Quin, Liam R. E. “Markup Formats In Context: A comparison of the strengths of some widely-used markup
systems.” Presented at Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8, 2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Quin01.
Balisage: The Markup Conference 2014 August 5 - 8, 2014
Balisage Paper: Markup Formats In Context
A comparison of the strengths of some widely-used markup systems
There are a number of popular text markup formats in use today. Some
of these, such as JSON and Markdown, have risen in popularity recently;
others, such as SGML or troff, have
waned. Whenever a format becomes more popular it gains proponents who
seem to want to see it used everywhere, for everything, for ever, right
away. A fairly simple (and possibly over-simplistic) analysis of the
rhetorical nature of some of these various formats is presented in this
paper. The results of this analysis suggest areas of use for the
different formats and demonstrate that, rather than being in competition
with one another, the formats complement one another.
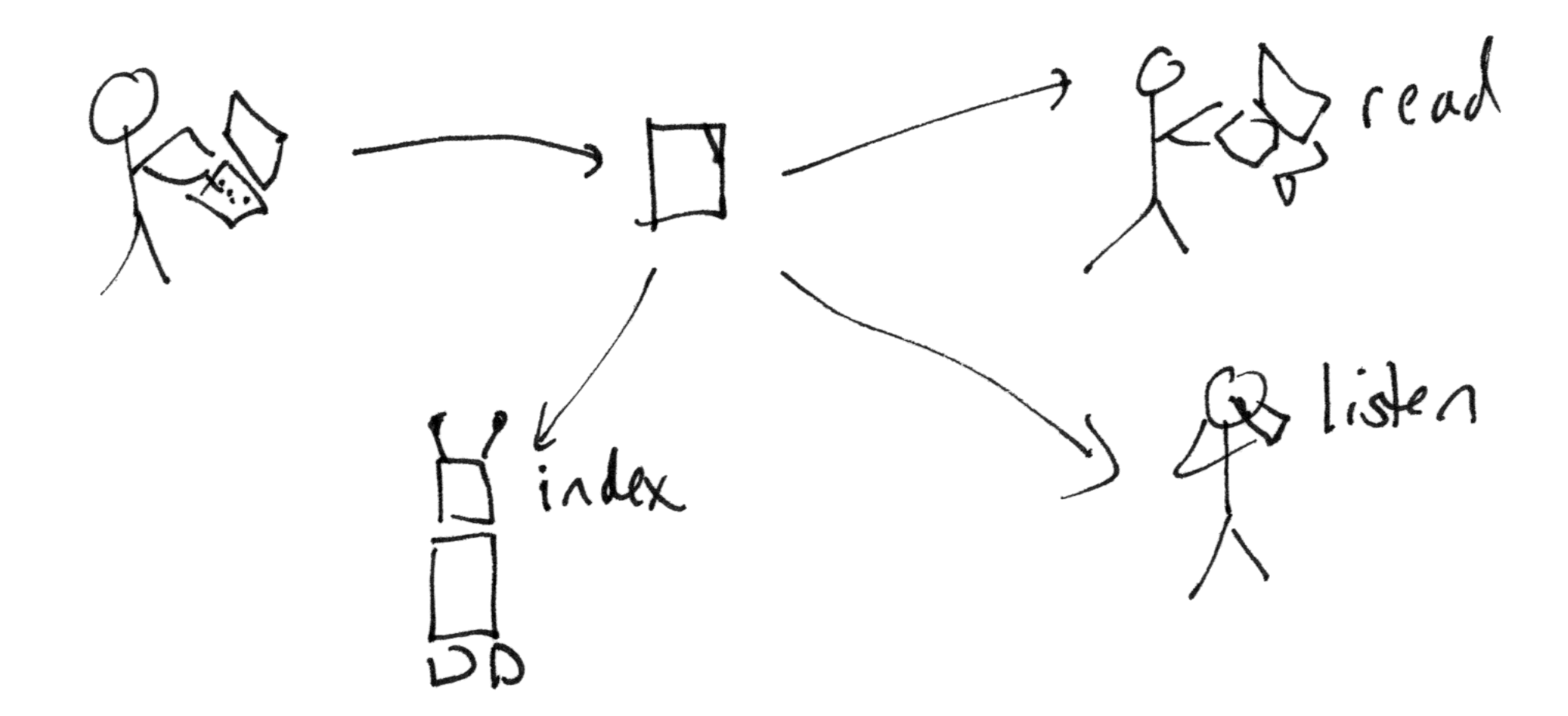
Figure 1: person-to-person communication using physical
transportation of pre-digital media objects.
When a human wishes to communicate extended ideas with another human not
physically present, paper and a pencil can be used. Historically, this
mechanism was extended using people trained to copy documents onto new,
additional sheets of paper, but this was slow and expensive, and, after
only a few thousand years, replaced by the automated printing
press.
Paper documents are difficult to revise and cannot easily be searched.
Paper documents are independent of software and with care can be archived indefinitely.
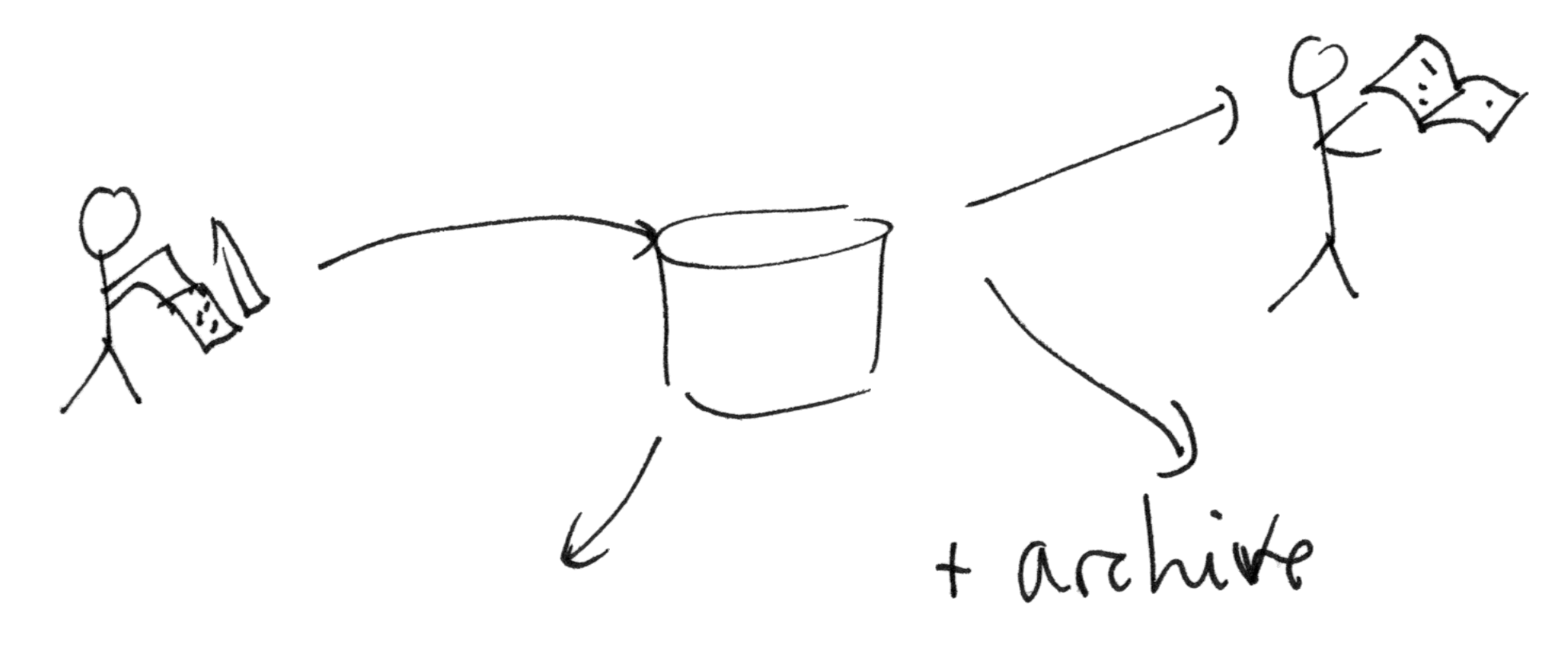
Electronic Paper
Figure 2
Figure 2: person-to-person communication using electronic
transportation of digital media objects.
Today if someone wants to write something for the benefit of another
reader, they can use a word processor and either send computer-printed
paper or send electronic files that the recipient can print and read.
Those files are sent sometimes as plain text (electronic mail), or for
longer documents or documents with more complex formatting, as PDF page
images or as word processing files.
Word processing files represent a document complete with formatting
but in an editable form, so that text can re-flow as needed. Such files
generally make use of system resources such as fonts, so that a document
may be differently paginated or, in the case of specialty symbol or
language-specific fonts, may be partly or entirely unreadable. For some
languages (Northern Cree and some of the scripts or writing systems used
in India and in Africa come to mind) it’s customary to write documents
using a font with a custom encoding, as Unicode coverage is (or is
perceived to be) incomplete or insufficient; this means that if the
recipient does not have the right font installed, the document may appear
correct but will have some characters in the document silently substituted
for others. To be fair this problem exists for all of the document formats discussed
in this
paper, but some of the formats alleviate the difficulties,
or at least let documents be explicit about what was done, more than others.
Word processor documents today use complex and proprietary formats
(although increasingly these are represented in XML). This means that they
can be difficult to search, although they are usually easy to revise.
Later versions of a word processor may interpret older files differently,
with or without warning, so that the documents become tied to specific
versions of software running in specific operating environments. Because
word processor formats are (implicitly or explicitly) tied to specific
versions of specific software, as well as to system resources such as
fonts, they are not suitable for archival use.
Portable Document Format (PDF), a document format produced and
maintained by Adobe Systems Inc. of California, USA, has a corresponding
ISO archival standard, although in practice PDF documents can and do make
use of extensions that are not archival. However, PDF files do contain all
needed resources such as fonts and images, and are in most cases
considered to be of archival quality. Software that creates PDF may have
options to create PDF/A, the archival variant.
PDF documents do not generally reflow text if printed or viewed on a
differently sized device than that for which they were created. The page
dimensions are part of a PDF document and cannot easily be altered;
hyphenation has been performed, footnotes have been numbered and so on.
PDF documents can be extremely difficult to read on smaller devices, as
the user may need to scroll horizontally back and forth to read each line
of text.
The formatting of both word processor documents and PDF files is
explicit (except as noted already) and it is therefore possible for a
search engine to process and index the text in them and then to display
formatted results and previews. However, because the formats are not
intended for this purpose, there are some difficulties. For example, PDF
does not require that the creating software explicitly mark word
boundaries, since each “glyph” can be positioned independently from any
other. If word and phrase boundaries are not clearly marked, indexing has
to use heuristics: sometimes one will run across search engine results in
which characters have been joined between paragraph breaks, or where words
have been incorrectly split, or where hyphenated words result in two
smaller sub-words being indexed separately.
Documents as essentially pictures of documents, whether because of
proprietary or poorly documented file formats, because of insufficient
information, or because the document actually contains bitmap (raster)
images of text rather than the actual text, can pose difficult or
insurmountable problems not only to search engines but also to people who
cannot easily read from the pictures, for example because the lines of
text do not reflow (creating a need for difficult sideways scrolling) or
because the user is relying on a text reader to speak the text out loud
and the document does not actually contain any text. Any system for
mediating communication between humans must be useable by all humans.
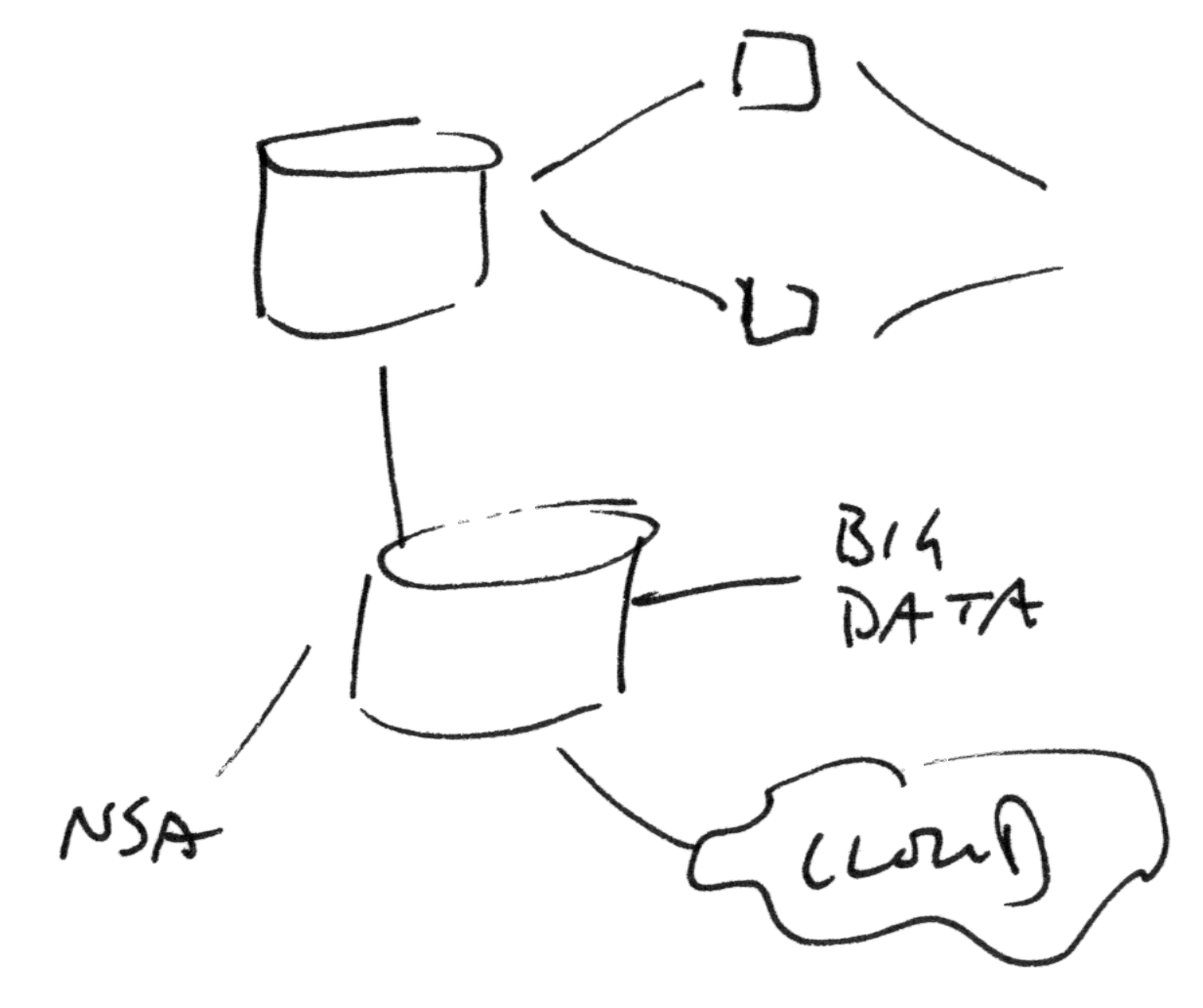
When Robots Watch
Figure 3
Figure 3: person-to-person communication designed also for
automated observers and mediators.
When people share documents and also expect their documents to be
processed by automatic robotic services such as search engine indexers
they must use formats that can be read by an unknown audience. HTML can be
a suitable format because it has well-defined behaviour: the robots know
where paragraphs start and end, which markup breaks up words or phrases
and which does not, and how relationships to other resources such as
images or linked documents are represented.
Although HTML 5 has added new structural elements such as article, it is common today for Web sites to use
div elements with CSS-based styling for
such things; this can increase the difficulty of determining the intended
formatting: the search engines can determine word and phrase breaks only
by applying the CSS styles. With the increased use of JavaScript-based
styling this becomes harder, but fortunately there are strong financial
incentives for commercial producers of HTML to use clear markup as
otherwise their Web sites do not appear in user’s search results.
HTML is a moving, changing format and is not necessarily safe for archival
purposes. PDF can be used with mediation, but PDF documents are not
necessarily sufficiently accessible; it is possible to create PDF
documents that consist of scanned bitmap page images rather than
text.
Documents that Last
Figure 4
Figure 4: person-to-person communication designed also for
automated observers and mediators.
When people share documents and need them to be archived for several years or longer,
a combination of formats may be best.
XML is a suitable basis for archival formatting because the syntax of XML
is not evolving significantly (unlike HTML). Since there are no
behavioural semantics within XML there is nothing to change: it is a
framework for carrying meaning. However, precisely
because XML does not have universal behavioural
semantics a robot, or a future human, cannot necessarily determine word,
phrase and paragraph boundaries, nor relationships to other resources, by
inspection. HyTime Architectural Forms (for use with the older SGML
standard document format) might have provided a way for robots to do this,
but they have not been adopted for XML.
Since XML documents cannot reliably be presented to humans or to robots it is necessary
to augment them, either with transformations or with alternate additional document
formats.
Whenever information is provided in multiple formats there is a
possibility of errors and contradictions between the various versions of
the documents. Providing one or more automated transformations, using
standardized and non-proprietary transformation languages such as XSLT or
XQuery, and clearly marking the XML version of the document as
authoritative, may be sufficient to minimize the impact of the lack of
default formatting for arbitrary XML vocabularies.
Suitably augmented XML, then, is suitable for archiving, can be
transmitted across networks, and can be formatted to reflow on different
devices or pages. The cost of attaining this goal can be high: it is the
cost of anticipating the needs of others (including later, older versions
of ourselves) as opposed to the cost of reacting only to our own
present-moment needs. To motivate the expenditure we must realize
short-term benefits. The ability to produce documents in multiple formats
is part of this; other benefits will be discussed later in this document.[1]
On Delivering XHTML or HTML
Many people have written to say that XHTML has no advantages over HTML, or even has
disadvantages. However, those writers all seem to be writing from a perspective in
which HTML is itself considered a good thing, and in which the primary purpose of
creating a document is to display it in a Web browser.
When a single document is to be consumed by many processes within a single
organization the ability to use XML tools on it can make XHTML very
useful. In addition, ebook readers are currently using XHTML and XML
rather than unrestricted HTML 5.
Even if XHTML documents are served on the Web as text/html and not as XML, the design of “polyglot” XHTML is
such that the result is predictable, and yet the document can still be
processed with XML tools. The value, then, is to the producer. Any value
to the consumer is coincidental, but there is also no significant
detriment.
When Documents are not Documents
Figure 3
Figure 5: Writing in the Clouds.
When information is divorced from any context and becomes a set of facts it can be
tempting to switch to RDF, the underlying knowledge representation used in the Linked
Data Initiative. That context, however, may still be needed over time, so in larger
projects RDF is most commonly used when it is automatically generated and known to
be context-free, or kept in named RDF graphs and regenerated as needed, for example
to support repudiation of facts or restrictions on sharing.
RDF cannot in general be represented in document format except through
visualizations of graphs, and thus is even harder to format in search
results or accessibility tools than XML (although since RDF can be
interchanged in XML there is clearly and necessarily some overlap).[2]
Programmer to Programmer, Machine to Machine: program-specific data
formats
When a computer program needs to communicate complex information to
another program different considerations apply from human-readable
documents.
Whatever format is used must map directly to data structures used
within the programs at both ends, as otherwise the primary goal of
communication between programs will not be achieved.
Programmers often consider efficiency to be an important goal, as
measured by number of lines of code for parsing, amount of memory
consumed, amount of processing used, and amount of data transmitted
for a given result. For this reason terse formats are often
preferred.
Flexibility of representation is not a benefit when one is
marshalling data, saving/restoring/transmitting objects, or exchanging
application-specific data. Instead, a very specific format may be
easier to parse.
Standardization is not usually considered important by developers
except insofar as widely-deployed code libraries might reduce work.
One therefore often sees one-off formats in use.
One widely-used program-to-program data format is JavaScript Object
Notation (JSON). Although, as the name suggests, this was originally a
serialized form of data structures such as are found in Web browsers, the
popularity of the World Wide Web and the desire to create and devour Web
browser data structures on Web servers has meant that most programming
languages today have libraries or native support available for handling
JSON.
Since object serializations are by nature tied to specific versions of
specific programs, and since JSON is not in general self-labelling with
regard to version or conformance, JSON cannot be said to be suitable for
archiving. None the less the syntax is compact and familiar to programmers
working with most of the widely-used languages today, languages whose
design was influenced by the C programming language.
Another widely used format is the “comma-separated values” (CSV) file.
There are dozens of different syntax variations and software that reads
CSV files often has to ask users to identify particular aspects of the
variant in use, showing that the format is not very suitable for
interchange or archiving. Recent work at W3C in supplying metadata for CSV
files may help in this area in the future.
Programs and Humans: program-specific text formats
A variant on machine-to-machine communication is the set of markup
formats designed by programmers for use in specific programs but intended
to be authored and edited by humans using text editors.
This list includes languages such as Markdown (used for formatting
wiki entries and for describing programs on github),
Microsoft-style “ini” files, but perhaps
also TeX and troff macros.
Over the years there have been many such formats, and long experience
suggests several difficulties with the use of such formats and several
strengths.
Ease of parsing can be so great there may not even be an
identifiable piece of code that’s a parser. This can be both a
strength (rapid prototyping and development) and a drawback (higher
cost of maintenance).
Ad-hoc formats tend not to have any explicit document format
version indication and yet be specific to specific versions of the
software for which they were written.
If there is only one interpreter for a language it’s common to
find that undocumented features become used, hindering future attempts
at a second implementation and frustrating attempts to interpret data
in the absence of the software for which it was created.
Errors in a file created in an ad-hoc format might go undetected,
and, without other implementations to compare, or without a concept of
validation, can become difficult, expensive or even impossible to
correct after the fact.
Ameliorating some of the concerns is the fact that many
human/programmer text formats are widely
implemented.
One such widely-implemented format, Markdown, is used in multiple
programs. Markdown is a text-based format designed for use in Web forms
such as Wiki pages, with a syntax such as using equals-signs to underline
a heading. It has the advantage that the text looks similar to the result
of formatting, although the markup for that same reason tends to be
presentational and not aimed at representing information which can be
re-purposed. Unfortunately, there are many incompatible variations of
Markdown and the format is not self-labeling, so that one can't be certain
which variation one is seeing.
A strength claimed for Markdown is that people unaccustomed to HTML
or other markup languages can work with it. Direct content-editing in Web
browsers removes much of that appeal, since a word-processor style of
input editing is presumably even more appealing to the same people who
don't like HTML. In fairness one should also mention programmers who want
a text-based document format but feel that XML and HTML are too verbose
for their needs.
Factors for Evaluation
This section describes some of the factors that determine
which format to use in a given situation. There is no complete list because
situational and contextual factors are always the most significant in
practice. Note that evaluation here is not in the sense of deciding one
format to be in some way superior to another, but to suggest
applications for which each is the most suited.
Information Life Cycle
Information that will be archived for future research purposes
must be clear when taken out of context. This might be achieved
through careful documentation and avoiding relying on application-specific
or opaque formats.
Information that will be used once and discarded, such as an API
message in a Web service or notification that a user moved a pointing device
could reasonably be in an application-specific format, but if multiple
programs might make use of the same message then there is greater
value in a more generic format.
Information that will be stored and processed and perhaps queried
will need to be in a format that supports that processing. This is the most
common case for documents today and the least common for data (since the
data is more easily queried in a data store than interchanged en masse).
Self-describing or clearly documented information will generally
make querying easier and
will facilitate recovery from an archive in the future, but that follows for all
possible data formats. However, not all data formats are such that documents
can easily, and routinely do, identify the format used and version of that format.
For example, neither CSV files nor Markdown documents can in any standard manner
identify the specification or language to which they might conform, and
HTML 5 documents do not identity the dated version of the "living standard" to which
they conform.
Audience Language and Culture
Information that contains mixed languages, scripts or dialects will
need a mechanism to indicate this, such as xml:lang in XML or lang in HTML.
Where human-readable content is included and could be in any language
(now or in the future), rich text (mixed content) will almost certainly be needed,
at a minimum for supporting Japanese or Chinese ruby annotations.
Where text may be translated, in part or whole, a text replacement
mechanism may be needed to make a translated version of a document.
It may also be necessary to mark which parts are to be left untranslated (push the
button labeled sokken: the label on the
physical vending machine on the platform doesn't change just because you have
an English guide book).
Universal Access
Any information presented to people will need to be accessible to
them. This means that accessibility must be built in at all levels.
Some of the formats described in this paper are accessibility-agnostic,
but others can include or encourage user interface elements that can be
harmful or exclusionary; in such cases extra vigilance may be needed on
the part of document authors and system developers.
Relationships between Documents
Sometimes a document or piece of data might stand alone,
but that surely is rare. A document might form part of a sequence, might
contain links, might be contained in, or
be a database, so that joins between
sets of values might be performed.
Link discovery requires a standard vocabulary such as HTML or XLink
or a standard discovery mechanism such as HyTime's architectural forms
for SGML years earlier.
Implicit links, such as might be found by joins, are thus format-dependent;
a dictionary site might make a link out of every word or phrase in a paragraph to
a corresponding definition, but might do so programmatically (often
with poor results in the face of homonyms). This ability is independent of format,
but explicit linking requires syntax as does marking terms not intended to participate
in such links.
Although simple querying can be performed on any of the formats, since
they are text based, structure-aware querying is currently defined only
for some formats, including RDF (SPARQL), XML (XQuery) and (although
not a standard) JSON (JSONIQ).
Structure-based querying often has difficulty when one syntax
is embedded within another: which HTML documents contain a definition
for a particular JavaScript function with a given type signature, or which
JSON documents contain a string with embedded HTML having a div element with a
particular class attribute. Such hybrid queries can involve complex textual escaping
conventions;
XQuery systems supporting SPARQL
queries of RDF embedded in XML provide a promising counterexample.
Default Formatting
Documents on the open Web need to be findable, and that generally
means that search engines will need to parse them and then in response
to user searches generate result snippets, short extracts that users can
use to decide whether to read the longer document. Phrase and word
breaks and basic formatting is necessary for the snippets.
Default formatting is also needed for operations such as copy and paste.
Validation
Although validation is a dirty word in some HTML circles, in other
circles it's an essential part of doing business: context determines function.
Validation can be at the syntax checking level, or at the business logic level
(every invoice must have a date, a customer number and an amount), or can be
at the application level (the file is OK if the program reads it). Of these, the application
level validation is the most powerful (arbitrary code) and the least portable. A standard
way to express business or grammar rules means that documents can be tested
against multiple programs and can also serve as documentation over time.
Data Typing
A document may contain components with identifiable data types such as
"numbers" or "sequence of characters, string" or "truth value". This is essential
for data binding and object dumping (as in JSON), but for some other systems it's
also
important to support user-defined types such as sock-colour or MailingAddress.
Program Compatibility
The constructs that a data format can represent should match the
objects that a program needs in order to manipulate that data. If a
format is too difficult to process it will not be popular with
developers.
This must be balanced by the fact that programmers may not be the
only, or even the most critical, stakeholders in a project.
In some cases (and some contexts)
a compromise can be reached using scripting languages
such as JavaScript, but then security implications must be considered.
The need to process data is intrinsic to computing with data;
having standard data processing and transformation languages can
help with staffing needs as well as system portability and longevity at
the expense of using languages that are not necessarily optimized for the particular
task at hand.
Information Modelling
One of the decisive factors for many projects in the past has been
whether the goal of using markup is to model information (which may
exist outside of the marked-up document, for example in a physical
book or manuscript being transcribed or quoted, or an existing
business process) or whether it is to guide presentation.
Markup as part of information modelling can be contrasted
with markup as a syntax for conveying data, such as node-and-arc graphs or
objects, which themselves may represent (or be) models.
HTML and Web Browsers
The markup in HTML is primarily driven today by the goals of Web
browser vendors.
Although lip-service is paid to so-called “semantic tagging” what is
meant is markup divorced from presentation specifics and yet tailored to a
specific type of software application, the Web browser. An HTML document
represents part of a Web Application, together with other resources such
as Cascading Style Sheets (CSS), images, JavaScript programs, and perhaps
input data in JSON or other formats.
So-called semantic tags (actually elements) added to HTML 5 have
mostly included markup for blogging. Transcribing a play, writing a poem,
even sharing song lyrics, these are not on the HTML agenda.[3]
Recent work on user-defined elements in HTML concentrates on their
“behaviour” rather than on what (if anything) is being represented.
Since Cascading Style Sheets have built-in support for HTML features
rather than being a general-purpose styling language for marked-up
documents it is more convenient to use HTML rather than some other XML
markup language when using CSS, whether for Web browser use or
otherwise.
Since the HTML language is intended for use with CSS and JavaScript,
primarily within a Web browser, and not for document modeling, it makes
sense to use XML for authoring, transcriptions, and archival purposes, and
to transform to HTML when needed.
Multiple Consumers: Transformations
The need for document creators to produce EPUB documents for
electronic readers alongside other formats has led to an increase in the
usage of XML, as opposed to (or as well as) proprietary page design or
word processing formats. There is nothing about XML that makes it
inherently more amenable to transformation than JSON, or than any format
that can be parsed reliably and in an interoperable manner. In practice,
however, the existence of XSLT, of XQuery and XPath, and the widespread
availability of tools implementing those languages, means that XML is a
particularly convenient choice. The use of XML schema languages to check
that documents meet specified constraints can also help to control the
scope of transformation programs.
It should be noted that a strength of XSLT is that it can be written,
read and maintained by people who do not see themselves as programmers,
but as document people. The declarative nature of XSLT, and the limited
control flow possibilities, help to make the XSLT transformations easy to
understand. As a result, organizations with people working on
predominantly textual documents are very likely to have staff who can
comfortably use XSLT, making XML in turn an excellent choice as a basis
for transformations.
HTML and JSON, by contrast, do not have such transformation languages;
JavaScript is much closer to “regular programming” than XSLT and may be
seen as inappropriate for technical writers to use.
Comparison of Formats
So far this paper has introduced some use cases and (indirectly)
markup formats. This section summarizes the strengths and weaknesses of
each format using the factors for evaluation described above, after a brief introduction
to
make clear what is meant in this paper by each format.
it should be stressed that this is not a complete list of markup
formats; the goal of this paper is to help the reader choose among several
of the most likely formats to be used today, and to provide a starting-point
for discussion.
Plain Text (Unstructured)
Mentioned here only for completeness, plain text files with no claim
to using any particular markup strategy can be read by humans and if
there is some regular ad-hoc syntax then a program can read the file,
but there is no Network Effect: if the syntax were widely enough used to
have multiple implementations and a user community it would no longer be
considered a plain text file, but would have identifiable
structure.
Since plain unstructured text does not by itself constitute a
markup language, it will not be compared further.
Markdown
Although there are a number of mostly-compatible variants of Markdown,
in this paper we will imagine a world in which a single variant dominates.
The stated intent of Markdown is as a text to HTML conversion tool for
Web writers.
Life Cycle: because Markdown is not a standard, variations between
versions may mean Markdown is not ideal for archiving. This is
exacerbated because Markdown files are not self-describing: they do not
label themselves as Markdown and do not identify the version of Markdown
to which they conform.
Audience, Language and Culture: Markdown is not internationalized. Lack
of support of mixed language paragraphs, indications of language in use,
explicit right-to-left markup, Ruby annotations and
script selection may make it unsuitable for mixed language content. Lack of
named identifiers for sections and paragraphs may make it difficult to keep
translations in sync.
Universal Access: Markdown has limited support for HTML
accessibility from a reader perspective; on the other hand Markdown has
found a use for people writing blogs, because it can fairly easily be
created in a text editor and uploaded, avoiding the user interface for
the blogging system.
Situations: Markdown is suitable for simple computer-mediated
human-to-human communication, since Markdown files can easily be read in
their text form as well as when converted to HTML. Markdown cannot
represent complex documents such as mathematical research papers.
Default formatting: Markdown files can be seen as text files or as HTML,
and it is reasonable to say that, although not as powerful r widely
supported as HTML in this regard,
Markdown documents are transparent with respect to the author's formatting
intentions.
Data Typing and Validation: not provided except for basic syntax checking.
Program Compatibility: Markdown is not significantly easier to process
in programs than HTML, and a common way to process it is in fact to convert
it to HTML first.
Use case: Markdown is primarily used where a text-based "rich text" is
needed for people uncomfortable dealing with HTML or XML directly, and where
no tools are available.
Information Modelling: not attempted.
JSON
JSON (JavaScript Object Notation) is a mechanism for transmitting
data that can easily be instantiated as programming-language-level objects by
the receiver. The format was originally defined for JavaScript but JSON is now supported
by most of the major programming languages. JSON is included in this paper
because, even though it is not perhaps a markup language, and does not attempt
to be particularly suited for textual documents, it is widely seen as a replacement
for XML in Web services and interactive Web usage (AJAX), where JSON strings contain
escaped fragments of HTML.
Situations: JSON is intended for program-to-program communication.
Life Cycle: JSON is primarily aimed at information that will be used once and discarded,
such as search results communicated from a Web server to a Web browser. However,
today there are databases for storing and querying "JSON documents".
Audience, Language and Culture: JSON documents do not have standard
ways (at the time of writing) to mark the natural language used for text strings;
even if it did, JavaScript objects are the wrong level of abstraction for this. It
is,
however, possible to embed escaped HTML string in JSON, and this can contain
language tags. JSON is not intended as an authoring format for textual documents.
Universal Access: since JSON is intended for program-to-program communication
this is not an issue. It is up to the creator of any HTML embedded inside JSON to
ensure accessibility, however.
Relations between Documents: JSON documents represent objects
with simple names; if it's known through some external source that the same
name in multiple documents represents the same information then database
query languages can associate the information. Additionally, JSON strings might
include escaped HTML markup with links, but there is no meaningful way to point
into a JSON file with a link, nor is there a standard meaning. JSON Schema defines
a mechanism to point to JSON objects using a reserved name, "id".
The JSONIQ query language gives an extended XPath-like syntax, and there are
other ways to refer to the inside of a JSON document, but pointing into an
object in a computer program isn't the same as linking to part of a document.
There are no widely used ways to transform JSON objects outside of a
programming language, although there is (or will be) JSON support in
XQuery 3.1, XSLT 3 and JSONIQ.
Default Formatting: There is no default presentation for JSON objects
beyond the "source code view" of the actual document.
Validation and Data Typing: The IETF JSON Schema language is still a
draft, and does not have large traction yet, but is gaining maturity. It
was influenced by XML Schema but does not support user-defined data
types. it is intended for use at a programmer and API level, not at a
business level.
Program Compatibility: This is the greatest strength of JSON: JSON
documents are also JavaScript fragments. They can be embedded in the
source code of programs, they can be read with "eval" (although security
implications suggest this should be preceded with validation) and they
can be generated directly from any object in a JavaScript program.
Although usage in other programming languages typically requires a
library, JSON's data structures usually map exactly onto data structures
in popular programming languages, unlike (for example) HTML or XML,
where attributes and mixed content must be modeled in terms of such data
structures.
Information Modelling: JSON is all about program modelling and not
information modelling. It's just syntax: one can map from SGML or HTML
or XML into JSON, but the primary strength of JSON is its convenience
for developers, not its easy (or otherwise) at modeling information.
Another indication of the JSON culture is that JSON Schema does not
provide for user-defined types, just number, string, boolean, array,
object and null. Schema authors can restrict the value space to say that
a field called socks_owned must be a whole number not less than zero,
but cannot say that socks_owned is of type socks_count; this reflects
the type system of JavaScript but is not for example a good match for
the way people think about documents or objects outside the
computer.
HTML
The HyperText Markup Language, standardized first at the IETF and
the ISO and later at W3C, is a fixed markup language aimed at delivering
documents to the World Wide Web. It is a vocabulary largely controlled by
Web browser makers.
A recent variant, HTML 5, adds support for "Web Components",
essentially user-defined HTML elements with content templates and
JavaScript and CSS styles to supply any required browser-side behaviour.
Unfortunately, HTML 5 is a "living standard" and features come and go
from time to time. This is balanced by excellent support from Web
browsers and clear documentation (in almost all cases) on exactly how a
Web browser should recover from errors.
Situations: HTML is primarily intended for computer-mediated human
to human communication of documents, but it is also increasingly used today for
computer-to-human interactions with "Web Applications."
HTML is also used for computer-to-computer messages, but in this case
the error recovery rules employed by Web browsers and by conforming HTML 5
implementations may not always be appropriate. Silent correction or acceptance
of errors has in other languages and systems famously led to deaths in space
missions and other engineering problems.
Information Life Cycle: HTML is implemented in perhaps a dozen
or more Web browsers, with a very large deployment. As a result it is difficult
for HTML to change in incompatible ways. None the less attempts to change
HTML in that way are often attempted, and, as a result, archived HTML documents
need to be explicit about the version of HTML they used.
The culture of HTML tends to be very much aimed at Web browser use.
As such, behavioural and presentation semantics are emphasized, with
"semantic" elements such as section and article being hailed as an
advance over equally generic names such as div. Again, the challenge
here for archiving is that the actual meanings of markup constructs will
and do change over time, and also that JavaScript code may or may not
continue working over a period of decades and may or may not
sufficiently describe behaviour and intent.
A large number of content management systems and databases for
storing HTML exist; some of them prefer XHTML, which can be parsed more
reliably; see the next section for more details.
Audience, Language and Culture: HTML has strong internationalization
and localization support, especially when used in conjunction with the Internationalization
Tag Set (ITS). Individual elements down to the word or sub-word level can
be marked for language, region and script, and can be marked as not to
be translated. Ongoing work, for example in supporting all forms of Chinese
and Japanese ruby annotations, is improving the situation still further, but,
overall, HTML offers one of the best formats for international and multilingual
documents today.
Early versions of HTML, unfortunately, put human-readable content
such as alternate replacement text for when an image is not available, in
attributes, precluding markup for mathematics, for Ruby annotations, for
emphasis; this defect is slowly being corrected, for example with the picture element.
Universal Access: Extensive and very helpful information is available for
document and application authors working with HTML. There are plenty of
challenges since not all HTML documents are automatically accessible, but
that is also true of other rich formats, especially when they are scriptable.
A complex system of fallbacks makes it possible to write Web applications that
will work on a wide range of devices and with assistive technologies such as
text readers, alternate pointing devices and even Braille terminals.
Relationships between Documents: HTML has a rich vocabulary
for representing relationships from one document to another, including
explicit hypertext links and link relations as well as implicit links (for example
with URI Templates) and links between information and remote descriptions
with microdata and RDFa annotations.
There is no automated mechanism today for link discovery when links
are implicit.
There is no widely-deployed standard HTML querying language, and there is no standard
way in HTML to represent relationships between documents outside of any document.
Default Formatting: HTML today is used for the representation and
formatting of best-selling printed books; it is not as sophisticated as
other publishing platforms but it growing rapidly in that area. HTML
documents have default associated formatting, although an increase in
the use of cascading style sheets to redefine the formatting and purpose
of elements can weaken that, and should be avoided.
Validation: There are widely-used syntax checkers for HTML, such as
that at validator.nu and the W3C HTML validator. Validation at the business
level, for example to say a heading must be followed by a paragraph, must
be handled with other mechanisms, such as by using XHTML and XML Schema.
Data Typing: HTML did not define any specific data model until HTML 5;
before that, although the HTML DOM was widely used, it was not mandated by HTML.
Like JavaScript objects, however, the HTML DOM is not strongly typed.
Program Compatibility: Unlike JSON, HTML documents cannot easily be
processed by programs in most traditional languages, even JavaScript.
Attempts to alleviate this, such as the popular jQuery library, have
been largely successful where they are available. HTML is not a strong
choice for object serialization and deserialization, which is why JSON
exists.
Information Modelling: HTML documents are closely (and increasingly) tied
to Web browser design. HTML is adequate in many cases for modelling a blog,
although it does not have standard support for song lyrics, poems, footnotes,
or a host of other basic rhetorical forms and devices.
XHTML
There are two main versions of XHTML in use today, and two meanings of
the term; XHTML 1 was designed to be an XML-based version of HTML 4 which can
be served to Web browsers as either XML or HTML. XHTML 5 is an XML serialization of
HTML 5 with the same goal: that when a Web browser reads an XHTML 5 document it
creates the same internal representation (DOM) regardless of whether the HTML or
the XML syntax was used. XHTML 5 is not, however, a successor to earlier
versions of XHTML.
All of the considerations for HTML apply to the XML syntax for HTML,
except that parsing of XHTML as XML means firstly that errors may be treated as
fatal and second that XML tools can be used with XHTML documents.
RDF and Linked Data
The Resource Description Framework, RDF, is a standard for
representing metadata as sets of decontextualized triples of atomic
values that form a (possibly disconnected) graph. RDF is most often
exchanged in three formats: RDF/XML; Turtle (a text-based syntax); and
SPARQL Results in XML, a format intended to be transformed (often with
XSLT) into a user-visible format such as HTML or SVG.
Linked Data (LD) is a name for the practice of publishing and
combining RDF-based graphs; it is mentioned here in the context of
making abstract RDF graphs available from documents.
Situation: RDF is primarily used in computer-to-computer communication,
although many RDF data sets are hand-authored.
Information Life Cycle: RDF documents are frequently stored in databases,
whether hybrid or RDF-only (RDF-only databases are often called triple stores).
Although RDF can be used for one-off communication it is more often
stored and queried. RDF is also commonly embedded in other formats,
especially HTML. The most common standard querying language for RDF is SPARQL.
Since RDF uses URIs, and URIs are defined to be opaque and
meaningless to an outside observer, RDF is strictly speaking not self
describing. In practice, though, URIs are normally made from natural
language words and represent what those words name. Most RDF
serializations do identify the file as conforming to a specific version
of RDF.
Audience, Language and Culture: RDF nodes have opaque identifiers
that are not in any natural language. it is possible to create
"labelFor" nodes in the RDF graph and give them language tags, although
it should be noted that RDF does not handle XML or HTML style mixed
content well.
The Linked Data culture wants all information about everything and
everyone to be public. Privacy and security remain challenges for the
various RDF communities. A talk at XML Prague suggested storing
RDF graphs in XML databases and using XQuery to construct a set of
triples for SPARQL queries based on security, but this should probably be seen as
an outlier; in the long term one can expect SPARQL itself to learn about security.
A technical challenge is that there is nowhere in a triple to store sharing or security
information.
Universal Access: RDF, like JSON, does not have any inherent user
interaction. Graphical visualizations, however, can be a challenge for
people who are not able to see them, and alternatives therefore need to
be considered.
Relationships between Documents: RDF is all about relationships,
but, oddly, cannot easily refer from one graph to another. RDF named graphs
(new in RDF 1.1) may provide a mechanism there, but it is too soon to measure
deployment.
Default Formatting: RDF documents do not have textual representations
other than (like JSON) as source. However, they are conventionally represented as
node and arc graphs. This visual representation conveys the overall structure of an
RDF
graph but not necessarily the actual content.
Validation: There has been recent work on RDF Shape Expressions for
constraining the shape of RDF graphs; this is not yet deployed.
Data Typing: RDF does support associating data types with values, and
these can be user defined.
Program Compatibility: The RDF model is graph based, not object based,
and does not correspond to the native data structures and type systems of
modern programming languages. However, those same current languages are
easily able to represent RDF graphs, and there is no mixed content to
complicate things.
Information Modelling: RDF is about modelling knowledge, not information.
it is a knowledge representation system used primarily for first-order logic and
inferencing.
XML
The Extensible Markup Language, defined at W3C as a subset or profile
of SGML (and originally known as Web SGML), is not really a single markup language
like HTML, but instead a framework for defining one's own markup languages,
all of which have a common syntax.
This paper distinguishes where appropriate between arbitrary XML documents and
documents in some specific XML-based markup language such as XHTML 5 or
DocBook.
Situation: XML is used in all areas of communication: person to
person, person to computer, and computer to computer, and can to some
extent also be used without computer mediation (that is, text-oriented
XML documents can be moderately readable, although not as much as
Markdown documents).
Information Life Cycle: XML documents have a life cycle that depends on
how they are used more than on the fact they are XML. For example, a message
from an automobile engine to a garage mechanic's diagnostic system, a
message from one operating system component to another when a user double-clicks
on a desktop icon, a transcription of an Anglo-Saxon poem,
a health-care provider's record of treatment for a patient, all are likely to be in
XML,
and each have different longevity and processing characteristics.
Trees based on parsing XML documents can be stored in relational, XML-native or hybrid
data stores,
and the XQuery language can be used to access them efficiently.
Audience Language and Culture: XML documents can support all of the
internationalization features of HTML and XHTML, but it depends on the specific
XML vocabulary. If you are designing an XML representation for text you should
consider adopting the HTML model where possible because of widespread
understanding and adoption.
The W3C Internationalization Tag Set (ITS) can be used directly in XML to
help with translation and localization.
Universal Access: Again, this depends on the ways in which the XML documents
are used. Awareness of the W3C Web Content Accessibility Guidelines can help
document designers to create accessible systems using XML.
Relationships between Documents: The XLink specification has not
gained much traction, and today people are more likely to use an ad-hoc attribute
called href, or possibly to use the HTML "a" element
by means of an XML namespace. it is also possible to embed RDF in XML documents.
Default Formatting: This is one of the two biggest weaknesses of XML:
since there are no default presentational semantics,
search engines cannot generate reliable snippets for results. Using XML on
the World Wide Web can therefore be a problem.
Validation: XML has a wide variety of validation mechanisms, from simple
and widely-supported DTDs, through to the baroque complexities of W3C XML Schema.
A part-way compromise is RELAXNG, but this does not perform the data binding
role of XML Schema, as described in the next paragraph. User-defined data types and
compound types are available.
Data Typing: XML Schema validation can assign type annotations to
elements in the parsed XML tree; type labels can be user-defined type names as well
as built-in types. Note that RELAXNG does not support assignment of type
annotations in a deterministic way, so that XML Schema is generally used where
data binding (object loading and dumping) is required.
Program Compatibility: This is the second of the two main weaknesses of XML:
the concept of an annotated tree of nodes is not a native data structure in most
programming languages. As with HTML, mixed content such as paragraphs with embedded
elements considerably complicates processing.
The situation is mitigated by the popularity of XSLT and XQuery, XML-specific
languages for querying and manipulating trees.
Information Modelling: This is the greatest strength of XML: that it
can be used, and culturally is used, to
model documents or other information outside of any particular
application or process. This strength comes at a cost: because XML
documents are usually independent of any one program they are also not
optimized for processing by any one program, and this can make XML
unpopular with application developers.
Some Use Cases
This section gives examples chosen to illustrate a typical use case
for each of the main formats discussed, together with indication of how to
represent the example in the other formats.
An Object Dump
Consider a JavaScript program running in node.js on a Web server, communicating with a database to
provide persistent storage of objects. Objects will have JavaScript
types and values; the obvious choice is JSON, which was designed for
this purpose.
One could use RDF instead; direct mappings from UML to RDF exist.
But then a library would be needed, and the various transfer syntaxes of
RDF are not as convenient for JavaScript programmers. In languages where
JSON also needs a library, or where JSON does not map well to objects,
RDF may be a stronger contender.
XML is also commonly used for object dumps. A library is needed,
both for serialization and for loading, but such libraries exist for
most languages. Since object dumps tend to be specific to a particular
state of a particular program at a particular time, they are not easily
reused by other programs; JSON may be more suited in that case. The
strongest use cases for XML are when documents will be used in multiple
ways.
The lack of standard transformation tools for JSON (compared to XML
for example) is likely to be short-lived; there are several contenders
as well as native-JSON NoSQL databases in widespread use.
A Technical Dictionary
In this example an organization edits a complex dictionary and
produces editions in print, in PDF, in HTML on a subscriber-only Web
site and in EPUB for ebook readers. Subsidiary products are also
produced and might include a dictionary defining only terms needed for
specific high-school (K12) or undergraduate courses, or subsets
containing, say, only entries that mention a specific compound.
Dictionaries are examples of documents that often feature mixed
content very heavily: superscript and subscripts, mathematics, terms
that are to link to definitions, multiple languages, symbols and small
diagrams may all occur in running text. Even a simple English dictionary
may contain relatively mixed content, as in the example in Figure
6
Figure 6
Figure 6: A definition from a 1730s dictionary showing mixed
English and Greek used in an etymology.
Since EPUB 3 used for electronic books is essentially a "Web site on
a stick" there is considerable pressure to use HTML. However, custom
markup can support business-level validation (for example, every major
definition must have at least three examples, and can help with research
and querying.
A compromise is to use (X)HTML augmented using ARIA attributes to
provide so-called so-called structural semantics, with microdata, or
even with custom XML elements; since HTML 5 Web Components provide a
standard way to add elements this approach is likely to become popular.
However, enforcing appropriate markup on authors may be necessary to
preserve the value of the work, and that may suggest a custom XML-based
markup with transformations to HTML as needed. Multilingual mixed
content is today the home turf of the XML team.
RDF metadata can be embedded in dictionary entries, or, more likely,
generated on the fly, perhaps with XQuery or XSLT, from the higher-level
XML notations that are more convenient for authors to work with.
Representing mixed content in RDF would typically involve explicit and
tedious representation of sequences of anonymous nodes.
Markdown quickly runs out of power to express complex texts, whether
multilingual like the English dictionary or containing chemical formulae
and mathematics as in the technical dictionary. Variants that are
sufficiently powerful start to stretch what is feasible with ad-hoc
text-based syntax and the extra difficulty of using HTML or XML for the
simpler parts probably pays off with consistent markup for the harder
parts.
Extended Journal Bibliography
In this example entries for different authors are to be connected;
any text formatting is minimal and formulaic. RDF is a strong candidate
here. JSON could also be used.
A common need with bibliographical data is powerful full text
searching, including similarity, starts-with, lexical containment,
proximity within a field or element, and more. The XPath and XQuery Full
Text extension was created with this in mind, suggesting that in some
environments an XML-compatible representation may be worth
investigating. Note that XQuery and XSLT 2 and later are defined to
operate on trees which, although commonly created from XML, could come
from any source that meets the necessary constraints.
Although Markdown again is not a likely choice, it should be noted
that the text-based format pioneered by Mike Lesk for the refer program in the 1970s, and later taken up
by BibTeX, is widely used and widely supported in technical and academic
communities.
Web-based Authoring Interface
This example considers a Wiki-like situation, with a large and
diverse group of authors for most of whom interaction with the Web site
is not a major part of their lives, so that they will have little
interest in learning about “syntax.”
This is a typical use case for
Markdown today. The Markdown markup is embedded in an HTML
form, and the user interacts with the Web browser's built-in text
editor.
More recently, the content-editable property of HTML elements
can be used to support word-processing style editing of parts
of documents in place, which may reduce the desire to use Markdown.
Hybrid Approaches
Just as it would be wrong to suggest that the various formats all
compete in the same space, so it would be wrong to insist that they stand
alone. Some obvious combinations are given in this section, but it is
necessarily not an exhaustive list.
RDF and JSON
People are already exchanging linked data using JSON instead of XML
or N3 to transmit RDF graphs. This is to be expected since RDF is
primarily a format for machine-to-machine communication and programmers
like the strong match between JSON and internal data structures.
There are a number of competing formats, including JSON-LD,
RDF/JSON, JSN3, JROn and more, although JSON-LD may at the time of
writing be winning out.
RDF and XML
There are three main approaches to adding RDF to XML: storing RDF
triples explicitly within XML documents alongside other XML information;
storing RDF separately from XML, perhaps in a triple store; generating
RDF from XML documents. Each has its place as circumstances dictate,and
combinations of these methods are also in use.
Converting from RDF to XML (other than serializing RDF as RDF/XML or
some other XML representation of RDF graphs) is not useful in general,
but the results of querying an RDF graph with SPARQL are often processed with XML tools such as XSLT
or XQuery for presentation in human-readable form.
Visualizations of RDF graphs as SVG and also using the XML-based
GraphML should also be mentioned here.
HTML and XML
Mixing two document formats, rather than a data format and a
document format, rarely seems to be productive. The combination of HTML
and XML is HTML represented in XML (XHTML). Another combination is found
commonly in RSS feeds and Atom, and is escaped HTML inside XML. This is
done because HTML (not XHTML) has different syntax rules that conflict
with XML, so that one cannot simply embed HTML inside XML.
Conclusions
It is not possible to give universal recommendations for when to use a
particular format because many unforeseeable considerations may apply. For
example, local knowledge of particular programming languages or ways of
working may dictate consideration of a subset of the formats, or may even
mandate the use of a particular format regardless of suitability to
task.
The formats discussed here do not compete with one another. They
complement one another, and are often used in conjunction with each
other.
[1] This is not to say that the benefits are not discussed in this
document but will be so discussed in some future version of this
document, but rather, that a reader proceeding in a linear fashion
forwards through this document, as published,
will encounter the discussion of those benefits later than
encountering the reference to this footnote. Those readers reading the
document backwards will already understand why
this is an important point.
[2] It should be noted that at least one mapping exists from the XML
Information Set into RDF, so that in theory at least one can represent
any XML document as RDF; in practice the mapping creates a separate
RDF graph node for every text character in the document, and is
unlikely to have much practical application. However, such RDF graphs
could, at least in principle, be returned to their XML form and hence
at least some of them could be represented as documents.