Murray, Gregory. “XQuery is not (just) a query language: Web application development with XQuery.” Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington, DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18 (2016). https://doi.org/10.4242/BalisageVol18.Murray01.
XML In, Web Out: International Symposium on sub rosa XML August 1, 2016
Balisage Paper: XQuery is not (just) a query language: Web application development with XQuery
Gregory Murray
Director of Academic Technology and Digital Scholarship Services
Greg Murray has worked in web development and XML processing for 16 years, mainly
in
academic libraries. He is currently a project manager (who still codes as much as
possible) helping develop web applications built with XQuery and MarkLogic Server
for
search and display of digitized library materials.
XQuery is widely known as a query language for XML, but it’s also a full-fledged,
functional programming language which, with a limited number of implementation-provided
extensions, can serve in a web development context as both the query language and
the
programming language. When you have data in XML form that needs to be delivered in
some way
on the web, using XQuery as the server-side programming language has significant practical
advantages. After briefly describing those advantages, this paper will lay out techniques
for developing web applications in XQuery—techniques that will reduce complexity and
help
developers produce well-organized, testable, portable code that will be comparatively
easy
to build upon and maintain over time. Topics include using MVC, keeping functions
testable,
and facilitating code portability by using available standardizations like RESTXQ
and by
isolating implementation-specific functions into separate modules.
XQuery is widely known as a query language for XML. In the domain of web application
development—where the classic technology stack is a relational database accessible
via SQL
paired with one of several popular programming languages (Java, .NET languages, Perl,
PHP,
Python, Ruby, etc.)—there is far less awareness that XQuery is actually a full-fledged,
functional programming language. Even less recognized is the fact that XQuery, with
a limited
number of implementation-provided extensions, can serve in a web development context
as both
the database query language and the server-side programming language. When describing
XQuery
to web developers or project managers accustomed to the classic technology stack,
it is
tempting to define XQuery in a way that someone in that context can easily latch onto:
XQuery
is to XML databases as SQL is to relational databases. This commonplace analogy seems
harmless
enough initially, but it is actually misleading and counter-productive if it is not
immediately qualified and expanded. Defining XQuery as a query language for XML is
the truth
but not the whole truth. When you have data in XML form that needs to be delivered
in some way
on the web, using XQuery as the server-side programming language has significant practical
advantages. After briefly describing those advantages, this paper will lay out techniques
for
developing web applications in XQuery—techniques that can reduce complexity and help
developers produce well-organized, testable, portable code that will be comparatively
easy to
build upon and maintain over time.
Advantages of XQuery for web delivery of XML content
XQuery is specifically designed to work hand-in-glove with XML data natively. There
is no
need to provide a mapping between the data and the programming language, such as the
“object-relational mapping” that is inherently necessary when working in an object-oriented
programming language in conjunction with a relational database. In fact, the need
for such a
mapping is not limited to relational data; an analogous kind of mapping—let’s call
it an
“object-document mapping”—is equally necessary when using an object-oriented language
to work
with data in XML form. Whether relational or XML-based, the data model still has to
be
translated or mapped to the facilities and affordances of the programming language.
The one is
not inherently designed to work with the other, and in fact the data and the language
collide
in a “clash of paradigms” (Seiferle, p. 20), resulting in the so-called
“impedance mismatch” (Kaufmann, §1; Seiferle, p. 20-21).
This gap between the data and the language must be bridged, adding a layer of complexity
to
the technology stack of the web application. With XQuery, there is no data-language
gap and
therefore no bridge.
If you don’t need a bridge, then you don’t need a web development framework (Ruby
on
Rails, CakePHP, Django, etc.) to provide it. Although such frameworks usually provide
services
in addition to object-relational mapping (scaffolding, templating, etc.; Seiferle, p. 3-4), all things considered, eschewing these frameworks actually
provides real advantages by entirely sidestepping layers of complexity that frameworks
can
only hide, not eliminate (Seiferle, p. 22). Not only do such frameworks lock
developers into the assumptions and requirements the framework espouses, they also
invariably
evolve over time, sometimes rapidly. Sooner or later it becomes necessary to upgrade
the
framework itself, either because there is a compelling reason (such as a new feature
or a
needed bug fix) or because there is an absolute necessity (such as a show-stopping
incompatibility between the framework and a change to the environment, like a newer
version of
the database server, programming language or operating system). The inherent technological
complexity and multiple moving parts of any given web development framework can end
up putting
developers into a hamster’s wheel of release notes, upgrades, deprecated features,
and
incompatibilities—all of which add up to time spent on mere maintenance rather than
intentional refactoring or development of new or improved functionality. By contrast,
the core
XML-related specifications—including XQuery and its accompanying and supporting specs—have
proven exceptionally stable. Their evolution has been characterized not only by infrequent
updates but also by a high degree of backward compatibility.
The differences between these technology stacks have concrete, real-world consequences.
Using a language designed for the data it is working with, thereby avoiding “the technology
jungle of mixing different technologies and data models” (Kaufmann, §7),
prevents a good deal of mundane work and frees developers to focus on the domain and
goals of
the application rather than an ever-changing web development environment.
Techniques for web application development with XQuery
Utilizing MVC
Despite the drawbacks of web development frameworks just described, there is one common
feature that is just as relevant for XQuery web development as for any other language:
the
utilization of MVC (model, view, controller). There are countless readily available
resources of varying depth, from books to blog posts, that describe MVC, including
and
especially in the domain of web application development, where the use of MVC has
become
wildly popular since the advent of Ruby on Rails. The problem is that as a concept
MVC is
general and flexible enough to allow many possible variations when the concept is
put into
practice. Various methodologies have proliferated, leaving the whole idea of MVC seeming
rather arcane to the uninitiated—and to the initiated, for that matter. (As the adage
goes,
ask five web developers how they use MVC and you’ll get six different answers.) MVC
is
commonly called an “architecture,” but that term is already overburdened and therefore
unilluminating. However, much of this confusion is unnecessary, because in its essence
MVC
is just a technique for organizing code, with the principal goal being the classic
“separation of concerns” whereby presentation code has no knowledge of how data is
stored
and accessed, and database-related code has no knowledge of how data is presented
to the
user.
If for now we set aside the variations and elaborations of MVC, a few core principles
remain. Models understand how data is represented (modeled) and handle database interaction.
Views construct the presentation of data to the user. Controllers receive input and
respond
accordingly, utilizing models and views to do so.
Admittedly this (deliberately minimal) definition leaves out some important decisions.
Any non-trivial web application will need multiple views, but some variations of MVC
allow,
or even require, multiple controllers or multiple models. Other methodologies differ
as to
which MVC component(s) can or cannot call upon the model for database interaction.
Some web
development frameworks, and indeed some web developers themselves, can be quite puristic
about these differentiations, but stridency in this context is unhelpful. How exactly
to
organize code within an MVC approach should be based more on the nature and goals
of a
particular web application than on abstract principles. A more complex application
may merit
a more complex use of the MVC components. This is not to say that we should be lax
or
inconsistent in our implementation of MVC, only that we should select an MVC methodology
based on practical considerations. To get started with MVC, there is nothing wrong
with
having one controller and one model, along with a view for each main kind of HTTP
response
the application provides.
The modular nature of XQuery lends itself easily and directly to the MVC concept.
Each
model, view, and controller is implemented as an XQuery library module.
Model
The model is responsible for interacting with the database; no other component should
create, read, update or delete data (think “no CRUD outside the model”). In this sense
it
acts as a kind of API (or like an encapsulated object, in object-oriented terms),
which
other modules call upon without needing to know anything about the database or how
to
interact with it. Ideally this separation of concerns is enforced to the point that
one
could swap out the underlying database server for a different one without touching
any
code in the controller(s) or views. (Conversely, we should be able to overhaul the
presentation or adjust business logic without touching any code in the model(s).)
However, in the context of this discussion, in which data is in XML form, there is
an
important additional consideration. We have to decide whether the model should not
only
handle all database interaction but also handle all navigation of the structure of
the XML
documents, which is to say, whether only the model should contain XPath expressions.
This
decision is essentially a question of how strictly we want to separate knowledge of
the
document structure from the knowledge of how the document content should be formatted
and
presented. For example, let’s say we have this kind of markup, containing information
about a book:
Let’s also assume that since the model handles database interaction, we have set up
a
function named get-xml-doc in the model to retrieve from the database any
given XML document in its entirety, given its unique identifier. To get values such
as
book title and author name that we need to display, one option is to allow the
presentation code to have knowledge of the document structure and grab the data directly:
import module namespace m = "http://balisage.net/ns/Bal2016murr0319/model" at ... ;
...
let $doc := m:get-xml-doc("ab1geschichtedes03gind")
let $title := fn:string($doc/doc/metadata/title)
let $name := fn:string($doc/doc/metadata/name)
Alternatively we can require the model alone to have knowledge of document structure
and
provide functions for retrieving the data from the model. If the model has these
functions:
module namespace m = "http://balisage.net/ns/Bal2016murr0319/model";
(:~ Returns the book title as a string. :)
declare function m:get-title($doc as document-node())
as xs:string
{
fn:string($doc/doc/metadata/title)
};
(:~ Returns the author name as a string. :)
declare function m:get-name($doc as document-node())
as xs:string
{
fn:string($doc/doc/metadata/name)
};
then the presentation code doesn’t need to carry any knowledge of the document structure:
import module namespace m = "http://balisage.net/ns/Bal2016murr0319/model" at ... ;
...
let $doc := m:get-xml-doc("ab1geschichtedes03gind")
let $title := m:get-title($doc)
let $name := m:get-name($doc)
In an example this simple, the difference is trivial, but in a real-world web application
the XPath expressions will likely be more elaborate as well as broadly distributed
throughout a sizable body of presentation code spanning multiple XQuery modules. Moreover,
the same XPath expressions will typically be needed more than once throughout the
presentation code. Abstracting knowledge of the markup into the model enforces a stricter
separation of concerns. With this approach, if the markup schema changes, only the
model
would need to be refactored, since knowledge of the markup is confined to the
model.
As mentioned above, there is nothing inherently wrong with having a single model for
a
given web application, but there are some use cases for separating database-related
code
into multiple models. In situations where a web application needs to work with documents
in multiple XML markup languages, it might make sense to have a different MVC model
(that
is, a discrete XQuery module) for each document type. Similarly, if an application
includes full-text searching capability, it is logical to group search-related functions
into a separate model. This is especially true if your chosen implementation provides
its
own functions for searching (as opposed to implementing the W3C XQuery Full-Text
recommendation), so that in addition to improving code organization per se the
search-specific model is isolating implementation-defined functions, to improve code
portability and sharing (more on this below).
View
The role of the view is to provide the presentation, whether for human- or
machine-readability. For example, a very commonplace pattern (used by all manner of
web
applications from Amazon to Zappos) is to provide searching, leading to search results,
leading to an item-level page showing all relevant information for a particular item.
In
this approach, the home page containing the search form, the search results page,
and the
item-level page are separate views, each one implemented as its own XQuery library
module
(all of which could be grouped in a single views directory). In a web
application designed for display in a browser, most views will return an HTML document,
whereas a web service might return data as JSON or XML, which is nonetheless a
view.
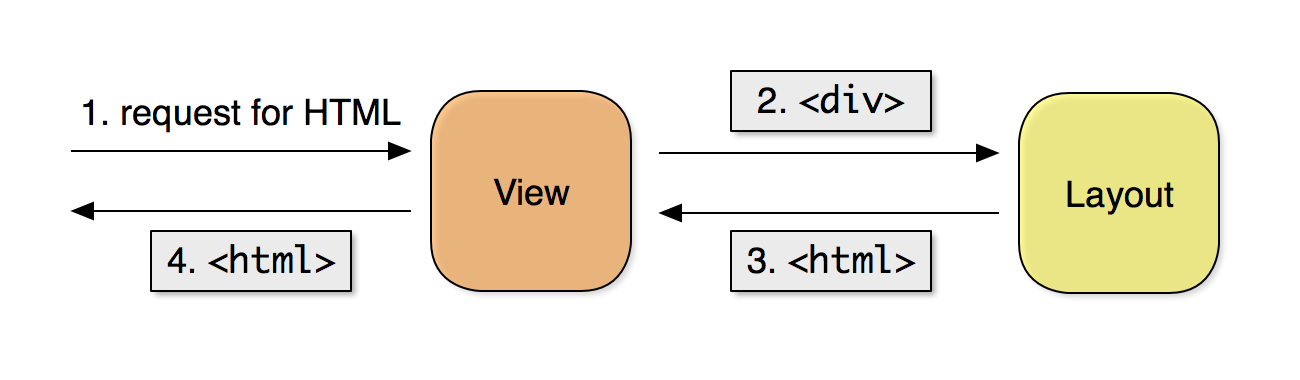
Because most web-based user interfaces are designed with shared components such as
headers, sidebars and footers, it makes sense to have an XQuery module that serves
as a
“layout” (or to have multiple layout modules, if more than one page layout is needed
within the same application). In this scenario the view constructs one or more HTML
elements constituting the main content of a page, then passes the element(s) (such
as a
<div>) to a function in the layout module, which returns a complete HTML document
with the main content inserted in the appropriate place within the encompassing page
layout. The view then returns the complete HTML document.
Figure 1
Figure 1: A view utilizing a layout to return a complete HTML document
Controller
The controller is responsible for receiving user input and responding accordingly.
It
“controls” what happens in response to input and how the model(s) and views are involved
in that process. In a web application context, the controller accesses the input from
the
HTTP request (URL parameters, form data, request headers, cookies) and then calls
the
appropriate view, as indicated by those input values. Since the XQuery language doesn’t
provide built-in functions for such HTTP-specific matters, the implementation must
supply
them, but multiple widely adopted implementations do so. (We will look at some practical
examples in BaseX and MarkLogic below.)
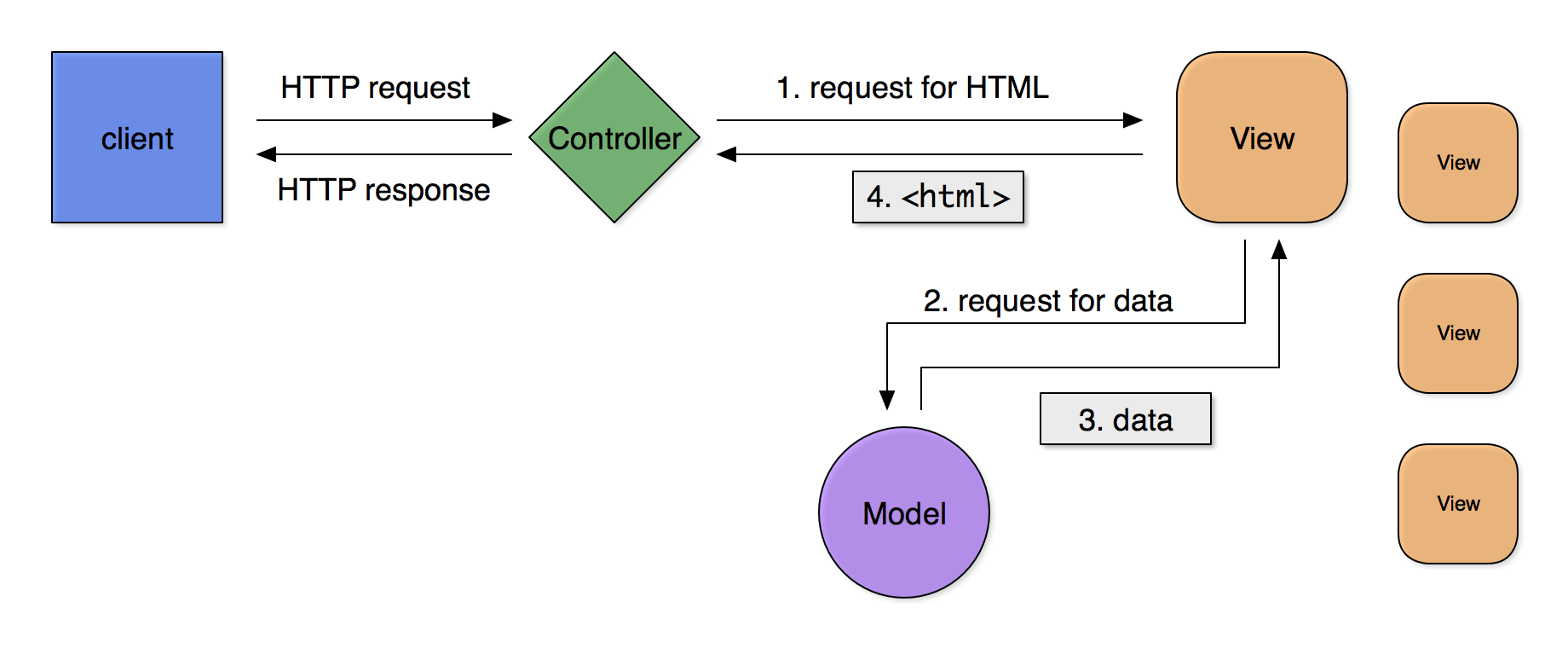
Some variations on MVC assert that only the controller should call upon the model
to
retrieve data, after which the controller passes that data to a view, such that a
view
never interacts directly with the model.
Figure 2
Figure 2: First option: only the controller calls the model
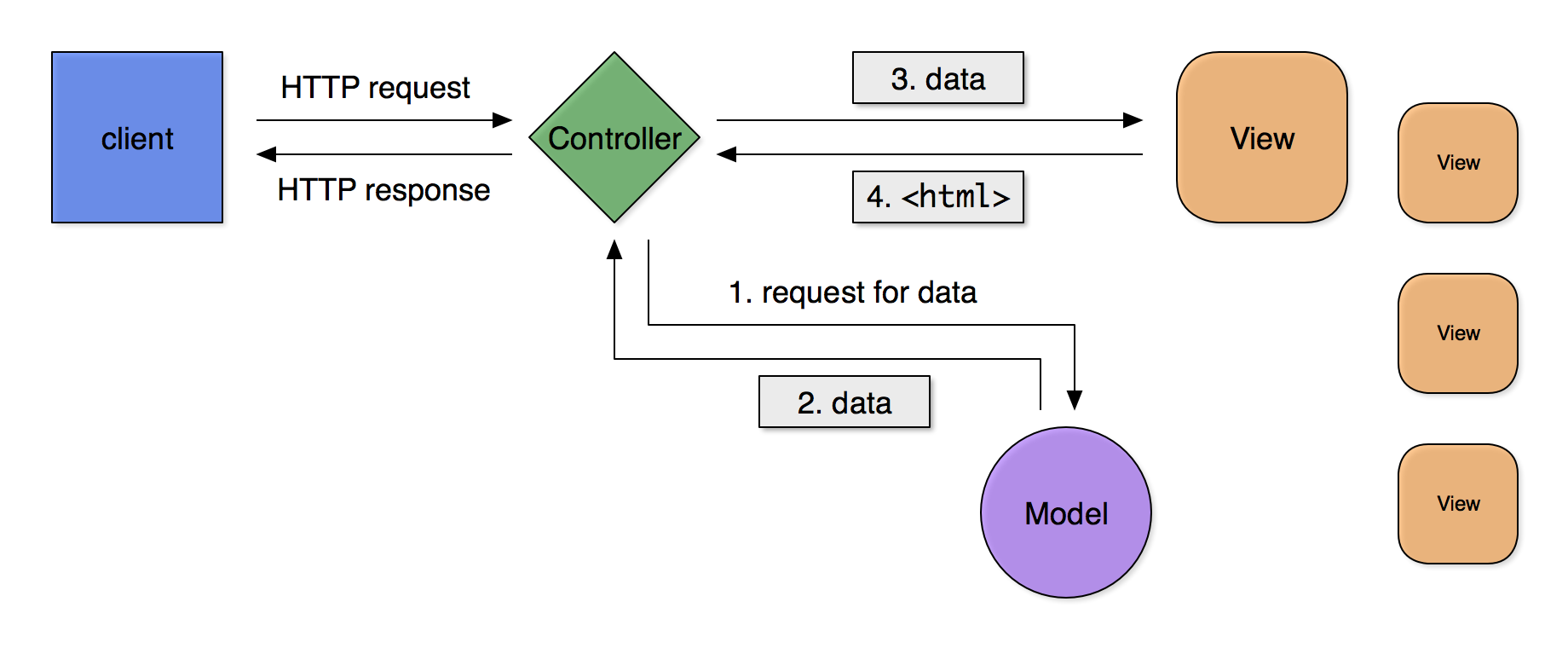
Other MVC variants allow the knowledge of what data is needed by a given view to reside
in
the view itself, giving it the authority to call the model to get the data it needs
to
construct a fully formed presentation of that data.
Figure 3
Figure 3: Second option: any given view can call the model
Each approach has its justifications. Each adheres to the principle of the separation
of
concerns, but in the former method the controller carries the knowledge of what data
is
needed for each view, while in the latter method the view itself holds that knowledge.
In
other words, in the first approach the controller is more controlling, and in the
second
the view is more autonomous and self-aware. (My own preference is for the latter,
because
it seems reasonable for the view to know what data it needs to display, and because
allowing only the controller to request data from the model seems arbitrary. However,
I’m
only speaking here of retrieving data; when creating/updating/deleting data in the
database, the data can and should pass directly from the controller to the model for
the
insert/update/delete operation, after which the controller calls a “confirmation page”
or
other appropriate view.)
Ancillary modules
In addition to the core MVC components, additional specialized XQuery library modules
are often helpful. A module that acts as a “config file” of global variable declarations
allows easy management of settings that might change later or might be needed by multiple
modules. Conversely, a “utility” module containing general-purpose, shared functions
provides convenience and reduces code duplication. In more complex applications, shared
functions that pertain to a particular problem domain or MVC component can be grouped
and
separated into discrete utility modules.
Keeping functions testable
As shown in Figures 2 and 3 above, when responding to
an HTTP request using XQuery and MVC, the chain of processing forms a loop in which
the
request is routed to the controller, which calls a view, which constructs a fully
formatted
representation and returns it to the controller, which returns the HTTP response.
Throughout
this loop, there will be decision points where a given function in a given module
must have
access to the input values from the HTTP request to make decisions and take actions
accordingly. For example, a “search results” view needs to know how the user wants
the
results sorted, how many results to display at a time, and so on, which can only be
known by
checking the input from the HTTP request. How best to make those values available
throughout
the codebase is not inherently obvious. One option is simply to call the
implementation-provided functions for accessing these input values wherever such a
value is
needed. For example, given a URL ending with ?id=abc123 we could do the
following:
(: MarkLogic example :)
let $id := xdmp:get-request-field("id")
(: BaseX equivalent of preceding example :)
import module namespace request = "http://exquery.org/ns/request";
...
let $id := request:parameter("id")
This approach has a major disadvantage: it leaves implementation-specific function
calls
strewn throughout the codebase, inhibiting code portability and sharing (more on this
below).
A less haphazard technique would be to assign the input values to variables using
global
(prolog-level) variable declarations in a library module, which could then be imported
by
any controller or view that needs to access those input values. This module would
be similar
to the “config file” module mentioned above, but instead of
supplying predefined values it would provide values retrieved dynamically from the
HTTP
request. Let’s call it the “parameters” module.
(: MarkLogic example :)
(: in the "parameters" module, we put the "id" value in a global variable :)
module namespace params = "http://balisage.net/ns/Bal2016murr0319/parameters";
declare variable $id as xs:string? := xdmp:get-request-field("id");
To access those values elsewhere in the codebase, we would simply import the parameters
module and reference the relevant variable.
(: in the item-level view, we use the previously defined global variable :)
import module namespace params = "http://balisage.net/ns/Bal2016murr0319/parameters" at "parameters.xqy";
...
let $id := $params:id
This technique seems reasonable enough and avoids repetitive, dispersed
implementation-specific function calls. However, it doesn't solve a deeper problem:
functions that access such global variables cannot be independently tested. Unit
testing—whereby a single unit of code is tested in isolation from the rest of the
program in
a deliberately controlled environment, using sample data—is a common and highly advisable
practice across many programming domains and languages. In a functional programming
language
like XQuery, the logical code unit for testing is the function. If a function relies
on a
global variable containing a value taken from the HTTP request, and if that function
gets
called (for testing purposes) outside the context of any HTTP request, the value of
the
global variable will always be empty. Therefore, we have no way to verify the real-world
behavior of the function.
This problem can be avoided by providing a function in the controller (since the
controller is responsible for receiving user input) that accesses URL parameters or
other
input values and adds them to an XQuery map (a set of key/value pairs, often called
a hash
or associative array in other programming languages). The controller can then pass
that map
to any given view, and each view in turn can pass the map to any functions that need
user
input values to make determinations about what data is needed, how to format it for
display,
or other such internal
decisions.
(: BaseX example :)
(: In the controller ... :)
module namespace c = "http://balisage.net/ns/Bal2016murr0319/controller";
import module namespace request = "http://exquery.org/ns/request";
import module namespace item = "http://balisage.net/ns/Bal2016murr0319/views/item" at "views/item.xqm";
(:~ Returns a map containing the HTTP request parameters. :)
declare function c:http-params()
as map(*)
{
map:merge(
for $name in request:parameter-names()
let $value := request:parameter($name)
return map:entry($name, $value)
)
};
(:~ Calls the appropriate view, based on user input. :)
declare function c:get-view()
as element(html)
{
(: get HTTP request parameters :)
let $params := c:http-params()
return
if (map:get($params, "id")) then
(: the presence of "id" indicates that the user is requesting the item-level page for this unique identifier :)
(: call the item-level view :)
item:get-html($params)
else if ... (: call some other view :)
else if ... (: call some other view :)
else (: call the view for the home page ... :)
};
(: In the item-level view ... :)
module namespace item = "http://balisage.net/ns/Bal2016murr0319/views/item";
(:~ Returns a complete HTML document for displaying a given item. :)
declare function item:get-html($params as map(*))
as element(html)
{
let $id := map:get($params, "id")
(: build an HTML document for displaying this item, passing $params to other functions as needed ... :)
(: return HTML ... :)
};
To test any given function artificially, outside the context of an actual HTTP request,
we
can simply construct a map containing sample input and pass it to the function being
tested.
(: In the testing module ... :)
import module namespace item = "http://balisage.net/ns/Bal2016murr0319/views/item" at "../views/item.xqm";
let $params := map {
"id": "abc123"
}
let $html := item:get-html($params)
(: Now we can verify the HTML returned by item:get-html ... :)
Improving code portability and sharing
As mentioned above, running a web application written in XQuery requires
implementation-specific extensions—not necessarily to the language itself, but to
provide
functions specific to the HTTP context, for such things as accessing URL parameters
of GET
requests and setting HTTP response headers. As a result, one’s codebase can quickly
become
peppered with implementation-specific function calls, resulting in code that not only
requires extensive refactoring to port a web application from one XQuery implementation
to
another, but also inhibits sharing code with others, thereby promoting fragmentation
within
the XQuery community (Retter, §1.2). There are, however, some techniques
that help alleviate this problem.
Using available standardizations
One such technique is to utilize what standardizations are available for XQuery web
application development. The EXQuery organization (exquery.org) has proposed several specifications for standardizing functionality
across XQuery implementations. Some of these proposals are specific to XQuery web
application development, and of these the most widely implemented is RESTXQ. Proposed
by
Adam Retter in 2012, RESTXQ utilizes XQuery 3.0 annotations to associate URLs with
XQuery
functions (Retter). In other words, RESTXQ standardizes URL rewriting,
the process whereby a clean, user-friendly URL accessed by the user (or by a program
accessing a web service such as a REST API) is translated into a different URL that
is
actually used by the web application behind the scenes. More accurately, RESTXQ doesn't
standardize URL rewriting so much as obviate the need for it altogether; instead of
rewriting URLs from user-friendly to code-friendly, RESTXQ maps URLs to XQuery
functions.
For example, returning to the commonplace behavior described above whereby a web application performs a search, leading to search results,
leading to an item-level page for each result, let’s say that any given item-level
page is
indicated by a URL in the format /id/abc123 where abc123 is a
unique identifier for a particular item. In an implementation that supports URL rewriting,
such as eXist or MarkLogic (Retter, §3.1.2 and §3.2.2), we could take
/id/abc123 and translate it to ?id=abc123 before handing it off
to the XQuery processor, so that id is available as an HTTP request parameter
name.
(: MarkLogic example :)
let $url:= xdmp:get-request-url()
let $regex-id := "/id/(.+)/?"
return
if (fn:matches($url, $regex-id)) then
(: extract identifier :)
let $id := fn:replace($url, fn:concat("^.*", $regex-id, ".*$"), "$1")
(: replace "/id/whatever" with "/" (implying "/default.xqy") and append "id=whatever" as a URL parameter :)
let $separator := if (fn:contains($url, "?")) then "&" else "?"
let $start := fn:replace($url, $regex-id, "/")
return fn:concat($start, $separator, "id=", $id)
(: else if ... :)
(: else if ... :)
else $url
Such URL rewriting code tends to be idiosyncratic and cumbersome, “creating a spaghetti
of
if/else statements” (Retter, §3.2.2). With RESTXQ, by contrast,
/id/abc123 can be simply and directly associated with a function, like so:
(: BaseX example :)
declare
%rest:path("/id/{$id}")
function c:get-item-view($id as xs:string)
{
(: the variable $id has the value "abc123" :)
...
};
The RESTXQ approach is concise and straightforward, and it locates the URL mapping
code at the function declaration itself (not in a separate “rewrite engine” module),
leading to code that is easier to read and maintain. RESTXQ is supported in BaseX,
eXist,
and MarkLogic (Walmsley, p. 430), making it effectively a de facto
standard. As a result, the code is portable across multiple implementations and shareable
among developers and projects.
The use of RESTXQ can easily be incorporated into an MVC approach to code organization
by adding RESTXQ annotations to functions in the controller (since the controller
receives
input from the HTTP request and takes action accordingly). Fleshing out the preceding
example a little more:
(: BaseX example :)
module namespace c = "http://balisage.net/ns/Bal2016murr0319/controller";
import module namespace item = "http://balisage.net/ns/Bal2016murr0319/views/item" at "views/item.xqm";
declare
%rest:path("/id/{$id}")
%output:method("html")
%output:version("5.0")
function c:get-item-view($id as xs:string)
as element(html)
{
(: the variable $id has the value "abc123" :)
(: call the item-level view :)
item:get-html($id)
};
Isolating implementation-specific functions
The main barrier to code portability across implementations and code sharing across
the XQuery web development community is the necessity of implementation-provided
functions. One technique to alleviate this problem is to abstract and isolate such
functions. This goal can be achieved by creating one or more library modules containing
generically named functions that internally utilize the corresponding
implementation-specific functions. Then, throughout the codebase, whenever
implementation-provided functionality is needed, we simply call the applicable generic
function instead of the implementation-specific one. This approach creates a layer
of
abstraction, separating and hiding implementation-dependent code from the rest of
the
codebase. For example, we could create an “implementation” module and set up a generically
named function for converting HTTP request parameters to an XQuery map, as shown above
in
a previous code example. Such a module written for BaseX would look like this:
xquery version "3.1";
(: BaseX example -- this module's filename is implementation-basex.xqm :)
module namespace imp = "http://balisage.net/ns/Bal2016murr0319/implementation";
import module namespace request = "http://exquery.org/ns/request";
declare function imp:http-params()
as map(*)
{
map:merge(
for $name in request:parameter-names()
let $value := request:parameter($name)
return map:entry($name, $value)
)
};
The same functionality written for MarkLogic would look like this:
xquery version "1.0-ml";
(: MarkLogic example -- this module's filename is implementation-ml.xqy :)
module namespace imp = "http://balisage.net/ns/Bal2016murr0319/implementation";
declare function imp:http-params()
as map:map
{
let $map := map:map()
let $empty :=
for $name in xdmp:get-request-field-names()
let $value := xdmp:get-request-field($name)
return map:put($map, $name, $value)
return $map
};
Elsewhere in the codebase, whenever a map of HTTP parameters is needed, we can import
the
module appropriate to our current implementation and call the generically named function,
imp:http-params(), rather than calling the implementation-specific function
directly:
(: BaseX example :)
module namespace c = "http://balisage.net/ns/Bal2016murr0319/controller";
import module namespace imp = "http://balisage.net/ns/Bal2016murr0319/implementation" at "implementation-basex.xqm";
(: somewhere in some function ... :)
let $params := imp:http-params()
To target MarkLogic, the controller code would be identical except that the filename
would
be implementation-ml.xqy for the module import. Each “implementation” module
acts as a kind of API for the rest of the web application code, such that we can change
the underlying implementation without changing the outward-facing interface of the
API.
With this technique, sharing XQuery code from this web application with an individual
or
project using a different XQuery implementation, or even porting the entire application
to
a different implementation, could potentially only require swapping out one
“implementation” module for another. Such a module could, of course, be utilized across
multiple applications, rendering more and more of one’s code
implementation-independent.
Conclusion
When you have XML content that needs to be presented on the web, developing web
applications with XQuery has notable advantages over the traditional technology stack
and its
accompanying web development frameworks. The techniques for web application development
with
XQuery described here are straightforward to apply, but they can have powerful and
wide-ranging effects on the resulting code, leaving it more organized, readable, maintainable,
testable, portable, and shareable.