Liuzzo, Pietro Maria. “EAGLE and EUROPEANA: Architecture Problems for Aggregation and Harmonization.” Presented at Symposium on Cultural Heritage Markup, Washington, DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup Technologies, vol. 16 (2015). https://doi.org/10.4242/BalisageVol16.Liuzzo01.
Symposium on Cultural Heritage Markup August 10, 2015
Balisage Paper: EAGLE and EUROPEANA
Architecture Problems for Aggregation and Harmonization
Research Associate in Digital Epigraphy and Networking Coordinator of the EAGLE project,
Pietro Liuzzo has a PhD in Ancient History and has worked on Greek Historiography,
Epigraphy and Ancient Greek History. Since 2009 he is involved in the EpiDoc community.
He has recently curated the proceedings of the EAGLE international conference Information Technologies for Epigraphy and Cultural Heritage. He is an active Wikidata and Wikimedia Commons user and works on translations of
inscriptions and new complex information workflows for ancient world data.
This work is licensed under a Creative Commons
Attribution-ShareAlike 3.0 Unported (CC BY SA 3.0) License.
Abstract
EAGLE, The Europeana network for Ancient Greek and Latin Epigraphy, a project co-founded
by the European Commission, has as its sole aim to harmonize and aggregate data for
Europeana the trusted source of cultural heritage. Very easy to say, but no easy task in practice. It is extremely challenging to achieve
the trust users have in the original resources with the aggregated content.
EAGLE, The Europeana network for Ancient Greek and Latin Epigraphy,[1] a project co-founded by the European Commission, has as its sole aim to harmonize
and aggregate data for Europeana:[2]the trusted source of cultural heritage. Very easy to say, but no easy task in practice. It is impossible to achieve the
trust users have in the original resources with the aggregated content.
There are 18 so called content providers, which are member since the beginning of the project and represent a large part of
all existing databases of epigraphy in Europe. These include members of the EAGLE
consortium (Electronic Archive of Greek and Latin Epigraphy).[3] Together with these, other new members join regularly with small and larger databases
to be aggregated.[4] Some Content providers have photos, some an epigraphic archive, some various materials
(books, drawings, squeezes, etc.) which can be related one way or another to inscriptions.[5]
Two orders of problems arise:
The problem of harmonization and models for aggregation.
How to provide a meaningful architecture to existing data.
Cultural Heritage Objects
The question here is very basic: what is a Cultural Heritage Object? The answer is
different for Europeana compared to digital epigraphers, but also among the content
providers of the EAGLE project.[6] Internally some think that the object bearing the inscription is what is described
and archived, and thus tend sometimes to include also object which are not inscribed.
Some other instead think primarily of the text and describe the object only when this
is possible, because some inscriptions are known to us only through previous collections
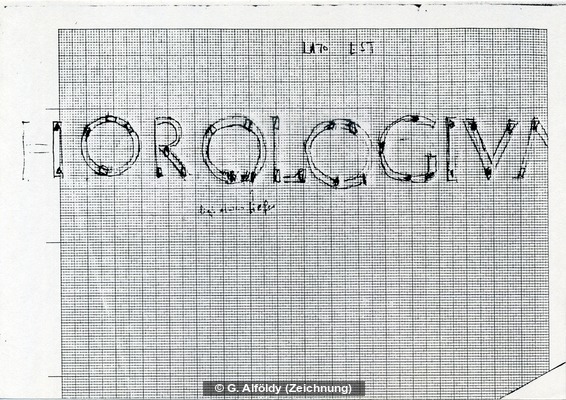
preserved in manuscripts from XVII-XVIII century (for example Figure 1). Some other instead try to take an holistic approach, inevitably falling one side
or the other nevertheless, partially because of the model and the tradition they actually
follow (EAGLE proceedings 1). I don't think there is anything wrong with any of such approaches, but they are
radically different when one wants to have firm grounds to provide a definition to
a machine.
Figure 1: Object or Inscription? Lost inscribed Instrumentum Domesticum
G. Alföldy, from the Heidelberg Photographic Database.
To try and harmonize we wanted to model the data in two levels: with TEI-EpiDoc,[7] which is tailored for epigraphic contents and captures the details about the text;
and in CIDOC-CRM to represent in an unambiguous way the object and its relations to
various kinds of information.[8] The CIDOC-CRM modelling had to stop in front of the Aristotelic complexity of precisely defining such object as an inscription which does not let one describe it primarily
as a stone to be kept in a museum rather than a book kept in a library, bringing to
the surface the traditional nature of documentation, linked to the institutions doing
it (two examples Figure 2 and Figure 2).
Figure 2: From the holes to the inscription
G. Alföldy, from the Heidelberg Photographic Database.
Figure 3: Reconstructing an inscription
G. Alföldy, from the Heidelberg Photographic Database.
Still, TEI-EpiDoc captures all the information that is typically connected to an inscription
and allows to harmonize data from all the content providers to be harvested by Europeana.[9] We had to leave out personal names because there is there a question, as for lexicon
and places,[10] of whether it is actually better to have all marked up on the one text (so different
intertwined semantic levels of markup) or it does make sense to mark up different
layers of information as separate annotations or as distinct layers of information.[11] So done, the problem comes again. Europeana intends a CHO (Cultural Heritage Object)
basically as a couple between a digital object/resource with a landing page. edm:isShownAt is so defined:
An unambiguous URL reference to the digital object on the provider’s web site in its
full information context) somewhere: photo, video, audio or text (edm:type).
But Text is not intended in reality as a text, but seems in practice to mean something closer
to a book or a document. This is partially forced by the other part of the basic and simple diad at the heart
of the Europeana model, edm:isShownBy:
An unambiguous URL reference to the digital object on the provider’s web site in the
best available resolution/quality.
So if I have a ScannedBook.djvu, described at my.book/0000 that is a CHO, if I have a PhotoOfAnInscription.JPG, described at my.inscription/0000, that is also a CHO, but a poor inscription.xml or inscription.html without a photo for the many reason for which a photo can just not be there, is not
fine, it fails to fullfill the definition.
First proof of concept: there is no place in the EDM (Europeana Data Model) for text,
it belongs in the description or is the digital object which needs to be something not just text as it simply is. In some cases a PDF file has been produced to be attached to the
description. Second proof of concept: if I have an Intellectual Property Right Statement
applied to the work carried out to encode (and thus the editorial and intellectual
work required to do so) an inscription (my non-existing text), that is ignored in
favour of the copyright of a photo (the real thing / digital object), of which those
marked up data are just descriptive metadata, including the text. There is no intellectual
property on the work done encoding and editing the text, which is the thing most of
as spend their life for.
So it is true that a simple system is very much desirable. But, as Einstein said,
everything should be made as simple as possible, but not simpler.
And a Cultural Heritage digital Object is not simple, as epigraphic archives are
not museums or libraries.[12]
EAGLE aggregation
Within the larger EAGLE network there are many partners with different datasets. Traditionally
a student in Epigraphy needs to be lectured about the different databases and their
history to be able to use them, although there aren’t that many inscriptions, compared
to how many manuscripts and ancient books survived to our days. So how to connect
the resources available, avoid duplication or triplication of work and harmonize a
competitive sector which needs not to be competitive and actually finds its own detriment
and decadence in such competition? In EAGLE we have looked at this from two points
of view.
bringing things together trying to harmonize vocabularies aligning them to concept
with multiple values
bringing in more and diverse players, by constantly enlarging the network and, e.g.
by mirroring collections to Wikimedia projects, which hosted already a wealth of community-created
data about epigraphy.
Figure 4: Object or Inscription? Lost inscribed Instrumentum Domesticum
A Screenshoot of a concept in the EAGLE vocabularies.
The first effort resulted in minting a series of URIs for concept related to fields
using controlled vocabularies in a digital epigraphic edition, which harmonize not
just different languages but also different usages, without the need of forcing a
strict hierarchy, although the latter seems to be for some more desirable than freedom
of markup.
The second effort materialized in three different ways, still under exam in terms
of their impact:
the upload of photos to Wikimedia Commons[13] with an ArtPhoto template (again here there is no specific template and some sort
of resistance to creating new ones). Then we have added information about the inscriptions
already there and to the newly uploaded following the criteria of the current practice
in Wikimedia Commons.
We have set up the first (and apparently only) instance of Wikibase outside Wikidata,[14] to allow people to enter translations of inscriptions, badly missing everywhere (there
are only around 3% of existing inscriptions available in translation) in a very simple
structure: identifiers, photos and translations with attribution.[15] Wikibase[16] is entirely free, properties can be created ad hoc and without too much of a problem.
although one cannot go to much into details as the description of the text, it could
describe everything one needs to describe in its own entirely idiosyncratic way. One
might wonder if this is actually useful, I can assure it is indeed very practical
and efficient.
We align our identifiers for controlled vocabularies and for places (provided by Trismegistos[17]) with Wikidata.
But still the path seems to be very long. How do we connect and annotate these resources
if we have to rely on arbitrary identifiers which are not inferable and readable?
How will users make their way through the wealth of available data if they do not
know what is there? Sticking information around to provide orientation is not enough,
as it is not enough to structure information, it perhaps needs to be going to the
users in the largest possible number of ways.
[Felle 2012] Felle, A. “Esperienze Diverse E Complementari Nel Trattamento Digitale Delle Fonti
Epigrafiche: Il Caso Di EAGLE Ed EpiDoc,” 10:117–30. Collectanea Graeco-Romana. Studi
E Strumenti per La Ricerca Storico-Giuridica. Torino, 2012.
[Feraudi-Gruénais 2010] Feraudi-Gruénais, Francisca, ed. “Latin on Stone: Epigraphic Research and Electronic
Archives.” Lexington Books, May 20, 2010.
[8] A dedicated workshop was run jointly between EAGLE members and CIDOC-CRM in March
in Nicosia, which recomended the definition of a subset of CIDOC-CRM especially for
epigraphy.
[9] The databases are converted from string to markup before going to the aggregator.
Documentation and XSLTs can be found in the EAGLE GIT repository. The results of this process provide accurate markup in most cases when
the underlying data is consistently following editorial conventions.
[10] The SNAP:DRNG project looks at these aspects of ancient world data and some of the EAGLE partners
contribute to it.
[11] As in the model for ancient world data which the Pelagios and Pleiades projects implement for places annotation.
[12] These aspects have arised from the discussion among the EAGLE and the Europeana team
during the aggregation process.
[13] A category collects all photos on which the EAGLE team has worked.
[15] An extra service for the needs of the epigraphic comunity is the result of the collaboration
with the Perseids project. This allows a new translation to be peer reviewed before it is published.
The Andrew W. Mellon Foundation has provided futher support (TIGLIO project) to the work required to establish a robust workflow for the provision of new translation
of inscribed texts, which will focus on the Attic Inscriptions Online website.
Felle, A. “Esperienze Diverse E Complementari Nel Trattamento Digitale Delle Fonti
Epigrafiche: Il Caso Di EAGLE Ed EpiDoc,” 10:117–30. Collectanea Graeco-Romana. Studi
E Strumenti per La Ricerca Storico-Giuridica. Torino, 2012.