Liuzzo, Pietro Maria. “Encoding the Ethiopic Manuscript Tradition: Encoding and representation challenges
of the project Beta maṣāḥəft: Manuscripts of Ethiopia and Eritrea.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Liuzzo01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Balisage Paper: Encoding the Ethiopic Manuscript Tradition
Encoding and representation challenges of the project Beta maṣāḥǝft: Manuscripts of
Ethiopia and Eritrea
Ancient Historian turned TEI and Digital Humanities advocate, he has worked for the
EAGLE project on Greek and Latin epigraphy and now leads all aspects of the technical
development of the project Beta maṣāḥǝft: Manuscripts of Ethiopia and
Eritrea.
The Beta maṣāḥǝft: Manuscripts of Ethiopia and Eritrea project aims to construct a virtual research environment to encode and manage the
rich and complex manuscript tradition of the Ethiopian and Eritrean Highlands. The
Ethiopic manuscript culture, consisting of varying and difficult-to-identify literary
works, is a living tradition. This project explores the difficulties in encoding and
managing the relationships not only between the manuscripts themselves, but also between
the manuscripts and the broader Ethiopian literary traditions that include Greek and
Arabic texts as well.
The project Beta maṣāḥǝft: Manuscripts of Ethiopia and Eritrea (Schriftkultur des
christlichen Äthiopiens: eine multimediale Forschungsumgebung) [1] is a long-term project funded within the framework of the Academies Programme
(coordinated by the Union of the German Academies of Sciences and Humanities) under
the
supervision of the Akademie der Wissenschaften in Hamburg funded for 25 years, from
2016–2040.
The project is hosted by the Hiob Ludolf Centre for Ethiopian Studies at the University
of
Hamburg and aims to create a virtual research environment for the management of complex
data
related to the manuscript tradition of the Ethiopian and Eritrean highlands.[2]
This is a huge challenge and opportunity for the community of scholars in Ethiopian
history, philology, codicology and language, as the project will digitally catalogue
all
manuscripts already catalogued in the past in print but will also digitize texts in
fidal
(the script used by classical Ethiopic or Gǝʿǝz) meaning both manuscript transcriptions
and
editions of texts.
The project scope includes also a prosopography, inherited in part from the work of
the
Encyclopaedia Aethiopica and a gazetteer of Ethiopian places, both ancient and modern.[3]
This means not just encoding but also creating semantically meaningful relationships
between descriptions of manuscripts,
works, places and persons, in a way which gives justice to the Ethiopian tradition
and its
specific characteristics. With a simple network of referenced entities in TEI as the
background
architecture, the project produces data at several different levels and serves it
in multiple
ways, displaying the contents and the semantic relationships encoded in it.
This article will highlight encoding choices for manuscripts' and works' descriptions
and
hint at the further development of persons' and places' records. Also the serialization
of
relationships and the data API [Distributed Text Services] will be presented.[4]
Structuring the data
This section describes a few challenges faced in the attempt to structure the data
architecture of the entire Ethiopic literary tradition and living manuscript
production.
The project's first phase deals currently with the digitization of manuscript's catalogues
and their structured description. A second phase will see also the digitization of
texts,
including both transcriptions of manuscripts and editions of texts. At the moment
the largest
portion of encoded Ethiopic text consists in the additions to manuscripts and already
amounts to
the largest existing collection of ancient Ethiopic documentary evidence.
Status
Beta maṣāḥǝft inherited a lot of good work. To begin with, it could avail itself of
the
data used for the Encyclopaedia Aethiopica [EAe], a long-term project
which led to the publication of an incredibly useful tool for the Ethiopian studies.
Secondly around 1000 manuscripts recorded in a MyCoRe XML
database by the EthioSPaRe project where converted to the Beta
maṣāḥǝft TEI schema. These shaped to a large extent the customization of the TEI schema
prepared for the project initial phase, i.e. the digitization of catalogue records
starting from out-of-copyright catalogues.
The major improvement introduced in this process was the possibility to nest and
organize msPart elements as well as msItem elements, which leads
to a much more interesting description than a flat list of consecutive parts, as these
are
often not consecutive especially in a tradition that has mainly complex manuscript
objects.
On the other side many pieces of information like incipit, abbreviated words, etc.
would have belonged to the manuscript's
transcription and had to be accommodated in other parts of the teiHeader as
notes.
During this phase of theorization of the encoding structure and initial schema definition,
Beta
maṣāḥǝft has benefited from the work of many predecessor projects, like the ones mentioned
above as well as EAGLE and the EpiDoc guidelines [Epidoc Guidelines 8.23] and schema.
The use of relation elements was introduced at this stage in conformance
with existing ontologies, although in an entirely non canonical way, which we hoped
would allow us to visualize the stratigraphy, showing the history of the manuscript
and allow the encoding of what cannot be hierarchically structured.
To describe the connections between the different entities in Beta
maṣāḥǝft we take relations names from the classes of the SAWS [SAWS] and SNAP [SNAP:DRGN]
projects for example, but we reuse also relation's names used by syriaca.org or simply
dcterms or geonames classes and properties names. We have had
sometimes anyway to add some value for relation/@name but only for relations specific to the Ethiopic milieu. For example bm:hasTabot indicates a relation between a person and a place, i.e. that the @active subject of the relation, a person, has a Tabot in the place at @passive.
The following is an example where we use a relation element to state which works
might be parts of another literary work and we are able to point to the
specific subject and object of the relationship. Note also that we use Zotero EthioStudies tags for our bibliography,
exploiting the Zotero API to retrive the TEI needed for the full export of TEI XML
files and for the visualization in the app, which uses a Zotero Style common to our
centre resources.
<relation name="ecrm:CLP46i_may_form_part_of" active="LIT1978Mashaf" passive="LIT1586Hayman">
<desc>The Maṣḥafa ṭomār is mostly contained in manuscripts with the Hāymānota ʾabaw, where it can precede or follow
the table of contents. It also circulates independently.</desc>
</relation>
<relation name="saws:isVersionInAnotherLanguageOf" active="LIT1978Mashaf#t1" passive="LIT1978Mashaf#t4arabic">
<desc>The Ethiopic version of the Maṣḥafa ṭomār was translated from the Arabic version based on a Syriac version.
Guidi suggests that the Maṣḥafa ṭomār may have been translated in the mid-16th century.
<bibl><ptr target="bm:Guidi1932storia"/><citedRange unit="page">72-73</citedRange></bibl>
<bibl><ptr target="bm:Graf1944GCALI"/><citedRange unit="page">295-297</citedRange></bibl></desc>
</relation>
<relation name="saws:isVersionInAnotherLanguageOf" active="LIT1978Mashaf#t4arabic" passive="LIT1978Mashaf#t7syriac">
<desc></desc>
</relation>
Although many relations might be inferred from the files with their name (for instance
the
relation between a manuscript and the repository or collection in which it is preserved),
many
and more complex relations, like authorship of a work, fail to be easily represented
as a
simple fact stated in an author element. Often in the Ethiopic tradition as in
many other mediaeval traditions, attested literary works are attributed to authors
or cannot
be assigned at all to an editorial will. A work can have as many authors assigned
as
needed and we use a relation element for this
purpose in order to connect author or translator and the exact part of work that is
attributed to him in each case.
In the following sections more details will be provided on the structuring of single
entities, focusing especially on manuscripts and literary works, which are the ones
most
developed at the current stage of the project.
Manuscripts
Anyone who has worked with codicologists and philologists knows it is very difficult
to
satisfy everybody. Different specialists will have their own opinion on
the importance of different parts of data and how to represent it.
Corpus analysis should also take into consideration the material structure of supports.
The manuscript collation (structure of leaves and quires) should be considered when
collating philologically texts coming from different manuscripts or manuscripts' parts.
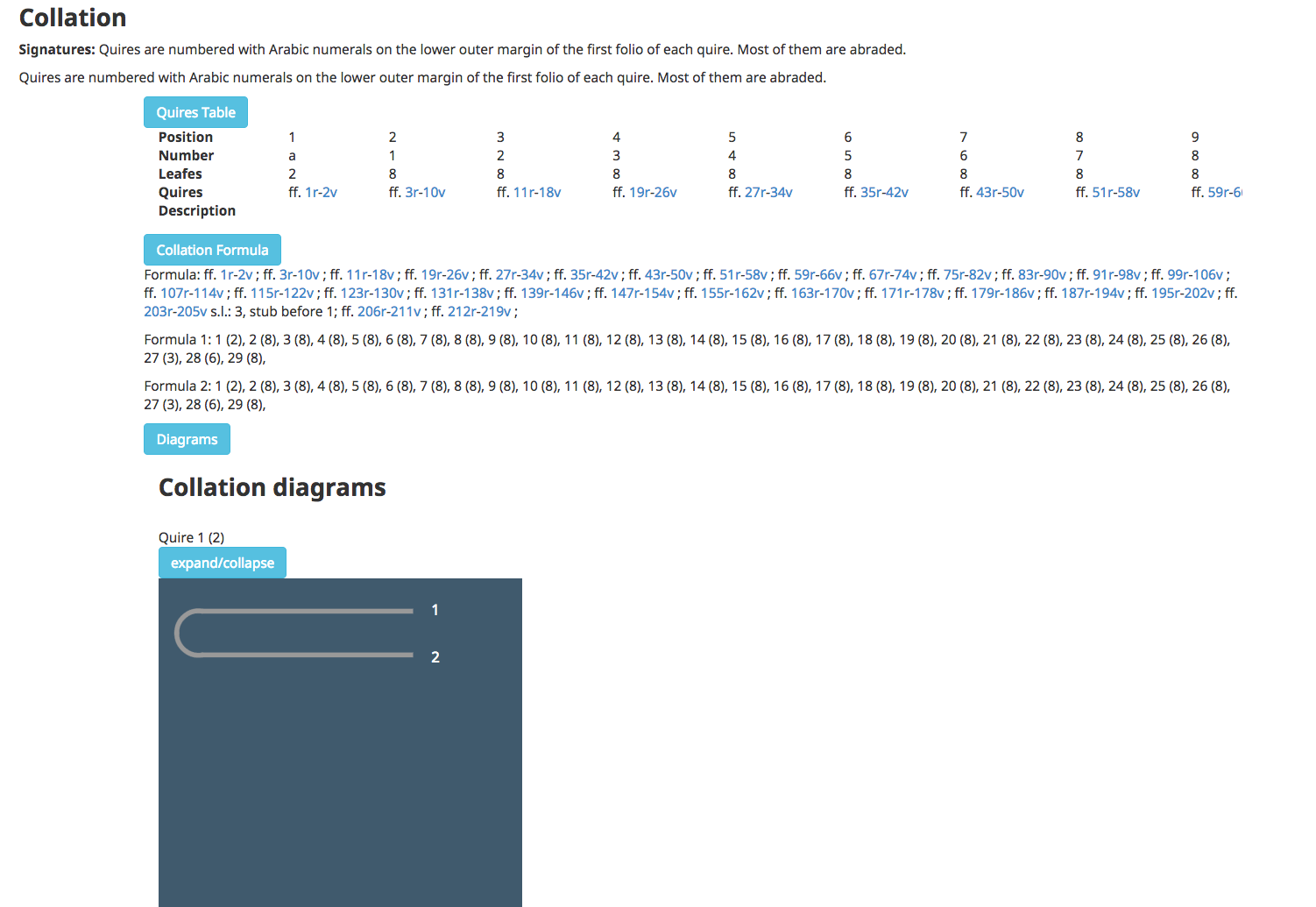
For the collation of the manuscript we use the very nice VisColl tool by Dot Porter
[VisColl] to visualize the structure of the quires, extracting the
information from a simple list encoding.
The
above XML structure is transformed in the intermediate format required by the tool
by an
XSLT and is then passed as a parameter to the VisColl XSLT library to produce the
following
result
Lists of contents are vital to understand what a manuscript contains and can alone
give
all the information a user actually needs. In Beta maṣāḥǝft these summary links to
records
with the data about each of the works or parts of works listed in the manuscript.
<msItem xml:id="ms_i1.6">
<locus from="105r" facs="f223"/>
<title type="complete" ref="LIT1812GospelLuke"/>
<msItem xml:id="ms_i1.6.1">
<locus from="105r" facs="f223"/>
<title type="complete" ref="LIT1812GospelLuke#TituliLuke"/>
</msItem>
<msItem xml:id="ms_i1.6.2">
<title type="complete" ref="LIT2713Luke" xml:lang="gez">ወንጌል፡ ዘሉቃስ።</title>
<note>
The text is divided in 85 (or 83) sections, which correspond approximately to the old
<foreign xml:lang="grc">τίτλοι</foreign>
.
</note>
<note>
The pericopes, the chapters of Ammonius and the 343 canons of
<persName ref="PRS3912Eusebius"/>
are indicated in the margins.
</note>
</msItem>
</msItem>
<msItem xml:id="ms_i1.7">
<locus from="163r" facs="f339"/>
<title type="complete" ref="LIT1693John"/>
<msItem xml:id="ms_i1.7.1">
<locus from="163r" facs="f339"/>
<title type="complete" ref="LIT1693John#TituliJohn"/>
</msItem>
<msItem xml:id="ms_i1.7.2">
<title type="complete" ref="LIT2715John" xml:lang="gez">ወንጌል፡ ዘዮሐንስ።</title>
<note>
The text is divided in 20 (or 19) sections, which correspond approximately to the old
<foreign xml:lang="grc">τίτλοι</foreign>
.
</note>
<note>
The pericopes, the chapters of Ammonius and the 232 canons of
<persName ref="PRS3912Eusebius"/>
are indicated in the margins.
</note>
</msItem>
</msItem>
When a title is given in the catalogue, then it is used otherwise the canonical title
of the work
is chosen.
Figure 2: Manuscript Contents Summary
Summary of contents linked to msParts descriptions
While we don't yet have the transcriptions of the main texts of the manuscript, we
do
have a lot of transcriptions of incipits, explicits, colophons and additions to the
main
manuscripts text of several kinds.
These, as well as decorations and keywords, are also separately visualized as a navigation
aid and as
small corpora of organized documentary sources.
Figure 3: Manuscript Additions
The extracted list of additions to all manuscripts.
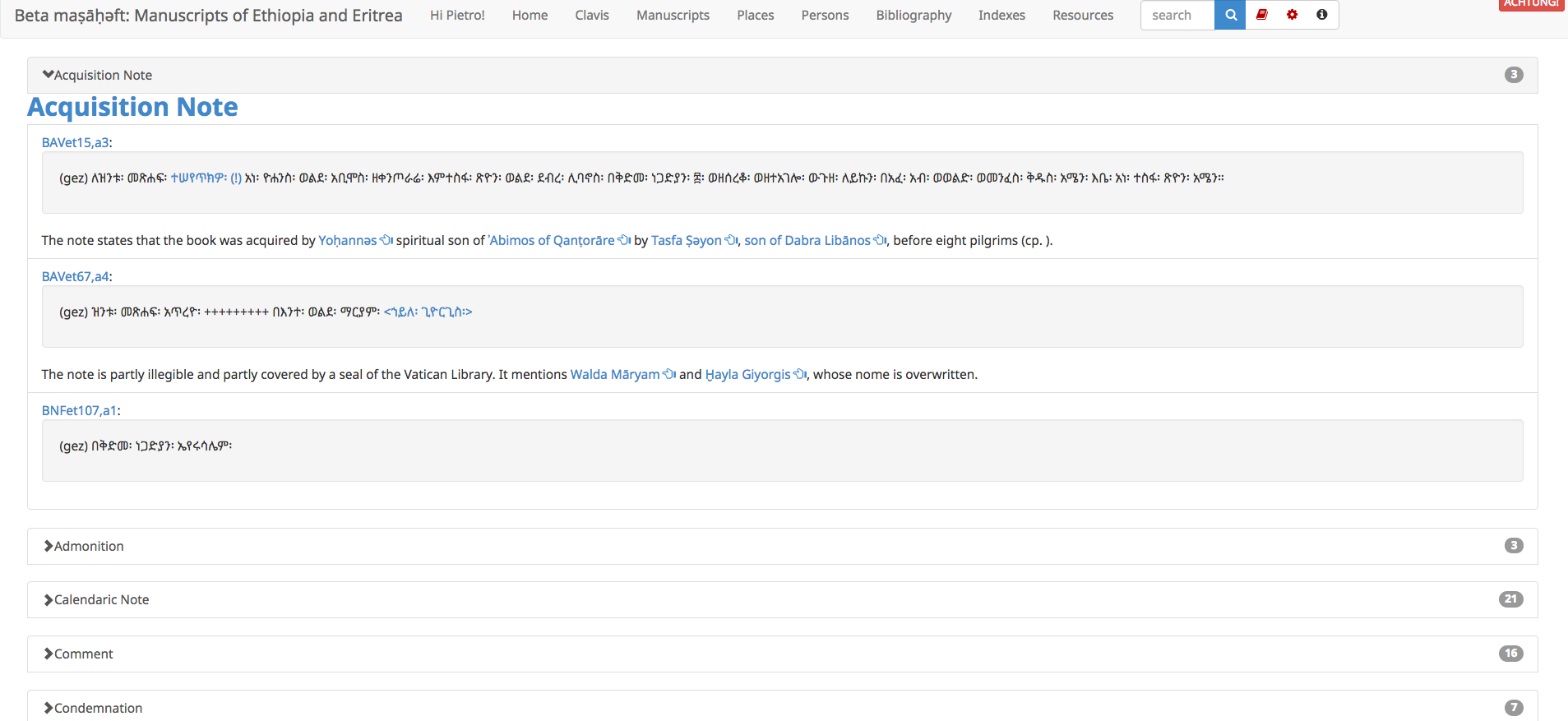
Dating is a central issue for the semantic organization of text corpora, but the
timespan in a manuscript catalogue is very wide also within each manuscript. Manuscripts
from this live tradition may present multiple layers of modification (material, textual,
etc.) continuing until today. While encoding this is fairly easy because dating
elements can be added anywhere in a TEI structure, this information offers challenges
in
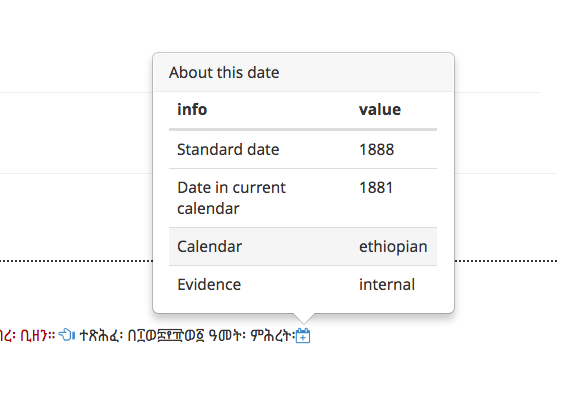
the analysis. We encode dates with several attributes like in the following example.
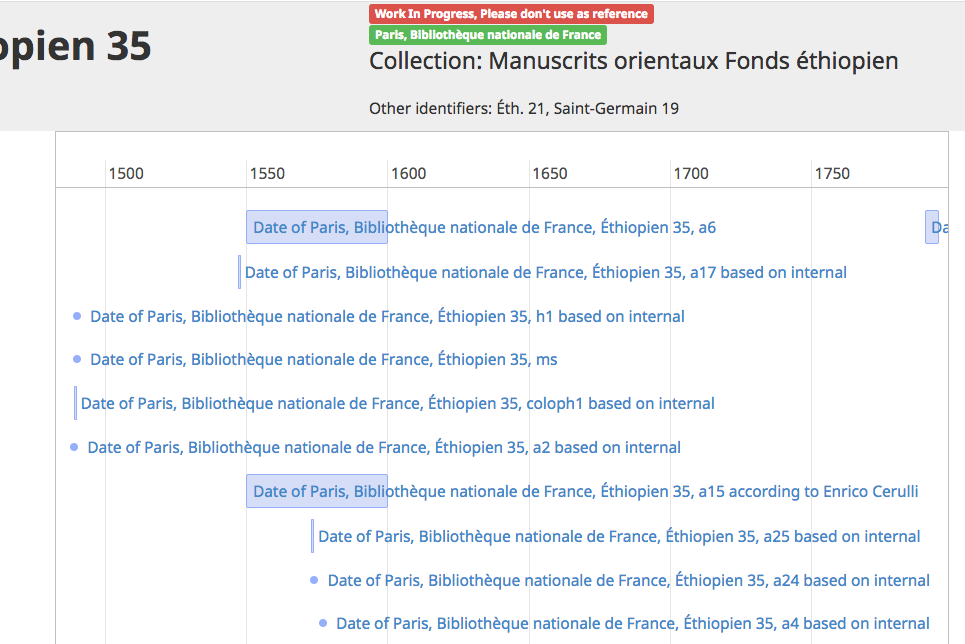
This is displayed in the record as a simple table, but is also used to extract information
to build a timeline of the manuscript transforming the XML to feed a script using
Vis.js.
Figure 4: Dates Display
The data in a date element.
Figure 5: Timeline
A manuscript timeline.
A way to encode the manuscript stratigraphy following Andrist Maniaci et al. 2013 is
currently under development and will hopefully be presented at the next TEI
conference.
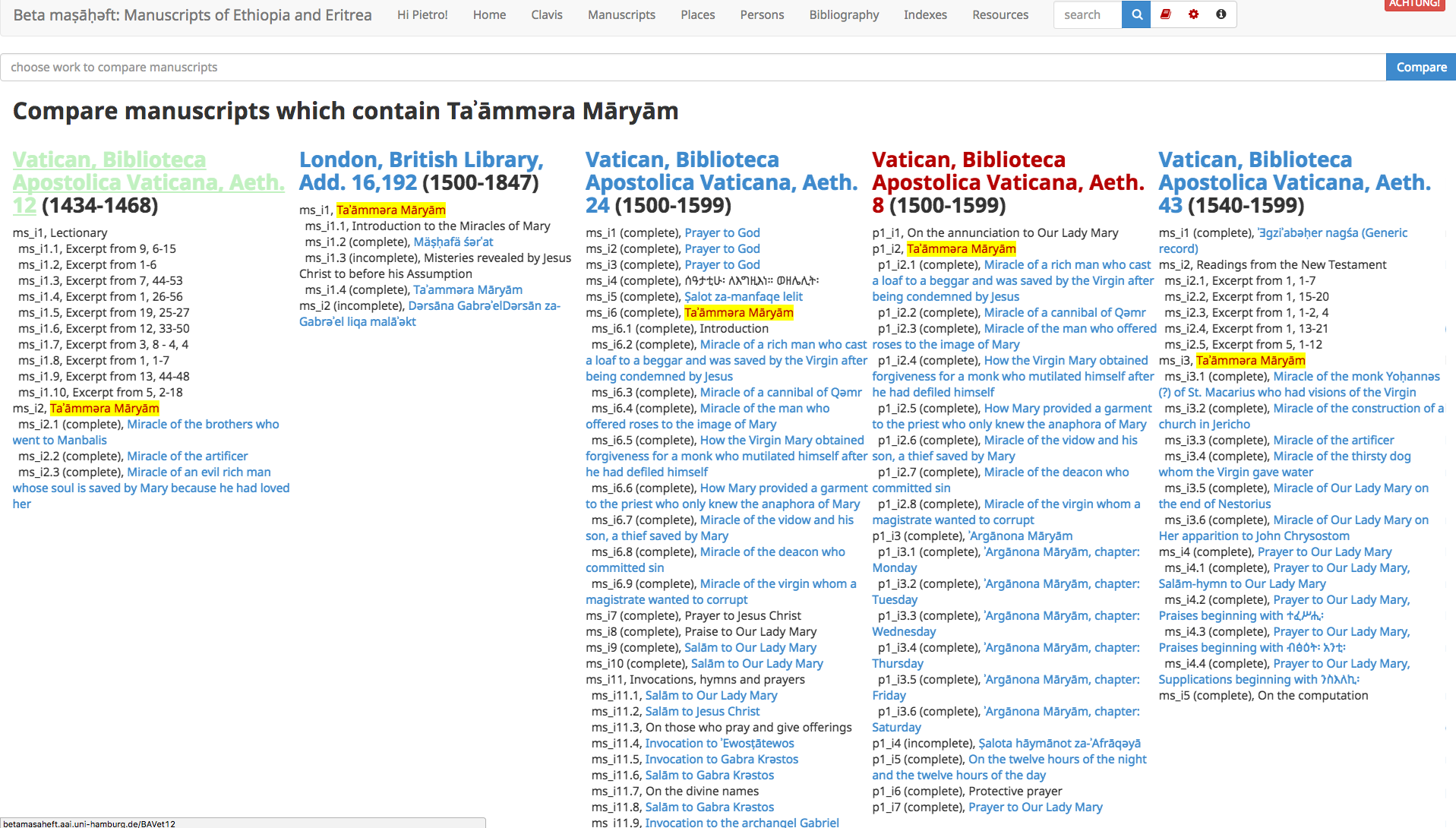
A single work can be contained in several manuscripts in different parts and together
with different texts. The selection and organization of these texts is also very important
and
might provide useful information. We then offer a way to pick a work from our canonical
list and see the structure of all manuscripts which contain it side by side. Hoovering
on
any title will also highlight if and where the same work appears in another manuscript.
The
manuscripts are here organized chronologically as much as possible to give also a
good
starting point for an evaluation of the history of the manuscript tradition of the
selected
work.
Figure 6: Manuscript Contents Comparison
The manuscript's contents comparison tool allows to immediately visualize and
compare the contents of each manuscripts containing an individual work.
Textual and Narrative Units
The Ethiopic manuscript culture is a living tradition. Manuscripts are still being
produced today. The literary works they contain vary and are difficult to identify.
The
author of this paper is not expert on this and will not dive into this issue if not
in as
much as it concerns the architecture of the Web application serving the data.
In the Oriental tradition it is difficult to uniquely identify texts under titles
(a
problematic category) and thus define distinct corpora. In our project
we try to identify and relate all independently circulating units and to keep a core
distinction between textual and narrative units as suggested by Orlandi 2013.
Although this is reflected in the encoding of texts, until now no satisfactory approach
has
been found to exploit this distinction. A solely narrative unit like a set miracle
account
used for saints or kings can be used to identify parts of a text. On the other side
a textual unit might still be considered a literary work in its own right or not.
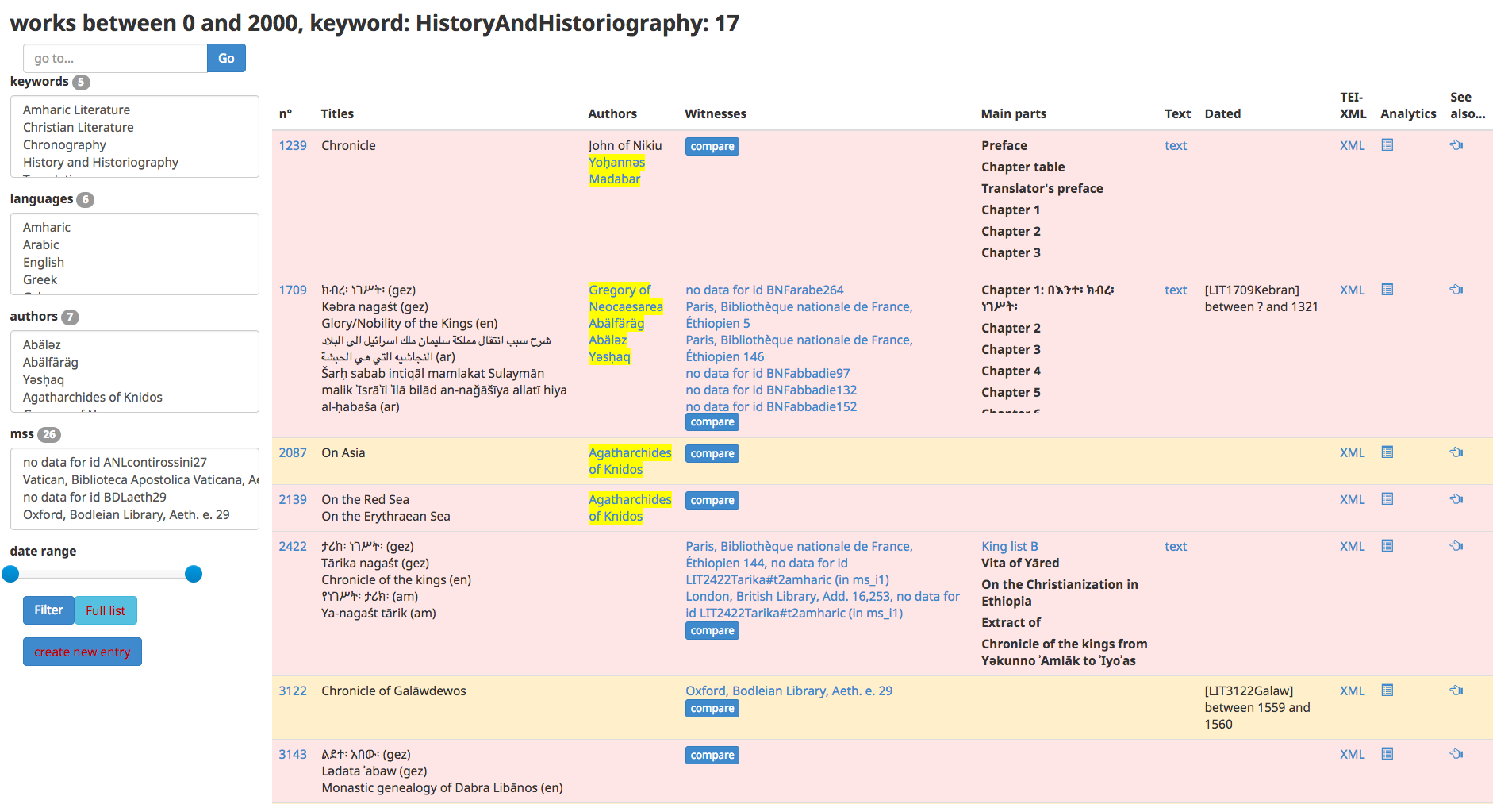
Figure 7: Works in the Ethiopic Literature Clavis.
The clavis lists all unique numeric IDs given to works and provides easy access to
collection browsing.
In the Ethiopic literary tradition the concepts of work (as a
quantifiable unit) and that of collection (as a grouping unit) are not
available in the same way as they are, almost intuitively, for Western European corpora.
Ethiopian literature
is characterized especially by its compilatory character. The treatment of work collections
(homilies, hagiographies, etc.) as grouping units is thus crucial to the project.
How can
the relationships between texts, manuscripts, narrative units which are so complex
and
variable be articulated with certainty in a canonic structure? Working with the outlines
defined by Orlandi 2013 and Bausi 2010, it is one of the main
concerns at the current stage to find working definitions of these concepts which
can
accommodate all Ethiopian literary works. How should this distinction impact
textual-critical analysis, computation and hermeneutic?
The entire traditional hierarchy of literature falls apart in the face of this problem,
but
encoding might still help in organizing the unorganized and TEI provides here the
necessary
rigour and flexibility. A work can have parts which do not have independent circulation
in
the Ethiopian tradition but can still be used as a reference in a list of contents
of a
manuscript.
<msItem xml:id="ms_i1.1">
<locus from="3r" to="10v"/>
<title type="complete" ref="LIT1560Gospel#IntroductionGospels">Introduction to the Gospels</title>
<msItem xml:id="ms_i1.1.1">
<locus from="3r"/>
<title type="complete">Maqdǝma wangel, “Introduction to the Gospels”</title>
</msItem>
<msItem xml:id="ms_i1.1.2">
<title type="complete" ref="LIT1349Epistl">Letter of Eusebius to Carpianus</title>
</msItem>
<msItem xml:id="ms_i1.1.3">
<locus from="4r" to="8v"/>
<title type="complete" ref="LIT1560Gospel#IntroductionCanons">Canon tables</title>
</msItem>
<msItem xml:id="ms_i1.1.4">
<locus from="9r" to="10v"/>
<title type="complete" ref="LIT1560Gospel#IntroductionGessawe" evidence="conjecture"/>
</msItem>
</msItem>
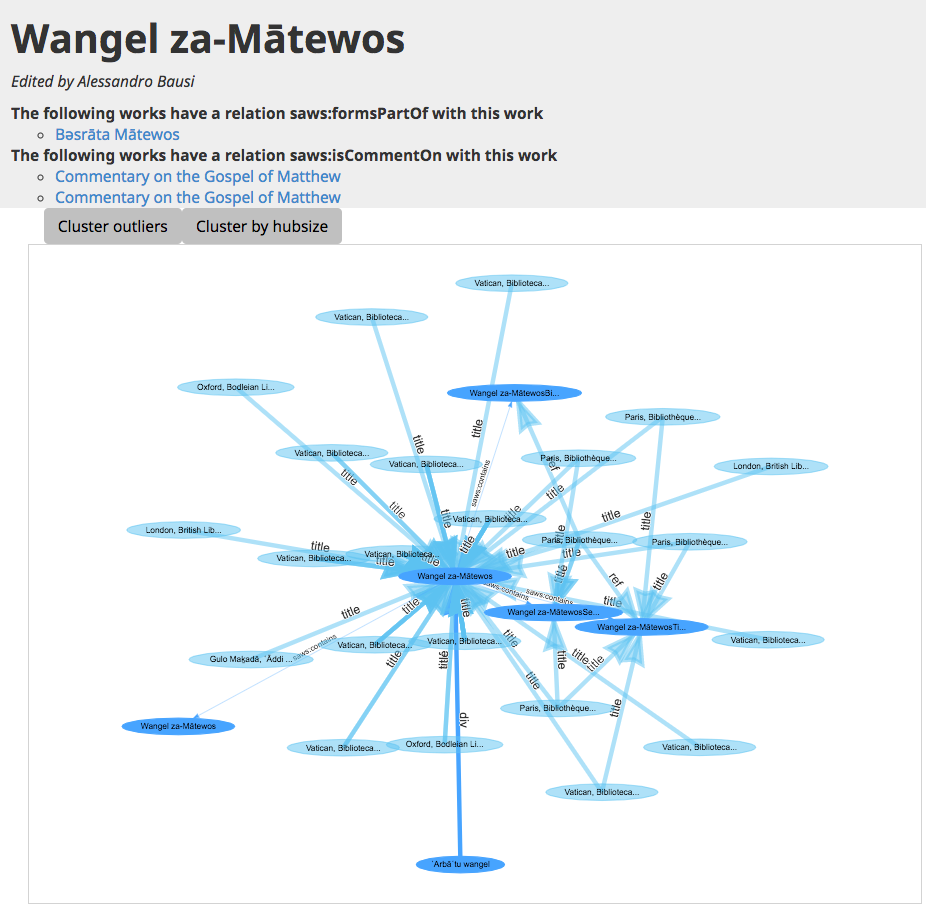
Being able to add as many relation elements as wanted, means that the articulation of the information does not need
to be forced into one value or the assertion of certainty about authorship does not
need to be an assumption.
Figure 8: Manuscript Contents Comparison
Each work has many relations to other works and manuscripts which are visualized
as a network graph.
These visualizations should help the user to obtain all the information needed without
forcing
too much of our structure to the organization of knowledge traditional of the Ethiopian
context.
The Ethiopian literary tradition cannot be studied outside a wider context of Oriental
traditions. Thus, whenever possible, we will take the relationship between translations
of
Greek and Arabic texts in Ethiopic with their Vorlage and versions in other
languages into consideration. The alignment of such units is complex and
requires referring to external reference works for specific traditions when they are
available.
We encode this information in two distinct places. We give all possible titles of
a work
and assign types and @xml:ids and @corresps in an orderly fashion.
<title xml:id="t1" xml:lang="en">(Ethiopic) Book of Kings 1</title>
<title xml:id="t2" xml:lang="gez">ነገሥት፡ ቀዳማዊ፡</title>
<title corresp="#t2" xml:lang="gez" type="normalized">Nagaśt qadāmāwi</title>
<title corresp="#t2" xml:lang="en">First Kings</title>
<title xml:id="t3" xml:lang="en">1 Sam (Septuagint)</title>
<title xml:id="t4" xml:lang="en">Book of Samuel 1</title>
In addition to this, we also link a bibliographic reference to relevant clavis in a bibl element
This information is then visualized in the list view and in the record view.
Figure 9: Works and connection to other traditions canonical ids.
Titles linked to clavis IDs and bibliographic records.
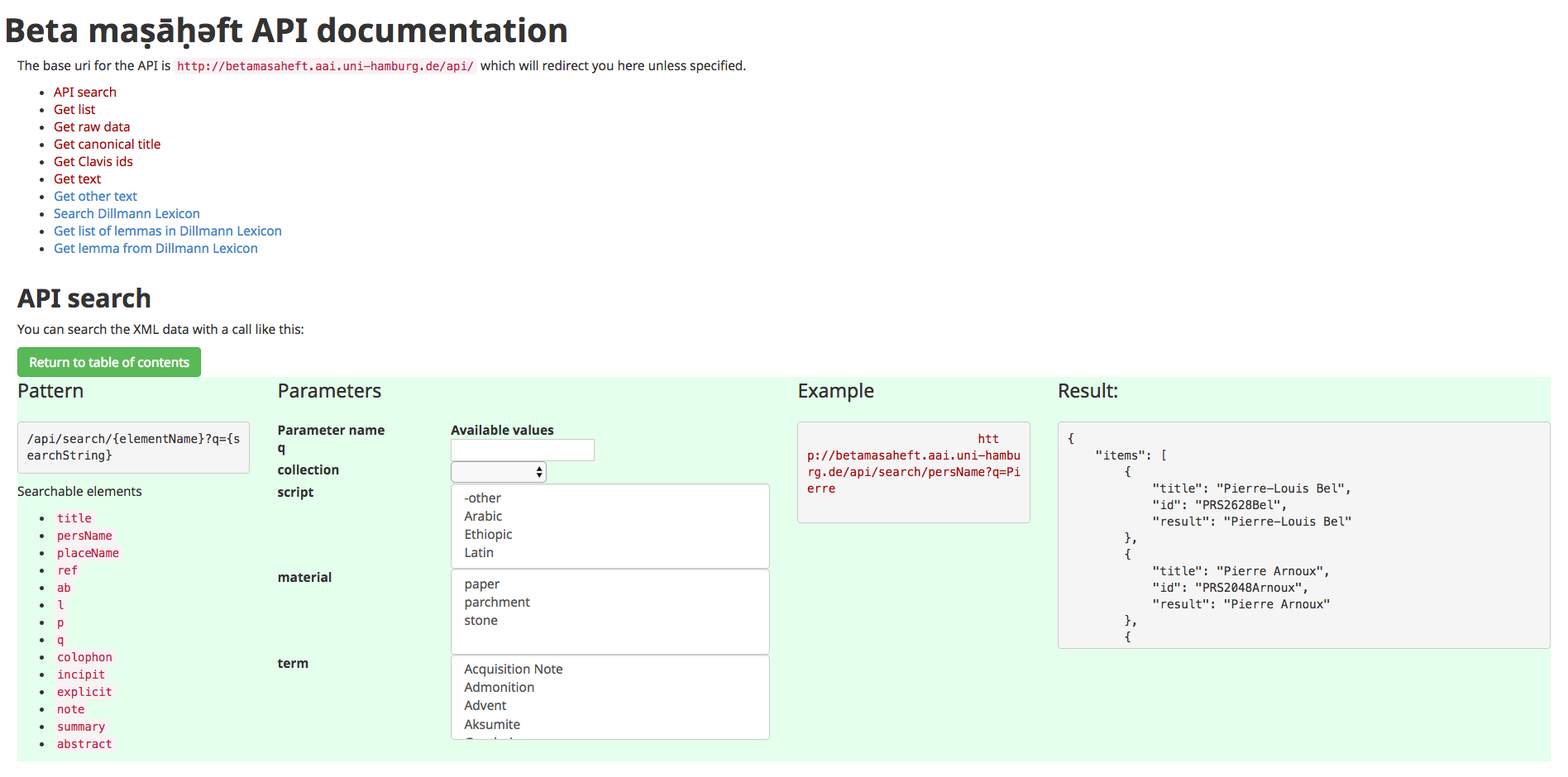
APIs
All project data is exposed through documented and testable data APIs, which allow
search, basic information and full record retrieval to all accredited users, both
in XML and
JSON.
This is the core technology behind the app, developed with eXist-db and
RESTXQ. It was primarily intended to serve data to our services and to
third parties in the formats required. For example the canonical titles of each record
are
always computed from the available information. A sister application (not in the scope
of
this presentation), which contains definitions of words, uses the API to get related
records
and the text of quoted passages.
This API is already available for third-party users, although the status of the data,
still at its initial phases, does not allow us to advertise it yet. We hope people
will find
it useful for example to resolve citations of literary works to the exact passage,
or to
include representations of the data we curate in other resources.
Figure 10: Works and connection to other traditions' canonical IDs.
The data API interactive documentation.
Of special interest is the development in the context of the Distributed Text Services's
endeavour of collection, text and citations APIs based on the TEI data.
References
[Orlandi 2013] Orlandi, Tito. A
Terminology for the Identification of Coptic Literary Documents. Journal of
Coptic Studies Proceedings of the Ninth International Congress of Coptic Studies,
Cairo 2008,
no. 15 (2013): 87–94. doi:https://doi.org/10.2143/JCS.15.0.3005414.
[Bausi 2010] Bausi, Alessandro. Composite and Multiple Text Manuscripts: The Ethiopian Evidence. In “One-Volume
Libraries”: Composite Manuscripts and Multiple Text Manuscripts. Proceedings of the
International Conference, Asien-Afrika-Institut, Universität Hamburg, October 7–10,
2010,
edited by Michael Friedrich and Jörg Quenzer. Studies in Manuscript Cultures. Berlin
- New
York: De Gruyter, forthcoming.
[Andrist Maniaci et al. 2013] Andrist, Patrick, Paul
Canart, and Marilena Maniaci. La syntaxe du codex.
Bibliologia ; 34 ; Bibliologia 34. Turnhout: Brepols, 2013.
[TEI Guidelines] Consortium, T. E. I., Lou Burnard, Syd
Bauman, and others. TEI P5: Guidelines for Electronic Text Encoding and
Interchange. TEI Consortium, 2008.
[EthioSPaRe] Nosnitsin, Denis. DomLib/Ethio-SPARE Manuscript Cataloguing Database. In Paper Presented at the
COMSt Workshop The Electronic Revolution? The Impact of the Digital on Cataloguing.
Copenhagen, 2012. http://www1.uni-hamburg.de/ethiostudies/ETHIOSPARE/.
[1] Beta maṣāḥǝft is a TEI (Text Encoding Initiative, www.tei-c.org) project.
We use GitHub to store our data and we deploy our data with eXist-db
(http://eXist-db.org/). The project is
extremely indebted for their continued support to the TEI and eXist-db communities.
We would like to thank the team at the
Hiob Ludolf Centre for Ethiopian Studies, the Akademie der Wissenschaften in Hamburg
and
the University of Hamburg for their support to the project and to the preparation
of this
contribution.
[3] A small grant has additionally been awarded for this task from the [Pelagios Commons] Resource Development Grant.
[4] The Distributed Text Services project is currently under development. We are just
early and eager users of it as we believe it will serve very well the community.
Orlandi, Tito. A
Terminology for the Identification of Coptic Literary Documents. Journal of
Coptic Studies Proceedings of the Ninth International Congress of Coptic Studies,
Cairo 2008,
no. 15 (2013): 87–94. doi:https://doi.org/10.2143/JCS.15.0.3005414.
Bausi, Alessandro. Composite and Multiple Text Manuscripts: The Ethiopian Evidence. In “One-Volume
Libraries”: Composite Manuscripts and Multiple Text Manuscripts. Proceedings of the
International Conference, Asien-Afrika-Institut, Universität Hamburg, October 7–10,
2010,
edited by Michael Friedrich and Jörg Quenzer. Studies in Manuscript Cultures. Berlin
- New
York: De Gruyter, forthcoming.
Nosnitsin, Denis. DomLib/Ethio-SPARE Manuscript Cataloguing Database. In Paper Presented at the
COMSt Workshop The Electronic Revolution? The Impact of the Digital on Cataloguing.
Copenhagen, 2012. http://www1.uni-hamburg.de/ethiostudies/ETHIOSPARE/.
Michelson D.A., ed. Digital
Catalogue of Syriac Manuscripts in the British Library. Syriaca.org:
The Syriac Reference Portal; forthcoming. http://syriaca.org/mss/.
Elliot, Tom, Gabriel Bodard,
Elli Mylonas, Simona Stoyanova, Charlotte Tupman, and Scott Vanderbilt. EpiDoc Guidelines: Ancient Documents in TEI XML, 2013-2007.
http://www.stoa.org/epidoc/gl/latest/.