Wickett, Karen M. “Accounting for Context in Markup: Which Situation, Whose Semantics?” Presented at Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14, 2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Wickett01.
Balisage: The Markup Conference 2015 August 11 - 14, 2015
Balisage Paper: Accounting for Context in Markup: Which Situation, Whose Semantics?
Karen M. Wickett
Assistant Professor
University of Texas at Austin
Karen M. Wickett is an Assistant Professor in the School of Information at the
University of Texas at Austin. Her research is on the conceptual and logical
foundations of information organization systems and artifacts. She is interested
in the analysis of common concepts in information systems, such as documents,
datasets, digital objects, metadata records, and collections.
Situation semantics - as developed by Barwise and Perry - is a general theory of
meaning for natural language, and can be used to understand the role of context in
markup semantics. While the notion of a discourse situation provides many of the
right hooks for accounting for contextual assignment of meaning to markup
structures, there are still many open questions. One critical issue is that
situation semantics itself is open enough to allow many different approaches to
identifying the relevant discourse situation. Three core types of discourse
situations for descriptive markup - documentary, transport, and discovery - lead to
distinct features in the discourse situations connected to those scenarios. Beyond
developing a fuller picture of the discourse situations that shape the meaning of
markup, this exercise lays groundwork for the full analysis of the assignment of
meaning to metadata records.
Markup systems are designed to control the assignment of meaning to particular
structures that appear within texts. Controlling the assignment of meaning lets us
create textual artifacts that are robust with respect to changes in technical
environments and domains. The controlled assignment of meaning to linguistic structures
means that the output of markup systems resemble artificial languages but they retain
many of the features of natural languages. Markup tags frequently use human-readable
labels, chunks of natural language text appear to system users, and much like in human
conversation there is a back-and-forth where information is exchanged between agents
via
linguistic structures.
Despite the intentions of markup systems to build independence from particular
technical environments for the interpretation, processing and use of their output,
context is still a major factor. The analysis of context in information systems has
received some attention in the last few years (Lee 2011), but we
could still use more discussion of the interplay between contextual factors and the
assignment of meaning in markup systems.
In (Wickett, 2010), situation semantics — formal machinery developed
by Barwise and Perry in Situations and Attitudes (Barwise and Perry 1983) — was
proposed to conceptualize markup semantics within a general theory of communication.
Barwise and Perry describe their general linguistic theory as a “relational theory
of
meaning”, and propose that the meaning of an expression is a relation between an
utterance of the expression and a described situation. Although the authors themselves
have expressed some skepticism about the general usefulness of the formal machinery
they
propose, they argue that “situation semantics is particularly well-suited to the study
of constraints and their central role in the flow of information.”
The following analysis focuses on markup systems for the creation, interchange, and
display of descriptive metadata. In terms of their meaning, descriptive metadata records
correlate roughly to singular noun phrases in natural language. A descriptive metadata
record is a bounded sequence of statements all referring to some single entity.
Therefore, the analysis here leans particularly on Barwise and Perry’s work on the
meaning of singular noun phrases and on the use of discourse situations to model their
meaning.
Wickett (2010) applied discourse situations to metadata records with a focus on the
notion of interoperability. In order to prepare for a complete analysis of the
assignment of meaning in descriptive metadata, the analysis here focuses the application
of discourse situations to descriptive metadata by analyzing three scenarios in which
a
metadata record is used to convey information: a documentary scenario, a transport
scenario and a discovery scenario. These scenarios highlight distinct aspects of the
purpose that metadata records are designed to serve. Purpose and function within an
information system are part of the overall context in which metadata records are created
and interpreted. The goal is to focus on how the specific functional roles that metadata
play shape the assignment of meaning to markup structures.
The next section describes these general metadata scenarios. In following section,
an
example is analyzed in terms of discourse situations and the relation theory of meaning.
In addition to providing insight on the functional aspect of context for metadata
semantics, this exercise will let us consider whether discourse situations are
expressive enough for accounting for the assignment of meaning to markup
structures.
Markup Scenarios
Documentary Scenarios
In a documentary scenario, metadata is created to describe, or document, a
resource. The resources here may be objects of any kind (intellectual, visual,
physical) and may come from a variety of domains (cultural, scientific, business).
The distinguishing factors of a documentary scenario reside in the purpose and
scoping of the creation of the metadata.
In a documentary scenario, the purpose is to make assertions about an object in
order to describe what it is. A metadata record may be embedded and stored as part
of a complex information object that also contains the resource itself, or stored
and managed separately from the resources being described. The claims made about a
resource during the creation of documentary metadata may pertain to entities with
varying relations to the resource, including the resource itself, logical or
physical parts of the resource, the creator of a resource, and the social or
commercial context of the resource. Assertions about the internal logical structure
of an object might also be embedded within an encoded version of the resource, as
is
the case with part of speech tagging; or they might be recorded externally to the
resource itself, as is typically the case with descriptions of physical artifacts
such as an outfit consisting of a matching dress, hat and shoes.
Metadata in these scenarios align well with Gilliland’s definition of descriptive
metadata: Metadata used to identify and describe collections and related information
resources (Gilliland, 2008). The purpose of interacting with a markup
system in a documentary scenario is to create a descriptive record that encodes the
assertions about the resource in a consistent way that is accessible within an
information system and can therefore, in some sense, “stand for” the resource. It
has been argued that the creation of this kind of descriptive record is part of the
process that makes objects from the world recognizable as documents, since any old
thing (like my watch) might be fairly considered a document if it is described and
arranged within a system that allows my watch to serve as evidence of (for example)
early 21st century fashion (Buckland, 1997).
The creation of documentary records of objects has been the focus of the subfield
of information organization within library and information science for much of the
20th century. The goal behind much of the research and development in information
organization was to create documentary systems and practices that would allow
descriptive metadata to be created consistently and in ways that would maximize
their usefulness. For example, Elaine Svenonius presents a number Principles of
Description that outline core motivating factors in the creation of descriptive
metadata Svenonius, 2000. Documentary scenarios are particularly
bound by the principle of representation and accuracy, which direct record creators
to represent resources as they represent themselves and emphasize the importance of
accurate recording in the process of metadata creation.
Transport Scenarios
In a transport scenario, attention is on the encapsulation and portability of some
metadata. In contrast to a documentary scenario, the primary object of attention in
a transport scenario is a metadata record, not the resource that the record
describes. The overall purpose in a transport scenario is to maintain the meaning
of
metadata across a change in institutional and technical environments.
Transport scenarios for metadata have become more prevalent as the resources
available for creating new descriptions of resources have become more limited.
Transport scenarios have received much attention in the digital age, with the
creation of protocols and metadata packaging standards for the transmission of
records via the Hypertext Transfer Protocol (HTTP). But enabling record sharing and
transmission while maintaining the fidelity of encodings and the semantics of
metadata were driving factors in the development of the MARC standards in the 1960s.
Many of the same general approaches and concerns are focal points of both current
and earlier efforts, such as the need for standardized record formatting and for
self-describing record structures.
The temporal scope of a transport scenario is determined by a transport event such
as a system migration or ingest of records from an institution into a federated
portal. There are efficiencies to be gained from making the protocols and procedures
involved in a record transport event as general as possible, but the essence of
record transport scenarios center around these exchange events. While system
designers will naturally hope that an exchange format can be accepted by many
systems, the critical issue is that each individual exchange event is successful in
the sense that there is no loss of information between a record in the originating
system and the transported record in the receiving system.
One of the more prevalent strategies for transporting metadata records is to
specify a data structure that is a container (or “wrapper”) for metadata records.
Generally this kind of container format will consist of a prologue or header
portion, along with one or more metadata records. The header typically contains
information that pertains directly to the transport event or supplies information
relevant for interpreting and processing the metadata records. The Open Archives
Initiative - Protocol for Metadata Harvesting (OAI-PMH) exemplifies this strategy.
This record format serves as metadata wrapper as well as a message protocol for
requesting and receiving metadata records. OAI-PMH uses HTTP as a transport layer
and relies on pre-defined HTTP methods for requesting data from a web server (Lagoze, et al. 2002).
The response to an OAI-PMH request is an XML document with three top-level
elements: a responseDate element that serves as a timestamp for the transaction, a
request element that contains details of the protocol request, and an element with
the same name as the verb of the request that generated the response (or an error
element). In responses to record requests (as opposed to requests to list
identifiers, for example), this final element will contain metadata records. Each
record occurs with a “record” element and the metadata is contained in a “metadata”
element with a child element that indicates a data standard that the record conforms
to. OAI-PMH responses are required to include Dublin Core metadata, but may also
include other formats if they are available for the requested records on the server.
Discovery Scenarios
In a discovery scenario, metadata records are used as the basis for information
system interactions where the user's goal is to locate a resource that is suitable
for some purpose. These system interactions are typically realized through search
functions that operate through keyword or field-based searching, or through the
construction of browsing interfaces that select and filter items based on a set of
fields. Records are retrieved and displayed to a user based on criteria provided by
the user.
Enabling the discovery and selection of information resources is one of the
primary goals of library and information science, and a primary motivator in
information organization and information retrieval practice and research. The human
agent interacting with a system is seen as a critical element of a discovery
scenario, and the system interaction is driven by the user’s “information need”, or
an “anomalous state of knowledge” Belkin, Oddy and Brooks, 1982. Library and
information science has traditionally been oriented around document management and
retrieval, so the strategy for addressing an information need is to locate and
retrieve a document that has a good chance of addressing the information need. To
be
more precise, a system will typically provide a user with a list of document
descriptions (metadata records) for documents that have a good chance of addressing
the underlying information need.
The functions that metadata serve in these scenarios emphasize particular semantic
features. For example, metadata classes are assumed to be mutually exclusive in
order to facilitate searching. This means that users can assume that if they are
only shown three items relevant to the subject of beekeeping, then there are only
three relevant items in the collection being searched. There is also an assumption
of monosemy between the user and the search index wherein it is assumed that users
are assigning meaning to terms they submit to a search engine in the same way that
meaning was assigned to terms in the construction of the index. This assumption is
a
departure from the way the way natural language generally functions — as Svenonius
notes, “it is only in constructed languages that an isomorphism exists between terms
and their referents” — and motivated the development of vocabulary control
mechanisms and thesauri (Svenonius, 2000).
Many of the practices and principles for metadata creation are designed to enable
discovery. This is particularly evident in the practices for bibliographic metadata,
which arose to supply data for systems that required labor-intensive human indexing
and searching. Although modern computational approaches have made data from any
fields in a record accessible for searching (instead of requiring the selection of
a
limited set of entry points), they still rely on basically on string-matching. This
means that search functions are constrained to operate at a syntactic rather than
a
semantic level, and the assignment of meaning to terms is, to a degree, opaque from
the perspective of a retrieval system. The concern over the potential mismatch of
semantics between a user and the information system can observed in the principles
of use warrant and literary warrant, which are designed to align descriptive
metadata with the vocabulary of users of an information system, and authors within
a
domain, respectivelySvenonius, 2000. The challenge of polysemy is
not limited to a potential gap between users and systems, but extends to differences
in term usage between authors and users, as demonstrated by the articulation of two
separate principles.
Applying Situation Semantics
The Relational Theory of Meaning
This section introduces some core concepts from situation semantics, as discussed
in Barwise and Perry’s Situations and Attitudes. Examples of metadata operating in
the three contexts described in the previous section are then modeled in terms of
these constructs.
The core motivating position of Situations and Attitudes is encapsulated by what
Barwise and Perry refer to as The Relational Theory of Meaning:
The meaning of an expression φ is conceived as a relation between
situations, namely, between an utterance u and
a described situation s, written u [φ] s.
The appeal of situation semantics for conceptualizing the meaning of descriptive
metadata lies in the observation that metadata records are expressions that,
intuitively, describe situations. The situation that a metadata record describes is
one in which the resource being described exists, and has the properties ascribed
to
it by the record. Since situation semantics is developed and employed by Barwise and
Perry to handle the semantics of spoken natural language, it’s reasonable to assume
that some adaptations will need to be made to use the theoretical apparatus for
accounting for the semantics of descriptive metadata. The purpose of this modeling
exercise to expose these differences, highlight the unique aspects of descriptive
metadata in terms of assigning meaning, and explore some approaches to adapting
situation semantics to metadata.
In the case of spoken natural language, an expression is uttered in a specific
space-time location by an agent, to some audience. This is a state of affairs
constituted by a space-time location, an individual in the role of the speaker, an
individual in the role of the addressee, and an expression that is uttered by the
speaker. Barwise and Perry have a general machinery for characterizing situations
using individuals, relations, and space-time locations (on which basic ordering and
inclusion operations are defined) as primitives. Relations, individuals and
locations can be combined together into a constituent sequence (of primitives),
which is associated with one of two truth values (which they typically express as
“yes” and “no”). This structure allows the expression of any number facts about
about a situation by constructing a constituent sequence out of an n-ary relation and n
individuals and then associating that sequence with one of the two truth values.
Situations that can be usefully generalized over (for example, situations in which
expressions are uttered) are classified with event types. The classification of
situations into event types uses basic indeterminates and roles. When all
indeterminates from an event type are anchored to specific individuals, relations,
or locations, the result is a course of events. The basic indeterminates come in the
same three flavors as the primitives: location indeterminates, relation
indeterminates, and individual indeterminates. Roles are complex indeterminates that
are defined for specific event types. The aspects of an event type that are common
across the courses of events that realize an event type are typically specified
directly, while the aspects that vary are represented with indeterminates.
The central event type for Barwise and Perry is the discourse situation. A
discourse situation is an event-type DU with:
DU := at l : speaking, a ; yes
addressing, a, b ; yes
saying, a, [α] ; yes
where the roles of speaker (a),
addressee (b), discourse location (l), and expression ([α]) are all uniquely
anchored. The anchor function assigns an individual to each indeterminate in an
event type, resulting in a course of events.
The speaker’s connections and the setting provided by other parts of an utterance
are both critical elements of Barwise and Perry’s account of the meaning of an
expression α: Thus we can think of the meaning of α as a
relation d, c,
[α] σ, e, between discourse
situations, connections, a setting σ provided by other parts of the
utterance, and a described situation. The modeling exercise here focuses on the
elements of the discourse situation that can be identified from metadata
records. The setting and the speaker's connections discussed in the final
section.
The next section discuss the discourse situations for descriptive metadata records
in the three scenarios for descriptive metadata. In each case, the discussion is
centered around a colloquial metadata records — information objects that follow
specified delimiter conventions and use defined vocabularies of attributes and
values, but do not have a specified formal semantics.
Metadata in Documentation
In documentary metadata scenarios, descriptive metadata is created to document a
resource. This process results in a record that represents the resource within the
context of an information system. The record may be co-located with or embedded in
the resource, or stored separately.
The figure below shows a portion of a metadata record that describes a digitized
map that is included in the David Rumsey Historical Map Collection.
Figure 1: A record from the David Rumsey Map Collection
This record was downloaded directly from the
website, which is a portal website for a collection of digital scans of historical
maps.
A discourse situation is constituted by the expression being uttered, the
time-space location of the utterance, the speaker and the addressee. The expression
being uttered (α) can be taken to be the descriptive metadata record in its
entirety. What is shown in Figure 1 is a styled version of the record as shown in
a
web browser, but the source for the displayed record is an HTML table generated by
a
script that pulls the attributes and values from the record database, along with an
image of the scanned map. Each attribute name is populated into a row, followed by
a
spacing character, and then the value for the attribute. The sequence of HTML
elements is the expression α.
There are a number of time-space locations that are relevant for analyzing this
metadata record. When viewing the record online, the serialization event that
generated the HTML table from the database is an interesting temporal location.
However, from the perspective of documentary metadata generation, the more relevant
events are in the creation of the data objects that are the source for the record
as
displayed. That is the point at which some agent is recording assertions about the
nature, function, and social, commercial, or historical context of the resource at
hand.
There is a similar debate concerning the speaker of the utterance for this
metadata record. There are many agents that can be identified as having, in some
sense, uttered this record. But, by viewing this record as the output of a
documentary process, we are guided toward the original cataloging event in which
this record was created. The speaker, then, will be the agent who recorded the
assertions about the object.
However, there are a few issues with identifying the speaker as the original
record creator in a documentary metadata context. The goal of documentary metadata
creation is often to construct a record that is useful for scholarly or scientific
purposes. This means that records in documentary contexts may be updated as more
information relevant to the interpretation of the object comes to light. This may
include information about the history of the object itself, about agents connected
to the object, or about the context in which the object was created or used. The
changes to the metadata record may involve adding fields or attributes, removing
attributes from a record, or modifying attribute values. If the same cataloger who
initiated the record makes the changes, we can still identify the single individual
as the speaker and consider the temporal location of the utterance to be dispersed
across editing events.
The case of a single individual creating and updating a descriptive metadata
record may occur in scholarly research environments when a scholar is documenting
an
object for some project or research program. But cataloging and metadata creation
practices in library science typically de-emphasize any individual and focus on
institutions as the producers and managers of metadata records. The preference for
identifying institutions as record creators can be observed in the definitions and
usages of MARC bibliographic fields (MARC 21), where the field
for ‘cataloging source’ refers to the “MARC code for or name of the organization(s)
that created” a metadata record. On the other hand, archival and museum paradigms
for metadata creation have typically given more emphasis to a metadata creator. For
example, the Encoded Archival Description (EAD) tag library (EAD, 2002) includes a “author” tag, which is intended to record the “name(s) of
institution(s) or individual(s) responsible for compiling the intellectual content
of the finding aid”. The metadata published by the David Rumsey Map Collection on
their website does not include a specific attribute to record information about the
creation of the records.
The most natural approach to understanding the relevant discourse situation is to
take the map collection as an organization and to identify it as the speaker for the
discourse situation in which this documentary record was uttered. The discourse
location is most interesting in terms of the temporal location (as opposed to a
physical location), and we can identify the temporal location as starting when the
record for this map was initiated. This may have happened in anticipation of the
scanning of a physical map, or as consequence of a scanning event. The temporal
location for the record creation may be dispersed across many editing and updating
events.
Identifying the addressee of a documentary metadata record is also challenging,
and is connected to the identification of the complete discourse location. One
approach, advocated by Wickett (2010), is to consider the discourse situation in
which a metadata record is uttered to be initiated with the creation of the record
and concluded with the retrieval and viewing of the record. On this account, the
temporal discourse location for the map record is concluded at the point when the
HTML table is generated. The addressee for the discourse situation is the user whose
system interactions triggered the table generation.
While identifying the addressee as a user retrieving the record and extending the
discourse location to that point in time satisfies the technical requirements of
Barwise and Perry’s theoretical apparatus (the roles must be uniquely anchored to
have a discourse situation), this solution does not align well with the documentary
perspective on metadata creation, where one of the implicit goals is to construct
a
record that is useful and meaningful to a diverse set of users. Identifying an
end-user as the addressee for a metadata record would imply that records are not
meaningful until they are accessed by a user. Perhaps this is the correct view, and
any counter-intuitive results can be handled by focusing on discourse situations
defined around narrower windows of time in the lifecycle of record. An approach that
aligns more closely to the purposes of documentary metadata creation views the
events during which a cataloger is creating and revising a record as discourse
situations, with the cataloger as the speaker and the system database as the
addressee. If a cataloger views the record during its construction, then the
discourse flips direction: the system is the speaker and the cataloger becomes the
addressee.
Metadata in Transport
Below is an OAI-PMH document issued by the Library of Congress that holds a
metadata record for a very similar historical map. This is an example of metadata
in
the context of a transport scenario.
Figure 2: An OAI-PMH document
The expression in this case is the OAI-PMH document, which is an XML document.
This XML document contains namespace information, a “responseDate” element, a
“request” element, and a “GetRecord” element. In general, the “GetRecord” will hold
as many “record” elements as correspond to the request issued to the server. In this
case, there is a single record, which consists of a “header” element and a
“metadata” element that contains Dublin Core metadata that describes the historical
map.
Although this particular record was generated and displayed in response to a user
action of loading a URL in a web browser, the more typical case is for OAI-PMH
responses to be generated and received via a programmatic procedures. An aggregator
that harvests content from the OAI-PMH server will request and retrieve records
without direct interaction from a human agent and process those records on receipt.
In terms of the relevant discourse situation, this means that in the typical
transport scenario, both the speaker and the addressee are information systems.
Focusing on the OAI-PMH response as shown here (as opposed to a request that
initiated the response), the speaker is indicated within the “request” element,
which shows what request verb was issued to what OAI_PMH server. Therefore, the
speaker for this discourse situation is the server OAI server at
http://memory.loc.gov. The temporal aspect of the discourse location is also
indicated in the OAI-PMH document itself, as the element content of the
“responseDate” element. This is a timestamp for the issuing of the response, so it
does not directly give us information about the receipt of the OAI-PMH document by
the requesting server. It is reasonable to suppose that the document is received
after the response is issued, and within the scope of some record ingest or
harvesting event.
There is also a “datestamp” element within the record header, but this does not
indicate the issuing of the response, rather the creation of the OAI-PMH record.
This is information that is specific to the functions of the OAI-PMH server,
intended for harvesters to be able to retrieve records added to the server before
or
after some point in time. Therefore it does not necessary indicate the creation of
the original metadata record, which would be a documentary metadata scenario.
Instead it seems to point to a transport-oriented event earlier in the lifecycle of
the metadata record.
Metadata in Discovery
In a discovery scenario, metadata is used to aid in search or browsing by an
individual user of an information system. Below is a screenshot of a search portal,
showing the historical map from the David Rumsey collection aggregated into the
Digital Public Library of America (DPLA).
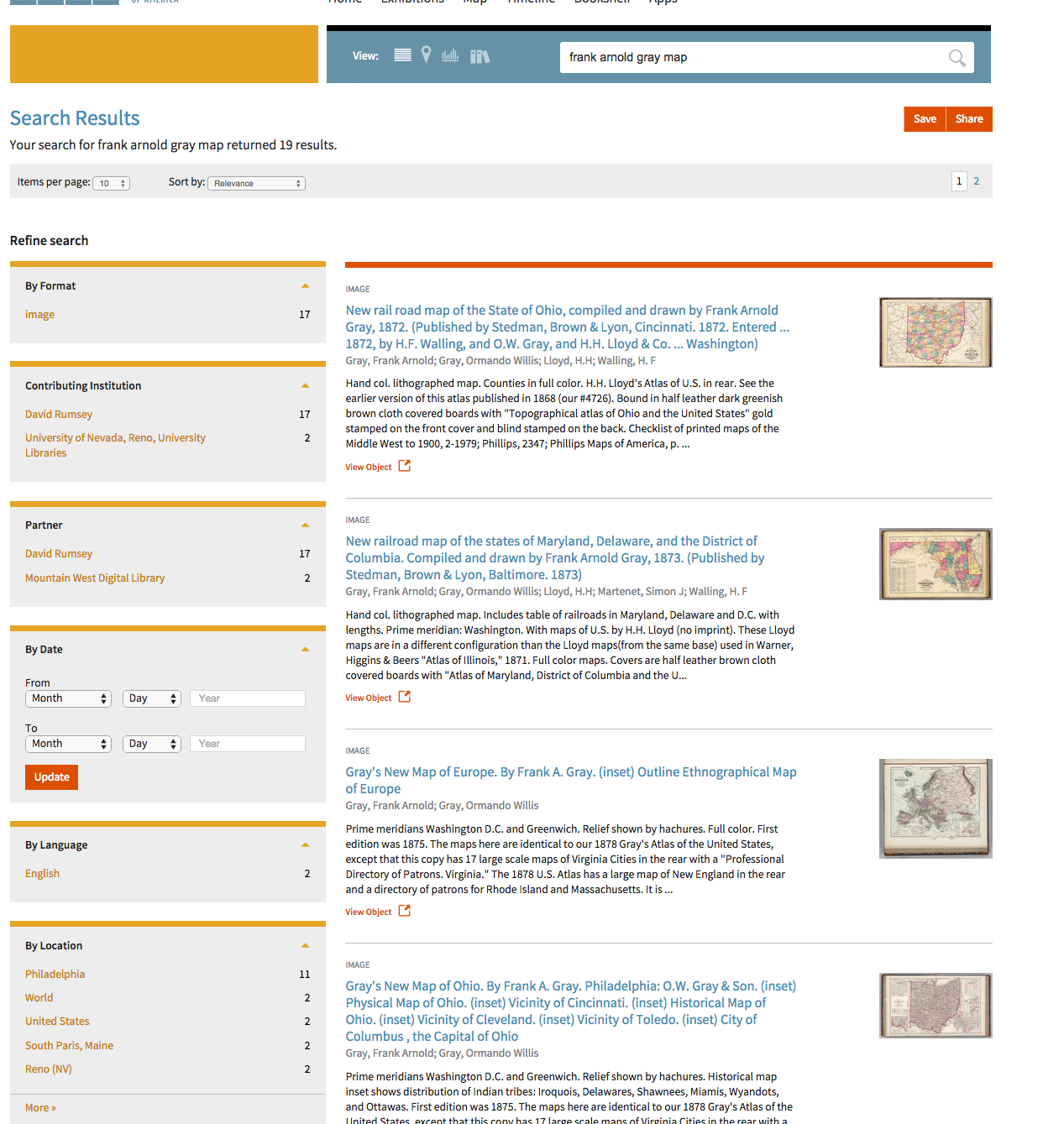
Figure 3: Search results from the DPLA portal.
The expression here is the results list, which was populated in response to a
query from an individual user. There is a subset of the results list that is
generated from a metadata record for the object. The information that appears in the
results list is typically a limited subset of the attribute values that are
available. In the case of DPLA, the entry in the results list consists of
information about type (e.g. “image”), title, a snippet of descriptive text, a
thumbnail image of the object (when available), and a link to the object as it is
represented by the institution who provided the data to the aggregation. Other
information from the record also contributes to the counts in the left-hand "Refine
Search" pane, including contributor, language and location information. This pane
can also be considered a part of the expression.
When our attention is on the generation of the results list, the speaker for the
discourse situation is the search portal, and the addressee is the individual user.
The temporal location of the discourse situation is bounded by the system
interactions that led to the generation of the results list. The event begins
shortly after the user issues the query, and ends when the results list has been
displayed to the user.
Discussion
By analyzing the three metadata scenarios in terms of discourse situations, we can
begin to make some observations about the differences between them and how that might
shape the interpretation of metadata. One primary distinction to be made focuses on
the
speakers and addressees in each scenario. In a documentary scenario, the speaker is
a
human agent recording assertions about an object, and the addressee is an information
system. In a transport scenario, both the speaker and addressee are information systems.
In a discovery scenario, the speaker is an information system and the addressee is
a
human agent. The temporal extent of the relevant discourse situation is also tied
to the
nature of the metadata scenario. In a discovery scenario the discourse situation is
bounded by a end-user system interactions and in a transport scenario it is bounded
by a
metadata harvesting event. Documentary scenarios are more complex, requiring
consideration of a much longer period of time that is undetermined at the time of
creation of the record, or shifting the focus to the interaction between a metadata
creator and an information system.
A discourse situation is any situation in which a speaker utters some expression and
lets us begin accounting for the context of use of an expression in a metadata scenario.
But the roles of speaker, addressee, location and expression do not, by themselves,
completely constrain the way an expression is used in an utterance. Fully address
meaning requires going beyond who said what, when, and to whom. There must be a way
to
directly account for the referential aspect of language, and to specify what things
are
referred to by expressions in the context of a particular utterance. Barwise and Perry
supplement the discourse situation to create a referential event-type with an additional
role that accounts for the reference relation between noun phrases and unique
individuals. When all of the referring phrases within an expression are linked to
the
objects to which they refer, the result is a partial function, called the speaker’s
connections, from words in the expression to individuals. The speaker’s connections
provides the link between the spoken utterance and the described situation.
Additionally, the assignment of referents in a phrase within an expression may be
influenced by other parts of an utterance. Expressions that are part of a larger
utterance may not have a link to a described situation on their own. This phenomenon
can
be seen clearly in the case of referring pronouns. At one point in a conversation,
I
might refer to my friend by her name “Molly”. At a later point in the conversation,
I
refer to the same person with the pronoun “she”. In isolation, a sentence with “she”
cannot be connected to a described situation. But in the context of the entire utterance
where the earlier expression was connected to an individual, “she” can be correctly
interpreted as pointing to the same individual. Barwise and Perry group situational
elements that come from a broader context of utterance for an expression and contribute
systematically to the interpretation of later elements into what they call the setting.
Accounting for discourse situations is only a starting point for this analysis, but
it
does seem promising. Identifying the correct scope in terms of events and artifacts
involved in the creation, management and use of metadata records is critical for
precisely characterizing the assignment of meaning. Completing the analysis will require
an account for the speaker’s connections and the settings. Analyzing the speaker's
connections in these scenarios will require accounting for the schemas and data
structures referred to by metadata creators and system designers. Furthermore, the
analysis here uses the concept of a metadata record, which is in many ways an
oversimplification of the construction, sharing and use of metadata. A complete anaylsis
will need to more carefully account for the levels of representation and encoding
involved in metadata creation and use.
References
[Barwise and Perry 1983] Barwise, J. and Perry,
J.Situations and Attitudes (1983). MIT Press,
Cambridge, MA.
[EAD, 2002] Encoded Archival Description Working
Group of the Society of American Archivists. Encoded Archival Description Tag Library
http://www.loc.gov/ead/tglib/
[MARC 21] Library of Congress Network Development
and MARC Standards Office. MARC 21 Format for Bibliographic Data. 1999 Edition Update
No. 1 (October 2000) through Update No. 20 (April 2015).
http://www.loc.gov/marc/bibliographic/
[Svenonius, 2000] Svenonius, Elaine. The Intellectual Foundation of Information
Organization(2000). MIT Press, Cambridge, MA.
[Wickett, 2010] Wickett, Karen M. Discourse
situations and markup interoperability: An application of situation semantics to
descriptive metadata. In Proceedings of Balisage: The Markup
Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010).
doi:https://doi.org/10.4242/BalisageVol5.Wickett01.
Belkin, Nicholas
J., Robert N. Oddy, and Helen M. Brooks. "ASK for information retrieval: Part I.
Background and theory." Journal of documentation 38.2
(1982): 61-71. doi:https://doi.org/10.1108/eb026722.
Encoded Archival Description Working
Group of the Society of American Archivists. Encoded Archival Description Tag Library
http://www.loc.gov/ead/tglib/
Lagoze, Carl, Herbert Van de
Sompel, Michael Nelson, and Simeon Warner, ed. 2002. The Open Archives Initiative
Protocol for Metadata Harvesting. Protocol Version 2.0 of 2002-06-14. Document Version
2015-01-08. Open Archives Initiative, 2002.
http://www.openarchives.org/OAI/2.0/openarchivesprotocol.htm
Lee, Christopher A. A framework for
contextual information in digital collections. Journal of
Documentation 67.1 (2011): 95-143. doi:https://doi.org/10.1108/00220411111105470.
Library of Congress Network Development
and MARC Standards Office. MARC 21 Format for Bibliographic Data. 1999 Edition Update
No. 1 (October 2000) through Update No. 20 (April 2015).
http://www.loc.gov/marc/bibliographic/
Wickett, Karen M. Discourse
situations and markup interoperability: An application of situation semantics to
descriptive metadata. In Proceedings of Balisage: The Markup
Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010).
doi:https://doi.org/10.4242/BalisageVol5.Wickett01.