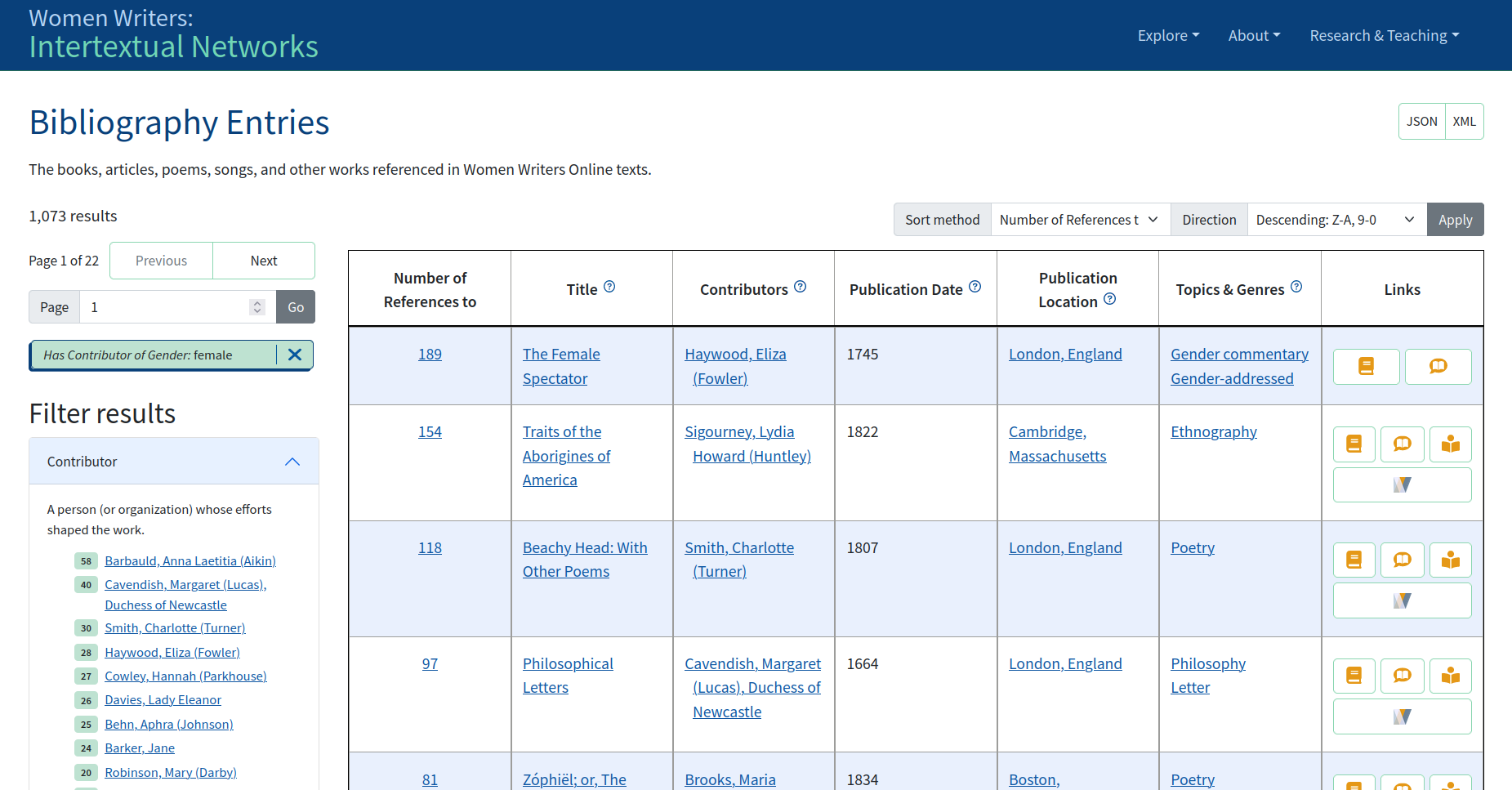
As an introduction to the WWIN website and its data, it seems useful to look
at two WWIN index pages, each of which corresponds closely to a TEI data source.
The first source is the TEI bibliography, a large document comprising all identifiable
works which have been referenced in WWO.[3] These works have been identified through research, and recorded in TEI
<biblStruct>s. Besides information about each work’s first known
publication, the WWP team also classified entries by topic or genre, using the
@ana attribute. Figure 1 is a simplified
example of one such entry.
Figure 1: TEI bibliography entry for the novel Zayde
<biblStruct xml:id="IT03823" corresp="#frbr.work" ana="#novel">
<monogr corresp="#frbr.expression">
<respStmt>
<resp>translator</resp>
<persName gender="unknown" ref="p:pporter.xem">Porter, P.</persName>
</respStmt>
<author>
<persName gender="female" ref="p:mdelave.ksv">de La Fayette, Madame
(Marie-Madeleine Pioche de la Vergne)</persName>
</author>
<title type="display">Zayde: A Spanish History or Romance</title>
<title type="full">Zayde: A Spanish History or Romance</title>
<title type="alt" xml:lang="fr">Zayde: Histoire Espagnole</title>
<imprint corresp="#frbr.manifestation">
<pubPlace>
<placeName>London, England</placeName>
</pubPlace>
<date when="1678">1678</date>
</imprint>
</monogr>
<note type="public" subtype="general">At the time of publication, the
authorship of "Zaïde" was attributed to Jean Renaud de Segrais; however, current
scholarship accepts Madame de La Fayette as the author, with possible assistance
from Segrais.</note>
</biblStruct>
WWIN bibliography entries generally contain:
an identifier;
genre or topic keywords;
one or more titles;
any contributors, including their
name,
presumed gender, and
WWP personography key;
information about the first edition published, including
WWIN can, and does, provide a web page for each bibliography entry. However, the goal
of
the interface was to allow exploration at scale, which is where the index page shines.
The
Bibliography is a paginated index of all bibliography entries, reduced to tabular
form. Next
to the table is a sidebar which lists out the top facets for a number of categories,
such as
the publication location and whether a work has a contributor of a given gender. Using
these
facets, one can start to perceive contours of the dataset, and one also narrow the
result set
to only those bibliography entries matching some criterion.
Figure 2: WWIN Bibliography index, filtered
By default, the Bibliography is sorted so that the most referenced entries appear
first.
This information is not part of the TEI bibliography; rather, the WWIN application
compiles
totals by counting references in the WWO markup. In WWO documents, intertextuality
is marked
by <title>s, <rs type="title">s, <quote>s, and
<bibl>s.
These tags have been augmented with identifiers, and attributes point to the
bibliography entries for the works being referenced. The WWP team calls these phenomena
intertextual gestures, defined as a reference to, or marked engagement
with, another work. A simplified example of a <title> appears in Figure 3.
Figure 3: Intertextual gesture toward the novel Zayde
<p><!-- [...] -->The interesting ro-
<lb/>mance of <title rend="case(smallcaps)" ref="b:IT03823" xml:id="t072"
><persName>Zaïde</persName></title> also, and some other
<lb/><rs type="properAdjective">Turkish</rs> tales, shewed her how frequent
<lb/>were such transformations; her romantic
<lb/>mind told her how probable were such ad-
<lb/>ventures <!-- [...] --></p>
Excerpt from Romance Readers and Romance Writers: A Satirical Novel
by Sarah Green, published in Women Writers Online by the Northeastern University Women
Writers Project.
Each intertextual gesture tagged in WWO has some obvious metadata attached to it:
an
identifier, one or more pointers, element name and type. One can process the element
itself to
generate HTML or plain text representations of the gesture’s textual contents. However,
there
is additional complexity because each gesture also carries contextual information
inferrable
from the TEI document around it.
In Figure 3, for instance, the WWIN classifies this gesture as a
title — if the gesture appeared in an <advertisement> instead
of running prose, it would be classified as an advertisement instead. From the
@xml:lang on the outermost element <TEI>, WWIN understands that
the textual content of this gesture is in English. And, from the lack of an
@author attribute on any of the element’s ancestors, WWIN can infer that the
primary author of the WWO text, Sarah Green, made this particular intertextual gesture.
See
the appendix section “Intertextual gestures” for more information on intertextual
encoding.
All in all, each intertextual gesture comprises a wealth of information about its
context,
as well as whatever can be gleaned from each of the bibliography entries associated
with it.
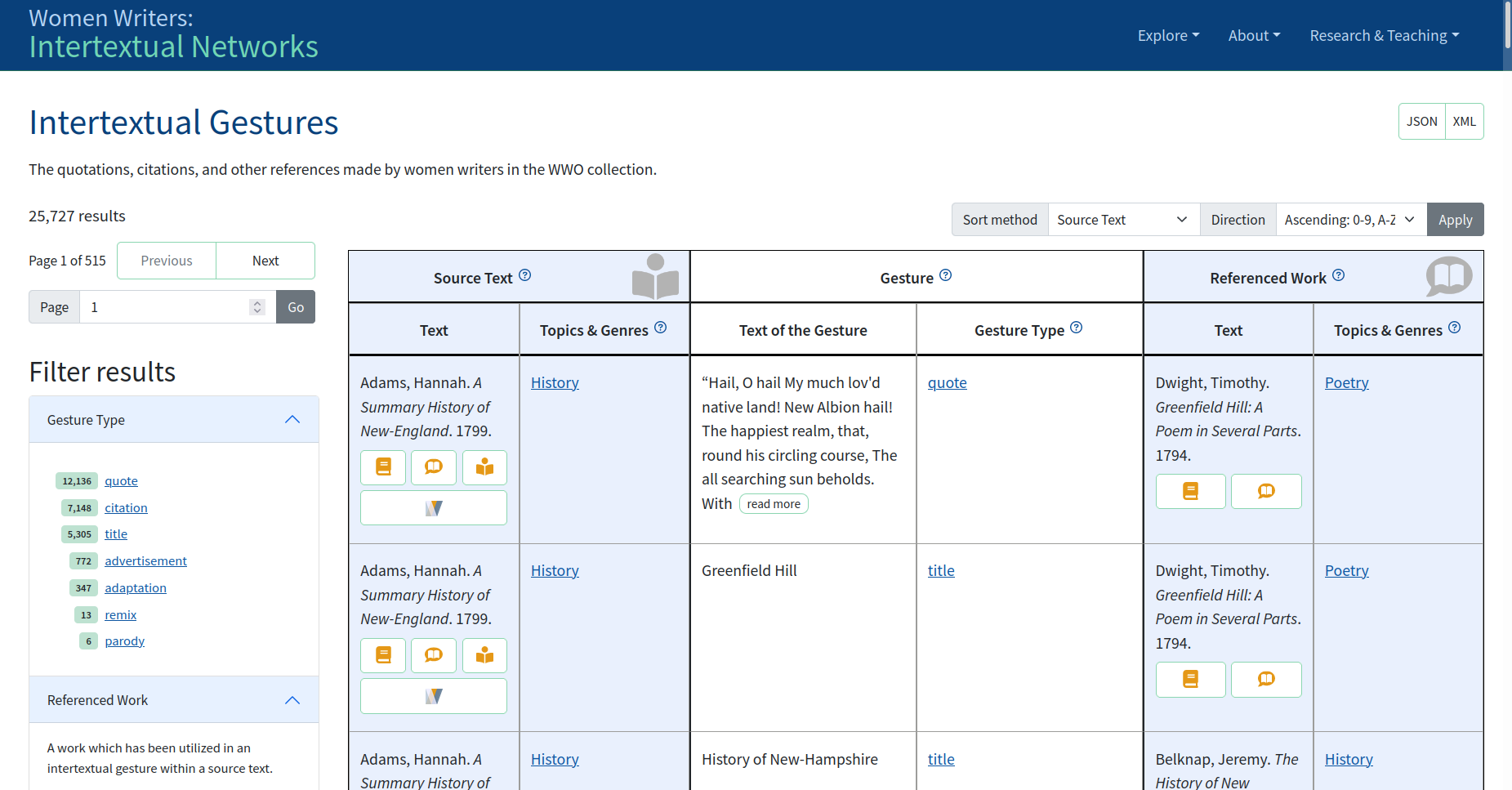
The WWIN Intertextual Gestures index is similar to the Bibliography index in
that it takes the form of a table alongside a list of actionable facets. In this case,
however, the column-heavy table of the Bibliography has been replaced with a table
which
reduces the amount of bibliographic data. The resulting table attempts to make clear
the
relationship between each gesture, its source WWO text, and its referenced works.
Figure 4: WWIN Intertextual Gestures index
Of summaries and scale
The Bibliography and Intertextual Gestures index pages form
the core of WWIN. However, the scale of the data represented in them can make those
indexes a
daunting place for readers to begin exploring. In Figure 4, for
example, the WWIN interface reports that there are a total of 25,727 intertextual
gestures
across 515 pages of results — far too many to skim for some interesting tidbit. The
Filter results sidebar helps a great deal, but each category is limited to
only the top ten filters. One would have to view the JSON or XML data to see all possible
filters at once.[4] Similarly, sorting allows page one to appear repopulated with a different set of
results. But even so, there is not much chance that a person will navigate through
every page
of results to build a picture of the full dataset.
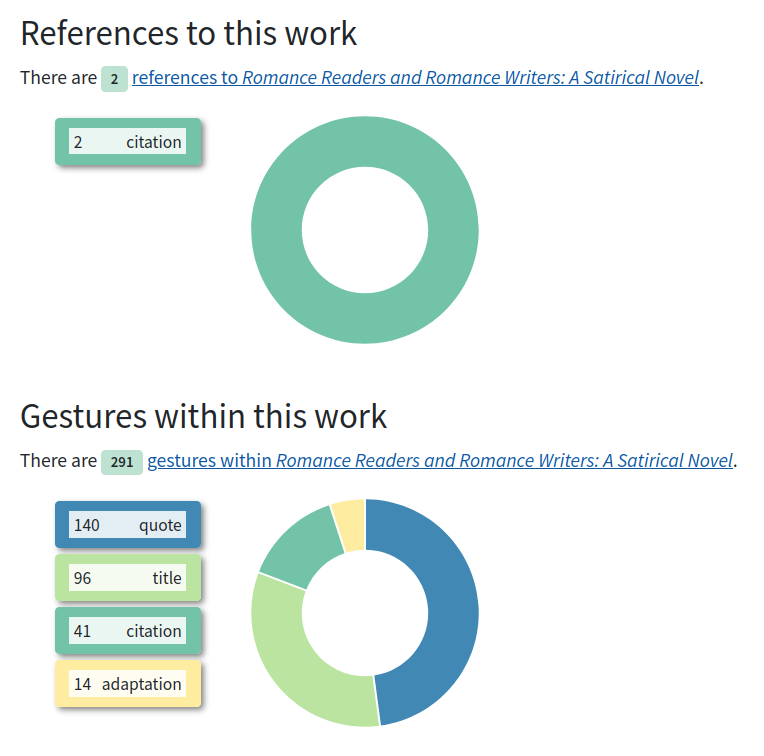
As previously mentioned, WWIN was intended to enable exploration: to make the scope
of
intertextuality in WWO visible, to bring patterns into focus, and to showcase the
interconnectivity of the data. To this end, the bibliography entry pages and two additional
indexes showcase donut chart visualizations which give a high-level overview of intertextual
usage across WWO.
Figure 5: Summaries of intertextual gestures by and within the novel Romance Readers and Romance Writers.
These visualizations — donut slices and the legend entries alike — also serve as links
into the Intertextual Gestures index, allowing readers to easily navigate to a
table of all relevant gestures. The visualizations summarize and break down the data,
yes, but
they also reward curiosity. The reader can interrogate the data behind the chart by
simply
clicking a link.
It is worth emphasizing that the website user has a lot of power to control their
experience of WWIN. To enable this level of control, the website must aggregate
all relevant data in order to display a single page of results. The
WWIN dataset is not a huge dataset, but it is large enough that aggregation has a
heavy
processing cost.
Another project might have chosen an easier approach; for example, by implementing
a
single index of source documents. Each record might then show a narrative view of
all the
intertextual gestures within that source text. This would have reduced the amount
of data that
we needed to compile. It also would have shifted our development more toward XSLT
rather than
XQuery.
However, this approach and others would have limited WWIN to document-by-document
explorations of intertextuality. The Women Writers Project was more interested in
giving users
the tools to explore intertextuality across the textbase, working at scale to find
patterns of
use, and then drilling down into the context of each individual gesture.
As a result, the author focused eir pre-publication efforts on building up the indexes
of WWIN.[5]
Enter the EXPath app
Behind the scenes, Women Writers: Intertextual Networks is an EXPath
application served out of the WWP’s eXist-db instance.[6] The EXPath package contains several XQuery scripts and libraries. One library
contains functions with RESTXQ annotations, and is used to serve out the WWIN website
pages.
The compiled EXPath package also includes: a clean, publication-friendly version of
the XML
bibliography (no comments, internal notes, or proofing flags, for instance); a JSON
representation of the bibliography; and a TEI personography derived from keyed contributor
names.
Besides the bibliography (stored in the application directory) and WWO documents (stored
in a WWO-specific data directory), the EXPath app maintains a separate directory of
intertextual data compiled from these two sources. In order to save processing on
inferred
knowledge, the RESTXQ endpoints draw from this data cache, rather than directly querying
the
TEI.
The data cache is generated ahead of time through a series of XQuery scripts. The
caching process was designed to be modular for debugging and logging purposes.[7] Each XQuery builds off the inferences made by the last, saving its output to a
staging directory. By the end of the process, a final script has moved all caches
out of the
staging directory and into the publication directory, ready for use. (A thorough description
of the XQuery workflow can be found in the Caching
Processes appendix.)
The published caches include:
each index page’s full dataset, with inferences made explicit;
lists of identifiers, pre-sorted by the index’s methods;
complete summaries of the facets available for each index;
XHTML representations of the bibliography citations and intertextual gestures;
and
cached responses for sizable single-filter-applied requests,[8] which themselves contain:
the parameter name and value of the applied filter,
lists of pre-sorted identifiers, and
facet summaries specific to this request.
Except for the XHTML serializations, the caches were stored in the W3C’s XML
serialization of JSON (nicknamed pseudo-JSON by the author).[9] With eXist able to index these files as XML, the web app could identify caches
that matched a request’s criteria. Cached XML was then parsed as maps or arrays, which
could
be passed around, augmented, and serialized quickly as JSON or XML, or (with a bit
more
effort) as HTML. An example of the cached pseudo-JSON can be found in Appendix C.
By spring 2022, the staging site for WWIN was admittedly a little slow, but stress
tests
with small groups of human users didn’t phase the test server too badly. And so, on
May
25th, 2022, with WWIN freshly installed on the WWP production instance of eXist, the
Women
Writers Project announced the public release of WWIN.
This is not where things went wrong
…because publishing WWIN did not reveal anything new about the quirks and eccentricities
of the web app. What publishing did was escalate the behaviors that were
already there, transforming quirks into legitimate problems.
When the Women Writers Project announced that WWIN had been published, traffic
skyrocketed. This was not just casual users and well-wishers, but also
bots. Bots which followed every link to every facet, causing the app to
spend a lot of time generating caches of XML for requests it hadn’t anticipated. The
processing time could take over a minute, in which case the Apache server would cut
the user’s
connection and display an error. While that user was refreshing the page, eXist might
still be
processing the original request, in which case the WWIN app would begin the process
again from
the start.
Once a response was cached, a subsequent request would get a much speedier response.
Still, bots were guaranteed to follow every combinatorial iteration of every index,
and WWIN
was struggling to keep up with so much traffic.
The WWP production server was struggling too. The server housed our entire main website,
as well as WWO and eXist. As eXist consumed more of the server’s memory and computational
power, the rest of the WWP universe also began to operate with a
noticable sluggishness.
The author’s first task post-launch was to move eXist off the WWP server and into
the
cloud. E coordinated with Northeastern Library developer and Amazon Web Services whiz
Robert
Chavez to create an Amazon EC2 instance, which would have only one job: to house eXist
and
send content to the WWP production server. We gave this new eXist instance a lot of
memory and
CPUs with which to work. This infrastructural update stabilized the WWIN app, and
freed the
production server to use its resources judiciously.
However, page load times were still high as bots continued to work through the indexes.
The WWP team was becoming superstitious about using eXist at all, fearful that any
nonessential request might bring down the database. Work on the WWIN application clearly
could
not stop at publication.
Analysis: or, processor pain points
Let’s step back for a moment to talk about some tasks which may be time-, memory-,
and processor-intensive:
making implicit data to be explicit, possibly
requiring complex XPaths to other resources;
generating a list of the facets which apply to a
dataset;
sorting large datasets;
serializing large datasets; and
identifying records which match some given
criteria.
Of the above tasks, WWIN was originally developed with the first four in mind. As
part of
the caching workflow, implicit data was made explicit, facets were generated, identifiers
were
sorted, and the cache format itself made serialization much easier.
The indexes’ responses were paginated, which reduced the number of full records that
needed to be retrieved and the amount of transformation work required. However, in
order to
sort or generate facets, the full dataset needed to be accessed even though only a
portion
would be serialized for display.
Data remodeling
Further, the choice to prioritize ease of serialization had significantly impacted
WWIN’s ability to identify which caches were relevant to any given user
request. The W3C serialization of JSON as XML uses datatypes as element names, and
uses the
@key attribute to hold the names of JSON object keys. As previously
mentioned, this serialization is remarkably efficient for converting between XML,
JSON, and
the new map and array structures.
This serialization does not work well with eXist’s Lucene range index,[10] however. The original configuration for WWIN had to rely heavily on a
@key index in order to get at crucial fields. As the author described the
problem in an informal presentation to eir coworkers:
But… if most elements have a @key attribute…
and you can’t depend on the element name for a field you’re interested in…
You have to index most elements and @key
attributes, just for the ability to search for the few fields you’re interested
in.
The usual advice for making efficient use of an index is that your first XPath step
should be the most precise, narrowly-defined criterion in your index. The eXist
documentation Tuning the database, for example, contains this bolded
recommendation: Always process the most selective filter/expression first —
If you need multiple steps to select nodes from a larger node set, try to process
the most selective steps first. The earlier you reduce the node set to process, the
faster your query.
Unfortunately, with the XML serialization of JSON, each field was so reliant on its
place in the hierarchy that it was difficult to construct XPaths which could return
results
efficiently.
As an example, WWIN relies heavily on identifiers. In the pseudo-JSON, most identifiers
were encoded as <fn:string key="id"> — this is one of the few fields where
the element name was always going to be string. So WWIN defined an index
field to match all of these identifying strings.
Unfortunately, this index could not account for competing uses of <fn:string
key="id"> in the cache. Depending on the context, nodes within this index might be
a record stating its identifier, or a facet’s unique key:
Even with a reliable encoding pattern, the index for identifiers held a lot of nodes
that were not useful for querying, but which had to be included — which is to say,
they
could not be excluded.
This problem could only be solved by restructuring the cache, using unique element
names
and attributes which could be indexed separately from each other. The author created
a
RelaxNG schema to draft a container format for the cached responses, capturing information
about the request endpoint, request parameters, the various sort methods, and compiled
facets. The latter are still stored as pseudo-JSON XML, since the facets will be serialized
more often than queried. A copy of the schema can be found in Appendix D, alongside a sample response in the revised format.
Similarly, each bibliography and intertextual gesture record is still stored in
pseudo-XML for serialization purposes. But now, each <fn:map> is wrapped in
a <record> element with an @ID attribute — easy to index, easy
to retrieve.
With the new data storage formats in place, WWIN takes two seconds at
most to load a page generated from a cached response. This is a far cry from
the 500 milliseconds that Firefox’s Network tool recommends. It is nonetheless a vast
improvement over the first WWIN.
Caching more to do less
After reviewing eir work, the author felt that WWIN’s initial implementation was a
good
start, but in many ways did not go far enough. To protect human users from the bots,
WWIN
needed to have more responses cached and ready for pagination and serialization.
To start, the author set the existing script to cache almost allsimple, one-filter responses, instead of just the sizable
ones. Because one-filter responses have fewer results than the full dataset, they
are better
starting places when compiling a response for, say, a request for a subset of data
with two
filters applied. WWIN was already set up to find the smallest cached subsets before
applying
filters. By caching more responses, the web application is able to do less processing
on the
filter combinations for which there isn’t yet a cache.
In fact, many complex (multi-filter) responses should also be cached,
especially responses with lots of results. The author set a target goal for all index
pages
to load within about 15 seconds. E experimented with page load times for complex responses
of various sizes. The results are summarized in the table below.
Table I
Page load times for the Intertextual Gestures index, already filtered to show only
quotes.
When this data was collected, cached responses were not available for the below
combinations.
Second filter
Total results
DOM load time
Referenced genre: Political writing
236
6s 470ms
Source (WWO) text: Bullard’s Reformation
306
7s 660ms
Referenced work: Revelation
374
10s 210ms
Referenced work’s genre: Drama
500
11s 410ms
Referenced work: Internal
703
15s 430ms
Referenced work’s genre: Theology
926
18s 870ms
Source text’s genre: Gender commentary
1,076
21s 380ms
Source text’s genre: Poetry
2,113
39s 510ms
Source text’s genre: Theology
4,103
1m 16s 800ms
Referenced work’s genre: Sacred text
4,398
1m 21s
Three more WWIN caching scripts were added in order to cache multi-filter responses.
The
new scripts iteratively identify requests that would yield results over a set amount
(currently 700), then generate and cache their responses.
Next steps
Improving efficiency in the WWIN application is now a lower priority — further development
is likely to add functionality to the web interface rather than to the backend. Even
so, the
author has other ideas for further improving WWIN’s performance:
Lower the threshold for pre-caching a complex request. Caching would take longer but
would cover more requests.
Run some pre-caching tasks in parallel, to reduce time before publishing a fresh set
of data.
Reduce duplication of result sets by allowing more than one
<request> in cached responses, specifically in cases where adding an a
given filter would make no difference to the result set.
For as-yet-uncached responses requested as HTML, return only the paginated records.
Schedule an XQuery job to compile the response’s facets. In the brower, use Javascript
to wait a bit before requesting and loading the facets.
Takeaways
This paper described the origins and evolution of the Women Writers: Intertextual
Networks
EXPath application. The application’s scale and choice of interface led to a data
ecosystem
that must do as much processing ahead of publication as possible. This ecosystem had
to be
further optimized for indexing and retrieval of cached data.
In general, the more power you give users to control their own experience of the data,
the
more work you may have to put into caching variations or subsets. If you are contemplating
an
index-heavy application like WWIN, decide ahead of time where you must
put the work. One of those tasks should be on indexing, both in terms of modelling
the XML for
retrieval, and in defining the index itself. The smaller and more precise the index,
the
quicker you’ll be able to obtain a result. The quicker the result gets to your users,
the more
wonderful their experience will be.
Acknowledgements
The author would like to thank Sarah Connell, Syd Bauman, Julia Flanders, and Rob
Chavez
for their support on this long journey toward a publication e could actually feel
proud of.
Thanks also to Meg McMahon, the Women Writers Project encoders, the Northeastern University
Library and the Digital Scholarship Group. Finally, thanks to the National Endowment
for the
Humanities for their generosity in funding this ambitious endeavor.
WWIN perserveres today because of the support of all these wonderful people. Thank
you.
Appendix A. Overview of WWIN data sources
Intertextual gestures
“Intertextual gestures” are references to, or marked engagement with, other works.
In
Women Writers Online, intertextual gestures are given identifiers (unique within the
document), and an
attribute points to the bibliography entry for the referenced work. Each intertextual
gesture is encoded according to type:
Advertisement
A notice of a published work.
Encoded in WWO as a <title> or <bibl> within
<advertisement>.
Citation
A prose description of the referenced work.
Encoded as a <bibl>.
Quote
A faithful extract from the referenced work.
Encoded as a <quote>.
Adaptation
A quote, intentionally modified from the referenced work.
Encoded as a <quote type="adaptation">.
Parody
A quote which has been modified for ironic effect.
Encoded as <quote type="parody">.
Remix
A combination of extracts, rearranged and adapted from the referenced
work.
Encoded as <quote type="remix">.
Title
A name of the work.
Proper titles are encoded as <title> in WWO. Other names of
works are marked with <rs type="title"> instead.
When written alongside chapter and verse information, books of the Bible are
usually not marked by <title> but are instead contained inside the
WWP custom element <regMe>.
In addition to its own structure and content, an intertextual gesture also carries
additional context drawn from the markup surrounding it, such as:
language;
who, specifically, made the gesture.
Figure 7: Original data model for an intertextual gesture
An intertextual gesture has few data fields of its own:
an identifier for its WWIN representation,
its original @xml:id,
the type of gesture it is,
the plain text content of the gesture, and
any links (this model imagined that WWIN would have a reading interface for
each WWO document, but that feature was not completed).
In addition, the intertextual gesture includes one or more
referenced works and one source WWO text, each of which
points to a bibliography entry.
Bibliography entries
There is one bibliography entry for every book, poem, folk song, etc. which is named,
quoted, or cited in Women Writers Online. Every work published in WWO is also represented,
even if it wasn’t referenced elsewhere.
The WWP decided that we were most interested in capturing metadata about the first
known
publication of a work. Even so, bibliography entries frequently have tangled history.
For
example, it may be clear that a WWO author is referencing a popular translation of
a French
or Spanish novel, in which case we may maintain entries for both, making sure the
two are
marked as related.
Figure 8: Original data model for a bibliography entry
Alternative titles that could refer to the same work
Authors, translators, and other contributors
Contributor role
Personal name (formatted with surname first)
Gender, if we can make a guess
A unique personography key
Earliest publication information available
Publication date
Publisher’s name
Publisher’s location
Any flags, for example:
Is this a published WWO work?
Is this a periodical?
Is this a fictional or hypothetical work?
Public notes
Pointers to related entries
In addition to the fields above, each bibliography entry in the WWIN application
includes the number of intertextual gestures made to that work. This field can only
be added
after all intertextual gestures have been compiled.
Appendix B. Caching workflow
The following steps are taken to build out the data cache for Women Writers: Intertextual
Networks.
Create a clean, public version of the TEI bibliography. This is done locally through
an Apache Ant task.
Cache bibliography entries from public bibliography. This is done locally through
an Apache Ant task.
Cache contributors’ data from public bibliography. This is done locally through an
Apache Ant task.
Generate the WWIN EXPath application with Ant, and install the app into
eXist.
Create prepped4publish versions of Women Writers Online source
documents, using local XSLT stylesheets. Store the munged TEI in the WWO data directory,
in a development instance of eXist.
Using a WWIN caching script, transform prepped-for-publish TEI into “source reader”
TEI. Most content is removed except for structural markup (e.g. <div>) and
intertextual gestures.
Women Writers: Intertextual Networks contains a modular set of XQuery scripts which
compile and cache data for quick reference by the app’s RESTXQ endpoints. To prevent
the
webapp from working off of unsynchronized cache files, the WWIN caching scripts write
their
output to an on deck collection. When all caches are generated, all files can
be moved to the publication folder at the same time.
Caches are generated and tested on the WWP’s development instance of eXist. By default,
each XQuery marks its progress in the eXist logs, and schedules the next XQuery job.
Using a WWIN caching script, cache gesture data from source reader TEI. Traits
inherited from ancestor nodes (e.g. language used) are explicitly stated. This process
yields one file of records for every WWO document containing intertextual gestures.
Also, compile gesture facets for each TEI document.
Also, compile WWO text summaries for each TEI document.
Using a WWIN caching script, edit cached bibliography entries:
Add the total number of references made to this entry throughout WWO.
Also, remove uncited entries (unless published in WWO).
Using a WWIN caching script, cache data on WWO authors. This data is compiled from
personography data and the WWO text summaries.
Using a WWIN caching script, compile lists of sorted identifiers for each index’s
defined sort methods.
Using a WWIN caching script, cache responses for requests to the indexes which (1)
have only one filter applied, and (2) match a set number of records.
In the original version of the script, responses were only pre-cached if they had
over
one thousand results. After refactoring, all single-faceted responses are pre-cached
as
long as there is more than one result.
Using a WWIN caching script, move all cached data from the on deck
folder to the cache folder, essentially publishing the new data.
The refactored application has an additional three steps, which were set up to recurse
over the published response caches:
Using a WWIN caching script, query the published response cache for facets that
contain more than a set number of results.
If there are uncached requests, generate a list and store it in XML.
If all such requests have been cached, stop.
As of this writing, the script is set to pre-cache combinatorial responses with 700
or
more results. Future versions may lower the threshold, or introduce a means of iteratively
lowering the threshold.
Using a WWIN caching script, use the list of uncached requests to generate and cache
responses into the on deck folder.
Using a WWIN caching script, delete the request list and move the new responses into
the cache folder, effectively publishing them. Return to step 10.
At this point, the pre-production WWIN site is tested and proofed. When all seems
acceptable, the cache is compressed into a ZIP file. The production instance of eXist
downloads the compressed cache, expands the files into its own on deck
collection, and publishes the results.
Appendix C. Sample cached response in original format
This cached response format simply stores the W3C’s XML interpretation of a JSON object.
The pseudo-JSON format focuses on preserving the datatypes of JSON constructs, with
keys
placed in attributes. This is not particularly helpful for indexing and retrieval,
because
the element names may be different between fields with the same key;
all @keys share a single index, making it hard for eXist to narrow down to the ones
you're interested in; and
because @keys are so dependent on their XML context, writing XPaths to get to them
is a nontrivial exercise.
namespace a = "http://relaxng.org/ns/compatibility/annotations/1.0"
namespace rng = "http://relaxng.org/ns/structure/1.0"
start =
## Data associated with a single RESTful API response.
element response { el.request?, el.results, el.facets? }
el.request =
## Data about the HTTP request to which this response applies.
element request {
attribute method { "GET" | "POST" }?,
## The request path or URL.
attribute endpoint { text }?,
el.parameter*
}
el.parameter =
## A key-value pair corresponding to an HTTP request parameter.
element parameter {
## The HTTP parameter name.
attribute name { xsd:token },
## A single value associated with the current HTTP parameter name.
element value {
## The datatype of this value.
attribute type { "boolean" | "number" | "string" | xsd:token },
text
}*
}
el.results =
## The results returned by this response.
element results {
attribute total { xsd:integer },
## A sorted group of entity references.
element sortedSet {
## A keyword corresponding to a sort method defined elsewhere.
attribute by { text },
## The direction of the sorted values, from top to bottom.
attribute direction { "ascending" | "descending" },
## An identifier or key for an entity that should appear in the response results.
element key { xsd:string }*
}*
}
el.facets =
## Information about the result set, intended for characterizing the results and/or for further filtering.
element facets { anything }
anything =
(element * {
attribute * { text }*,
anything
}
| text)*
Sample cached response in revised format
This cached response format is optimized so that request parameters are indexed
separately from other interesting XML phenomena.
<?xml version="1.0" encoding="UTF-8"?>
<response>
<!-- If a set of parameters can produce a predictable endpoint string, the @endpoint
attribute can be indexed to further improve retrieval time. -->
<request method="GET"
endpoint="bibliography?genre=political-writing&publicationLocation=undetermined">
<parameter name="genre">
<value type="string">political-writing</value>
</parameter>
<parameter name="publicationLocation">
<value type="string">undetermined</value>
</parameter>
</request>
<results total="19">
<!-- There can be more than one <sortedSet>, corresponding to defined sort
methods. Pre-sorting large result sets is important, since sorting can be
particularly time intensive, even with a separate cache of (all) pre-sorted
identifiers. -->
<sortedSet by="numberOfReferencesTo" direction="descending">
<!-- To reduce duplication, the bibliography entries are stored in a separate
cache. -->
<key>IT01223</key>
<key>IT07461</key>
<key>IT01443</key>
<key>IT07458</key>
<key>IT07456</key>
<key>IT00959</key>
<key>IT07485</key>
<key>IT03359x</key>
<key>IT07460</key>
<key>IT02726x</key>
<key>IT00498x</key>
<key>IT02393</key>
<key>IT02949x</key>
<key>IT03600</key>
<key>IT02325</key>
<key>IT01303</key>
<key>IT00792x</key>
<key>IT07459</key>
<key>IT07457</key>
</sortedSet>
</results>
<facets>
<!-- The <facets> element can hold any text or XML. We could have serialized the
facets as a JSON string, which would take up less space. Keeping the facets in
pseudo-JSON, however, will let us use XPath to iteratively generate lists of
more requests that could be cached, e.g. the above parameters AND genre=speech. -->
<fn:map xmlns:fn="http://www.w3.org/2005/xpath-functions">
<fn:array key="genre">
<fn:map>
<fn:string key="id">political-writing</fn:string>
<fn:number key="count">19</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">speech</fn:string>
<fn:number key="count">6</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">legal-writing</fn:string>
<fn:number key="count">3</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">slavery</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">petition</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
</fn:array>
<fn:array key="hasContributorOfGender">
<fn:map>
<fn:string key="id">male</fn:string>
<fn:number key="count">4</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">not applicable</fn:string>
<fn:number key="count">3</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">unknown</fn:string>
<fn:number key="count">2</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">female</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
</fn:array>
<fn:array key="contributor">
<fn:map>
<fn:string key="id">schurchil.bhy</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">rhayne.tqa</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">awedderbu.vtx</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">rwright.izs</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
<fn:map>
<fn:string key="id">nmachiave.inf</fn:string>
<fn:number key="count">1</fn:number>
</fn:map>
</fn:array>
<fn:array key="publicationLocation">
<fn:map>
<fn:string key="id">undetermined</fn:string>
<fn:number key="count">19</fn:number>
</fn:map>
</fn:array>
<fn:array key="referencing">
<fn:map>
<fn:string key="id">isReferenced</fn:string>
<fn:number key="count">19</fn:number>
</fn:map>
</fn:array>
</fn:map>
</facets>
</response>
[2] The first Intertextual Networks cohort consisted of Param Ajmera, Matt Bowser, Ash
Clark, Sarah Connell, Hannah Lee, Adam Mazel, Molly Nebiolo, Kenneth Oravetz, Lara
Rose,
and Katie Woods. For a full list of contributors and collaborators, please visit the
WWIN About
page.
[3] The Bibliography also lists all works published in WWO, whether or not the WWO text
has any intertextual encoding or is referenced itself.
[4] The ability to see all filters in a category in the HTML site would be very useful,
and may yet be added in the future. The author initially struggled to represent that
information in a way that did not distract, overwhelm, or cause navigational problems.
Now
that WWIN has settled into stability, there is more time and space for experimentation
and
improvement.
[5] The author left a narrative view of a WWO source text as a stretch goal for the
initial release of WWIN. This goal was not met before publication, due to the processing
issues described in the second half of this paper.
[7] Initial caching attempts used a single complex XQuery to generate all outputs. This
led to eXist using exorbitant amounts of memory as it worked through inferences. Also,
the author found it hard to debug the script — if the script failed, it could be
difficult to determine which caching step had just been completed, not to mention
what
inferences had been made explicit before the buggy step received its input.
To fix this, the author refactored the caching process so that cached data is
serialized to XML more often. By default, each XQuery will schedule the next in the
workflow. However, one can set a parameter in a script to halt the caching process.
This
is useful for tasks such as debugging an updated script, checking the cache contents,
or
running garbage collection via eXist’s Monex application.
[8] Originally, sizable meant responses with over a thousand
results.
[9] The XML serialization of JSON here referred to is the result of processing JSON with
the XPath 3.1 function fn:json-to-xml. The schema for this serialization is
available as part of the XPath and XQuery
Functions and Operators 3.1 W3C recommendation.
[10] The WWP uses eXist’s new range index rather than the legacy version.
For more information on the Lucene range index, see eXist’s Range
Index documentation.