Jett, Jacob, Timothy W. Cole, David Dubin and Allen H. Renear. “Discerning the Intellectual Focus of Annotations.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). https://doi.org/10.4242/BalisageVol17.Jett01.
Balisage: The Markup Conference 2016 August 2 - 5, 2016
Balisage Paper: Discerning the Intellectual Focus of Annotations
Jacob Jett
Jacob is a PhD candidate at the Graduate School of Library & Information Science at
the Univeristy of Illinois at Urbana-Champaign. His research interests include the
conceptual foundations of information access, organization, and retrieval, web and
data semantics, knowledge representation, data modeling, ontology development and
conceptual modeling.
Timothy W. Cole
Tim Cole is the Math Librarian and Professor of LIS at the University of Illinois
at Urbana-Champaign. He is a also a co-chair of the W3C's Web Annotation working group.
His research interests include metadata, linked open data, the annotation of digital
resources, and digital library interoperability.
David Dubin
David Dubin is a research associate professor at the Graduate School of Library and
Information Science at the University of Illinois at Urbana-Champaign. His research
interests include the foundations of information representation and description and
issues of expression and encoding in documents and digital information resources.
Allen H. Renear
Allen Renear is the dean of the Graduate School of Library and Information Science
at the University of Illinois at Urbana-Champaign. His research interests include
information organization and access, particularly the development of formal ontologies
for cultural and scientific objects and the application of those ontologies in information
system design, scholarly publishing, and data curation in the sciences and humanities.
Much attention has been given to strategies for anchoring annotations in digital documents,
but very little to identifying what the annotation is actually about. We may think
of annotations as being about their anchors, but that is not typically the case. Two
annotations may have the same anchor, such as a string of characters, but one annotation
is about the sentence represented by that string and the other about the claim being
made by that sentence. Identifying targets and making this information available for
computational processing would provide improved support for a variety of information
management tasks. We discuss this problem and explore a possible extension to the
W3C Web Annotation Data Model that would help with annotation target identification.
Digital objects such as textual documents may have associated annotations that differ
substantially in the kind of thing they are about. For instance, there may be notes
on formatting (identifying bad line breaks or word spacing), notes on linguistic features
(grammar, word lemmas, etc.) and notes on content (factual corrections, challenges
to the reasoning, etc.). These differences have consequences for subsequent processing.
In a production scenario that reformats a document the linguistic and content comments
might be retained, but comments on formatting are probably no longer be relevant.
If the text is translated into another language then neither the formatting nor linguistic
comments will be carried forward -- but the content comments will still apply and
might be included. Although the management of annotations in document processing and
publishing routinely reflects this differential treatment of annotations, there is
no general theoretical framework that would help us design systems that would support
the general systematic management of annotation propagation.
The issues here are not merely practical problems, but go to the heart of the nature
of annotation, which is itself a fundamental communicative activity in many spheres
of human intellectual life. Annotation is one of the important "primitive" activities
that scholars in many disciplines employ when they pursue a topic of interest [Unsworth 2000]. As more and more of the scholarly process has been enhanced by, and in some cases
migrated to, digital formats the need to create tools that permit scholars to enjoy
the same broad range of primitive activities that they do with physical formats has
become evident. This is especially true of the annotation primitive.
Research on systems and strategies for annotation in the digital environment began
with the early work on hypertext systems in the 1960s and has produced a considerable
body of academic research, experimental systems, as well as some steps towards an
analytical framework [Renear et al. 1999]. With the development of the Web the opportunity for practical annotation systems
began to attract interest in Web-oriented standards and sytems. Beginning in the late
1990s and early 2000s efforts, both large and small, began to coalesce with the ultimate
goal of extending the practice of annotating to digital documents.[1] These efforts were continued by more generalized, community-oriented, collaborator
initiatives such as the W3C Annotea Project[2][3] and more recently the Open Annotation Collaboration (OAC),[4] the Open Annotation Community Group (OACG),[5] and the World Wide Web Consortium (W3C)’s[6] Web Annotation Working Group (WAWG).[7]
While these efforts have been primarily concerned with the production of a technical
standard against which annotation tools and systems can be designed and implemented,
relatively little discussion has been given to the technical standard’s theoretical
underpinnings. In this paper we take up what we believe to be a particularly important
theoretical challenge for any annotation standard or system. In short it is unclear
exactly what is being annotated when we create a digital annotation.
We believe this is an important issue because it isn't clear what should happen to
annotations when the documents they annotate change or go away. Do annotations have
a broader target beyond the particular electronic document to which we anchored them?
For instance if we annotate an article on the CNN website, should that annotation
carry through to other copies of that article that appear on news aggregator websites?
What is it that we are really annotating? When we anchor an annotation by selecting
a string of characters that represents a sentence, are we annotating that string,
the byte sequence that encodes it, the sentence that it represents, or the propositional
content that the sentence communicates? If the only tools that we have to anchor the
substance of an annotation to its target is a selector that chooses a particular string
of text based on the strings immediately preceding and succeeding it, how do we know
whether or not the target of that annotation is the string that it is anchored to.
The W3C Web Annotation Data Model[8] has two relationships, motivation and purpose, that provide some help and orientation in addressing these issues. However those
relationships are not sufficient for supporting the functionality desired. This is
not surprising as target identification is a very difficult problem.
We are proposing to explore a possible third relationship, targetfocus which by providing additional semantic information will bring the W3C Web Annotation
Data Model closer to supporting the reliable identification of annotation targets.
In what follows we first describe the problem in more detail, providing additional
terminology that may be helpful to developing potential solutions. We than illustrate
the difficulties through several worked examples that employ the latest version of
the WAWG’s Web Annotation technical standard which provides a mechanism for anchoring
annotations of a particular representation. It does this through the use of a predicate
"hasTarget", which can be refined through a class called "Selector". We note that
the various kinds of selectors (e.g., "text quote selector", "fragment selector",
etc.) suggest that the focus of the annotation is different than the anchor. Finally
we suggest how an additional predicate, "hasTargetFocus," might be used to extend
the existing technical standard in ways that can better facilitate linking user intentions
regarding the intellectual focus of their annotations and the technological limitations
of anchoring on digital objects.
The Problem
A major challenge in designing standards and systems for annotation is identifying
the "target" of the annotation, that is, what the annotation is about in the sense of: "what is it annotating?." The target of an annotation can be distinguished
from the annotation's anchor. The anchor is, in the typical case of digital documents, a data structure feature
that locates the annotation in some part of the digital object. Although this location
does provide an indication of what the annotation is about it does not do so explicitly
and univocally, and in particular, it does not make this information available for
automated processing.
For example, several annotations anchored to a particular character sequence in a
document could in fact be about quite different things. An annotation anchored in
this way might be about propositional content: this is false; about a linguistic entity: this is in the passive voice; or about a layout feature: this is ugly. In the first case the annotation might be, more specifically, about a particular
claim, in the second case it might be about a sentence, and in the third case it might be about, say, letter spacing.
If an annotation's target cannot be reliably identified the functionality of annotation
standards and systems will be suboptimal. Obviously we will miss opportunities for
information extraction and retrieval, but management, preservation, and interoperability
will be diminished as well. For instance, reformatting should typically retain annotations
such as "this is false" and "this is passive voice", but not "this is a bad break";
while translation should typically retain "this is false" but neither "this is passive
voice" nor "this is a bad break".
Text and entities that contain or bear text frequently operate at multiple levels
of abstraction. Similarly annotations of text may actually be annotating one of these
other abstract entities. An annotation that anchors on a formatted string of text
may actually be annotating any of the following (or other abstract entities beyond
those illustrated here):
the font of the symbols that comprise that formatted string
the syntax of the sentence represented by that formatted string
the propositional content expressed by the sentence represented by that formatted
string
Recording and providing information with regards to precisely which level of intellectual
abstraction an annotation is about, will be helpful for indicating when annotation is applicable to additional representations
of a document beyond the one it is specifically anchored to.
When annotations are intended only for direct human engagement, disambiguating targets
across ontological categories is often relatively easy for the reader. The ostensive
demonstrative in our example ("this"), or its functional equivalent, will be charitably
given a referent appropriate for the predication being made. We know for instance
that sentences are the sort of things that are in the passive voice and so an assertion
that something is in the passive voice is probably an assertion about a sentence—dynamic
typing being one reason human communication systems are so efficient.
Of course some assistance will be found in statistical techniques for inducing the
target of the annotation from various cues, but even if this approach can sometimes
determine targets relatively accurately it is unlikely to be practical in all circumstances.
As Barend Mons has noted: "we wouldn’t have to mine the data if we didn’t bury it
in the first place" [Mons 2005]. In any case the problem of how to identify targets remains: the results of statistical
induction will still need to be recorded.
Applying automated processing to realize the full potential of digital annotations
will be assisted by the explicit identification of the objects being described or
characterized—we need to know exactly what we are talking about in order to extract
information, store information usefully, and further analyze or calculate for knowledge
discovery and management.
W3C Annotation Model
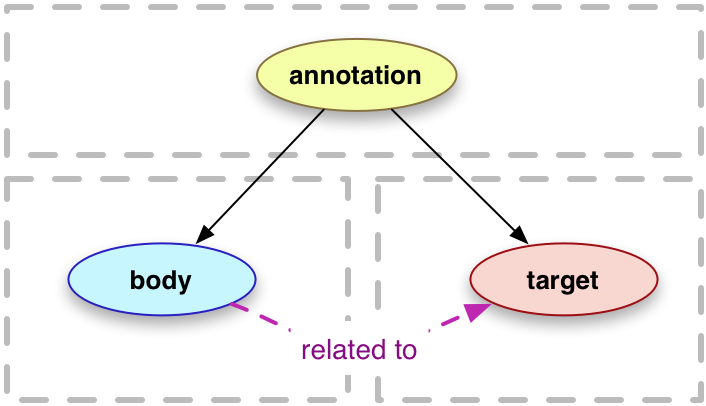
The WAWG conceptualizes an annotation in terms a body and a target [Figure 1].
While this basic model provides a very simple data structure to implement it does
so at the cost of semantic precision. It assumes that the annotator is just annotating
the representation in front of them. It makes no remarks upon how or in what way the
body relates to the target. It makes no remarks on the annotator’s intentions for
the annotating the target in the first place. It is completely agnostic with regards
to what kinds of things can annotate other kinds of things.
Designers of digital annotation standards and systems are aware of these problems
and the WAWG has provided additional vocabulary to facilitate recording information
regarding annotator intentions that goes some ways towards clarifying relationships
and types. In particular annotator intention is partially preserved by the concepts
of motivation and purpose. A motivation is the reason the annotation was created and, the purpose is the reason the body was associated with the target.
In some respects motivations are intended to provide conceptual clues regarding additional
class identities for an annotation. For example, in addition to being an annotation,
the annotation may also be a comment, or an edit, etc. Similarly a body’s purpose
provides some contextual clues regarding the class identity of the relationship between
the target and the body. The relationship might be that of correcting, explaining,
etc., but unlike the motivation, the purpose provides some distinct information regarding
the role that the body plays within the annotation, which suggests some potential
limitations for the class identities of either the body or the target.
Even though the annotation provides some information regarding the relationship between
the target and the body its real purpose in the digital ecosystem is to establish
a link between the stuff that the body is composed of and the stuff the target is
composed of. We call this linking process anchoring. The important factor is that anchoring always happens at the most concrete level
available (e.g., if I am writing in the margin of a book then the part of the paper
my pen scratches its ink into becomes the anchor).
The anchor and the target have subtle differences that are exacerbated by the agnosticism
regarding body and target class identities. By remaining agnostic about them and leaving
the door wide open with regards to what may be annotated and by what it may be annotated
the annotation begins to fall prey to a common ambiguity problem with regards to digital
resources in general and web resources in particular—the manifestation problem.
Expressing Annotator Intentions
Determining the semantic nature of the level of abstraction of an annotation’s focus
could be relived if there was a mechanism for recording the annotator’s intentions.
The WAWG’s Web Annotation technical standard tries to do this through motivation and purpose. However, some limitations immediately become apparent.
One limitation of this approach is that the motivations themselves can operate at
different levels of abstraction. Unfortunately, assuming that the motivation is meant
to express the focus of the annotation overloads the semantics of motivation as a concept. The annotation may have a motivation of "editing" but the annotator’s
intention was "suggesting." In the case of the WAWG, it was suggested that each motivation
not only supply some sense of additional class identity for annotations but also be
used as the basis for some expected user agent behavior. [Schepers 2015] This was a subject that had been discussed several times by the working group and
the general consensus was that motivations are much too coarsely defined for such
purposes.
To make matters worse, it is possible for motivations to actually obscure an annotator’s
intentions. For example, an editor may use an editing tool to suggest an alternative
sentence to one appearing in an editorial workflow but the purpose of the tool itself
is to produce edits. Constraints on the motivation may be placed by the tool. In the
example it may be the case that developers have provided the editor with some means
of providing motivation information or, it may be the case that the tool’s motivating
purpose is seen to be the overarching intention of its users by the developers and
so all annotations produced by the tool have the motivation of "editing" but no other
information. In this last case the annotator’s true motivation has been lost, subsumed
by the annotating software.
Providing information regarding the purpose that a body fulfills within the annotation
may help to alleviate this problem. The annotation may have a motivation of "editing"
while the body’s purpose is "suggesting." This is helpful because additional information
can be provided. It is also helpful in cases where an annotation has multiple bodies.
For instance, imagine another editing scenario where we are providing both the correction
to be made (e.g., a word has been misspelled and the corrected spelling is provided)
and the reason we provided (e.g., a second body appears with the purpose of "explaining"
that communicates the explanation "misspelled").
Unfortunately this approach is also vulnerable to the kind of silent assumptions that
developers build into tools. Annotators can only provide the information if the developer
has provided a way for them to and the developers may make assumptions as to the purposes
of bodies in the annotations produced by the tool. In the specific case of the Web
Annotation standard, there is an additional problem—purpose is strongly tied to bodies
whose class identity is text. In this case, only strings are allowed to have purposes.
This is problematic if we intend to annotate a target with an image or other non-text
media-type.
Expressing Annotator Focus
As with other hypermedia applications, annotation target anchors are linked regions
of whatever resource is receiving the annotator's attention [DeRose & Durand 1994]. But our usual methods of highlighting a region (pointing with a sprite, sweeping
with a cursor, drawing a rectangle, etc.) provide no distinctions among the levels
of abstraction to which our attention is actually drawn. A highlighted region of text,
for example, could be understood as anchoring a span of characters, a sentence, an
assertion, the proposition asserted, or some entity in the world to which the text
alludes. The annotator's attention may drift across these levels without conscious
effort, resulting in (for example) a claim that the targeted text is both misspelled
and misattributed. This would be an example of the same ontological variation in reference that complicates other kinds of markup interpretation [Renear et al. 2002]. Identification of the actual annotation target has implications for how the OA
markup is processed (as described above), so our goal is to simplify that identification.
In an earlier paper we suggested that an annotation framework structured as an enabling
architecture might offer domain and codomain constraints on the annotating relation
[Dubin et al. 2013], and one could imagine a "misspelled" relationship that would apply only to words
or a special "broken link" annotation, each of which would contribute its own codomain
constraints to specializing the annotation superproperty. But not only would this
approach require a large number of very specific annotation subproperties, it's likely
that most of them would require broad enough ranges to admit ambiguous targets. Both
physical artifacts and works of authorship, for example, could be "forged" or "lost
to history."
The OA "motivation" and "purpose" qualifiers are much too general to provide any
reliable disambiguation. We illustrate these difficulties using a figure from Pietro
Liuzzo's presentation at the 2015 Symposium on Cultural Heritage Markup. Liuzzo's
Figure 1 (encoded in the Balisage proceedings as a JPEG) presents a photograph of
a drawing in a manuscript [Liuzzo 2015]. The drawing depicts a bronze seal, upon which is a latin inscription that alludes
to two Romans who lived during the late third and early fourth centuries[10]. Our Figure 2 shows how an OA annotator might understand the text of the inscription to be an allusion
to or comment on Stefanilla Aemiliana, while in Figure 3, the paragraph on Stefanilla Aemiliana[11] might be understood to identify one of the people mentioned in the inscription. Of
course the only difference between the two examples is which web resources is tagged
as the annotation body and which the annotation target. General motivations like "Commenting"
or "tagging" give us no clue to either the relationship obtaining between these resources
or what persons, texts, objects, or images are participating in that relationship.
Figure 3 makes an image the annotation target, but which image is being tagged? Is it the
digital photograph of the drawing? Is it the drawing itself? Is it the original object
that bore the inscription? Is it all of them? Or, is the annotation not about the
images at all but about the text contained within it? A motivation like “tagging”
is simply too coarse for us to tell.
One can find a variety of different resources on the web that concern the seal, the
inscription, and the family to which it refers. Any of those might be a candidate
annotation body for an image annotation on Liuzzo's figure. Alternatively, someone
might offer a provenance connection to the manuscript, or even metadata on the JPEG
(such as a color profile). In our Figure 4, a epigraphic database record[12] about the inscription is understood to describe Liuzzo's figure 1:
Unfortunately we still have no idea if the annotation is using the description to
say something about the image, the thing in the image, or the text that the thing
in the image contains. If we also had a purpose associated with the annotation’s body we might be able to rule out some of the possibilities
and narrow our choices but, in this instance, since from the standard’s point of view
purpose is a property only simple textual bodies can have, the Web Annotation model works
against us.
It seems clear to us that the target construction conflates the intellectual focus of the annotation (i.e., what's actually
annotated) with the anchor for the annotation’s body (a region within an image, string, etc.). Class identities
for the targeted resources offer a partial solution to this problem, as shown in Figure 5:
Figure 5: Annotation Target Classes
liuzzo15:d40179e141 a dctype:Image .
abitofhistoryS:stefanillaaemiliana a dctype:Text .
eagle:HD032681 a dctype:Dataset .
Although these class identities tell us what kind of web resource has the annotator's
attention, they don't give us the level of representation to which that attention
is directed. The examples below make use of an proposed extension property, "hasTagetFocus",
for identifying that level in situations where the target class or anchoring representation
are unclear.
In Figures 6, 7, and 8 below, we've add this property to the prior examples. The target
foci are a person (Stefanilla Aemiliana), a string (the inscription text), and the
inscription itself, respectively. We've employed the CIDOC Conceptual Reference Model[13] to illustrate how the proposed property links the annotation to one possible domain-specific
interpretation of the target foci.
Figure 6: Annotation Example 1 with Target Focus
ex:anno1 a oa:Annotation ;
oa:hasBody liuzzo15:d40179e141 ;
oa:hasTarget abitofhistoryS:stefanillaaemiliana ;
oa:hasMotivation oa:Commenting ;
ex:hasTargetFocus ex:person1 .
ex:person1 a crm:E21_Person .
Figure 7: Annotation Example 2 with Target Focus
ex:anno2 a oa:Annotation ;
oa:hasBody abitofhistoryS:stefanillaaemiliana ;
oa:hasTarget liuzzo15:d40179e141 ;
oa:hasMotivation oa:Tagging ;
ex:hasTargetFocus ex:text1 .
ex:text1 a crm:E62_String .
Figure 8: Annotation Example 3 with Target Focus
ex:anno3 a oa:Annotation ;
oa:hasBody eagle:HD032681 ;
oa:hasTarget liuzzo15:d40179e141 ;
oa:hasMotivation oa:Describing ;
ex:hasTargetFocus ex:inscrip1 .
ex:inscrip1 a crm:E34_Inscription .
The proposed predicate allows distinctions to be drawn between the web resource to
which an annotation is attached (typically text, an image, or other digital data)
and the resource that participates in the relationship represented by the annotation.
Our proposed property doesn't resolve all ambiguities: for example, it's not obvious
in Figure 6 which particular person is denoted by ex:person1. But suppose that placeholder ID were generated by an annotation tool after the annotator
has chosen crm:E21_Person from a list of CIDOC/CRM classes. That class identity could inform processing and
presentation details for ex:anno1, and individual identity relations could later be asserted from ex:person1 to other annotation foci or to the subject of a more detailed description of that
historical person.
Conclusions
The proposed extension—adding a new predicate that expresses target focus—provides additional information that can be exploited by annotation clients and servers.
While this does not eliminate all uncertainty, it clearly provides clearer semantic
information than motivation and purpose by themselves and serves as at least a first step towards resolving this issue. One
potential use is to suggest circumstances under which an annotation’s body might appropriately
be anchored to other instances of the target’s content. For example, an annotation
that annotates the text contained within the image used in our examples should rightfully
annotate all depictions of that text.
Another potential use is clarify the ontological commitments being made by the annotators
themselves. If their intention is to annotate abstract entities like sentences, persons,
etc., then the annotation client’s data vocabulary needs to be rich enough to differentiate
between abstract entities and the concrete entities that depict them. It might not
necessarily need to realize the distinction between a proposition and the sentence
that denotes it, unless our hypothetical annotators are operating at that level, but
it does need to realize that there is a distinction between sentences and the strings
that depict them. Only by providing means to adequately record an annotator’s ontological
commitments can an annotation client begin to capture and record some sense of annotator
intentions.
There is no reason why target focus need be a monolithic solution. Like motivation and purpose, target focus should be represented using an extensible framework that fully engages the annotators
in the creation and transmission of their intentions. In the examples illustrated
in Figures 6-8, the CIDOC-CRM ontology was used to assign class identities to the
foci of the annotations. This is just one possible class assignment for those foci.
Other domain ontologies could have been used, (e.g., foaf:Person instead of crm:E21_Person).
By reusing domain-specific ontologies (or even allowing annotators to select the most
appropriate domain-specific ontology for themselves) the annotations can be more fully
embedded with the intellectual content they are meant to discuss, edit, tag, etc.
Our next step will be to begin exploring a possible extension to the Web Annotation
standard within a specific domain. This will allow us to ascertain the viability,
scalability, and utility of the proposed extension property while working directly
with domain users. One of the benefits that we anticipate is the ability to realize
the difference between tagging a web resource with a concept and assigning a class
descriptor from a class hierarchy to it, which under the current regime would be conflated
by the "tagging" motivation.
References
[DeRose & Durand 1994] DeRose, S. J. & Durand, D. G. (1994). Making Hypermedia Work: A User's Guide to HyTime. New York: Springer Science+Business Media.
[Dubin et al. 2013] Dubin, D., Senseney, M. & Jett, J. (2013). "What it is vs. how we shall: complementary
agendas for data models and architectures." Presented at Balisage: The Markup Conference
2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. doi:https://doi.org/10.4242/BalisageVol10.Dubin01.
[Liuzzo 2015] Liuzzo, P. M. (2015). "EAGLE and EUROPEANA: Architecture Problems for Aggregation
and Harmonization." Presented at Symposium on Cultural Heritage Markup, Washington,
DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup
Technologies 16. doi:https://doi.org/10.4242/BalisageVol16.Liuzzo01.
[Renear et al. 2002] Renear, A. H., Dubin, D., Sperberg-McQueen, C. M. & Huitfeldt, C. (2002). "Towards
a semantics for XML markup" Paper presented at DocEng '02, November 8 - 9, 2002, McLean, Virginia. doi:https://doi.org/10.1145/585058.585081.
[Unsworth 2000] Unsworth, J. (2000). "Scholarly Primitives: What Methods Do Humanities Researchers
Have in Common, and How Might Our Tools Reflect This?" Presentation at the symposium
on Humanities Computing: Formal Methods, Experimental Practice, London, United Kingdom,
May 13. http://people.brandeis.edu/~unsworth/Kings.5-00/primitives.html.
[1] See Hunter 2009 for an exhaustive account of these early annotation projects.
Dubin, D., Senseney, M. & Jett, J. (2013). "What it is vs. how we shall: complementary
agendas for data models and architectures." Presented at Balisage: The Markup Conference
2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. doi:https://doi.org/10.4242/BalisageVol10.Dubin01.
Hunter, J. (2009). Collaborative semantic tagging and annotation systems. Annual Review of Information Science " Technology 43(1), pp 1-84. doi:https://doi.org/10.1002/aris.2009.1440430111.
Liuzzo, P. M. (2015). "EAGLE and EUROPEANA: Architecture Problems for Aggregation
and Harmonization." Presented at Symposium on Cultural Heritage Markup, Washington,
DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup
Technologies 16. doi:https://doi.org/10.4242/BalisageVol16.Liuzzo01.
Renear, A. H., DeRose, S., Mylonas, E., & van Dam, A. (1999). An outline for a functional
taxonomy of annotation. Report to Microsoft Research. http://hdl.handle.net/2142/9098
Renear, A. H., Dubin, D., Sperberg-McQueen, C. M. & Huitfeldt, C. (2002). "Towards
a semantics for XML markup" Paper presented at DocEng '02, November 8 - 9, 2002, McLean, Virginia. doi:https://doi.org/10.1145/585058.585081.
Unsworth, J. (2000). "Scholarly Primitives: What Methods Do Humanities Researchers
Have in Common, and How Might Our Tools Reflect This?" Presentation at the symposium
on Humanities Computing: Formal Methods, Experimental Practice, London, United Kingdom,
May 13. http://people.brandeis.edu/~unsworth/Kings.5-00/primitives.html.