Marcoux, Yves. “Applying intertextual semantics to Cyberjustice: Many reality checks for the price
of one.” Presented at Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14, 2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Marcoux01.
Balisage: The Markup Conference 2015 August 11 - 14, 2015
Balisage Paper: Applying intertextual semantics to Cyberjustice
Many reality checks for the price of one
Yves Marcoux
Professeur agrégé
Université de Montréal
Yves Marcoux has been a faculty member at EBSI, University of Montréal, since 1991.
He
is mainly involved in teaching, research, standardization, and international cooperation
activities in the field of document informatics. Prior to his appointment at EBSI,
Dr.
Marcoux worked for 10 years in systems maintenance and development, in Canada, the
U.S.,
and Europe. He obtained his Ph.D. in theoretical computer science from Université
de
Montréal in 1991. His main research interests are intertextual semantics, the design
of
communication, markup languages and digital humanities.
We report on a project consisting in the application of the Intertextual Semantics
modeling method (IS; Marcoux 2006, Marcoux & Rizkallah 2007a, Marcoux & Rizkallah 2009) to a particular type of legal document: the Agreement as to the
conduct of the proceedings, used in the Province de Québec (Canada). This was done
as a sub-project of the Towards
Cyberjustice project in the Faculty
of Law at Université de
Montréal. One of the project objectives was to verify whether the availability of a
semantic model of a document type (more precisely, a IS model) would impact on (and
hopefully help) the development of an application for the collaborative authoring
of such
documents. We first explain how the project lead to many extensions to the then existing
rudimentary IS platform (Marcoux 2009), and describe the most important of them.
We then present a few unforeseen difficulties that arose in the process of modeling,
and the
lessons learned. Although no definite answer was obtained as to whether IS can directly
help
in the development of applications, the project showed it can at least help indirectly,
by
forcing fundamental questions to be asked early on in the process. In our case, applying
IS
modeling revealed that nobody really knew from the outset what the target community
was, nor
what their actual needs were. This is a good illustration of the kind of effect IS
can have
on application development projects: making sure fundamental questions do not go unasked
too
long.
The idea of that project came out of a discussion between the principal investigator
of
Towards Cyberjustice, Professor Karim Benyekhlef at the Faculty of
Law, and the author, in early 2012. It was concluded that the goals and philosophy
of
Intertextual Semantics (IS; Marcoux 2006, Marcoux & Rizkallah 2007a, Marcoux & Rizkallah 2009) were totally in line with the general objectives of Cyberjustice, both
in terms of access to justice and in terms of allowing individuals to conduct themselves
as
much as possible of their activities related to justice. It was agreed that a first
step
would be to simply apply the IS modeling method to a chosen legal document type, and
see
what would come out of it. Such an endeavor would simultaneously serve as a reality
check
for IS and was expected to prompt a number of improvements to the then existing IS
framework
and platform.
After considering of couple of possibilities, André Saintonge, technical lead of the
laboratory, suggested working on the Agreement as to the conduct of the
proceedings (EDI for short, after the French name Entente sur le
déroulement de l’instance), a document that the parties have to jointly produce
and submit to a judge at the beginning of a case in the Province de Québec (Canada).
There
were two (related) reasons for this suggestion: (1) it appeared that the preparation
of that
document by lawyers was time-consuming and that the judges found it generally difficult
to
consult; (2) there had already been two attempts at PDFying that document
type. For various reasons (among which the limitation in scope of applicability),
none of
these PDF versions had had any level of success. It appeared clear that what was needed
was
an online application for the joint preparation of the document by the parties. The
refined
goals of the sub-project thus became to (1) verify whether the availability
of a semantic model of a document type (more precisely, a IS model of the EDI) would
impact on (and hopefully help) the development of an application for the collaborative
authoring of such documents, and (2) prompt improvements to the
IS framework and platform.
What was done, current status, outcomes
Océane Chotard, M.S.I., was hired as a research assistant mid 2012 and started the
IS
modeling process. A first complete model hypothesis was ready for validation with
a domain
expert by late Summer and a first interview (which eventually turned out to be the
only one)
took place on September 5th. Other interviews were planned, but had to be canceled
for
personal reasons by the domain expert. Still, the results of the interview and of
further
discussions with other domain experts that took place during the Fall were enough
to
conclude that (1) the right answers to modeling issues depended on the
target community envisaged (judges, lawyers, or both) and or their needs, that
(2) nobody had realized the dependency yet, and thus that (3) nobody could tell us
what the target community of the envisaged application was nor what their needs were.
A strategic meeting was held on October 3rd during which the target community was
decided to be lawyers, and the necessity to conduct a needs analysis with them was
clearly
identified. Océane was willing to do that work, but had to leave the project for
administrative and personal reasons.
Since no replacement for Océane was found until Spring 2014, and nobody else from
the
IS team was available in the meantime, some subsequent steps were carried
out in the Cyberjustice Laboratory without the IS point of view (in particular, without
an
IS model of the EDI). A needs analysis was conducted with lawyers (for which, unfortunately,
no report is available) and a classical functional analysis (with partial interface
and
database design) was performed by a computer science student in late 2013. As of this
writing, no further development of the application has taken place or is planned.
For the original work plan to be followed, a more thorough needs analysis would have
had
to be carried out by the IS team, and the iterative modeling process continued and
completed. Only then would application development have been undertaken. At that time,
nobody from the IS team was available, so it was decided that modeling should be pursued
and
completed in a light way, with the goal of bringing it to a graceful conclusion.
In May 2014, Catherine Saint-Arnaud-Babin, M.S.I., was hired as a research assistant
to
do that. We decided the best approach was to complete the IS model by settling all
the
pending questions based on the best available evidence, or failing evidence, on the
most
reasonable assumptions. The material available comprised the report of the interview
conducted in 2012 and the output of the functional analysis of 2013 (which turned
out to be
of little help). When this material did not allow settling a pending question, Catherine
and
the author jointly settled it by discussing what the reasonable assumptions
might be. The model was completed in November 2014.
The ideal scenario would have been for the IS team to perform a needs analysis with
the
lawyers, iteratively elaborate the IS model, then actively take part in the design
and
development of the application, in order to demonstrate how the IS modeling might
integrate
into the whole cycle of user experience design. That scenario did not take place and
thus,
no definite answer was obtained as to whether IS can directly help in the development
of
applications. In that sense, the first goal of the project was not fully attained.
As a
reality check for IS, however, the project was a great success, and the second goal
can be
said to have been fully reached. Indeed, many improvements to the IS framework and
platform
have been not only prompted by the project, but actually implemented in the course
of the
project. This is mainly what we report on in this article.
Structure of the article
A summary of IS is presented in section “IS in a nutshell”, both the conceptual framework
and the platform as it existed in 2009.
In section “Reality check two: integration in a IT project”, we ponder on how the need to integrate into a IT (Information
Technology) project impacts on the appropriate method to perform IS modeling of a
document
type. In particular, we present some unforeseen difficulties in interacting with various
stakeholders in the project, how we addressed them, and what lessons we learned in
the
process.
Finally, in section “Conclusion”, we make some concluding remarks, in which we
muse on considering the reality-check relationships in the opposite direction: what
might
the confrontation with IS of Cyberjustice and IT reveal about Cyberjustice and IT
themselves, rather than about IS?
Intertextual Semantics (IS) is first and foremost a conceptual framework aimed at
giving
semantics to populated data structures, most importantly XML documents. The
domain of the semantics as a function, i.e., the set of objects to
which a meaning is given, is a set of data structures with content, for example, XML
documents. The most unusual aspect of IS is that the range of the
semantics as a function, i.e., the set of values that constitute the possible meanings
of
the populated data structures, is natural language (NL), rather than an
artificial formal language such as logic. Thus, IS assigns a meaning (i.e., a semantics)
to
populated data structures, a meaning which is expressed in natural language (NL).
In the IS view, the creators of the data structure (modelers) associate NL segments
and
composition rules to the various parts of the structure. These allow the meaning (in
NL) of
a given instance of the structure to be generated automatically and, for example,
presented
to a human user (author, reader, etc.). The goal of IS is to facilitate a common
understanding of the instance among the various human persons interacting with it
throughout
its entire life-cycle, including the persons who create the structure (the modelers),
the
persons who populate the instance (the authors), and the persons who consult it (the
readers). So far, only very weak composition rules have been explored, and it is extremely
important that these be weak, because too powerful mechanisms would “hide under the
carpet”
inherent interpretation complications which IS, in contrast, seeks to uncover.
In the realm of XML documents, the NL segments are specified by the modelers in a
IS Specification (ISS) for the tag-set. In the current state of the
IS framework, a ISS takes the form of a table giving, for each element type two NL
segments:
a “text-before” segment and a “text-after” segment (generically called “peritexts”).
Attributes are handled by the possibility of including in the peritexts “guarded segments,”
segments guarded by an attribute name, that are only included if the corresponding
attribute
is specified on the element, and that can refer to the attribute value. “Local” elements
(in
the sense of W3C schemas) are partly supported, in that different peritexts can be
assigned
depending on the ancestors of the element. The IS generation process is similar to
styling
the document with the peritexts, concatenating peritexts and element content as the
document
tree is traversed depth-first. The IS, or IS-meaning, or reference interpretation,
of the
document is the resulting character string. It is not necessarily linguistically correct,
but is what we call quasi-NL.
Modeler- and author-contributed segments are assumed to be distinguishable from each
other (for example, they could be of different colors). Modeler-contributed segments
can
contain some non-graphic characters (e.g., paragraph breaks) and the output of the
semantic
function as a whole can contain hyperlinks, in the form of URIs delimited by agreed-upon
modeler-contributed markers, for example [square brackets].
IS was introduced in Marcoux 2006, where it was considered only from the
perspective of modeler-author communication, and in the context of valid structured
documents (e.g., XML). In Marcoux & Rizkallah 2007b, it was applied to a more classical
database-like structure, again with only the facilitation of modeler-author communication
in
mind.
IS has similarities with various mechanisms aimed at presenting markup in more or
less
explicit or explicated forms. However, it is important to stress that the preoccupations
of
IS are not at the presentational level, but really at the semantic level. The “presentation”
obtained through the IS mechanism is intended to define the meaning of
a document. In the other approaches we are aware of, the presentation (if successful)
accurately represents the meaning of a document, but that meaning is defined elsewhere.
The
idea of using text-related techniques to improve systems design, though not widespread,
is
by no means exclusive to IS. Also, several approaches have been proposed in the past
to
provide semantics to structured documents. The reader is referred to Marcoux 2006
and Marcoux et al. 2009 for pointers to relevant related work.
The platform as of 2009
An operational platform capable of actually generating the IS-meaning of a document
from
its XML source and a ISS was developed in 2009 (Marcoux 2009). It is available,
with examples, at <http://grds.ebsi.umontreal.ca/IS/> (enriched
versions, including the ones discussed in this paper, are located in the
beta-version… sub-folders, the latest one being always in
beta-version/). It consists mainly in a XSLT 1.0 stylesheet which, when
linked to an XML document, locates the applicable ISS and produces an HTML output
whose
rendering in a browser represents the IS-meaning of the document.
While a discussion of the conceptual framework can remain vague on details such as
how
to link a particular ISS to an XML document, the actual language in which ISSs are
written,
what exactly is allowed within peritexts, and to which extent the ISS is allowed to
control
the presentation of the IS-meaning, an operational platform presupposes specific choices
for
all practical aspects of the framework.
The 2009 platform can be said to be purist with regards to the text-only
nature of IS. The IS-meaning of any document is 100% text. Peritexts and document
content
are presented differently (as the framework says they should), but the modeler (who
writes
the peritexts) has no way whatsoever of controlling the presentation of neither the
peritexts nor the document content. Indentation is used, but it is generated automatically
using a heuristics based on XML element embedding.
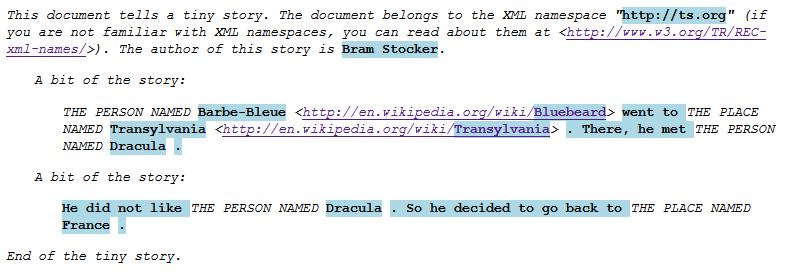
Figure 1 shows a typical display of IS-meaning with the 2009 platform.
Text with a colored background is document content (text content or attribute value),
everything else is peritext.
Figure 1
Typical display with the 2009 platform.
Attributes are handled by allowing within peritexts marked sections of
the form @attName[…@…]. Those sections are included in the output
only if the named attribute is present in the XML instance. There must be exactly
one
@ in the text between the square brackets in the marked section, and that
@ is replaced in the output by the value of the attribute. The
{{…}} delimiters can be used within peritexts to identify URIs, which
are then converted to clickable hyperlinks in the HTML output.
Figure 2 shows a typical display with a ISS using attributes and
hyperlinks.
Figure 2
Typical display with attributes and hyperlinks.
The very simple XML vocabulary with which ISSs are written can easily be inferred
by
looking at the following figures:
The file ISG.xsl (not given here) is the generic XSLT 1.0
stylesheet that realizes the IS-meaning generation. The convention used by this
stylesheet to retrieve the ISS is to use the file named TLgenID.iss.xml in
the same directory as the XML document, where TLgenID is the generic ID of
the document’s top level element.
In the ISS, a text-before and a text-after are grouped together in a
rule element. The paths attribute of a rule
element gives one or more paths, space-delimited, to which the
text-before and text-after (given by likewise-named attributes) apply. Those
paths are given in a restricted XPath-like syntax, each path consisting
in an element-type name, with or without partial or complete ancestral line.
For example, a rule with paths="/doc/sec appendix/subsec
proc" would apply to sec elements that are children of the
doc top-level element, as well as to subsec elements that
are children of appendix elements, and to all proc
elements.
If more than one rule could apply to an element, the first one, in ISS document
order, is chosen.
Figure 3
<?xml-stylesheet type="text/xsl" href="ISG.xsl" ?>
<story author="Bram Stocker">
<para><person>Dracula</person> went to France. There, he met
<person>Barbe-Bleue</person>.</para>
</story>
<?xml-stylesheet type="text/xsl" href="ISG.xsl" ?>
<story author="Bram Stocker" xmlns="http://ts.org">
<para>
<person key="Bluebeard">Barbe-Bleue</person> went to
<place key="Transylvania">Transylvania</place>. There, he met
<person>Dracula</person>.</para>
<para>He did not like <person>Dracula</person>. So he decided
to go back to <place>France</place>.</para>
</story>
<iss xmlns="http://grds.ebsi.umontreal.ca/ns/ISS/">
<rule paths="story" text-before="This document tells a tiny story.@xmlns[ The
document belongs to the XML namespace "@" (if you are not
familiar with XML namespaces, you can read about them at
{{http://www.w3.org/TR/REC-xml-names/}}).]@author[ The author of this story is
@.]" text-after="End of the tiny story."/>
<rule paths="para" text-before="A bit of the story: " text-after=""/>
<rule paths="person" text-before="THE PERSON NAMED " text-after="
@key[{{http://en.wikipedia.org/wiki/@}} ]"/>
<rule paths="place" text-before="THE PLACE NAMED " text-after="
@key[{{http://en.wikipedia.org/wiki/@}} ]"/>
</iss>
The project involved eliciting knowledge and understanding of the document type and
its
various uses from domain experts who were entirely unfamiliar with data or
information modeling or XML. In particular, it was necessary to present to these people—and
validate with them—the successive modeling hypotheses established by the modeler.
It quickly became clear that the rudimentary 2009 platform was not well suited to
communicating a model hypothesis to domain experts. Namely, the textual
purism of the plaftorm, which made it impossible for the modeler to control the
presentation of the IS-meaning of a document, was too limitative. It was rapidly felt
that
more freedom for the modeler to control the presentation of the output of the IS-generation
was required. More specifically:
A more precise control of indentation and linebreaks.
Possibility of emphasizing and otherwise styling a segment of text.
Better support for preparing and using printed copies of the IS-meaning of a
document, for offline study by the domain experts.
Another point is that, in validating a modeling hypothesis with a domain expert, the
question arises of choosing sample documents to present the various peritexts in the
IS
specification. Because of possible mutually exclusive choices in the model (which
all but
the most simplistic of models will contain), a single valid document cannot trigger
all the
rules of the IS specification. Thus, in order to validate all peritexts, we must either
resort to an invalid document, or to multiple documents. The
significance of this question, especially for long documents, such as the one we were
dealing with, had eluded us and came as a bit of a surprise in the preparation of
the first
interview.
Because modeling for a client is inherently an iterative process, the model hypothesis
is not only expected to change regularly, but almost certain to do so. In the process,
and
because a domain expert is not constantly available for discussion, it is only natural
that
questions will arise that must remain pending for a while, until they can be discussed
with
domain experts, and eventually settled by a decision.
We felt such steps in the elaboration of model hypotheses should be documented right
in
the IS model being developed. A natural way to include such documentation is in the
form of
rationale management notes (RMNs), that the modeler can
attach to a peritext, although they are not part of the peritext.
We identified five types of such notes:
Modeling questions still pending
Questions that the modeler intends to discuss with domain experts.
Modeling decisions
Decisions taken after a discussion (usually with domain experts). Often, a pending
question, once settled, will become a decision. As a good practice, all decisions
should be timestamped and the person(s) involved in the discussion identified.
Tips for developers
Information that is likely to be useful to developers of envisaged applications.
For example, description of relevant extra validations that XML DTD- or
schema-validation cannot perform.
Information for end-users
Information that developers should make sure is available to the end-users of
envisaged applications. For example, guidelines for establishing or interpreting the
content of an element (over and above validation rules).
Notes for the modelers themselves
Any information that the modelers deem worthy of inclusion in the model for its
documentation value. In this project, these notes were used as reminders of the
content models of the various elements. The need for such notes was felt because the
actual content models were in a DTD separate form the ISS .
The extensions done fall into three categories: (1) enrichment of the visual rendering
of
interpreted documents (display and print); (2) inclusion of the rationale management
mechanism
discussed earlier; and (3) extensions to the modeling method. In the course of these
extensions, the syntax of the peritexts was changed from the ad hoc
micro-format syntax of 2009 to an XML syntax, which made the inclusion of rationale
management
notes simpler, and rendered the parsing and validation of peritexts easier.
In this new XML syntax, peritexts were no longer text-only, but could contain subelements;
thus, they had to be made into subelements of the rule element, named
text-before and text-after, rather than attributes of
rule.
Presentation improvements
In response to the challenges posed by modeling for a client, a number of extensions
and
improvements to the presentation capabilities of IS were introduced:
The possibility of including <br/> and <span/>
elements in peritexts was added, with the same semantics as in HTML. Both elements
accept the class and style attributes, that are simply passed
on to the HTML output. Five predefined classes, em and em2 to
em5, are provided for various forms of emphasis.
A new display attribute was added to the rule element,
with possible values of inline, content-inline, and
block, allowing control of how an element is to be displayed. The
indentation heuristics has been removed, and indentation is solely controlled by XML
embedding. The new display attribute turns out to allow sufficient control
over paragraph layout and indentation.
Numbering of repeatable elements is possible using the <num/>
element, which can be inserted anywhere in a peritext, and is resolved to the sequence
number of the element among its siblings with the same generic ID, followed by a
superscript letter e.
A kind of catch-all method for controlling presentation is also
possible: it is to link the XML document not directly to the generic stylesheet
ISG.xsl, but rather to a model-specific stylesheet that provides any
required idiosyncratic presentation then imports ISG.xsl. This method was
primarily used in the process of gradually adding the above capabilities to the
platform, but eventually became unnecessary as the new features became available.
It is
currently deprecated.
It is possible to add to the HTML output (under the control of a stylesheet
paramater) the CSS apparatus necessary to number paragraphs of the output. These numbers
can serve as orientation landmarks either in the course of an interview or when sample
interpreted documents are printed for offline consultation.
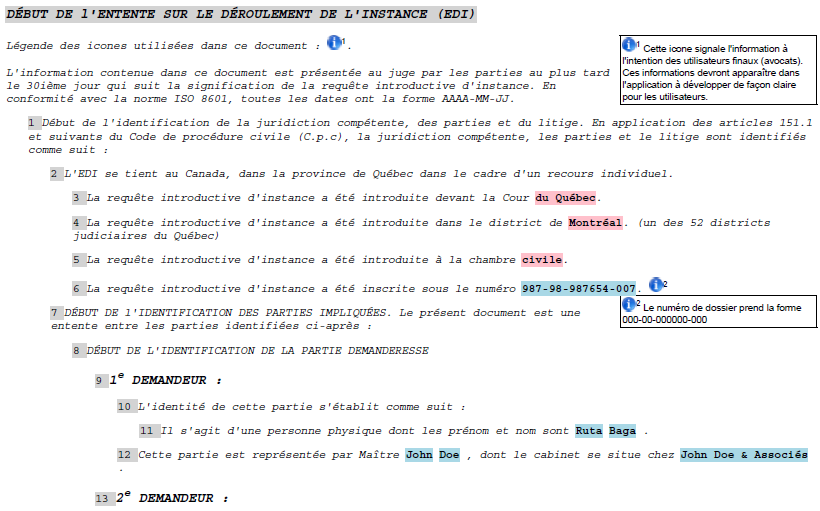
Figure 6 shows a typical display with paragraph numbering, and also
illustrates some other presentation-control capabilities.
Figure 6
Typical display with paragraph numbering and other presentation-control
features.
Rationale management notes
To implement a mechanism of Rationale Management Notes (RMNs) satisfactory with respect
to the requirements expressed in section “The models they are a-changin’”, we decided that RMNs should
congnitively act as post-it’s placed at arbitrary points in peritexts. Thus, they
would be
visible, but not interfere with the flow of the peritexts.
At the point where a RMN is present in a peritext, only the icon corresponding to
its
type will appear, thereby not interrupting the flow of text. The content of the RMN
will be
displayed either as a tool-tip or in a side-box, under the control of a stylesheet
parameter. When side-box display is asked for, the RMN icons are numbered in the peritexts,
and the same numbers identify the side-boxes. Of course, only side-box display is
appropriate for printing.
It is also possible, under stylesheet parameter control, to specify that some types
of
RMNs are simply to be ignored.
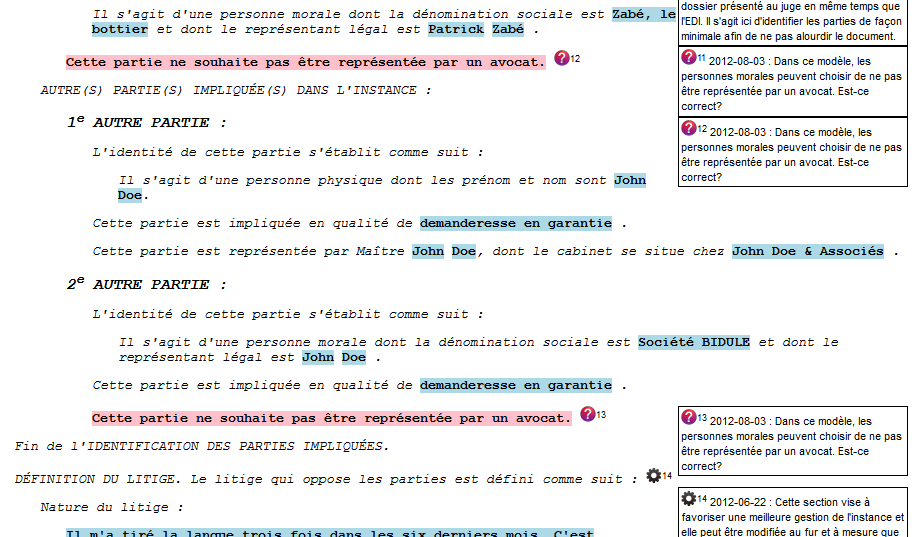
Figure 6 and Figure 7 show typical displays with RMNs in
side-boxes.
Figure 7
Typical display with RMNs in side-boxes.
Extensions to the modeling method
The discussion around the first example in Marcoux 2006 suggests a modeling
method which forms the basis of the one used in this project: starting with the prose
of
representative samples of the document type, the modeler identifies the variable parts
(which correspond to instance-specific content), and the fixed parts (which correspond
to
peritexts), then determines the content models: the repeatability and optionality
of each
part, as well as points of choice between possible parts. The actual XML names in
the model
(generic IDs, attribute names, etc.) are derived from the peritexts elaborated.
When working for a client, this whole method has to be embedded in a higher-level
iterative process by which successive model hypotheses are presented to domain experts
and
criticized and validated by them. A protocol for conducting interviews with domain
experts
was elaborated to make sure they were performed efficiently.
A step that had to be added prior to the interviews is the preparation of the fictional
documents presented to the domain expert. As explained in section “The need for communicating a model hypothesis”, the
documents have to be such that they will cause each rule to be fired at least once,
and
thus, each peritext is viewed at least once by the domain expert. Our choice here
was to use
only valid documents, because we deemed that dealing with invalid (and thus, semantically
inconsistent) documents would be too confusing for the interviewee. We used a first
big document covering as many rules as possible, and with at least two
occurrences of repeatable blocks, then one or two much smaller documents covering
the
remaining rules.
It was necessary to resort to fictional documents because real sample documents
contained sensitive data, and also because it would have taken too many real documents
to
trigger all the rules in the ISS.
Reality check two: integration in a IT project
Thinking in terms of document meaning
A point we had not foreseen was the difficulty of both the domain
and computer (IT) experts to think in terms of what the documents
meant. This difficulty was observed on two different levels: (1) difficulty thinking
of
information in terms of documents and (2) difficulty expressing needs and wishes otherwise
than at the interface-widget level. The first level (difficulty with the document
approach)
was all the more surprising that the whole endeavor consisted in modeling a document
type.
Thinking in terms of documents per se was not too hard for domain
experts; what was more challenging was to separate the ISs of the sample documents
presented
to them from what an actual real-life display would look like. However, we found that
after
due explanations were given, they were fairly at ease with the idea. However, they
continued
expressing needs and wishes in interface-widget parlance. This is not a big problem,
though,
since such expressions of needs are easy to translate into model features.
It was a different story with computer experts. They never quite saw any interest
in
viewing the output of the envisaged application as documents instead of database fields.
They never either quite understood our interest in the meaning of elements. We venture
to
say they were simply making a very common assumption about database fields: a field
name + a
data type is all we need to understand the meaning of a field.
Dealing with fuzziness and ambiguity
One particular point which was hard to grasp for computer (IT) experts is that in
trying
to understand the semantics of data, we neither aimed nor hoped to rule out all ambiguity
or
fuzziness from the application domain. The difficulty was probably exacerbated by
the
traditional database view of things, in which data entering any kind of persistent
container
is assumed (sometimes erroneously) to have clear and unambiguous semantics. Document
modeling, we believe, differs strongly from this view in that it can easily accommodate
varying degrees of precision and/or ambiguity, even simultaneously within a single
model, mainly by virtue of the presence of mixed content and choice
constructors in content model formalisms.
We had to regularly reiterate the fact that we were not trying to eliminate ambiguity
or
fuzziness, but only sought to detect them in order to model them. Our degree of success
in
conveying this idea was probably not very high.
Conclusion
As already mentioned in section “What was done, current status, outcomes”, the goal of the project which was to
verify whether the availability of a semantic model of a document type (more precisely,
a IS
model) would impact on (and hopefully help) the development of an application for
the
collaborative authoring of such documents was only partly attained, for the following
reasons:
The iterative IS modeling of the document type (the EDI) in consultation with domain
experts was not entirely completed.
A collaborative authoring application was not fully developed.
The few steps that were taken towards the development of a collaborative authoring
application were not performed with the IS view in mind.
In hindsight, we think the document type might have been too complex for the kind
of
experiment we were seeking. In fact, in another sub-project of Towards
Cyberjustice currently underway, we are working with a rather simpler document
type.
With respect to its second goal (serving as a reality check for IS), however, the
project
can be considered a great success. The better part of this article is a description
of the
challenges of applying IS in the setting of Cyberjustice, and of how these challenges
prompted
extensions and improvements to the IS framework and plaftorm.
In conclusion, we would like to consider the reality check relationships in
the opposite direction. The meeting of IS with Cyberjustice and IT in general has
been a
reality check for IS; has it been one also for Cyberjustice and IT?
Reality check for Cyberjustice
One important lesson we learned from the experience is that fuzziness is an essential
part of the world of law, but that at the same time, people who leverage that fuzziness
are
sometimes reluctant to make it clear that fuzziness not only exists, but is in fact
intentional. IS represents a bit of a clash with that attitude because, although fuzziness
and ambiguity are easily accounted for, their sheer existence must be
recognized and disclosed to the modeler during the modeling process.
Fully measuring the importance of fuzziness and ambiguity in their practice and
documents might have come as a reality check to some of the law people
involved in the project.
Reality check for IT
To us, the confrontation we observed of IT with the IS approach bears signs of
questionable trends in IT. For example, the difficulty for IT people of seeing value
in the
document approach may be a sign that static artefacts are currently undervalued in
IT,
compared to dynamic ones such as services. But important aspects of society are based
on (at
least relatively) static, stable artefacts (laws, contracts, books, works of art,
etc.) and
these aspects should not be neglected by IT. However, one must be cautious in that
kind of
generalization; after all, our view of IT in the project was extremely limited and
specific.
There is nevertheless one thing about IT that the project brought out: in spite of
all
the methodological approaches in vogue, there is always a risk of embarking on a project
without asking all the relevant questions. Recall from section “What was done, current status, outcomes” that at the
outset, nobody could tell what the target community of the envisaged application was
nor
what their needs were, despite the fact that two attempts at producing PDF versions
had
already taken place.
By raising basic questions about the meaning of a document type (the EDI), IS succeeded
in uncovering the fact that a fundamental question about the idea of developing an
authoring
application for that document type had never been asked. This, to us, is a perfect
illustration of the kind of effect IS can have on modeling projects, and in general,
on
application development projects: making sure fundamental questions do not go unasked
for
too long.
Acknowledgments
This work was supported by a SSHRC grant as part of the Towards
Cyberjustice GTRC, whose principal investigator is Professor Karim Benyekhlef,
Faculty of Law, Université de Montréal.
We wish to thank Océane Chotard, M.S.I., who painstakingly familiarized herself with
the
IS framework, suggested many improvements to the platform, and ever so patiently dealt
with
the numerous stakeholders of the project. We are also grateful to Catherine
Saint-Arnaud-Babin, M.S.I., who took over Océane’s work and brought it to a graceful
conclusion, essentially on her own. We cheerfully thank Élias Rizkallah, a significant
contributor to the development of IS, who supervised part of the work done in the
first phase
of this project. Karim Benyekhlef, Valentin Callipel, Catherine Piché, Nicolas Vermeys,
and
André Saintonge of the Cyberjustice laboratory, are all to be warmly thanked for their
faith
and engagement in the project.
[Marcoux & Rizkallah 2007b] MARCOUX, Yves;
RIZKALLAH, Élias. “Experience with the use of peritexts to support modeler-author
communication in a structured-document system.” Proceedings 25th ACM International
Conference
on Design of Communication (SIGDOC'07), 22-24 October 2007, El Paso, Texas (USA),
2007, pp.
142-147. doi:https://doi.org/10.1145/1297144.1297173.
[Marcoux & Rizkallah 2008] MARCOUX, Yves; RIZKALLAH,
Élias. “Knowledge organization in the light of intertextual semantics: A natural-language
analysis of controlled vocabularies.” In Arsenault, C.; Tennis, J.T. (Eds.), Culture
and
Identity in Knowledge Organization, Proceedings of the Tenth International ISKO Conference,
5-8 August 2008, Montréal, Canada. Ergon Verlag, 2008, pp. 36-42.
[Marcoux 2009] MARCOUX, Yves. “Intertextual semantics
generation for structured documents: a complete implementation in XSLT.” Proceedings
12e
Colloque international sur le Document Électronique (CiDE.12), Montréal, October 2009,
pp.
159-170.
[Marcoux & Rizkallah 2009] MARCOUX, Yves; RIZKALLAH,
Élias. “Intertextual semantics: A semantics for information design.” Journal of the
American
Society for Information Science & Technology, vol. 60, no 9, 2009, pp. 1895-1906.
doi:https://doi.org/10.1002/asi.21134.
[Marcoux et al. 2009] MARCOUX, Yves; SPERBERG-McQUEEN,
Michael; HUITFELDT, Claus. “Formal and informal meaning from documents through skeleton
sentences: Complementing formal tag-set descriptions with intertextual semantics and
vice-versa.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada,
August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series
on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Sperberg-McQueen01.
MARCOUX, Yves;
RIZKALLAH, Élias. “Experience with the use of peritexts to support modeler-author
communication in a structured-document system.” Proceedings 25th ACM International
Conference
on Design of Communication (SIGDOC'07), 22-24 October 2007, El Paso, Texas (USA),
2007, pp.
142-147. doi:https://doi.org/10.1145/1297144.1297173.
MARCOUX, Yves; RIZKALLAH,
Élias. “Knowledge organization in the light of intertextual semantics: A natural-language
analysis of controlled vocabularies.” In Arsenault, C.; Tennis, J.T. (Eds.), Culture
and
Identity in Knowledge Organization, Proceedings of the Tenth International ISKO Conference,
5-8 August 2008, Montréal, Canada. Ergon Verlag, 2008, pp. 36-42.
MARCOUX, Yves. “Intertextual semantics
generation for structured documents: a complete implementation in XSLT.” Proceedings
12e
Colloque international sur le Document Électronique (CiDE.12), Montréal, October 2009,
pp.
159-170.
MARCOUX, Yves; RIZKALLAH,
Élias. “Intertextual semantics: A semantics for information design.” Journal of the
American
Society for Information Science & Technology, vol. 60, no 9, 2009, pp. 1895-1906.
doi:https://doi.org/10.1002/asi.21134.
MARCOUX, Yves; SPERBERG-McQUEEN,
Michael; HUITFELDT, Claus. “Formal and informal meaning from documents through skeleton
sentences: Complementing formal tag-set descriptions with intertextual semantics and
vice-versa.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada,
August 11 -
14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series
on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Sperberg-McQueen01.