Holstege, Mary. “Markup as Index Interface: Thinking Like a Search Engine.” Presented at Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14, 2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Holstege01.
Balisage: The Markup Conference 2015 August 11 - 14, 2015
Mary Holstege is Principal Engineer at MarkLogic
Corporation. She has over 20 years experience as a software engineer in and
around markup technologies and information extraction. She holds a Ph.D. from
Stanford University in Computer Science, for a thesis on document
representation.
To a search engine, indexes are specified by the content: the words, phrases, and
characters that are actually present tell the search engine what inverted indexes
to create. Other external knowledge can be applied add to this inventory of indexes.
For example, knowledge of the document language can lead to indexes for word stems
or decompounding. These can unify different content into the same index or split the
same content into multiple indexes. That is, different words manifest in the content
can be unified under a single search key, and the same word can have multiple manifestations
under different search keys. Turning this around, the indexes represent the retrievable
information content in the document. Full text search is not an either/or yes/no system,
but one of relative fit (scoring). Precision balances against recall, mediated by
scoring.
The search engine perspective offers a different way to think about markup:
As a specification of the retrievable information content of the document.
As something that can, with additional information, unify different markup or provide
multiple distinct views of the same markup.
As something that can be present to greater or lesser degrees, with a goodness of
match (scoring).
As a specification that can be adjusted to balance precision and recall.
What does this search engine perspective on markup mean, concretely? Can we use it
to reframe some persistent conundrums, such as vocabulary resolution and overlap?
Let's see.
Full-text search engines have become ubiquitous in our digital lives. Traditionally,
markup in documents processed by search engines was seen largely as something to be
filtered out, before the real work of indexing content could begin. The modern view
is that markup provides contextual information that can improve indexing and improve
the relevance of search results. In this paper I propose that we regard markup as
a subject of indexing, as defining the interface to the indexes. Taking a step further,
the search indexes define an interface back to the document, an interface that may
provide multiple simultaneous views of its contents, or abstractions or distinctions
not manifest in the original.
Search Engine 101
Inverted Indexes
Search engines typically operate off a data structure called an inverted index that
maps words in documents to the set of documents that contain that word. The keys of
this index are the words in the document. Associated with each key is a list of postings:
the document identifiers, perhaps with word positions, and term frequency information
used for scoring. Details vary considerably in terms of what the postings look like,
how the information is compressed, and how the mapping is done. Generally speaking,
the keys are sorted in some data structure that allows efficient lookup for a single
key, a trie perhaps, or a lexicographically ordered list. Typically the postings are
kept sorted by document identifier. This allows boolean operators to be implemented
as set operations, which can be performed very efficiently via single passes over
the ordered set. Positional information is typically kept for each matching document
in positional order, so that proximity operations can be implemented via single passes
over the ordered sets of positions. See, for example, Lucene521 for details on one implementation, or the historically interesting BrinPage98 for another.
These details need not detain us right now: we are concerned with the general model.
Some pertinent attributes are:
The contents of the documents define what is in the inverted index.
An inverted index can, given a word, determine the set of documents that contain that
word by a simple lookup.
An inverted index can, given a boolean combination of words, determine the set of
documents that contain that combination of words by performing set operations on ordered
postings.
An inverted index that includes positional information can, given a query about proximity
or occurrences, determine the set of documents that satisfy that proximity or occurrence
constraint by filtering postings.
The contents of the documents define what is in the inverted index.
The contents of the index is not defined up front. No one sits down to enumerate all
possible words to ensure there is a slot in the index for each one. That would be
completely untenable and would make for a very unsatisfying user experience. Imagine
if every time a new word was encountered for the first time (a new company name, perhaps),
one had to reconfigure the search engine to index it.
Instead, search engines rely on general tokenization mechanisms to identify words,
and create an entry in the inverted index for each one that is encountered. Tokenization
may be as simple as breaking on white space and punctuation, or may involve complex
and contextual linguistic analysis. In this sense the documents themselves define
what the index contains. If a word is tokenized out of a document, an index entry
can be created for it.
On the other hand, what is a word? Should punctuation be added to the index? Space?
In theory, it can. In practice, it generally isn't because the posting lists get too
long and because it complicates phrase and proximity calculations. As I said, tokenization
may involve contextual linguistic analysis and tradeoffs about what words are useful
to have in the index. Is don't a single word? Or is it two: do, n't? Or should the apostrophe just disappear, as punctuation: don and t or perhaps dont? What about French d'accord, or discretionary hyphens? Is it worth bothering to index such ubiquitous words as
the?
The search engine defines a prism to view the contents of the document. If you look
for the term don and a document containing only don't is not given as a match because don't was indexed as do and n't then in effect the document doesn't contain don.
If you can't find it when you ask for it, it is as if it didn't exist.
An inverted index can, given a word, determine the set of documents that contain that
word by a simple lookup.
Figure 1: A small inverted index
brown 1 6
clock 2 5
cow 3 6
dog 1
Dogs 4
down 2
fox 1
foxes 4
How 6
jump 4
jumped 1 3
lazy 1
let 4
moon 3
mouse 2
now 6
one 5
over 1 3 4
quick 1
ran 2
struck 5
the 1 2 3
The 1 2 3 5
them 4
Source documents
1: The quick brown fox jumped over the lazy dog.
2: The mouse ran down the clock.
3: The cow jumped over the moon.
4: Dogs let foxes jump over them.
5: The clock struck one.
6: How now brown cow?
Figure 1 shows a small inverted index, where the term keys are arranged in order. A binary
search through the term keys can quickly lead to the posting list for that term, which
can be returned. This is the fundamental operation inverted indexes perform.
An inverted index can, given a boolean combination of words, determine the set of
documents that contain that combination of words by performing set operations on ordered
postings.
Figure 2: Resolving a simple boolean query out of inverted index: "over" AND "cow"
brown 1 6
clock 2 5
cow 3 6 => 3 6
dog 1
Dogs 4
down 2
fox 1
foxes 4
How 6
jump 4
jumped 1 3 => 3
lazy 1
let 4
moon 3
mouse 2
now 6
one 5
over 1 3 4 => 1 3 4
quick 1
ran 2
struck 5
the 1 2 3
The 1 2 3 5
them 4
The inverted index resolves each leaf query through a single lookup of the leaf term,
producing an ordered set of postings. Set operations such as conjunction (AND), disjunction (OR), and set difference (AND NOT) can be calculated by running through both the sets once side-by-side, keeping the
appropriate matches while maintaining ordering.
An inverted index that includes positional information can, given a query about proximity
or occurrences, determine the set of documents that satisfy that proximity or occurrence
constraint by filtering postings.
Figure 3
Resolving a positional query: "The" NEAR/2 "jumped"
brown 1[3] 6[3]
clock 2[2] 5[2]
cow 3[2] 6[4]
dog 1[9]
Dogs 4[1]
down 2[4]
fox 1[4]
foxes 4[3]
How 6[1]
jump 4[4]
jumped 1[5] 3[3] => 1[5] 3[3]
lazy 1[8]
let 4[2]
moon 3[6]
mouse 2[2]
now 6[2]
one 5[4] => 1[1+5] 3[1+3] => 3[1+3]
over 1[6] 3[4] 4[5]
quick 1[2]
ran 2[3]
struck 5[3]
the 1[7] 2[5] 3[5]
The 1[1] 2[1] 3[1] 5[1] => 1[1] 2[1] 3[1] 5[1]
them 4[6]
The inverted index resolves each leaf query through a single lookup of the leaf term,
producing an ordered set of postings. Each posting includes an ordered set of instances
of the term within a particular document. The conjunction remembers the positions
for the separate pieces. A proximity query amounts to adding some positional checking
to the set operations for each matching document.
Notice that if a particular inverted index does not include positional information,
the index cannot directly resolve a proximity query. Given a query for fox within ten words of dog, the best an inverted index can do if there are no word positions is to return documents
that contain both fox and dog.
Precision, Recall, and Scoring
Unlike classic boolean retrieval of data elements from a database, full-text search
concerns itself with the relative quality of the matches. The query used to obtain
a set of matching documents is understood as a proxy for an underlying information
need. Documents that are relevant to an information need may not be returned from
a particular query, and documents that are returned from a particular query may not
be relevant to the information need. It may seem strange. After all, if you search
for dog and a document contains dog how can it be irrelevant? How can a document that does not contain dog be relevant?
We are dealing with human language here. A query for the word dog might return a document that has the word dog in it used as a verb instead of a noun and would miss another document that contained
only the plural form dogs. From a human standpoint, the first document is a false positive, and the second
a false negative. (Maybe. As with all things involving humans, it depends.)
The two measures precision and recall capture the overall quality of the results. Precision is the fraction of the selected
documents that are actually relevant. A high precision means that the results are
not contaminated with a lot of irrelevant results. Recall is the fraction of the relevant
documents that are actually selected. A high recall means that there are few relevant
documents missing from the results. Unfortunately, increasing precision tends to decrease
recall and vice versa. It is trivial to obtain 100% recall by returning every document.
That would make for poor precision, however.
Relevance scoring or ranking estimates the relative quality of a specific document
in the set of matches in comparison to other matching documents as an answer to the
underlying information need. Commercial systems often use quite complex scoring algorithms
based partly on statistical models of documents and partly on specific knowledge of
the data and of the users.
Relevance is a psychological concept.
Search engines have typically used some variant of TF-IDF scoring for computing relevance
since it was introduced in 1972 Jones72. Term frequency (TF) is a count of the number of occurrences of a term in a particular document.
Inverse document frequency (IDF) is the one over (there's the "inverse" part) the fraction of the total number
of documents in the corpus that contain the term.
Even simple TF-IDF scoring can be quite effective. Typically scores are computed by
taking the logarithm of these values to avoid over-counting of common terms due to
Zipf's law and summing over all the terms in the query. Zipf's law is an empirical
observation Zipf49 that the distribution of word frequencies varies inversely to the range of the word
in frequency order:
Equation (c)
Frequency(rank) = Frequency(1)/(rank k)
(k is some constant.)
What Zipf's law tells us, in effect, is that common terms are not just more common,
but that they are much, much, much more common. Taking the logarithm turns the curve
into a straight line, giving more predictable scoring.
The net effect is to prefer documents that contain relatively large numbers of relatively
rare terms. There are a number of variants, involving normalizations of the frequencies
and document size.
Commercial search systems live and die on how well they balance recall and precision
and the relative importance between them for their customer base. Web scale search
engines tend to err on the side of recall, and rely on relevance scoring to sort the
results so that the false negatives tend to fall far down the list of matches, where
they disturb no one.
More Than Words
Let us widen our view to consider what a "term" might be. So far we have limited our
discussion to words, albeit with some acknowledgment of the linguistic and pragmatic
complexities in deciding what counts as a word. What matters is that there is a distinct
key that can be identified in the document and used to obtain a posting list. Each
entry in the inverted index can thus be understood as asserting a fact about the documents
listed.
Search engines do not typically confine their indexing to simple words. They typically
allow for indexing all sorts of variants of the base words, such as stems, case- or
diacritic-folded variants, or error corrections (soundex, OCR correction). They allow
for indexing fragments of words (e.g. wildcard indexes) and groups of words (e.g.
phrase indexes). More advanced systems may index results of deeper linguistic analysis,
such as part of speech analysis, entity recognition and normalization, or synonyms.
All of these terms can be understood as applying functions over the basic terms in
the document in order to improve precision, recall, or scoring.
Functions that improve recall map multiple inputs to a single (or a few) number of
outputs. They define equivalence classes over the base terms. Let's look at some examples.
The simplest example is case-folding so that Fox and fox both map to the same term. A search will then return documents matching either the
upper or lower case form of the word: more relevant documents returned, greater recall.
Inflectional stemming is a function that maps multiple word forms with the same part
of speech to a single stem. In cases where the word or its part of speech is ambiguous
stemming may produce multiple stems. For example, runs ⇨ run, ran ⇨ run, but running ⇨ run (verb) and running (noun). Stemming improves recall, because a single term combines various verb forms.
Separation by part of speech may improve precision by avoiding undesirable collisions.
It is undesirable for a search for the noun mappings to match a document containing map used as a noun. Notice how decisions about what the basic atoms of the text are makes
a difference to the functions that apply to those atoms: if don't is don and t then stemming don to do will degrade precision for searches for do (because the word don has a meaning of its own) whereas not stemming don to do will degrade recall (because not we miss documents with don't). If don't is do and n't, then that tradeoff doesn't arise.
Derivational stemming is another function mapping N words to 1 (or a small set) of
roots. In this case, related word forms are mapped to the same root, so lovely and love and lover may all end up mapped to a single root love. This even more dramatically increases recall but possibly with substantial loss
of precision. On the other hand, if the intent of a search is to look for general
concepts rather than specific words and phrases, perhaps there is no loss of precision
at all. "Relevance" is in the eye of the beholder.
Other normalizations have a similar recall-enhancing property. OCR correction maps
words containing characters that OCRs tend to misconstrue to their more likely alternatives
(o1ive ⇨ olive. 0live ⇨ Olive). Soundex maps proper names in a way that similar sounding spellings all map to the
same string (Holstege ⇨ H423, as does Holstage and Holstedge and even Halsted). Some linguistic analysis can be even more dramatic: synonym matching consolidates
very different words (hound ⇨ dog, mutt ⇨ dog, Pomeranian ⇨ dog) and part of speech analysis reduces a rich vocabulary to a handful of classes (mutt ⇨ Noun, their ⇨ Pronoun).
Some recall-enhancing functions break the atomic terms into multiple terms. For example,
decompounding in German breaks a long noun like Schiffskollisionen into constituent parts Schiffen+Kollision. A search for either component will match, but at the same word position as the whole.
Decompounding therefore constructs alternative readings of the same sequence of base
tokens.
Some recall-enhancing functions combine multiple base terms into single terms to account
for variations in tokenization. For example, dehyphenation collapses alternative hyphenations
to account for the presence or absence of discretionary hyphens or variations in spelling:
wild card = wild-card = wildcard. Dehyphenation therefore constructs alternative readings of the same sequence of
base tokens.
Functions that target precision map single terms to multiple distinct terms, generally
by applying some contextual information, or combine multiple distinct terms into a
single term.
Take stemming for example. Simply mapping running to both run and running improves recall, but determining that a particular instance of running is a noun, based on the sentence context, and only indexing the running improves precision. Similarly, knowing that a text is English rather than French
tells us that the stem of font should not match faire.
Word N-grams and noun phrase indexing are example of combining functions. By creating
single terms for the trigram the quick brown and quick brown fox, an inverted index can resolve a search for the quick brown fox by intersecting two posting lists to produce a fairly precise result, even if there
are no positions available. Furthermore, the TF-IDF for the quick brown will much more accurately reflect the distribution of the overall phrase in the corpus
compared to the TF-IDFs for the, quick, and brown on their own, as these words appear in many other different contexts.
Some precision-enhancing functions break the atomic terms into multiple terms. For
example, character N-grams create overlapping shingles: amazing ⇨ ama, maz, azi, zin, ing. A wildcard search for *zing can use these shingles to produce a more precise result than would be possible with
just leading wildcard terms.
Entity recognition and normalization may apply deep knowledge of the world and the
syntax and semantics of the text to improve either recall or precision. For example
consider the text: Paris is famous for being famous. She was seen in Paris last week. The first Paris and the She may be recognized and resolved to the entity Paris Hilton, and the second Paris may be recognized and resolved as a different entity Paris, France but not without a fair amount of knowledge about the world, the context of this scrap
of text, and anaphora. Assuming such knowledge is successfully applied, the term Paris, France as distinct from Paris Hilton enhances precision, and the recognition of Paris Hilton in this scrap at all enhances recall.
Search Engine 201
Fields and Specialized Indexes
It is also conventional to define search "fields" — specific parts of the document
that are indexed separately. Search engines rely on some basic markup parsing parsing
to identify the bounds of the field in documents. These days that would include XML/HTML
markup parsing; classically it would include regular expression definitions of formats
or built-in handling for a variety of document formats, including many binary formats.
Fields may be implemented as distinct inverted indexes, or as distinct terms within
the master inverted index. For example, the field subject may be defined to include all the text following the first colon on a line starting
with Subject:, thus matching the contents of an email subject. A search for words can be restricted
to words in the subject field, enhancing precision.
Fields might overlap. Perhaps there is a field over all the headers of emails, as
well as the field over just the subject line. Or consider the following CSV (comma-separate
values) file containing information from the USGS about earthquakes.
"QUKSIGX020,N,11,0","QUAKE_ID,N,11,0","YEAR,N,11,0","MONTH,N,11,0","DAY,N,11,0","HOUR,N,11,0","MINUTE,N,11,0","SECOND,N,16,3","LOCATION,C,82","LONGITUDE,N,16,3","LATITIUDE,N,16,3","DEPTH_KM,N,11,0","MB_GS,N,16,3","MS_GS,N,16,3","OTHER_MAG1,N,16,3","TYPE1,C,4","REF1,C,4","OTHER_MAG2,N,16,3","TYPE2,C,4","REF2,C,4","MMIO,C,2","FELT_AREA,C,11","SOURCE,C,10"
2858,2861,1965,4,29,15,28,43.7,"Near Seattle, Washington",-122.3,47.4,59,6.5,6.5,6.73,"Mw","LB",6.6,"UK","PAS","8","337,000","SUS"3182,3185,1971,2,9,14,0,41.8,"North of San Fernando, California",-118.4,34.412,8,6.2,6.5,6.63,"Mw","HK",6.4,"ML","KJ","11","212,000","SUS"
3245,3248,1972,7,30,21,45,14.1,"In southeast Alaska",-135.685,56.82,25,6.5,7.6,7.61,"Mw","SR",7.4,"Ms","ABE","7",,"SUS"
3268,3271,1973,2,21,14,45,57.2,"Off the coast of Ventura County, near Point Mugu, California",-119.039,34.099,17,5.7,5.2,5.3,"Mw","HK",5.9,"ML","PAS","7","52,000","SUS"
3625,3628,1977,6,21,2,43,6.6,"Southwest of French Camp, California",-121.67,37.665,11,4.7,3.5,4.15,"Mw","BAK",4.4,"ML","BRK","6","16,000","SUS"
3697,3700,1978,8,13,22,54,52.8,"Near Goleta, California",-119.682,34.397,13,5.5,
5.6,5.8,"Mw","ED",5.1,"ML","PAS","7","25,000","SUS"
One field (magnitudes) may consolidate the information all the magnitude columns (numbers 13, 14, 15, and
18) and another (magnitude1) may consolidate the information about one kind of magnitude measurement (e.g. columns
15, 16, and 17). See Figure 4.
Figure 4: Fields
Yellow highlighting is one field with all magnitudes; Blue bold text is a field with
all information about type1 magnitudes; Green italics is a field with all information
about type2 magnitudes.
It is also common to take the next logical step, and allow for fields with particular
scalar types, such as floating point numbers or unanalyzed strings. Specialized indexes
over these scalar fields support queries such as scalar comparisons. That is, not
only can you ask for documents that contain the number 12.0 (whether written as 12, 12.0, or 1.2E-01) but you can ask for documents where the field's value is less than 47.23.
Even more specialized indexes in support of geospatial or temporal operations are
also possible. For example, see Lucene spatial Spatial521. Here one can ask not only for documents containing the point (37.3175,-122.041944) (aka the location of Cupertino City Hall), but for documents containing points in
a polygon representing all of Santa Clara county.
Notice that there may be hierarchy values here: the point (37.3175,-122.041944) may also contain the two numeric values 37.3175 and -122.041944.
Support for RDF triples and specialized triple querying in full-text search engines
themselves is not common, but the integration of full-text search with RDF queries
is becoming more common. Entity extraction vendors now generally make entities available
as RDF triples as well as via the traditional character-offset method. I choose to
regard indexing and querying of triples as just another kind of specialized index
that a search engine might make available.
Scoring generally moves away from a TD-IDF paradigm for such specialized indexes and
queries, although scoring still plays a role in ordering results. For example, it
is common to order the matches of geospatial queries by the (geospatial) proximity
of the points: a scoring regime can be used to achieve this.
Term Vectors
Imagine the inverted index for a single document: For each term that appears in the
corpus, we have the frequency of occurrence of that term. Now imagine that instead
of listing the words, we just have a slot in the vector for each term.
Figure 5: A term vector
brown 1
clock 0
cow 0
dog 1
Dogs 0
down 0
fox 1
foxes 0
How 0 => [1,0,0,1,0,0,1,0,0,0,1,1,0,0,0,0,0,1,1,0,0,1,1,0]
jump 0
jumped 1
lazy 1
let 0
moon 0
mouse 0
now 0
one 0
over 1
quick 1
ran 0
struck 0
the 1
The 1
them 0
This vector of terms finds much use in statistical analysis of documents, clustering
and classification. Each term corresponds to a dimension in a high-dimensional term
space and the frequency gives a magnitude in that dimension. Suppose the entire vocabulary
of a corpus consists of the words cat, dog, horse, snake, and zebra (A very boring corpus, clearly.) A document with three occurrences of dog, and one each of horse, snake, and zebra would be represented by the vector [0,3,1,1,1]. Document similarly can be defined by mathematical comparisons of the vectors. Using
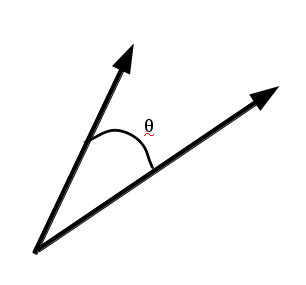
simple cosine distance, the document represented by the vector [0,2,0,1,0] would be more similar to that document (cos(θ)=0.28) than to the one represented
by [4,0,3,0,0] (cos(θ)=0). In the real world the term vectors are much longer, and consist largely
of zeroes.
Two kinds of manipulation occur to make practical use of term vectors: (1) the dimensionality
is reduced in some way, to pick out the "important" dimensions, and (2) the frequency
values are normalized or mapped in some way to embed the vectors into an appropriate
metrical space. Another way to think of the latter operation is that different distance
functions are used to measure how close two term vectors are. Classification becomes
the selection of a vector such that members of the class members are close using some
metric, and non-members are far away.
Figure 6: Two term vectors, and a measure of their closeness
Generalization and Application to Markup
What does all this have to do with markup? How can these same concepts be applied?
First, let's summarize and generalize the basics we have seen.
An inverted index contains a mapping from terms to posting lists.
Terms may represent atomic units of the document.
Terms may be defined by functions over the atomic units of the document.
Term-generating functions may apply contextual information from the document itself,
or external context.
There may be alternative, overlapping atomic units.
There may be hierarchies of atomic units.
The set of available terms affects the recall and precision of queries.
Specialized indexes store values of different types and provide mechanisms for returning
posting lists satisfying type-specific constraints.
Values may act as terms.
The set of available terms and of values contained in specialized indexes defines
the effective information content of the document.
Term vectors may be used to classify and cluster documents.
An inverted index contains a mapping from terms to posting lists.
Terms have some kind of key that can be selected quickly to return a posting list
from the inverted index. The essential feature of the key is that it can be ordered,
so we can quickly look it up, and that it be distinct, so that different terms have
different keys. It doesn't need to be a simple string. Indeed, it doesn't actually
necessarily need to be distinct, as long as we are willing to tolerate a certain loss
of precision. It is useful to know that the character N-gram dog is not the same term as the word dog, but it isn't a fundamental failure if those terms get consolidated.
Markup features can be used as terms. The fact that a particular element named {http://www.opengis.net/gml/3.2}Point exists in a document can be recorded in an inverted index just as well as the fact
that the word dog does. Where tokenization breaks word terms from documents; format-appropriate parsing
breaks markup elements from documents. A search for documents containing that markup
component will return the set of postings from the inverted index in exactly the same
way that a search for documents containing the word dog did.
Just as there was no need to define the set of words to index up front, there is no
need to define the set of XML elements or attributes or the set of JSON properties
or the set of RFC822 header types to add to the index. As long as there is a parser
that breaks out the markup elements for the index, the documents themselves define
the index.
Example:
Content-Type: text/plain; charset=utf-8; format=flowed; delsp=yes
To: "Nupoor Kotasthane" <Nupoor.Kotasthane@marklogic.com>
Date: Wed, 24 Jun 2015 12:20:28 -0700
Subject: interiorPoint
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
From: "Mary Holstege" <mary.holstege@marklogic.com>
Organization: Mark Logic
Message-ID: <op.x0q1cezwfi7tae@mary-z620.marklogic.com>
User-Agent: Opera Mail/12.16 (Linux)
That looks good to me. //mh
Markup components in the inverted index (I am using XPath syntax to indicate markup
components as distinct from words in the index.)
We have seen how (language-specific) tokenization identifies tokens of different kinds
(punctuation vs white space vs words), extracts words from documents, and those words
induce terms in the inverted index. Similarly, (format-specific) parsing identifies
markup components of different kinds (elements vs attributes vs text), extracts markup
components from documents, and those markup components induce terms in the inverted
index.
Consider the XML document:
<apidoc:function xmlns:apidoc="http://marklogic.com/xdmp/apidoc"
name="distance" type="builtin" lib="geo">
<apidoc:summary>Returns the distance between two points.</apidoc:summary>
</apidoc:function>
The atomic markup units are the three attributes (name, type, and lib), the two elements (apidoc:function and apidoc:summary), and perhaps also the document as a whole and the namespace declaration. An inverted
index might have:
Figure 7: Atomic markup components in inverted index
Given an XML parser, there is no need to define in advance what markup components
to add to the index: this is a generic operation.
Terms may be defined by functions over the atomic units of the document.
Various precision- or recall-enhancing functions may be applied to form new terms
from existing terms. These functions run the gamut from simple case-folding to advanced
linguistic analysis such as sentiment analysis. Generally functions that enhance recall
group existing terms into equivalence classes, and functions that enhance precision
provide more detailed subdivisions of other terms. Some of this is clearly a matter
of perspective: if you regard individual characters as the atoms of the text, then
simple word terms are the result of the precision-enhancing function of tokenization.
Precision-enhancing functions over markup atoms divide classes and create distinctions.
For example, we may add the specific information about which element is a root element
or which elements are contained in other elements:
Recall-enhancing functions over markup atoms create equivalence classes over them.
For example, it is possible to collapse markup from different formats to single indexes.
Consider the following XML, JSON, and INI file documents.
{"example":
{"nested": "here is some content",
"mixed": false
}
}
and
<example>
<nested>here is some content</nested>
<mixed>false</mixed>
</example>
and
[example]
nested: here is some content
mixed: false
From these we can produce the same markup indexes:
If everything looks the same in the index, it is as if they are the same in the document.
As with character N-grams, sometimes this can be a matter of perspective: micro-parsing
can be seen as either creating pieces of atomic units, or creating new, alternative
atomic units. For example, micro-parsing of the CSS in this piece of HTML adds new
atomic units/fragments of the attribute unit:
Term-generating functions may apply contextual information from the document itself,
or external context.
Adjacent or nearby terms may provide context, for example in disambiguating parts
of speech. The language of the text (which may be internally defined for XML documents,
or part of the external context, is necessary for performing stemming, decompounding,
noun phrase identification, or more advanced linguistic analysis. Extensive knowledge
of the world may be necessary for things like entity recognition or synonym identification.
Stemming, case-folding, and soundex indexing have the effect of mapping multiple distinct
words to a single term, creating equivalence classes of words. Analogous functions
can be applied to markup components as well: case-folding of JSON property names and
HTML element names, ignoring element namespaces, having attribute terms that ignore
the parent element, "stemming" RFC822 header names by stripping off X-. Functions that require more external knowledge also apply: simple vocabulary mapping
can treat p and para as synonyms. Similarly, we can map the rdf:Description element and attribute to the same index entry.
Just as word N-gram indexing creates molecules that enhance precision in searching
for phrases, so too can indexing element N-grams and terms formed from parent/child
or sibling/sibling relationships create molecules that enhance precision in searching
for matching paths: a path like //apidoc:function/apidoc:summary can be matched precisely with a element/child index entries, slightly less precisely
with an element/descendant index entries, and quite imprecisely with just separate
element index entries.
Beyond simple vocabulary mapping, one can create "synonyms" of markup, reconceptualizing
the manifest markup even across vocabularies:
There may be alternative, overlapping atomic units.
Dehyphenation and decompounding produce alternative word sequences that overlap with
one another. Character or word N-grams can be viewed as defining different sequences
of atomic units.
Similarly, milestone markup in XML can be interpreted as defining atomic markup units
("demilestoning"):
<example>Here is the <start id="2"/> milestones marking <start id="1"/>
something <end id="2"/> where there is intertwingling <end id="1"/> of
milestones.</example>
Given an understanding of the milestone markup this can be indexed as if there were
the sequence of words something where there is interwingling and the sequence of words milestones marking something, each within their own distinct element.
Markup formats such as LMNL are designed to represent overlapping atomic units, so
that such detailed knowledge of the markup is not necessary and the document itself
can define the interface to the index with no additional context:
[s}[l}He manages to keep the upper hand{l]
[l}On his own farm.{s] [s}He's boss.{s] [s}But as to hens:{l]
[l}We fence our flowers in and the hens range.{l]{s]
Here we have He manages to keep the upper hand On his own farm., He's boss., and But as to hens: We fence our flowers in and the hens range. each within its own s, intertwined with He manages to keep the upper hand, On his own farm. He's boss. But as to hens:, and We fence our flowers in and the hens range. each within its own l.
There may be hierarchies of atomic units.
Words consist of characters. Phrases consist of words. Other hierarchies (sentences,
paragraphs, topics, sentiment regions) are possible.
Markup languages such as XML, HTML, or even JSON are intrinsically hierarchical. Elements
contain other elements. Properties contain objects which contain properties.
The set of available terms affects the recall and precision of queries.
Each new kind of term enables the inverted index to directly resolve certain kinds
of queries. This in turn enhances precision for that kind of query where the alternative
is to return a poor "best effort" based on the terms that are available. Terms that
define equivalence classes over other terms enhance recall where the alternative is
to return the matches for a less expansive term.
Even without fuzzy matching, relevance is in the eye of the beholder. Scoring algorithms
attempt to capture intuitions about what makes a matching document "better". Adding
recall-enhancing functions that create larger equivalence classes tends to undermine
precision. However, an effective scoring algorithm can ameliorate that tradeoff: if
the irrelevant results end up at the bottom of the scoring ordering, they don't matter
for many practical applications.
TF-IDF regimes can be applied to markup terms just as well as non-markup terms, although
in truth for pure-markup matching, relevance scoring feels a little odd. Is a document
that contains ten title elements within section elements really a better match for a search for section//title than one that has only one? Perhaps. On the other hand, the relative rarity of a
particular markup element (IDF) may indeed make it more interesting (relevant) for
certain kinds of applications.
Figure 8: Is document 1 more relevant to section//title?
Certainly relevance makes sense applied to terms that combine markup with textual
content: a document that has several title elements that contain the word example is surely a better match for a query of title containing example than one than has only one such title element and is also surely a better match than one that has many instances of example and many instances of title but not of example in title.
Figure 9: Is document 1 more relevant for "title contains 'example'"?
<doc>
<section>
<title>not here</title>
example one
</section>
<section>
<title>not there</title>
another example
</section>
<section>
<title>or here either</title>
last example
</section>
</doc>
Specialized indexes store values of different types and provide mechanisms for returning
posting lists satisfying type-specific constraints.
Traditional search engine fields define specific parts of documents to index separately,
so that a search for a word in a particular field can be distinguished from a search
for a word in the document as a whole. It is common to take the next step and index
typed values in fields, including types that support more specialized search operations
such as geospatial or date/time values.
Fields are really just part of a continuum to markup-based indexing. Indeed, frequently
fields are defined in terms of markup: a field may defined by reference to an XML
element. Field value types may be manifest in the format or defined by reference to
a schema of some kind.
In the following JSON document, property names can automatically induce fields, with
the duck-typing specifying the value types:
More advanced value extraction from markup is possible by applying external knowledge
about the specific markup, just as more knowledge enables advanced linguistic analysis
and indexing based on it.
For example, knowledge of the KML specification KML220 means that the point value (37.3175,-122.041944) can be extracted from the following bit of markup:
Notice that simple concatenation is not enough: we have to understand the meaning
of the elements.
Given an understanding of both the KML specification and the GML specification GML321, it is possible to create a combined index containing points from either format.
(A recall-enhancing move.)
Values can also be defined by the markup, rather than being simply wrapped in the
markup. For example, MathML MathML30 defines empty elements that designate various mathematical operators.
Given an understanding of the MathML vocabulary, the content markup element <sin/> can be indexed identically to presentation markup <mi>sin</mi>, so that search for either matches the other.
Values may act as terms.
Typed values may support specialized query operations, even quite complex query operations
such as finding all the matches containing a polygon that intersects with a query
polygon. However, even relatively elaborate typed values ground out on basic term-based
queries: is it a fact that this document contains this value?
Search for markup atoms and molecules may also benefit from specialized query operators.
However, basic term-fact queries are the root of it all: return the documents about
which this markup fact is true.
Figure 10: Resolving a value-as-fact query: value=47
The set of available terms and of values contained in specialized indexes defines
the effective information content of the document.
From the point of view of a search engine relying on an inverted index, if a term
isn't in the index, it is as if it doesn't appear in the document, and if a term is
in the index, it is as if it were manifest in the document. It is common, for example,
for indexing to skip excessively common words such as the. These are called stop words. A search for a stop word would fail, because no such
entry exists: the behaviour is identical to a search for a word that never appears
in a corpus. From the search engine point of view, therefore, stop words do not exist.
On the other hand, suppose the word foxes never appears in the corpus, but its singular form fox does. With stemming, a search for foxes will match the documents containing fox. From the search engine point of view, therefore, all the forms of the word occur
in the document.
Similarly, if a search for the MathML <sin/> element returns a document in which, in fact, it never occurs but the equivalent
term <mi>sin</mi> does occur, in effect <sin/> does occur in that document. Conversely, if indexing treats XHTML <br/> elements as stop words and doesn't index them, from a search perspective it is as
if they did not occur in the documents.
If you can find it when you ask for it, it is as if it exists.
Term vectors may be used to classify and cluster documents.
The mathematics of term vectors applies without regard to what the terms signify.
Indeed, there is a rich and extensive literature on term vectors applied to a wide
variety of fields having nothing to do words at all. Classification and clustering
over term vectors referencing both word terms and markup terms can discriminate based
on both.
For example, SVM classification can readily discriminate the piggy documents from the market documents if there are terms in the term vector for elements.
<piggy>one little piggy went to market</piggy>
<piggy>two little piggies stayed home</piggy>
<market>one little piggy went to market</market>
<market>one little piggy went to market</market>
Selecting terms generated from recall-enhancing functions (that is, those that create
large equivalence classes) for clustering tasks enables detection of larger classes
using fewer terms, allowing for more effective operation. It can also reduce some
of the noise, leading to better results. Selecting terms generated from precision-enhancing
functions (that is, those that create subclasses) for clustering tasks enables the
detection of more fine-grained classes than would be possible otherwise.
For example, including vocabulary mapping terms makes detection of cross-vocabulary
classes easier. Including terms for parent/child relationships makes discrimination
of classes for distinct usages of specific elements possible. Combining markup terms
with content terms in term vectors can allow for classification and clustering tasks
to be accomplished that could not be done with purely content terms or purely markup
terms. How document similarity is computed depends on what kinds of terms are in the
document term vectors.
Control the term vectors, control document similarity.
Summary
Looking at documents through the lens of a search engine gives us another perspective
on markup. A document is a term vector, where the vector may include markup terms.
The choice of which terms to include in the term vector changes the effective information
content of the document. Different terms can give different views of the same document
and parts of the document simultaneously. Different terms can be used to adjust the
precision and recall of matching, relevance scoring of matching, and to enable the
detection of more general or more specific classes using statistical and machine learning
techniques.
We can see some classic markup-related issues as analogous to common search engine
operations as applied to words: vocabulary mapping is like stemming or concept indexing,
overlapping markup is like dehyphenation or decompounding.
[Jones72]
Jones, Karen.
A statistical interpretation of term specificity and its
application in retrieval. Journal of Documentation 28 (1): 11–21. 1972.
doi:https://doi.org/10.1108/eb026526.
[GML321]
Open Geospatial Consortium: Clemens Portele, editor.
OpenGIS® Geography Markup Language (GML) Encoding Standard Version 3.2.1. OGC, 2007.
www.opengeospatial.org/standards/gml
[Piez12]
Piez, Wendell.
Luminescent: parsing LMNL by XSLT upconversion. Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10,
2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies,
vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Piez01.
[MathML30]
W3C: David Carlisle, Patrick Ion, and Robert Miner, editors.
Mathematical Markup Language (MathML) Version 3.0, 2nd Edition
Recommendation. W3C, April 2014.
http://www.w3.org/TR/MathML3/
[Zipf49]
Zipf, George Kingsley.
Human Behaviour and the Principles of Least Effort.
Addison-Wesley, 1949.
Jones, Karen.
A statistical interpretation of term specificity and its
application in retrieval. Journal of Documentation 28 (1): 11–21. 1972.
doi:https://doi.org/10.1108/eb026526.
Open Geospatial Consortium: Clemens Portele, editor.
OpenGIS® Geography Markup Language (GML) Encoding Standard Version 3.2.1. OGC, 2007.
www.opengeospatial.org/standards/gml
Piez, Wendell.
Luminescent: parsing LMNL by XSLT upconversion. Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10,
2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies,
vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Piez01.
W3C: David Carlisle, Patrick Ion, and Robert Miner, editors.
Mathematical Markup Language (MathML) Version 3.0, 2nd Edition
Recommendation. W3C, April 2014.
http://www.w3.org/TR/MathML3/