Lee, David. “The Secret Life of Schema in Web Protocols, API's and Software Type Systems.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Lee01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Balisage Paper: The Secret Life of Schema in Web Protocols, API's and Software Type Systems
David Lee has over 30 years' experience in the software industry responsible for major
projects at
companies of all sizes and cross-industry and the developer of "xmlsh", a widely used
open source scripting
language. Examples include telephony automation, embedded systems, real-time video
streaming (IBM), CRM
systems (Sun, Centura Software), Security and infrastructure (Centura Software, RightPoint,
MarkLogic),
Software development frameworks (Centura, WebGain), Clinical information work-flows,
mass mobile device
information distribution (Epocrates), Core 'NoSQL'/'XML' Database development, Cloud
computing, Global secure
telemetry distribution (MarkLogic), Digital publishing (internet and physical media),
eCommerce and custom
messaging systems (Nexstra). He has a long history of independent research in effective
data processing and
markup use in industry and has been involved in multiple W3C working groups. He currently
serves an advisory
role as CTO of Nexstra, a digital publication and services company he co-founded over
10 years ago.
In this publication, I describe some of the results of several years’ research and
experimentation in the
field of Web API Protocols (JSON/XML/Media over HTTP) and Software APIs tracing the
migration of ‘Schema’ into
software class definitions, annotations, formal and semi-formal markup document types
describing their structure
and usefulness. Using a specific use case as a representative example, I demonstrate
the rationale, steps and
results of an experimental proof of concept. The proof of concept utilizes a wide
variety of easily available
techniques and tools rarely used together in a work-flow to reverse engineer a REST
API from its behavior. It
involves coupled transformations of data, schema, and software, through multiple representations
utilizing tools
from otherwise disparate domains to produce a largely auto-generated application to
aid in a real world business
problems.
The modern 'General Purpose Computer', the global internet, and the "Word Wide Web"
have enabled almost
all aspects of society, and domains of practice and theory, to directly express and automate
the processing of pre-existing and newly-invented ideas, processes, methodologies,
and communications both abstract and
physical. The physical barriers to the communication of ideas and practice across
geography and conceptional domains
have been largely eliminated. However the conceptual barriers between domains often remain
intact. It’s simply not obvious how concepts in one domain may relate to concepts in another domain. The
specialization of domain specific languages and terminology can exacerbate this both
by sharing common terms that
have different meanings, and by using different terms for concepts with similar meaning.
So
while the ability to communicate ones ideas to others, and by implication the benefit
of tools enabled by them, is
ubiquitous; understanding, and hence application is limited by the degree to which
one can recognize the similarity and
applicability across domains. To demonstrate by example the practical consequences
of this limitation, and the
tangible benefits of recognizing and breaking down these barriers, what follows is
a narrative that describes
a real problem and the path taken to solve it.
The fallacy of the obvious
The process of creating distribution media is fairly complex but well known and largely
automated. The
majority of the effort is describing the process details in a form that the both the
people and the machines can
replicate consistently. Physical digital media production (CDs, DVDs etc.) is similar
to digital printing, sharing
the same underlying technology and process. They also share the same problems. Unlike
mechanical or photographic
replication, the prototype to be replicated is not physical and may have never had
a physical representation. The
conceptualization is that the result is a copy or replication of some pre-existing object. But when there was never an original tangible object
to
compare, determining if the replication is accurate is subjective. For print, either books on
paper or the color label on a CD, the relevant attributes of the production is tangible
and largely objectively
described and measured. For the digital content, the relevant attributes extend well
beyond physical
representation. It’s well known how to compare the contents of one CD to another,
validate the physical process
worked as intended. It’s not always obvious whether the intent is accurately fulfilled --
i.e.. the set of files included, the directory structure and naming, spanning content
across multiple CDs,
usability in the intended environment.
The assumption that the representation of intent is obvious and objective is so common
that it’s often
inconceivable that may not be. In this case the intent is to produce media for a customer
that contains the
product that they purchased. It may be surprising that defining that intent in sufficient
detail is not only
difficult but the fact that it requires defining can be overlooked when the parties involved
all individually have a clear but different understanding of what that means.
Nexstra, which provides digital fulfillment services for software companies, was hired
by a software company
who had acquired another company's inventory to produce and ship physical media for
the customers who requested
it. The people responsible were in the sales, and support department of the organization.
The business concept of
a "Product", while sharing the same term, has a completely different meaning and model
then used by engineering
including completely unrelated computer systems, software and models for managing,
organizing, cataloging,
supporting and selling “Products”. The only place the two models intersected was in
the presentation layer. The
website hosting the download center. Since that was the one and only one visible representation
of the entire
product catalog, the illusion that the web site was a presentation of an integrated
data model rather than it
being the only authoritative source of the data model itself was quite good. And for
the most part didn’t matter
because distribution was largely 'self serve'. After buying a "Product" a customer
would then login and download
the files they wanted, directed by textual clues and restricted by an entitlement
mechanism. This didn’t require
the ability to directly map the business concept of "product" to the specific list
of files as long as the end
result was that the customer could then use the product they bought. The process is
a 'pull' mechanism and
implicitly relied on out of band shared understanding, human judgement. Mistakes were
resolved simply by logging
in and trying again until you had successfully acquired the components needed.
For this scenario, a formal schema and logical data model of products is not a business
requirement, it’s a
major artificial constraint. Analogous to a Buffet Restaurant where the product sold
and the pricing model is
quite simple, but not formal or logical. All you can eat, selected from any item,
for a fixed price. A more complex
product definition can be useful, but not a more formal one. For example “one main
course item, two sides and a
dessert”. If there is a common agreement of intent, this works quite well.
Until you’re asked to deliver “dinner” to someone else. A ‘push’ distribution model
that simply cannot satisfy
the intent without a great deal more information.
It’s ‘obvious’ to a production vendor that in order to produce something the supplier
needs to tell you exactly
what it is. It’s equally obvious to the supplier that the fact that customers have
for years successfully been able
to easily login and download the files for a product that simply putting those onto
a CD is purely a process of
labor and hardware. The fact that they are both correct, and communicate with each
other this shared understanding,
simply makes it even more difficult to recognize the existence of hidden assumptions
so obvious they were not
considered.
In this case, that is exactly what happened. The extent this was problematic not
recognized for quite some
time.
The Presentation Layer view of the Data Model
The Pivotal Download center is a publicly accessible web application that allows browsing
and downloading
components of the product catalog.
A Software Buffet. Pivotal download center.
This is the presentation model the customer and the company see when browsing the
product catalog before
purchase as well as downloading entitled artifacts after purchase. You are shown all
products to some level of
detail whether or not you are entitled to them.
Figure 1: Pivotal Download Center
The visible entities are Product Lines, Product Families, Product Groups and Product
Suites. They
are identified by the brand name, title, or description. These may vary over time
and language.
Figure 2: Product Detail
A specific version, usually 'the latest', is pre-selected. For simple products the
list of contained
files is shown with description and links to download. Other include non-software
files and components are
shown on the sidebar at the right.
Figure 3: Product Version List
Other versions may be selected, changing the available components.
The Process and Data Model from the fulfillment perspective
A long process of meetings, calls, email exchanges, ‘poking around’ the website, guesswork,
notes from
conversations, etc. ultimately produced, in combination, a repeatable, largely manual,
process that generally worked.
Since there was no way to validate the results beyond ‘seems to be right’ and waiting
for customer feedback about
missing, wrong, or unrecognizable files and disks, it took a few months to get the
process down.
But it was a very painful and tedious process. Since there was no automated notification
of product releases,
we didn’t know which products had been updated or if the same product ID and Version
had changed what files it
contained or the contents of the files. This meant every order required manually searching
through the web site,
subjectively determining what the “Latest” version for the customers entitlement,
manually accepting the EULA,
downloading the files, organizing and renaming them when there were conflicts, validating
the checksums and
sizes, partitioning to fit on the fewest CDs but not spilling over just 1 small README.txt
to a CD on itself.
That was pre-publication work and was significantly more than expected such that it
cost significantly more in
labor to produce per item then anticipated. The profit margin was near zero. We simply
didn’t account for the
amount of manual effort to translate an order into the set of artifacts, nor the time
required to correct errors
due to ill-defined and missing information.
The secret API
There had to be a better way. I set out to see if I could do something, even very
crude like screen scraping
and simulating mouse clicks to reduce the effort and inevitable mistakes.
In the course of random exploration of the web site, to get a rough idea of the effort,
we discovered that a REST API existed
with the same catalog information publicly available but unknown by the people in
the department with which we
were working. It looked like such a well-designed and documented API that not only
should we be able to automate
most of the process but also learn something from it to use for future work. It also
contained some information
not displayed in the web site. This caused us to suspect that it might be a direct
interface to the underlying data.
That could solve
the problem of having to guess to fill in missing data. It was one of the better REST
API’s I’ve encountered ‘in the
wild’: a true hidden treasure.
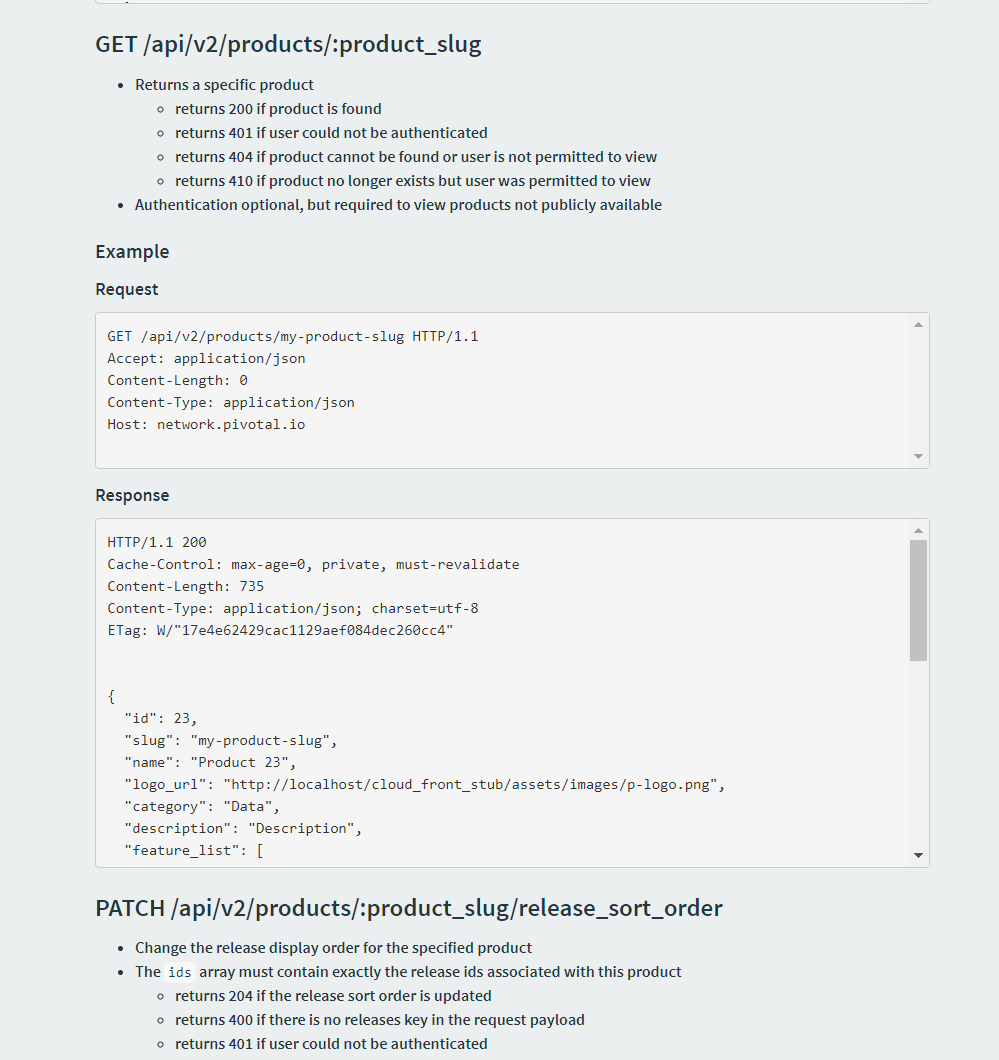
Figure 4: Example page from the Pivotal API online documentation.
This shows a representative page from the public pivotal API[1] documentation. Note the detail in resource
paths, response codes and HTTP HTTP Headers. An example JSON JSON format output is shown. Note also the absence of any
description whatsoever of the semantics of the request URI or the result. No indication
of structure type,
allowed values, optional fields, key values, enumerations, variant structure. The
presumption is that the
single sample is sufficiently self-destructing. I.e. it’s "obvious".
Implementation Details
Soon into the process of writing what I expected to be a very simple application to
query the product list,
resolve the files, and download, them I discovered a fundamental problem that I have
since found to be nearly
universal. The HTTP layer of the API was very detailed. It described both the structure
and semantics of the
required headers and HTTP methods, and the semantics of HTTP response codes. It even
included sample code (in curl, not shown).
That allowed one to quickly test an example and validate it was working as expected.
The structure and meaning
of the requests and response body were documented by example only. For each API there
was a short statement of
its purpose, an example of a request and response, and nothing else. Absolutely no
description, documentation,
schema, structure or semantics of any kind. Since the API followed a consistent REST
inspired pattern, the
domain, data and naming conventions used were simple terms with assumed common meaning
it was not at all obvious
what was missing or the extent that it was problematic. But when used in a real program
with real (not sample)
data, the task of reliably constructing the right queries, interpreting the responses
and validating that the
results required comparing the results to the web site, separately for each query.
The examples were good, but
were they representative? Did they contain all of the optional fields ? What was the
set of allowed values for
each field and what did they mean exactly, and was there relationships between fields
? Relationships between
resources was even more ambiguous. The fields consistently used common, generic terminology
such as “_links”,
“self” , “href” but frequently led nowhere - to a “404 Not Found”, an empty page or
an anonymous empty object
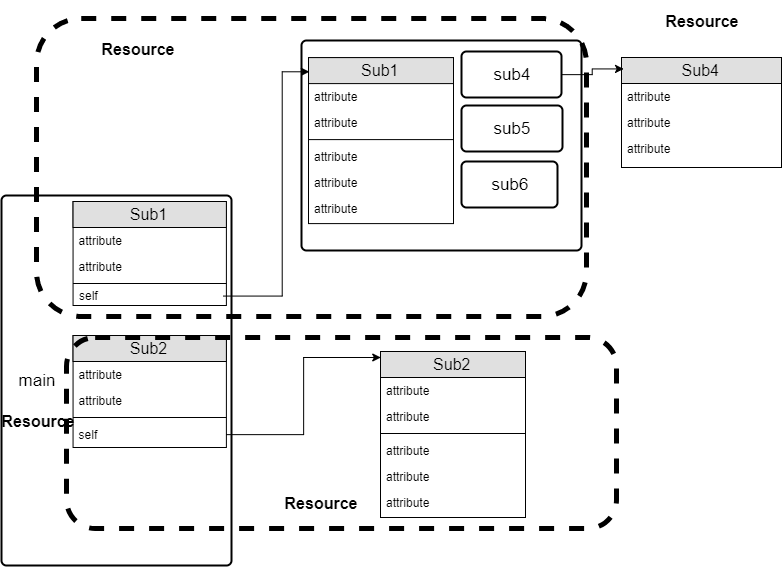
with a link to itself. The distinction between containment and reference was not explicit
so there was no way to
know if a referenced object was to be considered an included sub-resource, a shared
reference to node in a multi-rooted
tree or a structurally insignificant reference.
A few randomly chosen examples started to show a pattern indicating a kind of ‘hidden
structure’ that could
not be easily inferred accurately by a few examples. There was no way to be sure the
interpretation was correct
short of comparing every query against the web portal. Which was precisely the problem
I was attempting to
avoid. Even with that, there was no conceptual model to assume that the next new product
could interpreted the
same as the previous. Fortunately it was known that the set of products was small
and had previously been given
an estimate of the size of the total number of files. Assuming for the moment that
nothing changed, we could
simply download the entire data set, model it, and run an exhaustive search. The product
line was mature enough
that it’s likely all-important permeations were covered by existing data. Enough that
the errors should be much
less than the manual process produced.
It’s an interesting problem that’s related to a more general concept I’ve
been working on for a few years – that a form of “schema” is implicitly contained
in the structure of class
definitions in statically typed programming language API's. That the implicit schema
can be usefully extracted
and used to model the API in general and leveraged to dynamically construct instances
of class declarations
suitable for existing data mapping tools and support type safe invocation of dynamically
loaded API's in static
languages from purely data oriented representation provided at runtime. In this case,
the API has no programming
language binding to begin with, meaning the process would need to start with data
and end with a static API and
schema. The result should would demonstrate a reversible transformation was equally
viable.
Reverse Engineering a data model
The Pivotal API is a good candidate for a simple brute force approach at reverse engineering.
It’s known that
there is a manageable bounded set of data and it’s presumed that the API is idempotent
and doesn’t itself produced
new information. The examples show what appears to be a graph model with nodes and
links. It is not known if the
API is complete - if it exposes access to all the data available or needed, or if
it’s discoverable – that all
nodes in the graph can be reached from the set of known root nodes. The topology of
the graph is not known, nor if
the links are bidirectional. There are practical constraints that make exploration
more difficult but also make it
easier to reach a halting state.
Constraints
Invoking the API is slow compared to the number of expected requests such that it
is impractical to use it
directly for exploration without optimizing redundant queries.
The provided vendor account has access to only a subset of total products. The list
of entitled products
were identified by name not id or URI. This implies that we cannot distinguish between
nodes that are
inaccessible in the data model and nodes that are inaccessible only due to intermediate
nodes being
inaccessible.
We have authorization and a business need to use the API, but not to abuse it. The usage pattern of a simplistic exhaustive search has similar characteristics
as
a denial of service or penetration attack.
There is internal state associated with the account. Access to some resources require
a one-time
‘acceptance’ of the End User License Agreement (EULA). Since there is only indirect
access to this state it’s
difficult to know until after attempting a request if it required a prior acceptance.
The EULA acceptance
procedure is intended primarily for interactive use, but it can be achieved programatically
(with a bit of
reverse engineering).
Early failure detection. It’s pragmatic to determine as early as possible if either
theory or
implementation is obviously wrong.
With these constraints and a limited time allocated for ‘experimentation’ I built
a fairly simple framework
with tools at hand and minimal effort. A consequence demonstrating that this type
of approach can be easily
implemented with commonly available tools and minimal domain expertise, i.e. that
there is no part that could
not be done in many other ways using other tools and much better by someone else.
Components
A simple HTML browser based interface for interactive exploration
Tools for invoking basic HTTP requests including access to ‘low level’ HTTP meta-data
(headers, cookies
etc). Something that could perform any of the needed REST calls and extract the results.
Tools for query, creation, and transformation of the results into other formats.
A ‘database’ capable of storing and accessing efficiently the original and transformed
documents.
The ability to store and transform between multiple data formats is a significant
enabling feature allowing
use of tools that only operate on a specific format to be used in combination. Different
formats and tools have
evolved largely independently such that there are entirely independent sets of functionalities
easily available
for different data formats, markup and programming languages. This is precisely the
problem that markup
languages attempt to address, but are only successful to the extent that proliferation
of markup and programming
languages is constrained. Constraining invention has historically been demonstrated
to be both impossible and
undesirable for equally compelling reasons.
A common approach to overcoming interoperability in markup languages is data
transformation. Analogous approaches in programming language data structures and API's is
data mapping. I assert and intend to demonstrate that markup and transformation, data and
software, are interchangeable in both a theoretical and practical sense.
The resultant tool demonstrates part of this as a side effect of being useful for
exploration of the space
exposed by an API.
For this API the direct formats used are Resource Paths (Uri’s constructed form composite
strings), JSON,
HTML and HTTP headers (name/value string pairs with predefined semantics). API request
are composed of a
Resource Path and HTTP Headers. The results are HTTP Headers and JSON documents for
successful responses, and
HTTP Headers and JSON or HTML documents for unsuccessful or indirect responses. The
exploration tool stores
these requests and responses directly as well as transformations to HTML, XML, and
RDF. The database is used for
both caching of responses and for query of individual documents and across documents.
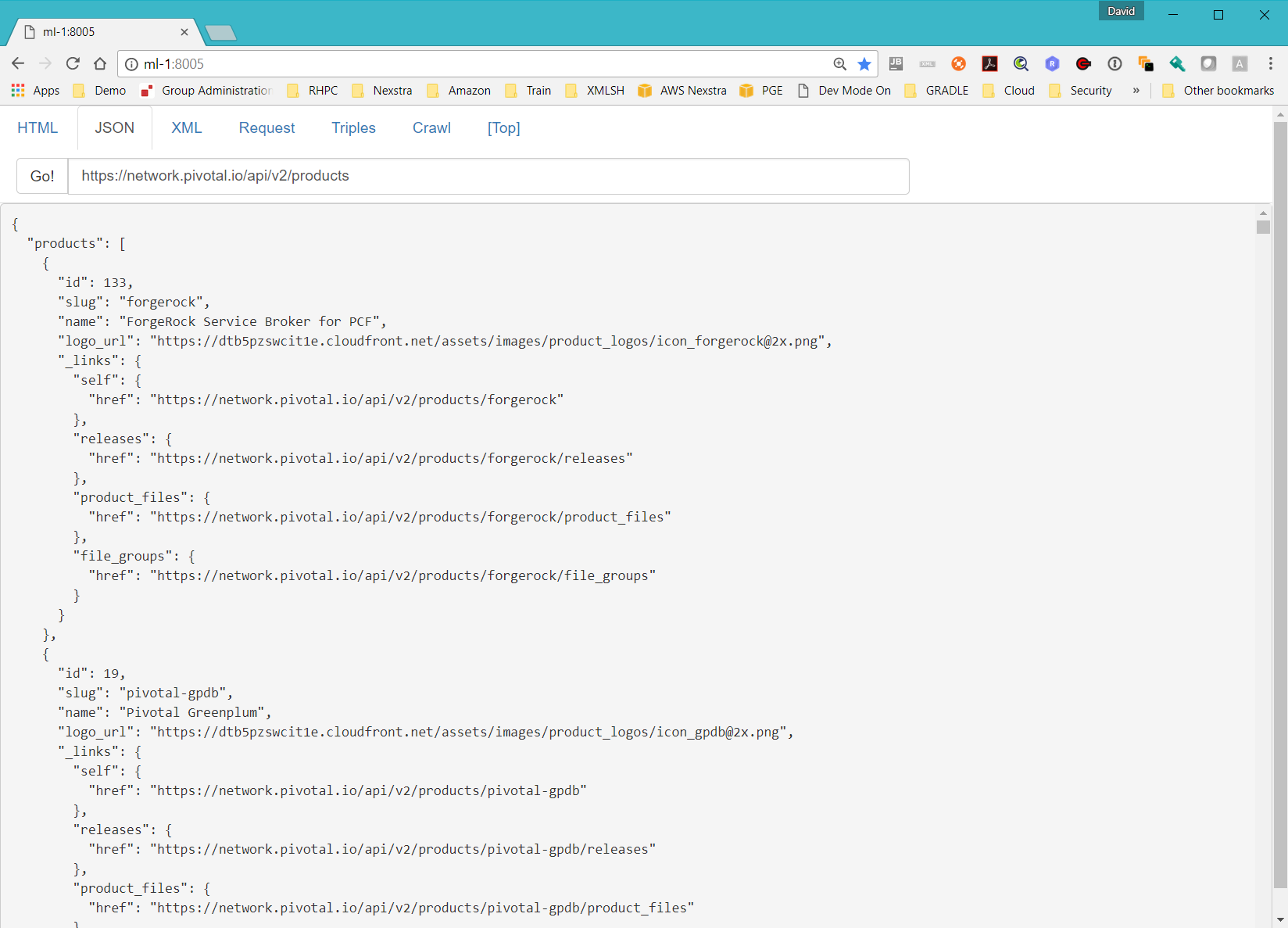
Exploration Tool Example
Example of the a single API call to the root endpoint of the “products” API.
As much as practical the transformations are direct with no domain knowledge applied
to specialize them. The
intent being to enable exploration of the API itself in order to discover without
prior-knowledge the underlying
model. This took a few iterations to learn enough of the structure so that it could
be displayed in a readable
format but without losing information when encountering unexpected results.
For each representation the domain knowledge and assumptions are indicated.
Figure 5: JSON
The ‘raw’ result in the original JSON format transformed with a simple ‘pretty print’
for easier reading.
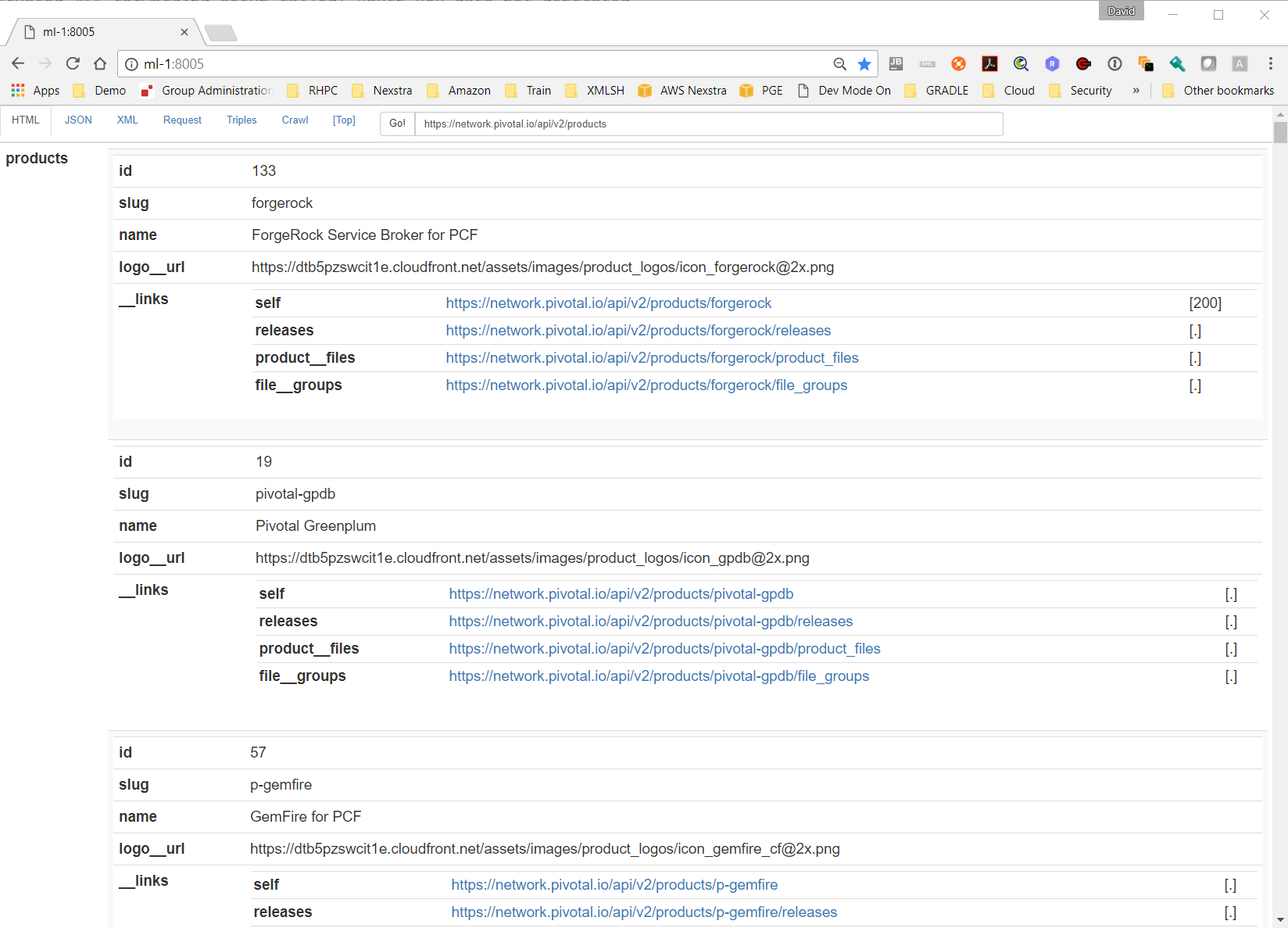
Figure 6: HTML
JSON to HTML transformed by the following rules
Fields containing objects produce a new table with 2 columns [field , body] and a
row for each
child field.
Fields containing arrays produce a new table with the same format as object but with
the only the
first row containing the parent field name.
The “__links” field is handled specially collapsing the nested “href” into the same
row as the parent
and converting it an <a> tag displaying the original value but linking back to the
application passing
the href as an encoded uri query parameter.
An indication of whether the link has been attempted to be indirected and cached along
with its
HTTP response code.
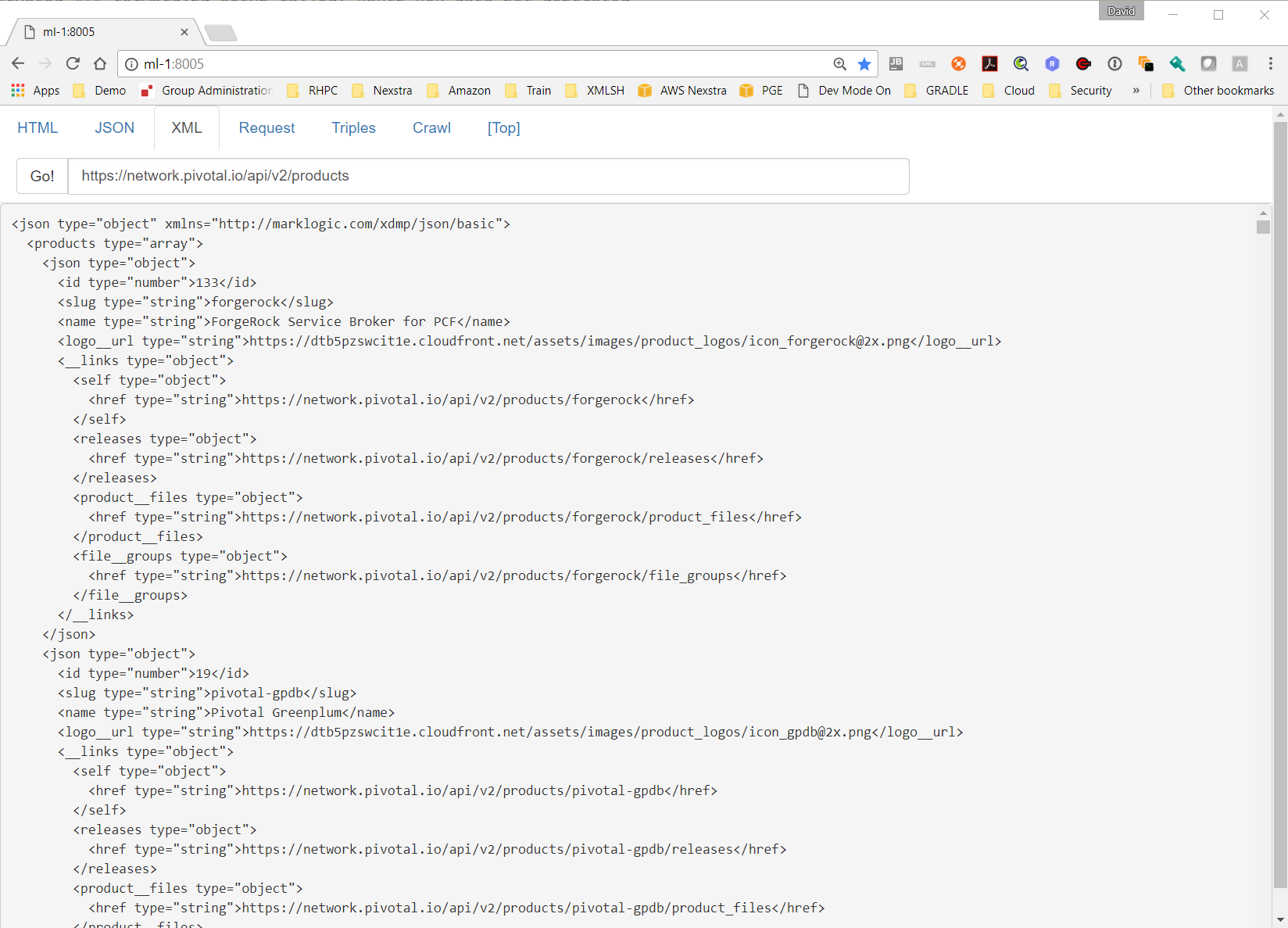
Figure 7: XML
XML is produced with the marklogic json:transform-to-json() function, which implements
a simple
bidirectional transformation similar to other independently implemented algorithms
such as JXON, JSONx, JXML
etc. An open source compatible function is available in xmlsh 2.0.
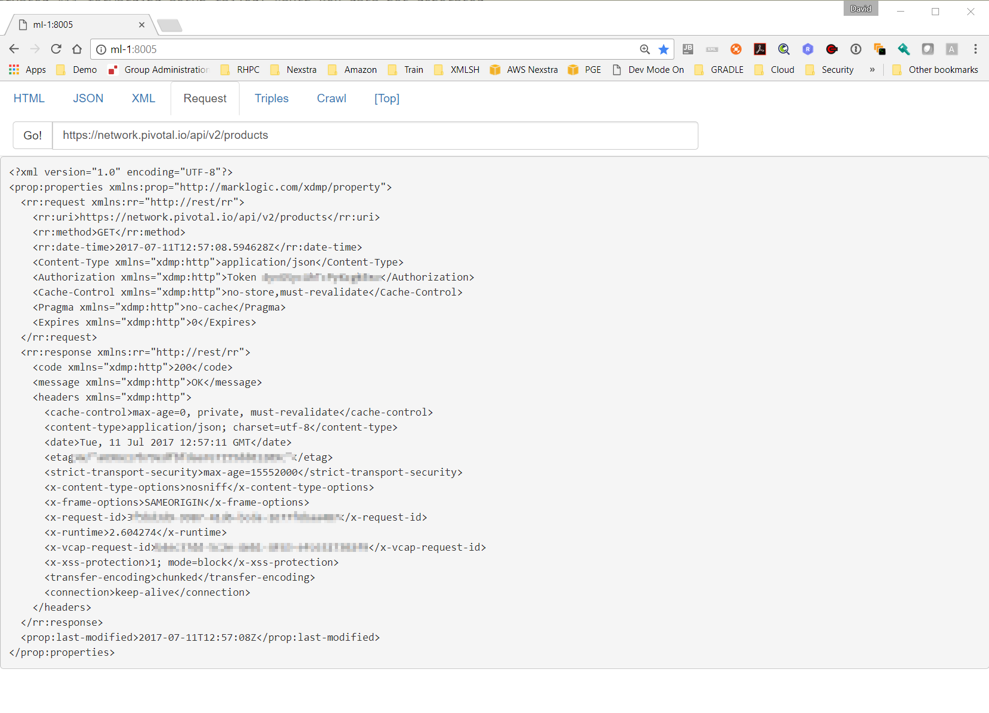
Figure 8: HTTP Headers
The request and response HTTP headers in XML format, unchanged from the output of
the MarkLogic
xdmp:http-get() and nested in a wrapping element so it can be stored as a properties
document for
convenience. This is used by the caching implementation as well as to debug problems
with requests.
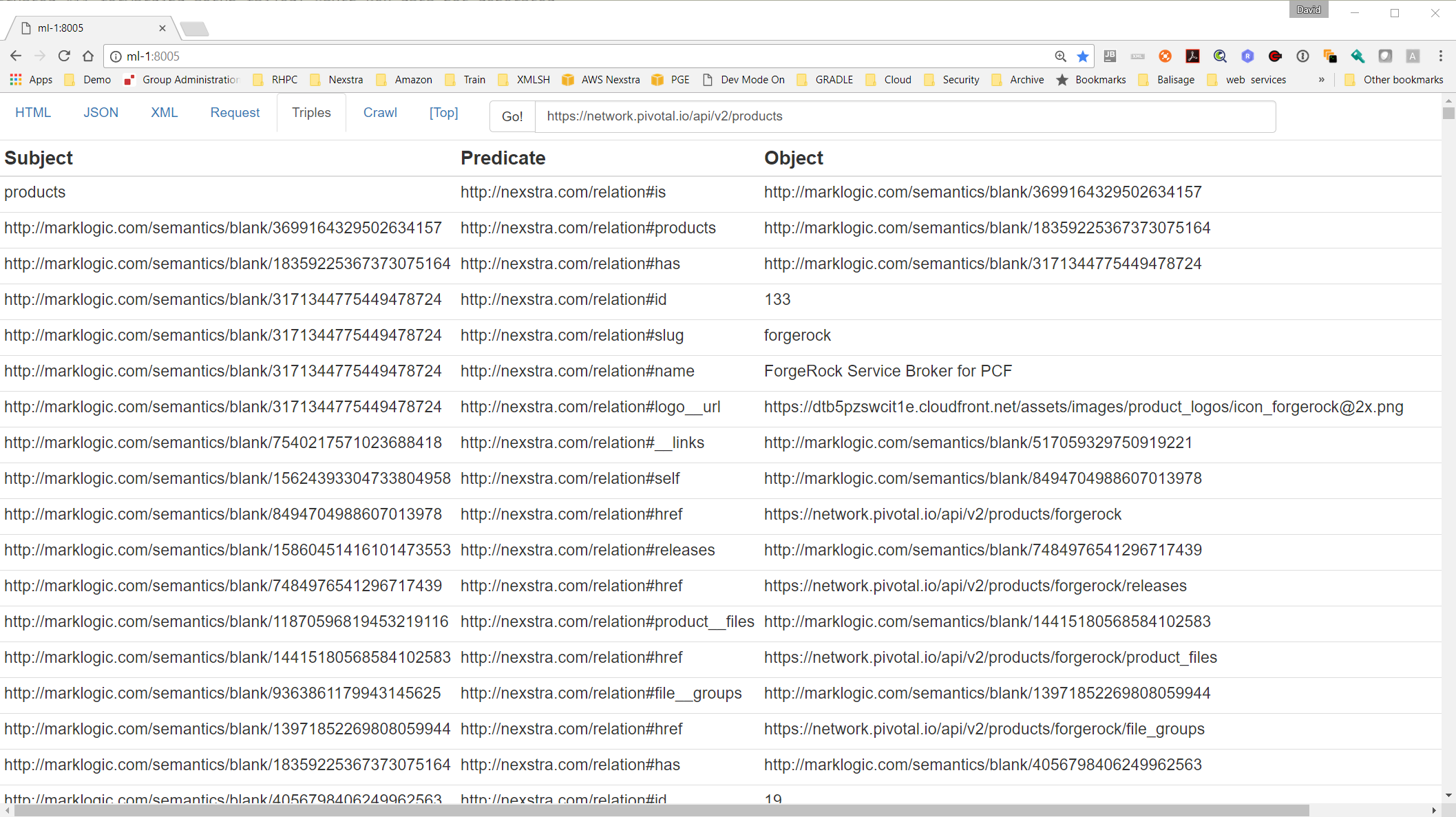
Figure 9: RDF
A very simplistic production of RDF by applying a few basic rules to the JSON data.
Note: there are some known errors in the implementation that omit triples in some
relations.
Top level field names produce the triple [ Subject , #is , #blank-node ]
Arrays produce a ‘#has’ relation with the triple [ parent#blank-node , #has , entry#blank-node
]
Fields containing atomic values produce the triple [ #blank-node , #field-name , value
]
Exploration
With the API Exploration tool, interactive browsing and database queries were possible.
Interactive
browser allowed for quick visual comparison of the data from the API compared to the
download center web site.
Since there was no documentation of data content, simply guessing based on the field
names only somewhat
successful. For example, was “product__files” a list of the files in the product?
Surprisingly, not always.
How about “file__groups”, should the link be dereferenced to get a list of groups
of files ? What was the set
of valid “release__type” values and was that relevant to determining if a release
should be distributed ? For
example “Beta Release” seems like something you wouldn’t ship to customers. More surprising
than validating
that guesses of the semantics were not always right was discovering that the presence
of links had no
relevance to if the resource it referred to existed.
For example, the following appears to indicate that there are resources associated
with the properties
self, eula__acceptance,product__files,file__groups,__user_groups.
Resolving the references led to surprising variants of “doesn’t exist”. Note that
these endpoints were all
explicitly listed as links in a successful response body.
eula_acceptance: HTTP Status 404
Resource does not exist at all
{
"status": 404,
"message": "no API endpoint matches 'products/dyadic-ekm-service-broker/releases/4186/eula_acceptance"
}
file_groups: HTTP Status 200
The resource ‘exists’ as a REST resource (a “file group” with no entries) and correctly
links back to
itself.
Resource is not viewable. The account has the rights to view all resources in this
product, unknown if the
resource exists.
{
"status": 403,
"message": "user cannot view user groups for this release '4186
}
Without a larger sample, it’s not obvious if these cases are constant or depend on
some property of the
resource. Since the presence and syntax of a uri was clearly insufficient to determine
its validity, every
resource would require checking of every link to see if it was valid and used.
Another example is apparent overloading of the term “Release”. In the following, is
the Release “Native
Client 9.0.7” a different product or newer version of “9.0.4” ?
To make sense of this, a larger sample set was needed. The solution was like a basic
‘Web Crawler’
incorporating caching and network loop detection so it wouldn’t run forever or spawn
too many threads. The
resulting dataset could then be directly queried and used a meta-data cache. The binary
resources (file
downloads) were not downloaded at this point.
Analysis and Data Modeling
With the complete (accessible) data set in a database instead of a REST interface,
queries could be done
across the corpus efficiently. There was no intent at this point to use the database
in production, rather
for forensics and exploration to help determine the scope of the problem, basic ‘shape’
of the resources, and
determine constant and variable feature. The source of the data could change at any
time with no reliable
notification mechanism so queries were inherently a point-in-time query with about
a day lifespan at
most.
Modeling the topology of the network (resource links) was needed to clarify what relationships
were
extensions or components of a single entity, what was containment of possibly shared
entities and what were
casual relationships. Simple statistics of unique attribute name and value distributions
exposed where the
same name was used in different types of entities, Co-occurrence queries validated
which attributes were
unique identifiers in what domain, which were optional, the complete set of attributes
for each entity. The
structure of the markup was regular and self consistent. It look like several
commonly used REST and hypermedia conventions, but it wasn’t identical. It would have
been useful to know
which convention or framework was used for the implementation. An example is the JSON
API specification (JSONAPI)
which a very similar link and
attribute convention but required attributes that did not exist such as ‘type’ Other
similar examples include,
JSON-LD. JSON-LD , JSON Hypertext Application
Language (HAL) HAL
Siren Siren
Collection+JSON Collection+JSON. The answer to why many
of the same names were used in different resources but with subsets of attributes
was consistent with the
“Expanded Resource” convention. Identifying those made the abstract model much simpler
and allowed one to ‘see
through’ the window of the API calls to the underlying model.
Note: that except for “self” there is no markup, naming convention, type or other
indication to
determine if a link refers to another entity, a separate contained entity or an expanded
entity. The intent of
this structure is to model one specific user interaction and presentation, one single
instance of the class of
Web Browser HTML Applications. Comparing individual REST requests to the equivalent
HTML page shows an exact
correlation. Tracking of the JavaScript HTTP request show the same.
From the perspective of a document or markup view, the API's present a data centric
structured view, but
from the perspective of the underlying resources the API's expose a presentation view.
There are very good
practical reasons for this design and it’s a common concept to have a summary and
detail interface. But
without some kind of Schema there is little clue that what your looking at is
a page layout resource that aggregates, divides and overlays the entity resource making
it quite obscure how
to query, extract and navigate the dataset as entities. The REST API provides another
method to address and
query the resources once you have their unique id by exposing several other top level
API's corresponding to
the sub-resources. However, it’s the same endpoints (URI's) as in the links and the
only way to get the ids is
by querying the parent resource.
In theory , denormalizing or refactoring the data structure into a resource or document
model should
produce a much better abstraction for resource centric queries and document creation
largely independent of
the REST abstraction or the database, query or programming language and tool-set.
It should be a simple matter of extracting the schema from the REST model, then refactoring
that into a
document or object schema. In order to make use of the new model, instances of the
source model need to be
transformed into instances of the data model using an equivalent transformation as
the schema. Separately
these are common tasks solved by existing tools in many different domains, markup
and programming languages.
Unfortunately, the REST and JSON domain doesn’t have a proliferation of compatible
tools, standards,
libraries, or conventions for schema and data transformations. XML Tools can do much
of this easily but lack
good support for schema refactoring and little support for automation of the creation
of transformations.
Modern programming languages, libraries and IDE's have very good support for class
and type refactoring
including binding to software refactoring, code generation from schema, schema generation
from code and data
mapping to a variety of markup languages. There is enough overlap in functionality
and formats that combining
the tools from multiple domains has more then enough functionality. In theory. With
the right theory, it
should be practical and useful yet I have not yet discovered implementation, proposals,
designs, or even
discussion about how to do it, why it’s easy or difficult or that the problem or solution
exists.
I assert that terminology, domain specialization, and disjoint conceptual abstractions
obscure the
existence of a common design a model that could be put to good use if recognized.
The Hidden life of Schema.
I am as guilty as any of assuming that my understanding of terminology is the only
one. Reluctant to use
the term “Schema” because it has such a specific meaning in many domains but lacking
a better word I
resorted to actually looking up the word in a few dictionaries. WD
a diagrammatic presentation; broadly : a structured framework or plan : outline
a mental codification of experience that includes a particular organized way of perceiving
cognitively and responding to a complex situation or set of stimuli
technical. A representation of a plan or theory in the form of an outline or
model.
‘a schema of scientific reasoning’
(in Kantian philosophy) a conception of what is common to all members of a
class; a general or essential type or form.
With these concepts in mind, looking for “schema” and “schema transformations” in
other domains,
particularly object oriented programming languages and IDE's finds schema everywhere
under different names and
forms, some explicit and some implicit. Starting with the core abstraction of object
oriented programming –
the Class.
A Concrete Class combines the abstract description of the static data model, the
static interface for behavior, and the concrete implementation of both. This supplies
the framework for both
Schema and Transformation within that language.
Annotations provide for Meta-data that ‘cross-cut’ class systems and
frameworks such that you can overlay multiple independent or inconsistent views on
types, classes and methods.
Serialization, Data Mapping and Transformation frameworks make heavy use of a combination
of the
implicit schema in static class declarations and annotations to provide customization
and generation of unique
transformations with minimal or no change to the class itself.
Multiple domains of programming language, markup and data definition languages have
followed a similar
path starting from a purely declarative document centric concept of Schema to ‘Code
First’ programming
language centric model and eventually introducing some form of annotation that augments
the data model schema
or the transformation. The ability to directly associate meta-data representing semantics
to targeted
locations and fragments of implementation allows for general purpose IDE's , static
refactoring, dynamic
generation and transformation tools to preserve the semantics and relationships between
schema, transformation
as a ‘free ride’, agnostic to specialized domain knowledge.
I set out to validate that this was not only a viable theory but that it would work
in practice, using
commonly available tools and general knowledge.
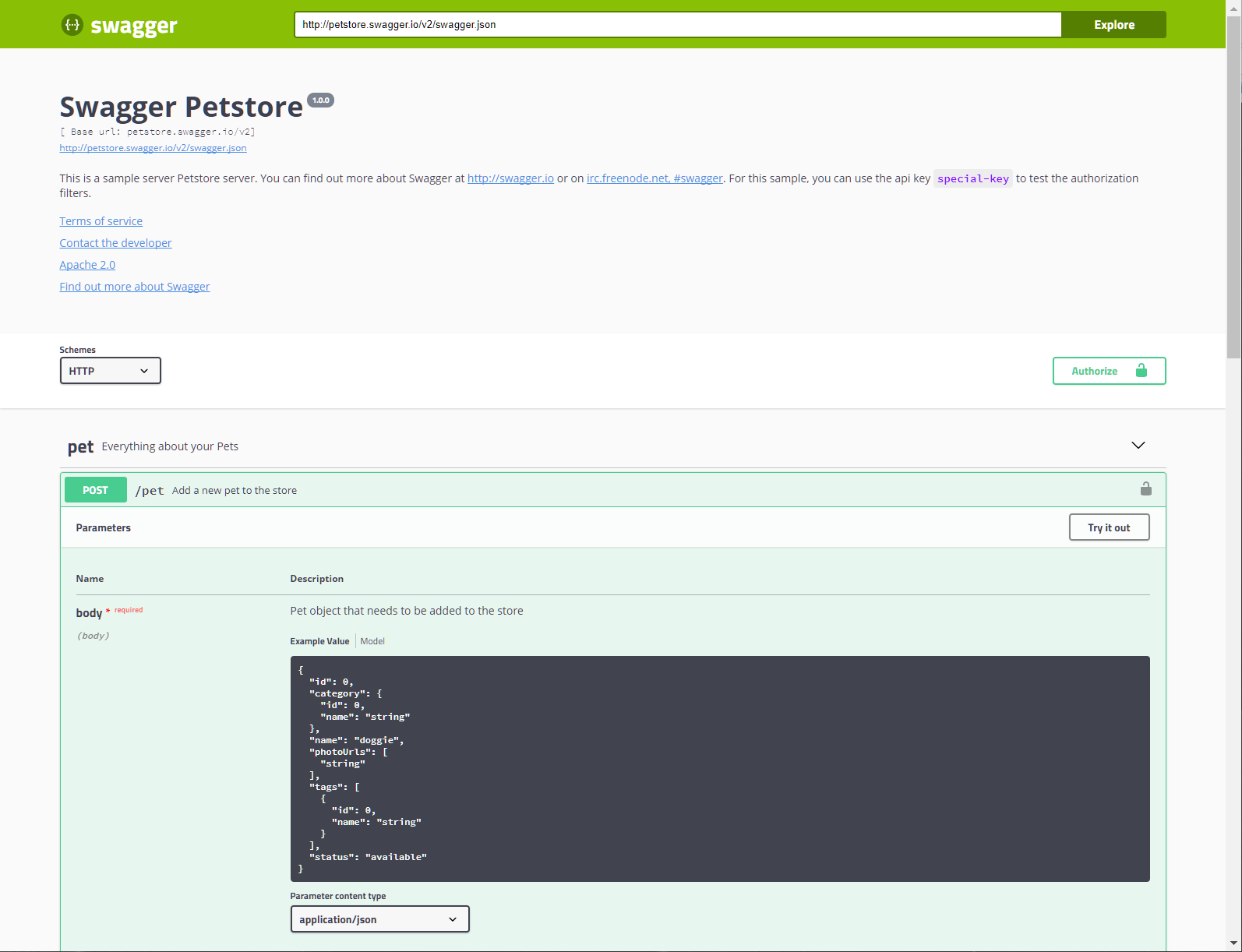
OpenAPI the “New WSDL”
REST based Web Services and JSON grew from a strong “No Schema” philosophy. A reaction
and rejection of
the complexity of the then-current XML based service API's. The XML Service frameworks
(WSDL, SOAP, JAXB,
JAXP,J2EE [2] ) had themselves started humbly as a simplification of the previous generation’s
binary protocols.
XMLRPC [3], the grandfather of SOAP is a very similar to REST in may respects. The schema for
XMLRPC defines the
same basic object model primates, integers, floats, strings, lists, maps with no concept
of derived or custom
types. XMLRPC, as the name implies, models Remote Procedure Calls while REST, as originally
defined reststyle, models Resources and representations. XMLRPC is a concrete specification of the
behavior and data format. REST, on the other hand, is an Architectural Style, “RESTful”
or “RESTful-style”, a set of design principals and concepts -
without a concrete specification. So while an implementation of an XMLRPC service
and a RESTful
service may be equivalent in function, complexity , data model and use, they are entirely
different abstract
concepts. XMLRPC evolved along a single path into SOAP and branching into a collection
of well defined albeit
highly complex interoperable standards. “REST”, the Architectural Style, has inspired
implementations and
specifications but is as ephemeral now as it ever was. As the current predominate
style of web services,
nearly universally with the term “REST” applied to an implementation, there is little
consensus as to what
that specifically means and much debate as to whether a given API is really “RESTful”
or not. Attempts to
define standards and specifications for “REST” is oxymoronic leading to the current
state of affairs expressed
well by the phrase The wonderful thing about standards is that there are so many of them to choose [4] So while the eternal
competing forces of constraints vs freedom play on, the stronger forces of usability, interoperability and adoption led a path of rediscovery and reinvention.
The Open API Initiative was formed and agreed on a specification for RESTful API's
that is quietly and
quickly gaining adoption. The Open API specification is explicitly markup and implementation
language
agnostic. It is not vendor or implementation based, rather it’s derived from a collection
of open source
projects based on the “Swagger” SG01 specification. A compelling indicator of mind-share adoption is the number of
“competing” implementations, vendors and specifications that support import and export
to Open API format but
not each other. While Open API has the major components of a mature API specification
– schema, declarative,
language agnostic, implementation independent – its documentation centric focus and
proliferation of
compatible tools in dozens of languages attracts a wide audience even those opposed
to the idea of standards
and specifications, schema and constraints. OpenAPI is more of an interchange format
then normative specification. Implementations can freely produce
or consume OpenAPI documents and the API's they describe without having themselves
to be based on OpenAPI.
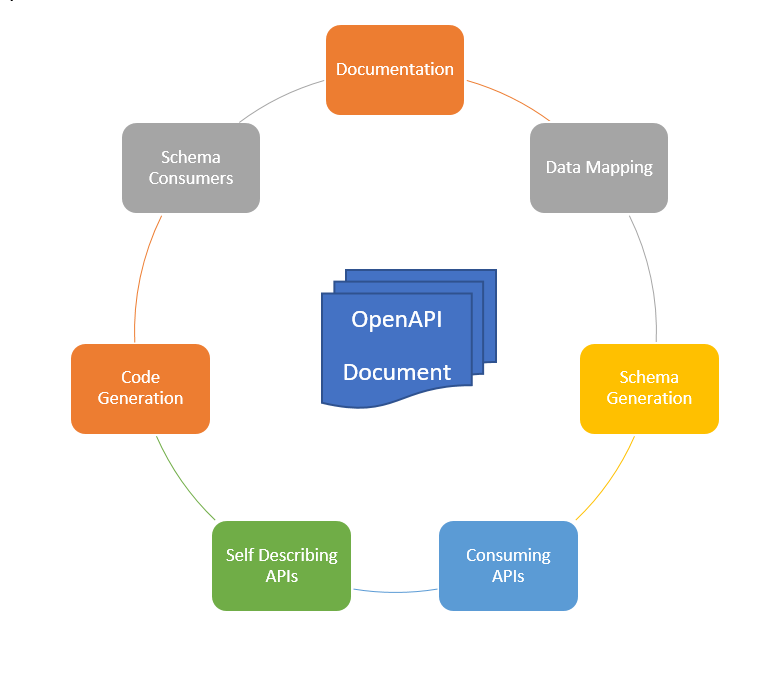
Figure 10: The OpenAPI Ecosystem
The OpenAPI Specification is the formal document describing only the OpenAPI document
format itself.
The ecosystem of tools and features are not part of the specification nor is their
functionality.
The agility to enter or leave this ecosystem at will allows one to combine with other
systems to
create work-flows and processing pipelines otherwise impractical. The Java ecosystem
has very good support for
data mapping, particularly JSON to Object mapping, manipulation of Java artifacts
as source and dynamically
via reflection and bytecode generation at runtime. The JSON ecosystem has started
to enter the realm of schema
processing, typically JSON Schema [5]JSCH1. Not nearly the extent of XML tools, there are very few
implementations that make direct use of JSON schema, but there are many tools that
can produce JSON Schema
from JSON Documents, produce sample JSON Documents from JSON Schema, and most interesting
in this context
produce Java Classes from JSON Schema and JSON Schema from Java Classes.
Combined together, along with some manual intervention to fill in the gaps and add
human judgment, a
processing path that spans software languages, markup and data formats, behavior,
along with the meta-data and
schema that describe them. Nowhere close to frictionless, lossless or easy – but it’s
becoming possible. If it’s shown to be useful as well then
perhaps motivation for filling the remaining holes and smoothing the cracks will inspire
people to explore the
possibilities.
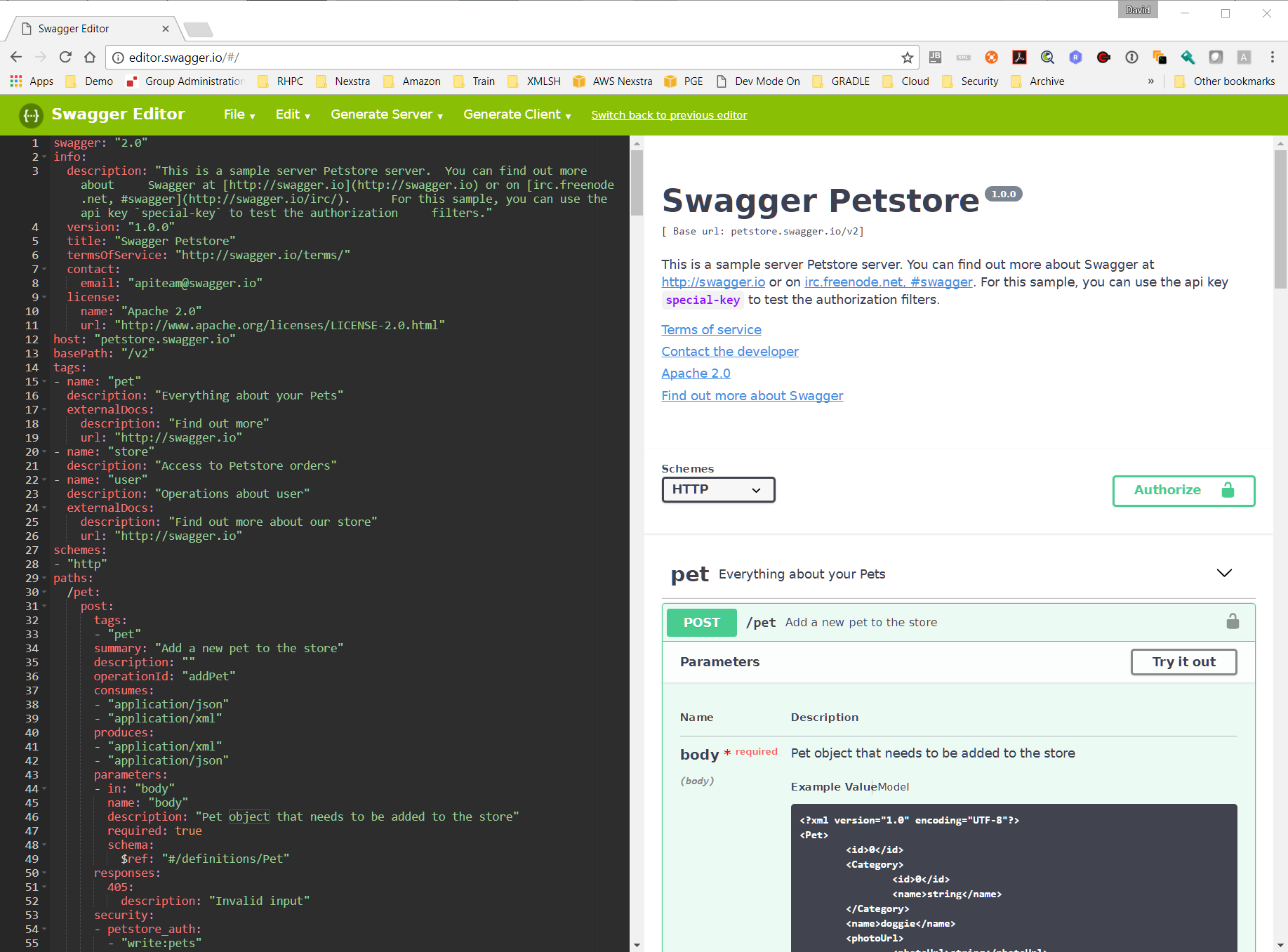
The left pane contains the editable content, the OpenAPI document in YAML format.
As you edit the
right pane adjusts to a real-time documentation view composed solely from the current
document content.
Note the native support for XML and JSON bodies. The sample shown is generated from
the schema alone
although it can be augmented with sample content, an optional element of the specification
for any type
description.
Included in the editor is the "Try it out" feature which will invoke the API as currently
defined in
the editor returning the results.
Code generation in several dozen software languages for client and server code is
included as part
of the open source "Swagger Coden" libraries and directly accessible from the editor.
This ranges from
simple stub code, Documentation in multiple formats and a few novel implementations
that provide fully
functional client and server code dynamically generating representative requests and
responses based on
the OpenAPI document alone.
Figure 12: Swagger UI
The Swagger UI tool provides no editing capability rather it is intended for live
documentation and
exploration of an API. A REST endpoint that supplies a definition of its API in OpenAPI
Format can be
opened, viewed and invoked interactively from this tool. There is no requirement that
the API be
implemented in any way using OpenAPI tools, the document could simply be a hand made
static resource
describing any API implemenation that can be described, even partially, by an OpenAPI
document. Both
Swagger Editor and Swagger IO provide both sample and semantic representations of
the model.
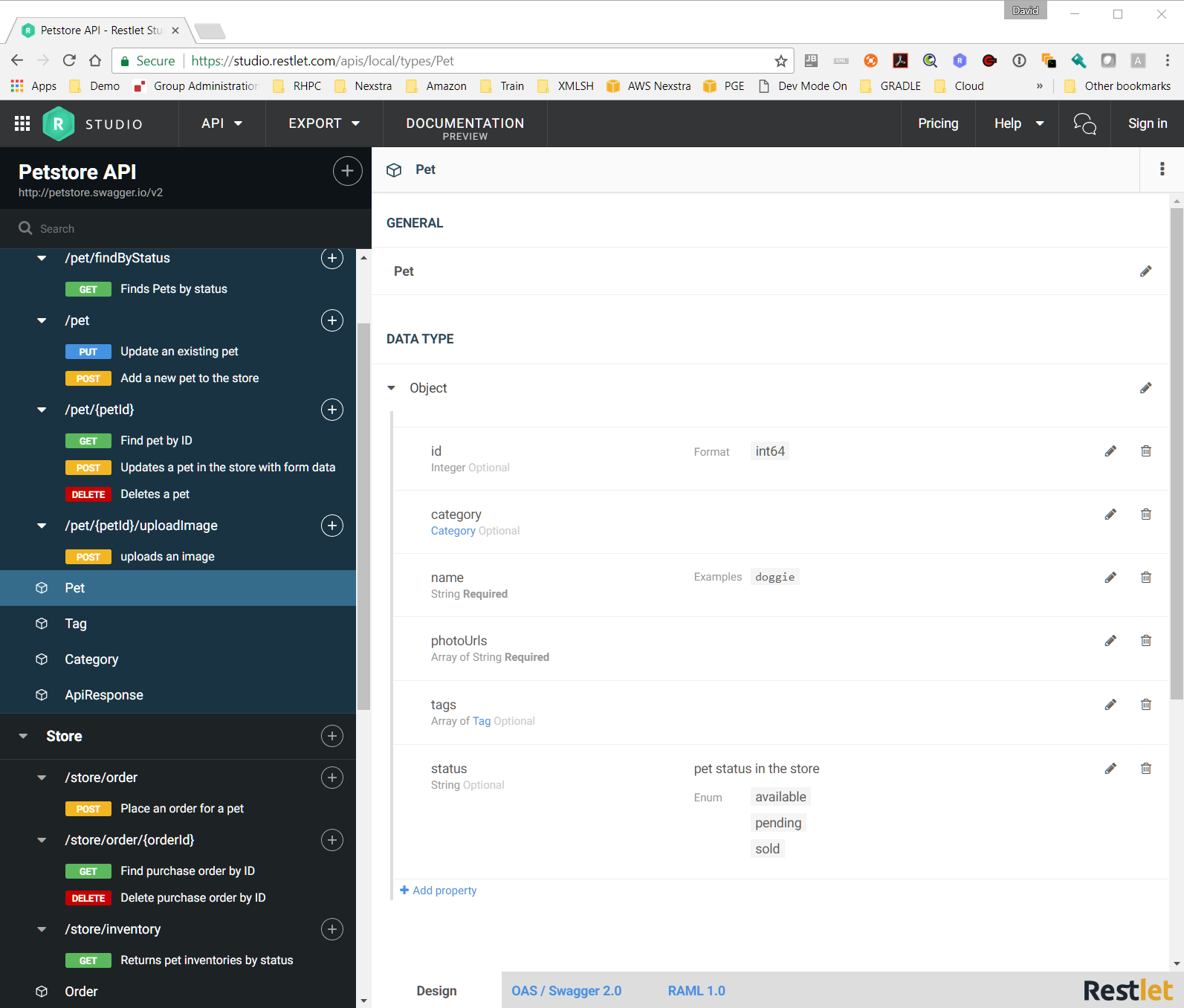
Figure 13: Restlet Studio
Restlet Studio [6] is a proprietary application from Restlet with a free version. It uses its own proprietery
formats not based on OpenAPI, but provides import and export to OpenAPI with a good
but not perfect
fidelity. Restlet Studio was used during the early schema refactoring due to its support
for editing the
data model in a more visual fashion.
A powerful refactoring feature is the ability to extract nested anonymous JSON Schema
types into
named top level types. This facilitated a very quick first pass at extracting common
types from multiple
resources.
Having named top level types instead of anonymous sub types translated into Java Classes
cleanly.
Reverse Engineering an Open API Document
It would have been very convenient if the pivotal API exposed an OpenAPI interface,
the tool-kits used
most likely have the capability, or a OpenAPI document manually created. This would
have provided generation of
documentation for the API including the complete schema for the data model as well
as enabling creation of
client API's in nearly any language by the consumer.
Instead, I attempted an experiment to see how difficult it is to reverse engineer
an open API document
from the behavior of the API. From that, the remaining tasks would be fairly simple.
To construct an Open API document requires a few essential components.
Declaration of the HTTP endpoint, methods, resource URI pattern and HTTP response.
These were all documented to sufficient detail to easily transcribe into OpenAPI
format.
A JSON Schema representation of the object model for each endpoint. The specifications
allow this to
be omitted by simply using ANY.
But the usefulness of ANY is None.
A shared ‘definition’ schema to allow for reuse of schema definition within a single
endpoint and
across endpoints.
The representation of JSON Schema in OpenAPI is a subset of the full JSON Schema plus
a few optional
extensions. Otherwise it can literally be copy and pasted into a standalone JSON Schema
document, or you can
reference an external JSON Schema. There are several good OpenAPI compatible authoring
and design tools
available, open source and commercial. These can be used for authoring JSON Schema
directly.
The Open API Document format itself is fully supported in both JSON and YAML formats.
This allows you to
choose which format you dislike least. The transformation from JSON to YAML is fully
reversible, since JSON is a
subset of YAML and OpenAPI only utilize JSON expressible markup. Available tools do
a fairly good job of this,
with the exception of YAML comments and multi-line strings. The former have no JSON
representing so are lost and
the later have to many representations so get mangled. That can be worked around by
adding comments later or by
a little human intervention.
To validate that there was no hidden dependence on specific implementation and that
it didn’t require a
great deal of software installation or expert knowledge, I picked a variety of tools
for the purpose ad-hoc
and generally used web sites that had online browser based implementations.
The Pivotal api has several useful top level endpoints exposing different paths to
the same data. To reuse
the schema across endpoints and to reduce redundancy within an endpoint, the definitions
feature of OpenAPI
was used. This required assigning type names to every refactored schema component.
Since JSON document
instances have no type name information in them, every extracted type would need to
be named. Using the
OpenAPI editors, some amount of refactoring was possible, producing automatically
generated names of dubious
value since there is no constraint that the schema for one fields value is the same
as another filed of the
same name. Identifying where these duplicate schema components could be combined into
one and where they were
semantically different was aided by the prior analysis of the data set.
I made use of several API IDE’s that were not OpenAPI native but did provide import
and export of Open
API. There was some issue with these where the import or export was not fully implemented.
For example the
extend type annotations in OpenAPI were unrecognized by the tools and either discarded
or required changing to
the basic JSON Schema types or their proprietary types. Enumerations and typed strings
were the most
problematic. I have since communicated with the vendors and some improvements been
made. I expect this to be
less of an issue over time.
The availability of tools that can convert between JSON Schema and Java Classes allows
for the use of Java
IDE’s to refactor JSON Schema indirectly.
Of course all the representations of data, schema, java source and API Specifications
were in plain text,
which any text editor accommodated.
The result was an interactive process of exploration and convenience switching between
different editing
environments fairly easy. Use of scripting and work-flow automation would have improved
the experience, but was
not necessary.
Validation
There are multiple OpenAPI Validation implementations. There is no specification of
validation itself in
OpenAPI which lead to differences in results. Difference in indication of the exact
cause and location
varied greatly. Some tools support semantic validation as well as schema and syntax
validation.
The ability to directly execute the API from some tools is a major feature that allowed
iterative
testing during editing and refactoring.
Code Generation
Code generation of client side API invocation in multiple languages provided a much
better validation
due to the data mapping involved. An incorrect schema would usually result in an exception
parsing the
response into the generated object model instances. Scripting invocation of the generated
application code
allowed testing across a large sample set then easily done interactively.
Particularly useful was the ability to serialize the resulting object back to JSON
using the generated
data model. The output JSON could then be compared against the raw response to validate
the fidelity of the
model in practice. It’s not necessary or always useful for the results to match exactly.
For example renaming
of field names, collapsing redundant structure, removal of unneeded elements can be
the main reason for
using the tools. I found it easier to first produce and validate a correct implementation
before modifying
it to the desired model, especially since I didn’t yet know what data was going to
be needed.
Refactoring JSON Schema via Java Class Representation
Tools to convert between JSON Schema and Java Classes are easily available. Typically
used for Data
Mapping and Serializing Java to and from JSON, they work quite well as a schema language
conversion.
A Java Class derived from JSON Schema preserves most of the features of JSON Schema
directly as Java
constructs. The specific mapping is implementation dependant, but the concept is ubiquitous.
Once in a Java
Class representaiton common refactoring functionality present in modern Java IDE's
such as Eclipse are
trivial. For example the result of extracting anonymous types into named types in
Restlet Studio resulted in a
large number of synthetic class names such as "links_href_00023". Renaming a class
to something more
appropriate could be done in a few seconds including updating all of the references
to it. Duplicate classes
of different names can be easily consolidated by a similar method. Type constraints
can be applied by
modifying the primitive types. For example where enumerated values are present but
the JSON to JSON Schema
conversion did not recognize them, the fields were left as 'string' values. These
could be replaced by Java
Enum classes. Fields can be reordered or removed if unneeded.
Overlapping types can sometimes be refactored into a class hierarchy or encapsulation
to reduce
duplication and model the intended semantics. Mistakes are immediately caught as compile
errors.
Since the IDE itself is not aware that the source of the classes was from JSON Schema
it will not
prevent you from making changes that have an ill-defined or non-existent JSON Schemea
representaiton, or one
that the conversion tool does not handle well. Several iterations may be necessary
to produce the desired
output.
Converting back from Java classes to JSON Schema preserves these changes allowing
one to merge the results back into the OpenAPI document.
Refactoring by API Composition
No amount of schema refactoring and code generation could account for the expanded
entities that spanned
API calls. The Open API document has no native provision for composition or transformation
at runtime. That
required traditional programming.
Once I had a working and reasonable OpenAPI document model and validated it across
a large sample set, I
then took exited the OpenAPI ecosystem and proceeded to some simple program enhancements.
The REST API was now
represented as an Object model, with an API object with methods for each REST endpoint.
From this basis it was
simple to refactor by composition. For example to expand a partially exposed resource
into the complete form
required either extracting the resource id and invoke a call in its respective endpoint
method, or in
dereferencing its ‘self’ link. The later actually being more difficult because the
semantics of the link was
not part of the data model. The resource ID was not explicitly typed either but the
generated methods to
retrieve a resource of a given type were modeled and provided static type validation
in the form of argument
arty and return type.
This is a major difference from using a REST API in a web browser. The architecture
and style impose a
resource model and implementation that is not only presentation oriented but also
browser navigation and
user interaction specific. This is explicitly stated as a fundamental architectural
feature highlighting the
advantage of media type negation for user experience.
End Application
To complete the application I added a simple command line parser and serialize. This
completed the
experiment and validated that the process is viable and useful. This also marked the
beginning. I could
invoke the API, retrieve the data in multiple formats reliably, optimize and compose
queries in a language
of choice and rely on the results.
Figure 14: A simple command line application
I could now begin to ask the question I started with. What are the transitive set
of digital artifacts
of the latest version of a software product?
Left as an exercise for the reader.
Reverse Engineering, Refactoring, Schema and Data Model Transformation Cycle.
Figure 15: A Continuous Cyclical Transformation Workflow
A flow diagram of the process described. Wherever the path indicates a possible loop
implies that an iterative
process can be used. The entire work-flow itself is iterable as well.
Since the work-flow is continuously connected including the ability to generate a
client or server API, any step
in the process can be an entry or exit point. This implies that not only can you start
at any point and
complete, but that any subset of the process can be used to enable transformations
between the respective
representations of the entry and end nodes in isolation.
REST API to JSON Document
Invoke REST API producing a JSON Document
API ‘Crawling’
Automated exhaustive search of API resources over hypermedia links.
Producing a representative sample set of JSON Documents
JSON to JSON Schema
JSON samples to JSON Schema automated generation.
JSON Schema to Open API Documents
Enrich JSON Schema with REST semantics to create an Open API Document.
( JSON or YAML)
Open API IDE
Cleanup and refactoring in Open API IDE's.
Open API to JSON Schema
Extract refactored JSON Schema from Open API
JSON Schema to Java Class
JSON Schema to Java Class automated generation.
Produces self standing Java source code.
Java IDE
Java IDE with rich class and source refactoring ability.
Refactor Java Class structure using standard techniques.
Enrich with Annotations
Produces refined and simplified Java Classes
Java Source to JSON Schema
Automated conversion of Java source to JSON Schema
Merge new JSON Schema to Open API
Merge Refactored JSON Schema back into Open API Document (JSON or YAML)
Open API IDE
Cleanup and refactoring in Open API IDE's.
Open API to JSON Schema
Extract JSON Schema from Open API
Iterate 6-11 as needed
Code Generation
Open API code generation tools to source code.
Optional customization of code generation templates to apply reusable data mapping
annotations
Documentation Generation
Open API to complete documentation, any format.
Generated Code to Application
Enrich and refactor generated code with Data Mapping annotation to produce custom
data model
preserving the REST interface.
Augment with business logic to produce custom application based on underlying data
model
directly.
Custom Application
Application operates on custom data model directly; data mapping converts between
data models and
generated code invokes REST API.
Output multiple markup formats
Side effect of open API tools and Data Mapping framework automate serialization to
multiple formats.
(JSON, XML, CSV)
Application to Open API
Generated code includes automated output of OpenAPI document at runtime, incorporating
any changes
applied during enrichment.
[2] WSDL, SOAP, JAXB, JAXP, J2EE are part of a large collection of related specifications
loosely comprising the industry standard for web services predominant in the 2000-2010
era.
[3] XMLRPC: An early HTTP remote procedure call specification using an XML body. XML-RPC