Kepper, Johannes, Perry Roland and Daniel Röwenstrunk. “Musical Variants: Encoding, Analysis and Visualization.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Kepper01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: Musical Variants: Encoding, Analysis and Visualization
Dr. Johannes Kepper is Musicologist at the University of Paderborn. He works
in the Freischütz Digital project and
participates actively in the development of MEI.
Johannes holds a Magister Artium in Musicology and a Diploma in Media
Informatics from the University of Paderborn. He finished his dissertation in
2009 on the topic of Music editions in the era of new
media.
Perry Roland is Music Metadata Librarian at the University of Virginia Music
Library where he participates in the creation of new digital resources and their
metadata.
Perry holds a Bachelor of Science in Music Education from Concord College,
Athens, West Virginia; a Master of Arts in Music Composition from the University
of Virginia, Charlottesville; and a Master of Science in Library and Information
Science from the University of North Carolina at Greensboro. He is the
originator of MEI.
Daniel Röwenstrunk is Computer Scientist and the Project Director of Freischütz Digital at the University of
Paderborn.
Daniel holds a Diploma in Business Computing with a focus on Decision Support
and Operations Research from the University of Paderborn. He has worked in
humanities projects since 2006 and has strong interests in digital editions and
modeling of music.
The following paper proposes a model for the encoding of variance in music that is
based on traditional models and implemented using the data framework offered by the
Music Encoding Initiative (MEI). It introduces concepts derived from the Functional
Requirements for Bibliographic Records (FRBR) to music editing. This combination is
then used to auto-generate proposals for the filiation of sources and to illustrate
the relationships between the encoded sources. The purpose of this system is to
structure the editorial process, provide a better overview of the material, and to
inform the editor's findings. It will be developed and used by the Freischütz Digital project, the goal of which is to
create a digital scholarly edition of Carl Maria von Weber's opera Der Freischütz based on complete encodings of all
relevant sources. The edition will be completed by Summer 2015.
The core tasks of a scholarly edition of music are the investigation, documentation,
and explanation of the transmission of the work. In traditional textual criticism,
this
is done by examining all available sources, comparing the textual version(s) they
contain, tracing the filiation of sources, selecting a main (or "base") source, and
providing an edited text that resembles the main source as closely as is reasonably
possible. The textual variation recorded in this process is traditionally documented
in
a separate list that identifies readings by movement, measure, and (sometimes) beat
within the measure and voice. In contrast to traditional print publications, which
restrict themselves to a single base text because of pragmatic and/or financial
considerations, in the digital medium one may include all pertinent sources without
regard to their relevance to filiation. In addition, the determination of a base source,
and thus a listing of variants compared only to it, is not necessary. The edition
can
therefore document all readings, not just a single edited version of the text [Bohl et al. 2011]. In fact, it is now possible to provide all historically
legitimate alternative versions of the text simultaneously.
Musical Variants
Based on earlier literature [Feder 1987], German musicologist
Bernhard R. Appel proposed a systematic model for variants in his article
Variatio delectat – Variatio perturbat [Appel 2005,
pp. 7–24]. He identifies four main types of local variation between sources: additions (Ergänzung), deletions (Streichung), substitutions (Ersetzungen) and rearrangements (Umstellungen). An addition denotes the introduction of new material to the musical text,
as compared with an older version (AB ⇒ AXB). In contrast, a deletion is characterized by leaving out parts of the text (ABC ⇒ AC). A
variant where a portion of the musical text is replaced by another is identified as
a
substitution (ABC ⇒ AXC). In this case, the
original portion and its replacement may differ in length. In the last species of
variant, rearrangements, the musical text itself is not
changed, but portions are reordered (ABC ⇒ ACB). With regard to their effect on the
musical text, Appel points out that all variants can be assigned to one of these four
types.
However, considering the fact that the actual filiation of sources is very often all
but clear [Feder 1987, p. 64], additions and deletions may be
consolidated into a larger category. That is, when it is not possible to establish
the
direction of dependency between two sources, the only possible observation in both
cases
is that one source holds text not present in the other. Therefore, considering both
additions and deletions as the exchange of something with
nothing, and thus special cases of substitution, the number of types may be reduced. A rearrangement may be thought of as two substitutions at different positions. What would be lost when taking
this perspective, though, is the identity of the material omitted in one place and
inserted at another, so that a rearrangement requires
an additional pairing of two atomic substitutions.
Therefore, the number of variant types may be reduced to only two—substitutions and rearrangements.
When comparing more than two sources, variants amongst them may also be classified
by
another taxonomy. German philology offers the terms Bindefehler and Trennfehler. A
Bindefehler is a variant reading shared by two or
more, but not all, sources. By sharing a particular variant, the sources are logically
connected and therefore have a closer filial relationship than sources that do not
share
this material. A Trennfehler describes the opposite
case. It denotes a variant that distinguishes two sources that have been subjected
to
either a substitution (in the broad sense mentioned
above) or a rearrangement. A Trennfehler argues for a distant relationship between sources. A variant
in the musical text transmitted in at least three sources is therefore always a
Bindefehler for some of these sources, and a
Trennfehler for others at the same time.[1]
Textual variation may appear at various levels—from single notes with a different
pitch to revised melody lines of almost any length and from the addition of measures and measure groups to the rearrangement of entire movements. It is also important to keep in mind
that, while common music notation (CMN) features a very clear structure of measures
and
staves, the visual structure of music notation does not limit the musical content
in any
way and must not be confused with the semantics of the musical content. Composers
and
copyists alike have never restricted themselves to changes that do not cross this
structure. When a melody line is replaced by another, changes to several measures
may be
required, without affecting the place of these measures in the context of the notation
as a whole. Like the conventions of line, paragraph, and page breaks in literary text,
the visual structures of CMN are simply conventions that facilitate reading and
writing—no more, no less.
Encoding Variants in MEI
In the case of editorial markup, MEI implements the same concepts and mechanisms as
TEI (Text Encoding Initiative). Those familiar with TEI can therefore safely assume
the
same concepts behind the elements of the same name in MEI. Thus, encoding variance
in
MEI is based on use of the <app> element, which is allowed at almost
every level. It identifies a portion of the musical text that varies among different
sources. Each distinct reading drawn from the available witnesses is held in a
<rdg> element that identifies its source or sources using its
@source attribute. This model matches the concept of Bindefehler and Trennfehler
almost perfectly. For sources sharing a reading, an <app> element
acts as a Bindefehler, while in the case of sources
with different readings, it acts as a Trennfehler.
However, the <app> element is not capable of adequately dealing
with all of the species of variance described earlier. MEI does offer a mechanism
for
additions, deletions, and substitutions; that is,
<add>, <del> and <subst>
elements. However, these elements are intended to describe scribal processes within
a
given witness, not variation across multiple sources. The more generic
<app> element could be used, which is designated to describe
variance of this kind as shown in the following encoding:
This approach works for substitutions but it falls
short on rearrangements. Here, it can only capture two
seemingly separate operations (deletion and subsequent
addition) in separate <app>
elements. To circumvent this restriction, additional markup is necessary.
Because the identification of a rearrangement
requires an additional step of interpretation, which may be made by the editor at
any
time in the editorial process, the encoding can begin with the use of two separate
<app> elements, but allow for enrichment of the basic markup
later. The simplest, and thus most useful, solution is to employ the
@corresp attribute to cross-link the corresponding
<rdg> elements:
<app>
<rdg xml:id="oldPos" source="#A #B" corresp="#newPos">
<!-- content at old position -->
</rdg>
<rdg source="#C"/>
</app>
...
<app>
<rdg source="#A #B"/>
<rdg xml:id="newPos" source="#C" corresp="#oldPos">
<!-- content at new position -->
</rdg>
</app>
Using these mechanisms clearly shows that the parallel segmentation method of
<app> and <rdg> suffices to address musical
variants occurring inside musical structures.
Example 1: Substitution over two measures
However, as mentioned earlier, substitutions (of
melodies, for example) often ignore the structural features of music notation like
measures and staves (see Example 1). In the given scenario, the musical
notation, as encoded in MEI, requires splitting the description of variance into two
separate <app> elements. This separation does not resemble a
Befund, which obviously permits only one difference between the two
sources. The fact that the change crosses the bar line results in a typical example
of
overlapping hierarchy issues confronted by any XML-based encoding system. For the
encoding of the musical text, MEI is well prepared to handle such overlaps. For
instance, slurs, one of the most common features of CMN that interfere with measure
and
staff structures, can be captured using various markup possibilities, including
attribute-based milestone techniques and standoff markup.
For overlapping variants that interfere with the notational structure
by crossing barlines, staves or similar boundaries, a mechanism like that proposed
for
rearrangements may be used. The difference here is
that instead of relating the descendant <rdg> elements, the
<app> elements themselves should be connected. Capturing cross
references with @xml:id and @corresp attributes is less than
ideal, however, as double-ended references can result in largely redundant pointers
requiring careful maintenance. For example, consider that even a small change in a
measure may affect a large number of staves.
A milestone approach, using elements such as TEI’s span elements
(<addSpan>, <delSpan>, etc.) is of no help
here, as CMN is a two-dimensional notation, making it impossible to describe an affected
region of the text with just one start and one end point. Instead, a standoff approach
allowing only single-direction pointers is more appropriate. The obvious solution
would
be to use the <annot> element (the MEI equivalent to TEI’s
<note>), which offers a @plist (participant list)
attribute. The <annot> element could be used to point to all related
<app> elements, and its @type attribute could be
used to identify its purpose. However, this solution also falls short with regard
to
explicitness. A standoff methodology explicitly identifying all relevant components
is
clearly the best strategy. But using generic <annot> elements,
distinguished only by simple typing, for all these specific cases, overloads its
semantics.
As an alternative, the authors propose adding specific grouping elements to MEI that
identify isolated members of a feature group. In the case of multiple
<app> elements, an <appGrp> element would be
appropriate. The <appGrp> element could use its own
@plist attribute to refer to a number of logically connected
<app> elements that, taken together, represent a specific
variant:
On a related topic, MEI currently lacks grouping mechanisms for the elements intended
for capturing simple editorial changes, such as additions (<add>) and deletions (<del>). Like the variation in source
material represented by <app>, these elements are also not bound to
notational structures. They too require a grouping mechanism that helps encoders to
overcome the hierarchical conflicts arising from a strict XML structure.
With the proposed models in place, it will be possible to encode all the types of
variants identified by Appel and their scope. The intention is to allow representation
of textual variation in stages or layers, from no interpretation to the capture of
complex relationships, in way that permits the editor to make informed decisions about
the filiation of the sources of the text.
Qualitative Analysis based on Encoding
The Functional Requirements for Bibliographical
Records (FRBR) conceptual model was proposed by the International Federation of Library Associations and Institutions (IFLA)
in 1998. It does not offer a ready-to-use data format, but rather generic concepts
that
help to create cataloging formats that address advanced user needs. As the FRBR
terminology is also applicable to music philology, especially with regard to the
filiation of sources, it has been adopted by MEI for its 2013 release.
FRBR is organized into three separate but related entity groups. Only the first group,
which provides work, expression, manifestation and item entities, has been adopted
by
MEI so far. These four so-called Group 1 entities provide a clear
terminology for dealing with the transmission of a work in manuscripts and prints
alike.
While a work entity represents only the conceptual idea of a musical piece, independent
from the details of its composition, such as its instrumentation, an expression
identifies a slightly less abstract entity that does include these details. In other
words, it also denotes a specific version of the text, even though this requires a
manifestation (MEI uses its pre-existing <source> element for this
entity) for its materialization. An item is a distinct physical instantiation of a
manifestation, for example, a copy of a certain print.
FRBR also allows specification of the relationships between the basic entities. In
MEI, some of the hierarchical relations are implicitly encoded using inheritance (an
expression for example is a child element of a work) while others, such as those between
expressions and manifestations, are dealt with using pointers. This change in approach
is necessitated by the many-to-many relationships that can exist between expressions
and
sources. For example, a single expression of a work may be transmitted by many sources
or a single source may contain multiple expressions of one or more works. FRBR offers
a
number of relation types, which establish an entity-relationship-model for bibliographic
and editorial needs. For example, an expression may be described as a translation
or
rearrangement of another and a print may be
identified as a copy of a manuscript source. These relations, however, clearly denote
the overall relation between two affected entities—they are not operating at the level
of individual variants, but on the global level of complete objects.
We believe the recommended types for relationships identified and provided by FRBR
are
also useful to describe processes behind textual variation at more granular levels.
For
example, isSupplementOf may be used for additions, isAbridgementOf for deletions, isRevisionOf for substitions and
isReconfigurationOf for rearrangements. Adding such relations to individual textual variants is
required to give a better overview of the arguments for a specific filiation of sources.
The suggested implementation mostly relies on existing MEI models. The only important
change is to allow the @rel attribute, which is currently only available on
the <relation> element to describe full-entity relations stored in
the header, to be used on <rdg> elements. In this implementation,
material added in a later and derived version of the text would be encoded so:
The example shows how one reading is identified as an addition to another. The empty reading serves as a placeholder for the
base text. By adding @cert and @evidence
attributes to <rdg>, the editor may also state the reliability of his
assessment. While at some point in the future it may be necessary to allow an alternate
encoding method that employs dedicated elements in order to capture divergent
interpretation from multiple editors, the simple approach described here will
suffice.
The purpose of filiation is to identify the relations (and their directionalities)
between sources and to create a stemma that illustrates these relations. The results
may
be expressed with FRBR, but they are based on the evaluation of individual variants
as
described above. This evaluation, stored in a FRBR-compliant way, can be used to provide
a better overview of all arguments and to inform the editor's interpretation of the
overall connection. It may also help to better explore the filiation of sources with
multiple intermingled ancestors and other complex situations often overlooked in
traditional filiation [Feder 1987]. However, a fully automated analysis
of those variants seems impossible; simply quantifying the number of variants indicating
a filiation from A to B vs. arguments for B to A is not particularly helpful, as some
arguments are more convincing than others [Feder 1987, p. 58]. The
swapping of two pitches has nearly no persuasiveness with regard to the derivation,
whereas a missing note in a manuscript is an almost unquestionable argument that it
was
copied from the source to which it is compared. To make full use of the encoding,
it is
therefore important to assess the impact of a particular variant based on the content
of
the readings it holds. Following this reasoning, a variant holding an additional staff
in one source and no corresponding material in another should be given more weight
than
a variant where the sources differ only on the pitch of a single note. Likewise, a
variant affecting substantial information of the text is more compelling than a
variation in the accidental layer of the text [Greg 1950]. Accurately
judging the impact of a variant by an automated examination is clearly a large-scale
project of its own, but it is fairly easy to get a first suggestion from less ambitious
algorithms. When considering the fact that the final evaluation must be based on the
editor's experience and judgment, it seems unnecessary to get a perfect analysis—it
just
needs to be good enough to be a helpful starting point. Under these circumstances,
it
seems logical not to hard-wire the weight given to each category of argument, but
instead to let the editor balance them according to his expertise.
An automated analysis of the variation across multiple sources must start with a
listing of all Trennfehler and Bindefehler for every combination of two sources. At this stage, the
variants do not require further argumentation and stand on their own. An initial graph
grouping the sources by their level of conformance with each other is already possible.
However, in order to assess the edges of this graph, the content of these variants
must
be evaluated. Simple pitch changes (which may be nothing more than mere copying errors),
will be treated differently than larger groups of non-corresponding measures. After
measuring the strength of these arguments, the next step is to identify their
directions. This process is also based on an evaluation of the content—is it more
likely
that the textual difference is a later addition to a formerly shorter text, or is
it
more likely that something has been canceled from a formerly richer text? Again, these
arguments will differ in their persuasiveness, but here the situation is much better,
as
additional information can be used to inform the determination of direction. For
example, if both sources can be precisely dated, the direction is already clear.
Likewise, the identification of scribal hands may help to determine filiation when
more
information about the scribe, such as birth and death dates or work locations, is
available.
Even when the general relationship between two sources seems to be clear, based on
a
number of arguments regarded as indisputable, it is important that all contradictory
variants remain available to the editor, as they may hint at a possible contamination
of
sources. Accordingly, the graphical interface for this analysis needs to differentiate
between parts of these sources and provide hints if there is a significant variation
in
the likely directionality of filiation amongst them. Very often, editors will be able
to
identify the filiation of sources very quickly. The purpose of an automated analysis
like this is to ensure that editors do not overlook possible alternatives or mixed
relationships, resulting in oversimplification of the filiations. Having the editor's
judgment explicitly recorded in @rel attributes on <rdg>
and a determination of a level of certainty for the assertion in @cert
attributes, permits better decision-making, ultimately making the edition more
transparent for the user.
Visualization and Analysis of Variants
As the purpose of the proposed encoding and analysis methodology is both to support
the editor and to better illustrate the editorial process to the user, an adequate
visualization is very important. Even though the encoding itself is designed to be
as
legible as possible, the vast amount of data requires provision of a condensed
view—without which the resulting information would likely be unusable.
Following the order of steps given above, a first visualization will provide an
overview of the variance of two or more sources under comparison.
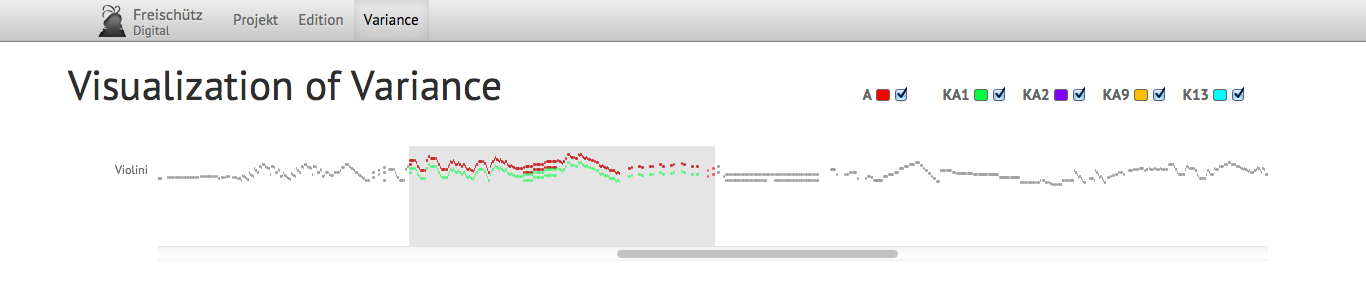
Example 2: Visualization of Variance with a kind of piano roll notation
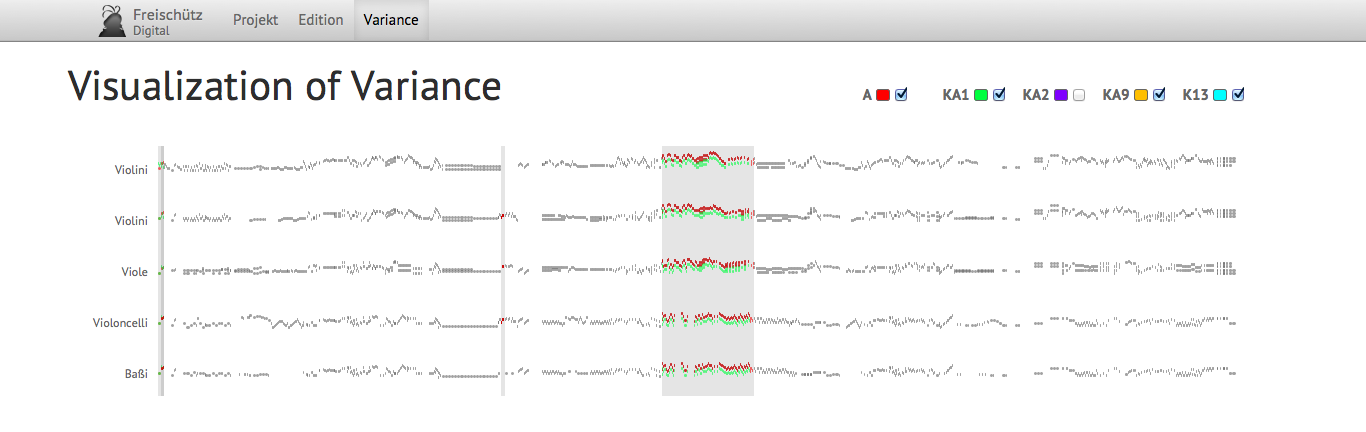
Example 3: Visualization of Variance in multiple voices
This visualization draws on the concept of piano roll notation (see Example 2 and Example 3), but compared to regular piano
roll notation, it is scaled down to a barely legible size, similar to Edward Tufte's
sparklines concept [Tufte 2008]. The idea is to provide an overview of
large segments of the source. Every source is assigned a distinct color. Everything
shown in black is shared amongst all sources, whereas the colored parts show the
differences between them. Piano roll notation represents only the substantial parts
of
the score, ignoring accidental components like articulation, dynamics, etc. In a proper
visualization, this kind of information is provided in a separate stream for every
staff. This stream could also be reduced, showing only a dot for each accidental sign
(not visible in the examples). Separation into multiple streams helps to distinguish
the
kind of variance even at this high-level overview stage. In the future, scaling may
also
be provided in this view, allowing the user to zoom into more and more detail,
terminating in the actual notation. Until then, this visualization provides an excellent
overview of the level of variance between the compared sources. It is also possible
to
highlight variants acting as Bindefehler between two
sources by putting them on a differently colored background.[2]
The next step is to make use of the FRBR-compatible classification of individual
variants. This is possible by making the interface customizable, allowing the user
to
highlight specific types of variants. The project intends to provide yet another
perspective on the data that resembles traditional stemmata more closely.
In the projected interface, there will be a stemma-like graph on the left side of
the
screen, paired with a list of all variants on the right side. These variants can be
ordered by their type, ascribed FRBR-relations, the editor's certainty, the estimated
relevance (following customizable categories), and the affected sources and their
position in the document. Manipulating this list will influence the stemma on the
left.
If, for instance, the editor (or user) decides to focus on a single movement of the
work, it will reflect only relations in that movement.
Conclusion
The system described in this paper can only operate on fully encoded sources. The
Freischütz Digital project will provide data of the
required verbosity for the first time. The amount of data contained in encodings of
music notation is already large and providing the additional details described in
this
paper will increase their complexity even further. However, the end result of doing
so—detailed insight into the transmission and transformation of musical works—is highly
desirable. While it has not been possible before, by leveraging the potentials of
both
MEI and FRBR it is possible to create intuitive tools that permit the exploration
and
communication of relations among sources containing notated music.
References
[Appel 2005] Appel, Bernhard R.: Variatio
delectat – Variatio perturbat, in: Varianten – Variants – Varientes
(Beihefte zu editio 22), edited by Christa Jansohn and Bodo Plachta, Tübingen
2005, doi:https://doi.org/10.1515/9783110926941.7
[Bohl et al. 2011] Bohl, Benjamin/Kepper,
Johannes/Röwenstrunk, Daniel: Perspektiven digitaler Musikeditionen aus der Sicht
des Edirom-Projekts in: DIE TONKUNST, July 2011, No. 3, Vol. 5 (2011), pp.
270–276
[Greg 1950] Greg, Walter Wilson: The
Rationale of Copy-Text, Studies in Bibliography Vol. 3, (1950/1951), pp.
19-36, Published by: Bibliographical Society of the University of Virginia
Appel, Bernhard R.: Variatio
delectat – Variatio perturbat, in: Varianten – Variants – Varientes
(Beihefte zu editio 22), edited by Christa Jansohn and Bodo Plachta, Tübingen
2005, doi:https://doi.org/10.1515/9783110926941.7
Bohl, Benjamin/Kepper,
Johannes/Röwenstrunk, Daniel: Perspektiven digitaler Musikeditionen aus der Sicht
des Edirom-Projekts in: DIE TONKUNST, July 2011, No. 3, Vol. 5 (2011), pp.
270–276
Greg, Walter Wilson: The
Rationale of Copy-Text, Studies in Bibliography Vol. 3, (1950/1951), pp.
19-36, Published by: Bibliographical Society of the University of Virginia