Stührenberg, Maik. “What, when, where? Spatial and temporal annotations with XStandoff.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Stuhrenberg01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: What, when, where? Spatial and temporal annotations with XStandoff
Maik Stührenberg received his Ph.D. in Computational Linguistics and Text Technology
from Bielefeld University in 2012. After graduating in 2001 he worked different
text-technological projects at Gießen University, Bielefeld University and the Institut
für Deutsche Sprache (IDS, Institute for the German Language) in Mannheim. He is currently
employed as research assistant at Bielefeld University.
His main research interests include specifications for structuring multiple annotated
data, schema languages, and query processing.
We describe an extension for the generalized standoff approach XStandoff to describe
spatial information over non-textual primary data objects. A use case for this kind
of
markup is the annotation of multimodal documents, that is text-image
combinations.
Not only since the advent of services such as Google Maps, demand for the annotation
of
(geo-) spatial information has risen. Therefore, first proposals for spatial markup
languages
have been developed, such as SpatialML (Mani et al., 2008, Mani et al., 2010). The International Organization for Standardization (ISO) has started a new project
in
2012 to create an international standard for the annotation of spatial and spatial-temporal
annotation as part of the Semantic Annotation Framework, ISO/NP 24617-7, ISO-Space
(ISO/NP 24617-7). As a member of a greater family of specifications, ISO-Space
borrows some concepts from SpatialML and should play well with other members, such
as
ISO-TimeML (ISO 24617-1:2012). Some of these markup languages annotate spatial
information represented in textual primary data (such as place names or paths which
are
traversed by an entity), however, Lee (2013) demonstrates that at least
ISO-Space can be used to describe spatial information in figures.
Standoff annotation is a valuable and common mechanism to annotate multiple hierarchies
and read-only media. One of these approaches, the XStandoff meta markup language,
was already
discussed in detail in Stührenberg and Jettka, 2009 and Jettka and Stührenberg, 2011.
Although XStandoff was developed for a variety of primary data formats (including
textual and
multimedia-based), its sequencing system was primarily designed for character- or
time-based
segments.
Since standoff annotation separates the markup from the data that is annotated, we
will
firstly define some concepts that will be used throughout the following text. The
data to be
annotated is called primary data (P). It should be
noted, however, that P but may consist of more than one member and may
even be empty under certain circumstances (see the following sections). The finite
set of
regions (spans) over P is called markables
(M). Each markable m as a member of
M is constructed by a set of coordinates in space or time and can be
identified. The set of coordinates is derived by a concept of
segmentation. The markables may be annotated afterwards by using a
finite set of annotationsA.
A key problem when using standoff annotation is the identification of the markables,
entities that are defined by a region of the corresponding primary data and that will
be used
as anchors for the annotation. In case of textual primary data, we have to deal with
a stream
of characters (or byte sequences) that can be delimited by using corresponding tokenization
methods (for example, splitting text into sentences by detecting sentence boundaries
and
sentences into words). In case of multimedia-based primary data one typically uses
points in
time to establish regions that are used as markables. Markables in spatial primary
data (in
contrast to spatial information provided in textual data) can be seen as two- or
three-dimensional objects, defined by a set of coordinates in space. While the demonstration
of describing spatial information given by Lee (2013) uses different iterations
of a figure to identify specific regions (first by using names, later on by using
coordinates), which are afterwards used as markables, it remains unclear how the different
iterations of the example figures are constructed (and processed). We therefore have
chosen to
adapt XStandoff's concept of segmentation to support the identification of spatial
markables
in non-textual primary data (that is, both still and moving pictures).
Using XStandoff for spatial and temporal annotation
Since XStandoff already has features for temporal segmentation (e. g. for annotating
multimedia-based primary data files such as video or audio files), we will concentrate
on the
aspect of adding spatial segmentation features. Defining a spatial markable is done
by
extending XStandoff's segment element. Usually, the element's content is either
empty or consists of metadata, therefore we concentrate on the attributes. Apart form
the
basic attributes start and end for defining the segment's range,
there are attributes for defining its type and its mode (value either
continuous or disjoint), both have been discussed
in Stührenberg and Jettka, 2009.
To extend the segment element to cover spatial markables we have added
further attributes. Firstly we opened up the value space of the type attribute by
including the value spatial. Then we created a new globally defined
attribute group spatial.attributes as a container for the newly developed
attributes. For the naming of these attributes we tried to stay as close as possible
to
already established specifications. A natural example for creating regions on non-textual
data
is HTML's image map.[1] An image map is created by referring to an external image using a map
element consisting of a number of area child elements. Each area
element has shape and coords attributes, amongst others. Therefore,
we decided to add these two attributes as well. In addition we introduced a
context attribute (with possible values 2d and
3d) borrowed from HTML5's canvas element (although HTML5
up to now only supports 2d contexts, 3d support is planned for future versions).
The coords attribute is used to depict coordinates on non-textual media file
(the relation between the segment element as bearer of the coords
attribute and the primary data file is established by the optional primaryData
attribute if more than one primary data file is used, see Figure 9 as
an example).
For demonstration purposes, we use Balisage's logo as a still picture example. The
graphic
is provided as png image file with dimensions of 2625 * 966 pixels at a resolution
of 300
pixels per inch (both horizontal and vertical).
Figure 1: Balisage's logo as an example
If we want to select the 2013 part of the image we use an image processing
programme to get the coordinates of the rectangular area starting at position
x1=2400,y1=125,
x2=2600,y2=125,
x3=2400,y3=945, and
x4=2600,y4=945.
XStandoff's 2.0 schema file defines the value range of the coords attribute
in terms of a regular expression pattern matching either pairs or triples of coordinates
separated by blanks, while the comma is used as in-pair separator. At least one pair
(or
triplet) has to be present for depicting a point in space. Since we use the blank
character as
separator between digit pairs it is feasible to use XPath's tokenize() function
to split the total string into the corresponding pairs of digits and use this to further
restrict the value space by using XSD 1.1 assertions (see Figure 2). When
dealing with 3d spatial coordinates, we use triplets instead of pairs.[2] Again, following HTML's image map approach, the starting point of the coordinate
system is not the lower left but the upper left corner of the
grid.
Figure 2: Declaration of the coords attribute
<xs:simpleType name="coord">
<xs:restriction base="xs:string">
<xs:pattern value="(\d+,\d+( \d+,\d+)*)|(\d+,\d+,\d+( \d+,\d+,\d+)*)+|C\d+,\d+ (\d+,\d+ \d+,\d+ \d+,\d+)+"/>
</xs:restriction>
</xs:simpleType>
<!-- [...] -->
<xs:assert test="if (@type='spatial' and @context='2d' and @shape='poly')
then count(tokenize(@coords,' ')) > 2
else
if (@type='spatial' and @shape='circle' and count(tokenize(@coords,' ')) = 1)
then (for $coord in tokenize(@coords,' ') return count(tokenize($coord,',')) = 3)
else
if (@type='spatial' and @shape='bezier')
then starts-with(@coords,'C')
else (@type!='spatial' or @context!='2d')">
</xs:assert>
Instead of strictly following HTML's shape attribute which provides values
for defining either a rectangle, a polygon or a circle, we only use
polygon, circle, and bezier
as valid values (since rectangles are a special form of polygons). The final form
of the shape
can be extracted by its coordinates (if three coordinates are given, we have to deal
with a
triangular shape, if four coordinates are supplied, the shape can either be a rectangle
or
polygon). Similar to HTML's image map approach a virtual line is constructed to connect
the
last coordinate given with the first one (coordinates are supplied in clockwise direction).
The full XStandoff instance describing the spatial segment of Balisage's logo can
be found in
Figure 3.
It is possible to define a Bézier curve as well. In this case, the shape
attribute uses the bezier value and the coords attribute
contains at least four coordinate pairs. We have chosen to adopt SVG's model of cubic
Bézier
curve commands (Section 8.3.6 in Dahlström, et al., 2011). The first coordinate pair starts
with the capital letter C (curveto with absolute
positioning) and depicts the start coordinate (since there is no equivalent to SVG's
moveto command). The following coordinates are construed as follows:
x2,y2 as control point at the beginning of the
curve, x3,y3 as the control point at the end of
the curve and x4,y4 as the end coordinate. After
the first set of four coordinate pairs, it is possible to use a multiplicity of triple
pairs
as additional coordinates. Note, that the Bézier curve will be closed via a line drawn
between
the last coordinate and the first (simulating SVG's closepath command
z, see Section 8.3.3 in Dahlström, et al., 2011).
Following Lee (2013), we introduced the possibility to name a segment (via
the corresponding attribute). Additionally, we added the width,
height, horizontalResolution, and verticalResolution
attributes to the primaryData element for describing spatial primary data
files.
For describing parts of moving pictures, we have to combine spatial and temporal
segmentation attributes (see Figure 4).
In this example we have an object in space which stays at the same coordinates during
the
time period starting at time code 00:00:00 and ending at 00:02:00. However, usually
the object
examined changes its position over time. Since XStandoff supports the construction
of segments
by referring to already established ones, we can use this mechanism to express a movement
of a
named markable over time (which can be expressed via path expressions in the other
mentioned
spatial markup languages). In the example given in Figure 5 we have the
segments s1 and s2 which both depict a spatial object named AnkleLeft. By
creating a segment s3 as a combination of s1 and s2 we express that the object named
AnkleLeft has moved over the timespan ranging form 00:00:00 to 00:01:15 from
the coordinates given in s1 to the coordinates given in s2. This defines a linear
movement. Up
to now, there is no inherent mechanism to describe non-linear movement (except as
content of
the optional metadata of a segment element in combination with the
disjoint value of the mode attribute, see Stührenberg and Jettka, 2009 for a further description).
Figure 5: Annotating movement in space and time via additional segments
An alternative representation makes use of XStandoff's logging functionality which
has
been changed in XStandoff 2.0 compared to previous versions (see Figure 6). While in SGF (Stührenberg and Goecke, 2008), logging was inherited from the
Serengeti annotation tool (Stührenberg et al., 2007) and was placed underneath a
seperate log element, XStandoff 2.0's schema contains a log model group
consisting of the elements update and delete which may be inserted
as children of the segment element and elements of imported layers.
Figure 6: Annotating movement in space and time via the update element
Although this construct may seem a bit awkward at first, it is not only conformant
to
XStandoff's already established mechanism but may be easier to realize than ISO-Space's
MOVELINK element demonstrated in Lee (2013). While the
representation given in Figure 5 is the preferred one, the second tends
to be more natural when dealing with sensor data (see below). Both serialization options
are
not stable since there are a couple of issues to resolve, for example the definition
of
non-linear movements.
We examine if XStandoff 2.0 can be used to store information gathered by eye-tracking
and
other motion-capture sensors (see section “Conclusion and future work”) as a base format for
annotating sensor information. Eye-trackers are used in a growing number of linguistic
and
psychological experiments and usability studies. Up to now, there is no common export
format
for the raw data that is collected by these sensors which are — in terms of XStandoff
—
resources that can be referenced via the optional creator attribute.[3] In the example given in Figure 5 we use two Microsoft Kinect
sensors, that deliver three-dimensional data (hence the 3d value of the
context attribute). This example introduces a change in XStandoff's paradigm,
since the primary data to be annotated is not already present but is construed from
the
segmentation.
Multimodal documents: a real-life example
Information is often encoded by a combination of visuals and text referring to each
other.
We will call members of this category multimodal documents. A prototypic example of
a
multimodal document is an instruction manual (for example for an electronic gadget),
another
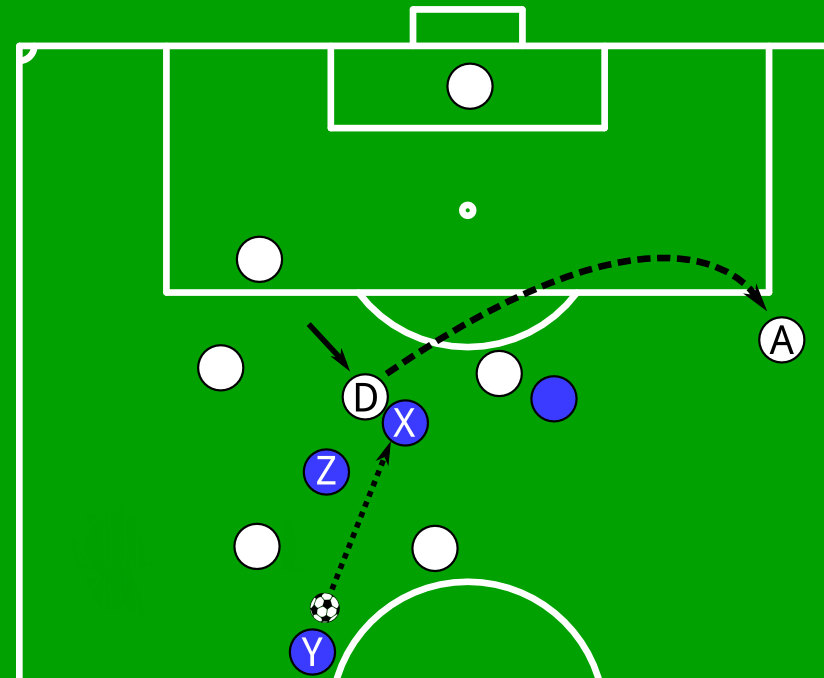
is the text-figure-combination which can often be found in the analysis of sport matches.[4] For demonstration purposes we have constructed an analysis of a fictional soccer
match between teams A and B shown in Figure 7.
Figure 7: Soccer analysis as an example of a multimodal document
Another situation in which team A is not able to finish its move: Y tries to pass
the
ball through the small gap to X (instead of passing it to G) while Z is unintentionally
obstructing Y's way. But before the ball reaches X, D intercepts and passes the ball
to
A.
Textual and graphical representation go hand in hand in this example. We can observe
that
there are two teams playing (color-coded in the graphic) and we are able to recognize
the
players and the ball in both representation formats. However, while the text refers
to a
player named G and a small gap, there are no corresponding parts
in the image. For a human reader it is easy to conclude which small gap was meant
and that the
player named G is represented by the blue circle without any letter, but a
software agent may have problems to draw the same conclusions. To make these text-image
mappings explicit we use an XStandoff 2.0 instance.
First we create an encoding of the information given in the textual part (Figure 8) which will afterwards be transformed into a single-level XSF
instance by using the XStandoff-Toolkit (Stührenberg and Jettka, 2009).[5]
Figure 8: Inline representation of the textal-encoded information
<text xmlns="http://www.xstandoff.net/examples/playbook"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.xstandoff.net/examples/playbook ../xsd/soccer.xsd">
Another situation in which <team name="teamA">team A</team> is not able to finish its move: <player name="Y">Y</player> tries to pass the ball through <place name="gap">the small gap</place> to <player name="X">X</player> (instead of passing it to <player name="G">G</player>) while <player name="Z">Z</player> is unintentionally obstructing <player name="Y">Y</player>'s way.
But before the ball reaches <player name="X">X</player>, <player name="D">D</player> intercepts and passes the ball to <player name="A">A</player>.
</text>
Some information is encoded in one of the two representation formats only: For example,
we
can definitely say which player belongs to which team by using the color information
(even for
the unnamed player) and use spatial attributes to create the according segments. Figure 9 shows the resulting XStandoff 2.0 instance after we have combined
both textual and spatial segments and the converted annotation layer.
Figure 9: XStandoff 2.0 instance containing both textual and visual primary data and
annotation
Elements of the annotation layer may refer either to segments of one of the primary
data
files only or both (as seen in the example). In the latter case the reference can
be seen as a
simple way of a text-to-image mapping.[6] Since we are uncertain if the unnamed blue dot refers to the player named
G in the running text, we have used TEI's certainty element to
express our degree of confidence. Note, that we have chosen this place for the
certainty element instead of placing it underneath the segment
element identified by seg17, since the segment as such is undisputed, but
not its reference to the entity mentioned in the running text.[7]
XStandoff 2.0 compared
There are already a couple of specifications that allow for spatial annotation, some
of
which have been mentioned already in section “Introduction” and section “Using XStandoff for spatial and temporal annotation”. The TEI supports spatial annotation by means of the
facsimile element introduced in the current version P5 (Chapter 11 in Burnard and Bauman, 2013). A possible serialization of a the text-picture combination shown in
Figure 7 can be seen in Figure 10. The appearance of the
player's zone elements as circles (or ellipses) is encoded by using
rendition child element underneath the tagsDecl metadata (the
example has been produced by using the Image Markup Tool (IMT)[8] and have been altered manually afterwards to include the textual content. Since we
use rectangular zones (that are rendered as ellipses in case of the players), the
coordinates
used define boxes. The point attribute, that uses a series of x,y coordinate
pairs to define complex 2d areas (similar to XStandoff's approach) is another option.
Figure 10: TEI's facsimile element
<?xml-model href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng" type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0" version="5.0" xml:id="tei-facsimile_instanz">
<teiHeader>
<fileDesc>
<!-- [...] -->
</fileDesc>
<encodingDesc>
<tagsDecl>
<rendition xml:id="player"><label>Player</label><code rend="ellipse"
lang="text/css">color: #ff0000</code></rendition>
<rendition xml:id="place"><label>Places</label><code rend="rectangle" lang="text/css">color:
#ffffff</code></rendition>
</tagsDecl>
</encodingDesc>
</teiHeader>
<facsimile xml:id="soccer-img">
<surface>
<desc>Visualization of a situation in a soccer game between teams A and B</desc>
<graphic url="soccer_balisage.png.png" width="824px" height="678px"/>
<zone xml:id="Y" rendition="player" ulx="290" uly="626" lrx="335" lry="674" rend="visible"/>
<zone xml:id="X" rendition="player" ulx="381" uly="397" lrx="430" lry="446" rend="visible"/>
<zone xml:id="Z" rendition="player" ulx="303" uly="448" lrx="349" lry="495" rend="visible"/>
<zone xml:id="D" rendition="player" ulx="343" uly="375" lrx="389" lry="420" rend="visible"/>
<zone xml:id="G" rendition="player" ulx="533" uly="376" lrx="576" lry="423" rend="visible"/>
<zone xml:id="A" rendition="player" ulx="758" uly="317" lrx="806" lry="365" rend="visible"/>
<zone xml:id="gap" rendition="place" ulx="343" uly="445" lrx="406" lry="630" rend="visible"/>
</surface>
</facsimile>
<text>
<body>
<p>Another situation in which <seg type="team">team A</seg> is not able to finish its move:
<seg facs="#Y" type="player">Y</seg> tries to pass the ball through <seg facs="#gap"
type="place">the small gap</seg> to <seg facs="#X" type="player">X</seg> (instead of
passing it to <seg facs="#G" type="player">G</seg>) while <seg facs="#Z" type="player"
>Z</seg> is unintentionally obstructing <seg facs="#Y" type="player">Y</seg>'s way. But
before the ball reaches <seg facs="#X" type="player">X</seg>, <seg facs="#D" type="player"
>D</seg> intercepts and passes the ball to <seg facs="#A" type="player">A</seg>.</p>
</body>
</text>
</TEI>
We have used TEI's seg element as bearer of the information encoded in the
element names in Figure 8. There are of course other (and better)
options to encode the information, especially the text-to-image mapping which in our
example
has been done by using the facs attribute. Although this attribute is defined in
the TEI to point[s] to all or part of an image which corresponds with the content of
the element, its (and the one of the facsimile element) main purpose is
to represent digital facsimiles. It remains to the reader to judge the tag abuse contained
in
Figure 10.
Another specification worth mentioning is Analyzed Layout and Text Object (ALTO)
originally developed as part of the Metadata Engine (METAe) project and which is nowadays
often used as an extension of the Metadata Encoding & Transmission Standard (McDonough, 2006). METS/ALTO supports several geographical shapes such as polygons,
ellipses and circles to define spatial areas and uses a similar point attribute
(Egger et al., 2010). However, the main purpose of ALTO is to store layout and content
information of OCR recognized text of pages of various printed document types.
Conclusion and future work
We have demonstrated the upcoming version 2.0 of the meta markup language XStandoff,
which
supports spatial segmentation and annotation of non-textual primary data. Although
we have
already annotated a medium-sized number of examples, using XStandoff for multimodal
documents
have just begun and further changes to the format cannot be excluded. We hope to create
a
web-based application for segmenting and annotating text and graphical-encoded information
as
a next step. Existing software such as the already-mentioned IMT or the Text-Image
Linking
Environment (TILE)[9] may serve as starting points. Furthermore we will examine the applicability of
XStandoff as pivot format for eye-tracking and other sensor data.
Acknowledgements
The author would like to thank the anonymous reviewers for their helpful comments
and
ideas, especially regarding (but not limited to) the availability of tools for spatial
annotation.
References
[Burnard and Bauman, 2013] Burnard, L. and S. Bauman
(2013). TEI P5: Guidelines for Electronic Text Encoding and Interchange. Text Encoding
Initiative Consortium, Charlottesville, Virginia. Version 2.4.0. Last updated on 5th
July
2013
[Egger et al., 2010] Egger, A., Stehno, B., Retti, G.,
Tiede, R., and J. Littman (2010). Analyzed Layout and Text Object (ALTO). Technical
report,
Library of Congress Network Development and MARC Standards Office.
[Lee (2013)] Lee, K. (2013). Multi-layered annotation of
non-textual data for spatial information. In: Bunt, H., editor, Proceedings of the
9th Joint
ISO - ACL SIGSEM Workshop on Interoperable Semantic Annotation, pages 15–23,
Potsdam
[ISO 24617-1:2012] ISO/TC 37/SC 4/WG 2 (2012).
Language Resource Management — Semantic annotation framework — Part 1: Time and events
(SemAF-Time, ISO-TimeML). International Standard ISO 24617-1:2012, International Organization
for Standardization, Geneva
[ISO/NP 24617-7] ISO/TC 37/SC 4/WG 2 (2012).
Language Resource Management — Semantic annotation framework — part 7: Spatial Information
(ISO-Space). Technical Report ISO/NP 24617-7, International Organization for Standardization,
Geneva
[Mani et al., 2008] Mani, I., Hitzeman, J., Richer, J.,
Harris, D., Quimby, R., and B. Wellner (2008). SpatialML: Annotation Scheme, Corpora,
and
Tools. In: Calzolari, N., Choukri, K., Maegaard, B., Mariani, J., Odjik, J., Piperidis,
S.,
and Tapias, D., editors, Proceedings of the Sixth International Language Re- sources
and
Evaluation (LREC 2008), pages 28–30, Marrakech. European Language Resources Association
(ELRA)
[Mani et al., 2010] Mani, I., Doran, C., Harris, D.,
Hitzeman, J., Quimby, R., Richer, J., Wellner, B., Mardis, S., and S. Clancy (2010).
SpatialML: annotation scheme, resources, and evaluation. Language Resources and Evaluation,
44(3):263280. doi:https://doi.org/10.1007/s10579-010-9121-0.
[Stührenberg et al., 2007] Stührenberg, Maik,
Goecke, Daniela, Diewald, Nils, Cramer, Irene, and Alexander Mehler (2007). Web-based
annotation of anaphoric relations and lexical chains. In: Proceedings of the Linguistic
Annotation Workshop (LAW), pages 140–147, Prague. Association for Computational Linguistics,
2007. doi:https://doi.org/10.3115/1642059.1642082.
[Stührenberg and Goecke, 2008] Stührenberg,
Maik, and Daniela Goecke (2008). SGF - An integrated model for multiple annotations
and its
application in a linguistic domain. In: Proceedings of Balisage: The Markup Conference
2008.
Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01.
[1] For various reasons we decided not to follow HyTime's approach of Finite Coordinate
Space Location (fcsloc) demonstrated in DeRose and Durand, 1994, p.
70ff. See section “XStandoff 2.0 compared” for a discussion of other
specifications.
[2] Note, that the assertion given in Figure 2 does not yet reflect 3d
contexts.
[3] The resource element is used to store information about human, software
or hardware agents that produced segmentation or annotation layers.
[5] For this example we use a representation format such as HTML, that allows us for
selecting the textual information character-wise and can therefore use the classic
XStandoff approach of segmentation.
[6] Of course it would be possible to make the mapping explicit by adding a special
annotation layer for this purpose.
[7] Another option could be to use two player elements (one for each primary
data) and to add the certainty information to the one referring to the segment of
the
graphical primary data only. But this would introduce an additional element not present
before in the original inline annotation.
Burnard, L. and S. Bauman
(2013). TEI P5: Guidelines for Electronic Text Encoding and Interchange. Text Encoding
Initiative Consortium, Charlottesville, Virginia. Version 2.4.0. Last updated on 5th
July
2013
Dahlström, E.. Dengler, P.,
Grasso, A., Lilley, C., McCormack, C., Schepers, D. and J. Watt (2011). Scalable Vector
Graphics (SVG) 1.1 (Second Edition). W3C Recommendation, World Wide Web Consortium
(W3C).http://www.w3.org/TR/2011/REC-SVG11-20110816/
DeRose, S. J., and D. G.
Durand (1994). Making Hypermedia Work. A User’s Guide to HyTime. Kluwer Academic Publishers,
Boston and Dordrecht and London. doi:https://doi.org/10.1007/978-1-4615-2754-1.
Egger, A., Stehno, B., Retti, G.,
Tiede, R., and J. Littman (2010). Analyzed Layout and Text Object (ALTO). Technical
report,
Library of Congress Network Development and MARC Standards Office.
Lee, K. (2013). Multi-layered annotation of
non-textual data for spatial information. In: Bunt, H., editor, Proceedings of the
9th Joint
ISO - ACL SIGSEM Workshop on Interoperable Semantic Annotation, pages 15–23,
Potsdam
ISO/TC 37/SC 4/WG 2 (2012).
Language Resource Management — Semantic annotation framework — Part 1: Time and events
(SemAF-Time, ISO-TimeML). International Standard ISO 24617-1:2012, International Organization
for Standardization, Geneva
Daniel Jettka, and
Maik Stührenberg (2011). Visualization of concurrent markup: From trees to graphs,
from 2d to
3d. In: Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup
Technologies, vol 7. doi:https://doi.org/10.4242/BalisageVol7.Jettka01.
Mani, I., Hitzeman, J., Richer, J.,
Harris, D., Quimby, R., and B. Wellner (2008). SpatialML: Annotation Scheme, Corpora,
and
Tools. In: Calzolari, N., Choukri, K., Maegaard, B., Mariani, J., Odjik, J., Piperidis,
S.,
and Tapias, D., editors, Proceedings of the Sixth International Language Re- sources
and
Evaluation (LREC 2008), pages 28–30, Marrakech. European Language Resources Association
(ELRA)
Mani, I., Doran, C., Harris, D.,
Hitzeman, J., Quimby, R., Richer, J., Wellner, B., Mardis, S., and S. Clancy (2010).
SpatialML: annotation scheme, resources, and evaluation. Language Resources and Evaluation,
44(3):263280. doi:https://doi.org/10.1007/s10579-010-9121-0.
McDonough, J. (2006). METS:
standardized encoding for digital library objects. International Journal on Digital
Libraries,
6:148–158. doi:https://doi.org/10.1007/s00799-005-0132-1.
Stührenberg, Maik,
Goecke, Daniela, Diewald, Nils, Cramer, Irene, and Alexander Mehler (2007). Web-based
annotation of anaphoric relations and lexical chains. In: Proceedings of the Linguistic
Annotation Workshop (LAW), pages 140–147, Prague. Association for Computational Linguistics,
2007. doi:https://doi.org/10.3115/1642059.1642082.
Stührenberg,
Maik, and Daniela Goecke (2008). SGF - An integrated model for multiple annotations
and its
application in a linguistic domain. In: Proceedings of Balisage: The Markup Conference
2008.
Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01.
Stührenberg,
Maik, and Daniel Jettka (2009). A toolkit for multi-dimensional markup: The development
of SGF
to XStandoff. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series
on
Markup Technologies, vol. 3. doi:https://doi.org/10.4242/BalisageVol3.Stuhrenberg01.